1. Introduction
Sea ice is one of the greatest physical constraints for shipping activities in the Arctic. Due to the lengthening of the open-water season, maritime traffic in the Arctic has increased three-fold over the past few years [
1]. The story is similar in the Canadian Arctic as well, with Hudson Strait being the most traffic prone area [
2]. However, although the ice extent and thickness are reducing across the Arctic, the risks and hazards involved in sailing through the Arctic are even more significant than in the past.
As the ice melts, the ice pack becomes more mobile, allowing hazards such as ice floes to break away. These ice floes move at high speeds in a dynamic fashion and can cause damage to vessels and man-made structures [
3]. Ice charting is performed by the Canadian Ice Services (CIS) for estimating sea ice concentration and stage of development (which includes floes size information) to make management decisions for ensuring safety and efficient maritime activities in the Canadian Arctic [
4]. CIS uses data from various data sources for the production of ice charts and the development of guidelines for mariners. One of the prominent data sources used for the task of sea ice monitoring is Synthetic Aperture Radar (SAR), which provides high spatial resolution images irrespective of the daylight conditions [
5]. This data is manually interpreted, for which highly skilled personnel are required for the job.
To process the vast volumes of available data in real-time, there is a need for automated methods for ice floe detection. Previous studies [
6,
7,
8,
9,
10,
11] used image processing techniques coupled with traditional machine learning on SAR images for the task of ice–water segmentation and ice floe separation. SAR images usually have intrinsic speckle noise due to the coherent nature of the imaging process [
12]. The presence of this speckle-noise has been identified as a limitation in classification accuracy [
6,
11]. To circumvent this issue, instead of using SAR images, some studies [
13,
14,
15,
16,
17] used data from vessel mounted cameras for identifying ice floes. This approach solves the issue of speckle-noise contamination. However, geometric error compensation is required to tackle the problem of underestimation/overestimation of ice cover caused due to oblique sensor placement [
14]. Information from shipboard sensors is also biased in the sense that the ships prefer to transit through regions with lower ice concentration.
In this paper, we present an end-to-end ResUnet-CRF (RUF)-architecture-based model with a dual loss for ice floe segmentation in SAR images. From the perspective of deep learning, the proposed RUF architecture integrates three main modules: encoder–decoder framework [
18], deep residual connections [
19], and a probabilistic graphical model [
20]. The encoder–decoder framework allows the network to learn the latent space representation of the data. Such networks have been shown to work with image noise for tasks such as image deblurring [
21] and super-resolution [
22]. Hence, such a network was chosen for the present study to aid in dealing with speckle noise typically present in SAR images. Residual connections ease the network training and the conditional random field aids in the refinement of segmentation boundaries. We train our proposed network architecture in an end-to-end manner using a dual loss function. The dual loss [
23] is a combination of BCE and Dice loss.
Our main contributions are as follows:
We propose a novel encoder–decoder-based deep residual network embedded with a dense probabilistic graphical model for sea ice floe segmentation. To the best of our knowledge, this is the first time such a network has been successfully implemented in the domain of sea ice segmentation.
Passive microwave data does not provide precise information about sea ice concentration (SIC) in low SIC areas with small ice floes due to a coarse resolution and low instrument sensitivity. Our method successfully detects ice floes in SAR images, especially in the regions with less than 20% SIC, which could be important for marine hazard monitoring and wildlife management.
The proposed approach, RUF, is able to achieve higher metric scores along with visually superior results when compared with standard state of the art segmentation backbone models such as FCN-8 and DeepLabV3. These results have been achieved with fewer weights than other leading approaches, as our approach uses 26 M parameters, while FCN-8 and DeepLabV3 use 54 M and 60 M parameters, respectively.
This paper is organized as follows: after a brief literature review (
Section 2), the description of the study area, image database, and data annotation are provided (
Section 3). Next, detailed information regarding the various components of our proposed network architecture is presented in
Section 4, followed by the description of evaluation metrics (
Section 5) used in this paper.
Section 6 provides information regarding the experimental setup, conducted experiments, and obtained results. Finally, the paper ends with the conclusion and future improvements in
Section 7.
