
Terrestrial Laser Scanning for Quantifying Timber Assortments from Standing Trees in a Mixed and Multi-Layered Mediterranean Forest

 ,
,  , ,
, ,  ,
,  , , and
, , and
Abstract
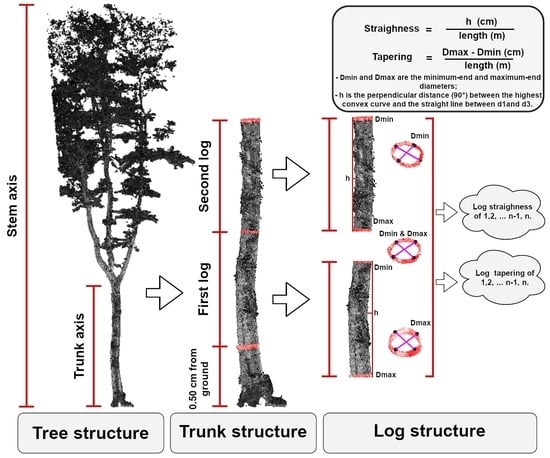
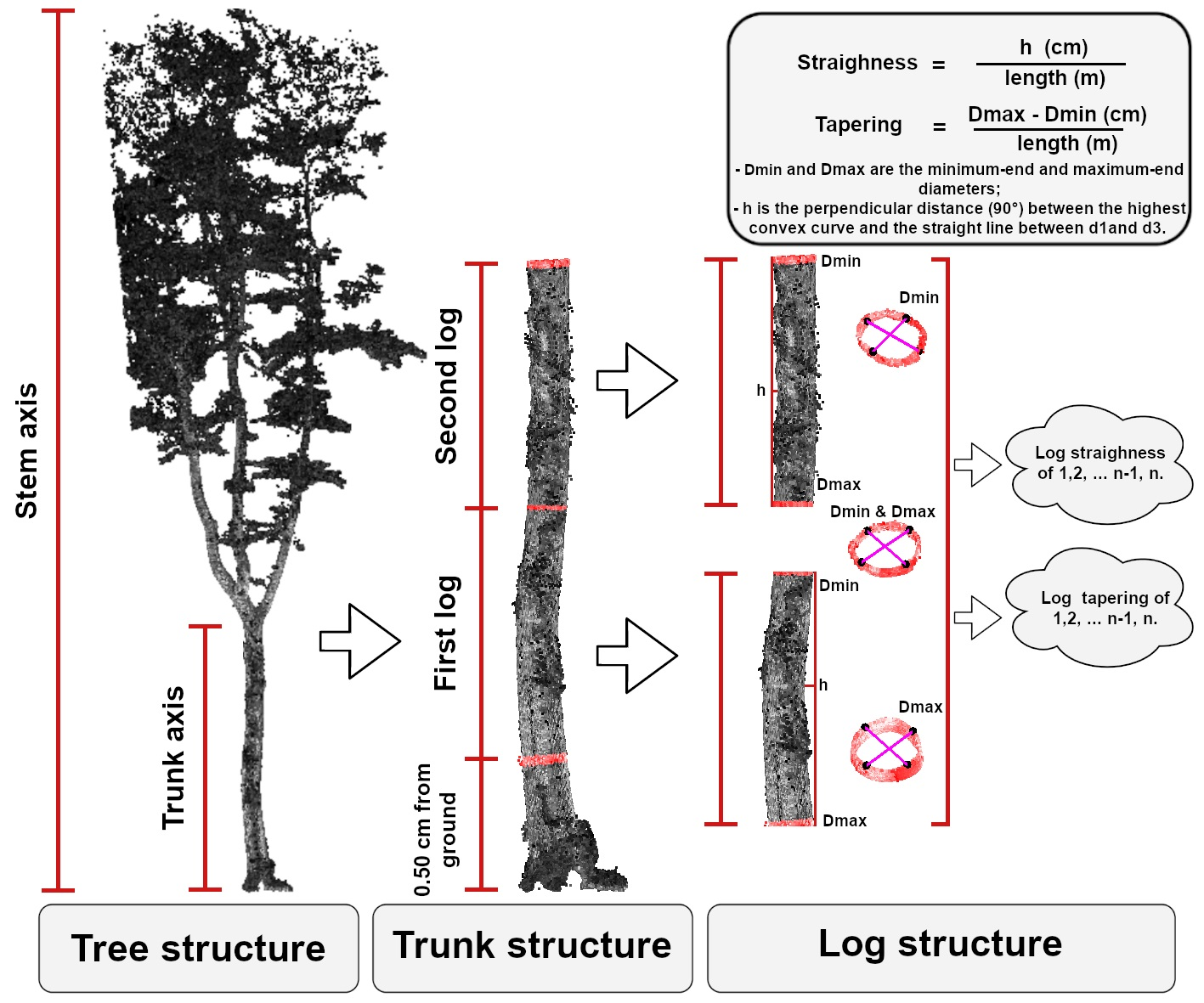
:
1. Introduction
2. Materials and Methods
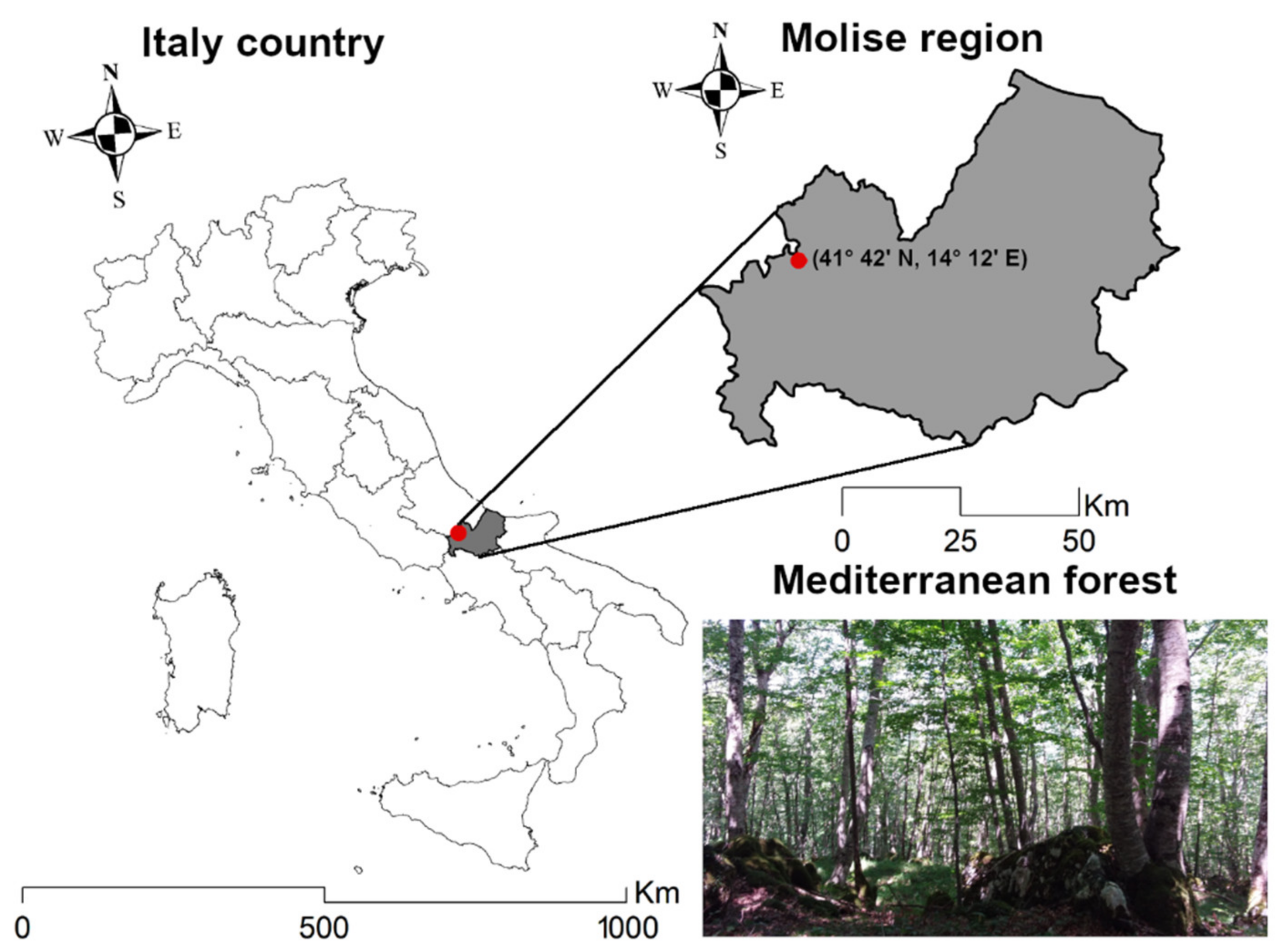
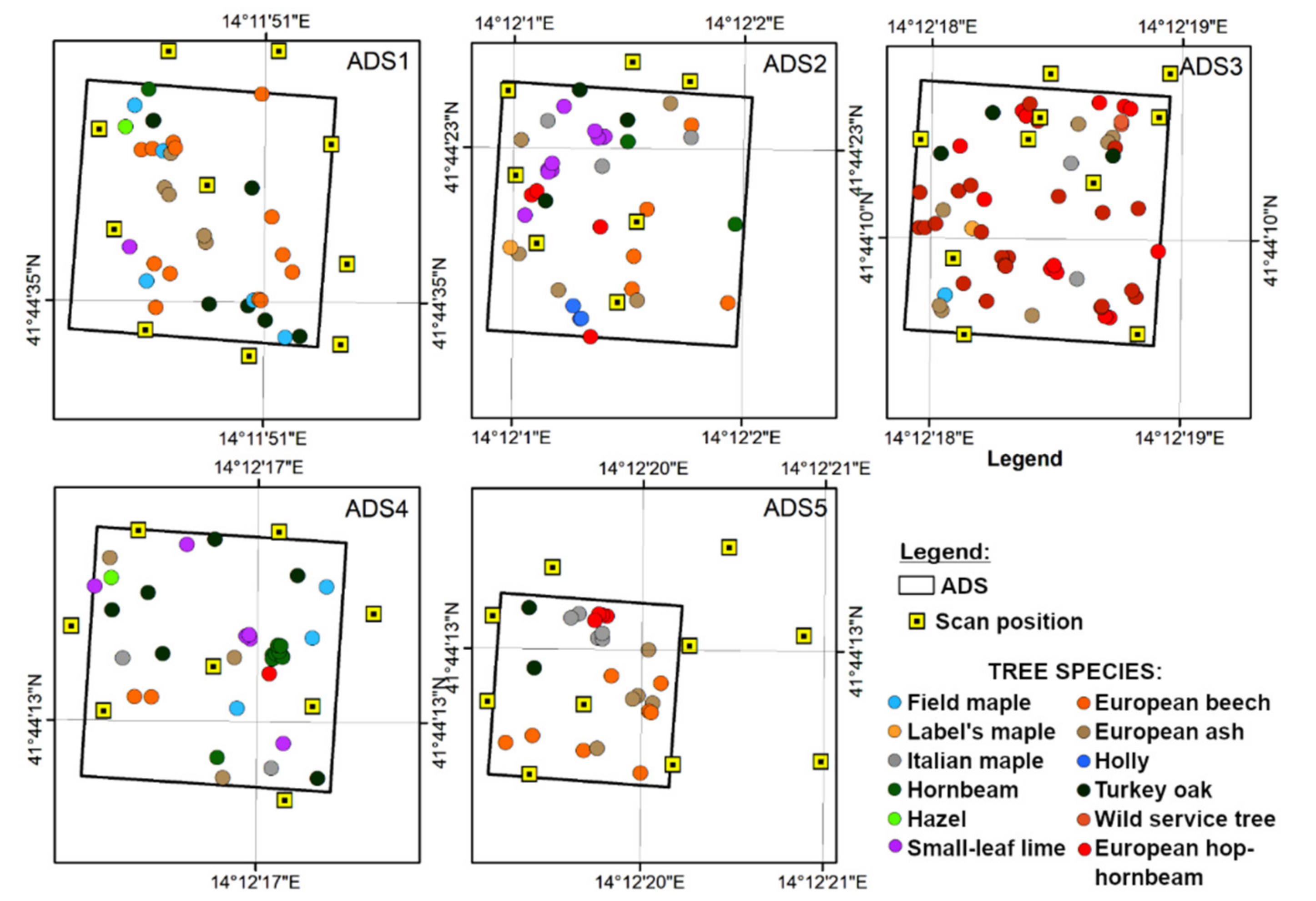
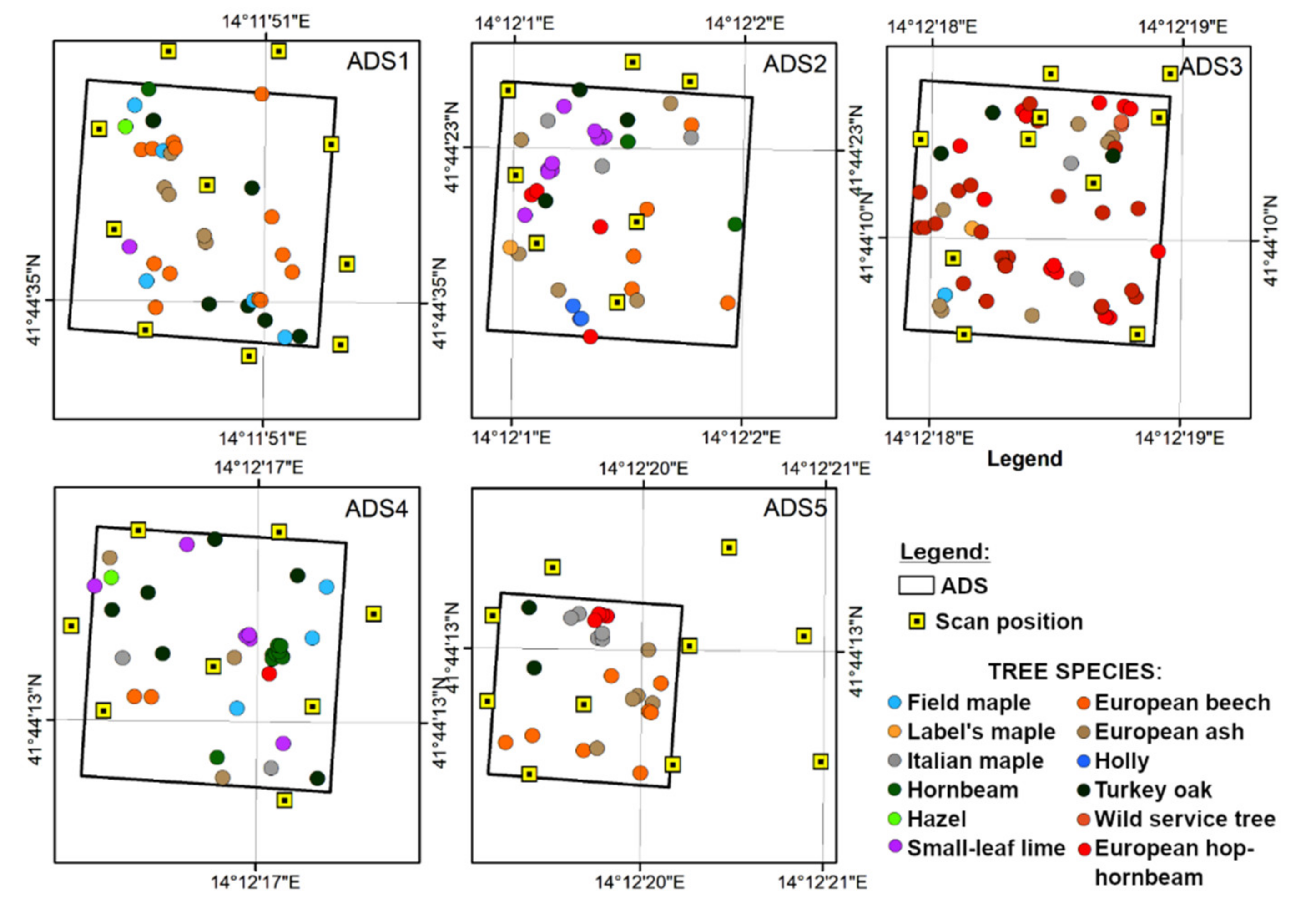
2.1. Study Area
2.2. Field Data
2.3. Terrestrial Laser Scanning Data
2.4. Data Analysis
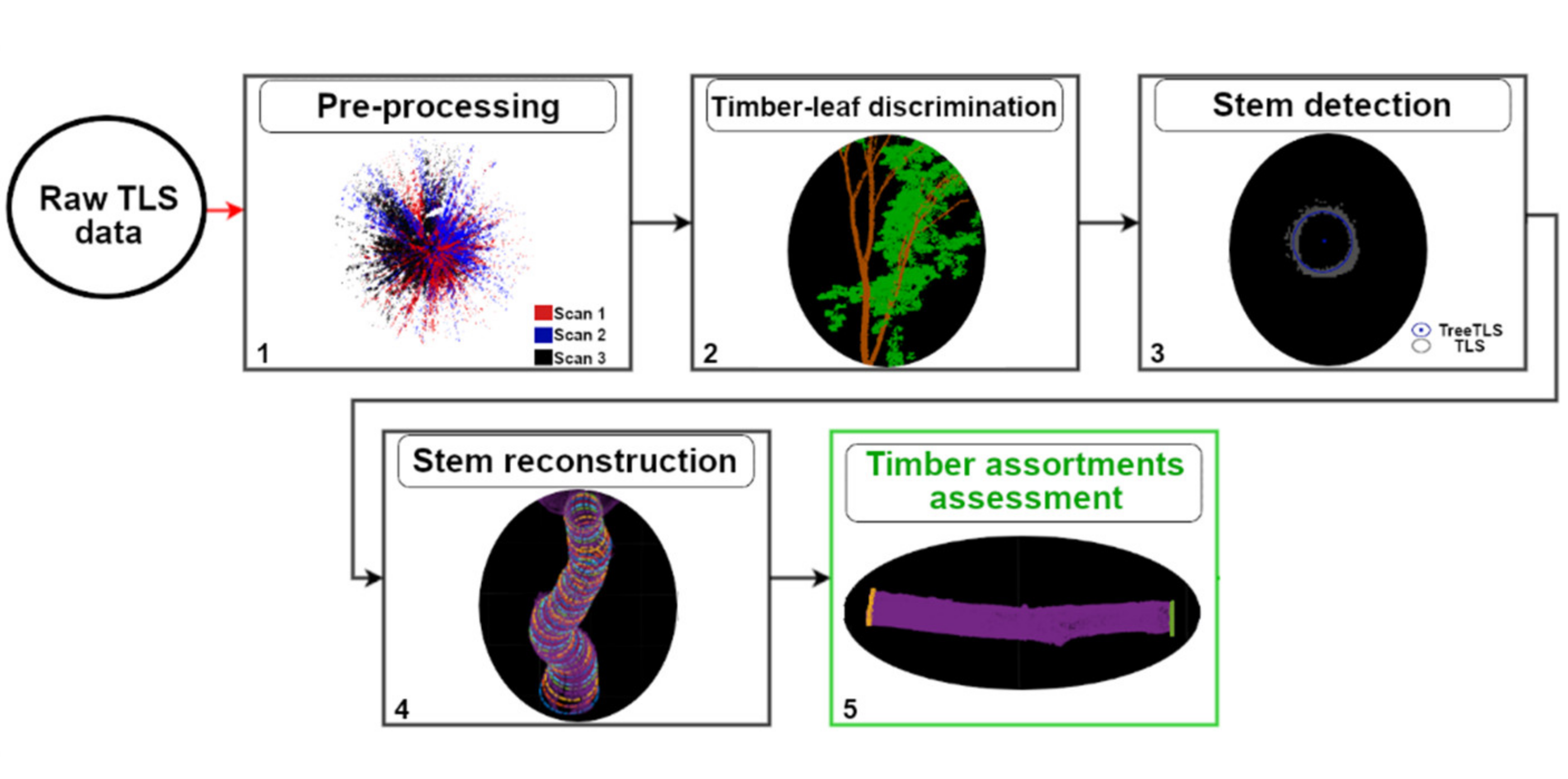
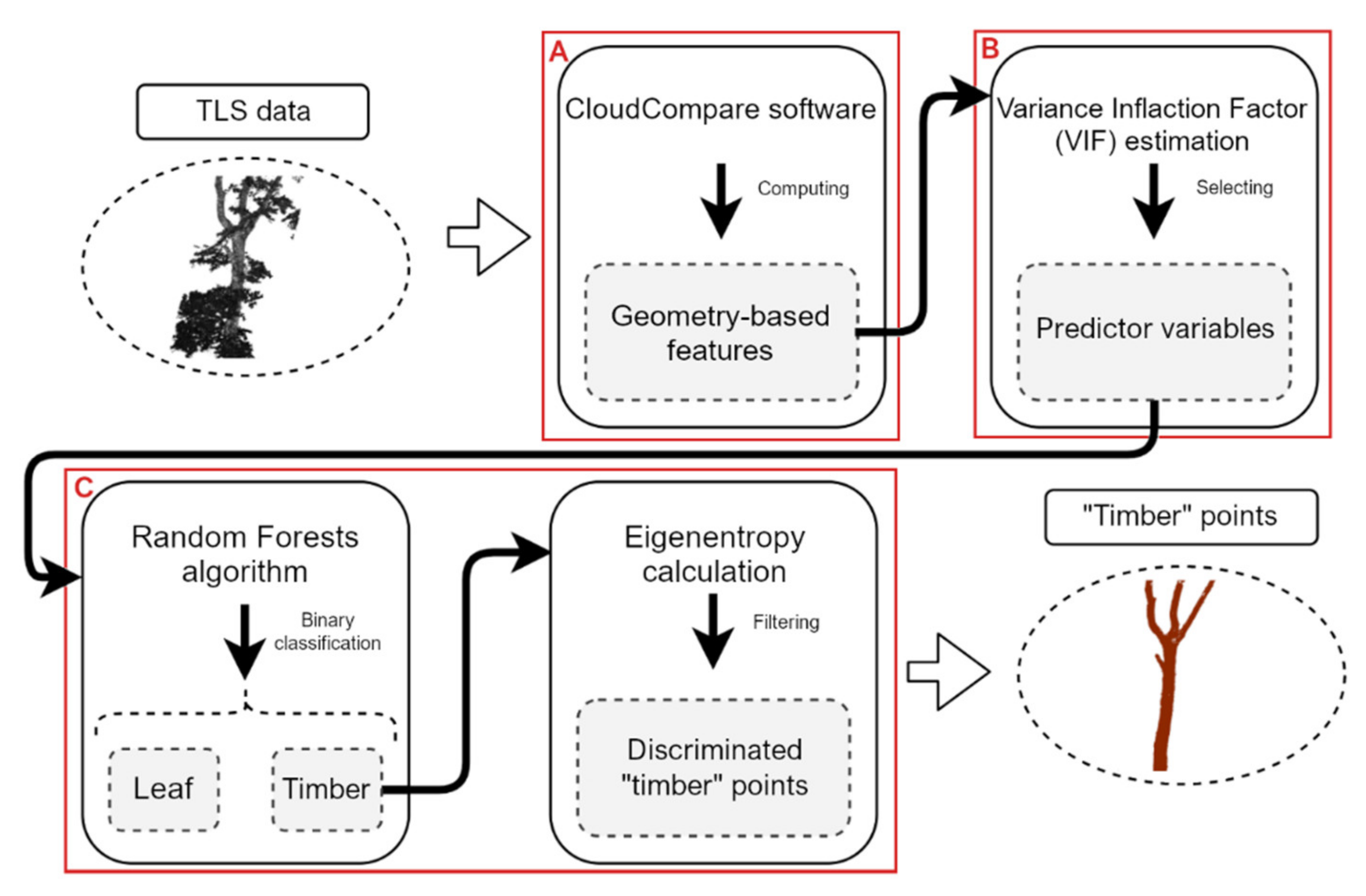
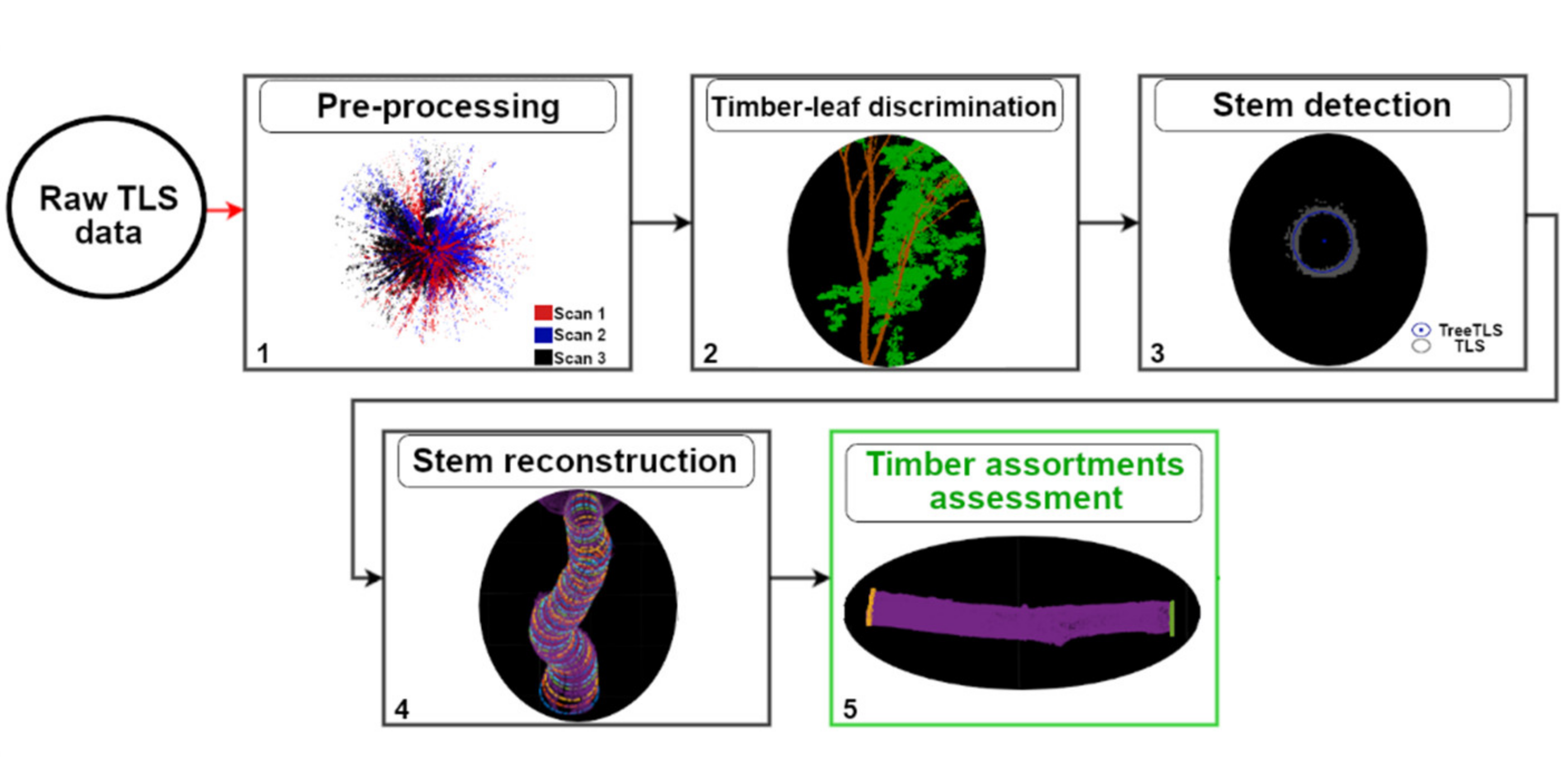
2.4.1. Pre-Processing of the Raw TLS Data
2.4.2. Timber-Leaf Discrimination
Geometry-Based Calculation
Predictor Variables Selection
Binary Classification
2.4.3. Stem Detection
2.4.4. Stem Reconstruction
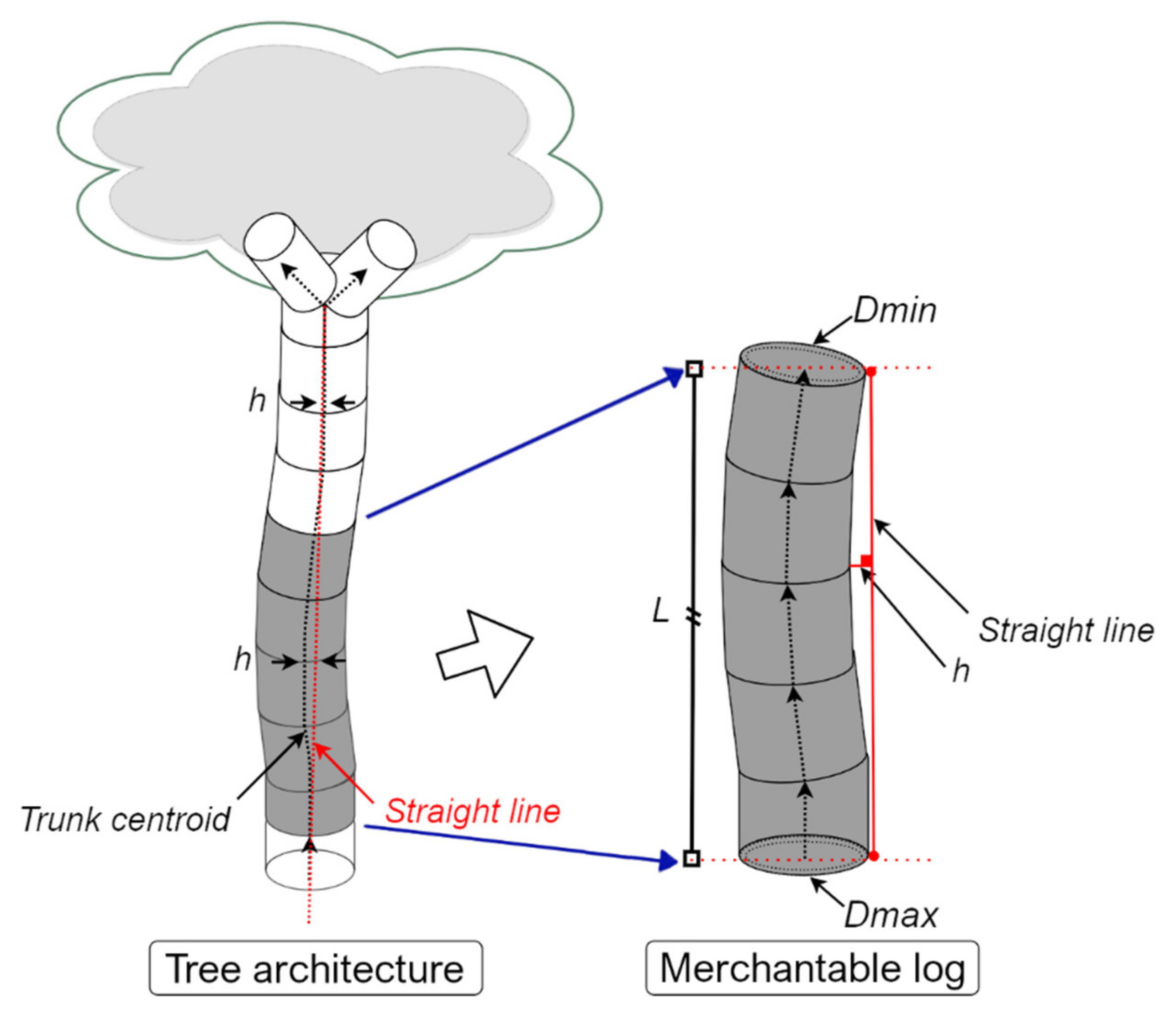
2.4.5. Timber Assortment Assessment
3. Results
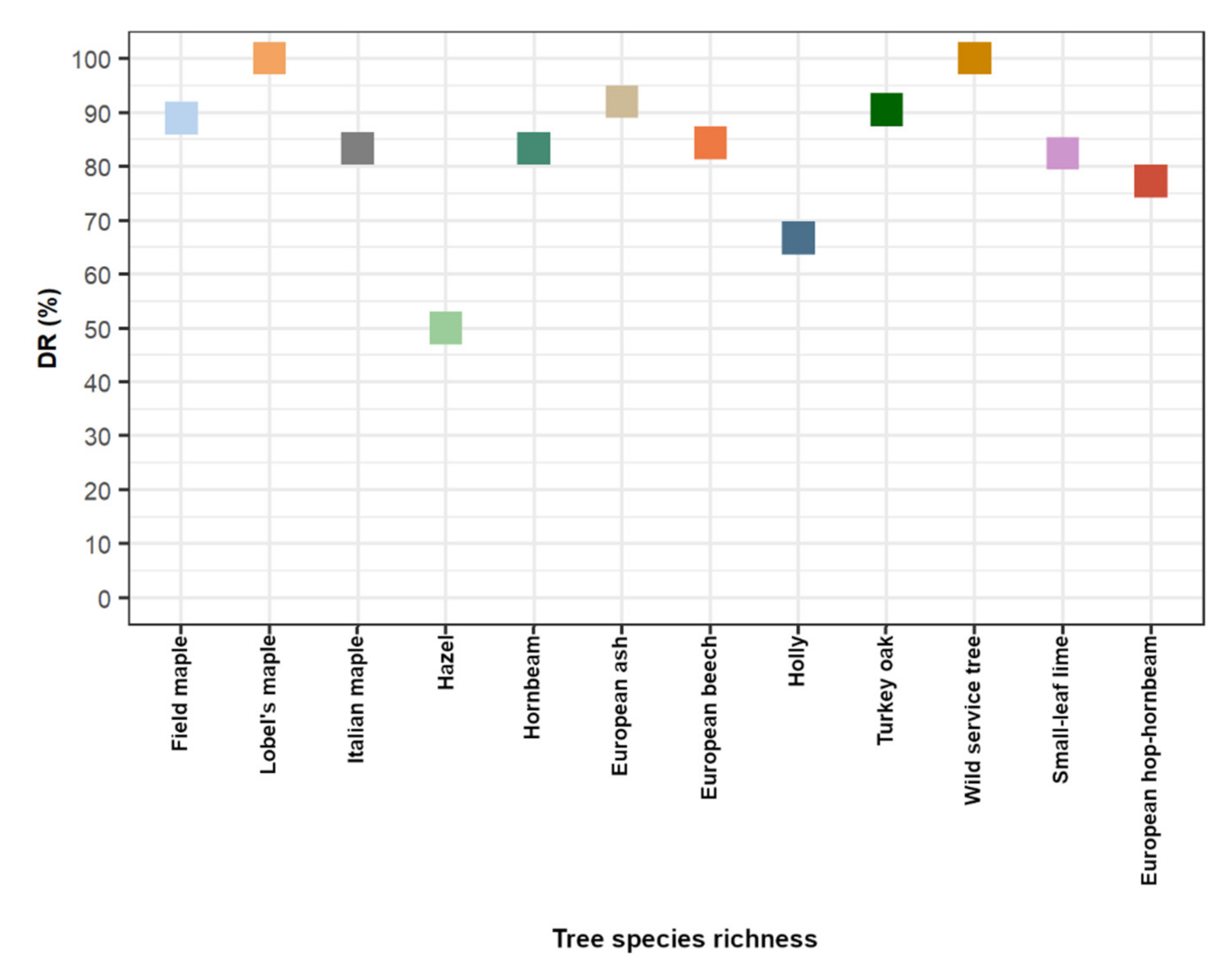
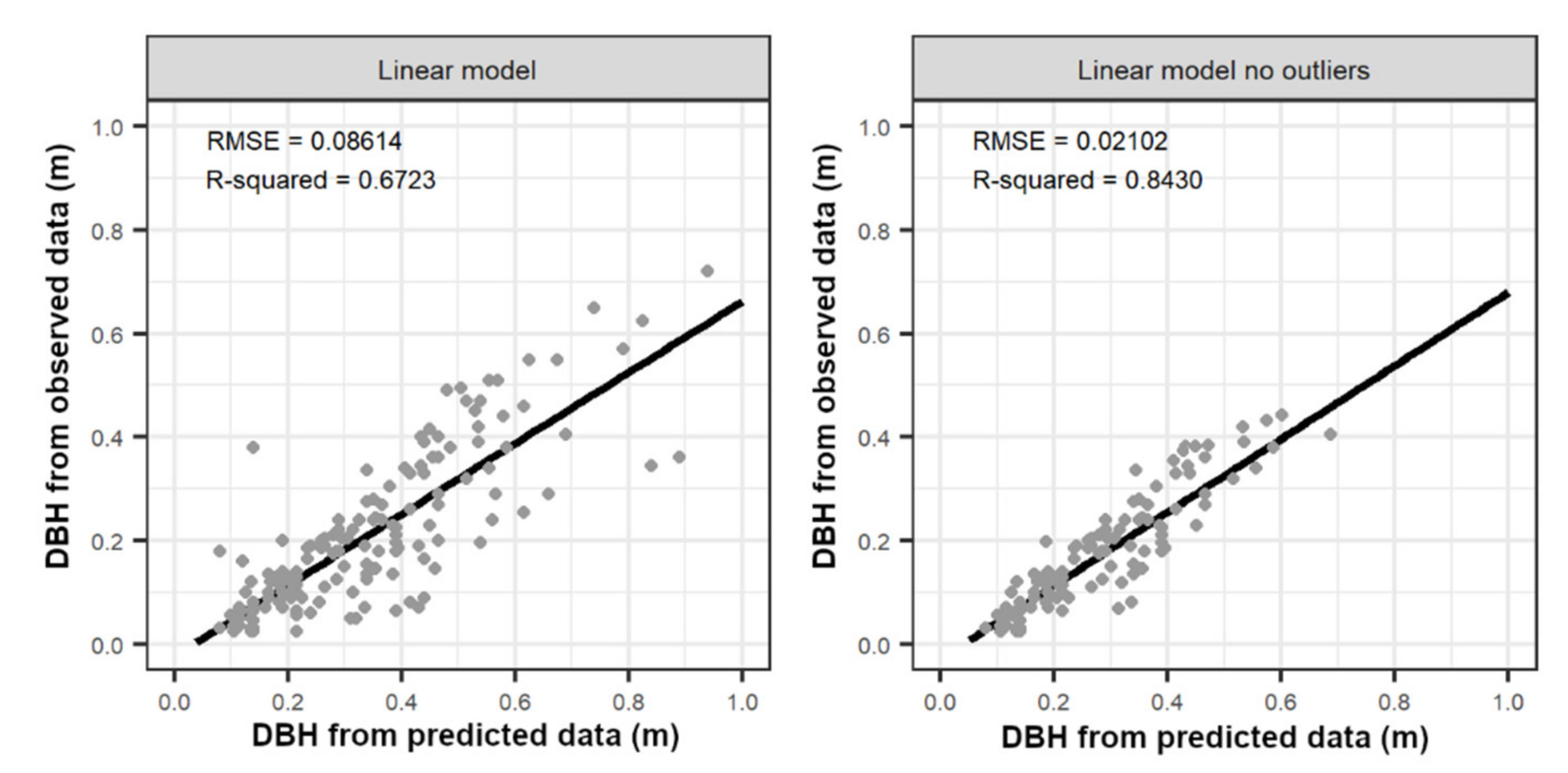
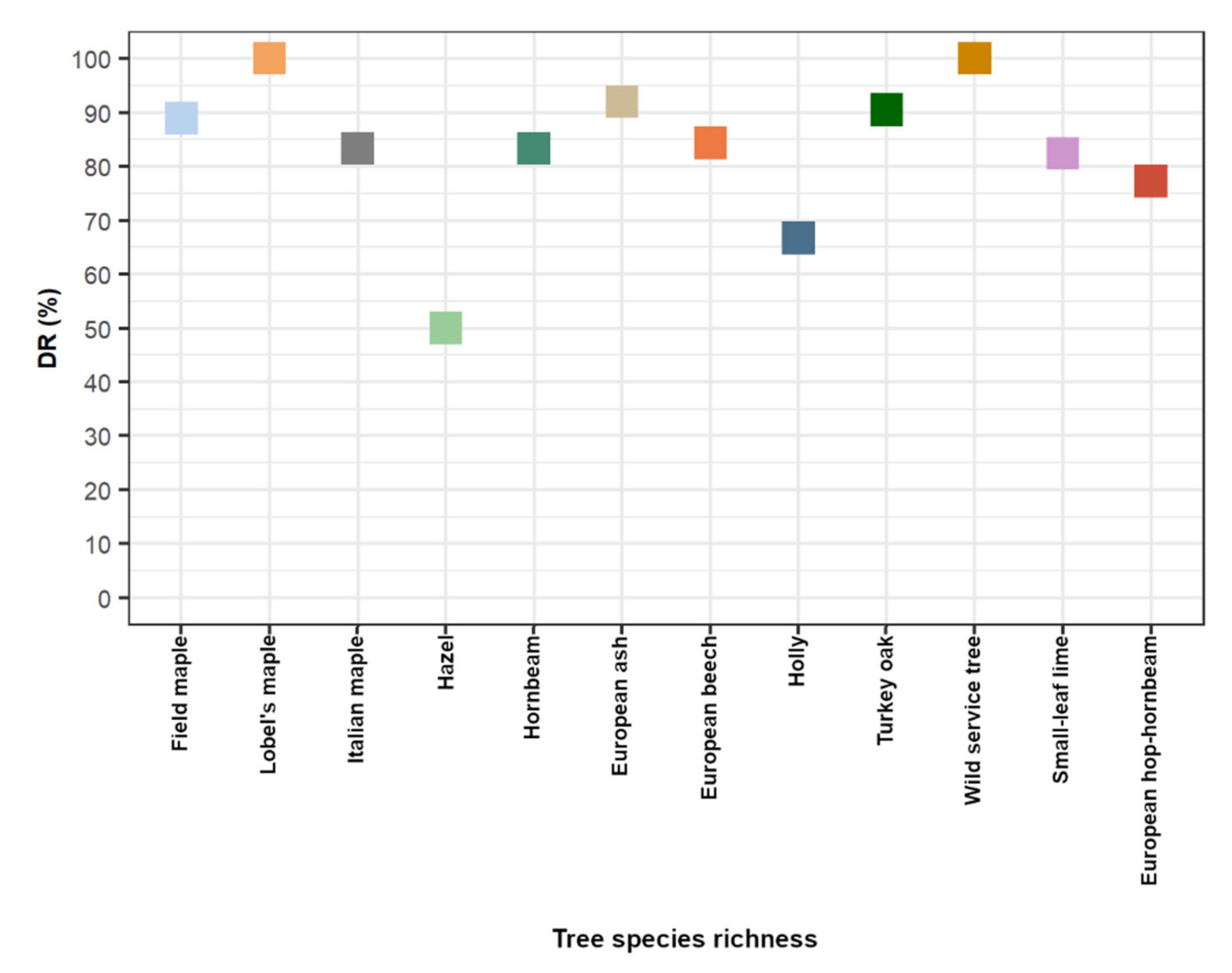
3.1. Timber-Leaf Discrimination, Stem Detection, and DBH Estimation
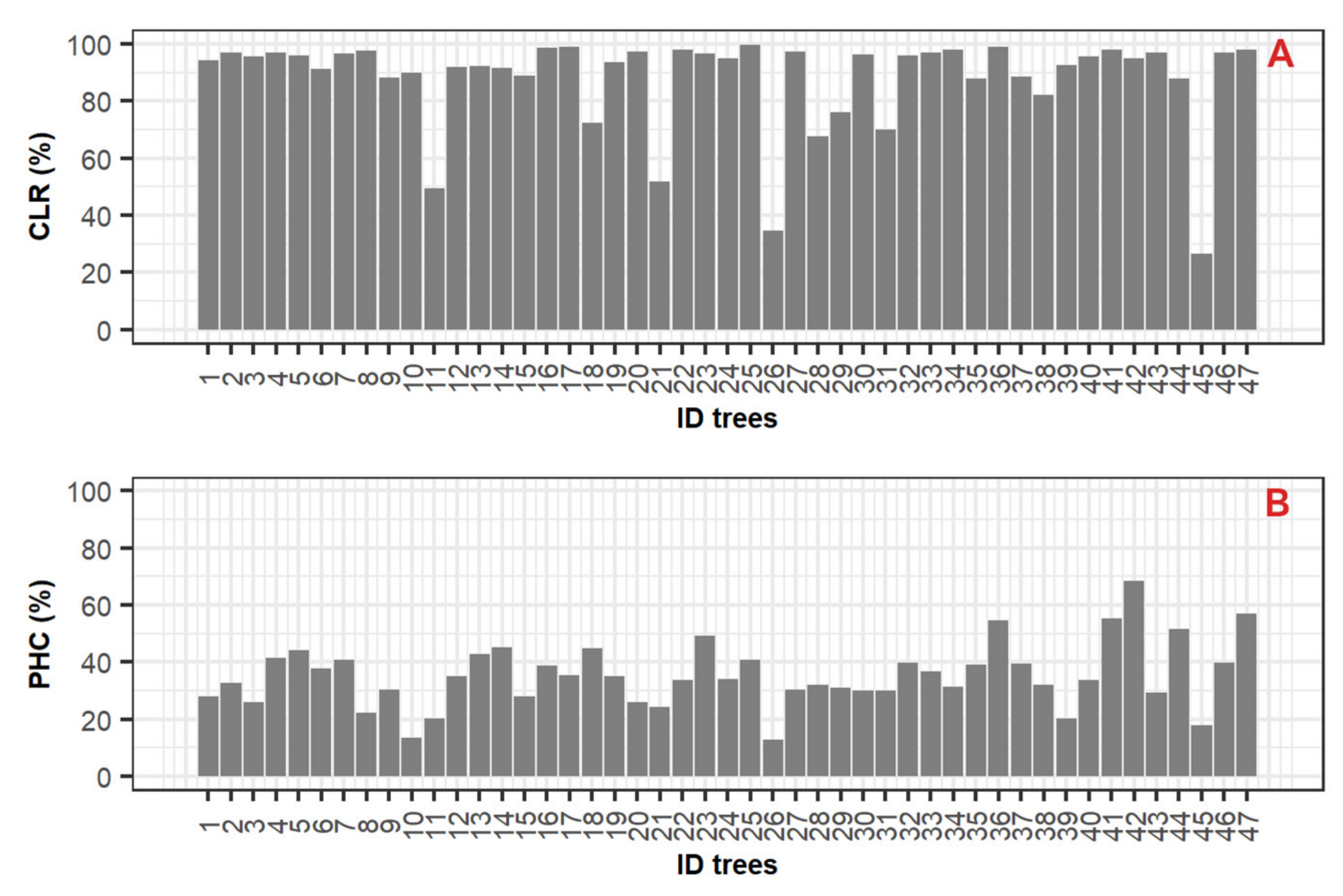
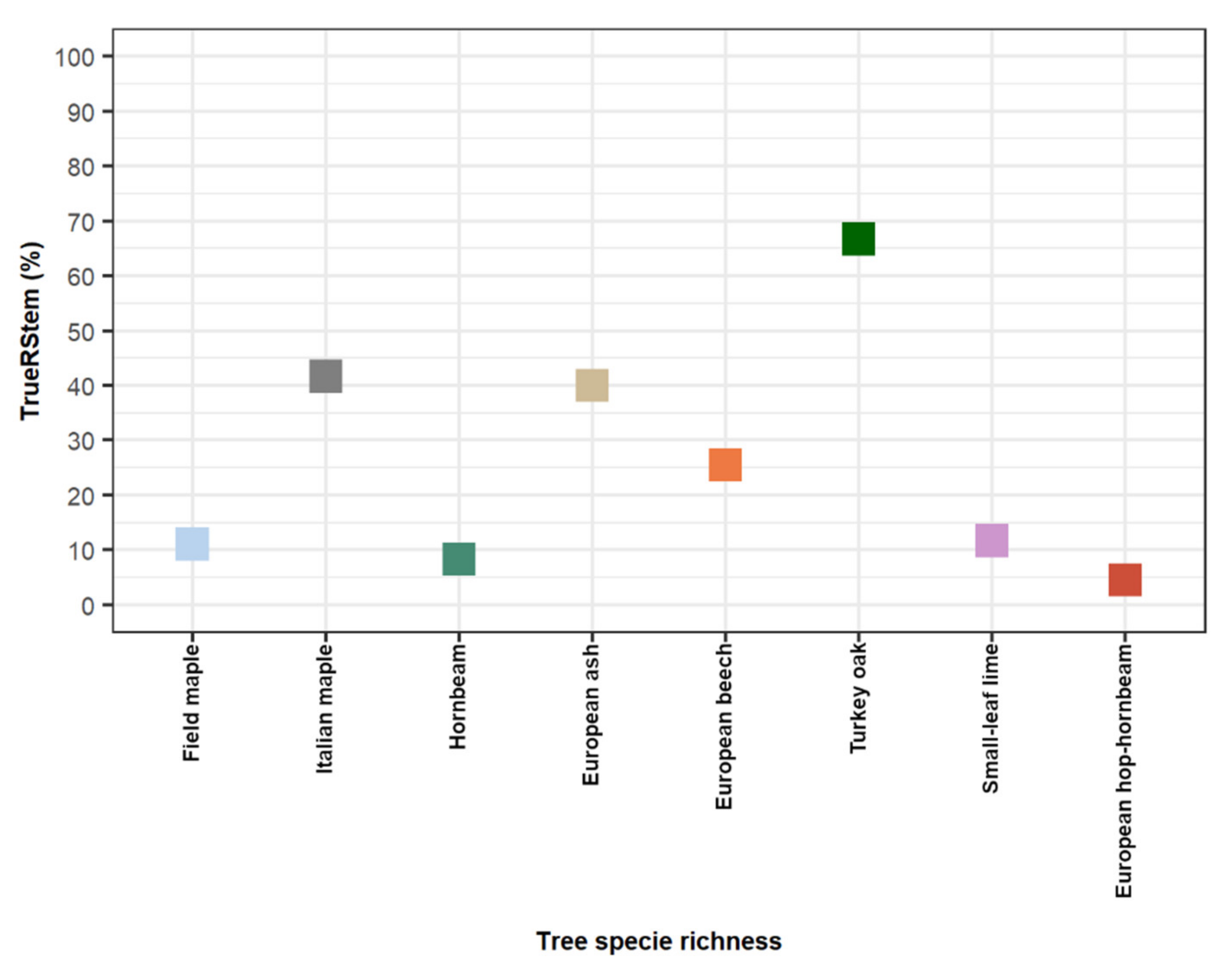
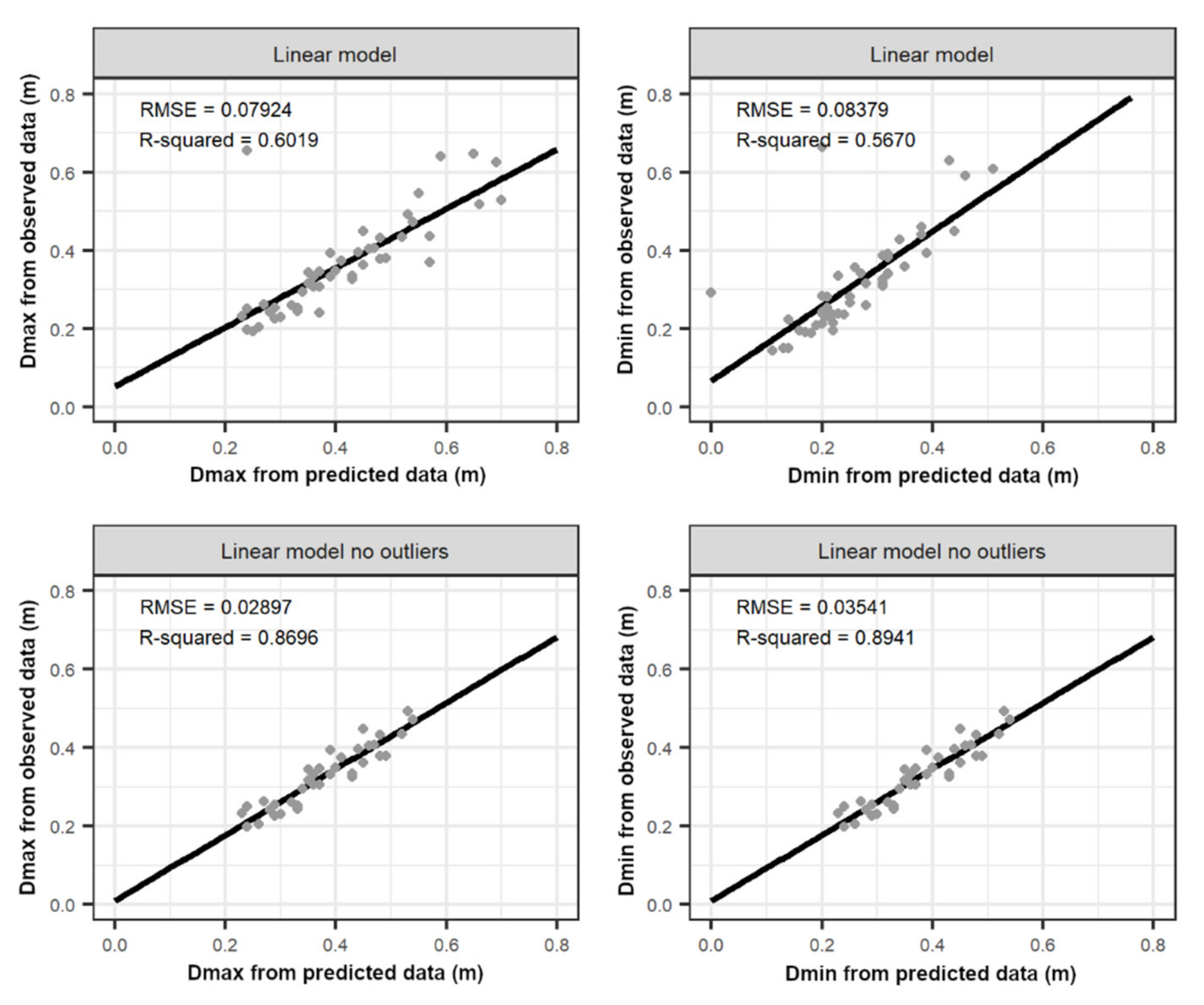
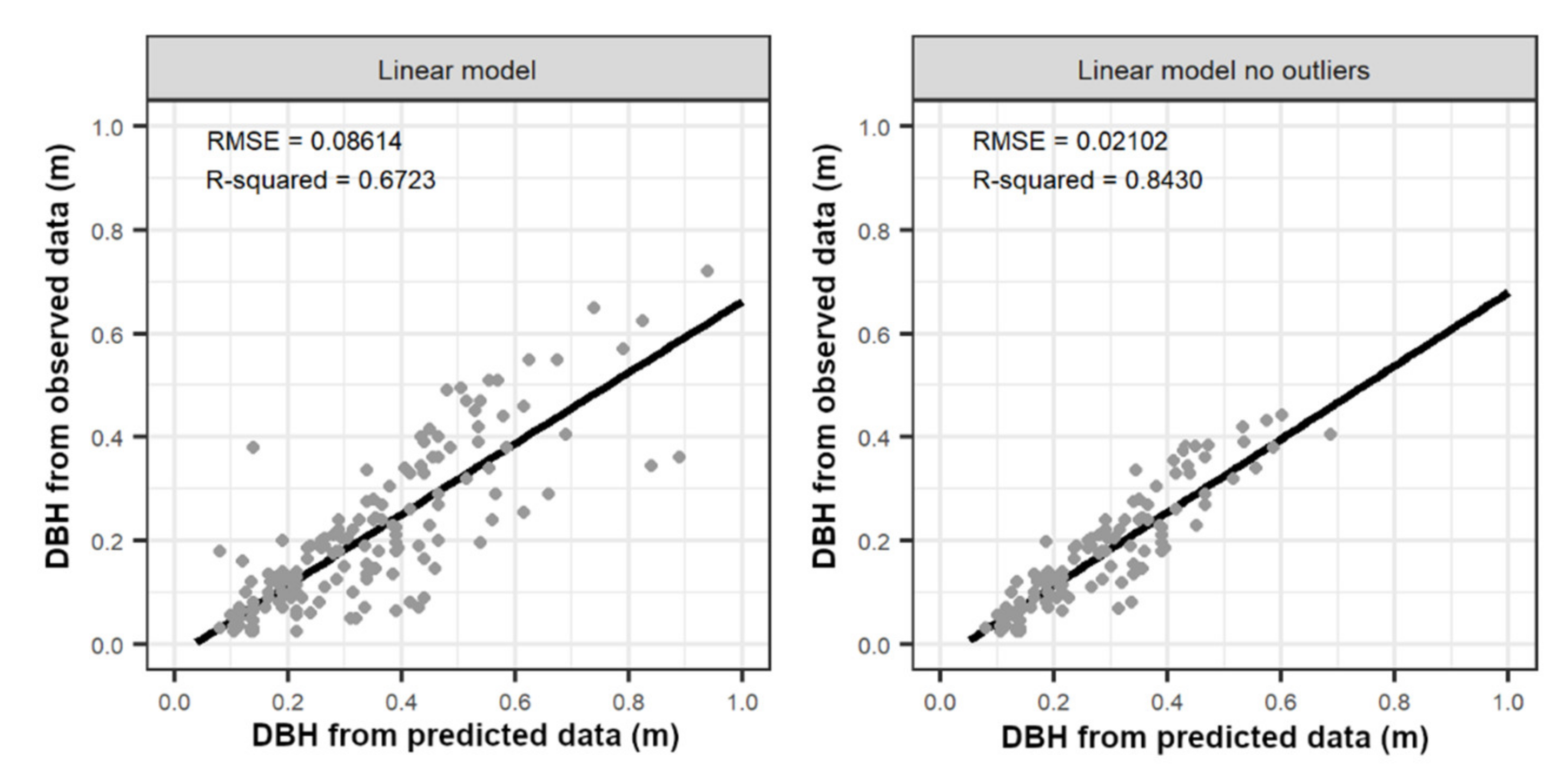
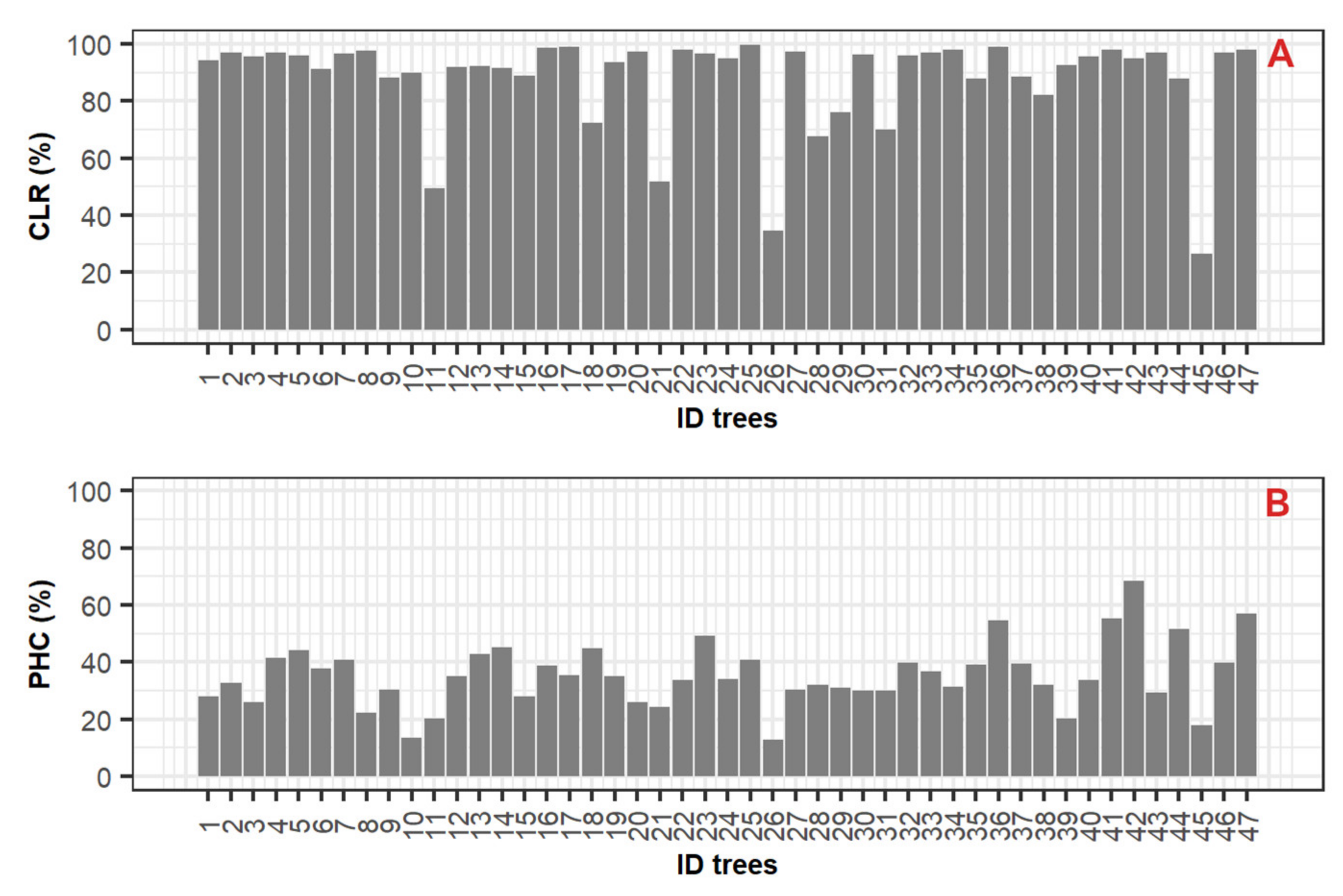
3.2. Stem Reconstruction
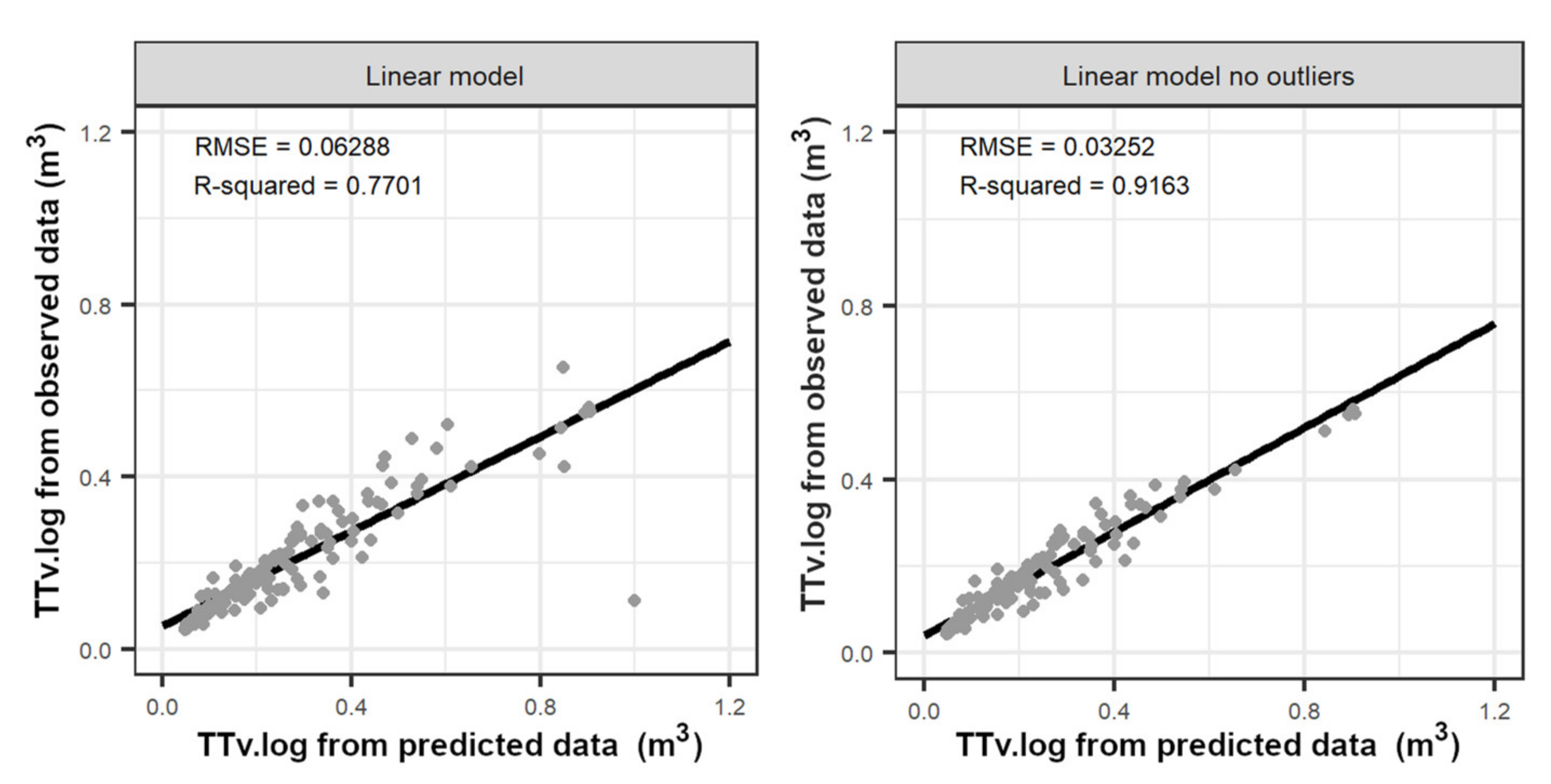
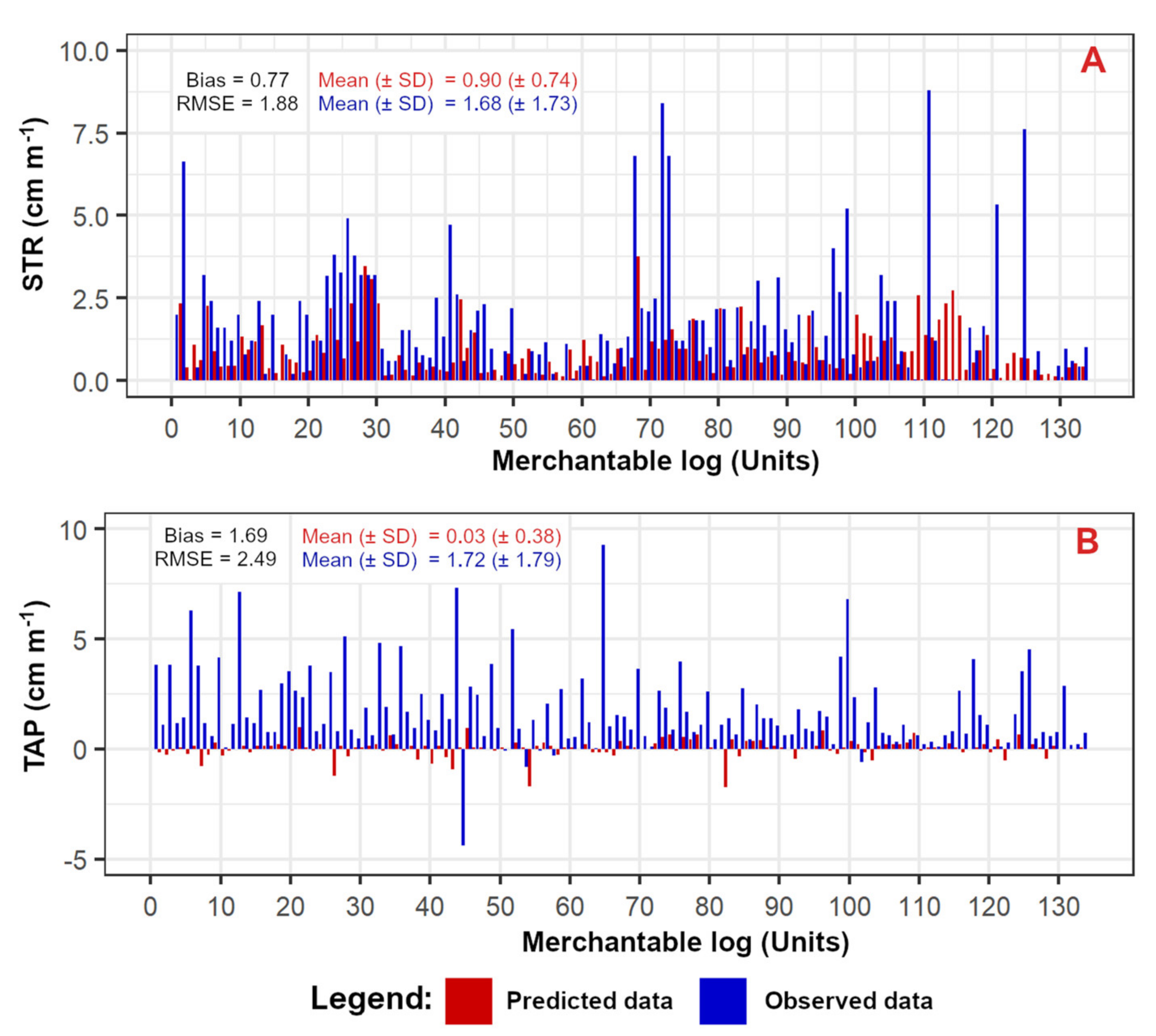
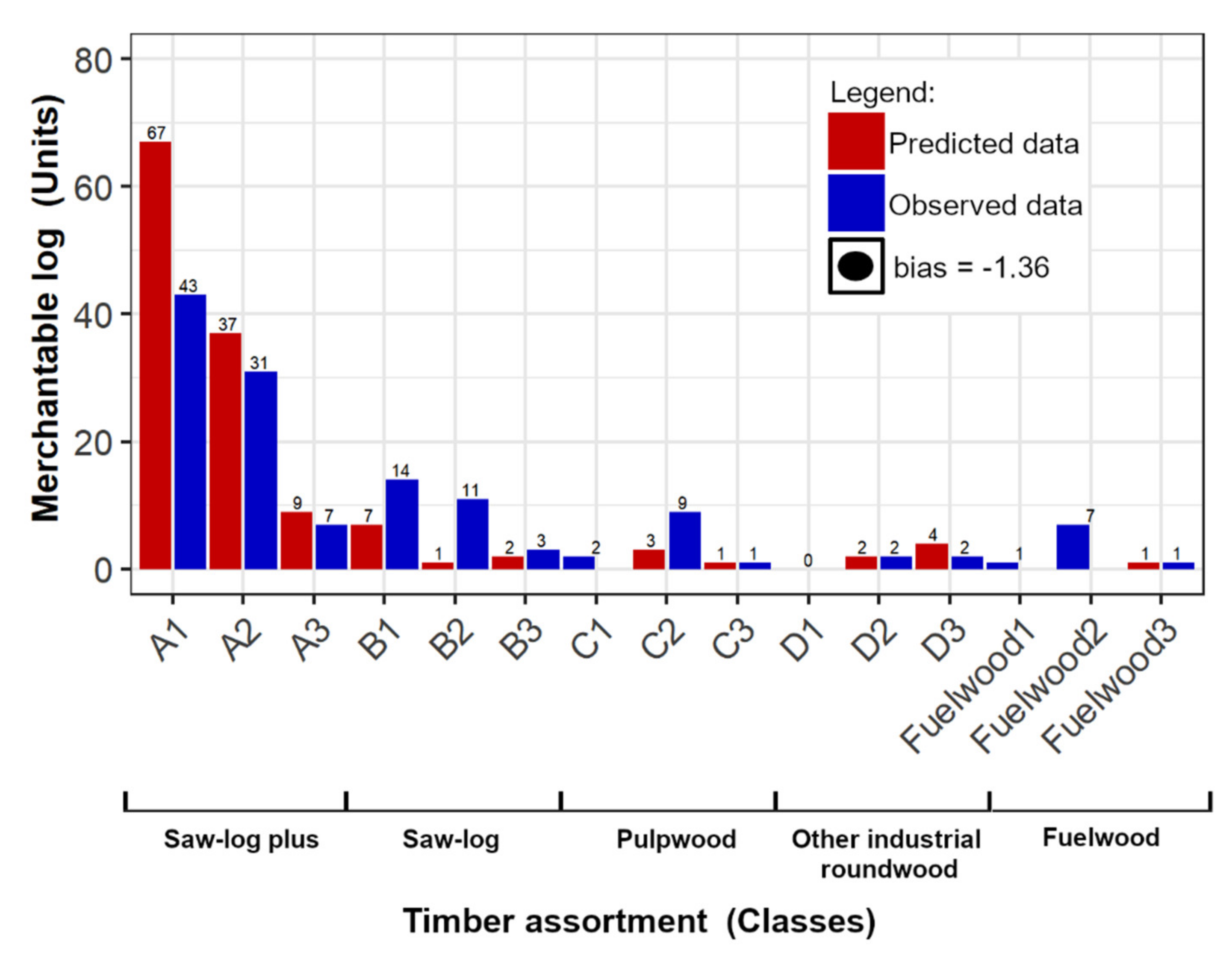
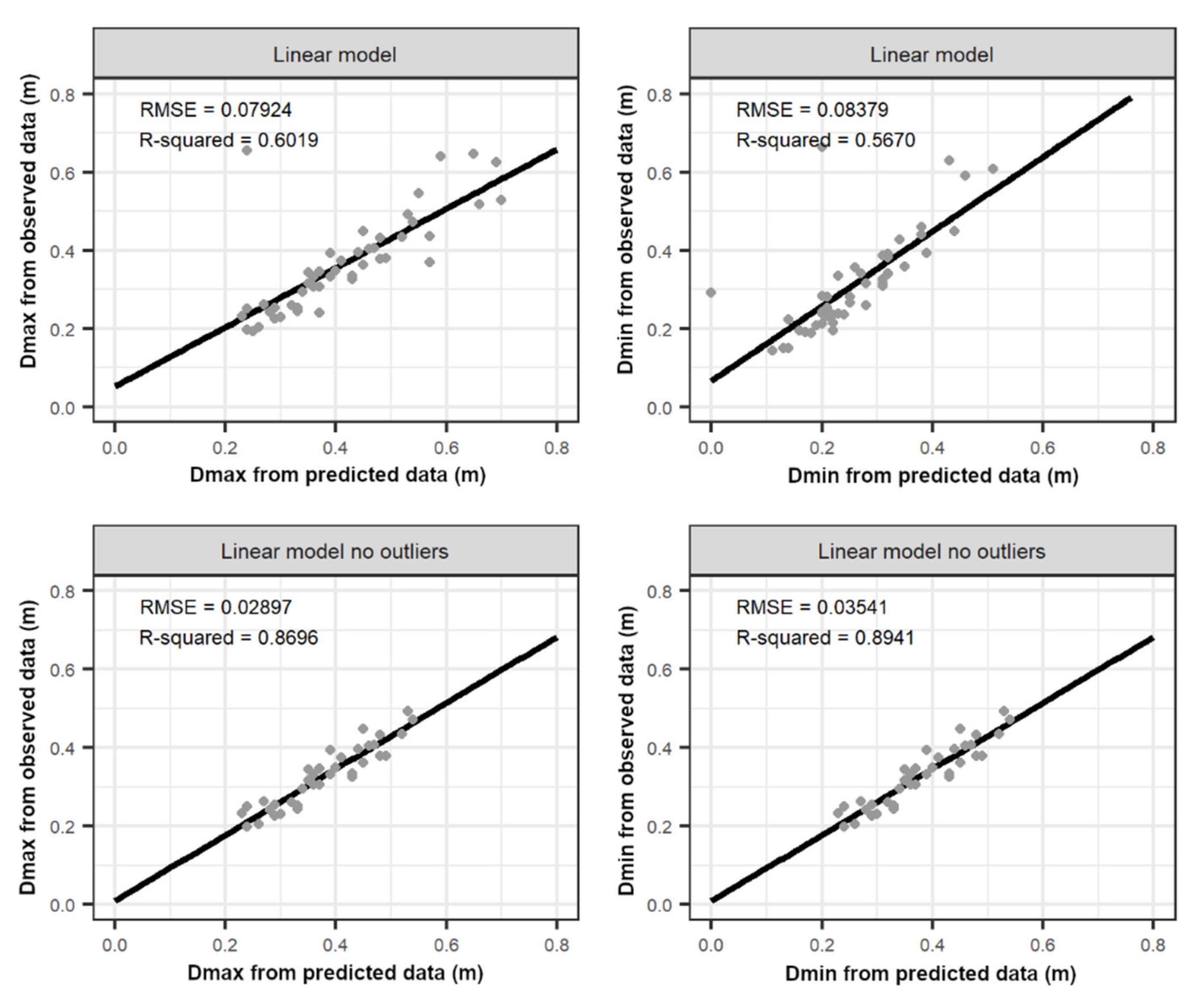
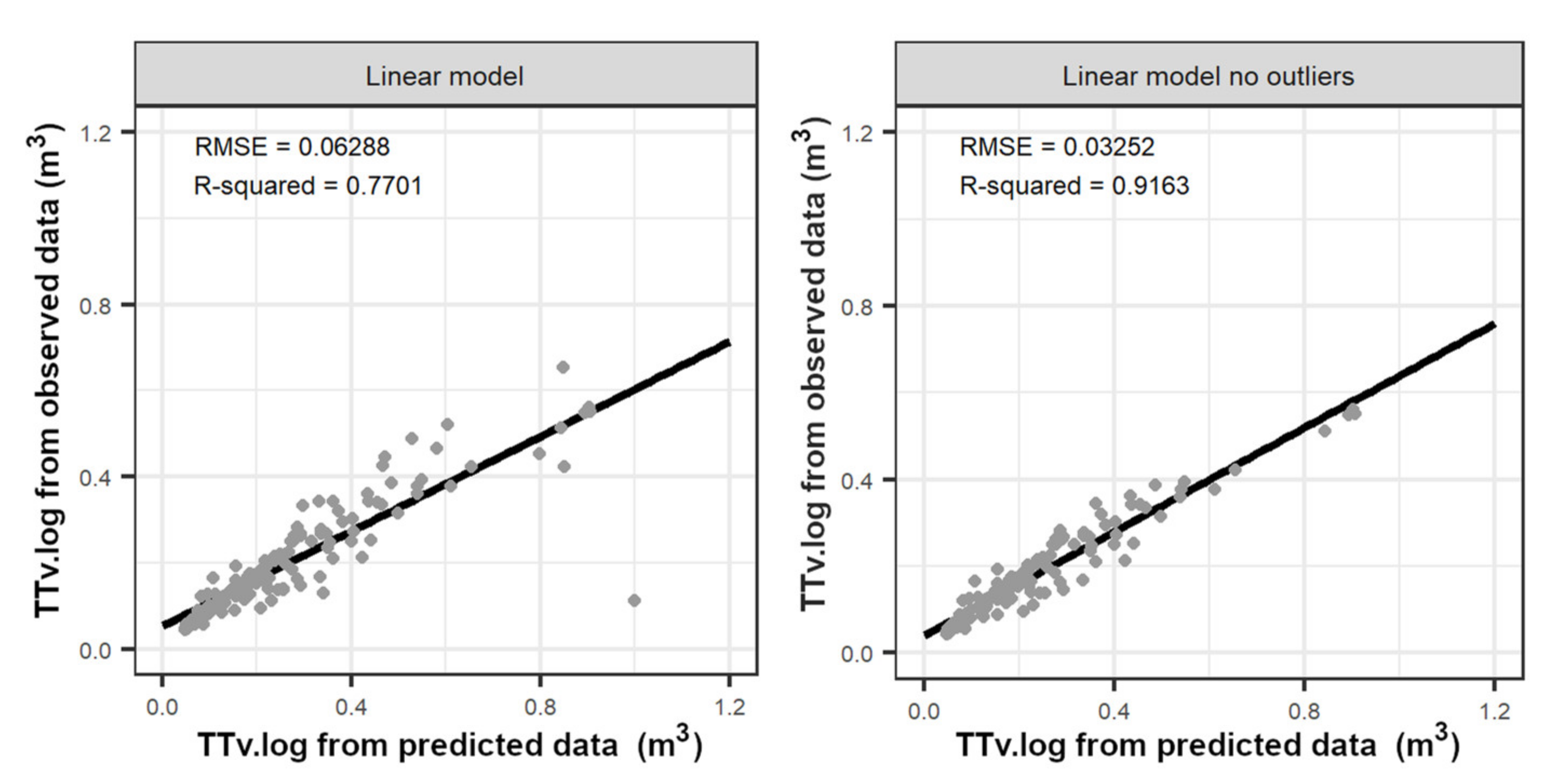
3.3. Timber Assortment Assessment
4. Discussion
4.1. Timber-Leaf Discrimination
4.2. Stem Detection and DBH Estimation
4.3. Stem Reconstruction
4.4. Timber Assortment Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B

Appendix C

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Merchantable (Units) | Non-merchantable (Units) | ||||||
|---|---|---|---|---|---|---|---|
| Tree Species | Observed Data | Predicted Data | Accuracy | Observed Data | Predicted Data | Accuracy | |
| 1 | Turkey oak | 62 | 43 | 10 | 11 | ||
| 2 | European beech | 42 | 36 | 12 | 10 | ||
| 3 | European ash | 45 | 34 | 10 | 6 | ||
| 4 | Field maple | 3 | 2 | 0 | 0 | ||
| 5 | Italian maple | 14 | 11 | 5 | 4 | ||
| 6 | Small-leaf lime | 8 | 4 | 1 | 1 | ||
| 7 | European Hop-hornbeam | 4 | 3 | 1 | 1 | ||
| 8 | Hornbeam | 1 | 1 | 1 | 1 | ||
| Sum | 179 | 134 | 40 | 34 | |||
| Bias * | 5.6 | 0.8 | |||||
| RMSE * | 8.3 | 1.7 | |||||
Appendix D
References
