
Multiscale Information Fusion for Hyperspectral Image Classification Based on Hybrid 2D-3D CNN

 ,
, 
Abstract
1. Introduction
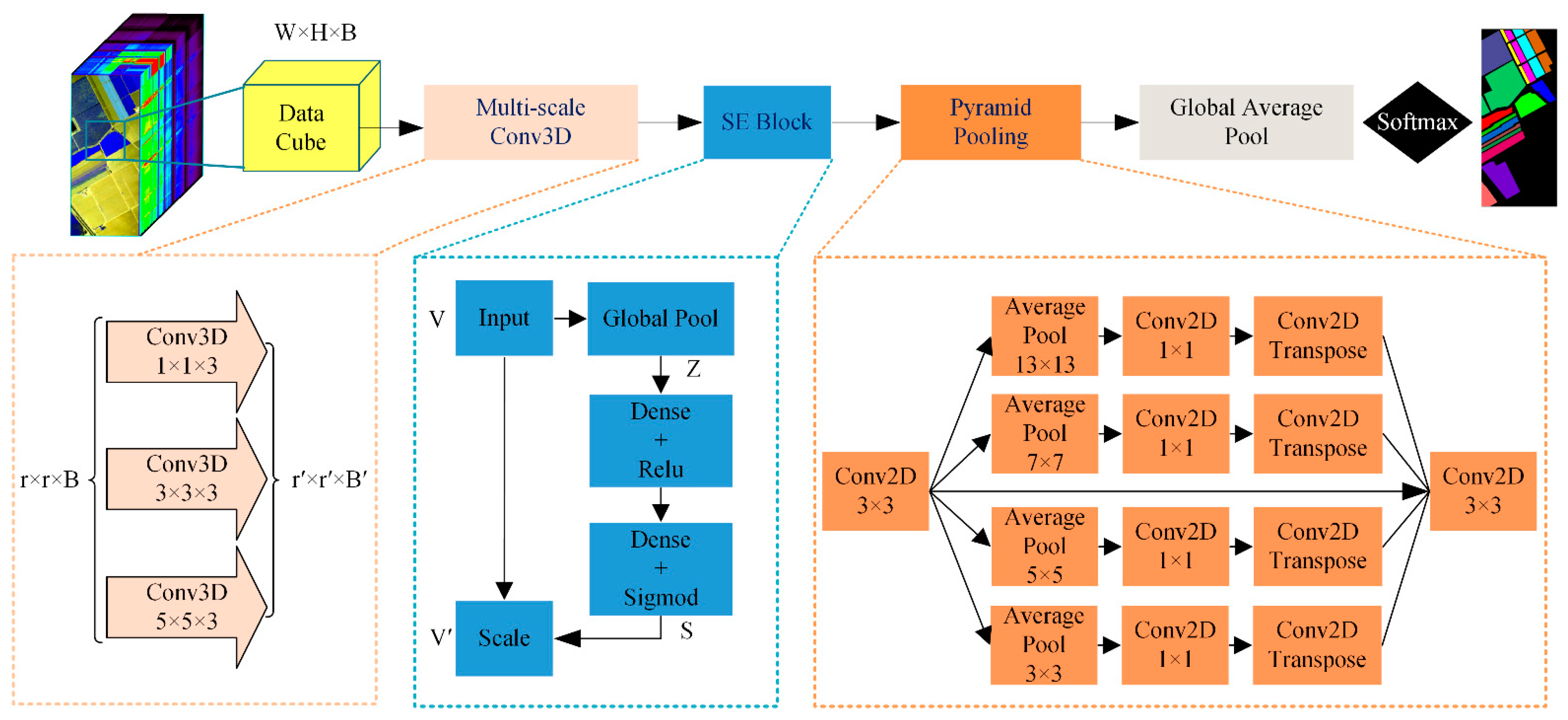
- To overcome the “small sample problem” of hyperspectral pixel-level classification, we designed a multiscale information fusion hybrid 2D-3D CNN named the multiscale squeeze-and-excitation pyramid pooling network (MSPN) model to improve the classification performance. The model can not only deepen the network vertically, but can also expand the multiscale spectral–spatial information horizontally. In terms of being lightweight, the frequently used fully connected layer at the tail is replaced for the first time by a global average pooling layer to reduce model parameters.
- The proposed MSPN was trained on a small sample with 5%, 0.5%, and 0.5% of the labeled data from the three public datasets of Indian Pine, Salinas, and Pavia University, respectively. The prediction accuracies reached up to 96.09%, 97%, and 96.56%, respectively. The MSPN achieved high classification performance on the small sample.
2. Methodology
2.1. Multiscale 3D-CNN
2.2. SE Block
2.3. Pyramid Pooling Module
3. Datasets and Details
- Each Indian Pine hyperspectral image is composed of 145 × 145 pixels with a spatial resolution of 20 m. The bands covering the water-absorbing area are removed, and the remaining 200 bands are used for classification. Indian Pine landscape mainly includes different types of crops, forests, and other perennial plants. The ground truth values are specified into 16 classes. The number of available sample points for all classes is 10,249. Each class includes a minimum of 20 and a maximum of 2455 sample points. As such, the distribution of sample points is very uneven. In addition, the crops are divided into two classes due to the different levels of tillage. For example, the first class is no-till corn and the second class is low-till corn. Both of them are cornfields.
- Each Salinas hyperspectral image consists of 512 × 217 pixels with a spatial resolution of 3.7 m. Similar to the Indian Pine images, the water absorption band is discarded and 204 bands remain. The Salinas scenes mainly include vegetation, bare soil, and vineyards. A total of 54,129 sample points are divided into 16 groups. Per class, the minimum number of sample points is 916 and the maximum number is 11,271, which is rather uneven. The Salinas dataset differs from the Indian Pine dataset in that there are more available labeled sample points and the spatial resolution is higher. There is also a similarity between several classes, e.g., classes 11, 12, 13, and 14 are longleaf lettuces, but they are divided into four classes depending on growth time. The advantage of this dataset is the high spatial resolution, which can help to improve the classification effect.
- Each Pavia University hyperspectral image consists of 610 × 340 pixels with a spatial resolution of 1.3 m. The dataset includes 103 spectral bands. The labeled samples are divided into nine classes. The scenes mainly include urban features, such as metal sheets, roofs, asphalt pavements, etc. Per class, the minimum number of sample points is 947 and the maximum number is 18,649. The total number of labeled sample points is 42,776.
