It has become commonplace to say that destructive flood hazards are reported widely and globally. Excessive urbanization and climate change are more often blamed as the main reasons for such hazards [
1,
2]. The massive human, economic, and infrastructure losses resulting from flood occurrences necessitate flood management, prediction, and early warning systems [
3,
4]. At a global scale, in the period 1995–2015, it was reported that 109 million people were influenced by flood hazards, with annual direct costs of 75 billion dollars [
5]; only between 2011–2012, indirect damages and losses were reported as 95 billion dollars [
6]. The annual human life losses due to flooding are estimated to be 20,000 people [
5]. This has led to the creation of some national flood mapping agencies and portals around the world, such as the USA (
www.fema.gov, accessed on 30 May 2021), Ireland (
www.floodinfo.ie, accessed on 30 May 2021), and Australia (
www.ga.gov.au, accessed on 30 May 2021), providing a database of flood studies, maps, metadata, weather warnings alert, and flood risk maps. Flood research, especially in the Queensland government and local government areas of Australia, is one of the extensive studies to manage the Brisbane river floodplain. According to historical devastating flood events (1893, 1974, and 2011) in the Brisbane basin, annual exceedance probability of 55.3% was estimated as the chance of flood occurrences with experiencing at least one in an 80-year lifetime (
https://cabinet.qld.gov.au/documents/2017/Apr/FloodStudies/Attachments/Overview.pdf, accessed on 30 May 2021), causing the emergency and timely response in the region. However, the mapping of potential hazardous areas remains unsettled. Certainly, prediction of probable zones for flood hazards and identification of the likelihood of flood occurrence as susceptibility mapping might assist the decision makers in timely flood mitigation, early warning, and decreasing the damages [
7,
8]. Precise monitoring, response, and urban management by the city planners require advanced technologies and large geospatial datasets [
9]. Today, remote sensors provide big data from the entire globe in no time. Such data prove their effectiveness in sustainable urban and environment management and the creation of urban informatics for better data representation, visualization, and interpretation of new information [
10,
11]. Along with big data collection, fast and accurate analysis and visualization are vital [
10]. Hence, data mining, modeling, and developing robust and accurate algorithms obtain more attention, especially for natural disaster management and urban planning [
12,
13]. In this context, the integration of remote sensing (RS) technologies and geographic information system (GIS) tackles the spatial, temporal, and regional challenges of flood processes, and the availability of various earth observation data helps to predict and map the flood events and susceptible areas [
1,
3,
14,
15]. Therefore, we tried to explore and exploit artificial and deep learning neural networks and proposed optimization to obtain higher accuracy. The effect of robust big data mining and modeling on the reliability of the flooded zone prediction as well as determining the most important conditioning factors for this hazard in the subtropical area will reveal new guidelines for the authorities to plan for effective flood management.
Related Studies
A lot of studies have been carried out on flood modeling and susceptibility mapping [
16,
17,
18,
19,
20], while the choice of appropriate flood conditioning factors and more accurate and certain algorithms is still under investigation. Chen et al. [
15] divided the two common groups of algorithms for flood modeling and mapping into qualitative and quantitative methods. It was stated that exploiting statistical and probabilistic models is the main focus of the quantitative methods such as weights-of-evidence (WOE), frequency ratio (FR), and logistic regression (LR). Some examples of qualitative models are analytic network process (ANP) and analytic hierarchy process (AHP) [
16]. However, the dynamic nature and complexity of the flood events in a large-scale region provoke the use of more robust models where linear and simple statistical methods seem unreliable [
1,
19]. In research performed by Dano et al. [
16], the intergradations of GIS and ANP for flood prediction and mapping were investigated. However, the calculation of the relative weights of flood conditioning factors was dependent on expert knowledge and questionnaires due to the ANP mathematical model. Although the proposed model exhibited simple procedures, its dependency on expert opinion makes it incompatible with quantitative methods and inapplicable in the broad area [
19].
Recently, machine learning (ML) algorithms (e.g., random forest (RF), support vector machine (SVM), decision tree (DT), and artificial neural networks (ANN)) and optimized models proved their abilities to handle large numbers of variables and large datasets timely and accurately [
1,
4,
21]. ML algorithms have been successfully applied in many applications such as landslide, flood, and wildfire susceptibility mapping [
13,
19,
22,
23]. However, the implementation and reliability of these methods still need further investigation in natural hazard prediction [
15,
19].
Khosravi et al. [
24] applied some multiple-criteria decision-making algorithms (MCDM) and ML algorithms (e.g., naive Bayes (NB) and naive Bayes tree (NBT)) to predict and locate the areas prone to flooding and report the outperformance of the ML algorithms. Accordingly, the altitude was mostly responsible for the flood events, whereas land surface curvature represented no influence. To predict the inundation area, Kia et al. [
25] applied ANN using seven conditioning factors and concluded that the most significant and insignificant factors influencing the flood in the area were elevation and geology, respectively. Again, ANN was exploited by Falah et al. [
26] to determine the flood susceptible areas using five factors, and it was highlighted that drainage density was the most and elevation was the least important factor in the region. Their results were assessed by the area under curve (AUC), and the values of 94.6% and 92.0% were obtained for training and validation, respectively. In another study [
27], the implementation of ANN and soil conservation service runoff (SCS) with seven conditioning factors was investigated. The best root mean square error (RMSE) was acquired by ANN as 0.16 at peak flow, promoting precipitation and normalized difference vegetation index (NDVI) as the most influential factors. The results of these studies also emphasized the case-specific selection of the flood causative factors according to the region and its conditions [
26]. However, the last three studies did not comprehensively explore and compare ANN performance with other popular methods. Hence, exploiting ANN might comprehensively examine its robustness to compare with other models in different sites, and it can be a suitable benchmark to evaluate the proposed ensemble algorithm.
Although ANN performs well in flood susceptibility mapping, it is limited to one or two hidden layers for the optimization and complex problems. Therefore, deep learning methods with multilayer architectures and higher performance and accuracy are in demand [
28]. The AUC values better than 0.96 were recorded by [
29] using a deep learning neural network (DLNN) to predict flash flood susceptibility, and this model outperformed multilayered perceptron neural network (MLP-NN) and SVM and proved to be a superior model for the GIS dataset in the study area. In this regard, the optimization and ensemble models also proved to be practical and effective to obtain more certainty and accuracy during the modeling [
1,
17,
19,
30,
31]. Bui et al. [
22] also predicted flash flood zones in tropical areas using optimized DLNN with four swarm intelligence algorithms (e.g., grasshopper optimization algorithm (GOA), social spider optimization (SSO), grey wolf optimization (GWO), and particle swarm optimization (PSO)). Their proposed methods exhibited higher accuracies than individual benchmarks such as PSO, SVM, and RF. However, the last two study areas suffer from flash floods that might be a consequence of heavy and intensive precipitation. Therefore, careful examination of other conditioning factors for flood susceptibility mapping is desired.
The ensemble of models reportedly improved the performance of the predictions. Tehrany et al. [
32] compared FR, SVM, and their ensemble models within a dataset including digital elevation model (DEM), slope, geology, curvature, river, stream power index (SPI), land use/cover, rainfall, topographic wetness index (TWI), and soil type to map the susceptible areas for flood, and they established the better performance of the proposed ensemble model. In another study, Tehrany et al. [
1] introduced a GIS-based ensemble method (evidential belief function and SVM with linear, polynomial, sigmoid kernel, and radial basis functions) for susceptibility mapping in the Brisbane catchment, Australia, using the 12 conditioning factors of altitude, slope, aspect, SPI, TWI, curvature, soil type, land use/cover, geology, rainfall, distance from road, and distance from river. The authors reached the maximum accuracies by the ensemble models (e.g., 92.11%) up to 7% higher than the individual algorithms. Another work [
15] conducted an investigation into ensemble-based machine learning techniques by deploying reduced-error pruning trees (REPTree) with bagging (Bag-REPTree) and random subspace (RS-REPTree) using 13 flood-influencing factors to estimate the probability of the flood zones. Their experiment also ranked the ensemble model’s performance as superior compared with the individual models. Four models, namely FR, the ensemble of FR and Shannon’s entropy index (SE), the ensemble of the FR and LR, and the statistical index (SI) model, were exploited by Liuzzo et al. [
18], and 10 factors affecting floods were included in the modeling. The highest performance was reported by the ensemble of the FR and LR, again.
The optimization was widely reported in recent years. Sachdeva et al. [
19] proposed an optimized model of PSO and SVM and compared its result with susceptibility maps from RF, neural networks (NN), and LR. They used 11 conditioning factors, namely elevation, slope, aspect, TWI, SPI, plan curvature, soil texture, land cover, rainfall, NDVI, and distance from rivers. Their findings highlighted the lowest (91.86%) and highest (96.55%) accuracies for the LR and optimized model, respectively. Li et al. [
31] applied a discrete PSO-based sub-pixel flood inundation mapping (DPSO-SFIM) algorithm to create flood maps and reported the success of optimization compared with the other four models. Adaptive neuro-fuzzy inference systems (ANFIS) with three optimization algorithms (ant colony optimization, genetic algorithm, and PSO) were studied by [
30], and the susceptible areas for flood were accurately mapped by ANFIS-PSO. In a study of flooded area mapping [
33], the authors used synthetic aperture radar (SAR) data and the interferometric SAR information about a flood hazard and improved the performance of a Fuzzy C-Means model by integration and optimization with PSO. Similarly, a model enhancement was reported by [
34] by the integration of PSO with Bayesian regulation back propagation NN using Landsat images of the flood events. Nevertheless, the focus of both works was on flood mapping and not flood susceptibility mapping. Thus, the applicability of optimized PSO-DLNN models in flood susceptibility mapping in different sites still needs more consideration, and testing the capabilities and level of improvement of the optimization method to map the susceptible flood zones was also the motivation to conduct this research.