- State of Europe Forests. Summary for Policy Markers State of Europe’s Forest. In Proceedings of the Ministerial Conference on the Protection of Forests in Europe, Bratislava, Slovakia, 14–15 April 2020; Liasion Unit Bratislava: Bratislava, Slovakia, 2020; Volume 4, pp. 64–75. [Google Scholar]
- Proskurina, S.; Junginger, M.; Heinimö, J.; Tekinel, B.; Vakkilainen, E. Global biomass trade for energy- Part 2: Production and trade streams of wood pellets, liquid biofuels, charcoal, industrial roundwood and emerging energy biomass. Biofuels Bioprod. Biorefining 2019, 13, 371–387. [Google Scholar] [CrossRef]
- West, P.W.; West, P.W. Tree and Forest Measurement, 3rd ed.; Springer: Berlin, Germany, 2009; p. 214. [Google Scholar]
- Kankare, V.; Vauhkonen, J.; Tanhuanpää, T.; Holopainen, M.; Vastaranta, M.; Joensuu, M.; Krooks, A.; Hyyppä, J.; Hyyppä, H.; Alho, P.; et al. Accuracy in estimation of timber assortments and stem distribution—A comparison of airborne and terrestrial laser scanning techniques. ISPRS J. Photogramm. Remote Sens. 2014, 97, 89–97. [Google Scholar] [CrossRef]
- Luoma, V.; Saarinen, N.; Kankare, V.; Tanhuanpää, T.; Kaartinen, H.; Kukko, A.; Holopainen, M.; Hyyppä, J.; Vastaranta, M. Examining Changes in Stem Taper and Volume Growth with Two-Date 3D Point Clouds. Forests 2019, 10, 382. [Google Scholar] [CrossRef] [Green Version]
- Laasasenaho, J. Taper curve and volume functions for pine, spruce and birch. Commun. Inst. For. Fenn. 1982, 108, 1–74. [Google Scholar]
- Togni, M. Classificazione commerciale del legname grezzo tondo: Regole per la classificazione visuale dei tronchi. In Ente Regionale per i Servizi All’Agricoltura e Alle Foreste; ERSAF: Lombardia, Italy, 2017; p. 97. [Google Scholar]
- Holopainen, M.; Vastaranta, M.; Rasinmäki, J.; Kalliovirta, J.; Mäkinen, A.; Haapanen, R.; Melkas, T.; Yu, X.; Hyyppä, J. Uncertainty in timber assortment estimates predicted from forest inventory data. Eur. J. For. Res. 2010, 129, 1131–1142. [Google Scholar] [CrossRef]
- Gazull, L.; Gautier, D. Woodfuel in a global change context. Wiley Interdiscip. Rev. Energy Environ. 2015, 4, 156–170. [Google Scholar] [CrossRef]
- Santopuoli, G.; Temperli, C.; Alberdi, I.; Barbeito, I.; Boseka, M.; Bottero, A.; Klopčič, M.; Lesinski, J.; Panzacchi, P.; Tognetti, R. Pan-European Sustainable Forest Management indicators for assessing Climate-Smart Forestry in Europe. Can. J. For. Res. 2021, 51, 1–10. [Google Scholar] [CrossRef]
- Dassot, M.; Constant, T.; Fournier, M. The use of terrestrial LiDAR technology in forest science: Application fields, benefits and Challenges The use of terrestrial LiDAR technology in forest science: Application fields benefits and challenges. Ann. For. Sci. 2011, 68, 959–974. [Google Scholar] [CrossRef] [Green Version]