2. Background
Sea ice charting is typically conducted by national ice services to identify the boundaries between ice and open water, and to identify the dominant ice types and ice concentration for a given region. In the past years, due to the improvement in both aerial and remote sensing sensors, numerous studies using sea ice data have emerged [
24]. These studies cover ice–water segmentation [
25,
26,
27], ice concentration estimation [
28,
29,
30], ice thickness estimation [
31,
32], ice type classification [
33,
34], and sea ice feature detection [
35,
36]. Methods using superpixel segmentation [
37,
38], watershed segmentation [
39,
40], and active contours [
41,
42] have been actively employed in SAR image segmentation. There are several related studies in the area of ship detection in ice-covered waters [
43,
44,
45]. The study in [
43] used a novel approach, combining depthwise convolution and pointwise convolution to enable a lightweight and efficient network. This may be interesting to explore in future work. Many studies on ship detection use the SAR detection dataset (SSDD), which consists of quad-pol SAR imagery with spatial resolution of 1–15 m. The ships appear in these images as small bright regions. The study [
45] also looked at a wide-swath Sentinel-1 image, which is comparable to the data source used here.
For the task of ice floe detection, various researchers have used different data platforms. Studies conducted by Hall et al. [
13], Lu et al. [
14], Heyn et al. [
15,
16], and Wang et al. [
17] used vessel mounted camera sensors to obtain photographic data to identify ice floes. However, due to the oblique sensor placement, accurate measurements of sensor height, tilt, and focal length are required to calculate the geometric distortion. Moreover, compensation for ship sway is required for the success of these methods.
Images obtained from SAR provide a continuous stream of high spatial resolution data irrespective of the weather conditions and natural illumination. Earlier studies [
6,
7,
8,
9,
10,
11] aimed to solve the problem of ice floe identification in two steps. The first step involved the ice–water segmentation while the second step involved delineating different floes. Studies by Steer et al. and Toyota et al. [
6,
7] involved different thresholding methods for sea ice segmentation followed by morphological dilation/erosion operations to split different floes. Holt et al. [
8] used local dynamic thresholding [
46] and shrinking/growing algorithm [
47] for floe segmentation. Hwang et al. [
9] proposed a segmentation technique using Kernel Graph Cuts (KGC) [
48] for ice–water segmentation and a combination of distance transformation, watershed [
49], and a rule-based boundary revalidation processing for floe splitting [
50]. Graphical models such as Markov Random Field and Conditional Random Field have also been used for the task of sea ice segmentation [
10,
11]. Due to the presence of speckle noise in SAR images, it can be difficult to segment sea ice floes using traditional machine learning techniques.
Recently, Convolutional Neural Networks (CNNs) have been proven to be good at learning the low- and high-level abstract features from raw images. Hence, they have been extensively used in tasks such as image classification [
19,
51,
52,
53], semantic segmentation [
18,
54], and object detection [
55,
56]. Long et al. [
54] introduced a fully convolutional network for the task of image segmentation, while Chen et al. [
57] proposed a combination of CNNs and CRFs to tackle poor localization of CNNs. Ronnerberger et al. [
18] proposed an encoder–decoder-based network for the task of medical image segmentation. Later, Chen et al. proposed the DeepLab family networks [
57,
58,
59] with dilated convolutions to reduce the computational complexity while maintaining the same receptive field.
Recently, Singh [
60] et al. compared various segmentation models (e.g., DeepLab [
57], UNet [
18], SegNet [
61], DenseNet [
9]) for the task of river ice floe segmentation. Zhang et al. [
62] introduced a convolutional network with dual attention streams for ice segmentation in rivers. Both of these studies use optical image datasets. To improve on pixel representations of CNNs and take advantage of residual learning, we propose RUF, an encoder–decoder network with residual blocks integrated with a convolutional CRF and trained in an end-to-end manner with dual loss function for the task of ice floe segmentation.
