
TRS: Transformers for Remote Sensing Scene Classification


Abstract
:1. Introduction
- (1)
- We apply the Transformer to remote sensing scene classification, and propose a novel “pure CNNs → CNN + Transformer → pure Transformers” structure called TRS. The TRS can well combine Transformers with CNNs to achieve better classification accuracy.
- (2)
- We propose the MHSA-Bottleneck. The MHSA-Bottleneck uses Multi-Head Self-Attention instead of the 3 × 3 spatial convolutions. The MHSA-Bottleneck has fewer parameters and better effects than the standard bottleneck and other bottlenecks improved by the attention mechanism.
- (3)
- We also provide a novel way to understand the structure of the bottleneck. We demonstrate the connection between the MHSA-Bottleneck and Transformer, and regard MHSA- Bottleneck as a 3D Transformer.
- (4)
- We complete training on four public datasets NWPU-RESISC45, UC-Merced, AID, and OPTIMAL-31. The experimental results prove that TRS surpasses the existing state-of-the-art CNNs methods.
2. Related Works
2.1. CNNs in Remote Sensing Scene Classification
2.2. Attention in CNNs
2.3. Transformer in Vision
3. Methodology
3.1. Overview of TRS
3.2. Stem Unit
3.3. Transformer Architecture
3.4. MHSA-Bottleneck Architecture
- (1)
- We regard conv1 and conv2 in Figure 5 as FNNs in the Transformer architecture. Both FNNs and convolutional layers were used to increase a certain dimension of the input matrix by 4 times, and then compress it to its original size.
- (2)
- Both the MHSA-Bottleneck and Transformer architecture used residual connections. The specific differences can be found in Figure 5.
- (3)
- The Layer Norm was used in the Transformer, and the Group norm was used in the MHSA-Bottleneck.
4. Experiments
4.1. Dataset Description
4.2. Training Details
4.3. Comparison with CNNs State-of-the-Art

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Top1 | |
|---|---|---|
| 50% for Training | 80% for Training | |
| VGGNet [75] | 94.14 ± 0.69 | 95.21 ± 1.20 |
| GoogleNet [75] | 92.70 ± 0.60 | 94.31 ± 0.89 |
| D-CNN with AlexNet [75] | - | 97.42 ± 1.79 |
| D-CNN with VGGNet-16 [75] | - | 96.67 ± 0.94 |
| APDCNet [32] | 95.01 ± 0.43 | 97.05 ± 0.43 |
| SRSCNN [79] | 97.88 ± 0.31 | 98.13 ± 0.33 |
| EfficientNet-B0-aux [76] | 98.01 ± 0.45 | - |
| EfficientNet-B3-aux [76] | 98.22 ± 0.49 | - |
| MobileNet V2 [80] | 97.88 ± 0.31 | 98.13 ± 0.33 |
| ResNeXt-101 [81] | - | 98.96 ± 0.31 |
| Contourlet CNN [77] | - | 98.97 ± 0.21 |
| SE-MDPMNet [82] | 98.57 ± 0.11 | 98.95 ± 0.12 |
| LiG with RBF kernel [83] | 98.32 ± 0.13 | 98.92 ± 0.35 |
| Xu’s method [37] | 98.61 ± 0.22 | 98.97 ± 0.31 |
| ResNeXt101-MTL [78] | - | 99.11 ± 0.25 |
| ARCNet-VGGNet16 [38] | 96.81 ± 0.14 | 99.12 ± 0.40 |
| TRS (ours) | 98.76 ± 0.13 | 99.52 ± 0.17 |
| Method | Top1 | |
|---|---|---|
| 20% for Training | 50% for Training | |
| VGGNet [75] | 86.59 ± 0.29 | 89.64 ± 0.36 |
| GoogleNet [75] | 83.44 ± 0.40 | 86.39 ± 0.55 |
| SPPNet [75] | 87.44 ± 0.45 | 91.45 ± 0.38 |
| MobileNet [80] | 88.53 ± 0.17 | 90.91 ± 0.18 |
| EfficientNet-B0-aux [76] | 93.96 ± 0.11 | - |
| EfficientNet-B3-aux [76] | 94.19 ± 0.15 | - |
| GBNet [36] | 90.16 ± 0.24 | 93.72 ± 0.34 |
| GBNet + global feature [36] | 92.20 ± 0.23 | 95.48 ± 0.12 |
| ResNet50 [10] | 92.39 ± 0.15 | 94.96 ± 0.19 |
| DenseNet-121 [84] | 93.76 ± 0.23 | 94.73 ± 0.26 |
| MobileNet V2 [80] | 94.13 ± 0.28 | 95.96 ± 0.27 |
| Contourlet CNN [77] | - | 97.36 ± 0.45 |
| LiG with RBF kernel [83] | 94.17 ± 0.25 | 96.19 ± 0.28 |
| ResNeXt-101 + MTL [78] | 93.96 ± 0.11 | 96.89 ± 0.18 |
| SE-MDPMNet [82] | 94.68 ± 0.07 | 97.14 ± 0.15 |
| Xu’s method [37] | 94.74 ± 0.23 | 97.65 ± 0.25 |
| TRS (ours) | 95.54 ± 0.18 | 98.48 ± 0.06 |
| Method | Top1 |
|---|---|
| 80% for Training | |
| Fine-tune AlexNet [85] | 81.22 ± 0.19 |
| Fine-tune VGGNet [85] | 87.15 ± 0.45 |
| Fine-tune GoogleNet [85] | 82.57 ± 0.12 |
| ARCNet-ResNet34 [38] | 91.28 ± 0.45 |
| GBNet [36] | 91.40 ± 0.27 |
| ARCNet-VGGNet16 [38] | 92.70 ± 0.35 |
| GBNet + global feature [36] | 93.28 ± 0.27 |
| EfficientNet-B0-aux [76] | 93.97 ± 0.12 |
| EfficientNet-B3-aux [76] | 94.51 ± 0.75 |
| TRS (ours) | 95.97 ± 0.13 |
4.4. Comparison with Other Attention Models
4.5. Comparison with Other Transformers
4.6. Training, Testing Time and Parameters
5. Discussion
5.1. Ablation Study
5.1.1. Number of Encoder Layers and Self-Attention Heads
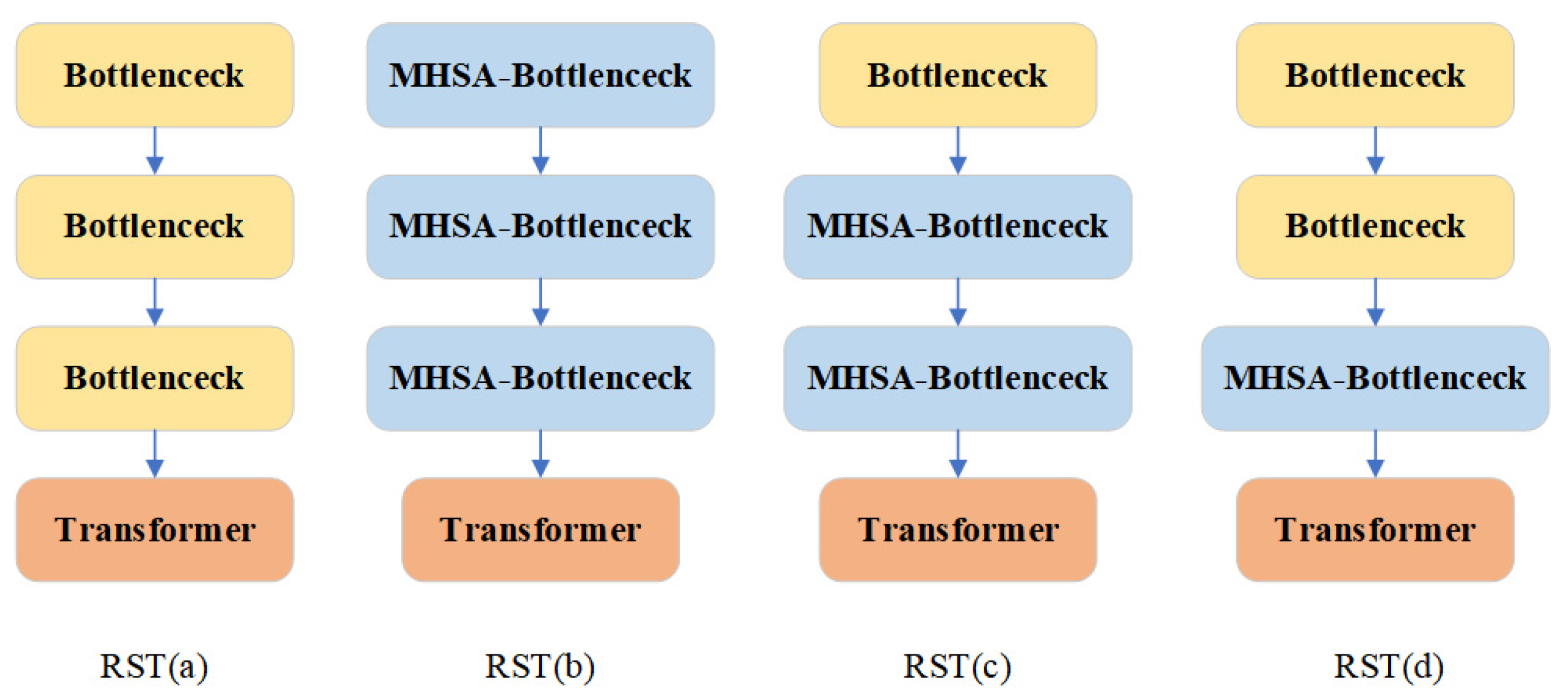
5.1.2. MHSA-Bottleneck Architecture
5.1.3. Position Embedding
5.2. Application Scenarios
