
How the Small Object Detection via Machine Learning and UAS-Based Remote-Sensing Imagery Can Support the Achievement of SDG2: A Case Study of Vole Burrows





Abstract
:1. Introduction
2. Motivation
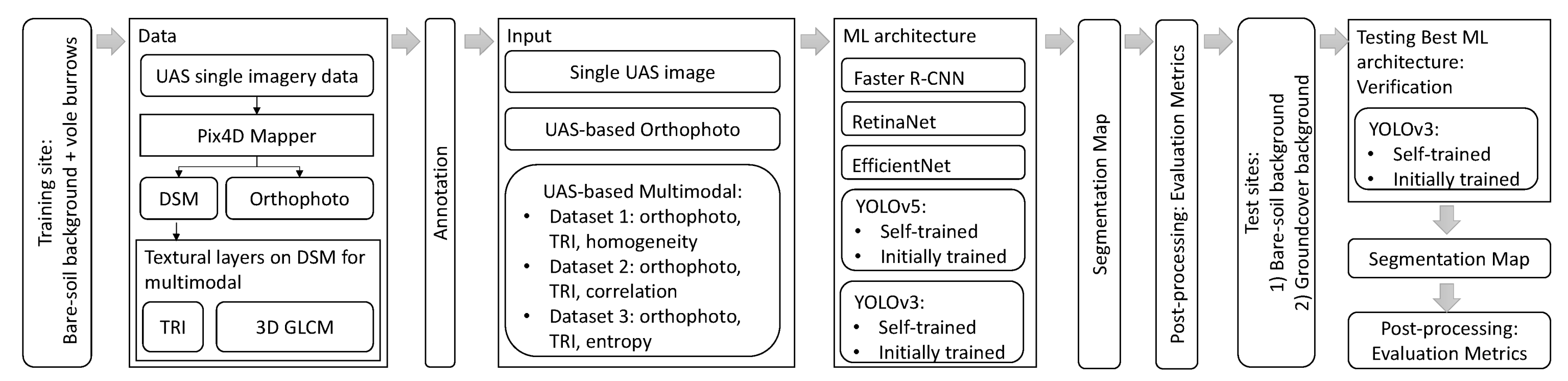
