
Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images

 , ,
, ,
Abstract
:
1. Introduction
- (1)
- The BMFR-Net is proposed to extract buildings from high-resolution remote sensing images accurately and completely. Experimental results on the Massachusetts Building Dataset [12] and WHU Building Dataset [38] shows that the BMFR-Net outperforms the other five state-of-the-art (SOTA) methods in both visual interpretation and quantitative evaluations
- (2)
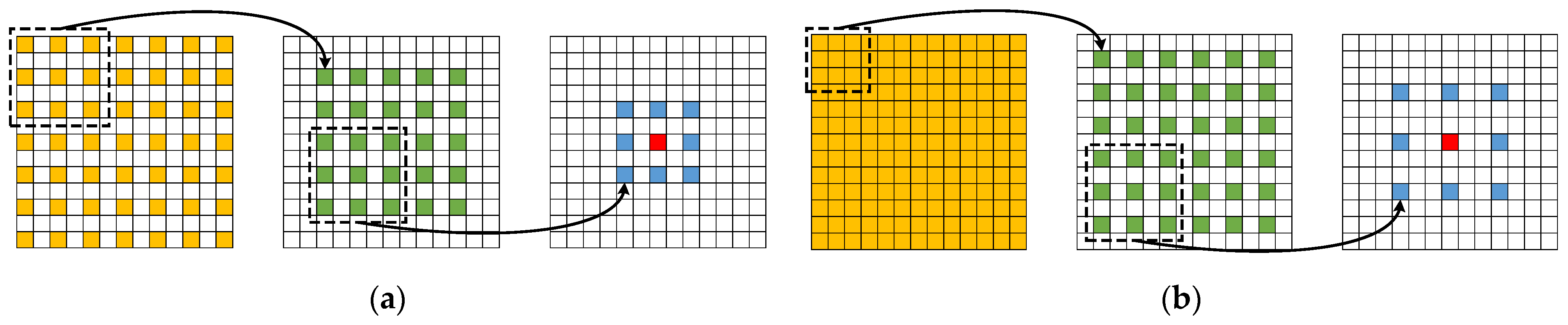
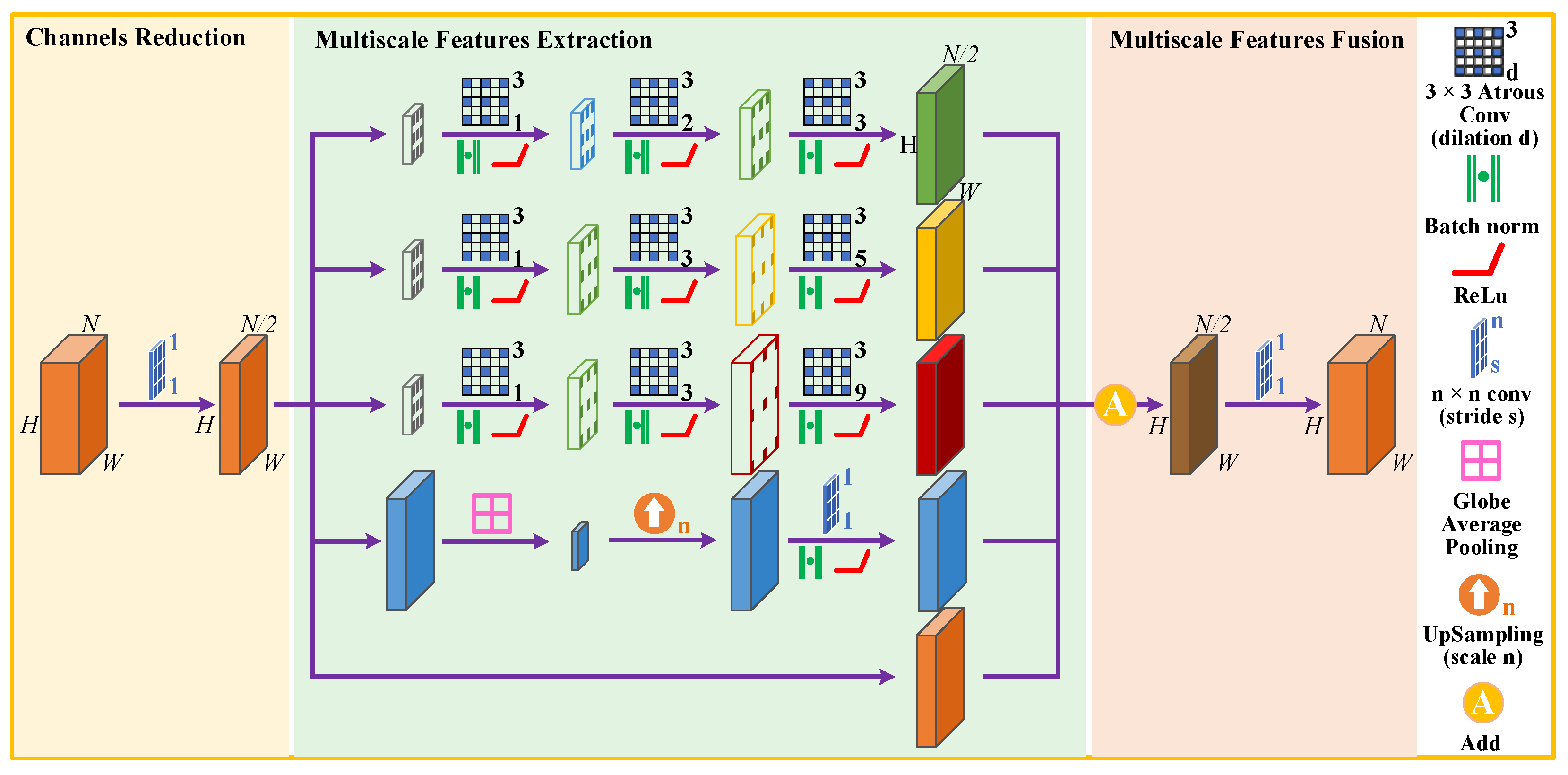
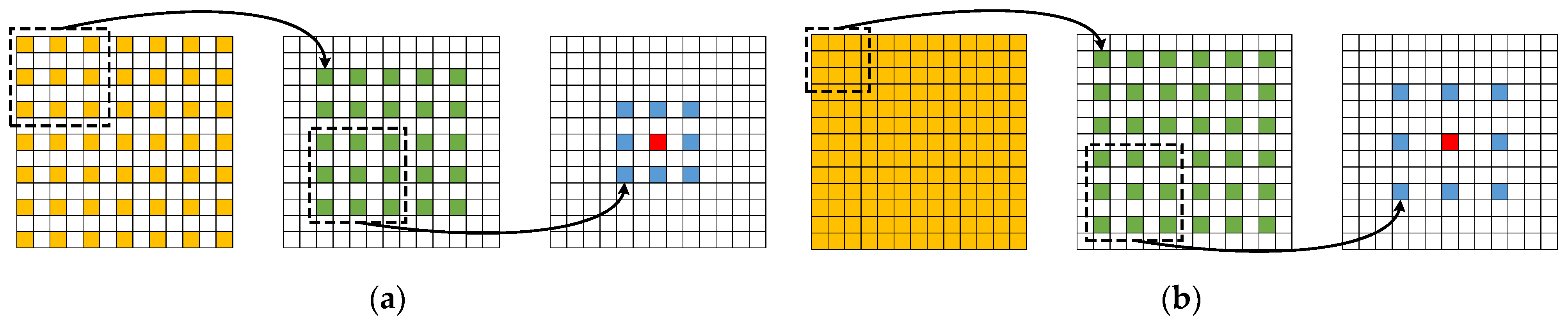
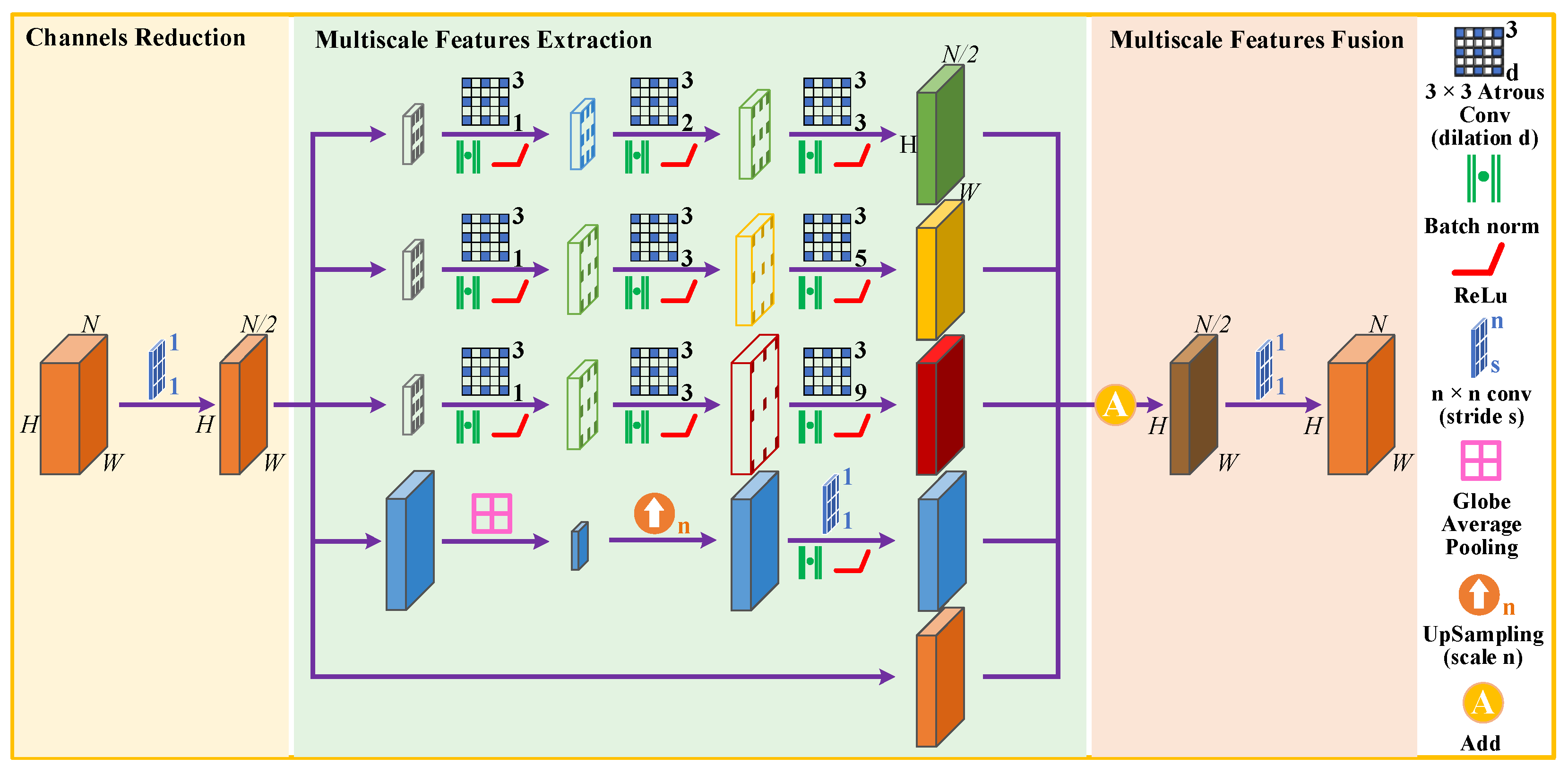
- This paper designed a new multiscale feature extraction and fusion module named CACP. By paralleling the continuous small-scale atrous convolution in line with HDC constraints for multiscale feature extraction at the end of the contracting path, which can reduce the loss of effective information and enhance the continuity between local information.
