
Making Low-Resolution Satellite Images Reborn: A Deep Learning Approach for Super-Resolution Building Extraction



Abstract
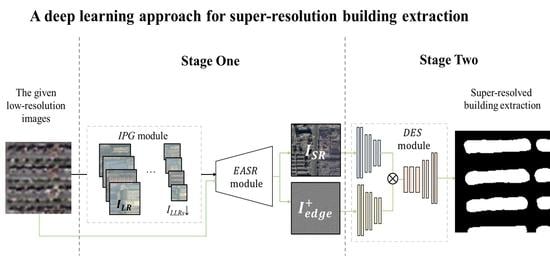
:
1. Introduction
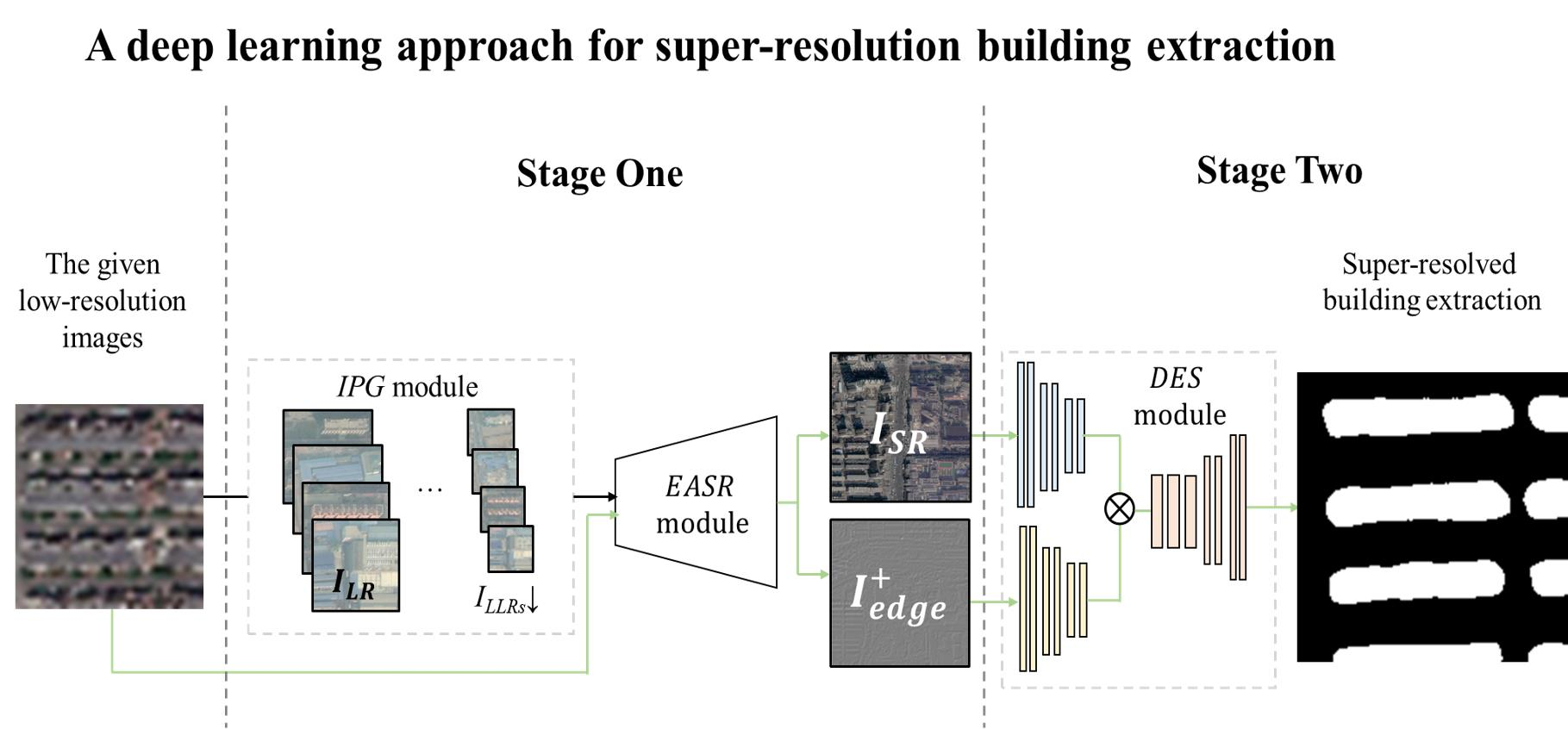
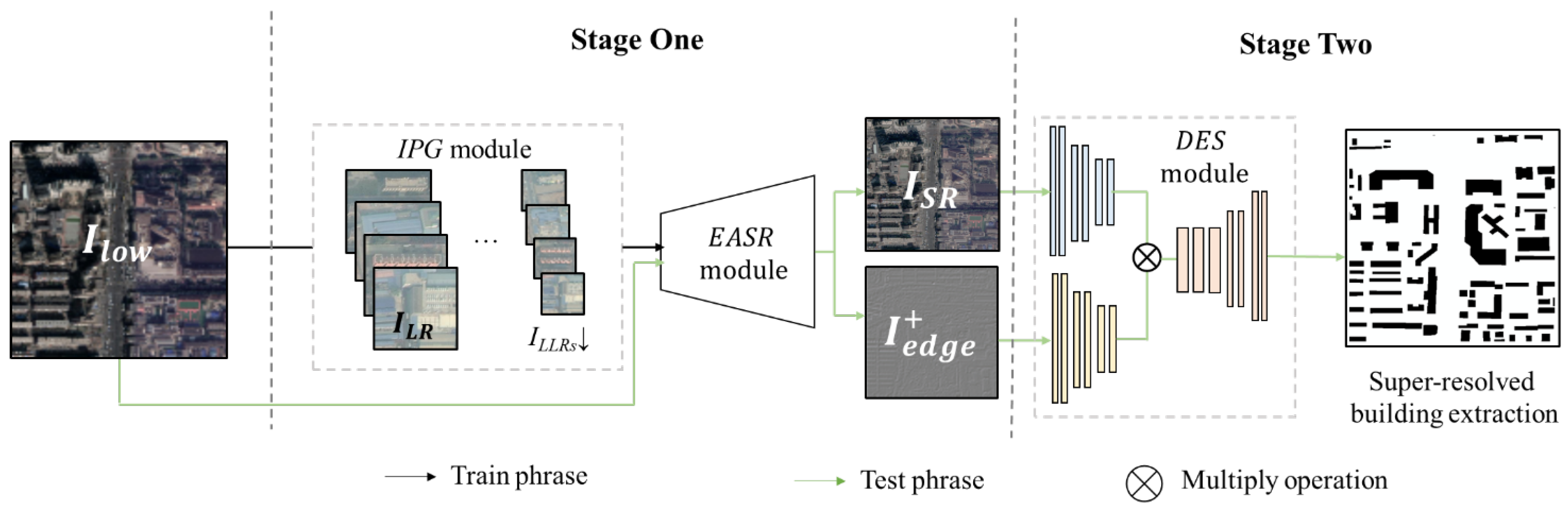
- We propose a two-stage framework for attaining super-resolution building extraction, named SRBuildingSeg, which can make use of the extracted features of the given low-resolution images to improve the performance of building extraction in high-resolution representation.
