
Fast and Fine Location of Total Lightning from Low Frequency Signals Based on Deep-Learning Encoding Features

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
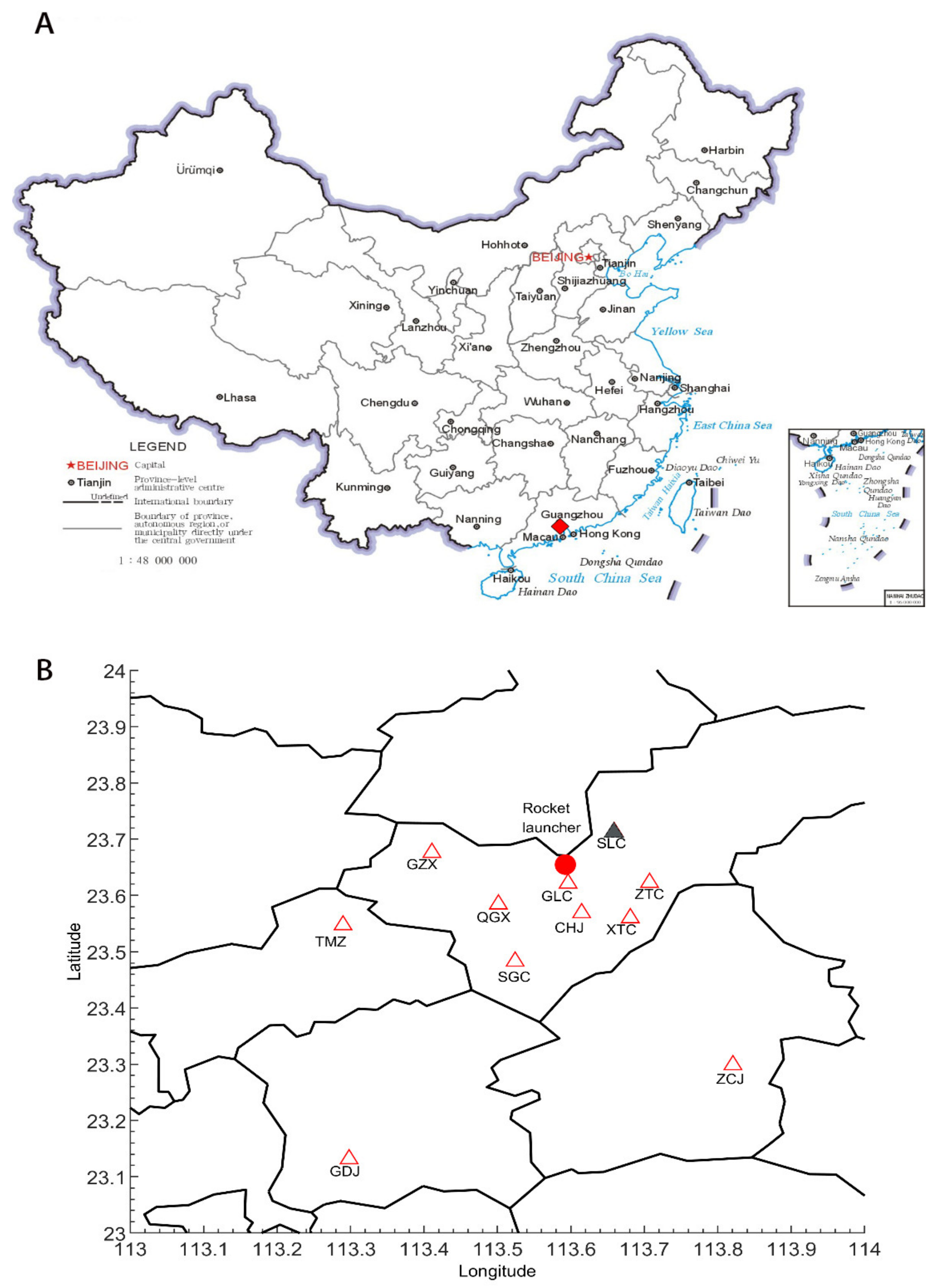
