
Learning Adjustable Reduced Downsampling Network for Small Object Detection in Urban Environments


Abstract
:
1. Introduction
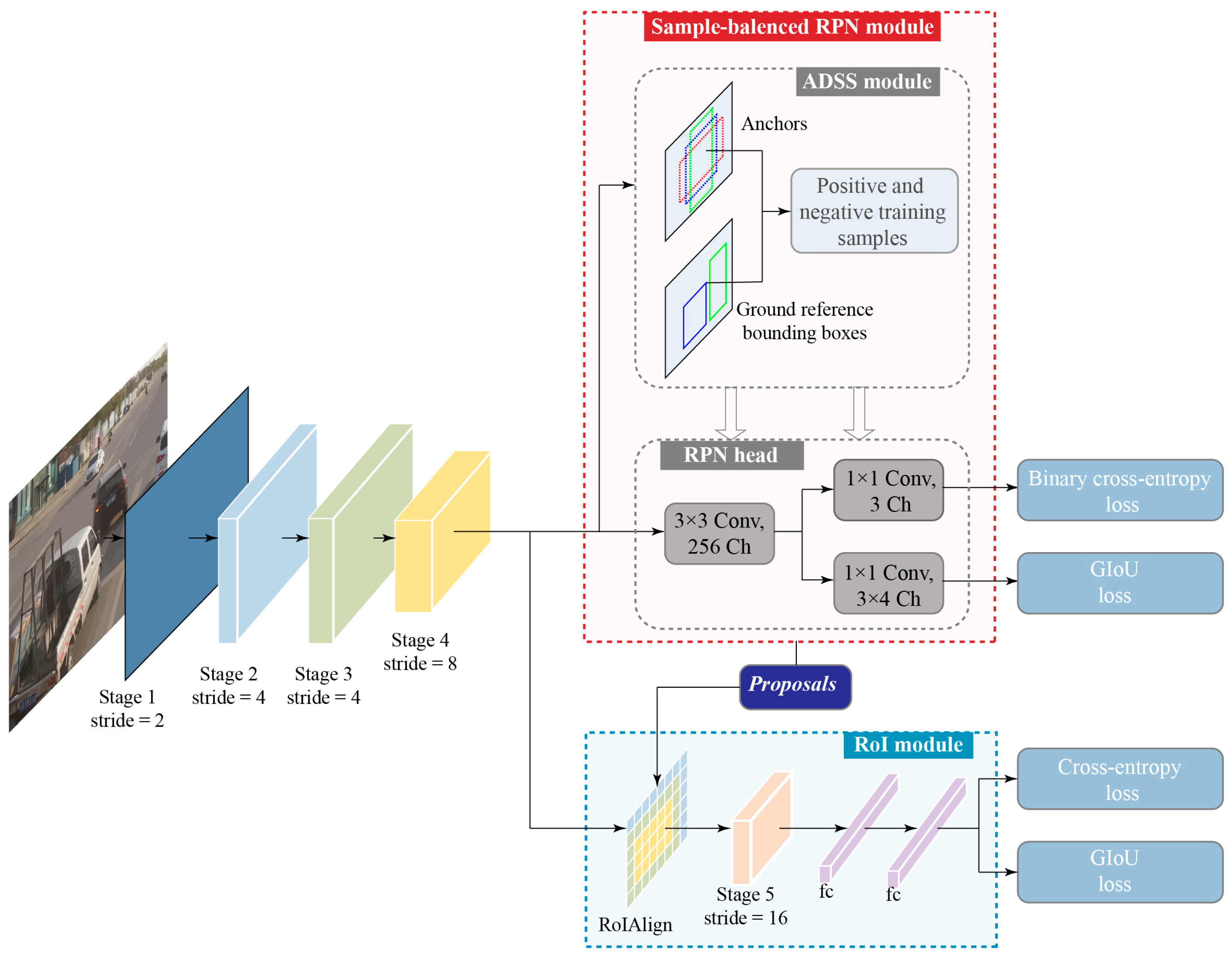
- We introduce a new backbone network, RD-Net, with low downsampling rate and small receptive field which preserves sufficient local information. The proposed RD-Net can extract high spatial resolution feature representations and improve small urban element detection performance.
- ADSS module is adopted, which defines positive and negative training samples based on statistical characteristics between the generated anchors and ground reference bounding boxes. With this sample selection strategy, we can assign positive-negative anchors in an adaptive and effective manner.
- We incorporate generalized Intersection-over-Union (GIoU) loss for bounding box regression to increase the convergency rate and training quality. GIoU is calculated to measure the extent of alignment between the proposed and ground reference bounding boxes. With a unified GIoU loss, we can bridge the gap between distance-based optimization loss and area-based evaluation metrics.