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, M.; Liu, D.; Qian, K.; Li, J.; Lei, M.; Zhou, Y. Lunar crater detection based on terrain analysis and mathematical morphology methods using digital elevation models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3681–3692. [Google Scholar] [CrossRef]
- Ye, F.; Xiao, H.; Zhao, X.; Dong, M.; Luo, W.; Min, W. Remote sensing image retrieval using convolutional neural network features and weighted distance. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1535–1539. [Google Scholar] [CrossRef]
- Li, J.; Benediktsson, J.A.; Zhang, B.; Yang, T.; Plaza, A. Spatial technology and social media in remote sensing: A survey. Proc. IEEE 2017, 105, 1855–1864. [Google Scholar] [CrossRef]
- Luo, F.; Huang, H.; Duan, Y.; Liu, J.; Liao, Y. Local geometric structure feature for dimensionality reduction of hyperspectral imagery. Remote Sens. 2017, 9, 790. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Wang, G.; Fan, B.; Xiang, S.; Pan, C. Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 4104–4115. [Google Scholar] [CrossRef]
- Yang, S.; Ramanan, D. Multi-scale recognition with DAG-CNNs. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1215–1223. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR 2015: International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liang, Y.; Monteiro, S.T.; Saber, E.S. Transfer learning for high resolution aerial image classification. In Proceedings of the 2016 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 18–20 October 2016; pp. 1–8. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2021; pp. 5998–6008. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Askell, A. Language models are few-shot learners. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K.N. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.L.; Chen, L.-C. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 108–126. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 68–80. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the ICLR 2021: The Ninth International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. arXiv 2021, arXiv:2101.11986. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Yu, Y.; Liu, F. Aerial scene classification via multilevel fusion based on deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 287–291. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Crete, Greece, 24–26 May 2019; pp. 6105–6114. [Google Scholar]
- Bi, Q.; Qin, K.; Zhang, H.; Xie, J.; Li, Z.; Xu, K. APDC-Net: Attention pooling-based convolutional network for aerial scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1603–1607. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1793–1802. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 82–96. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–15. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 519–531. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Joachims, T. Transductive inference for text classification using support vector machines. In Proceedings of the International Conference on Machine Learning (ICML), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 200–209. [Google Scholar]
- Gómez-Chova, L.; Camps-Valls, G.; Munoz-Mari, J.; Calpe, J. Semisupervised image classification with Laplacian support vector machines. IEEE Geosci. Remote Sens. Lett. 2008, 5, 336–340. [Google Scholar] [CrossRef]
- Ma, B. A new kind of parallel K_NN network public opinion classification algorithm based on Hadoop platform. Appl. Mech. Mater. 2014, 644, 2018–2021. [Google Scholar]
- La, L.; Guo, Q.; Yang, D.; Cao, Q. Multiclass Boosting with Adaptive Group-Based kNN and Its Application in Text Categorization. Math. Probl. Eng. 2012, 2012, 1–24. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Yao, W.; Loffeld, O.; Datcu, M. Application and evaluation of a hierarchical patch clustering method for remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 2279–2289. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral–structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogram. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. Feature significance-based multibag-of-visual-words model for remote sensing image scene classification. J. Appl. Remote Sens. 2016, 10, 035004. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised multilayer feature learning for satellite image scene classification. IEEE Trans. Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Smola, A. Resnest: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Romera-Paredes, B.; Torr, P.H.S. Recurrent instance segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 312–329. [Google Scholar]
- Olah, C. Understanding LSTM Networks. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs (accessed on 1 October 2015).