2.1. LFEDA System
2.2. Experiments with Artificially Triggered Lightning
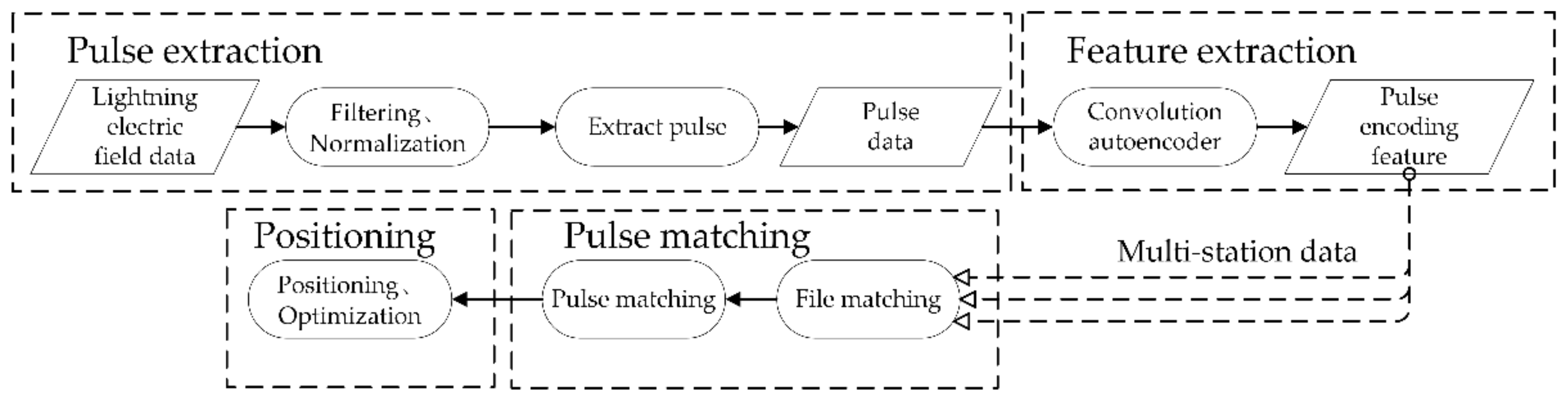
2.3. Location Method
2.4. Establishment of Convolutional Autoencoder Model
2.5. Selection of the Model Key Parameter
