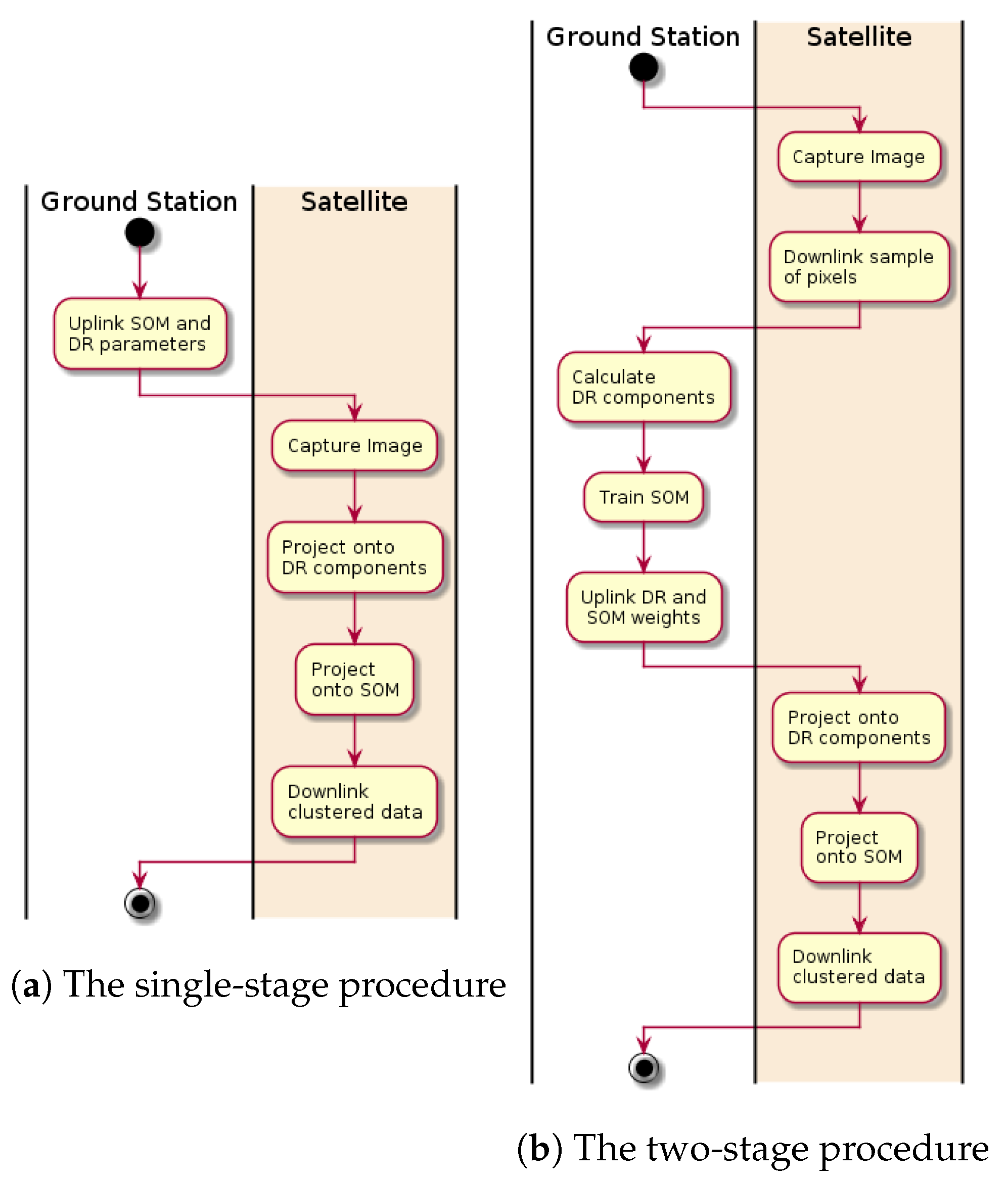
3.1. Computational Benchmarks on Target Hardware
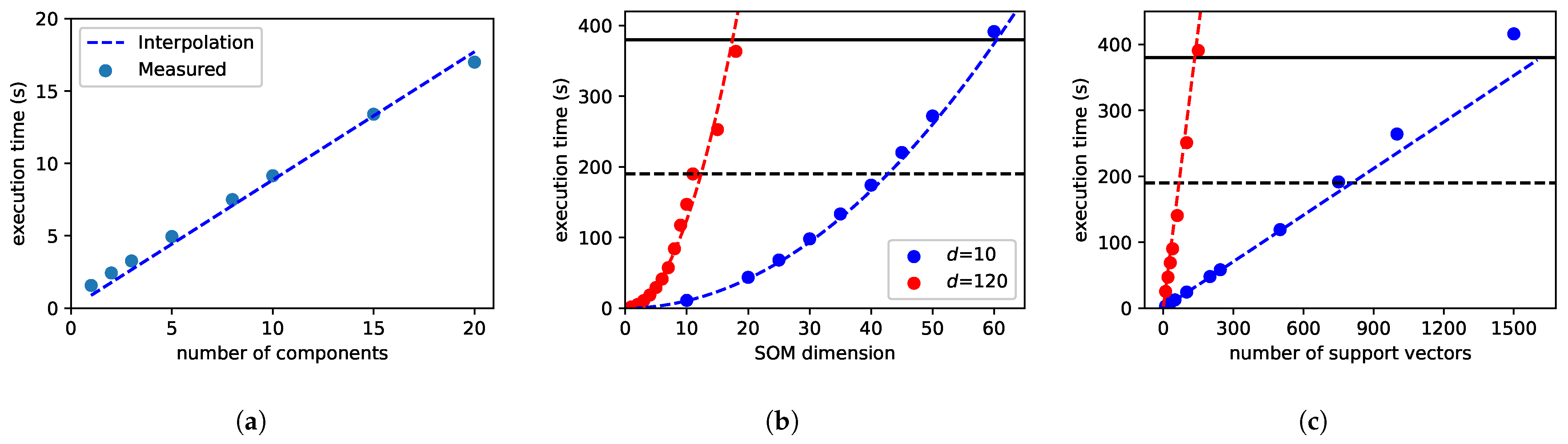
The computational time of each algorithm scales with its parameters, e.g., the SVM scales with the number of support vectors. To find parameters under which the models are computationally tractable within the constraints, they are tested on the target hardware (
Figure 4). Then, based on the measurements, runtime models are interpolated. They are interpolated with only the highest-order term in the asymptotic runtime to provide a simple equation. The runtime analysis is based on the standard cube size of 956 frames, with 684 pixels, and 120 bands each). The ideal and maximum computational times are 190 and 380 s, respectively, to meet the demands of HYPSO’s power budget.
