Author Contributions
Conceptualization, J.S. and R.W.; methodology, J.S., C.Z. and R.W.; software, C.Z.; validation, C.Z.; formal analysis, J.S., R.W. and Y.Z.; investigation, J.S. and Y.Z.; resources, R.W. and Y.Z.; data curation, Y.Z.; writing—original draft preparation, J.S.; writing—review and editing, R.W.; visualization, C.Z.; supervision, J.S., R.W. and Y.Z.; project administration, J.S. and R.W.; funding acquisition, J.S. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Examples from the NWPU-RESISC 45 dataset. The small objects in the images are critical to the classification of the scene.
Figure 1.
Examples from the NWPU-RESISC 45 dataset. The small objects in the images are critical to the classification of the scene.
Figure 2.
Illustration of the high inter-class similarity and high intra-class variance in the remote sensing image dataset. (a) Illustrates four images with different appearances, which are labelled as church. (b) Shows dense residential in the left two images, and medium residential in the right two images.
Figure 2.
Illustration of the high inter-class similarity and high intra-class variance in the remote sensing image dataset. (a) Illustrates four images with different appearances, which are labelled as church. (b) Shows dense residential in the left two images, and medium residential in the right two images.
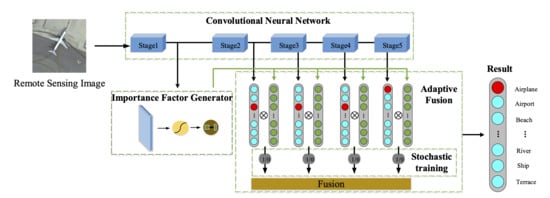
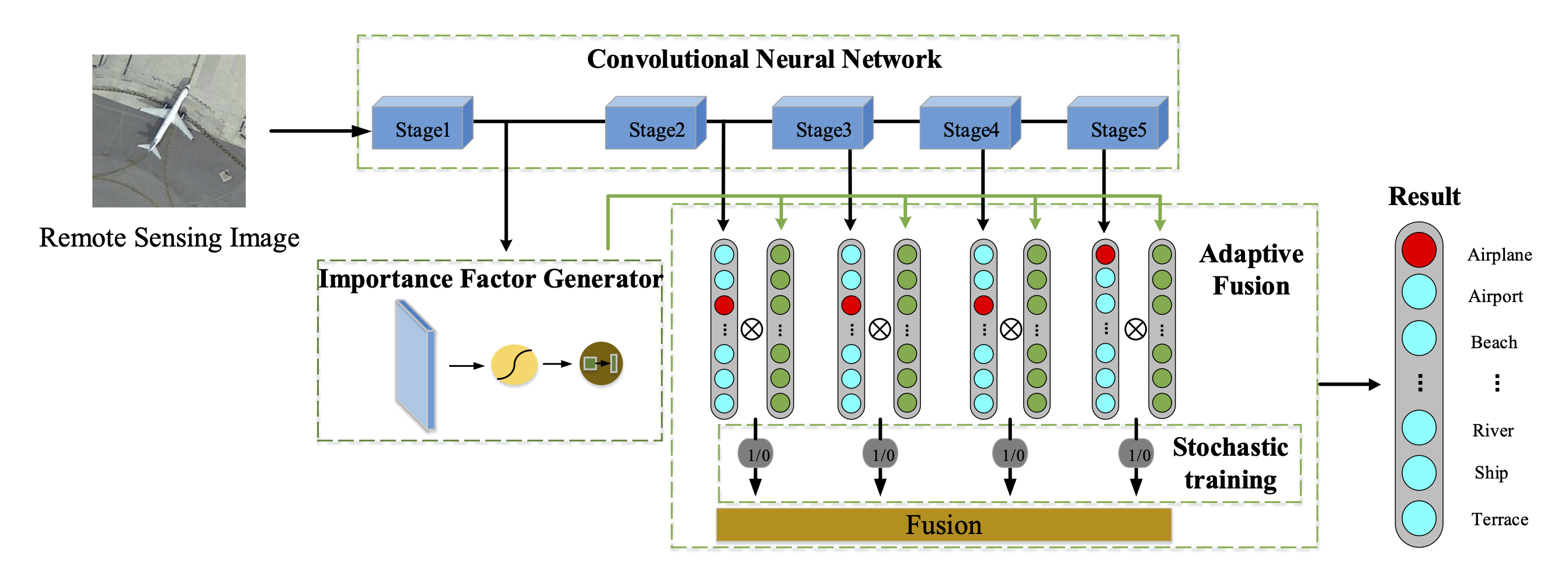
Figure 3.
The framework of the proposed adaptive decision-level fusion method. From top to bottom, the blue blocks represent different stages of a deep CNN backbone; the light blue rectangles with round corners are the classifiers based on the features of different stages; the green block is the importance factor generator, which is used to generate the importance factor matrix composed from “” to “”; the grey blocks named as “Lock 1” to “Lock 4” represent the stochastic decision-level fusion process.
Figure 3.
The framework of the proposed adaptive decision-level fusion method. From top to bottom, the blue blocks represent different stages of a deep CNN backbone; the light blue rectangles with round corners are the classifiers based on the features of different stages; the green block is the importance factor generator, which is used to generate the importance factor matrix composed from “” to “”; the grey blocks named as “Lock 1” to “Lock 4” represent the stochastic decision-level fusion process.
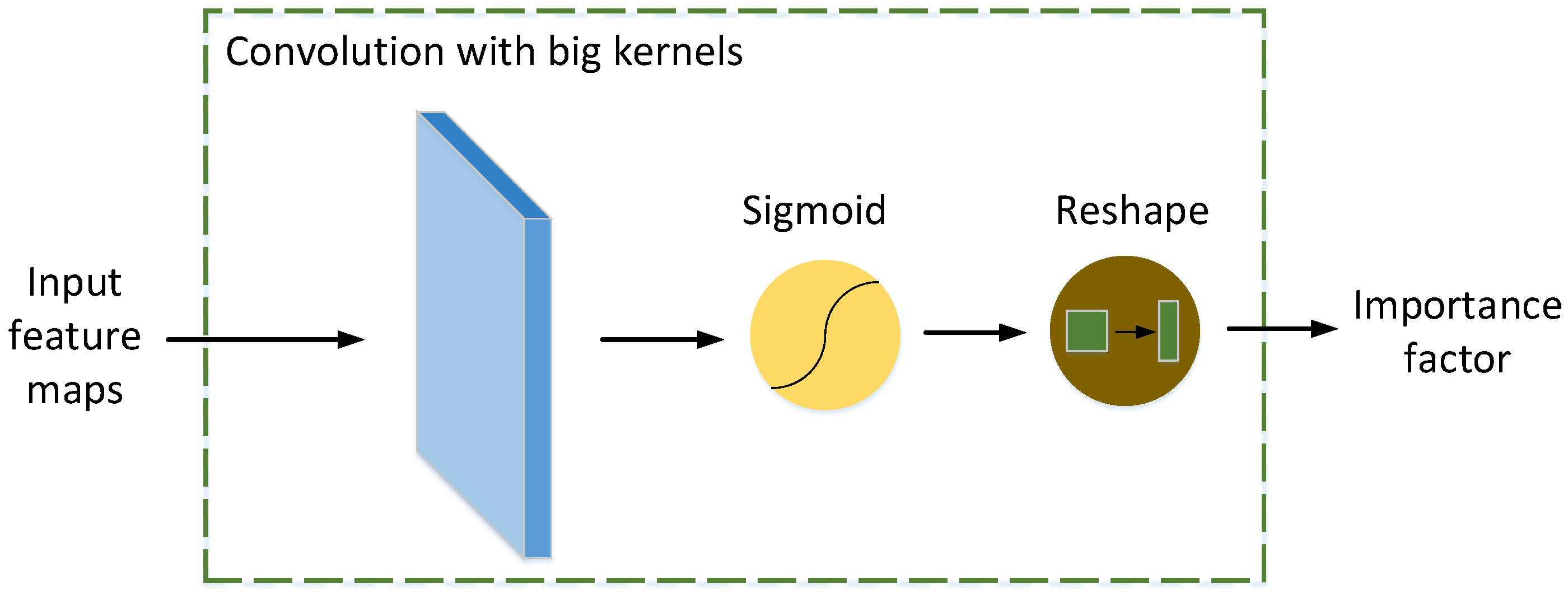
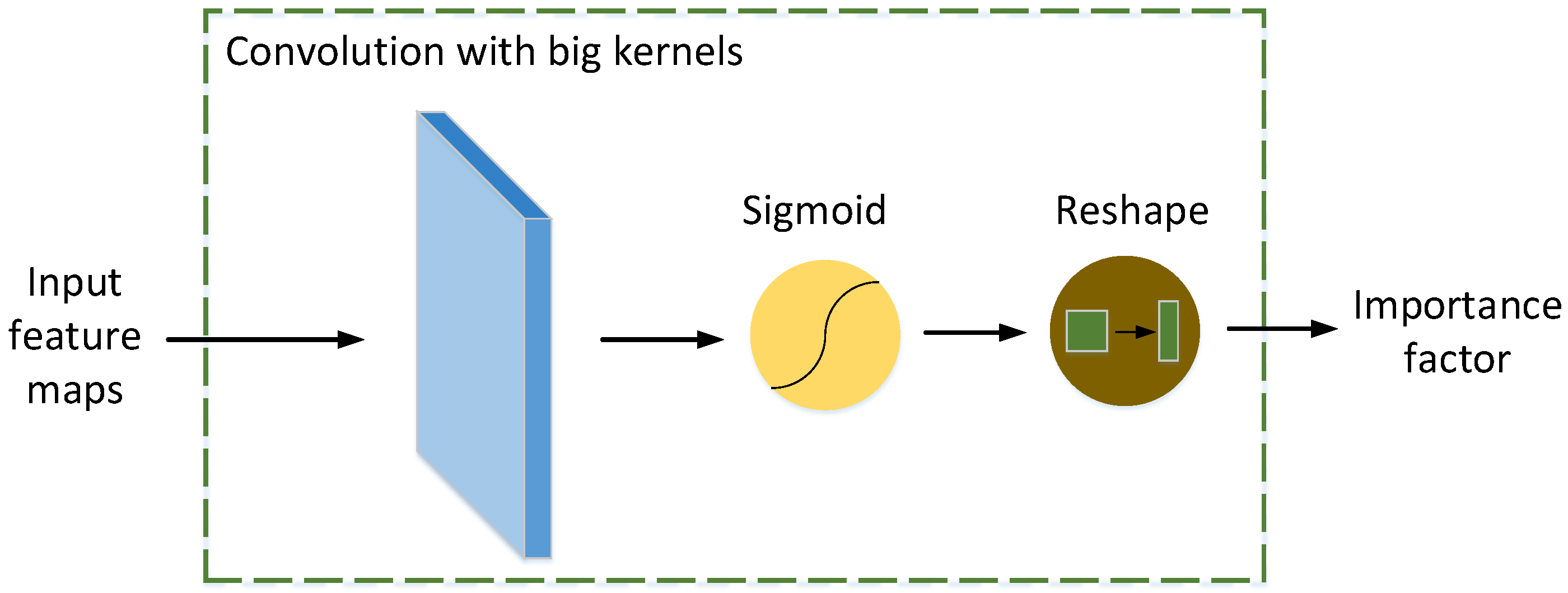
Figure 4.
