
A Fusion Method of Optical Image and SAR Image Based on Dense-UGAN and Gram–Schmidt Transformation



Abstract
:
1. Introduction
2. Background
2.1. GAN
2.2. Gram–Schmidt (GS) Transformation
3. Methods
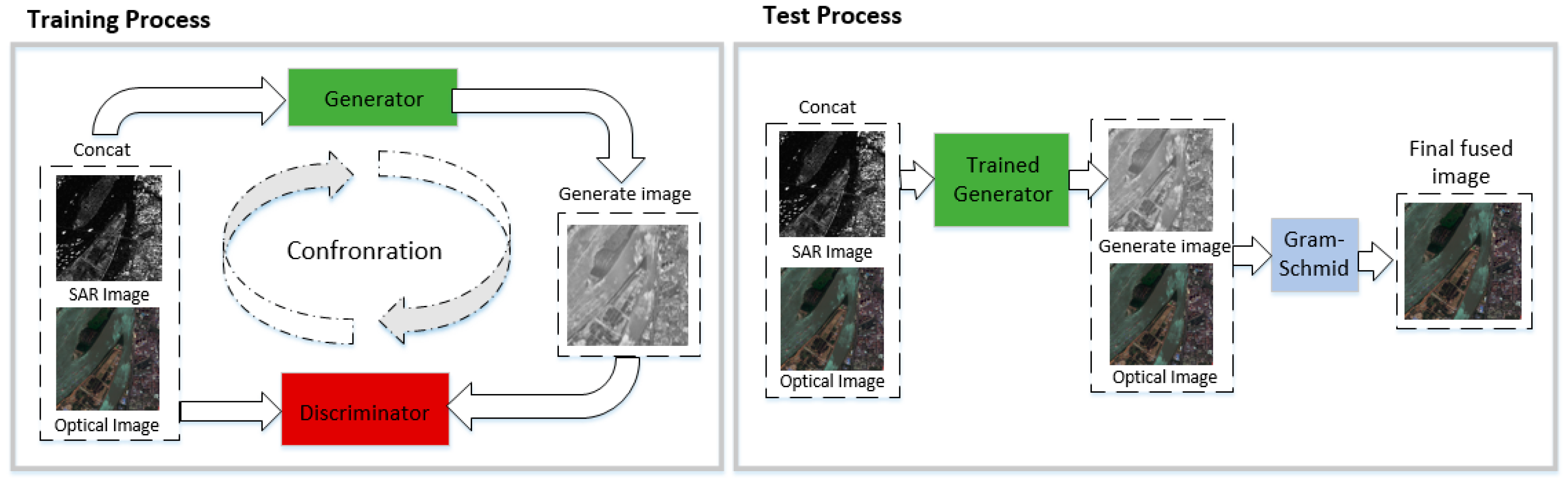
3.1. Overall Structure
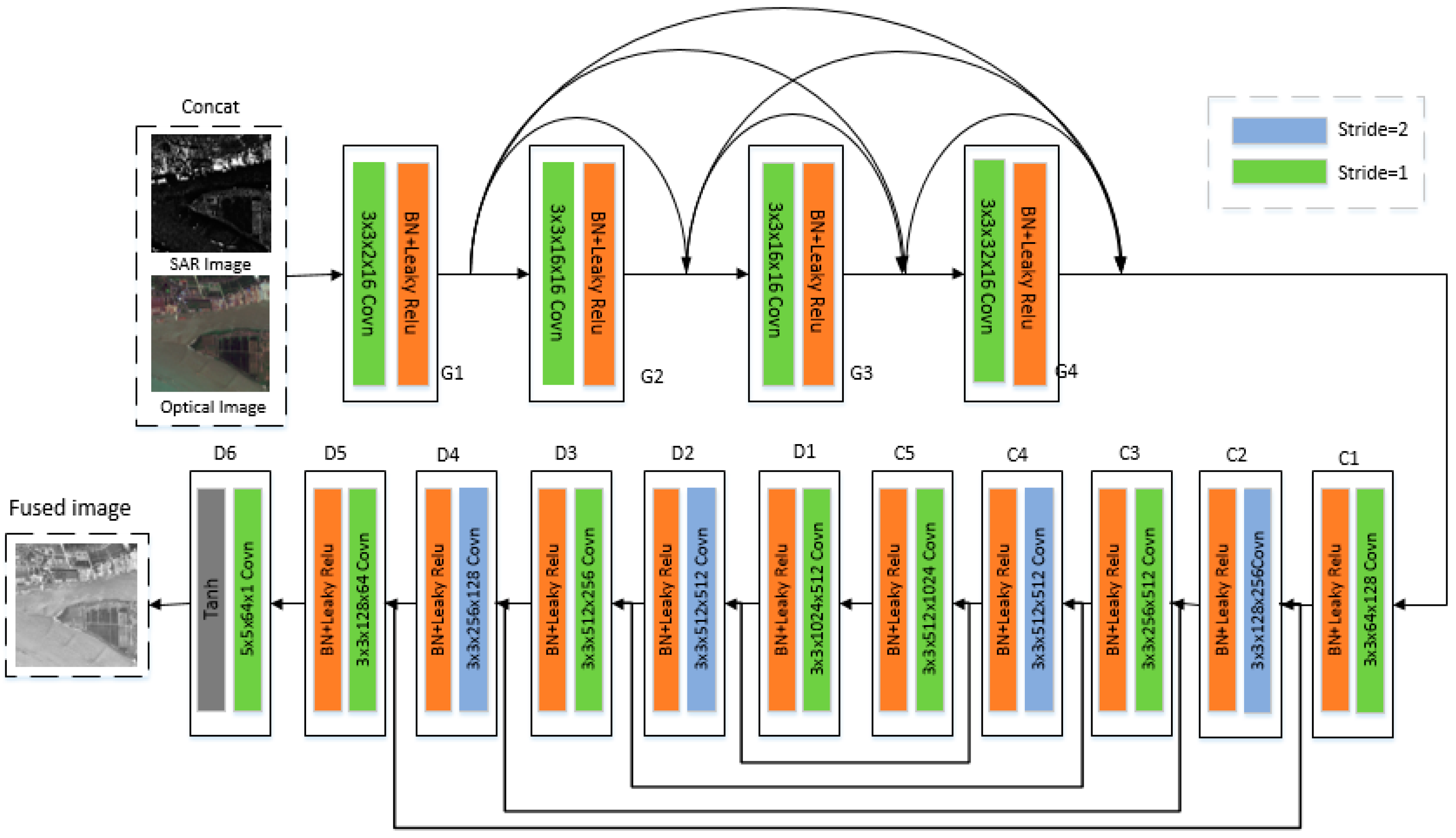
3.2. Network Architecture of Generator
3.3. Network Architecture of Discriminator
3.4. Loss Function
3.4.1. Generator Loss Function
- Adversarial loss
- Content loss
- Texture feature loss
- Peak signal-to-noise ratio loss
3.4.2. Discriminator Loss Function
- Adversarial loss
- SSIM loss
4. Result
4.1. Dataset and Parameter Settings
4.2. Valuable Metrics
- Entropy (EN)
- Average Gradient (AG)
- Peak signal-to-noise ratio (PSNR)
- Structural Similarity (SSIM)
- Spatial Frequency (SF)
- Spectral Distortion (SD)
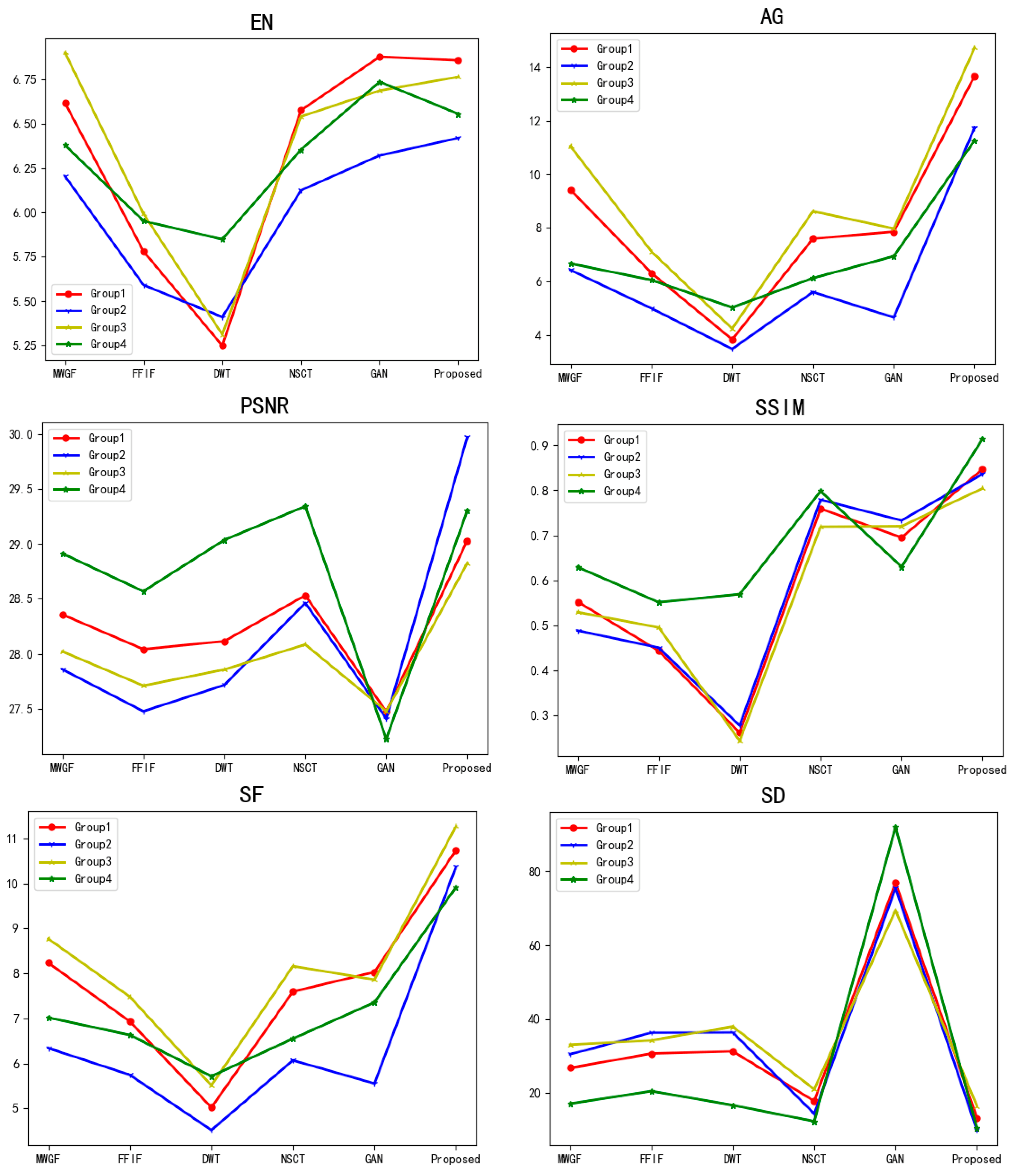
4.3. Results and Analysis
4.3.1. Network Structure Analysis
4.3.2. Loss Function Analysis
4.3.3. Different Algorithms Comparison
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, Y.H.; Li, D.R.; Sun, J.B. Data fusion techniques for multi-sources remotely sensed imagery. Remote Sens. Technol. Appl. 2000, 15, 41–44. [Google Scholar]
- Byun, Y. A texture-based fusion scheme to integrate high-resolution satellite SAR and optical images. Remote Sens. Lett. 2014, 5, 103–111. [Google Scholar] [CrossRef]
- Walessa, M.; Datcu, M. Model-based despeckling and information extraction from SAR images. IEEE Trans. Geosci. Remote Sens. 2000, 5, 2258–2269. [Google Scholar] [CrossRef]
- Yang, J.; Ren, G.; Ma, Y.; Fan, Y. Coastal wetland classification based on high resolution SAR and optical image fusion. In Proceedings of the Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; IEEE Press: New York, NY, USA, 2016; pp. 886–889. [Google Scholar]