2. Related Work
2.1. Traditional Urban Element Detection
2.2. CNN-Based Object Detection
2.3. CNN-Based Small Object Detection
2.4. CNN-Based Urban Element Detection
3. Method
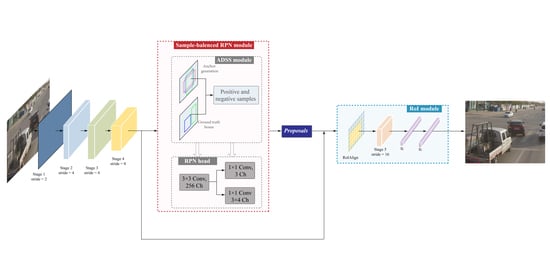
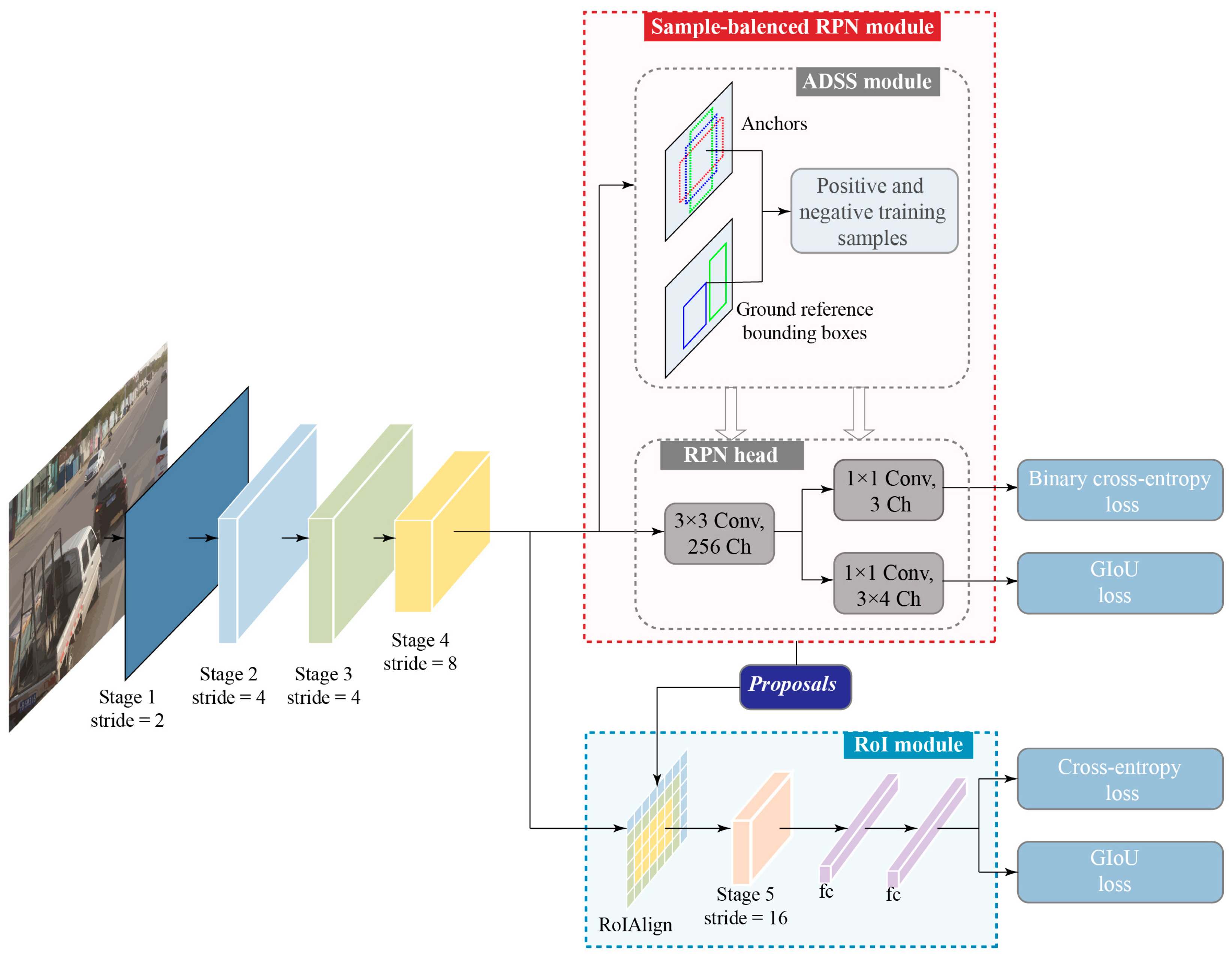
3.1. Overview of Our Method
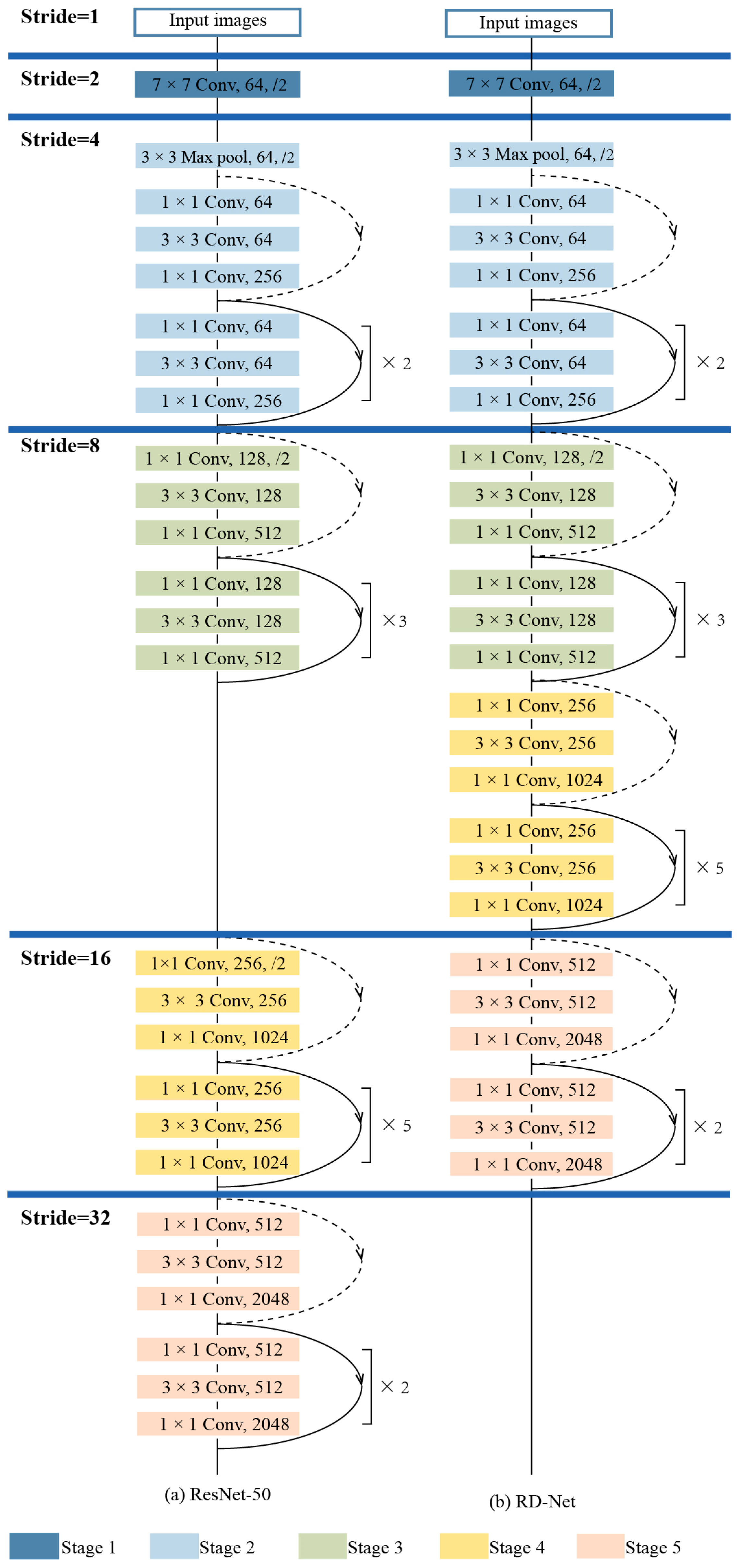
3.2. RD-Net
3.3. Adjustable Sample Selection Module
| Algorithm 1 Adjustable Sample Selection (ADSS) |
| Input: |
| M: feature maps from RD-Net backbone |
| T: a set of ground reference boxes |
| v: hyperparameter of anchor sizes in absolute pixels with default of [82, 162, 322, 642, 1282] |
| r: hyperparameter of anchor aspect ratios with default of [0.5, 1.0, 2.0] |
| k: hyperparameter to select anchors with default of 15 |
| n: hyperparameter of number of anchors per image to sample for training with default of 256 |
| Output: |
| : a set of positive samples for ground reference |
| : a set of negative samples for ground reference |
| 1: Generate a set of anchor boxes A from M with each cell creating anchors |
| 2: for each ground reference do |
| 3: Initialize a set of candidate positive samples by selecting top k anchors whose center are closest to the center of ground reference t based on L2 distance |
| 4: Calculate IoU between and ground reference t: |
| 5: Calculate mean of : |
| 6: Calculate standard deviation of : |
| 7: Set adjustable IoU threshold to select positive sample: |
| 8: for each positive candidate sample do |
| 9: if |
| 10: |
| 11: end if |
| 12: end for |
| 13: Calculate the number of negative samples for training : where is number of elements in |
| 14: Select anchors from randomly |
| 15: end for |
| 16: return , |
3.4. RoI Module
3.5. Loss Function
4. Experiments
4.1. Dataset, Implementation Details, and Evaluation Metrics
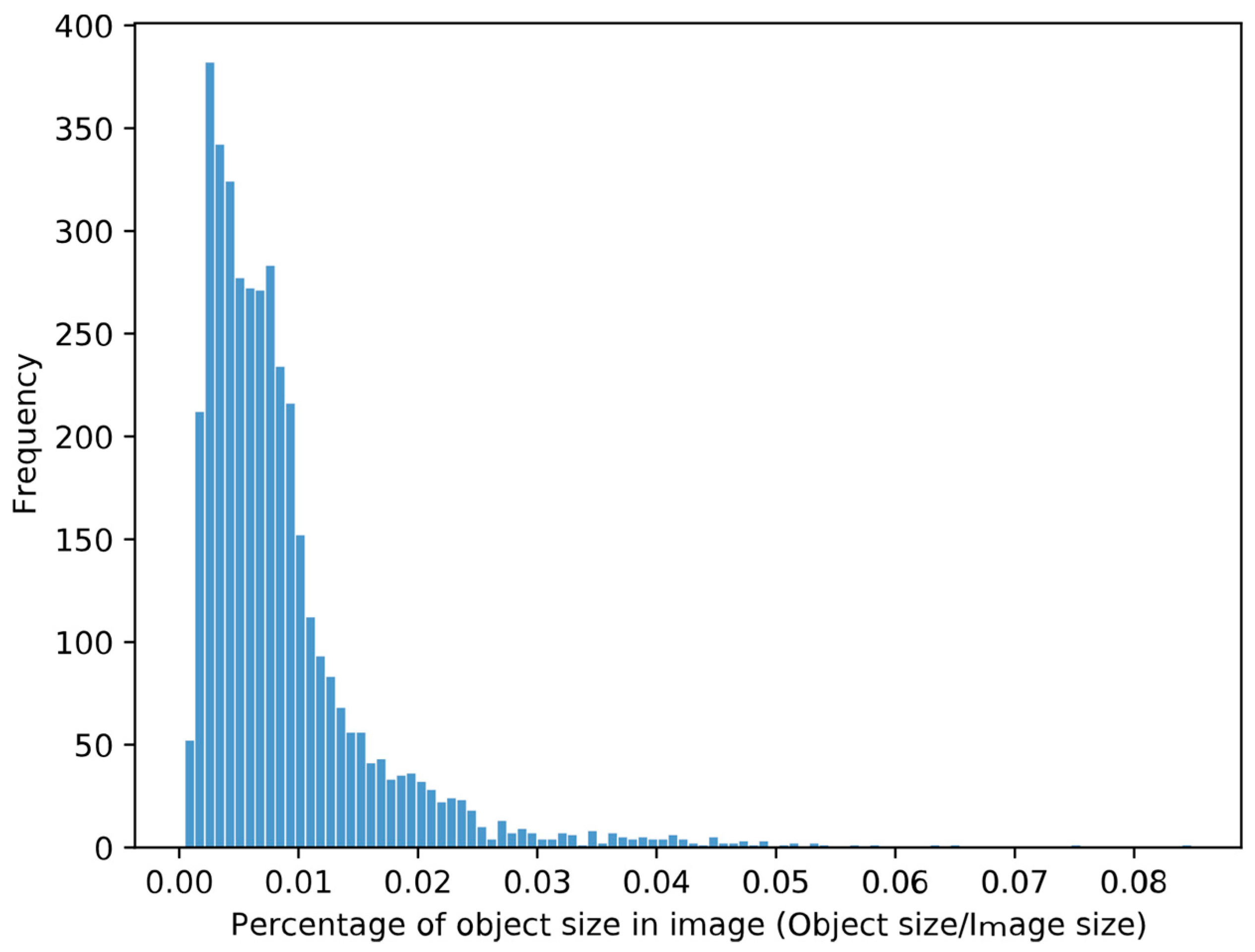
4.1.1. Dataset
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Ablation Study
4.2.1. Effect of RD-Net
4.2.2. Effect of ADSS Module
4.2.3. Effect of GIoU Loss
4.2.4. Computational Time
4.3. Backbone Network Analysis
4.4. Parameter Analysis
4.4.1. Hyperparameter k
4.4.2. Anchor Sizes
4.4.3. Anchor Aspect Ratios
4.5. Comparisons with State-of-the-Art Methods
5. Discussion
5.1. Effect of Proposed Modules
5.2. Sensitivity Analysis to Illumination and Occlusion
5.3. Analysis of Failure Cases
