
DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds




Abstract
:
1. Introduction
- We utilize an improved k-nearest neighbor (K-NN) search algorithm to construct a local dilated graph for each point, which models the long-range geometric correlation between each point and its neighbors to help the point neural network learn more local features of each point with a larger receptive field when conducting the convolution operation.
- We embed an offset–attention mechanism into a designed module called dilated graph attention module (DGAM), which can dynamically learn local discriminative attention features on the constructed dilated graph-like data, and employ a graph attention pooling to aggregate the most significant features and better capture the local geometric details of each point.
- We propose a novel DGANet for local feature extraction on point clouds and carry out extensive experiments on two competitive benchmark datasets. The experimental results demonstrate that our method achieves considerable performance and outperforms several existing state-of-the-art methods in both 3D object classification and segmentation tasks.
2. Related Work
2.1. Projection-Based Methods
2.2. Voxel-Based Methods
2.3. Point-Based Methods
2.4. Graph-Based Methods
2.5. Attention-Based Methods
3. Methods
3.1. Network Architecture
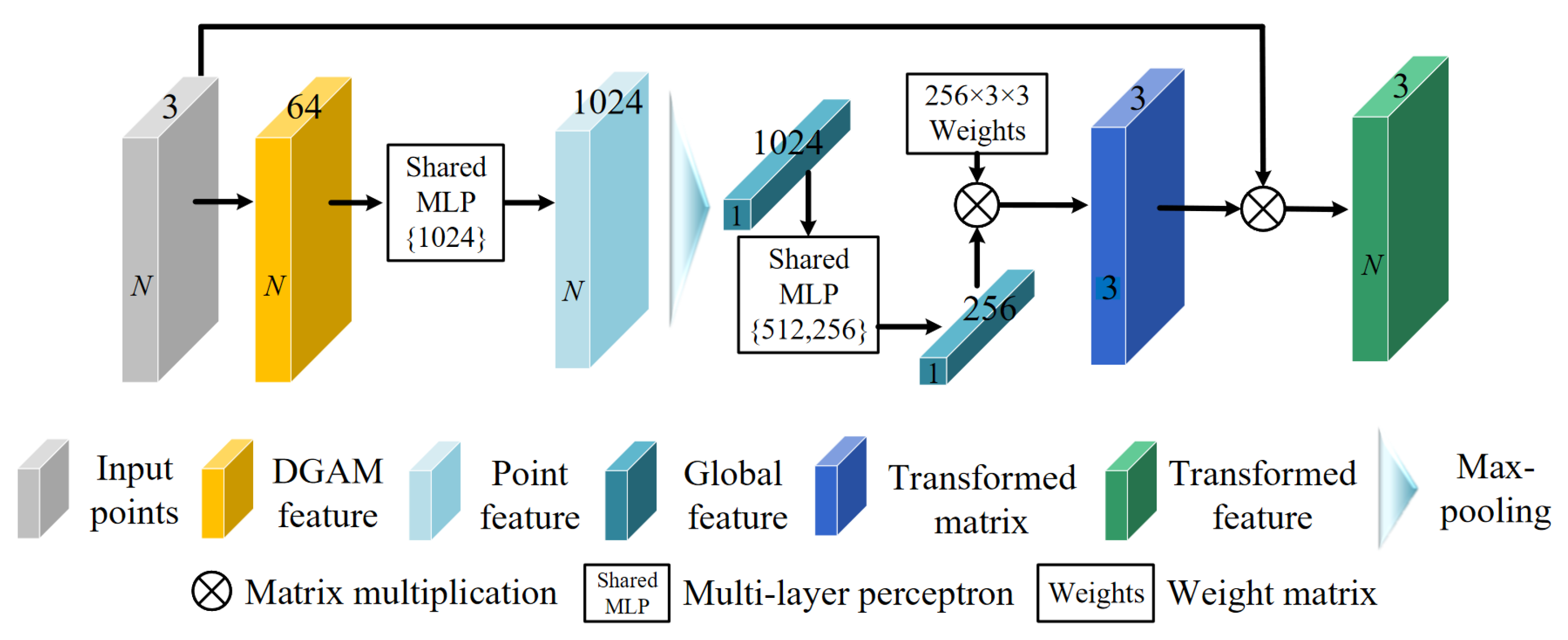
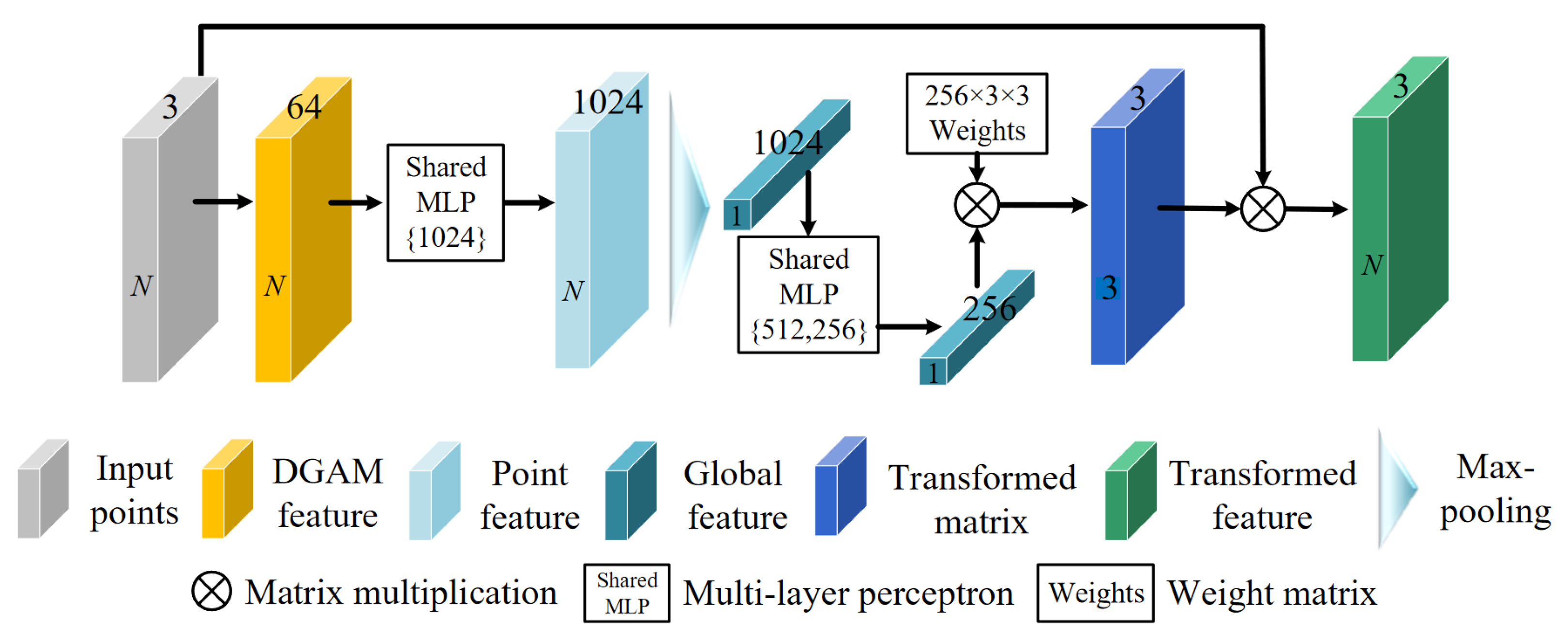
3.2. Spatial Transformation Embedding
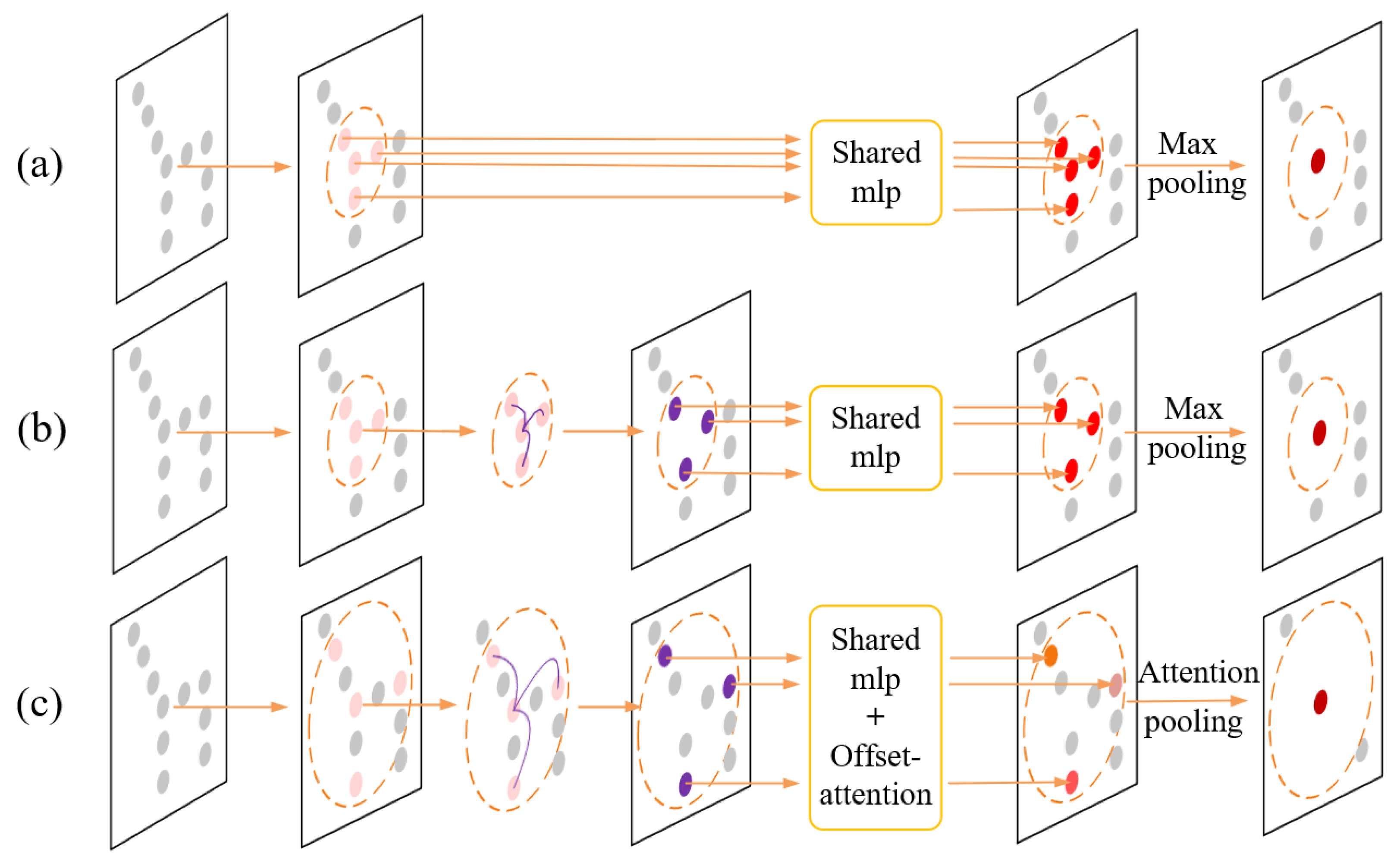
3.3. Local Dilated Graph Construction
3.3.1. Dilated K-NN Search
3.3.2. Edge Calculation
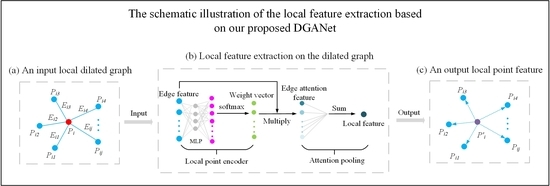
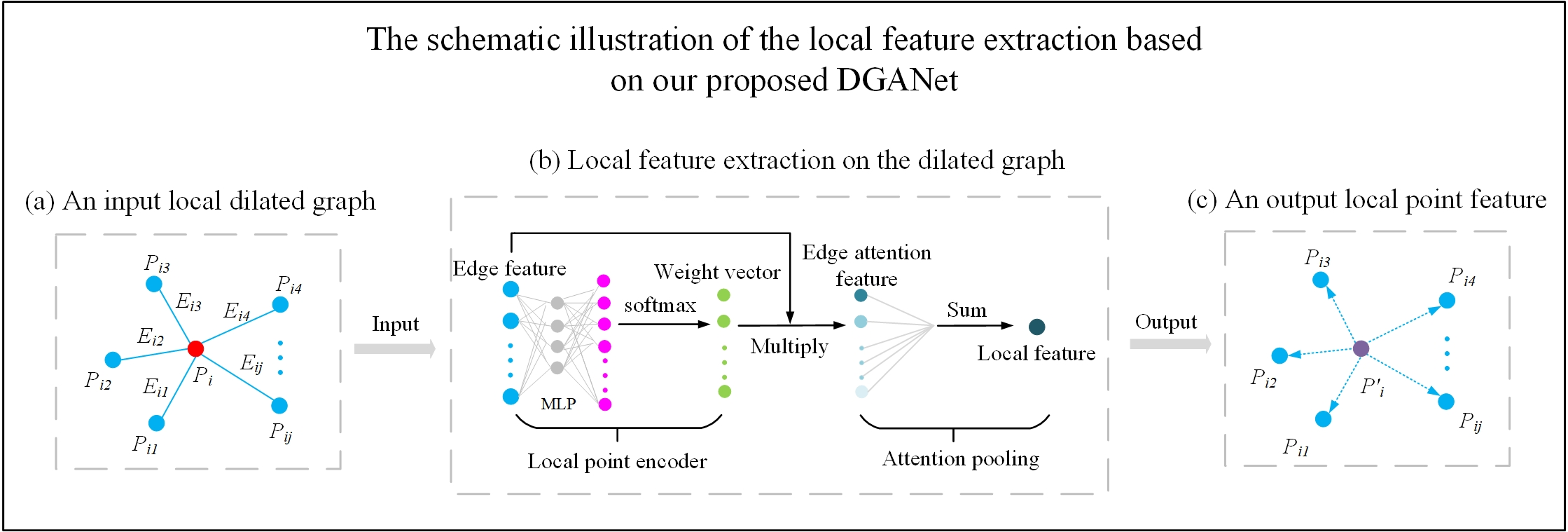
3.4. Dilated Graph Attention Module
3.4.1. Dilated Edge Attention Convolution
3.4.2. Graph Attention Pooling
3.5. Comparison with Existing Methods
4. Experiments
4.1. Classification on the ModelNet40 Dataset
4.1.1. Dataset
4.1.2. Task and Metrics
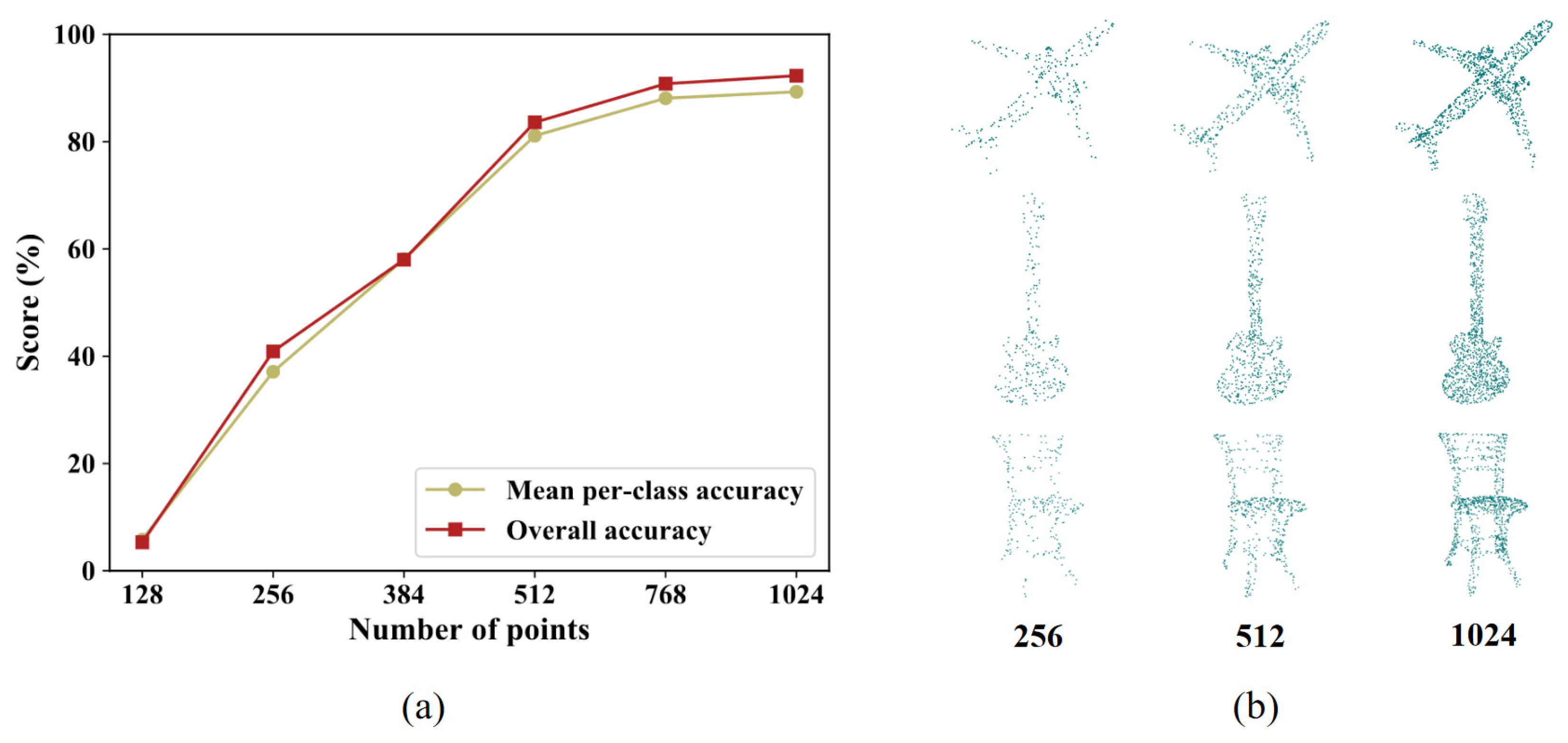
4.1.3. Implementation Details
4.1.4. Results and Discussion
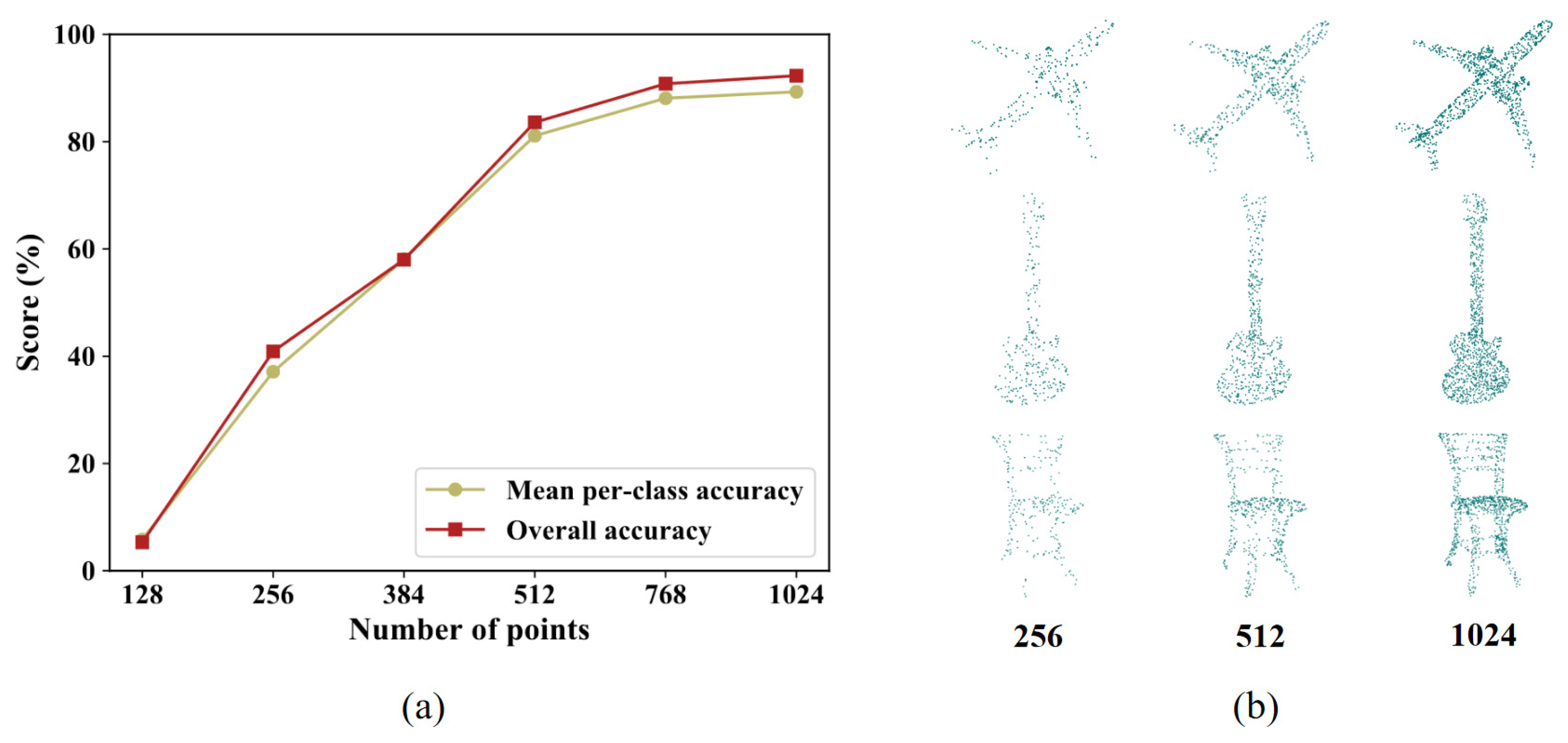
4.1.5. Ablation Studies and Analysis
4.2. Part Segmentation on the ShapeNet Part Dataset
4.2.1. Dataset
4.2.2. Task and Metrics
4.2.3. Implementation Details
4.2.4. Results and Discussion
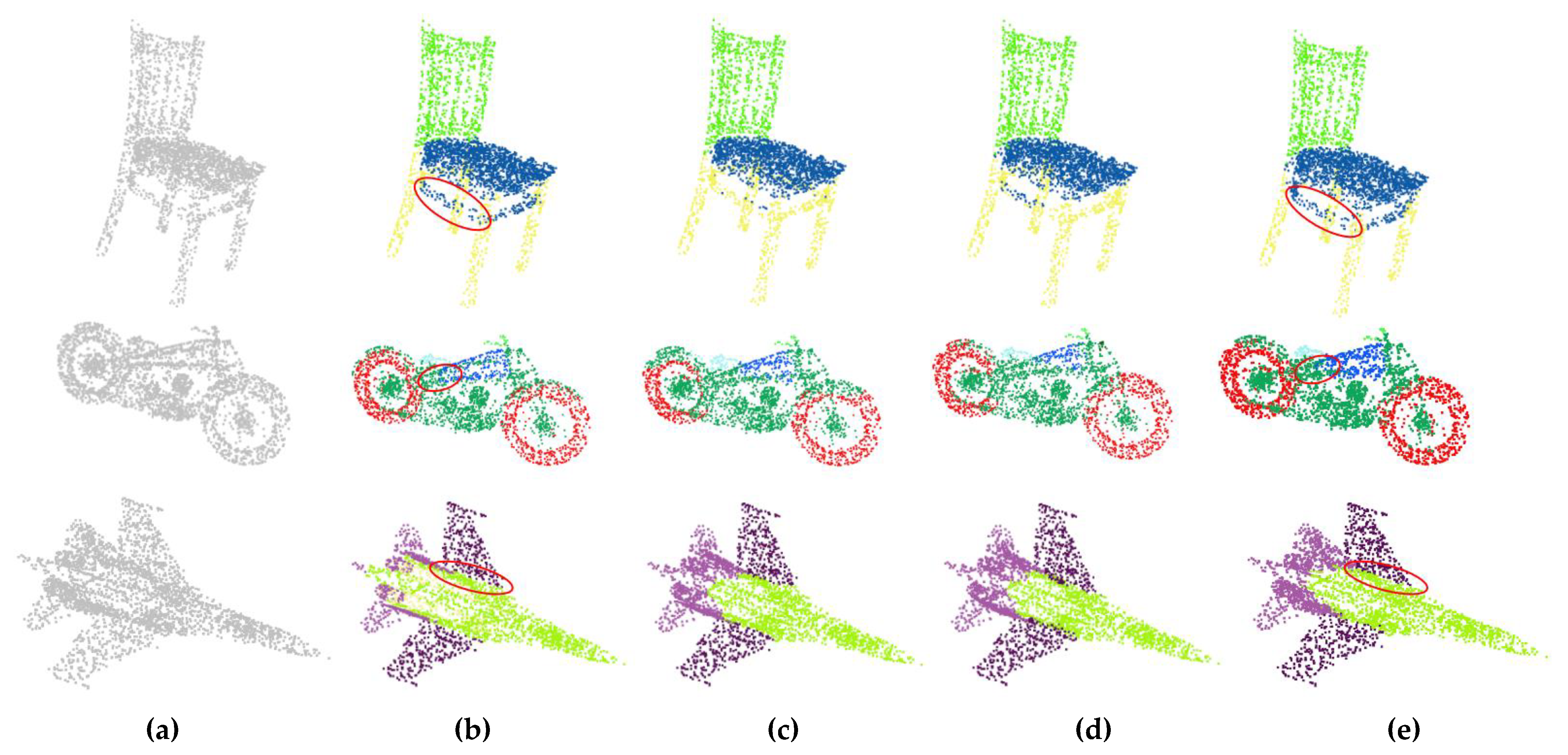
4.2.5. Ablation Studies and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, X.; Dong, Z.; Yang, B. A Point-Based Deep Learning Network for Semantic Segmentation of MLS Point Clouds. ISPRS J. Photogramm. Remote Sens. 2021, 175, 199–214. [Google Scholar] [CrossRef]
