
Review of Wide-Baseline Stereo Image Matching Based on Deep Learning




Abstract
:1. Introduction
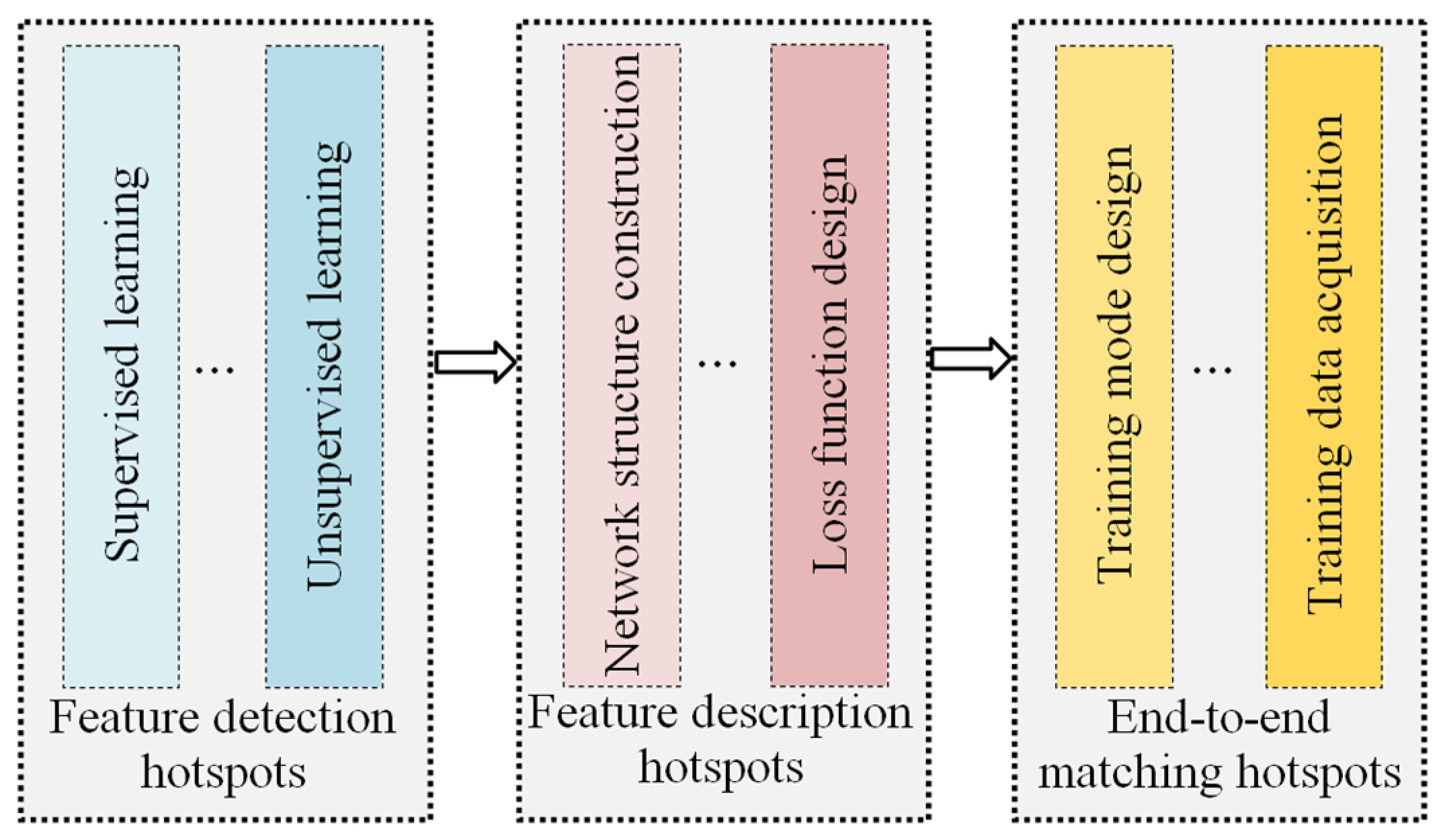
2. Deep-Learning Image-Matching Methodologies
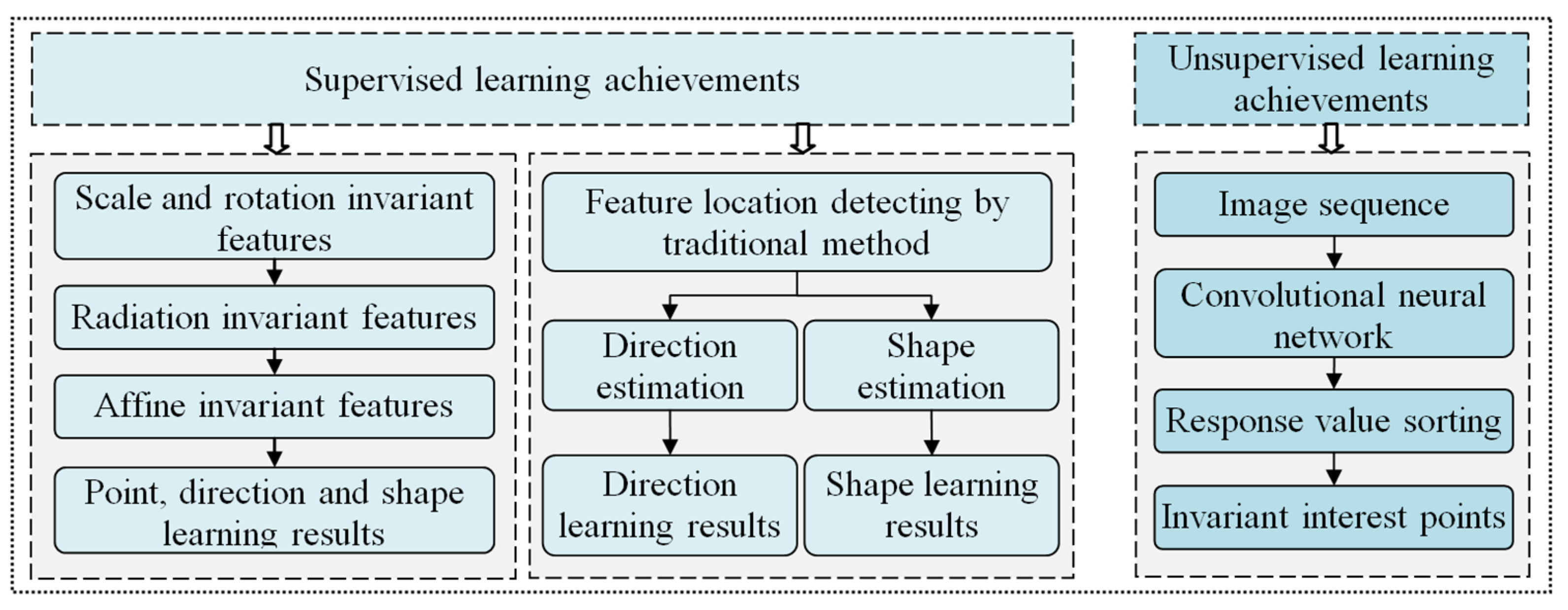
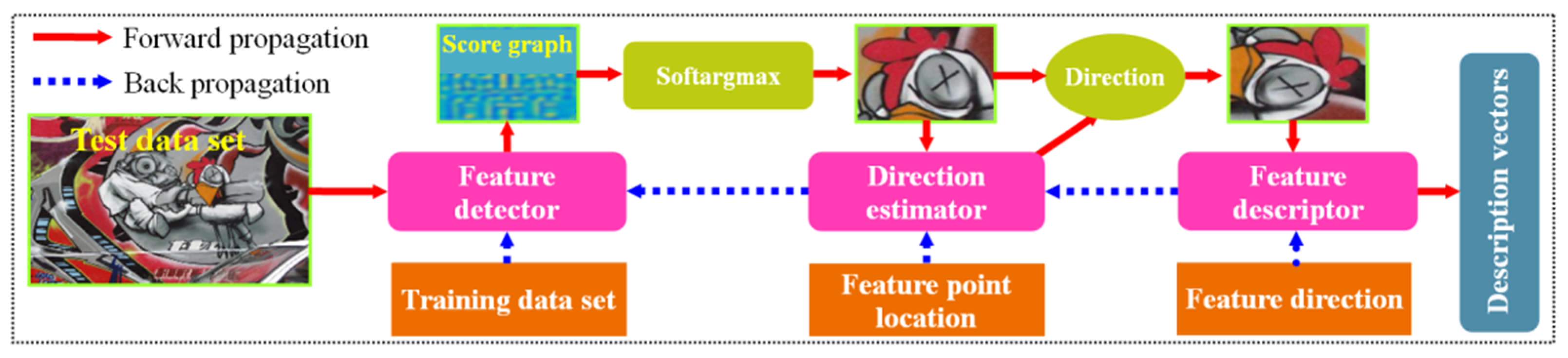
2.1. Deep-Learning-Based Feature Detection
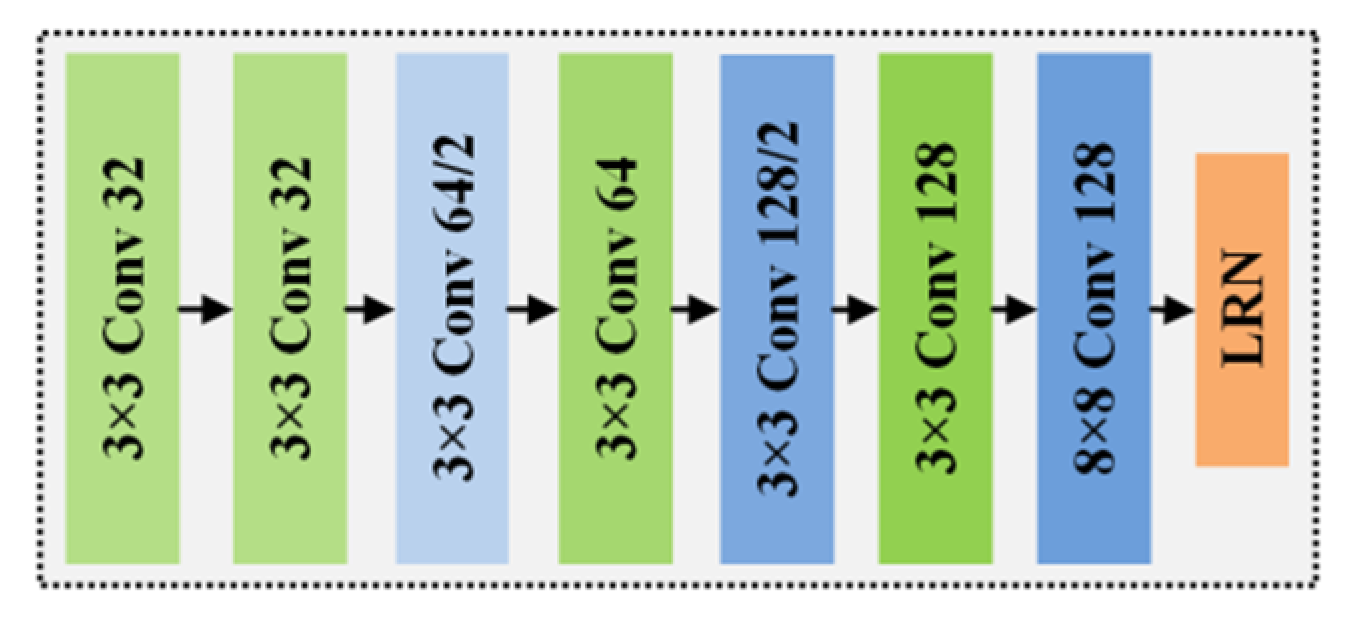
2.2. Deep-Learning Feature Description
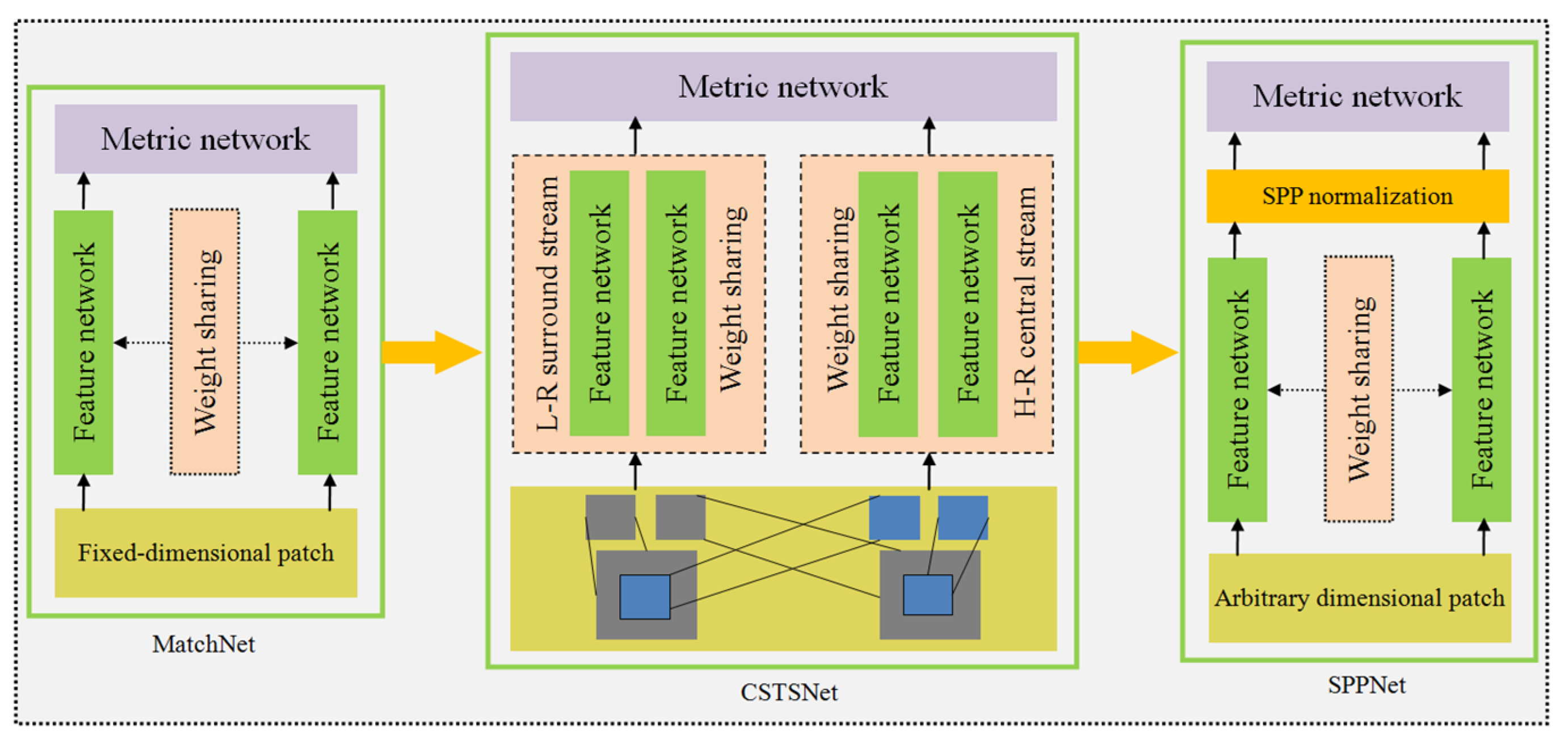
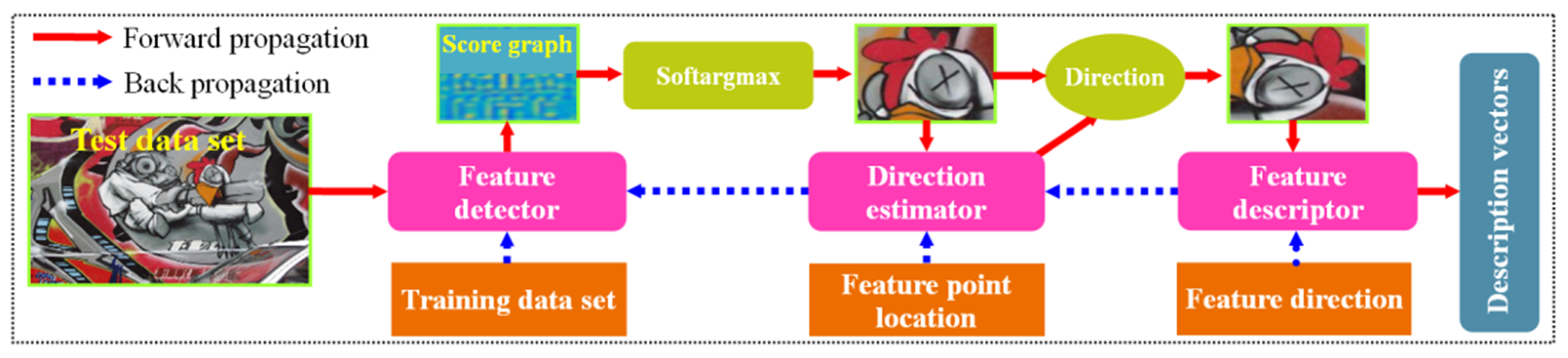
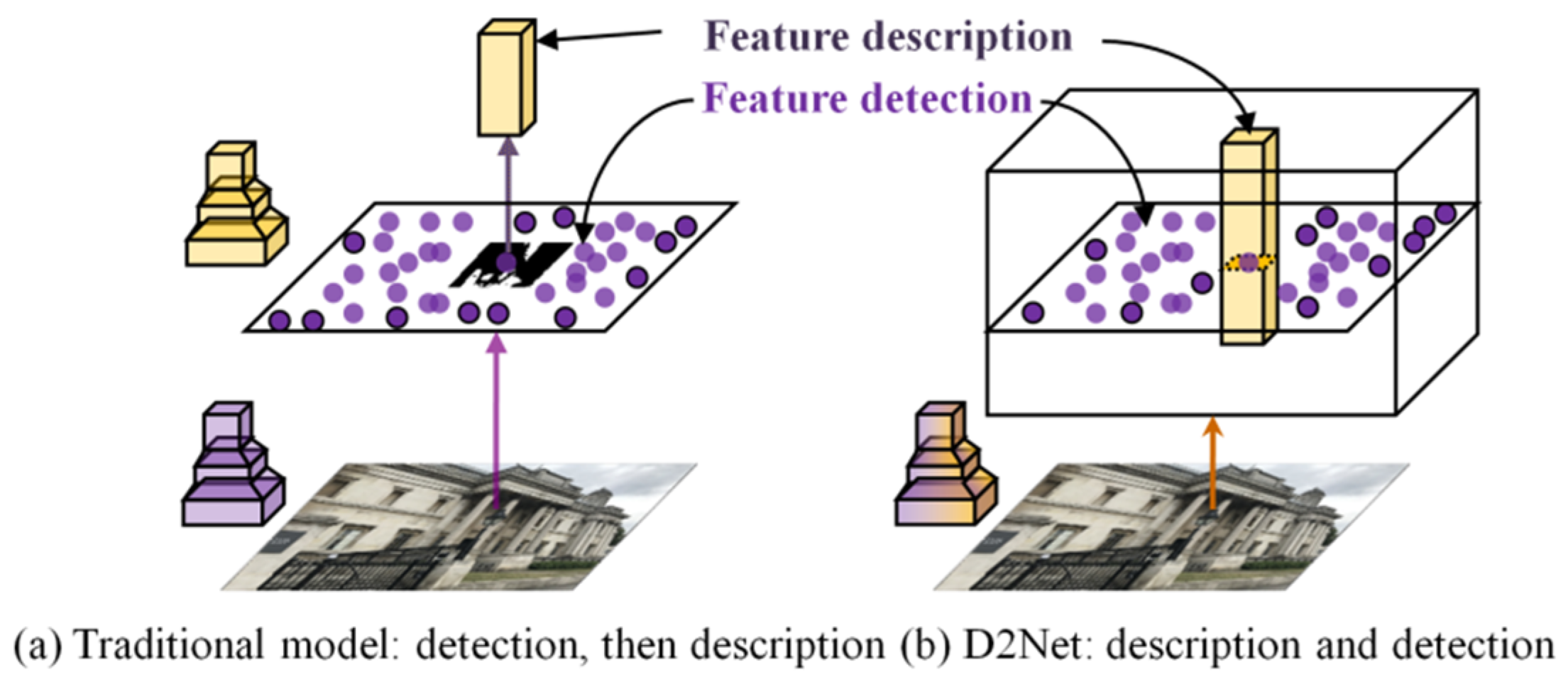
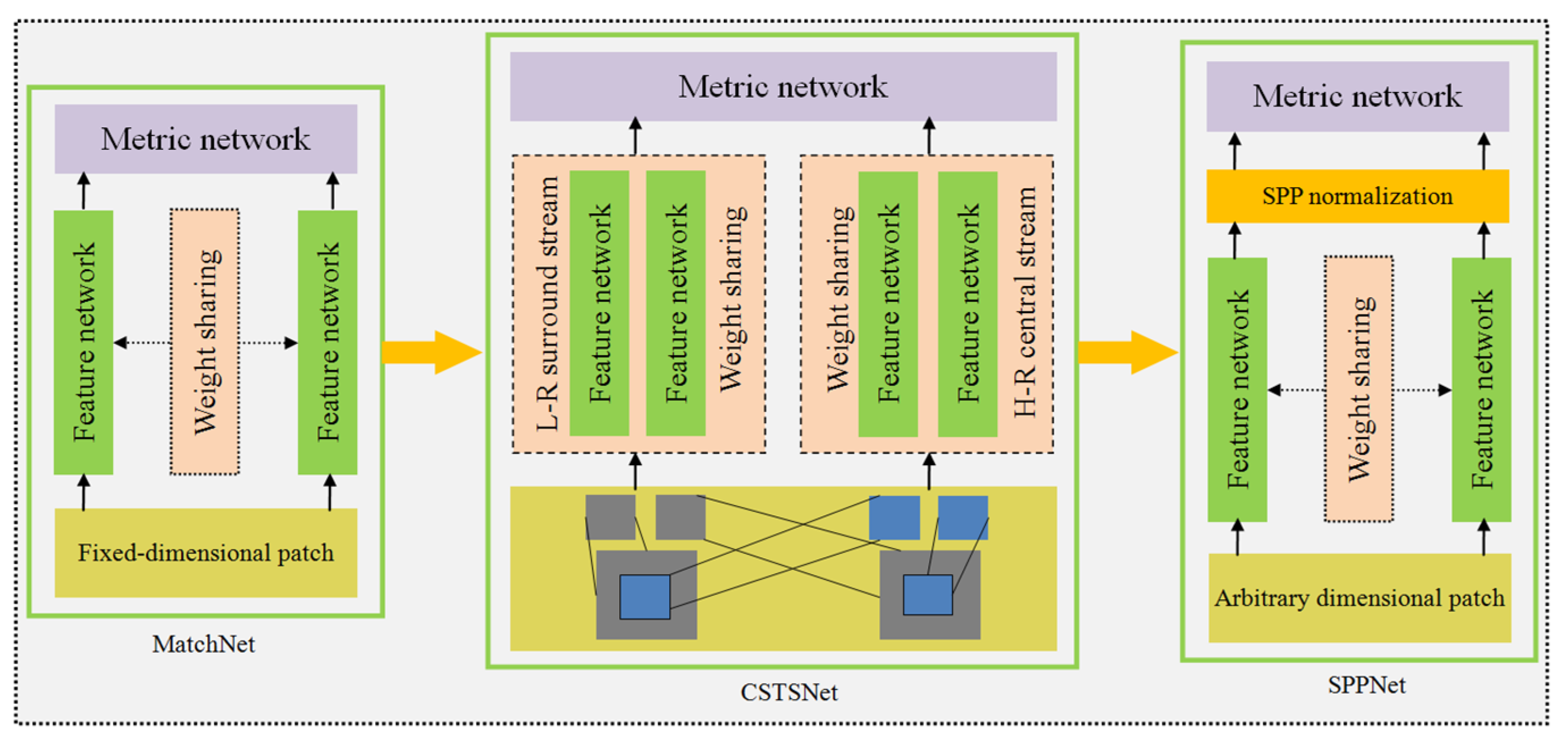
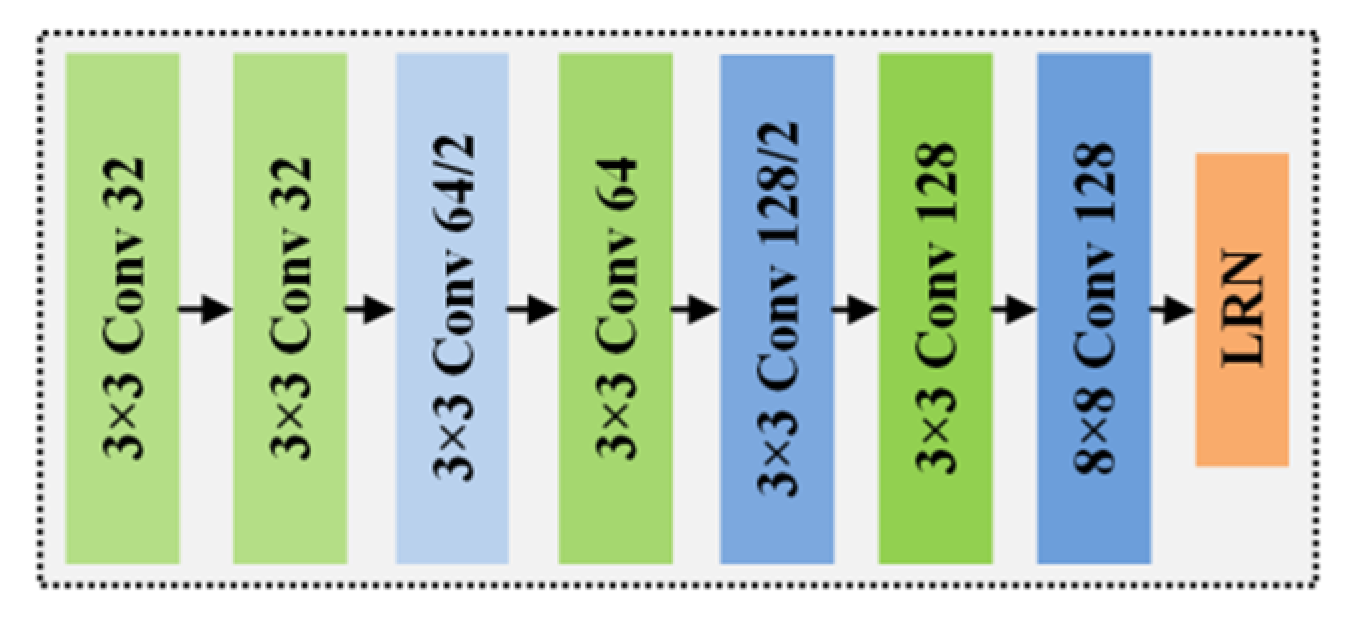
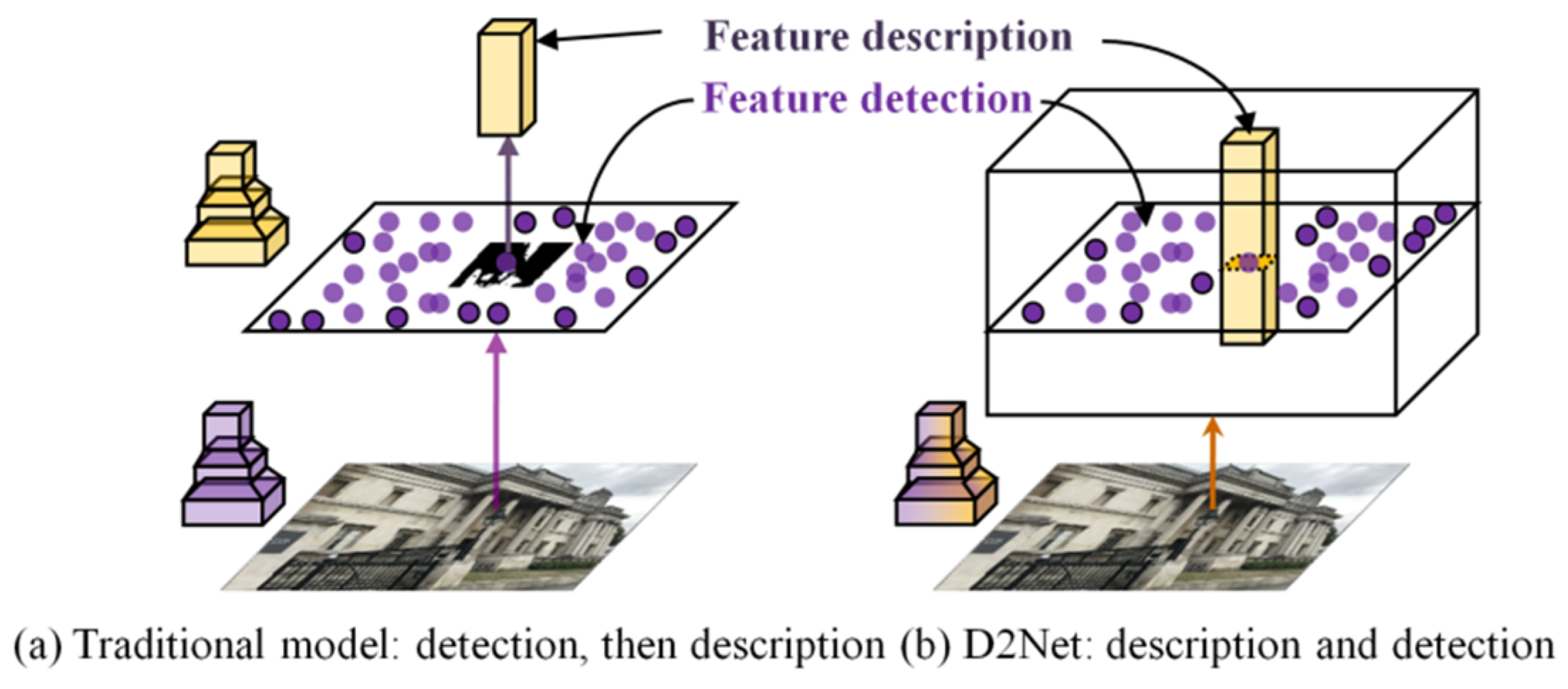
2.3. Deep-Learning End-to-End Matching
3. Results and Discussion
3.1. Representative Algorithms and Experimental Data
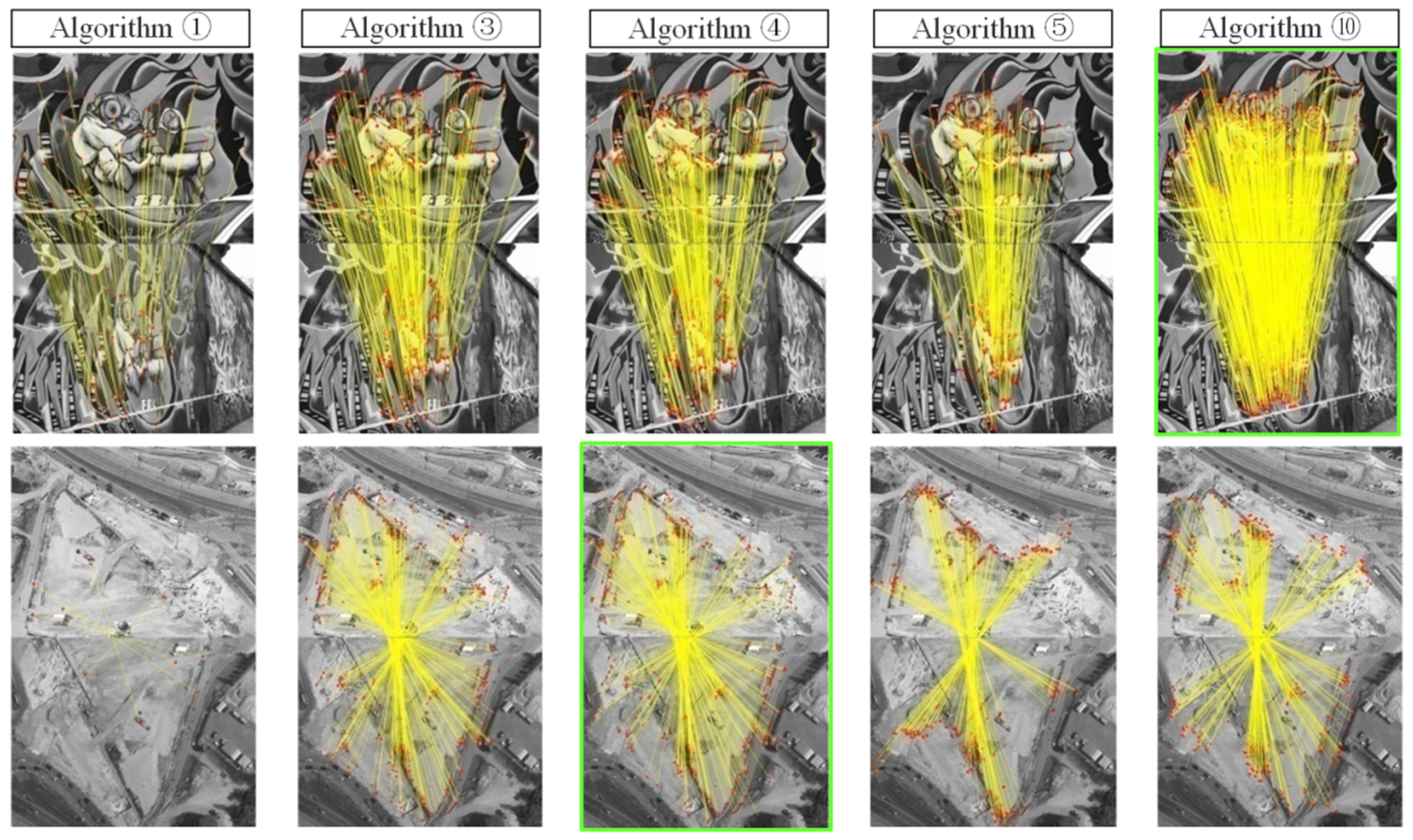
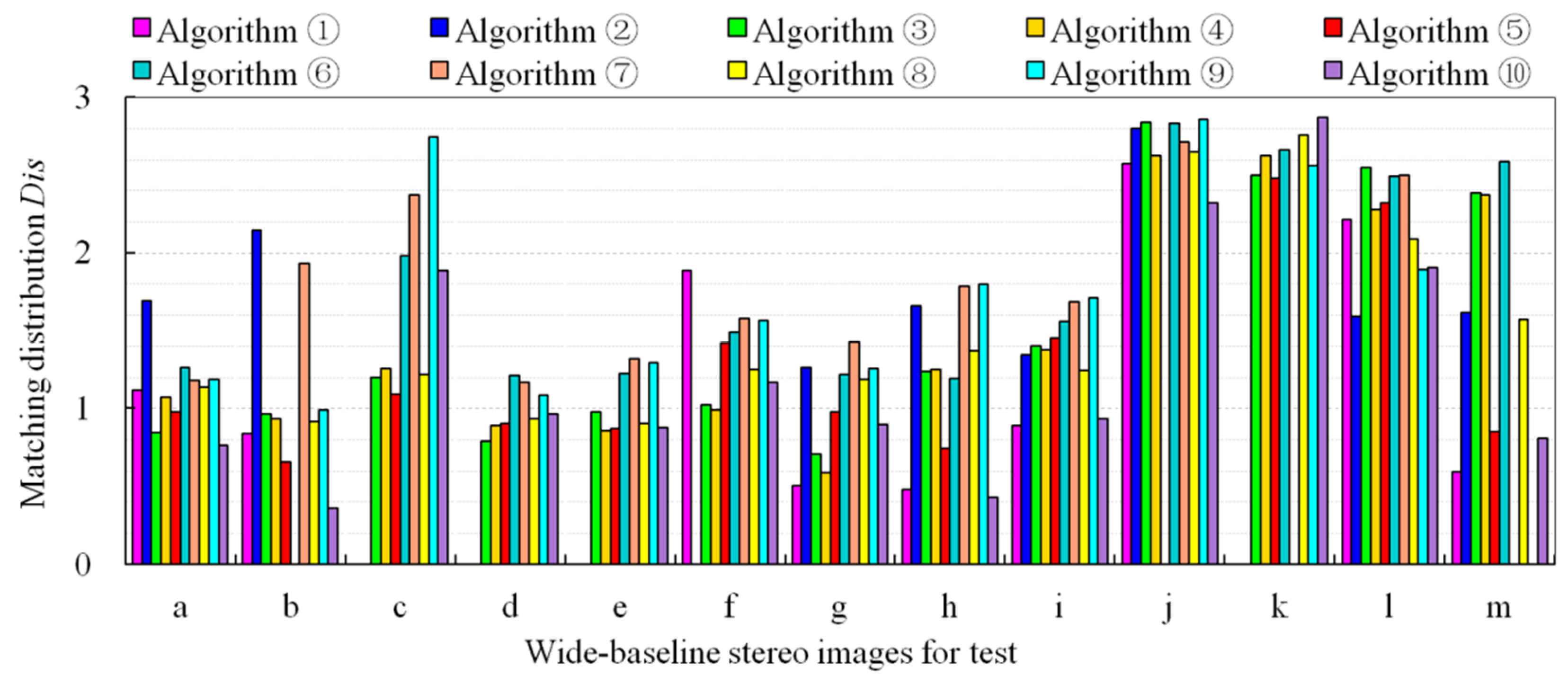
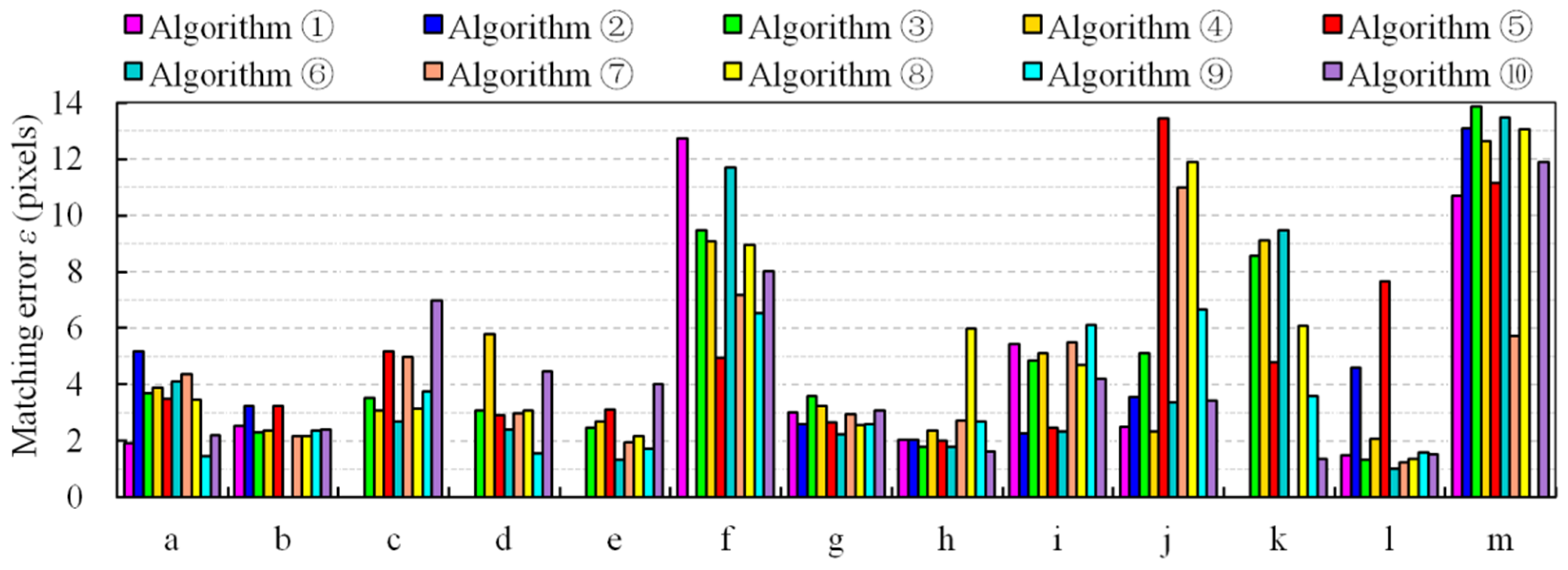
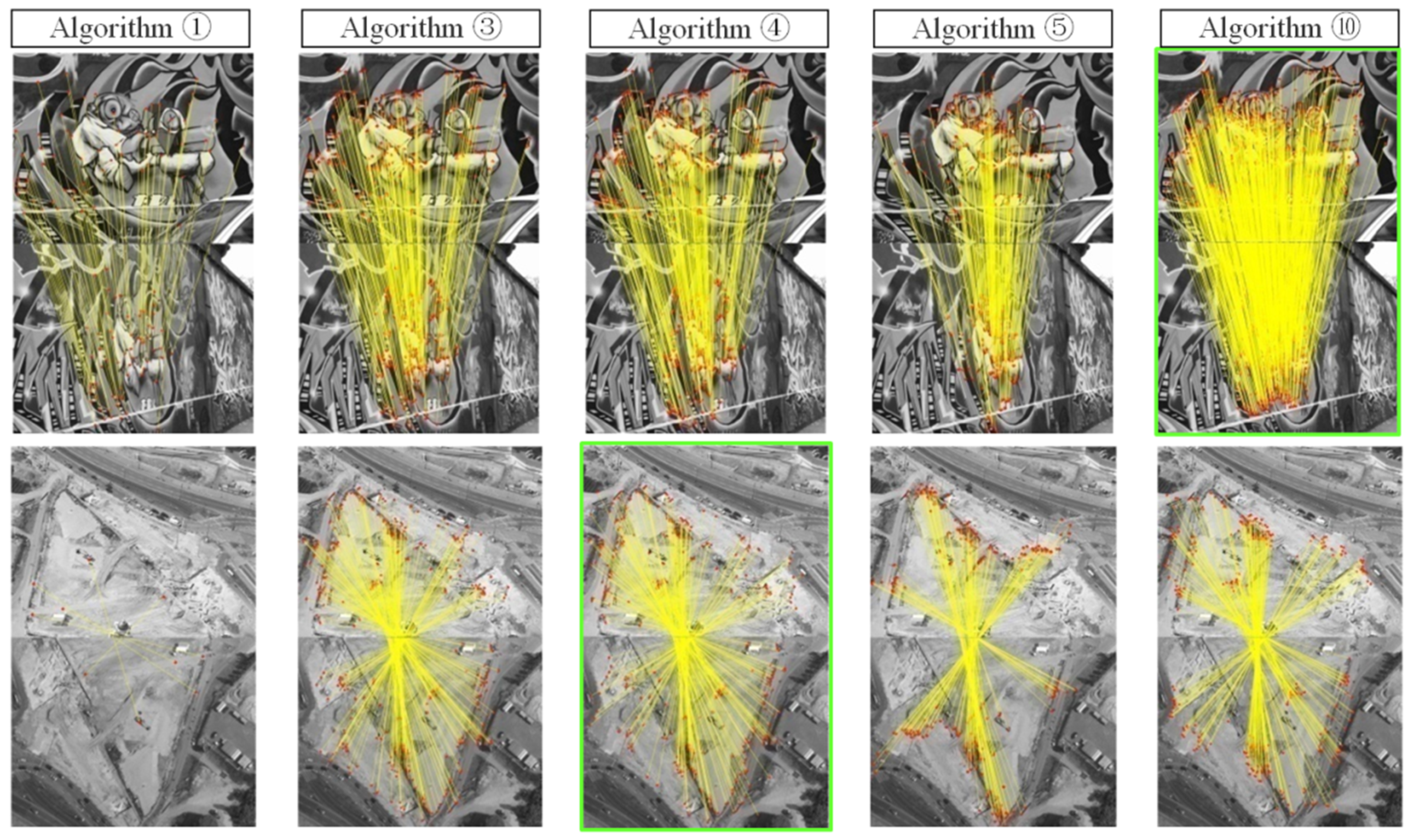
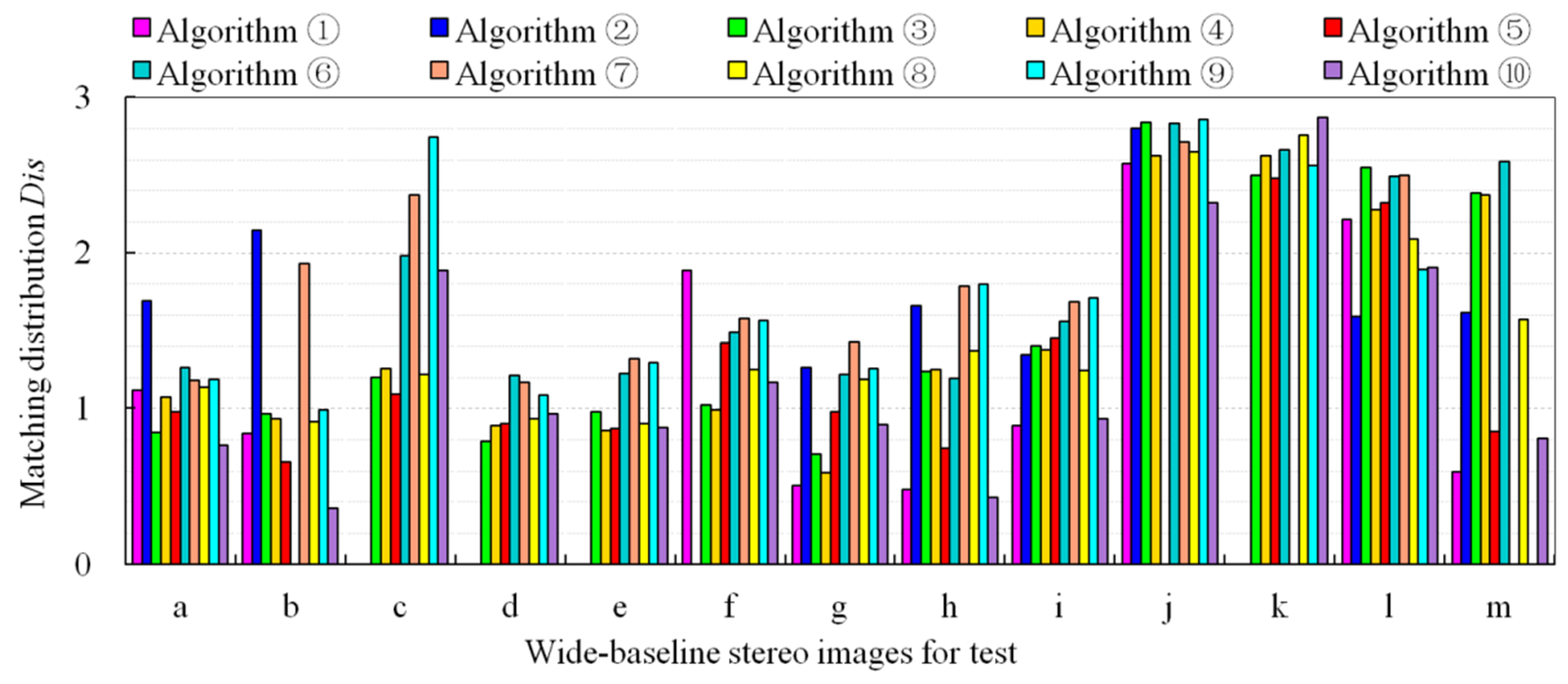
3.2. Experimental Results
3.3. Analysis and Discussion
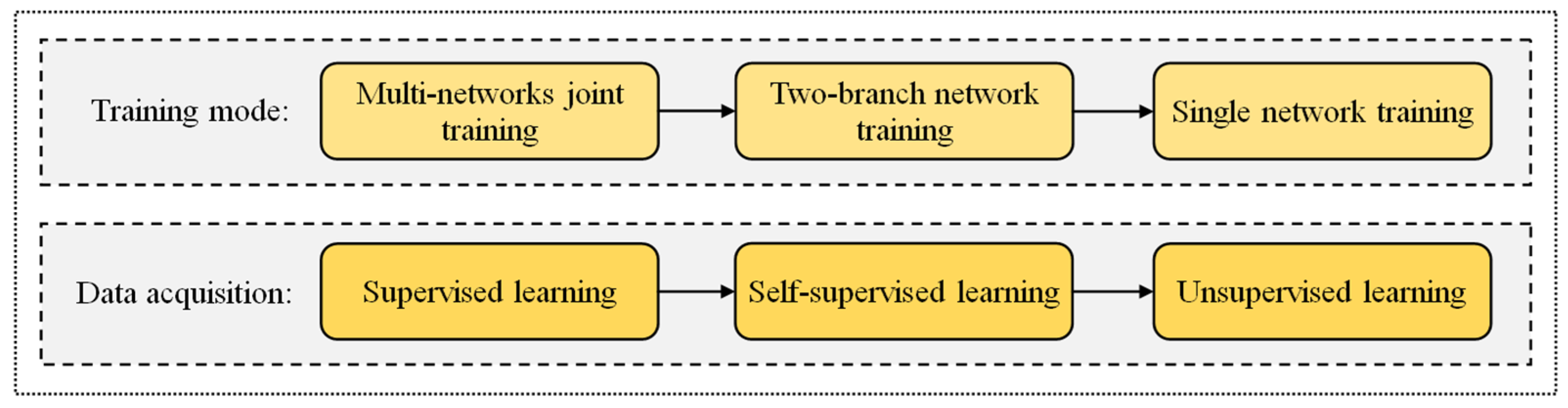
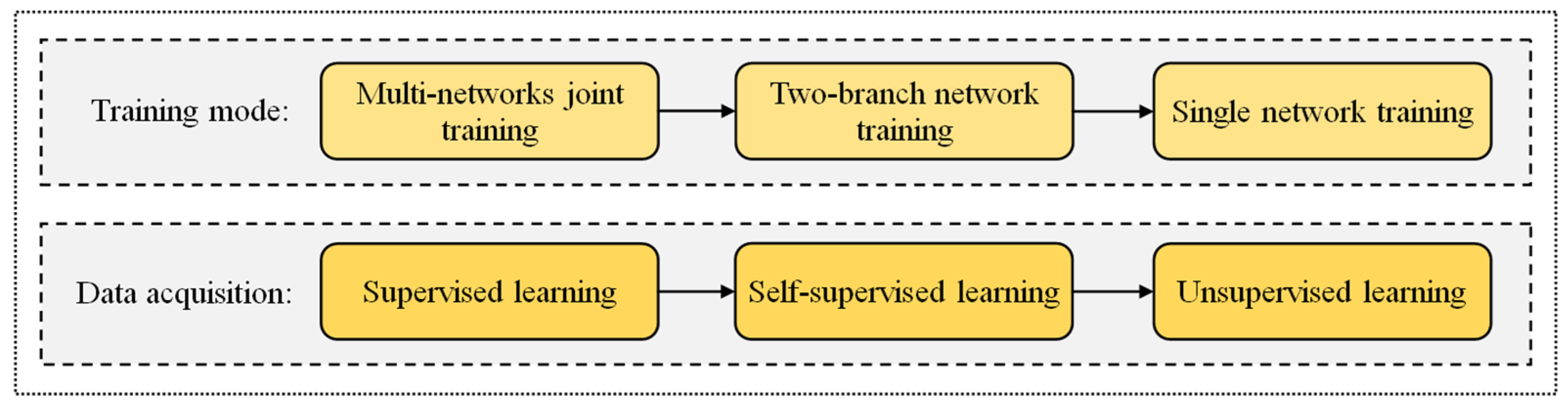
4. Summary and Outlook
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cao, M.; Gao, H.; Jia, W. Stable image matching for 3D reconstruction in outdoor. Int. J. Circuit Theory Appl. 2021, 49, 2274–2289. [Google Scholar] [CrossRef]
- Yao, J.; Qi, D.; Yao, Y.; Cao, F.; He, Y.; Ding, P.; Jin, C.; Jia, T.; Liang, J.; Deng, L.; et al. Total variation and block-matching 3D filtering-based image reconstruction for single-shot compressed ultrafast photography. Opt. Lasers Eng. 2020, 139, 106475. [Google Scholar] [CrossRef]
- Park, S.-W.; Yoon, R.; Lee, H.; Lee, H.-J.; Choi, Y.-D.; Lee, D.-H. Impacts of Thresholds of Gray Value for Cone-Beam Computed Tomography 3D Reconstruction on the Accuracy of Image Matching with Optical Scan. Int. J. Environ. Res. Public Health 2020, 17, 6375. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, Z.; Gong, J. Generalized photogrammetry of spaceborne, airborne and terrestrial multi-source remote sensing datasets. Acta Geod. Cartogr. Sin. 2021, 50, 1–11. [Google Scholar] [CrossRef]
- Chen, M.; Zhu, Q.; He, H.; Yan, S.; Zhao, Y. Structure adaptive feature point matching for urban area wide-baseline images with viewpoint variation. Acta Geod. Cartogr. Sin. 2019, 48, 1129–1140. [Google Scholar] [CrossRef]
- Zhang, L.; Ai, H.; Xu, B.; Sun, Y.; Dong, Y. Automatic tie-point extraction based on multiple-image matching and bundle adjustment of large block of oblique aerial images. Acta Geod. Cartogr. Sin. 2017, 46, 554–564. [Google Scholar] [CrossRef]
- Yao, G.; Deng, K.; Zhang, L.; Ai, H.; Du, Q. An algorithm of automatic quasi-dense matching and three-dimensional recon-struction for oblique stereo images. Geomat. Informat. Sci. Wuhan Univ. 2014, 39, 843–849. [Google Scholar]