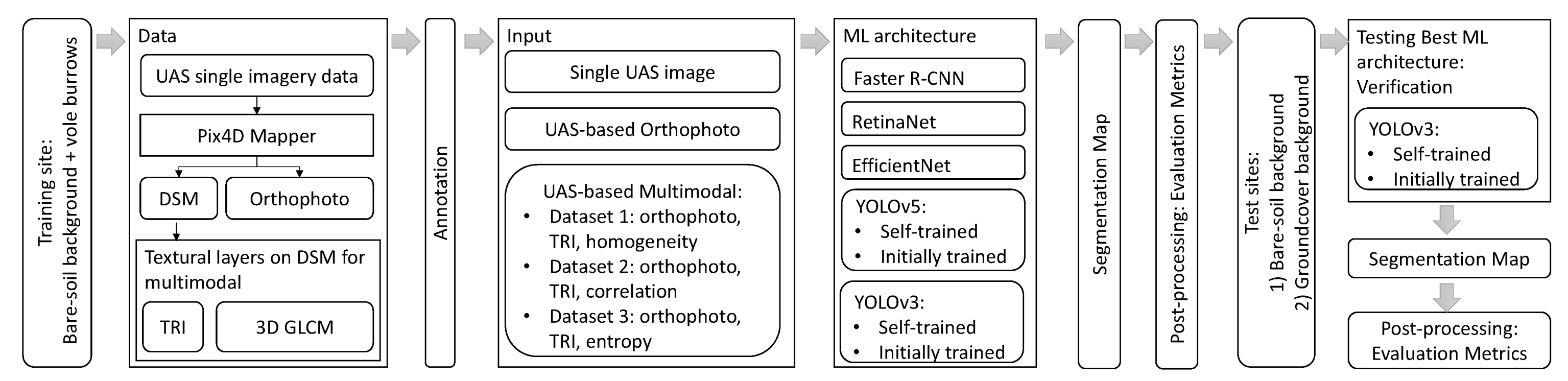
3. Materials and Methods
3.1. Object Detection Models
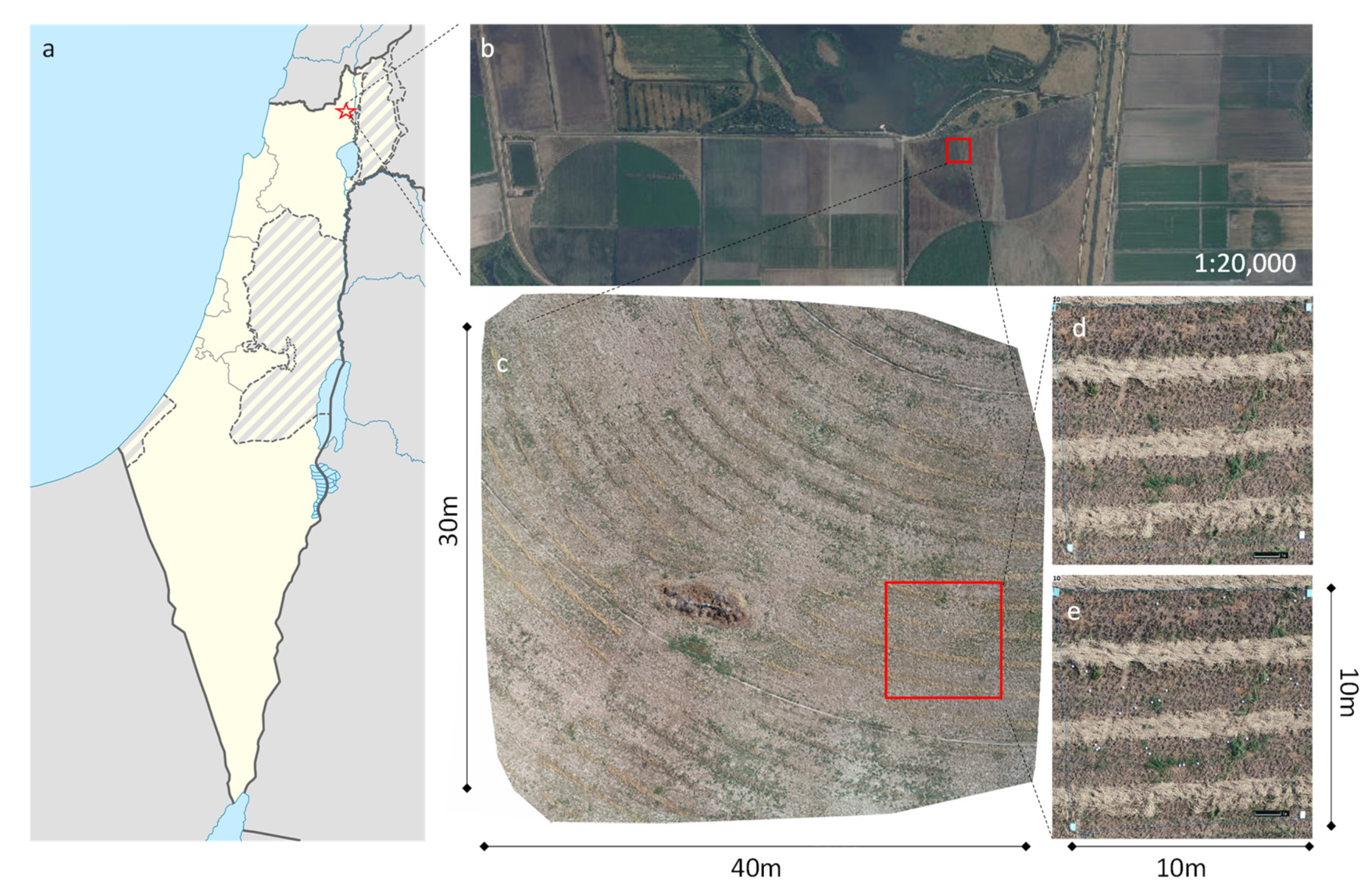
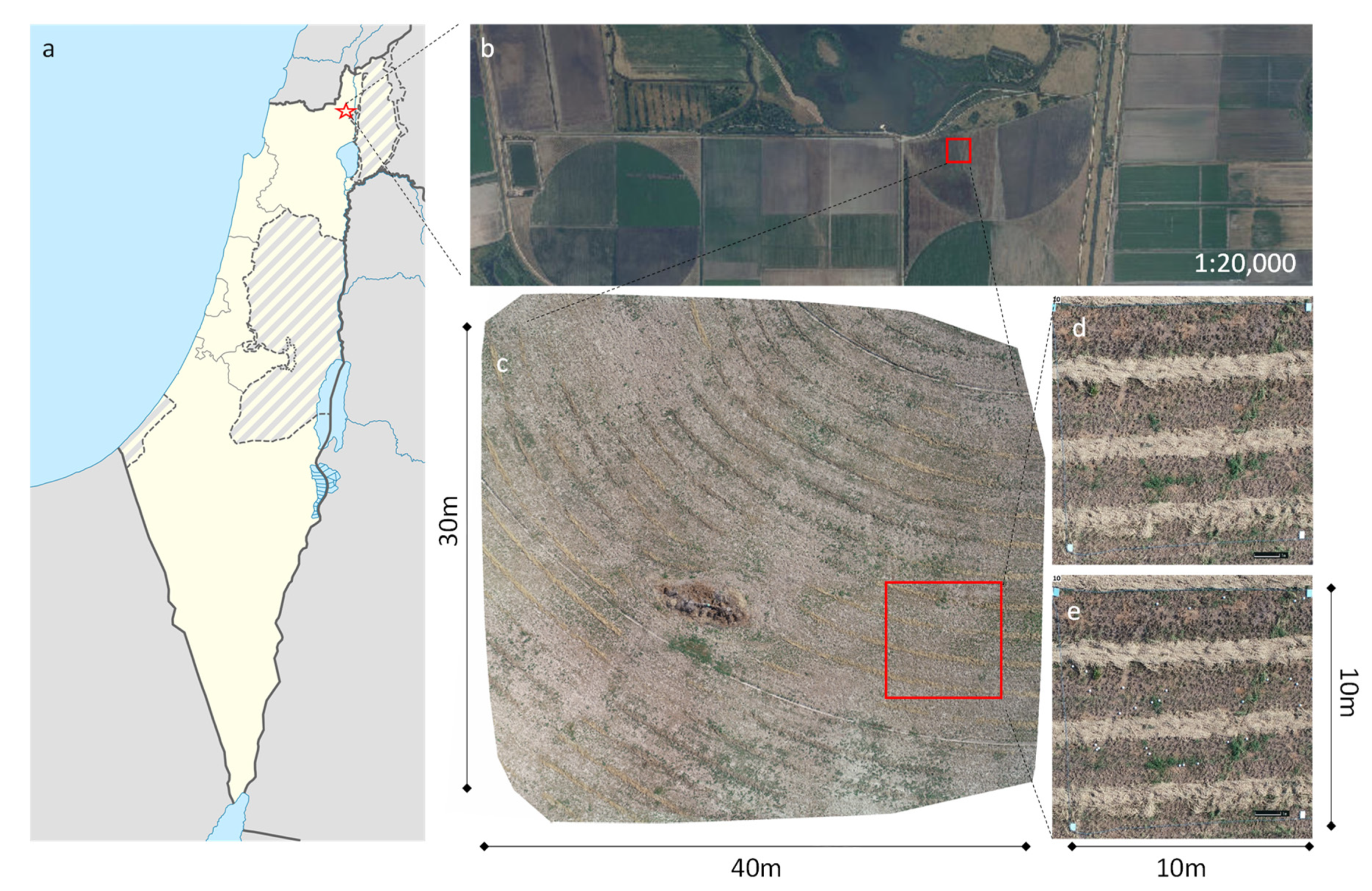
3.2. Field Study
3.2.1. Dataset
3.2.2. Training
4. Results
Effects of Different Backgrounds in the Validation Sets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. Conference STRATEGIC FRAMEWORK 2010–2019, C 2009/3. 2009. [Online]. Available online: www.fao.orgW/K5864/e (accessed on 23 November 2009).
