
IFRAD: A Fast Feature Descriptor for Remote Sensing Images


Abstract
:1. Introduction
- Explain a concept for Inter-Feature Relative Azimuth and Distance (IFRAD);
- Propose a novel feature descriptor base on IFRAD;
- Design a special similarity measure suitable for the proposed descriptor;
- Refine the proposed descriptor to improve the scale-invariance and matching accuracy.
2. Background
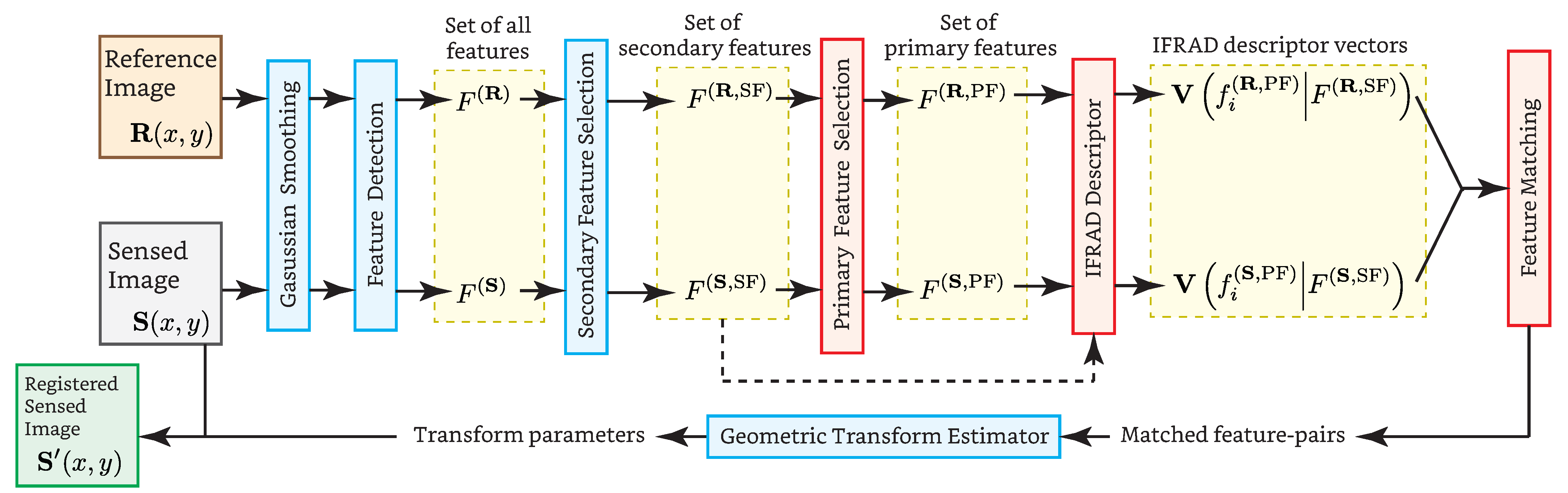
3. Methology
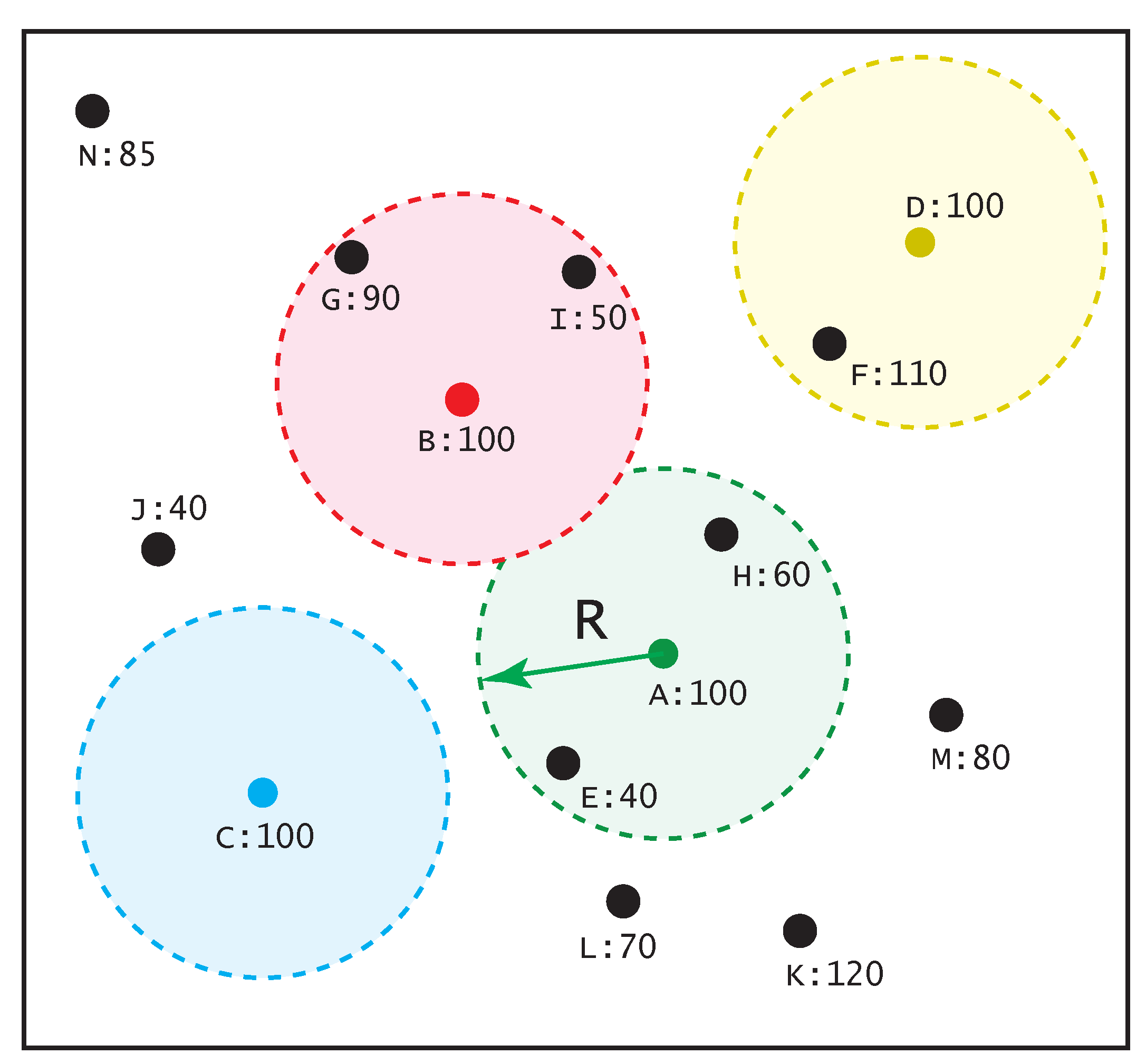
3.1. Criterion for Selecting Secondary and Primary Features
- Initial as an empty primary-feature set, that is, ;
- For each secondary-feature , define its feature domain with a radius of R, centered by :The radius R is an adjustable parameter, and will be further determined in experiments.