- Santopuoli, G.; Di Febbraro, M.; Maesano, M.; Balsi, M.; Marchetti, M.; Lasserre, B. Machine Learning Algorithms to Predict Tree-Related Microhabitats using Airborne Laser Scanning. Remote Sens. 2020, 12, 2142. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Pfeifer, N. Feasibility of machine learning methods for separating wood and leaf points from terrestrial laser scanning data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-2/W4, 157–164. [Google Scholar] [CrossRef] [Green Version]
- Torresan, C.; Chiavetta, U.; Hackenberg, J. Applying quantitative structure models to plot-based terrestrial laser data to assess dendrometric parameters in dense mixed forests. For. Syst. 2018, 27, e004. [Google Scholar] [CrossRef] [Green Version]
- Alvites, C.; Santopuoli, G.; Maesano, M.; Chirici, G.; Moresi, F.V.; Tognetti, R.; Marchetti, M.; Lasserre, B. Unsupervised algorithms to detect single trees in a mixed-species and multi-layered Mediterranean forest using LiDAR data. Can. J. For. Res. 2021, 1–55. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Francesco, P.; Hackenberg, J.; et al. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Pfeifer, N.; Gorte, B.; Winterhalder, D. Automatic reconstruction of single trees from terrestrial laser scanner data. In Proceedings of the 20th ISPRS Congress, Istanbul, Turkey, 12–23 July 2004; 2004; Volume 35, pp. 114–119. [Google Scholar]
- Lukács, G.; Marshall, A.D.; Martin, R.R. Geometric Least-Squares Fitting of Spheres, Cylinders, Cones and Tori; RECCAD: Budapest, Hungary, 1997; pp. 1–20. [Google Scholar]
- Raumonen, P.; Kaasalainen, M.; Åkerblom, M.; Kaasalainen, S.; Kaartinen, H.; Vastaranta, M.; Holopainen, M.; Disney, M.; Lewis, P. Fast Automatic Precision Tree Models from Terrestrial Laser Scanner Data. Remote Sens. 2013, 5, 491–520. [Google Scholar] [CrossRef] [Green Version]
- Hackenberg, J.; Spiecker, H.; Calders, K.; Disney, M.; Raumonen, P. SimpleTree —An Efficient Open Source Tool to Build Tree Models from TLS Clouds. Forests 2015, 6, 4245–4294. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Schmaltz, E.; Wieser, M.; Reifeltshammer, D.; Pfeifer, N. Tree Stem Shapes Derived from TLS Data as an Indicator for Shallow Landslides. Procedia Earth Planet. Sci. 2016, 16, 185–194. [Google Scholar] [CrossRef] [Green Version]
