Cluster-Wise Weighted NMF for Hyperspectral Images Unmixing with Imbalanced Data


Abstract

1. Introduction
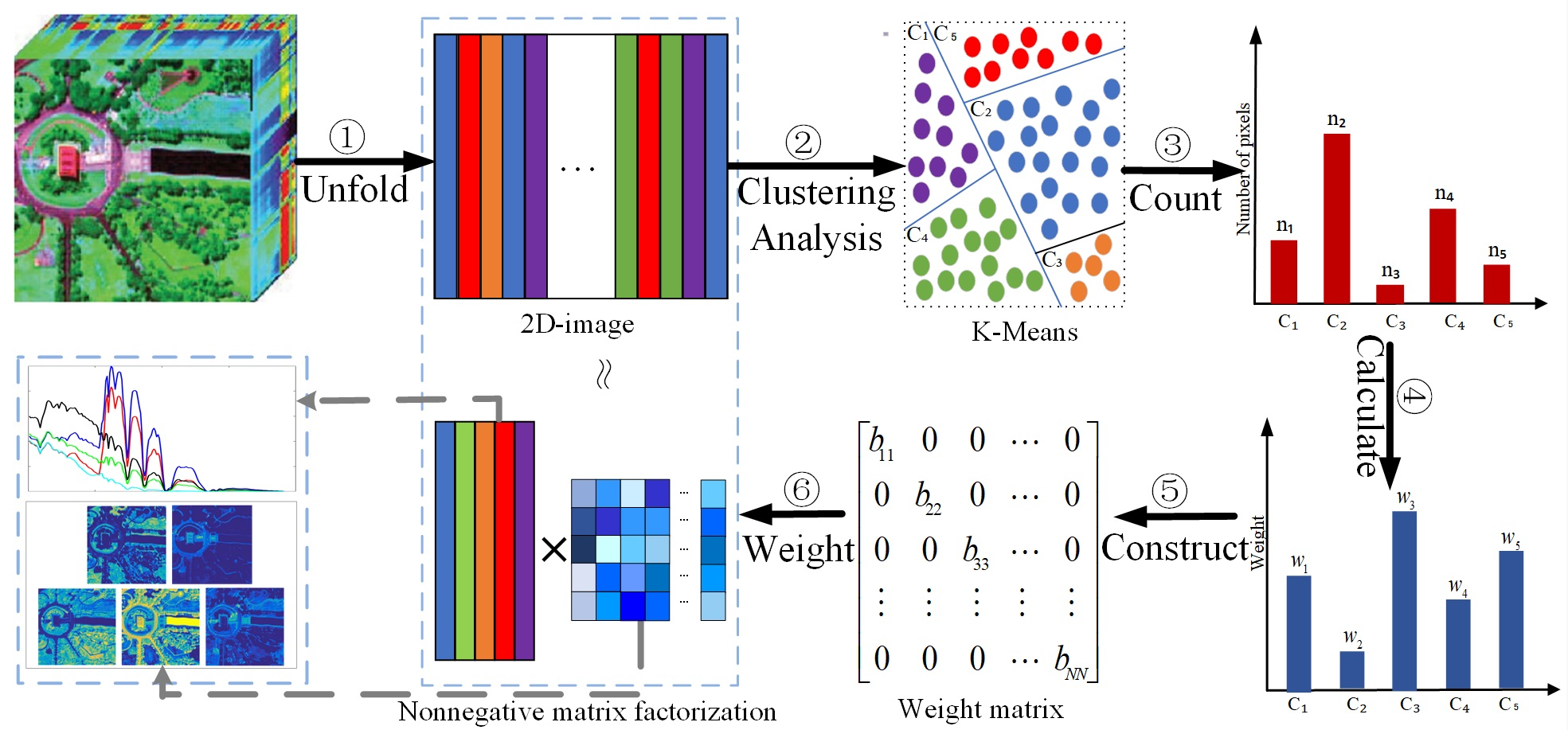
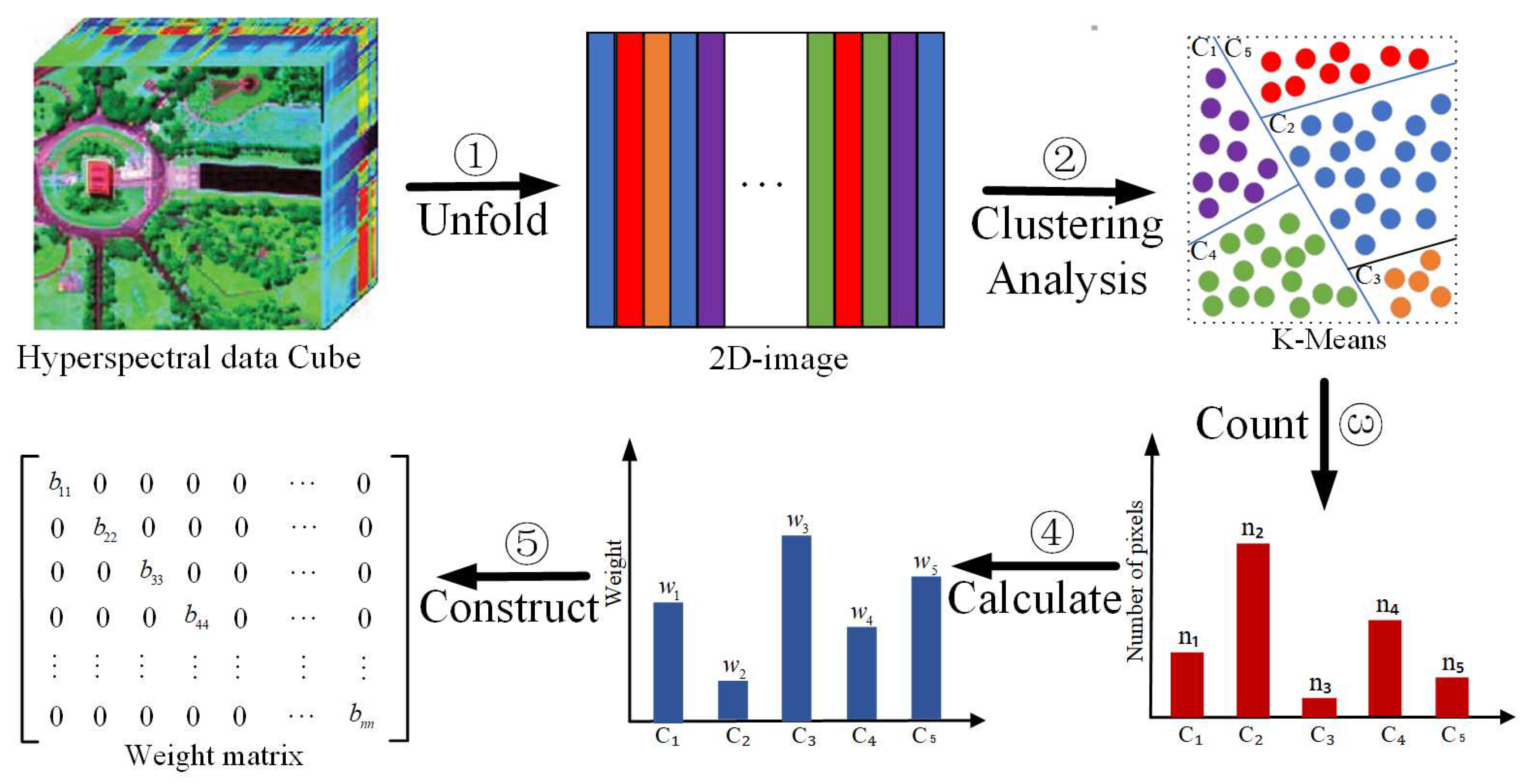
- We propose a novel NMF method for hyperspectral unmixing by exploiting the information of imbalance samples included in HSIs. Based on the clustering results of all the pixels, a weight matrix is generated to balance the impacts of each class of pixels to the reconstruction error of the standard NMF. This can reduce the adverse effect of imbalance samples to the estimation of endmembers that are only present in the pixels in a relatively small number, and thus improve the accuracy of the unmixing results.
- Our method provides a general framework for unmixing HSIs with imbalance pixels, and thus has good extensibility for incorporating additional constraints and regularization terms into the NMF-based unmixing model. Here, we extend the proposed method to other NMF-based unmixing approaches by adding the sparsity constraint of abundance and graph-based regularization, respectively.
- The performance of our methods is tested on both synthetic data and real-world HSIs. The experimental results show that our methods can achieve superior performance by comparing them with several state-of-the-art methods.
2. Related Work