- If there exists no other secondary-feature within that has a response stronger than , then . This criterion can be expressed by:

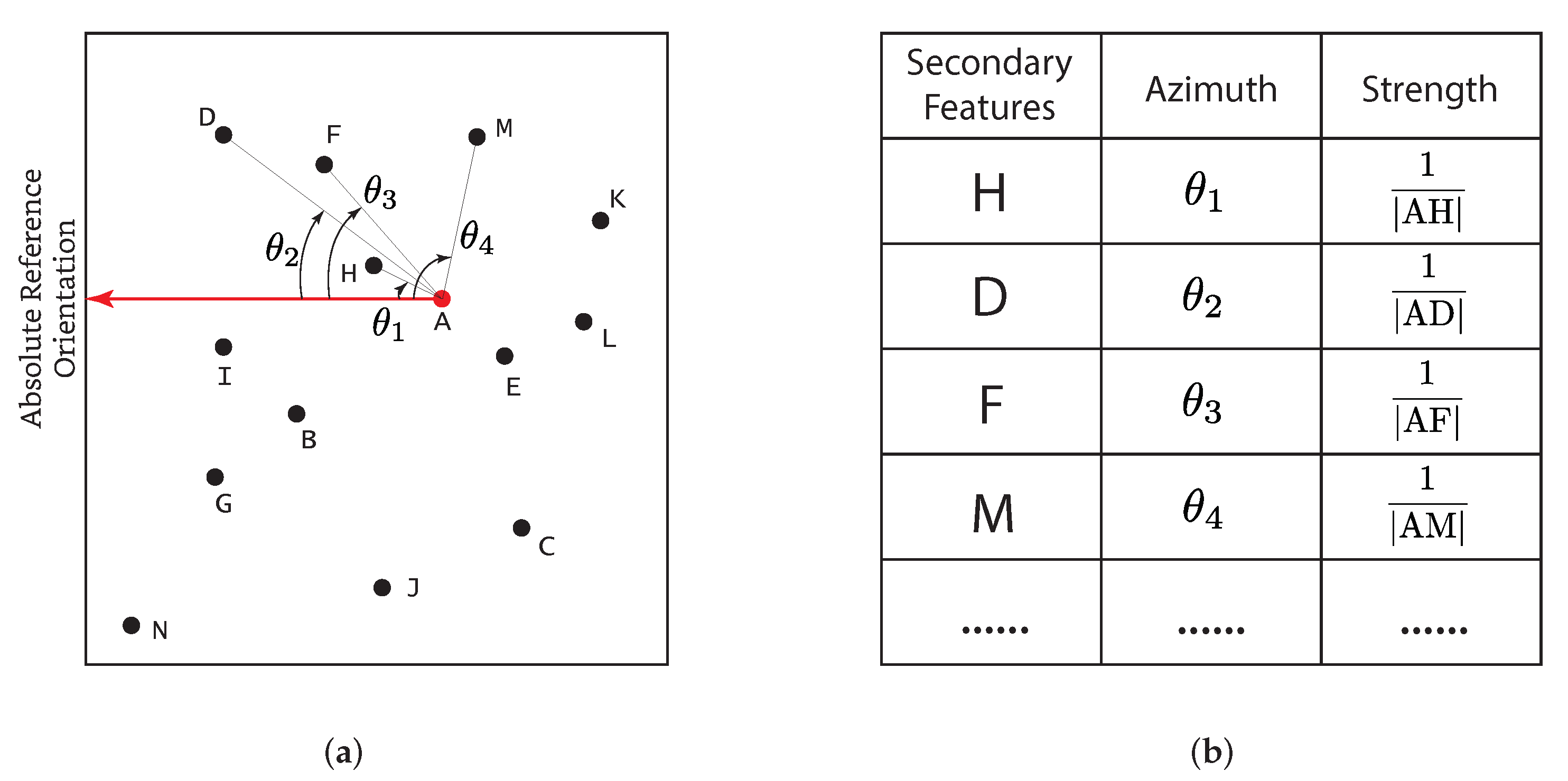
3.2. The Relationships among Features
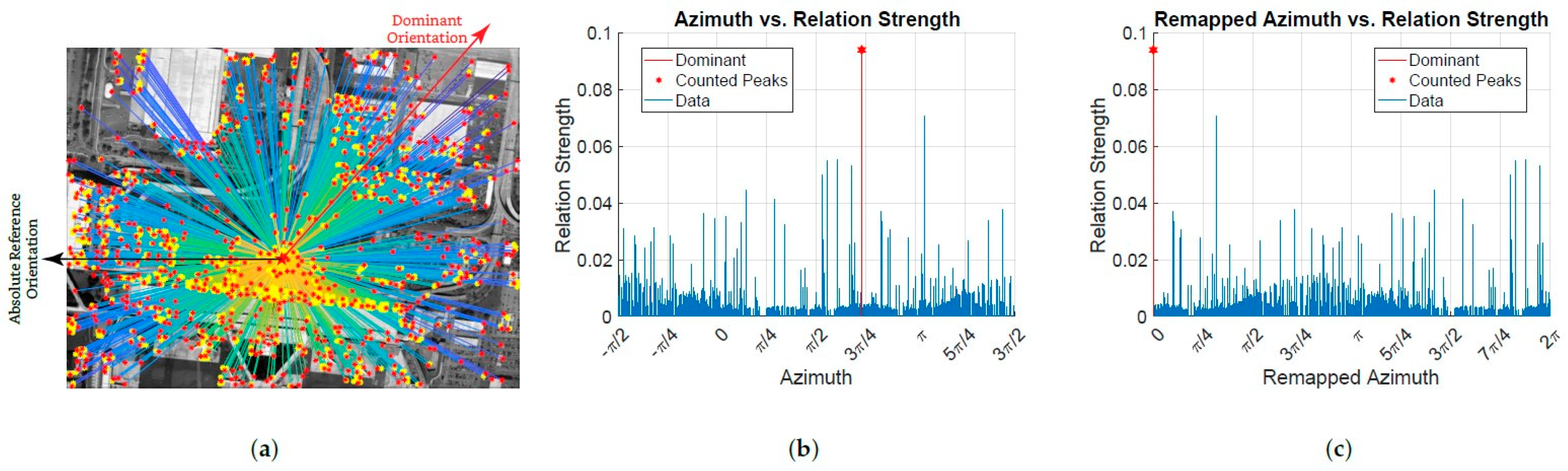
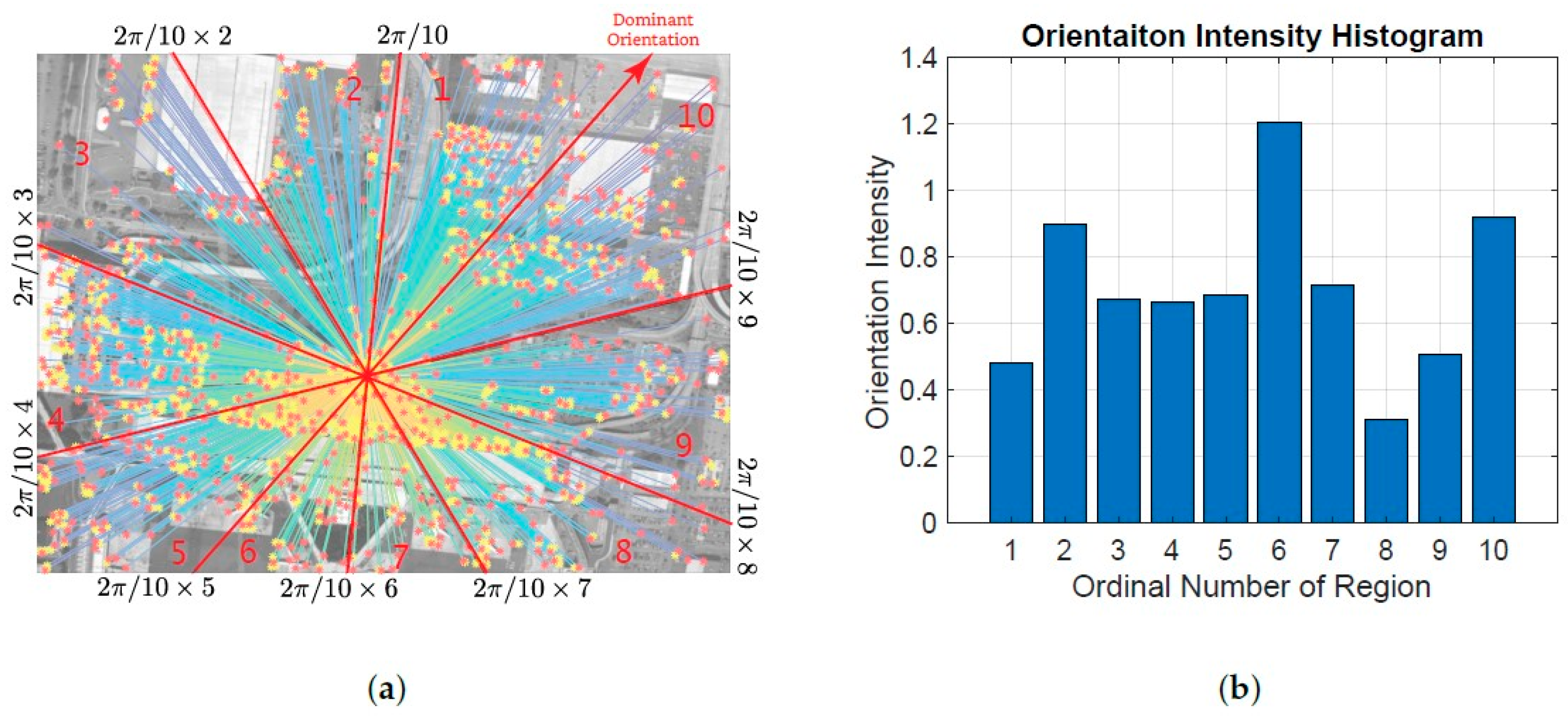
3.3. The IFRAD Descriptor: Orientation Intensity Histogram
- Divide the image into n fan-shaped regions according to the orientation of the feature, where n is an adjustable parameter and needs to be optimized in experiments, as shown in Figure 9a, in this example, ;
- Estimate the orientation intensity by calculating the sum of all relation-strengths within each fan-shaped region. This operation can be expressed by:where is an indicator function:
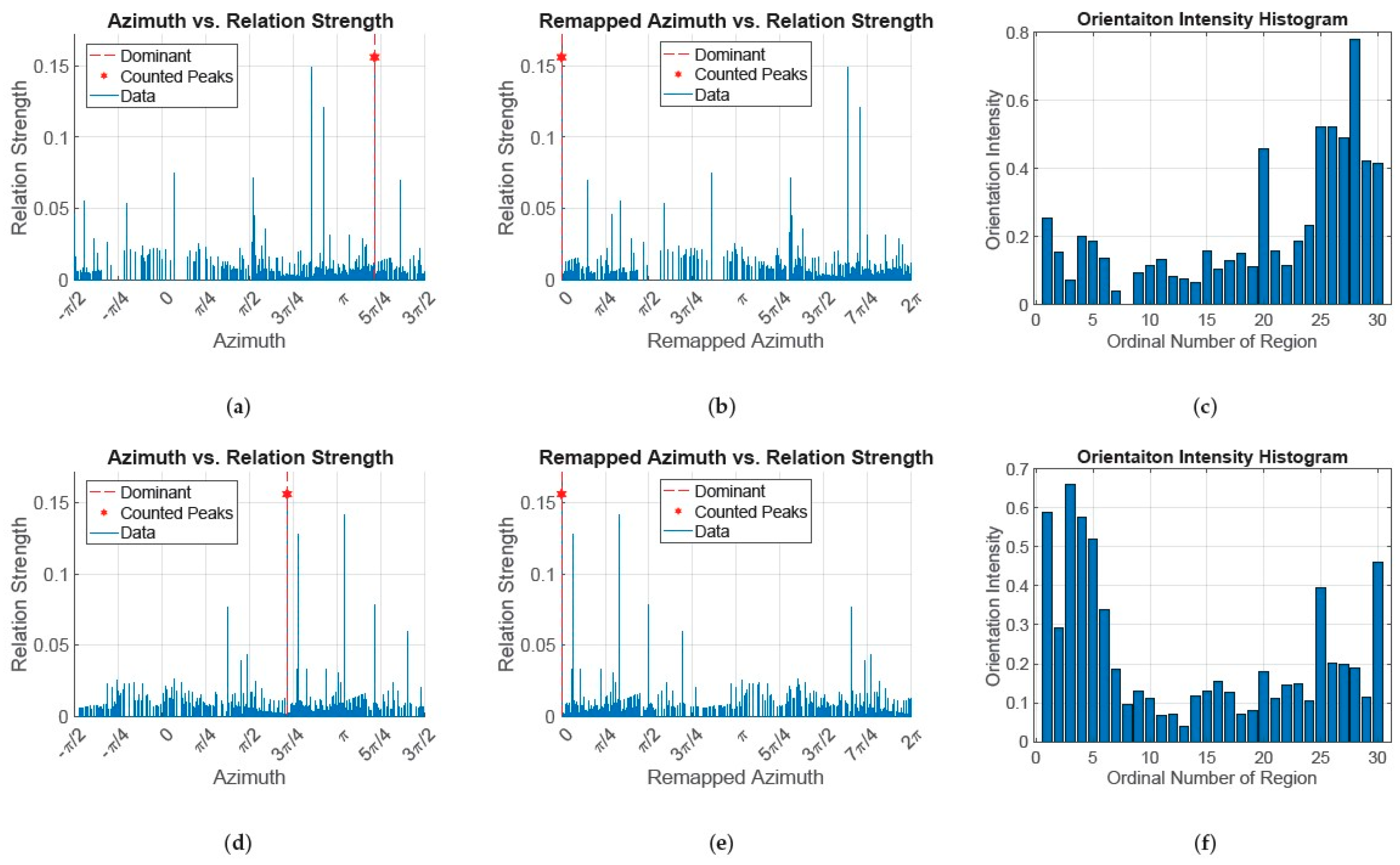
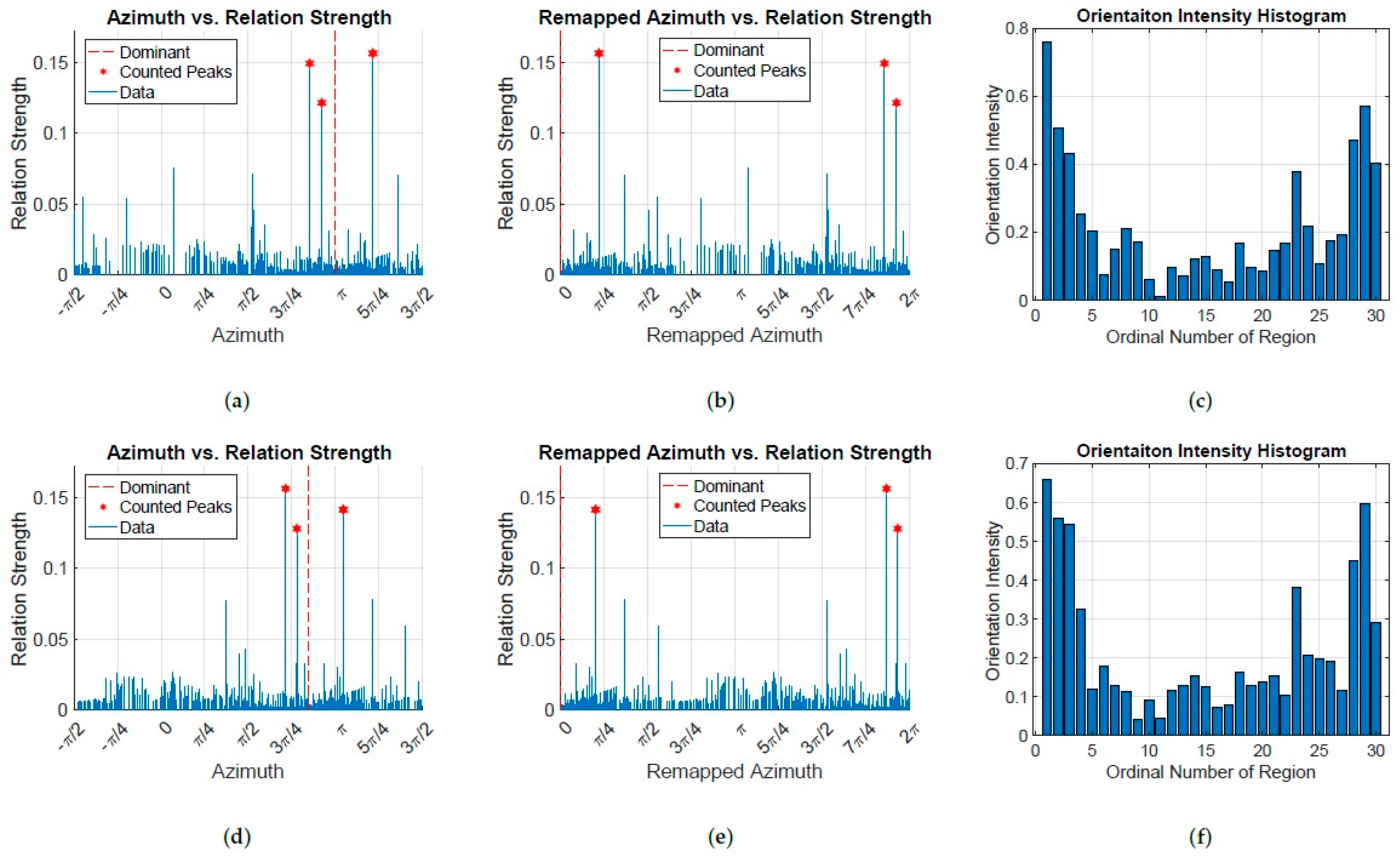
3.4. Feature-Matching
3.5. Refinements
3.6. Geometric Transform Estimation and Correctness of Matching
4. Experiments
4.1. Assessments Defination
4.2. Parameters Optimization
4.3. Comparisons
5. Discussion
- the scale-invariance of our method is limited within 1.45×;
- the range of applicable overlap area is narrowed to 50∼100%;
- more sensitive to illuminance changes.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Mathematical Notations | |
| or | Reference image |
| or | Sensed image |
| ith feature in image | |
| Location of a feature | |
| Response magnitude of a feature | |
| Secondary feature set in image | |
| ith secondary feature in image , | |
| Primary feature set in image | |
| ith primary feature in image , | |
| Feature set in image | |
| Azimuth of relative to | |
| Distance between and | |
| Strength of relationship between and | |
| The dominant orientation of | |
| kth orientation intensity of | |
| Indicator function | |
| IFRAD descriptor vector of | |
| Cosine distance | |
| Coefficient for selecting features with stronger relation | |
| t | Tolerance for allowing some features with competent response |
| M | Width of a image |
| N | Height of a image |
| n | the number of bins in OIH |
| R | radius of a feature domain |
| count of correctly matched feature-pairs | |