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.M.; Trulls, E. Image Matching across Wide Baselines: From Paper to Practice. Int. J. Comput. Vis. 2020, 129, 517–547. [Google Scholar] [CrossRef]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Van Gool, L. A Comparison of Affine Region Detectors. Int. J. Comput. Vis. 2005, 65, 43–72. [Google Scholar] [CrossRef] [Green Version]
- Kasongo, S.M.; Sun, Y. A deep learning method with wrapper based feature extraction for wireless intrusion detection system. Comput. Secur. 2020, 92, 101752. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2020, 129, 23–79. [Google Scholar] [CrossRef]
- Chen, L.; Rottensteiner, F.; Heipke, C. Feature detection and description for image matching: From hand-crafted design to deep learning. Geo-Spat. Inf. Sci. 2020, 24, 58–74. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yao, G.; Cui, J.; Deng, K.; Zhang, L. Robust Harris Corner Matching Based on the Quasi-Homography Transform and Self-Adaptive Window for Wide-Baseline Stereo Images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 559–574. [Google Scholar] [CrossRef]
- Mikolajczyk, K. Scale & Affine Invariant Interest Point Detectors. Int. J. Comput. Vis. 2004, 60, 63–86. [Google Scholar] [CrossRef]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Morel, J.-M.; Yu, G. ASIFT: A New Framework for Fully Affine Invariant Image Comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Zhang, Y.; Xia, G.; Wang, J.; Lha, D. A Multiple Feature Fully Convolutional Network for Road Extraction from High-Resolution Remote Sensing Image Over Mountainous Areas. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1600–1604. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar] [CrossRef] [Green Version]
- Sangwan, D.; Biswas, R.; Ghattamaraju, N. An effective analysis of deep learning based approaches for audio based feature extraction and its visualization. Multimedia Tools Appl. 2018, 78, 23949–23972. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised Deep Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 519–531. [Google Scholar] [CrossRef]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Appl. Sci. 2019, 9, 4825. [Google Scholar] [CrossRef] [Green Version]
- Saeedimoghaddam, M.; Stepinski, T.F. Automatic extraction of road intersection points from USGS historical map series using deep convolutional neural networks. Int. J. Geogr. Inf. Sci. 2019, 34, 947–968. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Cosgriff, C.V.; Celi, L.A. Deep learning for risk assessment: All about automatic feature extraction. Br. J. Anaesth. 2020, 124, 131–133. [Google Scholar] [CrossRef] [PubMed]
- Maggipinto, M.; Beghi, A.; McLoone, S.; Susto, G.A. DeepVM: A Deep Learning-based approach with automatic feature extraction for 2D input data Virtual Metrology. J. Process. Control 2019, 84, 24–34. [Google Scholar] [CrossRef]