- The WHU-Hi-LongKou dataset was acquired in 2018 in Longkou Town, China. Each hyperspectral image consists of 550 × 400 pixels with 270 bands from 400 to 1000 nm, and the spatial resolution of the hyperspectral imagery is about 0.463 m. It contains nine classes, namely Corn, Cotton, Sesame, Broad-leaf soybean, Narrow-leaf soybean, Rice, Water, Roads and houses, and Mixed weed. The minimum number of sample points is 3031 and the maximum number is 67,056. The total number of labeled sample points is 204,542.
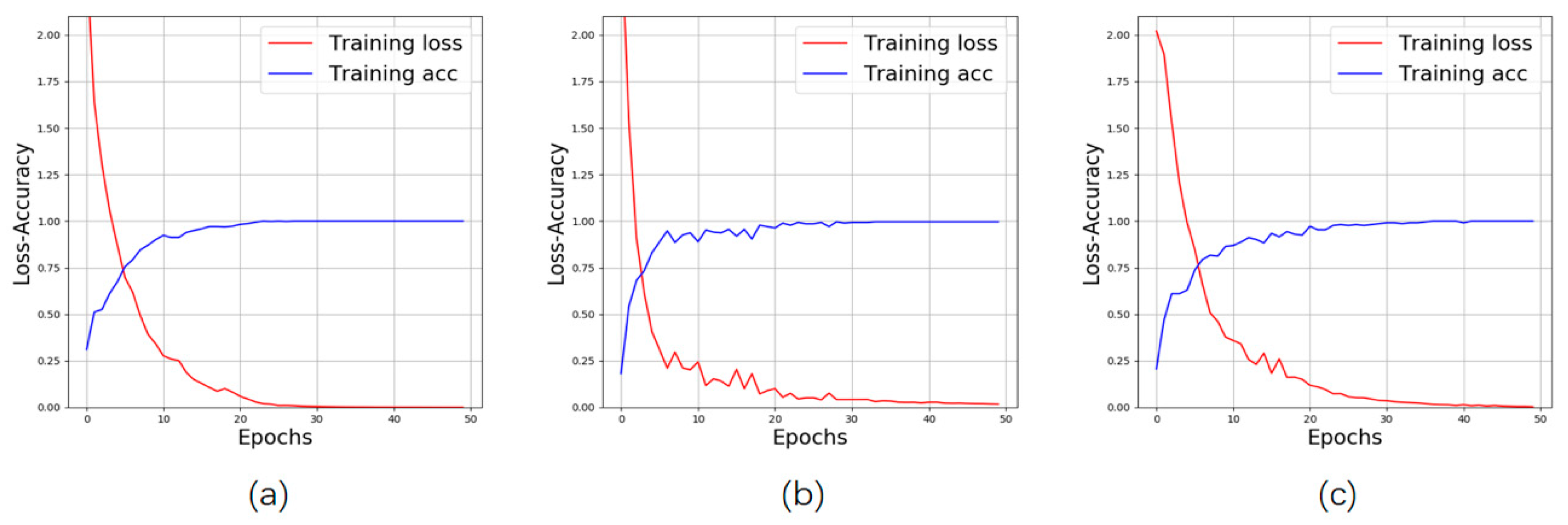
4. Results of Experiment
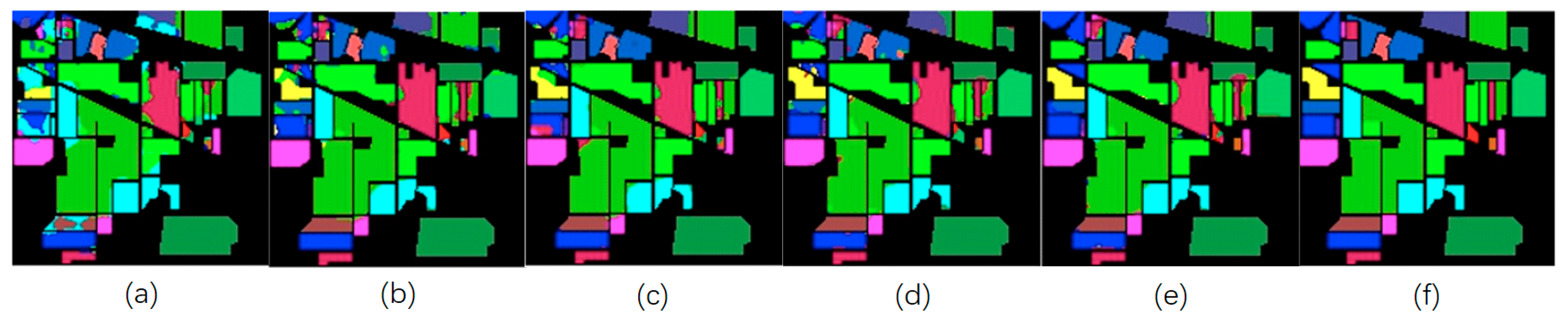
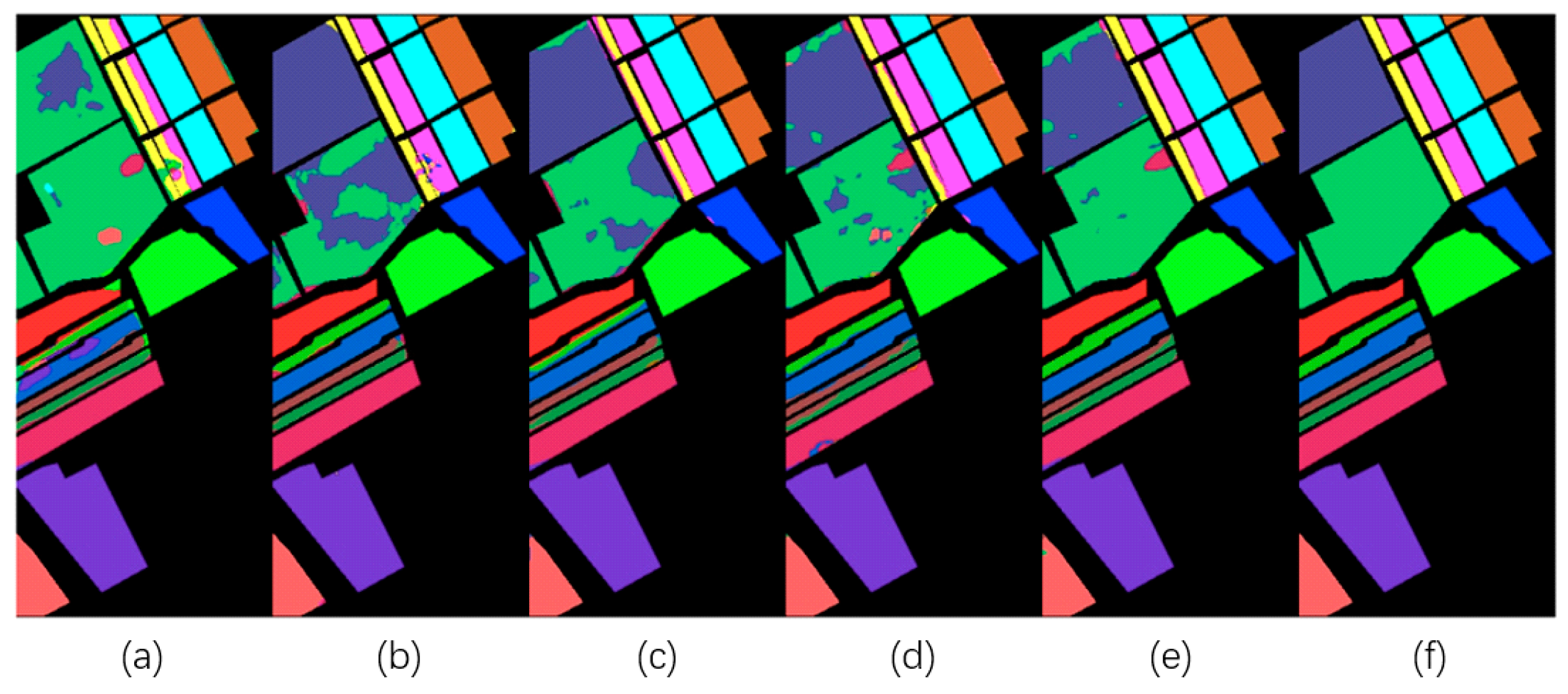
- The first experiment evaluated the classification performances of the proposed MSPN and other models in terms of overall accuracy (OA), average accuracy (AA), and kappa coefficient, using a different number of training samples of the three classic datasets.