First, the PCA DR projection is tested. The computational time of projecting a cube is expected to scale linearly with the number of projected components
d.
Figure 4a shows measurements of the computational time versus the number of components, as well as the interpolation. The resulting expected computational time in seconds is
, or about
s per pixel per component.
The computational time of the SVM is dominated by the RBF kernel calculation, which is
where
is the number of support vectors. From the measurements and corresponding interpolated model, the expected computational time is
Figure 4c shows the interpolated model for measurements with
and
bands. The measurements mainly support the linear model; however, there is some deviance for a large number of support vectors. For the ideal requirement of <190 s of computation and a cube with full dimension
, the upper limit on the number of support vectors is about 70, which is typically far below the number of support vectors in a model. Reducing the dimension to
gives time for about 750 support vectors.
The SOM method has a quadratic runtime in the dimension
z and the driving quadratic term also scales with the number of bands
d. The interpolated model,
dz
, is as seen in
Figure 4b. Without DR,
z must be 11 or less to fit within the target computational time. Reducing the dimensionality to
allows
z to be about 56.
3.2. Clustering
In this section, the SOMs’ ability to be trained on unlabelled data is evaluated. As the data acquired in the HYPSO-1 mission are initially unlabelled, this is a critical ability for SOMs in both operational plans. First, the structure of an SOM trained on the first North Sea scene without DR is investigated. Second, several SOMs are trained and evaluated on the first scene with DR. Next, the performance of transfer learning is tested by comparing SOMs that are trained and applied to different datasets to SOMs that are trained and applied to a single dataset. Finally, an SOM’s capacity to deal with noisy data is evaluated.
Before the process of optimizing a SOM architecture for the HYPSO-1 mission, the structure of a single SOM and its application to unlabelled data are explored in depth. The first SOM is trained using the full 86-band spectrum from the first North Sea HICO scene (
Figure 1a). The SOM consists of
nodes and is trained with an update radius decreasing from 32 to 1 and a constant learning rate of 0.1, in 100 steps of
pixels at a time in a randomized order.
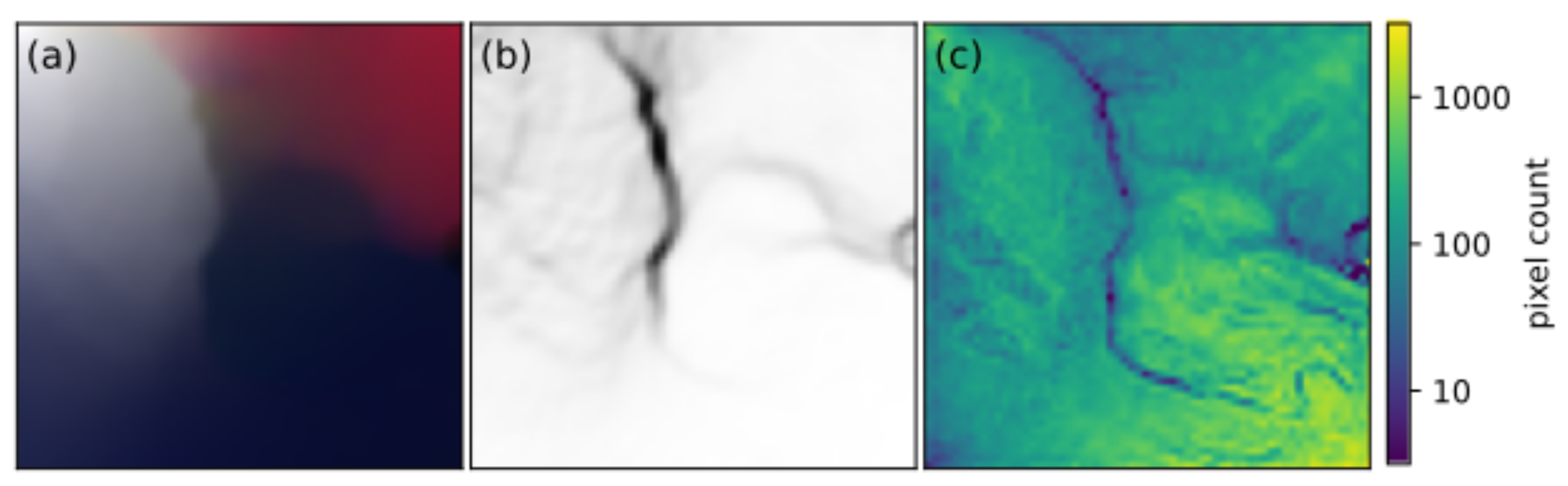
The initial SOM, while too large for on-board processing, because it lacks DR, gives a benchmark for SOM performance, and is interpretable in the sense that each node of the SOM can be represented as a spectrum. In
Figure 5a, the nodes of the trained SOM are colored according to the spectrum which each node represents (normalized to the maximum of each band). The nodes of the upper left corner are white, corresponding to cloud pixels, while the nodes of the upper right corner appear red, corresponding to the large infrared response of land pixels. Along the bottom, the nodes transition from a lighter blue on the left to a darker blue on the right, which corresponds to different spectra that water appears to have in the scene.