- Saarinen, N.; Kankare, V.; Pyörälä, J.; Yrttimaa, T.; Liang, X.; Wulder, M.A.; Holopainen, M.; Hyyppä, J.; Vastaranta, M. Assessing the Effects of Sample Size on Parametrizing a Taper Curve Equation and the Resultant Stem-Volume Estimates. Forests 2019, 10, 848. [Google Scholar] [CrossRef] [Green Version]
- Chianucci, F.; Puletti, N.; Grotti, M.; Ferrara, C.; Giorcelli, A.; Coaloa, D.; Tattoni, C. Nondestructive Tree Stem and Crown Volume Allometry in Hybrid Poplar Plantations Derived from Terrestrial Laser Scanning. For. Sci. 2020, 66, 737–746. [Google Scholar] [CrossRef]
- Santopuoli, G.; Di Cristofaro, M.; Kraus, D.; Schuck, A.; Lasserre, B.; Marchetti, M. Biodiversity conservation and wood production in a Natura 2000 Mediterranean forest. A trade-off evaluation focused on the occurrence of microhabitats. iForest Biogeosci. For. 2019, 12, 76–84. [Google Scholar] [CrossRef]
- Barbati, A.; Marchetti, M.; Chirici, G.; Corona, P. European Forest Types and Forest Europe SFM indicators: Tools for monitoring progress on forest biodiversity conservation. For. Ecol. Manag. 2014, 321, 145–157. [Google Scholar] [CrossRef] [Green Version]
- Santopuoli, G.; Di Febbraro, M.; Alvites, C.; Balsi, M.; Marchetti, M.; Lasserre, B. ALS data for detecting habitat trees in a multi-layered mediterranean forest. AIT Ser. Trends Earth Obs. 2019, 1, 69–72. [Google Scholar]
- Tabacchi, G.; Di Cosmo, L.; Gasparini, P. Aboveground tree volume and phytomass prediction equations for forest species in Italy. Eur. J. For. Res. 2011, 130, 911–934. [Google Scholar] [CrossRef]
- Malinen, J.; Piira, T.; Kilpeläinen, H.; Wall, T.; Verkasalo, E. Timber Assortment Recovery Models for Southern Finland. Balt. For. 2010, 16, 102–112. [Google Scholar]
- Nosenzo, A. Determinazione degli Assortimenti Ritraibili dai Boschi Cedui di Castagno: L’esempio della Bassa Valle di Susa (Torino). For. Riv. Selvic. Ecol. For. 2007, 4, 118–125. [Google Scholar] [CrossRef]
- Wei, H.; Zhou, G.; Zhou, J. Comparison of single and multi-scale method for leaf and wood points classification from terrestrial laser scanning data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV-3, 217–223. [Google Scholar] [CrossRef] [Green Version]
- Weinmann, M.; Jutzi, B.; Mallet, C. Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, II-3, 181–188. [Google Scholar] [CrossRef] [Green Version]
- Zuur, A.F.; Ieno, E.N.; Elphick, C.S. A protocol for data exploration to avoid common statistical problems. Methods Ecol. Evol. 2010, 1, 3–14. [Google Scholar] [CrossRef]