- Considering the self-similarity between each building in remotely sensed images, we develop an internal pairs generation module (IPG) and an edge-aware super-resolution module (EASR). Using the two proposed modules, we can fully utilize the internal information of the given images to improve the perceptional features for subsequent building segmentation without any external high-resolution images.
- We propose a dual-encoder integration module (DES) for building segmentation tasks which enables our approach to attain super-resolution building extraction by fully utilizing the texture features and enhanced perceptional features.
- We demonstrate that the reconstructed high frequency information of the super-resolved image can be transferred into the improvement of the super-resolution building extraction task. The assessment results reveal that our proposed approach ranks the best among all eight compared methods.
2. Related Work
2.1. Building Extraction Using Deep Learning Approaches
2.2. Single Image Super-Resolution
3. Methodology
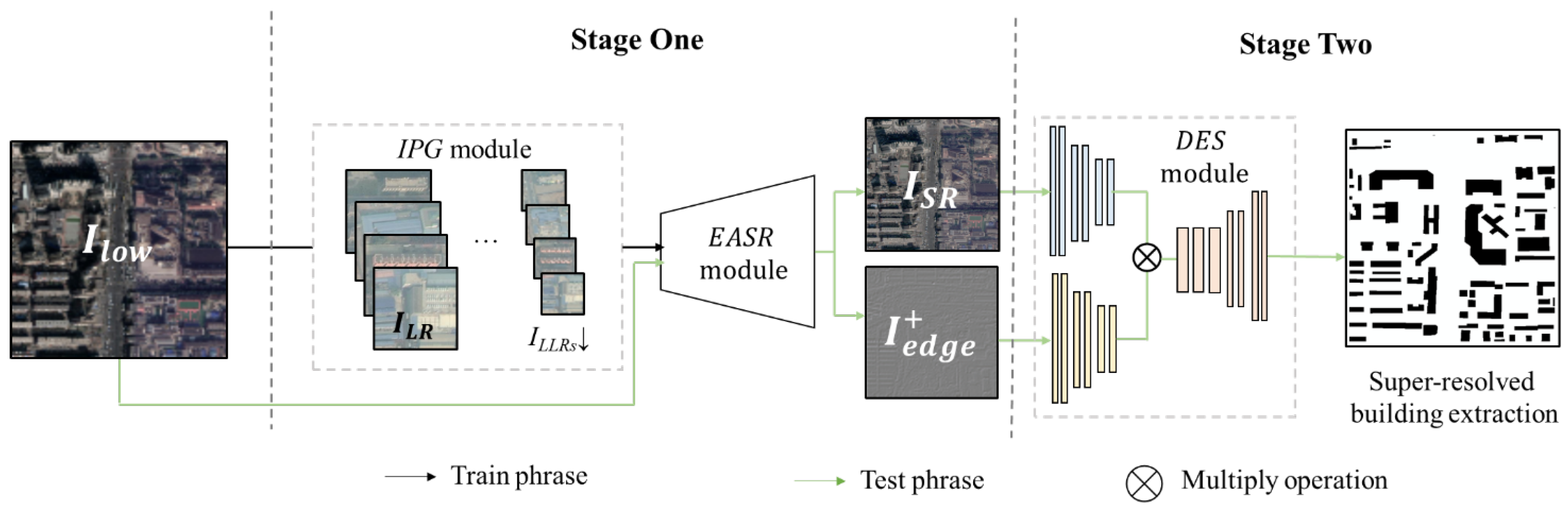
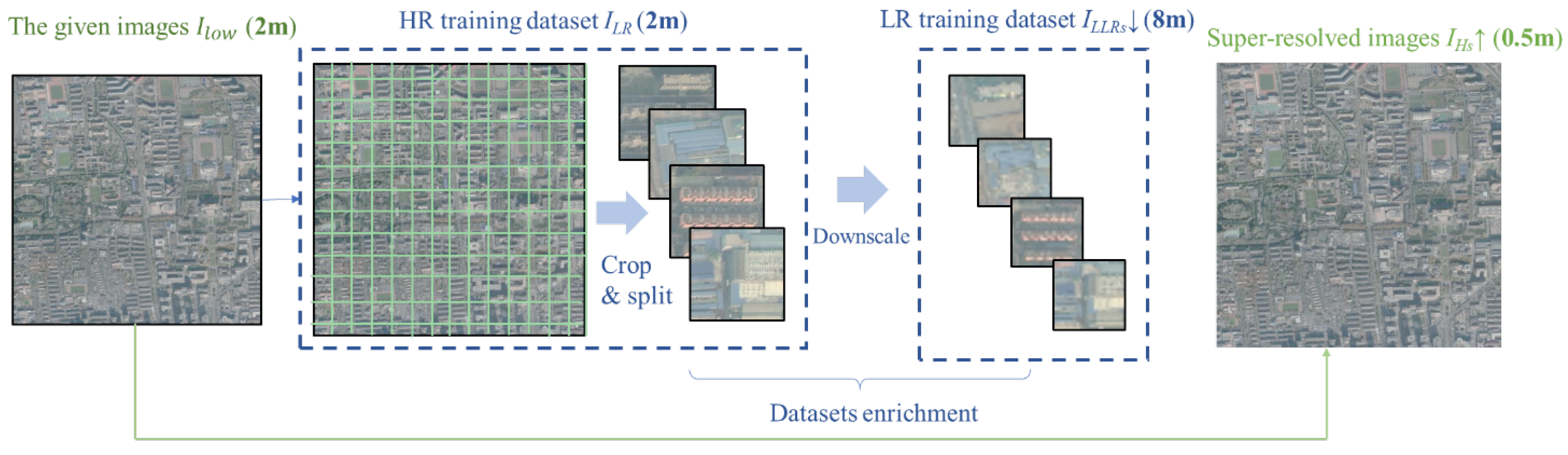
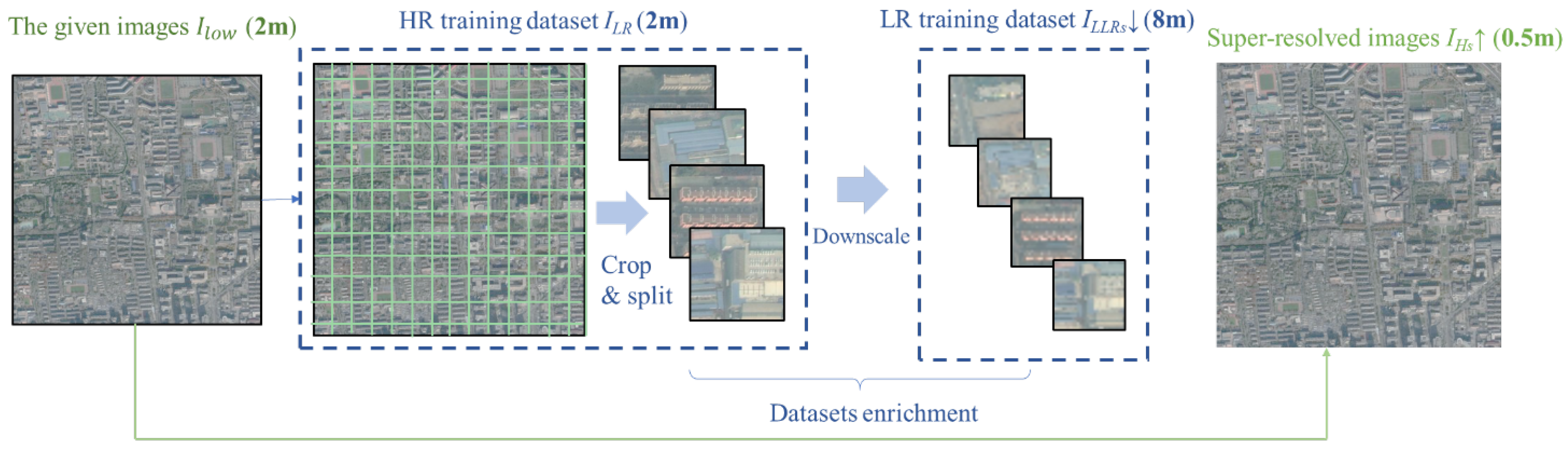
3.1. Internal Pairs Generation Module
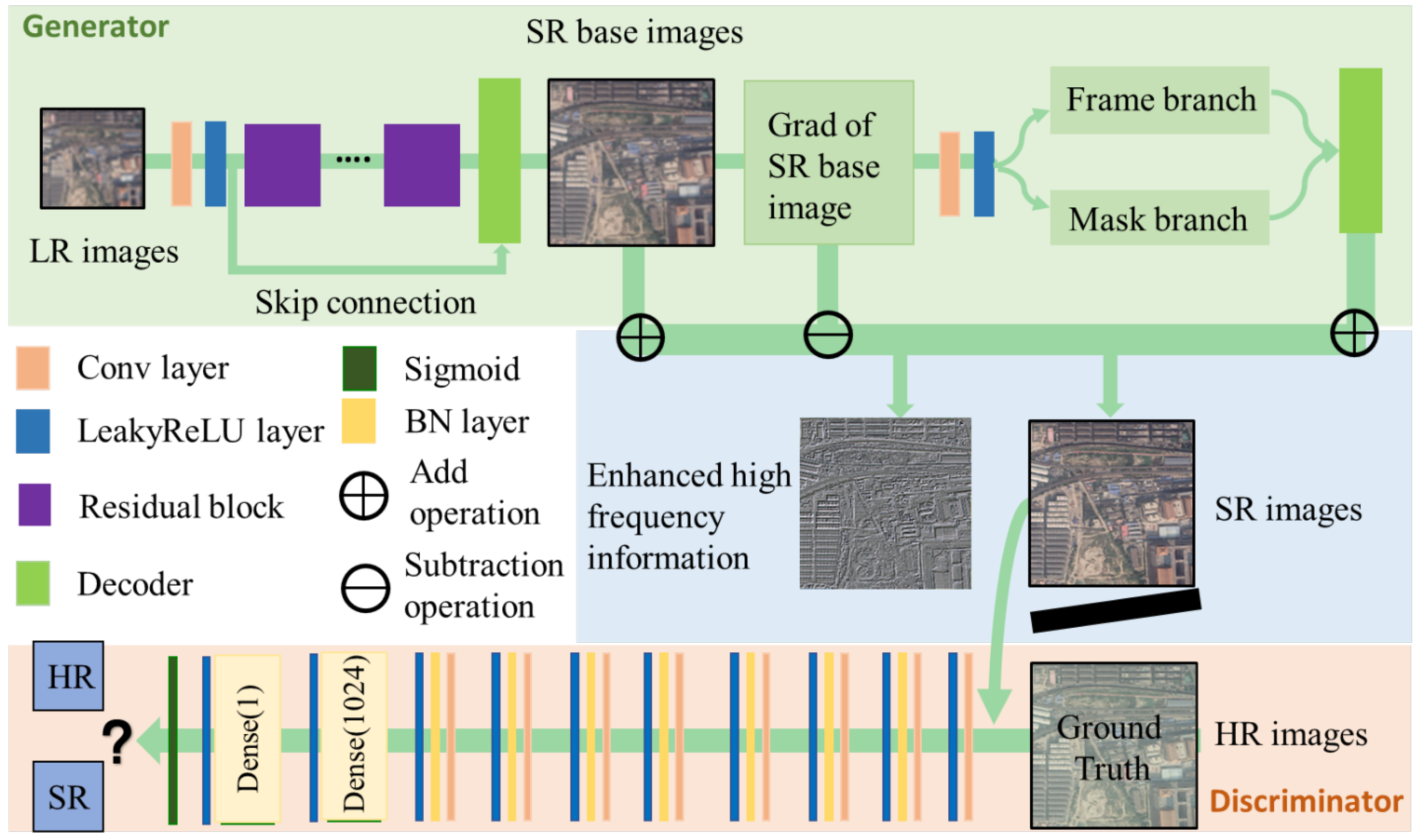
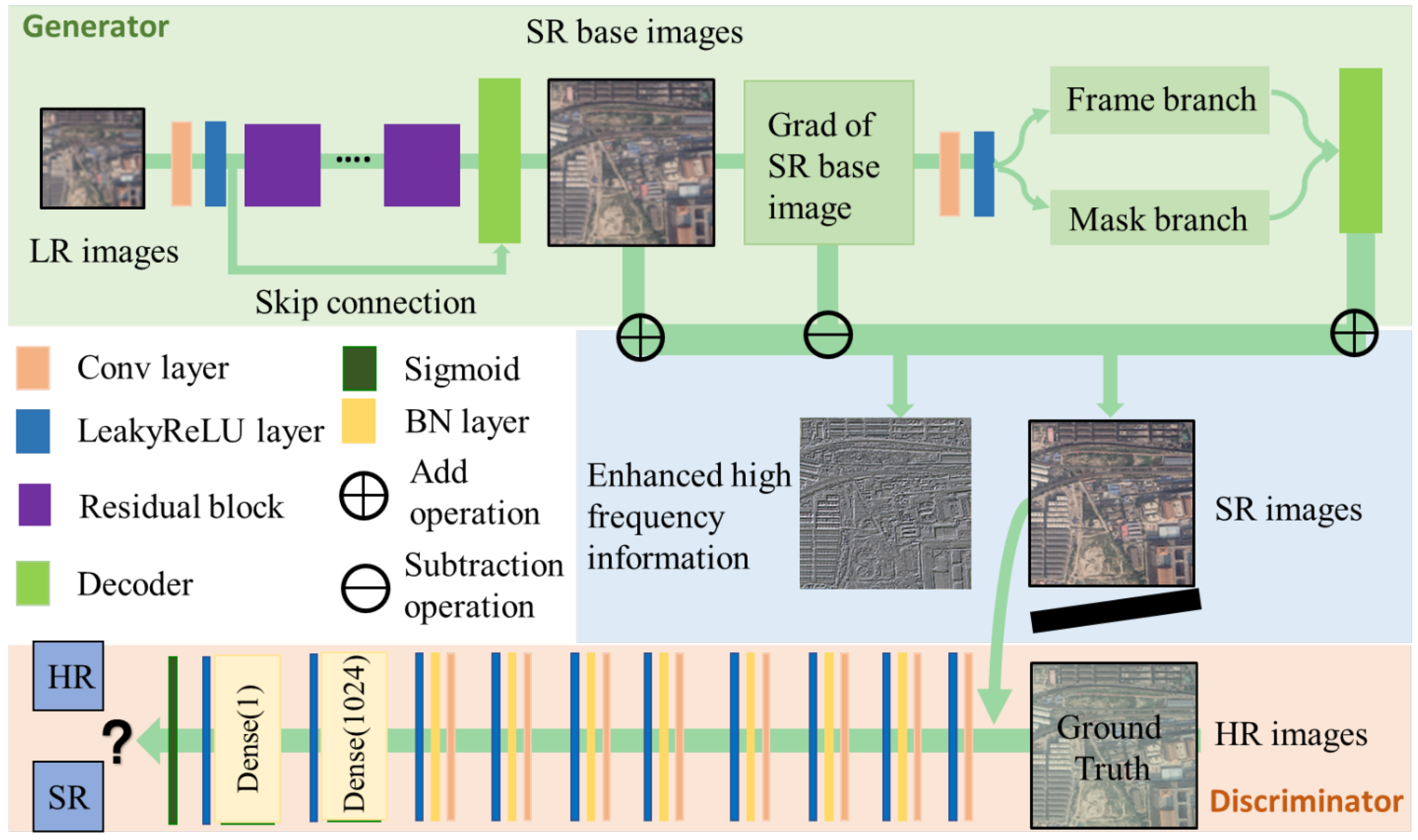
3.2. Edge-Aware Super-Resolution Module for Reconstructing High-Resolution Images
3.3. Segmentation Network for Building Extraction
3.4. Loss Function
4. Experiments
4.1. Study Area and Data
4.2. Implementation Details
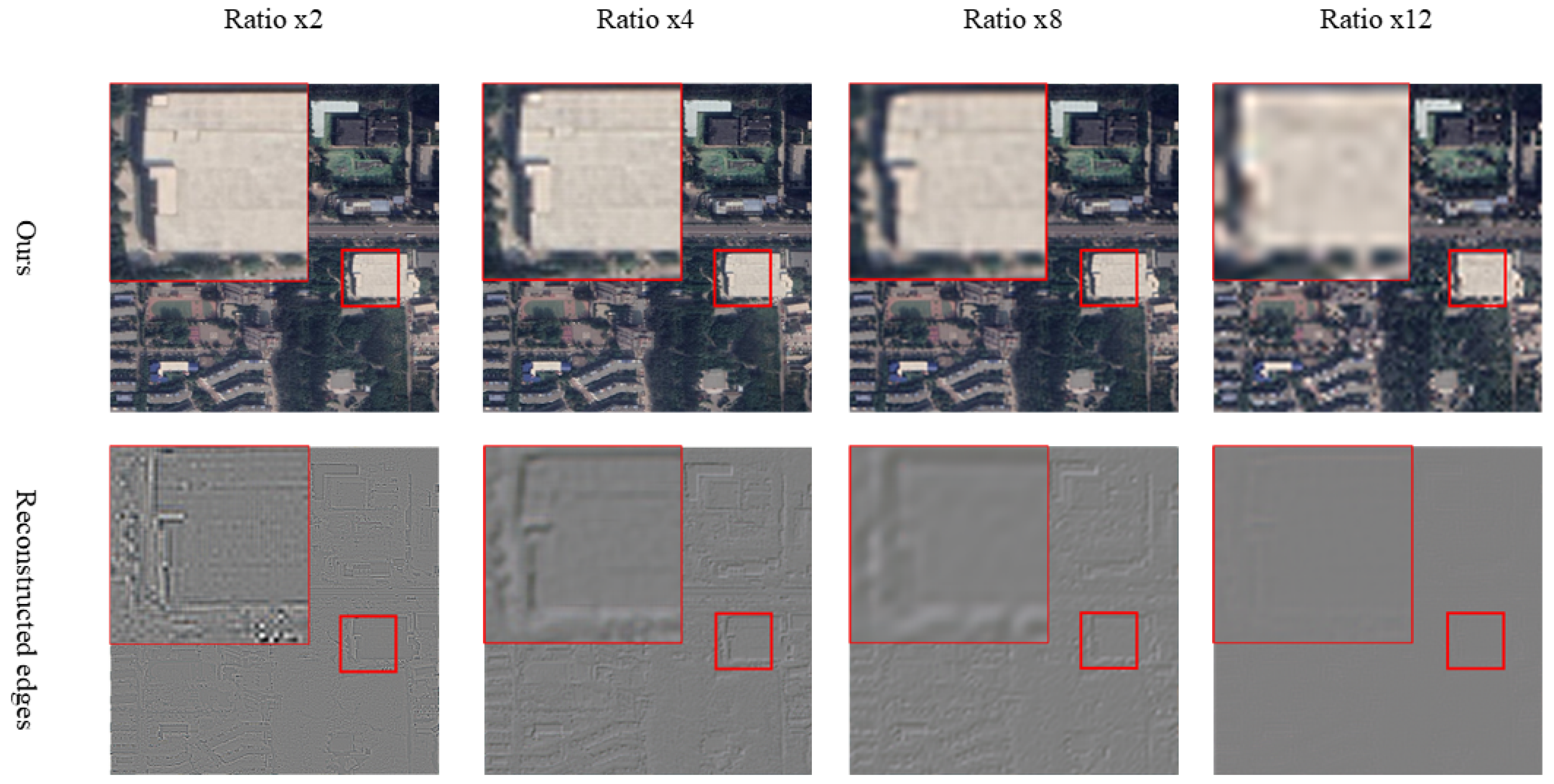
4.3. The Effect of Super-Resolution in Building Extraction
4.4. The Effect of the Segmentation Module in Building Extraction
5. Discussion
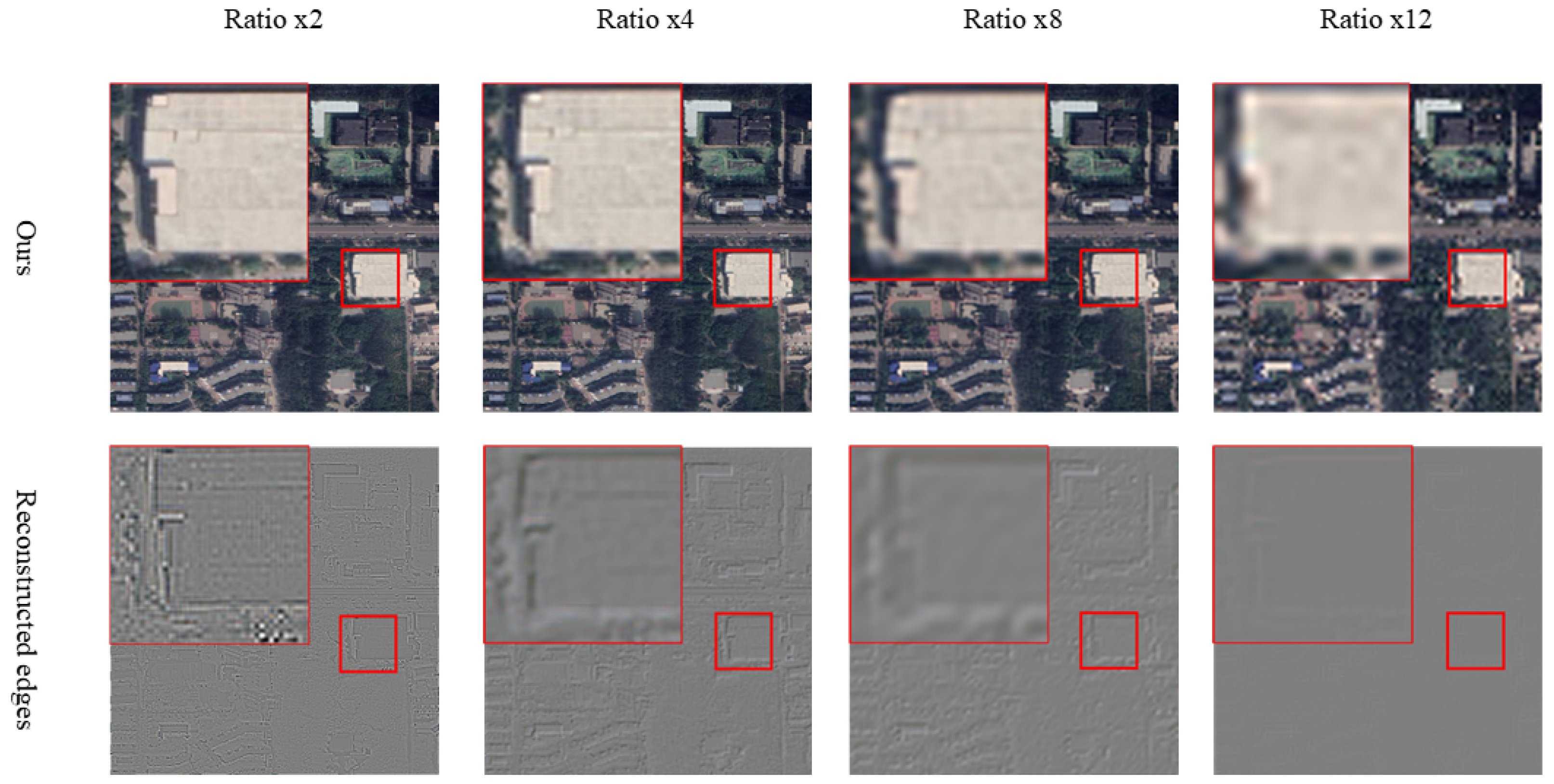
5.1. The Effectiveness of High Frequency Information in Building Extraction
5.2. The Limitations of the Proposed Approach
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, T.; Zhao, J. Review and comparison: Building extraction methods using high-resolution images. In Proceedings of the 2009 Second International Symposium on Information Science and Engineering, Shanghai, China, 26–28 December 2009; pp. 419–422. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Briese, C. A new method for building extraction in urban areas from high-resolution LIDAR data. In International Archives of Photogrammetry Remote Sensing and Spatial Information Sciences; Natural Resources Canada: Ottawa, ON, Canada, 2020; Volume 34, pp. 295–301. [Google Scholar]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image Classification Based on Wishart DBN and Local Spatial Information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Feng, W.; Sui, H.; Hua, L.; Xu, C.; Ma, G.; Huang, W. Building extraction from VHR remote sensing imagery by combining an improved deep convolutional encoder-decoder architecture and historical land use vector map. Int. J. Remote Sens. 2020, 41, 6595–6617. [Google Scholar] [CrossRef]
- Belgiu, M.; Dr Gut, L. Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 67–75. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Wu, B.; Fan, J. Analysis to the relationship of classification accuracy, segmentation scale, image resolution. In Proceedings of the IGARSS 2003, IEEE International Geoscience and Remote Sensing Symposium, Proceedings (IEEE Cat. No. 03CH37477), Toulouse, France, 21–25 July 2003; Volume 6, pp. 3671–3673. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Hikosaka, S. Building detection from satellite imagery using ensemble of size-specific detectors. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 223–2234. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote Sensing Single-Image Superresolution Based on a Deep Compendium Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Jozdani, S.; Chen, D. On the versatility of popular and recently proposed supervised evaluation metrics for segmentation quality of remotely sensed images: An experimental case study of building extraction. ISPRS J. Photogramm. Remote Sens. 2020, 160, 275–290. [Google Scholar] [CrossRef]
- Na, Y.; Kim, J.H.; Lee, K.; Park, J.; Hwang, J.Y.; Choi, J.P. Domain Adaptive Transfer Attack-Based Segmentation Networks for Building Extraction From Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5171–5182. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An Efficient Building Extraction Method from High Spatial Resolution Remote Sensing Images Based on Improved Mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef] [Green Version]