The importance factor generator.
Figure 4.
The importance factor generator.
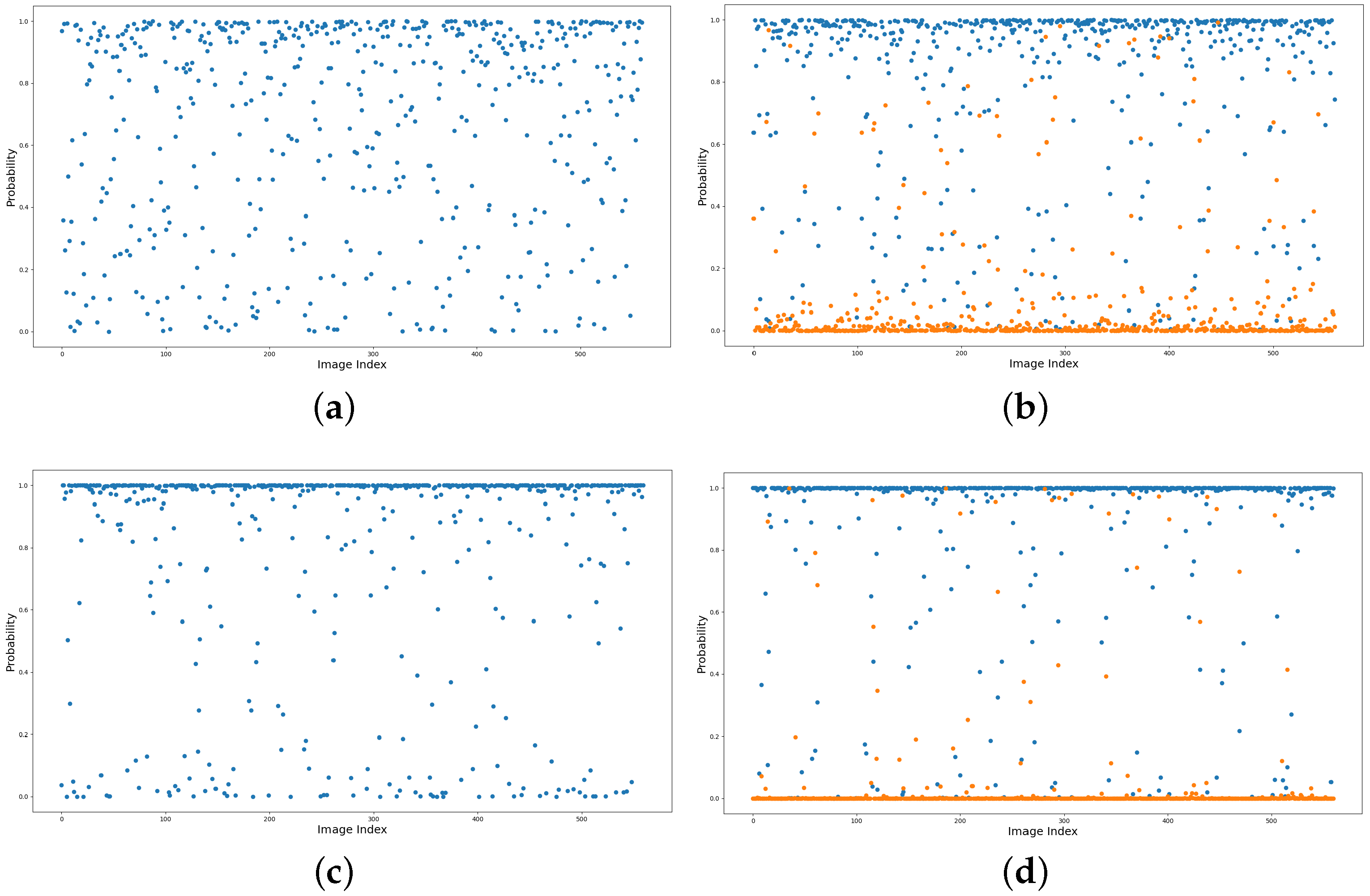
Figure 5.
An exemplar demonstration of the intra-class variance and inter-class similarity. The figures plot the output scores by ResNet-50 in (a,b) and that by our method in (c,d) for all images in the NWPU-RESISC 45 dataset. In (a,c), the blue points represent the predicted church probability of each image belonging on the true church class. In (b,d), the blue and yellow points represent the predicted probabilities on dense residential and medium residential, respectively, where the images actually belong to the dense residential class.
Figure 5.
An exemplar demonstration of the intra-class variance and inter-class similarity. The figures plot the output scores by ResNet-50 in (a,b) and that by our method in (c,d) for all images in the NWPU-RESISC 45 dataset. In (a,c), the blue points represent the predicted church probability of each image belonging on the true church class. In (b,d), the blue and yellow points represent the predicted probabilities on dense residential and medium residential, respectively, where the images actually belong to the dense residential class.
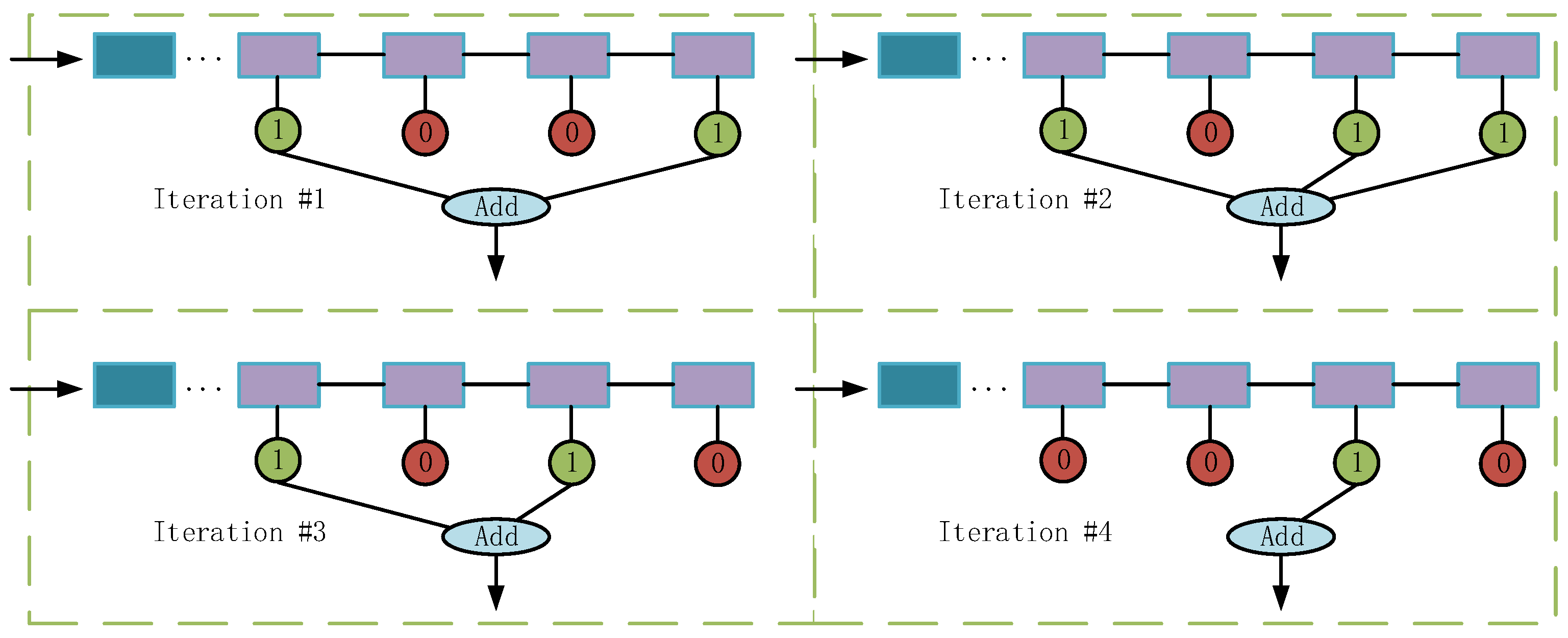
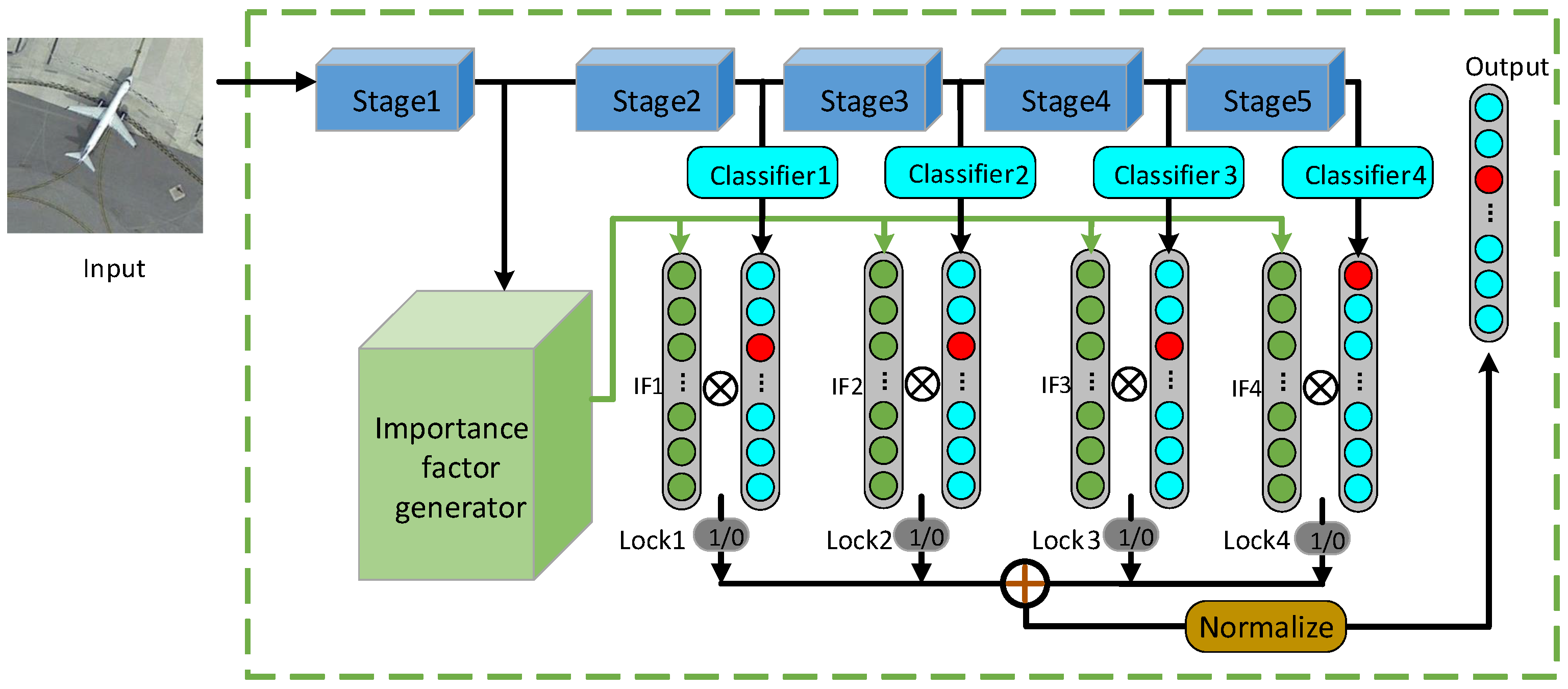
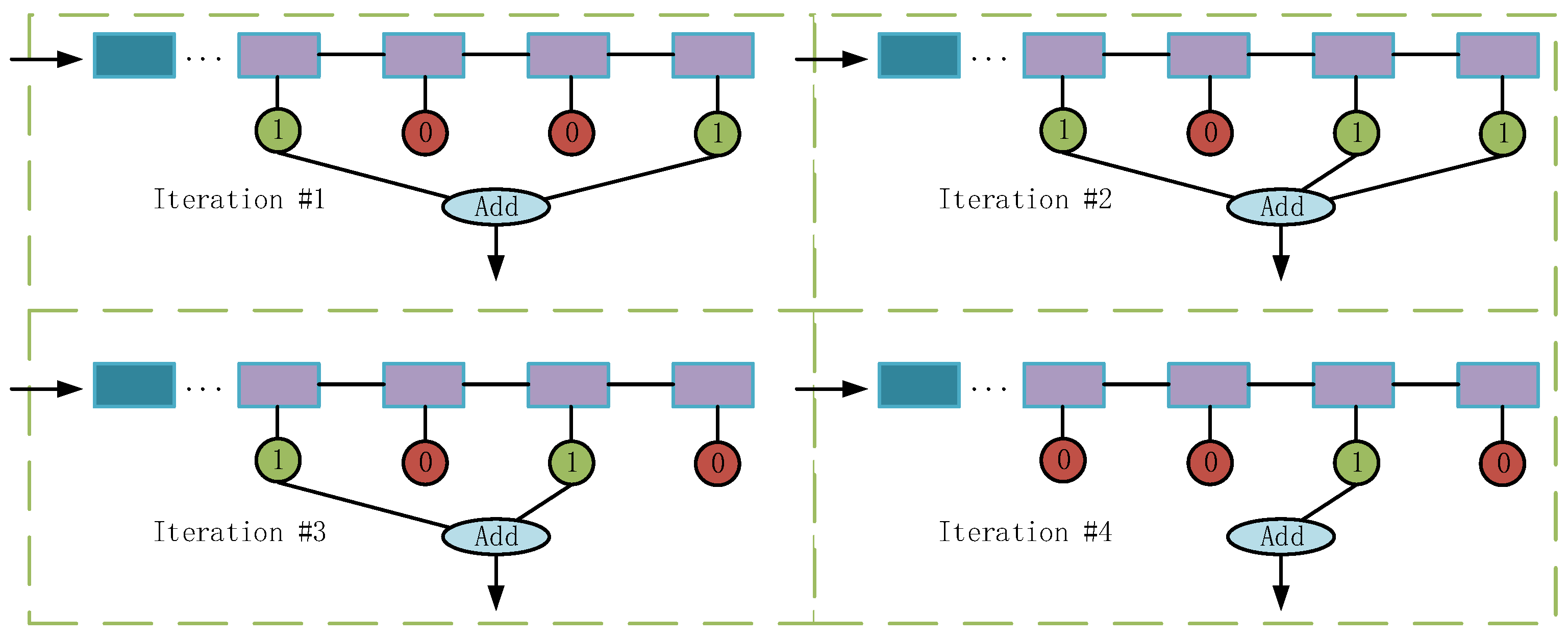
Figure 6.