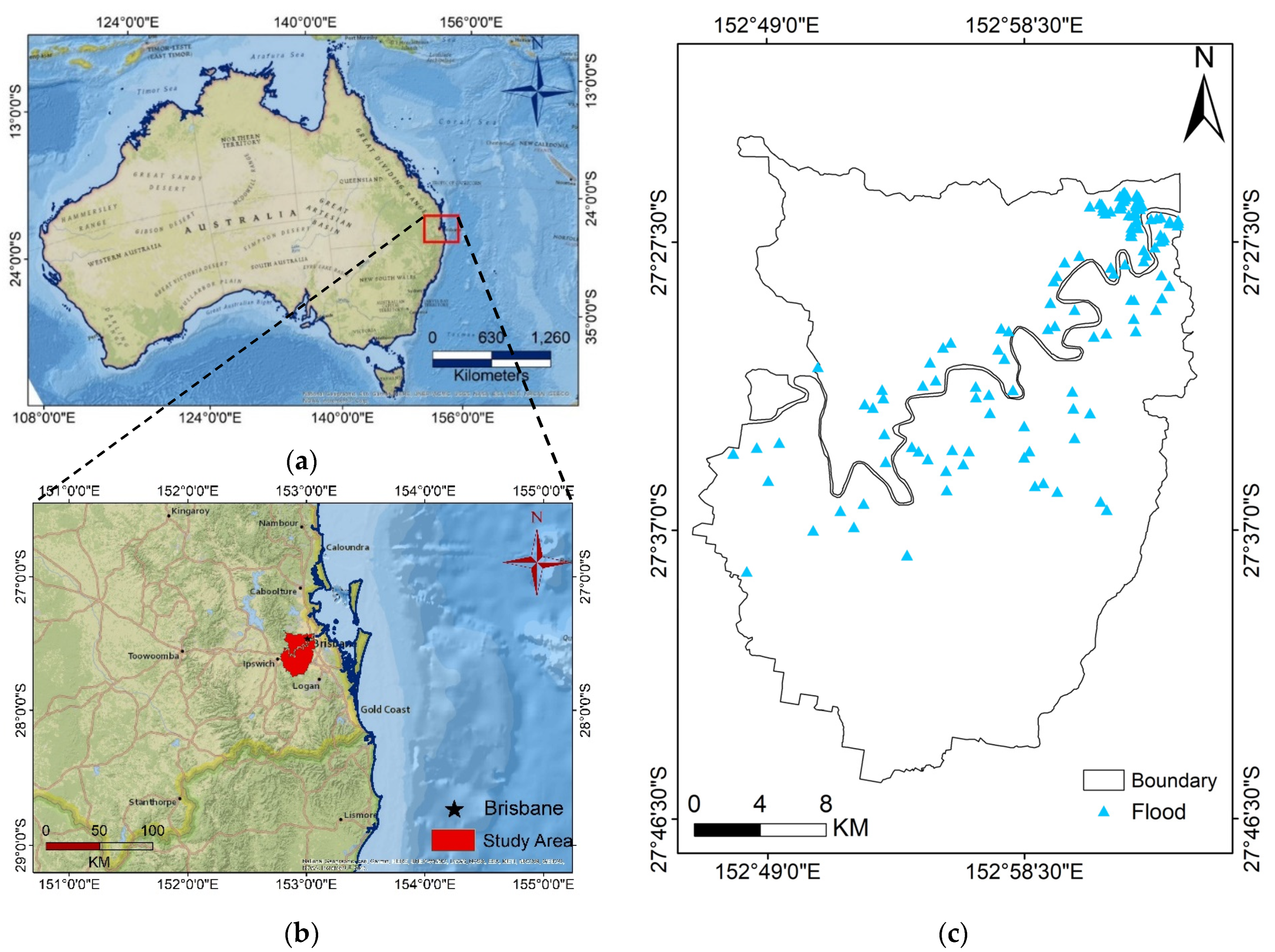
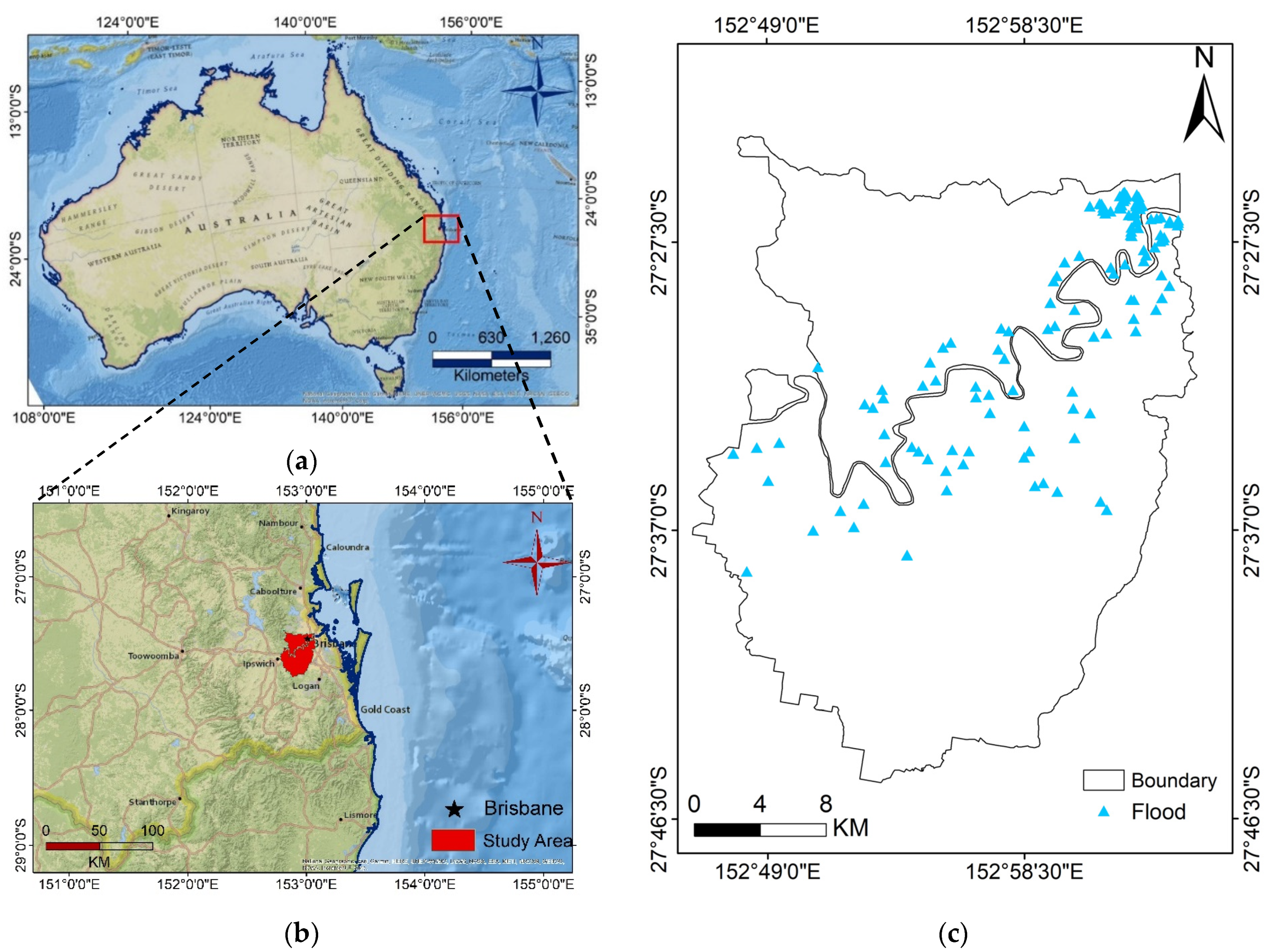
Flood susceptibility mapping of the Brisbane catchment, Australia, using other algorithms (SVM, evidential belief function, LR, and FR) was practiced by [
1,
15,
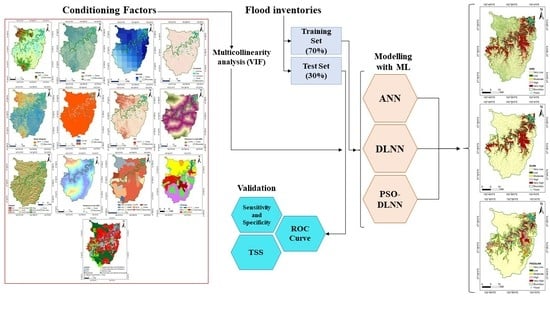
