
An Advanced SAR Image Despeckling Method by Bernoulli-Sampling-Based Self-Supervised Deep Learning

Abstract
:
1. Introduction
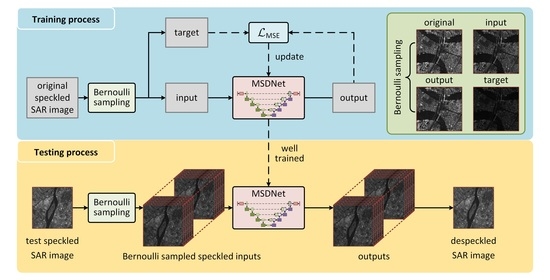
- To address the problem that no clean SAR images can be employed as targets to train the deep despeckling network, we propose a Bernoulli-sampling-based self-supervised despeckling training strategy, utilizing the known speckle noise model and real speckled SAR images. The feasibility is proven with mathematical justification, combining the characteristic of speckle noise in SAR images and the mean squared error loss function;
- A multiscale despeckling network (MSDNet) was designed based on the traditional UNet, where shallow and deep features are fused to recover despeckled SAR images. Dense residual blocks are introduced to enhance the feature extracting ability. In addition, the dropout-based ensemble in the testing process is proposed, to avoid the pixel loss problem caused by the Bernoulli sampling and to boost the despeckling performance;
- We conducted qualitative and quantitative comparison experiments on synthetic speckled and real SAR image data. The results showed that our proposed method significantly suppressed the speckle noise while reliably preserving image features over the state-of-the-art despeckling methods.
2. The Proposed Method
2.1. Basic Idea of Our Proposed SSD-SAR-BS
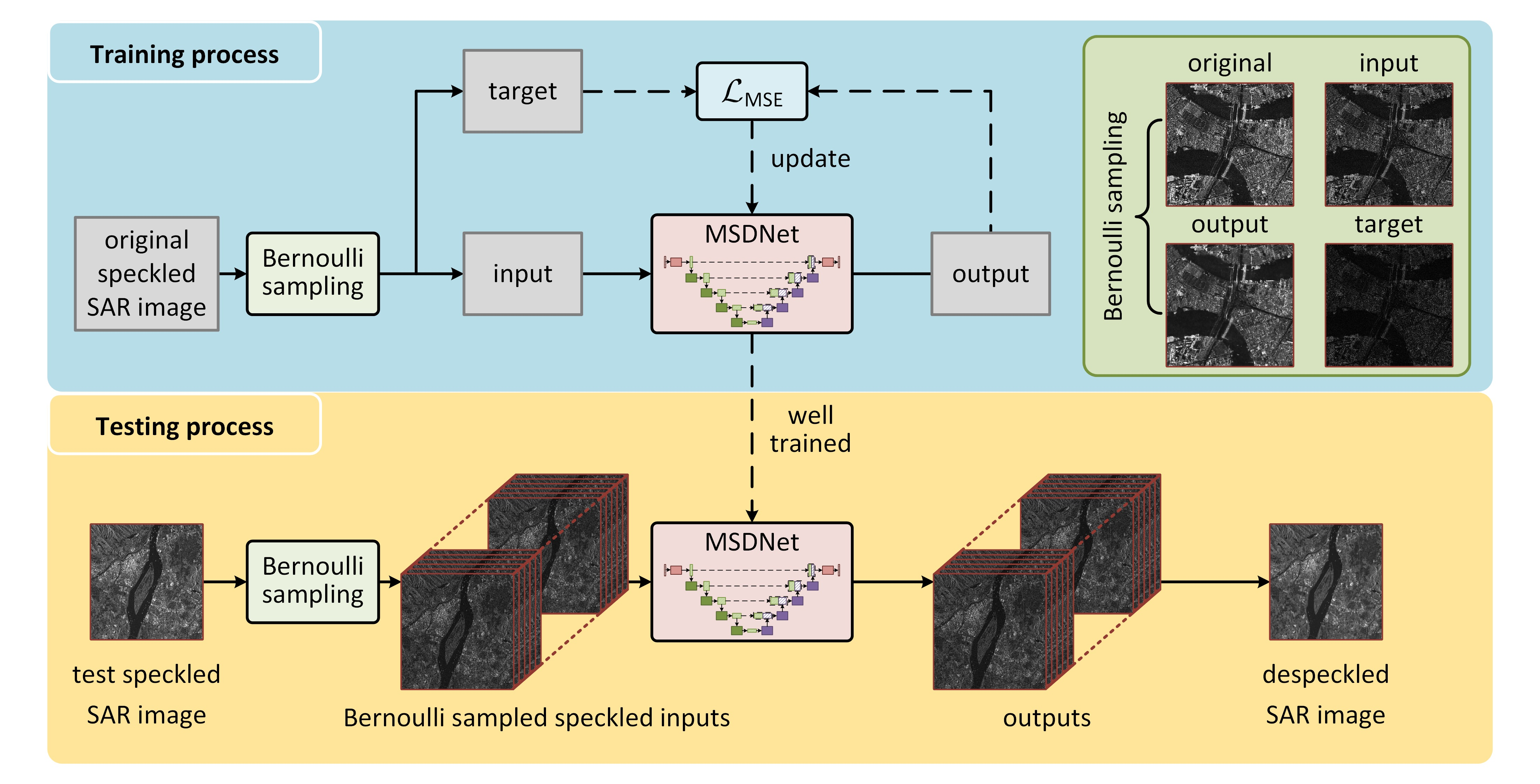
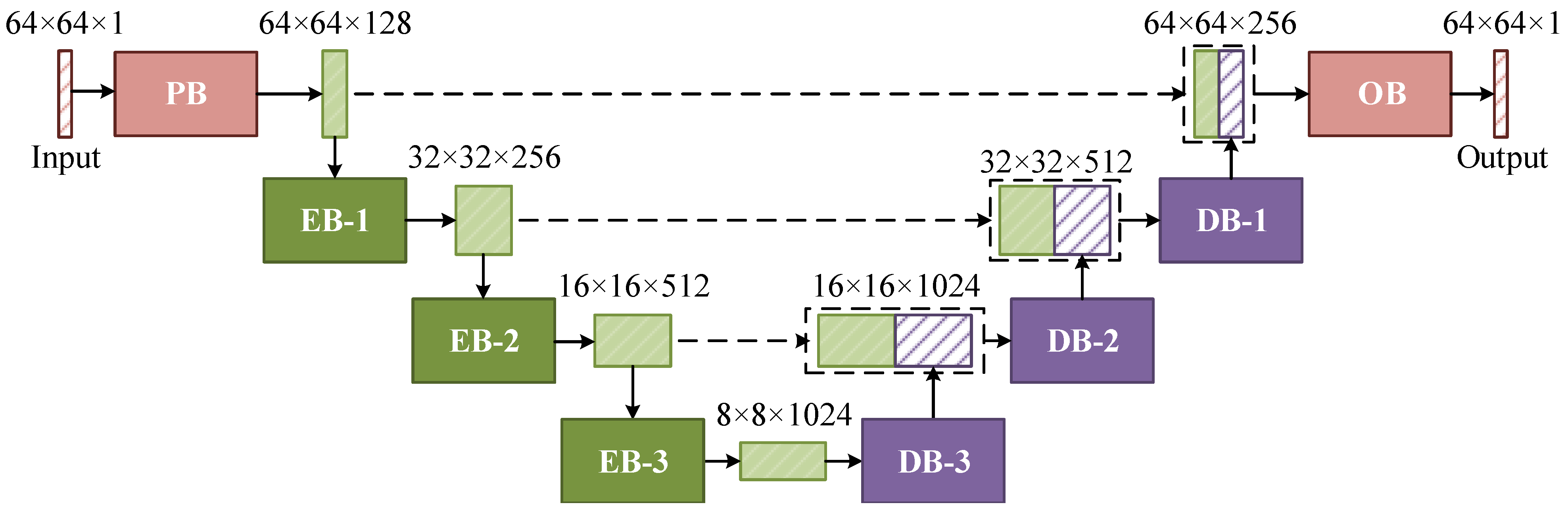
2.2. Multiscale Despeckling Network
2.2.1. Main Network Architecture
2.2.2. Dense Residual Block
2.3. Dropout-Based Ensemble for Testing
3. Experimental Results and Analysis
3.1. Experimental Setup
3.1.1. Compared Methods
3.1.2. Experimental Settings
3.2. Despeckling Experiments on Synthetic Speckled Data
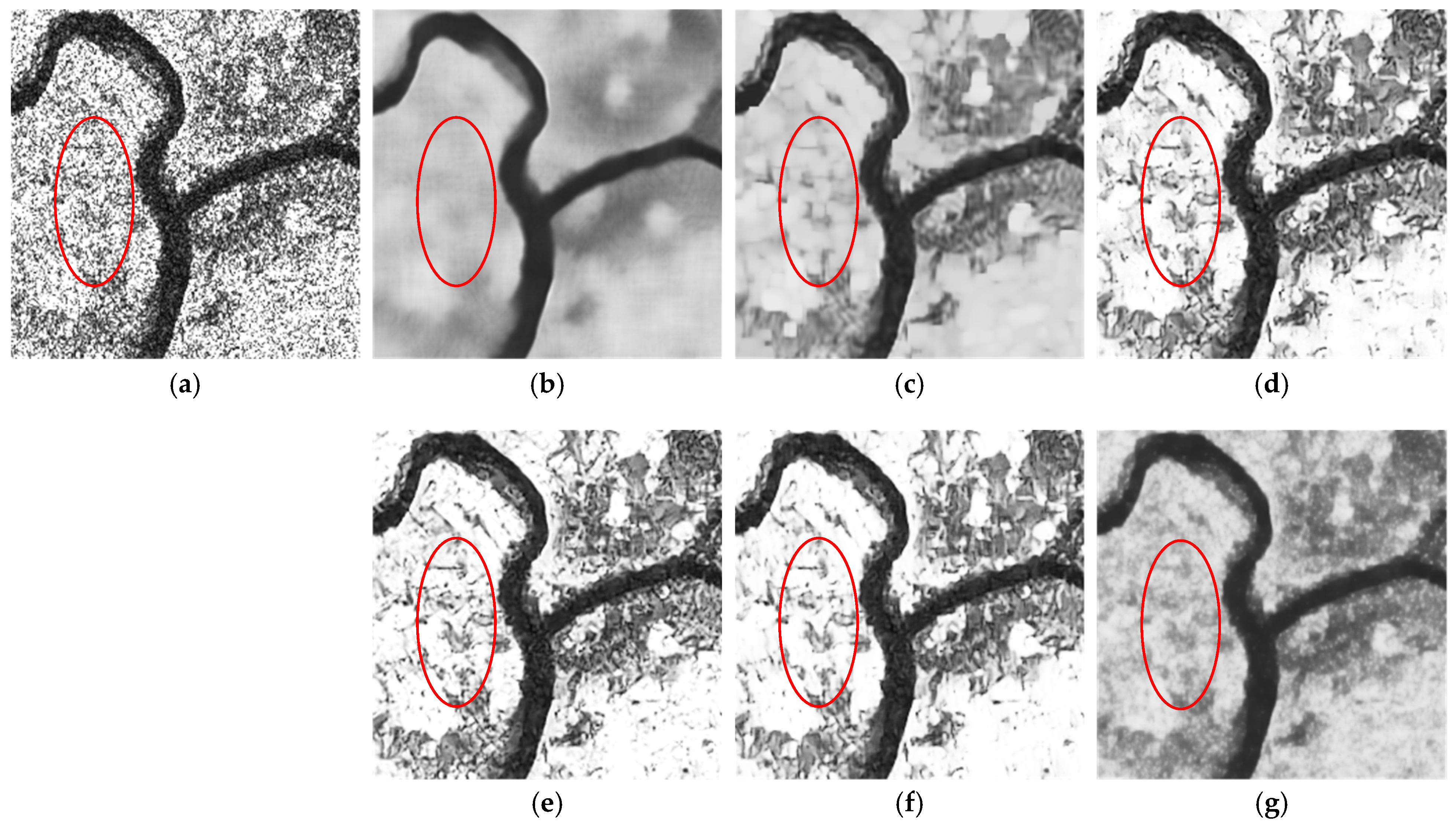
3.3. Despeckling Experiments on Real-World SAR Data
