1. Introduction
Remote sensing change detection (RSCD) aims to identify important changes, such as water-body variations, building developments, and road changes, between images acquired over the same geographical area but taken at distinct times. It has a wide range of applications in natural disaster assessment, urban planning, resource management, deforestation monitoring, etc. [
1,
2,
3,
4,
5,
6,
7,
8,
9]. With the development of Earth observation technologies, very-high-resolution (VHR) remote sensing images from various sensors (e.g., WorldView, QuickBird, GaoFen, and high-definition imaging devices on airplanes) are increasingly available, which has created new demands on RSCD algorithms [
10,
11]. To quickly and robustly obtain the required change information from massive VHR images, deep learning methods, especially convolutional neural networks (CNNs) with powerful deep feature representation and image problem modeling abilities, have attracted significant research interest [
11,
12,
13].
Research on RSCD has been carried out for decades. In the early stages, medium- and low-resolution remote sensing images were the common data source for RSCD and many relevant methods were proposed to establish a macro view of the surface [
11]. Those methods can typically be classified into two categories: pixel-based methods and object-based methods. Pixel-based methods generate change maps by comparing pairs of images at different times on a pixel-by-pixel basis. For ease of application, algebra-based techniques [
7,
14,
15,
16,
17] are utilized in pixel-based methods to obtain rough change maps. Furthermore, transform-based techniques [
8,
9,
18,
19,
20] are adopted for robust feature extraction. Unlike pixel-based methods, object-based methods regard image objects obtained from segmentation algorithms as the basic analysis unit. Various image objects [
21,
22,
23] are extracted to compare image difference. Some features, such as spectral, textural, and contextual information, can be embodied naturally in image objects to improve the performance of RSCD.
Compared with medium- and low-resolution images, VHR images contain abundant image details and spatial distribution information, such as colors, textures, and structure information of the ground objects, which provides a solid guarantee for monitoring finer Earth changes. However, complex scenes and vastly different scales of detected objects conveyed in VHR images also introduce new challenges for RSCD. Pixel-based methods may not work well on VHR images because spatial and contextual information are seldom considered in their image change analysis process [
24]. Although object-based methods partially make up for the drawback of pixel-based methods, most of them use low-level features (e.g., spectrum, texture, and shape) to extract change information, whereas these features cannot represent the semantics information of VHR images well [
25]. Furthermore, both traditional pixel- and object-based methods are highly dependent on empirically designed algorithms for feature extraction, which require abundant manual interference and thus lack scalability and flexibility, failing to achieve satisfactory results for VHR images.
Recently, CNNs have shown their strong advantages in many tasks of computer vision, such as image classification [
26], super-resolution [
27], and semantic segmentation [
28]. Researchers have introduced CNNs such as VGG [
26], UNet [
29], InceptionNet [
30], and ResNet [
31], to RSCD and achieved promising performance in terms of high accuracy and strong robustness [
32]. Compared with conventional RSCD algorithms, CNN-based methods are data-driven and have great capabilities to extract high-quality feature representations automatically, which meets the needs of large-scale change detection and could utilize spatial-context information in VHR images more efficiently [
11,
33]. The fundamental method of RSCD based on CNNs is to extract features from the input image pair and combine these extracted features, and then RSCD is cast as a pixel-wise classification task to generate change maps. Remote sensing images, especially VHR images, are easily affected by different atmospheric conditions and sensors, and thus have abundant interfering factors and noise. Therefore, a strong and robust ability of feature extraction is crucial for CNN-based RSCD to achieve high performance.
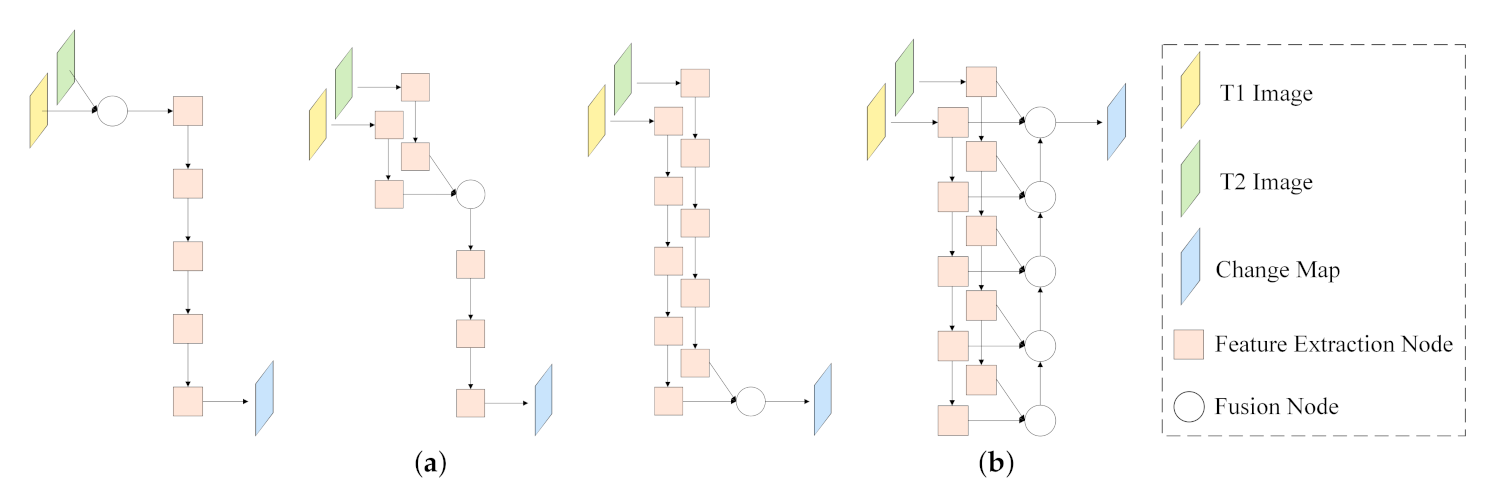
According to the feature extraction process for input image pairs, there are mainly two types of CNN-based RSCD networks: single-stream networks and Siamese networks [
33]. Single-stream networks fuse a pair of images as one input before sending them into the model, and then generate change maps directly. Peng et al. [
34] directly took concatenated image pairs as the input and proposed a single-stream network based on UNet++ [
35] with nested dense skip pathways to learn multi-scale feature maps from different semantic levels. Papadomanolaki et al. [
36] integrated fully convolutional long short-term memory layers into the skip-connection process of a simple U-net [
29] architecture to compute spatial features and temporal change patterns from the concatenated co-registered image pairs. In [
37], bi-temporal images were first preprocessed using MMR [
38], and then a fully convolutional network within pyramid pooling (FCN-PP) was applied to efficiently exploit spatial multi-scale features from those preprocessed data. Unlike single-stream networks, Siamese networks extract deep features from pre-change and post-change images, respectively. In Siamese networks, powerful CNNs can be utilized as feature extractors naturally to improve the quality of feature representations. For example, in [
39], multi-level deep features of bi-temporal images were extracted in parallel through a two-stream VGG [
26] architecture and were then fused by subtraction and concatenation operations to generate final change maps. Zhang et al. [
40] exploited the DeepLabv2 [
41] model for RSCD. Liu et al. [
42] took the SE-ResNet [
43] network structure as the basic encoding module and used building extraction as an auxiliary task to learn discriminative object-level features.
Although the existing CNN-based methods have achieved promising performance in relation to RSCD, there are still two key challenges that need to be urgently addressed.