The U-matrix (
Figure 5b) shows the distance of nodes from their neighbors, so that folds in the SOM appear as dark lines. Two folds are apparent: a vertical one extends down from the top and separates the nodes associated with clouds on the left from nodes associated with nodes associated with land, while a horizontal one extends from the right side and separates the land-pixels from the water pixels. The number of pixels in the original image that are identified with a particular node are plotted (logarithmically) in
Figure 5c. The counts are distributed fairly uniformly over the SOM, except along the folds that are visible in the U-matrix, which indicates that the SOM expresses the content of the scene. The mean and median relative quantization error for the scene are 0.87% and 0.63%, respectively, which further indicates that the SOM has captured the pixel distribution of the scene.
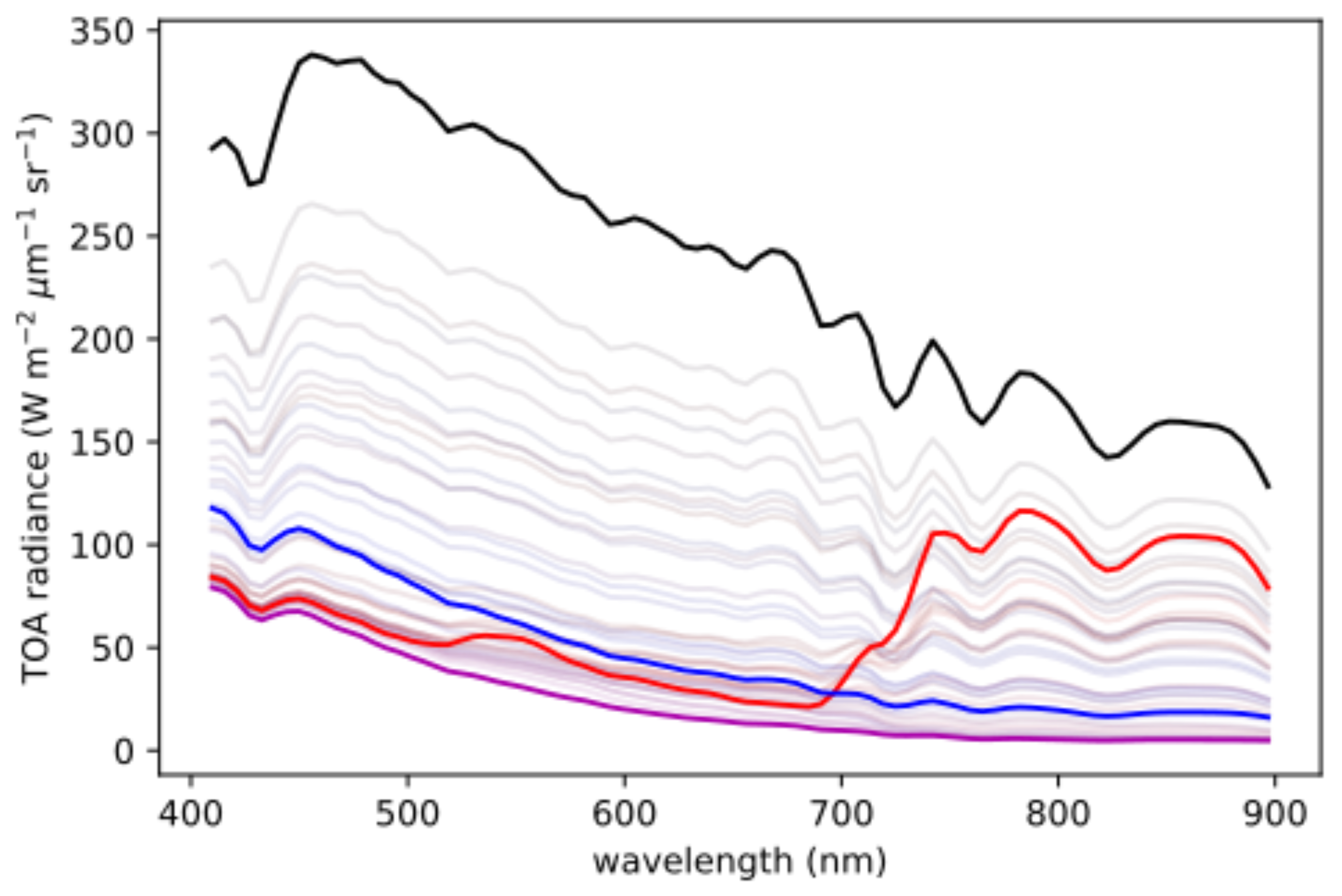
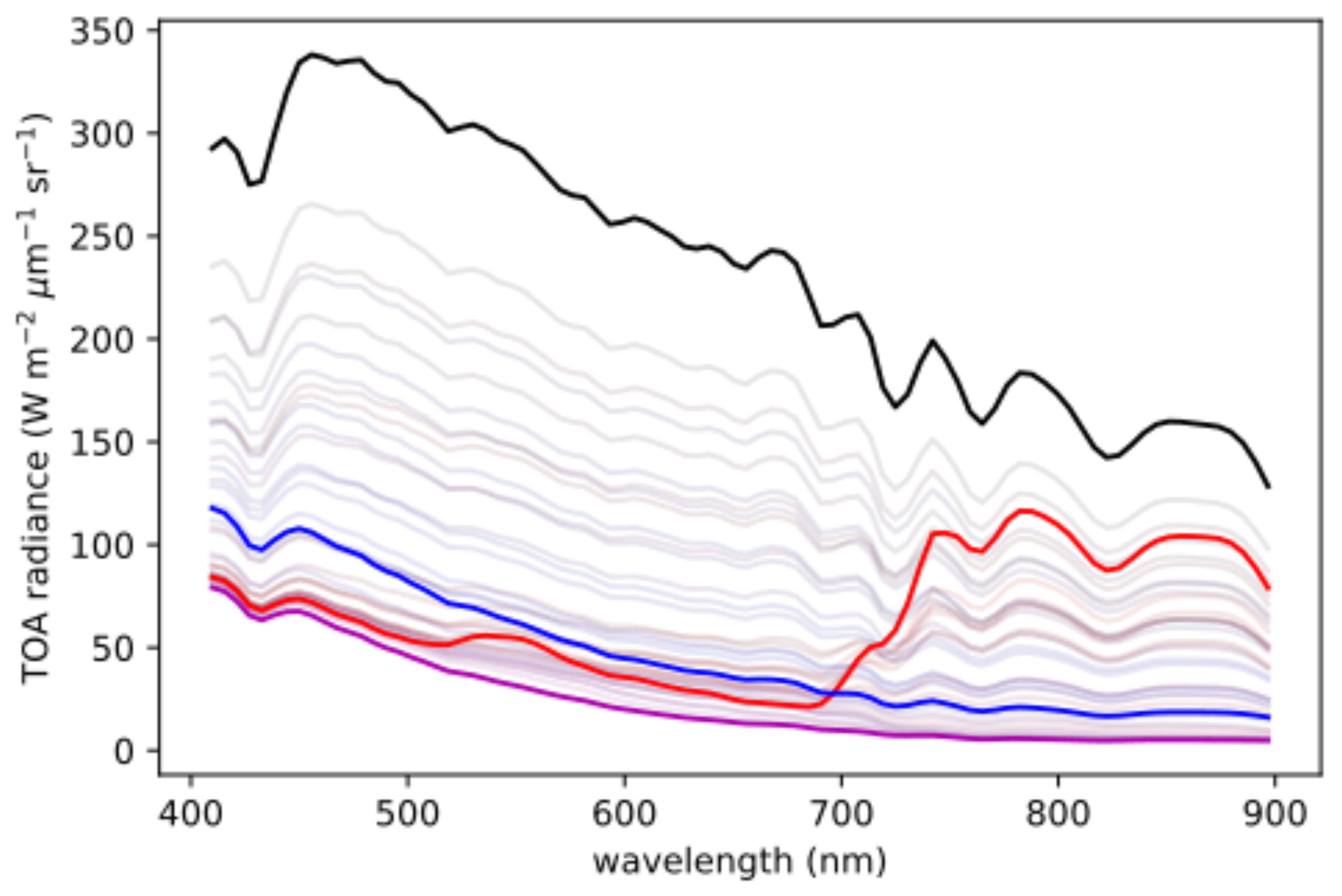
The physical interpretation of the SOM is apparent from both the spectra of the nodes and the spatial distribution of pixel clusters in the scene. In
Figure 6, the spectra for the nodes of the SOM are shown, with the spectra of the nodes in the four corners highlighted. The clustering of the first North Sea image is shown in
Figure 7, with (a) showing the column number and (b) showing the row number.
The information depicted by the labels corresponds with what can be visually observed in the original color image (
Figure 1). First, the regions that are bright in both (a) and (b) appear to be clouds, which is consistent with the observation that they are most similar to the black line in
Figure 6, which itself has characteristics of the spectrum of a cloud (e.g., relatively bright and spectrally smooth). Likewise, the regions dark in (a) but bright in (b) appear to be land, consistent with the red-colored spectral curve. The regions that are dark in both seem to be water, which is consistent with the blue- and purple-colored spectra. Finally,
Figure 7c, which depicts the per-pixel relative quantization, shows that the error is relatively larger on land than on either clouds or water. It is suspected that the SOM learns the spectra of the land pixels less well because they are more diverse.