| Total count of matched feature-pairs | |
| Abbreviations | |
| BRISK | Binary Robust invariant scalable keypoints |
| CMR | correctly matched rate |
| ET | Exposure time |
| FAST | Features from Accelerated Segment Test |
| FMT | Fourier-Mellin transform |
| FREAK | Fast Retina Keypoint |
| GLOH | Gradient location and orientation histogram |
| IFRAD | Inter-feature relative azimuth and distance |
| MLESAC | Maximum Likelihood Estimation Sample Consensus |
| OIH | Orientation intensity histogram |
| ORB | Oriented FAST and Rotated BRISK |
| RANSAC | Random sample consensus |
| RNL | Relative noise level |
| SAD | Sum of absolute distance |
| SIFT | Scale Invariant Feature Transform |
| SSD | Sum of squared distance |
| STE | Stability of transform estimation |
| SURF | Speed Up Robust Features |
References
- Ma, W.; Wen, Z.; Wu, Y.; Jiao, L.; Gong, M.; Zheng, Y.; Liu, L. Remote Sensing Image Registration With Modified SIFT and Enhanced Feature Matching. IEEE Geosci. Remote Sens. Lett. 2017, 14, 3–7. [Google Scholar] [CrossRef]
- Li, Q.; Wang, G.; Liu, J.; Chen, S. Robust Scale-Invariant Feature Matching for Remote Sensing Image Registration. IEEE Geosci. Remote Sens. Lett. 2009, 6, 287–291. [Google Scholar] [CrossRef]
- Yang, Z.; Dan, T.; Yang, Y. Multi-Temporal Remote Sensing Image Registration Using Deep Convolutional Features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Cao, W. Applying image registration algorithm combined with CNN model to video image stitching. J. Supercomput. 2021. [Google Scholar] [CrossRef]
- Chen, S.; Zhong, S.; Xue, B.; Li, X.; Zhao, L.; Chang, C.I. Iterative Scale-Invariant Feature Transform for Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3244–3265. [Google Scholar] [CrossRef]
- Lu, J.; Jia, H.; Li, T.; Li, Z.; Ma, J.; Zhu, R. An Instance Segmentation Based Framework for Large-Sized High-Resolution Remote Sensing Images Registration. Remote Sens. 2021, 13, 1657. [Google Scholar] [CrossRef]
- Sara, D.; Mandava, A.K.; Kumar, A.; Duela, S.; Jude, A. Hyperspectral and multispectral image fusion techniques for high resolution applications: A review. Earth Sci. Inform. 2021. [Google Scholar] [CrossRef]