The stochastic decision-level fusion training strategy. The detailed backbones and classifiers are omitted. The blue and purple rectangles represent different stages. The green circles with “1” indicate the classification scores that participate in the fusion process, while the red circles with “0” do not participate.
Figure 6.
The stochastic decision-level fusion training strategy. The detailed backbones and classifiers are omitted. The blue and purple rectangles represent different stages. The green circles with “1” indicate the classification scores that participate in the fusion process, while the red circles with “0” do not participate.
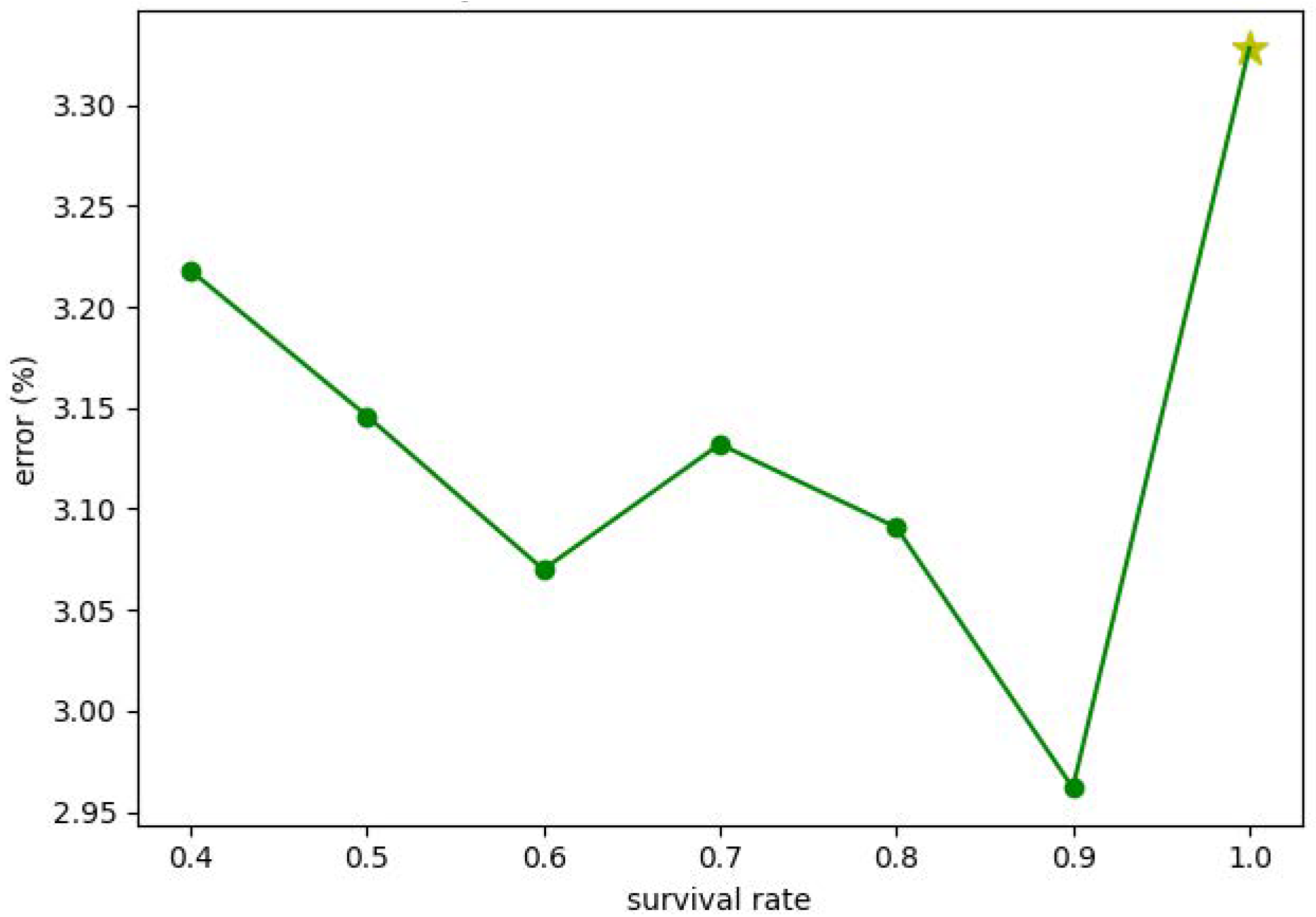
Figure 7.
The performance of the proposed method with different survival rates.
Figure 7.
The performance of the proposed method with different survival rates.
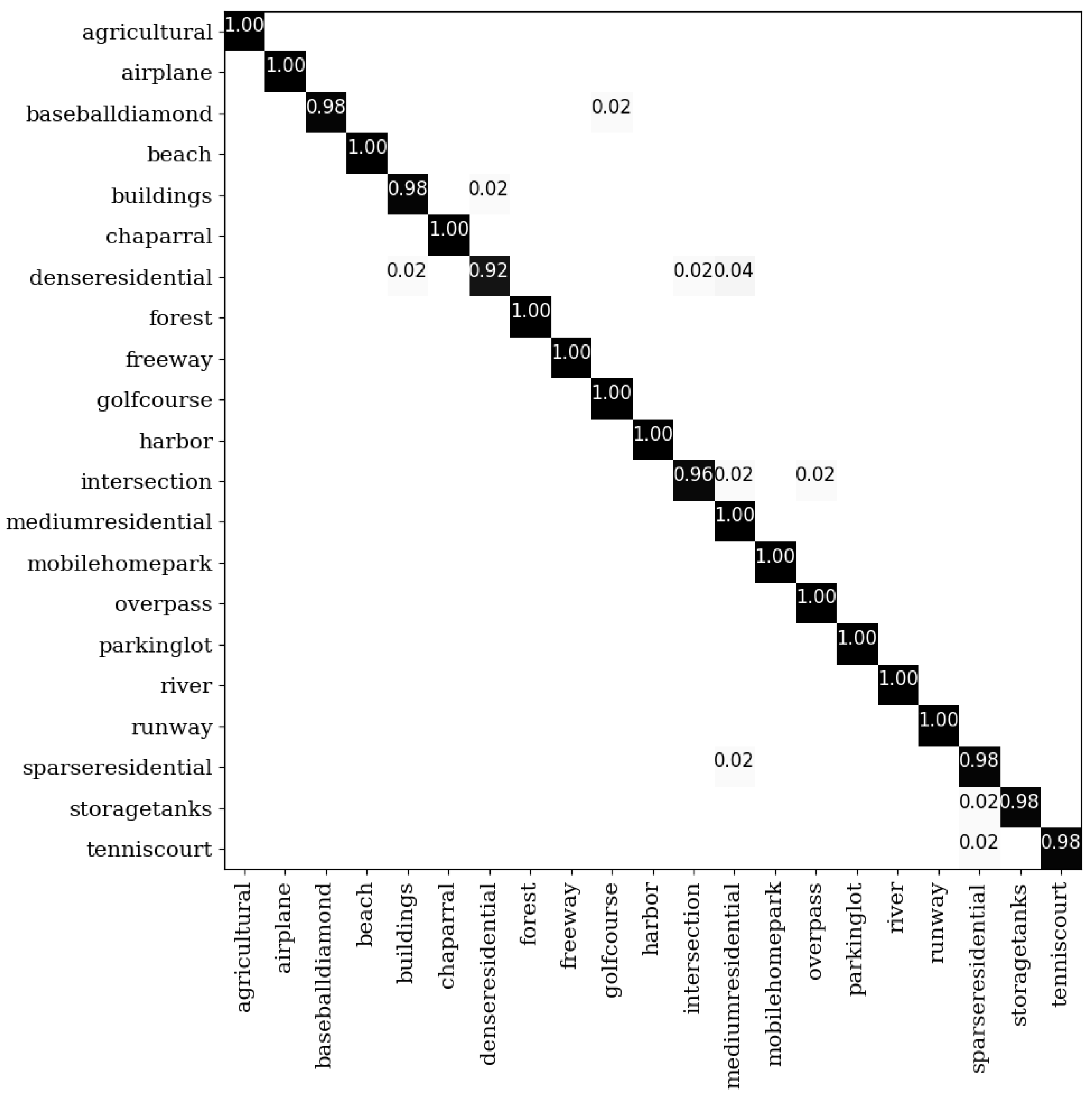
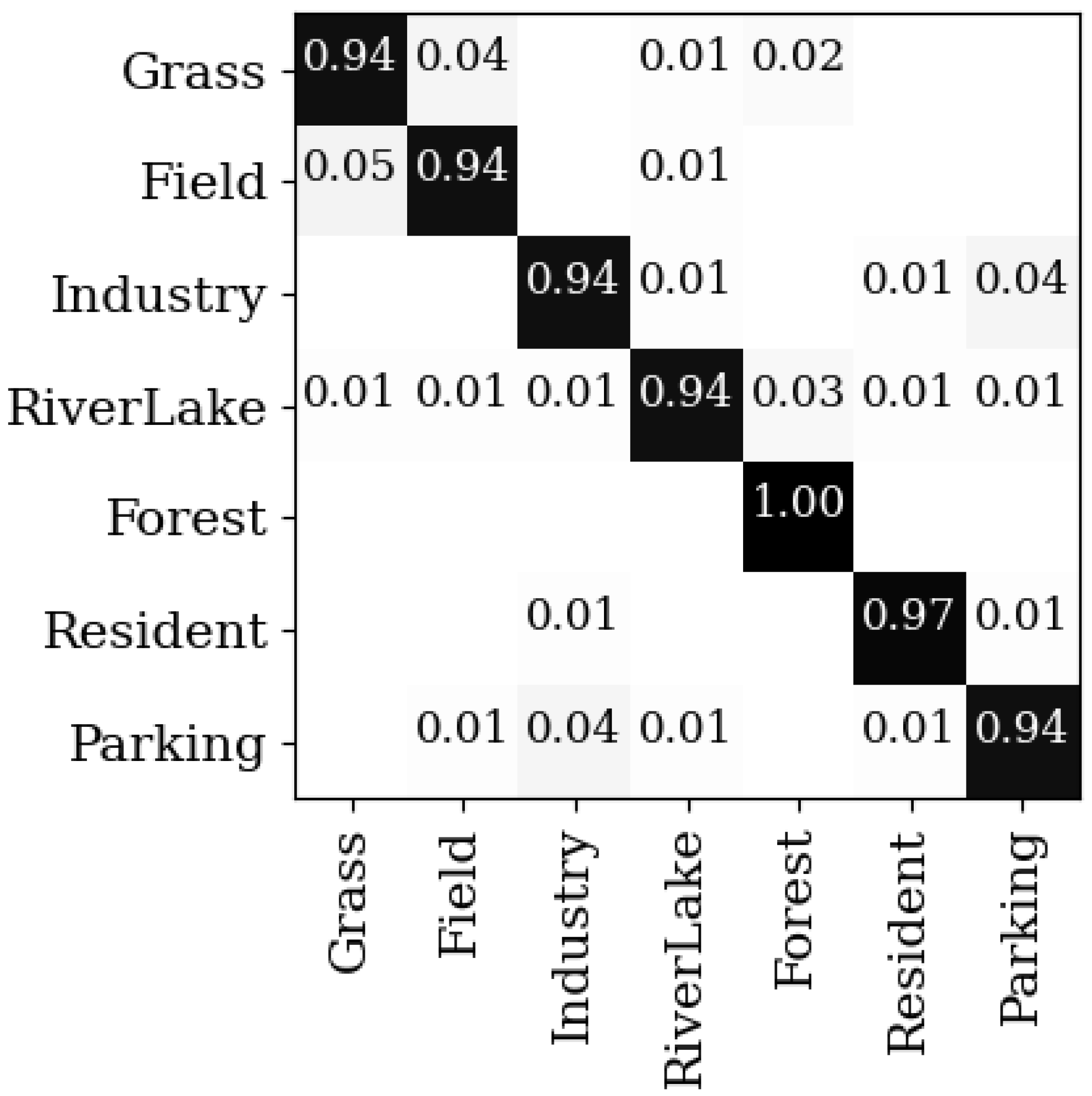
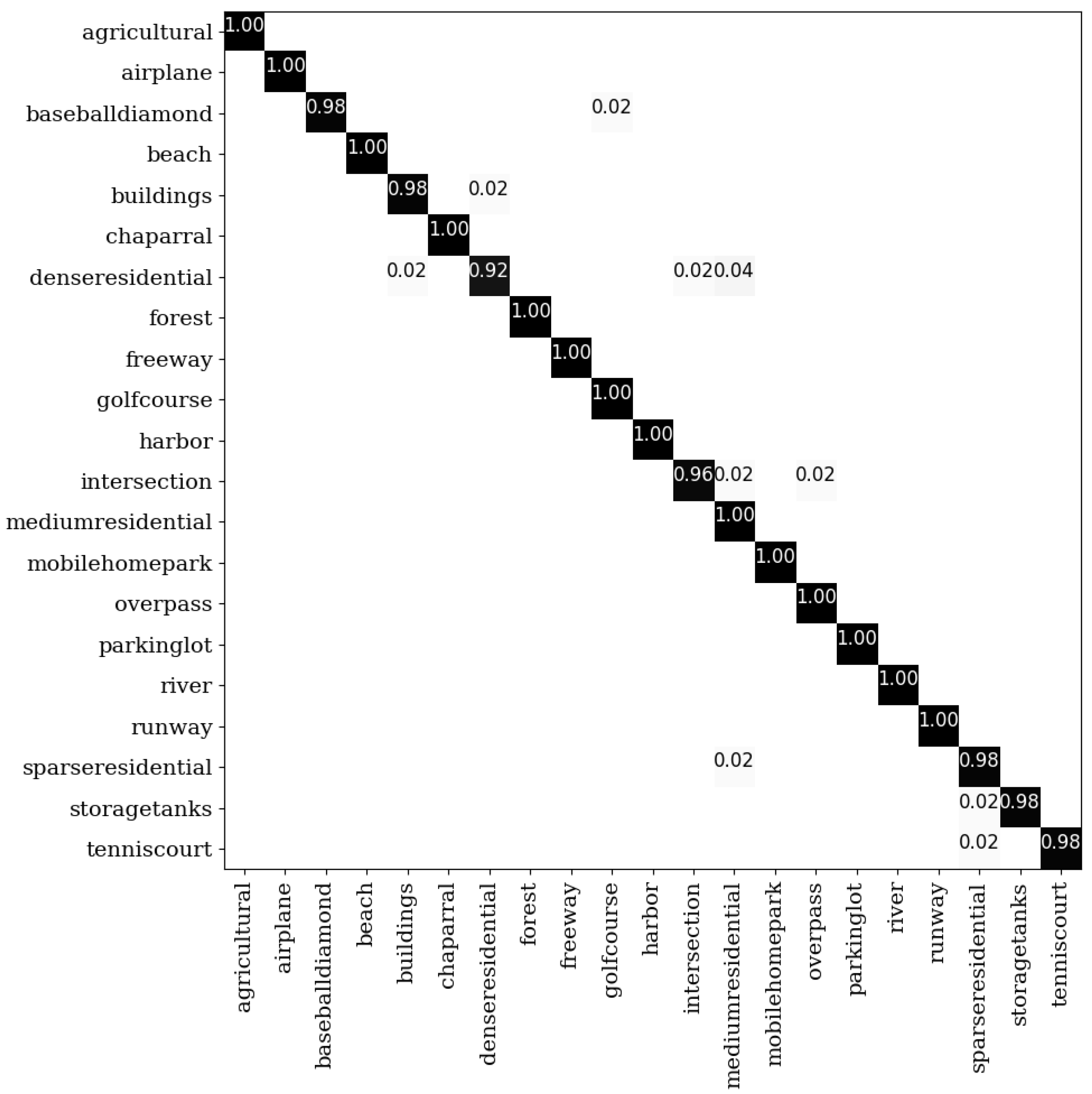
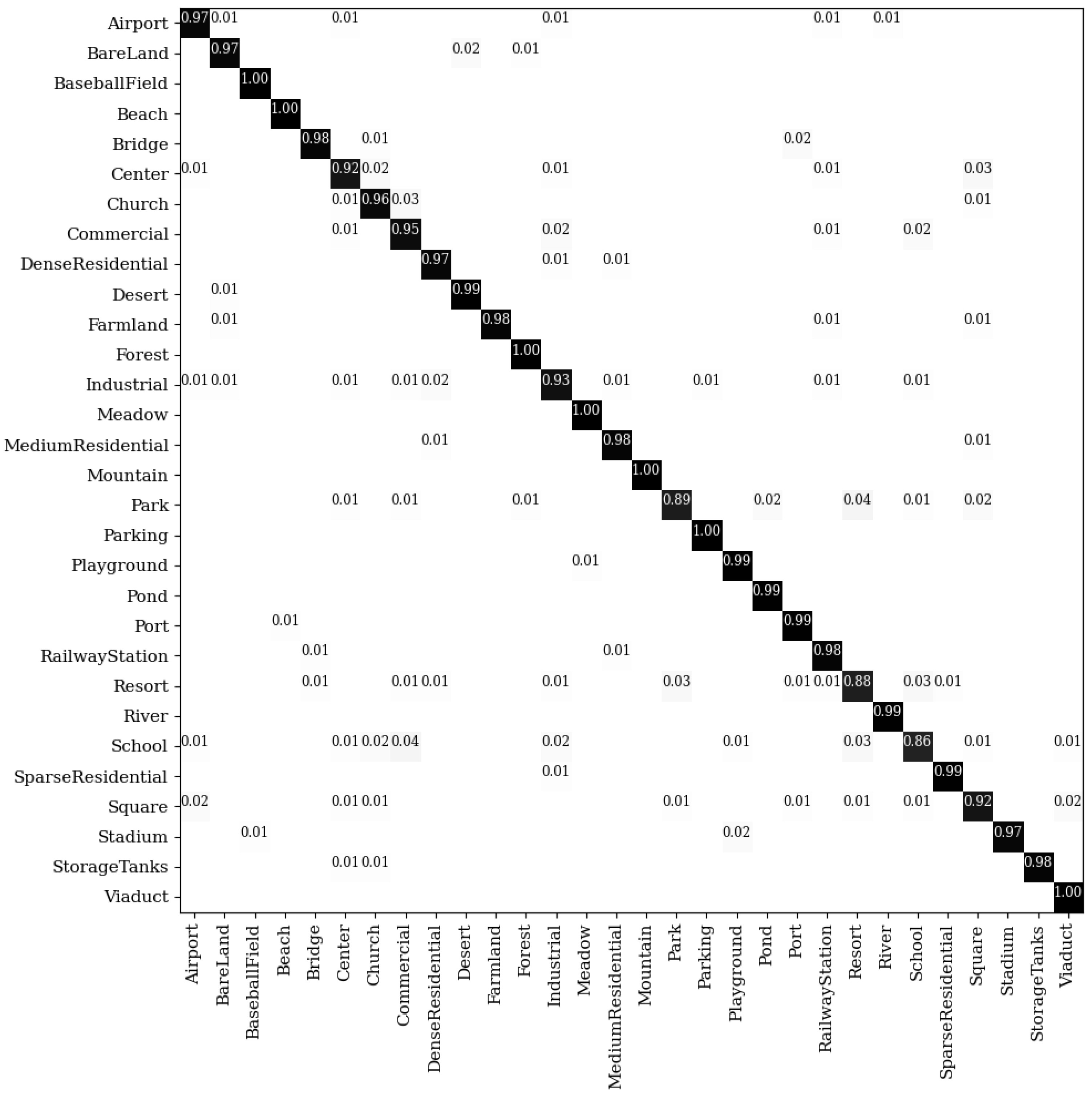
Figure 8.