- Bello, S.A.; Yu, S.; Wang, C.; Adam, J.M.; Li, J. Review: Deep Learning on 3D Point Clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual Classification of Lidar Data and Building Object Detection in Urban Areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Reitberger, J.; Schnörr, C.; Krzystek, P.; Stilla, U. 3D Segmentation of Single Trees Exploiting Full Waveform LIDAR Data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 561–574. [Google Scholar] [CrossRef]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban Land Cover Classification Using Airborne LiDAR Data: A Review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Chen, Z.; Xie, M. Measuring the similarity between multipolygons using convex hulls and position graphs. Int. J. Geogr. Inf. Sci. 2021, 35, 847–868. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2432–2443. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. arXiv 2020, arXiv:1911.11236. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Lyu, Y.; Huang, X.; Zhang, Z. Learning to Segment 3D Point Clouds in 2D Image Space. arXiv 2020, arXiv:2003.05593. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a MetricSpace. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. arXiv 2018, arXiv:1801.07829. [Google Scholar] [CrossRef] [Green Version]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep Projective 3D Semantic Segmentation. In Proceedings of the Computer Analysis of Images and Patterns; Felsberg, M., Heyden, A., Krüger, N., Eds.; Springer International Publishing: Basel, Germany, 2017; pp. 95–107. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-View Harmonized Bilinear Network for 3D Object Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef] [Green Version]
- Kalogerakis, E.; Averkiou, M.; Maji, S.; Chaudhuri, S. 3D Shape Segmentation with Projective Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6630–6639. [Google Scholar]
- Le, T.; Bui, G.; Duan, Y. A Multi-View Recurrent Neural Network for 3D Mesh Segmentation. Comput. Graph. 2017, 66, 103–112. [Google Scholar] [CrossRef]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution. In ECCV 2020, Proceedings of the Computer Vision, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Basel, Germany, 2020; pp. 685–702. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection. arXiv 2021, arXiv:2012.15712. [Google Scholar]
- Hůlková, M.; Pavelka, K.; Matouskova, E. Automatic Classification of Point Clouds for Highway Documentation. Acta Polytech. 2018, 58, 165. [Google Scholar] [CrossRef]
- Klokov, R.; Lempitsky, V. Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree Generating Networks: Efficient Convolutional Architectures for High-Resolution 3D Outputs. arXiv 2017, arXiv:1703.09438. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 828–838. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9613–9622. [Google Scholar]
- Zhang, Y.; Rabbat, M. A Graph-CNN for 3D Point Cloud Classification. arXiv 2018, arXiv:1812.01711. [Google Scholar]
- Te, G.; Hu, W.; Guo, Z.; Zheng, A. RGCNN: Regularized Graph CNN for Point Cloud Segmentation. arXiv 2018, arXiv:1806.02952. [Google Scholar]
- Liang, Z.; Yang, M.; Wang, C. 3D Graph Embedding Learning with a Structure-Aware Loss Function for Point Cloud Semantic Instance Segmentation. IEEE Robot. Autom. Lett. 2020, 5, 4915–4922. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10288–10297. [Google Scholar]
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S.Z.; Mian, A. Point Attention Network for Semantic Segmentation of 3D Point Clouds. arXiv 2019, arXiv:1909.12663. [Google Scholar]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q.-Y. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3887–3896. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4548–4557. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters. In Proceedings of the Computer Vision-ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Volume 11212, pp. 90–105. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. SO-Net: Self-Organizing Network for Point Cloud Analysis. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Atzmon, M.; Maron, H.; Lipman, Y. Point Convolutional Neural Networks by Extension Operators. ACM Trans. Graph. 2018, 37, 71:1–71:12. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2569–2578. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Points | mA (%) | OA (%) | Params (Million) | FLOPs (108) |
|---|---|---|---|---|---|---|
| 3DShapeNets [7] | C | 1 k | 77.3 | 84.7 | - | - |
| VoxNet [12] | C | 1 k | 83 | 85.9 | 0.77 | - |
| PointNet [14] | C | 1 k | 86.2 | 89.2 | 3.48 | 1.88 |
| Kc-Net [37] | C | 1 k | - | 91 | 0.9 | - |
| Kd-Net [27] | C | 32 k | 88.5 | 91.8 | 2 | - |
| PointNet++ (ssg) [15] | C | 1 k | - | 90.7 | 1.47 | 1.37 |
| PointNet++ (msg) [15] | C, N | 5 k | - | 91.9 | 1.74 | 6.41 |
| PointCNN [29] | C | 1 k | 88.1 | 92.2 | 0.45 | - |
| SpiderCNN [38] | C, N | 1 k | - | 92.4 | - | - |
| DGCNN [17] | C | 1 k | 89.5 | 91.9 | 1.84 | 4.63 |
| PointCov [23] | C, N | 1 k | - | 92.2 | 1.96 | 1.87 |
| Ours | C | 1 k | 89.4 | 92.3 | 1.72 | 4.31 |
| Number of Neighbors (k) | Search Method of Local Graph Construction | mA (%) | OA (%) |
|---|---|---|---|
| 10 | normal K-NN (d = 1) | 87.6 | 91.2 |
| 10 | dilated K-NN (d = 3) | 88.7 | 91.9 |
| 10 | dilated K-NN (d = 5) | 87.2 | 90.7 |
