
MAMOTH: An Earth Observational Data-Driven Model for Mosquitoes Abundance Prediction

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Related Work
1.2. Our Approach
- Design an auto-calibrated mosquito forecasting model:This combines Earth Observational and entomological information. Our approach allows for a generic framework that wraps itself around each case through automated feature selection and hyper parameters tuning process. This approach of feature selection prevents the injection of human bias into the model, while allowing for further analysis on the selected feature set. Framework’s description is presented in Section 3.
- Accurate robust forecasting model, tested in actual measurements: This is for mosquito populations, independently of location and genus contextual constraints. The ML approach followed in combination with the automated selection of features enabled for an auto adjusted and accurate framework validated upon five different cases (consisting of 4 different areas of interest and 3 different mosquito species), with different contextual constraints delivering high performance presented in Section 4.
- Comparative study: This is due to the replicability of our framework that uses the same architecture and the same mathematical principles offers the extensive capability of comparative studies among different cases, responding to: “which characteristics seem important in one case and which in another?” We can see in the comparative study of Section 4.
2. Datasets
2.1. Open EO Data
2.2. Meteorological Data
2.3. Auxiliary Data
2.4. Remote Sensing Data Preparation
2.5. Entomological Network
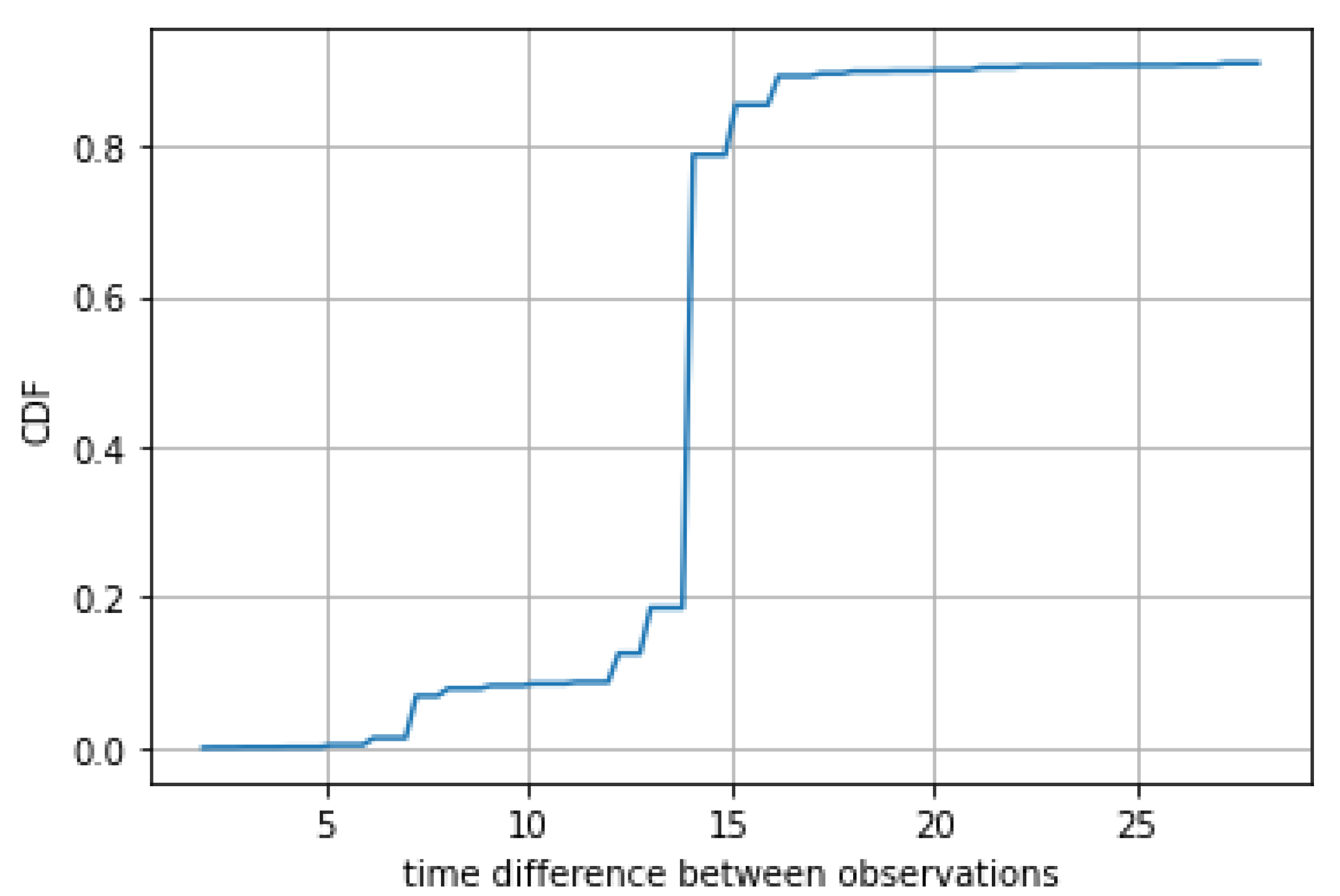
2.6. Data Pre-Processing
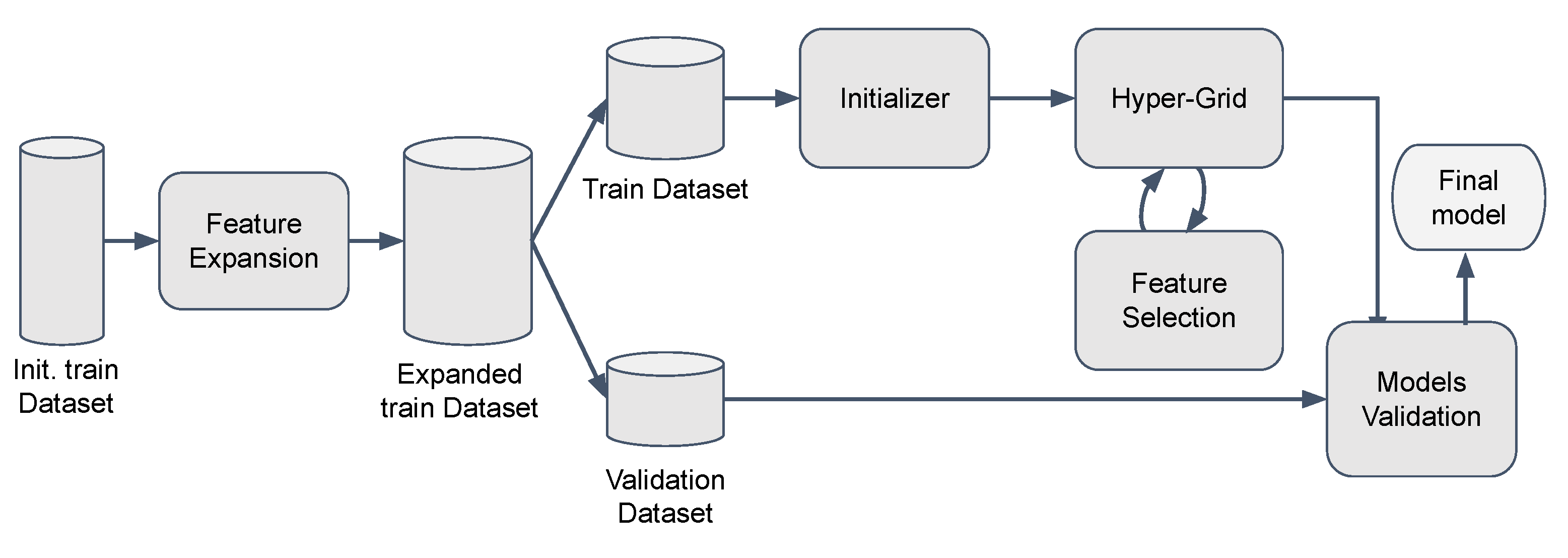
3. MAMOTH Principles and Methodology
3.1. MAMOTH’s Cost Function
3.2. MAMOTH’s Feature Space and Solver
3.3. Feature Extraction/Engineering Module
3.4. Initialization Module
3.5. Hyper-Parameters Grid Module
3.6. Features Selection
3.7. Model Selection
3.8. Computational Cost
4. Experimentation
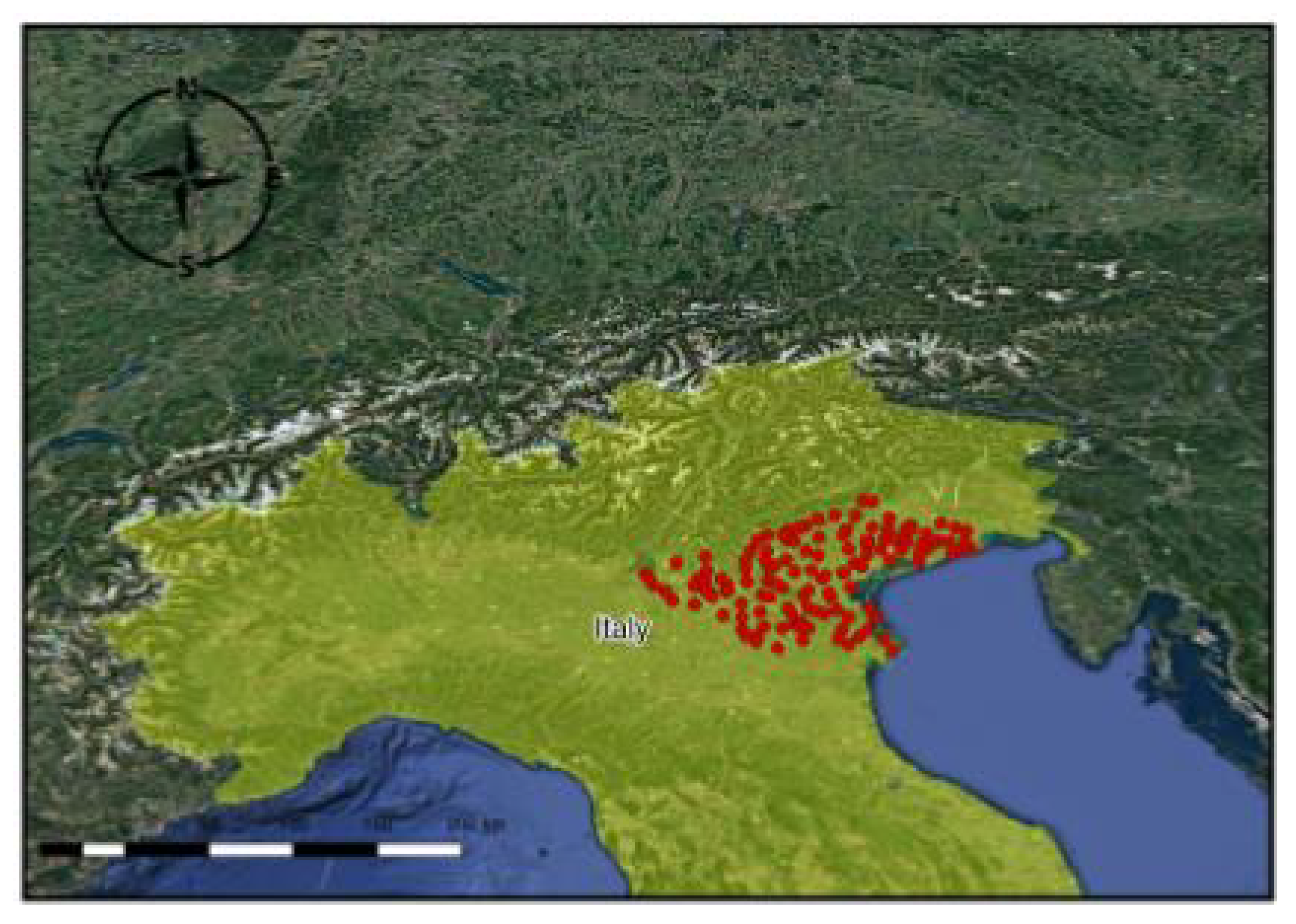