- Naimi, B. usdm R library: Uncertainty analysis for species distribution models. In R Package Version; 2017; pp. 1–18. Available online: https://cran.r-project.org/web/packages/usdm (accessed on 15 August 2021).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Williams, G.J.; Huang, J.Z. wsrf: An R Package for Classification with Scalable Weighted Subspace Random Forests. J. Stat. Softw. 2017, 77, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Robin, X.A.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Muller, M.J. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Cook, R.D. Influential observations in linear regression. J. Am. Stat. Assoc. 1979, 74, 169–174. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3rd ed.; Sage: Thousand Oaks, CA, USA, 2019; Available online: https://socialsciences.mcmaster.ca/jfox/Books/Companion/ (accessed on 15 August 2021).
- Wickham, H.; Francois, R. dplyr: A Grammar of Data Manipulation. R Package Version 0.5.0. 2021. Available online: https://cran.r-project.org/web/packages/dplyr/dplyr.pdf (accessed on 15 August 2021).
- Vicari, M.B.; Disney, M.; Wilkes, P.; Burt, A.; Calders, K.; Woodgate, W. Leaf and wood classification framework for terrestrial LiDAR point clouds. Methods Ecol. Evol. 2019, 10, 680–694. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Zheng, G.; Eitel, J.U.H.; Moskal, L.M.; He, W.; Huang, H. Improved Salient Feature-Based Approach for Automatically Separating Photosynthetic and Nonphotosynthetic Components Within Terrestrial Lidar Point Cloud Data of Forest Canopies. IEEE Trans. Geosci. Remote Sens. 2016, 54, 679–696. [Google Scholar] [CrossRef]
- Tao, S.; Guo, Q.; Xu, S.; Su, Y.; Li, Y.; Wu, F. A Geometric Method for Wood-Leaf Separation Using Terrestrial and Simulated Lidar Data. Photogramm. Eng. Remote Sens. 2015, 81, 767–776. [Google Scholar] [CrossRef]
- Liang, X.; Litkey, P.; Hyyppa, J.; Kaartinen, H.; Vastaranta, M.; Holopainen, M. Automatic Stem Mapping Using Single-Scan Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2011, 50, 661–670. [Google Scholar] [CrossRef]
- Olofsson, K.; Holmgren, J.; Olsson, H. Tree Stem and Height Measurements using Terrestrial Laser Scanning and the RANSAC Algorithm. Remote Sens. 2014, 6, 4323–4344. [Google Scholar] [CrossRef] [Green Version]
- Koreň, M.; Mokroš, M.; Bucha, T. Accuracy of tree diameter estimation from terrestrial laser scanning by circle-fitting methods. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 122–128. [Google Scholar] [CrossRef]