- (3)
- The MOFC structure is explored in this paper, which can enhance the ability of the network to aggregate multiscale semantic information from the context by integrating each layer output results into the expanding path. In addition, we use the multilevel output results to construct the multilevel joint weighted loss function and determine the best combination of weights to effectively update network parameters.
2. Methodology
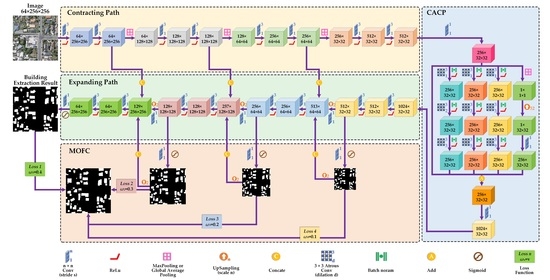
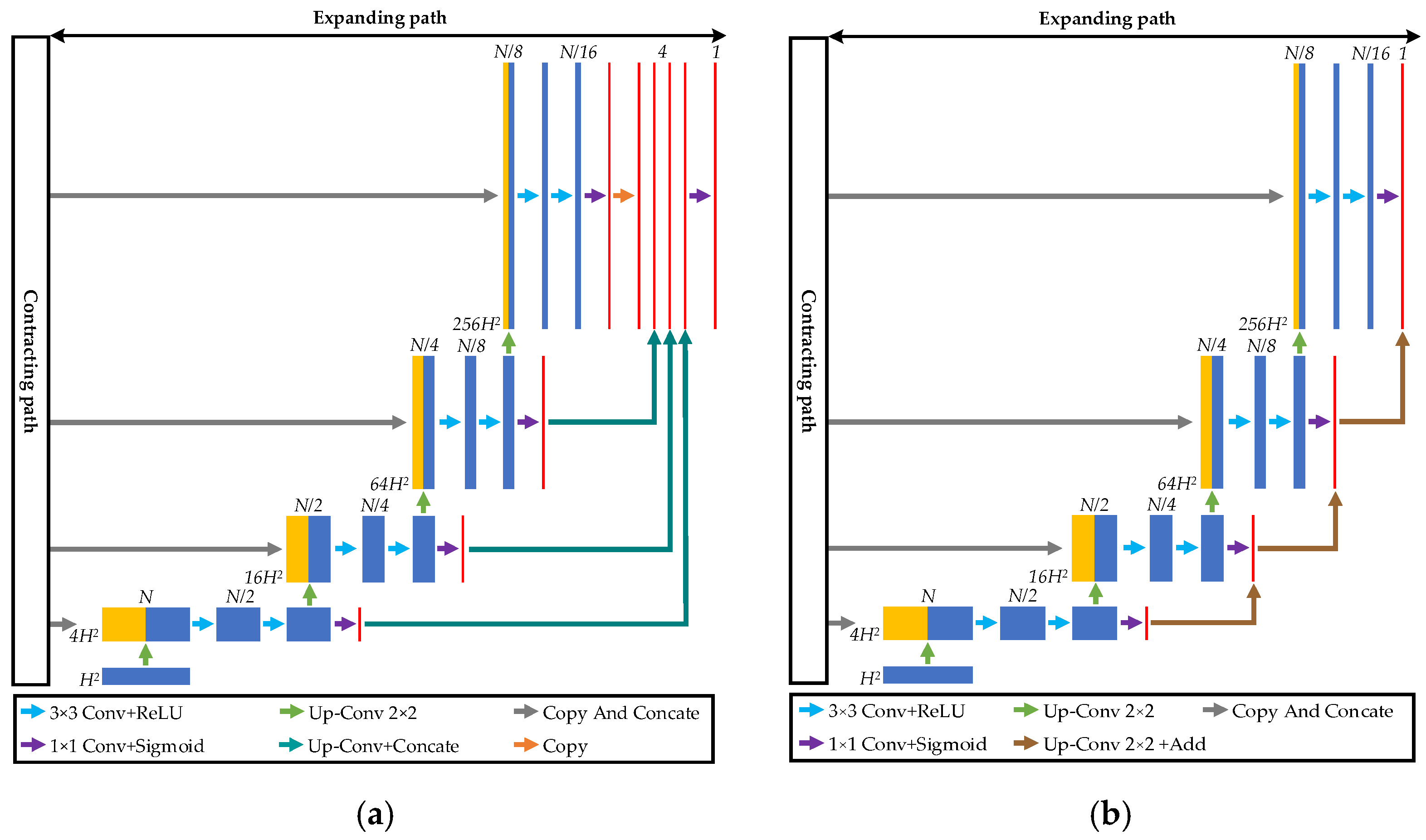