- Stenseth, N.C.; Leirs, H.; Skonhoft, A.; Davis, S.A.; Pech, R.P.; Andreassen, H.P.; Singleton, G.R.; Lima, M.; Machang’u, R.S.; Makundi, R.H.; et al. Mice, rats, and people: The bio-economics of agricultural rodent pests. Front. Ecol. Environ. 2003, 1, 367–375. [Google Scholar] [CrossRef]
- Buckle, A.; Smith, R. Rodents in agriculture and forestry. In Rodent Pests Control; Buckle, A.P., Smith, R.H., Eds.; School of Biological Sciences, University of Reading: Reading, UK, 2015; pp. 33–80. [Google Scholar]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector with Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1758–1770. [Google Scholar] [CrossRef]
- Jones, P.V.M.J. Robust Real-time Object Detection. Int. J. Comput. Vis. 2001, 4, 34–47. [Google Scholar]
- Gu, Y.; Wylie, B.K.; Boyte, S.P.; Picotte, J.; Howard, D.M.; Smith, K.; Nelson, K.J. An Optimal Sample Data Usage Strategy to Minimize Overfitting and Underfitting Effects in Regression Tree Models Based on Remotely-Sensed Data. Remote Sens. 2016, 8, 943. [Google Scholar] [CrossRef] [Green Version]
- Al-Najjar, H.A.H.; Kalantar, B.; Pradhan, B.; Saeidi, V.; Halin, A.A.; Ueda, N.; Mansor, S. Land Cover Classification from fused DSM and UAV Images Using Convolutional Neural Networks. Remote Sens. 2019, 11, 1461. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Han, L.; Han, L.; Zhu, L. How Well Do Deep Learning-Based Methods for Land Cover Classification and Object Detection Perform on High Resolution Remote Sensing Imagery? Remote Sens. 2020, 12, 417. [Google Scholar] [CrossRef] [Green Version]
- Jogin, M.; Mohana; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature Extraction using Convolution Neural Networks (CNN) and Deep Learning. In Proceedings of the 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bengaluru, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Dyrmann, M.; Jørgensen, R.N.; Midtiby, H.S. RoboWeedSupport-Detection of weed locations in leaf occluded cereal crops using a fully convolutional neural network. Adv. Anim. Biosci. 2017, 8, 842–847. [Google Scholar] [CrossRef]
- Dias, D.; Dias, U. Flood detection from social multimedia and satellite images using ensemble and transfer learning with CNN architectures. In Proceedings of the CEUR Workshop Proceedings, Sophia Antipolis, France, 29–31 October 2018; p. 2283. [Google Scholar]
- Bargoti, S.; Underwood, J. Image classification with orchard metadata. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; Institute of Electrical and Electronics Engineers (IEEE), Australian Centre for Field Robotics: Sydney, Australia, 2016; pp. 5164–5170. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. DSOD: Learning Deeply Supervised Object Detectors from Scratch. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO v3.0: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Hua, Y.; Mou, L.; Zhu, X.X. LAHNet: A Convolutional Neural Network Fusing Low- and High-Level Features for Aerial Scene Classification. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4728–4731. [Google Scholar]
- Lu, X.; Li, Q.; Li, B.; Yan, J. MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection. arXiv 2020, arXiv:2009.11528. [Google Scholar]
- Pham, V.; Pham, C.; Dang, T. Road Damage Detection and Classification with Detectron2 and Faster R-CNN. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data) 2020, Atlanta, GA, USA, 10–13 December 2020; pp. 5592–5601. [Google Scholar]
- Benton, T.; Vickery, J.A.; Wilson, J. Farmland biodiversity: Is habitat heterogeneity the key? Trends Ecol. Evol. 2003, 18, 182–188. [Google Scholar] [CrossRef]