2.1. Linear Mixing Model
2.2. Non-Negative Matrix Factorization
3. Methodology
3.1. CW-NMF
3.2. Updating Rules
3.3. Implementation Issues
| Algorithm 1 CW-NMF Algorithm For HU |
 |
3.4. Computational Complexity Analysis
4. Method Extension
4.1. CW-NMF
4.2. CW-GLNMF
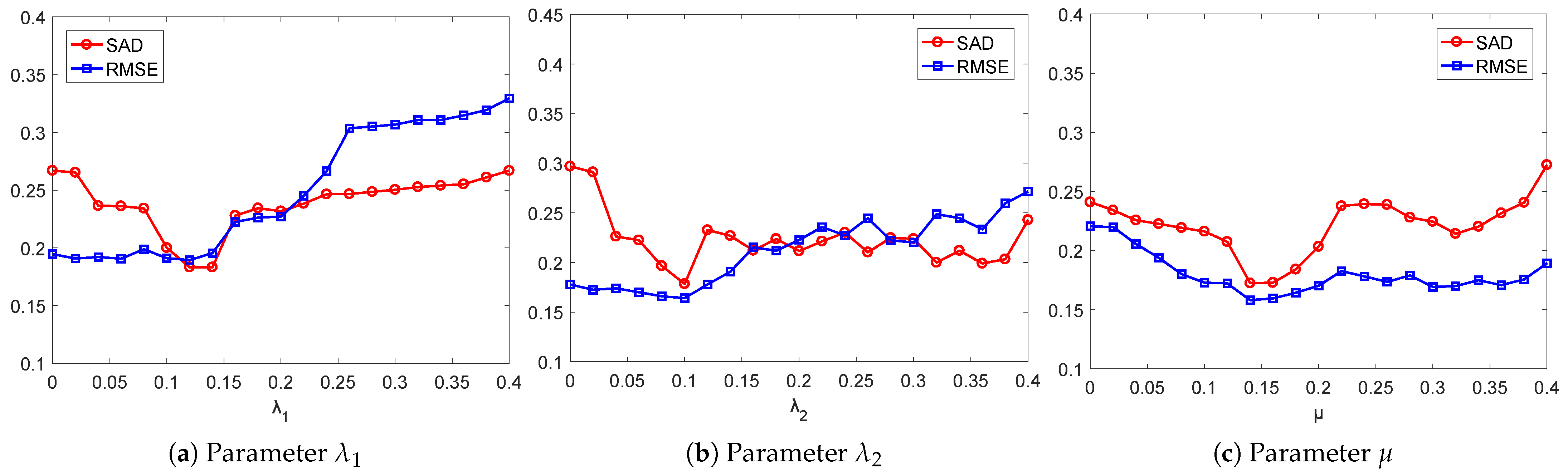
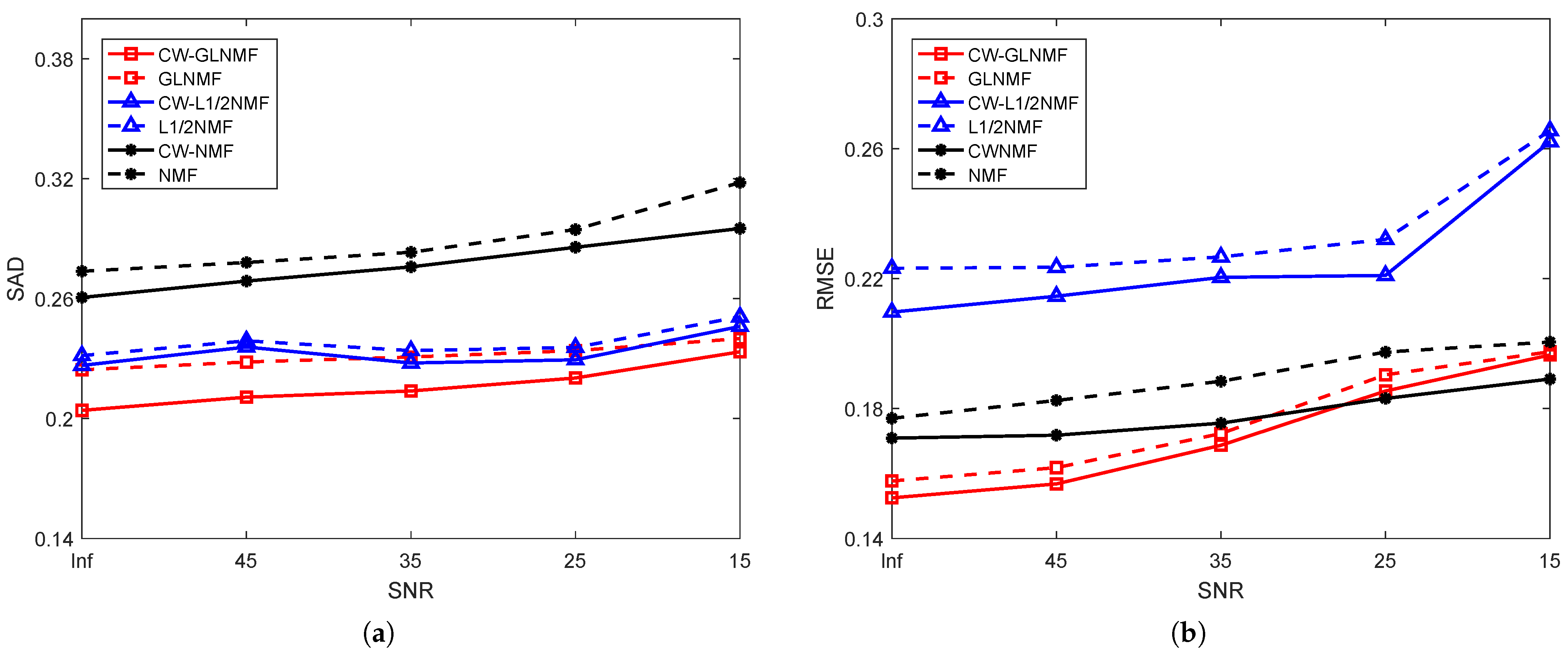
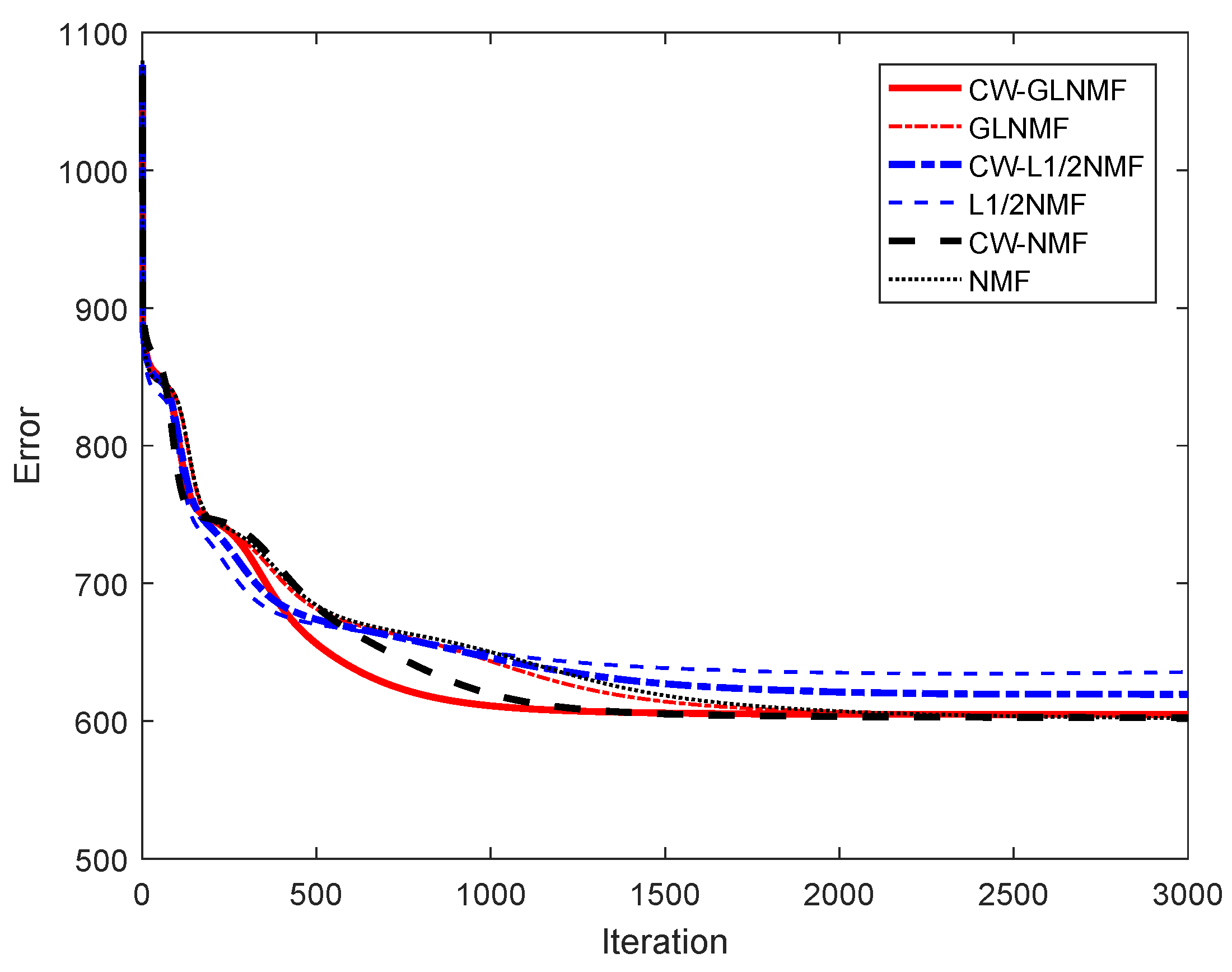
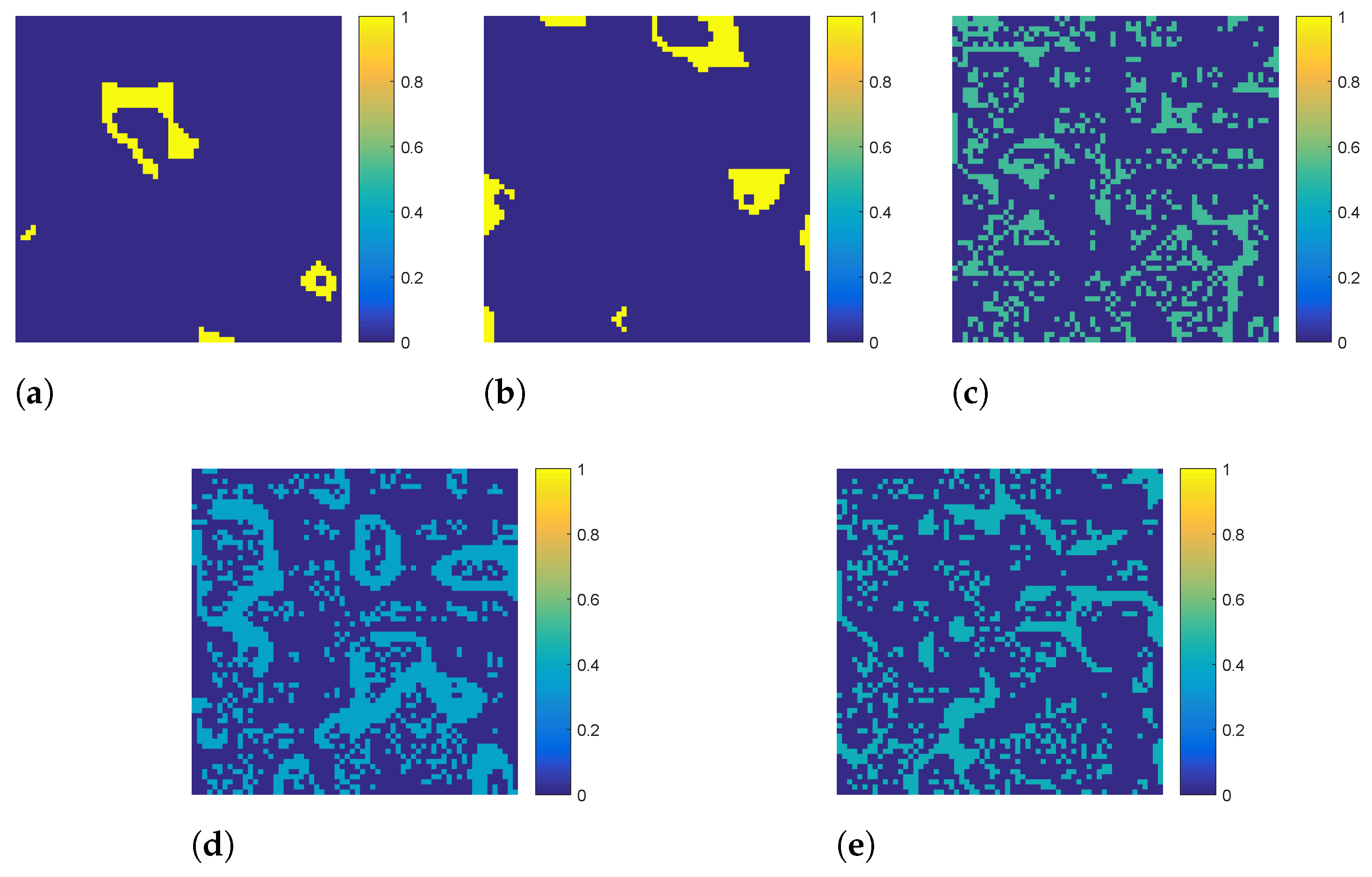
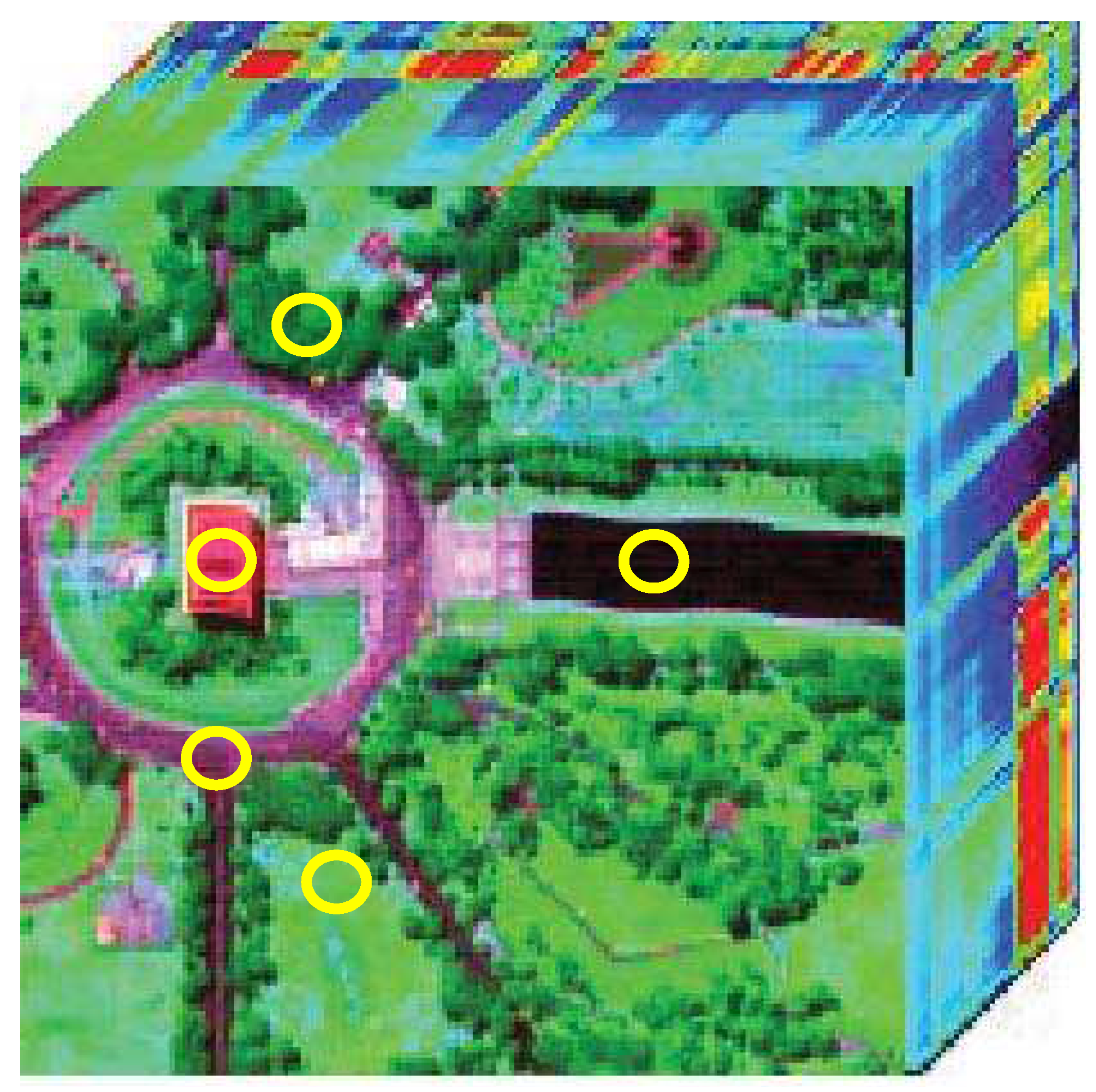
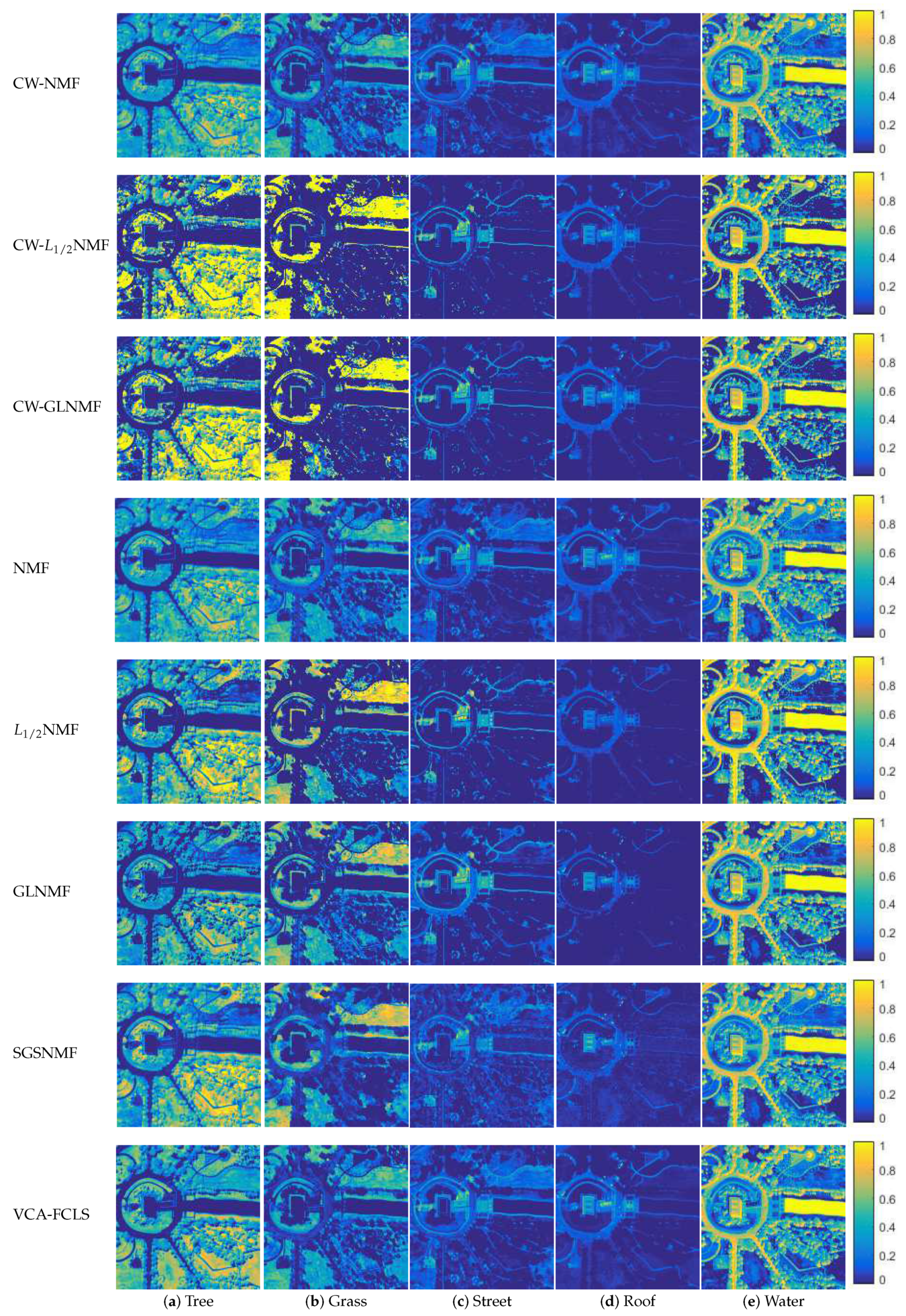
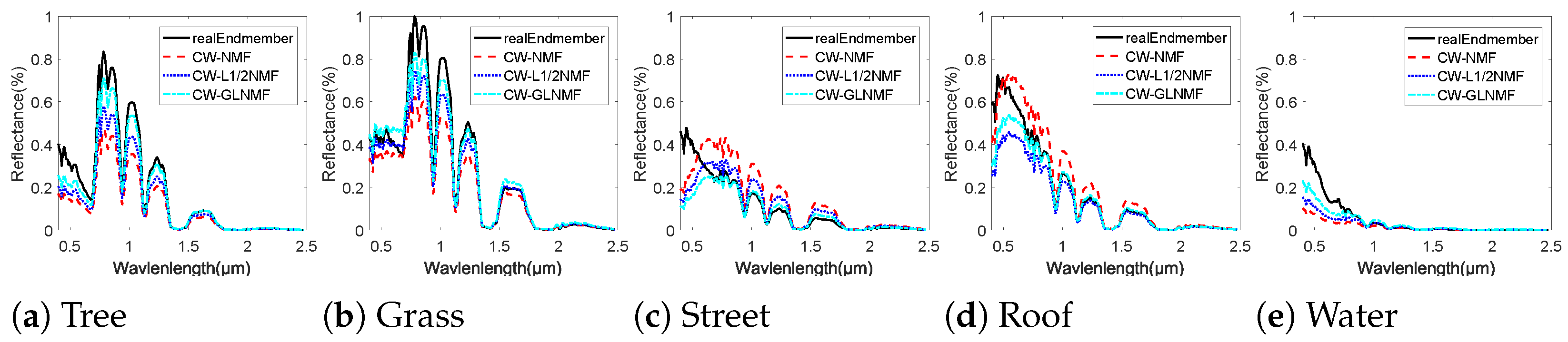
5. Experimental Results
5.1. Experiments on Synthetic Data
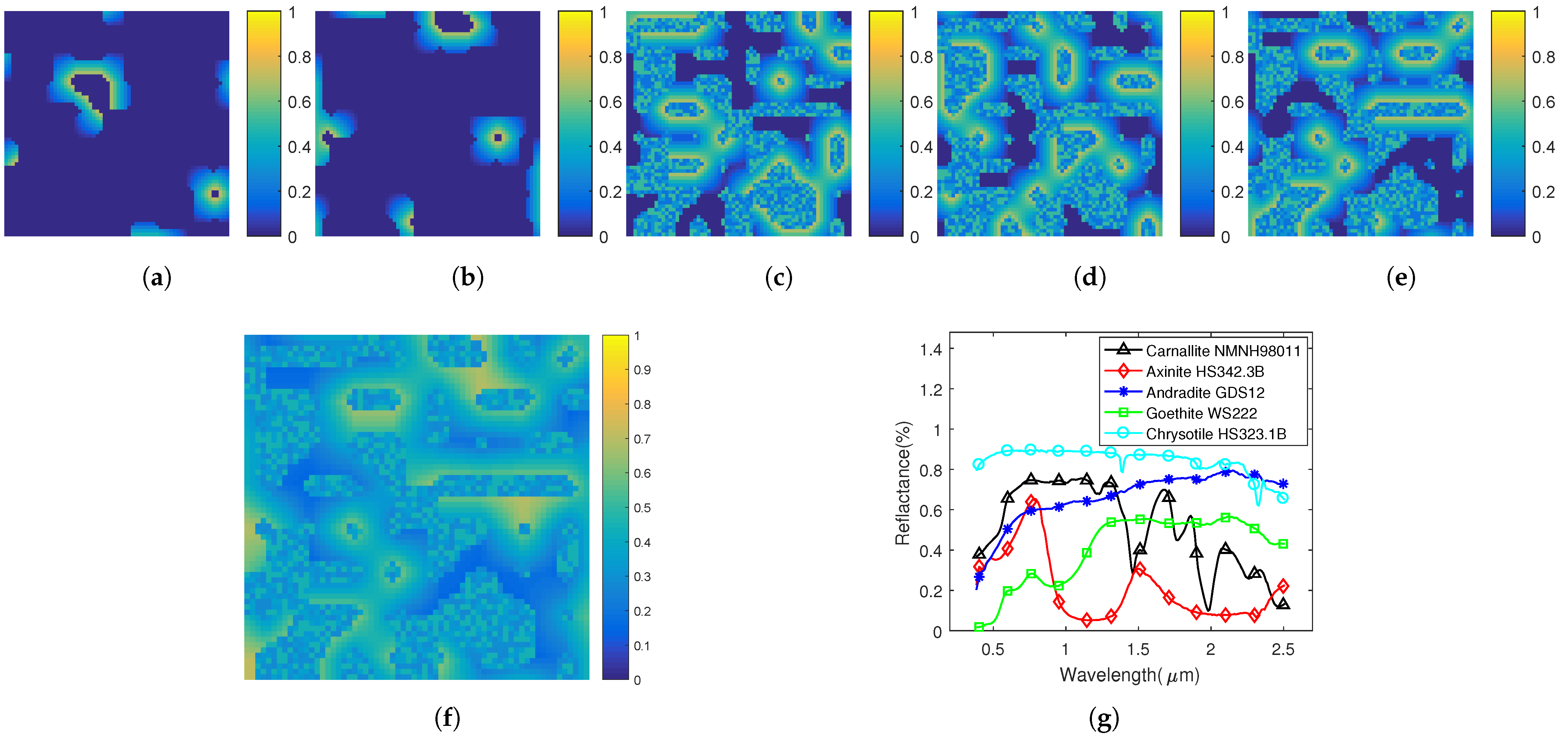
5.2. Experiments on Real Hyperspectral Data
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral remote sensing image |
| HU | Hyperspectral unmixing |
| NMF | Non-negative matrix factorization |
| CW-NMF | Cluster-wise weighted nonnegative matrix factorization |
| NMF | regularized NMF |
| GLNMF | the graph regularized NMF |
| SGSNMF | the spatial group sparsity regularized NMF |
| ANC | Abundance non-negative constraint |
| ASC | Abundance sum-to-one constraint |
| VCA | Vertex component analysis |
| FCLS | Fully constrained least squares |
| LMM | Linear spectrum mixture model |
| SNR | Signal-to-noise ration |
| SAD | Spectral angle distance |
