1. Introduction
The Tibetan Plateau is the security barrier of the Asian ecosystem and is also well-known as the world’s third pole [
1] and Asia’s water tower [
2]. There are numerous lakes on the Tibetan Plateau, which differ greatly in size and account for the majority of the lake area in China [
3]. Lakes have an important research value as the sentinel of environmental change and the signal of climate change [
4]. In recent years, it has been shown that global warming accelerates glacial melt [
5] and permafrost degradation [
6], with most of the lakes expanding in the last 30 years. It can also be confirmed that the lake area of the Tibetan Plateau expands at a pace of 0.83%/year due to increased glacial runoff [
7]. The overflow of the salt lakes not only causes pollution of the land and freshwater lakes, which damages the ecological environment, but also disturbs the life of the residents.
More remote sensing satellites, such as multi-spectral satellites, hyper-spectral satellites, and high-resolution satellites, have been developed as global observation technology and sensor equipment evolve. The obtained remote sensing images not only capture detailed ground information but also allow accurate analysis of interesting regions. As the ability to analyze the amount of information contained in the remote sensing images has gradually grown, so has the need for analysis of the target region. Therefore, the automatic extraction of lake water bodies is important for monitoring the changes of lakes in remote sensing images.
The automatic extraction of water bodies from remotely sensed images is an important part of water resource management and an essential part of remote sensing science. In order to eliminate misleading information such as mountain shadows, cloud shadows, and glacial snow accumulation, traditional methods for water body extraction from a large number of remote sensing images have been proposed, which can be mainly divided into a spectral analysis method based on water indices, and a classification method based on machine learning.
With the increasing demand for massive remote sensing data processing, the water index method is a commonly used method for water extraction, which is mainly designed to enhance water features and suppress non-water features, and then to achieve water extraction by selecting the optimal threshold value. McFeeters et al. [
8] used the low reflectance of water in the near-infrared band and the high reflectance in the green band to enhance the features of water bodies, resulting in the Normalised Difference Water Index (NDWI). The proposal of NDWI has contributed to the rapid development of the water extraction field from remote sensing images, with numerous studies carried out by subsequent researchers based on NDWI. In order to solve the problem that NDWI cannot suppress noise well in built-up areas as well as vegetation and soil noise, Xu et al. [
9] replaced the near-infrared band with the shortwave-infrared band to enhance the features of open water bodies in remote sensing images by naming it modified NDWI (MNDWI). NDWI has also been used by some researchers in combination with other metrics to remove the interference of shadows on the accuracy of water body extraction. Xie et al. [
10] combined NDWI with the morphological shadow index (MSI), which is used to describe shadow areas, to propose NDWI-MSI, which is able to highlight water bodies while suppressing shadow areas. Kaplan et al. [
11] proposed the water extraction surface temperature index (WESTI) in combination with NDWI and the surface temperature variability between the water body and other noise to improve the extraction accuracy of water bodies in cold regions.
Although the accuracy of water body extraction based on water index methods is improving, they all require a threshold to distinguish between water and non-water areas, where subjective and static thresholds can lead to over-or underestimation of surface water areas [
12]. Due to the advantages of avoiding the manual selection of threshold and better image understanding, the classification methods based on machine learning are often used to extract water bodies from remote sensing images. They mainly use manually-designed waterbody features to form a feature space, which is then fed into a machine learning classifier to achieve water body extraction. Balázs et al. [
13] used principal component analysis to reduce the correlation of bands with spectral indices which were fed into a classifier with principal components (PCs) to distinguish between three water-related categories: water bodies, saturated soils, and non-water. Saghafi et al. [
14] used the data fusion method to improve the resolution of multispectral images and perform information enhancement, and then used the extracted features to classify high-resolution multispectral images, which demonstrated the significance of multisensor fusion for water body extraction. Although all of the above methods achieve good classification accuracy, they often require a certain amount of a priori knowledge to extract features manually. At the same time, the manually extracted features have certain limitations and lack some generalization ability.
In the special field of computer vision, a deep convolutional neural network (DCNN) has higher accuracy compared to traditional machine learning methods. In 2012, AlexNet [
15] was formally proposed for the ImageNet classification task, which established the foundation for the wide application of DCNN. In addition, various backbone networks have been proposed to improve the drawbacks of AlexNet. For example, ResNet [
16], ResNeXt [
17], and RegNet [
18], which use residual learning modules to avoid degradation problems caused by increasing network depth. The lightweight network represented by MobileNet [
19] reduces the number of trainable parameters, which divides the general convolution into depthwise convolution and pointwise convolution. Densely-connected convolutional neural networks, such as DenseNet [
20], connect the current layer to all previous layers.