- Witmer, G.W.; Moulton, R.S.; Baldwin, R.A. An efficacy test of cholecalciferol plus diphacinone rodenticide baits for California voles (Microtus californicusPeale) to replace ineffective chlorophacinone baits. Int. J. Pest Manag. 2014, 60, 275–278. [Google Scholar] [CrossRef]
- Kross, S.M.; Bourbour, R.; Martinico, B. Agricultural land use, barn owl diet, and vertebrate pest control implications. Agric. Ecosyst. Environ. 2016, 223, 167–174. [Google Scholar] [CrossRef]
- Motro, Y. Economic evaluation of biological rodent control using barn owls Tyto alba in alfalfa. In Proceedings of the Julius-Kühn-Archiv 8 th European Vertebrate Pest Management Conference, Berlin, Germany, 26–30 September 2011; pp. 79–80. [Google Scholar] [CrossRef]
- Cohen-Shlagman, L.; Hellwing, S.; Yom-Tov, Y. The biology of the Levant vole, Microtus guentheri in Israel. II. The reproduction and growth in captivity. Z. Für Säugetierkd. 1984, 49, 148–156. [Google Scholar]
- Cohen-Shlagman, L.; Hellwing, S.; Yom-Tov, Y. The biology of the Levant vole, Microtus guentheri in Israel. I: Population dynamics in the field. Z. Für Säugetierkd. 1984, 49, 135–147. [Google Scholar]
- Yom-Tov, Y.; Yom-Tov, S.; Moller, H. Competition, coexistence, and adaptation amongst rodent invaders to Pacific and New Zealand islands. J. Biogeogr. 1999, 26, 947–958. [Google Scholar] [CrossRef] [Green Version]
- US EPA; Grube, A.; Donaldson, D.; Kiely, T.; Wu, L. Pesticides Industry Sales and Usage; US EPA: Washington, DC, USA, 2011; p. 41. [Google Scholar]
- Stone, W.B.; Okoniewski, J.C.; Stedelin, J.R. Poisoning of Wildlife with Anticoagulant Rodenticides in New York. J. Wildl. Dis. 1999, 35, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Terrell, P.S.; Salmon, T.P.; Lawrence, S.J. Anticoagulant Resistance in Meadow Voles (Microtus californicus). Proc. Proc. Vertebr. Pest Conf. 2006, 22. [Google Scholar] [CrossRef] [Green Version]
- Buckle, A. Anticoagulant resistance in the United Kingdom and a new guideline for the management of resistant infestations of Norway rats (Rattus norvegicusBerk.). Pest Manag. Sci. 2013, 69, 334–341. [Google Scholar] [CrossRef]
- Meyrom, K.; Motro, Y.; Leshem, Y.; Aviel, S.; Izhaki, I.; Argyle, F.; Charter, M. Nest-box use by the Barn Owl Tyto alba in a biological pest control program in the Beit She’an valley, Israel. Ardea 2009, 97, 463–467. [Google Scholar] [CrossRef]
- Peleg, O.; Nir, S.; Leshem, Y.; Meyrom, K.; Aviel, S.; Charter, M.; Roulin, A.; Izhak, I. Three Decades of Satisfied Israeli Farmers: Barn Owls (Tyto alba) as Biological Pest Control of Rodents. Proc. Proc. Vertebr. Pest Conf. 2018, 28. [Google Scholar] [CrossRef] [Green Version]
- Khosla, R. Precision agriculture: Challenges and opportunities in a flat world. In Proceedings of the Soil Solutions for a Changing World, Brisbane, Australia, 1–6 August 2020. [Google Scholar]
- Zhang, C.; Kovacs, J.M. The application of small unmanned aerial systems for precision agriculture: A review. Precis. Agric. 2012, 13, 693–712. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Xie, Z.; Zhang, W.; Xu, X. ResNet and Model Fusion for Automatic Spoofing Detection. Interspeech 2017, 102–106. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Pham, M.-T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects under Various Backgrounds in Remote Sensing Images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018, IEEE/CVF Conference on Computer Vision a8759&nd Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Tmušić, G.; Manfreda, S.; Aasen, H.; James, M.R.; Gonçalves, G.; Ben-Dor, E.; Brook, A.; Polinova, M.; Arranz, J.J.; Mészáros, J.; et al. Current Practices in UAS-based Environmental Monitoring. Remote Sens. 2020, 12, 1001. [Google Scholar] [CrossRef] [Green Version]