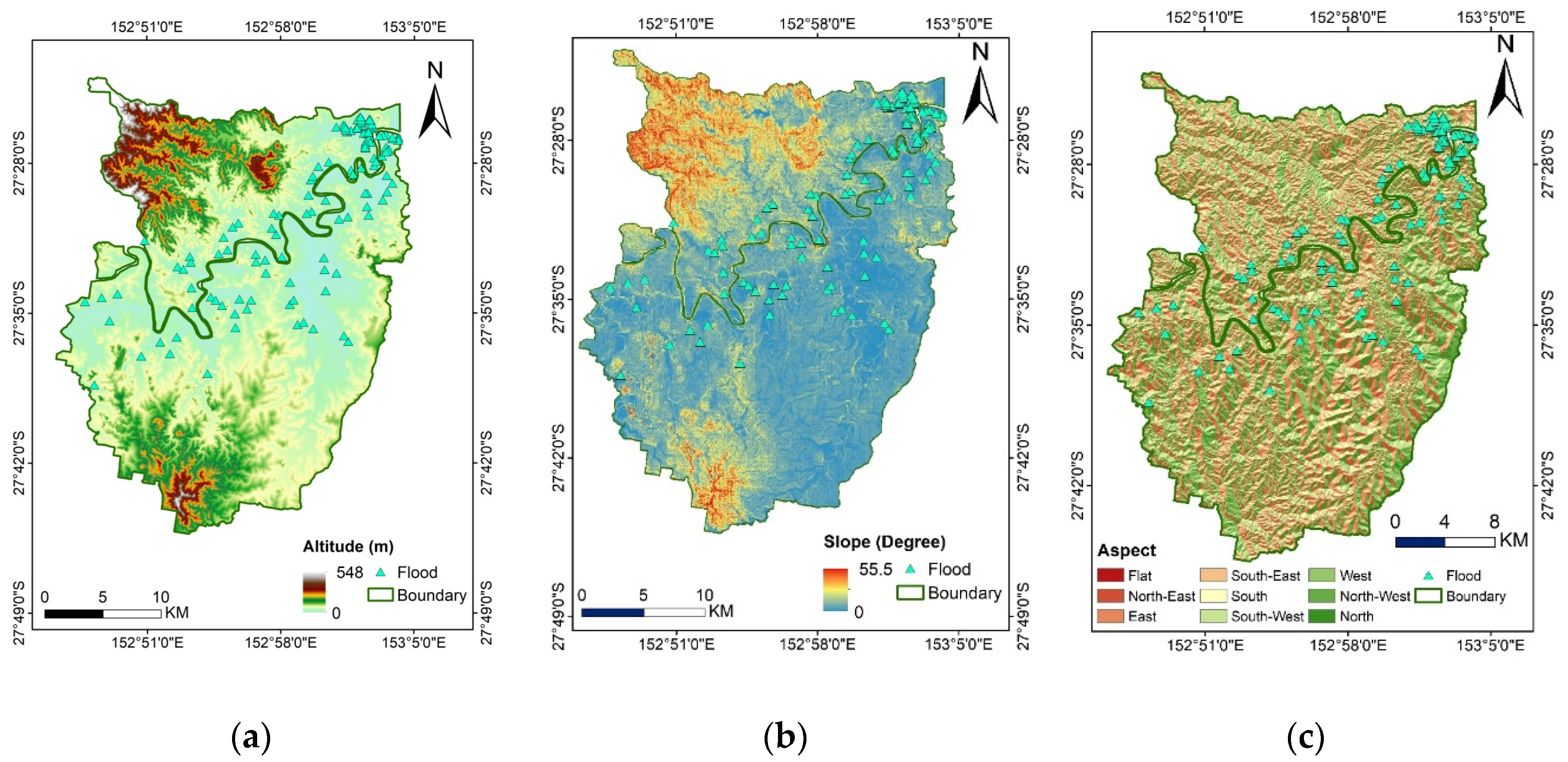
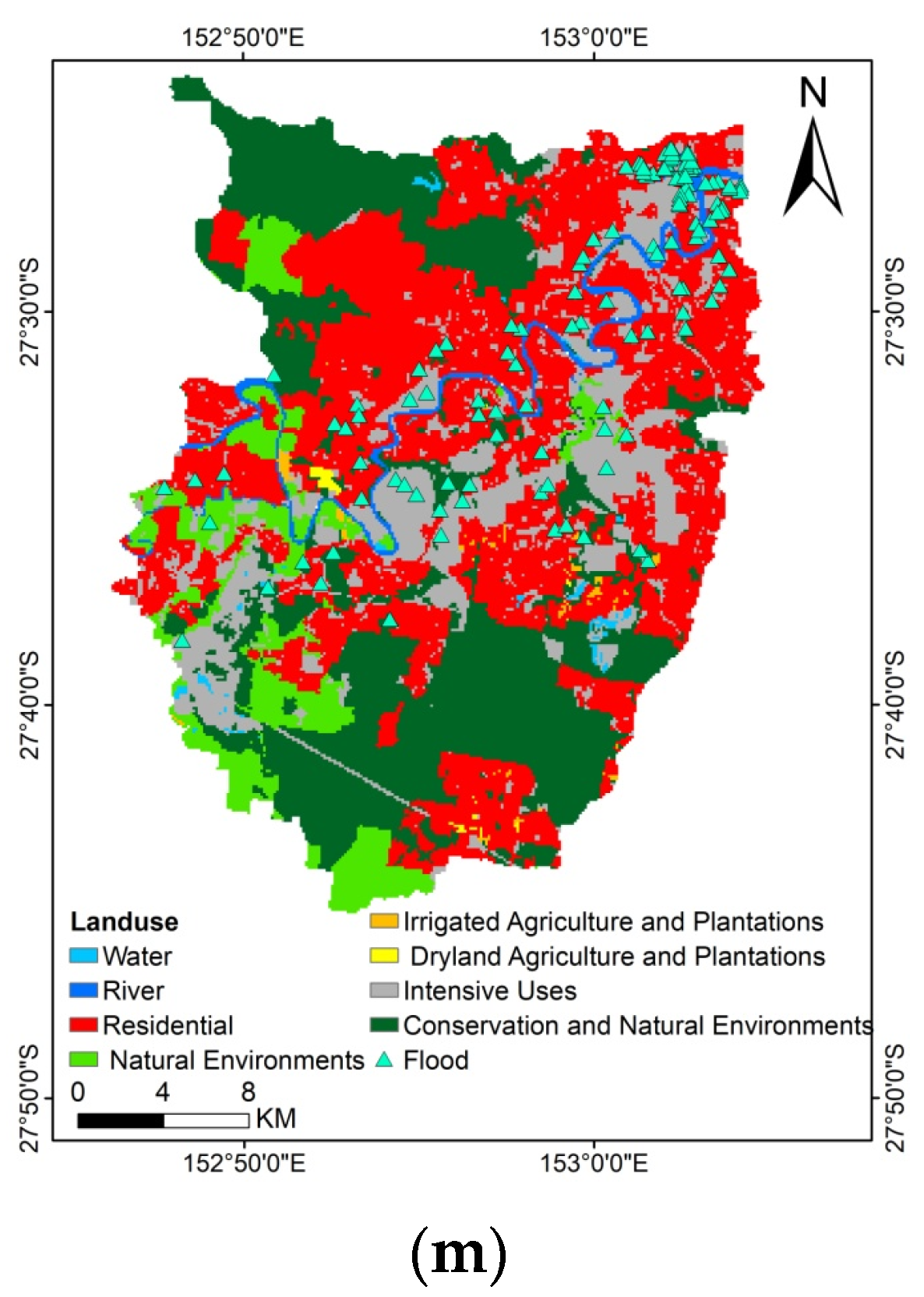
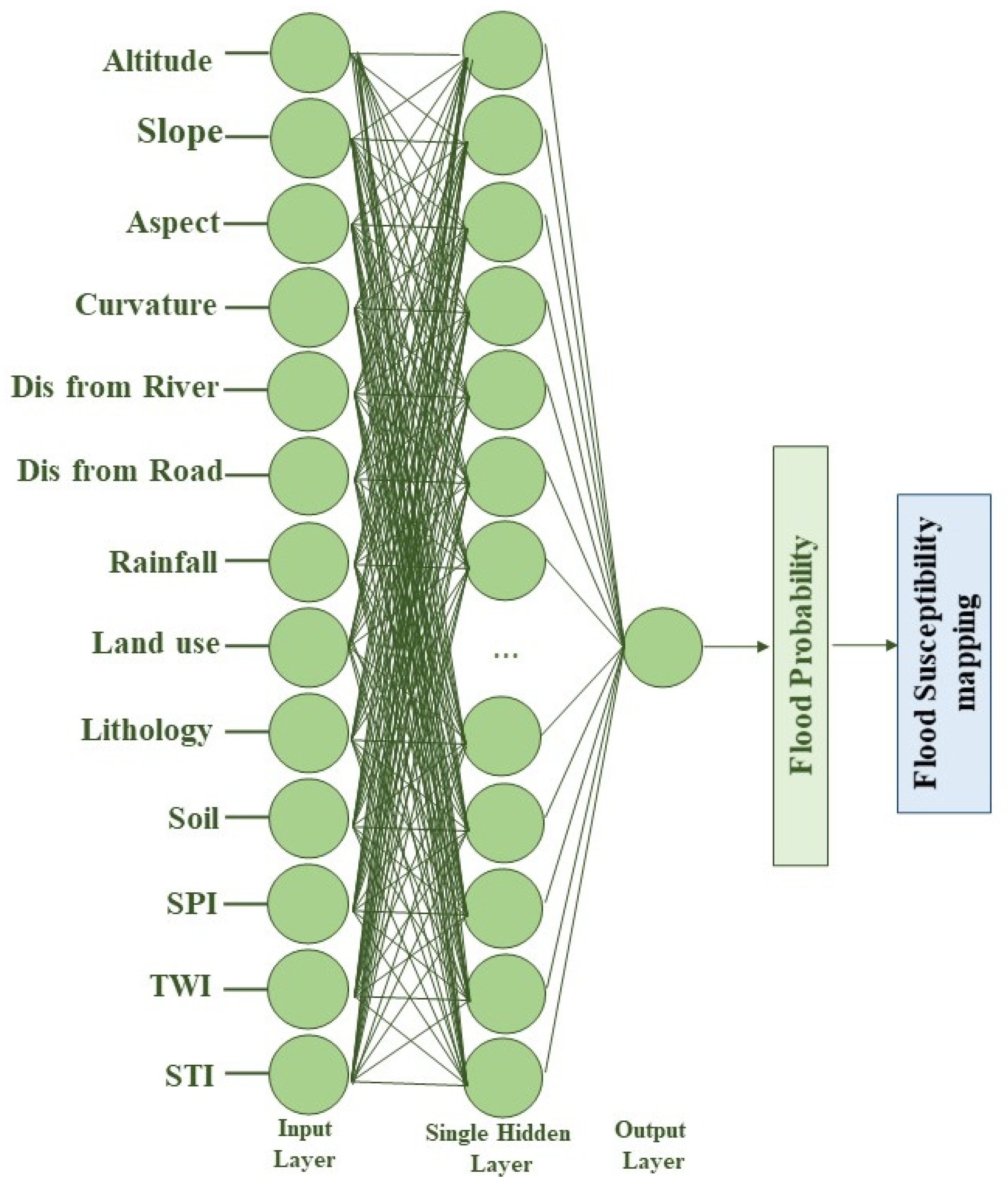
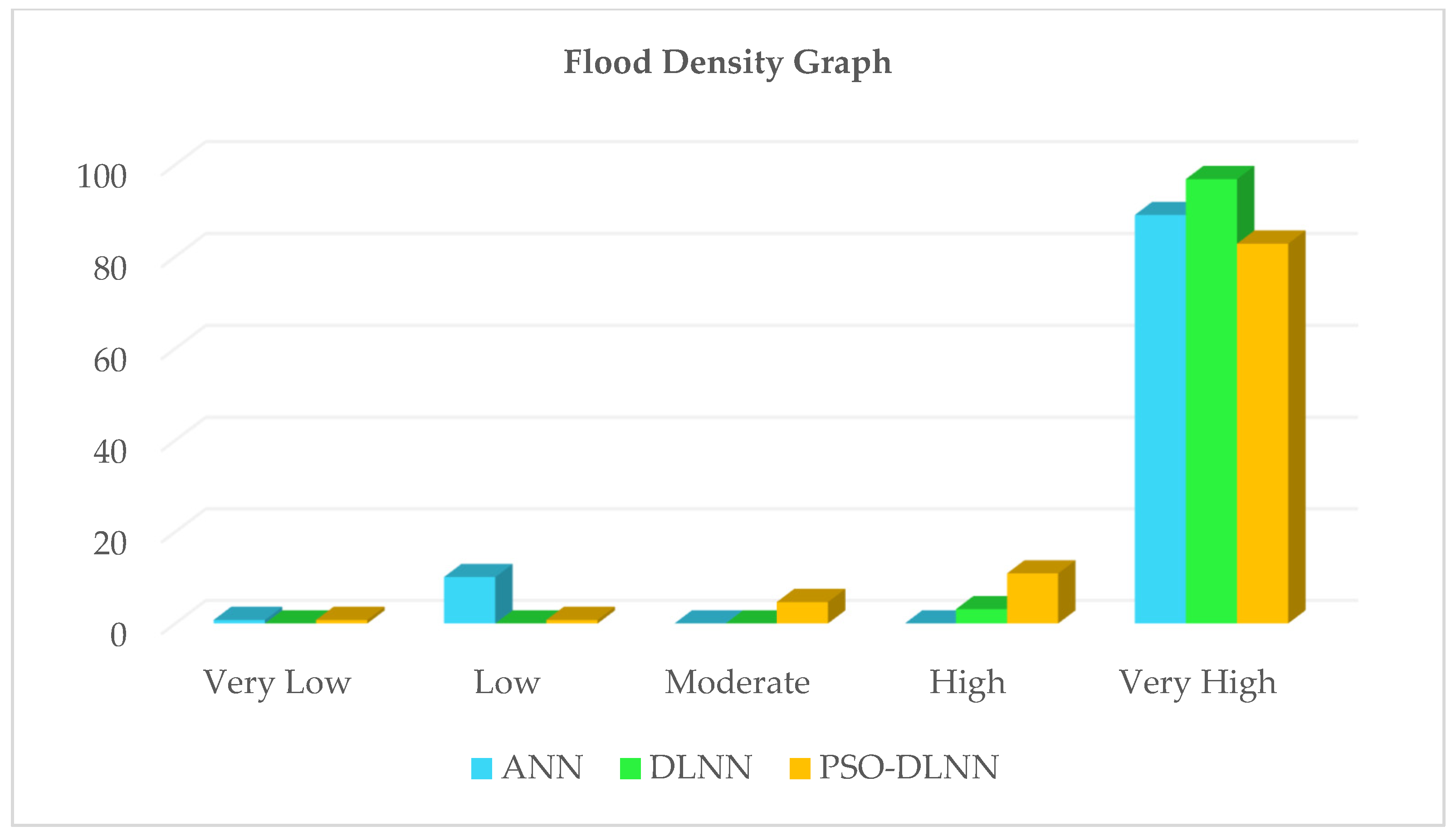
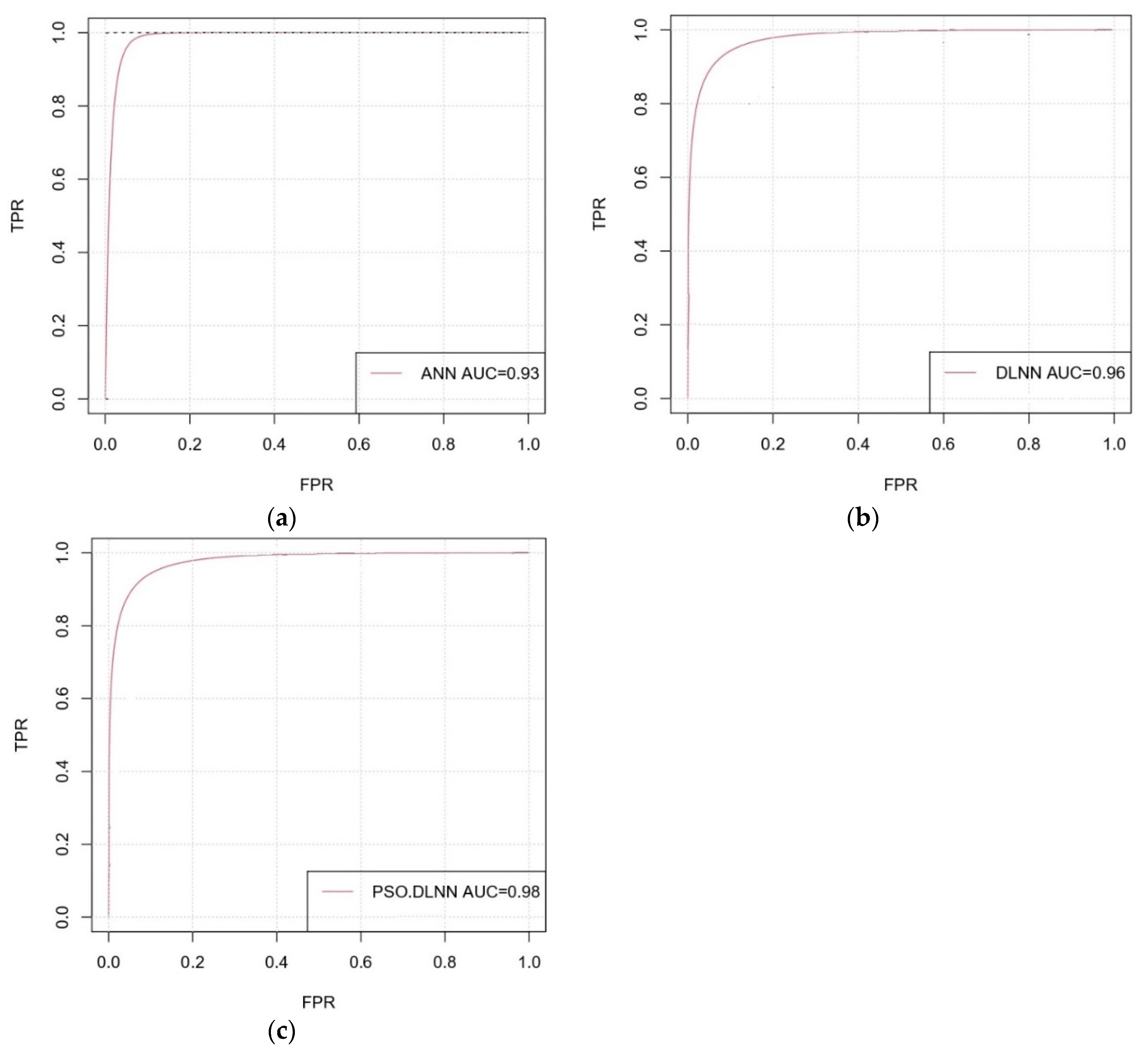
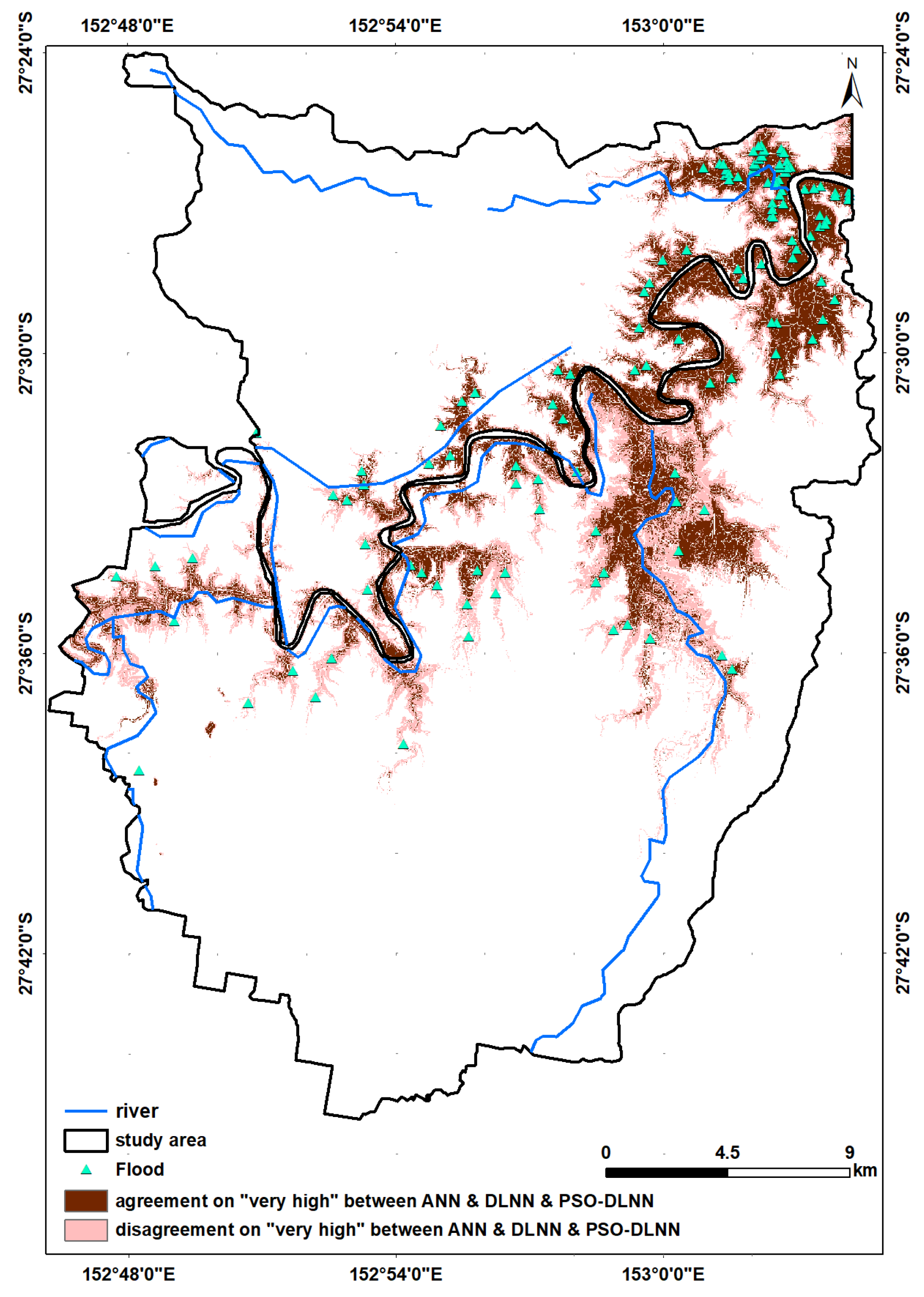
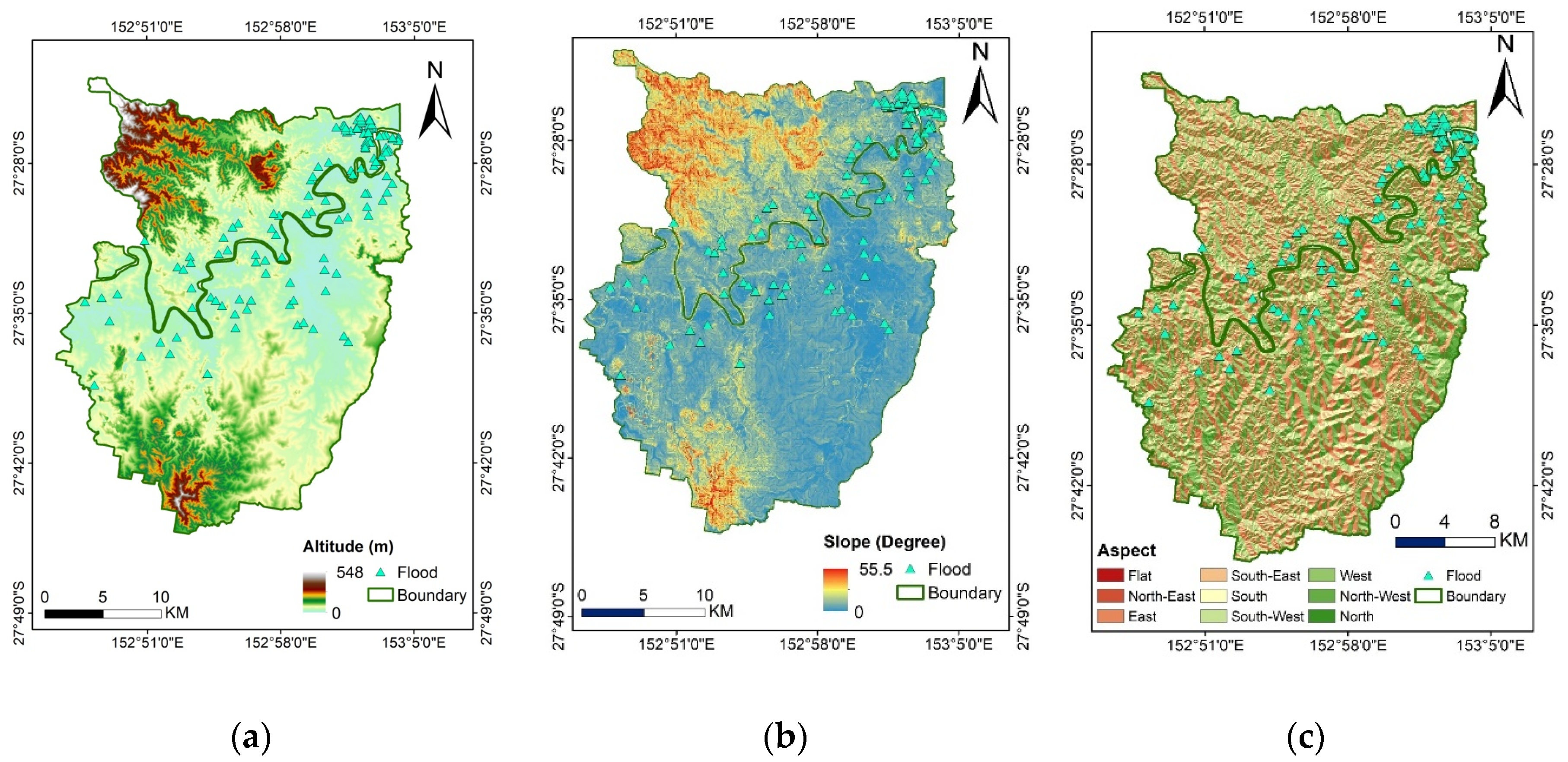
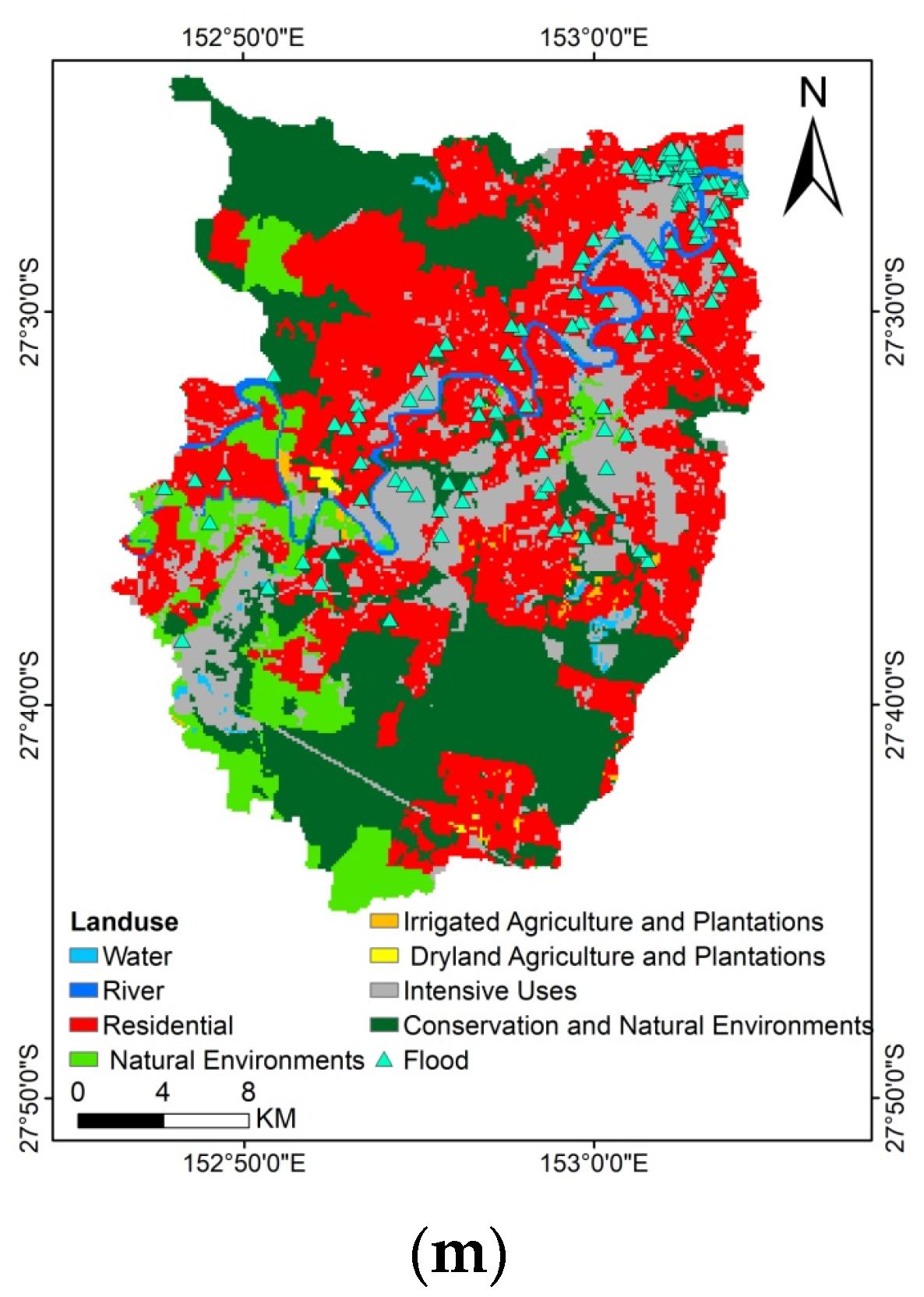