- Hua, C.; Zhiguo, T.; Kai, Z.; Jiang, W.; Hui, W. Study on infrared camouflage of landing craft and camouflage effect evaluation. Infrared Technol. 2008, 30, 379–383. [Google Scholar]
- Do, M.N.; Vetterli, M. The contourlet transform: An efficient directional multiresolution image representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef] [Green Version]
- Xiao-Bo, Q.; Jing-Wen, Y.; Hong-Zhi, X.; Zi-Qian, Z. Image Fusion Algorithm Based on Spatial Frequency-Motivated Pulse Coupled Neural Networks in Nonsubsampled Contourlet Transform Domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar]
- Da Cunha, A.L.; Zhou, J.P.; Do, M.N. The nonsubsampled contourlet transform: Theory, design, and applications. IEEE Trans. Image Process. 2006, 15, 3089–3101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hao, F.; Aihua, L.; Yulong, P.; Xuejin, W.; Ke, J.; Hua, W. The effect evaluation of infrared camouflage simulation system based on visual similarity. Acta Armamentarii 2017, 38, 251–257. [Google Scholar]
- Limpitlaw, D.; Gens, R. Dambo mapping for environmental monitoring using Landsat TM and SAR imagery: Case study in the Zambian Copperbelt. Int. J. Remote Sens. 2006, 27, 4839–4845. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z.F. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Liping, Y.; Dunsheng, X.; Fahu, C. Comparison of Landsat 7 ETM+ Panchromatic and Multispectral Data Fusion Algorithms. J. Lanzhou Univ. (Nat. Sci. Ed.) 2007, 7-11+17. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional net-works for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Yan, B.; Kong, Y. A Fusion Method of SAR Image and Optical Image Based on NSCT and Gram-Schmidt Transform. In Proceedings of the IEEE International Conference on Geoscience & Remote Sensing Symposium, Waikoloa, HI, USA, 26 September 2020. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Maurer, T. How to pan-sharpen images using the gram-schmidt pan-sharpen method–A recipe. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-1/W1, 239–244. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep net-work training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, p. 6. [Google Scholar]
- Ye, S.N.; Su, K.N.; Xiao, C.B.; Duan, J. Image quality evaluation based on structure information extraction. Acta Electron. Sin. 2008, 5, 856–861. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Rao, Y.J. In-fibre bragg grating sensors. Meas. Sci. Technol. 1997, 8, 355. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2020, 80, 8423–8444. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef] [Green Version]
- Shanshan, H.; Qian, J.; Xin, J.; Xinjie, L.; Jianan, F.; Shaowen, Y. Semi-supervised remote sensing image fusion combining twin structure and generative confrontation network. J. Comput. Aided Des. Graph. 2021, 33, 92–105. [Google Scholar]
- Gao, J.; Yuan, Q.; Li, J.; Zhang, H.; Su, X. Cloud Removal with Fusion of High Resolution Optical and SAR Images Using Generative Adversarial Networks. Remote Sens. 2020, 12, 191. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhou, Z.; Li, S.; Wang, B. Multi-scale weighted gradient-based fusion for multi-focus images. Inf. Fusion 2014, 20, 60–72. [Google Scholar] [CrossRef]
- Pajares, G.; de la Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Zhan, K.; Xie, Y.; Wang, H.; Min, Y. Fast filtering image fusion. J. Electron. Imaging 2017, 26, 063004. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EN | AG | PSNR | SSIM | SF | SD | |
|---|---|---|---|---|---|---|
| GAN | 6.875 | 17.851 | 27.474 | 0.645 | 8.031 | 76.886 |
| DCGAN | 7.012 | 13.412 | 27.598 | 0.461 | 10.092 | 70.832 |
| U-net | 7.012 | 16.442 | 27.435 | 0.617 | 7.128 | 81.224 |