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the ICLR 2021: The Ninth International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Abnar, S.; Dehghani, M.; Zuidema, W. Transferring inductive biases through knowledge distillation. arXiv 2020, arXiv:2006.00555. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Li, W.; Cao, D.; Peng, Y.; Yang, C. MSNet: A Multi-Stream Fusion Network for Remote Sensing Spatiotemporal Fusion Based on Transformer and Convolution. Remote Sens. 2021, 13, 3724. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Brock, A.; De, S.; Smith, S.L. Characterizing signal propagation to close the performance gap in unnormalized ResNets. In Proceedings of the ICLR 2021: The Ninth International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2012, 51, 818–832. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple yet effective fine-tuning of deep CNNs using an auxiliary classification loss for remote sensing scene classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Jiao, L.; Liu, X.; Li, L.; Liu, F.; Yang, S. C-CNN: Contourlet convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2636–2649. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When self-supervised learning meets scene classification: Remote sensing scene classification based on a multitask learning framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhu, Q.; Qin, Q. Scene classification based on a deep random-scale stretched convolutional neural network. Remote Sens. 2018, 10, 444. [Google Scholar] [CrossRef] [Green Version]
- Pan, H.; Pang, Z.; Wang, Y.; Wang, Y.; Chen, L. A new image recognition and classification method combining transfer learning algorithm and mobilenet model for welding defects. IEEE Access 2020, 8, 119951–119960. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 1492–1500. [Google Scholar]
- Zhang, B.; Zhang, Y.; Wang, S. A lightweight and discriminative model for remote sensing scene classification with multidilation pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Pour, A.M.; Seyedarabi, H.; Jahromi, S.H.A.; Javadzadeh, A. Automatic detection and monitoring of diabetic retinopathy using efficient convolutional neural networks and contrast limited adaptive histogram equalization. IEEE Access 2020, 8, 136668–136673. [Google Scholar] [CrossRef]
- Aral, R.A.; Keskin, Ş.R.; Kaya, M.; Hacıömeroğlu, M. Classification of trashnet dataset based on deep learning models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2018; pp. 2058–2062. [Google Scholar]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M.A. Striving for Simplicity: The All Convolutional Net. In Proceedings of the ICLR (Workshop Track), San Diego, CA, USA , 7–9 May 2015. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 936–944. [Google Scholar]
- Cheng, B.; Schwing, A.G.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. arXiv 2021, arXiv:2107.06278. [Google Scholar]