The purpose of semantic segmentation is to assign a class label to each pixel based on the probability map calculated by softmax or sigmoid function. DCNNs have achieved superior performance in natural image segmentation, and they are also being used in remote sensing image analysis in recent years [
21,
22,
23,
24]. However, the complex background of remote sensing images and targets with multi-scale features lead the advanced network not to model the foreground correctly. Therefore, its performance is poor. The remote sensing image analysis is also an important application field of attention mechanism used to minimize noise interference, such as building footprint extraction [
25,
26,
27,
28], road extraction [
29,
30], water body extraction [
31,
32,
33], land cover segmentation [
34,
35,
36,
37].
Lakes are important indicators of global climate change. Traditional water body extraction methods all suffer from the drawbacks of poor generalization ability, high computational complexity, and low extraction accuracy. Many researchers have used DCNN for the extraction of water bodies. Restricted receptive field deconvolution network (RRF DeconvNet) [
21] was proposed to perform accurate extraction of water bodies in remotely sensed images, but without using pre-trained weights to initialize the model. To overcome the boundary-blurring problem of DCNN which is caused by the loss of boundary information during the downsampling process, it proposes a new edge-weighted loss function to assign greater weights to the pixels near the boundary. However, due to the single expansion rate, it is not enough to deal with common problems such as noise interference and multiscale features. Weng et al. [
22] improved the feature extraction method by introducing depthwise separable convolution to reduce the risk of overfitting and expanding the receptive field by dilated convolution. The information of the small water body is obtained by using cascading methods in the encoder stage. Guo et al. [
23] used four parallel dilated convolutions to form a multiscale feature extractor which guarantees the accuracy of small water body extraction. All the above methods use dilated convolution to capture more multiscale contextual information, however, the shallower encoder cannot extract enough features for pixel classification in the regions with strong noise interference. To reduce the risk of overfitting, Wang et al. [