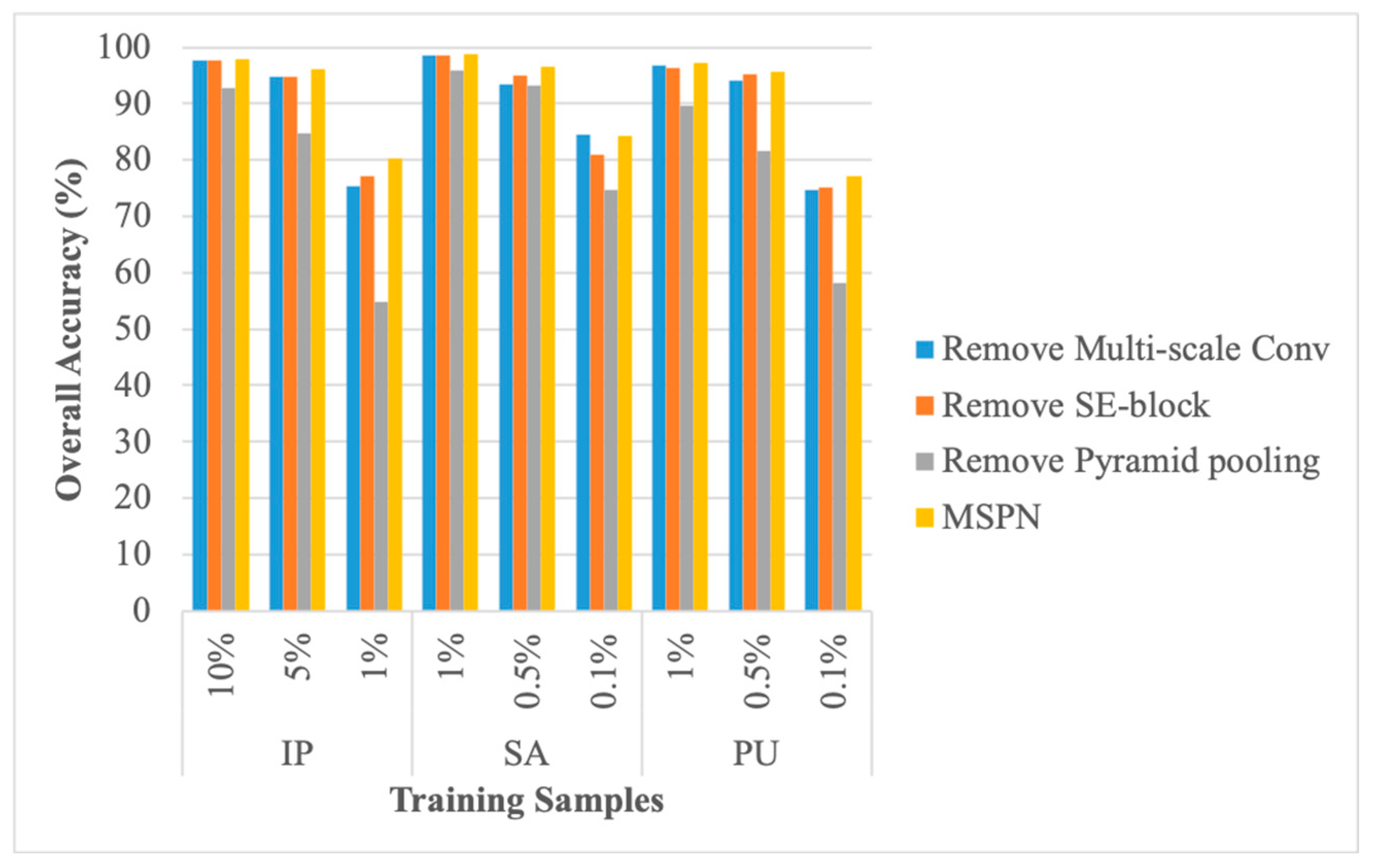
- The second experiment compared the classification performances of the original MSPN model and its variants, such as by removing the multiscale 3D-CNN, SE block, or pyramid pooling module.
