
Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints

Abstract
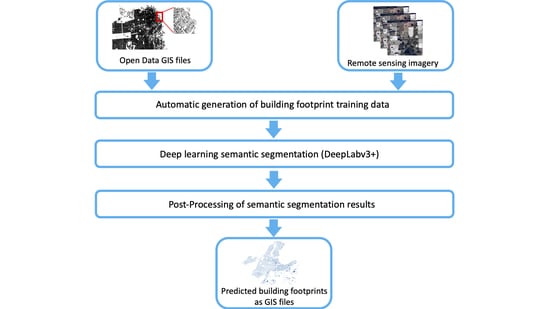
:
1. Introduction
- Builds on previous research works, a framework for building feature extraction from satellite/aerial images is proposed. This uses a state-of-the-art deep semantic segmentation algorithm and a postprocessing step that convert predicted probability maps into GIS files that include building footprint polygons. It also utilizes openly available building foot-print GIS files to automatically generate labeled training data, which is a more scalable solution in comparison to the approaches that are based on the costly manual generation of training data.
- To the best of our knowledge this is the first attempt to explore the usage of such a high volume of training data (i.e., 15 cities and five counties from various regions of the USA, which include 8,607,677 buildings) that have been automatically generated using openly available public records and that have not been manually curated/de-noised.
- The proposed pipeline is tested and compared with another dataset of US building footprints that has been generate using a framework that also uses deep semantic segmentation and satellite images.
2. Datasets
2.1. Building Footprint GIS Open Data
2.2. Remote Sensing Imagery
2.3. Microsoft Building Footprint Dataset