- Bauwens, S.; Bartholomeus, H.; Calders, K.; Lejeune, P. Forest Inventory with Terrestrial LiDAR: A Comparison of Static and Hand-Held Mobile Laser Scanning. Forests 2016, 7, 127. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Wang, Y.; Pyörälä, J.; Lehtomäki, M.; Yu, X.; Kaartinen, H.; Kukko, A.; Honkavaara, E.; Issaoui, A.E.I.; Nevalainen, O.; et al. Forest in situ observations using unmanned aerial vehicle as an alternative of terrestrial measurements. For. Ecosyst. 2019, 6, 20. [Google Scholar] [CrossRef] [Green Version]
- Saarinen, N.; Kankare, V.; Vastaranta, M.; Luoma, V.; Pyörälä, J.; Tanhuanpää, T.; Liang, X.; Kaartinen, H.; Kukko, A.; Jaakkola, A.; et al. Feasibility of Terrestrial laser scanning for collecting stem volume information from single trees. ISPRS J. Photogramm. Remote Sens. 2017, 123, 140–158. [Google Scholar] [CrossRef]
- Musat, E.C.; Salca, E.A.; Ciobanu, V.D.; Dumitrascu, A.E. The influence of log defects on the cutting yield of oak veneer. BioResources 2017, 12, 7917–7930. [Google Scholar] [CrossRef]
- Kankare, V.; Puttonen, E.; Holopainen, M.; Hyyppä, J. The effect of TLS point cloud sampling on tree detection and diameter measurement accuracy. Remote Sens. Lett. 2016, 7, 495–502. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Puttonen, E.; Pfeifer, N. Automatic and Self-Adaptive Stem Reconstruction in Landslide-Affected Forests. Remote Sens. 2016, 8, 974. [Google Scholar] [CrossRef] [Green Version]
- Kankare, V.; Holopainen, M.; Vastaranta, M.; Puttonen, E.; Yu, X.; Hyyppä, J.; Vaaja, M.; Hyyppä, H.; Alho, P. Individual tree biomass estimation using terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2013, 75, 64–75. [Google Scholar] [CrossRef]
- Liang, X.; Kankare, V.; Yu, X.; Hyyppa, J.; Holopainen, M. Automated Stem Curve Measurement Using Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 1739–1748. [Google Scholar] [CrossRef]
- Cowell, A.M. Growing Timber Trees with Straight Stems: An Exploration of Relationships between Morphological Traits in some Broadleaved Tree Species. Master’s Thesis, De Montfort University, Leicester, UK, 2004. [Google Scholar]
- Wan, P.; Wang, T.; Zhang, W.; Liang, X.; Skidmore, A.K.; Yan, G. Quantification of occlusions influencing the tree stem curve retrieving from single-scan terrestrial laser scanning data. For. Ecosyst. 2019, 6, 43. [Google Scholar] [CrossRef] [Green Version]
- Henning, J.G.; Radtke, P.J. Detailed stem measurements of standing trees from ground-based scanning lidar. For. Sci. 2006, 52, 67–80. [Google Scholar] [CrossRef]
- Puletti, N.; Grotti, M.; Scotti, R. Evaluating the Eccentricities of Poplar Stem Profiles with Terrestrial Laser Scanning. Forests 2019, 10, 239. [Google Scholar] [CrossRef] [Green Version]