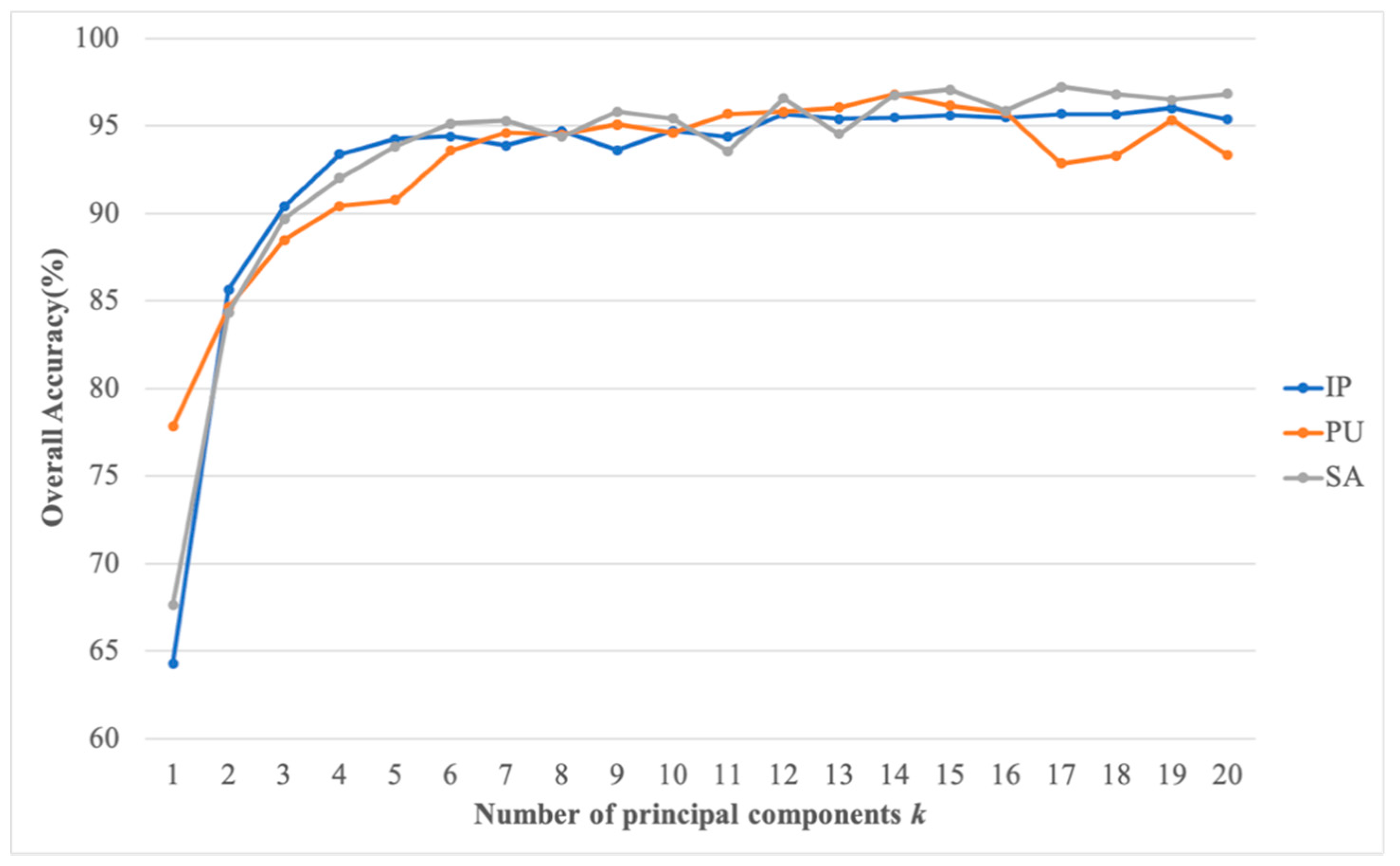
- The third experiment verified the influence of the selection of principal components on the model performance.
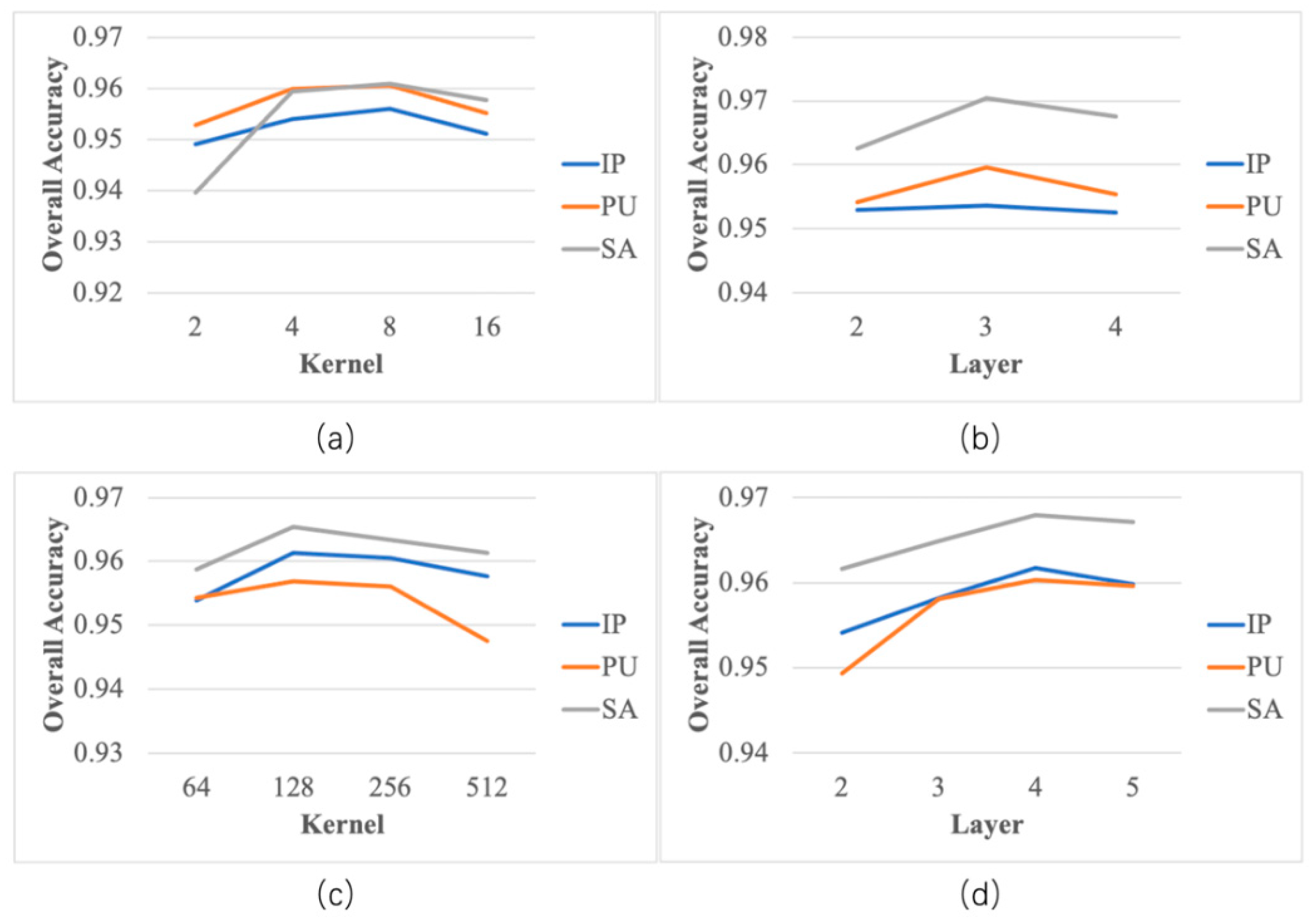
- The fourth experiment determined the proper number of convolutional kernels and the number of parallel convolutional layers.