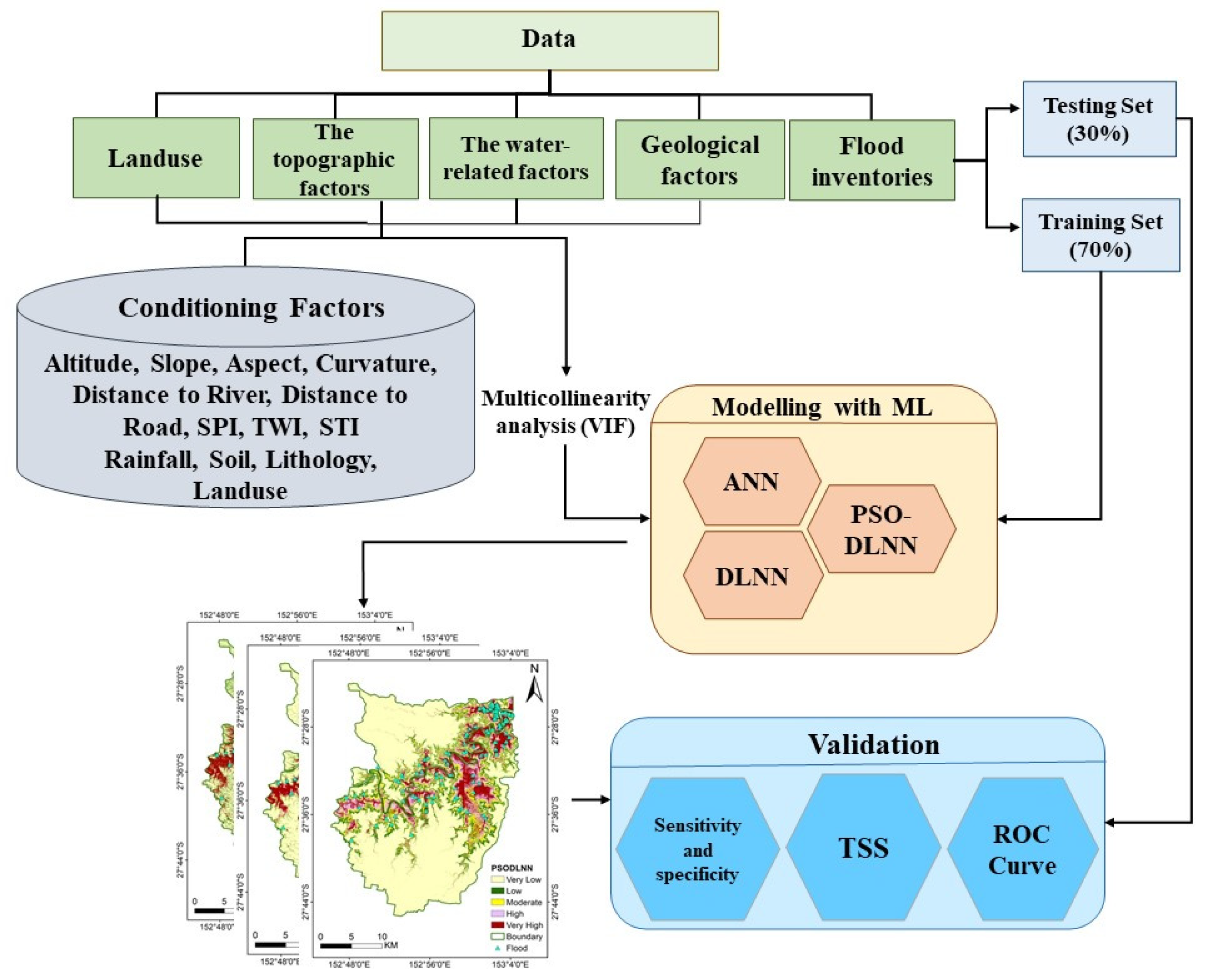
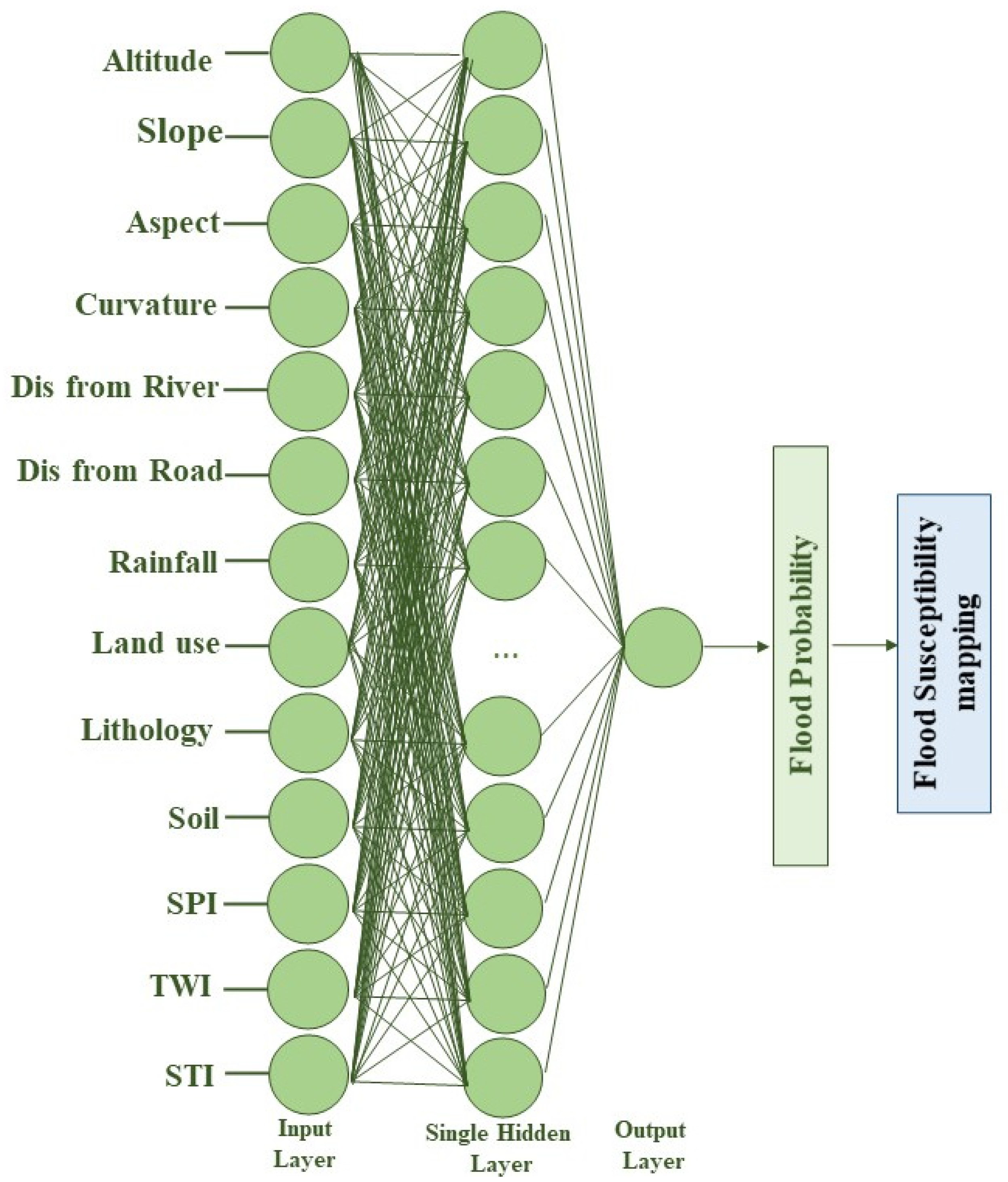
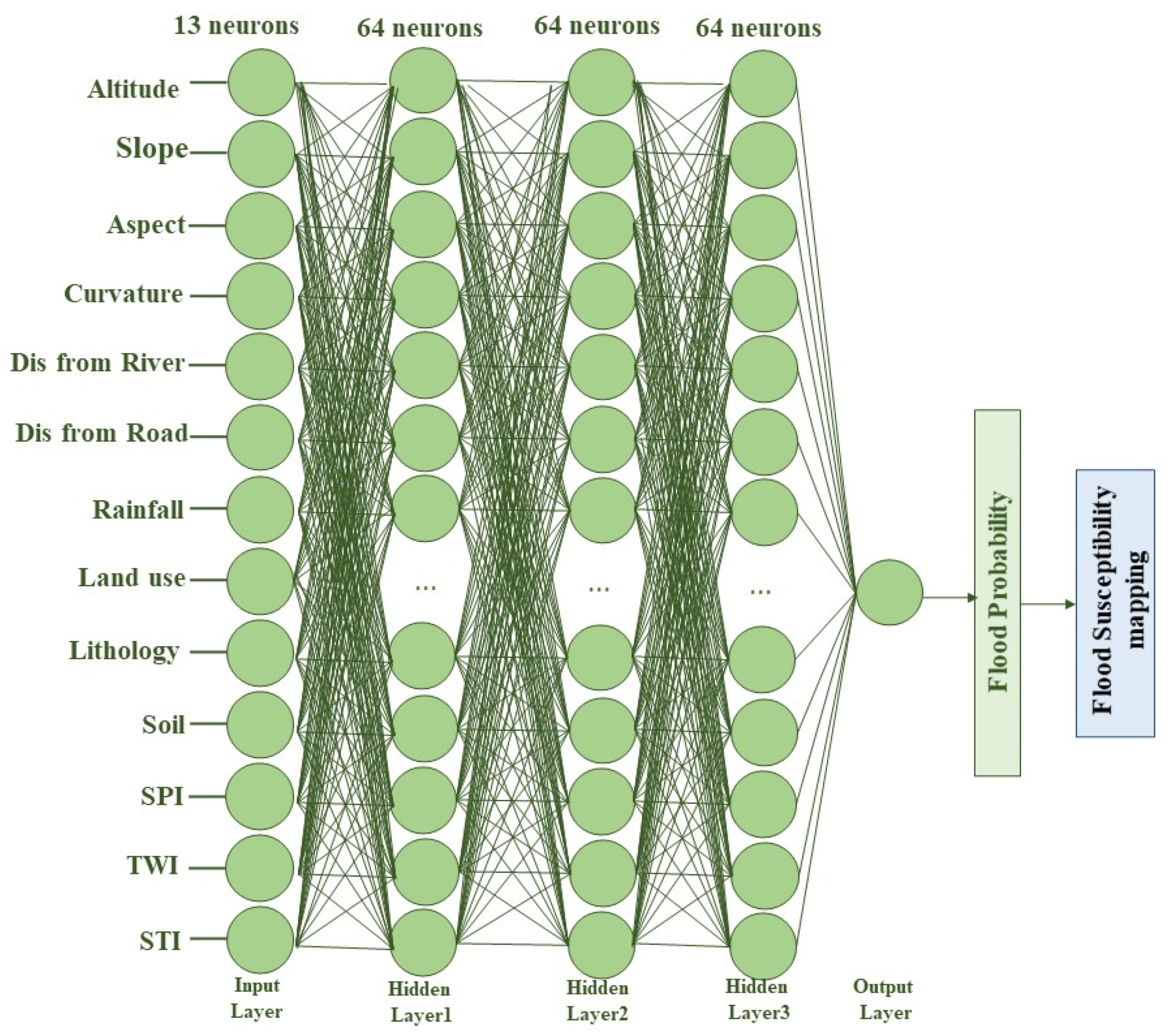
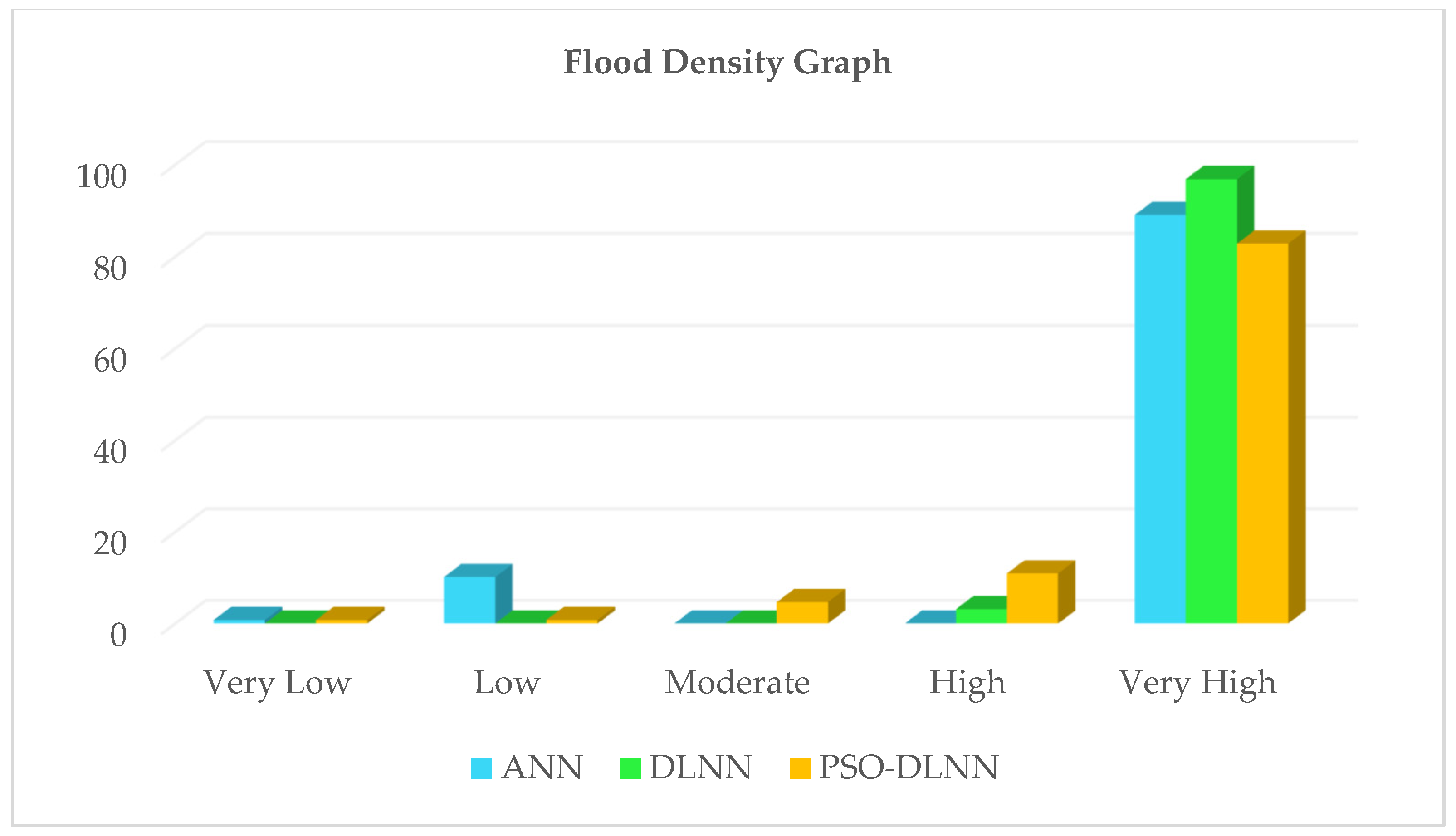
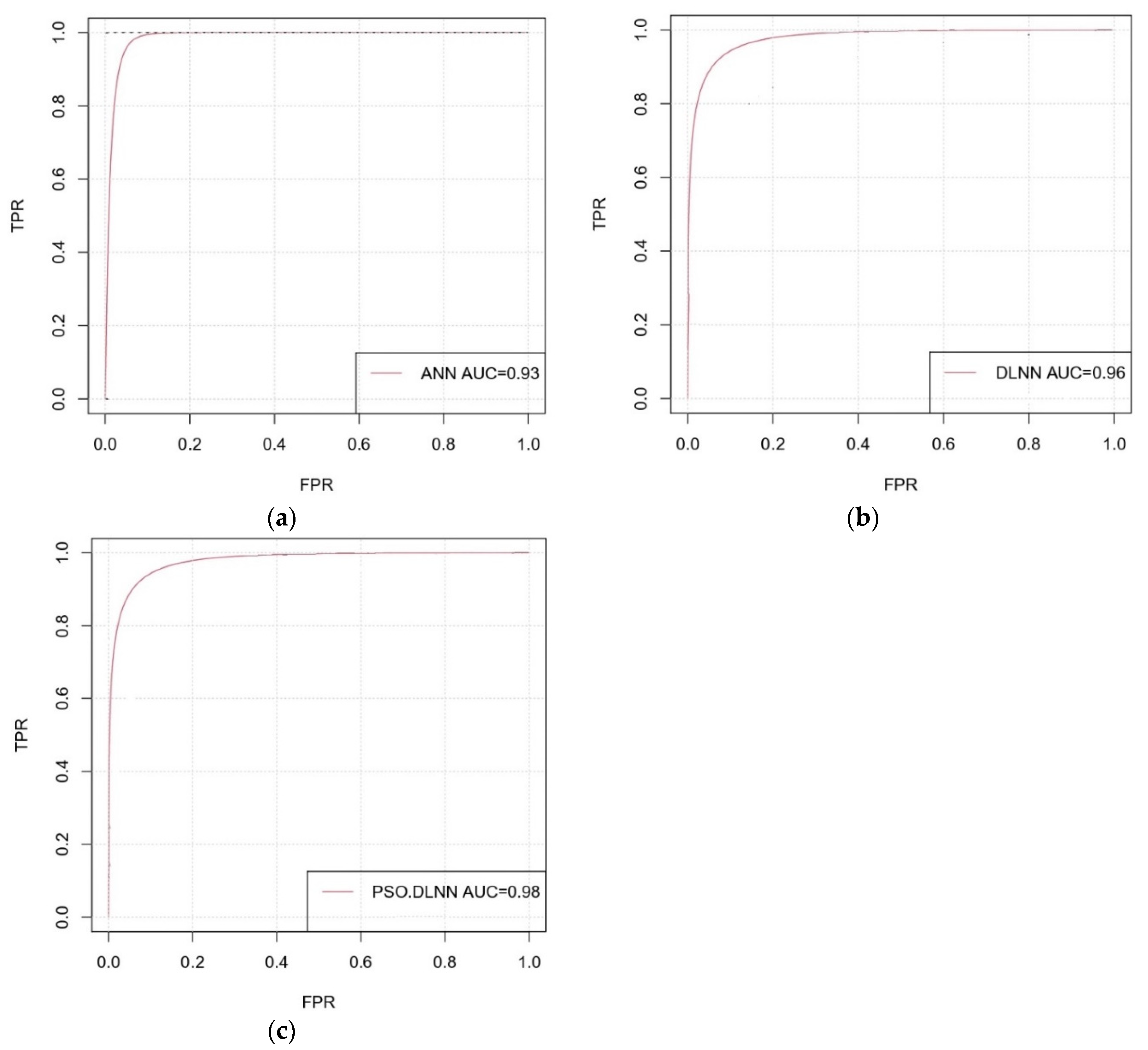
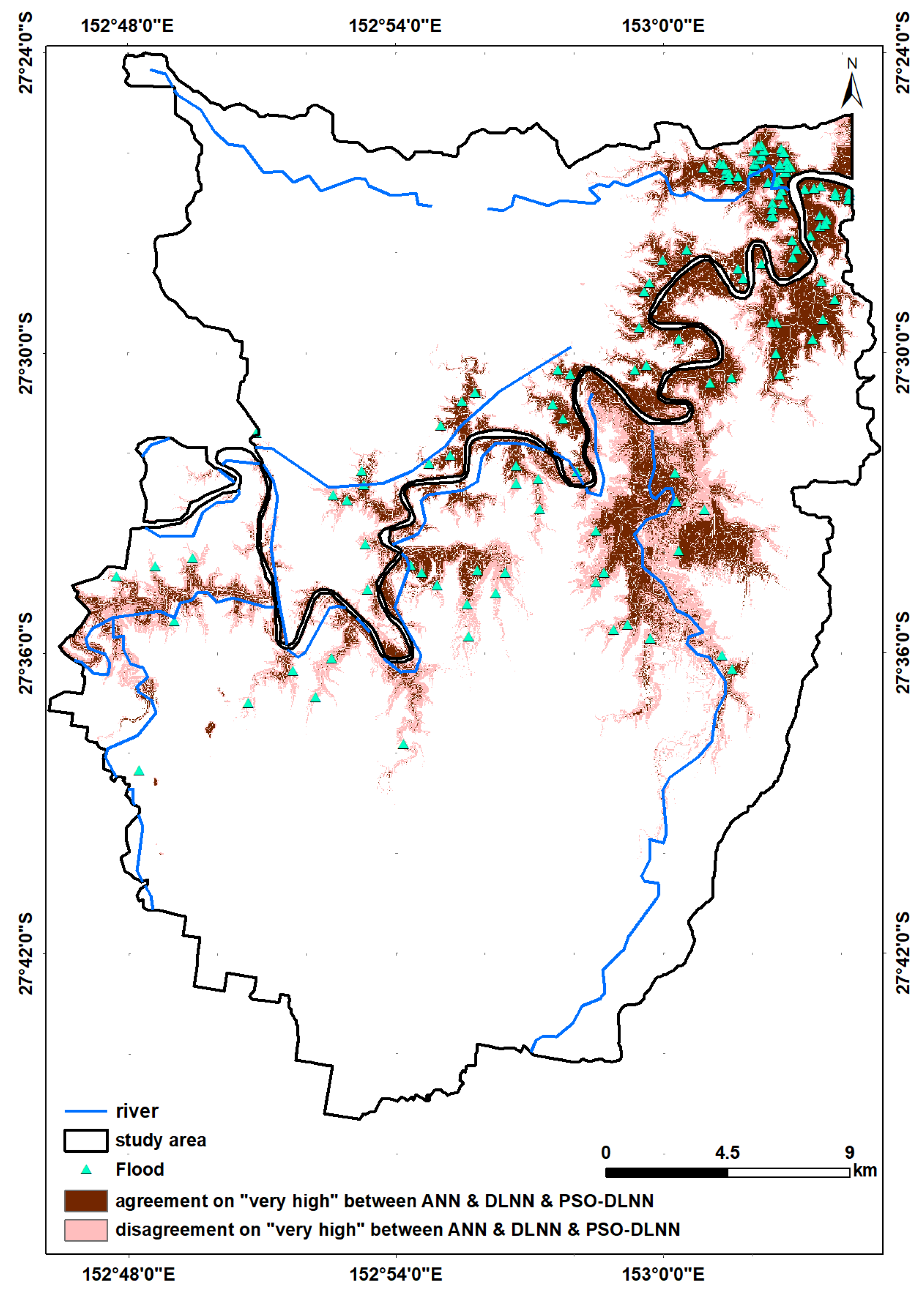
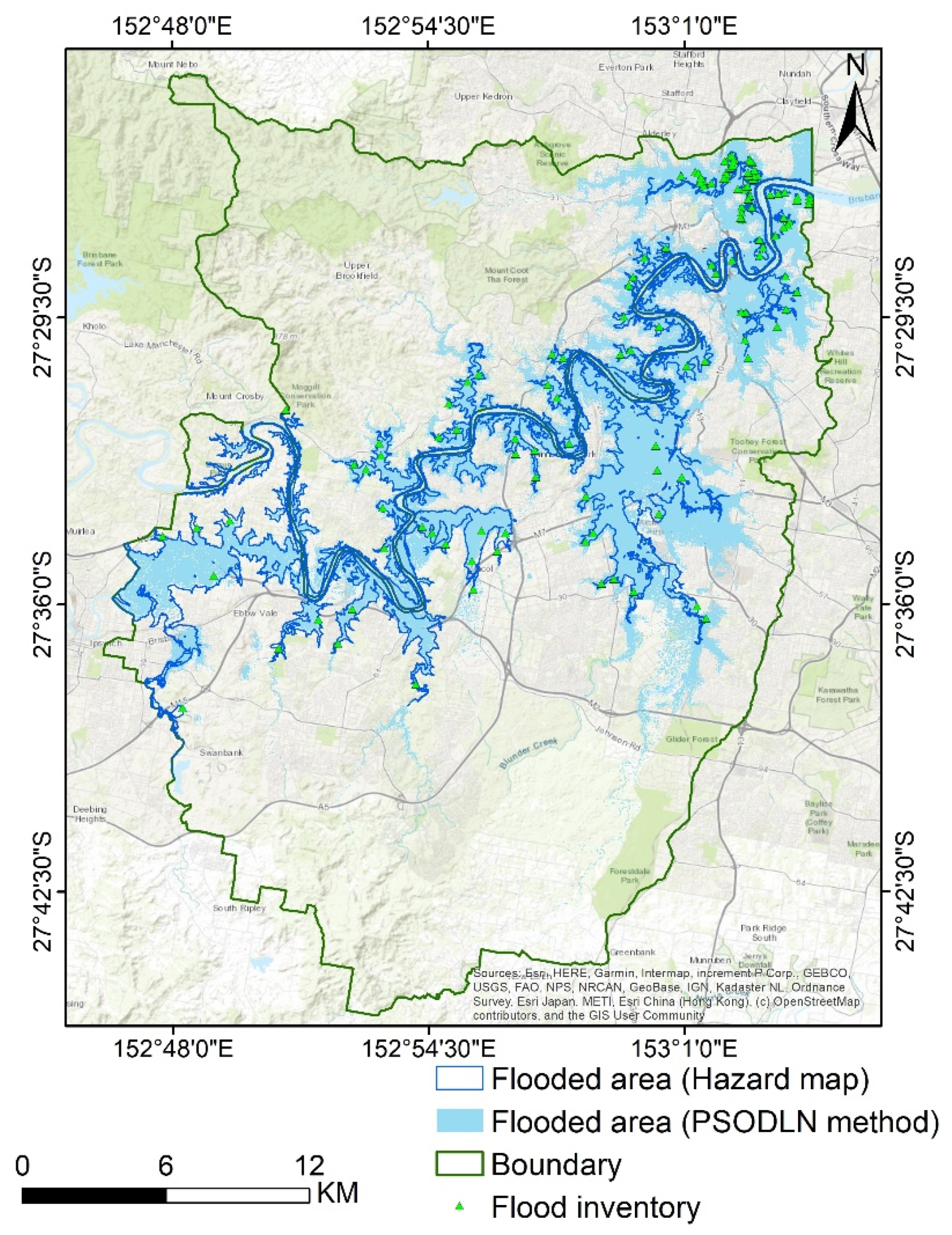