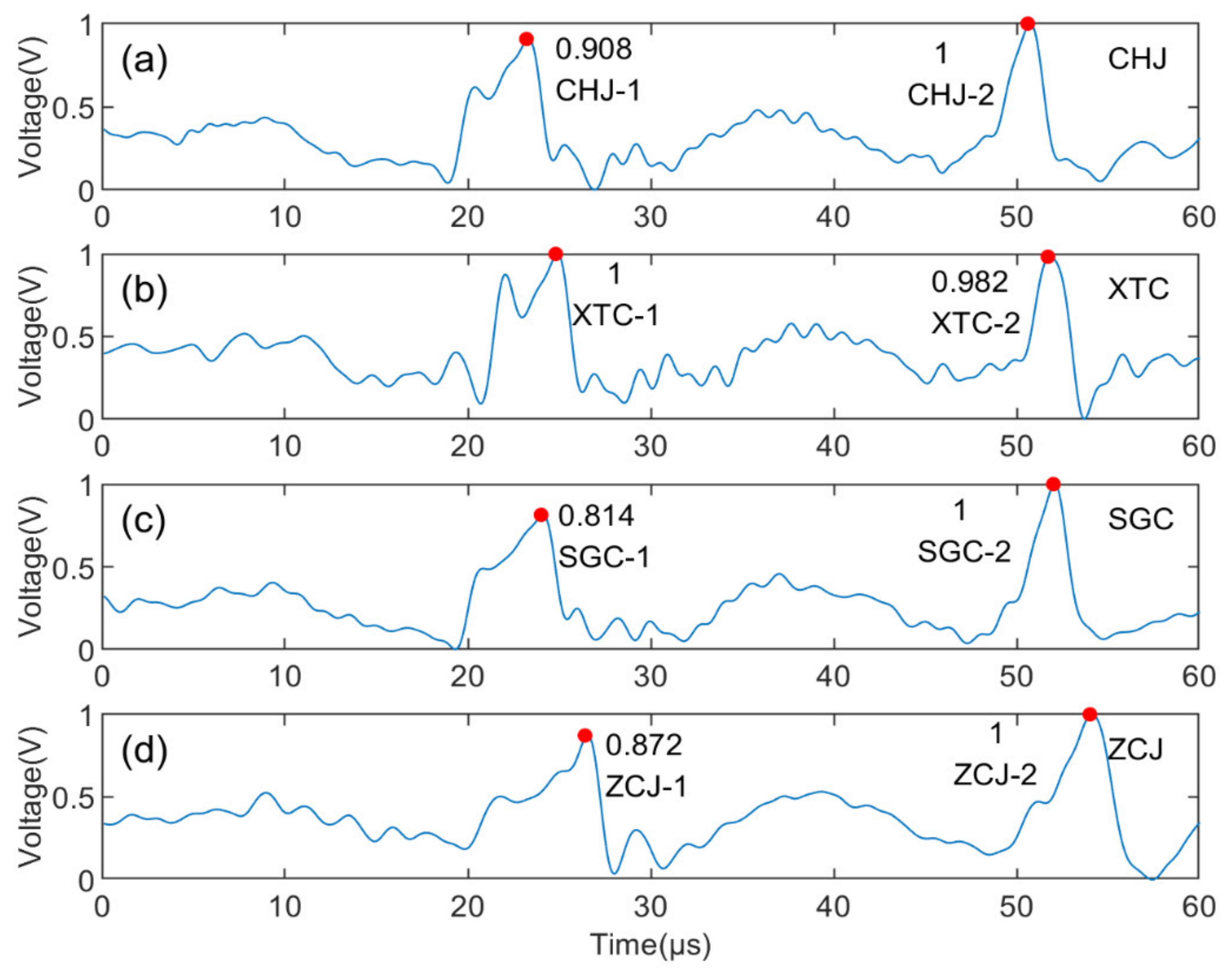
2.6. Matching Ability of New Algorithm
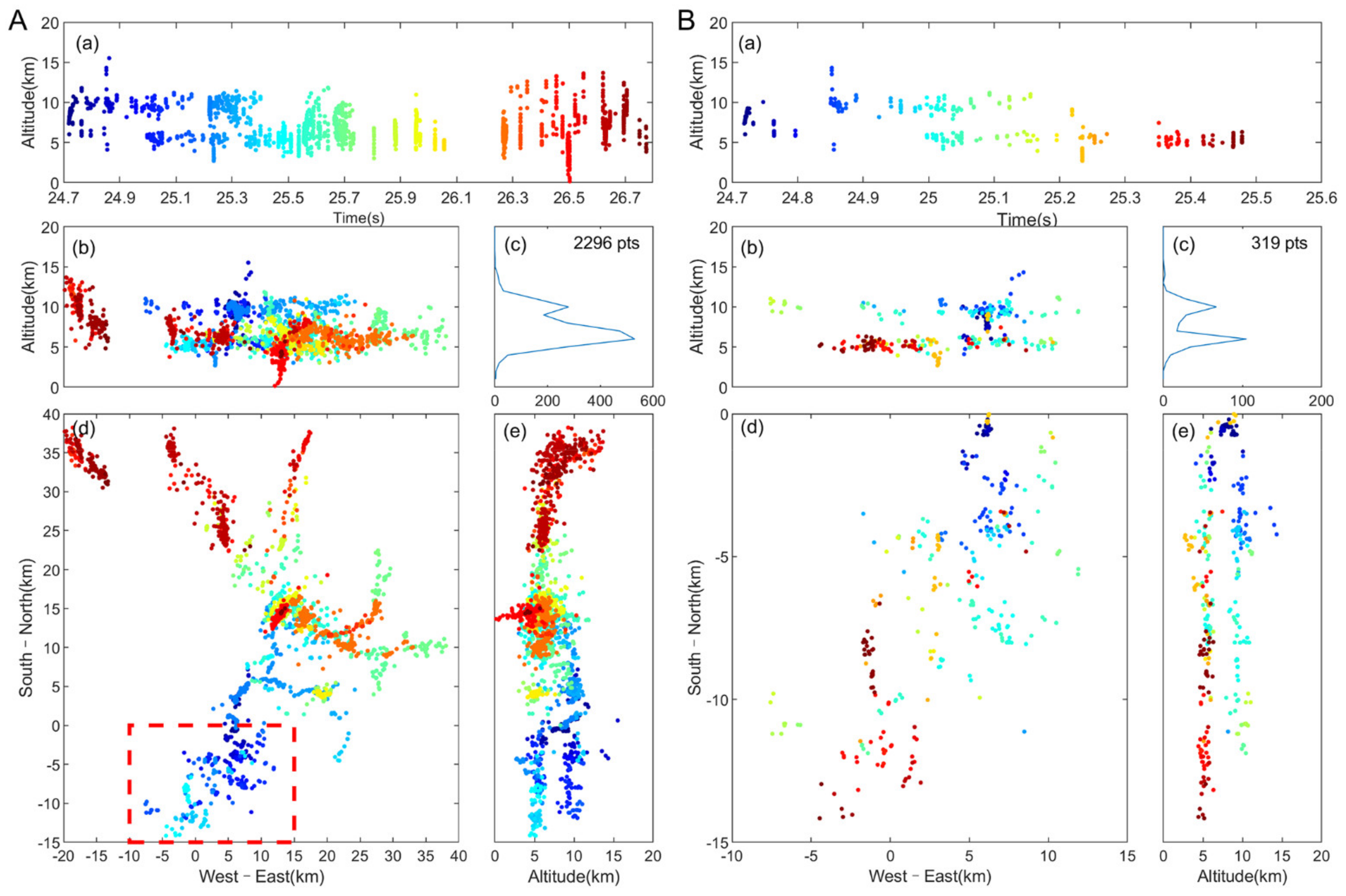
3. Results
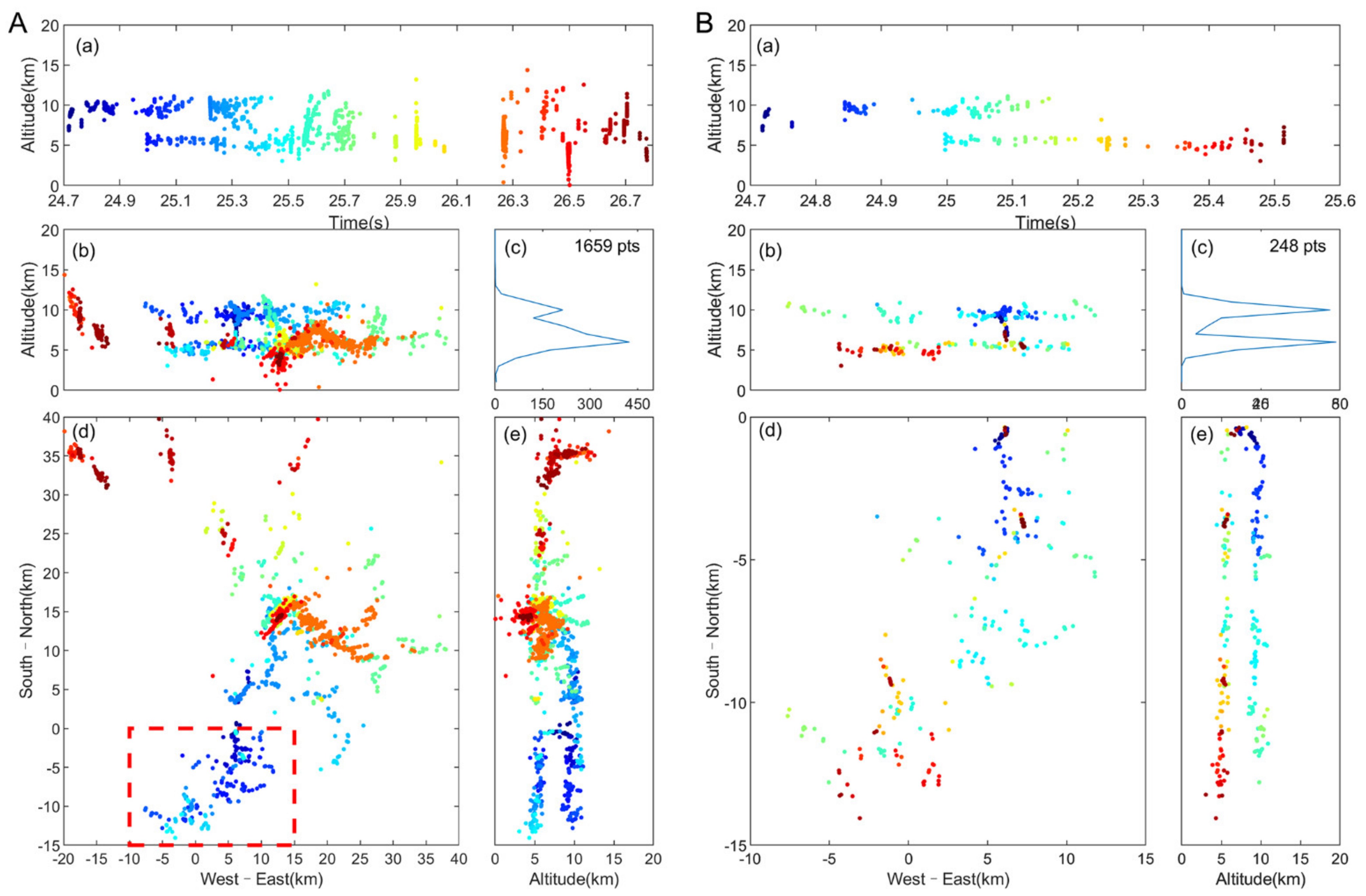
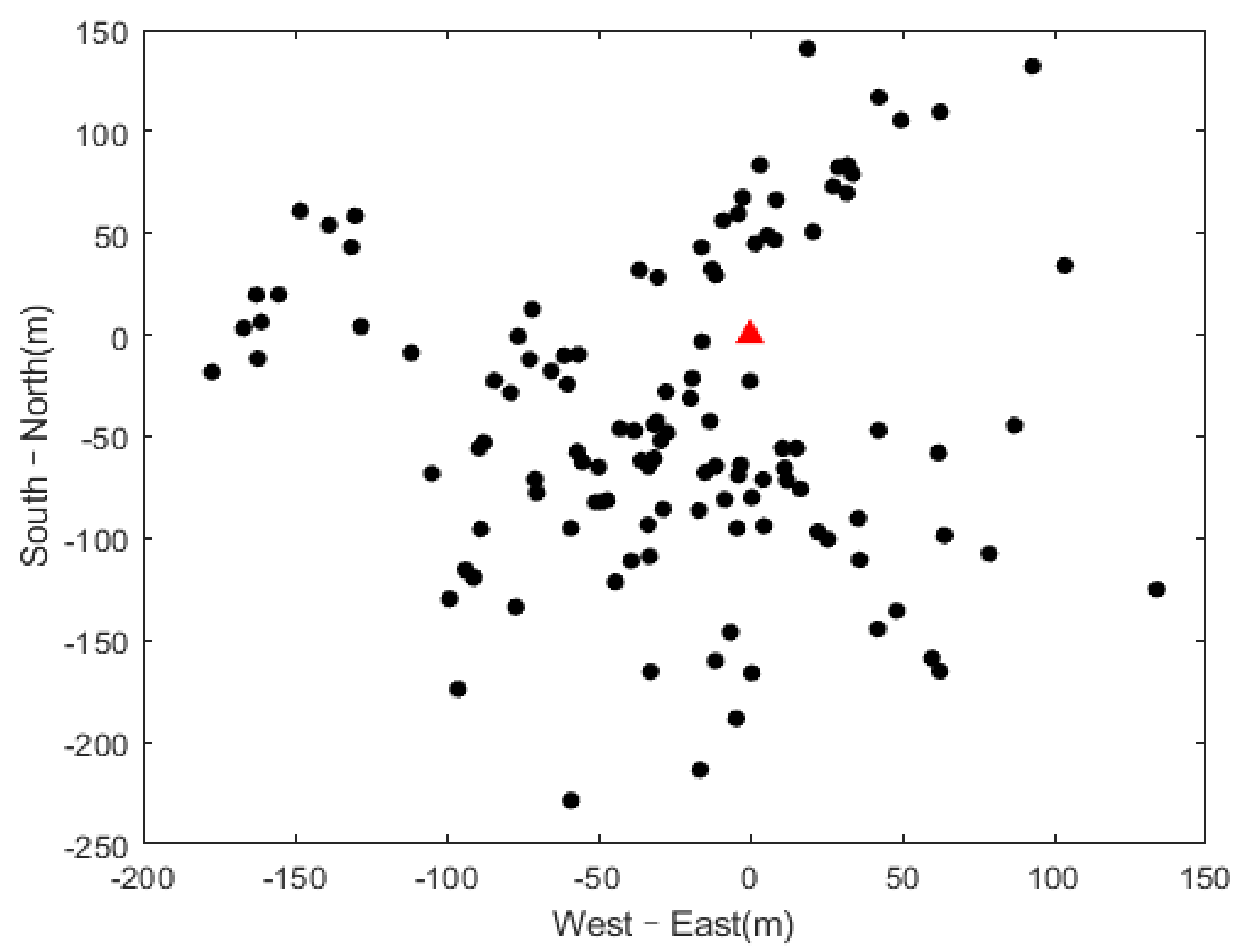
