1. Introduction
Deep convolutional neural networks have promoted tremendous advances in computer vision, particularly in the field of object detection. Two networks have attracted the most attentions of object detection researchers: the Faster RCNN [
1], the representative of two-stage algorithms, and YOLO [
2], a typical case of one-stage algorithms. The two-stage algorithms usually present high recognition rates, and have been extensively used for detection on remote sensing images. High-resolution remote sensing images usually cover vast lands and oceans with targets in various sizes, so identifying targets in them is quite challenging. The two-stage algorithms usually generate object proposals first, that is, to localize target areas. Thus, object proposals have become the critical issue in detection tasks on remote sensing images.
Object proposal methods intend to outline candidate areas from images that hypothetically contain targets. These results exclude class information. Hosang et al. [
3] demonstrated that “for object detection improving proposal localization accuracy is as important as improving recall”. The higher the recall of proposal regions, the greater the accuracies of the final detection results. Object proposal methods use coordinates to mark the positions of objects [
3], and hardly have any prior information, like object category, to fulfill this task.
Techniques to generate object proposals can be categorized into three groups [
3]: grouping methods [
4,
5], window scoring methods [
6,
7,
8], and deep learning methods [
1]. Grouping methods and window scoring methods depend on artificially designed features. They are inept at large amount of images and diversified scenarios. Within the framework of the Faster RCNN, He et al. [
1] designed a fully-convolutional network, Region Proposal Network(RPN), to simultaneously predict object boundaries and object scores, integrating region proposal and object classification into an end-to-end process. RPN inspired a series of object proposal methods based on deep neural networks, including AttractioNet [
9], DeepMask [
10], SharpMask [
11] that is based on DeepMask [
10], and FastMask [
12]. Among them, DeepMask [
10] is outstanding. It outperforms the RPN model in the average recall rate when being applied to the public image dataset COCO. Different from the RPN [
1] model, it uses object instance segmentation to generate candidate areas.
Many researchers have applied the regional proposal methods for natural images to remote sensing images. However, remote sensing images are quite different from natural images: a remote sensing image usually covers a vast area involving large amount of data, rich texture information, and targets that almost blend into backgrounds; objects in them hold various sizes, and smaller ones usually crowded together [
13]. Some scholars have intended to improve traditional regional proposal methods specifically for remote sensing images. Zhong et al. [
14] improved the accuracy of region proposals by a position-sensitive balancing framework. Li et al. [
15] introduced multi-angle anchor points based on the Faster R-CNN [
1] framework to construct a rotation-insensitive RPN, which effectively solved the problem of rotation changes of geospatial objects. Based on Faster R-CNN, Tang et al. [
16] combined a region proposal network with hierarchical feature maps to extract vehicle-like targets, and improved the accuracy of region proposals. Although some of their efforts have paid off, their approaches can still hardly improve the accuracy for complex situations, like diversified sizes of objects co-existing in images where the recall rate of regional proposals for smaller targets stays low.
Attention mechanism, one of the most valuable breakthroughs in deep Learning, has been widely used in many fields, such as natural language processing, image recognition, speech recognition, and image caption [
17,
18]. Three types of attention mechanism are popular: spatial attention [
19,
20], channel attention [
21], and hybrid attention [
22,
23]. The spatial attention focuses on ’where’ is an informative part, which transforms the spatial information in the original image into another space and retains the key information [
23]. Many networks have been proposed deploying the spatial attention networks, like Spatial Transformer Network (STN) proposed by Google Deep Mind [
19], and dynamic capacity networks [
20]. The spatial attention locates targets, and then performs certain transformations or assigns weights. It is proper for tasks of locating regions of interest.
For natural images, some approaches adopted attention mechanism to generate proposals specifically for small targets. Christuan Wihms et al. [
24] designed AttentionMask based on FastMask [
12]. They added an extra module to the backbone network of FastMask to focus on the small objects that might be missed before. They also deployed a Scale-specific Objectness Attention Model (SOAM) that utilizes the vision attention mechanism [
17]. The whole performance of AttentionMask has risen
from that of FastMask. However, given the difference between natural images and remote sensing images, AttentionMask are not quite prepared for remote sensing images. In AttentionMask, the sliding windows for the attention mechanism are selected subjectively, bringing uncertainty to the whole system.