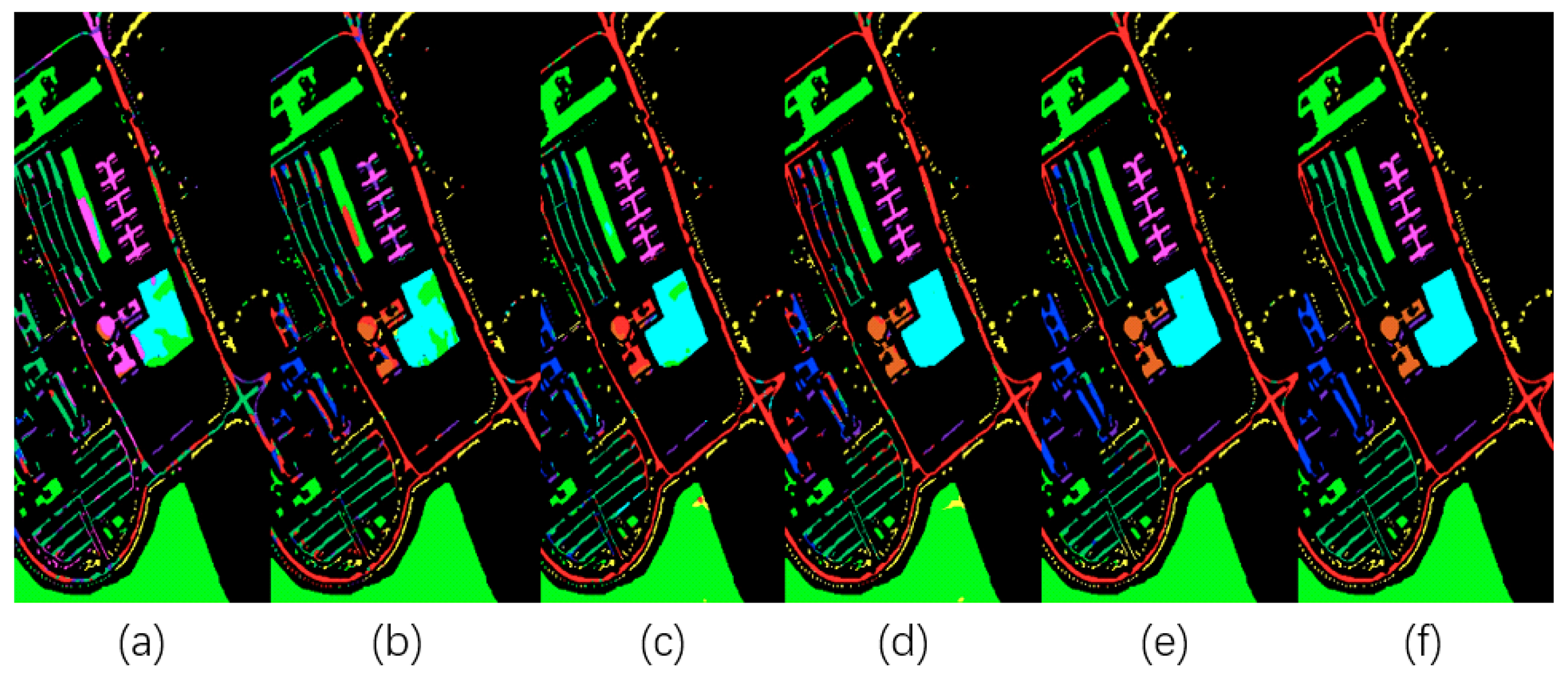
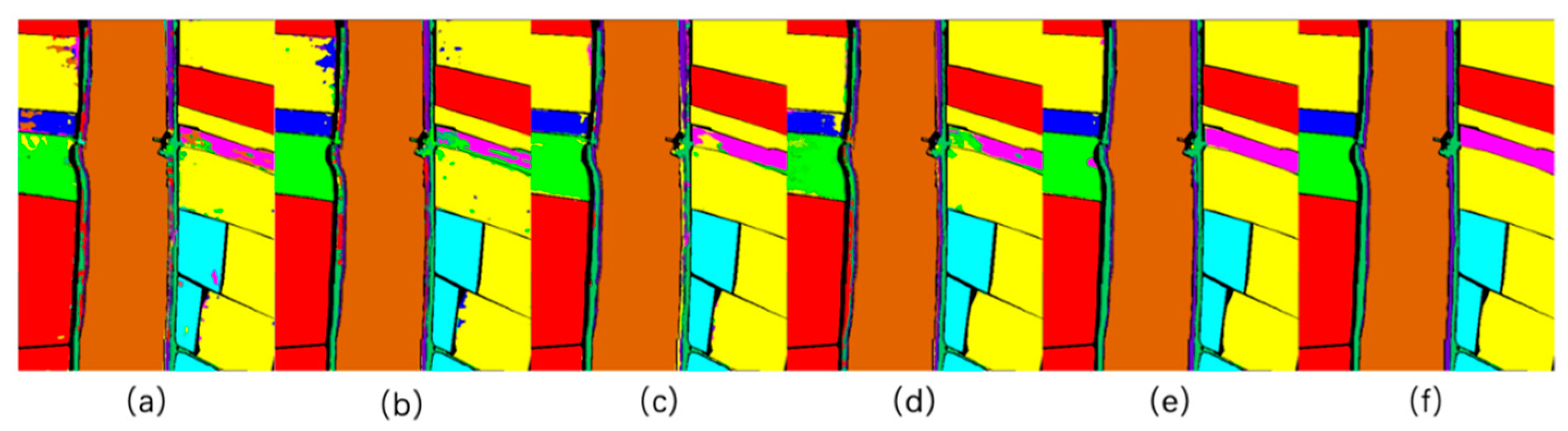
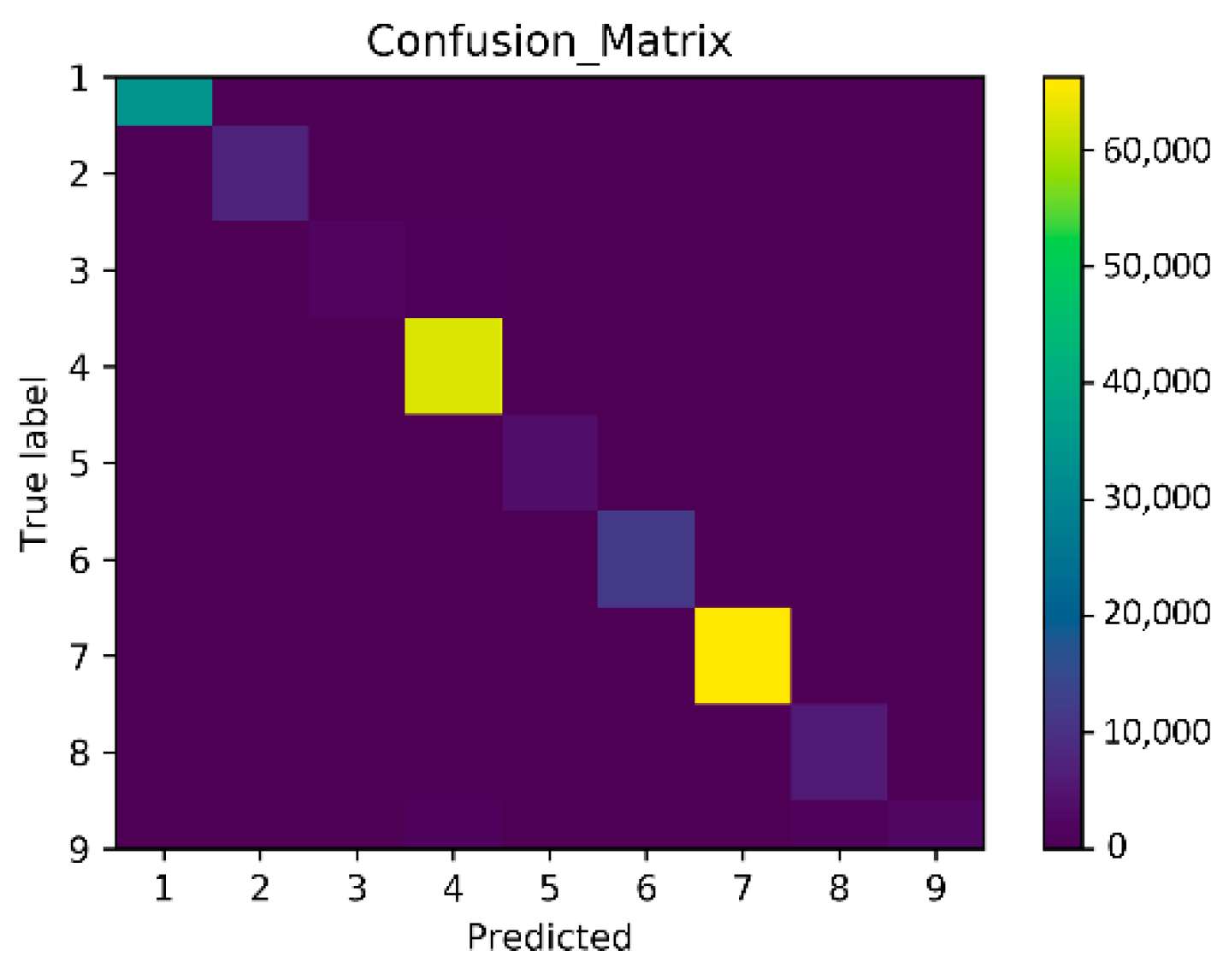
- The fifth experiment aimed to challenge the latest high-resolution remote sensing images in the WHU-Hi-LongKou dataset. We compared our proposed MSPN model with other methods by taking 0.1% of the sample points as a training sample. At the same time, a confusion matrix was used to visualize the classification results of our proposed model.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Huang, R.; He, M. Band selection based on feature weighting for classification of hyperspectral data. IEEE Geosci. Remote Sens. Lett. 2005, 2, 156–159. [Google Scholar] [CrossRef]
- Hang, L.; Zhang, L.; Tao, D.; Huang, X.; Du, B. Hyperspectral Remote Sensing Image Subpixel Target Detection Based on Supervised Metric Learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4955–4965. [Google Scholar] [CrossRef]
- Luo, B.; Yang, C.; Chanussot, J.; Zhang, L. Crop yield estimation based on unsupervised linear unmixing of multidate hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 162–173. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Plaza, A.; Li, Y. Discriminative Low-Rank Gabor Filtering for Spectral-Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1381–1395. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Pietikäinen, M. Local Binary Patterns. Scholarpedia 2010, 5, 9775. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspec- tral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Hyperspectral image segmen- tation using a new Bayesian approach with active learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3947–3960. [Google Scholar] [CrossRef]
- Huang, K.; Li, S.; Kang, X.; Fang, L. Spectral–Spatial Hyperspectral Image Classification Based on KNN. Sens. Imaging Int. J. 2016, 17, 1–13. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Arvelyna, Y.; Shuichi, M.; Atsushi, M.; Nguno, A.; Mhopjeni, K.; Muyongo, A.; Sibeso, M.; Muvangua, E. Hyperspectral mapping for rock and alteration mineral with Spectral Angle Mapping and Neural Network classification method: Study case in Warmbad district, south of Namibia. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 1752–1754. [Google Scholar]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear versus nonlinear PCA for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Villa, A.; Benediktsson, J.A.; Chanussot, J.; Jutten, C. Hyper- spectral image classification with independent component discrimi- nant analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4865–4876. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Jia, S.; Shen, L.; Li, Q. Gabor feature-based collaborative repre- sentation for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1118–1129. [Google Scholar]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral image classification with imbalanced data based on orthogonal complement subspace projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. Joint learning of words and meaning representations for open-text semantic parsing. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, 12–15 April 2012; pp. 127–135. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral-spatial classification of hyper- spectral data based on deep belief network. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H.-C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sensors 2015, 2015, 1–12. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through con volutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Zhu, J.; Fang, L.; Ghamisi, P. Deformable Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1254–1258. [Google Scholar] [CrossRef]
- Pan, B.; Xu, X.; Shi, Z.; Zhang, N.; Luo, H.; Lan, X. DSSNet: A Simple Dilated Semantic Segmentation Network for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1968–1972. [Google Scholar] [CrossRef]
- Li, X.; Ding, M.; Pižurica, A. Deep Feature Fusion via Two-Stream Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2615–2629. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar]
- Sellami, A.; Ben Abbes, A.; Barra, V.; Farah, I.R. Fused 3-D spectral-spatial deep neural networks and spectral clustering for hyperspectral image classification. Pattern Recognit. Lett. 2020, 138, 594–600. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep Pyramidal Residual Networks for Spectral-Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Swalpa, K.R.; Gopal, K.; Shiv, R.D.; Bidyut, B.C. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial–Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral Image Classification Method Based on 2D–3D CNN and Multibranch Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1063–6919. [Google Scholar]
- Liang, M.; Jiao, L.; Yang, S.; Liu, F.; Hou, B.; Chen, H. Deep multiscale spectral-spatial feature fusion for hyperspectral images classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 2911–2924. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.N.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction with Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S. A CNN with Multiscale Convolution and Diversified Metric for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Roy, S.K.; Chatterjee, S.; Bhattacharyya, S.; Chaudhuri, B.B.; Platos, J. Lightweight Spectral–Spatial Squeeze-and- Excitation Residual Bag-of-Features Learning for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5277–5290. [Google Scholar] [CrossRef]
- Kim, J.H.; Lee, H.; Hong, S.J.; Kim, S.; Park, J.; Hwang, J.Y.; Choi, J.P. Objects Segmentation From High-Resolution Aerial Images Using U-Net With Pyramid Pooling Layers. IEEE Geosci. Remote Sens. Lett. 2018, 16, 115–119. [Google Scholar] [CrossRef]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An End-to-End Neural Network for Road Extraction from Remote Sensing Imagery by Multiple Feature Pyramid Network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indian Pine | Salinas | Pavia University | WHU-Hi-LongKou | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Order | Class | Samples | Order | Class | Samples | Order | Class | Samples | Order | Class | Samples |
| 1 | Alfalfa | 46 | 1 | Brocoli_green_weeds_1 | 2009 | 1 | Asphalt | 6631 | 1 | Corn | 34,511 |
| 2 | Corn-notill | 1428 | 2 | Brocoli_green_weeds_2 | 3726 | 2 | Meadows | 18,649 | 2 | Cotton | 8374 |