The confusion matrix on the UCM dataset under the 50% training samples.
Figure 8.
The confusion matrix on the UCM dataset under the 50% training samples.
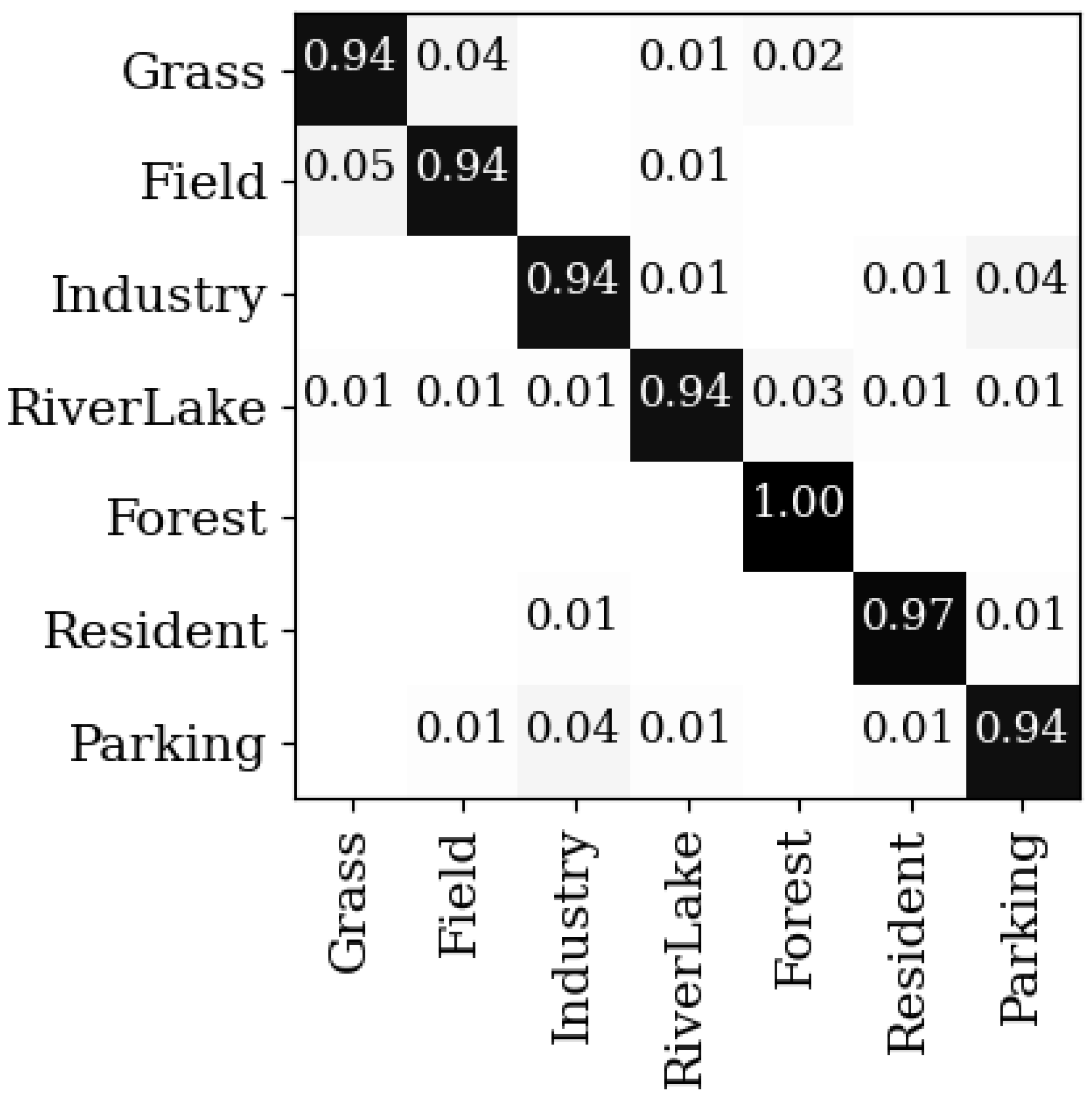
Figure 9.
The confusion matrix on the RSSCN 7 dataset under the 50% training samples.
Figure 9.
The confusion matrix on the RSSCN 7 dataset under the 50% training samples.
Figure 10.
The confusion matrix on the AID dataset under the 50% training samples.
Figure 10.
The confusion matrix on the AID dataset under the 50% training samples.
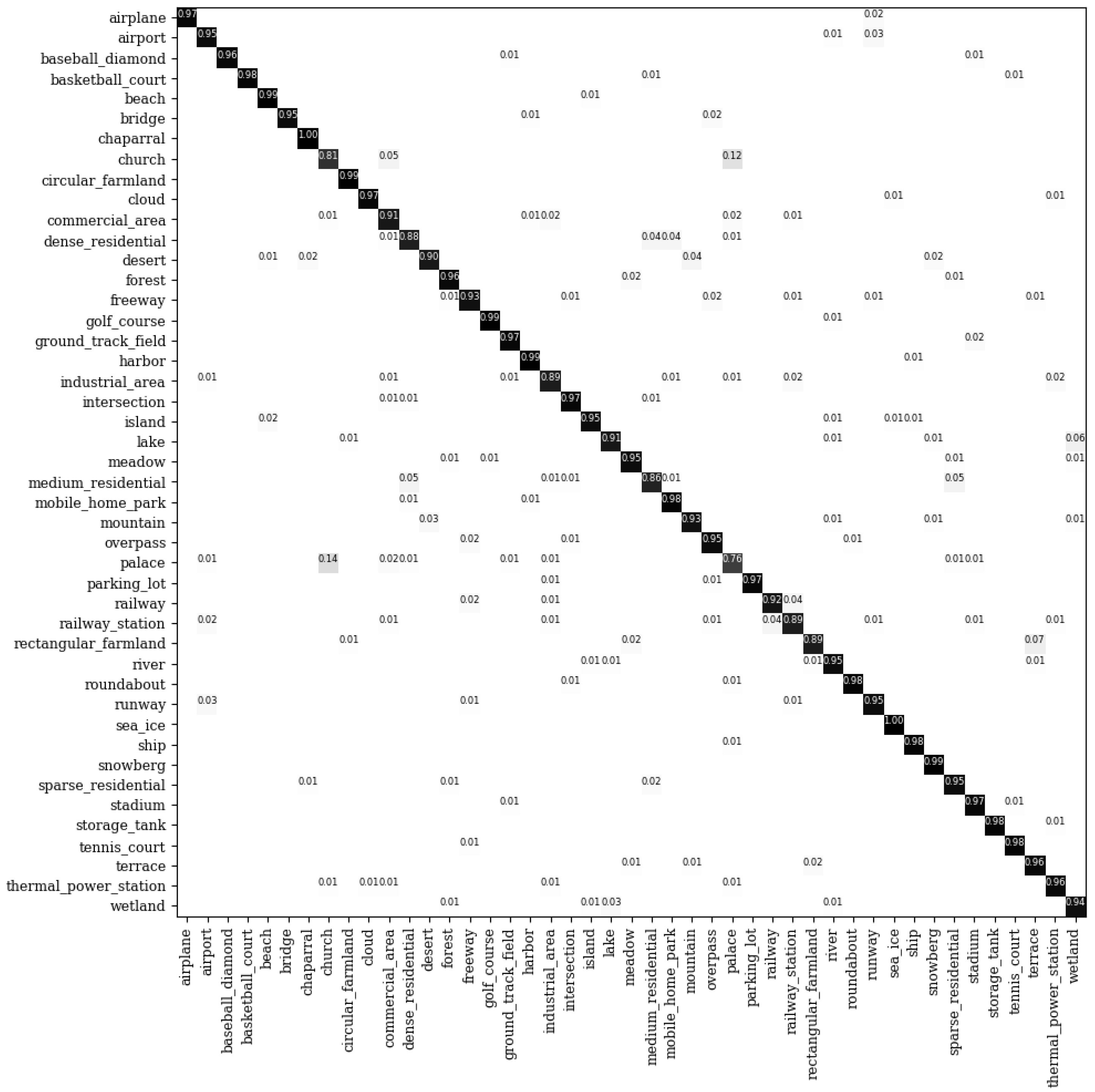
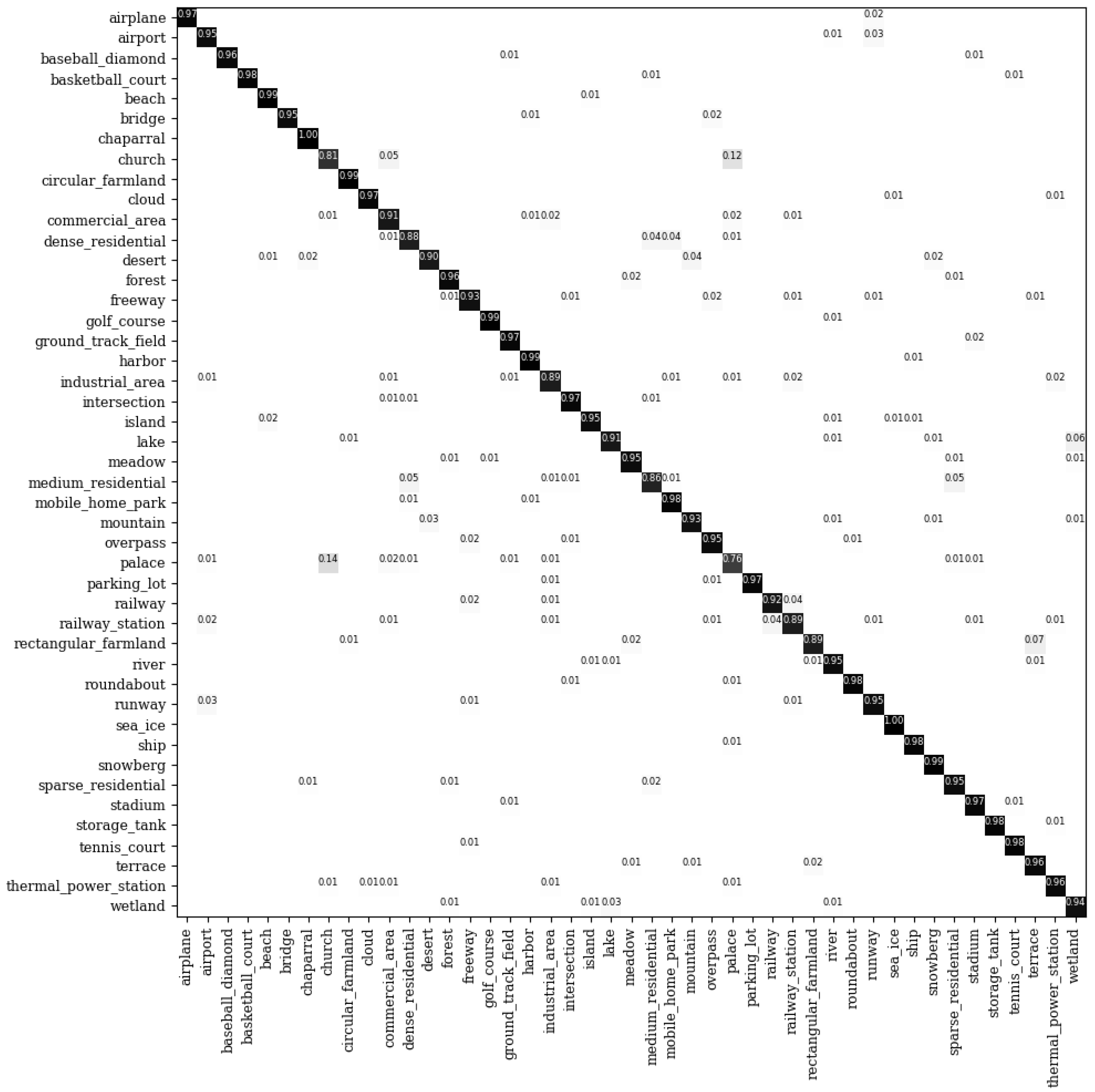
Figure 11.