- Bagan, H.; Yamagata, Y. Landsat analysis of urban growth: How Tokyo became the world’s largest megacity during the last 40 years. Remote Sens. Environ. 2012, 127, 210–222. [Google Scholar] [CrossRef]
- Dong, L.; Shan, J. A comprehensive review of earthquake-induced building damage detection with remote sensing techniques. ISPRS J. Photogramm. Remote Sens. 2013, 84, 85–99. [Google Scholar] [CrossRef]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Chen, B.; Xu, B.; Zhu, Z.; Yuan, C.; Suen, H.P.; Guo, J.; Xu, N.; Li, W.; Zhao, Y.; Yang, J. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar]
- Shrivastava, N.; Rai, P.K. Automatic building extraction based on multiresolution segmentation using remote sensing data. Geogr. Pol. 2015, 88, 407–421. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Qin, Q.; Yang, X.; Wang, J.; Ye, X.; Qin, X. Automated road extraction from multi-resolution images using spectral information and texture. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 533–536. [Google Scholar] [CrossRef]
- Deng, C.; Zhu, Z. Continuous subpixel monitoring of urban impervious surface using Landsat time series. Remote Sens. Environ. 2020, 238, 110929. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, K.; Shen, Z.; Deng, J.; Gan, M.; Liu, X.; Lu, D.; Wang, K. Mapping impervious surfaces in town–rural transition belts using China’s GF-2 imagery and object-based deep CNNs. Remote Sens. 2019, 11, 280. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Li, X.; Zhang, W. 40-Year (1978–2017) human settlement changes in China reflected by impervious surfaces from satellite remote sensing. Sci. Bull. 2019, 64, 756–763. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhao, D.; Zhang, J.; Xiong, R.; Gao, W. Interpolation-dependent image downsampling. IEEE Trans. Image Process. 2011, 20, 3291–3296. [Google Scholar] [CrossRef]