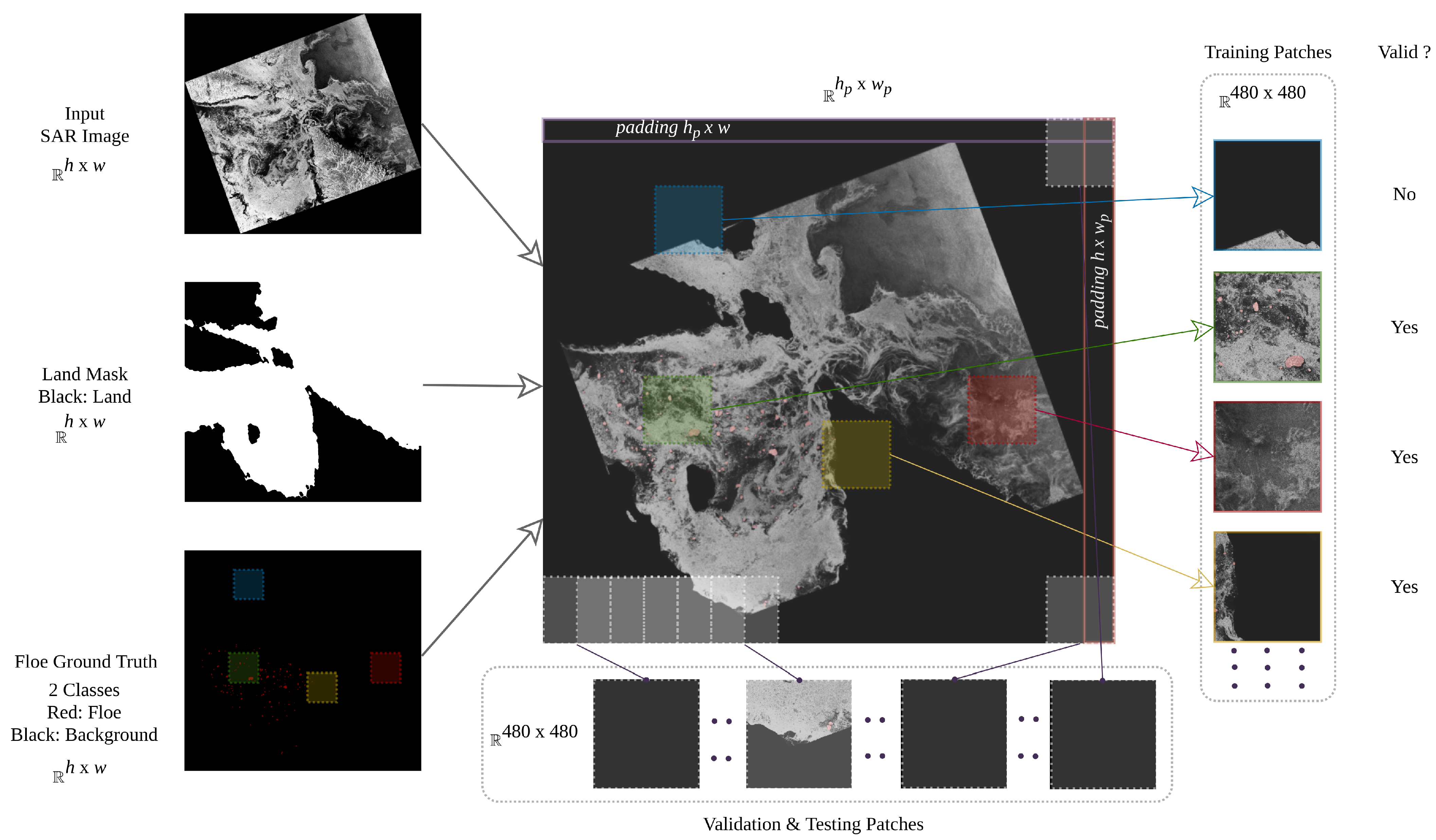
3. Dataset
The geographical area of interest for the dataset used in this paper spans over the Hudson Strait located in Eastern Canada, and its outflow into the Labrador Sea in the North Atlantic. The dataset is composed of 9 RADARSAT-2 C-band ScanSAR wide-beam mode images acquired in HH (horizontal transmit and horizontal receive) polarization. The images were acquired at a center frequency of 5.405 GHz with a 500-Km swath width and provide a nominal pixel spacing of 50 m. The SAR images were captured from the area as shown in
Figure 1, with the red polygon describing the extent of one SAR image. Information regarding the image acquisition dates, central latitude and longitude, and instances of annotated floes is given in
Table 1.