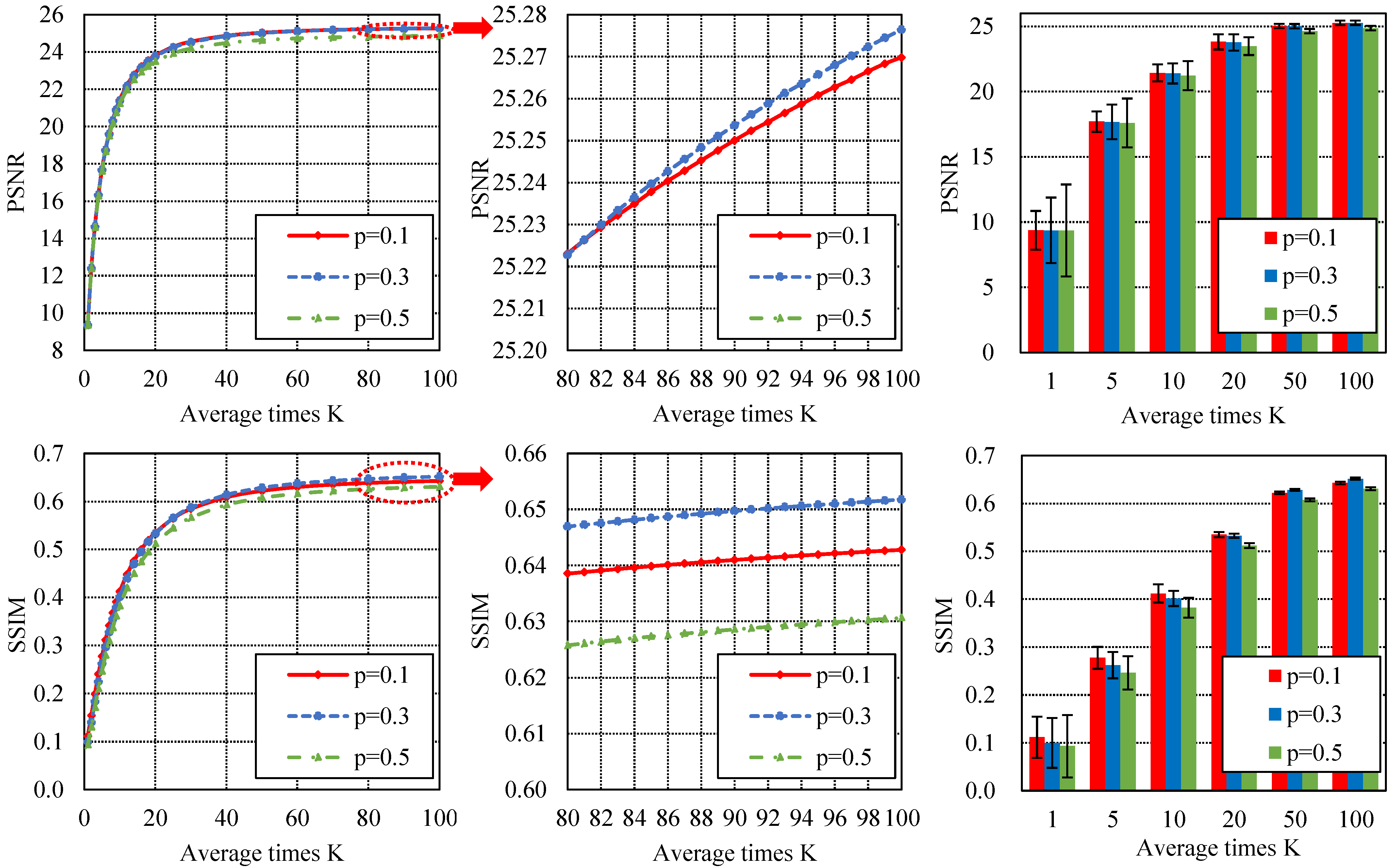
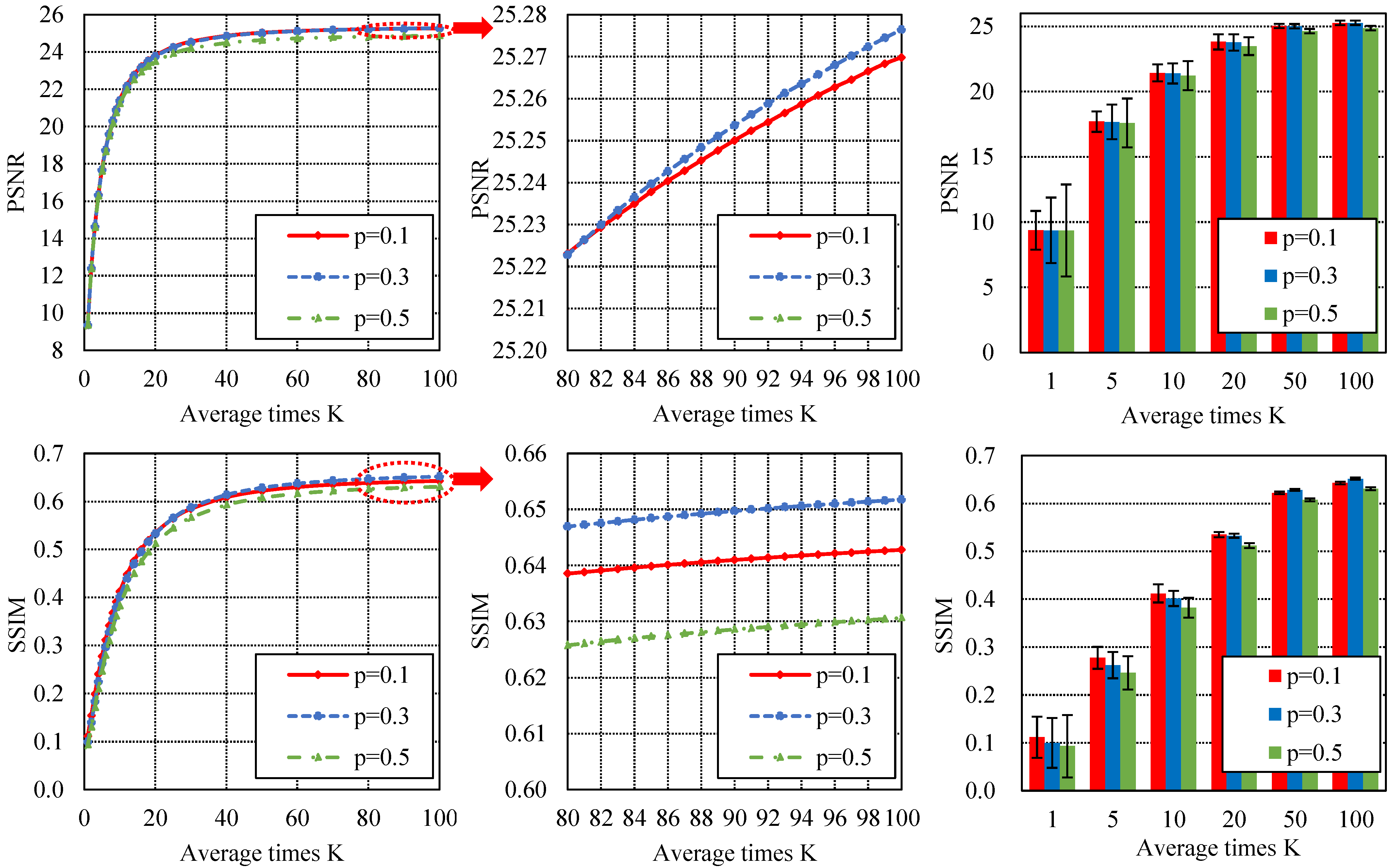
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File Name |
|---|
| S1A_IW_SLC__1SDV_20200905T213825_20200905T213852_034229_03FA38_D30D |
| S1A_IW_SLC__1SDV_20201003T061814_20201003T061842_034628_040844_46B4 |
| S1A_IW_SLC__1SDV_20201005T193328_20201005T193356_034665_04099B_FC66 |
| S1A_IW_SLC__1SDV_20201006T174956_20201006T175023_034679_040A12_D42A |
| S1A_IW_SLC__1SDV_20201007T122309_20201007T122339_034690_040A66_E864 |
| S1A_IW_SLC__1SDV_20201009T095727_20201009T095754_034718_040B5E_6849 |
| S1A_IW_SLC__1SDV_20201009T134427_20201009T134454_034720_040B72_5974 |
| S1A_IW_SLC__1SDV_20201010T103359_20201010T103427_034733_040BE5_C884 |
| S1A_IW_SLC__1SDV_20201011T225118_20201011T225144_034755_040CB3_DF67 |
| S1A_IW_SLC__1SDV_20201012T084229_20201012T084247_034761_040CDF_D6DA |
| S1A_IW_SLC__1SDV_20201012T170031_20201012T170058_034766_040D08_5C39 |
| S1A_IW_SLC__1SDV_20201012T170301_20201012T170328_034766_040D08_26A8 |
| S1A_IW_SLC__1SDV_20201012T232833_20201012T232901_034770_040D2D_97F3 |
| S1A_IW_SLC__1SDV_20201013T174039_20201013T174106_034781_040D94_28F8 |
| S1A_IW_SLC__1SDV_20201014T004524_20201014T004552_034785_040DBB_F086 |
| S1A_IW_SLC__1SDV_20201016T034517_20201016T034546_034816_040ED4_46C5 |
| S1A_IW_SLC__1SDV_20201017T170619_20201017T170646_034839_040FAE_0D60 |
| S1A_IW_SLC__1SDV_20201021T113553_20201021T113620_034894_041182_F0F4 |
| S1A_IW_SLC__1SDV_20201022T025850_20201022T025919_034903_0411D0_0F57 |
| S1A_IW_SLC__1SDV_20201022T103450_20201022T103517_034908_0411F7_2CCB |
| File Name |
|---|
