Our experiment was carried out on a server with Ubuntu 14.04, Titan X Pascal and 12G memory. The experiment first provides the dataset and evaluation protocol, followed by a detailed ablation analysis and an overall evaluation of the proposed method.
3.1. Datasets and Evaluation Protocol
DOTA [
47] is a large and challenging aerial image dataset in the field of object detection, including 2806 pictures and 15 categories, with a picture scale ranging from 800 × 800 to 4000 × 4000. It contains a training set, validation set, and test set, which account for 1/2, 1/6, and 1/3 of the total data set, respectively. Among them, the training and validation sets were marked with 188,282 instances, with an arbitrary direction quadrilateral box. In this study, we used the 1.0 version of rotating object detection, and the image was cropped into 600 × 600 slices. It was scaled to 800 × 800 during the training. Short naming is defined as plane (PL), baseball diamond (BD), bridge (BR), ground field track (GTF), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer-ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP), and helicopter (HC). The official evaluation protocol of the DOTA in terms of the mAP is used.
HRSC2016 [
48] is a dataset dedicated to ship detection is in the field of object detection. The dataset contains 1061 images from two scenarios, including ships on the sea and ships close to the shore. There are three levels of tasks (for single class, four types, and 19 types of ship detection and identification). The image sizes range from 300 × 300 to 1500 × 900, and most of them are larger than 1000 × 600. Among them, the training set was 436, the verification set was 181, and the test set was 444. The example is marked by a rotating rectangular box, and the standard evaluation protocol of HRSC2016 in terms of mAP is used.
3.3. Ablation Study
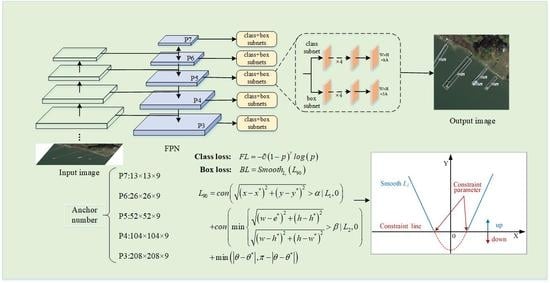
The ablation study includes the effect of the modulation mechanism and the constrained mechanism on the network, as well as the convergence and generality of the proposed constrained loss function. (For the convenience of comparison, the validation set in the DOTA is used for evaluation, because the test set label has not been released.)
Effects of the modulation mechanism: We experimented with the proposed decoupling modulation mechanism in the regression loss function, and compared it with popular loss functions, such as
, smooth-
, IoU-smooth-
[
33], and
[
38]. In the experiment, we used the same backbone network (resnet50) and five-parameter regression method, and used RetinaNet as the baseline method. The experimental results show that in
Table 2, our modulation mechanism has achieved better performance than
[
38], which has increased by 0.4 and 0.6 in DOTA and HRSC2016, respectively. This further proves our idea that decoupling the regression parameters can improve the performance of the network model.
Effects of the constraint mechanism: To verify the effectiveness of the constraint loss function (
), we experimented with the center point constraint and the size constraint, respectively and explored the influence of different constraint domains on the performance of the model. In the experiment, the CPs
and
are designed to be 5,4,3,2,1,0, and test them, respectively, where 0 indicates an unconstrained state. To ensure fairness of the experiment, each comparison experiment was trained for 30 epochs (training times per epoch was 20,673). In addition, the proposed decoupling modulation loss is used. The experimental results are shown in
Figure 9. Obviously, there are some positive and negative effects due to the introduction of
and
. Compared with the unconstrained case, the effective CPs accelerate the network convergence speed. In particular, when CPs = 4 or 5, the network convergence speed is faster, but the model performance is sacrificed. The network convergence speed and model performance were improved when CPs = 1, 2, or 3. The performance of the model is the best when
= 2 and
= 3, which are improved by 3.5 and 3.2, respectively. Although this is not the final result (only 30 epochs are trained), and this improvement will become smaller as the training expands, this is sufficient to confirm our method. The introduction of CPs can not only improve the performance of the model, but more importantly, it greatly improves the convergence speed of the model and reduces resource consumption.
Based on the above experiments, we found that appropriate center point constraints and size constraints can have a positive effect on network training. Therefore, it is necessary to explore these combinations. In the experiment, we predefined an optimal combination (
,
) = (2,3) (from the ablation experiment of the center point constraint and size constraint), and designed some other combinations. The results are shown in
Table 3. The predefined combination (
,
) = (2,3) and
led to the best performance compared to other combinations and loss functions, which confirmed our idea.