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cabo, C.; Ordóñez, C.; Garcia-Cortes, S.; Martínez-Sánchez, J. An algorithm for automatic detection of pole-like street furniture objects from Mobile Laser Scanner point clouds. ISPRS J. Photogramm. Remote Sens. 2014, 87, 47–56. [Google Scholar] [CrossRef]
- Wu, F.; Wen, C.; Guo, Y.; Wang, J.; Yu, Y.; Wang, C.; Li, J. Rapid Localization and Extraction of Street Light Poles in Mobile LiDAR Point Clouds: A Supervoxel-Based Approach. IEEE Trans. Intell. Transp. Syst. 2016, 18, 292–305. [Google Scholar] [CrossRef]
- Rodríguez-Cuenca, B.; García-Cortés, S.; Ordóñez, C.; Alonso, M.C. Automatic Detection and Classification of Pole-Like Objects in Urban Point Cloud Data Using an Anomaly Detection Algorithm. Remote Sens. 2015, 7, 12680–12703. [Google Scholar] [CrossRef]
- Li, L.; Li, D.; Zhu, H.; Li, Y. A dual growing method for the automatic extraction of individual trees from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 120, 37–52. [Google Scholar] [CrossRef]
- Xu, S.; Wang, R.; Zheng, H. Road curb extraction from mobile LiDAR point clouds. IEEE Trans. Geosci. Remote Sens. 2016, 55, 996–1009. [Google Scholar] [CrossRef] [Green Version]
- Jung, J.; Che, E.; Olsen, M.; Parrish, C. Efficient and robust lane marking extraction from mobile lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 147, 1–18. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Zhong, Z.; Chapman, M.A. Generation of Horizontally Curved Driving Lines in HD Maps Using Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1572–1586. [Google Scholar] [CrossRef]
- Yang, B.; Wei, Z.; Li, Q.; Li, J. Semiautomated Building Facade Footprint Extraction From Mobile LiDAR Point Clouds. IEEE Geosci. Remote Sens. Lett. 2012, 10, 766–770. [Google Scholar] [CrossRef]
- Xia, S.; Wang, R. Extraction of residential building instances in suburban areas from mobile LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 144, 453–468. [Google Scholar] [CrossRef]
- Shen, X. A survey of Object Classification and Detection based on 2D/3D data. arXiv 2019, arXiv:1905.12683. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, Z.; Liu, Y.; Liu, L.; Tang, X.; Xie, J.; Gao, X. Detecting Small Objects in Urban Settings Using SlimNet Model. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8445–8457. [Google Scholar] [CrossRef]