| 3 | Corn-mintill | 830 | 3 | Fallow | 1976 | 3 | Gravel | 2099 | 3 | Sesame | 3031 |
| 4 | Corn | 237 | 4 | Fallow_rough_plow | 1394 | 4 | Trees | 3064 | 4 | Broad-leaf soybean | 63,212 |
| 5 | Grass-pasture | 483 | 5 | Fallow_smooth | 2678 | 5 | Paintedmetalsheets | 1345 | 5 | Narrow-leaf soybean | 4151 |
| 6 | Grass-trees | 730 | 6 | Stubble | 3959 | 6 | Bare Soil | 5029 | 6 | Rice | 11,854 |
| 7 | Grass-pasture-mowed | 28 | 7 | Celery | 3579 | 7 | Bitumen | 1330 | 7 | Water | 67,056 |
| 8 | Hay-windrowed | 478 | 8 | Grapes_untrained | 11,271 | 8 | Self-Blocking Bricks | 3682 | 8 | Roads and houses | 7124 |
| 9 | Oats | 20 | 9 | Soil_vinyard_develop | 6203 | 9 | Shadows | 947 | 9 | Mixed weed | 5229 |
| 10 | Soybean-notill | 972 | 10 | Corn_senesced_green_weeds | 3278 | ||||||
| 11 | Soybean-mintill | 2455 | 11 | Lettuce_romaine_4wk | 1068 | ||||||
| 12 | Soybean-clean | 593 | 12 | Lettuce_romaine_5wk | 1927 | ||||||
| 13 | Wheat | 205 | 13 | Lettuce_romaine_6wk | 916 | ||||||
| 14 | Woods | 1265 | 14 | Lettuce_romaine_7wk | 1070 | ||||||
| 15 | Buildings-Grass-Trees-Drives | 386 | 15 | Vinyard_untrained | 7268 | ||||||
| 16 | Stone-Steel-Towers | 93 | 16 | Vinyard_vertical_trellis | 1807 | ||||||
| Order | Class | 2D-CNN | M3D-CNN | HybridSN | R-HybridSN | MSPN |
|---|---|---|---|---|---|---|
| 1 | Alfalfa | 0.85 | 1.00 | 0.96 | 1.00 | 0.91 |
| 2 | Corn-notill | 0.85 | 0.90 | 0.92 | 0.90 | 0.95 |
| 3 | Corn-mintill | 0.91 | 0.94 | 0.97 | 0.98 | 0.95 |
| 4 | Corn | 0.92 | 0.87 | 0.98 | 0.92 | 1.00 |
| 5 | Grass-pasture | 0.91 | 0.99 | 0.94 | 0.98 | 0.97 |
| 6 | Grass-trees | 0.48 | 0.97 | 1.00 | 1.00 | 1.00 |
| 7 | Grass-pasture-mowed | 1.00 | 1.00 | 1.00 | 1.00 | 0.90 |
| 8 | Hay-windrowed | 0.90 | 1.00 | 0.95 | 0.91 | 1.00 |
| 9 | Oats | 0.00 | 0.93 | 0.75 | 1.00 | 0.93 |
| 10 | Soybean-notill | 0.98 | 0.92 | 0.88 | 0.87 | 0.90 |
| 11 | Soybean-mintill | 0.92 | 0.89 | 0.92 | 0.96 | 0.97 |
| 12 | Soybean-clean | 0.89 | 0.84 | 0.97 | 0.96 | 0.95 |
| 13 | Wheat | 0.98 | 1.00 | 1.00 | 0.95 | 0.99 |
| 14 | Woods | 1.00 | 0.97 | 0.99 | 0.93 | 0.98 |
| 15 | Buildings-Grass-Trees-Drives | 0.87 | 0.98 | 0.98 | 0.94 | 0.97 |
| 16 | Stone-Steel-Towers | 0.93 | 0.92 | 0.97 | 0.80 | 0.99 |
| OA/% | 85.56 | 92.65 | 94.19 | 93.66 | 96.09 | |
| Kappa/% | 83.49 | 91.57 | 93.34 | 92.77 | 95.53 | |
| AA/% | 71.43 | 86.83 | 86.79 | 87.57 | 91.53 |
| Order | Class | 2D-CNN | M3D-CNN | HybridSN | R-HybridSN | MSPN |
|---|---|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 0.94 | 1.00 | 0.98 | 1.00 | 1.00 |
| 2 | Brocoli_green_weeds_2 | 0.92 | 1.00 | 0.97 | 1.00 | 1.00 |
| 3 | Fallow | 1.00 | 0.95 | 1.00 | 1.00 | 1.00 |
| 4 | Fallow_rough_plow | 0.48 | 0.90 | 0.96 | 0.98 | 0.98 |
| 5 | Fallow_smooth | 1.00 | 0.98 | 1.00 | 0.91 | 0.97 |
| 6 | Stubble | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 |
| 7 | Celery | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 |
| 8 | Grapes_untrained | 0.64 | 0.92 | 0.99 | 0.95 | 0.94 |
| 9 | Soil_vinyard_develop | 0.91 | 0.99 | 0.95 | 1.00 | 0.99 |
| 10 | Corn_senesced_green_weeds | 0.88 | 1.00 | 1.00 | 0.90 | 0.90 |
| 11 | Lettuce_romaine_4wk | 1.00 | 0.99 | 1.00 | 0.96 | 1.00 |