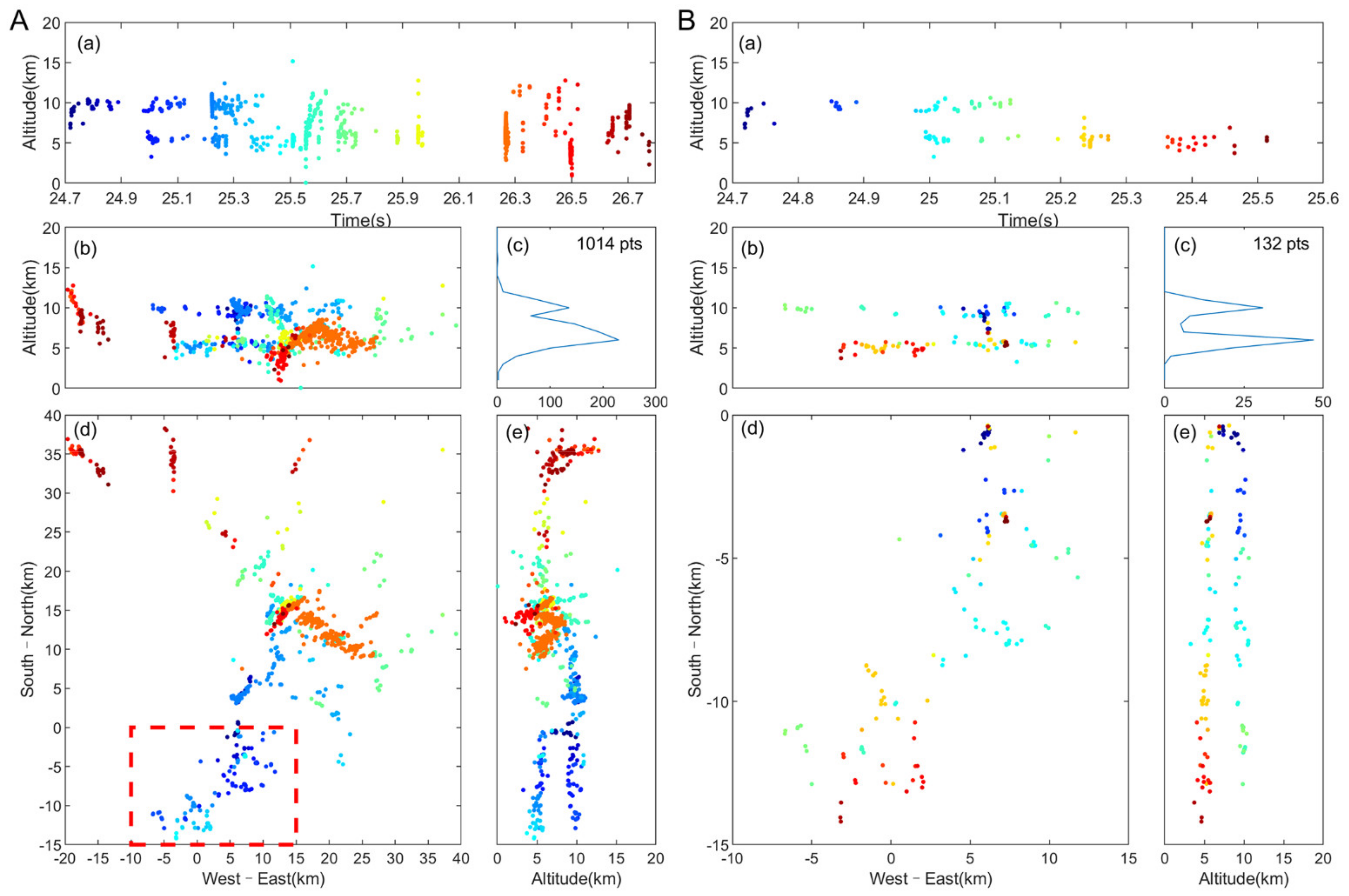
3.1. Positioning Results
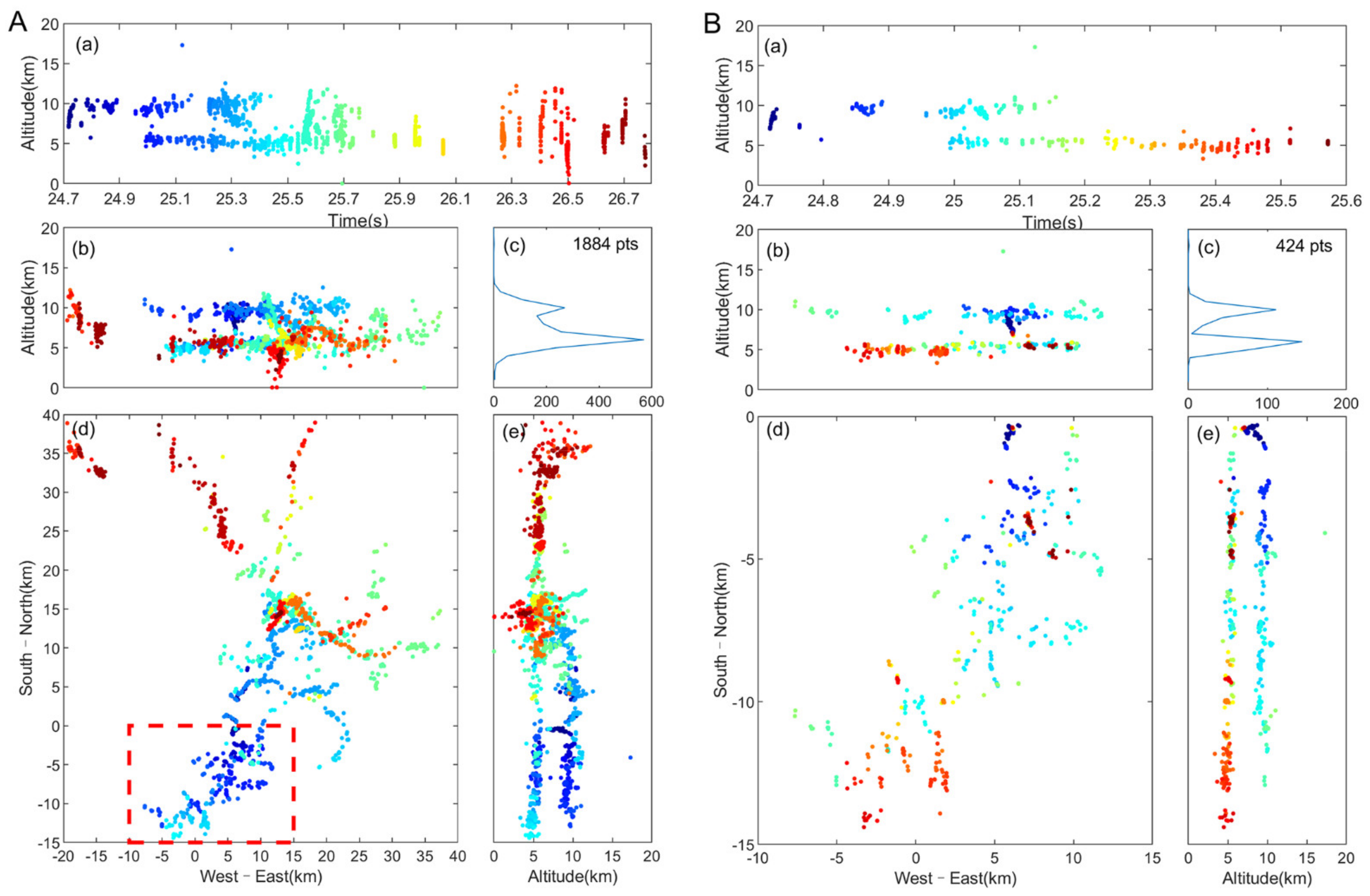
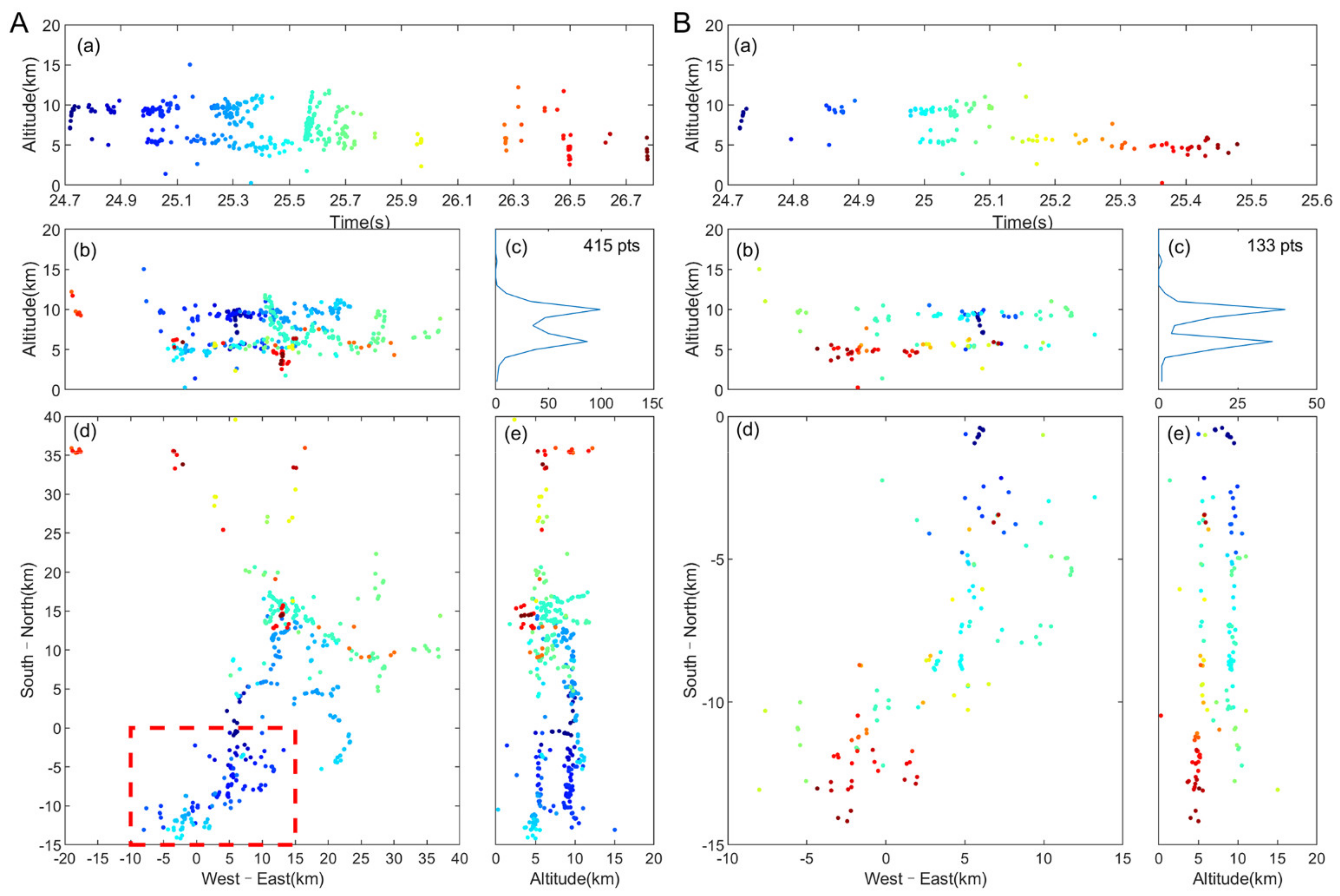
3.2. Performance Evaluation of New Algorithm
4. Analysis and Discussion
4.1. Matching Efficiency of the New Algorithm
4.2. Positioning Capability under Low SNR Signal
5. Conclusions
- A low-frequency total lightning TOA method based on deep-learning encoding feature matching is proposed. This method uses deep-learning convolutional autoencoders to accurately extract the characteristics of lightning discharge pulses. Compared to the pulse-peak feature matching and waveform cross-correlation matching methods (TOA-TR method), the matching efficiency is greatly improved, by up to 50%, which improves the efficiency of positioning calculation and the ability of real-time positioning.