- Özay, E.K.; Tunga, B. A novel method for multispectral image pansharpening based on high dimensional model representation. Expert Syst. Appl. 2021, 170, 114512. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; pp. 1508–1515. [Google Scholar] [CrossRef]
- Rosten, E.; Porter, R.; Drummond, T. Faster and Better: A Machine Learning Approach to Corner Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Luan, K.; Stilla, U.; Ye, Z.; Xu, Y.; Gao, S.; Xie, H.; Du, Q.; Liu, S.; Xu, X.; et al. Image Registration With Fourier-Based Image Correlation: A Comprehensive Review of Developments and Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4062–4081. [Google Scholar] [CrossRef]
- Reddy, B.; Chatterji, B. An FFT-based technique for translation, rotation, and scale-invariant image registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Tao, S.; Liu, C.; Qu, H. An Improved Fourier-Mellin Transform-Based Registration Used in TDI-CMOS. IEEE Access 2021, 9, 64165–64178. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B. Determining Optical Flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Yuen, J.; Torralba, A. SIFT Flow: Dense Correspondence across Scenes and Its Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 978–994. [Google Scholar] [CrossRef] [Green Version]
- Feng, R.; Du, Q.; Shen, H.; Li, X. Region-by-Region Registration Combining Feature-Based and Optical Flow Methods for Remote Sensing Images. Remote Sens. 2021, 13, 1475. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar] [CrossRef] [Green Version]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Zhang, W.; Shi, Y.; Wang, X.; Cao, W. GA-ORB: A New Efficient Feature Extraction Algorithm for Multispectral Images Based on Geometric Algebra. IEEE Access 2019, 7, 71235–71244. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 506–513. [Google Scholar] [CrossRef]
- Xu, W.; Zhong, S.; Zhang, W.; Wang, J.; Yan, L. A New Orientation Estimation Method Based on Rotation Invariant Gradient for Feature Points. IEEE Geosci. Remote Sens. Lett. 2020, 18, 791–795. [Google Scholar] [CrossRef]