| TSX_OPER_SAR_SM_SSC_20110201T171615_N44-534_E009-047_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20111209T231615_N13-756_E100-662_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20151220T220958_N37-719_E119-096_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20170208T051656_N53-844_E014-658_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20170208T051704_N53-354_E014-517_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20170525T033725_S25-913_E028-125_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20180622T162414_N40-431_E021-741_0000_v0100.SIP |
| TSX_OPER_SAR_SM_SSC_20180912T055206_N52-209_E006-941_0000_v0100.SIP |
References
- Lee, H.; Yuan, T.; Yu, H.; Jung, H.C. Interferometric SAR for wetland hydrology: An overview of methods, challenges, and trends. IEEE Geosci. Remote Sens. Mag. 2020, 8, 120–135. [Google Scholar] [CrossRef]
- White, L.; Brisco, B.; Dabboor, M.; Schmitt, A.; Pratt, A. A collection of SAR methodologies for monitoring wetlands. Remote Sens. 2015, 7, 7615–7645. [Google Scholar] [CrossRef] [Green Version]
- Aghababaei, H.; Ferraioli, G.; Ferro-Famil, L.; Huang, Y.; Mariotti D’Alessandro, M.; Pascazio, V.; Schirinzi, G.; Tebaldini, S. Forest SAR tomography: Principles and applications. IEEE Geosci. Remote Sens. Mag. 2020, 8, 30–45. [Google Scholar] [CrossRef]
- Perko, R.; Raggam, H.; Deutscher, J.; Gutjahr, K.; Schardt, M. Forest assessment using high resolution SAR data in X-band. Remote Sens. 2011, 3, 792–815. [Google Scholar] [CrossRef] [Green Version]
- Nagler, T.; Rott, H.; Ripper, E.; Bippus, G.; Hetzenecker, M. Advancements for snowmelt monitoring by means of Sentinel-1 SAR. Remote Sens. 2016, 8, 348. [Google Scholar] [CrossRef] [Green Version]
- Tripathi, G.; Pandey, A.C.; Parida, B.R.; Kumar, A. Flood inundation mapping and impact assessment using multitemporal optical and SAR satellite data: A case study of 2017 Flood in Darbhanga district, Bihar, India. Water Resour. Manag. 2020, 34, 1871–1892. [Google Scholar] [CrossRef]