Dimensionality reduction is investigated as a way of reducing the computational requirements of the SOMs. It is first tested by reducing the number of bands used in the training of the above SOM from 86 to 5. As the evaluation of a SOM is linear in the number of bands, this corresponds roughly to a speed improvement of about . The relative quantization error only increases to a mean and median of 1.0% and 0.8%, or by about 20% relative to using all bands.
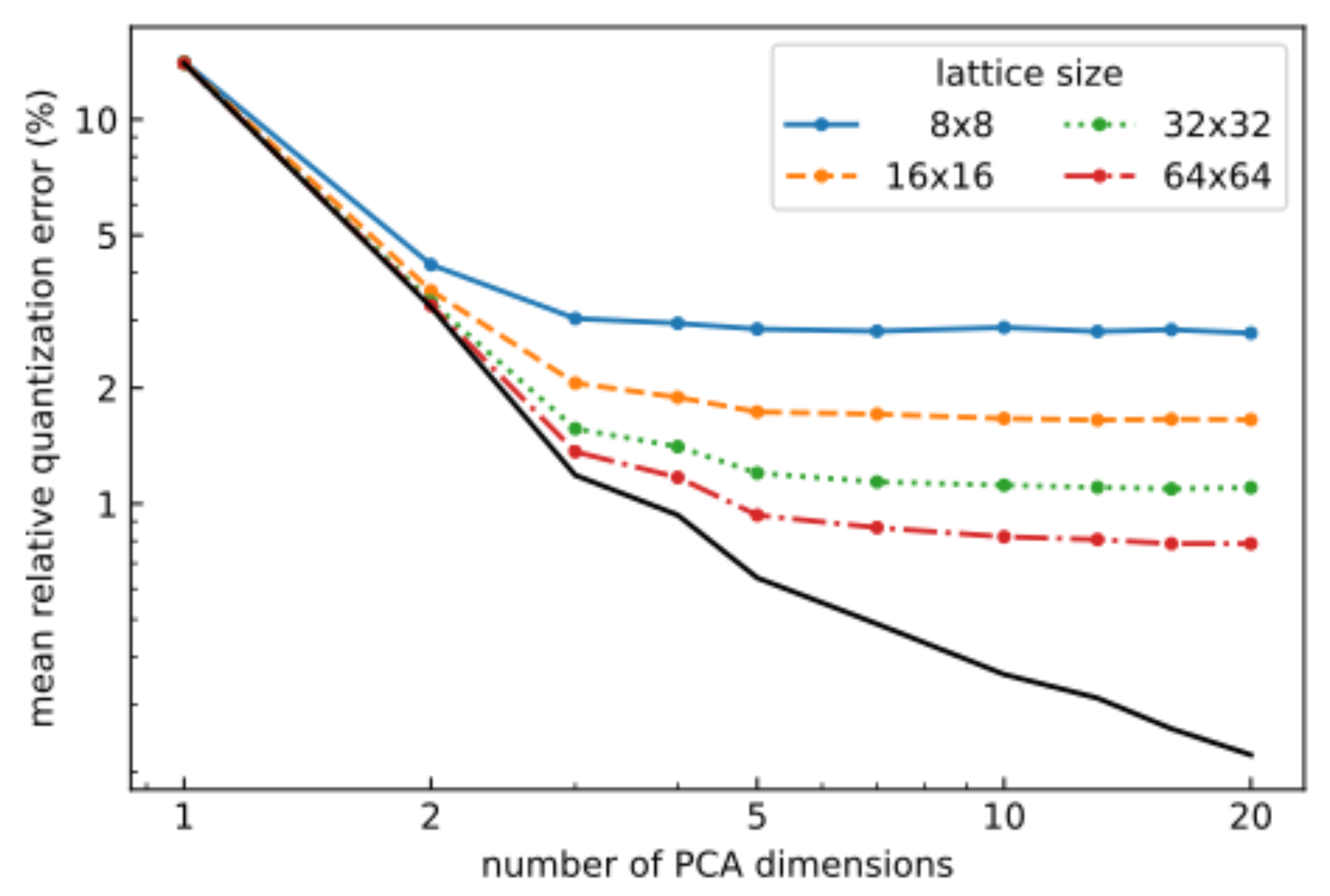
The performance of DR is further evaluated by considering how SOMs of several different sizes with varying numbers of dimensions performed on the first North Sea scene (
Figure 8). It is found that, in general, the quantization error decreases with both an increasing number of dimensions and SOM network size. However, for a given network size, there is a critical number of dimensions, above which there is no further reduction in the quantization error. For these reasons, the rest of the paper will work with five PCA dimensions, unless otherwise noted.