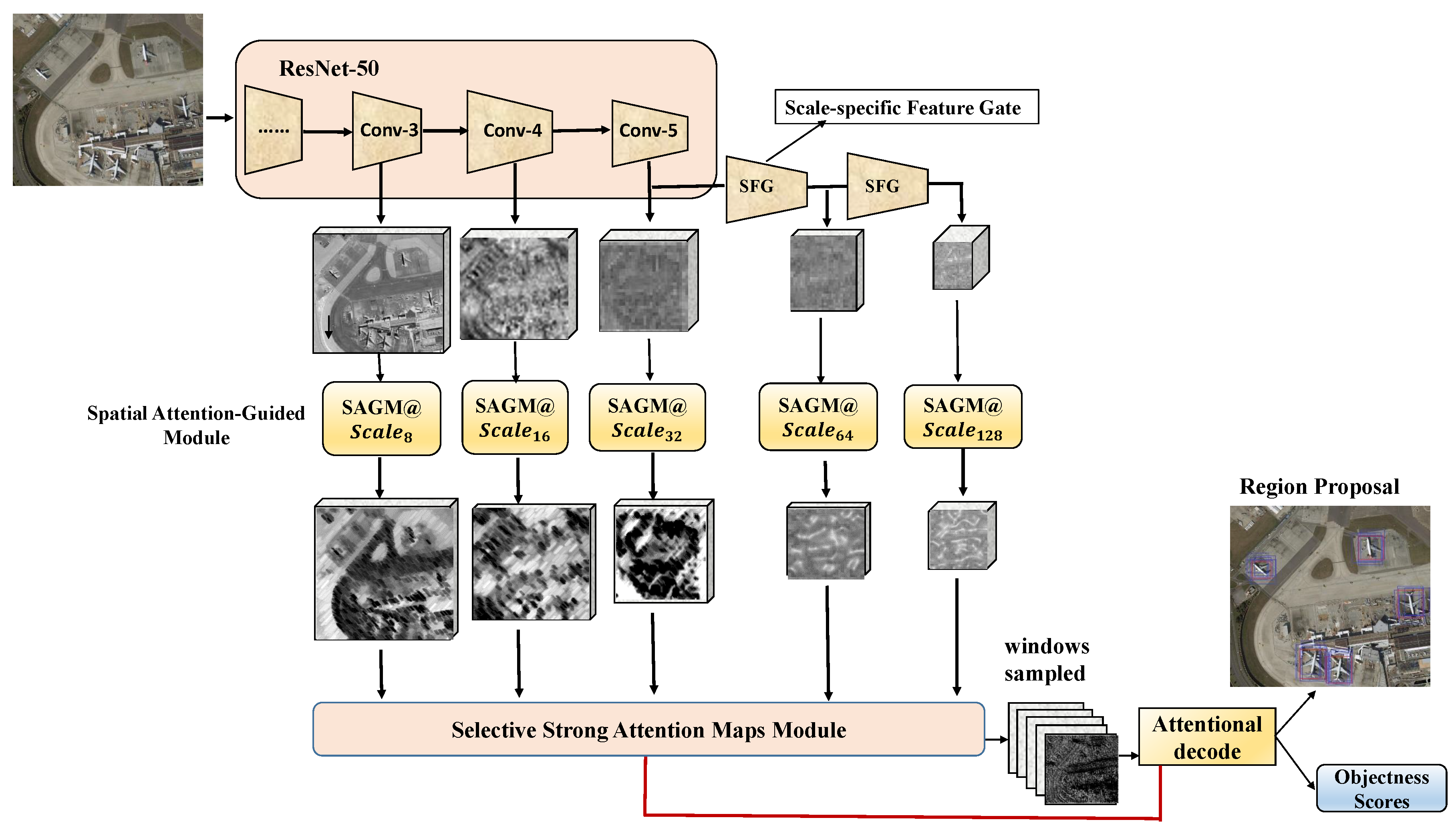
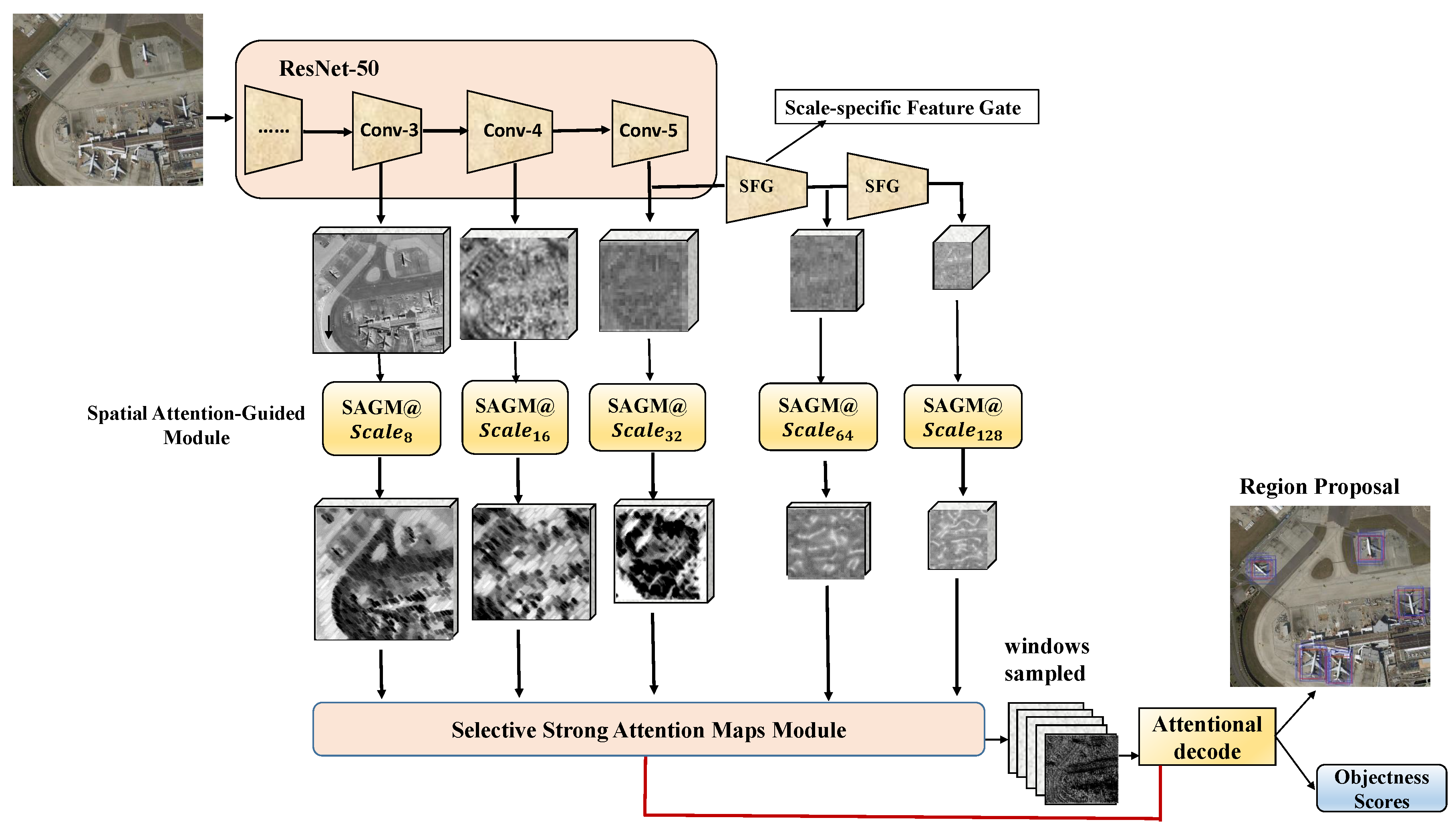
Therefore, this paper proposes a regional proposal generation method for remote sensing images, and focuses on two problems: first, the candidate regions of small objects would be missed or mis-identified among those of diversified sizes of objects; Second, the subjectively-selected sliding windows would impose uncertainty on final results. This approach extracts multi-scale features from deep convolutional nerves and the attention mechanism to efficiently generate region proposals. It can lay the foundation for consequent target detection, and improve the accuracy and efficiency of the detection. Experimental on the LEVIR dataset [
25] demonstrates that the proposed approach holds a 2%∼3% higher recall rate, compared with those of the state-of-the-art methods, including RPN [
1], FastMask [
12], AttentionMask [
24], etc.
