
Lessons Learned While Implementing a Time-Series Approach to Forest Canopy Disturbance Detection in Nepal

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Materials and Methods
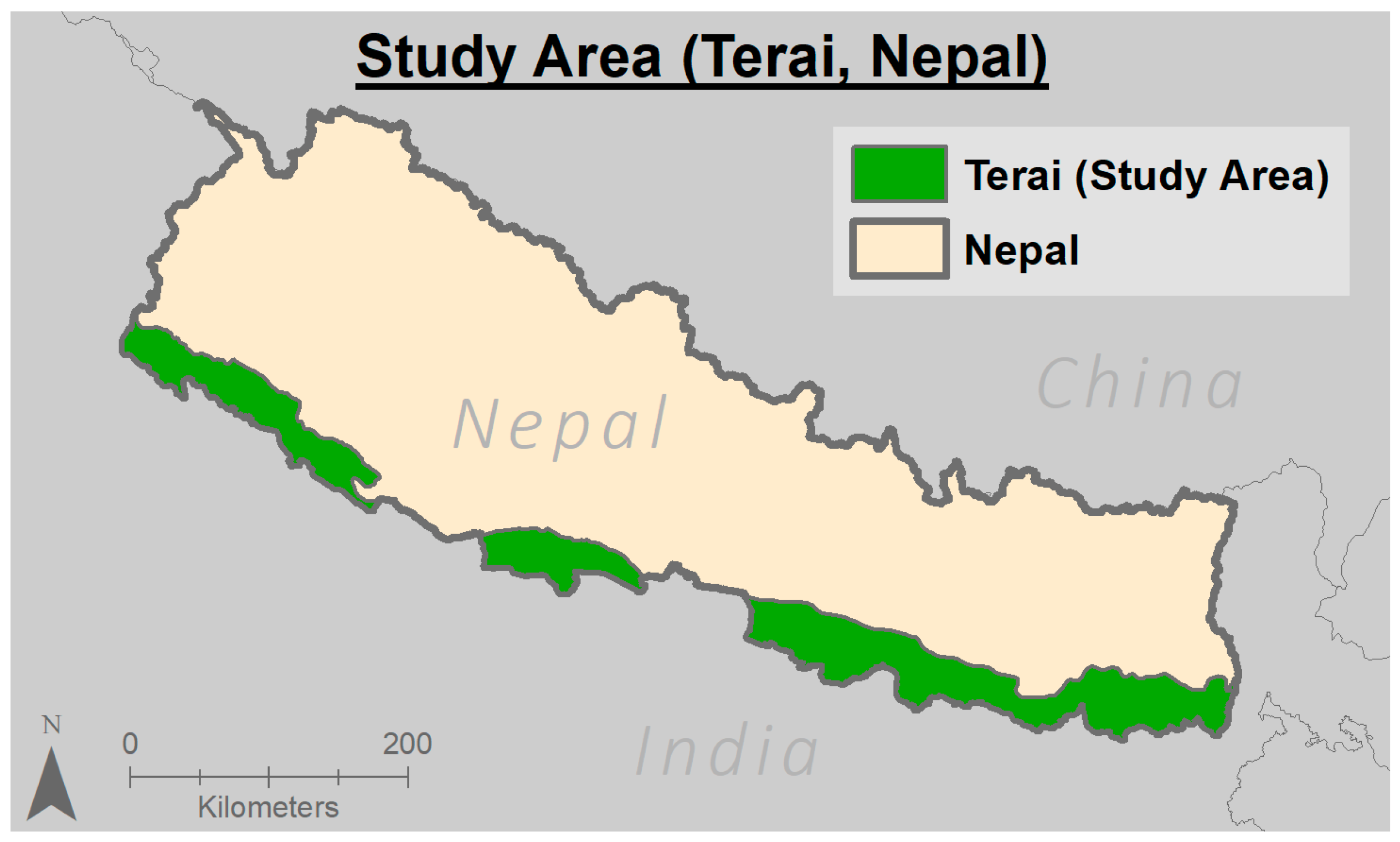
2.1. Study Region
2.2. CODED
2.3. Parameter Testing
2.4. Accuracy Assessments and Unbiased Area
3. Results
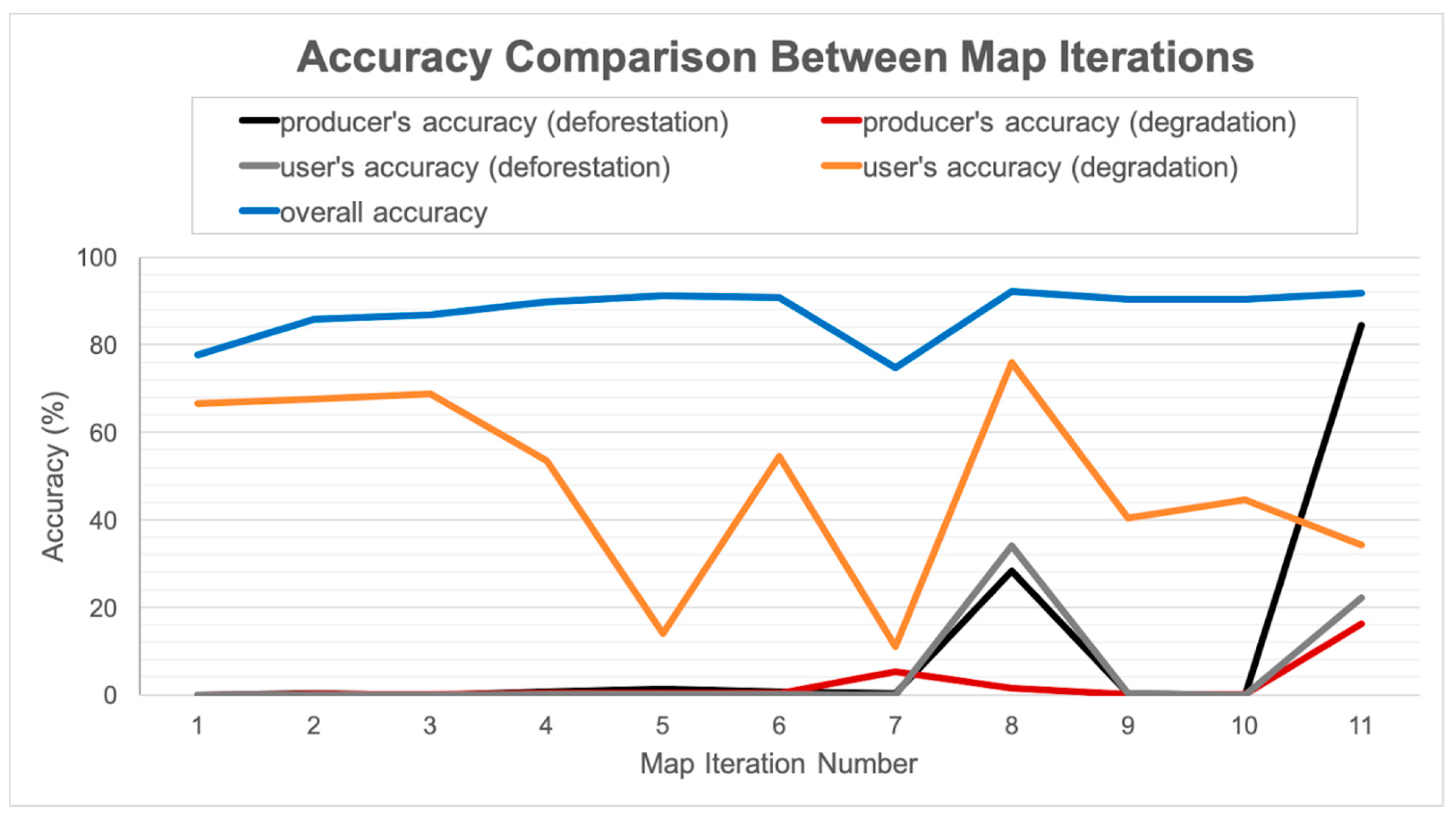
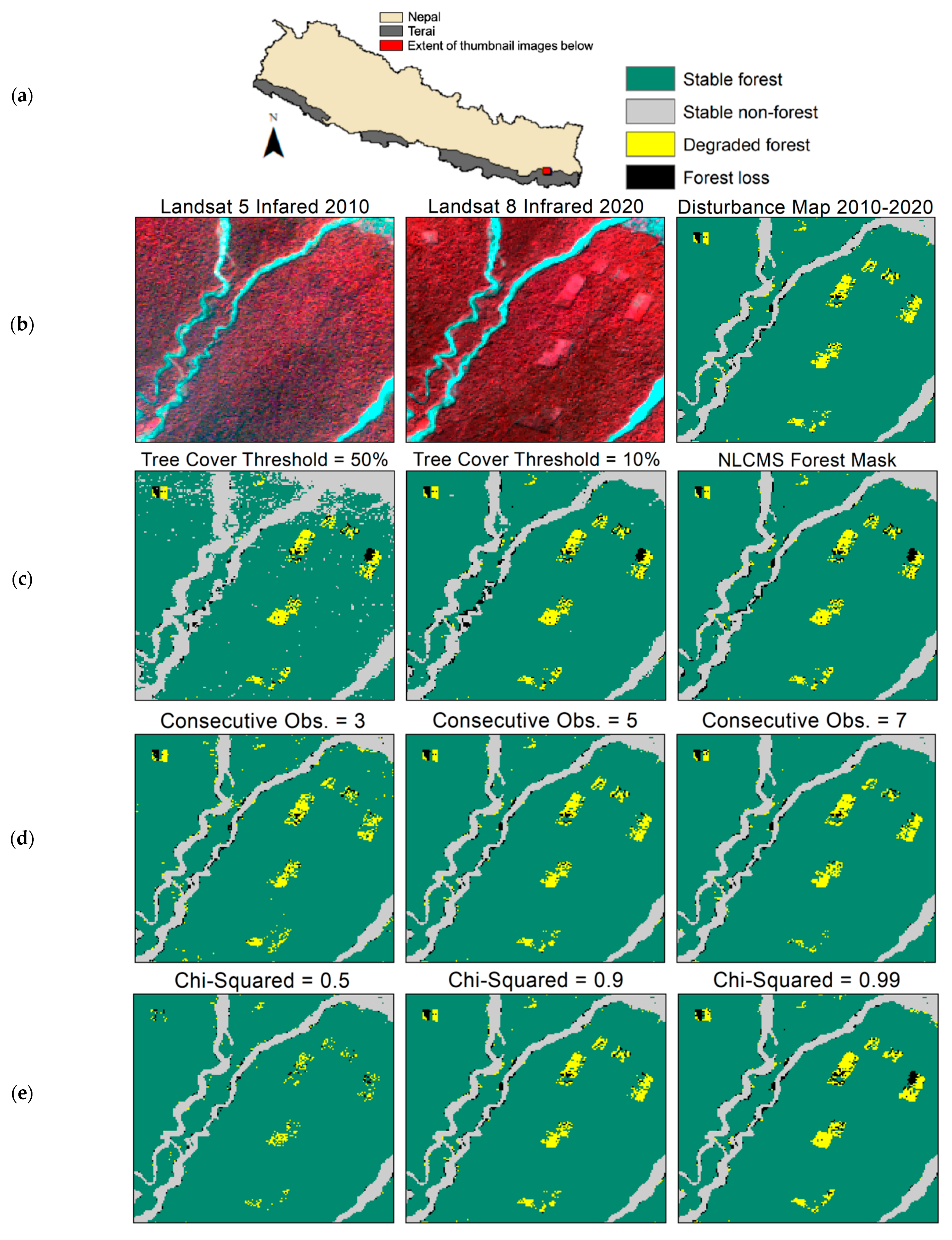
3.1. Parameter Testing
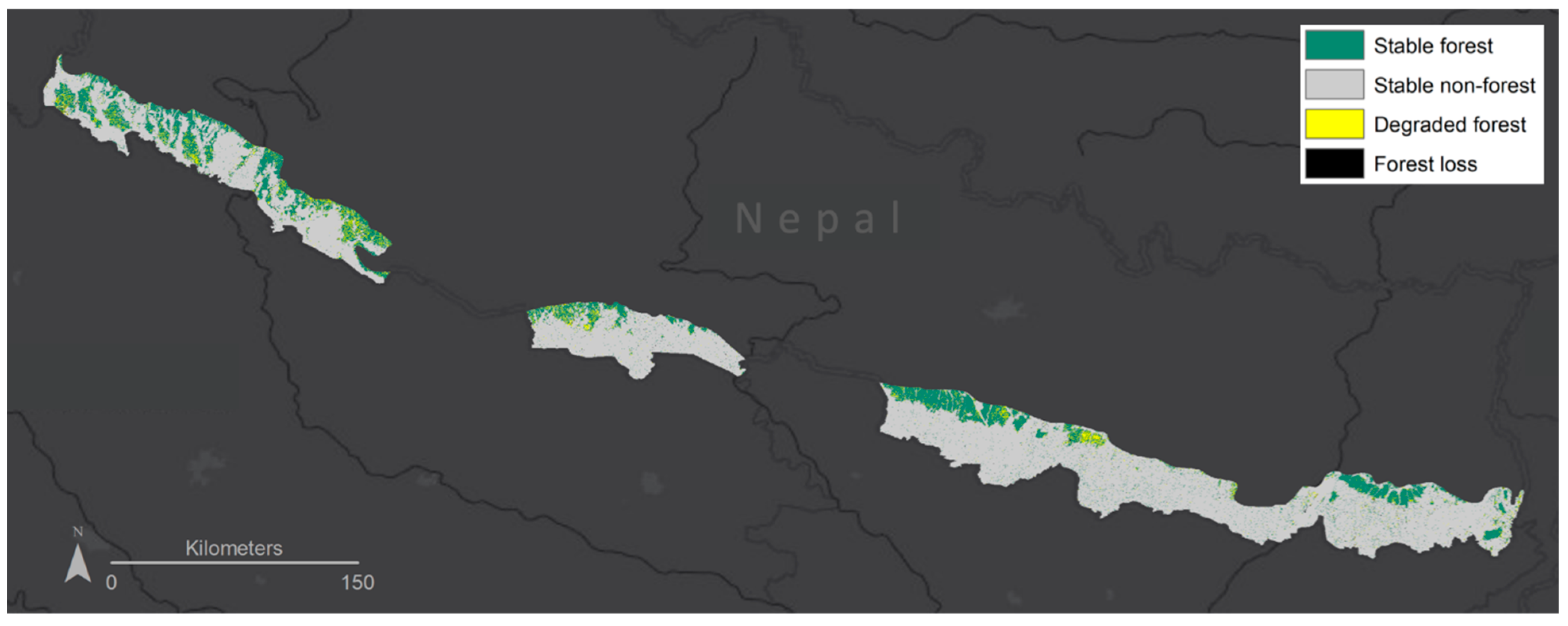
3.2. Final Map
4. Discussion
Lessons Learned from Using CODED in an Applied REDD+ Context
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Murdiyarso, D.; Skutsch, M.; Guariguata, M.; Kanninen, M.; Cecilia, L.; Pita, V.; Osvaldo, S. Measuring and Monitoring Forest Degradation for REDD Implications of Country Circumstances. Cent. Int. For. Res. 2008, 16, 1–5. [Google Scholar]
- GFOI. Integrating Remote-Sensing and Ground-Based Observations for Estimation of Emissions and Removals of Greenhouse Gases in Forests: Methods and Guidance from the Global Forest Observations Initiative, 2nd ed.; Food and Agriculture Ornaization: Rome, Italy, 2016; 164p. [Google Scholar]