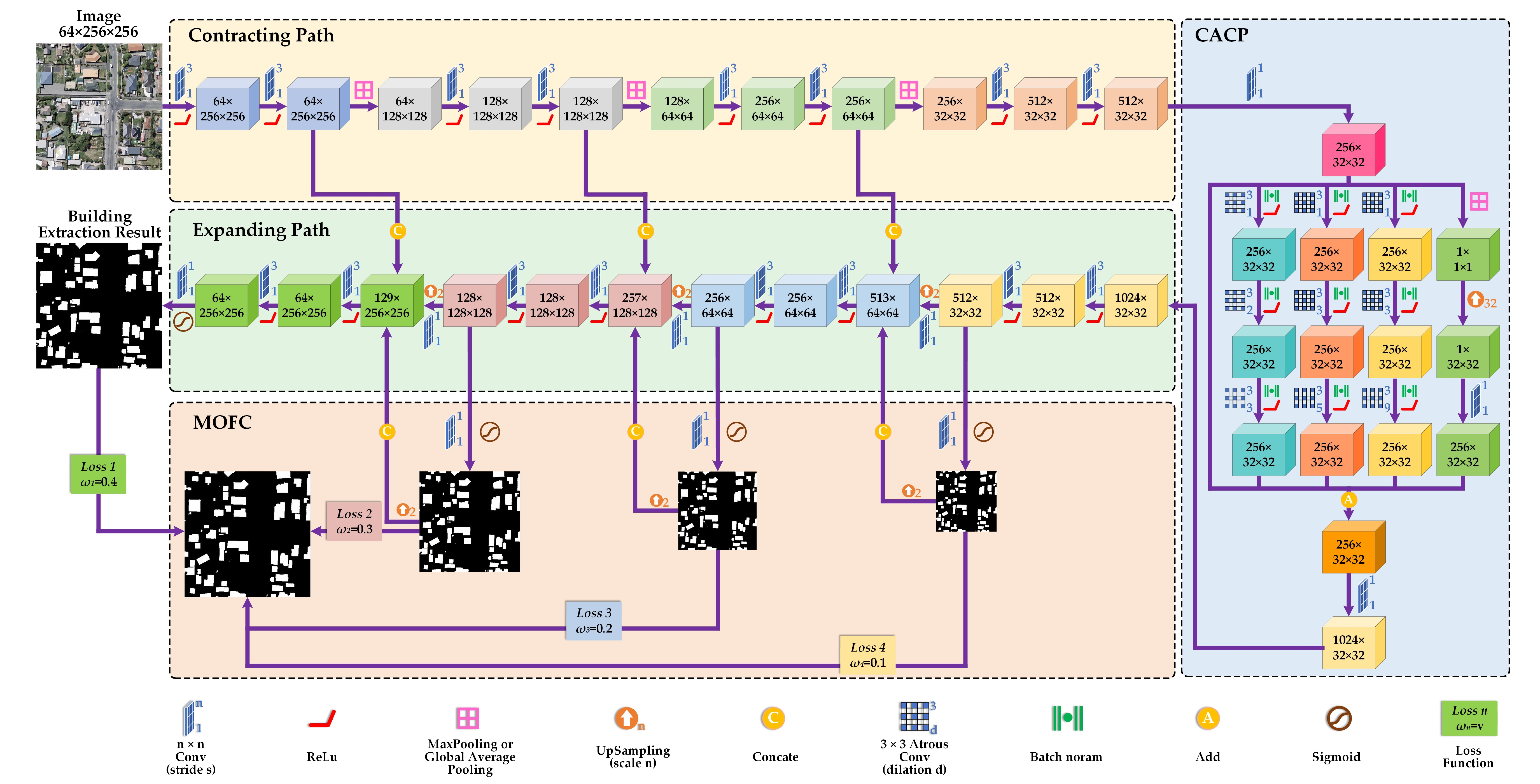
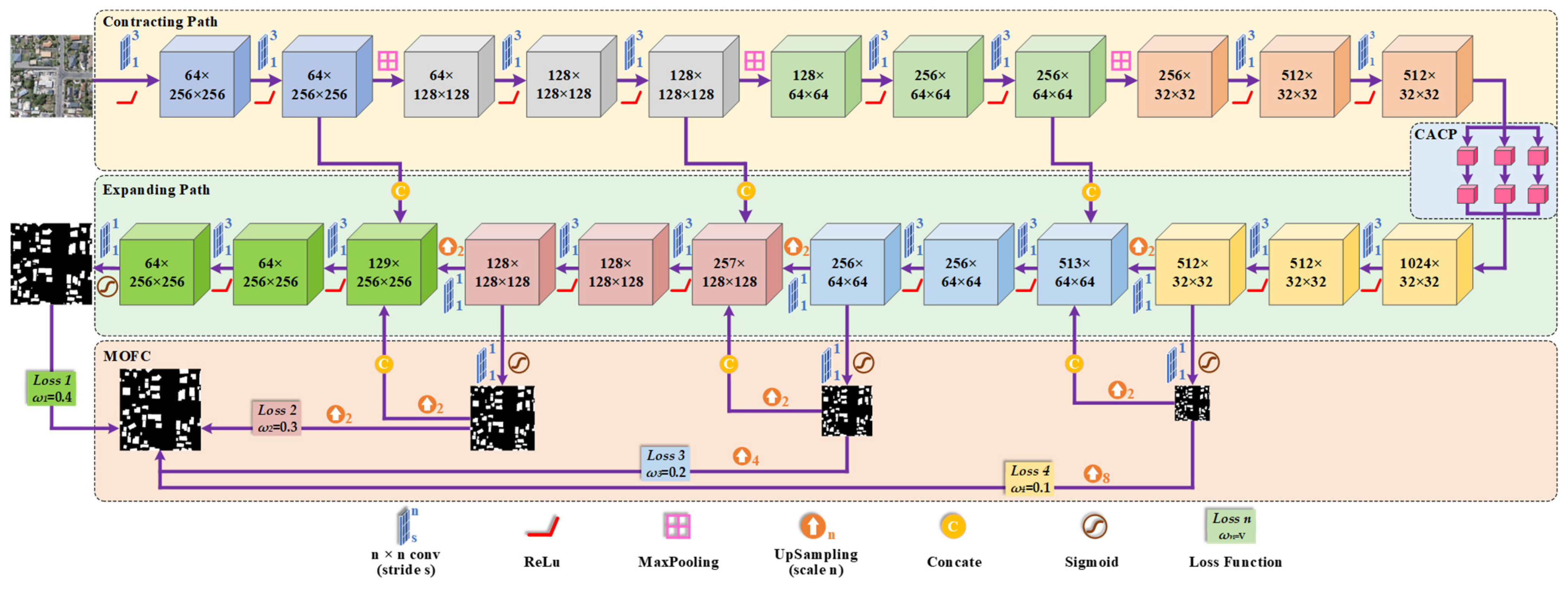
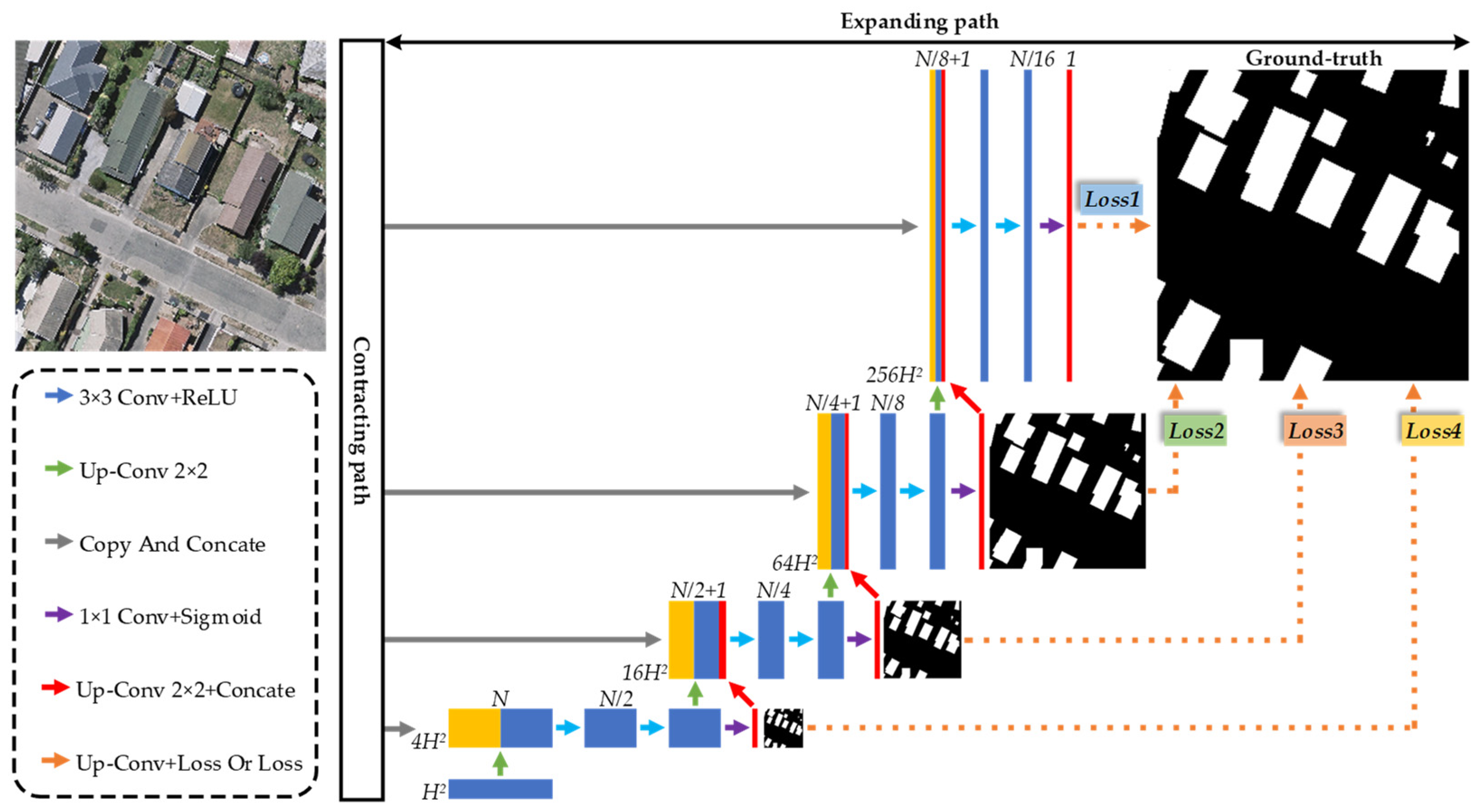
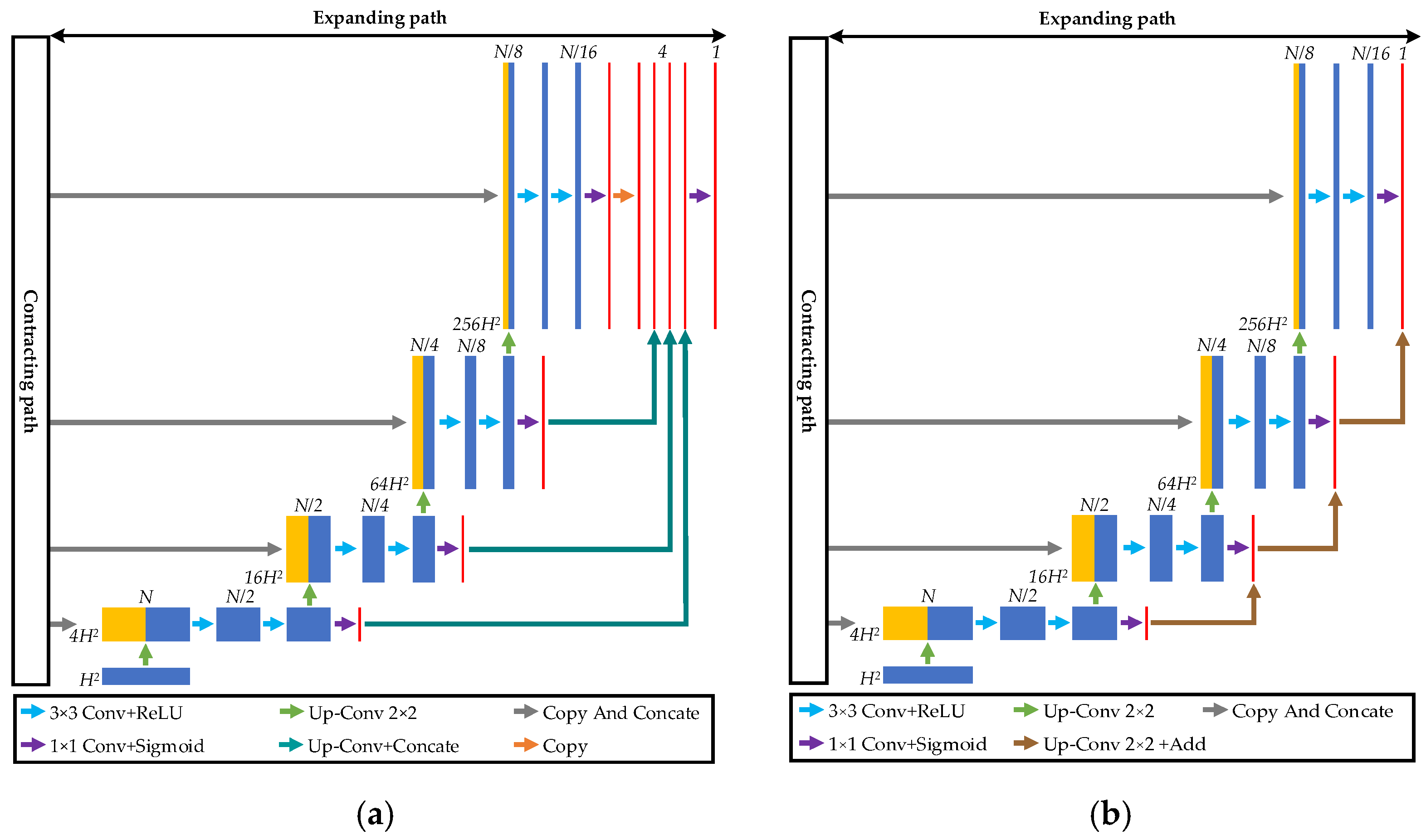
2.1. Overall Framework
2.2. Continuous Atrous Convolution Pyramid Module
2.3. Multiscale Output Fusion Constraint Structure
2.4. Multilevel Joint Weighted Loss Function
3. Experiments and Results
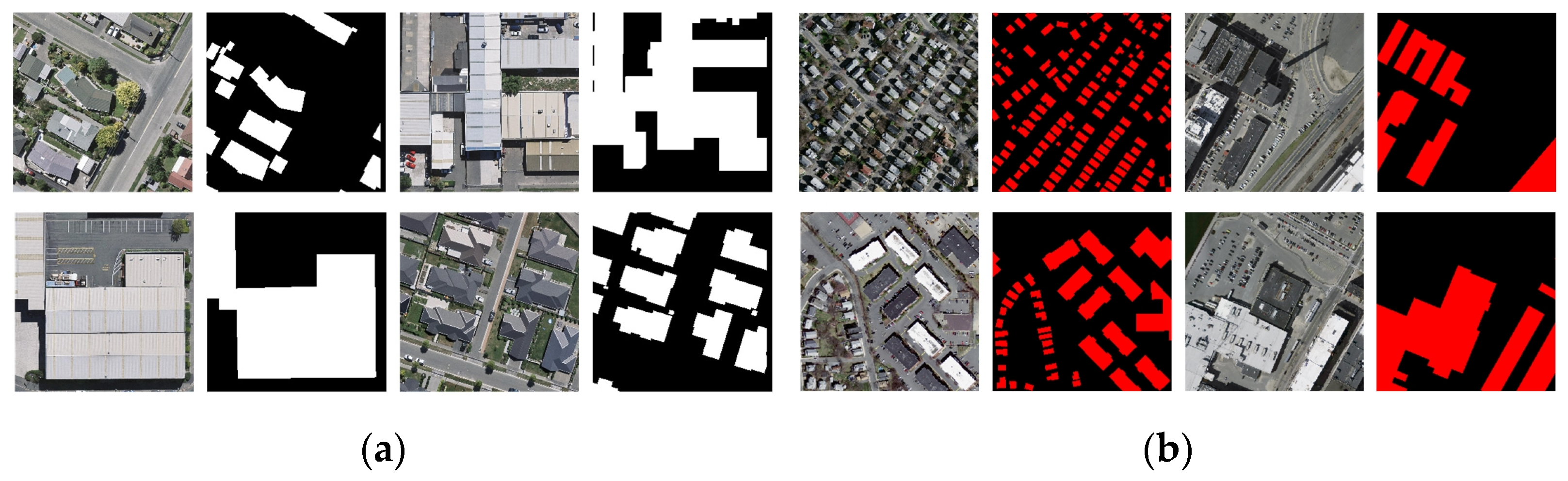
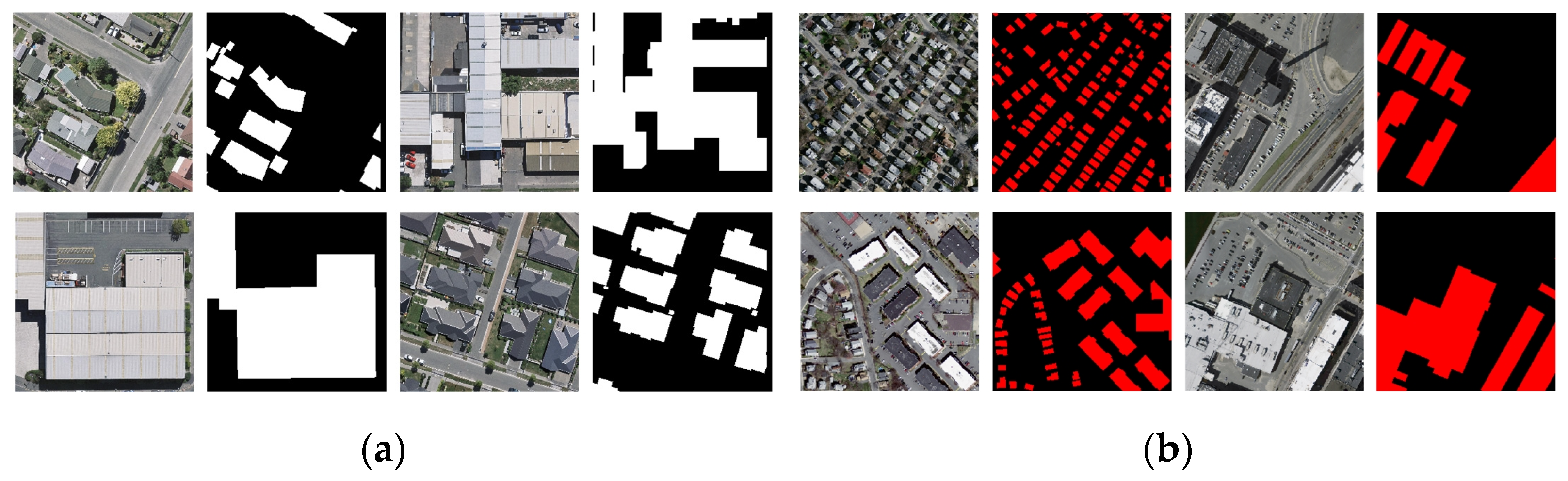
3.1. Dataset
- WHU Building Dataset
- 2.
- Massachusetts Building Dataset
3.2. Experiment Settings