| 12 | Lettuce_romaine_5wk | 0.99 | 0.91 | 1.00 | 0.86 | 1.00 |
| 13 | Lettuce_romaine_6wk | 0.91 | 0.89 | 0.74 | 0.76 | 0.91 |
| 14 | Lettuce_romaine_7wk | 1.00 | 0.91 | 0.87 | 0.83 | 0.90 |
| 15 | Vinyard_untrained | 0.94 | 0.60 | 0.84 | 0.85 | 0.98 |
| 16 | Vinyard_vertical_trellis | 0.87 | 1.00 | 1.00 | 0.86 | 1.00 |
| OA/% | 82.88 | 89.67 | 95.52 | 93.55 | 97.00 | |
| Kappa/% | 80.77 | 88.60 | 95.02 | 92.83 | 96.66 | |
| AA/% | 84.91 | 95.32 | 95.57 | 93.24 | 97.33 |
| Order | Class | 2D-CNN | M3D-CNN | HybridSN | R-HybridSN | MSPN |
|---|---|---|---|---|---|---|
| 1 | Asphalt | 0.94 | 0.76 | 0.78 | 0.94 | 0.95 |
| 2 | Meadows | 0.90 | 0.85 | 0.94 | 0.99 | 0.98 |
| 3 | Gravel | 0.71 | 0.68 | 0.80 | 0.74 | 0.87 |
| 4 | Trees | 1.00 | 0.93 | 0.93 | 0.94 | 0.96 |
| 5 | Painted metal sheets | 0.26 | 1.00 | 0.93 | 0.99 | 1.00 |
| 6 | Bare Soil | 0.97 | 0.99 | 0.93 | 0.96 | 0.99 |
| 7 | Bitumen | 0.96 | 0.75 | 0.78 | 0.86 | 0.99 |
| 8 | Self-Blocking Bricks | 0.46 | 0.67 | 0.81 | 0.71 | 0.93 |
| 9 | Shadows | 0.35 | 0.54 | 0.97 | 0.84 | 0.95 |
| OA/% | 74.77 | 81.95 | 89.10 | 92.54 | 96.56 | |
| Kappa/% | 66.53 | 75.21 | 85.35 | 90.12 | 95.42 | |
| AA/% | 61.10 | 68.25 | 76.92 | 89.50 | 94.55 |
| Train time/s | Test time/s | |
|---|---|---|
| 2D-CNN | 418.4 | 1512.4 |
| R-HybridSN | 332.3 | 1336.1 |
| MSPN | 310.7 | 1035.5 |
| Order | Class | 2D-CNN | M3D-CNN | HybridSN | R-HybridSN | MSPN |
|---|---|---|---|---|---|---|
| 1 | Corn | 0.95 | 0.95 | 0.98 | 0.95 | 0.99 |
| 2 | Cotton | 0.91 | 0.83 | 0.93 | 0.75 | 0.94 |
| 3 | Sesame | 0.93 | 0.97 | 1.00 | 0.71 | 1.00 |
| 4 | Broad-leaf soybean | 0.97 | 0.97 | 0.95 | 0.99 | 0.96 |
| 5 | Narrow-leaf soybean | 0.76 | 0.96 | 0.81 | 0.96 | 0.84 |
| 6 | Rice | 0.97 | 0.99 | 0.96 | 0.99 | 1.00 |
| 7 | Water | 0.97 | 0.98 | 1.00 | 1.00 | 1.00 |
| 8 | Roads and houses | 0.84 | 0.85 | 0.84 | 0.83 | 0.91 |
| 9 | Mixed weed | 0.91 | 0.93 | 0.86 | 0.90 | 0.86 |
| OA/% | 95.49 | 96.04 | 96.39 | 96.03 | 97.31 | |
| Kappa/% | 94.05 | 94.76 | 95.24 | 94.79 | 96.45 | |
| AA/% | 84.32 | 84.87 | 86.62 | 87.81 | 89.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, H.; Li, Q.; Li, C.; Dai, H.; He, Z.; Wang, W.; Li, H.; Han, F.; Tuniyazi, A.; Mu, T. Multiscale Information Fusion for Hyperspectral Image Classification Based on Hybrid 2D-3D CNN. Remote Sens. 2021, 13, 2268. https://doi.org/10.3390/rs13122268
Gong H, Li Q, Li C, Dai H, He Z, Wang W, Li H, Han F, Tuniyazi A, Mu T. Multiscale Information Fusion for Hyperspectral Image Classification Based on Hybrid 2D-3D CNN. Remote Sensing. 2021; 13(12):2268. https://doi.org/10.3390/rs13122268
Chicago/Turabian StyleGong, Hang, Qiuxia Li, Chunlai Li, Haishan Dai, Zhiping He, Wenjing Wang, Haoyang Li, Feng Han, Abudusalamu Tuniyazi, and Tingkui Mu. 2021. "Multiscale Information Fusion for Hyperspectral Image Classification Based on Hybrid 2D-3D CNN" Remote Sensing 13, no. 12: 2268. https://doi.org/10.3390/rs13122268
APA StyleGong, H., Li, Q., Li, C., Dai, H., He, Z., Wang, W., Li, H., Han, F., Tuniyazi, A., & Mu, T. (2021). Multiscale Information Fusion for Hyperspectral Image Classification Based on Hybrid 2D-3D CNN. Remote Sensing, 13(12), 2268. https://doi.org/10.3390/rs13122268