- Boon, M.A.; Greenfield, R.; Tesfamichael, S. Wetland assessment using unmanned aerial vehicle (uav) photogrammetry. ISPRS -Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2016, XLI-B1, 781–788. [Google Scholar] [CrossRef] [Green Version]
- Brook, A.; Shtober-Zisu, N. Rock surface modeling as a tool to assess the morphology of inland notches, Mount Carmel, Israel. Catena 2020, 187, 104256. [Google Scholar] [CrossRef]
- Sieberth, T.; Wackrow, R.; Chandler, J.H. Automatic detection of blurred images in UAV image sets. ISPRS J. Photogramm. Remote Sens. 2016, 122, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Hirschmüller, H. Semi-Global Matching Motivation, Developments and Applications. In Proceedings of the Photogramm Week, Stuttgart, Germany, 5–9 September 2011. [Google Scholar]
- Alidoost, F.; Arefi, H. An Image-Based Technique For 3d Building Reconstruction Using Multi-View Uav Images. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-1/W5, 43–46. [Google Scholar] [CrossRef] [Green Version]
- Höhle, J.; Höhle, M. Accuracy assessment of digital elevation models by means of robust statistical methods. ISPRS J. Photogramm. Remote Sens. 2009, 64, 398–406. [Google Scholar] [CrossRef] [Green Version]
- Ivelja, T.; Bechor, B.; Hasan, O.; Miko, S.; Sivan, D.; Brook, A. Improving vertical accuracy of uav digital surface models by introducing terrestrial laser scans on a point-cloud level. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B1-2, 457–463. [Google Scholar] [CrossRef]
- Glenn, N.; Streutker, D.R.; Chadwick, D.J.; Thackray, G.D.; Dorsch, S.J. Analysis of LiDAR-derived topographic information for characterizing and differentiating landslide morphology and activity. Geomorphology 2006, 73, 131–148. [Google Scholar] [CrossRef]
- Berti, M.; Corsini, A.; Daehne, A. Comparative analysis of surface roughness algorithms for the identification of active landslides. Geomorphology 2013, 182, 1–18. [Google Scholar] [CrossRef]
- Soh, L.-K.; Tsatsoulis, C. Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 1999, 37, 780–795. [Google Scholar] [CrossRef] [Green Version]
- Yan, L.; Xia, W. A modified three-dimensional gray-level co-occurrence matrix for image classification with digital surface model. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 133–138. [Google Scholar] [CrossRef] [Green Version]
- Kurani, A.S.; Xu, D.H.; Furst, J.; Raicu, D.S. Co-occurrence matrices for volumetric data. In Proceedings of the Seventh IASTED International Conference on Computer Graphics and Imaging, Kauai, HI, USA, 17–19 August 2004; pp. 426–443. [Google Scholar]
- Flach, P.A.; Kull, M. Precision-Recall-Gain curves: PR analysis done right. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Koitka, S.; Friedrich, C.M. Optimized Convolutional Neural Network Ensembles for Medical Subfigure Classification. Comput. Vis. 2017, 57–68. [Google Scholar] [CrossRef]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Detecting Apples in Orchards Using YOLOv3 and YOLOv5 in General and Close-Up Images. In Proceedings of the Advances in Neural Networks—ISNN 2020, Cairo, Egypt, 4–6 December 2020; pp. 233–243. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [Green Version]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Jeon, I.; Ham, S.; Cheon, J.; Klimkowska, A.M.; Kim, H.; Choi, K.; Lee, I. A REAL-TIME DRONE MAPPING PLATFORM FOR MARINE SURVEILLANCE. ISPRS Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, 42, 385–391. [Google Scholar] [CrossRef] [Green Version]
- Shapiro, L.G.; Stockman, G.C. Motion from 2D Image Sequences. Comput. Vis. 2001, 9, 1–3. [Google Scholar]