The proposed approach innovates in the following aspects,
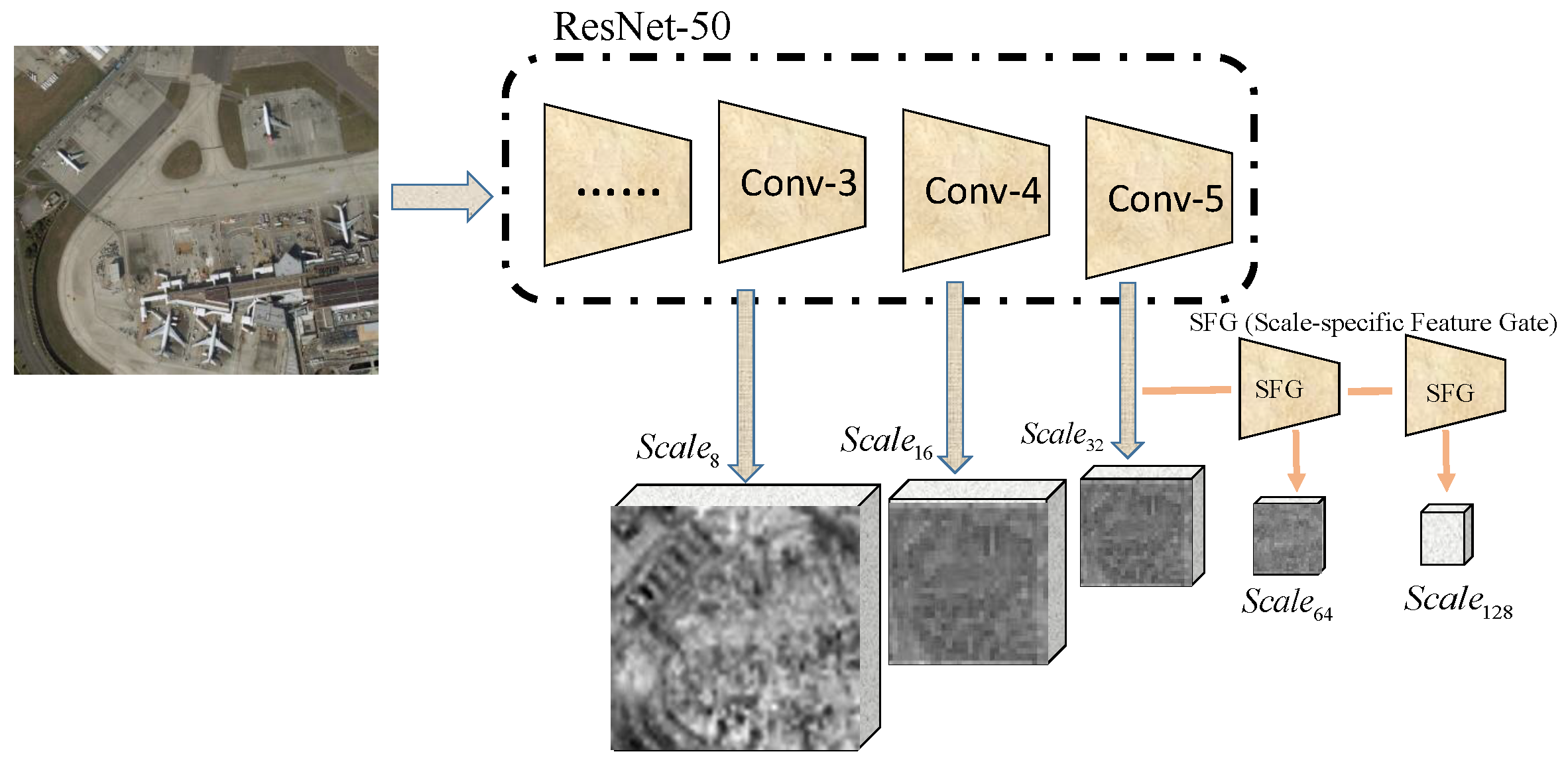