- FAO. Terms and Definition; Food and Agriculture Organization of the United Nations: Rome, Italy, 2015. [Google Scholar]
- Kennedy, E.R.; Andréfouët, S.; Cohen, W.B.; Gómez, C.; Griffiths, P.; Hais, M.; Healey, S.P.; Helmer, E.H.; Hostert, P.; Lyons, M.B.; et al. Bringing an ecological view of change to Landsat-based remote sensing. Front. Ecol. Environ. 2014, 12, 339–346. [Google Scholar] [CrossRef]
- Langner, A.; Miettinen, J.; Kukkonen, M.; Vancutsem, C.; Simonetti, D.; Vieilledent, G.; Verhegghen, A.; Gallego, J.; Stibig, H.-J. Towards Operational Monitoring of Forest Canopy Disturbance in Evergreen Rain Forests: A Test Case in Continental Southeast Asia. Remote Sens. 2018, 10, 544. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, A.L.; Rosenqvist, A.; Mora, B. Current remote sensing approaches to monitoring forest degradation in support of countries measurement, reporting and verification (MRV) systems for REDD+. Carbon Balance Manag. 2017, 12, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herold, M.; Roman-Cuesta, R.M.; Mollicone, D.; Hirata, Y.; Van Laake, P.; Asner, G.P.; Souza, C.; Skutsch, M.; Avitabile, V.; MacDicken, K. Options for monitoring and estimating historical carbon emissions from forest degradation in the context of REDD+. Carbon Balance Manag. 