- Połap, D.; Włodarczyk-Sielicka, M.; Wawrzyniak, N. Automatic ship classification for a riverside monitoring system using a cascade of artificial intelligence techniques including penalties and rewards. ISA Trans. 2021. [Google Scholar] [CrossRef]
- Tings, B.; Bentes, C.; Velotto, D.; Voinov, S. Modelling ship detectability depending on TerraSAR-X-derived metocean parameters. CEAS Space J. 2019, 11, 81–94. [Google Scholar] [CrossRef] [Green Version]
- Bentes, C.; Velotto, D.; Tings, B. Ship Classification in TerraSAR-X images with convolutional neural networks. IEEE J. Ocean. Eng. 2017, 43, 258–266. [Google Scholar] [CrossRef] [Green Version]
- Velotto, D.; Bentes, C.; Tings, B.; Lehner, S. First comparison of Sentinel-1 and TerraSAR-X data in the framework of maritime targets detection: South Italy case. IEEE J. Ocean. Eng. 2016, 41, 993–1006. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A tutorial on speckle reduction in synthetic aperture radar images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef] [Green Version]
- Lee, J. Digital image enhancement and noise filtering by use of local statistics. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 2, 165–168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frost, V.S.; Stiles, J.A.; Shanmugan, K.S.; Holtzman, J.C. A model for radar images and its application to adaptive digital filtering of multiplicative noise. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 4, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Aubert, G.; Aujol, J.F. A variational approach to removing multiplicative noise. SIAM J. Appl. Math. 2008, 68, 925–946. [Google Scholar] [CrossRef]
- Shi, J.; Osher, S. A nonlinear inverse scale space method for a convex multiplicative noise model. SIAM J. Appl. Math. 2008, 1, 294–321. [Google Scholar] [CrossRef] [Green Version]
- Deledalle, C.A.; Denis, L.; Tupin, F. Iterative weighted maximum likelihood denoising with probabilistic patch-based weights. IEEE Trans. Image Process. 2009, 18, 2661–2672. [Google Scholar] [CrossRef] [Green Version]