3.3. Evaluation Metrics
3.4. Comparisons and Analysis
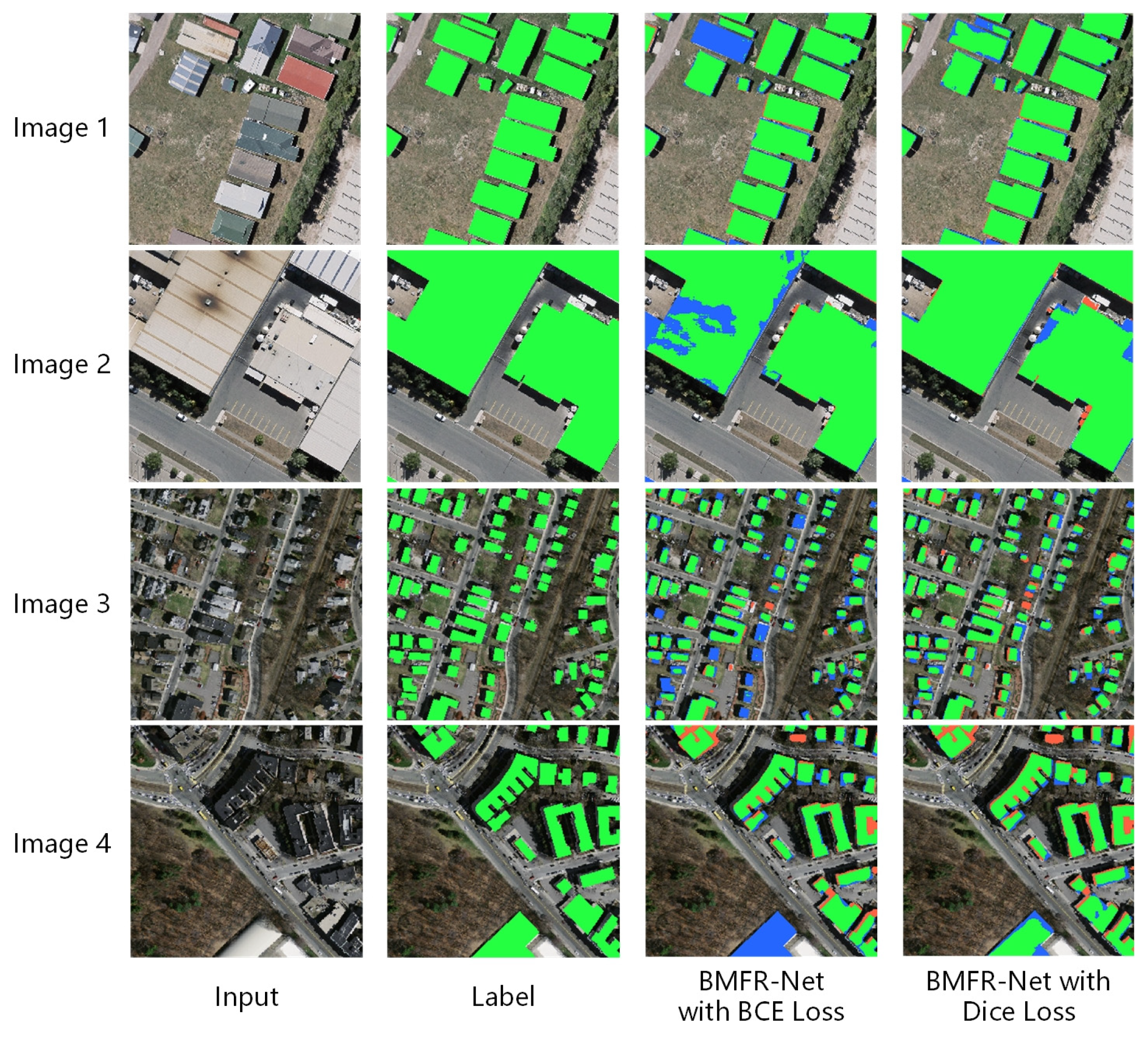
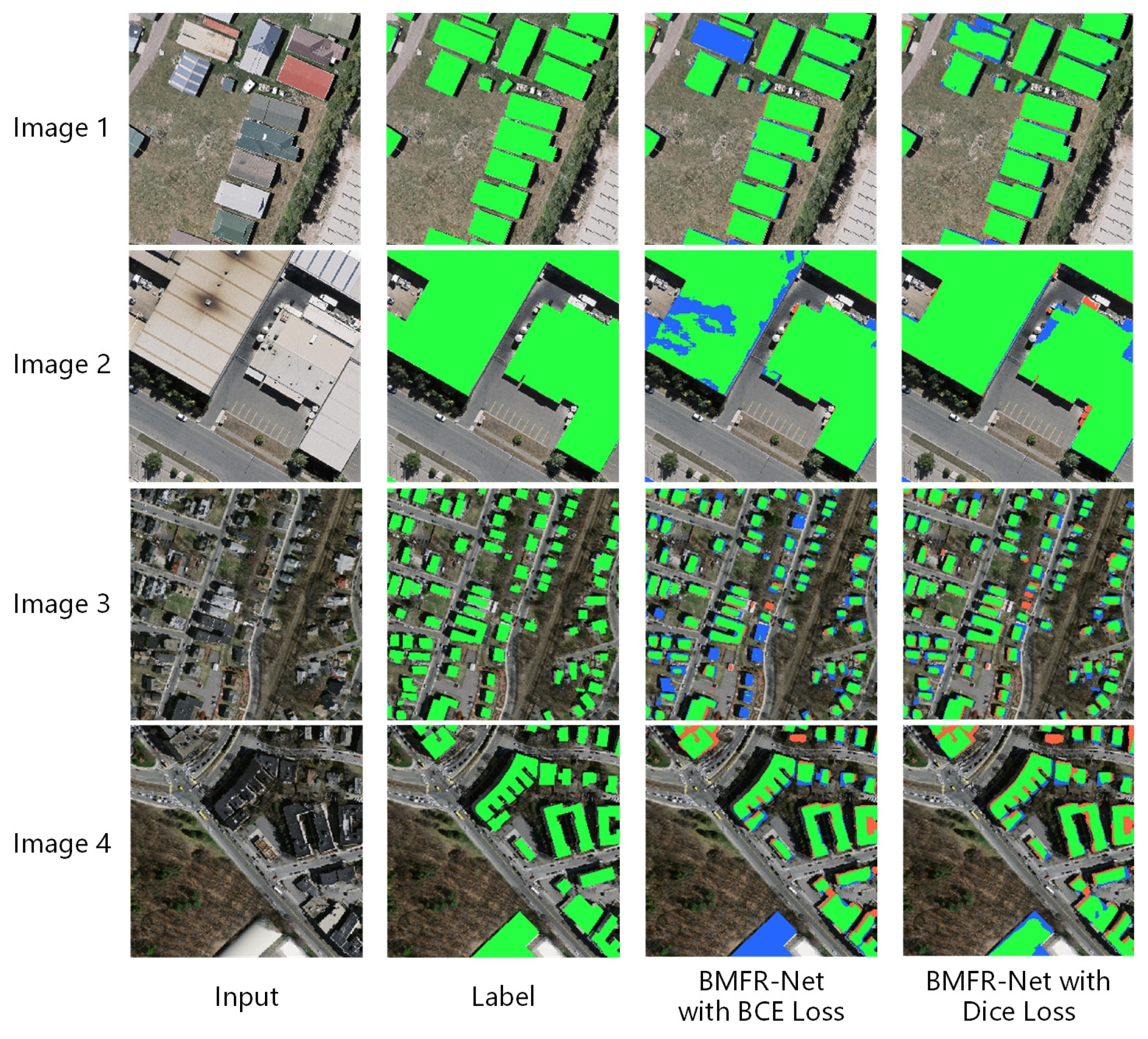
3.4.1. Comparative Experiments of Different Loss Functions
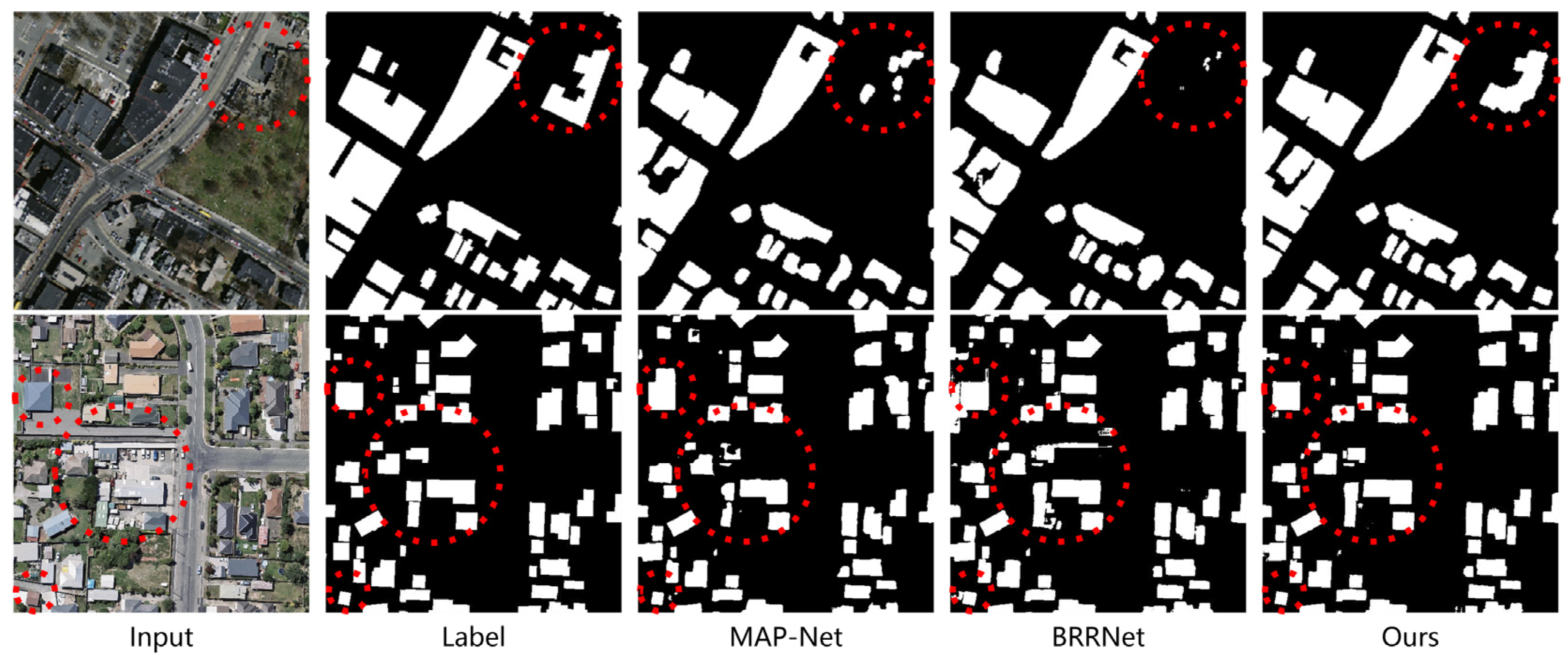
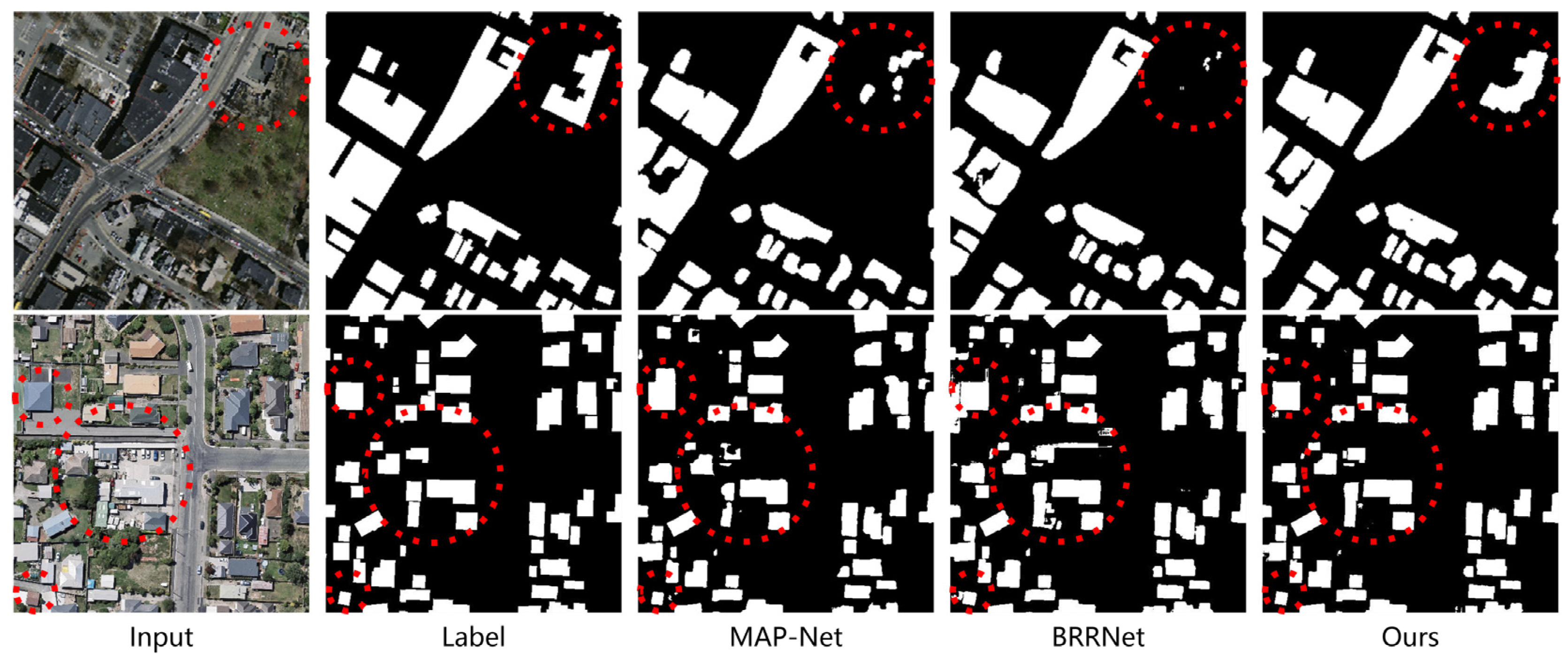
3.4.2. Comparative Experiments with SOTA Methods
- The comparative experiments on the WHU Building Dataset
- 2.
- The comparative experiments on the Massachusetts Building Dataset
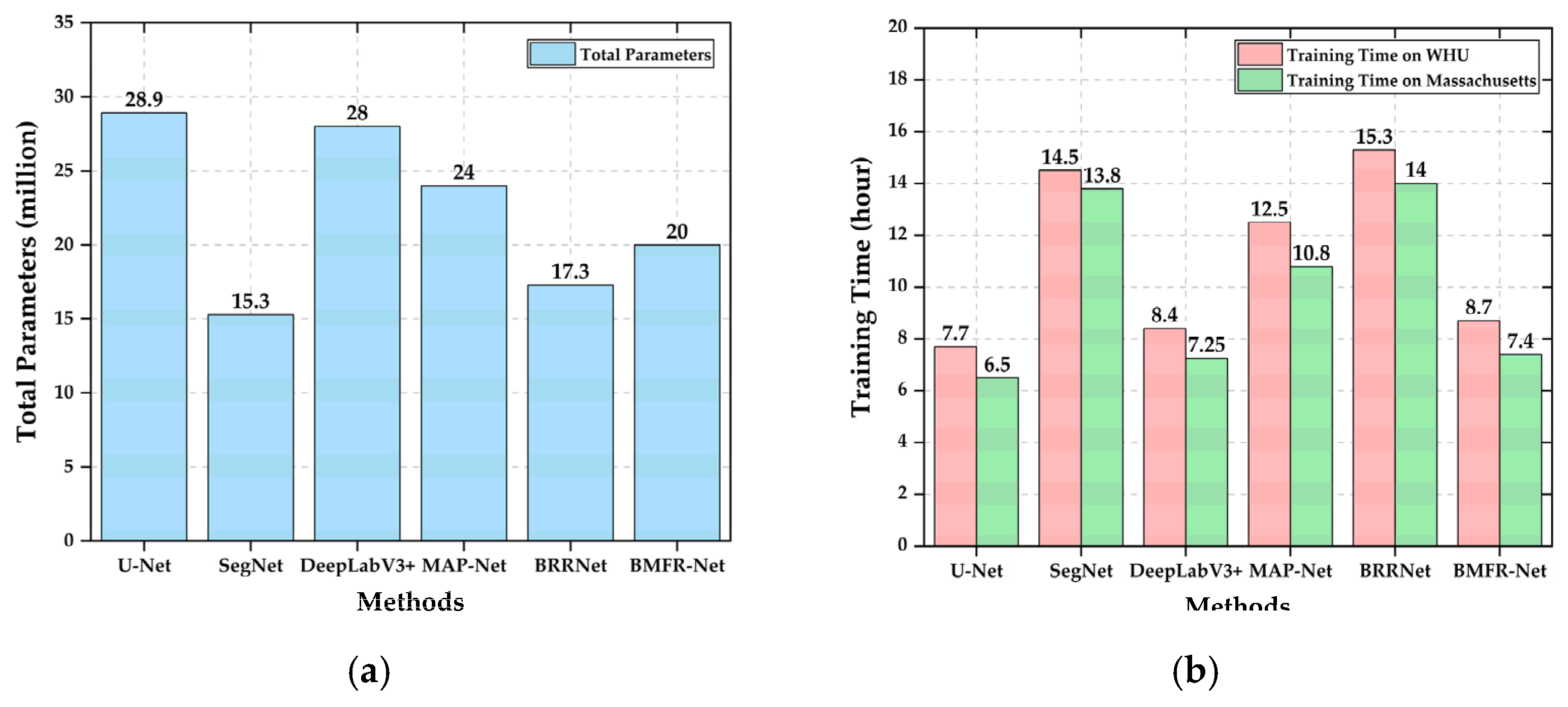
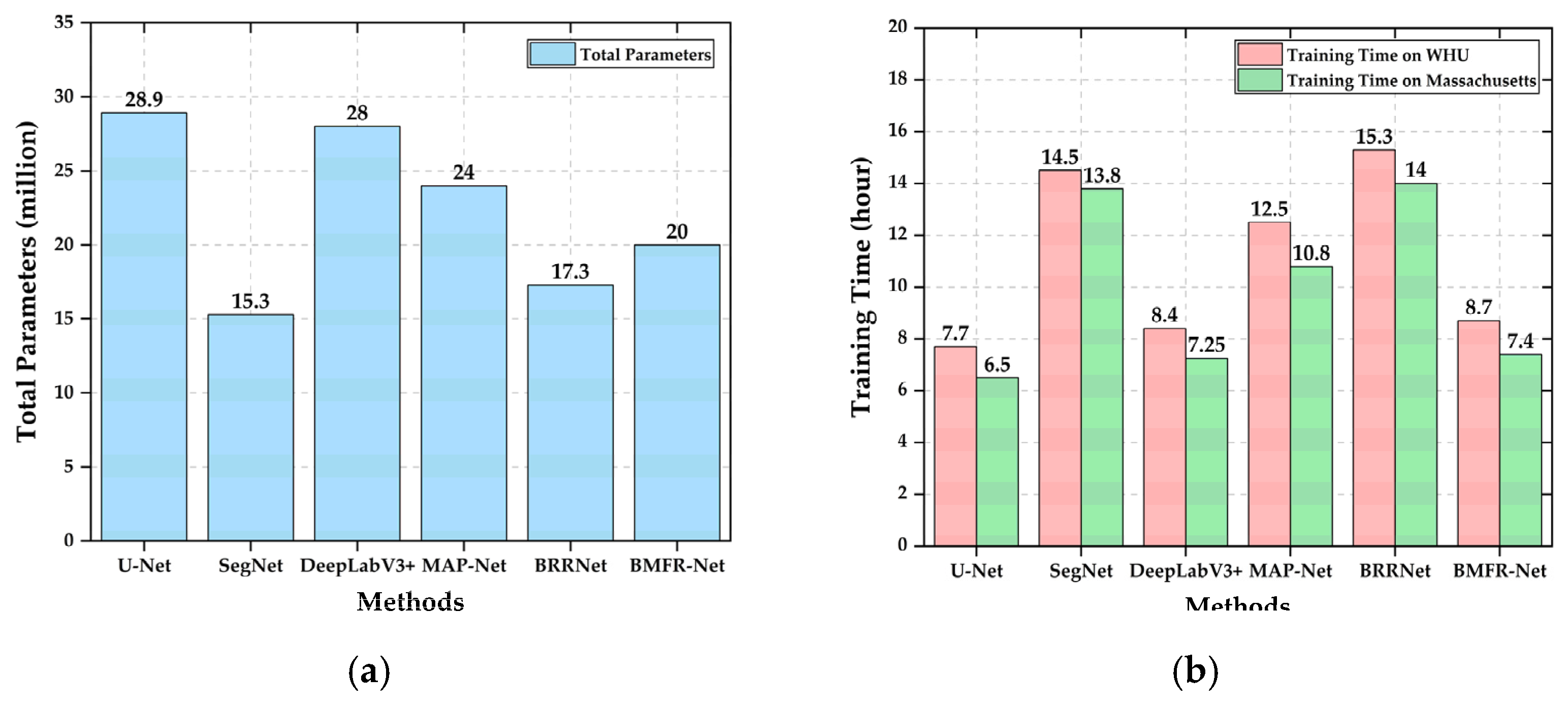