2011, 6, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herold, M.; Skutsch, M. Monitoring, reporting and verification for national REDD+ programmes: Two proposals. Environ. Res. Lett. 2011, 6, 014002. [Google Scholar] [CrossRef]
- Bullock, E.L.; Woodcock, C.E.; Souza, C.; Olofsson, P. Satellite-based estimates reveal widespread forest degradation in the Amazon. Glob. Chang. Biol. 2020, 26, 2956–2969. [Google Scholar] [CrossRef]
- Goetz, S.; Hansen, M.; Houghton, R.A.; Walker, W.; Laporte, N.T.; Busch, J. Measurement and Monitoring for REDD+: The Needs, Current Technological Capabilities, and Future Potential. SSRN Electron. J. 2014, 392. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Intergovernmental Panel for Climate Change (IPCC). Definitions and Methodological Options to Inventory Emissions from Direct Human-Induced Degradation of Forests and Devegetation of Other Vegetation Types; IPCC: Hayama, Japan, 2003. [Google Scholar]
- Intergovernmental Panel for Climate Change (IPCC). IPCC Guidelines for National Greenhouse Gas Inventories; IPCC: Hayama, Japan, 2006. [Google Scholar]
- Pearson, T.R.H.; Brown, S.; Murray, L.; Sidman, G. Greenhouse gas emissions from tropical forest degradation: An underestimated source. Carbon Balance Manag. 2017, 12, 3. [Google Scholar] [CrossRef] [Green Version]
- World Bank. Carbon Fund Methodological Framework. 2013. Available online: https://www.forestcarbonpartnership.org/carbon-fund-methodological-framework (accessed on 10 April 2021).
- MoFSC. Nepal’s Readiness Preparation Proposal REDD; Ministry of Forests and Environment Singh: Kathmandu, Nepal, 2010; pp. 68–70.
- MoFSC. Understanding Drivers and Causes of Deforestation and Forest Degradation in Nepal: Potential Policies and Measures for REDD+; Ministry of Forests and Environment Singh: Kathmandu, Nepal, 2014.
- MoFSC. National Forest Reference Level of Nepal (2000–2010); Ministry of Forests and Environment Singh: Kathmandu, Nepal, 2016; pp. 1–74.
- Poudel, K.C. Silviculture for forest management in Nepal. Banko Janakari 2018, 27, 15–20. [Google Scholar] [CrossRef]
- MoFE. Nepal National REDD+ Strategy (2018–2022); Ministry of Forests and Environment Singh: Kathmandu, Nepal, 2018.