- Sedaghat, A.; Mokhtarzade, M.; Ebadi, H. Uniform Robust Scale-Invariant Feature Matching for Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4516–4527. [Google Scholar] [CrossRef]
- Fan, B.; Wu, F.; Hu, Z. Rotationally Invariant Descriptors Using Intensity Order Pooling. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 2031–2045. [Google Scholar] [CrossRef] [PubMed]
- Ordonez, A.; Heras, D.B.; Arguello, F. Surf-Based Registration for Hyperspectral Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 63–66. [Google Scholar] [CrossRef]
- Song, Z.L.; Zhang, J. Remote Sensing Image Registration Based on Retrofitted SURF Algorithm and Trajectories Generated From Lissajous Figures. IEEE Geosci. Remote Sens. Lett. 2010, 7, 491–495. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Yu, J.; Kumar, M.; Mao, Y. Remote sensing image mosaic technology based on SURF algorithm in agriculture. EURASIP J. Image Video Process. 2018, 85. [Google Scholar] [CrossRef]
- Ramkumar, B.; Laber, R.; Bojinov, H.; Hegde, R.S. GPU acceleration of the KAZE image feature extraction algorithm. J. Real-Time Image Process. 2020, 17, 1169–1182. [Google Scholar] [CrossRef]
- Kusamura, Y.; Kozawa, Y.; Amagasa, T.; Kitagawa, H. GPU Acceleration of Content-Based Image Retrieval Based on SIFT Descriptors. In Proceedings of the 2016 19th International Conference on Network-Based Information Systems (NBiS), Ostrava, Czech Republic, 7–9 September 2016; pp. 342–347. [Google Scholar] [CrossRef]
- Chen, C.; Yong, H.; Zhong, S.; Yan, L. A real-time FPGA-based architecture for OpenSURF. Int. Soc. Opt. Photonics 2015, 9813, 98130K. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Fast Matching of Binary Features. In Proceedings of the 2012 Ninth Conference on Computer and Robot Vision, Toronto, ON, Canada, 28–30 May 2012; pp. 404–410. [Google Scholar] [CrossRef] [Green Version]
- Torr, P.; Zisserman, A. MLESAC: A New Robust Estimator with Application to Estimating Image Geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Tao, S.; Zhang, X.; Xu, W.; Qu, H. Realize the Image Motion Self-Registration Based on TDI in Digital Domain. IEEE Sens. J. 2019, 19, 11666–11674. [Google Scholar] [CrossRef]