3.4.3. Comparison of Parameters and the Training Time of Different Methods
4. Discussion
4.1. Ablation Experiments of Multiscale Feature Extraction and the Fusion Module
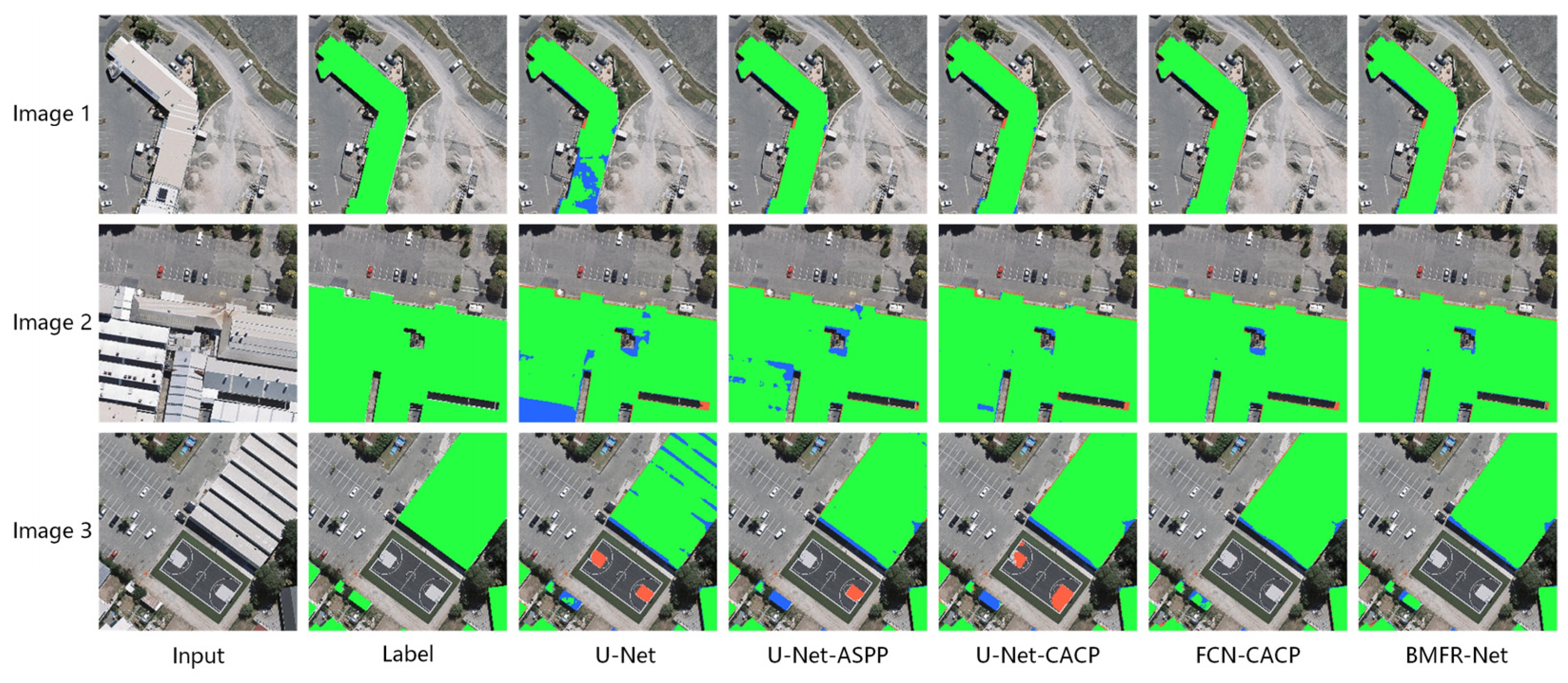
- Compared with the other four networks, the evaluation metrics of the original U-Net were improved by adding the multiscale feature extraction and fusion module, demonstrating the efficacy of the multiscale feature extraction and fusion module.
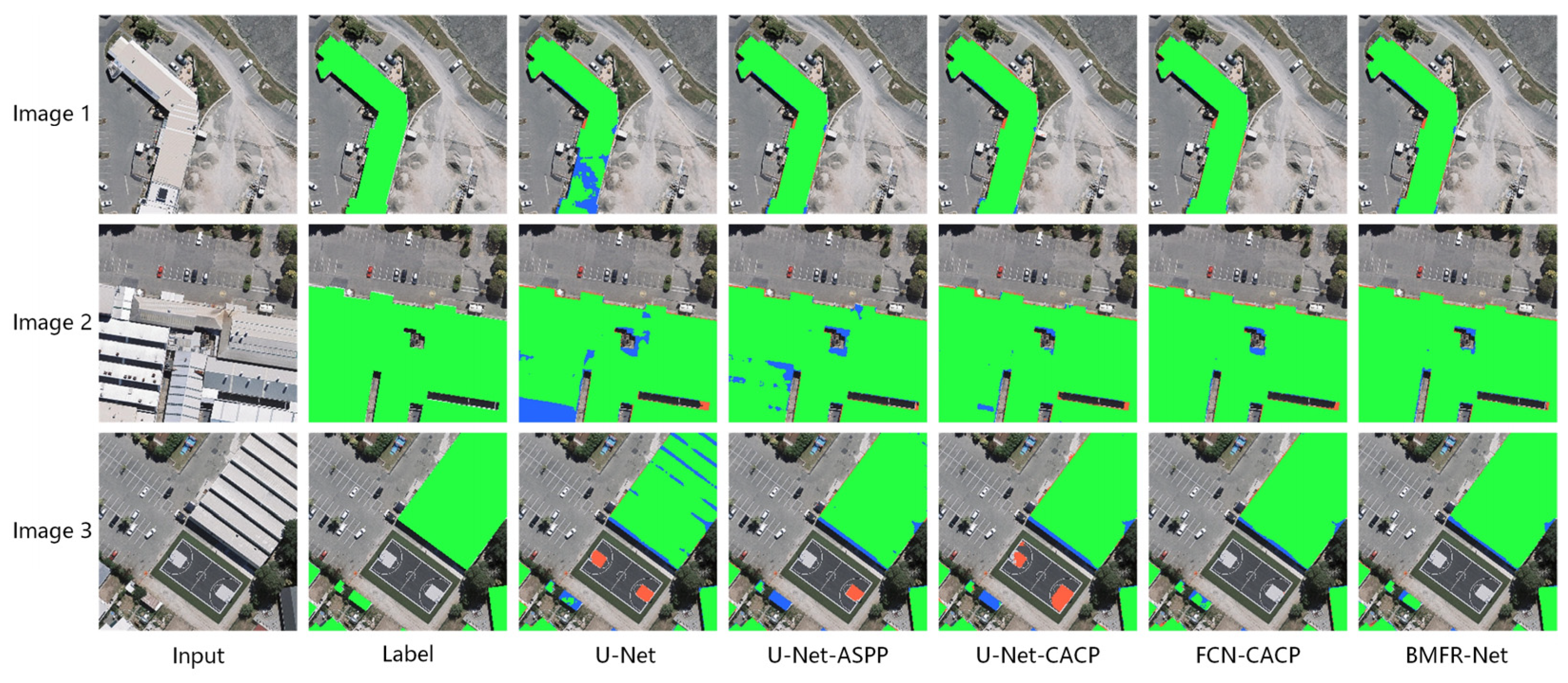
- By comparing the experimental results of U-Net-CACP and U-Net-ASPP, the pixel-based IoU and F1-Score of the network were improved by 0.53% and 0.3%, respectively, after replacing the ASPP module with the CACP module. Since the CACP module utilized the continuous small-scale atrous convolution in line with HDC constraints, it effectively slowed down the loss of high-level semantic information unique to buildings and enhanced the consistency of local information such as texture and geometry. Thus, the accuracy and recall of building extraction were improved.