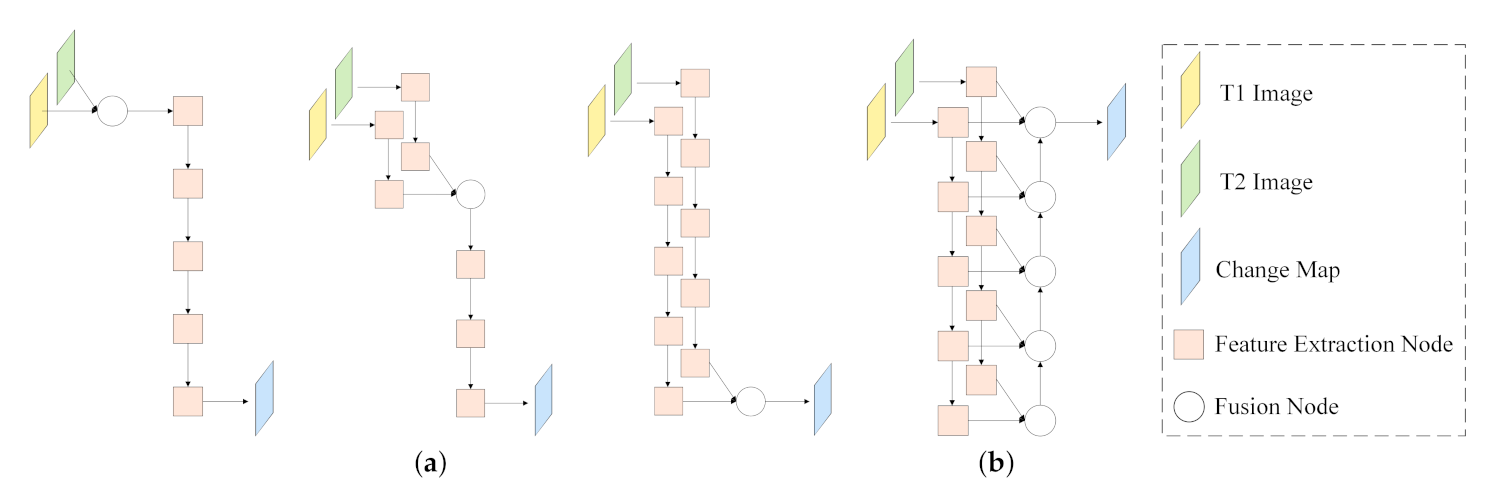
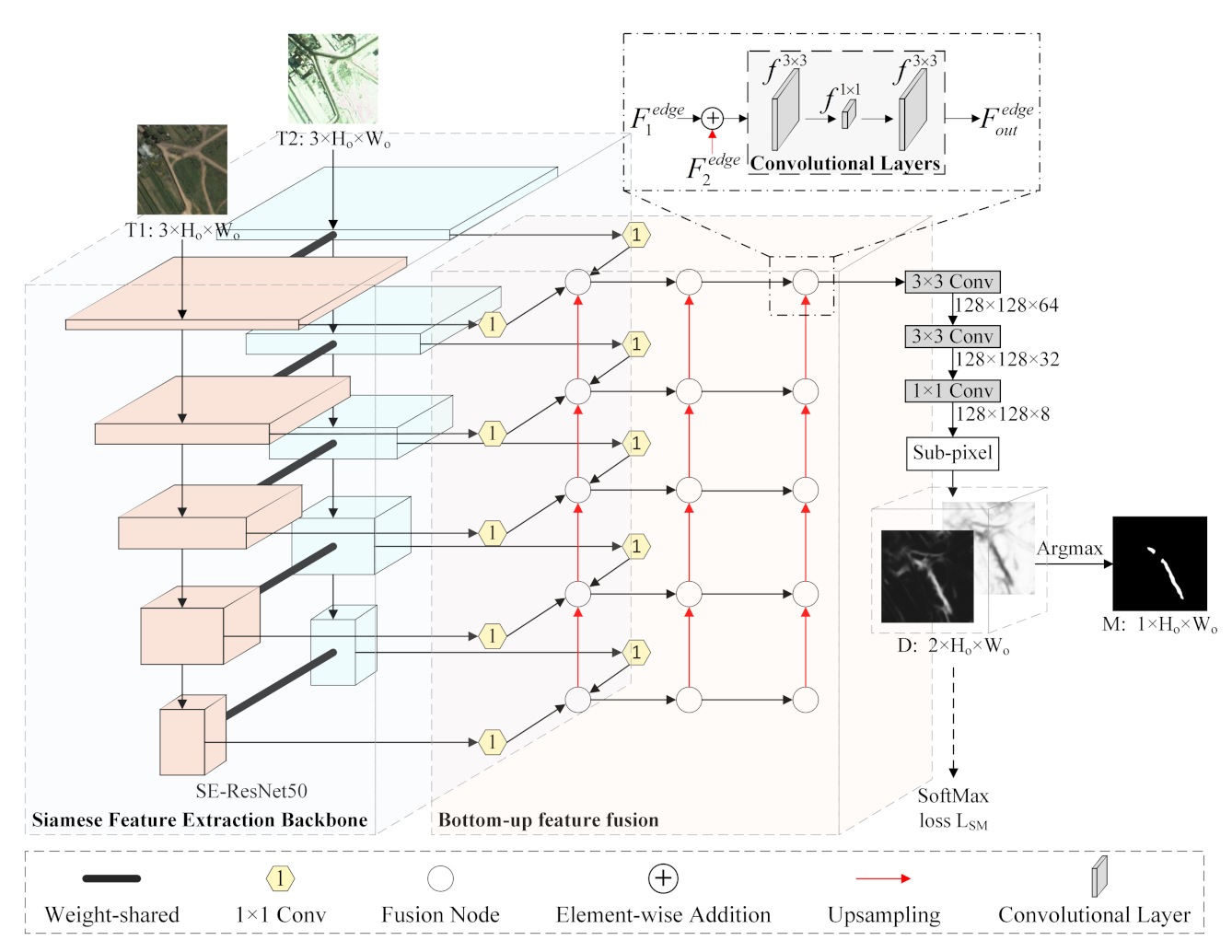
1.1. Challenge 1: Efficient Feature Fusion Strategy
As illustrated previously, most of the CNN-based methods focus on enhancing the feature extraction ability of the model to detect changed features well, but they pay less attention to the further improvement of feature fusion. Since the change map is jointly determined by the input image pairs [
44], the method of fusing the information from different temporal images is also critical for RSCD. While fusing different extracted features, many previous works [
34,
36,
39,
40,
45] have tended to follow a one-way simple fusion strategy, which results in two main limitations.
(1) The flexibility and diversity of information propagation are hindered by the one-way fusion flow. It has been proved that low-level features, which are extracted by shallow convolutional layers, are helpful for large instance identification [
46,
47]. However, one-way fusion flow merges features in a top-down or bottom-up way, leading to a monotonous and restricted path from low-level features to high-level features, and thus increases the difficulty in aggregating accurate localization information of the changed areas. In this case, several guidelines for improving feature aggregation, such as shortcut connection [
29,
31], dense connection [
48], and parallel paths [
49], can be beneficial.
(2) Simple feature fusion operations, such as summation, subtraction, or concatenation, ignore semantic gaps between high-level and low-level features, resulting in some discrepancy and confusion for the network [
12]. Besides, not all features extracted by CNNs are useful for RSCD. Such irrelevant noise would increase the training difficulty of the network and undermine the accuracy of predicted change maps if we fuse them directly without filtering.
1.2. Challenge 2: Appropriate Loss Function
A good performance network needs a well-designed loss function. As a gold standard for pixel-wise classification, per-pixel cross-entropy (PPCE) loss is widely used in RSCD [
33,
34,
39,
50,
51]. Although PPCE loss measures the per-pixel difference between predicted results and ground-truth images, which could provide per-pixel exact change maps theoretically, we argue that it has two drawbacks in the RSCD task.
(1) The optimization objective of PPCE loss is too harsh for RSCD models to converge well. For example, consider two identical remote sensing images offset from each other by one pixel. Despite their visual similarity they would be very different as measured by PPCE loss [
27]. Remote sensing image pairs, especially VHR image pairs, usually have position deviations (caused by alignment errors or geometric correction errors) and spectral differences (caused by the solar altitude angle, illumination conditions, or seasonal changes) [
33]. These deviations result in inaccurate pixel-level mapping between two images and poor representation of the changes of the same objects in two images, which limits the effectiveness of PPCE loss in the RSCD task. In this case, some loss function optimization methods, such as remapping [
28] and joint training [
39], could be beneficial.
(2) PPCE loss treats each pixel independently and thus cannot measure the perceptual similarity between the predicted change map and its ground truth [
27,
52]. For example, a pleasant visual change map should preserve the internal compactness and semantic boundary of each object. Since PPCE loss does not take the neighborhood of each pixel into account [
52], it is unable to capture that similarity. As a result, change maps predicted by the models trained with PPCE loss usually have missing parts in the structure of detected objects and have incorrect geometric edges.