Convergence analysis: We experimented with the network under different CPs and recorded the number of training required for the model to stabilize. The results are shown in
Table 4, where different CPs have significant differences in the consumption of training resources of the network. Larger CPs mean greater tolerance for predicting bounding boxes, less training resources are required, and faster convergence and stability, while smaller CPs have the opposite.
Adjustability: By combining the characteristics of different CPs, an experiment of cascade constraint sequence was designed. We designed 30 epochs and divided them into six equal parts, defined as A0,
…, A5 = [epoch1, epoch5],
…, [epoch 26, epoch30]. Subsequently, a series of sequence experiments were designed, and the results are listed in
Table 5. As the sequence complexity increased, the performance of the model improved. In particular, in the G4 case, the model’s mAP was improved by 2.7 compared to the G0 case, which confirms the effectiveness of the cascade constraint sequence.
Generalizability: To verify the generality of the constraint loss function, we experimented with our method in the popular regression loss function. In the experiment, RitinaNet was used as the baseline method, and Resnet50 was used as the backbone network. The constraint parameter sequence adopts the G4 sequence in
Table 5 owing to its excellent performance. In the experiment, the performance of different regression loss functions in the OBB and HBB tasks of DOTA were tested, and the results are shown in
Table 6. Obviously, after the optimization of
or CPs proposed by us, the performance of the model has been improved to varying degrees. In particular, it has better performance in the deviation-based method, which increases the Huber loss by 2.4 mAP on the DOTA, and increases the MAE loss by 1.9 mAP on the HRSC2016. One possible explanation is that
plays an important role in the OBB task.
Effects of data augmentation: Many studies have proved that data enhancement can effectively improve detector performance. We extended the data by random horizontal, vertical flipping, random graying, random rotation, and random change channels. In addition, additional enhancements have been made to categories with a small number of samples (such as helicopters and bridges). The experimental results are shown in
Table 7, and a 3.1% improvement was obtained on the DOTA (from 67.9% to 71.0%); a 1.7% improvement was obtained improvement on the HRSC2016 (from 86.2% to 87.9%). We also explored a larger backbone network, and the results showed that a larger backbone can result in better performance. The final performance of our improvement was 74.3% and 88.9% using ResNet152 as the backbone network. In addition, our training times is 8 × 10
, which is far less than that of the popular method, and the resource consumption due to training as greatly reduced.
3.4. Overall Evaluation
We compare our proposed constraint loss function with the state-of-the-art rotating object detection method on two datasets DOTA [
47] and HRSC2016 [
48].
Results in DOTA: We first experimented with our method on the DOTA dataset and compared it with popular rotated object detection methods, as depicted in
Table 8. The results of the overall evaluation experiment were obtained by submitting our model to the official DOTA evaluation server. In the experiment, the training and verification sets of the DOTA were used as training samples, and the test set was used to verify the performance of the model. The compared methods include scene file detection methods R
CNN [
50], RRPN [
30], popular rotated object detection method ICN [
51], RoI Transformer [
31], Gliding Vertex [
36], and methods that consider sudden changes in loss, such as SCRDet [
33], R
Det [
35], and RSDet [
38]. The performance of our method is 1.1 better than the best result in the comparison method (RSDet+ResNet152+Refine). Although our method did not achieve state-of-the-art performance in the DOTA rankings, it showed the best performance in the one-stage detector. In addition, our method saves more than 30% of the computing resources compared with most methods. The visualization results are shown in
Figure 10.
Results in HRSC2016: We also experimented with our method in HRSC2016 and compared it with popular detectors, and the results are shown in
Table 9. First, a comparative experiment was carried out using the methods proposed in scene text detection, RRPN, and R2CNN, and the detection accuracy was not ideal. RoI Transformer and Gliding Vertex have achieved good detection accuracy but require more training resources. RetinNet-H and RetinaNet-R were used as baseline methods, among which RetinaNet-R obtained 89.1% detection accuracy. R
Det [
35] achieved a better detection accuracy than the above method. In the end, our method achieved an accuracy of 89.7%, achieved the state-of-the-art performance under the optimization of
and CPs, and nearly half of the training resources were saved. The visualization results are shown in
Figure 11.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}