
Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework




Abstract
:
1. Introduction
2. Literature Review
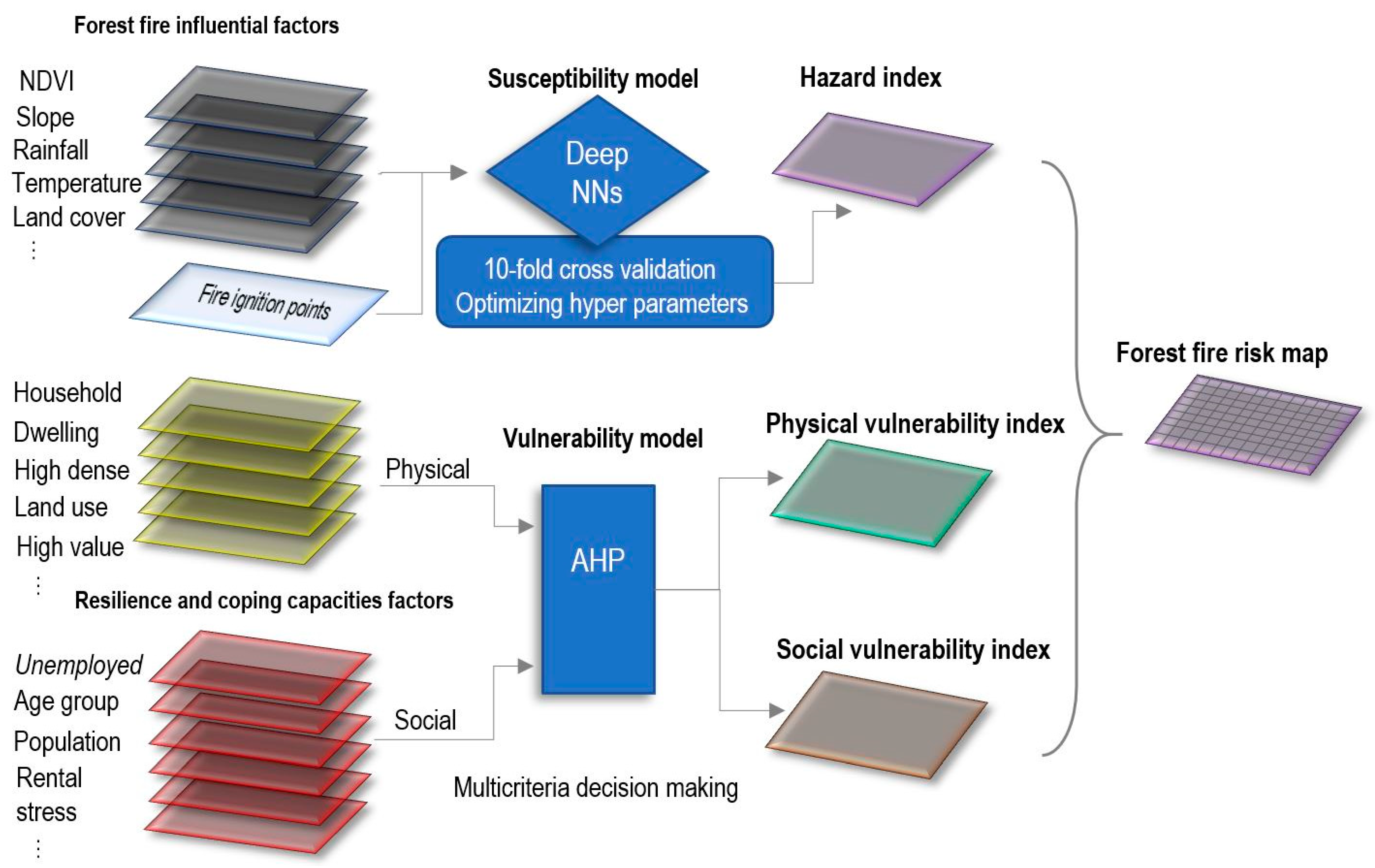
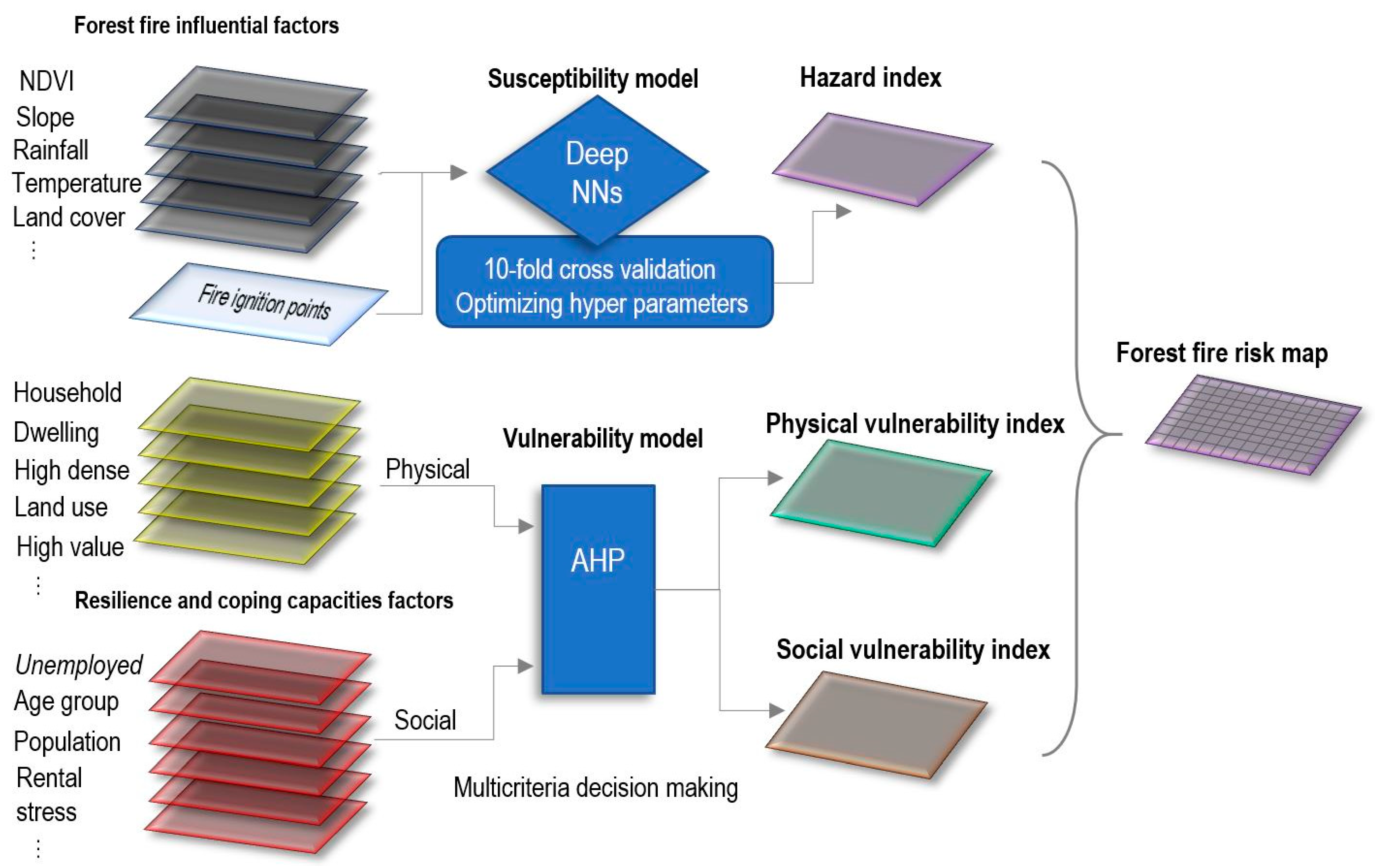
3. Forest Fire Risk Prediction Framework
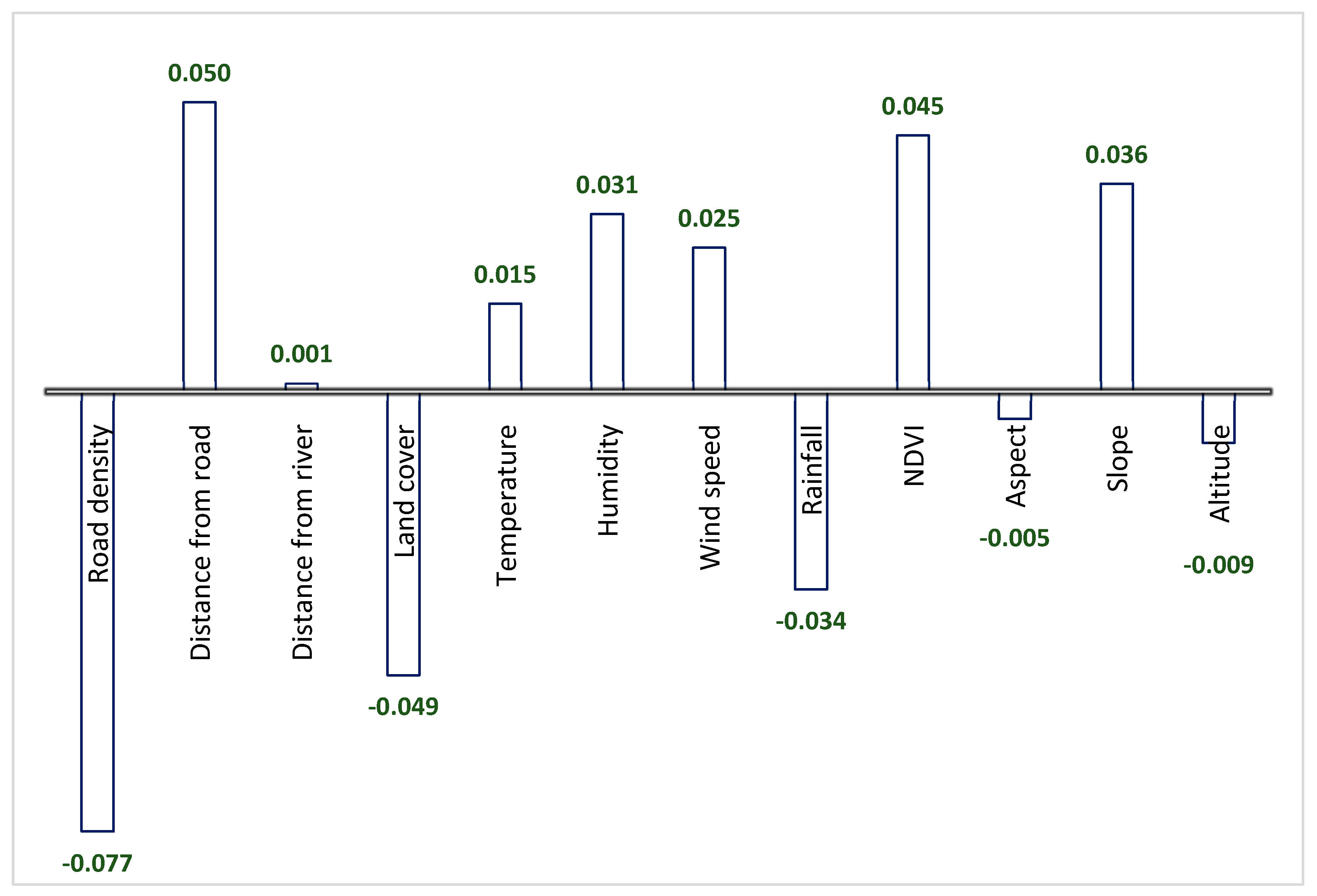
3.1. Contributing Factors
3.2. Susceptibility Model
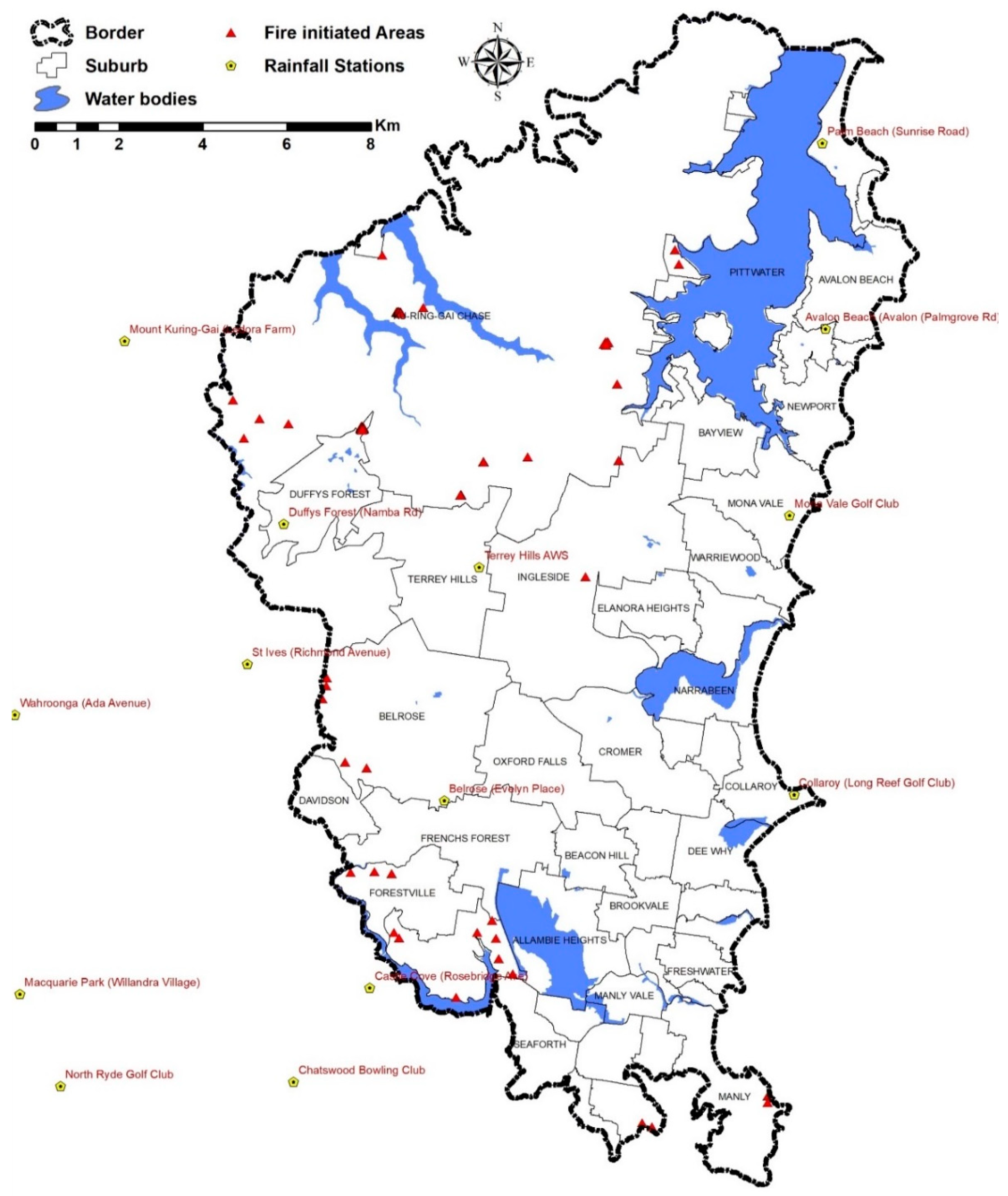
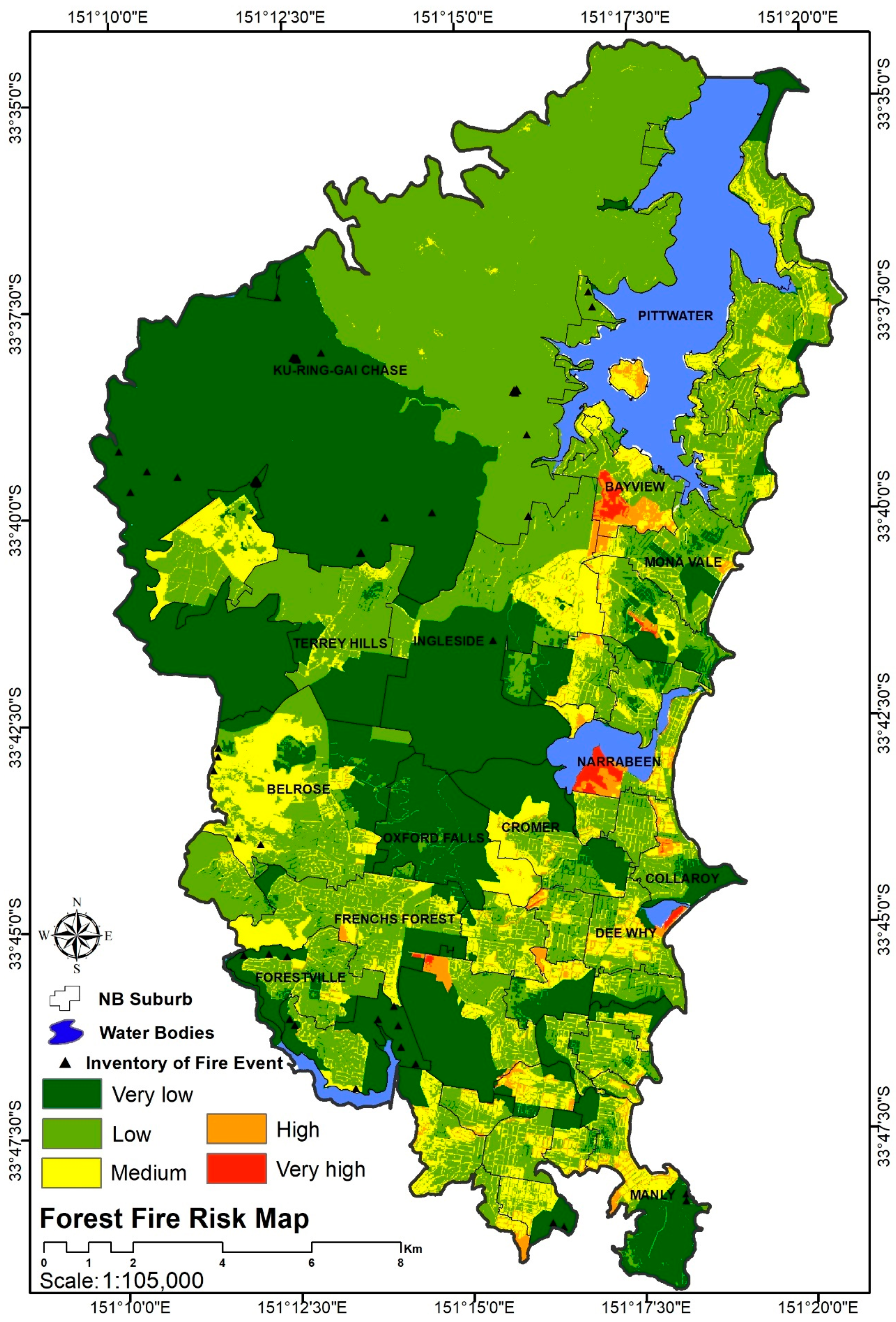
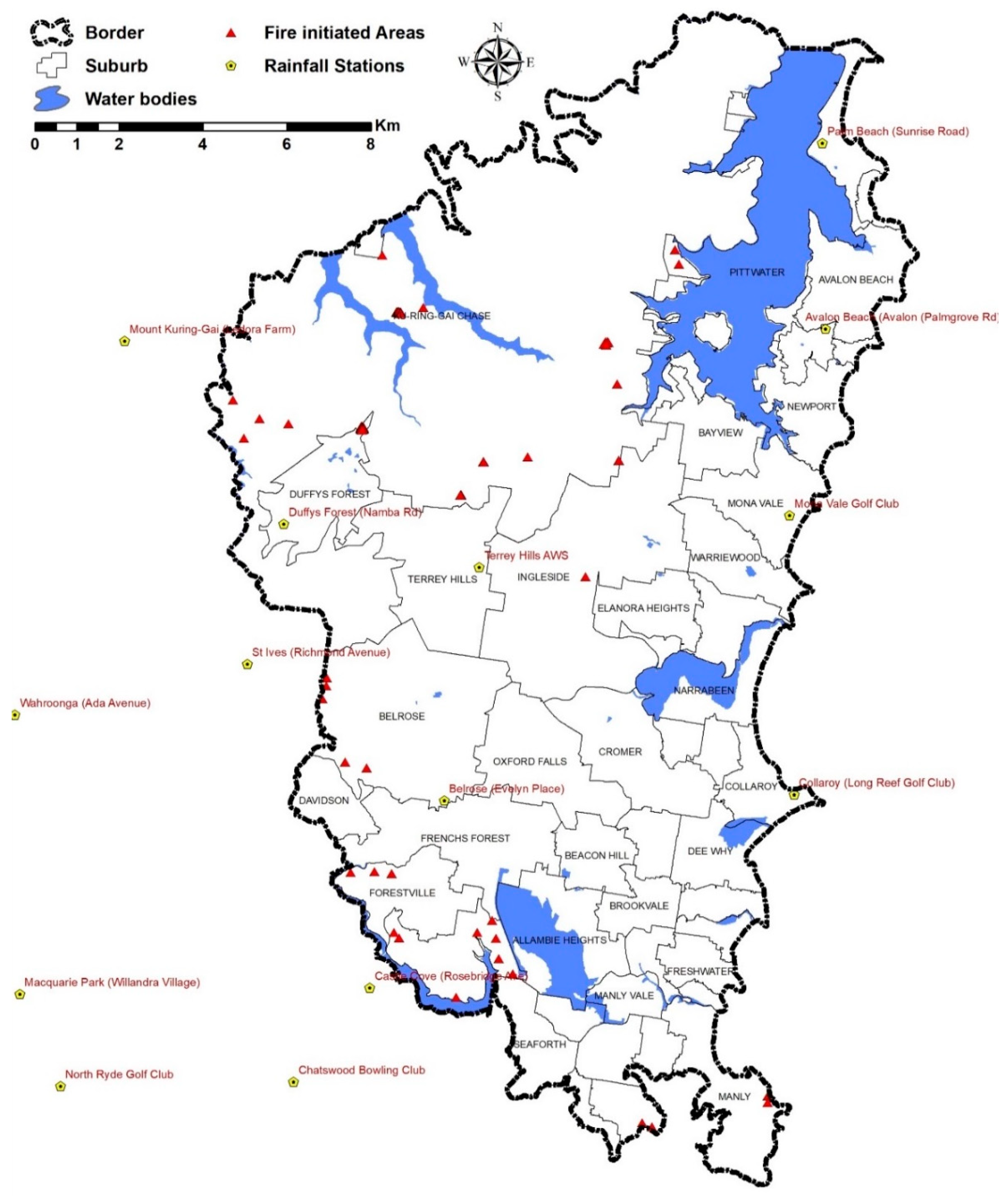
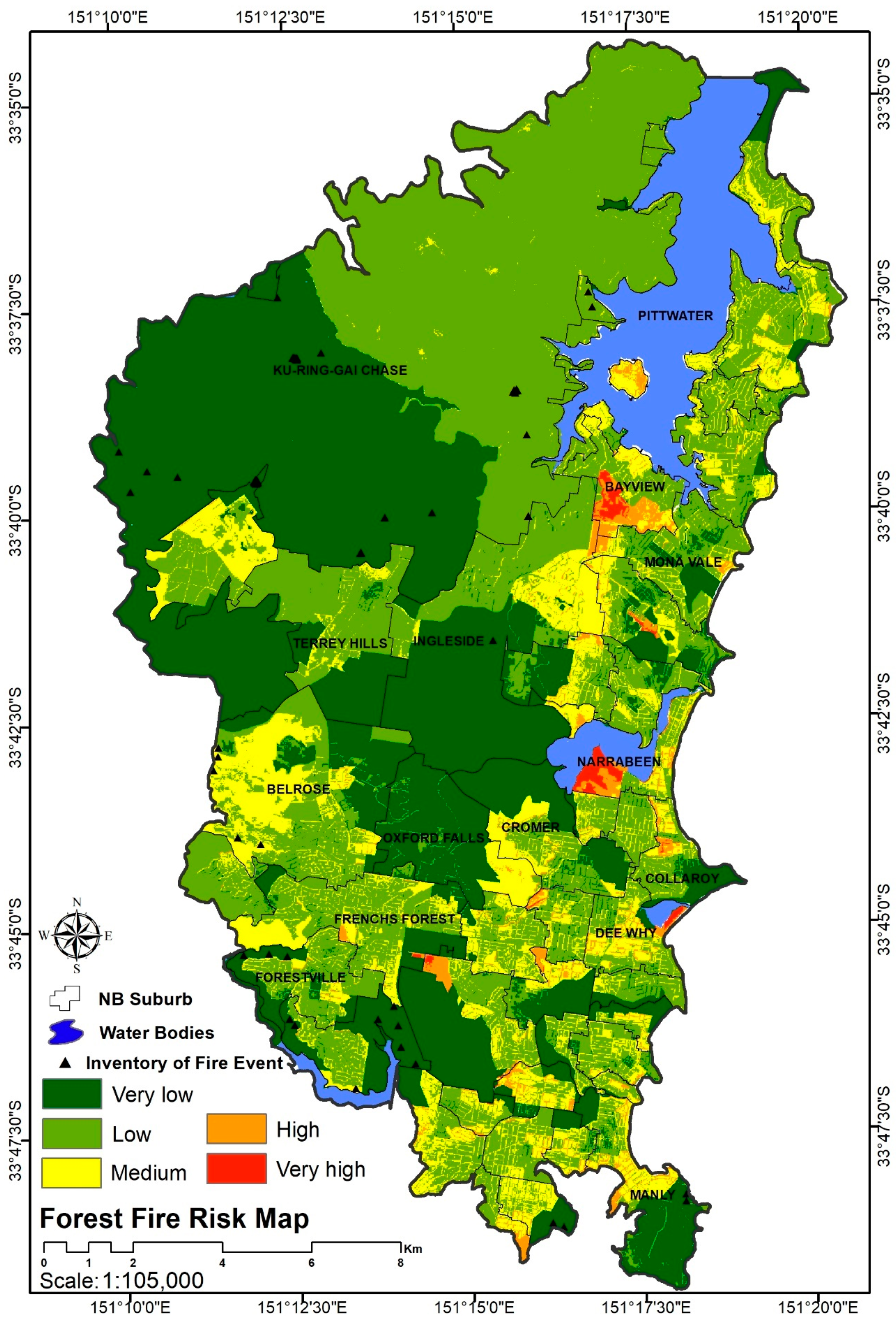
3.2.1. Fire Inventory Map
3.2.2. MLP–NN Architect Model
3.2.3. NNs Model Optimization Process