- Feng, Q.; Tao, S.; Xu, C.; Jin, G. BM3D-GT&AD: An improved BM3D denoising algorithm based on Gaussian threshold and angular distance. IET Image Process. 2019, 14, 431–441. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
| 16 | 3.83 | 4.28 | 5.34 | 4.78 | 5.79 | 4.65 | 5.19 | 5.60 | 5.21 | 6.71 | 5.41 | 6.08 | 5.83 | 5.44 | 6.89 |
| 20 | 5.55 | 5.07 | 3.92 | 4.90 | 5.50 | 5.72 | 5.62 | 4.70 | 5.58 | 6.25 | 5.91 | 5.75 | 5.43 | 5.93 | 6.96 |
| 25 | 4.87 | 4.56 | 5.46 | 5.46 | 5.40 | 5.07 | 5.69 | 5.75 | 5.68 | 6.14 | 5.80 | 5.95 | 6.57 | 6.06 | 6.66 |
| 30 | 5.49 | 5.33 | 5.17 | 4.94 | 5.15 | 5.68 | 6.16 | 5.90 | 5.70 | 5.51 | 6.57 | 6.36 | 6.18 | 5.97 | 6.03 |
| 40 | 5.08 | 5.04 | 4.92 | 4.79 | 5.48 | 5.27 | 6.13 | 5.68 | 5.84 | 6.12 | 5.38 | 6.39 | 6.32 | 5.98 | 6.24 |
| 50 | 4.92 | 6.93 | 5.07 | 5.53 | 6.37 | 5.56 | 7.10 | 5.86 | 5.84 | 6.68 | 5.75 | 7.22 | 6.60 | 6.26 | 6.95 |
| 60 | 3.88 | 5.34 | 5.17 | 6.39 | 6.04 | 4.71 | 5.49 | 6.21 | 7.18 | 6.25 | 5.15 | 7.44 | 6.32 | 7.61 | 6.56 |
| 80 | 4.28 | 5.80 | 5.28 | 5.97 | 5.19 | 5.11 | 6.54 | 5.71 | 6.23 | 5.95 | 5.60 | 6.78 | 5.83 | 7.12 | 6.72 |
| 100 | 3.33 | 5.27 | 4.20 | 4.89 | 5.30 | 4.44 | 5.82 | 4.54 | 6.69 | 5.80 | 5.20 | 6.28 | 5.08 | 7.30 | 6.28 |
| 120 | 4.03 | 5.35 | 4.34 | 4.83 | 5.07 | 4.47 | 5.57 | 4.62 | 6.97 | 5.72 | 4.79 | 5.90 | 4.91 | 7.31 | 6.03 |
| t | |||||||||||||||
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
| 16 | 5.80 | 6.77 | 6.00 | 5.57 | 7.12 | 5.21 | 5.29 | 5.76 | 5.34 | 6.80 | 4.21 | 4.86 | 5.38 | 4.87 | 6.57 |
| 20 | 6.64 | 5.78 | 5.85 | 6.45 | 7.86 | 5.81 | 5.67 | 4.90 | 5.65 | 6.43 | 5.63 | 5.19 | 4.50 | 5.20 | 6.17 |
| 25 | 5.82 | 6.30 | 6.97 | 6.35 | 6.70 | 5.18 | 5.95 | 6.23 | 5.69 | 6.27 | 5.03 | 5.28 | 5.59 | 5.52 | 6.08 |
| 30 | 6.68 | 6.64 | 6.34 | 6.76 | 6.46 | 5.74 | 6.18 | 6.04 | 5.80 | 5.83 | 5.53 | 5.40 | 5.73 | 5.38 | 5.49 |
| 40 | 5.91 | 6.56 | 6.69 | 6.33 | 6.25 | 5.38 | 6.15 | 5.93 | 5.88 | 6.12 | 5.18 | 6.04 | 5.57 | 5.52 | 5.69 |
| 50 | 6.39 | 8.64 | 6.74 | 6.26 | 7.33 | 5.60 | 7.19 | 6.55 | 5.98 | 6.70 | 5.35 | 7.05 | 5.59 | 5.79 | 6.49 |
| 60 | 5.76 | 7.73 | 6.34 | 7.81 | 7.06 | 5.04 | 6.23 | 6.30 | 7.19 | 6.52 | 4.46 | 5.45 | 5.67 | 6.76 | 6.13 |