- Montaghi, A.; Corona, P.; Dalponte, M.; Gianelle, D.; Chirici, G.; Olsson, H. Airborne laser scanning of forest resources: An overview of research in Italy as a commentary case study. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 288–300. [Google Scholar] [CrossRef] [Green Version]
- Kelly, M.; Di Tommaso, S. Mapping forests with Lidar provides flexible, accurate data with many uses. Calif. Agric. 2015, 69, 14–20. [Google Scholar] [CrossRef]



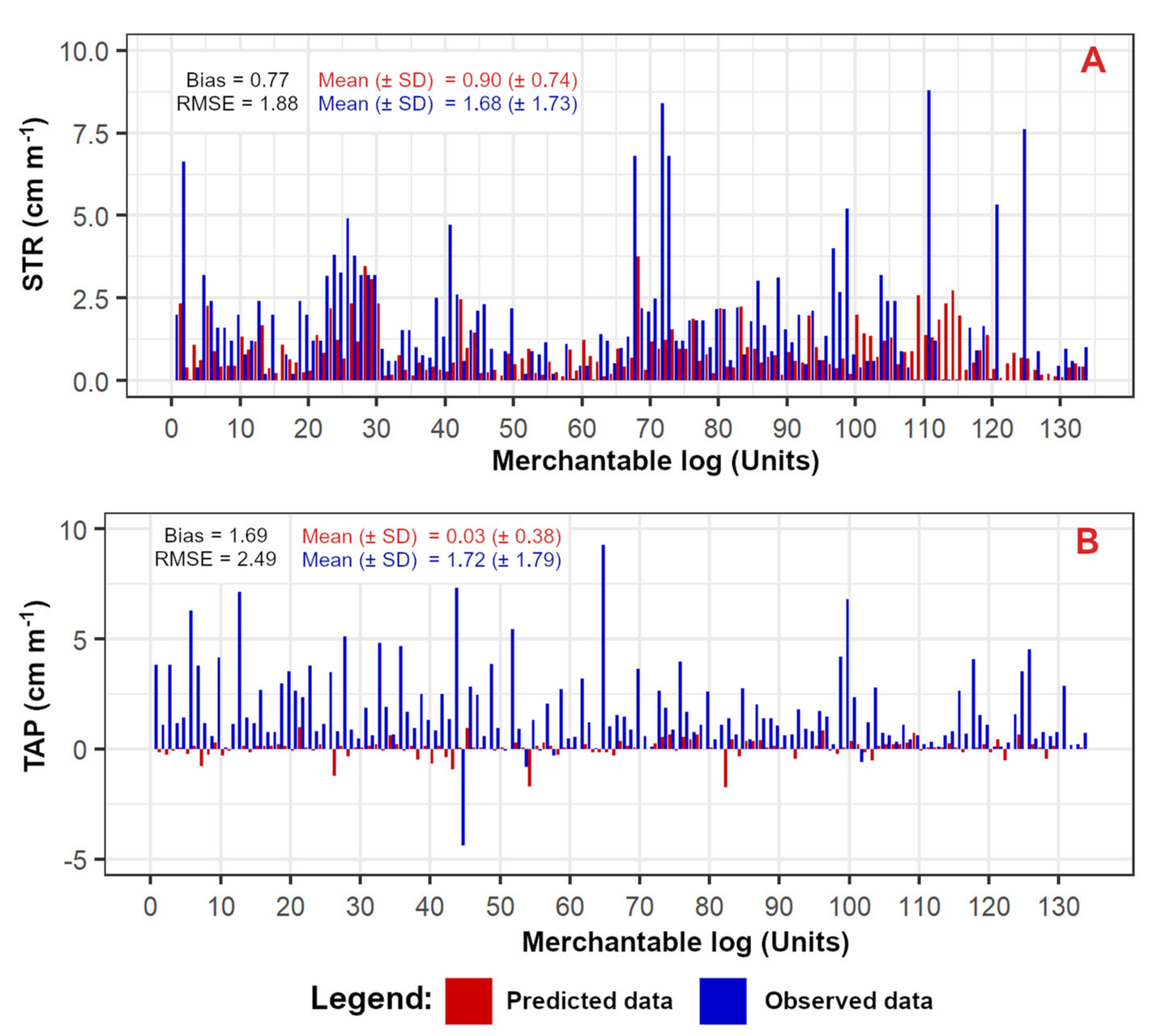
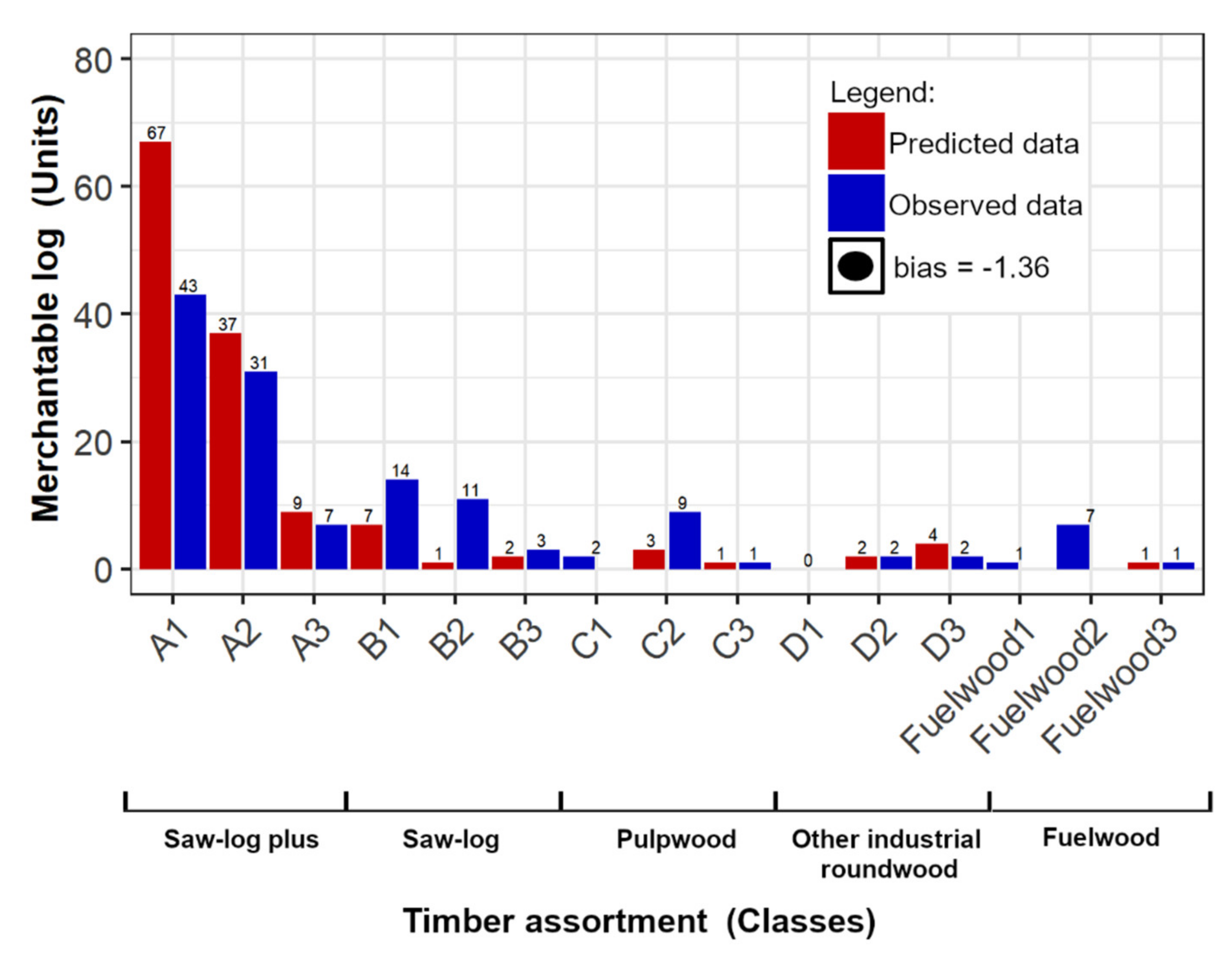
| Timber Assortments | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Assortments | Types | Saw-log Plus | Saw-log | Pulpwood | Other Industrial Roundwood | Fuelwood | ||||||||||
| Classes | A1 | A2 | A3 | B1 | B2 | B3 | C1 | C2 | C3 | D1 | D2 | D3 | Fuelwood1 | Fuelwood2 | Fuelwood3 | |
| Requirements | STR (cm m−1) | x ≤ 2 | 2 < x ≤ 3.4 | 3.4 < x ≤ 5 | 5 < x ≤ 6.6 | x > 6.6 | ||||||||||
| Dmin | Large | Medium | Small | Large | Medium | Small | Large | Medium | Small | Large | Medium | Small | Large | Medium | Small | |
| Forest structure | TLS data | ||||||
|---|---|---|---|---|---|---|---|
| ADS | Trees ADS−1 (Trees ha−1) | Stem Density (Level) | Mean (±SD) | Total | Point Density and Spacing (pts m−2 and mm) | ||
| DBH (m) | TH (m) | TSV (m3) | TSR (Units) | ||||
| 1 | 33 (623) | moderate | 0.20 (±0.09) | 18.52 (±5.16) | 13.20 | 7 | 92,244; 3.19 |
| 2 | 36 (679) | moderate | 0.20 (±0.19) | 13.28 (±8.19) | 23.86 | 9 | 44,310; 4.75 |
| 3 | 52 (981) | high | 0.16 (±0.13) | 13.72 (±6.79) | 16.32 | 8 | 64,836; 3,92 |
| 4 | 33 (623) | moderate | 0.21 (±0.14) | 21.27 (±8.97) | 22.81 | 9 | 44,210; 4.76 |
| 5 | 24 (453) | low | 0.26 (±0.15) | 23.1 (±10.22) | 25.29 | 5 | 36,622; 5.22 |
| Sum | 178 | ||||||
| Mean | 36 (672) | ||||||
| Type of logs | ADS | N° logs (Units) | STR (cm m−1) | TAP (cm m−1) | TTv.log (m3) |
|---|---|---|---|---|---|
| Mean (±SD) | Mean (±SD) | Sum | |||
| Merchantable | 1 | 88 | 2.9 (±1.9) | 1.5 (±0.7) | 7.2 |
| 2 | 45 | 1.6 (±1.3) | 1.8 (±1) | 10.9 | |
| 3 | 35 | 1.4 (±1.1) | 1.6 (±0.4) | 6.7 | |
| 4 | 56 | 1.8 (±1.4) | 1.1 (±0.5) | 12.9 | |
| 5 | 82 | 1.6 (±0.9) | 1.2 (±0.4) | 12.4 | |
| TOT | 306 *1 | 1.8 (±1.3) *2 | 1.4 (±0.6) *2 | 10.0 *2 | |
| Non-merchantable | 1 | 30 | 2.1 (±4) | 1.3 (±2.6) | 1.1 |
| 2 | 13 | 1.7 (±2.5) | 0.9 (±1.3) | 1.2 | |
| 3 | 11 | 1.4 (±1.7) | 0.5 (±1.2) | 0.7 | |
| 4 | 8 | 2.1 (±2.9) | 1 (±1.4) | 0.4 | |
| 5 | 17 | 1.3 (±2.6) | 1 (±1.3) | 1.2 | |
| TOT | 79 *1 | 1.7 (±2.7) *2 | 0.9 (±1.6) *2 | 0.9 *2 |