3. Methodology
- A data preprocessing step, which aims to generate training data with a very limited manual effort using openly available data sources:
- Automatic generation of training feature masks by querying city/county footprint GIS open data
- Deep learning modeling, using a state-of-the-art fully convolutional neural network architecture model, DeeplabV3+
- A postprocessing of the model results step, which aims to generate results that are easily transformable into GIS data formats:
- Prediction cleaning
- Prediction transformation (i.e., converting predictions that are pixel-based masks into polygons with geographic coordinates)
3.1. Data Pre-Processing
3.2. Deep Semantic Segmentation
3.2.1. Model
3.2.2. Loss Function
3.2.3. Model Training
3.3. Post-Processing
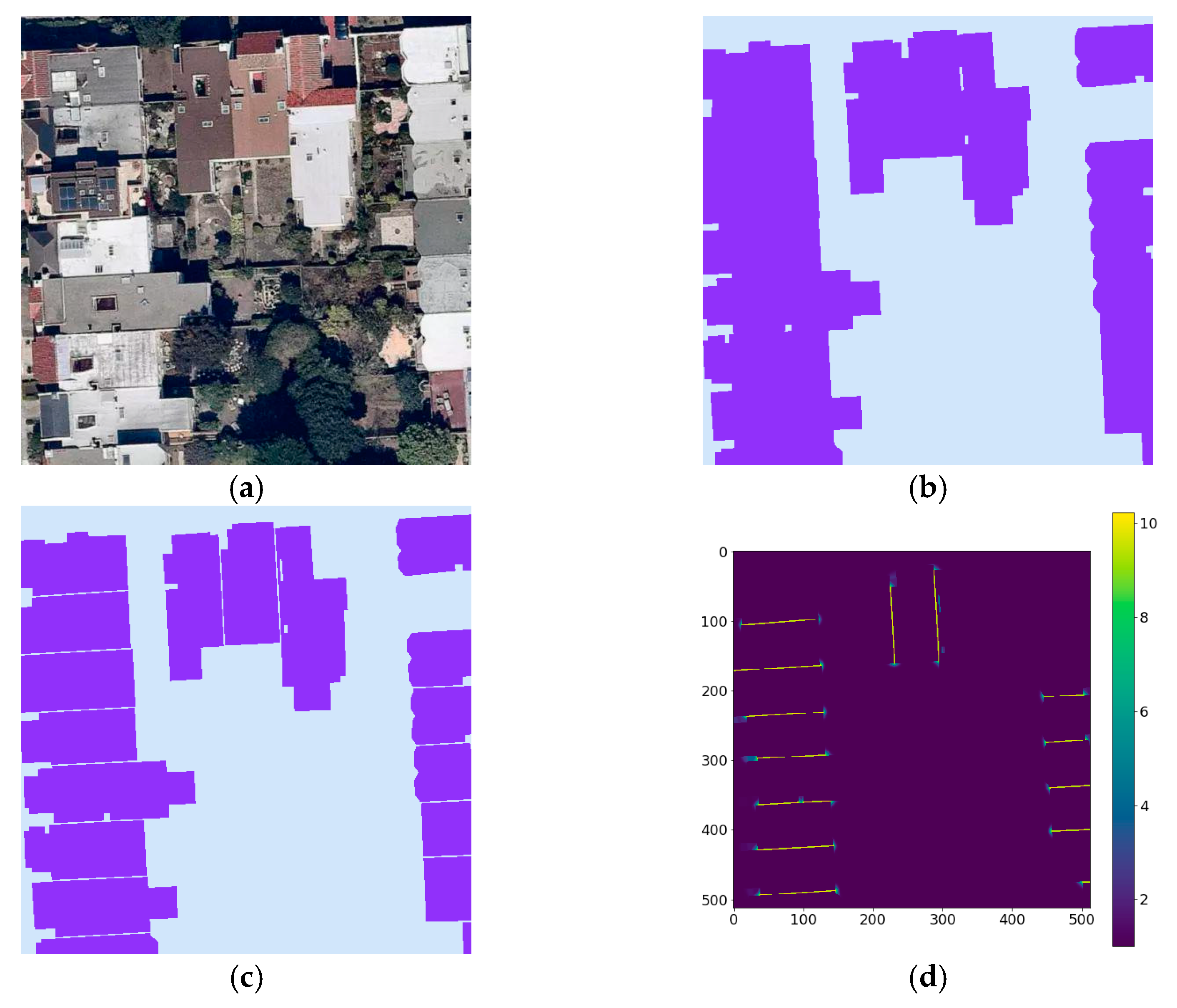
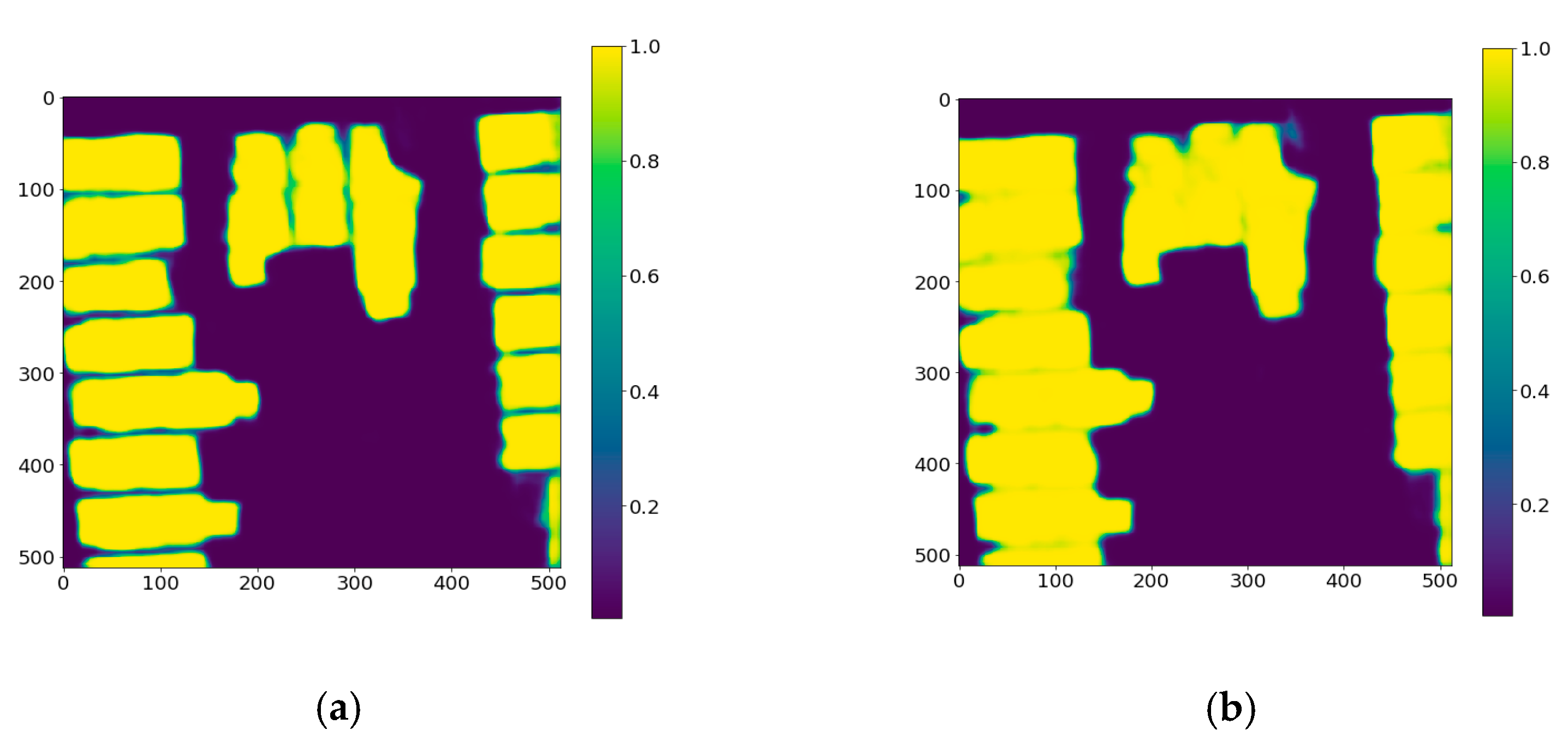
- Converting probability maps into binary masks: The DeepLabv3+ model provides probability masks as outputs, which are converted into a binary mask using 0.5 as a threshold (see an example in Figure 2d).
- Opening morphological operation: this operation is used to remove small objects from the mask while preserving the size and the shape of the larger building footprints (see an example in Figure 2e). This is done by first eroding objects (i.e., remove noise and shrink objects) in the masks and then dilating the eroded objects (i.e., re-expand the objects).
- Polygonization: this is done by detecting the contours of each predicted building footprint, i.e., extracting the curve joining all the pixels having the same color (see an example in Figure 2f).
- Polygon simplification: this step aims to approximate the curve that forms the extracted contour with another curve with fewer vertices (see an example in Figure 2g). The distances between the two curves are less or equal to a precision that is specified by the user. In this work the Douglas-Peucker [35] algorithm was used.
- Converting the polygons’ pixel-based coordinates into geographic coordinates: the result of this step is a GeoJSON GIS file.
- Polygons merging: in this step polygons that represent the same building footprint, yet were split due to tile boundaries, are merged to obtain a single building footprint.
- Increase the size of each detected polygon (i.e., building footprint): in order to improve the detection of building boundaries that are nearly overlapping, the surface area of each polygon in the training data was decreased by a factor of ~8%. Therefore, the model was trained to underestimate. To overcome this, the reverse operation is applied, and the area of each polygon is increased by 8%.