| SC-GAN | 7.232 | 15.324 | 27.61 | 0.641 | 10.763 | 58.497 |
| Dense-UGAN | 7.365 | 25.665 | 27.56 | 0.649 | 13.636 | 65.767 |
| EN | STD | AG | PSNR | SSIM | SD | |
|---|---|---|---|---|---|---|
| 6.324 | 20.56 | 14.24 | 28.727 | 0.648 | 18.435 | |
| 6.696 | 27.708 | 11.873 | 28.251 | 0.834 | 17.343 | |
| 6.515 | 23.788 | 10.973 | 29.049 | 0.781 | 14.341 | |
| 6.618 | 25.646 | 10.928 | 29.22 | 0.848 | 12.745 | |
| 6.551 | 24.923 | 9.203 | 28.294 | 0.816 | 16.415 | |
| 6.65 | 25.785 | 12.87 | 29.32 | 0.853 | 12.298 |
| EN | AG | PSNR | SSIM | SF | SD | |
|---|---|---|---|---|---|---|
| MWGF | 6.615 | 9.414 | 28.357 | 0.552 | 8.236 | 26.633 |
| DWT | 5.78 | 6.313 | 28.041 | 0.443 | 6.934 | 30.525 |
| FFIF | 5.25 | 3.828 | 28.114 | 0.261 | 5.02 | 31.151 |
| NSCT | 6.574 | 7.591 | 28.531 | 0.759 | 7.596 | 17.683 |
| Fusion-GAN | 6.875 | 7.851 | 27.474 | 0.695 | 8.031 | 76.886 |
| Proposed | 6.855 | 13.669 | 29.029 | 0.847 | 10.741 | 13.115 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Hong, F.; Leung, H.; Peng, X. A Fusion Method of Optical Image and SAR Image Based on Dense-UGAN and Gram–Schmidt Transformation. Remote Sens. 2021, 13, 4274. https://doi.org/10.3390/rs13214274
Kong Y, Hong F, Leung H, Peng X. A Fusion Method of Optical Image and SAR Image Based on Dense-UGAN and Gram–Schmidt Transformation. Remote Sensing. 2021; 13(21):4274. https://doi.org/10.3390/rs13214274
Chicago/Turabian StyleKong, Yingying, Fang Hong, Henry Leung, and Xiangyang Peng. 2021. "A Fusion Method of Optical Image and SAR Image Based on Dense-UGAN and Gram–Schmidt Transformation" Remote Sensing 13, no. 21: 4274. https://doi.org/10.3390/rs13214274
APA StyleKong, Y., Hong, F., Leung, H., & Peng, X. (2021). A Fusion Method of Optical Image and SAR Image Based on Dense-UGAN and Gram–Schmidt Transformation. Remote Sensing, 13(21), 4274. https://doi.org/10.3390/rs13214274