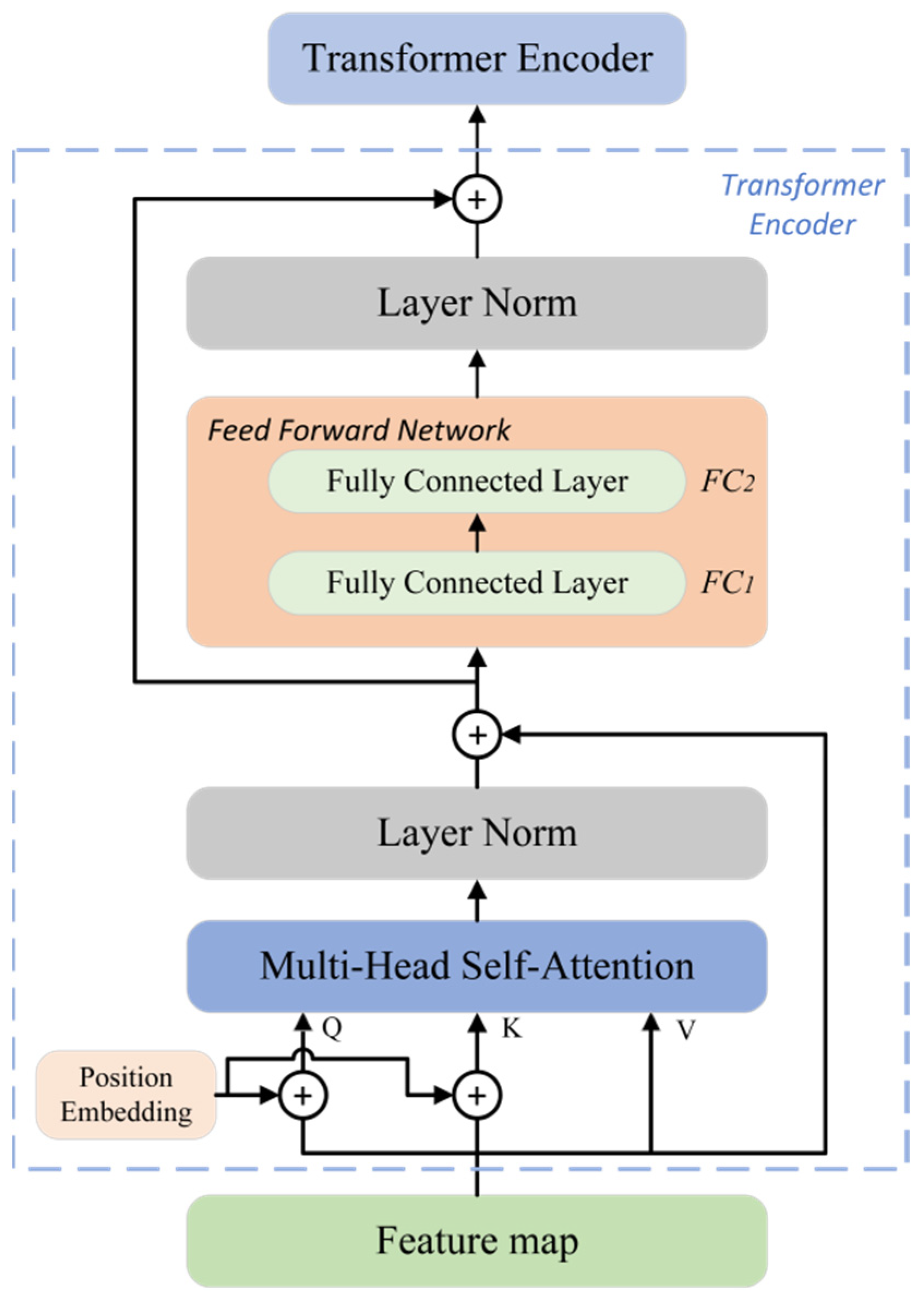
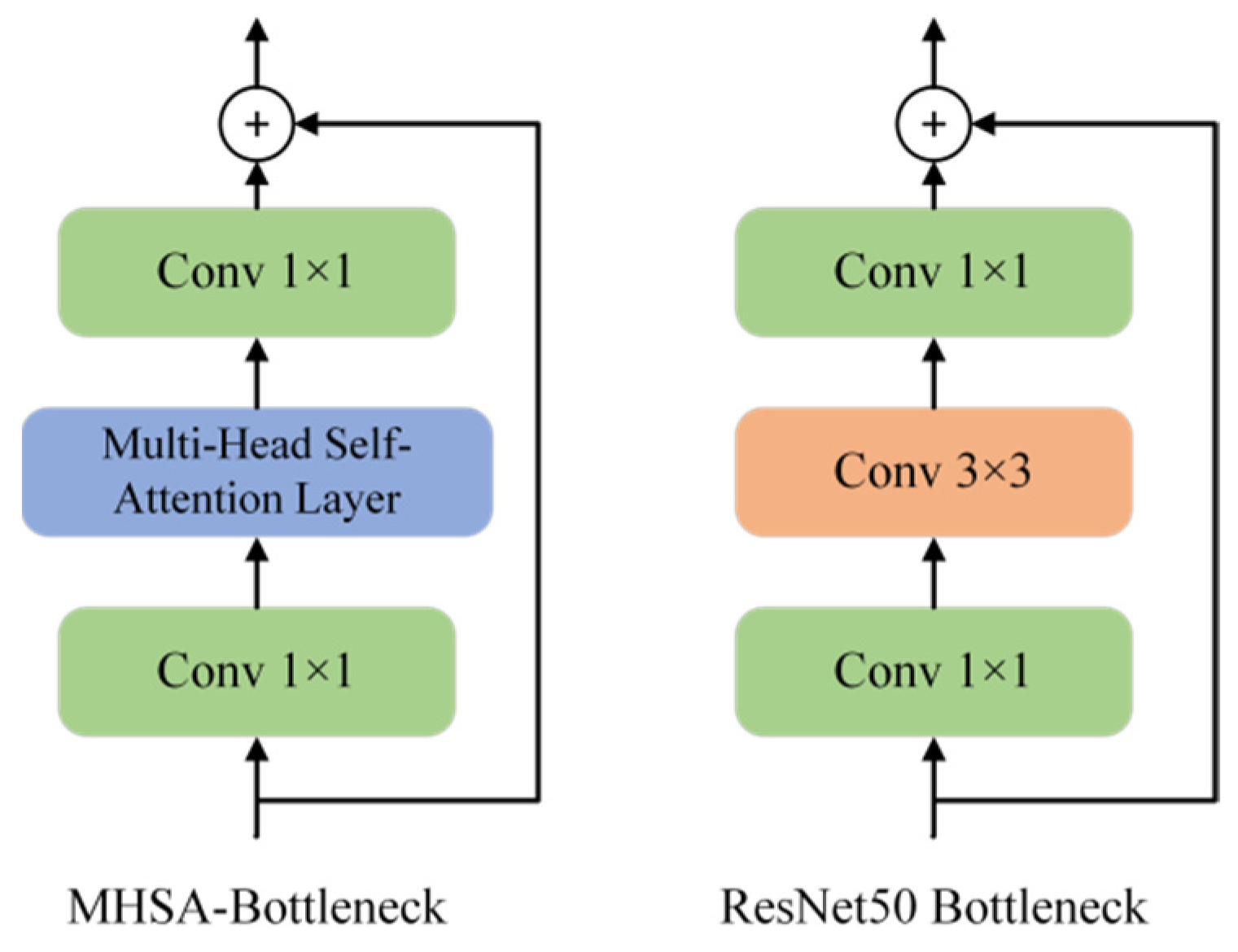
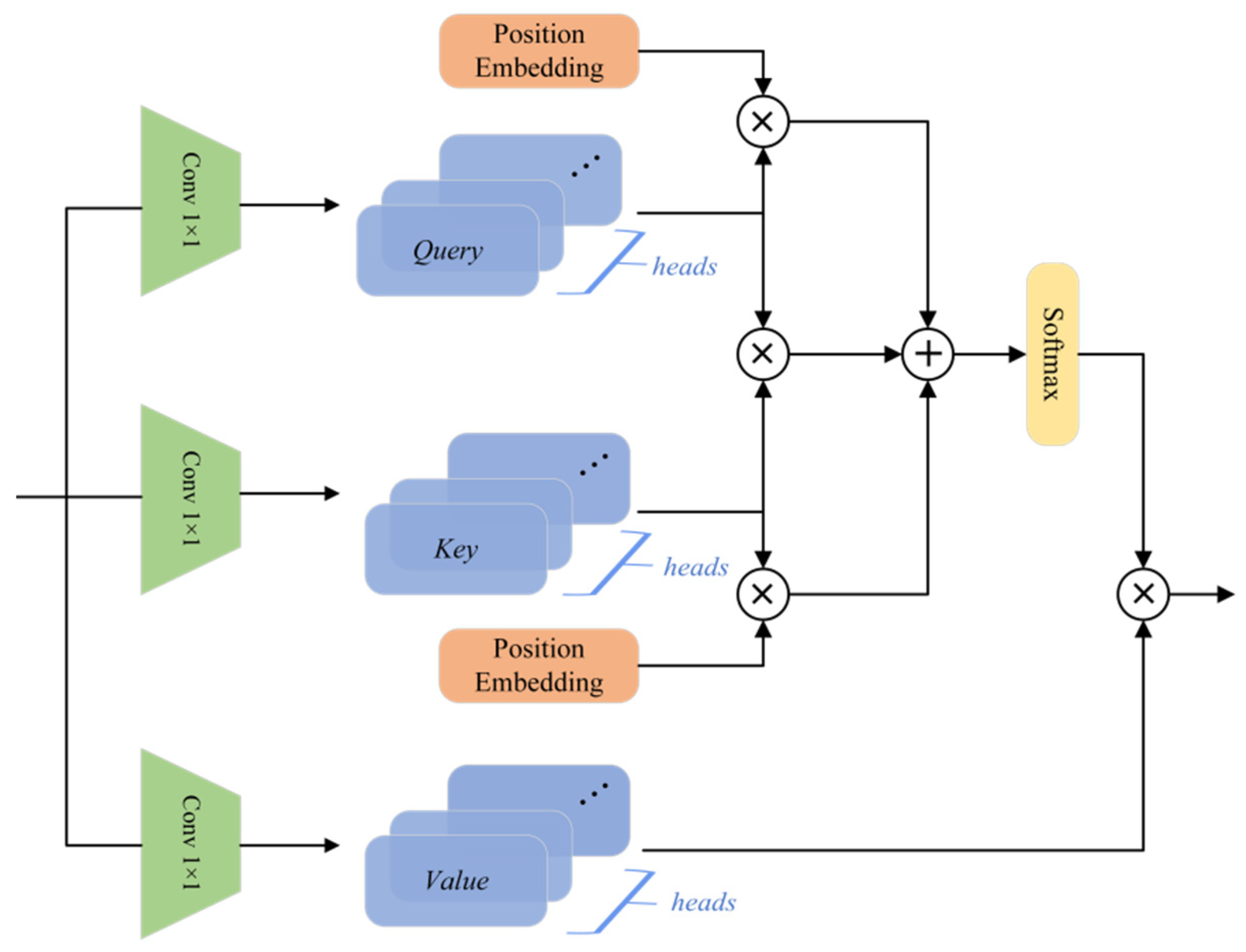
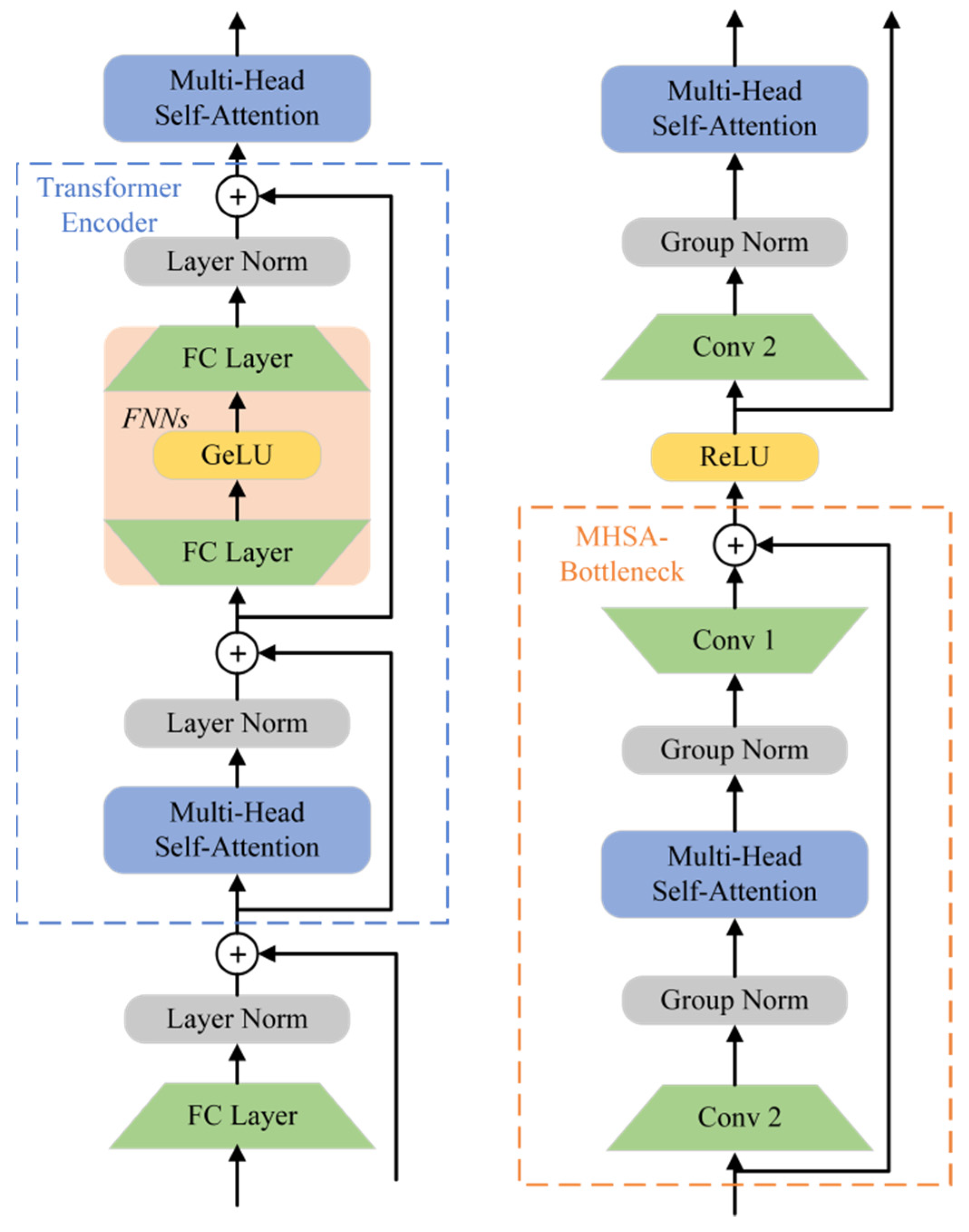

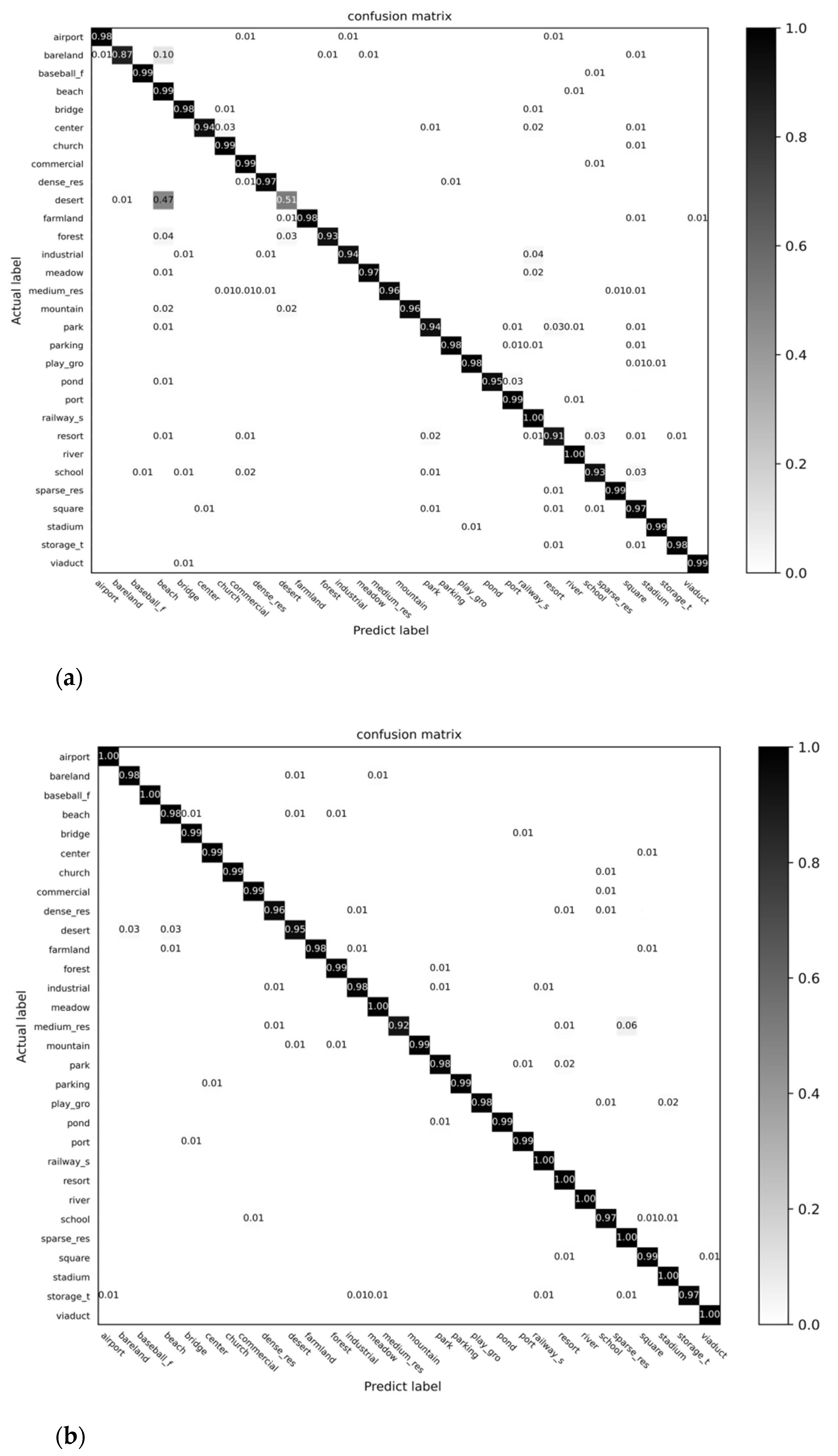
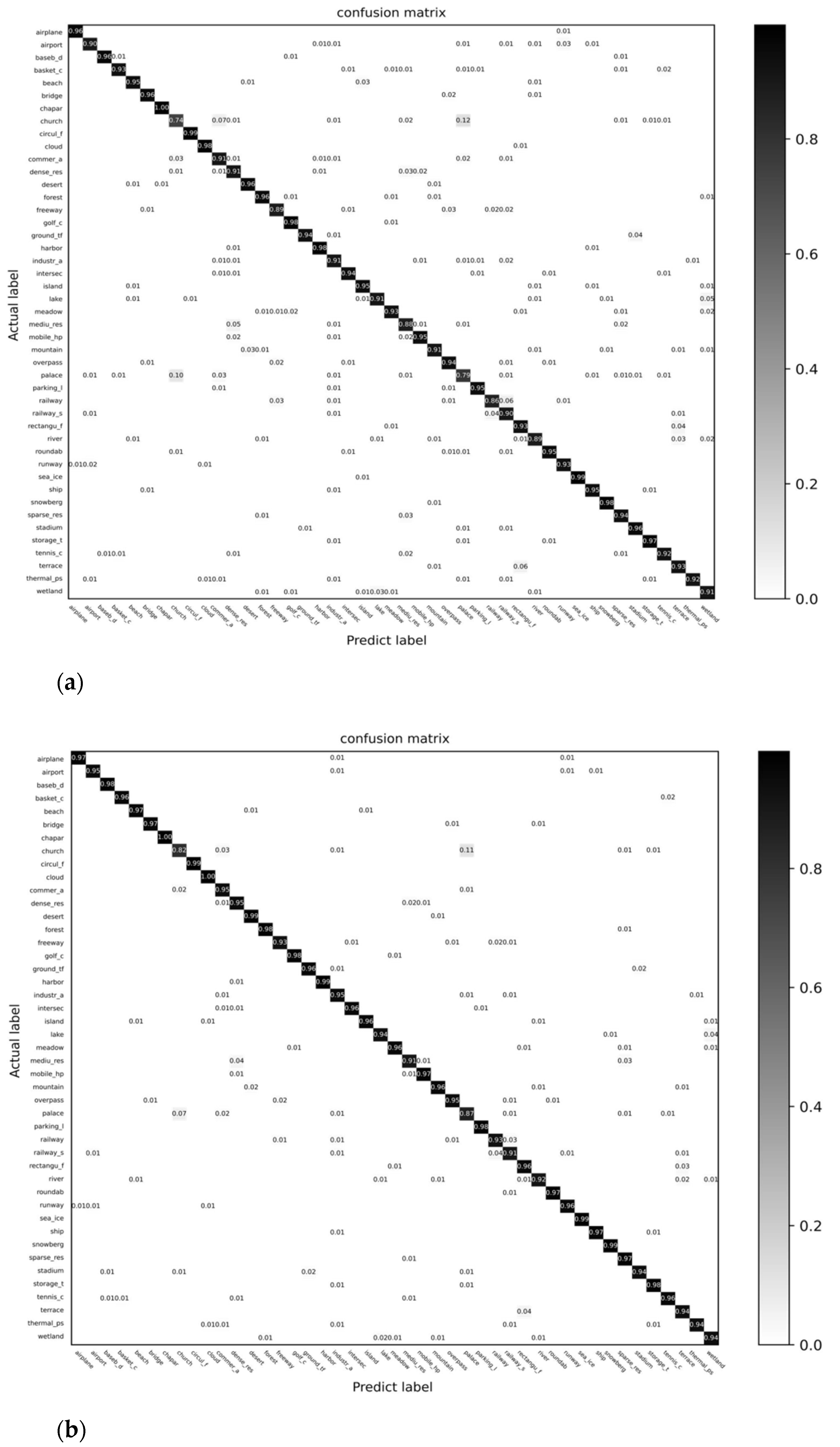
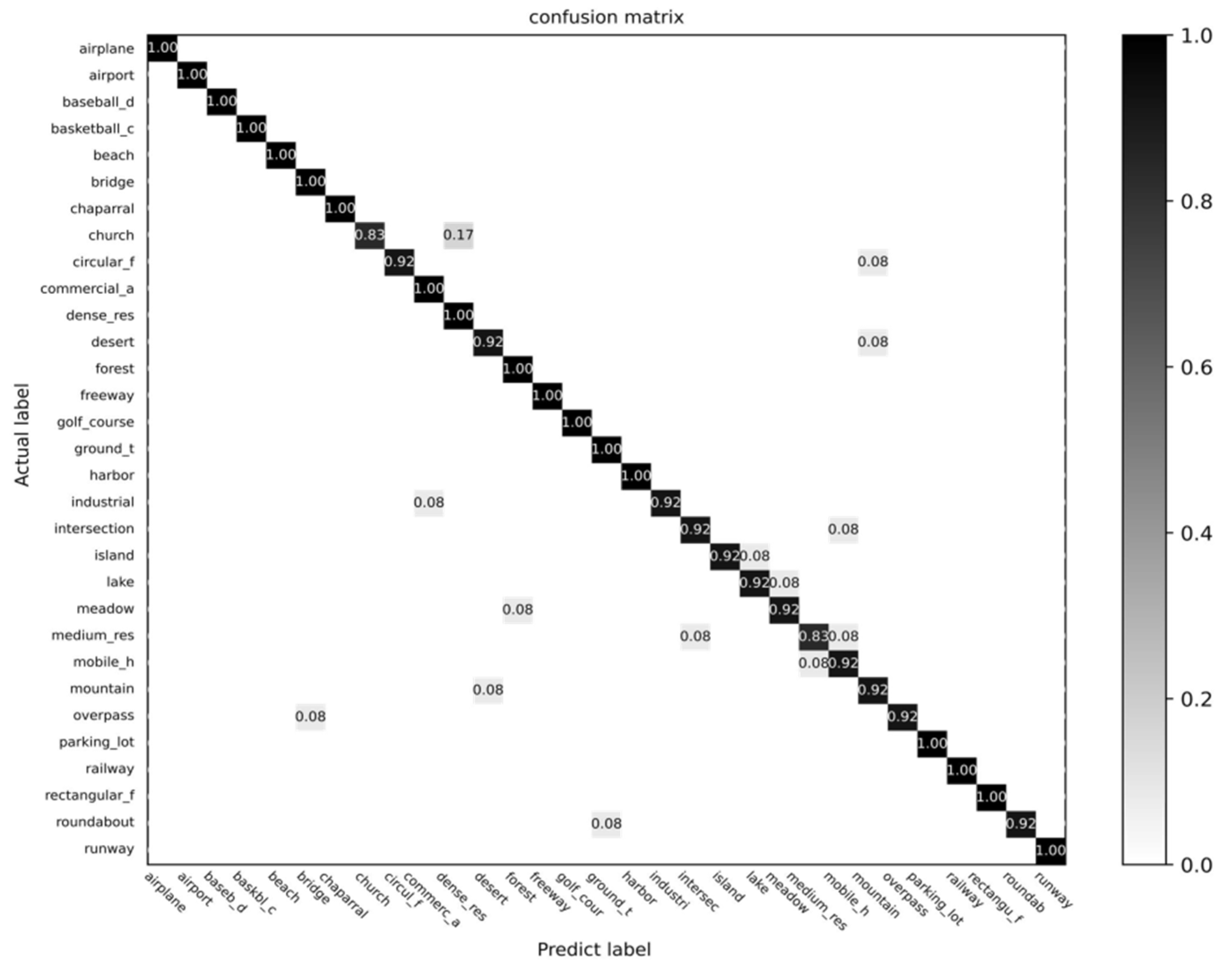

| Stage | Output | ResNet50 | TRS |
|---|---|---|---|
| S1 | 112 × 112 | 7 × 7, 64, stride 2 | 7 × 7, 64, stride 2 |
| S2 | 56 × 56 | 3 × 3 max pool, stride 2 | 3 × 3 max pool, stride 2 |
| 1 × 1, 64 3 × 3, 64 ×3 1 × 1, 256 | 1 × 1, 64 3 × 3, 64 ×3 1 × 1, 256 | ||
| S3 | 28 × 28 | 1 × 1, 128 3 × 3, 128 ×4 1 × 1, 512 | 1 × 1, 128 3 × 3, 128 ×4 1 × 1, 512 |
| S4 | 14 × 14 | 1 × 1, 256 3 × 3, 256 ×6 1 × 1, 1024 | 1 × 1, 256 MHSA, 256 ×9 1 × 1, 1024 |
| S5 | 7 × 7 | 1 × 1, 512 3 × 3, 512 ×3 1 × 1, 2048 | Transformer Encoder ×12 |
| 197 × 768 | |||
| S6 | 1 × 1 | Average pooling Fc.softmax | Fc.softmax |
| Operation System | Ubuntu 20.04 Server |
|---|---|
| CPU | 2 × Intel(R) Xeon(R) E5-2690 v4 @ 2.60GHz |
| Memory | 256 GB |
| Framework | PyTorch 1.7 |
| GPU | 4 × NVIDIA TITAN XP |
| Method | Top1 | |
|---|---|---|
| 10% for Training | 20% for Training | |
| AlexNet [75] | 76.69 ± 0.19 | 76.85 ± 0.18 |
| VGGNet [75] | 76.47 ± 0.18 | 79.79 ± 0.65 |
| GoogleNet [75] | 76.19 ± 0.38 | 78.48 ± 0.26 |
| SPPNet [75] | 82.13 ± 0.30 | 84.64 ± 0.23 |
| D-CNN with AlexNet [75] | 85.56 ± 0.20 | 87.24 ± 0.12 |
| D-CNN with VGGNet-16 [75] | 89.22 ± 0.50 | 91.89 ± 0.22 |
| DenseNet-121 [84] | 88.31 ± 0.35 | 90.47 ± 0.33 |