- Thévenaz, P.; Blu, T.; Unser, M. Image interpolation and resampling. Handb. Med. Imaging Process. Anal. 2000, 1, 393–420. [Google Scholar]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef] [Green Version]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A. Remote Sensing Image Superresolution Using Deep Residual Channel Attention. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9277–9289. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Deng, J. Remote Sensing Image Super-Resolution Using Sparse Representation and Coupled Sparse Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2663–2674. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Hengel, V.D. Effective semantic pixel labelling with convolutional networks and conditional random fields. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 36–43. [Google Scholar] [CrossRef]
- Lin, J.; Jing, W.; Song, H.; Chen, G. ESFNet: Efficient Network for Building Extraction From High-Resolution Aerial Images. IEEE Access 2019, 7, 54285–54294. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Schuegraf, P.; Bittner, K. Automatic Building Footprint Extraction from Multi-Resolution Remote Sensing Images Using a Hybrid FCN. ISPRS Int. J. Geo-Inf. 2019, 8, 191. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Wu, G.; Song, X.; Yuan, W.; Chen, Q.; Zhang, H.; Shi, X.; Xu, M.; Xu, Y.; Shibasaki, R.; et al. Super-Resolution Integrated Building Semantic Segmentation for Multi-Source Remote Sensing Imagery. IEEE Access 2019, 7, 99381–99397. [Google Scholar] [CrossRef]
- Dong, X.; Sun, X.; Jia, X.; Xi, Z.; Gao, L.; Zhang, B. Remote Sensing Image Super-Resolution Using Novel Dense-Sampling Networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1618–1633. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote Sensing Image Super-Resolution via Mixed High-Order Attention Network. IEEE Trans. Geosci. Remote Sens. 2020, 1–14. [Google Scholar] [CrossRef]
- Zou, F.; Xiao, W.; Ji, W.; He, K.; Yang, Z.; Song, J.; Zhou, H.; Li, K. Arbitrary-oriented object detection via dense feature fusion and attention model for remote sensing super-resolution image. Neural Comput. Appl. 2020, 32, 14549–14562. [Google Scholar] [CrossRef]
- Yang, D.; Li, Z.; Xia, Y.; Chen, Z. Remote sensing image super-resolution: Challenges and approaches. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; pp. 196–200. [Google Scholar] [CrossRef]