- Sun, Y.; Yen, G.G.; Yi, Z. Evolving Unsupervised Deep Neural Networks for Learning Meaningful Representations. IEEE Trans. Evol. Comput. 2018, 23, 89–103. [Google Scholar] [CrossRef]
- Lee, K.; Lim, J.; Ahn, S.; Kim, J. Feature extraction using a deep learning algorithm for uncertainty quantification of channelized reservoirs. J. Pet. Sci. Eng. 2018, 171, 1007–1022. [Google Scholar] [CrossRef]
- Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5279–5288. [Google Scholar] [CrossRef] [Green Version]
- Shukla, S.; Arac, A. A Step-by-Step Implementation of DeepBehavior, Deep Learning Toolbox for Automated Behavior Analysis. J. Vis. Exp. 2020, e60763. [Google Scholar] [CrossRef]
- Yan, M.; Li, Z.; Yu, X.; Jin, C. An End-to-End Deep Learning Network for 3D Object Detection From RGB-D Data Based on Hough Voting. IEEE Access 2020, 8, 138810–138822. [Google Scholar] [CrossRef]
- Laguna, A.B.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters. In Proceedings of the IEEECVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–29 October 2019. [Google Scholar] [CrossRef] [Green Version]
- Balntas, V.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Learning local feature descriptors with triplets and shallow convolutional neural networks. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Pan, B.; Zhang, J. Power tower detection in remote sensing imagery based on deformable network and transfer learning. Acta Geod. Cartogr. Sin. 2020, 49, 1042–1050. [Google Scholar] [CrossRef]
- Yao, Y.; Park, H.S. Multiview co-segmentation for wide baseline images using cross-view supervision. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass, CL, USA, 1–5 March 2020; pp. 1942–1951. [Google Scholar]
- Liu, J.; Wang, S.; Hou, X.; Song, W. A deep residual learning serial segmentation network for extracting buildings from remote sensing imagery. Int. J. Remote Sens. 2020, 41, 5573–5587. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, Z.; Liao, G.; Yuan, K. New loss functions for medical image registration based on VoxelMorph. In Image Processing of Medical Imaging, Proceedings of the SPIE Medical Imaging, Houston, TX, USA, 15–20 February 2020; p. 11313. [CrossRef]
- Cao, Y.; Wang, Y.; Peng, J.; Zhang, L.; Xu, L.; Yan, K.; Li, L. DML-GANR: Deep Metric Learning with Generative Adversarial Network Regularization for High Spatial Resolution Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8888–8904. [Google Scholar] [CrossRef]
- Yang, Y.; Li, C. Quantitative analysis of the generalization ability of deep feedforward neural networks. J. Intell. Fuzzy Syst. 2021, 40, 4867–4876. [Google Scholar] [CrossRef]
- Wang, L.; Qian, Y.; Kong, X. Line and point matching based on the maximum number of consecutive matching edge segment pairs for large viewpoint changing images. Signal Image Video Process. 2021, 1–8. [Google Scholar] [CrossRef]