- Bindu, S.; Prudhvi, S.; Hemalatha, G.; Sekhar, N.R.; Nanchariah, M.V. Object Detection from Complex Background Image Using Circular Hough Transform. J. Eng. Res. Appl. 2014, 4, 23–28. Available online: www.ijera.com (accessed on 15 April 2014).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | ||
| Recall | ||
| F1 |
| Method | Recall | Precision | Mean Average Precision (mAP) | F1-Score (%) |
|---|---|---|---|---|
| Faster R-CNN | 0.4 | 0.78 | 0.32 | 52.88 |
| RetinaNet | 0.67 | 0.84 | 0.58 | 74.54 |
| EfficientNet | 0.72 | 0.89 | 0.66 | 79.60 |
| YOLOv5 initially trained | 0.68 | 0.85 | 0.6 | 75.56 |
| YOLOv5 self-trained | 0.69 | 0.88 | 0.61 | 77.35 |
| YOLOv3 initially trained | 0.77 | 0.91 | 0.72 | 83.42 |
| YOLOv3 self-trained | 0.85 | 0.96 | 0.82 | 90.17 |
| Method | Recall | Precision | Mean Average Precision (mAP) | F1-Score (%) |
|---|---|---|---|---|
| Faster R-CNN | 0.41 | 0.70 | 0.33 | 51.71 |
| RetinaNet | 0.53 | 0.78 | 0.47 | 63.11 |
| EfficientNet | 0.52 | 0.75 | 0.49 | 61.42 |
| YOLOv5 initially trained | 0.61 | 0.80 | 0.64 | 69.22 |
| YOLOv5 self-trained | 0.64 | 0.81 | 0.68 | 71.50 |
| YOLOv3 initially trained | 0.77 | 0.88 | 0.76 | 82.13 |
| YOLOv3 self-trained | 0.78 | 0.89 | 0.81 | 83.14 |
| Method | Input Dataset (1) | Input Dataset (2) | Input Dataset (3) | |||
|---|---|---|---|---|---|---|
| Mean Average Precision (mAP) | F1-Score (%) | Mean Average Precision (mAP) | F1-Score (%) | Mean Average Precision (mAP) | F1-Score (%) | |
| Faster R-CNN | 0.30 | 50.82 | 0.33 | 52.64 | 0.25 | 34.12 |
| RetinaNet | 0.39 | 52.62 | 0.4 | 53.12 | 0.33 | 53.18 |
| EfficientNet | 0.52 | 66.45 | 0.51 | 64.58 | 0.60 | 70.84 |
| YOLOv5 initial training | 0.63 | 68.89 | 0.67 | 70.62 | 0.68 | 72.45 |
| YOLOv5 self-training | 0.64 | 69.42 | 0.70 | 74.15 | 0.75 | 80.93 |
| YOLOv3 initial training | 0.69 | 73.15 | 0.79 | 83.15 | 0.81 | 83.84 |
| YOLOv3 self-training | 0.72 | 76.32 | 0.80 | 83.78 | 0.86 | 93.39 |
| Method/Input Data | Single UAS Image | Orthophoto | Multimodal | ||||
|---|---|---|---|---|---|---|---|
| Mean Average Precision (mAP) | F1-Score (%) | Mean Average Precision (mAP) | F1-Score (%) | Mean Average Precision (mAP) | F1-Score (%) | ||
| Background 1: bare soil | YOLOv3 initially trained | 0.65 | 65.57 | 0.66 | 67.06 | 0.72 | 72.43 |
| YOLOv3 self-trained | 0.68 | 69.07 | 0.76 | 78.56 | 0.83 | 90.80 | |
| Background 2: groundcover | YOLOv3 initially trained | 0.63 | 61.23 | 0.69 | 77.54 | 0.76 | 77.13 |
| YOLOv3 self-trained | 0.66 | 68.86 | 0.67 | 73.89 | 0.75 | 74.91 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ezzy, H.; Charter, M.; Bonfante, A.; Brook, A. How the Small Object Detection via Machine Learning and UAS-Based Remote-Sensing Imagery Can Support the Achievement of SDG2: A Case Study of Vole Burrows. Remote Sens. 2021, 13, 3191. https://doi.org/10.3390/rs13163191
Ezzy H, Charter M, Bonfante A, Brook A. How the Small Object Detection via Machine Learning and UAS-Based Remote-Sensing Imagery Can Support the Achievement of SDG2: A Case Study of Vole Burrows. Remote Sensing. 2021; 13(16):3191. https://doi.org/10.3390/rs13163191
Chicago/Turabian StyleEzzy, Haitham, Motti Charter, Antonello Bonfante, and Anna Brook. 2021. "How the Small Object Detection via Machine Learning and UAS-Based Remote-Sensing Imagery Can Support the Achievement of SDG2: A Case Study of Vole Burrows" Remote Sensing 13, no. 16: 3191. https://doi.org/10.3390/rs13163191
APA StyleEzzy, H., Charter, M., Bonfante, A., & Brook, A. (2021). How the Small Object Detection via Machine Learning and UAS-Based Remote-Sensing Imagery Can Support the Achievement of SDG2: A Case Study of Vole Burrows. Remote Sensing, 13(16), 3191. https://doi.org/10.3390/rs13163191