- Parrilli, S.; Poderico, M.; Angelino, C.V.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Di Martino, G.; Poderico, M.; Poggi, G.; Riccio, D.; Verdoliva, L. Benchmarking framework for SAR despeckling. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1596–1615. [Google Scholar] [CrossRef]
- Połap, D.; Srivastava, G. Neural image reconstruction using a heuristic validation mechanism. Neural Comput. Appl. 2021, 33, 10787–10797. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.; Wu, J. UNet 3+: A full-scale connected UNet for medical image segmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Połap, D.; Wozniak, M.; Korytkowski, M.; Scherer, R. Encoder-decoder based CNN structure for microscopic image identification. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Bangkok, Thailand, 23–27 November 2020; pp. 301–312. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR image despeckling through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Verdoliva, L.; Scarpa, G.; Poggi, G. Nonlocal CNN SAR image despeckling. Remote Sens. 2020, 12, 1006. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, H.; Patel, V.M. SAR image despeckling using a convolutional neural network. IEEE Signal Process. Lett. 2017, 24, 1763–1767. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yuan, Q.; Li, J.; Yang, Z.; Ma, X. Learning a dilated residual network for SAR image despeckling. Remote Sens. 2018, 10, 196. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Shi, J.; Yang, X.; Wang, C.; Kumar, D.; Wei, S.; Zhang, X. Deep multiscale recurrent network for synthetic aperture radar images despeckling. Remote Sens. 2019, 11, 2462. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, Y.; Xiao, Y.; Bai, Y. HDRANet: Hybrid dilated residual attention network for SAR image despeckling. Remote Sens. 2019, 11, 2921. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Lai, R.; Guan, J. Spatial and transform domain CNN for SAR image despeckling. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Li, Y. SAR image despeckling using multiconnection network incorporating wavelet features. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1363–1367. [Google Scholar] [CrossRef]
- Shen, H.; Zhou, C.; Li, J.; Yuan, Q. SAR image despeckling employing a recursive deep CNN prior. IEEE Trans. Geosci. Remote Sens. 2021, 59, 273–286. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S.D. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems (ACM-GIS), San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.; Zhu, X. The Sen1-2 dataset for deep learning in SAR-optical data fusion. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, IV-1, 141–146. [Google Scholar] [CrossRef] [Green Version]
- Lehtinen, J.; Munkberg, J.; Hasselgren, J.; Laine, S.; Karras, T.; Aittala, M.; Aila, T. Noise2Noise: Learning image restoration without clean data. In Proceedings of the International Conference on Machine Learning (ICML), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2971–2980. [Google Scholar]
- Ma, X.; Wang, C.; Yin, Z.; Wu, P. SAR image despeckling by noisy reference-based deep learning method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8807–8818. [Google Scholar] [CrossRef]
- Quan, Y.; Chen, M.; Pang, T.; Ji, H. Self2Self with dropout: Learning self-supervised denoising from single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1887–1895. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R.S. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 4898–4906. [Google Scholar]
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Sentinel-1. Available online: https://scihub.copernicus.eu/ (accessed on 23 October 2020).