4. Experiments and Results
4.1. Accuracy Metrics
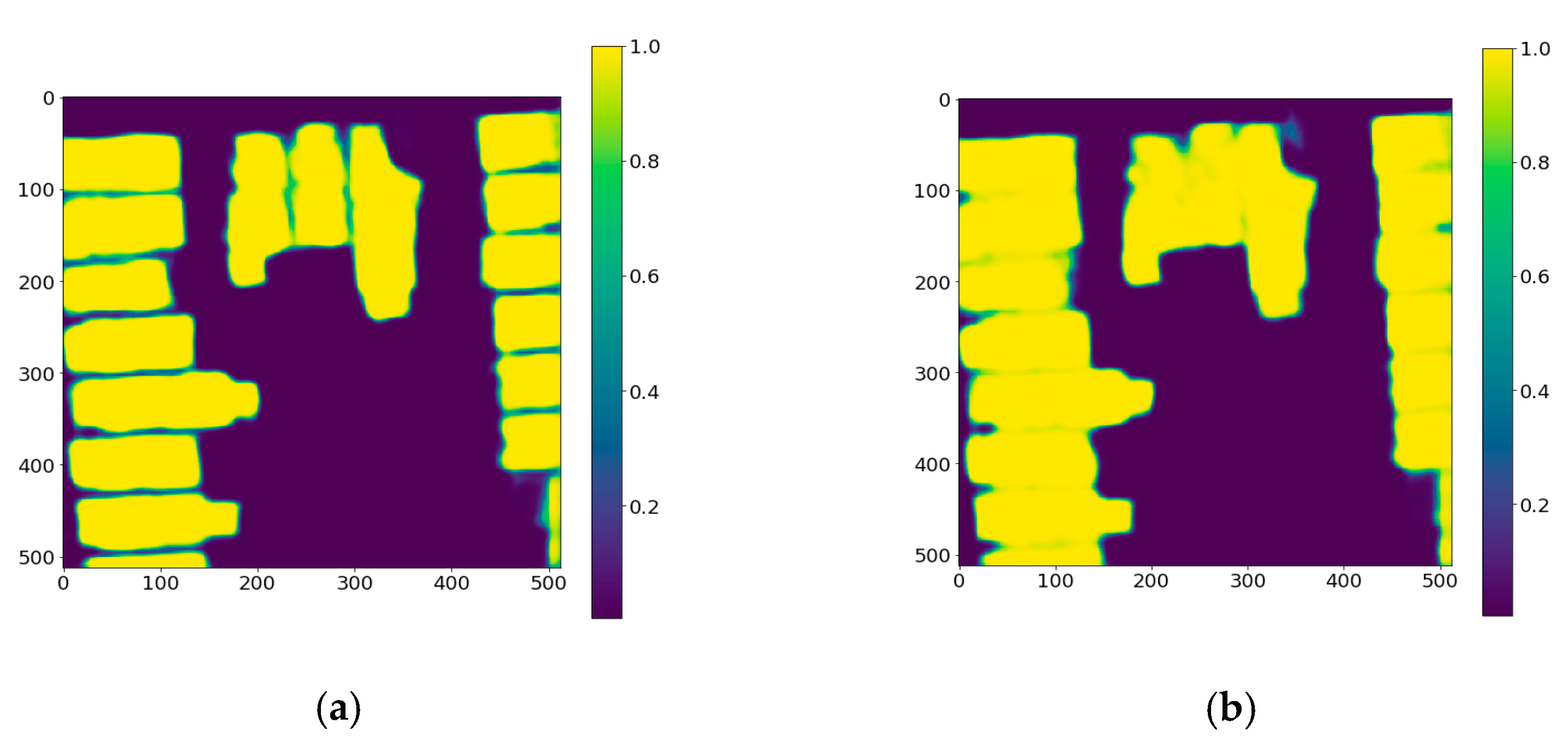
4.2. Impact of the Spatial Weighting in the Loss Function
4.3. Comparison with Microsoft Building Footprint Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City or County | Data Source |
|---|---|
| Austin, TX | https://data.austintexas.gov/ |
| Boston, MA | https://data.boston.gov/ |
| Chicago, IL | https://data.cityofchicago.org/ |
| Denver, CO | https://www.denvergov.org/opendata/ |
| Houston, TX | https://geo-harriscounty.opendata.arcgis.com/ |
| Indianapolis, IN | https://data.indy.gov/ |
| New York city, NY | https://opendata.cityofnewyork.us/ |
| Newark, NJ | http://data.ci.newark.nj.us/ |
| Philadelphia, PA | https://www.opendataphilly.org/ |
| San Francisco, CA | https://datasf.org/ |
| San Jose, CA | https://data.sanjoseca.gov/ |
| Seattle, WA | https://data-seattlecitygis.opendata.arcgis.com/ |
| Tampa, FL | https://city-tampa.opendata.arcgis.com/ |
| Virginia Beach, VA | https://gis.data.vbgov.com/ |
| Washington, DC | https://opendata.dc.gov/ |
| Allegheny County, PA | http://www.wprdc.org/ |
| Fulton County, GA | https://gisdata.fultoncountyga.gov/ |
| Los Angeles county, CA | https://geohub.lacity.org/ |
| Miami Dade county, FL | https://gis-mdc.opendata.arcgis.com/ |
| Portland, OR | https://gis-pdx.opendata.arcgis.com/ |
References
- Robinson, C.; Hohman, F.; Dilkina, B. A deep learning approach for population estimation from satellite imagery. In Proceedings of the 1st ACM SIGSPATIAL Workshop on Geospatial Humanities, New York, NY, USA, 7–10 November 2017; pp. 47–54. [Google Scholar]
- Rodriguez, A.C.; Wegner, J.D. Counting the uncountable: Deep semantic density estimation from space. In German Conference on Pattern Recognition; Springer: Cham, Switzerland, 2018; pp. 351–362. [Google Scholar]
- Chen, Y.; Hong, T.; Luo, X.; Hooper, B. Development of City Buildings Dataset for Urban Building Energy Modeling. Energy Build. 2019, 183, 252–265. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Goel, S.; Makhmalbaf, A. Commercial Building Energy Asset Score Program Overview and Technical Protocol (Version 1.1); Technical Report, PNNL-22045 Rev. 1.1.; Pacific Northwest National Laboratory: Richland, WA, USA, August 2013.
- Yu, M.; Yang, C.; Li, Y. Big data in natural disaster management: A review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef] [Green Version]
- Cerovecki, A.; Gharahjeh, S.; Harirchian, E.; Ilin, D.; Okhotnikova, K.; Kersten, J. Evaluation of Change Detection Techniques using Very High Resolution Optical Satellite Imagery. Preface 2015, 2, 20. [Google Scholar]