The confusion matrix for the NWPU-RESISC 45 dataset under the 20% training samples.
Figure 11.
The confusion matrix for the NWPU-RESISC 45 dataset under the 20% training samples.
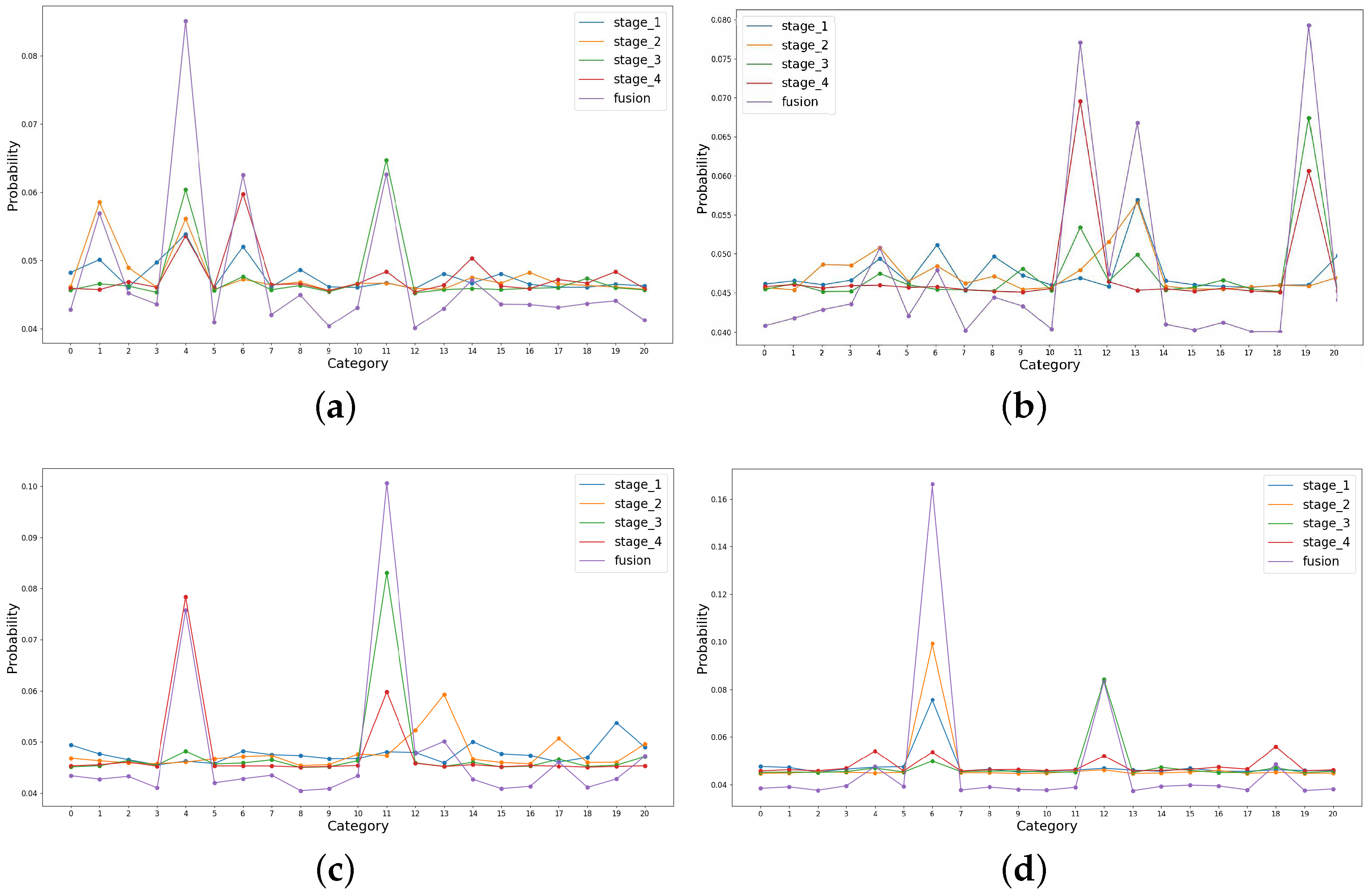
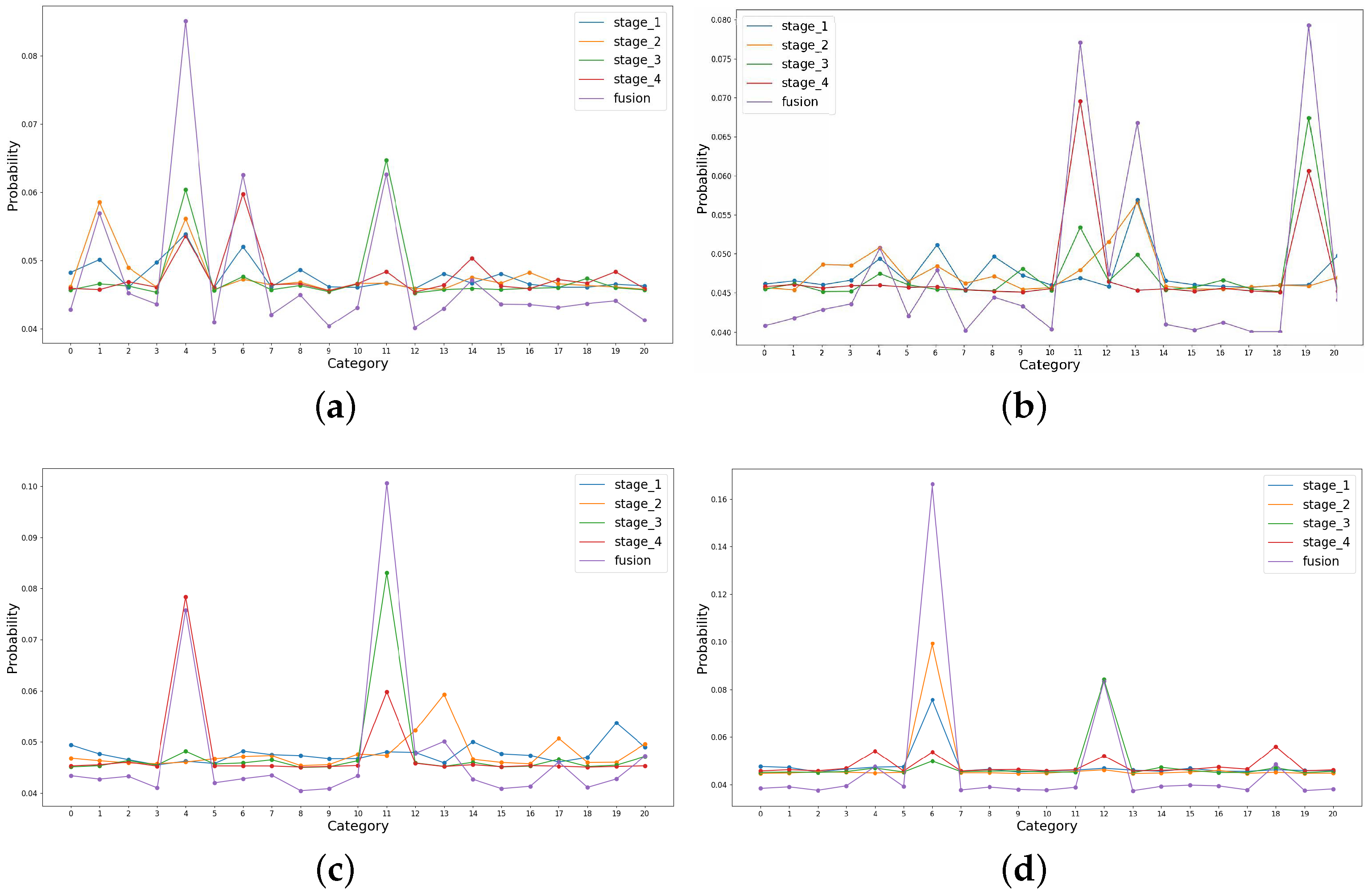
Figure 12.
Visualization of the output scores in different stages. (a–d) illustrate the results of the images belonging to buildings, storage tanks, intersection, and dense residential respectively. All the selected images are correctly classified by the adaptive fusion method, as indicated by the purple lines.
Figure 12.
Visualization of the output scores in different stages. (a–d) illustrate the results of the images belonging to buildings, storage tanks, intersection, and dense residential respectively. All the selected images are correctly classified by the adaptive fusion method, as indicated by the purple lines.