| RMSE | Root mean square error |
| MUR | Multiplicative update rule |
| USGS | United States Geological Survey |
| HYDICE | Hyperspectral Digital Imagery Collection Experiment |
References
- Zhang, W.; Lu, X.; Li, X. Similarity Constrained Convex Nonnegative Matrix Factorization for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4810–4822. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Wang, Z.; Chen, C.; Liu, X. Hyperspectral Image Classification in the Presence of Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 851–865. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Zhu, L.; Liu, Y. Centroid and Covariance Alignment-Based Domain Adaptation for Unsupervised Classification of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2305–2323. [Google Scholar] [CrossRef]
- Nalepa, J.; Myller, M.; Kawulok, M. Validating Hyperspectral Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1264–1268. [Google Scholar] [CrossRef]
- Swarna, M.; Sowmya, V.; Soman, K.P. Band selection using variational mode decomposition applied in sparsity-based hyperspectral unmixing algorithms. Signal Image Video Process. 2018, 12, 1463–1470. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Wang, W.; Qian, Y.; Liu, H. Multiple Clustering Guided Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 5162–5179. [Google Scholar] [CrossRef]
- Dobigeon, N.; Tourneret, J.; Richard, C.; Bermudez, J.C.M.; McLaughlin, S.; Hero, A.O. Nonlinear Unmixing of Hyperspectral Images: Models and Algorithms. IEEE Signal Process. Mag. 2014, 31, 82–94. [Google Scholar] [CrossRef]
- Ma, W.; Bioucas-Dias, J.M.; Chan, T.; Gillis, N.; Gader, P.; Plaza, A.J.; Ambikapathi, A.; Chi, C. A Signal Processing Perspective on Hyperspectral Unmixing: Insights from Remote Sensing. IEEE Signal Process. Mag. 2014, 31, 67–81. [Google Scholar] [CrossRef]
- Boardman, J.W. Automated spectral unmixing of AVIRIS data using convex geometry concepts. In Proceedings of the JPL Airborne Geoscience Workshop, Arlington, VA, USA, 25–29 October 1993; Volume 1, pp. 11–14. [Google Scholar]
- Winter, M.E. N-FINDR: An algorithm for fast autonomous spectral end-member determination in hyperspectral data. Proc. SPIE Int. Soc. Opt. Eng. 1999, 3753, 266–275. [Google Scholar]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Chang, C.; Wu, C.; Liu, W.; Ouyang, Y. A New Growing Method for Simplex-Based Endmember Extraction Algorithm. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2804–2819. [Google Scholar] [CrossRef]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold Regularized Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Yuan, Y.; Fu, M.; Lu, X. Substance Dependence Constrained Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2975–2986. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, B.; Pan, X.; Yang, S. Group Low-Rank Nonnegative Matrix Factorization With Semantic Regularizer for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 1022–1029. [Google Scholar] [CrossRef]
- Jutten, C.; Herault, J. Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture. Signal Process. 1991, 24, 1–10. [Google Scholar] [CrossRef]
- Wang, J.; Chang, C. Applications of Independent Component Analysis in Endmember Extraction and Abundance Quantification for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2601–2616. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Tong, L.; Zhou, J.; Qian, Y.; Bai, X.; Gao, Y. Nonnegative-Matrix-Factorization-Based Hyperspectral Unmixing With Partially Known Endmembers. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6531–6544. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Zhang, L.; Xu, Y. Spatial Group Sparsity Regularized Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6287–6304. [Google Scholar] [CrossRef]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral Unmixing via L1/2 Sparsity-Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef]
- Miao, L.; Qi, H. Endmember Extraction From Highly Mixed Data Using Minimum Volume Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2007, 45, 765–777. [Google Scholar] [CrossRef]
- Wang, W.; Qian, Y. Adaptive L1/2 Sparsity-Constrained NMF With Half-Thresholding Algorithm for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2618–2631. [Google Scholar] [CrossRef]
- Liu, X.; Xia, W.; Wang, B.; Zhang, L. An Approach Based on Constrained Nonnegative Matrix Factorization to Unmix Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 757–772. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L. Total Variation Regularized Reweighted Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3909–3921. [Google Scholar] [CrossRef]
- Ravel, S.; Bourennane, S.; Fossati, C. Hyperspectral images unmixing with rare signals. In Proceedings of the 2016 6th European Workshop on Visual Information Processing (EUVIP), Marseille, France, 25–27 October 2016; pp. 1–5. [Google Scholar]
- Marrinan, T.; Gillis, N. Hyperspectral Unmixing with Rare Endmembers via Minimax Nonnegative Matrix Factorization. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 1015–1019. [Google Scholar]
- Fossati, C.; Bourennane, S.; Cailly, A. Unmixing improvement based on bootstrap for hyperspectral imagery. In Proceedings of the 2016 6th European Workshop on Visual Information Processing (EUVIP), Marseille, France, 25–27 October 2016; pp. 1–5. [Google Scholar]