- Shocher, A.; Cohen, N.; Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126. [Google Scholar] [CrossRef] [Green Version]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A New Deep Generative Network for Unsupervised Remote Sensing Single-Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- Chen, S.; Han, Z.; Dai, E.; Jia, X.; Liu, Z.; Xing, L.; Zou, X.; Xu, C.; Liu, J.; Tian, Q. Unsupervised image super-resolution with an indirect supervised path. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 468–469. [Google Scholar] [CrossRef]
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised learning for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3408–3416. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-shot learning through cross-modal transfer. arXiv 2018, arXiv:1301.3666. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet With Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, Z.; Ji, K.; Yang, J. Semantic segmentation network combined with edge detection for building extraction in remote sensing images. In Proceedings of the MIPPR 2019: Pattern Recognition and Computer Vision, International Society for Optics and Photonics, Xi’an, China, 8–11 November 2019; Volume 11430, p. 114300. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-Enhanced GAN for Remote Sensing Image Superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Aly, H.A.; Dubois, E. Image up-sampling using total-variation regularization with a new observation model. IEEE Trans. Image Process. 2005, 14, 1647–1659. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar] [CrossRef]
- Nagadomi. Waifu: Image Super-Resolution. [EB/OL]. Available online: http://waifu2x.udp.jp/ (accessed on 4 June 2021).
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised Degradation Representation Learning for Blind Super-Resolution. arXiv 2021, arXiv:2104.00416. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 36, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage One | Stage Two | Scale | IoU | Precision | Recall | F1 Score | Kappa |
|---|---|---|---|---|---|---|---|
| BCI | DlinkNet | 2 | 0.6206 | 0.7420 | 0.7914 | 0.7659 | 0.6684 |
| TSE | 0.6403 | 0.7720 | 0.7896 | 0.7807 | 0.7157 | ||