3.2.4. AHP Model
3.2.5. Accuracy Assessment Methods
- Kappa coefficient
- ROC and PRC curves
- Root mean squared error (RMSE)
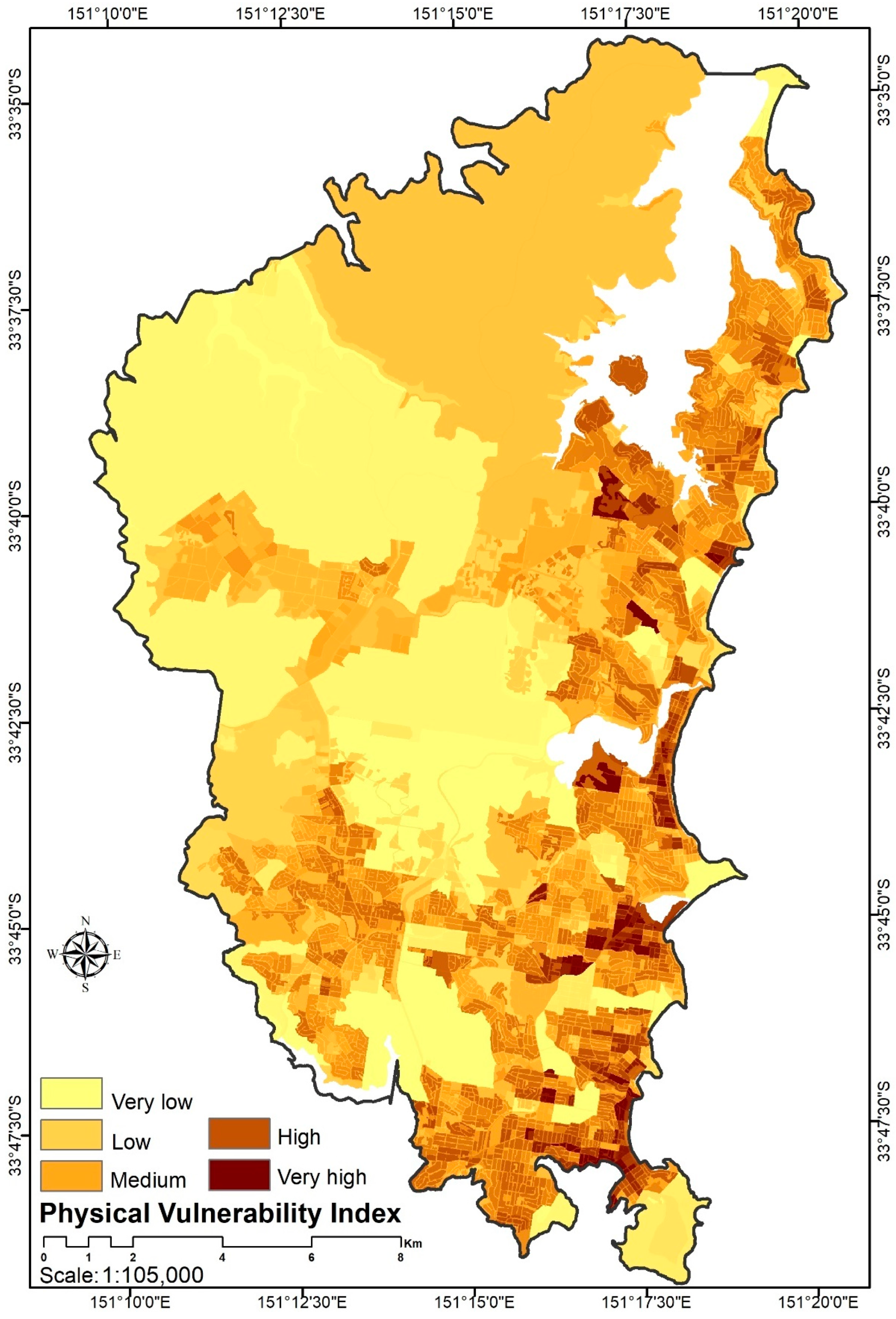
3.3. Vulnerability Model
3.4. Risk Model
4. Implementation and Results
4.1. Study Area
4.2. Datasets
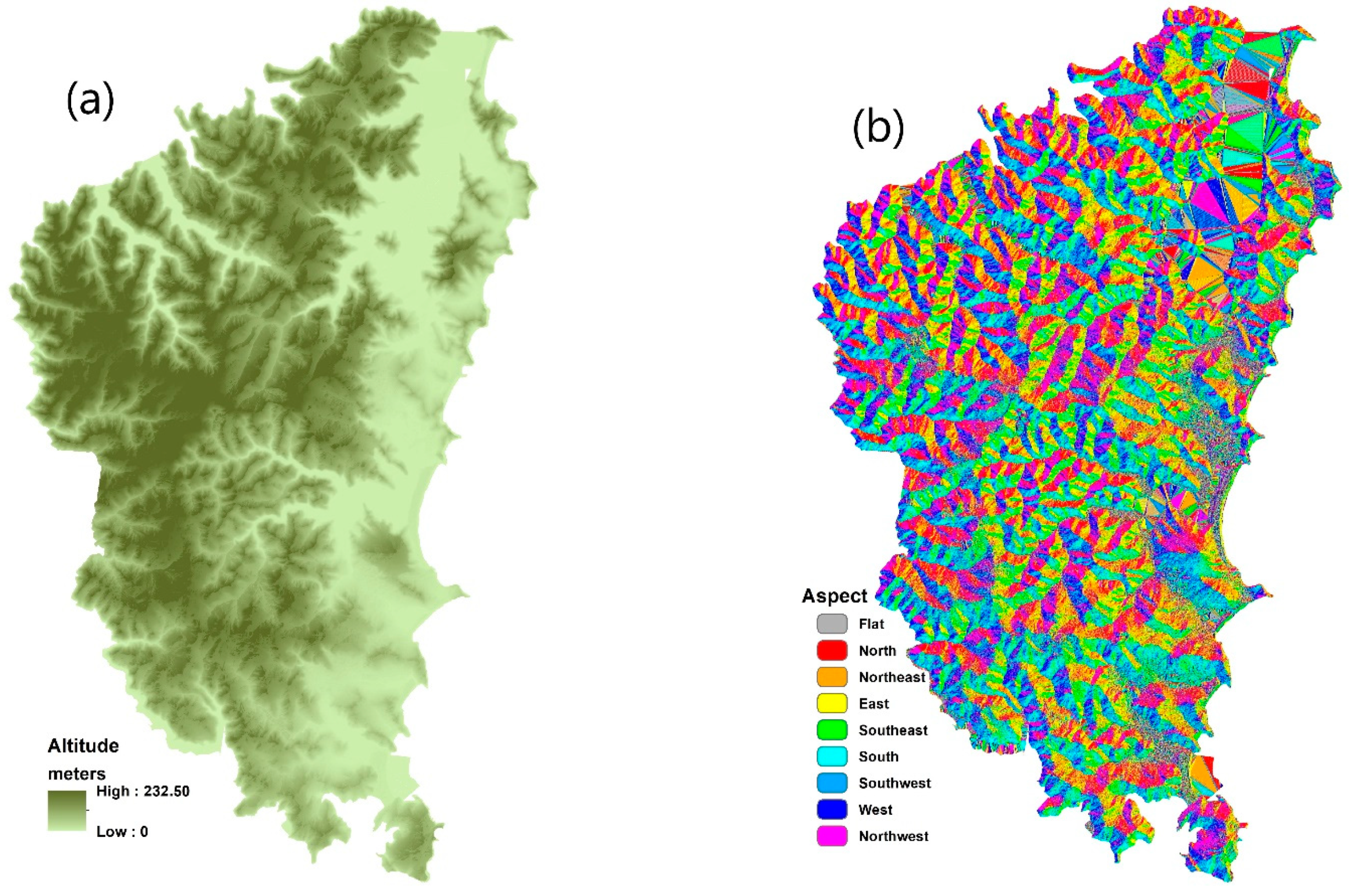
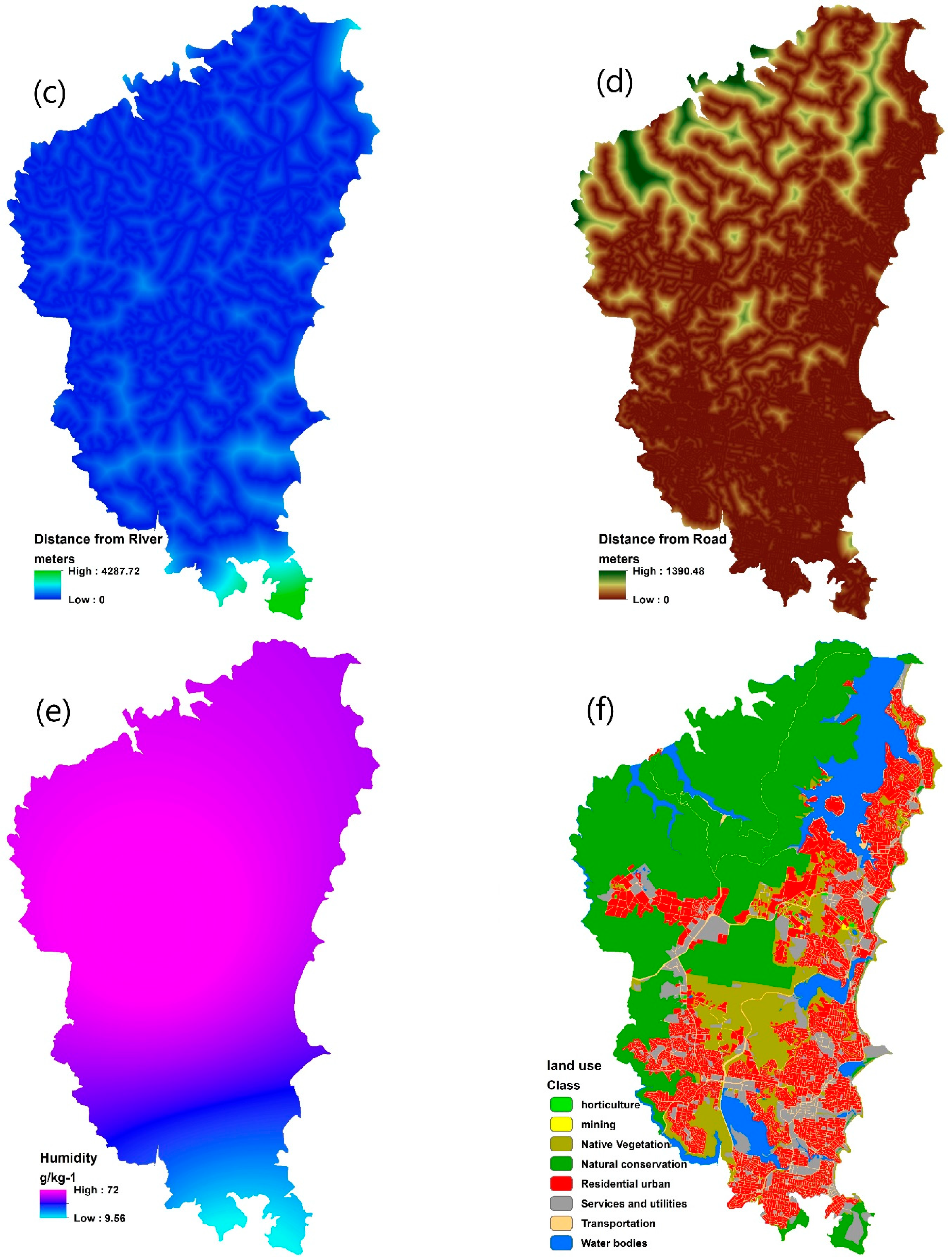
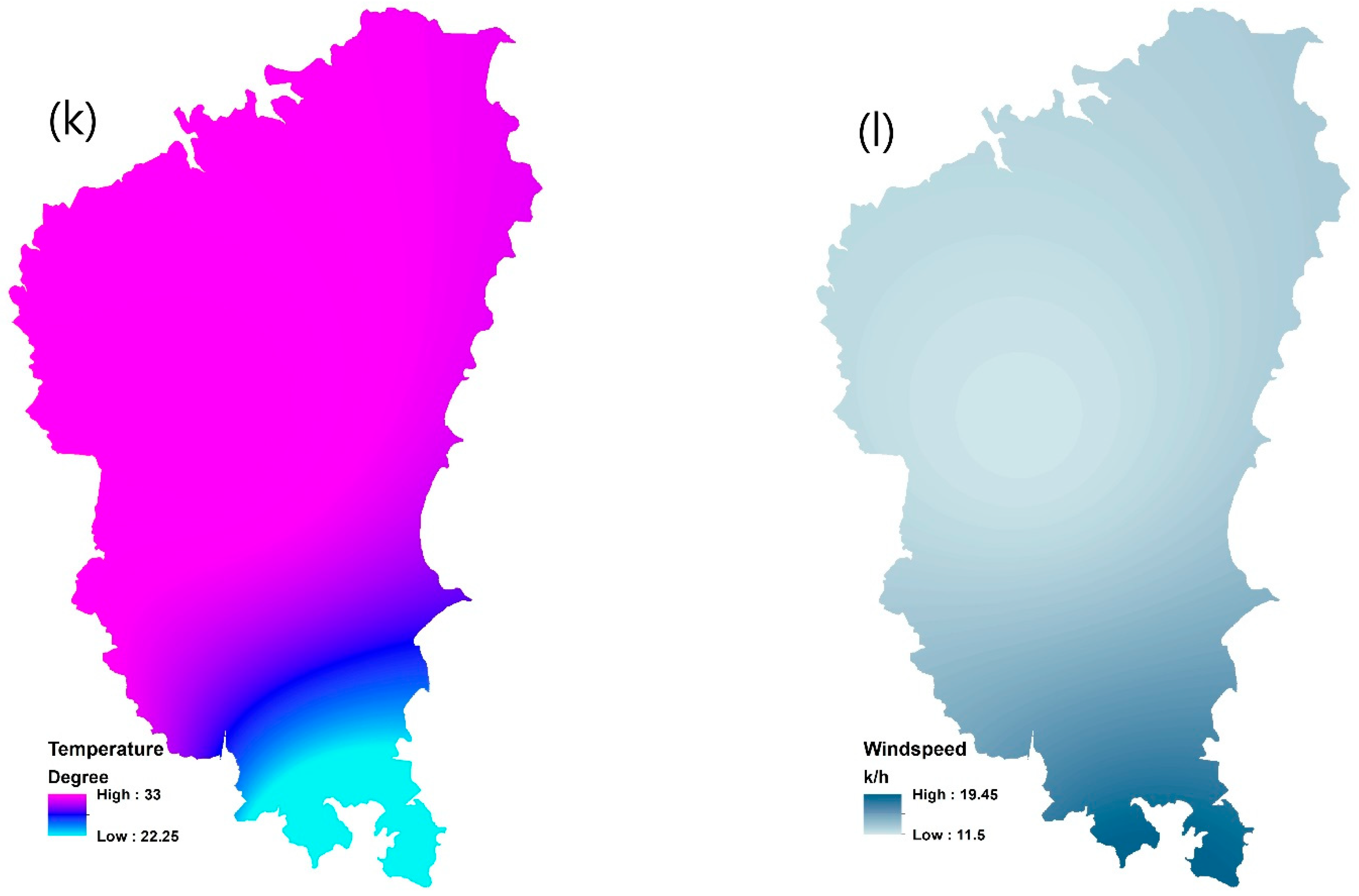
4.3. Contributing factors
- Climate contributing factors: Weather and climate data were collected from 22 meteorological stations in or near the Northern Beaches area. The