- Zheng, B.; Qi, S.; Luo, G.; Liu, F.; Huang, X.; Guo, S. Characterization of discontinuity surface morphology based on 3D fractal dimension by integrating laser scanning with ArcGIS. Bull. Int. Assoc. Eng. Geol. 2021, 80, 2261–2281. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, S.; Jia, Y.; Liu, S. Prediction of terrain occlusion in Change-4 mission. Measures 2020, 152. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, X. Efficient and de-shadowing approach for multiple vehicle tracking in aerial video via image segmentation and local region matching. J. Appl. Remote Sens. 2020, 14, 014503. [Google Scholar] [CrossRef]
- Yuan, X.; Yuan, W.; Xu, S.; Ji, Y. Research developments and prospects on dense image matching in photogrammetry. Acta Geod. Cartogr. Sin. 2019, 48, 1542–1550. [Google Scholar]
- Liu, J.; Ji, S. Deep learning based dense matching for aerial remote sensing images. Acta Geod. Cartogr. Sin. 2019, 48, 1141–1150. [Google Scholar] [CrossRef]
- Chen, X.; He, H.; Zhou, J.; An, P.; Chen, T. Progress and future of image matching in low-altitude photogrammetry. Acta Geod. Cartogr. Sin. 2019, 48, 1595–1603. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Liu, H. Unsupervised Deep Feature Learning for Urban Village Detection from High-Resolution Remote Sensing Images. Photogramm. Eng. Remote Sens. 2017, 83, 567–579. [Google Scholar] [CrossRef]
- Chen, Q.; Liu, T.; Shang, Y.; Shao, Z.; Ding, H. Salient Object Detection: Integrate Salient Features in the Deep Learning Framework. IEEE Access 2019, 7, 152483–152492. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. FE-YOLO: A Feature Enhancement Network for Remote Sensing Target Detection. Remote Sens. 2021, 13, 1311. [Google Scholar] [CrossRef]
- Lenc, K.; Vedaldi, A. Learning Covariant Feature Detectors. In Proceedings of the ECCV Workshop on Geometry Meets Deep Learning, Amsterdam, The Netherlands, 31 August–1 September 2016; pp. 100–117. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Yu, F.X.; Karaman, S.; Chang, S.-F. Learning Discriminative and Transformation Covariant Local Feature Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4923–4931. [Google Scholar] [CrossRef]
- Doiphode, N.; Mitra, R.; Ahmed, S.; Jain, A. An Improved Learning Framework for Covariant Local Feature Detection. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2019; pp. 262–276. [Google Scholar] [CrossRef] [Green Version]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 84–92. [Google Scholar] [CrossRef] [Green Version]
- Yi, K.M.; Verdie, Y.; Fua, P.; Lepetit, V. Learning to Assign Orientations to Feature Points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 107–116. [Google Scholar] [CrossRef] [Green Version]
- Zitnick, C.L.; Ramnath, K. Edge foci interest points. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 359–366. [Google Scholar] [CrossRef]
- Mishkin, D.; Radenović, F.; Matas, J. Repeatability Is Not Enough: Learning Affine Regions via Discriminability. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 287–304. [Google Scholar] [CrossRef] [Green Version]