- TerraSAR-X. Available online: https://tpm-ds.eo.esa.int/oads/access/collection/TerraSAR-X (accessed on 22 August 2020).
- Mullissa, A.G.; Marcos, D.; Tuia, D.; Herold, M.; Reiche, J. deSpeckNet: Generalizing deep-learning-based SAR image despeckling. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]













| Main Parts | Subparts | Configurations |
|---|---|---|
| PB | Preprocessing | Conv (c = 64, k = 3, s = 1, p = 0) + PReLU |
| Conv (c = 128, k = 3, s = 1, p = 0) + PReLU | ||
| DRB × 2 | Conv (c = 64, k = 3, s = 1, p = 0) + PReLU | |
| Conv (c = 64, k = 3, s = 1, p = 0) + PReLU | ||
| Conv (c = 128, k = 3, s = 1, p = 0) + PReLU | ||
| EB-i (i = 1, 2, 3) | Downsampling | Conv (c = 128 , k = 3, s = 2, p = 1) + PReLU |
| DRB × 2 | Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | |
| Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | ||
| Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | ||
| DB-i (i = 3, 2, 1) | Upsampling | TConv (c = 128 , k = 2, s = 2) + PReLU |
| DRB with dropout | Dropout + Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | |
| Dropout + Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | ||
| Dropout + Conv (c = 128 , k = 3, s = 1, p = 0) + PReLU | ||
| OB | Dropout + Conv (c = 128, k = 3, s = 1, p = 0) + PReLU | |
| Dropout + Conv (c = 64, k = 3, s = 1, p = 0) + PReLU | ||
| Dropout + Conv (c = 1, k = 3, s = 1, p = 0) |
| Data | Index | PPB | SAR-BM3D | ID-CNN | SAR-DRN | SAR-RDCP | SSD-SAR-BS |
|---|---|---|---|---|---|---|---|
| PSNR | 21.6044 ± 0.0797 | 22.4332 ± 0.0726 | 22.5192 ± 0.1544 | 23.6811 ± 0.1186 | 23.7348 ± 0.1291 | 24.3064 ± 0.1637 | |
| Airport | SSIM | 0.4421 ± 0.0033 | 0.5589 ± 0.0025 | 0.5567 ± 0.0012 | 0.6610 ± 0.0008 | 0.6666 ± 0.0028 | 0.7040 ± 0.0029 |
| ENL | 171.3710 ± 12.1654 | 296.7359 ± 22.8984 | 210.7900 ± 10.1910 | 431.0681 ± 33.3892 | 671.5572 ± 32.9589 | 1033.1749 ± 53.6550 | |
| PSNR | 19.1143 ± 0.0904 | 20.1459 ± 0.0842 | 19.9878 ± 0.2748 | 20.4174 ± 0.1308 | 20.2166 ± 0.1325 | 20.4868 ± 0.0903 | |
| Beach | SSIM | 0.3014 ± 0.0048 | 0.4665 ± 0.0031 | 0.4370 ± 0.0057 | 0.5309 ± 0.0034 | 0.5184 ± 0.0017 | 0.5577 ± 0.0010 |
| ENL | 138.4539 ± 9.2195 | 256.1158 ± 39.5277 | 179.2292 ± 8.0433 | 339.4192 ± 16.4669 | 285.4422 ± 17.5407 | 648.0094 ± 61.1982 | |
| PSNR | 19.2132 ± 0.0843 | 22.9632 ± 0.0779 | 23.7254 ± 0.1719 | 24.4793 ± 0.1316 | 24.4762 ± 0.1251 | 24.6219 ± 0.1126 | |
| Parking | SSIM | 0.5047 ± 0.0029 | 0.6599 ± 0.0021 | 0.6566 ± 0.0005 | 0.7107 ± 0.0003 | 0.7121 ± 0.0007 | 0.7306 ± 0.0027 |
| ENL | 139.1330 ± 9.4936 | 198.7999 ± 30.6818 | 102.3522 ± 6.0899 | 223.5714 ± 10.2016 | 220.4327 ± 14.9143 | 596.4893 ± 43.9951 | |
| PSNR | 19.5109 ± 0.0890 | 20.9744 ± 0.0836 | 21.1025 ± 0.2659 | 21.6210 ± 0.1105 | 21.5683 ± 0.1467 | 21.9281 ± 0.1305 | |
| School | SSIM | 0.3891 ± 0.0037 | 0.5405 ± 0.0026 | 0.5398 ± 0.0066 | 0.5997 ± 0.0016 | 0.6018 ± 0.0028 | 0.6228 ± 0.0015 |
| ENL | 115.2169 ± 8.2786 | 246.6993 ± 38.0744 | 71.6737 ± 5.0797 | 225.4230 ± 12.7912 | 142.2418 ± 9.1001 | 342.7139 ± 17.3803 |