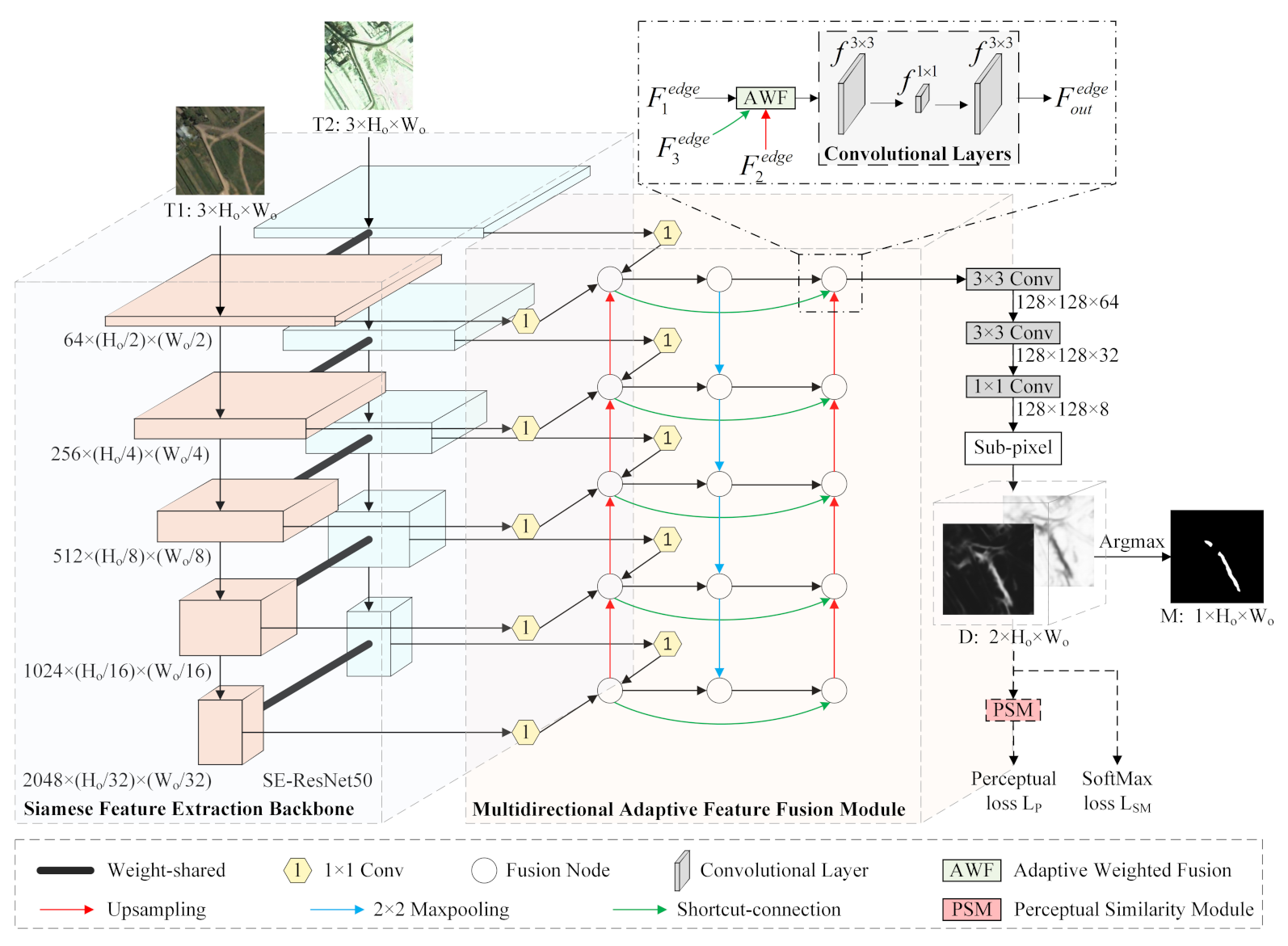
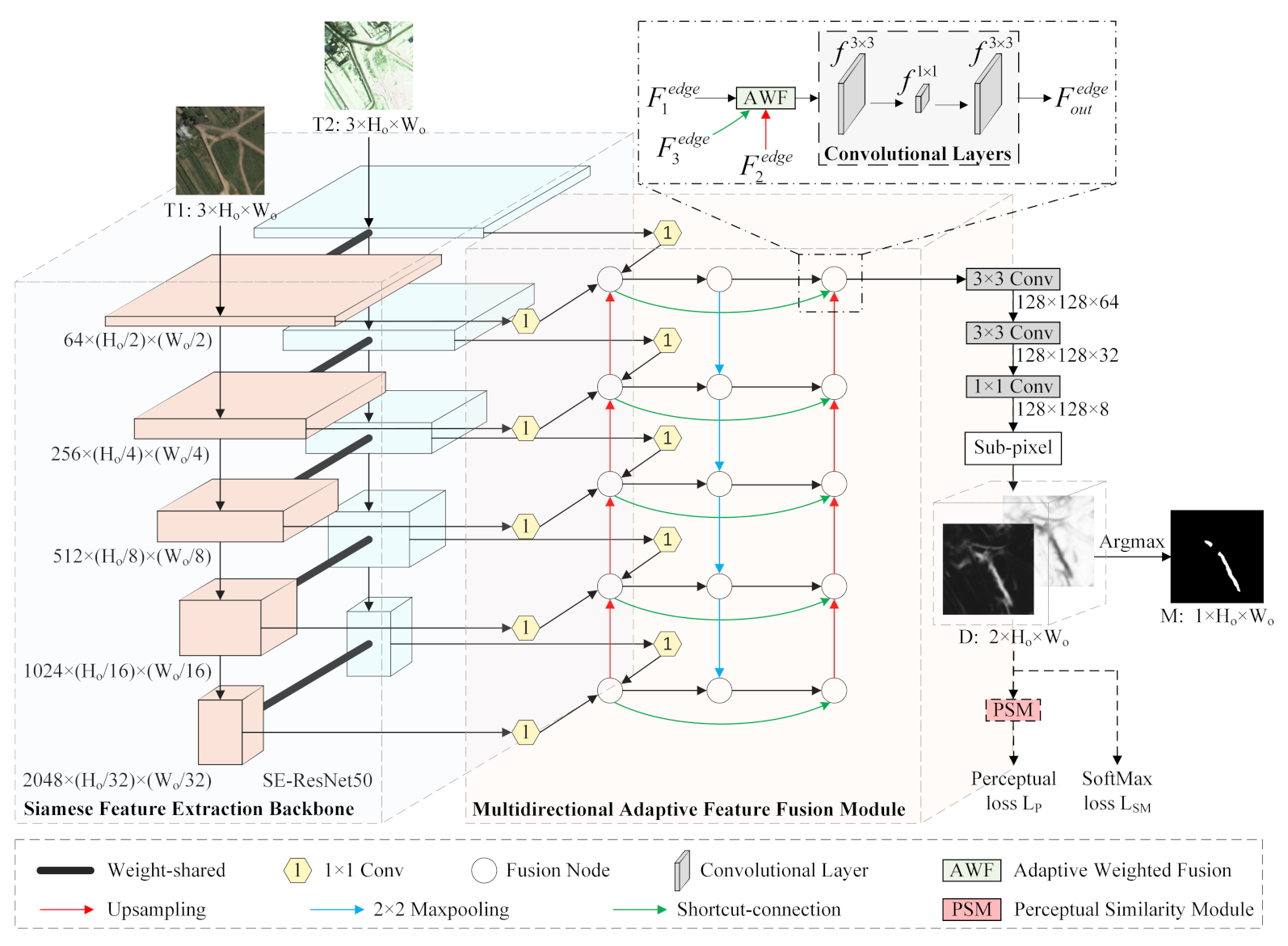
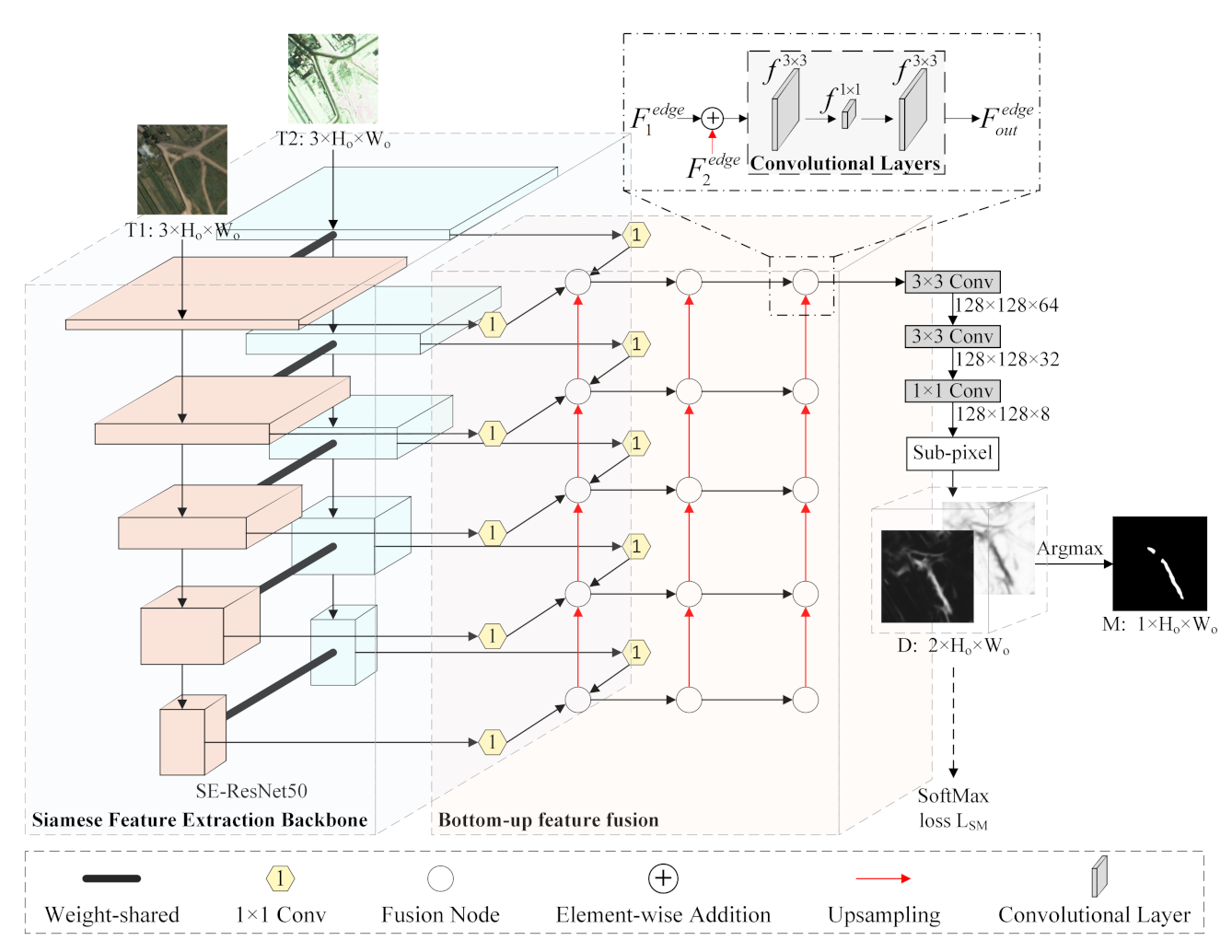
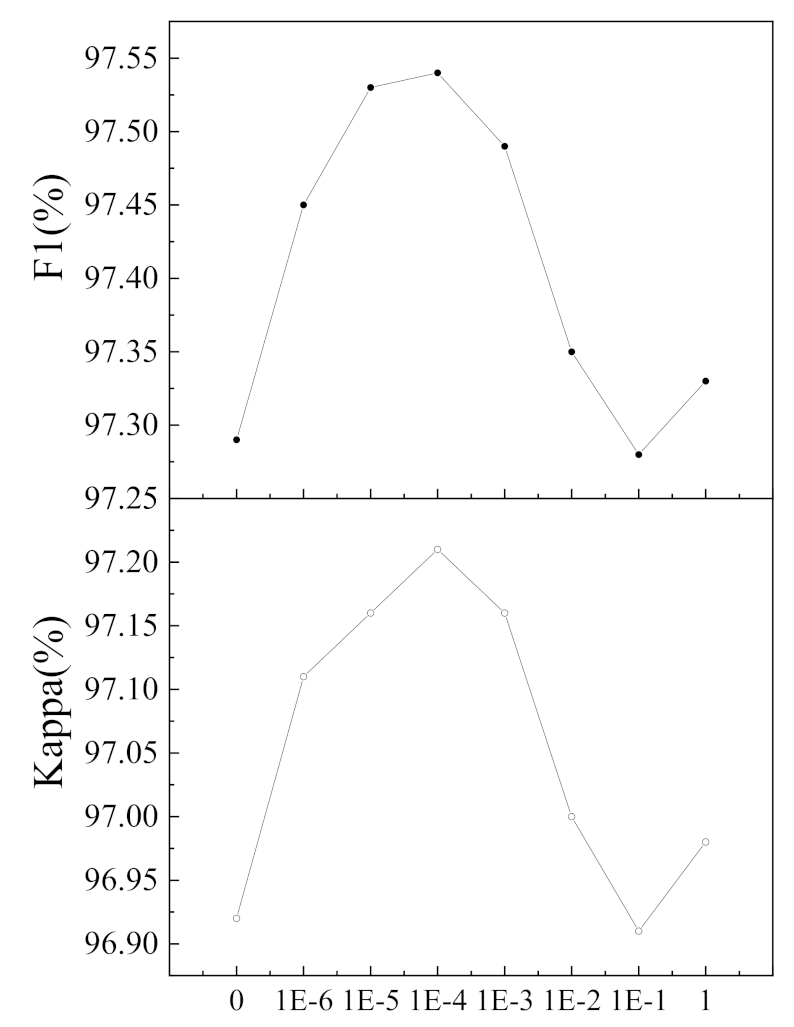
In this paper, we present a CNN-based network named the multidirectional fusion and perception network (MFPNet) for RSCD to address the above problems effectively. The main contributions of this article are as follows.