- Savinov, N.; Seki, A.; Ladicky, L.; Sattler, T.; Plooeleys, M. Quad-networks: Unsupervised learning to rank for interest point detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1822–1830. [Google Scholar]
- De Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Sokooti, H.; Staring, M.; Išgum, I. A deep learning framework for unsupervised affine and deformable image registration. Med. Image Anal. 2019, 52, 128–143. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdullah, T.; Bazi, Y.; Al Rahhal, M.M.; Mekhalfi, M.L.; Rangarajan, L.; Zuair, M. TextRS: Deep Bidirectional Triplet Network for Matching Text to Remote Sensing Images. Remote Sens. 2020, 12, 405. [Google Scholar] [CrossRef] [Green Version]
- Wei, X.; Zhang, Y.; Gong, Y.; Zheng, N. Kernelized subspace pooling for deep local descriptors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 346–361. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE T. Pattern. Anal. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, D.; Dong, Y.; Zhang, Y. Satellite image matching method based on deep convolution neural network. Acta Geod. Cartogr. Sin. 2018, 47, 844–853. [Google Scholar] [CrossRef]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6128–6136. [Google Scholar] [CrossRef]
- A Brown, M.; Hua, G.; Winder, S. Discriminative Learning of Local Image Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 43–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A Benchmark and Evaluation of Handcrafted and Learned Local Descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3852–3861. [Google Scholar] [CrossRef] [Green Version]
- Mishchuk, A.; Mishkin, D.; Radenovic, F. Working hard to know your neighbor’s margins: Local descriptor learning loss. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4826–4837. [Google Scholar]
- Ebel, P.; Mishchuk, A.; Yi, K.M.; Fua, P.; Trulls, E. Beyond cartesian representations for local descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 253–262. [Google Scholar]
- Tian, Y.; Yu, X.; Fan, B.; Wu, F.; Heijnen, H.; Balntas, V. SOSNet: Second Order Similarity Regularization for Local Descriptor Learning. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11008–11017. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Shen, T.; Zhou, L.; Zhu, S.; Zhang, R.; Yao, Y.; Fang, T.; Quan, L. GeoDesc: Learning Local Descriptors by Integrating Geometry Constraints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 170–185. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Shen, T.; Zhou, L.; Zhang, J.; Yao, Y.; Li, S.; Fang, T.; Quan, L. ContextDesc: Local Descriptor Augmentation with Cross-Modality Context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2522–2531. [Google Scholar] [CrossRef] [Green Version]