spline method was used for integrating them in GIS. The highest and lowest ranges for these layers are spatially mapped in Figure 4. Warmer temperatures, lower relative humidity and precipitation can make the forest surface fuels more sensitive to fire ignition. Wind not only can cut off the soil/surface moisture but also pushes fire flames and sparks into new fuel. Stronger winds supply oxygen to fire, preheating the fuels in the path of the fire. When hot, dry, and windy conditions happen at the same time, fire ignition can be occurred and spread quickly.
- Human-induced contributing factors: Human activity is one of the main causes of forest fire, with most fires being triggered near roads, camping parks, riverbanks, etc. Hence, we spatially mapped some of the key factors in this category, such as road density, land cover, distance from the road, and distance from the river. Euclidian distance analysis was applied on the road and river networks to rasterize these approximate maps. Density analysis was used to calculate road density, and a land cover map was converted to a raster format to represent the general typology coverage, including natural conservation, native vegetation, water bodies, services and utilities, transportation, horticulture, mining, and residential urban.
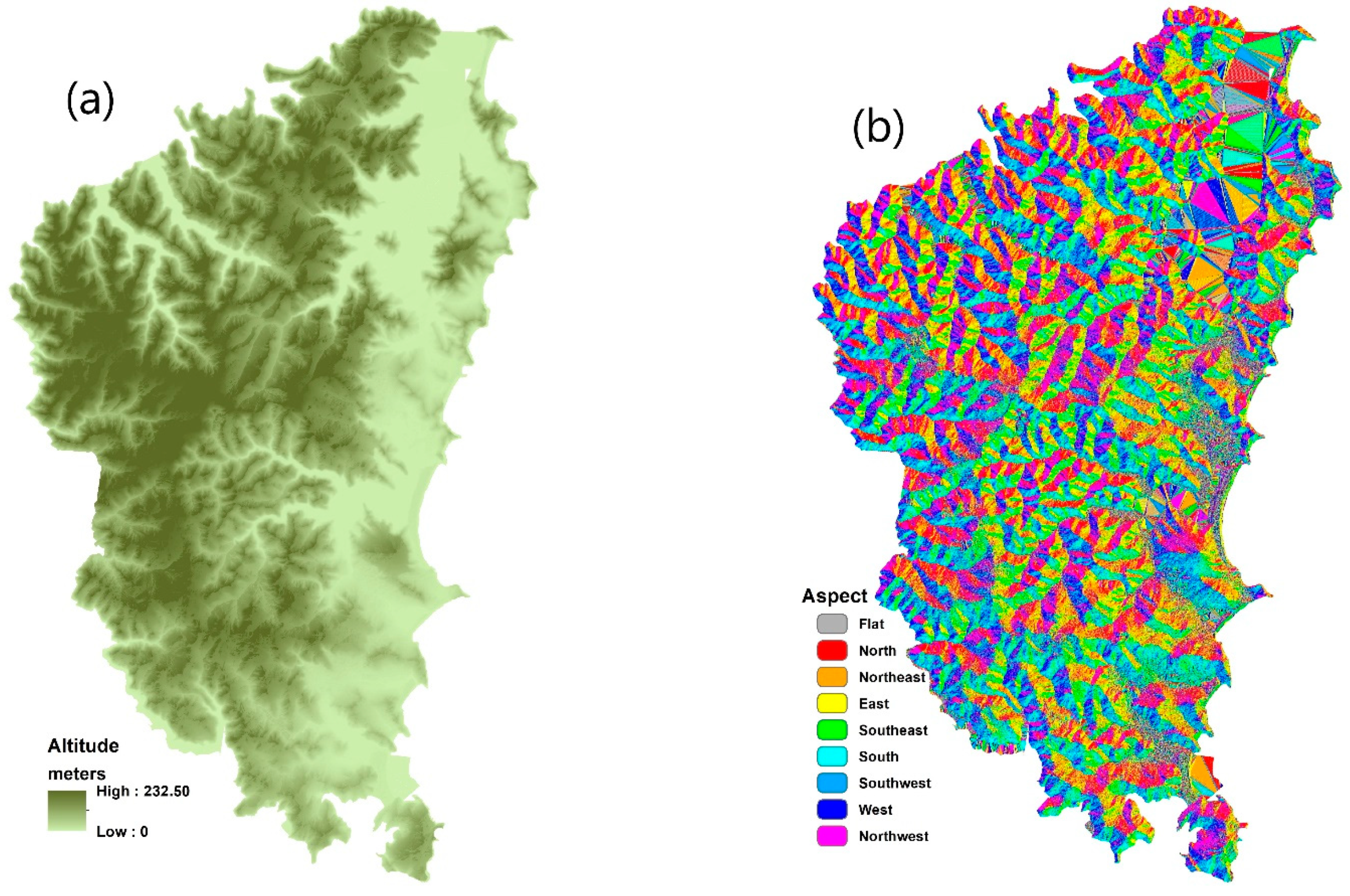
- Physical contributing factors: Four key physical contributing factors in relation to forest fire are investigated in this study, namely altitude, NDVI, aspect, and slope. The altitude was generated from a LiDAR point cloud. NDVI was generated from the red and infrared bands of the Spot-6 satellite image. The highest and lowest ranges for these layers are spatially mapped in Figure 4.