24] used ResNet-101, which introduces depthwise separable convolution, as an encoder to prevent overfitting. Although a high accuracy rate is obtained, its training time is too long.
Attentional mechanisms, an important area of research in the field of computer vision, had been applied by many researchers to the extraction of water bodies from remote sensing images with a focus on the adaptive weighting of different important information. A network of two-branch attention mechanisms [
31] was proposed, where a deeper one is used to extract multiscale channel features and another shallower one is used to extract location information, and the two branches were fused to segment the water body. However, it cannot accurately extract small water bodies and edge information. Xia et al. [
32] localized the water body by shallow features and a large-scale attention module while segmenting the edges of the water body using deep features and a small-scale attention module, but they used a conditional random field (CRF) to further enhance the extraction capability. Zeng et al. [
33] proposed an adaptive row and column self-attention mechanism to achieve high accuracy extraction of aquatic ponds without using post-processing.
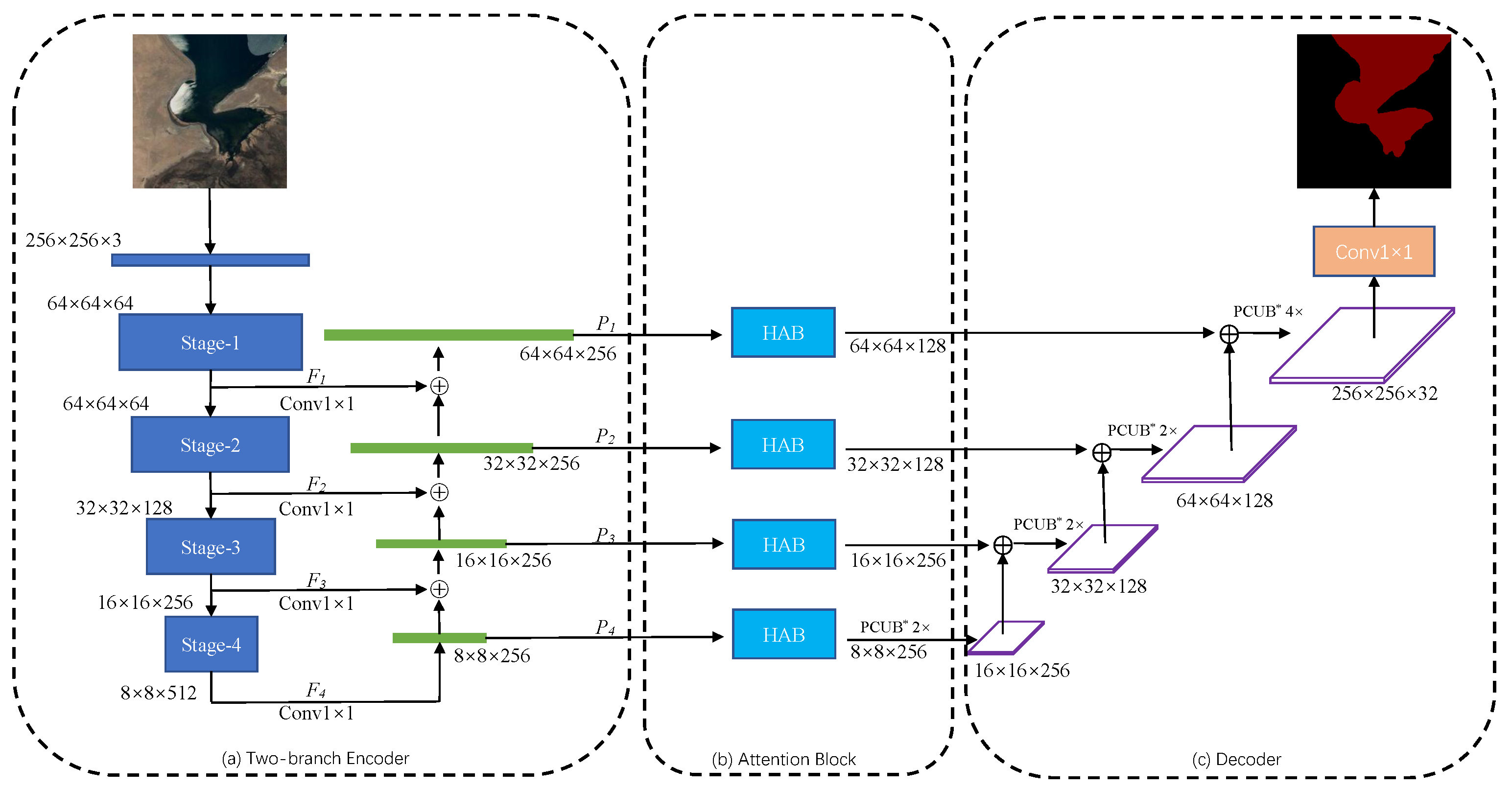
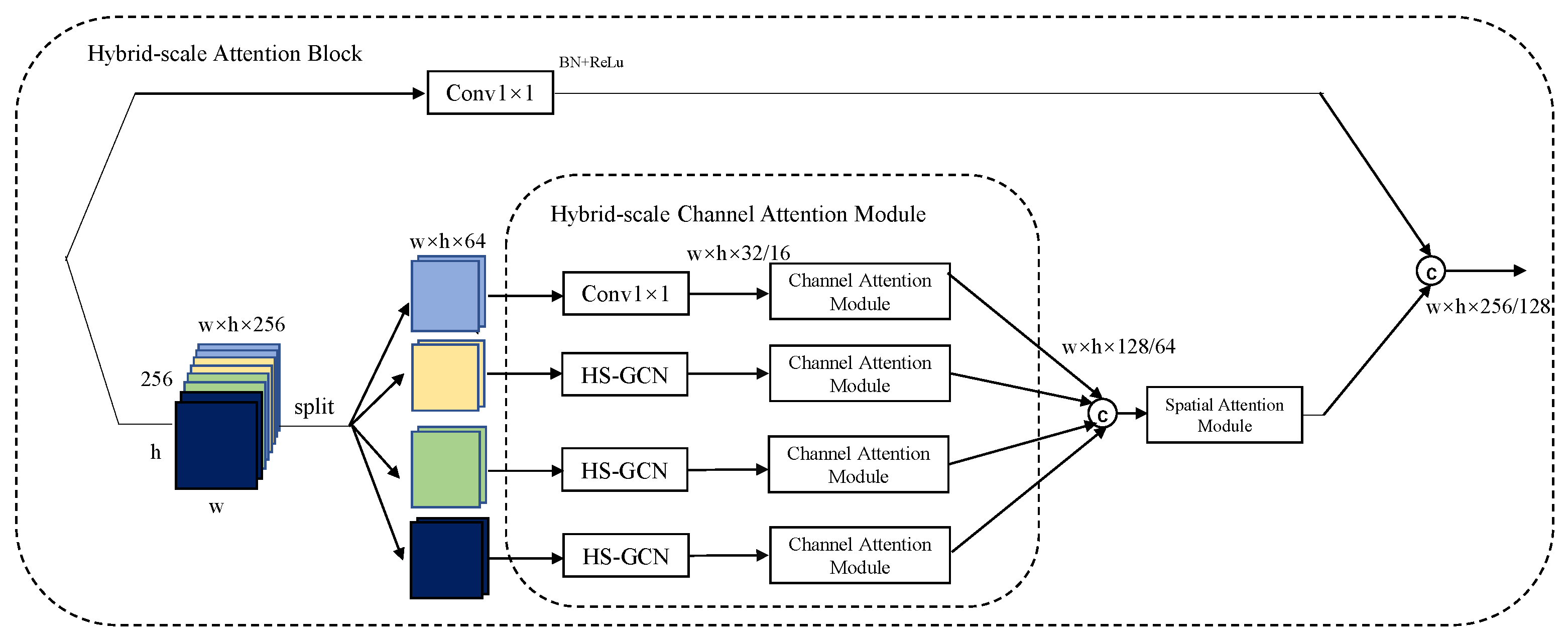
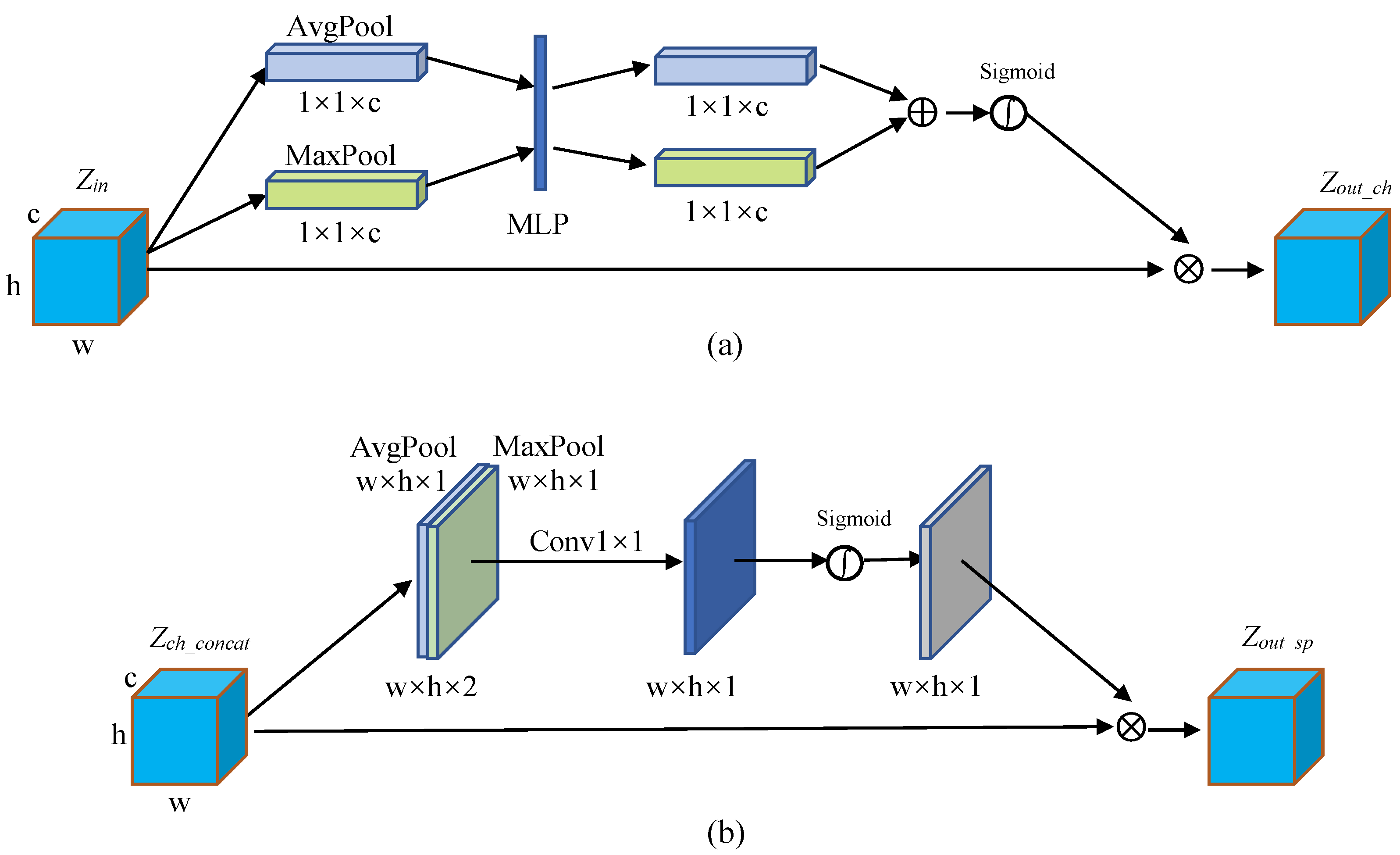
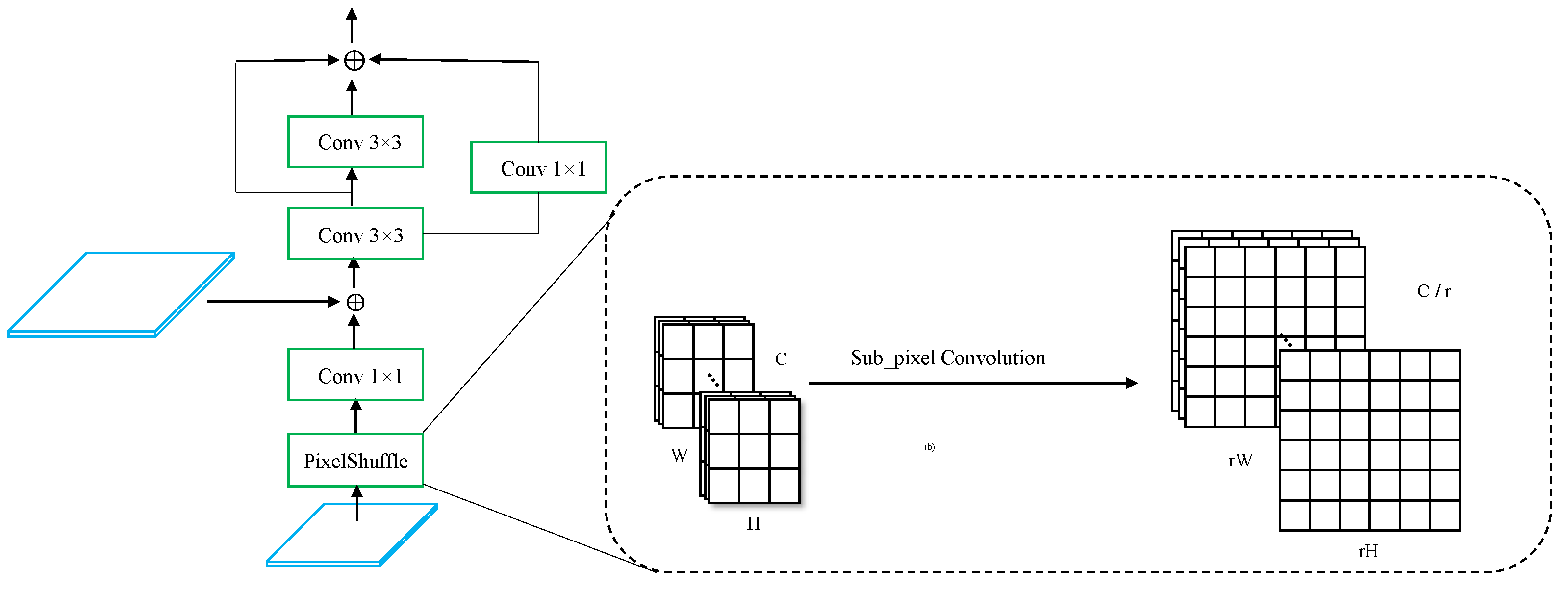
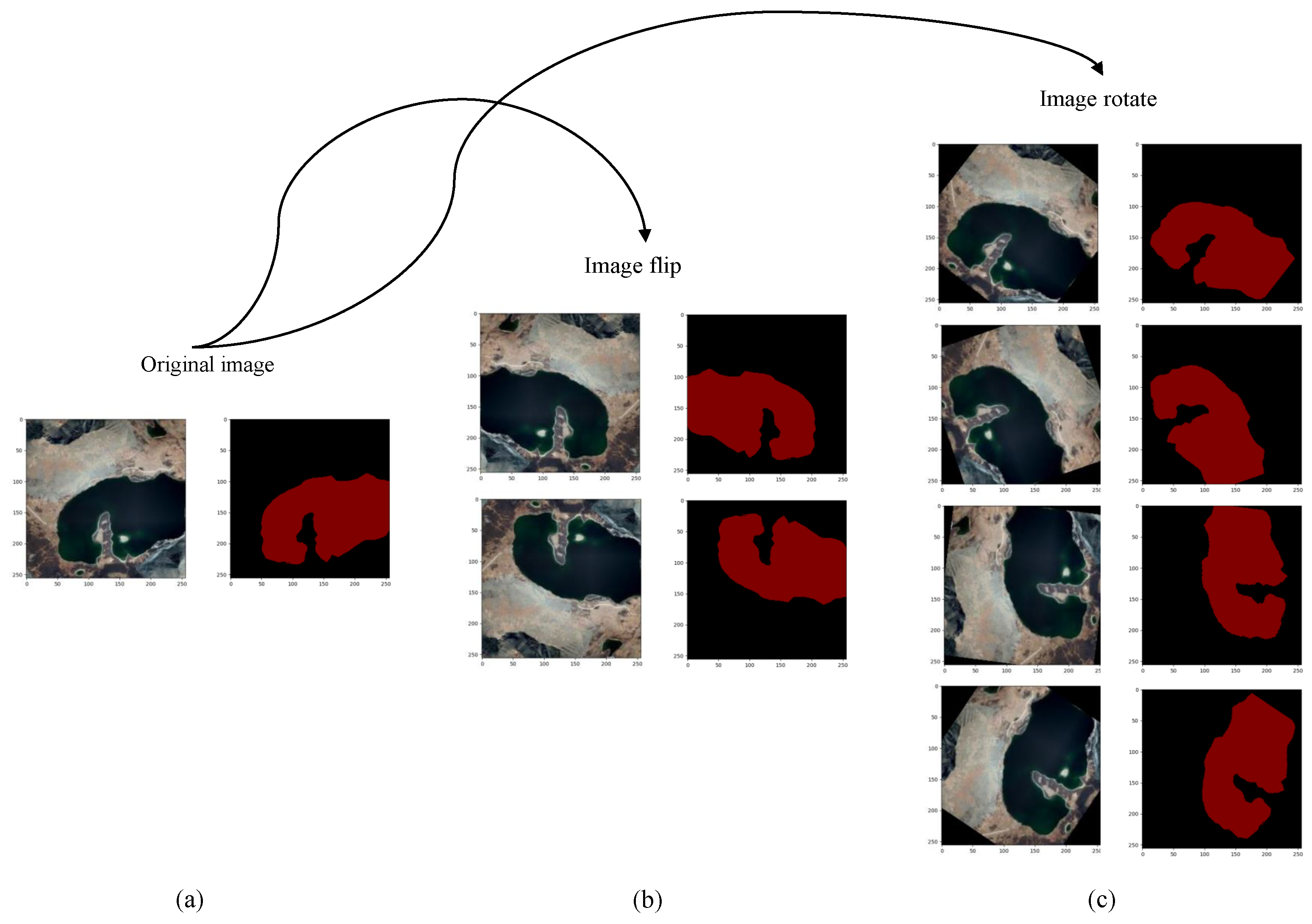
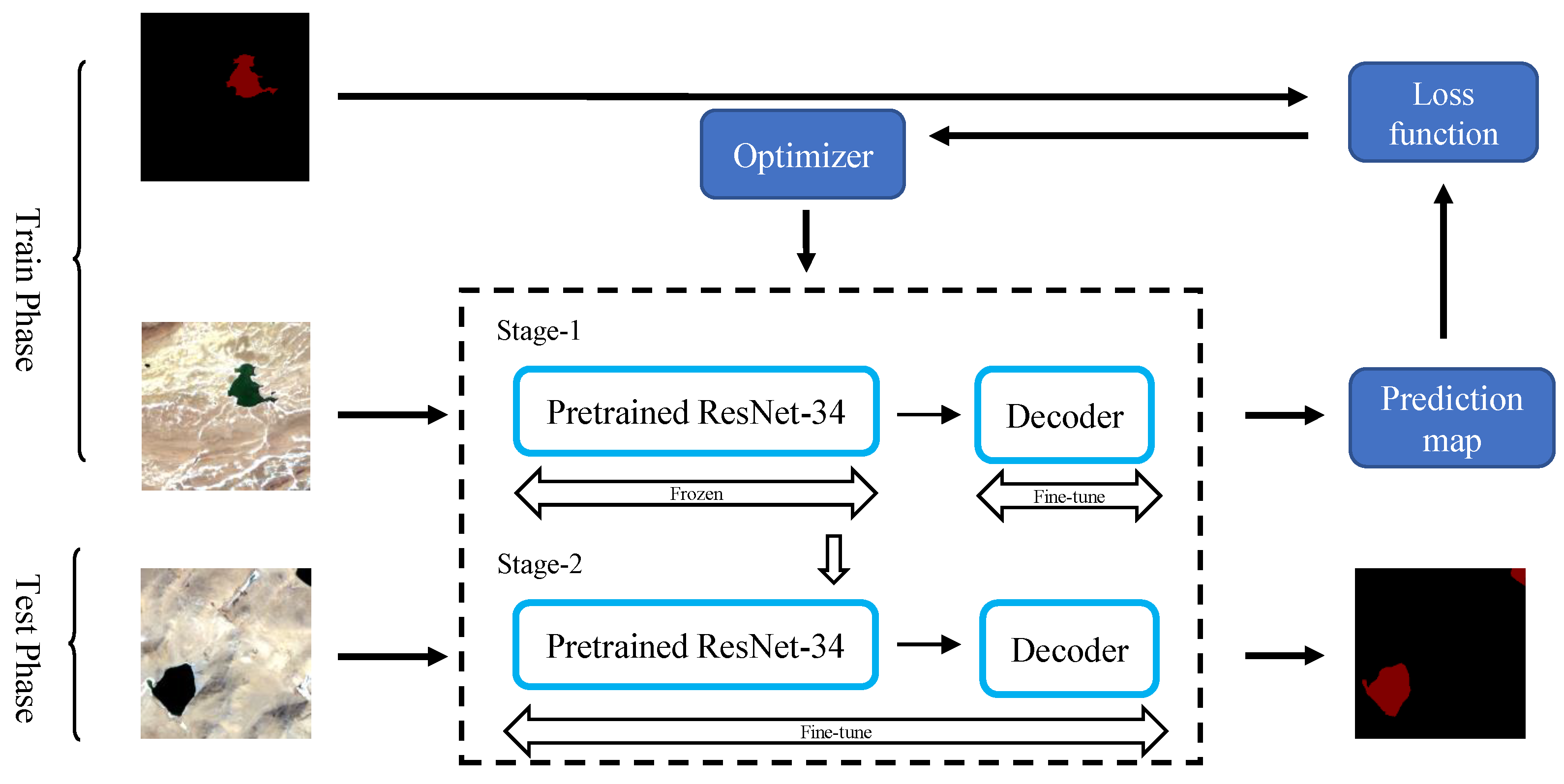
In this paper, a model based on a fully convolutional neural network is proposed to perform pixel classification on the Google dataset and validate the robustness of the Landsat-8 dataset. Firstly, we propose a two-branch encoder structure, which uses ResNet-34 to extract deep semantic features of lake water bodies and a feature pyramid network (FPN) to fuse the extracted features of different resolutions. Due to the low interclass variance and high intraclass variance features, we use hybrid-scales attention block (HAB) to weight the spatial and channel information for feature maps to reduce the interference of noise. During upsampling, the pixelshuffle convolution upsample block (PCUB) is used to recover the low-resolution feature maps to the spatial resolution of the original image and refine the segmentation boundaries. The main contributions of this paper are summarized in the following five points.
- 1.
A Hybrid-scale Attention Network, named HA-Net, is proposed in this paper for the effective extraction of the lake water body.