| ResNet50 [10] | 86.23 ± 0.41 | 88.93 ± 0.12 |
| MobileNet [80] | 80.32 ± 0.16 | 83.26 ± 0.17 |
| MobileNet V2 [80] | 90.16 ± 0.12 | 93.00 ± 0.18 |
| EfficientNet-B0-aux [76] | 89.96 ± 0.27 | - |
| EfficientNet-B3-aux [76] | 91.08 ± 0.14 | - |
| Fine-tune EfficientNet [31] | 89.93 ± 0.19 | 91.16 ± 0.23 |
| Contourlet CNN [77] | 85.93 ± 0.51 | 89.57 ± 0.45 |
| LiG with RBF kernel [83] | 90.23 ± 0.11 | 93.25 ± 0.12 |
| ResNeXt-101 [81] | 91.18 ± 0.29 | 93.68 ± 0.31 |
| SE-MDPMNet [82] | 91.80 ± 0.07 | 94.11 ± 0.03 |
| ResNeXt-101 + MTL [78] | 91.91 ± 0.18 | 94.21 ± 0.15 |
| Xu’s method [37] | 91.91 ± 0.15 | 94.43 ± 0.16 |
| TRS (ours) | 93.06 ± 0.11 | 95.56 ± 0.20 |
| Methods | AID 50% | NWPU 20% |
|---|---|---|
| ResNet50 [10] | 94.96 | 88.93 |
| SENet-50 [19] | 95.38 | 91.26 |
| CBAM + ResNet50 [20] | 95.01 | 90.79 |
| Non-Local + ResNet50 [21] | 95.87 | 93.17 |
| ResNeSt50 [51] | 96.71 | 93.52 |
| TRS (ours) | 98.48 | 95.58 |
| Method | UC-Merced | AID | ||
|---|---|---|---|---|
| 50% for Training | 80% For Training | 20% for Training | 50% for Training | |
| ViT-Base [23] | 93.57 | 95.81 | 91.16 | 94.44 |
| ViT-Large [23] | 94.00 | 96.06 | 91.88 | 95.13 |
| ViT-Hybrid [23] | 98.16 | 99.03 | 92.39 | 96.20 |
| DeiT-Base [24] | 97.93 | 98.56 | 93.41 | 96.04 |
| PVT-Medium [26] | 96.42 | 97.28 | 92.84 | 95.93 |
| PVT-Large [26] | 96.91 | 97.70 | 93.69 | 96.65 |
| T2T-ViT-19 [60] | 96.88 | 97.70 | 92.39 | 95.42 |
| V16_21k [84] | 98.14 | - | 94.97 | - |