4.1. Area of Interest and Entomological Network
4.2. Culex Veneto Results
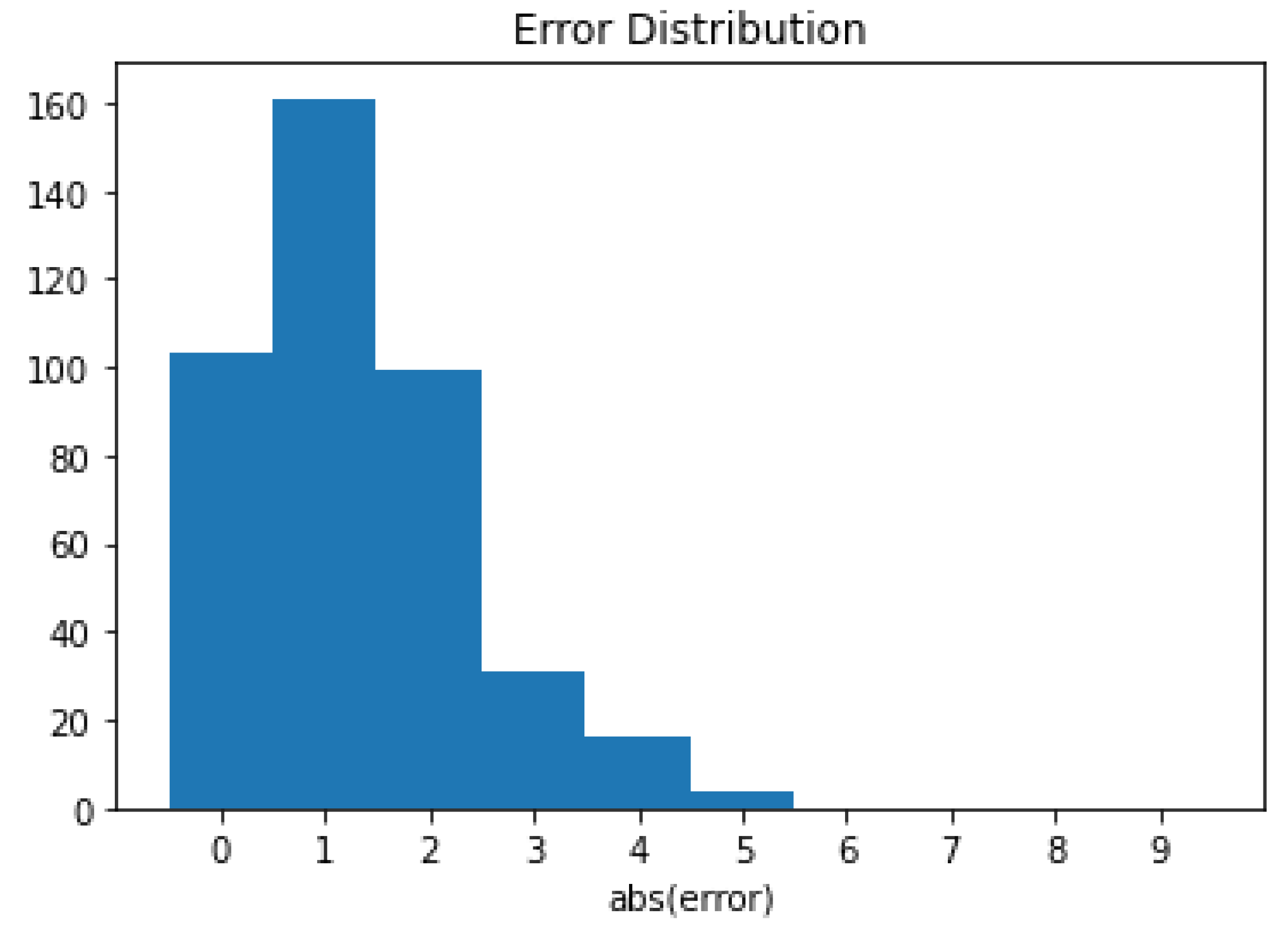
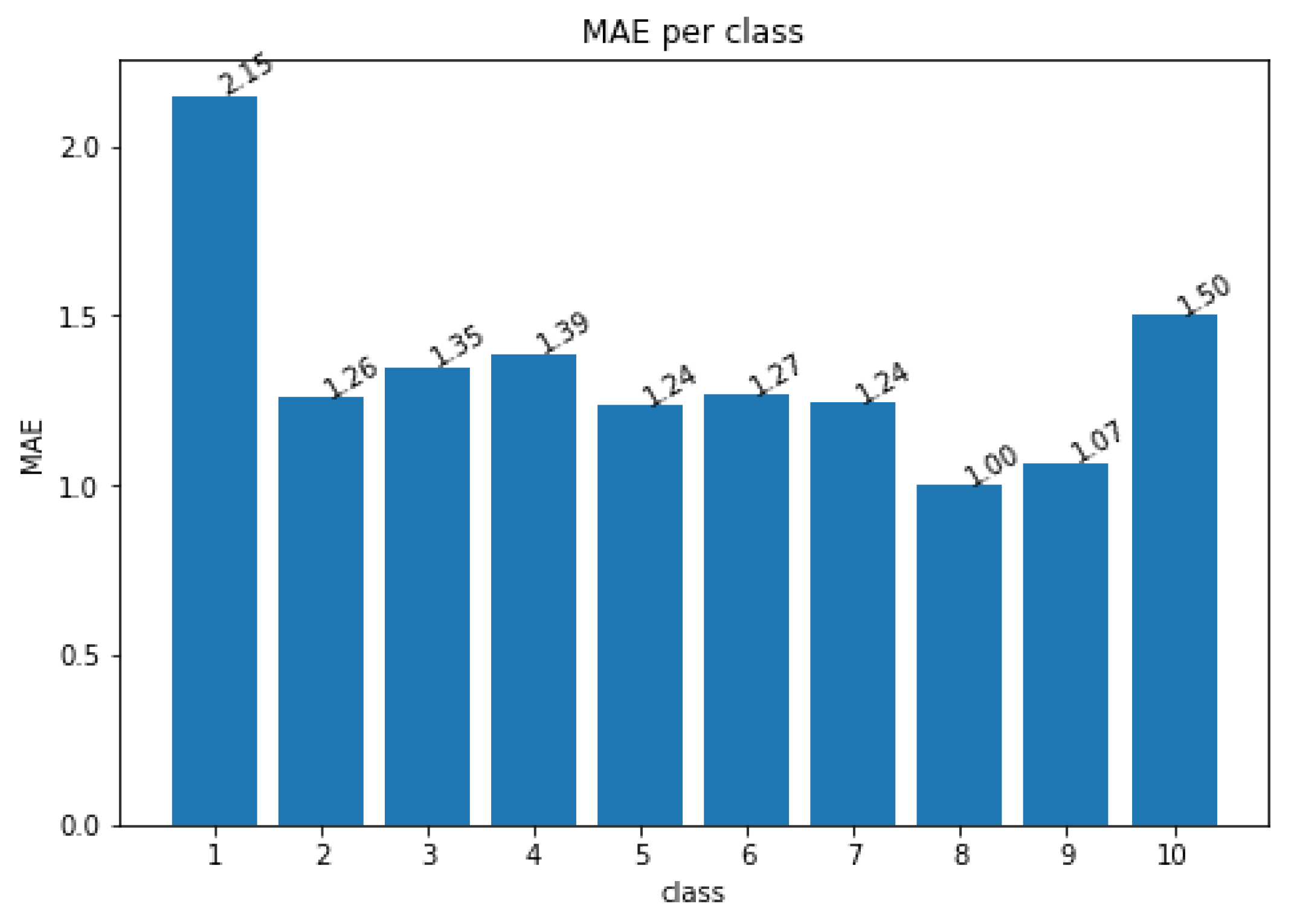
4.2.1. Error Distribution among Risk Classes
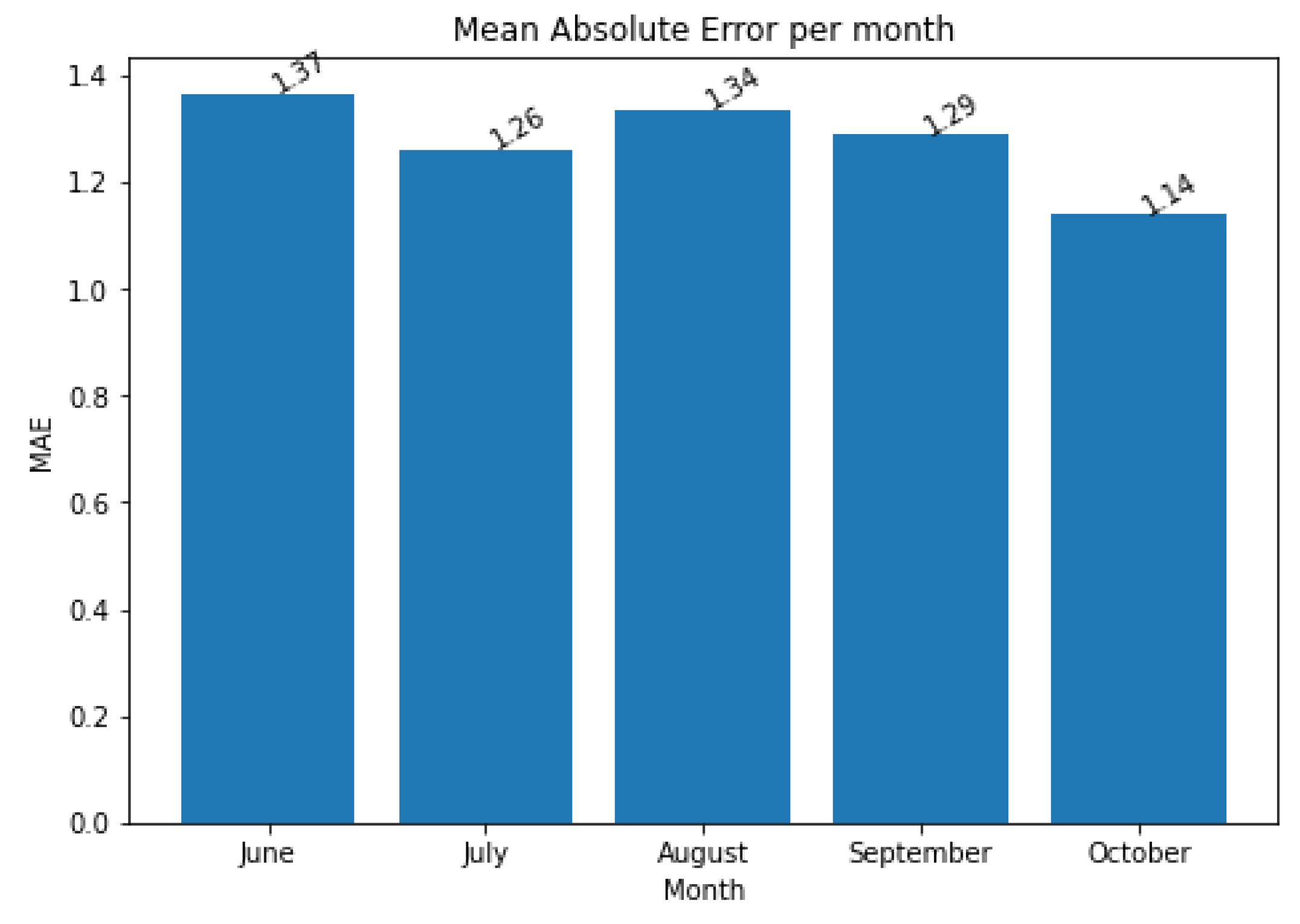
4.2.2. Results per Month
4.2.3. Performance without the Entomological Features
4.2.4. Performance without the EO Features
4.3. Other Cases
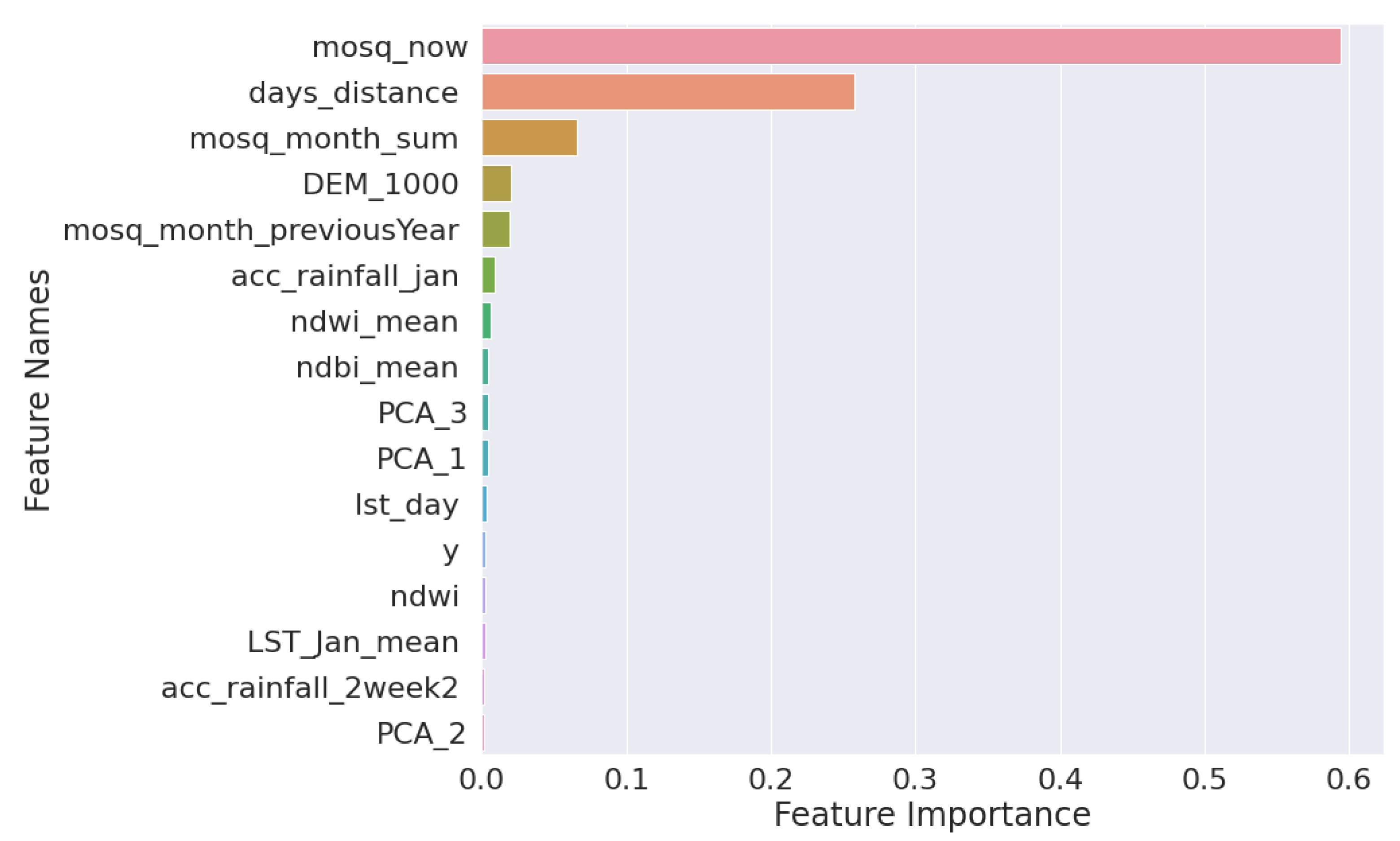
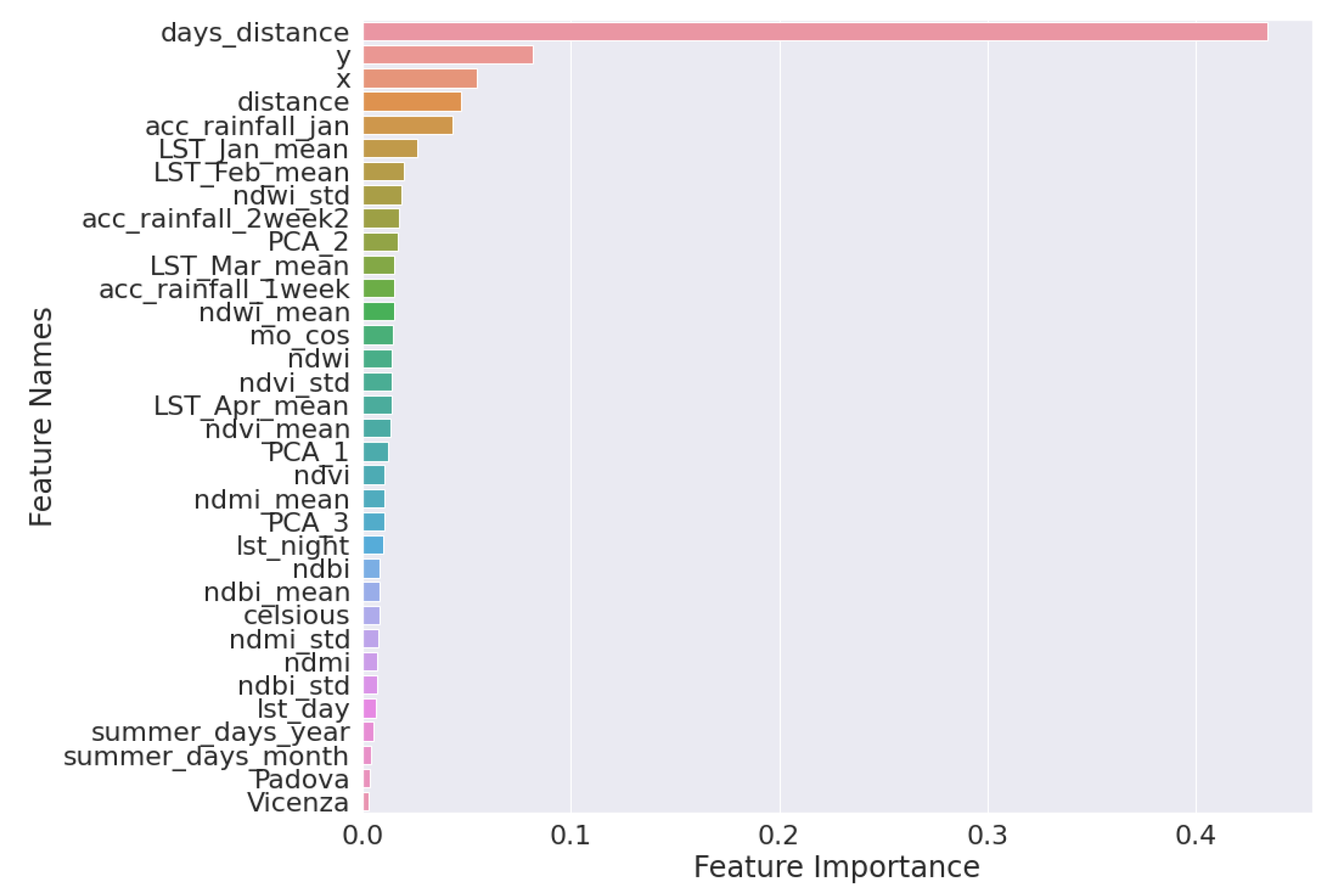
- For all cases, previous mosquito populations seem to play a preponderant role, as is expected for the seasonal development of mosquito populations during summer months, depending on the intensity of mosquito control applications in the AOI.