- In contrast with the first three networks, the FCN-CACP had the best performance in the quantitative evaluation results, with the pixel-based and object-based F1-score reaching the highest of 93.84% and 89.93%, respectively. As shown in Figure 15, FCN-CACP had the highest accuracy and contained the fewest holes and defects. By removing the last stage of U-Net, FCN-CACP retained the scale of the input CACP module function feature at 32 × 32. Consequently, it will reduce the calculation, minimize information loss of small-scale buildings and make multiscale feature extraction easier. Except for pixel-based recall, FCN-CACP had lower evaluation metrics than BMFR-Net because the addition of the MOFC structure to the BMFR-Net enhanced network performance.
4.2. Ablation Experiments of Multiscale Output Fusion Constraint
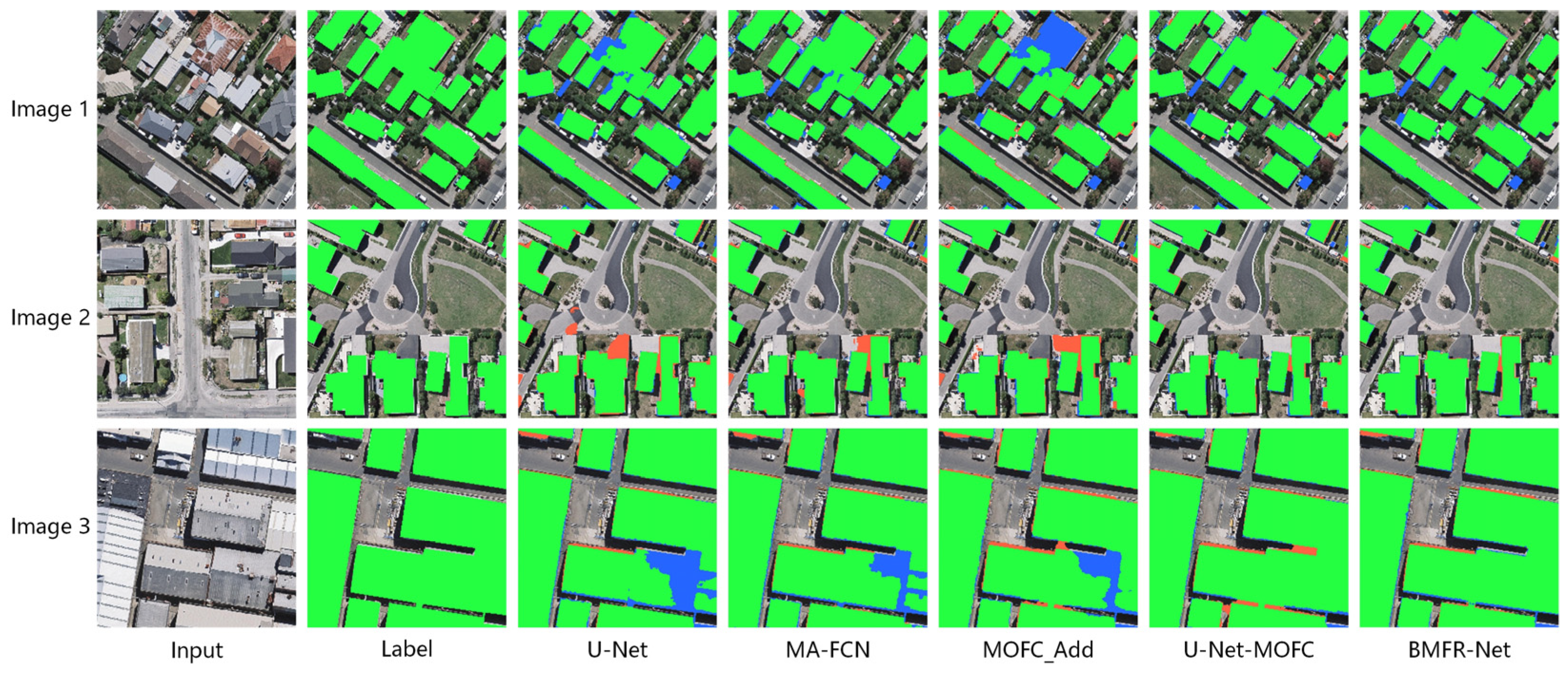
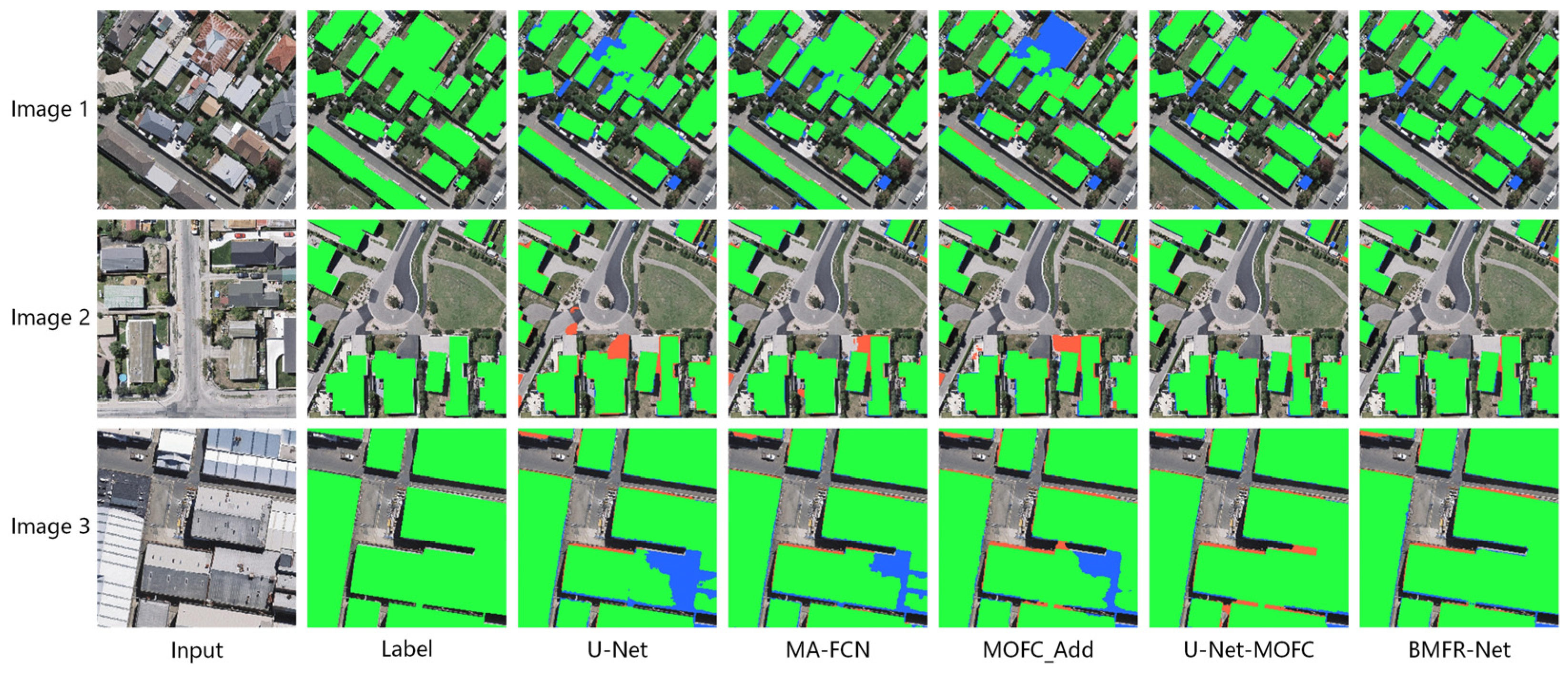
- Compared with the original U-Net, the evaluation metrics of U-Net-MOFC and MA-FCN were significantly improved, especially the pixel-based IoU and F1-score of U-Net-MOFC that increased by 2.94% and 1.68%, respectively. In contrast, most of the evaluation metrics of MOFC_Add were reduced. It indicates that the MOFC structure was better at aggregating multiscale meaning semantic information than the others.
- The MA-FCN performed better in pixel-based and object-based evaluation indexes than the original U-Net, but the network performance was still not as good as U-Net-MOFC. At each step of the expanding path, MA-FCN will improve the use of feature information. However, the upsampling scale was too large, resulting in a loss of effective information and a decrease in network performance. MOFC_Add had a higher recall but a lower precision, which was a significant difference. Aside from that, global performance was the worst. This is because MOFC_Add did not actively add results, making it challenging to synthesize the semantic information from different levels.
- The second-best overall performer was U-Net-MOFC. The MOFC structure enhanced the ability to aggregate multiscale semantic information frsom the context of the network by fusing the output results of each level into the network. Furthermore, multilevel joint constraints will effectively update parameters in the contracting path layer, improving the object-based IoU and F1-score from the original U-Net by 1.28% and 1.24%, respectively. In terms of buildings with complex architectures or variable spectral characteristics in Figure 17, U-Net-MOFC can achieve more complete extraction outcomes. The highest score of F1-score belonged to BMFR-Net. After removing the last level of U-Net-MOFC and adding the CACP module, F1 increased by 0.59%.
4.3. Ablation Experiments of the Weighted Combination of the Multilevel Joint Constraint
- The global extraction effect of (1,0,0,0) was the worst. It had a poor pixel-based recall of 93.71% but a high pixel-based precision of 94.56%. The explanation for this is that BMFR-Net has deep layers and it is difficult to effectively update the parameters in the contracting path in BMFR-Net, which are located far away from the output layer due to the single level loss constraint. As a result, the ability of the network to learn local information such as the color and edge from low-level features is harmed and the recall of building extraction results is reduced. As shown in image 1 in Figure 18, the BMFR-Net buildings with the weight combination of (1,0,0,0) were missing, while the buildings extracted by the BMFR-Net with multilevel joint constraints were more complete.
- By contrast, the pixel-based and object-based F1-score of (0.4,0.3,0.2,0.1) was the highest, reaching 94.23% and 89.30%, respectively. From the bottom to the top of the BMFR-Net expanding path, the resolution and global meaning semantic information of the feature maps gradually increased and were enriched. The loss function became increasingly influential in updating the parameters as it progressed from the low-level to high-level. Therefore, the weight combination of (0.4,0.3,0.2,0.1) was best for balancing the requirement of primary and secondary constraints in the network, and the building extraction effect was better. As shown in images 2 and 3 in Figure 18, the accuracy and integrity of building extraction results in (0.4,0.3,0.2,0.1) were higher than others.