| ZZSR | 0.6492 | 0.7760 | 0.7989 | 0.7873 | 0.7066 | ||
| SRGAN * | 0.6538 | 0.7638 | 0.8195 | 0.7907 | 0.7537 | ||
| EEGAN * | 0.6633 | 0.7805 | 0.7986 | 0.7976 | 0.7438 | ||
| waifu | 0.6448 | 0.7807 | 0.7627 | 0.7837 | 0.7235 | ||
| DASR * | 0.6530 | 0.7874 | 0.7834 | 0.7922 | 0.7586 | ||
| EASR(ours) | 0.6721 | 0.7965 | 0.8288 | 0.8039 | 0.7771 | ||
| BCI | DlinkNet | 4 | 0.6069 | 0.7499 | 0.7221 | 0.7554 | 0.6069 |
| TSE | 0.6184 | 0.7693 | 0.7592 | 0.7642 | 0.6969 | ||
| ZZSR | 0.6224 | 0.7786 | 0.7563 | 0.7673 | 0.6972 | ||
| SRGAN * | 0.6263 | 0.7787 | 0.7842 | 0.7702 | 0.7160 | ||
| EEGAN * | 0.6336 | 0.7875 | 0.7643 | 0.7757 | 0.6940 | ||
| waifu | 0.6220 | 0.7769 | 0.7612 | 0.7630 | 0.6863 | ||
| DASR * | 0.6391 | 0.7814 | 0.7850 | 0.7889 | 0.7234 | ||
| EASR(ours) | 0.6413 | 0.7919 | 0.7916 | 0.7814 | 0.7361 | ||
| BCI | DlinkNet | 8 | 0.5616 | 0.7206 | 0.7180 | 0.7193 | 0.6152 |
| TSE | 0.5822 | 0.6978 | 0.7785 | 0.7359 | 0.6866 | ||
| ZZSR | 0.5925 | 0.7366 | 0.7518 | 0.7441 | 0.6906 | ||
| SRGAN * | 0.5863 | 0.7225 | 0.7568 | 0.7392 | 0.6589 | ||
| EEGAN * | 0.6060 | 0.7647 | 0.7339 | 0.7547 | 0.7041 | ||
| waifu | 0.6078 | 0.7001 | 0.7372 | 0.7356 | 0.6534 | ||
| DASR * | 0.5908 | 0.7308 | 0.7552 | 0.7428 | 0.6691 | ||
| EASR(ours) | 0.6237 | 0.7818 | 0.7551 | 0.7682 | 0.7214 |
| Stage One | Stage Two | Scale | IoU | Precision | Recall | F1 Score | Kappa |
|---|---|---|---|---|---|---|---|
| EASR(ours) | Unet | 2 | 0.6081 | 0.7546 | 0.7580 | 0.7563 | 0.6654 |
| DeepLabv3p | 0.6536 | 0.8162 | 0.7664 | 0.7905 | 0.7160 | ||
| PSPNet | 0.6522 | 0.7991 | 0.7801 | 0.7895 | 0.7125 | ||
| DlinkNet | 0.6721 | 0.7805 | 0.8288 | 0.8039 | 0.6684 | ||
| UNet++ | 0.6431 | 0.8066 | 0.7614 | 0.7846 | 0.7270 | ||
| HRNet | 0.6986 | 0.8103 | 0.8035 | 0.8019 | 0.7614 | ||
| DES(ours) | 0.7070 | 0.8265 | 0.8305 | 0.8278 | 0.7761 | ||
| EASR(ours) | Unet | 4 | 0.5889 | 0.7037 | 0.7830 | 0.7413 | 0.6585 |
| DeepLabv3p | 0.6336 | 0.7716 | 0.7643 | 0.7757 | 0.6940 | ||
| PSPNet | 0.6385 | 0.7646 | 0.7947 | 0.7794 | 0.6296 | ||
| DlinkNet | 0.6413 | 0.7787 | 0.7842 | 0.7814 | 0.7206 | ||
| UNet++ | 0.6231 | 0.7473 | 0.7808 | 0.7686 | 0.6772 | ||