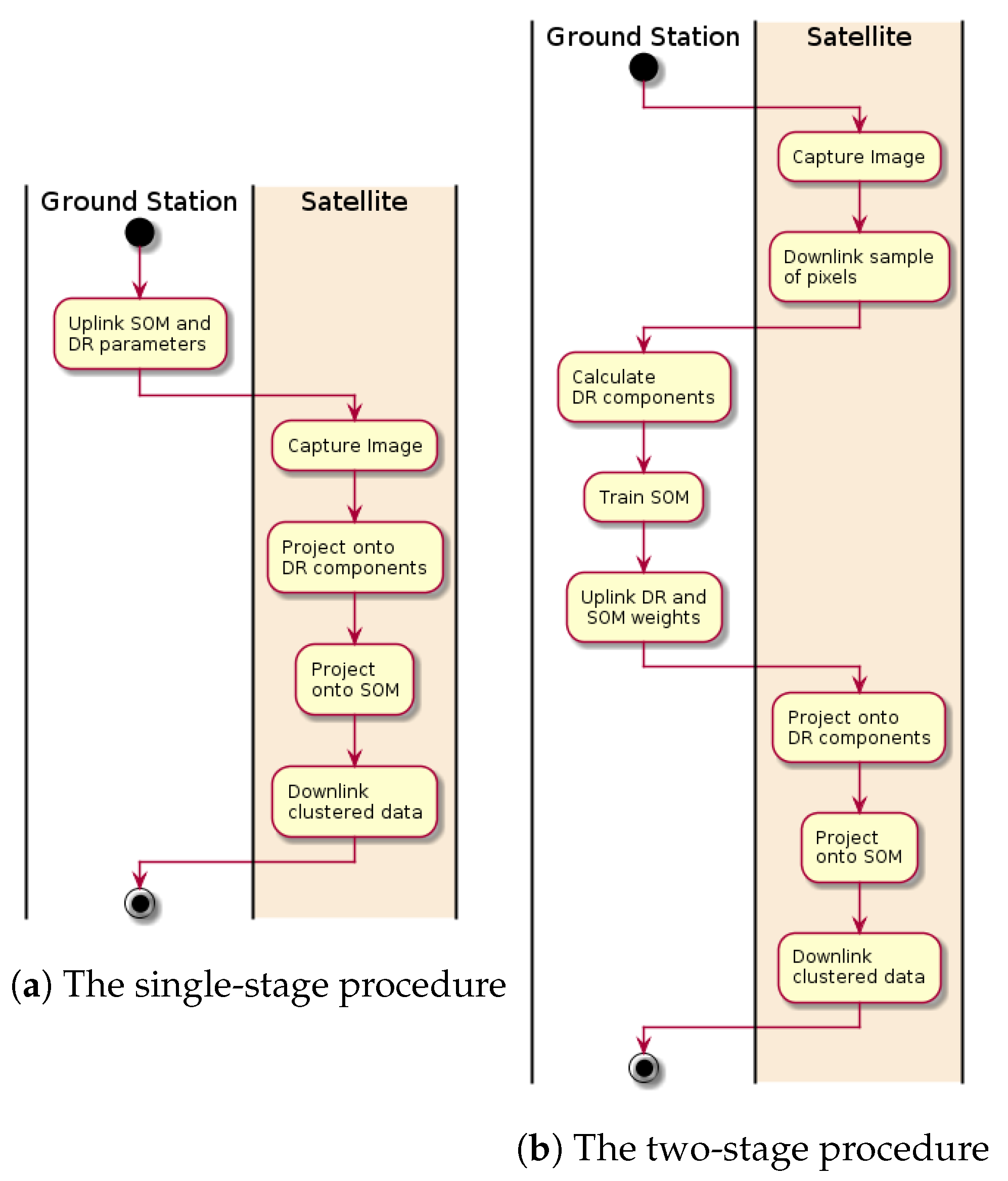
The second operational procedure (
Table 4) relies on training an SOM with a limited number of downlinked pixels. Therefore, the ability of a SOM to learn from a small amount of data is tested. A
SOM is trained with an update radii of 8, 2.8 and 1 and a number of pixels ranging from
to
. The training is performed as it would be during operations: both the determination of the PCA components and the training of the SOM are performed with a limited number of samples. Then, the SOM is evaluated on the full image. The procedure is repeated four times and the averages are presented in
Figure 9.
For a given number of samples, the performance does tend to improve as the update radius is decreased, as is found above. For a given update radius, the performance improves with an increasing number of samples up to a certain value, , above which it remains constant. Below , the training data significantly underestimate the error, while above this, the training data provide a decent estimate of the error. These results validate the two-stage operational procedure.
The first operational procedure (
Table 4) relies on transfer learning, particularly the application of an SOM trained on one image to a second image. This ability is tested by applying an SOM trained on the first North Sea image to the other images. It is found that the quantization error in the clustering of an SOM on a different training image results in a notable increase (
) relative to the image that it was originally trained on (
Table 5 and
Table 6). The different scenes on which the SOM is applied lead to significantly different quantization errors. In addition, the SOM performed better on the freshwater scene (Erie) than it did on the same location on which it was trained (North Sea), which suggests that it is difficult to anticipate how well an SOM will perform on a particular scene prior to its application.
The performances of the two operational procedures, in terms of the relative quantization error of the resulting datasets, are compared by applying each to the test datasets. A
SOM is trained from a random sampling of 4096 pixels on each test image, and the trained SOM is tested on the same image (
Table 5). Then, the SOM trained on the first North Sea scene is applied to the other scenes.
