1. Introduction
A hyperspectral image (HSI) can be represented as a three-dimensional data cube, containing both spectral and spatial information to characterize radiation properties, spatial distribution and geometric characteristics of ground objects [
1,
2]. Compared with panchromatic, RGB and multispectral pictures that have only several broad bands, HSI usually has hundreds of spectral bands. The rich spectral information of HSI can be used to discriminate subtle differences between similar ground objects, which makes HSI suitable for different applications, such as target recognition, mineral detection, precision agriculture [
1,
2,
3]. Due to the scattering of ground surface and low spatial resolution of the hyperspectral sensor, an observed HSI pixel is often a mixture of multiple ground materials [
4,
5,
6]. This is the so called “mixed pixel”. The presence of “mixed pixels” seriously affects the application of HSIs. To address the problem of mixed pixels, hyperspectral unmixing (HU) techniques have been developed [
4,
5,
6,
7,
8]. HU aims to decompose a mixed spectral into a collection of pure spectra (endmembers) while also providing the corresponding fractions (abundances). In terms of the spectral mixture mechanism, HU algorithms can be roughly categorized into linear and non-linear ones [
4,
5]. Although, in general, the nonlinear mixing assumption represents the most-real cases better, the linear mixing assumption (although more simplified) has been proved to work very satisfactory in many cases in practice. Taking into account its mathematical tractability, it has attracted significant attention from the scientific community. For these reasons, the linear mixture model is adopted in the present paper, in which a measured spectral can be represented as a linear combination of several endmembers.
Nonnegative matrix factorization (NMF) is a widely used linear HU method [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. In this framework, HU is regarded as a blind source separable problem, and decomposes an observed HSI matrix into the product of the pure pixel matrix (endmember matrix) and corresponding proportion matrix (abundance matrix). Respecting the physical constraints, nonnegative constraints on the endmembers and abundances, and abundance sum-to-one constraint (ASC) are imposed. The NMF algorithm has the characteristics of intuition and interpretability. However, due to the existence of large number of unknown dependent variables, the solution space of NMF model is too large. To restrict its solution space, many NMF variants are proposed by adding constraints on the abundance or endmember [
10,
11,
12,
13,
14,
15,
16]. Miao et al. incorporated a volume constraint of endmember into the NMF formulation and proposed a minimum volume constrained NMF (MVC-NMF) model [
10], which can perform unsupervised endmember extraction from highly mixed image data without the pure-pixel assumption. Jia et al. introduced two constraints to the NMF [
11], i.e., piecewise smoothness of spectral data and sparseness of abundance fraction. Similarly, two constraints on abundance (i.e., abundance separation constraint and abundance smoothness constraint) were added into the NMF [
12]. Qian et al. imposed an
-norm-based sparse constraints on the abundance and proposed an
-NMF unmixing model [
13]. Lu et al. considered the manifold structure of HSI and incorporated manifold regularization into the
-NMF [
14]. Wang et al. added endmember dissimilarity constraint into the NMF [
15].
Although the aforementioned NMF methods improved the classical NMF unmixing model at a certain extent, they ignored the effect of noise. As the objective function of NMF is the least squares loss, NMF is sensitive to noise and corresponding unmixing results are usually inaccurate and unstable. To suppress the effect of noise and improve the robustness of the model, many robust NMF methods were proposed [
17,
18,
19,
20]. He et al. proposed a sparsity-regularized robust NMF by adding a sparse matrix into the linear mixture model to model the sparse noise [
17]. Du et al. introduced a robust entropy-induced metric (CIM) and proposed a CIM-based NMF (CIM-NMF) model, which can effectively deal with non-Gaussian noise [
18]. Wang et al. proposed a robust correntropy-based NMF model (CENMF) [
19], which contained a correntropy-based loss function and an
-norm sparse constraint on the abundance. Based on the Huber’s M-estimator, Huang et al. constructed
-norm and
-norm based loss functions to obtain a new robust NMF model [
20,
21]. Defining the
-norm (
-norm) based loss function actually assumes that the column-wise (row-wise) approximation residual follows Laplacian (Gaussian) distribution from the viewpoint of maximum likelihood estimation (MLE). However, in practice this assumption may not hold well, especially when HSI contains complex mixture noise, such as impulse noise, stripes, deadlines, and other types of noise [
22,
23].
Inspired by the robust regression theory [
23,
24], we design the approximation residual as an MLE-like estimator and propose a robust MLE-based
-NMF model (MLENMF) for HU. It replaces the least-squares loss in the original NMF by a robust MLE-based loss, which is a function (associated with the distribution of the approximation residuals) of the approximation residuals [
24]. The proposed MLENMF can be converted to a weighted
-NMF model and can be solved by a re-weighted multiplication update iteration algorithm [
9,
13]. By choosing an appropriate weight function, MLENMF can automatically assign small weights to bands with large residuals, which can effectively reduce the effect of noisy bands and improve the unmixing accuracy. Experimental results on simulated and real hyperspectral data sets show the superiority of MLENMF over existing NMF methods.
The rest of the paper is organized as follows.
Section 2 introduces the NMF and
-NMF.
Section 3 describes our proposed MLENMF method. The experimental results and analysis are provided in
Section 4.
Section 5 discusses the effect of parameters in the algorithm. Finally,
Section 6 concludes the paper.
2. NMF Unmixing Model
Under the linear spectral mixing mechanism, an observed spectral
can be represented linearly by the endmember
[
4,
10,
11,
12,
13]:
where
represents the endmember matrix,
is the coefficient (abundance) vector, and
is the residual. Applying the above linear mixing model (1) for all hyperspectral pixels
, the following matrix representation can be obtained:
where
,
are nonnegative hyperspectral data matrix and abundance matrix, respectively.
is the residual matrix.
In Equation (2), to make the decomposition result as accurate as possible, the residual should be minimized. Then, an NMF unmixing model can be obtained by considering the nonnegative property of endmember and abundance matrices:
where
denotes the Frobenius norm, and
means that each element of
is nonnegative. As each column of abundance matrix
records the proportion of endmembers in representing a pixel, the columns of
(each one corresponding to a pixel) should satisfy the sum-to-one constraint, i.e.,
.
The above NMF Model (3) can be easily solved by the multiplication update algorithm [
9,
13]. However, its solution space is very large [
13]. To restrict the solution space, an
-constraint can be added to the abundance matrix
, and an
-NMF model can be obtained as [
13]:
where
is a regularization parameter and
is the
-regularizer [
13]. As proved in Refs. [
13,
25],
-regularizer is a good choice in enforcing the sparsity of hyperspectral unmixing because the sparsity of the
(
) solution increases as
decreases, whereas the sparsity of the solution for
(
) shows little change with respect to
. Meanwhile, the sparsity represented by
also enforces the volume of the simplex to be minimized [
13].
3. MLENMF Unmixing Model
In the NMF model (3) or (4), the objective function is the least-squares (LS) function which is sensitive to noise. Here, we employ a new robust MLE-based loss to replace the LS objective function and propose an MLE-based NMF (MLENMF) model for HU.
Firstly, the matrix norm form is transformed into vector norm form:
where
is the
-th row of matrix
.