- Yu, Y.; Guan, H.; Ji, Z. Automated detection of urban road manhole covers using mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3258–3269. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Li, J.; Liu, P.; Zhao, H.; Wang, C. Automated extraction of manhole covers using mobile LiDAR data. Remote Sens. Lett. 2014, 5, 1042–1050. [Google Scholar] [CrossRef]
- Sultani, W.; Mokhtari, S.; Yun, H.-B. Automatic pavement object detection using superpixel segmentation combined with conditional random field. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2076–2085. [Google Scholar] [CrossRef]
- Niigaki, H.; Shimamura, J.; Morimoto, M. Circular object detection based on separability and uniformity of feature distributions using Bhattacharyya coefficient. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2009–2012. [Google Scholar]
- Pasquet, J.; Desert, T.; Bartoli, O.; Chaumont, M.; Delenne, C.; Subsol, G.; Derras, M.; Chahinian, N. Detection of manhole covers in high-resolution aerial images of urban areas by combining two methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1802–1807. [Google Scholar] [CrossRef] [Green Version]
- Chong, Z.; Yang, L. An Algorithm for Automatic Recognition of Manhole Covers Based on MMS Images. In Proceedings of the Chinese Conference on Image and Graphics Technologies, Beijing, China, 8–9 July 2016; pp. 27–34. [Google Scholar]
- Wei, Z.; Yang, M.; Wang, L.; Ma, H.; Chen, X.; Zhong, R. Customized mobile LiDAR system for manhole cover detection and identification. Sensors 2019, 19, 2422. [Google Scholar] [CrossRef] [Green Version]
- Shashirangana, J.; Padmasiri, H.; Meedeniya, D.; Perera, C. Automated License Plate Recognition: A Survey on Methods and Techniques. IEEE Access 2020, 9, 11203–11225. [Google Scholar] [CrossRef]
- Du, S.; Ibrahim, M.; Shehata, M.; Badawy, W. Automatic license plate recognition (ALPR): A state-of-the-art review. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 311–325. [Google Scholar] [CrossRef]
- Hongliang, B.; Changping, L. A hybrid license plate extraction method based on edge statistics and morphology. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; pp. 831–834. [Google Scholar]
- Jia, W.; Zhang, H.; He, X.; Piccardi, M. Mean shift for accurate license plate localization. In Proceedings of the 2005 IEEE Intelligent Transportation Systems, Vienna, Austria, 16 September 2005; pp. 566–571. [Google Scholar]
- Deb, K.; Jo, K.-H. HSI color based vehicle license plate detection. In Proceedings of the 2008 International Conference on Control, Automation and Systems, Seoul, Korea, 14–17 October 2008; pp. 687–691. [Google Scholar]