- The accumulated rainfall from the beginning of the year is important for all the cases, and, for the cases of Culex spp., the accumulated rainfall of the last two weeks seems important, as well.
- In all Culex spp. cases, the rainfall and the water indices, NDWI, are more important than the temperature, LST.
- Anopheles is the only mosquito genus in which the most important feature is not the previous state of the mosquito population but the direct time distance, as well as several geomorphological features, which could indicate the preference of mosquitoes of this genus of stagnant water surfaces in specific altitudes.
- Aedes albopictus prediction is the only case where the direct time distance is not important for the model. Furthermore, the Aedes albopictus populations seem to be very sensible to temperature, more than to precipitation, while both are important factors for the creation and durability of breeding sites for this container breeding species.
- NDWI metrics are very important for the prediction of Aedes albopictus populations compared with the other mosquito species.
5. Discussion/Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Explanation |
|---|---|
| dt_placeme | Date of the observation |
| stationid | Station ID |
| x | Longitude |
| y | Latitude |
| mosq_now | Mosquito population in trapping sites at the date of observation |
| NDVI | Proxy for the vegetation density and distribution Extracted pixel value of overlapping station ID coordinates |
| NDVI_mean | Proxy for the vegetation density and distribution Mean value of neighboring pixels (window of 3 × 3) |
| NDVI_std | Proxy for the vegetation density and distribution Standard deviation of neighboring pixels (window of 3 × 3) |
| NDWI | Proxy for changes in water content Extracted pixel value of overlapping station ID coordinates |
| NDWI_mean | Proxy for changes in water content Mean value of neighboring pixels (window of 3 × 3) |
| NDWI_std | Proxy for changes in water content Standard deviation of neighboring pixels (window of 3 × 3) |
| NDMI | Proxy for determination of vegetation water content Extracted pixel value of overlapping station ID coordinates |
| NDMI_mean | Proxy for determination of vegetation water content Mean value of neighboring pixels (window of 3 × 3) |
| NDMI_std | Proxy for determination of vegetation water content Standard deviation of neighboring pixels (window of 3 × 3) |
| NDBI | Proxy for mapping urban built-up areas Extracted pixel value of overlapping station ID coordinates |
| NDBI_mean | Proxy for mapping urban built-up areas Mean value of neighboring pixels (window of 3 × 3) |
| NDBI_std | Proxy for mapping urban built-up areas Standard deviation of neighboring pixels (window of 3 × 3) |
| LST_day | Land surface temperature at day |
| LST_night | Land surface temperature at night |
| LST_Jan_mean | Mean temperature in January |
| LST_Feb_mean | Mean temperature in February |
| LST_Mar_mean | Mean temperature in March |
| LST_Apr_mean | Mean temperature in April |
| wind_max | Max magnitude of wind |
| wind_mean | Mean magnitude of wind hourly |
| wind_min | Min magnitude of wind |
| acc_rainfall_1week | Accumulated precipitation counting towards one week before the date of placement |
| acc_rainfall_2week2 | Accumulated precipitation counting towards two weeks before the date of placement |
| acc_rainfall_jan | Accumulated precipitation counting from the 1st of January of each year |
| WC_L_1 km | Combination of breeding site length and water course of national hydrological data within a buffer zone of 1000 m around each sampling/trapping site |
| PG_area_1 km | Total area of temporarily inundated areas (polygons) within a buffer zone of 1 km from each sampling/trapping site |
| DEM_1000 | Mean elevation (resolution = 12.5 m), within a buffer of 1000 m around trapping sites |
| Aspect_1000 | Mean aspect (12.5 m), within a buffer of 1000 m around trapping sites |
| Slope_1000 | Mean slope (12.5 m), within a buffer of 1000 m around trapping sites |
| Coast_dist_1000 | Mean Distance of sampling/trapping site within a buffer of 1000 m from coastline |
| WC_dist_1000 | Distance of combination of breeding site length and length of watercourses of national hydrological data within a buffer zone of 1000 m around each sampling/trapping site |
| Flow_acc_1000 | Mean flow accumulation within a buffer of 1000 around trapping sites |
| mosq_month_sum | Cumulative mosquito population of the past 30 days |
| mosq_month_previousYear | Cumulative mosquito population of the month on previous year |
| mosq_bins | Mosquito bin based on the population on the date of observation |
| days_distance | Time difference in days between the date of placement and a specific date regardless the year |
| province (multiple features) | Province in which trap is located (transformed in one hot encoded features out of the names of the provinces of each region) |
| mo_cos | Cosine transformation of the month of date of placement |