We can regard the least squares objective function as the sum of approximation residuals, and then construct an MLE-like robust estimator to approximate the minimum of objective function. Denote the approximation residual of the
-th band as
and define residual vector
, the above Formula (5) can be rewritten as:
Assume that
are independent and identically distributed (i.i.d) random variables, which follow the same probability distribution function
, where
is the distribution parameter. The likelihood function can be expressed as:
According to the principle of MLE, the following objective function should be minimized:
where
. If we replace the objective function
in Equation (4) by the loss in Equation (8), we can get the following optimization problem:
In fact, the aim is to construct a loss function to replace the least squares function to reduce the impact of noise. To construct the loss function, we analyze its Taylor expansion. Assume that
is symmetric, and
if
. We can infer that: (1)
is global maximum of
and
is the global minimum of
; (2)
; (3)
if
. For simplicity, we assume
. Define
. According to the first-order Taylor expansion around
,
can be approximated as [
24]:
where
is the first order derivative of
at
, and
is the Hessian matrix. We can get the mixed partial derivatives
(
) as the error residuals
and
are assumed i.i.d., and hence
is a diagonal matrix. Taking the derivative of
with respect to
, it gets
As
is the global minimum of
, the minimum of
is
.
should also reach its minimum at
for it is an approximation of
, so
and then we can derive the following formulas from Equation (11):
where
is the
-th diagonal element of
. Denote
, Equation (13) can be written as
As
is a nonlinear and nonconvex function, it is difficult to solve the model (9) directly. Inspired by the above Formula (14), we can get:
and then the Model (9) can be expressed as a weighted NMF model:
The objective function of Model (16) can be rewritten as:
where
,
. Then, the Model (16) can be expressed as:
It is easy to see that model (18) is also an
-NMF algorithm, and can be solved by the multiplication update iteration rule as follows [
9,
13]:
The final endmember matrix is .
In the model (18), a key factor is the weight. In this paper, the weight function is set as the logistic function [
23,
24,
26]:
where
are positive scalars. Parameter
controls the decreasing rate from 1 to 0, and
controls the location of demarcation point [
24]. It is clear that the value of weight function decreases rapidly with the increase of residual
.
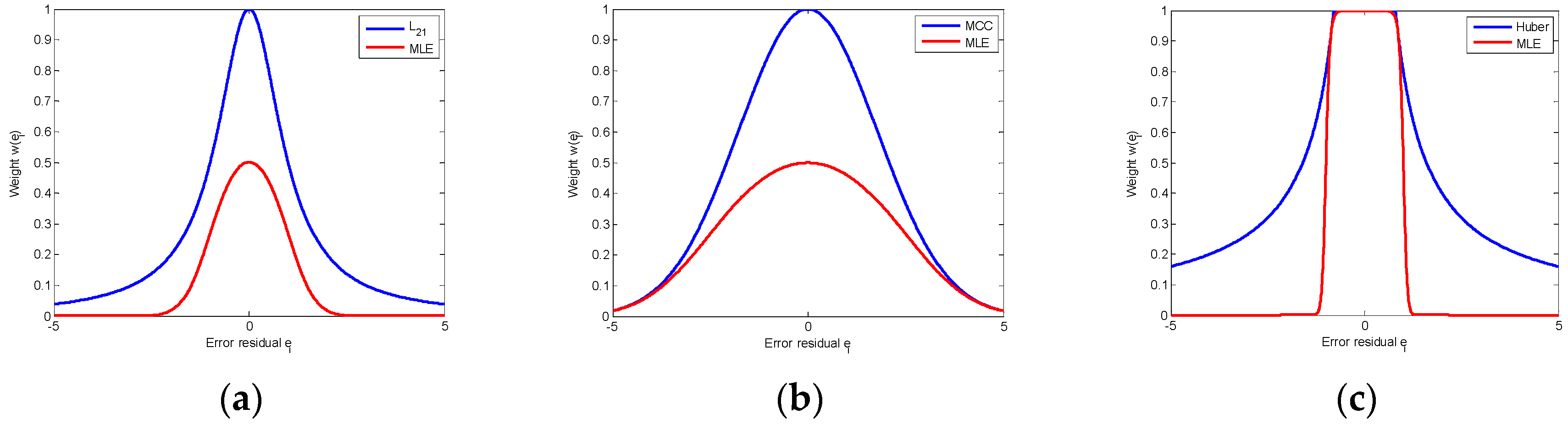
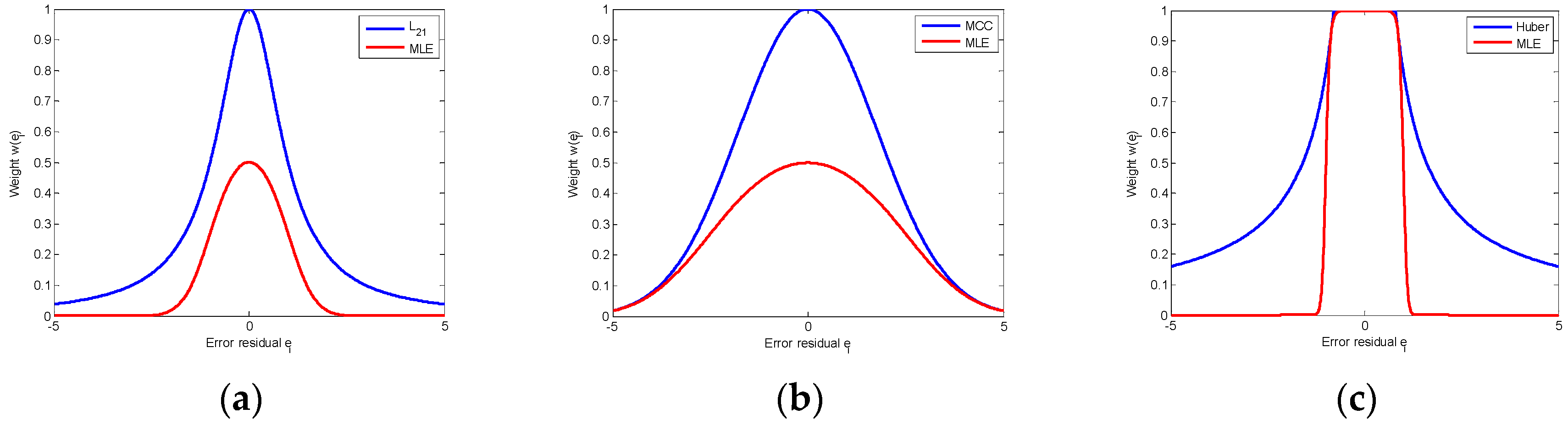
MLE weight function in Equation (21) can approximate the weight of commonly used loss functions, such as , maximum correntropy and Huber weights.
When
and
, the MLE weight function is:
which is close to
weight:
. The corresponding weights are shown as red and blue lines in
Figure 1a.
When
and
, the MLE weight function is:
which is close to the weight of maximum correntropy criterion:
(
is a parameter). The corresponding weights are shown in
Figure 1b.
By choosing appropriate parameters, the MLE weight can also approximate the Huber weight:
as shown in
Figure 1c.