- Hsu, G.-S.; Chen, J.-C.; Chung, Y.-Z. Application-oriented license plate recognition. IEEE Trans. Veh. Technol. 2012, 62, 552–561. [Google Scholar] [CrossRef]
- Ma, R.-G.; Ma, Z.-H.; Wang, Y.-X. Study on positioning technology of mileage piles based on multi-sensor information fusion. J. Highw. Transp. Res. Dev. 2016, 10, 7–12. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Zhu, Y.; Urtasun, R.; Salakhutdinov, R.; Fidler, S. segdeepm: Exploiting segmentation and context in deep neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4703–4711. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Zagoruyko, S.; Lerer, A.; Lin, T.-Y.; Pinheiro, P.O.; Gross, S.; Chintala, S.; Dollár, P. A multipath network for object detection. arXiv 2016, arXiv:1604.02135. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure inference net: Object detection using scene-level context and instance-level relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6985–6994. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Boller, D.; Moy de Vitry, M.; Wegner, J.D.; Leitão, J.P. Automated localization of urban drainage infrastructure from public-access street-level images. Urban Water J. 2019, 16, 480–493. [Google Scholar] [CrossRef]
- Hebbalaguppe, R.; Garg, G.; Hassan, E.; Ghosh, H.; Verma, A. Telecom Inventory management via object recognition and localisation on Google Street View Images. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 725–733. [Google Scholar]
- Liu, W.; Cheng, D.; Yin, P.; Yang, M.; Li, E.; Xie, M.; Zhang, L. Small manhole cover detection in remote sensing imagery with deep convolutional neural networks. ISPRS Int. J. Geo-Inform. 2019, 8, 49. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wang, P.; You, M.; Shen, C. Reading car license plates using deep neural networks. Image Vis. Comput. 2018, 72, 14–23. [Google Scholar] [CrossRef]
- Montazzolli, S.; Jung, C. Real-time brazilian license plate detection and recognition using deep convolutional neural networks. In Proceedings of the 2017 30th SIBGRAPI conference on graphics, patterns and images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017; pp. 55–62. [Google Scholar]