| Swin-Base [63] | 98.21 | 98.91 | 94.86 | 97.80 |
| Swin-Large [63] | 98.68 | 99.14 | 95.09 | 98.46 |
| TRS (ours) | 98.76 | 99.52 | 95.54 | 98.48 |
| Method | NWPU | OPTIMAL-31 | |
|---|---|---|---|
| 10% for Training | 20% for Training | 80% for Training | |
| ViT-Base [23] | 87.59 | 90.87 | 89.73 |
| ViT-Large [23] | 89.16 | 91.94 | 91.14 |
| ViT-Hybrid [23] | 89.22 | 91.97 | 91.99 |
| DeiT-Base [24] | 91.86 | 93.83 | 93.09 |
| PVT-Medium [26] | 90.51 | 92.66 | 91.80 |
| PVT-Large [26] | 90.59 | 92.72 | 92.45 |
| T2T-ViT-19 [60] | 90.38 | 92.98 | 92.08 |
| V16_21k [84] | 92.60 | - | 95.07 |
| Swin-Base [63] | 91.80 | 94.04 | 93.64 |
| Swin-Large [63] | 92.67 | 95.52 | 95.11 |
| TRS (ours) | 93.06 | 95.56 | 95.97 |
| Methods | UC-Merced 50% | ||||
|---|---|---|---|---|---|
| Acc. | Train (s/epoch) | Test (s/epoch) | Parameters (M) | FLOPs (G) | |
| ResNet-101 [10] | 92.47 | 11.1 | 3.9 | 46.0 | 7.6 |
| ResNet-152 [10] | 92.95 | 12.5 | 4.3 | 60.0 | 11.0 |
| ResNeXt-101 [81] | - | 21.2 | 7.2 | 84.0 | 32.0 |
| SE-Net [19] | 95.38 | 24.7 | 11.6 | 146.0 | 42.0 |
| ViT-Base [23] | 93.57 | 13.4 | 5.8 | 86.4 | 17.5 |
| ViT-Hybrid [23] | 98.16 | 19.3 | 7.2 | 112.0 | 21.3 |
| PVT-Medium [26] | 96.42 | 13.6 | 4.5 | 62.6 | 10.1 |
| Swin-Base [63] | 98.21 | 16.4 | 5.2 | 88.0 | 15.4 |
| TRS (ours) | 98.76 | 11.4 | 4.3 | 46.3 | 8.4 |
| Transformer Encoder Layers | Heads | AID 50% | NWPU 20% |
|---|---|---|---|
| 0 | 0 | 91.47 | 86.32 |