For all the scenes, the SOM trained on a sub-sampling of pixels resulted in smaller relative quantization errors 4–10× than when transfer learning is used. The SOM transferred to the Lake Erie scene shows that while the SOM captures the algal bloom, it does not resolve the gradations in the chlorophyll content, and has much more relative error over the whole scene compared to the first North Sea image, particularly over the water (
Figure 10). On the other hand, the SOM trained on a sub-sampling of the Lake Erie pixels shows the algal bloom quite clearly. The relative quantization error over the bloom is mostly less than 1%. The Laguna San Rafael scene gives the largest quantization error for both procedures, perhaps because the scene contains diverse surfaces, including fresh water, ocean water, mountains, glaciers, swamps, and clouds (
Figure 11). While the second North Sea scene gives a higher quantization error than the Lake Erie scene under transfer learning, it gives a lower error than the latter when the sub-sampled SOM is applied.
One additional concern regarding hyperspectral imaging on cube-satellites is that their small-form factor limits the size of the imaging optics, which, in turn, limits the signal-to-noise ratio of the collected data.
The effect of noise on SOMs is investigated by adding noise to the first North Sea image. The signal-to-noise ratio of the median observation (over all bands and pixels) is varied from 1 to about 10
by adding noise to the scene, poissonian rather than gaussian in order to better approximate photon counting statistics. A
SOM is initialized and trained on 10
pixels from each noisy dataset, and is then evaluated on both the noisy and original datasets (
Figure 12 and
Figure 13).
It is found that the SOM-processed data better approximate the original, noiseless scene by a factor of almost 5 compared than the raw noisy observations, although this effect begins to vanish at signal-to-noise ratios above 1000. This noise reduction seems to originate from the way that each SOM node gives the average of several pixels, together with the selection of only five PCA dimensions [
58,
62]. As the averaging is non-local, it does not harm the spatial resolution of the scene. Thus the use of SOMs is not inhibited by noise and, in fact, may even alleviate some of the effects of noise.
3.3. Classification
Operationally, it is advantageous for hyperspectral images to not only be clustered, but also classified with labels that indicate distinct materials. For example, if the HYPSO-1 satellite could partition images into water, land, and clouds, then it could select only water pixels to downlink, which could ease the data budget. Similarly, Unmanned Aerial Vehicles (UAVs) will collaborate with HYPSO-1 by performing hyperspectral imaging under the clouds, which the satellite cannot observe. If HYPSO-1 downlinks a map of where the clouds as it images, the map could guide the UAVs to the locations they need to scan. Therefore, the capacity of SOMs to classify data is tested by labelling the nodes of a SOM and applying it to the test scenes.
Labels are applied to a few regions of the first North Sea scene, which is, in turn, used to label the nodes of an SOM that is used to apply labels to the whole scene. The broad classes of water, land, and cloud are used because distinguishing between those three components in within the expected skill level of satellite operators, who may not be experts in remote sensing. The regions of the scene which are selected as representative of the class are colored in
Figure 14a. The pixels of each labelled class are mapped to the SOM, the counts of which are depicted in
Figure 15a. These counts are then converted into probabilities using the neighborhood function of the SOM (
Figure 15b). Finally, the probabilities are used to label the different nodes of the SOM (
Figure 15c). The pixels in the scene are then classified according to their BMU (
Figure 14c). Repeating the procedure with DR produces similar results (
Figure 14e).
Classification fits more naturally with the first operational procedure (
Table 3), because, in that plan, spatial information can be used to assist labelling different regions. Therefore, the
SOM trained on the first North Sea scene is labelled according to the above procedure. Then, its node labels are used to classify the three other scenes (
Figure 14, right column). The water is identified fairly well in all scenes, although, in the second North Sea scene, numerous water pixels are classified as land along the coast. In the Luguna San Rafael scene, the snowy mountainous region is classified as a mixture of water and clouds, perhaps because there is no snow in the training data. Moreover, in the same scene, clouds at the leftmost edge of the image are mistakenly classified as land. In the Lake Erie scene, a number of water pixels are classified as clouds. Thus, it is possible to transfer labelled SOMs to classify new scenes, but more pixels will be mislabelled than in the original data.
By testing the SOM classification on several common benchmark scenes, the preservation of the information in a scene is evaluated. The SOMs are benchmarked against support vector machines (SVMs), which are a state-of-the-art single-pixel classification technique. While more sophisticated classification techniques could be applied to data clustered by a SOM, for example, by including information about neighboring pixels, the focus here is on single-pixel techniques. SOMs and SVMs are compared on four different scenes: Samson, Jasper, Pavia University, and Indian Pines, with sizes on the first three scenes, and on the latter.
The training procedure is the same as that which is applied to HICO, shown above. Each scene is partitioned into a training set consisting of 90% of the pixels and a test set consisting of 10% of the pixels. The effect of the size of the training set is the subject of an additional test. The SOM is trained on all of the pixels in each image, except for the test set. The labels are then applied using the training data. The same training/test partition is used to train the SVMs.
The SOMs classify the two simpler scenes, with 3 or 4 classes, about as well as the SVMs, but their performance relative to the SVMs degrades for the more complex scenes, with 9 or 16 classes (
Table 7). The relative quantization error of the SOM clustering also increases with the complexity of the scene, with the SOM describing less than half of the variance on the Indian Pines scene.