| mo_sin | Sine transformation of the month of date of placement |
| celsius | LST_day to celsius conversion |
| summer_days_year | Days with over 30o celsius within the year |
| summer_days_month | Days with over 30o celsius within the month |
| PCA components | 3 PCA components extracted from the whole dataset |
| distance | Euclidean distance of coordinates between a specific point and the trap site |
| Area of Interest Mosquito | Auto-Tuned Model Parameters | MAE in Nb Classes | Prediction < 3 Classes Error |
|---|---|---|---|
| Serbia Culex spp. | Nb of features = 37 Nb_estimators = 11 Max_depth = 14 | test = 1.88, train = 0.81 | 87% |
| Germany Culex spp. | Nb of features = 22 Nb_estimators = 31 Max_depth = 4 | test = 1.18, train =1.07 | 89% |
| Italy Anopheles spp. | Nb of features = 51 Nb_estimators = 33 Max_depth = 6 | test = 1.48, train = 0.54 | 94% |
| France Aedes albopictus | Nb of features = 42 Nb_estimators = 20 Max_depth = 14 | test = 0.72, train = 0.96 | 87% |
| Italy Culex spp. | Nb of features = 34 Nb_estimators = 27 Max_depth = 9 | test = 1.20, train = 0.60 | 96% |
| Area of Interest Mosquito | Auto-Tuned Model Parameters | MAE in Nb Classes | Prediction < 3 Classes Error |
|---|---|---|---|
| Serbia Culex spp. | Nb of features = 3 Nb_estimators = 20 Max_depth = 7 | test = 1.73, train = 1.18 | 86% |
| Germany Culex spp. | Nb of features = 4 Nb_estimators = 28 Max_depth = 4 | test = 1.04, train = 0.99 | 90% |
| Italy Anopheles spp. | Nb of features = 20 Nb_estimators = 26 Max_depth = 9 | test = 1.54 train = 0.27 | 92% |
| France Aedes albopictus | Nb of features = 13 Nb_estimators = 26 Max_depth = 3 | test = 0.74, train = 0.63 | 91% |
| Italy Culex spp. | Nb of features = 15 Nb_estimators = 24 Max_depth = 8 | test = 1.16, train = 0.76 | 95% |
| Aedes-France | Anopheles-Italy | ||
|---|---|---|---|
| feature names | importance | feature names | importance |
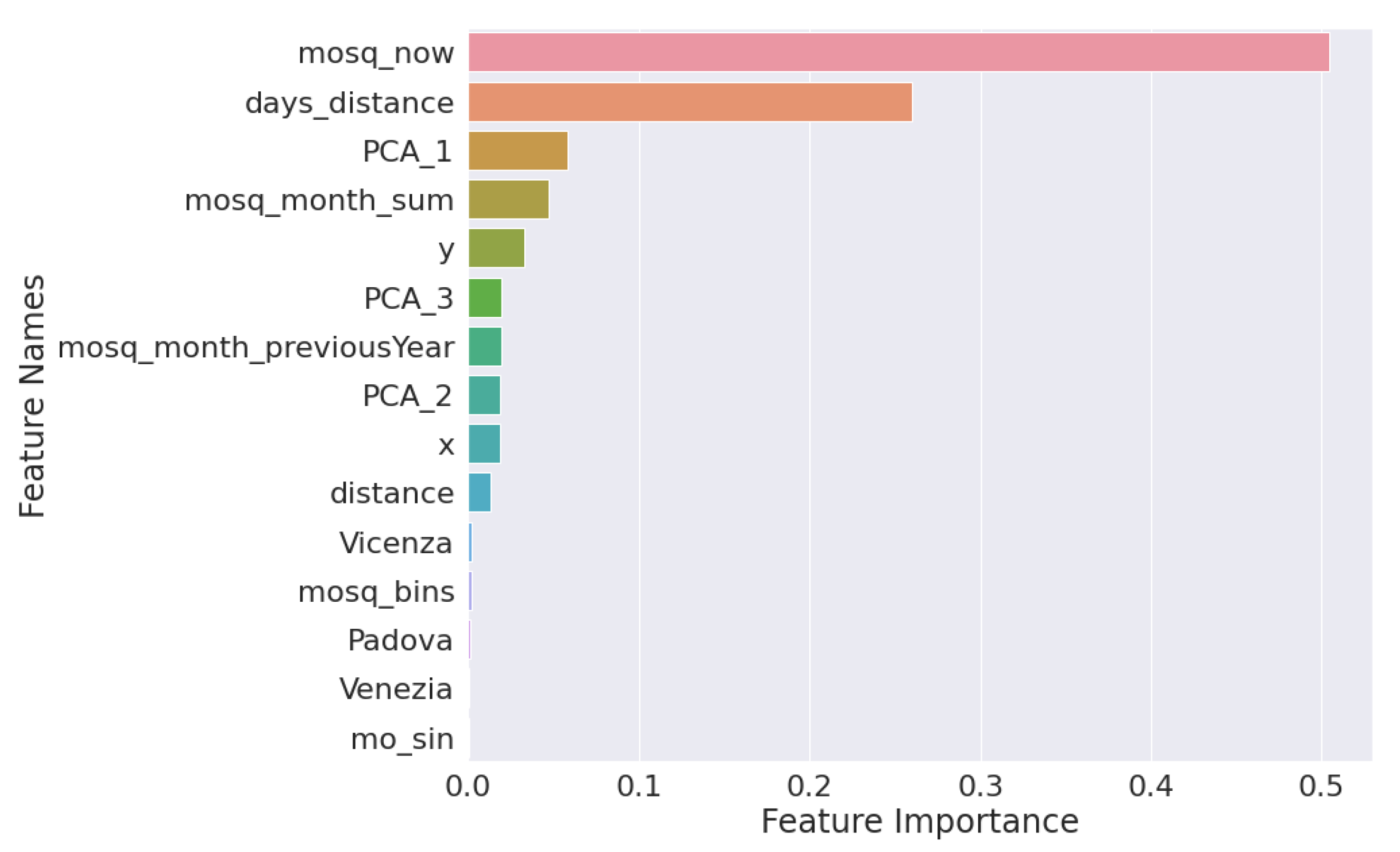
| mosq_now | 0.561 | days_distance | 0.303 |
| days_disance | 0.200 | mosq_now | 0.209 |
| PCA_3 | 0.049 | distance | 0.077 |
| mosq_monh_sum | 0.040 | mosq_monh_sum | 0.077 |
| PCA_1 | 0.035 | mosq_monh_previousYear | 0.072 |
| PCA_2 | 0.031 | PCA_3 | 0.071 |
| x | 0.026 | PCA_1 | 0.067 |
| y | 0.022 | PCA_2 | 0.063 |
| mo_sin | 0.017 | Treviso | 0.012 |
| mosq_month_previousYear | 0.015 | Padova | 0.010 |
| distance | 0.004 | Rovigo | 0.009 |
| HAUE-CORSE | 0.000 | mosq_bins | 0.009 |
| mosq_bins | 0.000 | Venezia | 0.008 |
| Vicenza | 0.004 | ||
| mo_sin | 0.002 | ||
| Verona | 0.002 | ||
| Gorizia | 0.002 | ||
| mo_cos | 0.002 | ||
| Pordenone | 0.001 | ||
| Udine | 0.000 | ||
| Culex-Serbia | Culex-Germany | ||
| feature names | importance | feature names | importance |
| PCA_1 | 0.397 | mosq_now | 0.592 |
| days_distance | 0.388 | mosq_bins | 0.223 |
| mosq_monh_previousYear | 0.215 | mo_cos | 0.105 |
| PCA_3 | 0.079 | ||
| Aedes-France | Anopheles-Italy | ||
|---|---|---|---|
| feature_names | importance | feature_names | importance |
| x | 0.150 | days_distance | 0.274 |
| lst_night | 0.137 | DEM_1000 | 0.082 |
| PCA_2 | 0.059 | PCA_3 | 0.049 |
| ndwi | 0.055 | ndwi | 0.041 |
| ndvi | 0.039 | Slope_1000 | 0.039 |
| acc_rainfall_2week2 | 0.038 | LST_Jan_mean | 0.038 |
| ndvi_std | 0.038 | PCA_2 | 0.038 |
| days_distance | 0.035 | ndwi_std | 0.033 |
| ndwi_mean | 0.034 | ndvi_std | 0.032 |
| PCA_1 | 0.033 | ndvi_mean | 0.026 |
| ndmi | 0.031 | lst_night | 0.023 |
| ndbi_mean | 0.030 | acc_rainfall_jan | 0.023 |
| PCA_3 | 0.028 | ndwi_mean | 0.023 |
| acc_rainfall_jan | 0.026 | celsius | 0.021 |
| ndvi_mean | 0.024 | lst_day | 0.021 |
| summer_days_month | 0.024 | acc_rainfall_2week2 | 0.019 |
| ndwi_std | 0.022 | acc_rainfall_1week | 0.016 |
| acc_rainfall_1week | 0.021 | y | 0.015 |
| ndmi_mean | 0.021 | ndmi | 0.014 |
| distance | 0.020 | ndvi | 0.014 |
| Culex-Serbia | Culex-Germany | ||
| feature_names | importance | feature_names | importance |
| days_distance | 0.118 | acc_rainfall_jan | 0.343 |
| acc_rainfall_1week | 0.076 | days_distance | 0.158 |
| mean_wind | 0.071 | y | 0.155 |
| acc_rainfall_jan | 0.063 | distance | 0.058 |
| PCA_3 | 0.037 | acc_rainfall_2week2 | 0.054 |
| y | 0.035 | mo_cos | 0.025 |
| PCA_2 | 0.034 | x | 0.023 |
| DEM_1000 | 0.034 | ndmi_mean | 0.023 |
| lst_night | 0.029 | WAW | 0.020 |
| PCA_1 | 0.027 | lst_night | 0.017 |
| Aspect_1000 | 0.027 | acc_rainfall_1week | 0.015 |
| ndwi_std | 0.027 | ndvi_std | 0.014 |
| max_wind | 0.025 | ndmi | 0.013 |
| ndvi_mean | 0.024 | DEM_1000 | 0.011 |
| LST_Jan_mean | 0.023 | LST_Apr_mean | 0.011 |
| acc_rainfall_2week2 | 0.022 | LST_Jan_mean | 0.011 |
| Slope_1000 | 0.020 | PCA_3 | 0.011 |
| ndwi | 0.020 | ndwi | 0.009 |
| Sremski | 0.018 | ndwi_mean | 0.009 |
| LST_Feb_mean | 0.018 | celsius | 0.007 |
References
- World Health Organization. Vector-Borne Diseases. 2020. Available online: https://www.who.int/en/news-room/fact-sheets/detail/vector-borne-diseases (accessed on 30 December 2020).