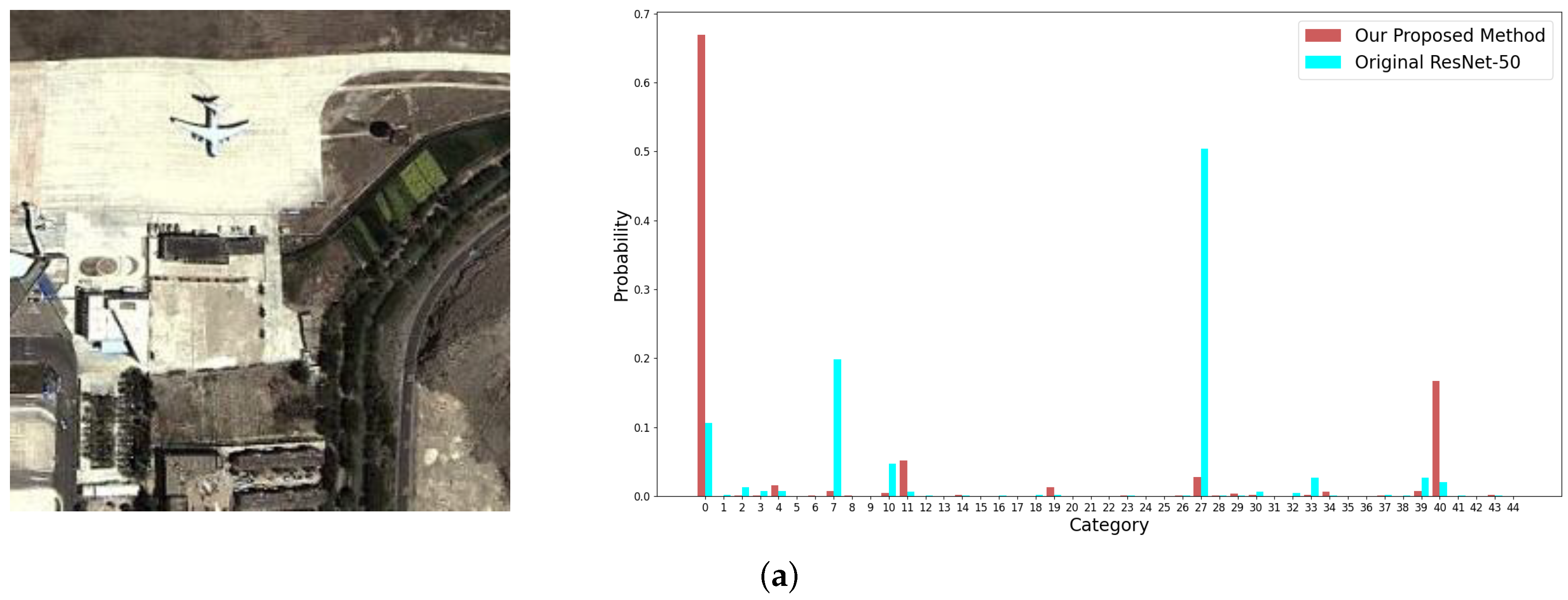
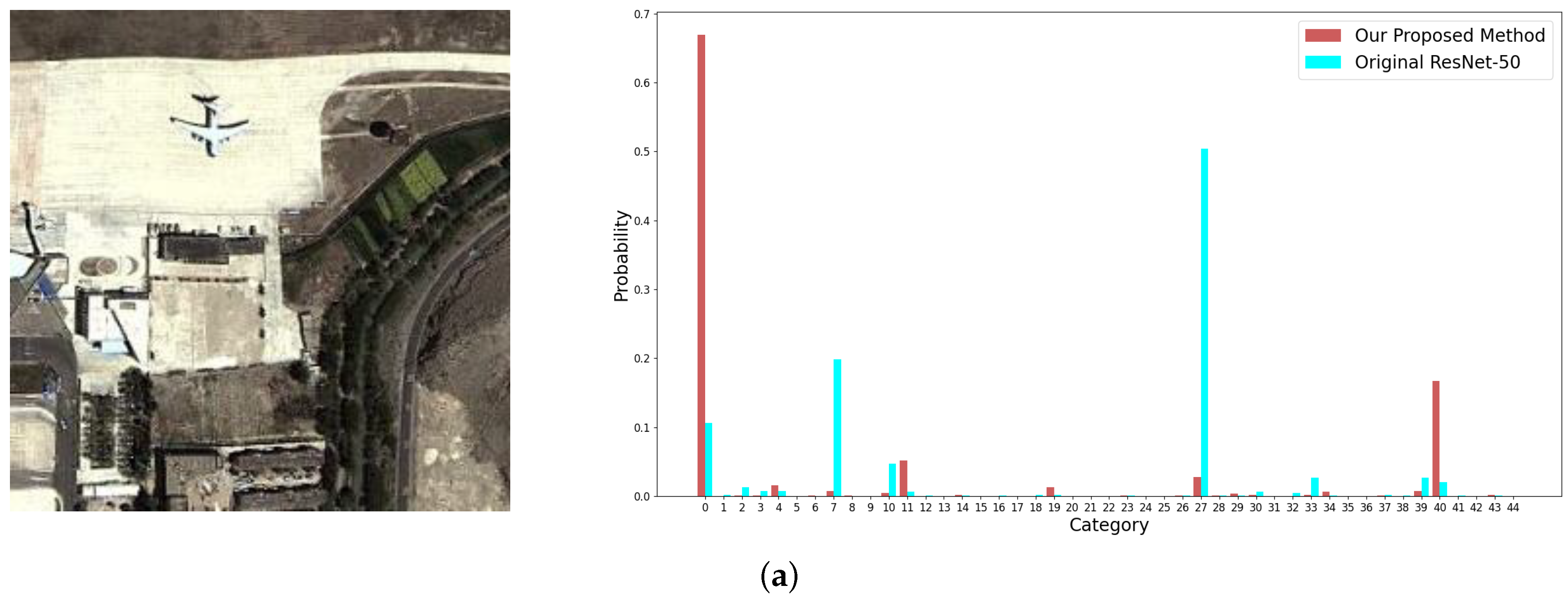
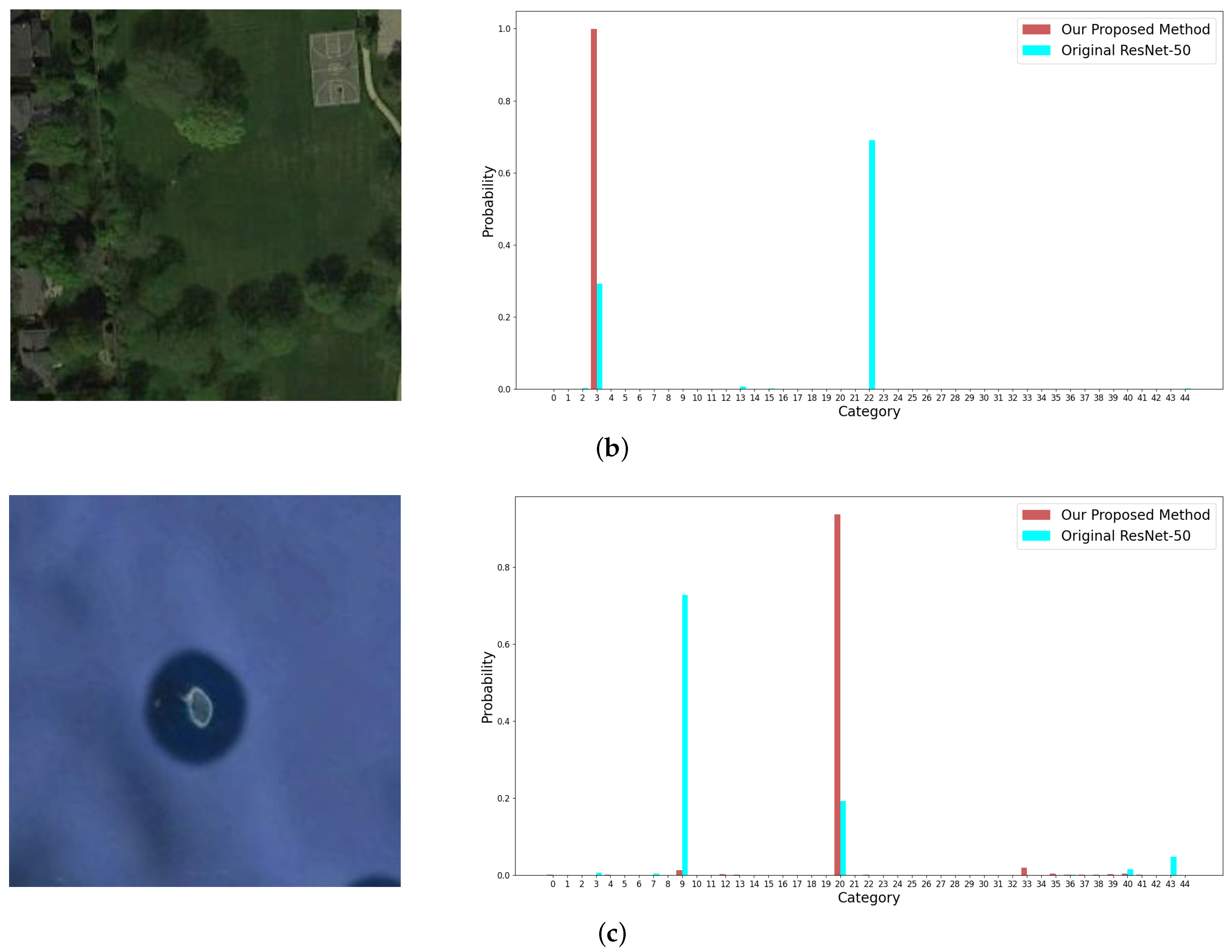
Figure 13.
Examples from the NWPU-RESISC 45 dataset with small objects and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a–c) are labelled as airplane, basketball court, and island, respectively.
Figure 13.
Examples from the NWPU-RESISC 45 dataset with small objects and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a–c) are labelled as airplane, basketball court, and island, respectively.
Figure 14.
Examples from the NWPU-RESISC 45 dataset and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a,b) are labelled as medium residential and dense residential, respectively.
Figure 14.
Examples from the NWPU-RESISC 45 dataset and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a,b) are labelled as medium residential and dense residential, respectively.