- 2.
Combining ResNet-34 and FPN, a two-branch encoder structure is proposed to model the foreground, which can better solve the multiscale problem of the lake water body.
- 3.
Inspired by Inception [
38], where using convolutional kernels of different sizes can improve the expression ability of the model, we design a hybrid-scale attention block.
- 4.
PCUB, by combining Pixelshuffle [
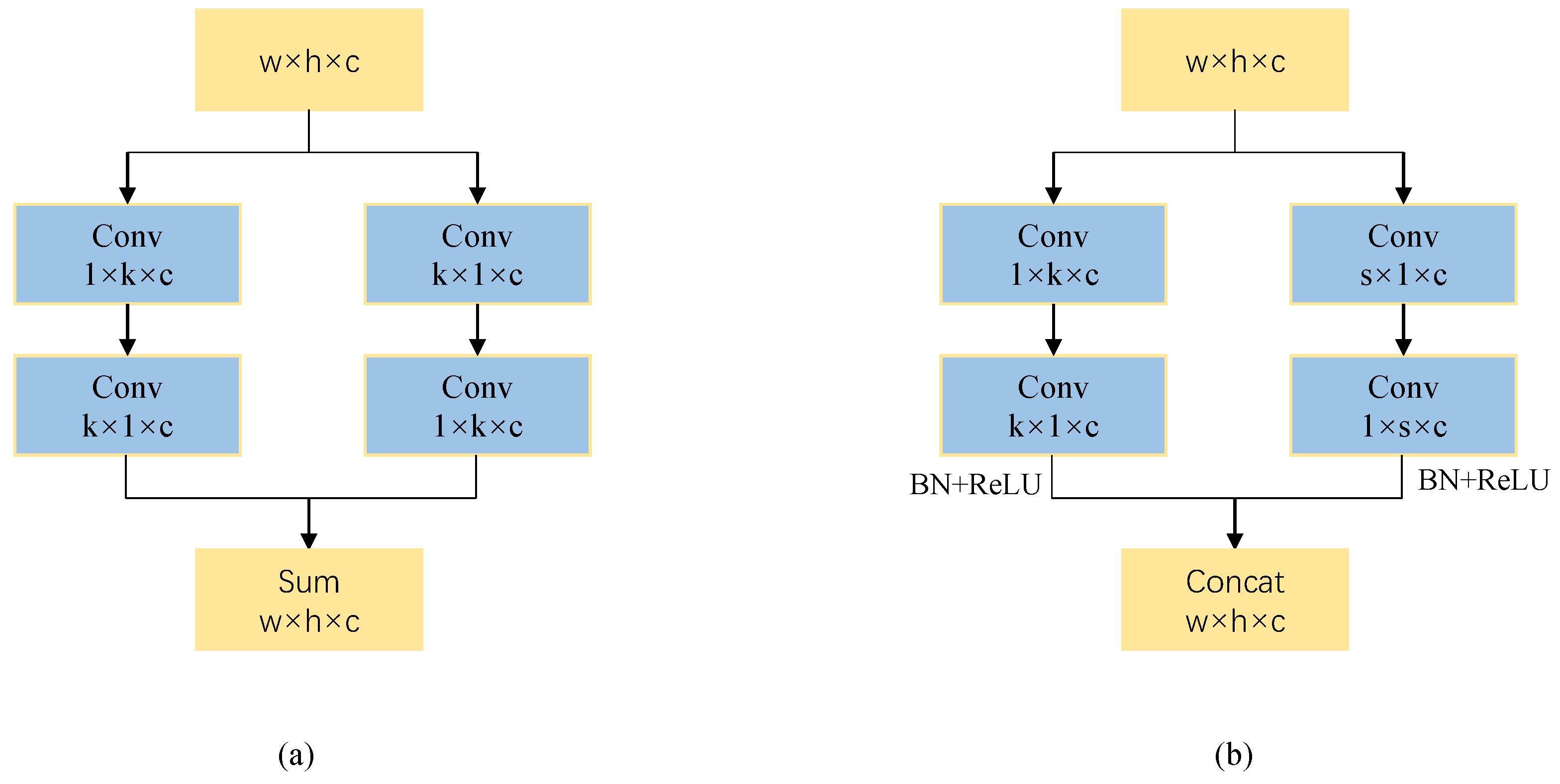
39] and densely-connected convolution, is proposed to perform upsampling, which has better segmentation performance compared to bilinear interpolation upsampling, nearest interpolation upsampling, and transposed convolution upsampling.
- 5.
Compared to other state-of-the-art models, such as DeepLab V3+, PSPNet, Unet, MSLWENet, MWEN, and SR-segnet, HA-Net achieves the best performance on the Google dataset and demonstrates better robustness on the Landsat-8 dataset.
5. Discussion
In this paper, compared to Pre_DeepLab V3+ and Pre_PSPNet for natural image segmentation, Pre_Unet for medical image segmentation, MSLWENet, SR-segnet, and MWFE for water body extraction, our proposed model achieves the best performance on both the Google dataset