- Parselia, E.; Kontoes, C.; Tsouni, A.; Hadjichristodoulou, C.; Kioutsioukis, I.; Magiorkinis, G.; Stilianakis, N.I. Satellite Earth Observation Data in Epidemiological Modeling of Malaria, Dengue and West Nile Virus: A Scoping Review. Remote Sens. 2019, 11, 1862. [Google Scholar] [CrossRef] [Green Version]
- Zeller, H.; Marrama, L.; Sudre, B.; Van Bortel, W.; Warns-Petita, E. Mosquito-borne disease surveillance by the European Centre for Disease Prevention and Control. Eur. Soc. Clin. Microbiol. Infect. Dis. 2013, 19, 693–698. [Google Scholar] [CrossRef] [Green Version]
- Paz, S.; Semenza, J.C. Environmental Drivers of West Nile Fever Epidemiology in Europe and Western Asia—A Review. Int. J. Environ. Res. Public Health 2013, 10, 3543–3562. [Google Scholar] [CrossRef] [Green Version]
- ECDC. West Nile Virus Infection-Annual Epidemiological Report for 2018. Available online: https://www.ecdc.europa.eu/en/publications-data/west-nile-virus-infection-annual-epidemiological-report-2018 (accessed on 25 November 2020).
- ECDC. Malaria-Number and Rates of Confirmed Malaria Reported Cases, EU/EEA 2008–2012. Available online: https://www.ecdc.europa.eu/en/publications-data/number-and-rates-confirmed-malaria-reported-cases-eueea-2008-2012 (accessed on 25 November 2020).
- ECDC. Malaria-Annual Epidemiological Report for 2018. Available online: https://www.ecdc.europa.eu/en/publications-data/malaria-annual-epidemiological-report-2018 (accessed on 25 November 2020).
- Guo, S.; Ling, F.; Hou, J.; Wang, J.; Fu, G.; Gong, Z. Mosquito Surveillance Revealed Lagged Effects of Mosquito Abundance on Mosquito-Borne Disease Transmission: A Retrospective Study in Zhejiang, China. PLoS ONE 2014, 9, e112975. [Google Scholar] [CrossRef] [Green Version]
- Kotchi, S.O.; Bouchard, C.; Ludwig, A.; Rees, E.E.; Brazeau, S. Using Earth observation images to inform risk assessment and mapping of climate change-related infectious diseases. Can. Commun. Dis. Rep. 2019, 45, 133–142. [Google Scholar] [CrossRef]
- Guo, H.; Nativi, S.; Liang, D.; Craglia, M.; Wang, L.; Schade, S.; Corban, C.; He, G.; Pesaresi, M.; Li, J.; et al. Big Earth Data science: An information framework for a sustainable planet. Int. J. Digit. Earth 2020, 13, 743–767. [Google Scholar] [CrossRef] [Green Version]
- Kioutsioukis, I.; Stilianakis, N.I. Assessment of West Nile virus transmission risk from a weather-dependent epidemiological model and a global sensitivity analysis framework. Acta Trop. 2019, 193, 129–141. [Google Scholar] [CrossRef] [PubMed]
- Jutla, A.; Huq, A.; Colwell, R.R. A Diagnostic approach for monitoring hydroclimatic conditions related to emergence of west nile virus in west virginia. Front. Public Health 2015, 3, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valiakos, G.; Papaspyropoulos, K.; Giannakopoulos, A.; Birtsas, P.; Tsiodras, S.; Hutchings, M.R.; Spyrou, V.; Pervanidou, D.; Athanasiou, L.V.; Papadopoulos, N.; et al. Use of wild bird surveillance, human case data and GIS spatial analysis for predicting spatial distributions of West Nile virus in Greece. PLoS ONE 2014, 9, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Calistri, P.; Ippoliti, C.; Candeloro, L.; Benjelloun, A.; El Harrak, M.; Bouchra, B.; Danzetta, M.L.; Di Sabatino, D.; Conte, A. Analysis of climatic and environmental variables associated with the occurrence of West Nile virus in Morocco. Rev. Vet. Med. 2013, 110, 549–553. [Google Scholar] [CrossRef]
- Yao, J.; Meng, D.; Zhao, Q.; Cao, W.; Xu, Z. Nonconvex-Sparsity and Nonlocal-Smoothness-Based Blind Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 2991–3006. [Google Scholar] [CrossRef]
- Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar]
- Lary, D.; Alavi, A.; Gandomi, A.; Walker, A. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Sudheer, C.; Sohani, S.K.; Kumar, D.; Malik, A.; Chahar, B.R.; Nema, A.K.; Panigrahi, B.K.; Dhiman, R.C. A Support Vector Machine-Firefly Algorithm based forecasting model to determine malaria transmission. Neurocomputing 2014, 129, 279–288. [Google Scholar]
- Guo, P.; Liu, T.; Zhang, Q.; Wang, L.; Xiao, J.; Zhang, Q.; Luo, G.; Li, Z.; He, J.; Zhang, Y.; et al. Developing a dengue forecast model using machine learning: A case study in China. PLoS Negl. Trop. Dis. 2017, 11. [Google Scholar] [CrossRef]
- Chuang, T.W.; Wimberly, M.C. Remote sensing of climatic anomalies and West Nile virus incidence in the northern Great Plains of the United States. PLoS ONE 2012, 7, e46882. [Google Scholar] [CrossRef] [PubMed]
- Sewe, M.O.; Tozan, Y.; Ahlm, C.; Rocklöv, J. Using remote sensing environmental data to forecast malaria incidence at a rural district hospital in Western Kenya. Sci. Rep. 2017, 7, 2589. [Google Scholar] [CrossRef]
- Scavuzzo, J.M.; Trucco, F.; Espinosa, M.; Tauro, C.B.; Abril, M.; Scavuzzo, C.M.; Frery, A.C. Modeling Dengue vector population using remotely sensed data and machine learning. Acta Trop. 2018, 185, 167–175. [Google Scholar] [CrossRef] [Green Version]
- Young, S.G.; Tullis, J.A.; Cothren, J. A remote sensing and GIS-assisted landscape epidemiology approach to West Nile virus. Appl. Geogr. 2013, 45, 241–249. [Google Scholar] [CrossRef]
- Dohm, D.J.; O’Guinn, M.L.; Turell, M.J. Effect of environmental temperature on the ability of Culex pipiens (Diptera: Culicidae) to transmit West Nile virus. J. Med. Entomol. 2002, 39, 221–225. [Google Scholar] [CrossRef]
- Myer, M.H.; Johnston, J.M. Spatiotemporal Bayesian modeling of West Nile virus: Identifying risk of infection in mosquitoes with local-scale predictors. Sci. Total Environ. 2019, 650, 2818–2829. [Google Scholar] [CrossRef] [PubMed]
- Stilianakis, N.I.; Syrris, V.; Petroliagkis, T.; Pärt, P.; Gewehr, S.; Kalaitzopoulou, S.; Mourelatos, S.; Baka, A.; Pervanidou, D.; Vontas, J.; et al. Identification of Climatic Factors Affecting the Epidemiology of Human West Nile Virus Infections in Northern Greece. PLoS ONE 2016, 11, e0161510. [Google Scholar] [CrossRef]