Based on Equations (14) and (21), the objective function of MLE can be obtained as:
From Equations (8) and (25), we can see that the probability distribution function
has the form:
If
,
, the probability distribution function
is actually a Gaussian distribution:
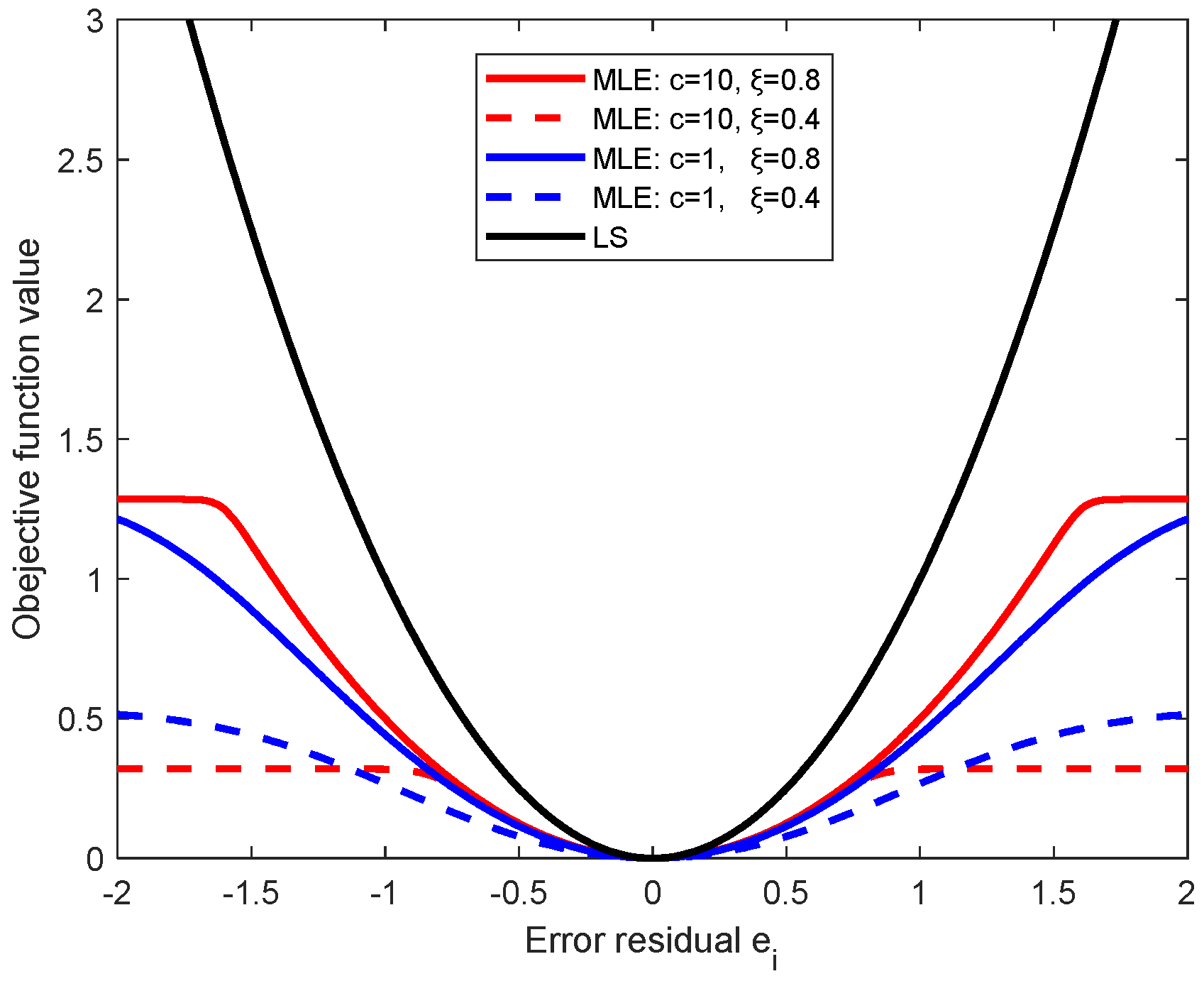
In this case, the weight defined in Equation (21) is: , which is the LS case.
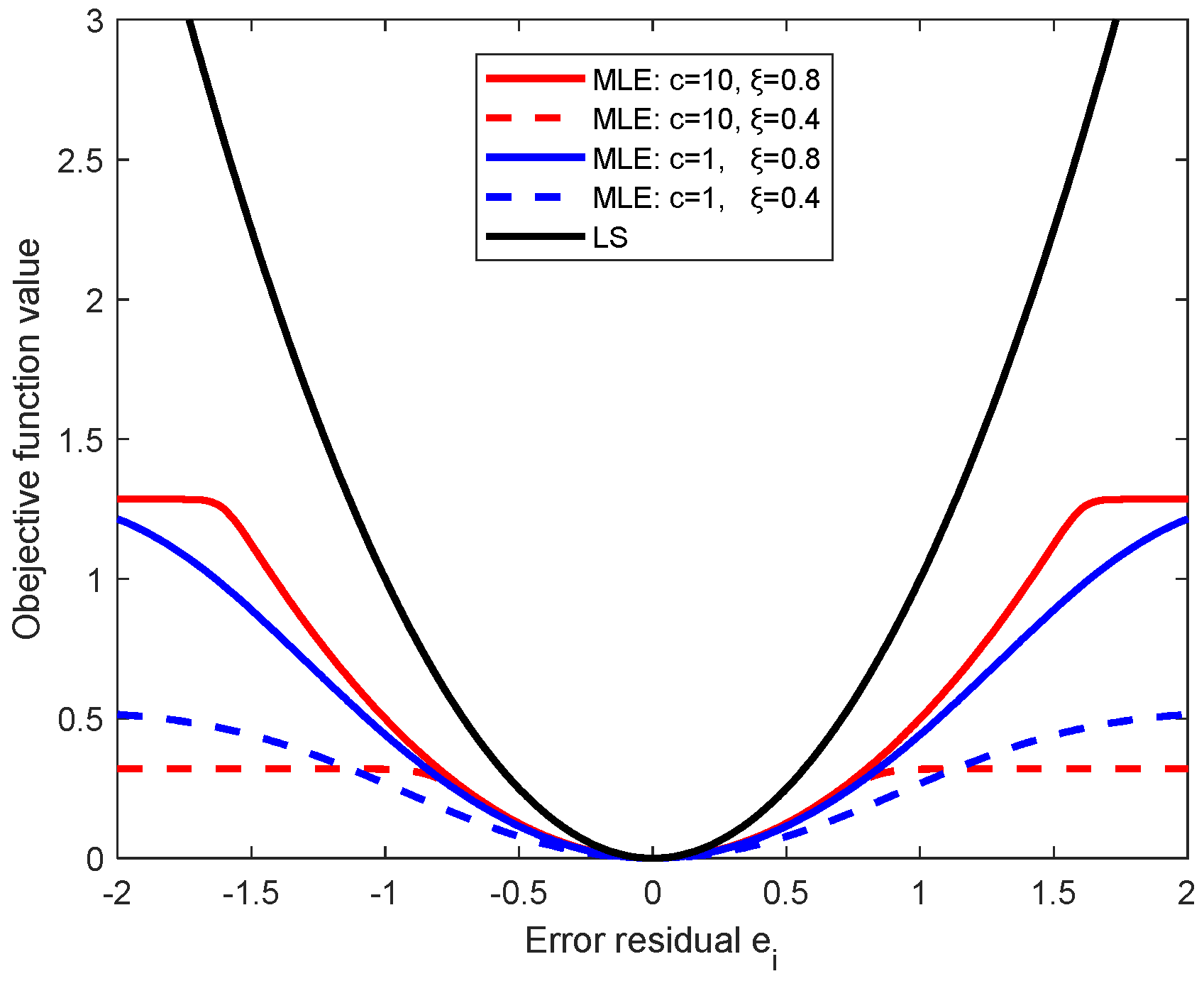
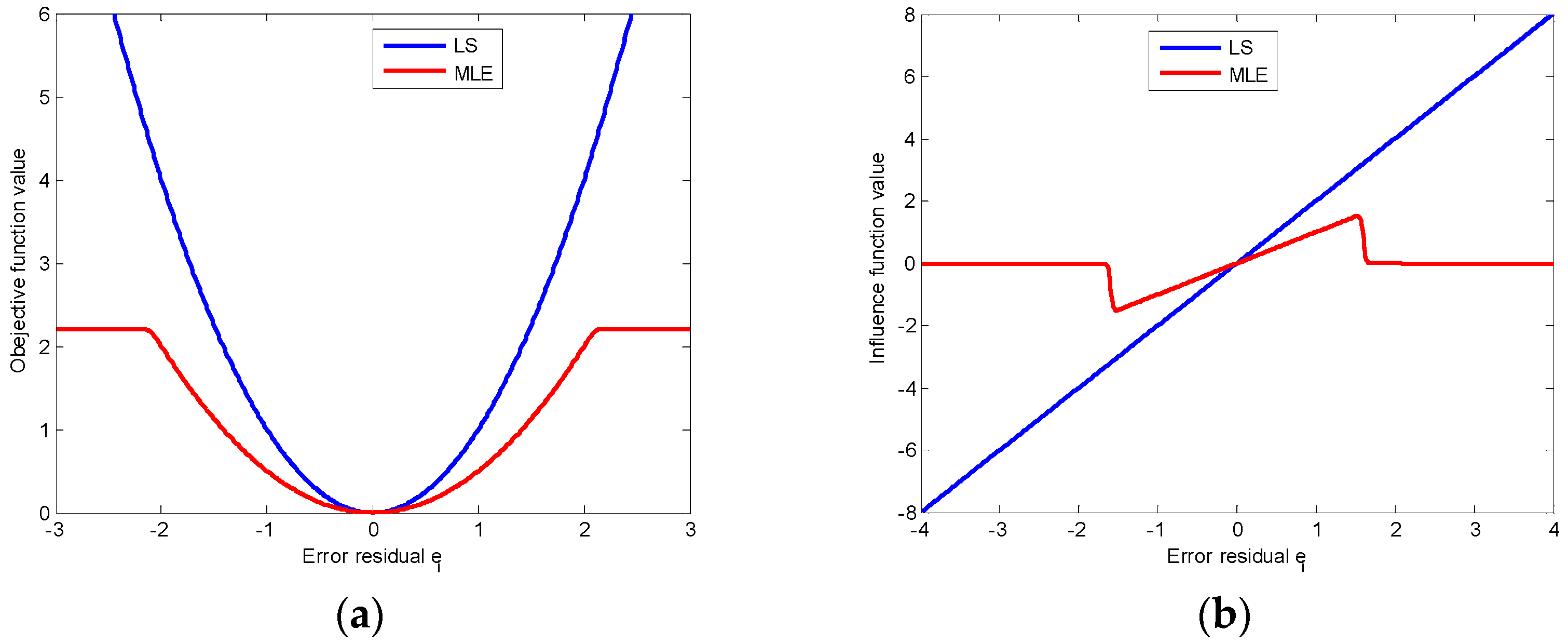
In
Figure 2a, we compare the MLE objective function with the LS loss function. MLE objective function is controlled by the parameters
, and is truncated to a constant for large residuals (e.g.,