| ADS | TR (Units) | TLS results | ||||||
|---|---|---|---|---|---|---|---|---|
| TreeTLS | TruePos | FalsePos | FalseNeg | DR (%) | Completeness (%) | Correctness (%) | ||
| (Units) | (Units) | (Units) | (Units) | |||||
| 1 | 33 | 45 | 30 | 15 | 3 | 90.9 | 90.9 | 66.7 |
| 2 | 36 | 54 | 29 | 25 | 7 | 80.6 | 80.6 | 53.7 |
| 3 | 52 | 71 | 45 | 26 | 7 | 86.5 | 86.6 | 63.4 |
| 4 | 33 | 36 | 28 | 8 | 5 | 84.8 | 84.9 | 77.8 |
| 5 | 24 | 26 | 19 | 7 | 5 | 79.2 | 79.2 | 73.1 |
| Sum | 178 | 232 | 151 | 81 | 27 | |||
| Mean (±SD) | 36 (±10) | 46 (±17.2) | 30 (±9.4) | 16 (±9.0) | 5 (±1.7) | 84.4 (±4.7) | 84.4 (±4.7) | 66.9 (±9.3) |
| Stem Reconstruction Results | ||||||
|---|---|---|---|---|---|---|
| Description | ADS | TOTAL | ||||
| 1 | 2 | 3 | 4 | 5 | ||
| TR | 13 | 14 | 13 | 13 | 17 | 70 |
| RStem | 10 | 7 | 7 | 11 | 12 | 47 |
| TrueRStem | 76.9 | 50 | 53.8 | 84.6 | 70.6 | 67.2 (14.9) |
| Observed Data | Predicted Data | |||||
|---|---|---|---|---|---|---|
| Log Section | Logs | Length of Log (m) | N°logs | Length of Log (m) | ||
| Mean (±SD) | Sum | Mean (±SD) | Sum | |||
| Merchantable | 179 | 2.50 (±0) | 447.5 | 134 | 2.78 (±0.12) | 372.51 |
| Non-merchantable | 40 | 1.35 (±0.69) | 53.9 | 34 | 1.62 (±0.57) | 54.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvites, C.; Santopuoli, G.; Hollaus, M.; Pfeifer, N.; Maesano, M.; Moresi, F.V.; Marchetti, M.; Lasserre, B. Terrestrial Laser Scanning for Quantifying Timber Assortments from Standing Trees in a Mixed and Multi-Layered Mediterranean Forest. Remote Sens. 2021, 13, 4265. https://doi.org/10.3390/rs13214265
Alvites C, Santopuoli G, Hollaus M, Pfeifer N, Maesano M, Moresi FV, Marchetti M, Lasserre B. Terrestrial Laser Scanning for Quantifying Timber Assortments from Standing Trees in a Mixed and Multi-Layered Mediterranean Forest. Remote Sensing. 2021; 13(21):4265. https://doi.org/10.3390/rs13214265
Chicago/Turabian StyleAlvites, Cesar, Giovanni Santopuoli, Markus Hollaus, Norbert Pfeifer, Mauro Maesano, Federico Valerio Moresi, Marco Marchetti, and Bruno Lasserre. 2021. "Terrestrial Laser Scanning for Quantifying Timber Assortments from Standing Trees in a Mixed and Multi-Layered Mediterranean Forest" Remote Sensing 13, no. 21: 4265. https://doi.org/10.3390/rs13214265
APA StyleAlvites, C., Santopuoli, G., Hollaus, M., Pfeifer, N., Maesano, M., Moresi, F. V., Marchetti, M., & Lasserre, B. (2021). Terrestrial Laser Scanning for Quantifying Timber Assortments from Standing Trees in a Mixed and Multi-Layered Mediterranean Forest. Remote Sensing, 13(21), 4265. https://doi.org/10.3390/rs13214265