| 3 | 12 | 96.63 | 91.59 |
| 6 | 12 | 97.25 | 93.21 |
| 9 | 12 | 98.36 | 95.33 |
| 12 | 1 | 95.96 | 94.89 |
| 12 | 6 | 98.43 | 95.50 |
| 12 | 12 | 98.48 | 95.58 |
| Architecture | AID 50% | NWPU 20% |
|---|---|---|
| ResNet50 | 94.96 | 88.93 |
| TRS (a) | 96.20 | 91.97 |
| TRS (b) | 95.69 | 89.94 |
| TRS (c) | 97.31 | 94.52 |
| TRS (d) | 98.48 | 95.58 |
| Heads | Norm | AID 50% | NWPU 20% |
|---|---|---|---|
| 1 | Group norm | 93.25 | 88.04 |
| 6 | Batch norm | 98.26 | 95.41 |
| 6 | Group norm | 98.48 | 95.58 |
| 12 | Batch norm | 98.01 | 94.85 |
| 12 | Group norm | 98.13 | 95.39 |
| Transformer | MHSA-Bottleneck | AID 50% | NWPU 20% |
|---|---|---|---|
| None | None | 90.44 | 86.60 |
| Abs | Abs | 95.73 | 93.16 |
| Rel | Rel | 98.48 | 95.53 |
| Abs | Rel | 98.48 | 95.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhao, H.; Li, J. TRS: Transformers for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 4143. https://doi.org/10.3390/rs13204143
Zhang J, Zhao H, Li J. TRS: Transformers for Remote Sensing Scene Classification. Remote Sensing. 2021; 13(20):4143. https://doi.org/10.3390/rs13204143
Chicago/Turabian StyleZhang, Jianrong, Hongwei Zhao, and Jiao Li. 2021. "TRS: Transformers for Remote Sensing Scene Classification" Remote Sensing 13, no. 20: 4143. https://doi.org/10.3390/rs13204143
APA StyleZhang, J., Zhao, H., & Li, J. (2021). TRS: Transformers for Remote Sensing Scene Classification. Remote Sensing, 13(20), 4143. https://doi.org/10.3390/rs13204143