| Data | Image | Index | PPB | SAR-BM3D | ID-CNN | SAR-DRN | SAR-RDCP | SSD-SAR-BS |
|---|---|---|---|---|---|---|---|---|
| Sentinel-1 | ENL | 17.6246 ± 1.1437 | 22.9777 ± 3.0547 | 17.8801 ± 1.1527 | 17.7781 ± 1.4860 | 15.4355 ± 1.1983 | 35.2740 ± 2.6669 | |
| #1 | Cx | 0.2382 ± 0.0081 | 0.2086 ± 0.0154 | 0.2365 ± 0.0080 | 0.2372 ± 0.2267 | 0.2545 ± 0.0105 | 0.1684 ± 0.0067 | |
| MoR | 0.9880 ± 0.0004 | 1.0095 ± 0.0006 | 0.9844 ± 0.0012 | 0.9996 ± 0.0008 | 0.9947 ± 0.0009 | 1.0003 ± 0.0006 | ||
| ENL | 31.3902 ± 1.8247 | 35.2162 ± 3.1990 | 18.5404 ± 1.3791 | 18.6595 ± 1.4495 | 14.3300 ± 1.2413 | 42.0500 ± 3.5104 | ||
| #2 | Cx | 0.1785 ± 0.0054 | 0.1685 ± 0.0082 | 0.2322 ± 0.0092 | 0.2315 ± 0.2219 | 0.2642 ± 0.0122 | 0.1542 ± 0.0069 | |
| MoR | 0.9687 ± 0.0006 | 0.9959 ± 0.0019 | 0.9842 ± 0.0003 | 0.9889 ± 0.0009 | 0.9819 ± 0.0007 | 1.0021 ± 0.0003 | ||
| TerraSAR-X | ENL | 59.3150 ± 3.1960 | 45.4120 ± 3.9193 | 11.6018 ± 0.8807 | 8.2538 ± 0.5720 | 12.4337 ± 0.8996 | 68.9492 ± 4.8888 | |
| #1 | Cx | 0.1298 ± 0.0037 | 0.1484 ± 0.0068 | 0.2936 ± 0.0118 | 0.3481 ± 0.3354 | 0.2836 ± 0.0108 | 0.1204 ± 0.0045 | |
| MoR | 0.9608 ± 0.0014 | 0.9803 ± 0.0013 | 0.9618 ± 0.0012 | 0.9514 ± 0.0002 | 0.9282 ± 0.0010 | 0.9828 ± 0.0008 | ||
| ENL | 57.7479 ± 2.9501 | 47.5173 ± 5.0632 | 15.6736 ± 0.9855 | 11.5313 ± 0.8143 | 10.9757 ± 0.8569 | 82.3089 ± 5.6541 | ||
| #2 | Cx | 0.1316 ± 0.0035 | 0.1451 ± 0.0084 | 0.2526 ± 0.0083 | 0.2945 ± 0.2835 | 0.3018 ± 0.0126 | 0.1102 ± 0.0040 | |
| MoR | 0.9736 ± 0.0018 | 0.9880 ± 0.0016 | 0.9600 ± 0.0005 | 0.9625 ± 0.0004 | 0.9590 ± 0.0011 | 1.0119 ± 0.0006 |
| Image Size | PPB | SAR- | ID- | SAR- | SAR- | SSD-SAR-BS | |||
|---|---|---|---|---|---|---|---|---|---|
| (Pixels × Pixels) | BM3D | CNN | DRN | RDCP | K = 40 | K = 60 | K = 80 | K = 100 | |
| 64 × 64 | 1.3955 | 0.6210 | 0.1089 | 0.1066 | 0.1167 | 0.2582 | 0.3751 | 0.4946 | 0.5433 |
| 128 × 128 | 3.0085 | 2.6615 | 0.1072 | 0.1059 | 0.1165 | 0.7562 | 1.2069 | 1.7837 | 2.2278 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Wu, Y.; Fu, Y.; Wu, Y.; Zhang, L.; Jiang, Y. An Advanced SAR Image Despeckling Method by Bernoulli-Sampling-Based Self-Supervised Deep Learning. Remote Sens. 2021, 13, 3636. https://doi.org/10.3390/rs13183636
Yuan Y, Wu Y, Fu Y, Wu Y, Zhang L, Jiang Y. An Advanced SAR Image Despeckling Method by Bernoulli-Sampling-Based Self-Supervised Deep Learning. Remote Sensing. 2021; 13(18):3636. https://doi.org/10.3390/rs13183636
Chicago/Turabian StyleYuan, Ye, Yanxia Wu, Yan Fu, Yulei Wu, Lidan Zhang, and Yan Jiang. 2021. "An Advanced SAR Image Despeckling Method by Bernoulli-Sampling-Based Self-Supervised Deep Learning" Remote Sensing 13, no. 18: 3636. https://doi.org/10.3390/rs13183636
APA StyleYuan, Y., Wu, Y., Fu, Y., Wu, Y., Zhang, L., & Jiang, Y. (2021). An Advanced SAR Image Despeckling Method by Bernoulli-Sampling-Based Self-Supervised Deep Learning. Remote Sensing, 13(18), 3636. https://doi.org/10.3390/rs13183636