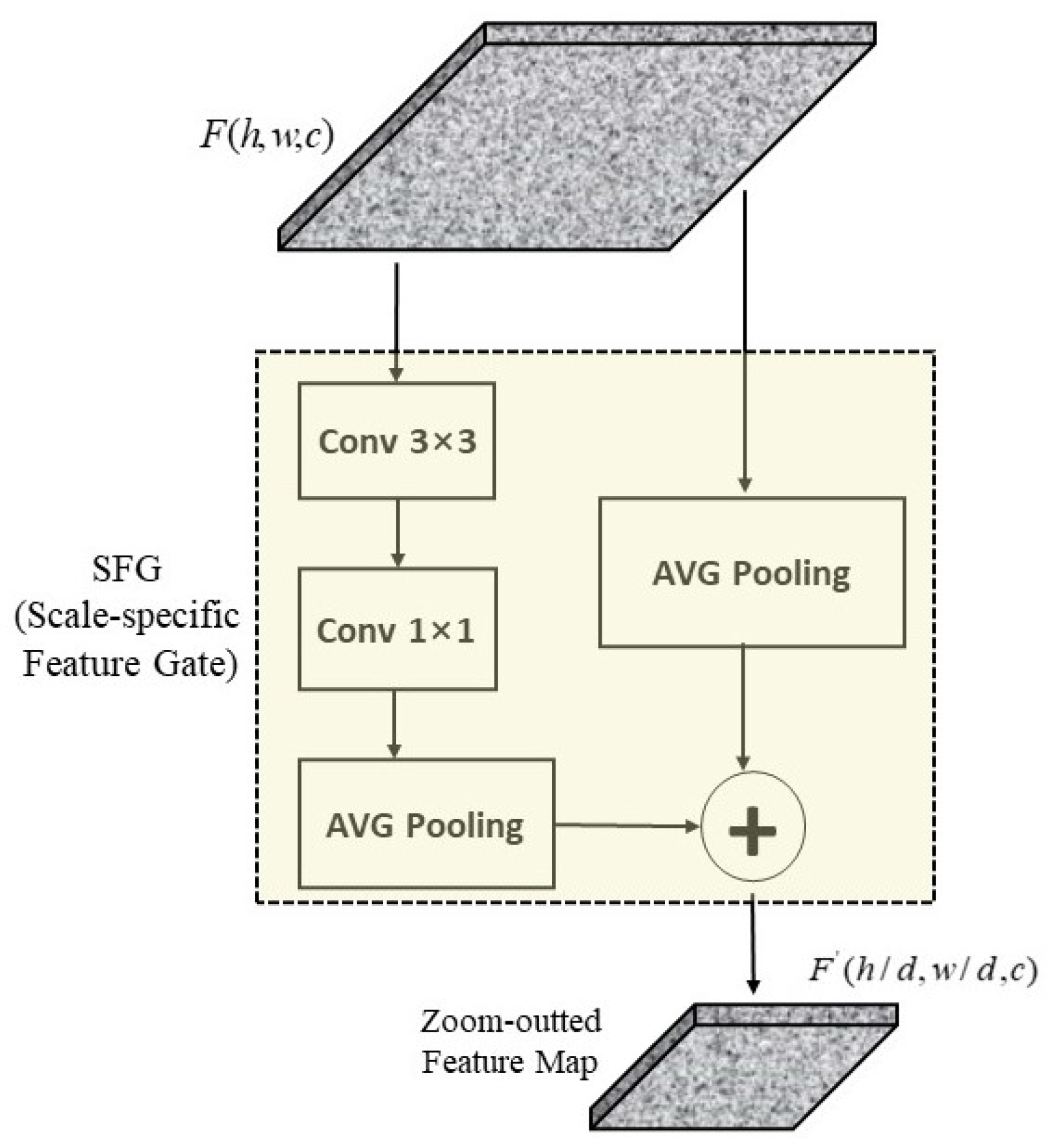
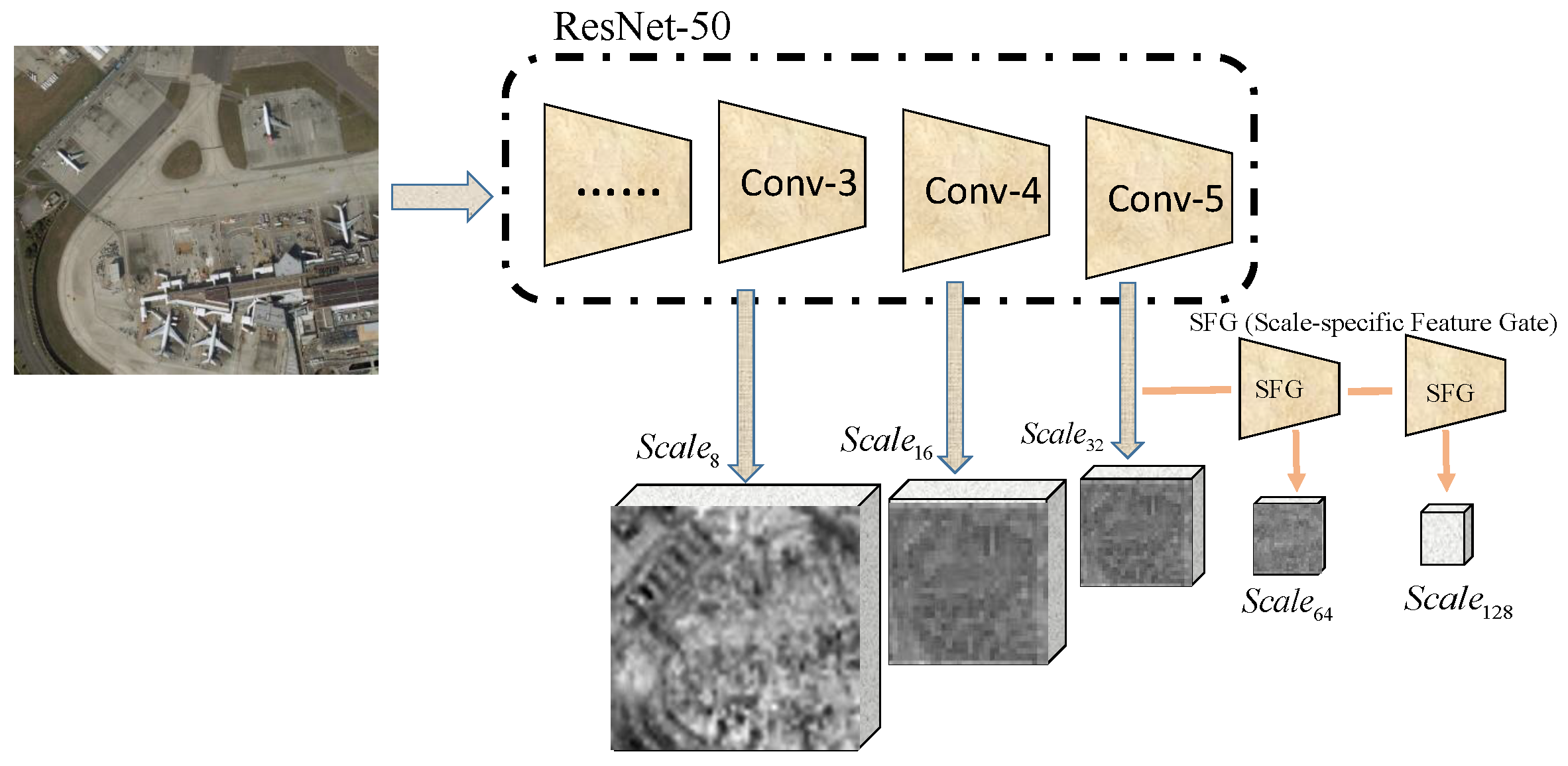
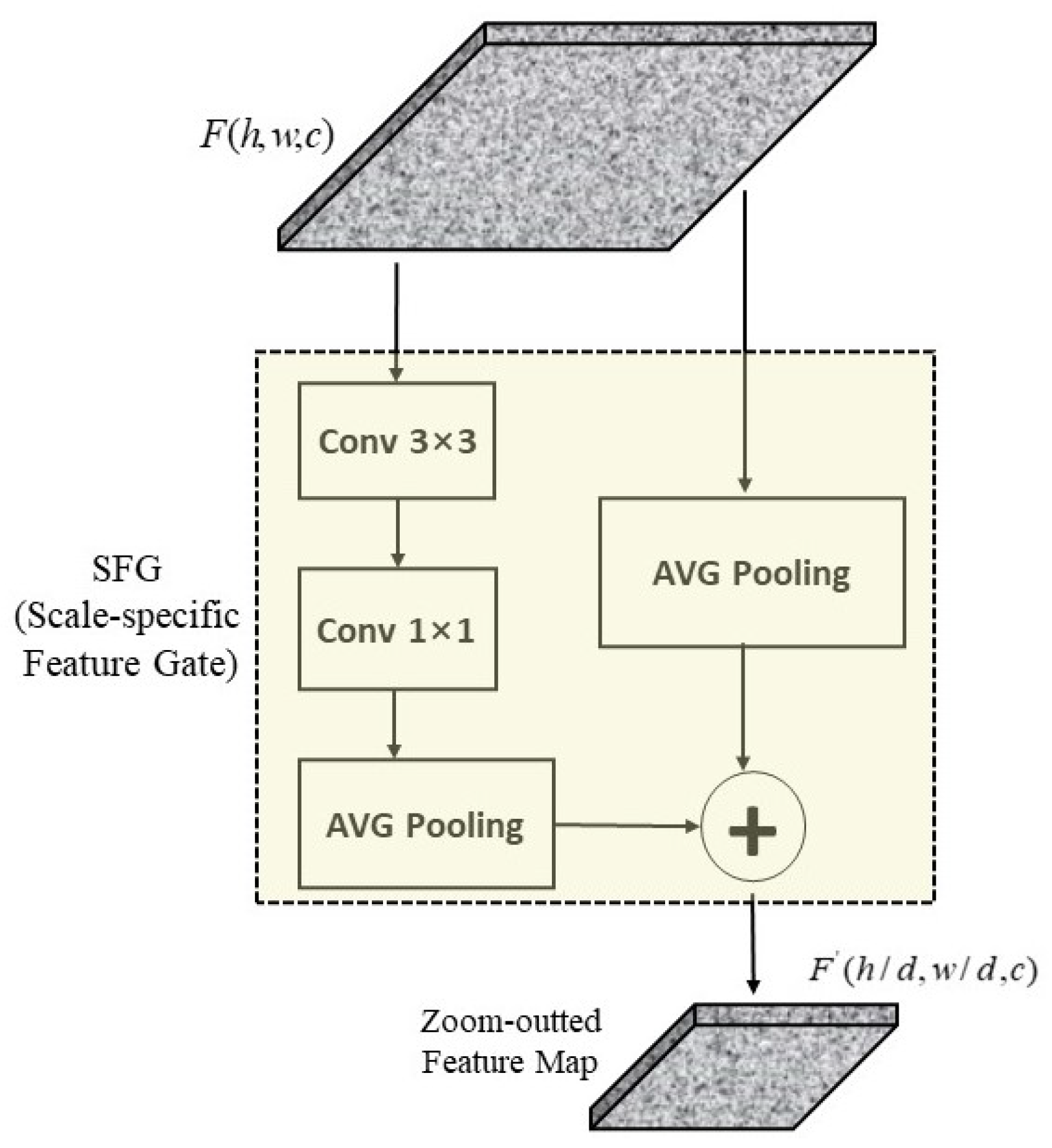
Development of the scale-specific feature gate that can obtain features from multi-scales, representing semantic information of objects of different sizes. It avoids the misidentification of regional proposals that are caused by various sizes of objects.