- Yao, G.; Yilmaz, A.; Zhang, L.; Meng, F.; Ai, H.; Jin, F. Matching Large Baseline Oblique Stereo Images Using an End-To-End Convolutional Neural Network. Remote Sens. 2021, 13, 274. [Google Scholar] [CrossRef]
- Mahapatra, D.; Ge, Z. Training data independent image registration using generative adversarial networks and domain adaptation. Pattern Recognit. 2019, 100, 107109. [Google Scholar] [CrossRef]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar] [CrossRef] [Green Version]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Chapelle, O.; Wu, M. Gradient descent optimization of smoothed information retrieval metrics. Inf. Retr. 2009, 13, 216–235. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, R.; Zhou, L.; Shen, T.; Fang, T.; Tan, P.; Quan, L. Very Large-Scale Global SfM by Distributed Motion Averaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4568–4577. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–33712. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Li, F. Image Encode Method Based on IFS with Probabilities Applying in Image Retrieval. In Proceedings of the Fourth Global Congress on Intelligent Systems (GCIS), Hong Kong, China, 2–3 December 2013; pp. 291–295. [Google Scholar] [CrossRef]
- Lie, W.-N.; Gao, Z.-W. Video Error Concealment by Integrating Greedy Suboptimization and Kalman Filtering Techniques. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 982–992. [Google Scholar] [CrossRef]
- Revaud, J.; Weinzaepfel, P.; De, S. R2D2: Repeatable and reliable detector and descriptor. arXiv 2019, arXiv:1906.06195. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Mooyi, K. LF-Net: Learning local features from images. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6234–6244. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8084–8093. [Google Scholar] [CrossRef]
- Xu, X.-F.; Zhang, L.; Duan, C.-D.; Lu, Y. Research on Inception Module Incorporated Siamese Convolutional Neural Networks to Realize Face Recognition. IEEE Access 2019, 8, 12168–12178. [Google Scholar] [CrossRef]
- Li, J.; Xie, Y.; Li, C.; Dai, Y.; Ma, J.; Dong, Z.; Yang, T. UAV-Assisted Wide Area Multi-Camera Space Alignment Based on Spatiotemporal Feature Map. Remote Sens. 2021, 13, 1117. [Google Scholar] [CrossRef]
- Hasheminasab, S.M.; Zhou, T.; Habib, A. GNSS/INS-Assisted Structure from Motion Strategies for UAV-Based Imagery over Mechanized Agricultural Fields. Remote Sens. 2020, 12, 351. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.-H.; Yoo, J.; Park, M.; Kim, J.; Kwon, S. Robust Extrinsic Calibration of Multiple RGB-D Cameras with Body Tracking and Feature Matching. Sensors 2021, 21, 1013. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2041–2050. [Google Scholar] [CrossRef] [Green Version]