3.1. Data Preprocessing
SAR images have a grainy ‘salt and pepper’ appearance, also called speckle noise, which is caused due to random interference between coherent returns. To reduce this intrinsic contamination of speckle noise, the SAR images were downsampled four-fold. The downsampling operation was carried out by averaging over
pixel nonoverlapping blocks. Downsampling operation changed the nominal pixel spacing to 200 m with a reduction in data volume to
of the original. The local average filtering operation helps to reduce the speckle noise [
63,
64]. Downsampling is the result of this average filtering. The local average filtering also helps with reducing the data volume and makes it more manageable for training the neural network models.
Note that the Hudson Strait and the neighboring geographical areas of interest have a long coastline, and the images have significant land cover. As ice floes are a water body phenomenon, pixels representing land in the images were masked as black, as shown in
Figure 2. To generate the land masks for the images, we applied a threshold of 0 m-elevation to the elevation masks and later a Gaussian blur with
kernel size to remove the rough edges along the sea–land boundaries. The elevation masks were generated using
digital elevation model with bilinear interpolation using the European Space Agency (ESA) toolbox, Sentinel Application Platform.
3.2. Data Annotation
The dataset contains 9 images with 1627 manual annotations of ice floes. For our experiments, a single class was defined for annotation, namely, ‘floe’, and all the remaining pixels were categorized as background. In the pixel-level annotations, we used the following criteria to annotate a closed contour as a floe:
The contour contains consolidated ice as determined via visual inspection.
At least 30% of the contour boundary is in contact with seawater.
The contour contains at least 60 pixels.
These criteria were chosen to eliminate the closed contours in ice covers (frozen in floes) and to reduce noise artifacts. The floes were annotated through visual inspection of the imagery using the Computer Vision Annotation Tool (CVAT).
3.3. Dataset Split
We split the dataset into the train, validation, and test sets with a rough 60:20:20 ratio split, such that the training set contains
of annotated floes while validation and test sets each contain
of floe annotations. Full SAR images were placed in each set in order to have truly independent samples across different sets, as shown in
Table 1. Splitting the dataset as such allows us to ascertain better generalization of the model.
4. Methodology
This section introduces the proposed RUF network architecture. The proposed model leverages the advantages of residual CNNs and Convolutional Conditional Random Fields (Conv-CRFs) [
20] alongside a dual loss function. Residual blocks allow a network to train easily while the UNET skip connections help with easy information propagation between different layers of the network. To facilitate learning of the network weights, we jointly train the RES-UNET and Conv-CRF parts with the dual loss function. The overall architecture of the proposed network is illustrated in
Figure 3. Information about various components of the network is given in the subsequent subsections.
4.1. RES-UNET
4.1.1. Residual Block
Neural network architectures with multiple layers, commonly known as deep neural networks, can learn richer features than their shallower counterparts [
65,
66]. Even though these deep neural network architectures are effective, they do struggle with a degradation problem where, upon adding more layers to an already deep neural network, the training accuracy of the model decreases. This is counter-intuitive since a deeper model should be able to fit the training data as well as a shallower model. To overcome this degradation problem, He et al. [
19] proposed residual neural networks with stacked residual blocks. Given an input
and output of the
l-th residual unit
, a residual block can be illustrated as
where
is the residual function,
is an activation function, and
is an identity mapping function.
4.1.2. UNET
The UNET [
18] is a fully convolutional image segmentation architecture with symmetric downsampling and upsampling paths. To help with projecting the discriminatory features learned at different levels of the downsampling path, UNET uses skip connections. Skip connections help in integrating the location information in the downsampling paths to the contextual information in the upsampling paths. Rather than adding the input to the output in the case of residual blocks, a skip connection concatenates the input from the downsampling path to the output of the upsampling path.