). As the constant has no effect on the optimization model, the negative effect of noise (points with large residuals) can be automatically diminished. Compared with the MLE function, LS loss function is global and increases quadratically as the increase of residual. When there has heavy noise, the objective function of LS model will be dominated by the points with heavy noise.
Figure 2b shows the influence function [
22,
27] of MLE and LS. The influence function of a loss
is defined as:
, which measures the robustness of loss function as the increase of error residual. For residual
, the influence function of MLE increases first, then decreases and finally reaches the zero value. It means that larger errors finally have no effect on the MLE-based model. However, the influence function of LS continues to grow linearly. So, the LS loss function is seriously affected by noise. In the presence of noise, MLE is obviously more robust than LS.
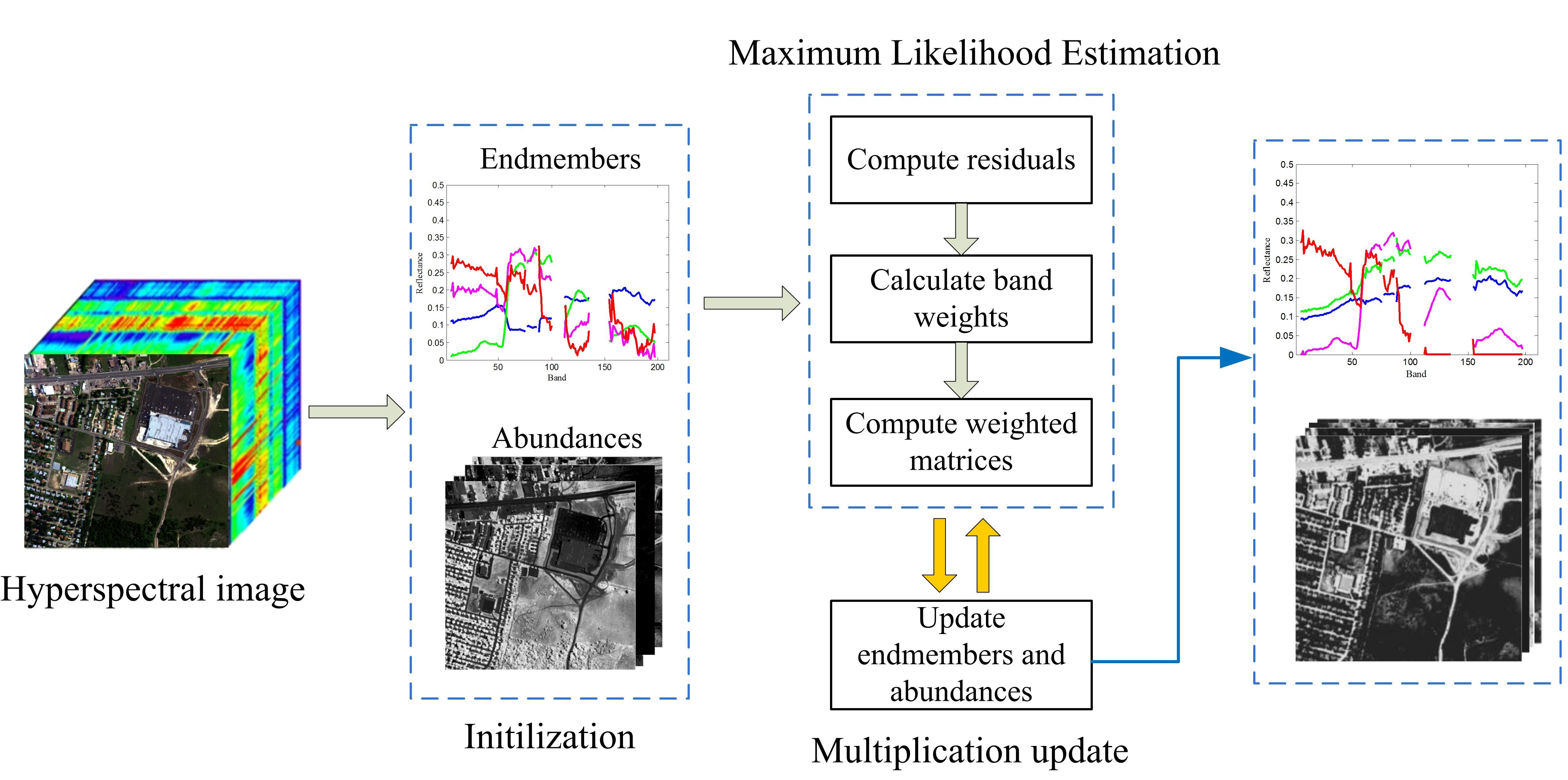
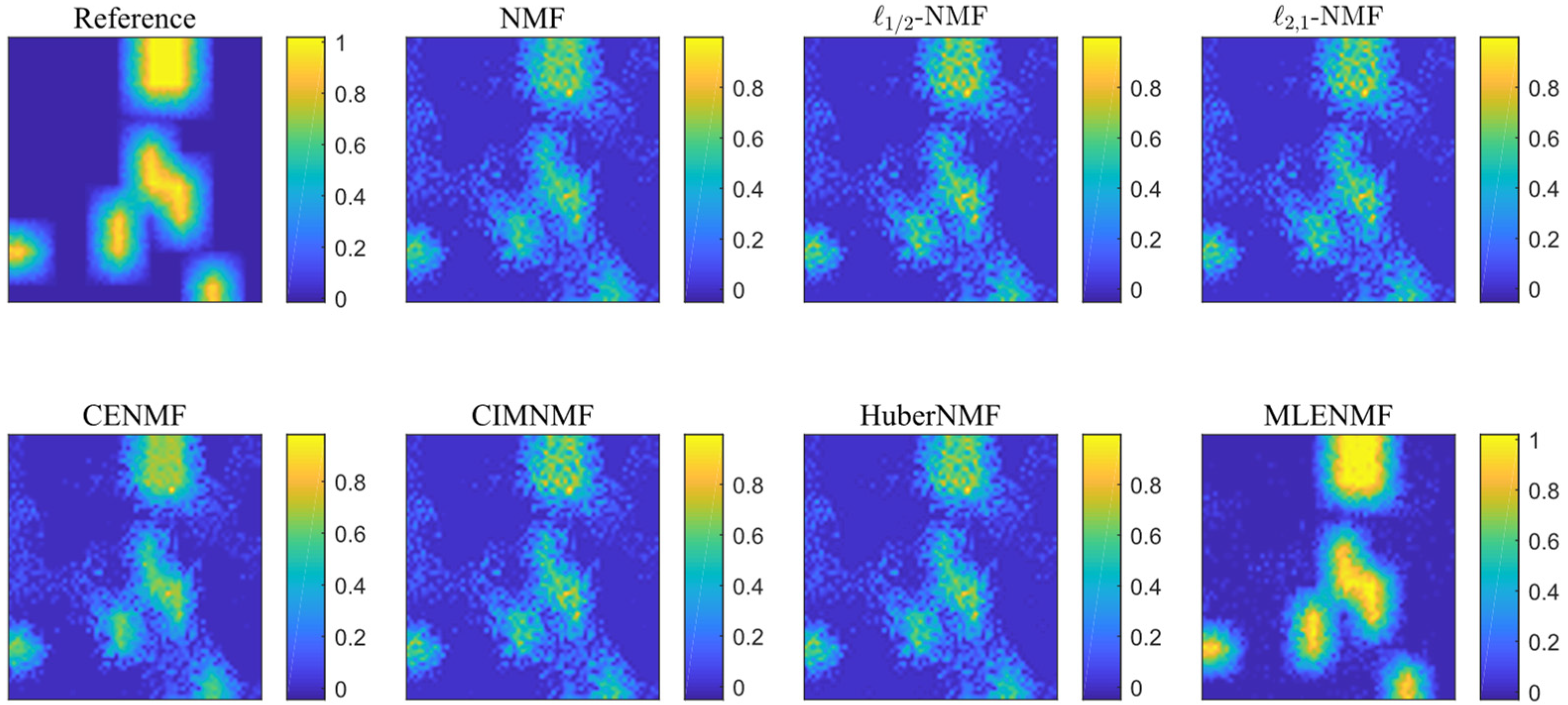
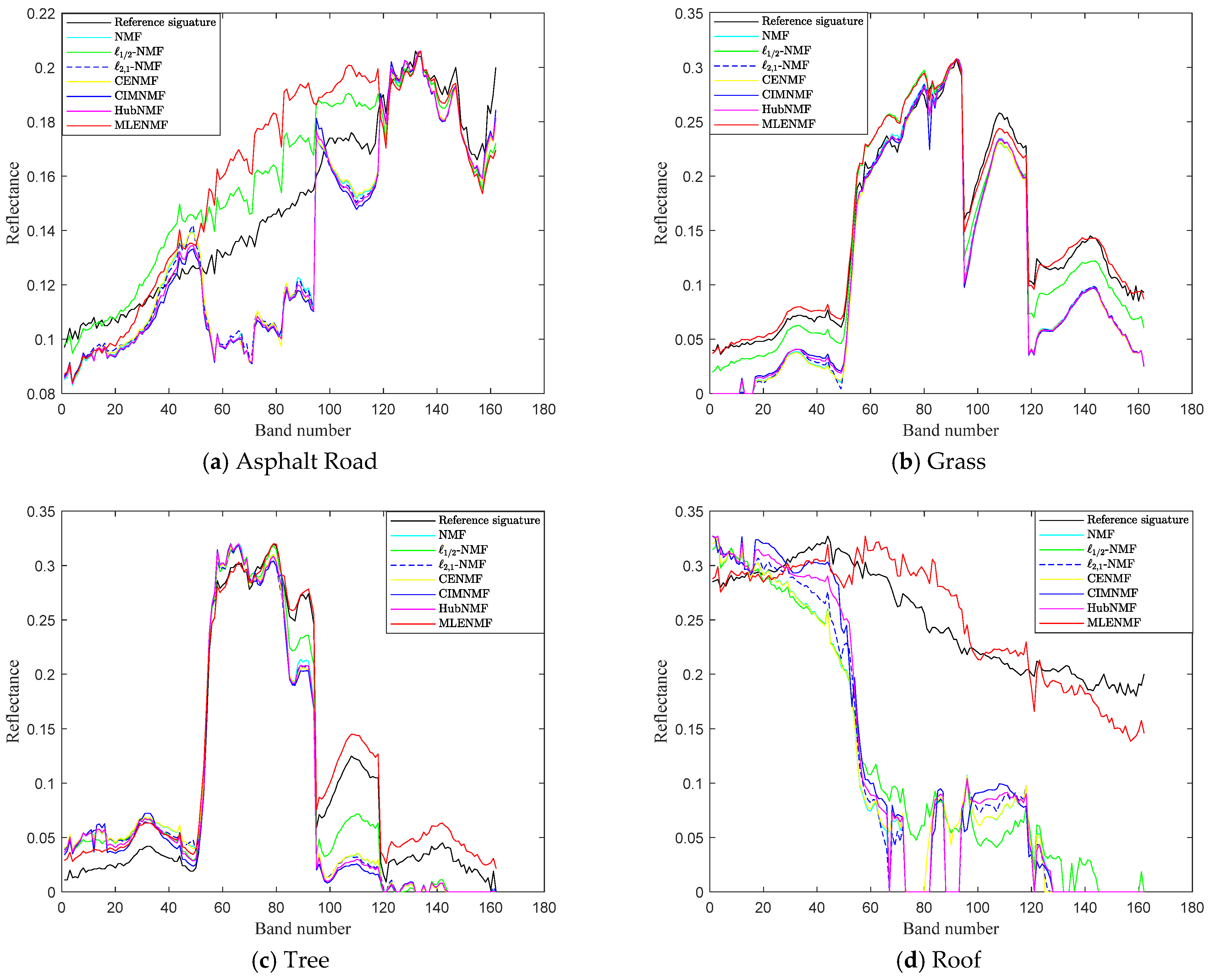
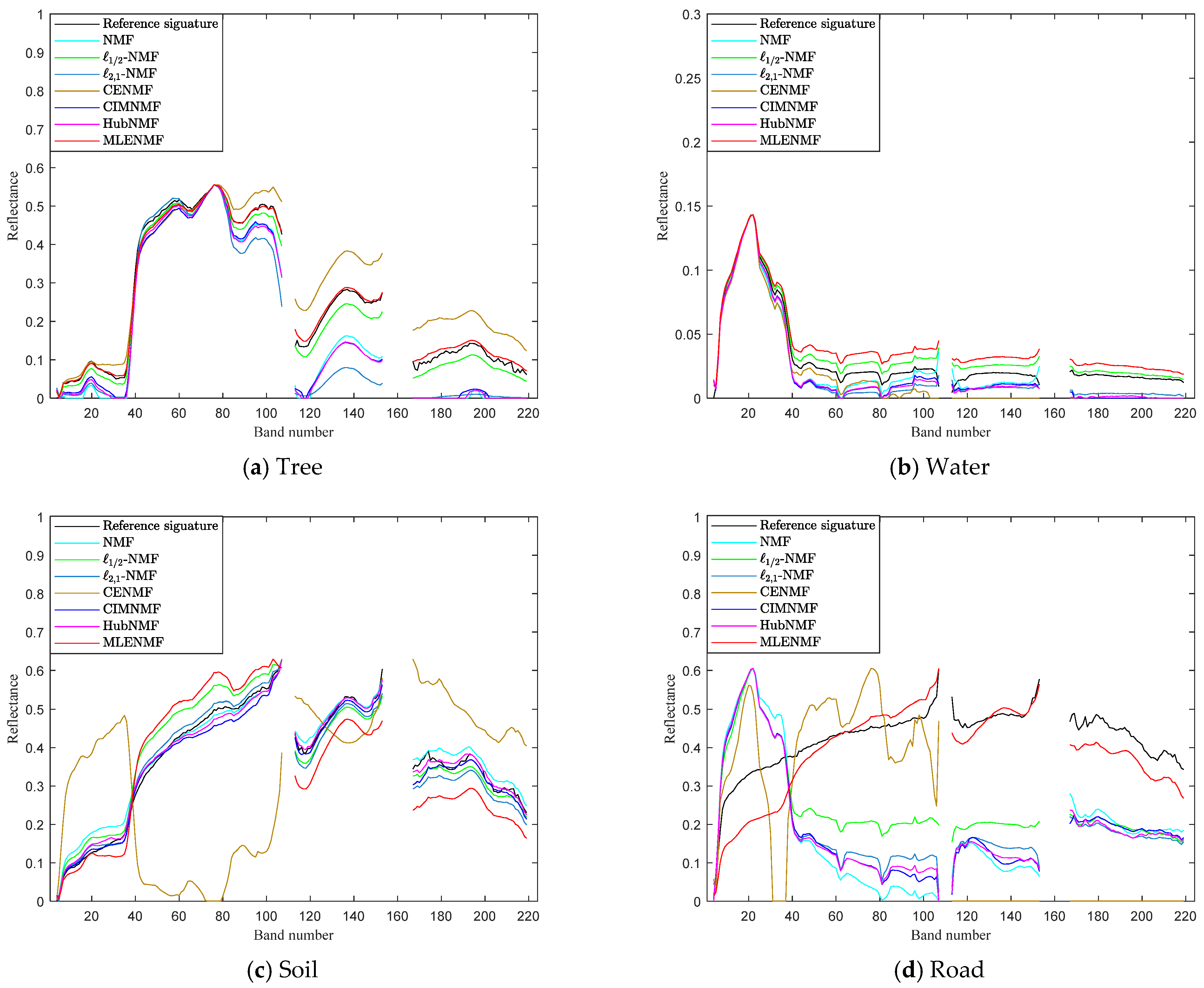
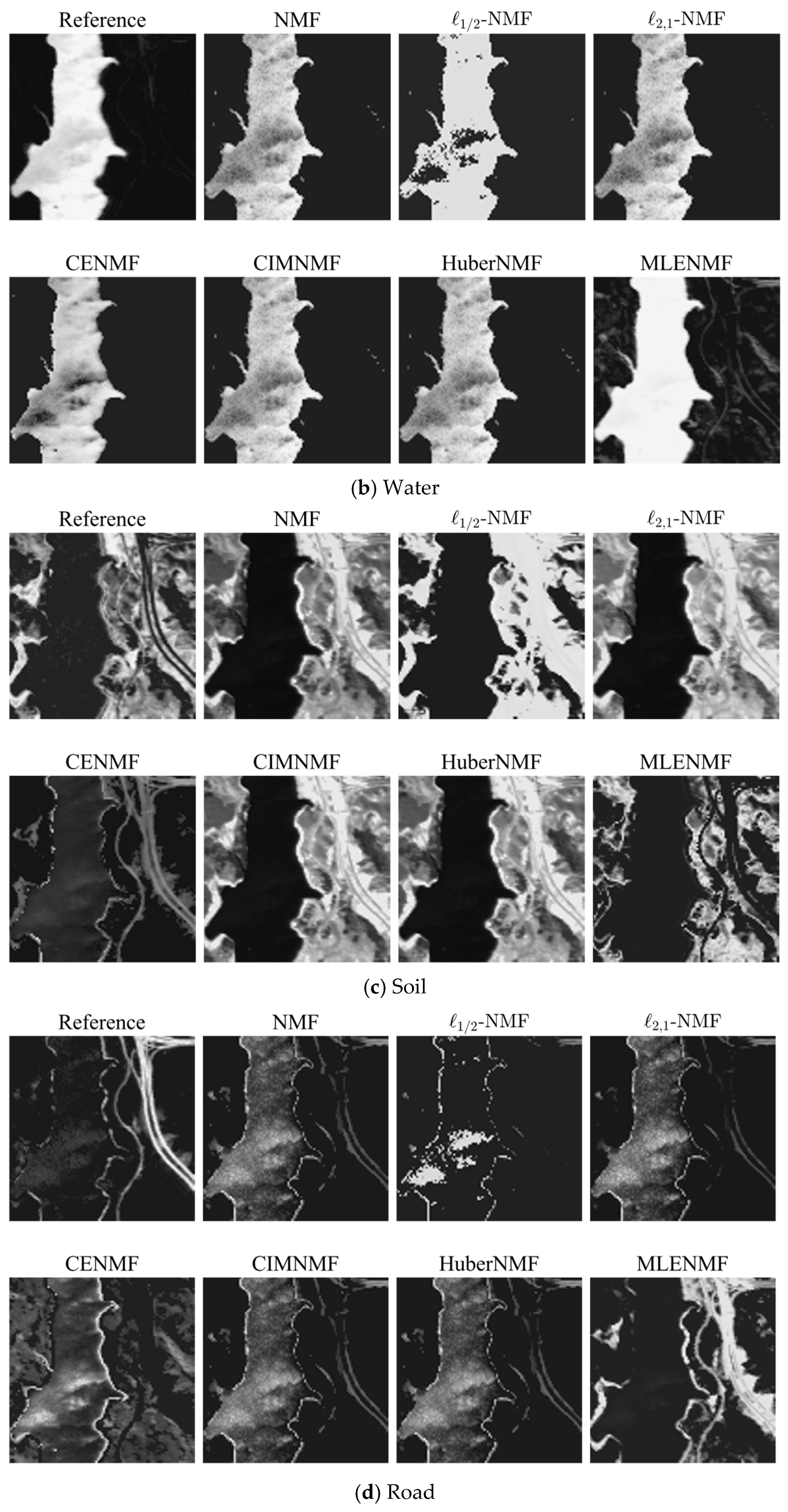
The procedure of the proposed MLENMF is shown in Algorithm 1.
| Algorithm 1 MLENMF. |
Input: hyperspectral matrix , the parameter
Initialization: endmember and abundance ,
Output: estimated endmember and abundance matrices. - 1.
Initialize - 2.
Run the following steps until convergence: (b) Calculate the weight of each entry: (c) Compute the weighted matrices: (d) Updating endmember matrix and weighted abundance matrix: (e)
|
Remark. In the current method, it assumes that different bands are independent and then an MLE solution can be deduced. The band independence assumption is only used in the derivation of MLE estimator. By means of this assumption, it can finally generate a weighted NMF model where the weight function can be used to reduce the effect of noisy bands. Although hyperspectral bands are not independent from each other in practice, the final weighted NMF model (i.e., MLENMF) can still alleviate negative effects of noise.