and Landsat-8 dataset. More importantly, the HA-Net achieves an MIoU of 97.38%, which is a 1.04% improvement over MSLWENet, but reduces the training time by about 100s at each epoch. The Recall and TWR have increased by 0.36% and 0.77% when compared to MSLWENet, despite the OA improvement not being substantial. Since Pre_DeepLab V3+ and Pre_PSPNet use pre-trained weights, their segmentation performance is comparable to the MSLWENet.
In the small lake and noisy regions, it can be seen from the visualization results that our method has comparable performance with MSLWENet. Meanwhile, as shown by the quantitative analysis, OA and MIoU improved by 0.37% and 0.75%, respectively. HA-Net has great segmentation performance on the fuzzy boundaries in the boundary regions. In particular, we discuss the effect of various encoders on classification accuracy. As the depth of ResNet increases, the training time of the model becomes longer, but there is a slight decrease in its performance. This is mainly because the number of parameters in the deeper models becomes larger, making it slightly overfit. The performance of both the shallow network represented by VGG and the densely connected network represented by DenseNet decreases significantly, thus proving the superiority of ResNet, which is mainly due to the fact that the dilated convolution expands the receptive field and allows more useful information to be extracted. EfficientNet takes full consideration of depth, width, and resolution of the input image, although achieving OA of 98.83%, the training time is greatly increased. Finally, we conduct a comparison experiment between the hybrid-scale attention block and the pixelshuffle upsampling convolution block to demonstrate the superiority of HA-Net. When transferring the optimal weights to the Landsat-8 dataset, our model has more robustness compared to other advanced models. On the other hand, we also perform a common non-parametric test method to assess whether our performance improvements are statistically significant in terms of MIoU metrics compared to other current state-of-the-art methods, resulting in a p-value score. From the
p-values shown in
Table 1 and
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, it is clear that there is a statistically significant improvement in the MIoU metric for our method at the 5% level (all
p-values are less than 0.05).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}