- García-Haro, F.J.; Gilabert, M.; Meliá, J. Linear Spectral Mixture Modelling to Estimate Vegetation Amount from Optical Spectral Data. Int. J. Remote Sens. 1996, 17, 3373–3400. [Google Scholar] [CrossRef]
- Li, Z.; Tang, J.; He, X. Robust Structured Nonnegative Matrix Factorization for Image Representation. IEEE Trans. Neural Net. Learn. Syst. 2018, 29, 1947–1960. [Google Scholar] [CrossRef]
- Chang, C.; Du, Q. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 608–619. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral Subspace Identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef]
- Zhu, F.; Wang, Y.; Xiang, S.; Fan, B.; Pan, C. Structured sparse method for hyperspectral unmixing. ISPRS J. Photogramm. Remote Sens. 2014, 88, 101–118. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Endmembers | CW-NMF | CW-NMF | CW-GLNMF | NMF [19] | NMF [22] | GLNMF [14] | SGSNMF [21] | VCA [12] |
|---|---|---|---|---|---|---|---|---|
| Tree | 0.2177 ± 2.66 | 0.1732 ± 12.48 | 0.1462 ± 16.26 | 0.2413 ± 8.01 | 0.1842 ± 1.18 | 0.1821 ± 14.30 | 0.1763 ± 1.03 | 0.2018 ± 0.67 |
| Grass | 0.2906 ± 5.61 | 0.1296 ± 8.98 | 0.1557 ± 10.44 | 0.2559 ± 4.68 | 0.2345 ± 4.11 | 0.2102 ± 6.67 | 0.1646 ± 19.78 | 0.2699 ± 6.56 |