- Shen, T.; Luo, Z.; Zhou, L.; Zhang, R.; Zhu, S.; Fang, T.; Quan, L. Matchable Image Retrieval by Learning from Surface Reconstruction. In Computer Vision–ACCV, Proceedings of the 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 415–431. [Google Scholar] [CrossRef] [Green Version]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-Scale Data for Multiple-View Stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef] [Green Version]
- Yao, G.; Deng, K.; Zhang, L.; Yang, H.; Ai, H. An automated registration method with high accuracy for oblique stereo images based on complementary affine invariant features. Acta Geod. Cartogr. Sin. 2013, 42, 869–876. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Wu, B.; Xu, Z.-X.; Qing, Z. Seed Point Selection Method for Triangle Constrained Image Matching Propagation. IEEE Geosci. Remote Sens. Lett. 2006, 3, 207–211. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Algorithms | Code links |
|---|---|---|
| Deep learning end-to-end matching | ①SuperPoint [81] | https://github.com/rpautrat/SuperPoint |
| ②D2Net [86] | https://github.com/mihaidusmanu/d2-net | |
| Deep learning feature detection and description | ③AffNet [57] + HardNet [70] | https://github.com/DagnyT/hardnet |
| ④AffNet [57] + SOSNet [72] | https://github.com/scape-research/SOSNet | |
| ⑤DetNet [51] + Contexdesc [74] | https://github.com/lzx551402/contextdesc | |
| ⑥DetNet [51] + HardNet [70] | https://github.com/lenck/ddet | |
| Deep learning feature detection and handcrafted feature description | ⑦AffNet [57] + SIFT [14] | https://github.com/ducha-aiki/affnet |
| Handcrafted feature detection and deep learning feature description | ⑧Hessian [16] + HardNet [70] | https://github.com/doomie/HessianFree |
| Handcrafted matching | ⑨MSER [17] + SIFT [14] | https://github.com/idiap/mser |
| ⑩ASIFT [18] | https://github.com/search?q=ASIFT |
| Testdata | Left Image (Pixels) | Right Image (Pixels) | Description for Image Pair | True Perspective Transform Matrix H or True Fundamental Matrix F | |
|---|---|---|---|---|---|
| Ground close-ranges data | a | 800 × 640 | 800 × 640 | Close-range stereo images with 60 deg viewpoint change | H is provided by Reference [10] |
| b | 1000 × 700 | 880 × 680 | Close-range stereo images with repetitive patterns and 60 deg viewpoint change | H is provided by Reference [10] | |
| c | 850 × 680 | 850 × 680 | Close-range stereo images with about 45 deg rotation and 2.5 times scale transform | H is provided by Reference [10] | |
| Low attitude data | d | 900 × 700 | 900 × 700 | UAV stereo images with 90 deg rotation and significant oblique viewpoint change | H is estimated by manual work |
| e | 800 × 600 | 800 × 600 | UAV stereo images with 90 deg rotation, large oblique view change, and radiometric distortion | H is estimated by manual work | |
| f | 900 × 700 | 900 × 700 | UAV stereo images with rare texture, large view change, and radiometric distortion | H is estimated by manual work | |
| g | 800 × 600 | 800 × 600 | UAV stereo images with significant scale deformation, oblique view change, radiometric distortion, and numerous 3D scenes | F is estimated by manual work | |