- Comparing the results of (0.4,0.3,0.2,0.1) with (0.7,0.1,0.1,0.1), it is clear that when is enlarged, the overall performance of the network will decrease. Although the last level loss function is the primary constraint of the network, an unrestricted increase in its weight and a decrease in the weight of other levels would cause the network parameters to overfit the key constraints. Therefore, the parameters in the contracting path layers can not be effectively updated, limiting the accuracy of building extraction.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shrestha, S.; Vanneschi, L. Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, L. Morphological Building/Shadow Index for Building Extraction From High-Resolution Imagery Over Urban Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A Multidirectional and Multiscale Morphological Index for Automatic Building Extraction from Multispectral GeoEye-1 Imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Jung, C.R.; Schramm, R. Rectangle Detection based on a Windowed Hough Transform. In Proceedings of the 17th Brazilian Symposium on Computer Graphics & Image Processing, Curitiba, Brazil, 17–20 October 2004; pp. 113–120. [Google Scholar]
- Sirmacek, B.; Unsalan, C. Urban-Area and Building Detection Using SIFT Keypoints and Graph Theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar]
- Gao, X.; Wang, M.; Yang, Y.; Li, G. Building Extraction From RGB VHR Images Using Shifted Shadow Algorithm. IEEE Access. 2018, 6, 22034–22045. [Google Scholar] [CrossRef]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Boulila, W.; Sellami, M.; Driss, M.; Al-Sarem, M.; Ghaleb, F.A. RS-DCNN: A novel distributed convolutional-neural-networks based-approach for big remote-sensing image classification. Comput. Electron. Agric. 2021, 182, 106014. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks. J. Imaging Sci. Technol. 2016, 60, 10402.10401–10402.10409. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sens. 2019, 11, 2912. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic Segmentation of Aerial Images with an Ensemble of CNSS. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016; pp. 473–480. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yu, Y.; Ren, Y.; Guan, H.; Li, D.; Yu, C.; Jin, S.; Wang, L. Capsule Feature Pyramid Network for Building Footprint Extraction From High-Resolution Aerial Imagery. IEEE Geosci. Remote Sens. Lett. 2021, 18, 895–899. [Google Scholar] [CrossRef]
- Hui, J.; Du, M.; Ye, X.; Qin, Q.; Sui, J. Effective Building Extraction From High-Resolution Remote Sensing Images With Multitask Driven Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 786–790. [Google Scholar] [CrossRef]
- Bittner, K.; Adam, F.; Cui, S.; Körner, M.; Reinartz, P. Building Footprint Extraction From VHR Remote Sensing Images Combined With Normalized DSMs Using Fused Fully Convolutional Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2615–2629. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Hu, Q.; Zhen, L.; Mao, Y.; Zhou, X.; Zhou, G. Automated building extraction using satellite remote sensing imagery. Autom. Constr. 2021, 123, 103509. [Google Scholar] [CrossRef]
- Zhu, Q.; Li, Z.; Zhang, Y.; Guan, Q. Building Extraction from High Spatial Resolution Remote Sensing Images via Multiscale-Aware and Segmentation-Prior Conditional Random Fields. Remote Sens. 2020, 12, 3983. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Liu, W.; Xu, J.; Guo, Z.; Li, E.; Liu, W. Building Footprint Extraction From Unmanned Aerial Vehicle Images Via PRU-Net: Application to Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2236–2248. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction From Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction From High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.; Ji, S.; Lu, M. Toward Automatic Building Footprint Delineation From Aerial Images Using CNN and Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2178–2189. [Google Scholar] [CrossRef]
- Hosseinpoor, H.; Samadzadegan, F. Convolutional Neural Network for Building Extraction from High-Resolution Remote Sensing Images. In Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), Tehran, Iran, 18–20 February 2020; pp. 1–5. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Boer, P.T.D.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Google. TensorFlow 1.14. Available online: https://tensorflow.google.cn/ (accessed on 15 July 2021).
- Chollet, F. Keras 2.2.4. Available online: https://keras.io/ (accessed on 15 July 2021).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated Detection of Arbitrarily Shaped Buildings in Complex Environments From Monocular VHR Optical Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1701–1717. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | BCE Loss | Dice Loss | Pixel-Based Performance Parameter | Object-Based Performance Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |||
| WHU Building Dataset | √ | 98.68 | 93.93 | 94.27 | 88.85 | 94.10 | 91.38 | 89.64 | 86.56 | 90.01 | |
| √ | 98.74 | 94.31 | 94.42 | 89.32 | 94.36 | 91.67 | 89.61 | 86.68 | 90.12 | ||
| Massachusetts Building Dataset | √ | 94.38 | 86.92 | 82.29 | 73.22 | 84.54 | 88.12 | 72.13 | 67.65 | 78.28 | |
| √ | 94.46 | 85.39 | 84.89 | 74.12 | 85.14 | 90.49 | 79.78 | 75.56 | 84.14 | ||
| Methods | Pixel-Based Performance Parameter | Object-Based Performance Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |
| U-Net [34] | 98.20 | 90.25 | 94.00 | 85.34 | 92.09 | 90.01 | 88.60 | 85.46 | 88.85 |
| SegNet [33] | 98.03 | 89.43 | 93.36 | 84.08 | 91.35 | 88.98 | 88.34 | 84.38 | 88.13 |
| DeepLabV3+ [48] | 98.28 | 91.80 | 92.84 | 85.73 | 92.32 | 89.22 | 87.44 | 83.84 | 87.74 |
| MAP-Net [31] | 98.10 | 91.30 | 91.61 | 84.26 | 91.46 | 88.83 | 88.68 | 84.04 | 88.10 |
| BRRNet [32] | 98.33 | 91.52 | 93.68 | 86.19 | 92.58 | 90.31 | 88.86 | 85.54 | 89.09 |
| BMFR-Net (ours) | 98.74 | 94.31 | 94.42 | 89.32 | 94.36 | 91.67 | 89.61 | 86.68 | 90.12 |
| Methods | Pixel-Based Performance Parameter | Object-Based Performance Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |
| U-Net [34] | 94.01 | 85.33 | 82.06 | 71.91 | 83.66 | 89.44 | 80.10 | 75.39 | 83.80 |
| SegNet [33] | 93.66 | 81.42 | 85.60 | 71.61 | 83.46 | 88.68 | 80.29 | 75.21 | 83.70 |
| DeepLabV3+ [48] | 93.39 | 81.62 | 83.39 | 70.21 | 82.50 | 88.30 | 77.64 | 72.42 | 81.93 |
| MAP-Net [31] | 94.18 | 84.72 | 84.00 | 72.95 | 84.36 | 88.28 | 78.57 | 73.36 | 82.35 |
| BRRNet [32] | 94.12 | 85.03 | 83.17 | 72.55 | 84.09 | 86.86 | 77.28 | 71.45 | 80.95 |
| BMFR-Net (ours) | 94.46 | 85.39 | 84.89 | 74.12 | 85.14 | 90.49 | 79.78 | 75.56 | 84.14 |
| Methods | Pixel-Based Performance Parameter | Object-Based Performance Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |
| U-Net | 98.20 | 90.25 | 94.00 | 85.34 | 92.09 | 90.01 | 88.60 | 85.46 | 88.85 |
| U-Net-ASPP | 98.54 | 93.40 | 93.70 | 87.62 | 93.40 | 90.78 | 89.46 | 85.85 | 89.59 |
| U-Net-CACP | 98.60 | 93.54 | 93.87 | 88.15 | 93.70 | 90.80 | 89.33 | 86.14 | 89.56 |
| FCN-CACP | 98.62 | 93.05 | 94.65 | 88.39 | 93.84 | 91.29 | 89.55 | 86.56 | 89.93 |
| BMFR-Net | 98.74 | 94.31 | 94.42 | 89.32 | 94.36 | 91.67 | 89.61 | 86.68 | 90.12 |
| Methods | Pixel-Based Performance Parameter | Object-Based Performance Parameter | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |
| U-Net | 98.20 | 90.25 | 94.00 | 85.34 | 92.09 | 90.01 | 88.60 | 85.46 | 88.85 |
| MA-FCN | 98.34 | 91.24 | 94.14 | 86.33 | 92.66 | 90.84 | 89.30 | 86.25 | 89.60 |
| MOFC_Add | 98.08 | 88.39 | 95.31 | 84.70 | 91.72 | 89.22 | 88.74 | 85.31 | 88.52 |
| U-Net-MOFC | 98.61 | 93.41 | 94.14 | 88.28 | 93.77 | 91.00 | 90.05 | 86.74 | 90.09 |
| BMFR-Net | 98.74 | 94.31 | 94.42 | 89.32 | 94.36 | 91.67 | 89.61 | 86.68 | 90.12 |
| Pixel-Based Performance Parameter | Object-Based Performance Parameter | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | Precision | Recall | IoU | F1-Score | Precision | Recall | IoU | F1-Score | |
| (1,0,0,0) | 98.70 | 94.56 | 93.71 | 88.92 | 94.13 | 90.52 | 88.38 | 85.34 | 88.92 |
| (0.25,0.25,0.25,0.25) | 98.73 | 94.62 | 93.91 | 89.15 | 94.26 | 90.99 | 89.74 | 86.24 | 89.84 |
| (0.4,0.3,0.2,0.1) | 98.74 | 94.31 | 94.42 | 89.32 | 94.36 | 91.67 | 89.61 | 86.68 | 90.12 |
| (0.1,0.2,0.3,0.4) | 98.71 | 93.99 | 94.42 | 89.04 | 94.20 | 91.27 | 89.56 | 86.57 | 89.92 |
| (0.7,0.1,0.1,0.1) | 98.72 | 94.22 | 94.25 | 89.10 | 94.23 | 90.45 | 89.14 | 85.93 | 89.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, S.; Gao, X.; Yang, Y.; Li, S.; Zhang, G.; Wang, P. Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 2794. https://doi.org/10.3390/rs13142794
Ran S, Gao X, Yang Y, Li S, Zhang G, Wang P. Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images. Remote Sensing. 2021; 13(14):2794. https://doi.org/10.3390/rs13142794
Chicago/Turabian StyleRan, Shuhao, Xianjun Gao, Yuanwei Yang, Shaohua Li, Guangbin Zhang, and Ping Wang. 2021. "Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images" Remote Sensing 13, no. 14: 2794. https://doi.org/10.3390/rs13142794
APA StyleRan, S., Gao, X., Yang, Y., Li, S., Zhang, G., & Wang, P. (2021). Building Multi-Feature Fusion Refined Network for Building Extraction from High-Resolution Remote Sensing Images. Remote Sensing, 13(14), 2794. https://doi.org/10.3390/rs13142794