| HRNet | 0.6301 | 0.7814 | 0.7711 | 0.7700 | 0.6963 | ||
| DES(ours) | 0.6595 | 0.7875 | 0.8195 | 0.7948 | 0.7361 | ||
| EASR(ours) | Unet | 8 | 0.5414 | 0.7404 | 0.6683 | 0.7025 | 0.6045 |
| DeepLabv3p | 0.6155 | 0.7849 | 0.7313 | 0.7620 | 0.6786 | ||
| PSPNet | 0.6317 | 0.7854 | 0.7634 | 0.7743 | 0.6974 | ||
| DlinkNet | 0.6237 | 0.7818 | 0.7551 | 0.7682 | 0.7214 | ||
| UNet++ | 0.6121 | 0.7632 | 0.7584 | 0.7613 | 0.7036 | ||
| HRNet | 0.6275 | 0.7976 | 0.7321 | 0.7635 | 0.7172 | ||
| DES(ours) | 0.6346 | 0.7955 | 0.7682 | 0.7765 | 0.7310 |
| Methods | Scale | IoU | Precision | Recall | F1 Score | Kappa | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| BCI | 2 | 0.6206 | 0.7420 | 0.7914 | 0.7659 | 0.6684 | ||||
| Ours | 0.7070 | 0.8265 | 0.8305 | 0.8278 | 0.7761 | |||||
| BCI | 4 | 0.6069 | 0.7499 | 0.7221 | 0.7554 | 0.6069 | ||||
| Ours | 0.6595 | 0.7875 | 0.8195 | 0.7948 | 0.7361 | |||||
| BCI | 8 | 0.5616 | 0.7206 | 0.7180 | 0.7193 | 0.6152 | ||||
| Ours | 0.6346 | 0.7955 | 0.7682 | 0.7765 | 0.7310 | |||||
| BCI | 12 | 0.5279 | 0.7270 | 0.6584 | 0.6910 | 0.5837 | ||||
| Ours | 0.5414 | 0.7404 | 0.6683 | 0.7025 | 0.6045 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Dong, R.; Yuan, S.; Li, W.; Zheng, J.; Fu, H. Making Low-Resolution Satellite Images Reborn: A Deep Learning Approach for Super-Resolution Building Extraction. Remote Sens. 2021, 13, 2872. https://doi.org/10.3390/rs13152872
Zhang L, Dong R, Yuan S, Li W, Zheng J, Fu H. Making Low-Resolution Satellite Images Reborn: A Deep Learning Approach for Super-Resolution Building Extraction. Remote Sensing. 2021; 13(15):2872. https://doi.org/10.3390/rs13152872
Chicago/Turabian StyleZhang, Lixian, Runmin Dong, Shuai Yuan, Weijia Li, Juepeng Zheng, and Haohuan Fu. 2021. "Making Low-Resolution Satellite Images Reborn: A Deep Learning Approach for Super-Resolution Building Extraction" Remote Sensing 13, no. 15: 2872. https://doi.org/10.3390/rs13152872
APA StyleZhang, L., Dong, R., Yuan, S., Li, W., Zheng, J., & Fu, H. (2021). Making Low-Resolution Satellite Images Reborn: A Deep Learning Approach for Super-Resolution Building Extraction. Remote Sensing, 13(15), 2872. https://doi.org/10.3390/rs13152872