| Roof | 0.1261 ± 3.82 | 0.1785 ± 3.21 | 0.1482 ± 2.48 | 0.1428 ± 3.57 | 0.1670 ± 4.43 | 0.1600 ± 3.61 | 0.3019 ± 6.79 | 0.1505 ± 4.10 |
| Water | 0.1738 ± 25.42 | 0.2437 ± 20.25 | 0.1857 ± 33.39 | 0.1936 ± 27.86 | 0.1734 ± 15.60 | 0.1402 ± 11.68 | 0.1226 ± 1.16 | 0.2144 ± 28.12 |
| Street | 0.4342 ± 18.87 | 0.4295 ± 13.67 | 0.4227 ± 16.52 | 0.4642 ± 14.46 | 0.4456 ± 12.57 | 0.4716 ± 15.56 | 0.4905 ± 28.98 | 0.4827 ± 11.57 |
| Average | 0.2485 ± 11.27 | 0.2309 ± 11.72 | 0.2117 ± 15.82 | 0.2596 ± 11.72 | 0.2409 ± 7.58 | 0.2328 ± 10.36 | 0.2512 ± 11.55 | 0.2639 ± 10.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, X.; Wang, W.; Liu, H. Cluster-Wise Weighted NMF for Hyperspectral Images Unmixing with Imbalanced Data. Remote Sens. 2021, 13, 268. https://doi.org/10.3390/rs13020268
Lv X, Wang W, Liu H. Cluster-Wise Weighted NMF for Hyperspectral Images Unmixing with Imbalanced Data. Remote Sensing. 2021; 13(2):268. https://doi.org/10.3390/rs13020268
Chicago/Turabian StyleLv, Xiaochen, Wenhong Wang, and Hongfu Liu. 2021. "Cluster-Wise Weighted NMF for Hyperspectral Images Unmixing with Imbalanced Data" Remote Sensing 13, no. 2: 268. https://doi.org/10.3390/rs13020268
APA StyleLv, X., Wang, W., & Liu, H. (2021). Cluster-Wise Weighted NMF for Hyperspectral Images Unmixing with Imbalanced Data. Remote Sensing, 13(2), 268. https://doi.org/10.3390/rs13020268