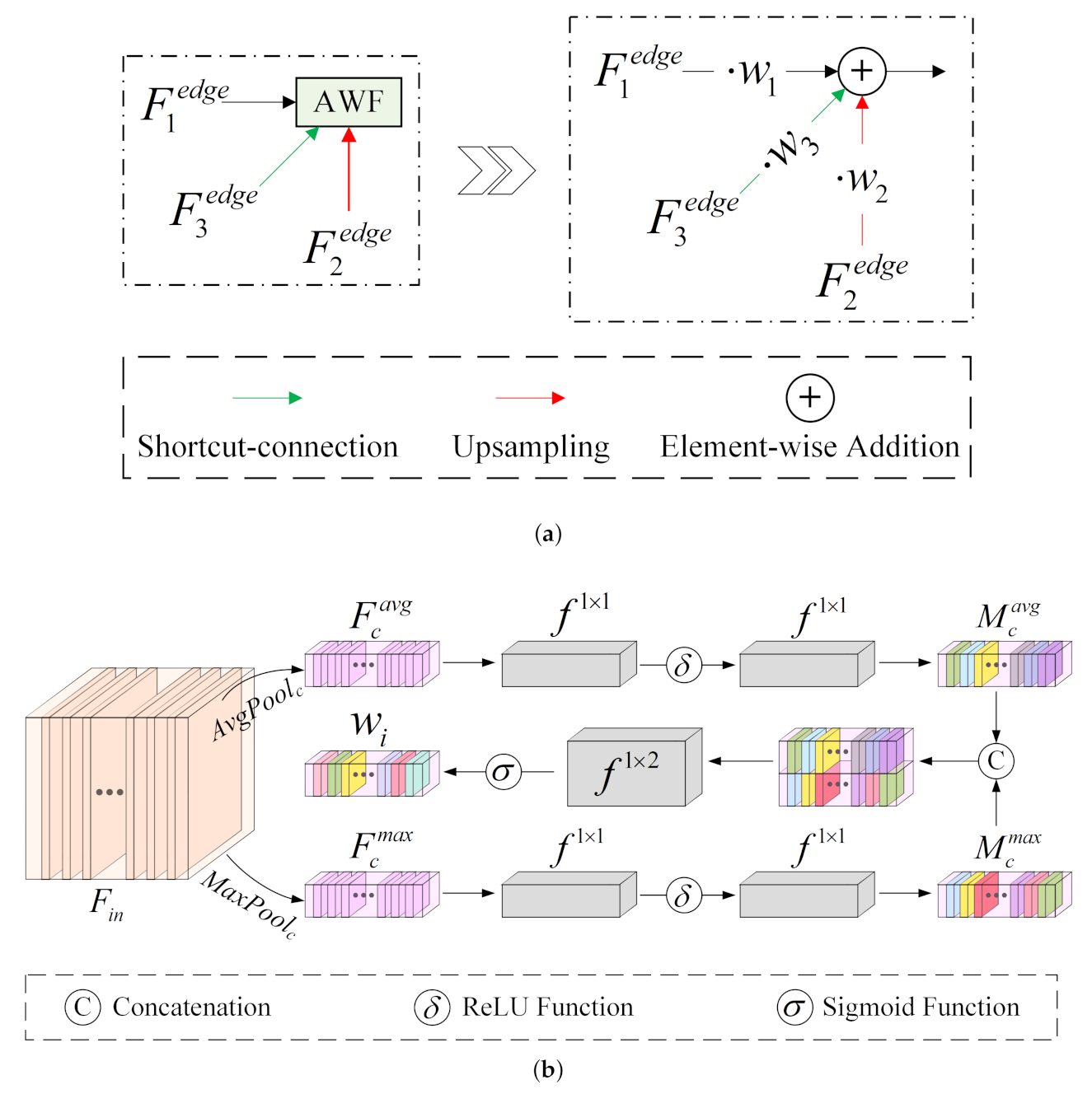
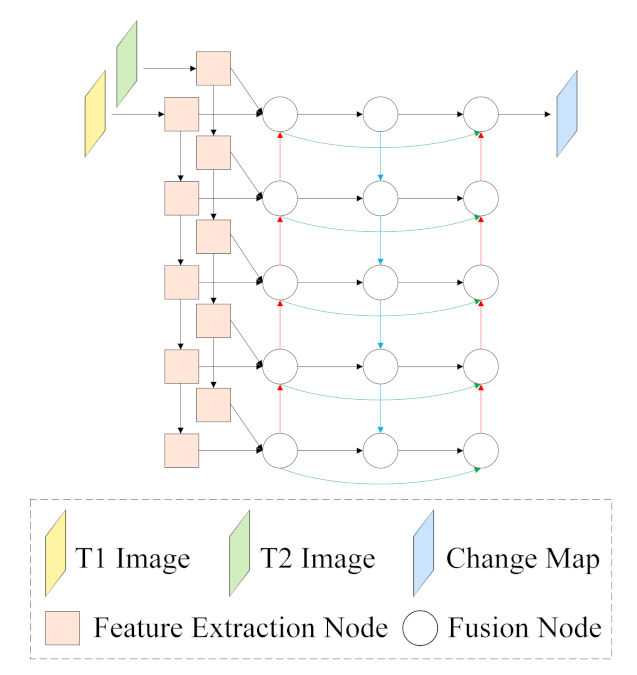
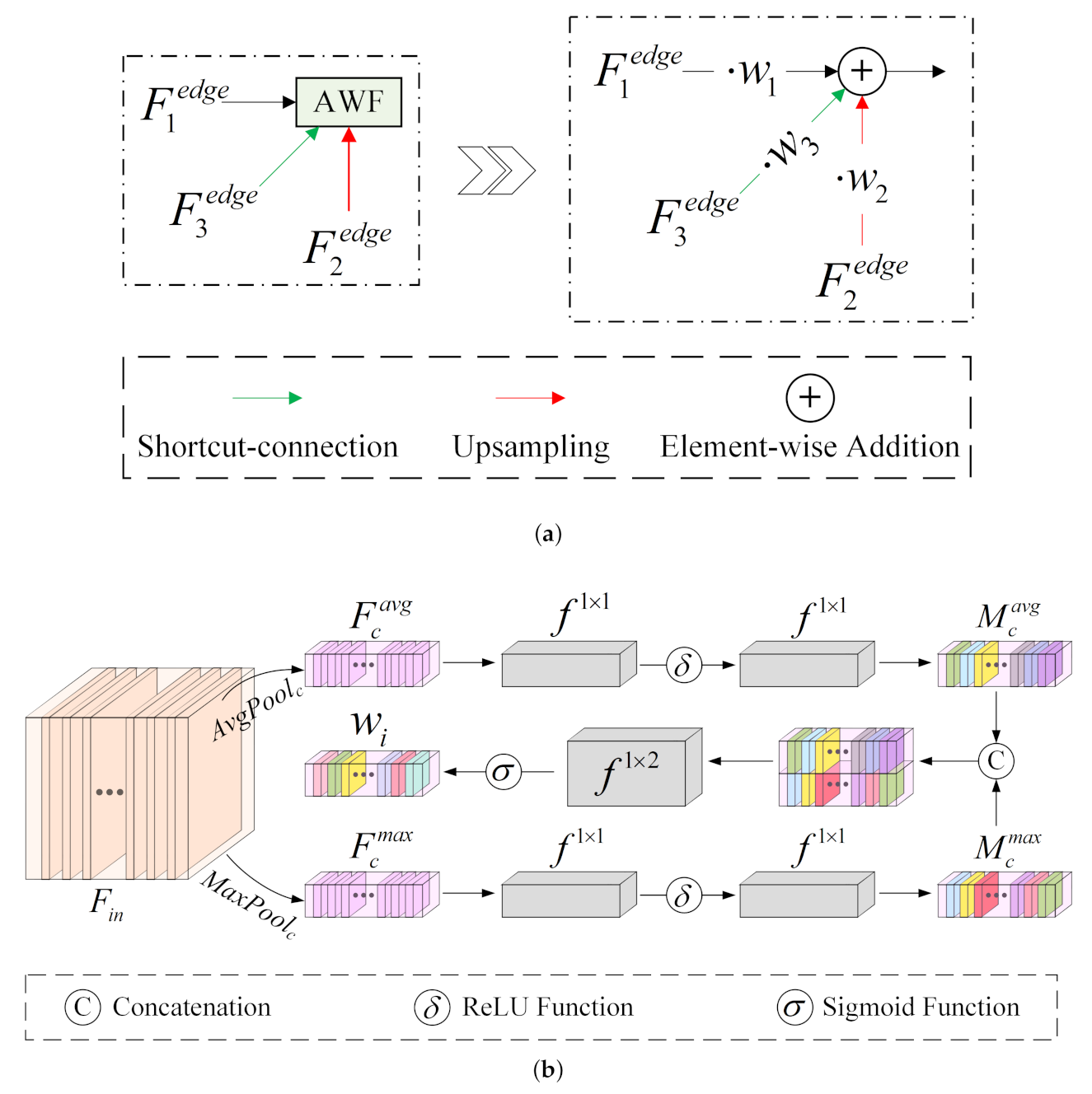
(1) We propose a new multidirectional adaptive feature fusion module (MAFFM) for RSCD, which consists of a multidirectional fusion pathway (MFP) and an adaptive weighted fusion (AWF) strategy to perform cross-level feature fusion efficiently. The MFP fuses different features in bottom-up, top-down, and shortcut-connection manners to overcome the limitation of one-way information flow and improve the process of feature fusion. The AWF strategy provides adaptive weight vectors for features from multidirectional edges to consider their semantic relationship and emphasize vital feature maps.