- Chuang, T.-W.; Hildreth, B.M.; Vanroekel, L.D.; Wimberly, C.M. Weather and Land Cover Influences on Mosquito Populations in Sioux Falls, South Dakota. J. Med. Entomol. 2011, 48, 669–679. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richman, M.; Trafalis, T.; Adrianto, I. Missing Data Imputation Through Machine Learning Algorithms. Artif. Intell. Methods Environ. Sci. 2009, 153–169. [Google Scholar] [CrossRef]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer New York Inc.: New York, NY, USA, 2001; p. 367. [Google Scholar]
- Witten, I.; Frank, E.; Hall, M.; Pal, C. Chapter 6—Trees and rules. In Data Mining, 4th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017; pp. 209–242. [Google Scholar]










| Class | Number of Mosquitoes | Probability of at Least One Mosquito Positive to WNV | Risk Class |
|---|---|---|---|
| 1 | 0–3 | 0.23 % | low |
| 2 | 4–9 | ||
| 3 | 10–18 | 1.07 % | medium |
| 4 | 19–34 | ||
| 5 | 35–58 | 2.82 % | |
| 6 | 59–100 | ||
| 7 | 101–167 | 6.35 % | high |
| 8 | 168–293 | ||
| 9 | 294–568 | 8.01 % | |
| 10 | >568 |
| Area of Interest-Mosquito | Year | # of Traps | # of Observations |
|---|---|---|---|
| Italy-Culex pipiens | 2010–2020 | 140 | 4840 |
| Serbia-Culex pipiens | 2010–2019 | 124 | 926 |
| Germany-Culex pipiens | 2010–2019 | 86 | 3763 |
| France-Aedes Albopictus | 2017–2019 | 81 | 1729 |
| Italy-Anopheles spp. | 2010–2020 | 130 | 629 |
| Area of Interest Mosquito | Auto-Tuned Model Parameters | Performance in Pre-Operational Validation | Performance in Operational Validation |
|---|---|---|---|
| Serbia Culex spp. | Nb of features = 12 Nb_estimators = 23 Max_depth = 4 | MAE_test = 1.54 MAE_train = 1.27 % error < 3 = 90% | - |
| Germany Culex spp. | Nb of features = 33 Nb_estimators = 23 Max_depth = 4 | MAE_test = 0.97 MAE_train = 0.87 % error < 3 = 92% | MAE_test = 1.19 % error < 3 = 90% |
| Italy Anopheles spp. | Nb of features = 47 Nb_estimators = 20 Max_depth = 8 | MAE_test = 1.47 train = 1.04 % error < 3 = 95% | MAE_test = 1.60 % error < 3 = 95% |
| France Aedes albopictus | Nb of features = 11 Nb_estimators = 15 Max_depth = 6 | MAE_test = 0.71, MAE_train = 0.63 % error < 3 = 92% | MAE_test = 1.08 % error < 3 = 95% |
| Italy Culex spp. | Nb of features = 16 Nb_estimators = 23 Max_depth = 5 | MAE_test = 1.14, MAE_train = 1.01 % error < 3 = 97% | MAE_test = 1.27 % error < 3 = 97% |
| Aedes—France | Anopheles—Italy | ||
|---|---|---|---|
| feature names | importance | feature names | importance |
| mosq_now | 0.501 | days_distance | 0.314 |
| lst_night | 0.089 | mosq_now | 0.188 |
| lst_day | 0.079 | DEM_1000 | 0.054 |
| ndwi_mean | 0.073 | PCA_3 | 0.041 |
| mosq_month_previousYear | 0.053 | Slope_1000 | 0.038 |
| ndwi_std | 0.043 | ndwi | 0.027 |
| acc_rainfall_jan | 0.042 | lst_day | 0.025 |
| ndwi | 0.041 | ndvi_mean | 0.024 |
| PCA_2 | 0.029 | celsius | 0.024 |
| PCA_3 | 0.027 | ndvi_std | 0.021 |
| mo_cos | 0.023 | y | 0.020 |
| LST_jan_mean | 0.017 | ||
| mosq_month_sum | 0.014 | ||
| Culex—Serbia | Culex—Germany | ||
| feature names | importance | feature names | importance |
| mosq_month_sum | 0.265 | mosq_now | 0.675 |
| days_distance | 0.257 | days_distance | 0.095 |
| mosq_now | 0.187 | mosq_bins | 0.049 |
| acc_rainfall_jan | 0.083 | acc_rainfall_2week2 | 0.039 |
| LST_Mar_mean | 0.039 | acc_rainfall_jan | 0.027 |
| DEM_1000 | 0.036 | acc_rainfall_1week | 0.022 |
| acc_rainfall_2week2 | 0.036 | mo_cos | 0.014 |
| Slope_1000 | 0.027 | LST_Apr_mean | 0.014 |
| max_wind | 0.022 | ndwi_mean | 0.011 |
| mosq_month_previousYear | 0.021 | LST_Jan_mean | 0.005 |
| PCA_2 | 0.016 | x | 0.005 |
| celsious | 0.011 | Aspect_1000 | 0.004 |
| mosq_month_sum | 0.004 | ||
| Area of Interest Mosquito | PCA_1 | PCA_2 | PCA_3 |
|---|---|---|---|
| Italy Culex spp | W_area_1 km | Flow_acc_1000 | Coast_dist_1000 |
| Coast_dist_1000 | W_area_1 km | W_area_1 km | |
| Flow_acc_1000 | Coast_dist_1000 | lst_night | |
| WC_L_1 km | lst_night | Flow_acc_1000 | |
| WC_dist_1000 | WC_L_1 km | WC_L_1 km | |
| Serbua Culex spp | PG_area_1 km | Coast_dist_1000 | Flow_acc_1000 |
| Flow_acc_1000 | lst_night | WC_dist_1000 | |
| Coast_dist_1000 | mosq_month_previousYear | WC_L_1 km | |
| WC_L_1 km | WC_dist_1000 | mosq_month_sum | |
| lst_night | PG_area_1 km | mosq_now | |
| Germany Culex spp | Flow_acc_1000 | mosq_month_sum | lst_day |
| LST_Mar_mean | mosq_now | lst_night | |
| lst_day | lst_night | LST_Apr_mean | |
| LST_Feb_mean | acc_rainfall_jan | mosq_month_sum | |
| LST_Apr_mean | lst_day | LST_Mar_mean | |
| Italy Anopheles spp. | W_area_1 km | Flow_acc_1000 | Coast_dist_1000 |
| Coast_dist_1000 | Coast_dist_1000 | W_area_1 km | |
| Flow_acc_1000 | W_area_1 km | Flow_acc_1000 | |
| WC_L_1 km | WC_L_1 km | WC_L_1 km | |
| mosq_month_sum | WC_dist_1000 | WC_dist_1000 | |
| France Aedes Albopictus | Coast_dist_1000 | PG_area_1 km | Flow_acc_1000 |
| PG_area_1 km | Flow_acc_1000 | PG_area_1 km | |
| WC_L_1000 | Coast_dist_1000 | WC_L_1 km | |
| Flow_acc_1000 | WC_L_1 km | LST_Jan_mean | |
| lst_day | DEM_1000 | Coast_dist_1000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsantalidou, A.; Parselia, E.; Arvanitakis, G.; Kyratzi, K.; Gewehr, S.; Vakali, A.; Kontoes, C. MAMOTH: An Earth Observational Data-Driven Model for Mosquitoes Abundance Prediction. Remote Sens. 2021, 13, 2557. https://doi.org/10.3390/rs13132557
Tsantalidou A, Parselia E, Arvanitakis G, Kyratzi K, Gewehr S, Vakali A, Kontoes C. MAMOTH: An Earth Observational Data-Driven Model for Mosquitoes Abundance Prediction. Remote Sensing. 2021; 13(13):2557. https://doi.org/10.3390/rs13132557
Chicago/Turabian StyleTsantalidou, Argyro, Elisavet Parselia, George Arvanitakis, Katerina Kyratzi, Sandra Gewehr, Athena Vakali, and Charalampos Kontoes. 2021. "MAMOTH: An Earth Observational Data-Driven Model for Mosquitoes Abundance Prediction" Remote Sensing 13, no. 13: 2557. https://doi.org/10.3390/rs13132557