- Xie, L.; Ahmad, T.; Jin, L.; Liu, Y.; Zhang, S. A new CNN-based method for multi-directional car license plate detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 507–517. [Google Scholar] [CrossRef]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonçalves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the YOLO detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Hendry; Chen, R.-C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar] [CrossRef]
- Kessentini, Y.; Besbes, M.D.; Ammar, S.; Chabbouh, A. A two-stage deep neural network for multi-norm license plate detection and recognition. Expert Syst. Appl. 2019, 136, 159–170. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: Design backbone for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–350. [Google Scholar]
- Zhu, R.; Zhang, S.; Wang, X.; Wen, L.; Shi, H.; Bo, L.; Mei, T. ScratchDet: Training single-shot object detectors from scratch. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2268–2277. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2. Available online: https://research.fb.com/wp-content/uploads/2019/12/4.-detectron2.pdf (accessed on 6 May 2020).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 248–255. [Google Scholar]
- Mhaskar, H.; Liao, Q.; Poggio, T. When and why are deep networks better than shallow ones? In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2104–2114. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small object detection in optical remote sensing images via modified faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Image Size (Pixel) | Object Size (Pixel) | # of Object | # of Small Objects (P% < 1) | # of Object (1% < P% < 2%) | Mean (P%) | Median (P%) | Std (P%) | Min (P%) | Max (P%) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Trainval data | manhole | 1024 2048 | 41 92 to 175 198 | 840 | 694 | 146 | 0.78 | 0.77 | 0.25 | 0.14 | 1.68 |
| lcz | 492 756 to 642 756 | 14 25 to 90 239 | 934 | 582 | 205 | 1.16 | 0.78 | 1.10 | 0.08 | 8.48 | |
| numplate | 492 756 to 592 756 | 8 25 to 115 136 | 1599 | 1192 | 302 | 0.74 | 0.48 | 0.65 | 0.05 | 4.34 | |
| Test data | manhole | 1024 2048 | 29 99 to 126 178 | 145 | 122 | 23 | 0.74 | 0.71 | 0.26 | 0.06 | 1.51 |
| lcz | 492 756 to 642 756 | 16 27 to 143 214 | 174 | 104 | 43 | 1.17 | 0.81 | 1.04 | 0.10 | 6.31 | |
| numplate | 492 756 to 592 756 | 13 36 to 122 137 | 280 | 214 | 52 | 0.77 | 0.54 | 0.71 | 0.08 | 5.15 | |
| Total data | manhole | 1024 2048 | 29 99 to 175 198 | 985 | 816 | 169 | 0.77 | 0.76 | 0.25 | 0.06 | 1.68 |
| lcz | 492 756 to 642 756 | 14 25 to 143 214 | 1108 | 686 | 248 | 1.17 | 0.78 | 1.09 | 0.08 | 8.48 | |