- Oludare, V.; Kezebou, L.; Panetta, K.; Agaian, S. Semi-supervised learning for improved post-disaster damage assessment from satellite imagery. In Multimodal Image Exploitation and Learning 2021; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 11734, p. 117340O. [Google Scholar]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Xu, D.; Wang, N.; Shi, Z.; Chen, Q. Road Extraction from Very-High-Resolution Remote Sensing Images via a Nested SE-Deeplab Model. Remote Sens. 2020, 12, 2985. [Google Scholar] [CrossRef]
- Sharifzadeh, S.; Tata, J.; Sharifzadeh, H.; Tan, B. Farm Area Segmentation in Satellite Images Using DeepLabv3+ Neural Networks. In International Conference on Data Management Technologies and Applications; Springer: Cham, Switzerland, 2019; pp. 115–135. [Google Scholar]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. EU-Net: An Efficient Fully Convolutional Network for Building Extraction from Optical Remote Sensing Images. Remote Sens. 2019, 11, 2813. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gross, L.; Li, Z.; Li, X.; Fan, X.; Qi, W. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access. 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Valentijn, T.; Margutti, J.; van den Homberg, M.; Laaksonen, J. Multi-Hazard and Spatial Transferability of a CNN for Automated Building Damage Assessment. Remote Sens. 2020, 12, 2839. [Google Scholar] [CrossRef]
- Bai, Y.; Hu, J.; Su, J.; Liu, X.; Liu, H.; He, X.; Meng, S.; Mas, E.; Koshimura, S. Pyramid Pooling Module-Based Semi-Siamese Network: A Benchmark Model for Assessing Building Damage from xBD Satellite Imagery Datasets. Remote Sens. 2020, 12, 4055. [Google Scholar] [CrossRef]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? Th Inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Schiefelbein, J.; Rudnick, J.; Scholl, A.; Remmen, P.; Fuchs, M.; Müller, D. Automated urban energy system modeling and thermal building simulation based on OpenStreetMap data sets. Build. Environ. 2019, 149, 630–639. [Google Scholar] [CrossRef]
- Brovelli, M.; Zamboni, G. A new method for the assessment of spatial accuracy and completeness of OpenStreetMap building footprints. ISPRS Int. J. Geoinf. 2018, 7, 289. [Google Scholar] [CrossRef] [Green Version]
- Touzani, S.; Wudunn, M.; Zakhor, A.; Pritoni, M.; Singh, R.; Bergmann, H.; Granderson, J. Machine Learning for Automated Extraction of Building Geometry. In Proceedings of the ACEEE Summer Study on Energy Efficiency in Buildings, Pacific Grove, CA, USA, 17–21 August 2020. [Google Scholar]
- Mapbox 2019. Available online: https://docs.mapbox.com/ (accessed on 25 September 2019).