| 80 | 5.89 | 7.15 | 6.53 | 7.67 | 6.74 | 5.19 | 6.61 | 5.72 | 6.83 | 6.12 | 5.09 | 5.91 | 5.66 | 6.22 | 5.61 |
| 100 | 5.49 | 6.32 | 5.34 | 7.46 | 6.35 | 5.09 | 5.88 | 4.76 | 7.00 | 6.15 | 4.15 | 5.76 | 4.33 | 6.17 | 5.57 |
| 120 | 5.88 | 6.16 | 5.16 | 7.67 | 6.75 | 4.57 | 5.77 | 4.69 | 7.14 | 5.76 | 4.35 | 5.51 | 4.46 | 6.73 | 5.51 |
| F/ET (ms) | 0.2 | 0.25 | 0.3 | 0.4 | 0.5 | 0.6 | 0.8 | 1.0 | 1.2 | 1.6 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20.81 | 28.22 | 55.99 | 33.36 | 58.14 | 59.17 | 65.95 | 56.21 | 62.76 | 64.34 |
| 1 | 24.58 | 35.10 | 57.12 | 37.63 | 58.74 | 62.45 | 66.37 | 58.98 | 62.83 | 65.69 |
| 2 | 27.08 | 37.51 | 57.50 | 39.28 | 59.46 | 63.46 | 66.71 | 59.69 | 64.00 | 66.23 |
| 3 | 27.41 | 40.27 | 57.64 | 39.94 | 59.79 | 63.88 | 67.20 | 59.97 | 64.03 | 65.82 |
| 4 | 30.90 | 40.46 | 58.55 | 41.24 | 60.18 | 63.85 | 66.93 | 59.74 | 63.81 | 65.27 |
| 5 | 31.61 | 40.56 | 58.62 | 40.39 | 59.59 | 63.42 | 66.38 | 59.69 | 62.81 | 64.29 |
| 6 | 31.30 | 40.35 | 58.13 | 39.88 | 59.28 | 60.97 | 65.96 | 58.03 | 62.45 | 64.04 |
| 7 | 27.93 | 38.28 | 57.64 | 38.56 | 58.36 | 56.47 | 61.98 | 54.96 | 60.92 | 64.03 |
| 8 | 27.09 | 35.90 | 57.34 | 34.06 | 58.10 | 55.35 | 60.44 | 54.14 | 57.13 | 62.62 |
| 9 | 24.75 | 31.96 | 56.68 | 27.15 | 54.47 | 53.04 | 58.68 | 53.61 | 54.22 | 62.22 |
| 10 | 21.10 | 28.14 | 55.40 | 23.26 | 52.46 | 50.65 | 54.62 | 52.82 | 53.64 | 61.92 |
| Method/Scale | 1.00 | 1.05 | 1.10 | 1.15 | 1.20 | 1.25 | 1.30 | 1.35 | 1.40 | 1.45 | 1.50 | 1.55 | 1.60 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SURF | 76.9 | 76.6 | 73.8 | 73.2 | 70.5 | 70.4 | 71.0 | 70.5 | 68.4 | 70.3 | 68.5 | 68.3 | 63.2 |
| KAZE | 96.7 | 96.7 | 96.2 | 94.2 | 89.6 | 88.1 | 92.8 | 95.1 | 96.1 | 96.8 | 96.9 | 96.4 | 95.6 |
| BRISK | 95.9 | 95.7 | 96.2 | 95.3 | 95.4 | 94.6 | 93.9 | 94.8 | 94.3 | 95.2 | 95.0 | 95.8 | 94.9 |
| IFRAD | 87.8 | 87.1 | 88.4 | 83.0 | 71.8 | 70.3 | 55.5 | 53.3 | 35.9 | 41.1 | 23.3 | 8.1 | 11.8 |
| Method/Scale | 1.00 | 1.05 | 1.10 | 1.15 | 1.20 | 1.25 | 1.30 | 1.35 | 1.40 | 1.45 | 1.50 | 1.55 | 1.60 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SURF | 1.788 | 1.774 | 1.776 | 1.736 | 1.716 | 1.727 | 1.717 | 1.673 | 1.694 | 1.662 | 1.651 | 1.668 | 1.627 |