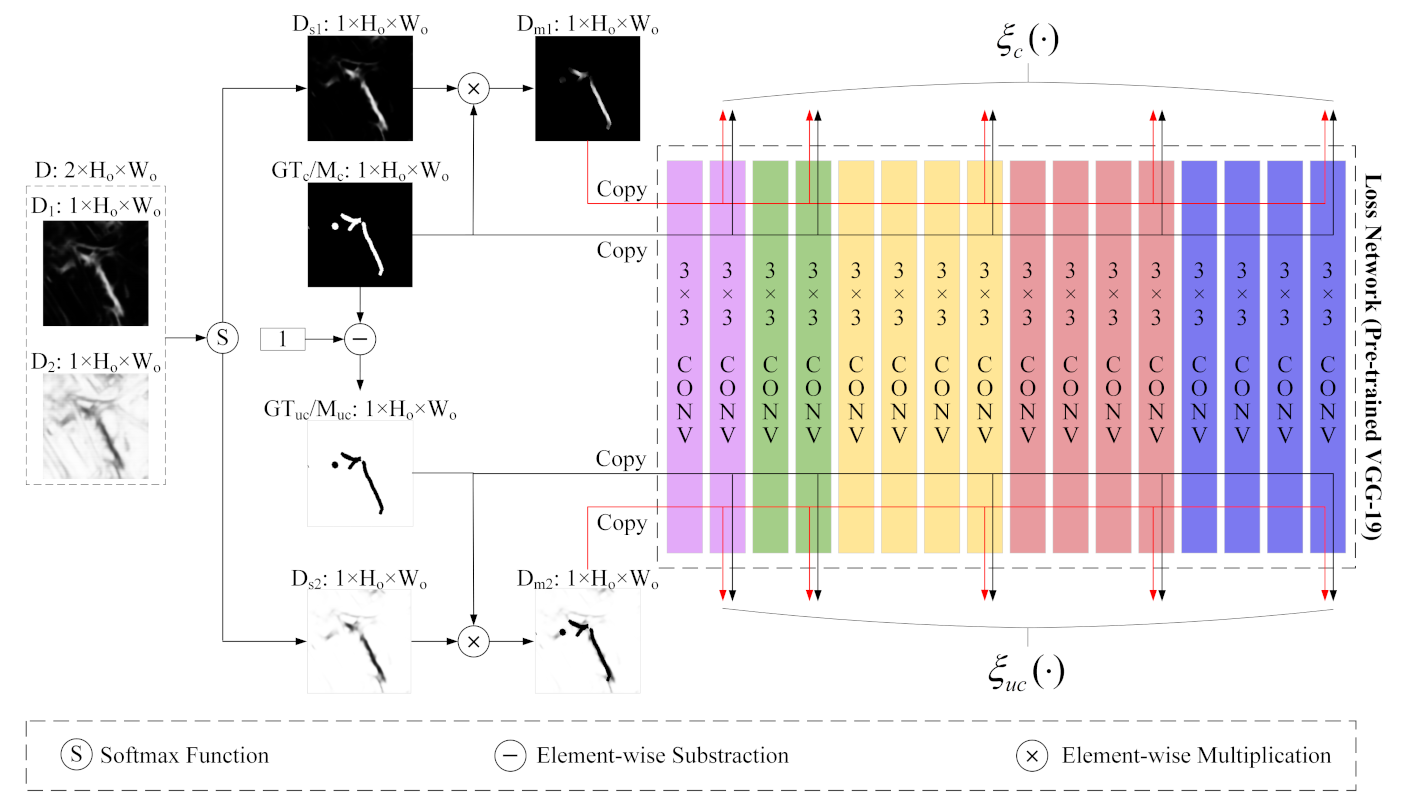
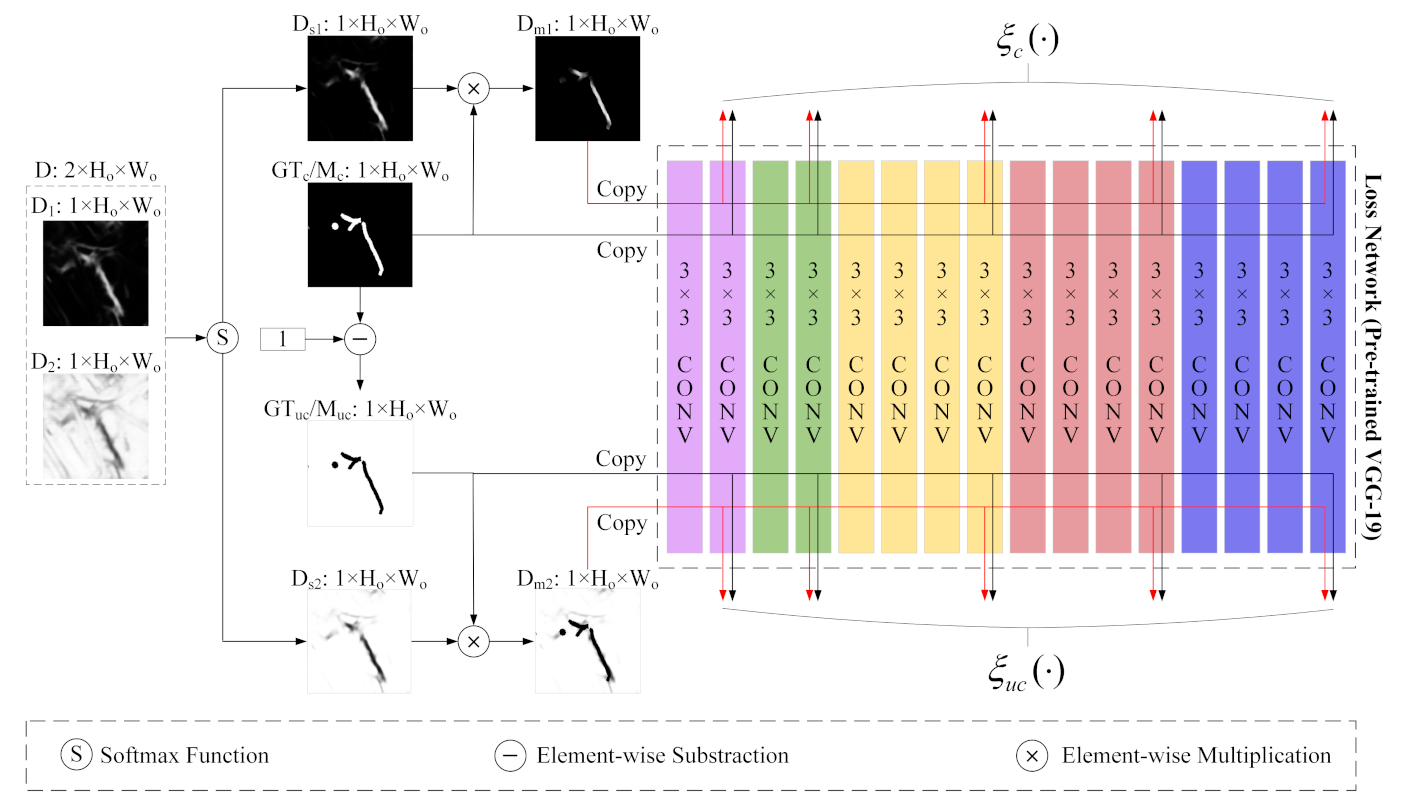
(2) We propose a novel perceptual similarity module (PSM) for RSCD that allows networks to benefit from perceptual loss in a targeted manner. In particular, the PSM minimizes perceptual loss for changed areas and unchanged areas, respectively, which reduces the distance between predicted change maps and their ground-truth images as well as overcoming the drawbacks of PPCE loss.