5. Discussion
As described in
Section 4.2,
is the
-th percentile of residual vector
, and
,
. By tuning the parameters
and
, the MLE objective function in Equation (26) can be truncated, as shown in
Figure 9. Parameter
and
control the decreasing rate and the location of truncation point, respectively. The larger the value of
, the greater the degree of truncation. The smaller the value of
, the more forward the position of the truncation point. As shown in
Figure 9, when the noise or residual is large, it is better to choose a larger
and a smaller
that truncates the weight of larger residuals to a constant (seeing the red dotted line).
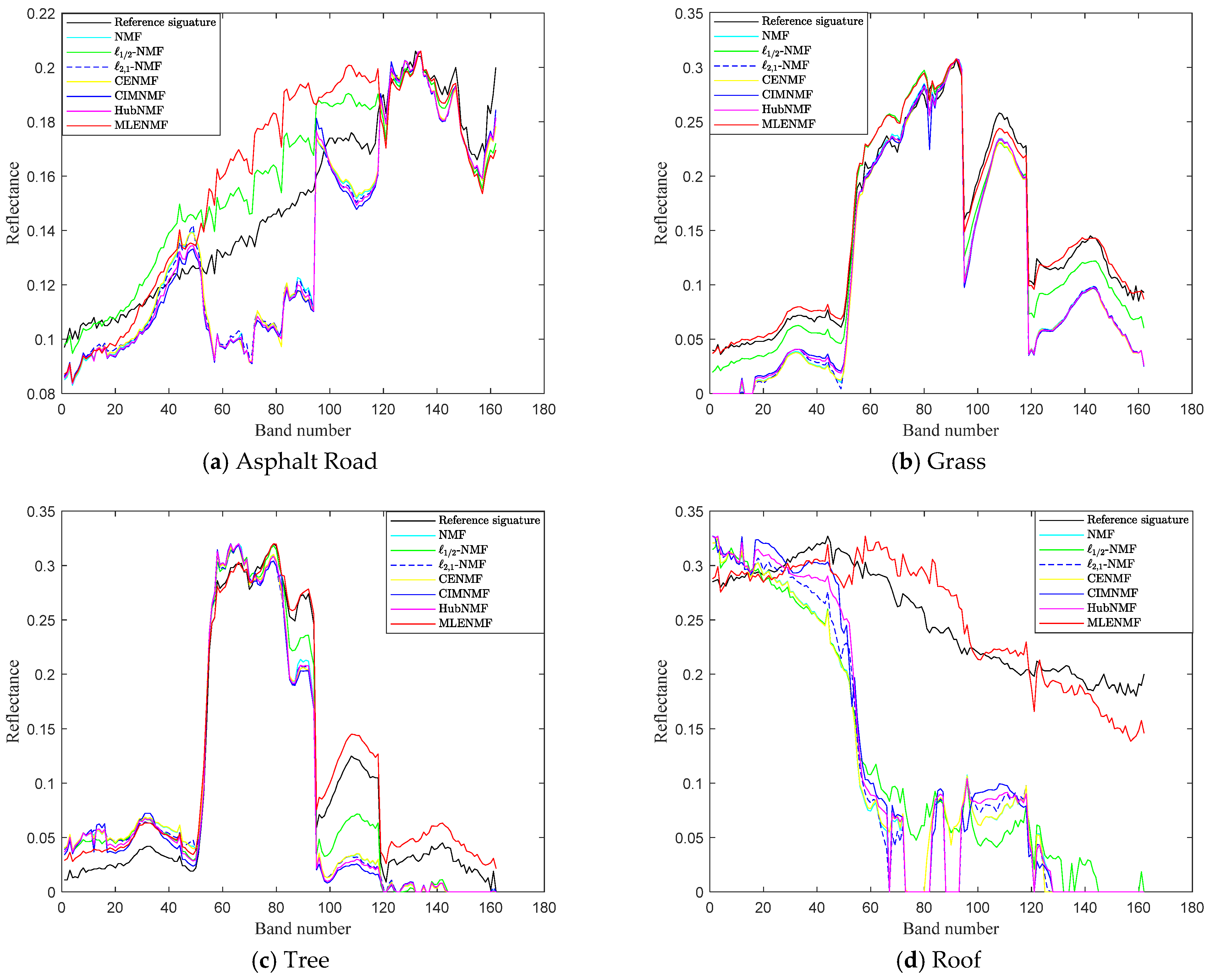
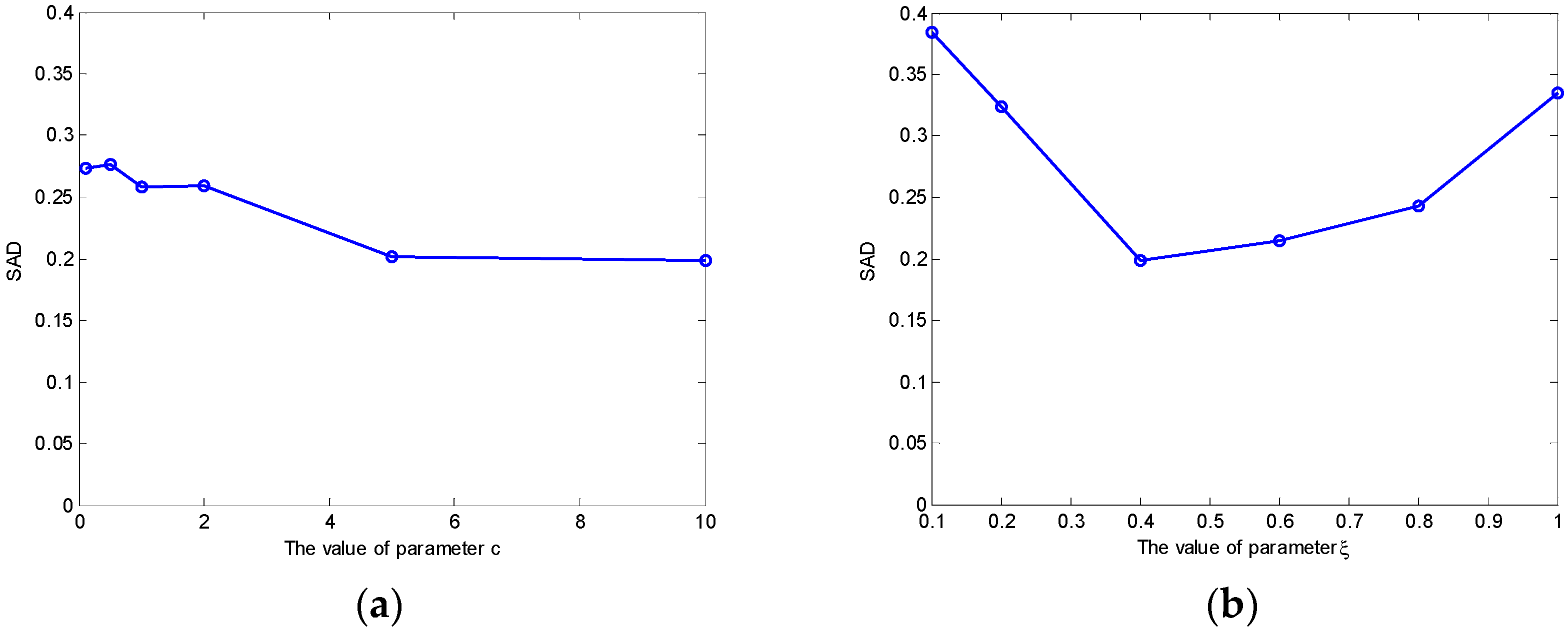
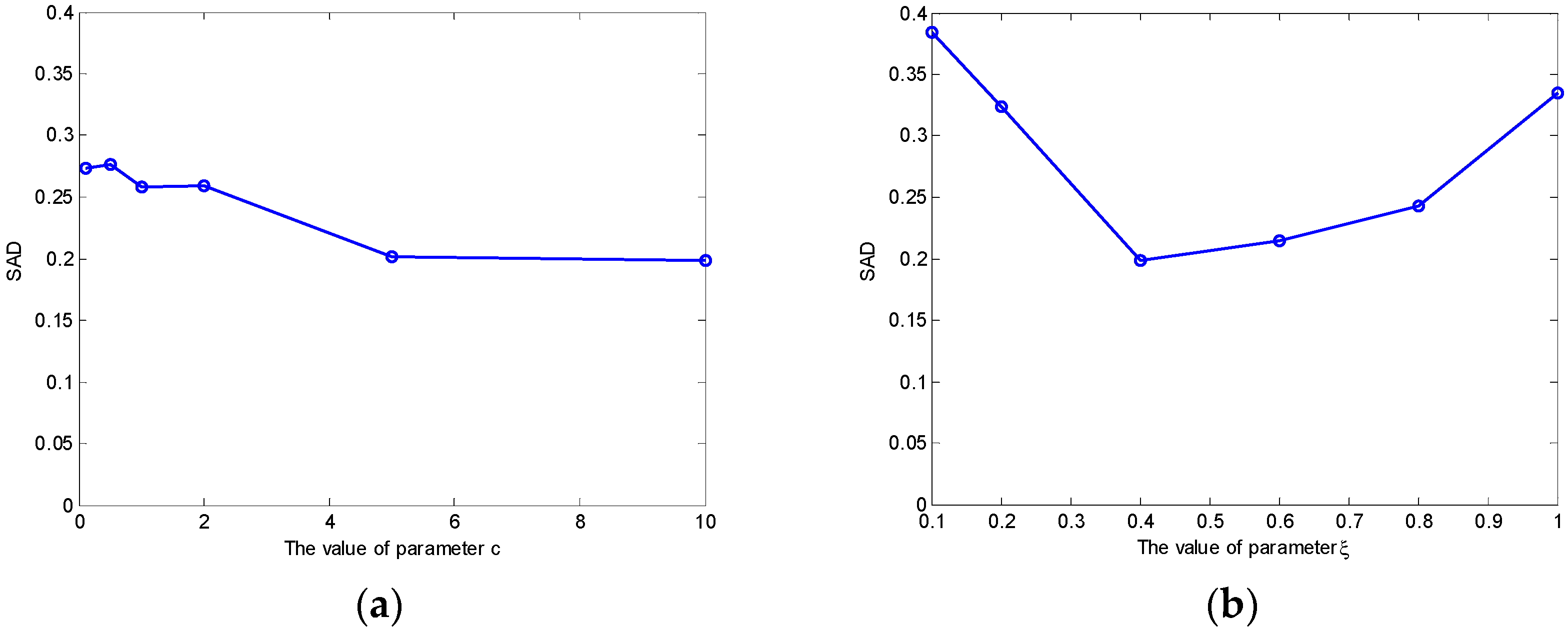
We take the Urban data set as an example to show the effect of parameters
and
.
Figure 10 shows the SAD results of MLENMF on Urban data with 210 bands. The results in
Figure 10a are obtained by fixing
and changing
in the set
. When
is fixed, larger
values correspond to better unmixing results. As shown in
Figure 9,
affects the degree of truncation. If choosing a large
, the weight of large errors can be truncated to a constant (e.g., the objective function values are constant for errors larger than 1.5, showing as the red solid line in