- ERPD. People and Forests—A Sustainable Forest Management-Based Emission Reduction Program in the Terai Arc Landscape; Nepal Ministry of Forests and Environment: Kathmandu, Nepal, 2018.
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vogt, P.; Riitters, K.H.; Estreguil, C.; Kozak, J.; Wade, T.G.; Wickham, J.D. Mapping Spatial Patterns with Morphological Image Processing. Landsc. Ecol. 2007, 22, 171–177. [Google Scholar] [CrossRef]
- Soille, P.; Vogt, P. Morphological segmentation of binary patterns. Pattern Recognit. Lett. 2009, 30, 456–459. [Google Scholar] [CrossRef]
- Shapiro, A.C.; Aguilar-Amuchastegui, N.; Hostert, P.; Bastin, J.-F. Using fragmentation to assess degradation of forest edges in Democratic Republic of Congo. Carbon Balance Manag. 2016, 11, 11. [Google Scholar] [CrossRef]
- Bullock, E.L.; Woodcock, C.E.; Olofsson, P. Monitoring tropical forest degradation using spectral unmixing and Landsat time series analysis. Remote Sens. Environ. 2020, 238, 110968. [Google Scholar] [CrossRef]
- Souza, C.M.; Roberts, D.A.; Cochrane, M.A. Combining spectral and spatial information to map canopy damage from selective logging and forest fires. Remote Sens. Environ. 2005, 98, 329–343. [Google Scholar] [CrossRef]
- LRMP. Land Resource Mapping Project Report, Nepal; Land Resources Mapping Project, Survey Department, HMGN and Kenting Earth Sciences: Kathmandu, Nepal, 1986. [Google Scholar]
- Forest Resource Assessment. Terai Forests of Nepal; Forest Resource Assessment: Kathmandu, Nepal, 2014. [Google Scholar]
- Bajpai, O.; Pandey, J.; Chaudhary, L.B. Periodicity of different phenophases in selected trees from Himalayan Terai of India. Agrofor. Syst. 2016, 91, 363–374. [Google Scholar] [CrossRef]
- Chapagain, P.S.; Aase, T.H. Changing forest coverage and understanding of deforestation in Nepal Himalayas. Geogr. J. Nepal 2020, 13, 1–28. [Google Scholar] [CrossRef]
- Bullock, E.L.; Nolte, C.; Segovia, A.L.R.; Woodcock, C.E. Ongoing forest disturbance in Guatemala’s protected areas. Remote Sens. Ecol. Conserv. 2020, 6, 141–152. [Google Scholar] [CrossRef] [Green Version]
- Berenguer, E.; Ferreira, J.; Gardner, T.A.; Aragão, L.E.O.C.; De Camargo, P.B.; Cerri, C.E.; Durigan, M.; De Oliveira, R.C.; Vieira, I.; Barlow, J. A large-scale field assessment of carbon stocks in human-modified tropical forests. Glob. Chang. Biol. 2014, 20, 3713–3726. [Google Scholar] [CrossRef] [Green Version]
- Baccini, A.; Walker, W.; Carvalho, L.; Farina, M.; Houghton, R.A. Response to Comment on Tropical forests are a net carbon source based on aboveground measurements of gain and loss. Science 2019, 363, eaat1205. [Google Scholar] [CrossRef] [Green Version]
- Souza, C.; Barreto, P. An alternative approach for detecting and monitoring selectively logged forests in the Amazon. Int. J. Remote Sens. 2000, 21, 173–179. [Google Scholar] [CrossRef]
- Eric, B. Versions—Coded 0.2 Documentation. 2018. Available online: https://coded.readthedocs.io/en/latest/versions.html?highlight=version (accessed on 28 May 2021).
- Global Forest Watch. World Resources Institute. 2014. Available online: https://www.wri.org/initiatives/global-forest-watch (accessed on 19 October 2020).