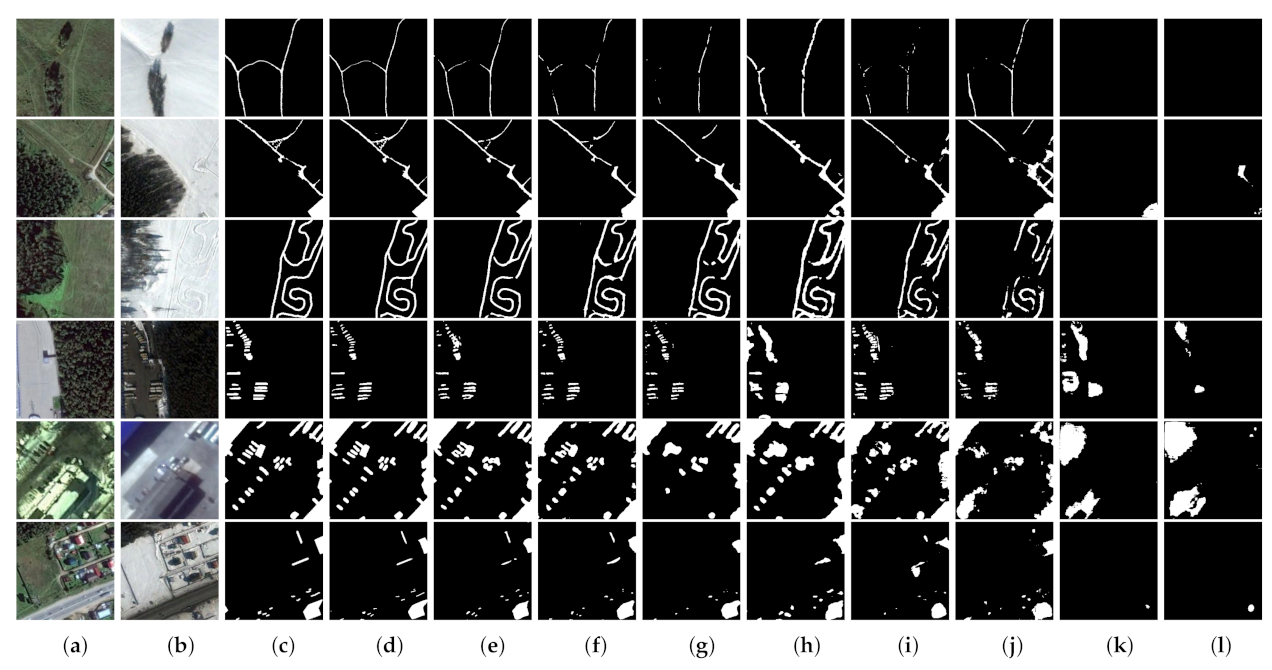
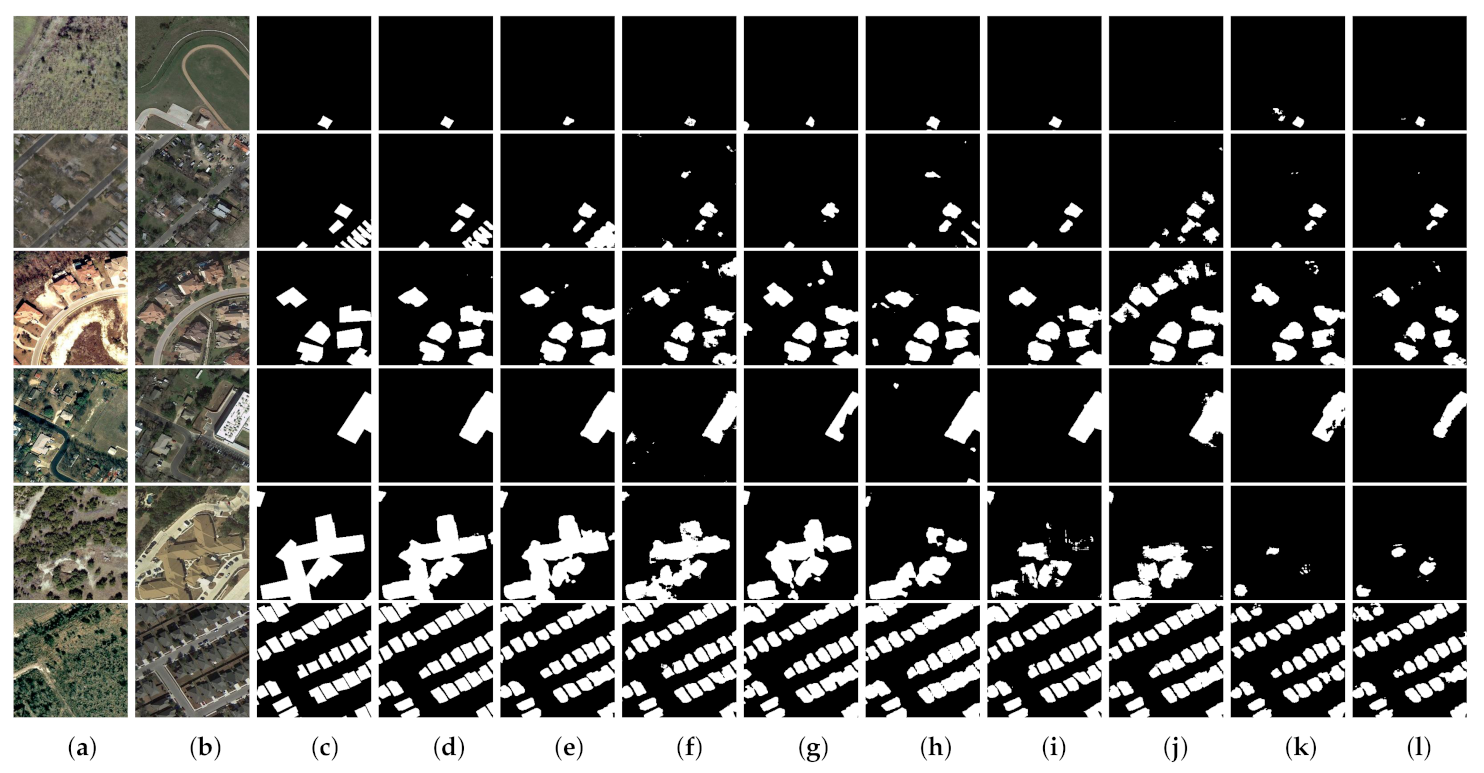
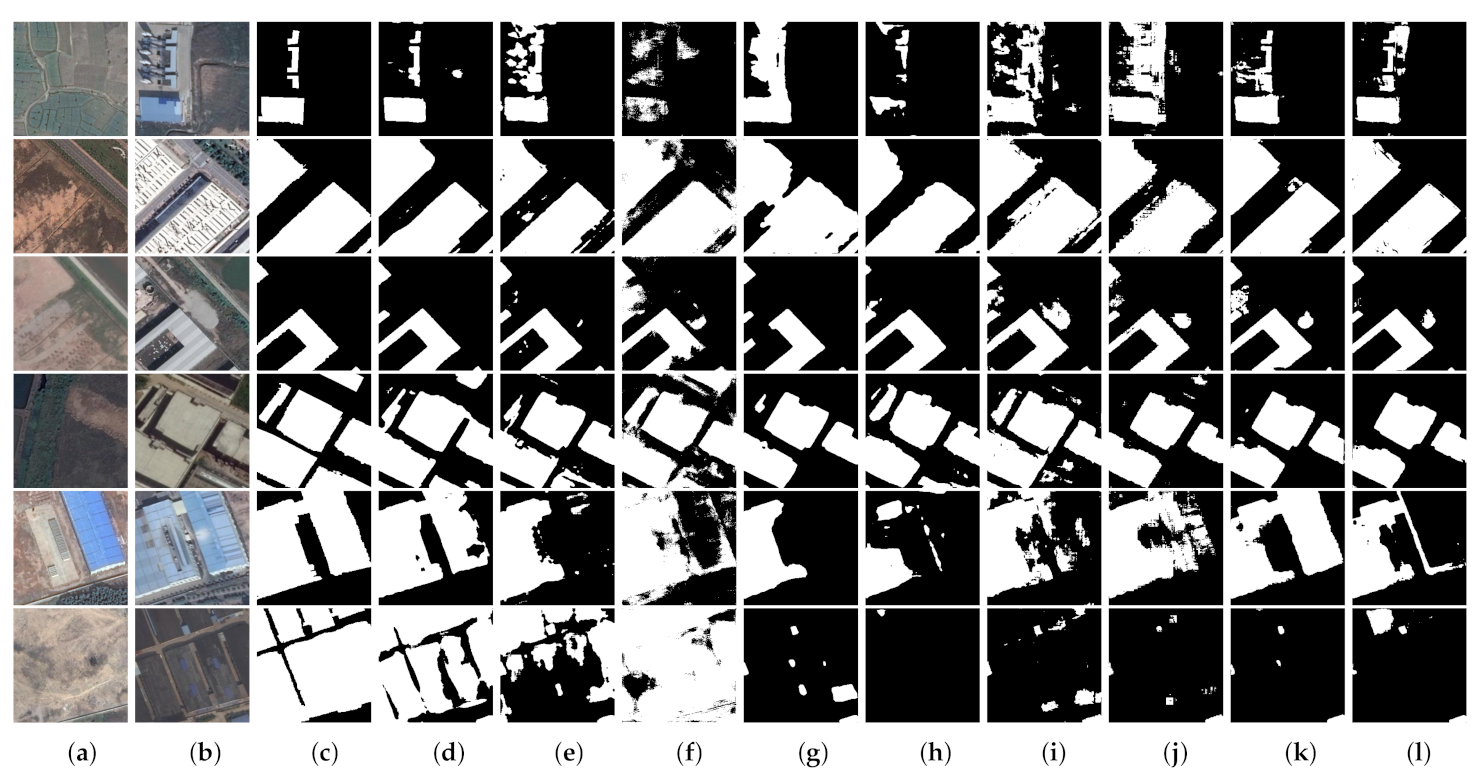
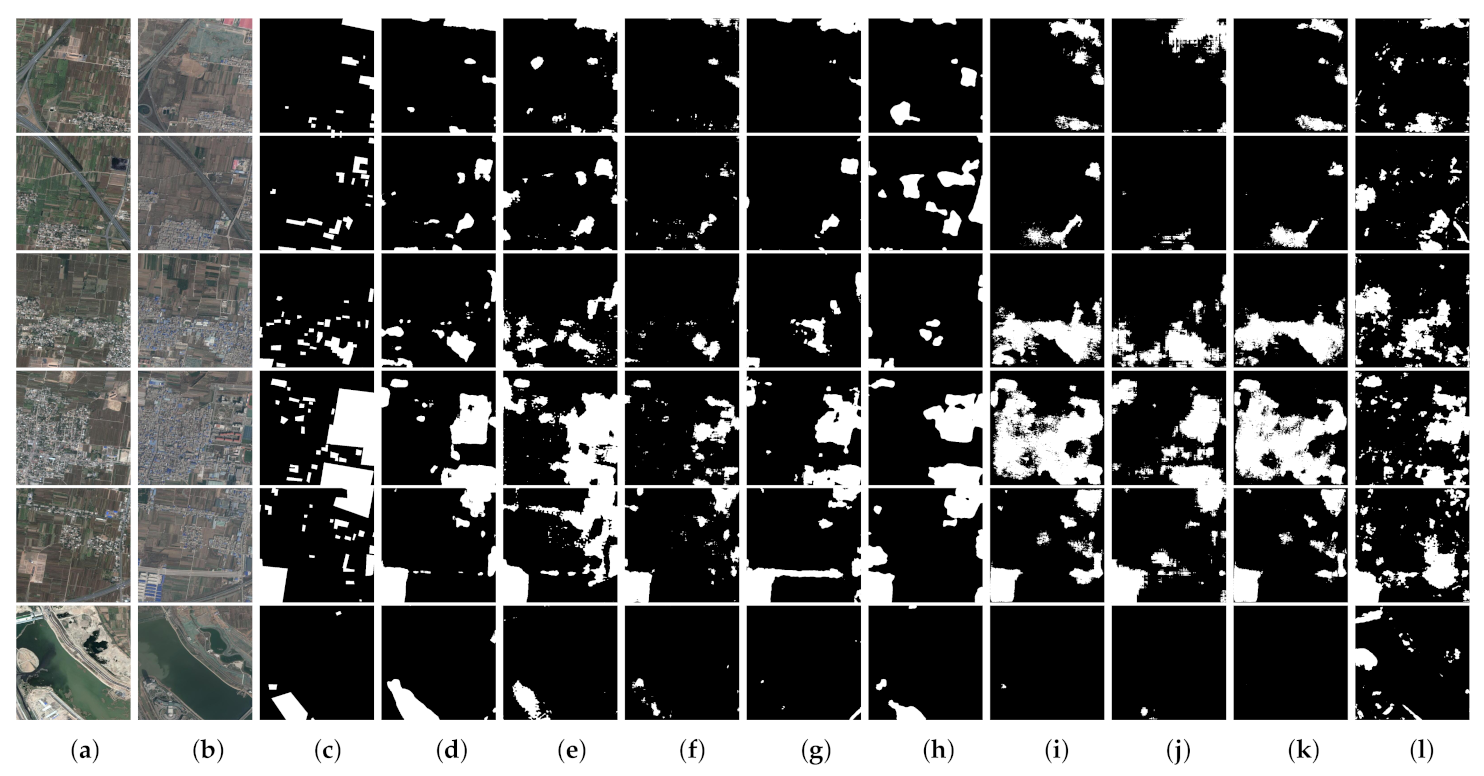
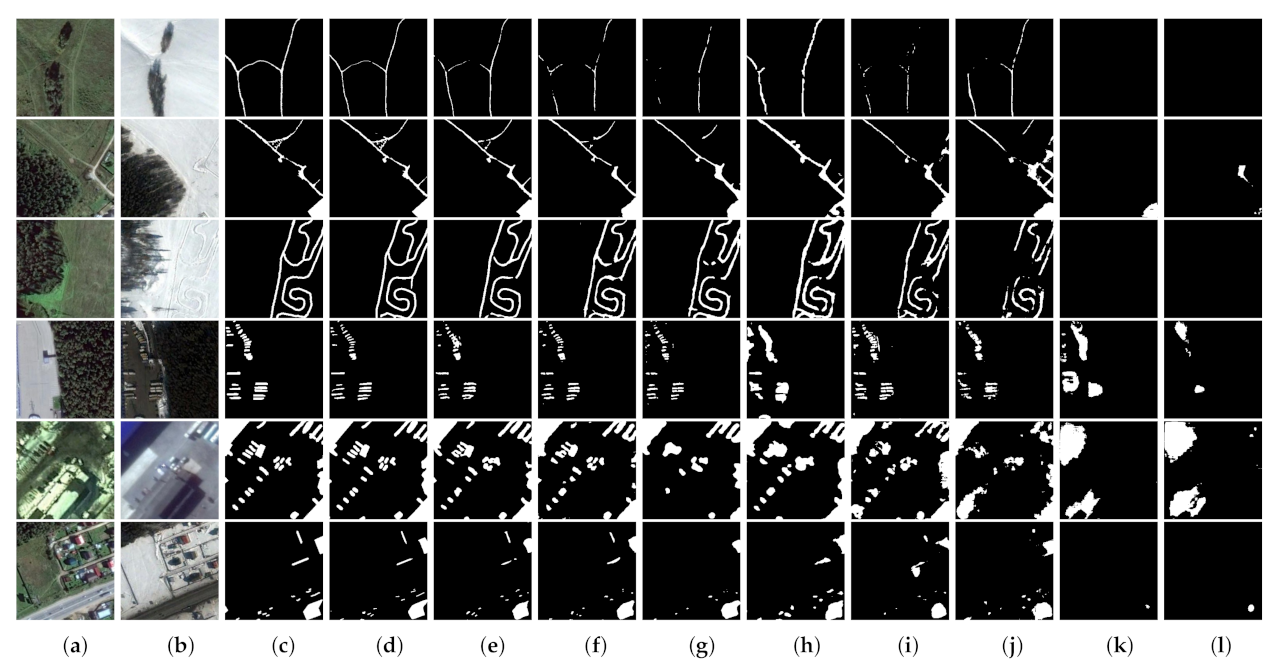
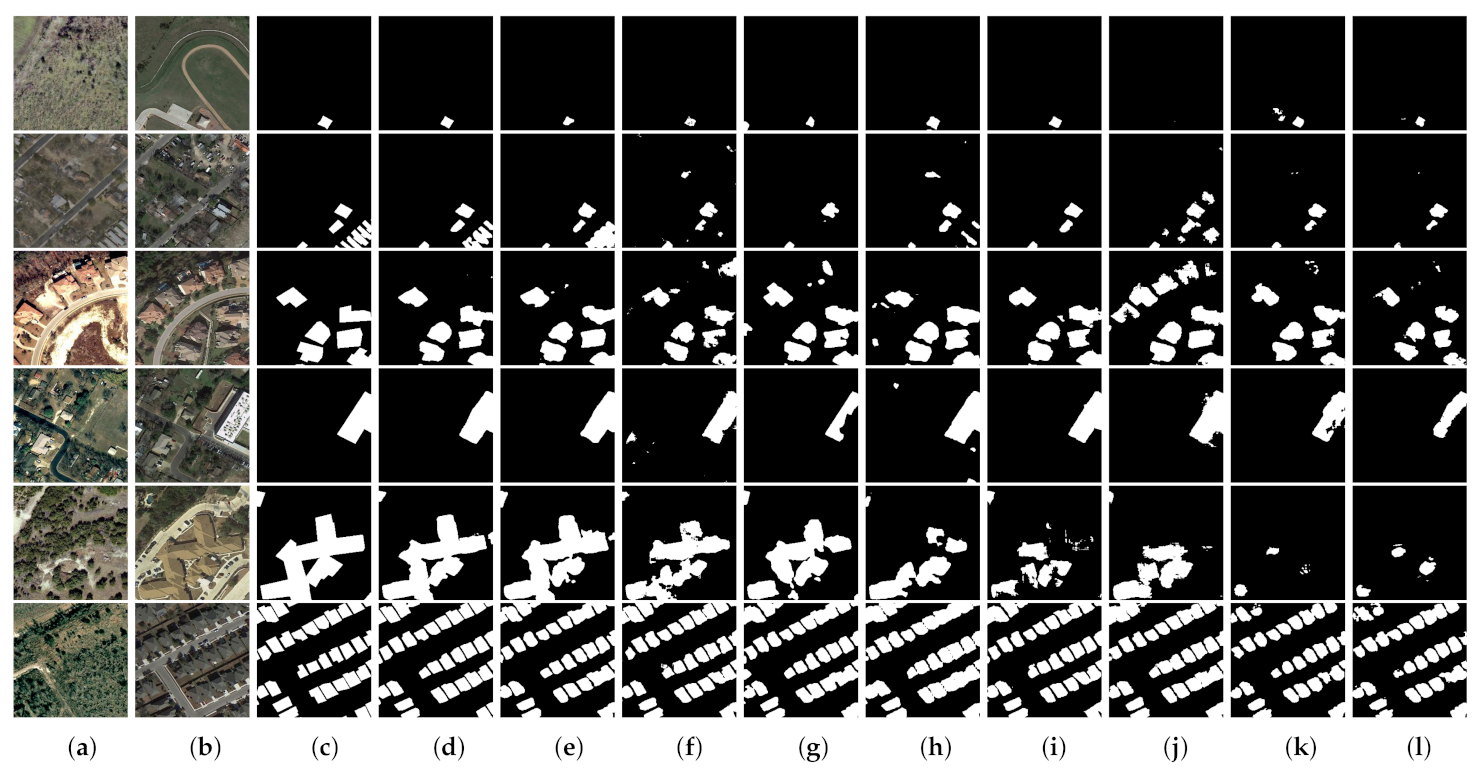
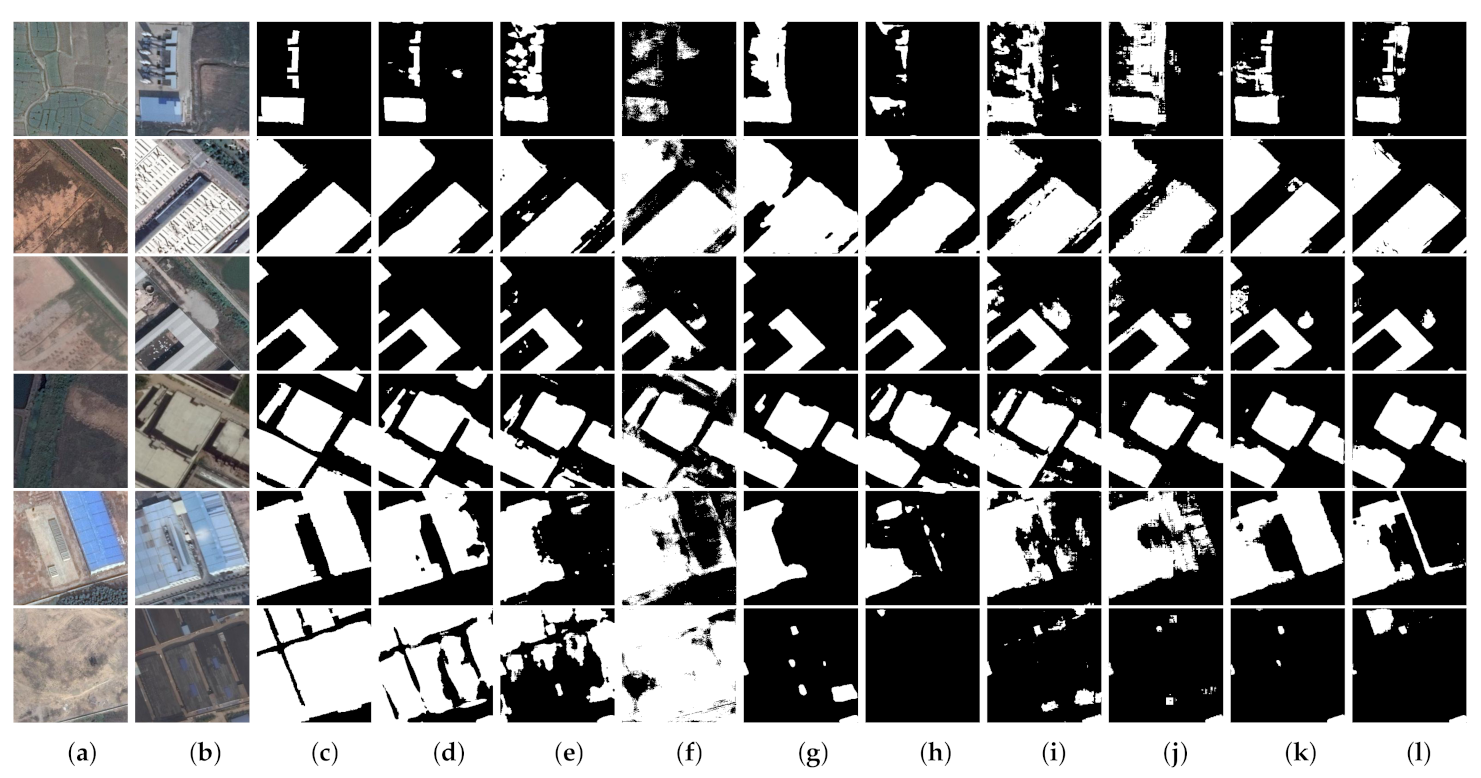
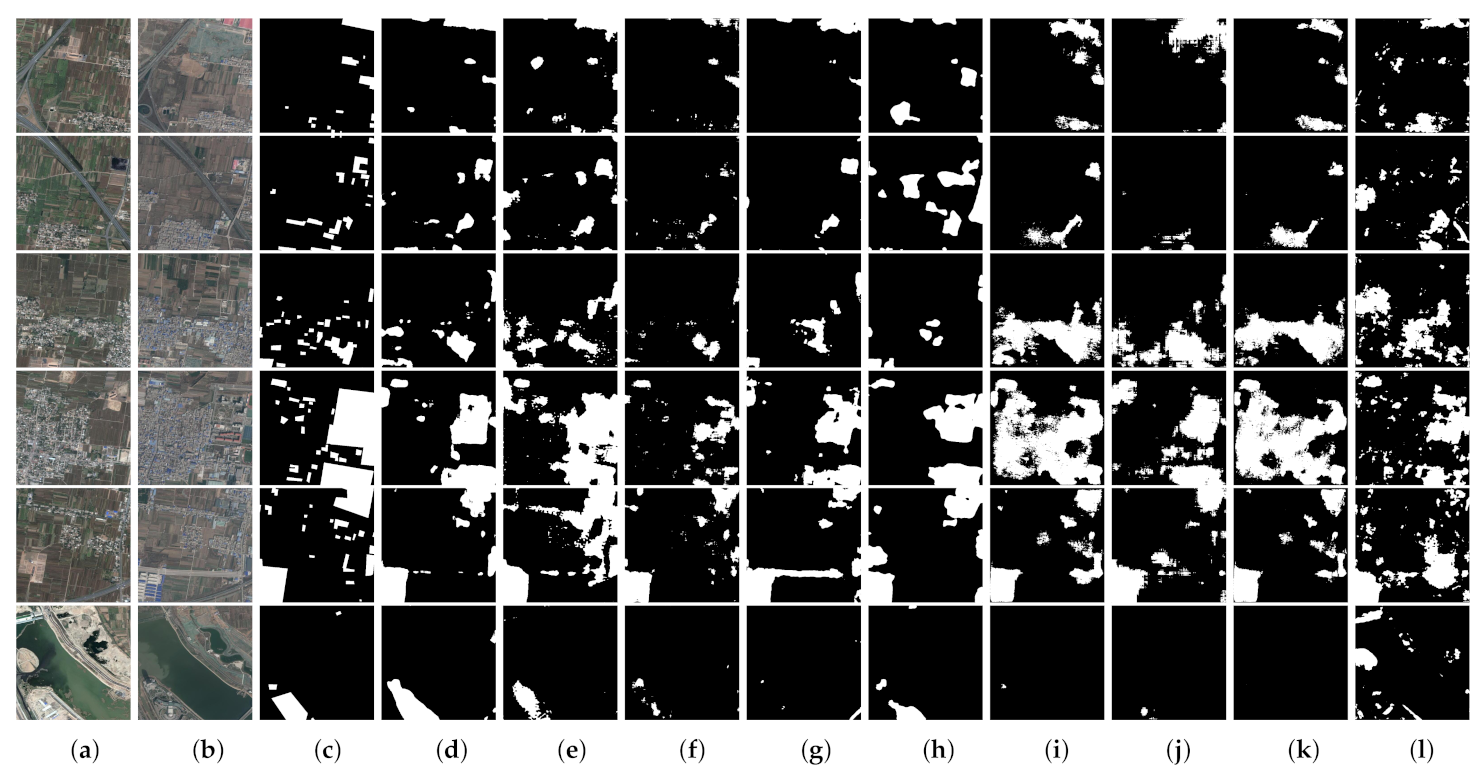
(3) Comprehensive comparative experiments on four benchmark datasets demonstrate that our proposed network outperforms eight state-of-the-art change detection networks with considerable improvement. Furthermore, we discuss the rationality of our proposed approaches and also port the proposed AWF and PSM to other CNN-based methods to evaluate their versatility and portability.
The rest of the article is organized as follows.
Section 2 introduces the related work.
Section 3 illustrates the proposed MFPNet in detail. Experimental results on the effectiveness of the proposed method are presented and discussed in
Section 4. Finally, the conclusions of this paper are drawn in
Section 6.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}