- Mapbox, 2018. Available online: https://www.openstreetmap.org/user/pratikyadav/diary/43954. (accessed on 7 December 2020).
- OSM Wiki: Slippy Map 2020. Available online: https://wiki.openstreetmap.org/wiki/Slippy_Map (accessed on 15 September 2020).
- USBuildingFootprints, 2018. Microsoft. Available online: https://github.com/microsoft/USBuildingFootprints. (accessed on 10 March 2020).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ng, V.; Hofmann, D. Scalable Feature Extraction with aerial and Satellite Imagery. In Proceedings of the 17th Python in Science Conference (SCIPY 2018), Austin, TX, USA, 9–15 July 2018; pp. 145–151. [Google Scholar]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Ravanbakhsh, M.; Fraser, C.S. Automatic detection of residential buildings using LIDAR data and multispectral imagery. ISPRS J. Photogramm. Remote. Sens. 2010, 65, 457–467. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Fraser, C.S. Automatic segmentation of raw LiDAR data for extraction of building roofs. Remote Sens. 2014, 6, 3716–3751. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Building detection in complex scenes thorough effective separation of buildings from trees. Photogramm. Eng. Remote Sens. 2012, 78, 729–745. [Google Scholar] [CrossRef] [Green Version]







| Precision | Recall | F1 Score | mIoU | |
|---|---|---|---|---|
| dicewce | 0.91 | 0.89 | 0.90 | 0.89 |
| dicece | 0.90 | 0.90 | 0.90 | 0.89 |
| Precision | Newark, NJ | Houston, TX | NY City, NY | |
|---|---|---|---|---|
| DeepLabV3+ | Precision | 0.88 | 0.94 | 0.93 |
| Recall | 0.81 | 0.75 | 0.9 | |
| F1 score | 0.84 | 0.83 | 0.92 | |
| mIoU | 0.81 | 0.81 | 0.88 | |
| Microsoft | Precision | 0.88 | 0.9 | 0.84 |
| Recall | 0.82 | 0.76 | 0.92 | |
| F1 score | 0.85 | 0.82 | 0.88 | |
| mIoU | 0.82 | 0.79 | 0.82 |
| Newark, NJ | Houston, TX | NY City, NY | |
|---|---|---|---|
| Ground truth | 44,853 | 198,671 | 120,886 |
| Microsoft | 24,930 | 144,072 | 20,939 |
| DeepLabV3+ | 41,409 | 185,814 | 47,788 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Touzani, S.; Granderson, J. Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints. Remote Sens. 2021, 13, 2578. https://doi.org/10.3390/rs13132578
Touzani S, Granderson J. Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints. Remote Sensing. 2021; 13(13):2578. https://doi.org/10.3390/rs13132578
Chicago/Turabian StyleTouzani, Samir, and Jessica Granderson. 2021. "Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints" Remote Sensing 13, no. 13: 2578. https://doi.org/10.3390/rs13132578
APA StyleTouzani, S., & Granderson, J. (2021). Open Data and Deep Semantic Segmentation for Automated Extraction of Building Footprints. Remote Sensing, 13(13), 2578. https://doi.org/10.3390/rs13132578