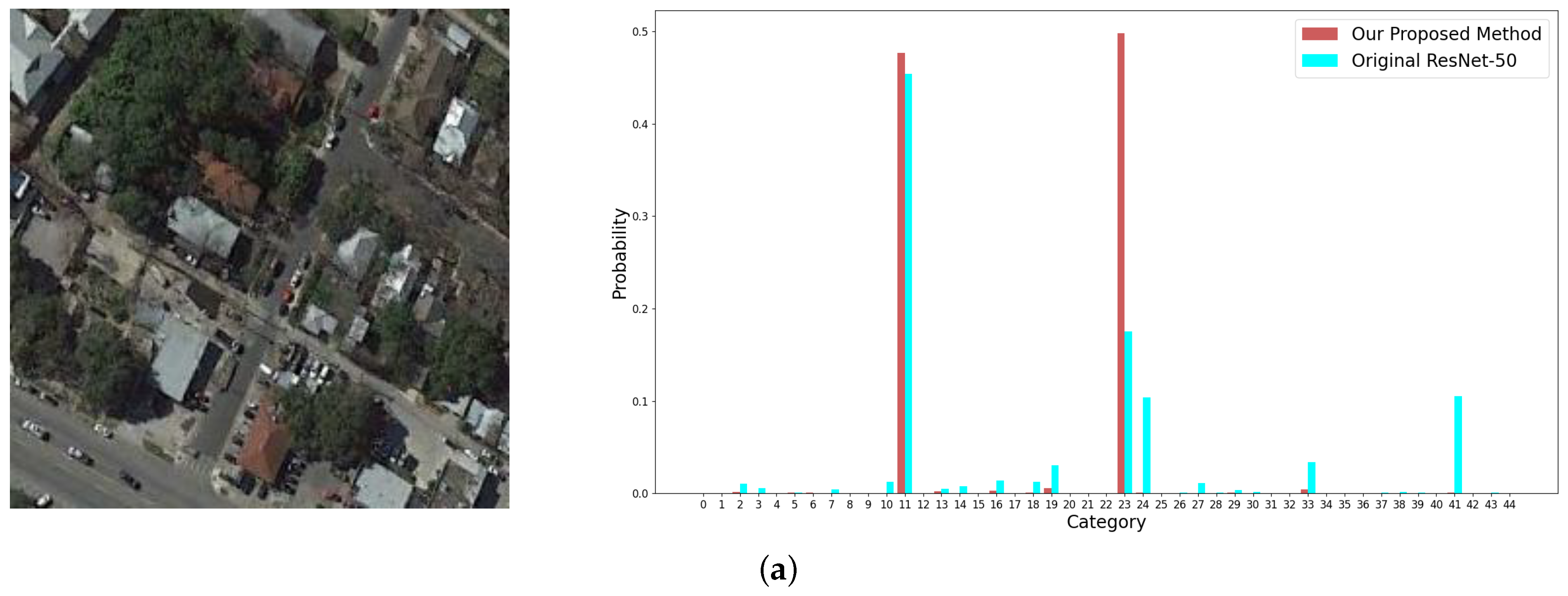
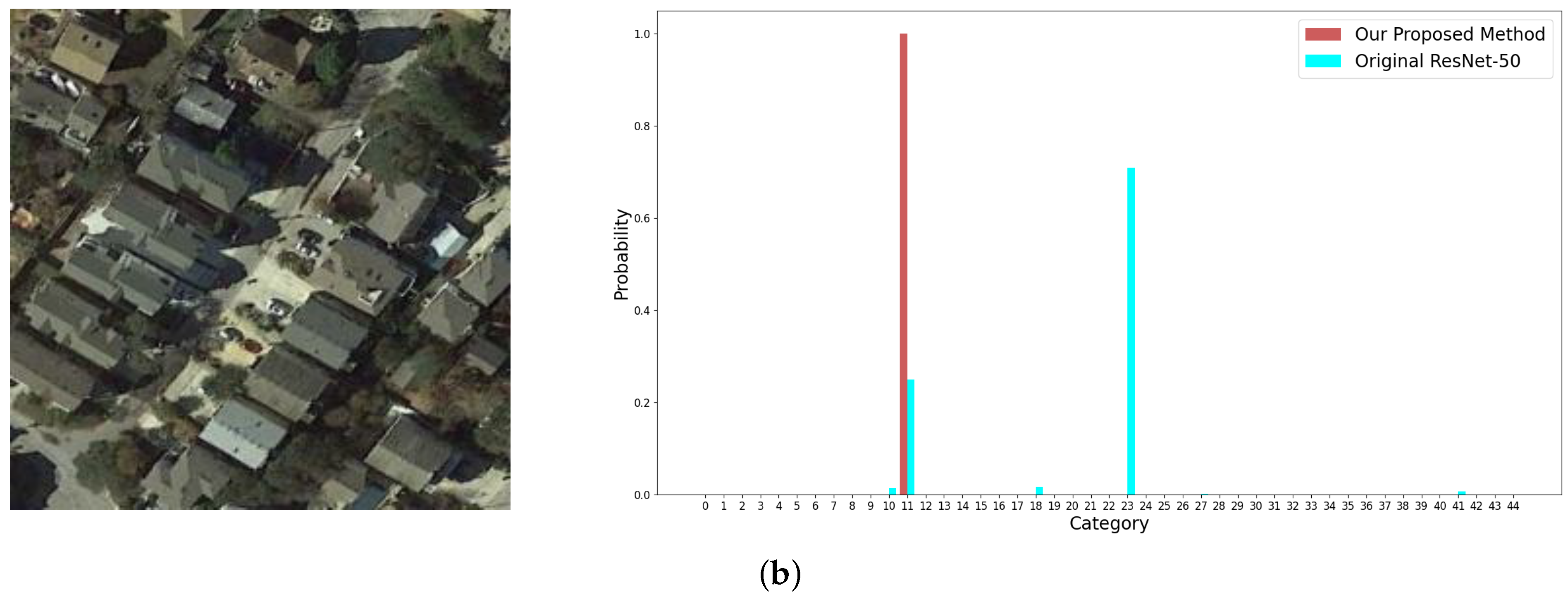
Figure 15.
Examples from the NWPU-RESISC 45 dataset and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a,b) are both labelled as church.
Figure 15.
Examples from the NWPU-RESISC 45 dataset and the corresponding output probabilities of categories by the original ResNet-50 (plotted in blue columns) and by our proposed method (plotted in red columns). The images in (a,b) are both labelled as church.
Table 1.
Comparison of sizes of the models before and after improvement.
Table 1.
Comparison of sizes of the models before and after improvement.
| Model | Parameters (MB) |
|---|
| UCM | RSSCN 7 | AID | NWPU 45 |
|---|
| ResNet-50 | 23.55 | 23.52 | 23.57 | 23.60 |
| Ours | 24.11 | 24.25 | 24.01 | 23.85 |
| Increment (%) | 2.4 | 3.1 | 1.9 | 1.1 |
Table 2.
Comparison of the FLOPs of the models before and after improvement.
Table 2.
Comparison of the FLOPs of the models before and after improvement.
| Model | FLOPs (MB) |
|---|
| UCM | RSSCN 7 | AID | NWPU 45 |
|---|
| ResNet-50 | 4087.18 | 4087.15 | 4087.20 | 4087.23 |
| Ours | 4098.06 | 4092.18 | 4098.86 | 4095.05 |
| Increment (%) | 0.3 | 0.1 | 0.3 | 0.2 |
Table 3.
The performance comparison on RSSCN 7 dataset with different backbones. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance on different backbones.
Table 3.
The performance comparison on RSSCN 7 dataset with different backbones. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance on different backbones.
| Method | 50% for Training |
|---|
| Fine_tune MobileNet V2 [41] | 92.46 ± 0.66 |
| Ours (MobileNet V2) | 94.21 ± 0.56 |
| Ours+SDFTS (MobileNet V2) | 94.59 ± 0.32 |
| Fine_tune VGG-16 [42] | 93.00 |
| Ours (VGG-16) | 94.72 ± 0.42 |
| Ours+SDFTS (VGG-16) | 95.70 ± 0.28 |
| Fine_tune ResNet-50 [42] | 92.29 |
| Ours (ResNet-50) | 95.15 ± 0.64 |
| Ours+SDFTS (ResNet-50) | 95.49 ± 0.55 |
| Fine_tune ResNet-152 [42] | 91.36 |
| Ours (ResNet-152) | 95.09 ± 0.47 |
| Ours+SDFTS (ResNet-152) | 95.76 ± 0.34 |
Table 4.
The setting of survival rate in different classification tasks.
Table 4.
The setting of survival rate in different classification tasks.
| Dataset | UCM | RSSCN7 | AID | NWPU 45 |
|---|
| Training ratio | 50% | 80% | 50% | 20% | 50% | 10% | 20% |
| Survival rate | 0.9 | 0.8 | 0.8 | 0.8 | 0.9 | 0.8 | 0.6 |
Table 5.
The performance comparison on the UC Merced Land-Use dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
Table 5.
The performance comparison on the UC Merced Land-Use dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
| Method | 50% for Training | 80% for Training |
|---|
| ResNet-50 | 97.22 ± 0.45 | 98.81 ± 0.51 |
| ADFF [43] | 97.22 ± 0.45 | 98.81 ± 0.51 |
| Standard RGB [45] | 96.22 ± 0.38 | 96.80 ± 0.51 |
| TEX-Net-LF [45] | 96.91 ± 0.36 | 97.72 ± 0.54 |
| SiameseNet [46] | 90.95 | 94.29 |
| PANet50 [34] | - | 99.21 ± 0.18 |
| HABFNet [33] | 98.47 ± 0.47 | 99.29 ± 0.35 |
| SPM-CRC [47] | - | 97.95 |
| WSPM-CRC [47] | - | 97.95 |
| R.D [48] | 91.71 | 94.76 |
| RIR+ResNet50 [49] | 98.28 ± 0.34 | 99.15 ± 0.40 |
| GBNet [31] | 97.05 ± 0.19 | 98.57 ± 0.48 |
| MSCP+MRA [50] | - | 98.40 ± 0.34 |
| FACNN [30] | - | 98.81 ± 0.24 |
| ResNet_LGFFE [44] | - | 98.62 ± 0.88 |
| ARCNet [51] | 96.81 ± 0.14 | 99.12 ± 0.40 |
| DCNN [21] | - | 98.93 ± 0.10 |
| Proposed [52] | 97.37 ± 0.44 | 99 ± 0.35 |
| Ours | 98.65 ± 0.49 | 99.71 ± 0.21 |
| Ours+SDFTS | 98.90 ± 0.47 | 99.64 ± 0.16 |
Table 6.
The performance comparison on the RSSCN 7 dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
Table 6.
The performance comparison on the RSSCN 7 dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
| Method | 50% for Training |
|---|
| VGG 16 | 93.00 |
| ResNet-50 | 92.29 |
| Standard RGB [45] | 93.12 ± 0.55 |
| TEX-Net-LF [45] | 94.00 ± 0.57 |
| SPM-CRC [47] | 93.86 |
| WSPM-CRC [47] | 93.9 |
| Proposed [42] | 93.14 |
| ADFF [43] | 95.21 ± 0.50 |
| LCNN-BFF [19] | 94.64 ± 0.21 |
| Ours | 95.15 ± 0.64 |
| Ours+SDFTS | 95.49 ± 0.55 |
Table 7.
The performance comparison for the AID dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
Table 7.
The performance comparison for the AID dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
| Method | 20% for Training | 50% for Training |
|---|
| ResNet50 | 86.48 ± 0.49 | 89.22 ± 0.34 |
| Standard RGB [45] | 88.79 ± 0.19 | 92.33 ± 0.13 |
| TEX-Net-LF [45] | 93.81 ± 0.12 | 95.73 ± 0.16 |
| SPM-CRC [47] | - | 95.1 |
| WSPM-CRC [47] | - | 95.11 |
| GBNet [31] | 92.20 ± 0.23 | 95.48 ± 0.12 |
| MSCP+MRA [50] | 92.21 ± 0.17 | 96.56 ± 0.18 |
| FACNN [30] | - | 95.45 ± 0.11 |
| MF2Net [20] | 93.82 ± 0.26 | 95.93 ± 0.23 |
| TFADNN [17] | 93.21 ± 0.32 | 95.64 ± 0.16 |
| ARCNet [51] | 88.75 ± 0.40 | 93.10 ± 0.55 |
| DCNN [21] | 90.82 ± 0.16 | 96.89 ± 0.10 |
| ResNet_LGFFE [44] | 90.83 ± 0.55 | 94.46 ± 0.48 |
| Ours | 94.69 ± 0.23 | 96.67 ± 0.28 |
| Ours+SDFTS | 95.05 ± 0.24 | 97.04 ± 0.20 |
Table 8.
The performance comparison for the NWPU-RESISC 45 dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
Table 8.
The performance comparison for the NWPU-RESISC 45 dataset. SDFTS represents the stochastic decision-level fusion training strategy. The bold values denote the best performance of different training ratio.
| Method | 10% for Training | 20% for Training |
|---|
| ResNet-50 | 89.88 ± 0.26 | 92.35 ± 0.19 |
| ADFF [43] | 86.01 ± 0.15 | 88.79 ± 0.17 |
| RIR [49] | 92.05 ± 0.23 | 94.06 ± 0.15 |
| SiameseNet [46] | - | 92.28 |
| R.D [48] | - | 92.67 |
| MI-VGG-16 [53] | 91.47 ± 0.20 | 93.14 ± 0.16 |
| MSCP+MRA [50] | 88.07 ± 0.18 | 90.81 ± 0.13 |
| MF2Net [20] | 90.17 ± 0.25 | 92.73 ± 0.21 |
| TFADNN [17] | 87.78 ± 0.11 | 90.86 ± 0.24 |
| LCNN-BFF [19] | 86.53 ± 0.15 | 91.73 ± 0.17 |
| DCNN [21] | 89.22 ± 0.50 | 91.89 ± 0.22 |
| Ours | 91.47 ± 0.41 | 94.11 ± 0.16 |
| Ours+SDFTS | 92.03 ± 0.23 | 94.40 ± 0.13 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}