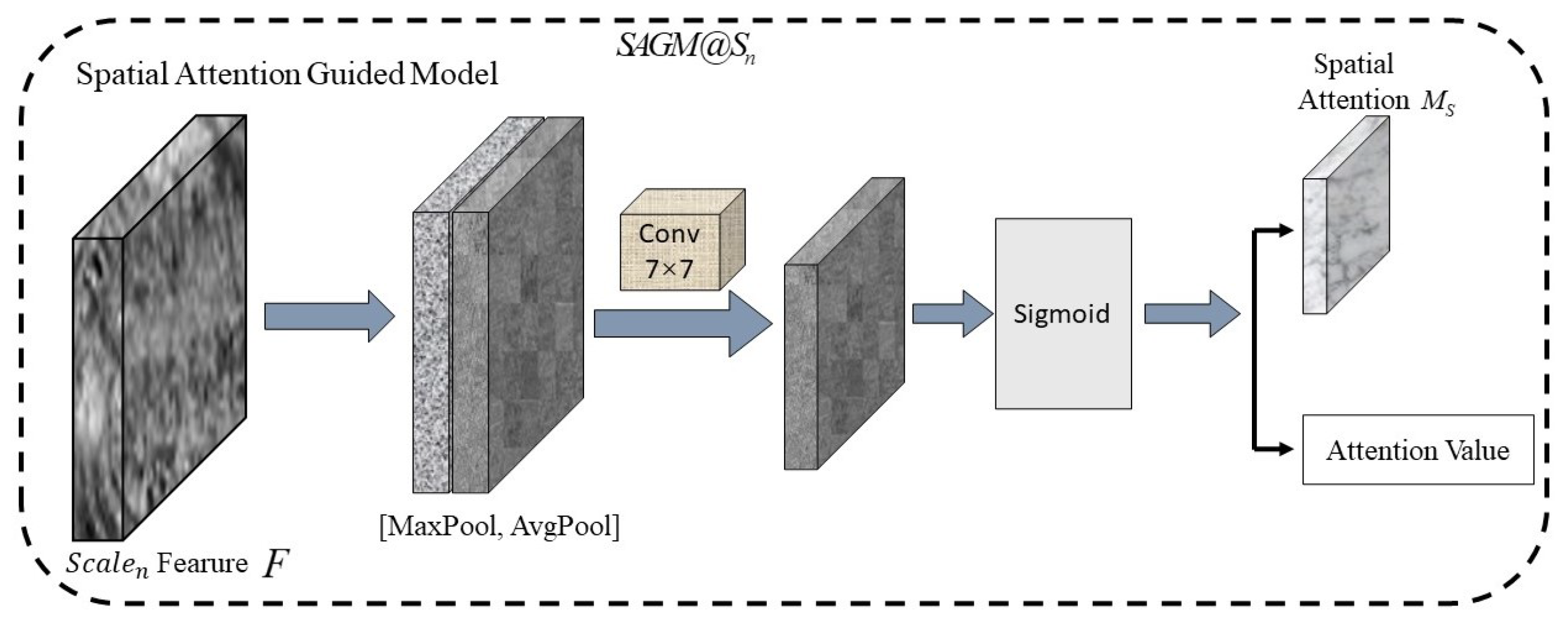
Development of the spatial attention-guided module that uses the multi-scale features to greatly reduce the computing power and improve the accuracy of candidate region generation. It can help the system notice the small objects that might be missed.
Development of a selective attention module that can adaptively select the appropriate sampling windows based on the feedback of the system, instead of subjectively selecting part of the sliding window of the attention mechanism. It lifts the uncertainty that the subjectively-selected sliding windows might bring.
The rest of the article is organized as follows:
Section 2 describes the principles and workflows of the proposed method; Experiments are shown in
Section 3;
Section 4 reports the experimental results on the LEVIR dataset in comparison with other state-of-the-art methods, and some ablation experiment results; Conclusions are drawn in
Section 5.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}