| h | 800 × 600 | 800 × 600 | UAV stereo images with large oblique view change, and numerous 3D scenes | F is estimated by manual work | |
| i | 1084 × 814 | 1084 × 814 | UAV stereo images with significant oblique view change, radiometric distortion, and complex 3D scenes | F is estimated by manual work | |
| j | 5472 × 3468 | 5472 × 3468 | UAV stereo images with significant view change, surface discontinuity, object occlusion, and rare texture | F is estimated by manual work | |
| k | 4200 × 3154 | 4200 × 3154 | UAV stereo images with about 90 deg rotation, significant oblique view change, single texture, and large area of water | F is estimated by manual work | |
| Sallite data | l | 2316 × 2043 | 2316 × 2043 | Satellite optical stereo image with notable rotation, significant topography variation, and rare texture | F is estimated by manual work |
| m | 2872 × 2180 | 2872 × 2180 | Satellite optical stereo images with significant surface discontinuity, radiometric distortion, dense 3D buildings, and single texture | F is estimated by manual work | |
| Algorithms | a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ①SuperPoint | 65 | 277 | 0 | 0 | 0 | 5 | 337 | 498 | 523 | 618 | 0 | 419 | 3856 |
| ②D2Net | 7 | 118 | 0 | 0 | 0 | 0 | 36 | 38 | 32 | 23 | 0 | 33 | 114 |
| ③AffNet + HardNet | 239 | 414 | 54 | 617 | 229 | 200 | 147 | 152 | 178 | 147 | 141 | 198 | 62 |
| ④AffNet + SOSNet | 263 | 421 | 39 | 690 | 233 | 208 | 152 | 151 | 178 | 120 | 134 | 237 | 58 |
| ⑤DetNet + Contexdesc | 201 | 540 | 119 | 939 | 607 | 152 | 102 | 207 | 339 | 22 | 18 | 79 | 489 |
| ⑥DetNet + HardNet | 7 | 0 | 29 | 15 | 48 | 7 | 45 | 67 | 90 | 7 | 144 | 38 | 21 |
| ⑦AffNet + SIFT | 33 | 59 | 6 | 131 | 36 | 7 | 7 | 16 | 24 | 16 | 0 | 49 | 7 |
| ⑧Hessian + HardNet | 180 | 313 | 64 | 620 | 191 | 176 | 124 | 131 | 154 | 144 | 142 | 188 | 53 |
| ⑨MSER + SIFT | 37 | 185 | 6 | 54 | 29 | 6 | 17 | 31 | 50 | 16 | 8 | 224 | 0 |
| ⑩ASIFT | 855 | 2339 | 22 | 1287 | 223 | 175 | 153 | 188 | 348 | 528 | 275 | 1304 | 2580 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, G.; Yilmaz, A.; Meng, F.; Zhang, L. Review of Wide-Baseline Stereo Image Matching Based on Deep Learning. Remote Sens. 2021, 13, 3247. https://doi.org/10.3390/rs13163247
Yao G, Yilmaz A, Meng F, Zhang L. Review of Wide-Baseline Stereo Image Matching Based on Deep Learning. Remote Sensing. 2021; 13(16):3247. https://doi.org/10.3390/rs13163247
Chicago/Turabian StyleYao, Guobiao, Alper Yilmaz, Fei Meng, and Li Zhang. 2021. "Review of Wide-Baseline Stereo Image Matching Based on Deep Learning" Remote Sensing 13, no. 16: 3247. https://doi.org/10.3390/rs13163247
APA StyleYao, G., Yilmaz, A., Meng, F., & Zhang, L. (2021). Review of Wide-Baseline Stereo Image Matching Based on Deep Learning. Remote Sensing, 13(16), 3247. https://doi.org/10.3390/rs13163247