- Stehman, S.V. Estimating area and map accuracy for stratified random sampling when the strata are different from the map classes. Int. J. Remote Sens. 2014, 35, 4923–4939. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Saah, D.; Johnson, G.; Ashmall, B.; Tondapu, G.; Tenneson, K.; Patterson, M.; Poortinga, A.; Markert, K.; Quyen, N.H.; Aung, K.S.; et al. Collect Earth: An online tool for systematic reference data collection in land cover and use applications. Environ. Model. Softw. 2019, 118, 166–171. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Stehman, S.V.; Liknes, G.C.; Næsset, E.; Sannier, C.; Walters, B. The effects of imperfect reference data on remote sensing-assisted estimators of land cover class proportions. J. Photogramm. Remote Sens. 2018, 142, 292–300. [Google Scholar] [CrossRef]
- Pengra, B.W.; Stehman, S.V.; Horton, J.A.; Dockter, D.J.; Schroeder, T.A.; Yang, Z.; Cohen, W.B.; Healey, S.P.; Loveland, T.R. Quality control and assessment of interpreter consistency of annual land cover reference data in an operational national monitoring program. Remote Sens. Environ. 2020, 238, 111261. [Google Scholar] [CrossRef]
- Olofsson, P.; Arévalo, P.; Espejo, A.B.; Green, C.; Lindquist, E.; McRoberts, R.E.; Sanz, M.J. Mitigating the effects of omission errors on area and area change estimates. Remote Sens. Environ. 2020, 236, 111492. [Google Scholar] [CrossRef]
- Dwomoh, F.K.; Wimberly, M.C. Fire Regimes and Their Drivers in the Upper Guinean Region of West Africa. Remote Sens. 2017, 9, 1117. [Google Scholar] [CrossRef] [Green Version]
- Montellano, A.R.; Armijo, E. Detecting Forest Degradation Patterns in Southeast Cameroon. Simpósio Bras. Sens. Remoto 2011, 8, 1608–1611. [Google Scholar]
- Franke, J.; Navratil, P.; Keuck, V.; Peterson, K.; Siegert, F. Monitoring Fire and Selective Logging Activities in Tropical Peat Swamp Forests. J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1811–1820. [Google Scholar] [CrossRef]
- Carlson, K.; Curran, L.M.; Asner, G.; Pittman, A.M.; Trigg, S.N.; Adeney, J.M. Carbon emissions from forest conversion by Kalimantan oil palm plantations. Nat. Clim. Chang. 2013, 3, 283–287. [Google Scholar] [CrossRef]
- Miettinen, J.; Stibig, H.-J.; Achard, F. Remote sensing of forest degradation in Southeast Asia—Aiming for a regional view through 5–30 m satellite data. Glob. Ecol. Conserv. 2014, 2, 24–36. [Google Scholar] [CrossRef]