Figure 9). As their objective function values are constant, they have no influence on the model. For Urban data with all 210 bands, MLENMF with a larger
can effectively alleviate the effect of noisy bands. By fixing
and changing
in the set
,
Figure 10b shows the SAD of MLENMF versus parameter
. It is better to set the parameter
in the interval [0.4 0.8] when
is fixed. Parameter
determines the ratio of inliers. As the data contains noisy bands, the value of
should be less than 1.
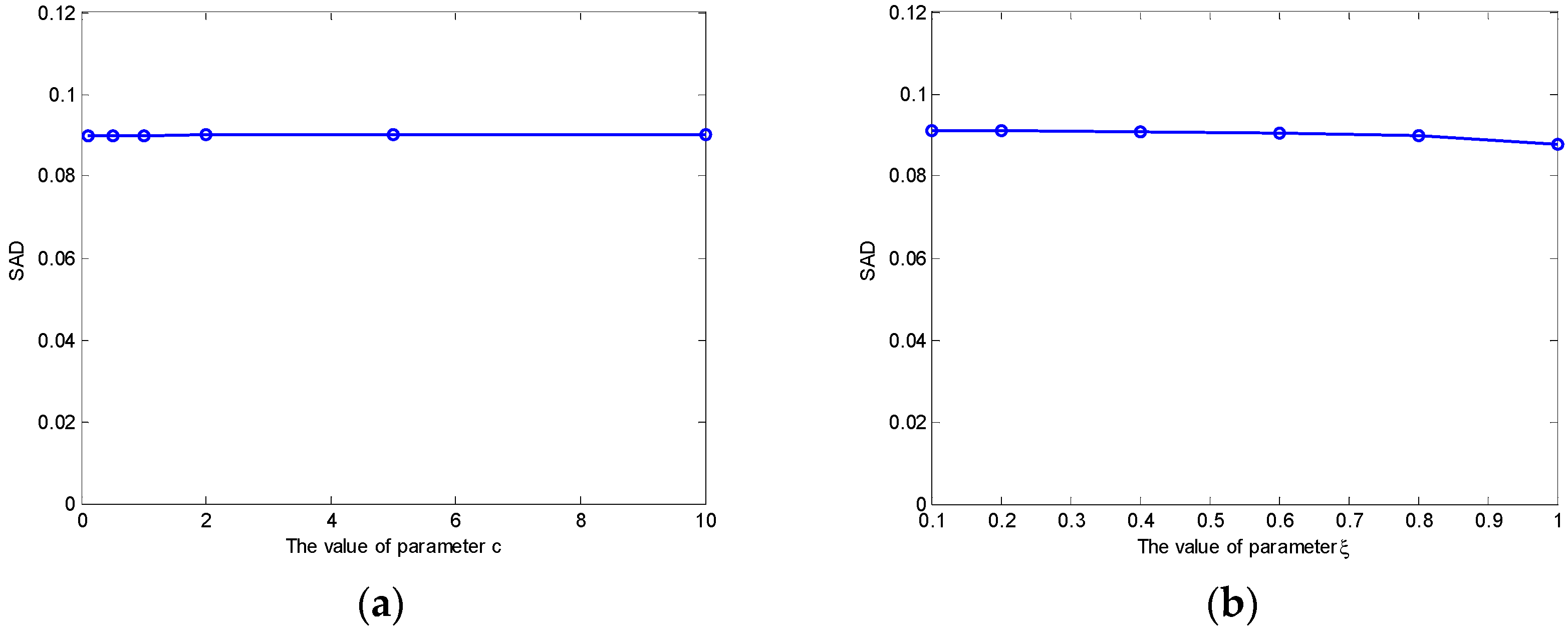
When the known noisy bands on the Urban data are removed, the experimental results on Urban data with 162 bands are obtained at fixing
and
, respectively. The results are shown in
Figure 11. From
Figure 11a, we can see that the proposed MLENMF is not sensitive to parameter
because different
values generate similar results for small errors in the case of low noise or no noise data as shown in
Figure 9. From
Figure 11b, the best result is achieved at
, which means that the data points are almost inliers.
The above analysis recommends setting the parameter
in the interval [0.4 0.8]. For data with heavy noise,
can be set to be a small value, such as
. Parameter
is chosen in the interval [
1,
10]. For data with heavy noise, it can set
. Otherwise, a moderate value
is recommended.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}