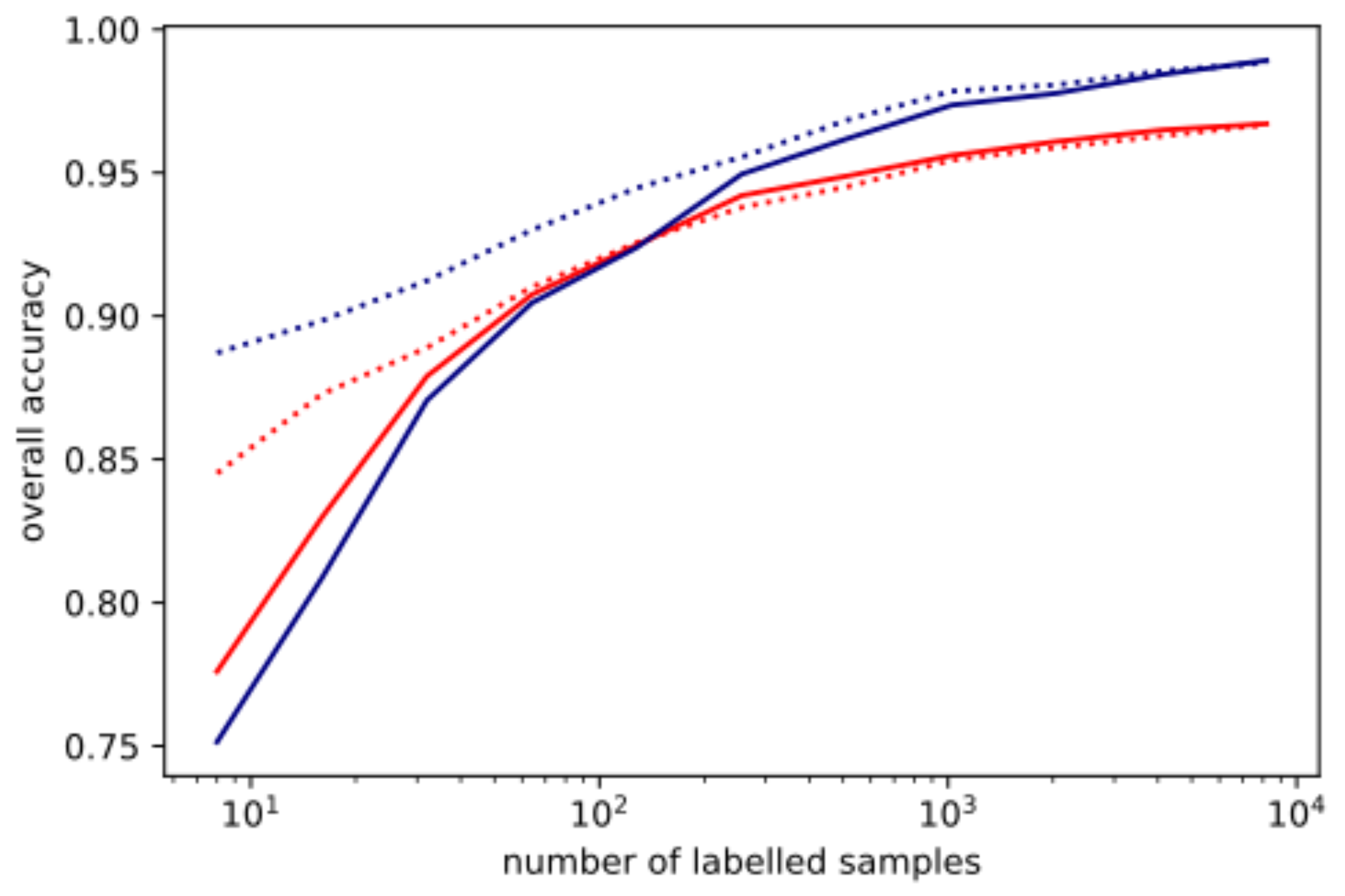
The effect of the number of labelled pixels on classification is tested on the Jasper scene, because it is more complex than Samson, but the number of different members are more balanced than the Indian Pines or Pavia University scenes, so that even a sample size of 16 pixels can contain all the different classes.
As expected, the overall accuracy of the SOM classification increases with the number of labelled samples (
Figure 16). Whether the SOM is trained with only the labelled samples or both labelled and unlabelled samples matters little (solid vs. dotted red line). Both show an overall accuracy above 90% when a few hundred samples are used. For sample sizes below 100, the SOM and SVM show a similar overall accuracy, while the SVM shows more improvement with additional samples. Each procedure is repeated four times and averaged. This is evidence that operational procedure 2, in which the SOM is trained on a sampling of the raw data, will retain enough information for further image processing and scientific analysis (
Table 4).
On the final two scenes, the performance of the SOM degrades relative to the SVM classification, although it is also notable that the SVM uses more support vectors than on the prior scenes, but the SOM does not increase in complexity. The Indian Pines scene shows the worst performance in both the SOM clustering and classification (
Figure 17). First, the mean relative quantization error is over 0.5, which indicates that the scene itself is too complex to describe with an SOM of this size, even accounting for the fact that the SOM is slightly larger than those used before (
. In light of the very high relative quantization error, it is notable that the SOM is able to still achieve 66% overall accuracy in the classification.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}