| 20 | normal K-NN (d = 1) | 88.6 | 91.9 |
| 20 | dilated K-NN (d = 2) | 89.4 | 92.3 |
| 20 | dilated K-NN (d = 3) | 88.4 | 91.1 |
| 30 | normal K-NN (d = 1) | 88.2 | 91.6 |
| 30 | dilated K-NN (d = 2) | 89.3 | 91.8 |
| 30 | dilated K-NN (d = 3) | 88.1 | 90.9 |
| Method | pIoU | Air | Bag | Cap | Car | Cha. | Ear | Gua. | Kin. | Lam. | Lap | Mot. | Mug | Pis. | Roc. | Ska. | Tab. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kd-Net [27] | 82.3 | 80.1 | 74.6 | 74.3 | 70.3 | 88.6 | 73.5 | 90.2 | 87.2 | 81.0 | 94.9 | 57.4 | 86.7 | 78.1 | 51.8 | 69.9 | 80.3 |
| Kc-Net [37] | 83.7 | 82.8 | 81.5 | 86.4 | 77.6 | 90.3 | 76.8 | 91.0 | 87.2 | 84.5 | 95.5 | 69.2 | 94.4 | 81.6 | 60.1 | 75.2 | 81.3 |
| PointNet [14] | 83.7 | 83.4 | 78.7 | 82.5 | 74.9 | 89.6 | 73.0 | 91.5 | 85.9 | 80.8 | 95.3 | 65.2 | 93.0 | 81.2 | 57.9 | 72.8 | 80.6 |
| 3DmFV [39] | 84.3 | 82.0 | 84.3 | 86.0 | 76.9 | 89.9 | 73.9 | 90.8 | 85.7 | 82.6 | 95.2 | 66.0 | 94.0 | 82.6 | 51.5 | 73.5 | 81.8 |
| PCNNet [40] | 85.1 | 82.4 | 80.1 | 85.5 | 79.5 | 90.8 | 73.2 | 91.3 | 86.0 | 85.0 | 95.7 | 73.2 | 94.8 | 83.3 | 51.0 | 75.0 | 81.8 |
| DGCNN [17] | 85.1 | 84.2 | 83.7 | 84.4 | 77.1 | 90.9 | 78.5 | 91.5 | 87.3 | 82.9 | 96.0 | 67.0 | 93.3 | 82.6 | 59.7 | 75.5 | 82.0 |
| SpiderCNN [38] | 85.3 | 83.5 | 81.0 | 87.2 | 77.5 | 90.7 | 76.8 | 91.1 | 87.3 | 83.3 | 95.8 | 70.2 | 93.5 | 82.7 | 59.7 | 75.8 | 82.8 |