- Grassi, G.; Monni, S.; Federici, S.; Achard, F.; Mollicone, D. Applying the conservativeness principle to REDD to deal with the uncertainties of the estimates. Environ. Res. Lett. 2008, 3, 035005. [Google Scholar] [CrossRef]
- Forest Carbon Partnership Facility. Buffer Guidelines. 2020. Available online: https://forestcarbonpartnership.org/sites/fcp/files/2020/April/FCPF%20Buffer%20Guidelines_2020_1_Final_Posted.pdf. (accessed on 28 May 2021).

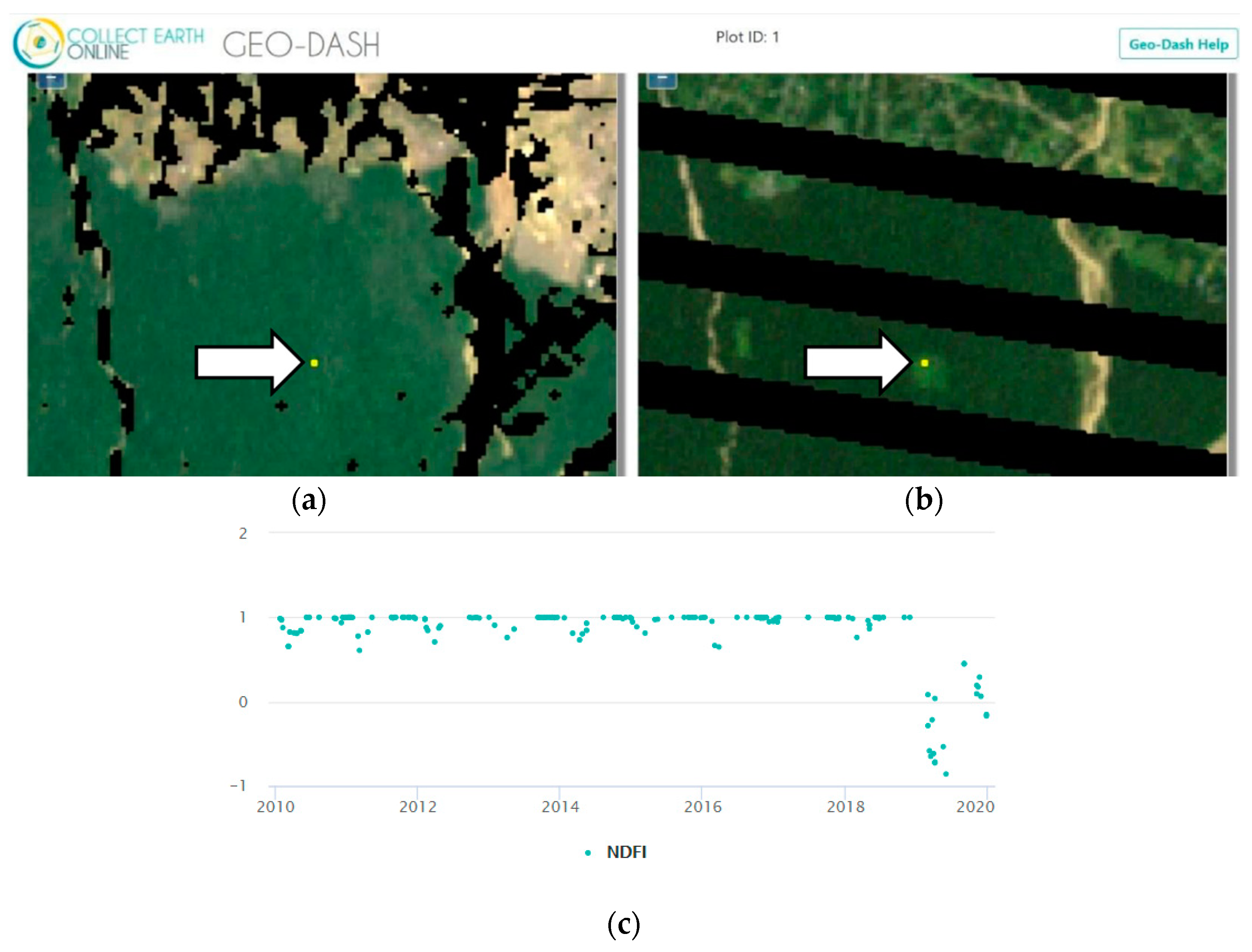
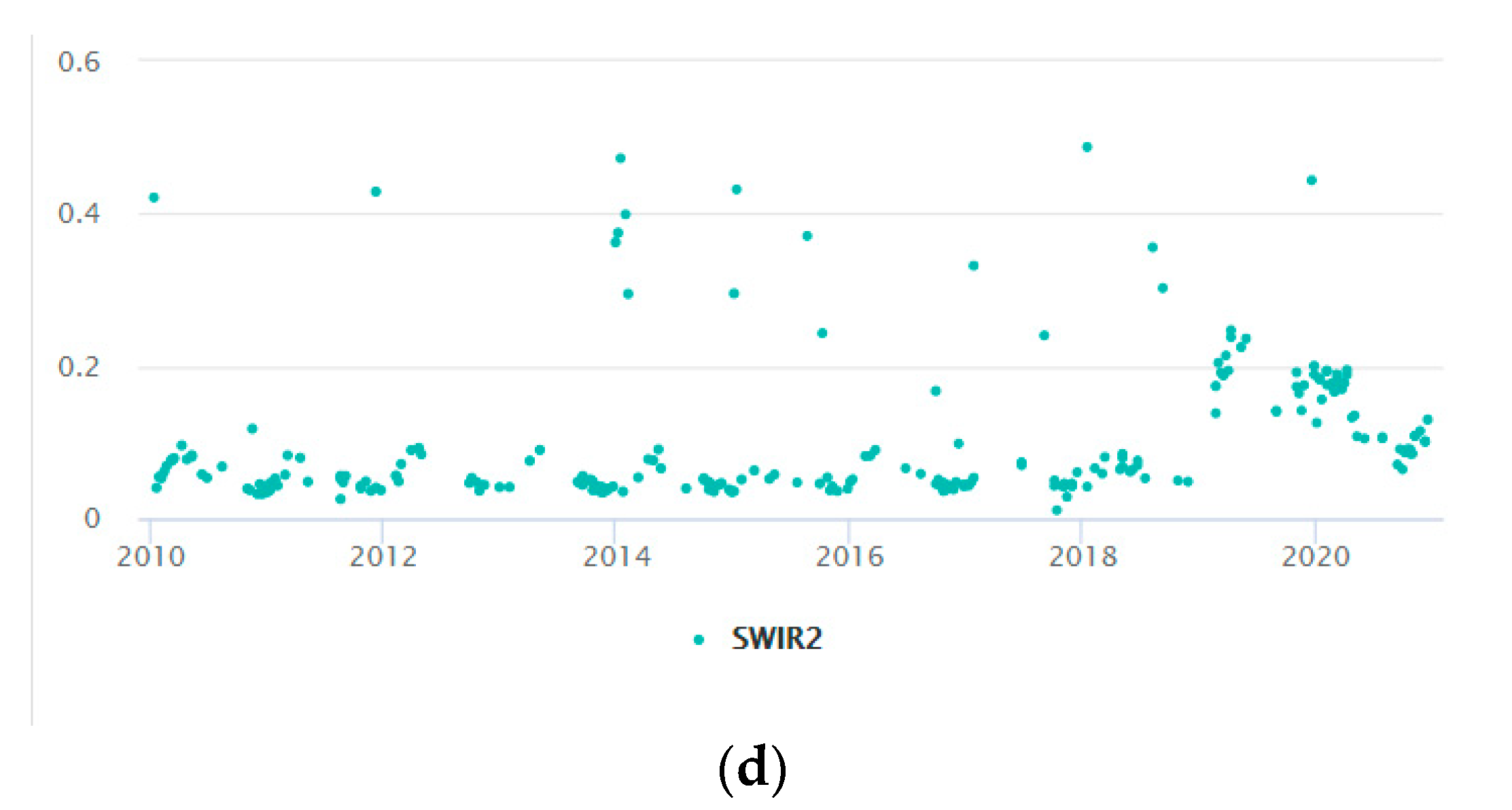

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs and Parameters | |||||||
|---|---|---|---|---|---|---|---|
| Iteration Number | CODED Version | Training Data | Forest Mask | Tree Cover Threshold | Number of Consecutive Observations | Chi-Squared | Change Magnitude Threshold |
| 1 | Original | Original | Created * | N/A | 3 | N/A | 1 * |
| 2 | Updated | Original | GFW * | 80 * | 4 * | 0.99 * | 1 * |
| 3 | Updated | Original | GFW * | 50 | 4 * | 0.99 * | 1 * |
| 4 | Updated | 2017 only | GFW * | 50 | 4 * | 0.99 * | 1 * |
| 5 | Updated | 2017 only | GFW * | 20 | 4 * | 0.99 * | 1 * |
| 6 | Updated | 2017 only | UMD | 10 | 4 * | 0.99 * | 1 * |
| 7 | Updated | 2017 only | NLCMS | N/A | 4 * | 0.99 * | 1 * |
| 8 | Original | 2017 only | Created * | N/A | 4 * | N/A | 1 * |
| 9 | Updated | 2017 only | GFW * | 20 | 6 | 0.99 * | 1 * |
| 10 | Updated | 2017 only | GFW * | 20 | 10 | 0.99 * | 1 * |
| 11 | Updated | 2017 only | Created (Map 8) | N/A | 5 | 0.90 | 0.4 |
| Stable Forest | Stable Nonforest | Degradation | Deforestation | Total | |
|---|---|---|---|---|---|
| Stable forest | 208 | 25 | 92 | 26 | 351 |
| Stable nonforest | 1 | 249 | 37 | 1 | 288 |
| Degradation | 28 | 13 | 116 | 21 | 178 |
| Deforestation | 0 | 35 | 88 | 60 | 183 |
| Total | 237 | 322 | 333 | 108 |
| Model Variable | Variable Name in CODED | Variable Controls | Increase If You Want To | Decrease If You Want To |
|---|---|---|---|---|
| Chi-squared | chiSquareProbability | Size of the window for detecting statistical change | Strongly decrease the amount of change detected | Strongly increase the amount of change detected |