4.4. Vulnerability Model
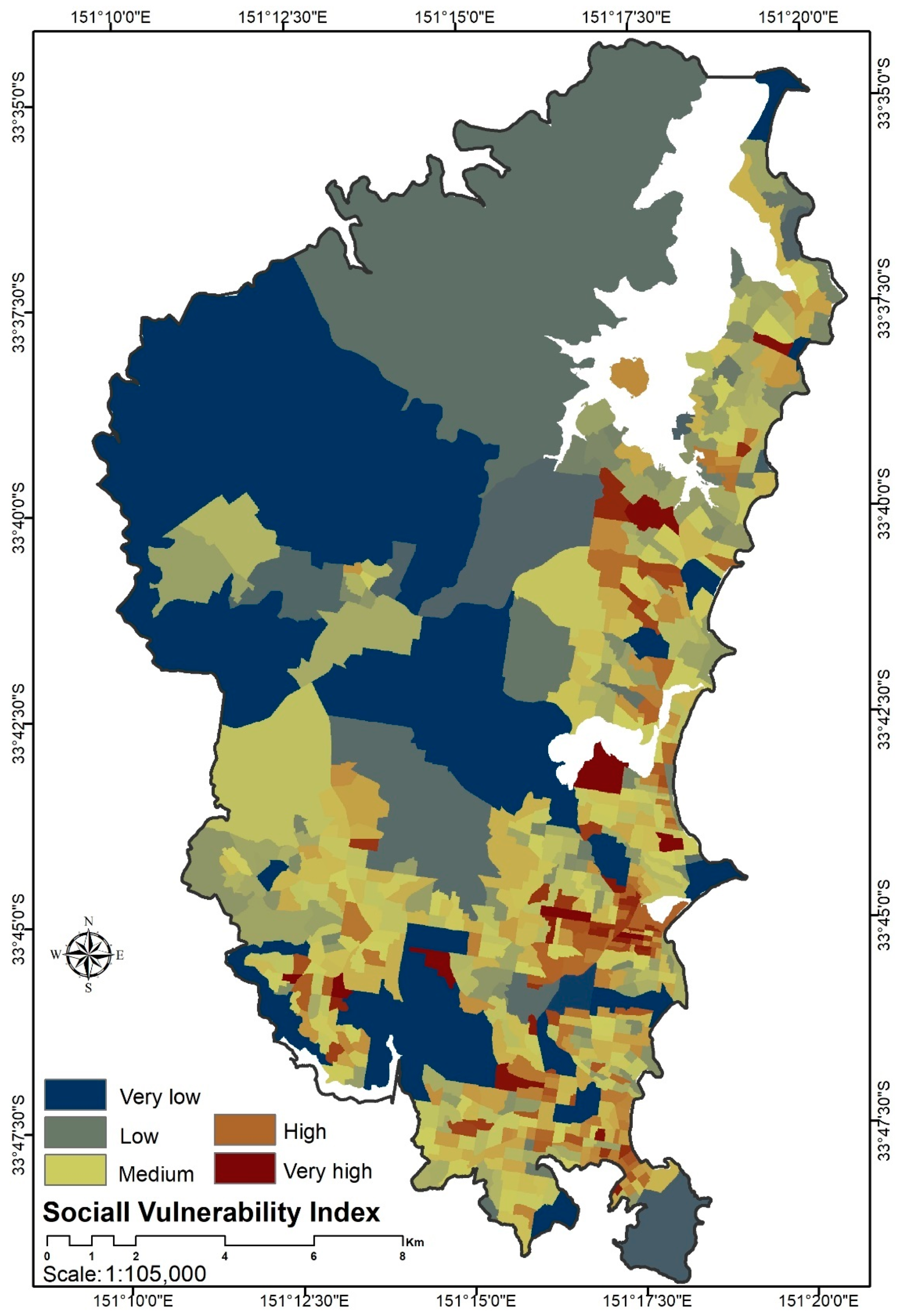
4.4.1. Social factors
- The rental population: The housing tenure demographic can provide insights into the resident’s socio-economic status. For instance, a large number of renters in a particular area might indicate that the housing affordability in that area may attract low-income young people who wish to buy a house, whereas a high number of homeowners in a particular area might indicate it is a more settled area where the population is less socially vulnerable. Additionally, tenure data might indicate built form distribution, where a higher concentration of renters indicates many high-density dwellings whereas a lower concentration of renters indicates the presence of homeowners living in separate houses.
- Families without a car: A family’s access to public services and health facilities can be affected by their access to the public/private transport system. The number of vehicles per family indicates accessibility to private transport and indirectly reflects those who need to access the public transportation system. Therefore, car ownership is an indicator to measure how quickly families can react to an evacuation in the case of a fire. Families without a car are more vulnerable to hazard such as a forest fire as they need to find a vehicle to vacate fire-affected areas.
- Rental stress: Families whose incomes are in the bottom 40% of the population and who spend more than 30% of their weekly income on rent are said to be suffering rental stress.
- Unemployment: Unemployment data is one of the most important socio-economic parameters that indicate the ability of the family to cope with unexpected events. The unemployment rate indicates the number of individuals looking for jobs as a ratio of the labor force. Families with a higher unemployment rate may not have savings, which makes them more vulnerable to disasters such as forest fires.
- Families with no educational qualification: Educational qualifications are one of the most important indicators of socio-economic status. This parameter identifies the number of people aged over 15, who have not finished high school, or their qualifications are not recognized in Australia. Individuals without any recognized qualifications tend to be disadvantaged as Australian employers tend to require formal qualifications. These families might face difficulties finding well-paid jobs and are hence more vulnerable when faced with a disaster event.
- Families with a disabled member: This parameter identifies families who have a family member who requires support and assistance in their daily lives with self-care, communication, or body movement due to a disability, health illness, or old age. This parameter indicates the number of families who may not be able to evacuate an area quickly in the event of a disaster; hence, they are classified as highly vulnerable in natural disasters.
- Low-income families: Low-income families, defined as those whose income is less than $650 per week, may not have sufficient savings, which makes them vulnerable in the event of a disaster. Household income is one of the most important indicators of socio-economic status. Low-income families then are more vulnerable to forest fires as they are not resilient to disaster.
- Older lone persons: Older lone person households often indicate an area that has been through its suburb life cycle and now mainly consists of an elderly population that needs relevant support services. The type of household and family structure of the population are important indicators. It generally shows the vulnerable areas and provides strategic awareness to the degree of request for facilities and services in case of emergency and hazard.
- Newly arrived families from overseas: This parameter indicates the spatial distribution of foreigners who recently arrived in Australia. These families usually do not have comprehensive information about their neighborhood of residence or the surrounding environment, and they are also probably unfamiliar with the likelihood of potential disaster, which makes them vulnerable in a disaster event.
- Parents with a child under 15: Generally, families with dependent children are more vulnerable than families without dependent children in the case of fire evacuations.
- Single parent with a child under 15: In general, households with children need more services and emergency facilities than other household types, and their needs tend to be dependent on the children’s age. Single-parent families with dependent children are much more vulnerable to natural disasters than couple families with dependent children, particularly in the case of a fire evacuation. Understanding spatial socio-economic information can help urban planners make evidence-based decisions about the allocation of emergency response centers.
- Families with members in a vulnerable age group: Identifying the population in the vulnerable age group is an indicator of a low coping capacity in the event of a disaster. The age structure of a population is usually indicative of an area’s life cycle stage and provides key insights into the level of demand for age-specific services and facilities. Children under 15 years or people aged above 60 are considered dependent populations who need assistance in the case of a forest fire.
- Population: Population is one of the key indicators for vulnerability assessment. Those areas with a large population need to have emergency contingency plans in place in the event of a disaster. In this study, population data were demographically mapped at the mesh block level for the Northern Beaches area and is combined with other basic demographic information, such as gender and age structure.
- Population density: Population density indicates the average number of persons per hectare in our study area. The population density indicator might be misleading as some of the regions might not be used for residence. Basically, areas with highly populated residential housing have a higher density value than areas where most of the land is used for other purposes such as industry or parkland.