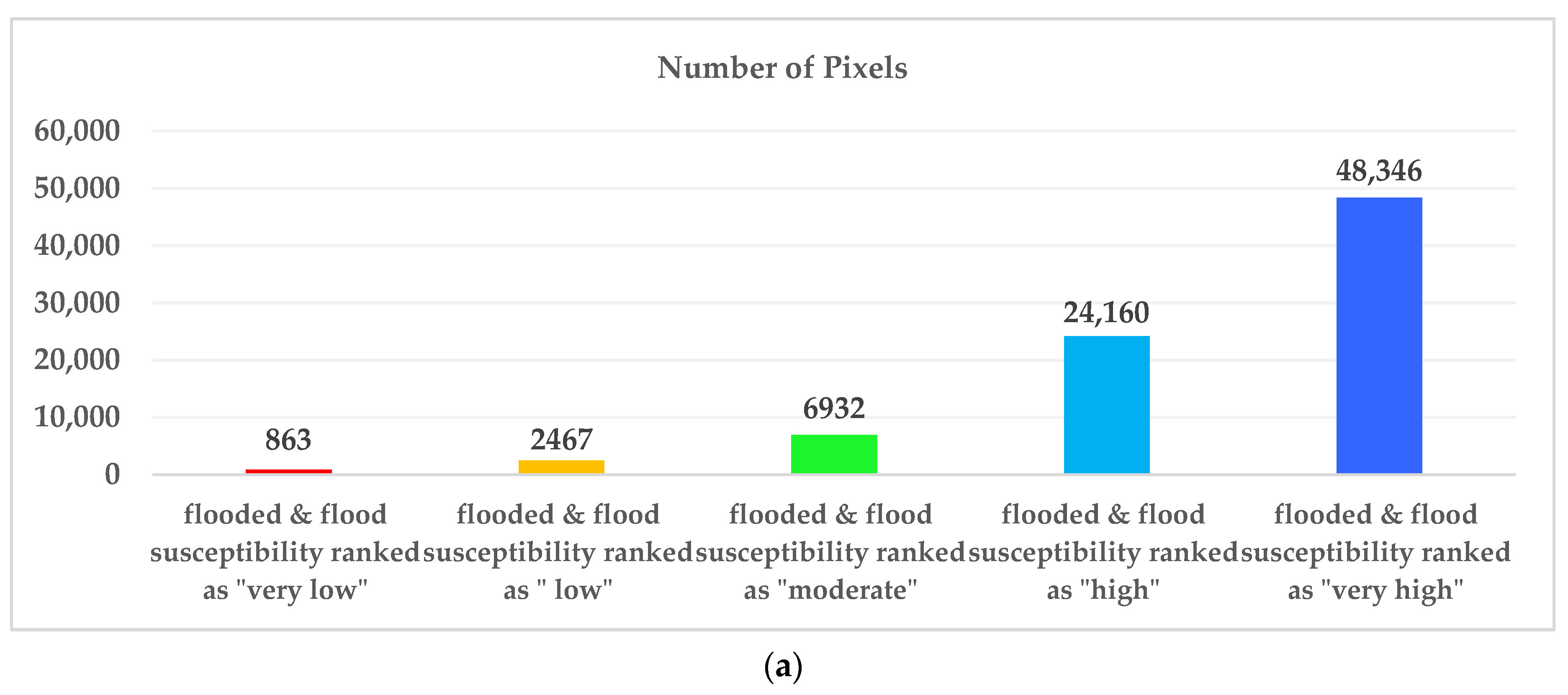
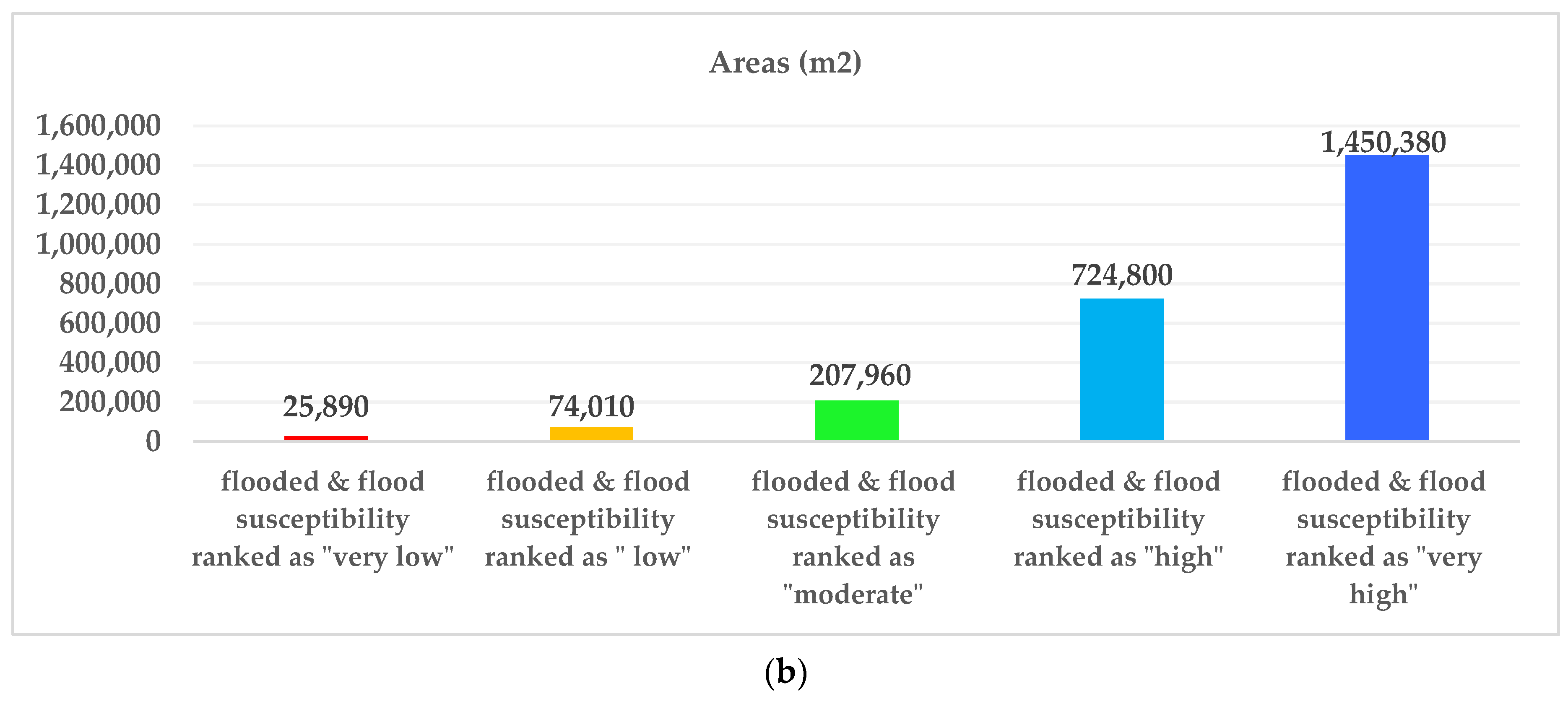
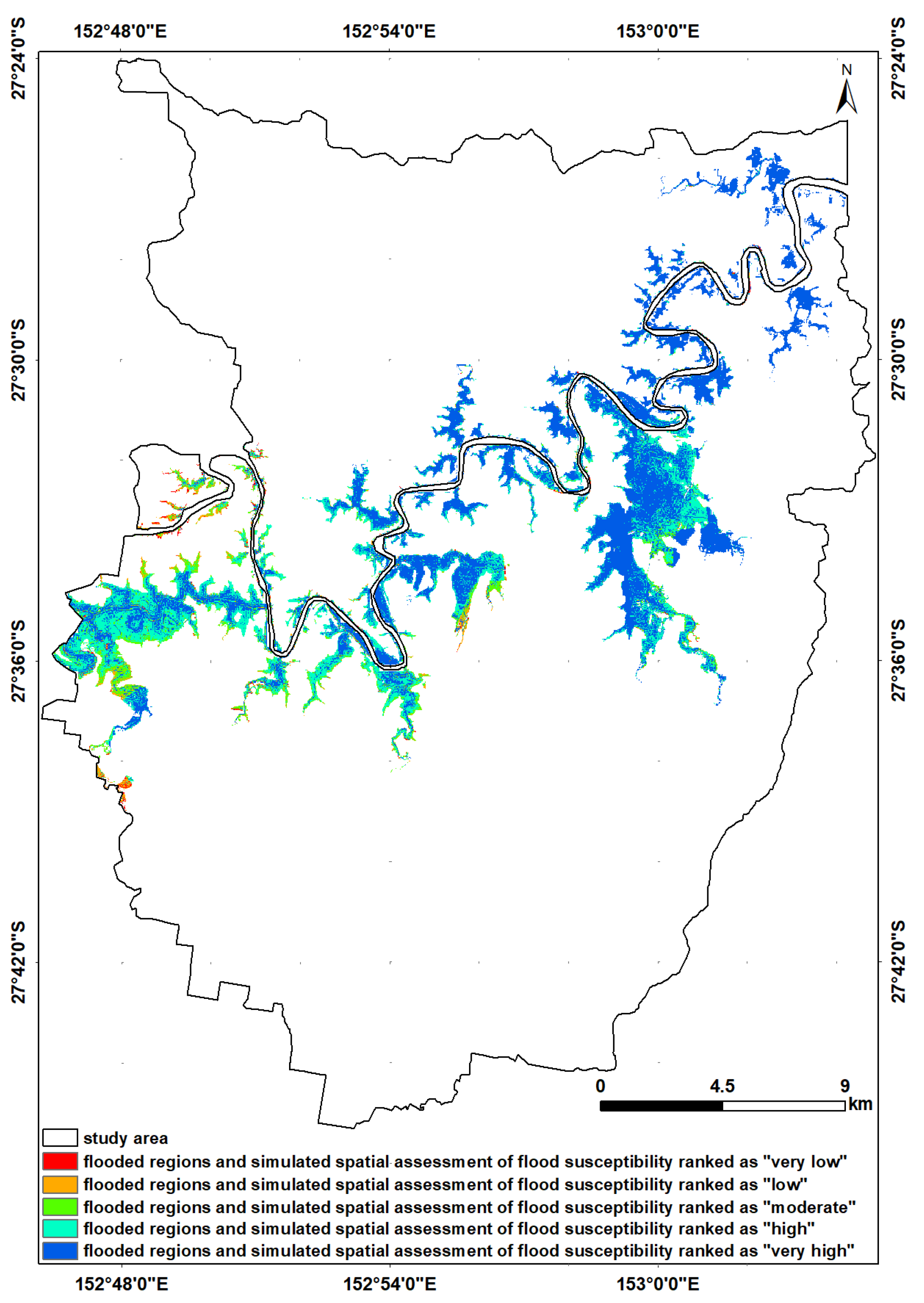
16], and at best, higher performance accuracy of 92.11% was obtained. Then, we looked for a way to achieve better performance. To the best of the authors’ knowledge, there is no comprehensive study fully exploring the optimized DLNN via PSO to map flood susceptibility in the Brisbane catchment, Australia. Therefore, we aimed (1) to classify the flood susceptible zones in the study area into five probability classes (i.e., very low, low, moderate, high, and very high) using three models, namely ANN, DLNN, and the optimized DLNN using PSO (PSO-DLNN); (2) to assess and compare the accuracy and reliably of the three models based on sensitivity, specificity, the area under curve (AUC), and true skill statistic (TSS) tests; and (3) to determine the most important factors (i.e., altitude, slope, aspect, curvature, distance from river, distance from road, rainfall, land use, lithology, soil, SPI, TWI, and sediment transport index (STI)), influencing the flood occurrence, in the subtropical climate region.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