| Consecutive observations of change | Consecutive Obs | Required number of observed NDFI values outside the predicted range for the algorithm to identify a disturbance event | Detect even short-duration forest disturbances, but potentially have overestimation from outlier pixels | Exclude potential errors and short-duration forest disturbances |
| Threshold for defining GFW forest mask | Tree cover threshold | The percentage of tree cover required to categorize a pixel as forest when making the forest max within the algorithm | Include sparse forests in the generated forest mask, including more area in the analysis | Include only dense canopy forests in the forest mask, potentially excluding sparse or deciduous forests from the analysis |
| Minimum threshold of NDFI change to define disturbance | Minimum Change Magnitude | The cutoff magnitude in post-processing for what NDFI change events will be counted as a disturbance in the final output | Include only severe changes, like deforestation, and ignore less drastic changes to the forest that may be erroneous degradation detections | Observe lower-magnitude changes in NDFI and accept some small erroneous detections |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aryal, R.R.; Wespestad, C.; Kennedy, R.; Dilger, J.; Dyson, K.; Bullock, E.; Khanal, N.; Kono, M.; Poortinga, A.; Saah, D.; et al. Lessons Learned While Implementing a Time-Series Approach to Forest Canopy Disturbance Detection in Nepal. Remote Sens. 2021, 13, 2666. https://doi.org/10.3390/rs13142666
Aryal RR, Wespestad C, Kennedy R, Dilger J, Dyson K, Bullock E, Khanal N, Kono M, Poortinga A, Saah D, et al. Lessons Learned While Implementing a Time-Series Approach to Forest Canopy Disturbance Detection in Nepal. Remote Sensing. 2021; 13(14):2666. https://doi.org/10.3390/rs13142666
Chicago/Turabian StyleAryal, Raja Ram, Crystal Wespestad, Robert Kennedy, John Dilger, Karen Dyson, Eric Bullock, Nishanta Khanal, Marija Kono, Ate Poortinga, David Saah, and et al. 2021. "Lessons Learned While Implementing a Time-Series Approach to Forest Canopy Disturbance Detection in Nepal" Remote Sensing 13, no. 14: 2666. https://doi.org/10.3390/rs13142666
APA StyleAryal, R. R., Wespestad, C., Kennedy, R., Dilger, J., Dyson, K., Bullock, E., Khanal, N., Kono, M., Poortinga, A., Saah, D., & Tenneson, K. (2021). Lessons Learned While Implementing a Time-Series Approach to Forest Canopy Disturbance Detection in Nepal. Remote Sensing, 13(14), 2666. https://doi.org/10.3390/rs13142666