4.2. Convolutional Conditional Random Field: Conv-CRF
In a semantic segmentation task, the pixelwise predictions of the CNN models are prone to having inaccurate boundaries. To reduce inaccuracies in the boundary, global and contextual information models such as CRFs can be used in conjunction with the CNNs [
57].
In the case of semantic segmentation, the label of each pixel is
, where
i is a pixel in image
I with
N pixels. In modern approaches, a fully connected CRF (FC-CRF) takes the CNN’s output to compute the unary potentials [
57,
67]:
. Further, the pairwise potentials that account for the joint distribution of pixel pairs
as
, where
is a compatibility transformation such as in Potts model
, and
K is a kernel function such as the Gaussian kernel function.
Conv-CRFs [
20] have an add-on assumption of conditional independence over the FC-CRFs. In the Conv-CRF model, two pixels
are considered conditionally independent when their L1 norm is greater than a threshold:
, where
is the L1 norm and
k is the distance threshold or the filter size. This means that the pairwise potential is zero for all the pixels at a distance greater than the threshold
k. The Gibbs energy for a label sequence
x can then be written as
This greatly reduces the computational complexity. Teichmann et al. [
20] also introduced a new message passing kernel that is similar to 2d convolutions of CNNs and can be efficiently implemented using convolutional libraries.
Efficient computations and exact message-passing lead to better run-time and performance when compared to FC-CRFs, which makes Conv-CRFs a better candidate for our architecture.
4.3. End-To-End Training
For training the proposed architecture, we first feed the SAR images to the base RES-UNET network, where pixelwise segmentation maps from the base network are fed to the Conv-CRF network as the unary. The Conv-CRF network cleans up spurious predictions and enhances object boundary predictions. Training these two parts in an end-to-end manner allows the gradients to flow through the whole pipeline and enables both networks to learn simultaneously. Hence, with this approach, we optimize both models with respect to each other to provide optimum results.
4.4. Dual Loss Function
For the task of multiclass classification, network weights are generally trained using the categorical cross entropy loss. In case of segmentation, losses involving ground truth and prediction overlap are generally employed. To train our network, we optimize the proposed RUF architecture using a weighted dual loss function including Binary Cross Entropy (BCE) loss and Soft Dice (SD) loss:
where
is the weight parameter. BCE loss measures the classification accuracy of the model prediction and it increases as the prediction diverges from the ground truth [
68]. SD loss, which is derived from Dice Coefficient, measures the similarity between two sets [
69]. BCE loss and SD loss can be defined as Equations (
4) and (
5), respectively:
where
is the label or ground truth and
is the prediction for the
ith pixel.
4.5. RUF Architecture
RUF is a five-level deep convolutional network with symmetric downsampling and upsampling paths, as shown in
Figure 3. The downsampling path encodes the image into a condensed representation while the upsampling path decodes this information into pixelwise categorization. The downsampling path has four residual blocks. Each residual block contains multiple residual units built with two
convolutional layers and a residual connection. The convolutional layers are accompanied by a BatchNorm2d layer with a ReLu activation function. Rather than employing a max-pooling operation to downsample the feature maps [
18], we use down-convolutional blocks with strided convolutions. Max-pooling downsamples the feature maps by taking the maximum value in pooling window to represent the pixels in that window, whereas strided convolutions allow the network to summarize the pixels in that receptive field. Strided convolutions allow the network to learn the spatial relationships without losing localization accuracy, as in max-pooling when downsampling is performed multiple times. A bottleneck in the network forces the model to compress the information to learn useful features from the previous layers. The upsampling path has a similar structure to the downsampling path. Feature maps are upsampled at each level using up conv blocks employing transposed convolutions. Skip connections concatenate the output of each level in the downsampling path to the upsampling path and help in combining coarse information with finer information. At the final level, a
convolution projects the multichannel feature maps to our intermediate segmentation mask. This mask is then processed in conjunction with the input image to calculate the unary and pairwise potentials of the Conv-CRF for further refinement. A softmax operation is applied to the output of Conv-CRF, which is later thresholded at 50 percent confidence to obtain the prediction mask.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}