| KAZE | 27.6 | 27.7 | 29.0 | 27.7 | 27.6 | 27.7 | 27.6 | 27.2 | 27.8 | 27.1 | 26.7 | 27.5 | 26.7 |
| BRISK | 7.648 | 7.096 | 7.086 | 6.599 | 6.256 | 5.909 | 5.617 | 5.232 | 5.032 | 4.673 | 4.394 | 4.235 | 4.028 |
| IFRAD | 1.014 | 0.948 | 0.910 | 0.848 | 0.826 | 0.784 | 0.741 | 0.697 | 0.680 | 0.652 | 0.633 | 0.628 | 0.605 |
| Method/Scale | 1.00 | 1.05 | 1.10 | 1.15 | 1.20 | 1.25 | 1.30 | 1.35 | 1.40 | 1.45 | 1.50 | 1.55 | 1.60 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SURF | 1834 | 1715 | 1463 | 1290 | 1117 | 1015 | 1008 | 942 | 924 | 882 | 748 | 690 | 618 |
| KAZE | 32,398 | 29,941 | 23,977 | 14,521 | 7003 | 4737 | 6023 | 7904 | 8857 | 8407 | 7238 | 5698 | 4089 |
| BRISK | 6309 | 5713 | 4747 | 3655 | 2905 | 2625 | 2403 | 2395 | 2341 | 2122 | 1912 | 1735 | 1483 |
| IFRAD | 896 | 832 | 785 | 702 | 645 | 587 | 518 | 396 | 175 | 84 | 32 | 7 | 4 |
| Methods/Overlap Area (%) | 100 | 80 | 60 | 50 | 40 | 30 | 25 | 20 |
|---|---|---|---|---|---|---|---|---|
| SURF | 100.00 | 96.63 | 95.80 | 95.65 | 96.09 | 95.19 | 93.50 | 93.36 |
| KAZE | 100.00 | 99.33 | 99.29 | 99.28 | 99.34 | 99.04 | 98.99 | 98.95 |
| BRISK | 100.00 | 96.10 | 96.03 | 96.20 | 97.04 | 96.61 | 96.59 | 96.54 |
| IFRAD | 100.00 | 97.06 | 96.35 | 85.42 | 34.17 | 10.25 | 5.49 | 5.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Q.; Tao, S.; Liu, C.; Qu, H.; Xu, W. IFRAD: A Fast Feature Descriptor for Remote Sensing Images. Remote Sens. 2021, 13, 3774. https://doi.org/10.3390/rs13183774
Feng Q, Tao S, Liu C, Qu H, Xu W. IFRAD: A Fast Feature Descriptor for Remote Sensing Images. Remote Sensing. 2021; 13(18):3774. https://doi.org/10.3390/rs13183774
Chicago/Turabian StyleFeng, Qinping, Shuping Tao, Chunyu Liu, Hongsong Qu, and Wei Xu. 2021. "IFRAD: A Fast Feature Descriptor for Remote Sensing Images" Remote Sensing 13, no. 18: 3774. https://doi.org/10.3390/rs13183774
APA StyleFeng, Q., Tao, S., Liu, C., Qu, H., & Xu, W. (2021). IFRAD: A Fast Feature Descriptor for Remote Sensing Images. Remote Sensing, 13(18), 3774. https://doi.org/10.3390/rs13183774