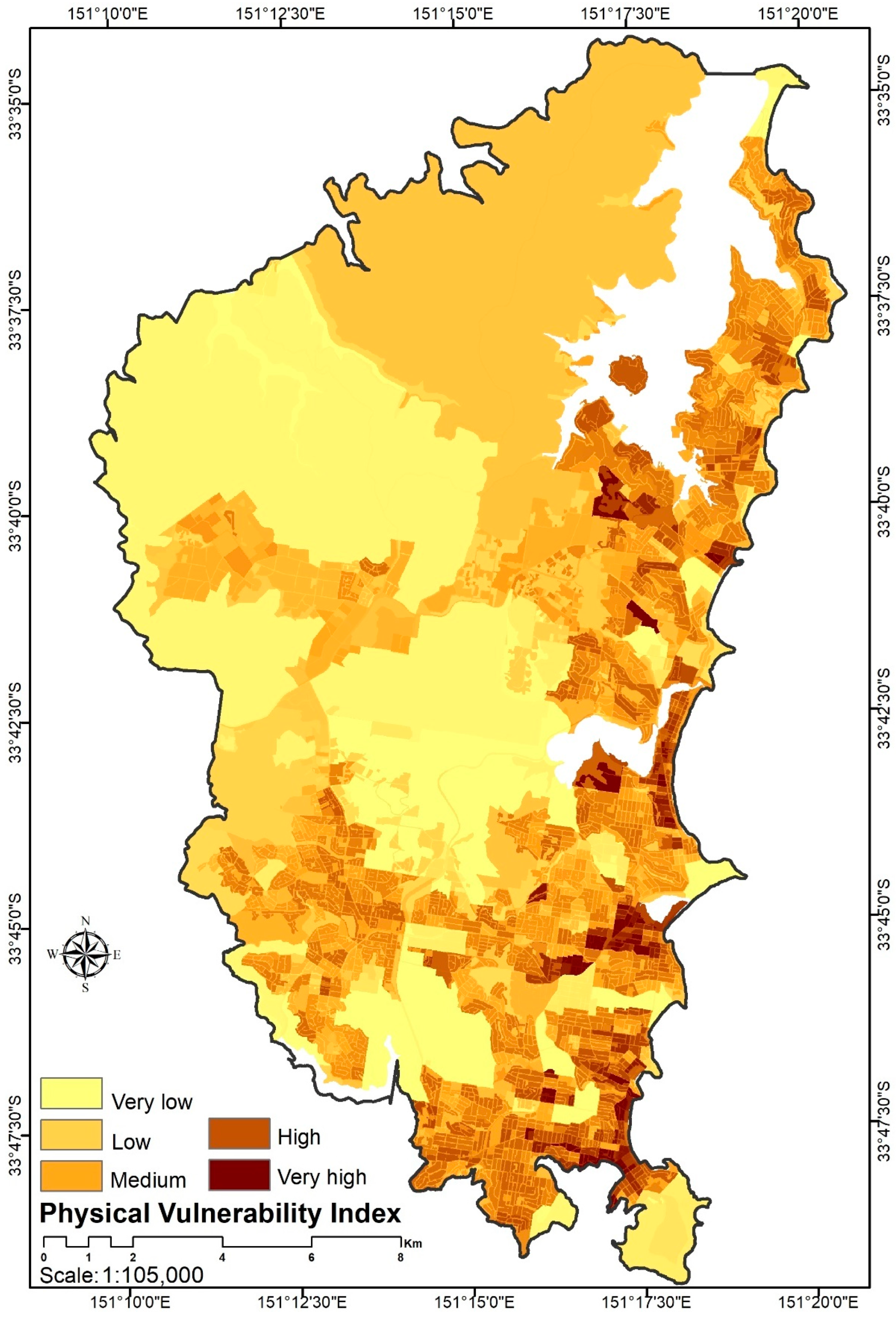
4.4.2. Physical Vulnerability
- High-density housing: The residential built form often reflects planning policy, such as building denser forms of housing around public transport nodes or employment centers. A greater concentration of flats, units, and apartments will accommodate more of the population. This indicator shows high-density dwellings, which include flats that are three or more stories high. High-density housing is common in inner-city areas and some suburban areas close to railway stations, as well as some coastal resorts. This type of housing has increased in popularity in Australia in recent years.
- Number of households: The number of households is one of the informative indicators that show high/low populated neighborhoods. It indicates a house and its occupants regarded as a unit. Average household size is calculated by dividing the number of occupied dwellings by the total number of inhabitants.
- Dwellings: The location of dwellings represents people’s assembly points across the night and part of a day. Therefore, the spatial mapping of dwellings can also help us to zoom down up to the vital areas that have to be preserved in terms of hazard. It is very essential to implement protective actions such as biological and mechanical plans to save human lives gathered in dwellings.
- High rental dwellings: High rental is defined as a rental payment of more than $600 per week in this study. High rental payments may indicate desirable areas with mobile populations who rent, or a housing shortage, or gentrification. Low rental payments may indicate public housing or areas where there are many low-income households looking for a lower cost of living. However, rental payments are not directly comparable over time because of inflation.
- Land usage: The land use was ranked from zero to one regarding the degree of physical importance, rehabilitation and heritage to the community, as summarized in Table 1. Zero indicates low vulnerable land zone uses, and one indicates highly vulnerable land use zones.
4.5. Results Analysis
4.5.1. Model Training and Finetuning
4.5.2. Forest Fire Hazard Index
4.5.3. Forest Fire Vulnerability
4.5.4. Forest Fire Risk Level
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Said, S.N.B.M.; Zahran, E.-S.M.M.; Shams, S. Forest fire risk assessment using hotspot analysis in GIS. Open Civ. Eng. J. 2017, 11, 786–801. [Google Scholar] [CrossRef]
- Pearce, D.W. The economic value of forest ecosystems. Ecosyst. Health 2001, 7, 284–296. [Google Scholar] [CrossRef]
- Ajin, R.; Ciobotaru, A.; Vinod, P.; Jacob, M.K. Forest and Wildland fire risk assessment using geospatial techniques: A case study of Nemmara forest division, Kerala, India. J. Wetl. Biodivers. 2015, 5, 29–37. [Google Scholar]
- Vadrevu, K.P.; Eaturu, A.; Badarinath, K. Fire risk evaluation using multicriteria analysis—A case study. Environ. Monit. Assess. 2010, 166, 223–239. [Google Scholar] [CrossRef] [PubMed]
- Naderpour, M.; Rizeei, H.M.; Khakzad, N.; Pradhan, B. Forest fire induced Natech risk assessment: A survey of geospatial technologies. Reliab. Eng. Syst. Saf. 2019, 191, 106558. [Google Scholar] [CrossRef]
- Calkin, D.E.; Ager, A.; Thompson, M.P.; Finney, M.A.; Lee, D.C.; Quigley, T.M.; McHugh, C.W.; Riley, K.L.; Gilbertson-Day, J.M. A Comparative Risk Assessment Framework for Wildland Fire Management; The 2010 Cohesive Strategy Science Report; National Agroforestry Center: Lincoln, NE, USA, 2011.