| numplate | 492 756 to 592 756 | 8 25 to 122 137 | 1879 | 1406 | 354 | 0.75 | 0.49 | 0.66 | 0.05 | 5.15 |
| Backbone | Method | RD-Net | ADSS Module | GIoU Loss | AP (%) | AP50 (%) | AP75 (%) | APmanhole (%) | APlcz (%) | APnumplate (%) | ms/ Image 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Resnet-50 | Baseline | 80.51 | 96.58 | 94.42 | 79.21 | 82.22 | 80.10 | 274.20 | |||
| Baseline + ADSS | √ | 80.28 | 96.09 | 95.05 | 77.82 | 81.96 | 81.04 | 271.07 | |||
| Baseline + GIoU_loss | √ | 78.35 | 96.58 | 94.45 | 77.06 | 79.55 | 78.45 | 274.12 | |||
| Baseline + ADSS + GIoU_loss | √ | √ | 79.62 | 97.01 | 95.14 | 78.61 | 80.55 | 79.71 | 270.90 | ||
| RD-Net | Baseline + RD-Net | √ | 81.28 | 96.88 | 94.91 | 79.73 | 82.67 | 81.42 | 342.47 | ||
| Baseline + RD-Net + ADSS | √ | √ | 81.31 | 97.04 | 94.89 | 80.38 | 82.44 | 81.10 | 323.53 | ||
| Baseline + RD-Net + GIoU_loss | √ | √ | 81.38 | 97.27 | 95.23 | 81.19 | 82.05 | 80.90 | 339.81 | ||
| Baseline + RD-Net + ADSS + GIoU_loss | √ | √ | √ | 81.71 | 97.40 | 95.78 | 81.55 | 82.94 | 80.64 | 322.89 |
| ResNet-101 | ResNet-50 | ResNet-50-S3 (DR-Net) | ResNet-50-S4 | ResNet-50-S5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| # of Block | Stride | # of Block | Stride | # of Block | Stride | # of Block | Stride | # of Block | Stride | |
| Stage 1 | 0 | 2 | 0 | 2 | 0 | 2 | 0 | 2 | 0 | 2 |
| Stage 2 | 3 | 4 | 3 | 4 | 3 | 4 | 3 | 4 | 3 | 4 |
| Stage 3 | 4 | 8 | 4 | 8 | 4 | 4 | 4 | 8 | 4 | 8 |
| Stage 4 | 23 | 16 | 6 | 16 | 6 | 8 | 6 | 8 | 6 | 16 |
| Stage 5 | 3 | 32 | 3 | 32 | 3 | 16 | 3 | 16 | 3 | 16 |
| AP (%) | 80.49 | 80.51 | 81.28 | 80.66 | 79.97 | |||||
| k | AP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| 3 | 80.28 | 96.77 | 94.53 |
| 6 | 79.30 | 96.28 | 93.69 |
| 9 | 81.17 | 97.39 | 95.47 |
| 12 | 81.32 | 97.43 | 95.03 |
| 15 × 1 | 81.71 | 97.40 | 95.78 |
| 15 × 3 | 81.22 | 97.35 | 94.55 |
| 15 × 5 | 81.17 | 97.09 | 94.71 |
| 15 × 7 | 81.06 | 97.44 | 94.93 |
| 15 × 9 | 81.03 | 96.86 | 95.62 |
| Anchor Sizes | AP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| [322, 642, 1282, 2562, 5122] | 80.55 | 97.02 | 94.94 |
| [162, 322, 642, 1282, 2562] | 81.32 | 96.78 | 95.52 |
| [82, 162, 322, 642, 1282] | 81.71 | 97.40 | 95.78 |
| [42, 82, 162, 322, 642] | 80.73 | 97.09 | 94.74 |
| Aspect Ratio | k | AP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|---|
| [0.5, 1, 2] | 15 | 81.71 | 97.40 | 95.78 |