| SGPN [41] | 85.8 | 80.4 | 78.6 | 78.8 | 71.5 | 88.6 | 78.0 | 90.9 | 83.0 | 78.8 | 95.8 | 77.8 | 93.8 | 87.4 | 60.1 | 92.3 | 89.4 |
| Ours | 85.2 | 84.6 | 85.7 | 87.8 | 78.5 | 91.0 | 77.3 | 91.2 | 87.9 | 82.4 | 95.8 | 67.8 | 94.2 | 81.1 | 59.7 | 75.7 | 82.0 |
| Method | STE | DGAM | pIoU (%) | OA (%) |
|---|---|---|---|---|
| Network A | × | × | 83.7 | 93.6 |
| Network B | √ | × | 84.1 | 93.8 |
| Network C | × | √ | 84.7 | 94.0 |
| Ours | √ | √ | 85.2 | 94.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, J.; Xie, Z.; Xu, Y.; Zeng, Z.; Yuan, D.; Qiu, Q. DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote Sens. 2021, 13, 3484. https://doi.org/10.3390/rs13173484
Wan J, Xie Z, Xu Y, Zeng Z, Yuan D, Qiu Q. DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote Sensing. 2021; 13(17):3484. https://doi.org/10.3390/rs13173484
Chicago/Turabian StyleWan, Jie, Zhong Xie, Yongyang Xu, Ziyin Zeng, Ding Yuan, and Qinjun Qiu. 2021. "DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds" Remote Sensing 13, no. 17: 3484. https://doi.org/10.3390/rs13173484
APA StyleWan, J., Xie, Z., Xu, Y., Zeng, Z., Yuan, D., & Qiu, Q. (2021). DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote Sensing, 13(17), 3484. https://doi.org/10.3390/rs13173484