- Sikder, I.U.; Mal-Sarkar, S.; Mal, T.K. Knowledge-based risk assessment under uncertainty for species invasion. Risk Anal. Int. J. 2006, 26, 239–252. [Google Scholar] [CrossRef] [PubMed]
- Ager, A.A.; Finney, M.A.; Kerns, B.K.; Maffei, H. Modeling wildfire risk to northern spotted owl (Strix occidentalis caurina) habitat in Central Oregon, USA. For. Ecol. Manag. 2007, 246, 45–56. [Google Scholar] [CrossRef]
- Naderpour, M.; Rizeei, H.M.; Ramezani, F. Wildfire prediction: Handling uncertainties using integrated bayesian networks and fuzzy logic. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Sivrikaya, F.; Sağlam, B.; Akay, A.E.; Bozali, N. Evaluation of forest fire risk with GIS. Pol. J. Environ. Stud. 2014, 23, 187–194. [Google Scholar]
- He, Y.; Lin, Y.; Wu, M. The effect on organizational performance by human resource management practices: Empirical research on Chinese manufacturing industry. In Proceedings of the 2010 International Conference on Management and Service Science, Wuhan, China, 24–26 August 2010; pp. 1–6. [Google Scholar]
- Alexakis, D.; Sarris, A. Environmental and human risk assessment of the prehistoric and historic archaeological sites of Western Crete (Greece) with the use of GIS, remote sensing, fuzzy logic and neural networks. In Proceedings of the Euro-Mediterranean Conference, Lemessos, Cyprus, 8–13 November 2010; pp. 332–342. [Google Scholar]
- Garg, S.; Aryal, J.; Wang, H.; Shah, T.; Kecskemeti, G.; Ranjan, R. Cloud computing based bushfire prediction for cyber–physical emergency applications. Future Gener. Comput. Syst. 2018, 79, 354–363. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Forest fire susceptibility and risk mapping using social/infrastructural vulnerability and environmental variables. Fire 2019, 2, 50. [Google Scholar] [CrossRef] [Green Version]
- Pourghasemi, H.R.; Beheshtirad, M.; Pradhan, B. A comparative assessment of prediction capabilities of modified analytical hierarchy process (M-AHP) and Mamdani fuzzy logic models using Netcad-GIS for forest fire susceptibility mapping. Geomat. Nat. Hazards Risk 2016, 7, 861–885. [Google Scholar] [CrossRef] [Green Version]
- Suryabhagavan, K.; Alemu, M.; Balakrishnan, M. GIS-based multi-criteria decision analysis for forest fire susceptibility mapping: A case study in Harenna forest, southwestern Ethiopia. Trop. Ecol. 2016, 57, 33–43. [Google Scholar]
- Ghorbanzadeh, O.; Blaschke, T. Wildfire susceptibility evaluation by integrating an analytical network process approach into GIS-based analyses. In Proceedings of the ISERD International Conference, Tehran, Iran, 11–12 July 2019. [Google Scholar]
- Dutta, R.; Das, A.; Aryal, J. Big data integration shows Australian bush-fire frequency is increasing significantly. R. Soc. Open Sci. 2016, 3, 150241. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuter, N.; Yenilmez, F.; Kuter, S. Forest fire risk mapping by kernel density estimation. Croat. J. For. Eng. J. Theory Appl. For. Eng. 2011, 32, 599–610. [Google Scholar]
- Kim, S.J.; Lim, C.-H.; Kim, G.S.; Lee, J.; Geiger, T.; Rahmati, O.; Son, Y.; Lee, W.-K. Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sens. 2019, 11, 86. [Google Scholar] [CrossRef] [Green Version]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H.b. Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat. Nat. Hazards Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef] [Green Version]
- Neupane, B.; Horanont, T.; Aryal, J. Deep learning-based semantic segmentation of urban features in satellite images: A review and meta-analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Werbos, P. Beyond regression: New tools for prediction and analysis in the behavior science. Unpubl. Dr. Diss. Harv. Univ. 1974, 10019522029. [Google Scholar]
- Mia, M.; Dhar, N.R. Prediction of surface roughness in hard turning under high pressure coolant using Artificial Neural Network. Measurement 2016, 92, 464–474. [Google Scholar] [CrossRef]
- Yang, W.T.; Ahuja, A.; Tang, A.; Suen, M.; King, W.; Metreweli, C. Ultrasonographic demonstration of normal axillary lymph nodes: A learning curve. J. Ultrasound Med. 1995, 14, 823–827. [Google Scholar] [CrossRef]
- Liao, S.-H.; Chu, P.-H.; Hsiao, P.-Y. Data mining techniques and applications–A decade review from 2000 to 2011. Expert Syst. Appl. 2012, 39, 11303–11311. [Google Scholar] [CrossRef]
- Woo, M.W.; Daud, W.R.W.; Tasirin, S.M.; Talib, M.Z.M. Optimization of the spray drying operating parameters—A quick trial-and-error method. Dry. Technol. 2007, 25, 1741–1747. [Google Scholar] [CrossRef]
- Zhang, Y.; Maxwell, T.; Tong, H.; Dey, V. Development of a Supervised Software Tool for Automated Determination of Optimal Segmentation Parameters for Ecognition. In Proceedings of the ISPRS TC VII Symposium—100 Years ISPRS, Vienna, Austria, 5–7 July 2010; p. 20. [Google Scholar]
- Tong, D.; Murray, A.T. Spatial optimization in geography. Ann. Assoc. Am. Geogr. 2012, 102, 1290–1309. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Jankowski, P.; Gessler, P.E. An heuristic approach for mapping landslide hazard by integrating fuzzy logic with analytic hierarchy process. Control Cybern. 2006, 35, 121–146. [Google Scholar]
- Ridd, M.K.; Liu, J. A comparison of four algorithms for change detection in an urban environment. Remote Sens. Environ. 1998, 63, 95–100. [Google Scholar] [CrossRef]
- Pontius, R., Jr.; Millones, M. Death to kappa and to some of my previous work: A better alternative. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Stein, A.; Aryal, J.; Gort, G. Use of the Bradley-Terry model to quantify association in remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 852–856. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Nampak, H.; Pradhan, B.; Manap, M.A. Application of GIS based data driven evidential belief function model to predict groundwater potential zonation. J. Hydrol. 2014, 513, 283–300. [Google Scholar] [CrossRef]
- Pradhan, B. Remote sensing and GIS-based landslide hazard analysis and cross-validation using multivariate logistic regression model on three test areas in Malaysia. Adv. Space Res. 2010, 45, 1244–1256. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Miller, C.; Ager, A.A. A review of recent advances in risk analysis for wildfire management. Int. J. Wildland Fire 2013, 22, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Wigtil, G.; Hammer, R.B.; Kline, J.D.; Mockrin, M.H.; Stewart, S.I.; Roper, D.; Radeloff, V.C. Places where wildfire potential and social vulnerability coincide in the coterminous United States. Int. J. Wildland Fire 2016, 25, 896–908. [Google Scholar] [CrossRef] [Green Version]
- Eidsvig, U.; McLean, A.; Vangelsten, B.; Kalsnes, B. Socio-economic vulnerability to natural hazards–proposal for an indicator-based model. Geotech. Saf. Risk 2011, 2011, 141–148. [Google Scholar]
- Borden, K.A.; Schmidtlein, M.C.; Emrich, C.T.; Piegorsch, W.W.; Cutter, S.L. Vulnerability of US cities to environmental hazards. J. Homel. Secur. Emerg. Manag. 2007, 4, 5. [Google Scholar]
- Guettouche, M.S.; Derias, A. Modelling of environment vulnerability to forests fires and assessment by GIS application on the forests of Djelfa (Algeria). J. Geogr. Inf. Syst. 2013, 5, 9. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land Usage | Area (ha) | Vulnerability Rank |
|---|---|---|
| Electricity substations and transmission | 24.63 | 0.08 |
| Farm buildings/infrastructure | 0.70 | 0.06 |
| Grazing native vegetation | 19.39 | 0.01 |
| Intensive horticulture | 23.20 | 0.04 |
| Landfill | 58.91 | 0.00 |
| Landscape | 46.49 | 0.03 |
| National parks | 11,275.70 | 0.05 |
| Other minimal use | 130.82 | 0.04 |
| Ports and water transport | 71.47 | 0.07 |
| Public services | 455.50 | 0.06 |
| Quarries | 8.66 | 0.03 |
| Recreation and culture | 1418.28 | 0.04 |
| Residential and farm infrastructure | 12.74 | 0.09 |
| Residual native cover | 2615.83 | 0.02 |
| Roads | 1963.70 | 0.06 |
| Rural residential with agriculture | 963.53 | 0.08 |
| Rural residential without agriculture | 0.16 | 0.10 |
| Seasonal flowers and bulbs | 1.24 | 0.01 |
| Seasonal vegetables and herbs | 0.97 | 0.02 |
| Services | 628.60 | 0.07 |
| Sewage/sewerage | 12.98 | 0.05 |
| Shade houses | 4.78 | 0.09 |
| Urban residential | 4918.32 | 0.10 |
| Utilities | 2.34 | 0.09 |
| Waste treatment and disposal | 0.00 | 0.07 |
| Water bodies | 2959.92 | 0.02 |
| Architect | Hyper-Parameter | Optimal Value |
|---|---|---|
| MLP | Batch size | 100 |
| Seed value | 5 | |
| Momentum rate | 0.7 | |
| Learning rate | 0.9 | |
| Hidden layer attribute | 9, 7, 5 | |
| Hidden layer class | 3 |
| Architecture | TP Rate | FP Rate | RMSE | K Coefficient | ROC Area | PRC Area | n |
|---|---|---|---|---|---|---|---|
| MLP | 0.912 | 0.066 | 0.1652 | 0.943 | 0.951 | 0.938 | 560 |
| Category | Vulnerability Indicators | AHP Weight |
|---|---|---|
| Social factors | Family with vulnerable age group (>15 or <60) | 0.068 |
| Population | 0.057 | |
| Population density | 0.075 | |
| Tenant who stays in rental houses | 0.022 | |
| Families with rental stress | 0.038 | |
| Family without any car | 0.041 | |
| Unemployed family | 0.053 | |
| Low-income family | 0.03 | |
| Family with no educational qualification | 0.012 | |
| Family with disabled member | 0.084 | |
| Elderly people who live alone | 0.072 | |
| New arrival from overseas family | 0.014 | |
| Parents with less than 15-year-old child | 0.016 | |
| Single parent with less than 15-year-old child | 0.025 | |
| Physical factors | Expensive dwellings | 0.051 |
| CR = 0.012 | ||
| Number of dwellings | 0.057 | |
| land use | 0.063 | |
| High-density houses | 0.071 | |
| Number of households | 0.075 | |
| CR = 0.004 |
| Risk Class | Area (ha) | Area (%) |
|---|---|---|
| Very low | 9705.02 | 38.36 |
| Low | 11,479.91 | 45.37 |
| Medium | 3511.76 | 13.88 |
| High | 499.50 | 1.97 |
| Very high | 105.55 | 0.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naderpour, M.; Rizeei, H.M.; Ramezani, F. Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework. Remote Sens. 2021, 13, 2513. https://doi.org/10.3390/rs13132513
Naderpour M, Rizeei HM, Ramezani F. Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework. Remote Sensing. 2021; 13(13):2513. https://doi.org/10.3390/rs13132513
Chicago/Turabian StyleNaderpour, Mohsen, Hossein Mojaddadi Rizeei, and Fahimeh Ramezani. 2021. "Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework" Remote Sensing 13, no. 13: 2513. https://doi.org/10.3390/rs13132513
APA StyleNaderpour, M., Rizeei, H. M., & Ramezani, F. (2021). Forest Fire Risk Prediction: A Spatial Deep Neural Network-Based Framework. Remote Sensing, 13(13), 2513. https://doi.org/10.3390/rs13132513