| [0.5, 1, 1.5, 2] | 20 | 81.20 | 97.35 | 94.57 |
| [0.5,0.75,1, 2] | 20 | 80.69 | 96.74 | 94.47 |
| [0.5,0.75,1, 1.5, 2] | 25 | 81.48 | 97.10 | 95.74 |
| Method | Backbone | AP (%) | AP50 (%) | AP75 (%) | APmanhole (%) | APlcz (%) | APnumplate (%) |
|---|---|---|---|---|---|---|---|
| ResNeXt | ResNext-50-32x4d | 73.58 | 94.31 | 90.22 | 67.78 | 78.44 | 74.53 |
| FPN | ResNet-50 | 80.53 | 96.51 | 95.43 | 78.10 | 82.60 | 80.88 |
| DCN | ResNet-50-Deformable | 80.42 | 96.76 | 94.81 | 78.99 | 82.64 | 79.62 |
| TridentNet-Fast | ResNet-50 | 80.62 | 96.23 | 94.46 | 79.17 | 81.97 | 80.71 |
| Cascade R-CNN | ResNet-50 | 80.51 | 96.10 | 94.51 | 78.40 | 81.87 | 81.27 |
| Mask R-CNN | ResNet-50 | 80.48 | 95.52 | 94.43 | 79.05 | 82.11 | 80.28 |
| Cascade Mask R-CNN | ResNet-50 | 81.23 | 97.20 | 95.62 | 80.65 | 81.45 | 81.60 |
| RetinaNet | ResNet-50 | 79.91 | 96.97 | 94.88 | 79.13 | 80.30 | 80.31 |
| Ours | RD-Net | 81.71 | 97.40 | 95.78 | 81.55 | 82.94 | 80.64 |
| Method | S4 | ADSS Module | GIoU Loss | AP (%) | APmanhole (%) | APlcz (%) | APnumplate (%) |
|---|---|---|---|---|---|---|---|
| Baseline | 80.51 | 79.21 | 82.22 | 80.10 | |||
| Baseline + S4 | √ | 80.66 | 78.30 | 83.44 | 80.24 | ||
| Baseline + S4 + ADSS | √ | √ | 80.83 | 80.37 | 82.13 | 79.98 | |
| Baseline + S4 + GIoU_loss | √ | √ | 80.81 | 79.50 | 81.90 | 81.03 | |
| Baseline + S4 + ADSS + GIoU_loss | √ | √ | √ | 81.44 | 79.87 | 82.74 | 81.71 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; An, L.; Chu, V.W.; Stow, D.A.; Liu, X.; Ding, Q. Learning Adjustable Reduced Downsampling Network for Small Object Detection in Urban Environments. Remote Sens. 2021, 13, 3608. https://doi.org/10.3390/rs13183608
Zhang H, An L, Chu VW, Stow DA, Liu X, Ding Q. Learning Adjustable Reduced Downsampling Network for Small Object Detection in Urban Environments. Remote Sensing. 2021; 13(18):3608. https://doi.org/10.3390/rs13183608
Chicago/Turabian StyleZhang, Huijie, Li An, Vena W. Chu, Douglas A. Stow, Xiaobai Liu, and Qinghua Ding. 2021. "Learning Adjustable Reduced Downsampling Network for Small Object Detection in Urban Environments" Remote Sensing 13, no. 18: 3608. https://doi.org/10.3390/rs13183608
APA StyleZhang, H., An, L., Chu, V. W., Stow, D. A., Liu, X., & Ding, Q. (2021). Learning Adjustable Reduced Downsampling Network for Small Object Detection in Urban Environments. Remote Sensing, 13(18), 3608. https://doi.org/10.3390/rs13183608