- The new algorithm has better fine 3D channel positioning capabilities. Compared to the TOA method based on the pulse-peak feature matching, the TOA–TR algorithm, and the EMD–TOA algorithm, the new algorithm had the most abundant location points and more continuous location channels. Moreover, the EMD–TOA algorithm requires complex waveform processing, and the TOA–TR method requires multiple spatial optimizations, both of which require considerable computing time (the positioning time of the above two methods for the same lightning was more than 0.5 h), resulting in a significant reduction in location efficiency (speed). The new algorithm produces results in less than 2 min.
- The new algorithm has good anti-interference ability. Under the condition of a low SNR, high-quality positioning effects can be obtained, which is beneficial to the positioning of weak lightning and long-distance lightning. For the lightning example of the same 5 dB SNR signal, the TOA method based on pulse-peak feature matching and the TOA–TR method have significantly fewer positioning points.
- The test results based on artificially triggered lightning showed that the new algorithm has a high positioning accuracy and positioning efficiency. The average location accuracy of the new algorithm is 100 m, and the location efficiency of the return strokes is 99.17%. While the location accuracy and location efficiency of the TOA–TR method are 150 m and 95.6%, respectively. The corresponding values of the TOA method based on pulse-peak feature matching is 102 m and 90.78%, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qie, X.; Zhang, Y. A review of atmospheric electricity research in China from 2011 to 2018. Adv. Atmos. Sci. 2019, 36, 994–1014. [Google Scholar] [CrossRef]
- De Miranda, F.J.; Pinto, O.; Saba, M.M.F. A study of the time interval between return strokes and k-changes of negative cloud-to-ground lightning flashes in Brazil. J. Atmos. Sol. Terr. Phys. 2003, 65, 293–297. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Xie, M.; Zheng, D.; Lu, W.; Chen, S.; Yan, X. Characteristics and correlation of return stroke, m component and continuing current for triggered lightning. Electr. Power Syst. Res. 2016, 139, 10–15. [Google Scholar] [CrossRef]
- Saraiva, A.C.V.; Saba, M.M.F.; Pinto, O.; Cummins, K.L.; Krider, E.P.; Campos, L.Z.S. A comparative study of negative cloud-to-ground lightning characteristics in São Paulo (Brazil) and Arizona (United States) based on high-speed video observations. J. Geophys. Res. 2010, 115. [Google Scholar] [CrossRef]
- Wu, B.; Zhang, G.; Wen, J.; Zhang, T.; Li, Y.; Wang, Y. Correlation analysis between initial preliminary breakdown process, the characteristic of radiation pulse, and the charge structure on the Qinghai-Tibetan plateau. J. Geophys. Res. Atmos. 2016, 121, 12434–12459. [Google Scholar] [CrossRef]
- Shi, D.; Wang, D.; Wu, T.; Takagi, N. Temporal and spatial characteristics of preliminary breakdown pulses in intracloud lightning flashes. J. Geophys. Res. Atmos. 2019, 124, 12901–12914. [Google Scholar] [CrossRef]
- Harley, J.; Zimmerman, L.A.; Edens, H.E.; Stenbaek-Nielsen, H.C.; Haaland, R.K.; Sonnenfeld, R.G.; McHarg, M.G. High-speed spectra of a bolt from the blue lightning stepped leader. J. Geophys. Res. Atmos. 2021, 126. [Google Scholar] [CrossRef]
- Kotovsky, D.A.; Uman, M.A.; Wilkes, R.A.; Jordan, D.M. High-speed video and lightning mapping array observations of in-cloud lightning leaders and an m component to ground. J. Geophys. Res. Atmos. 2019, 124, 1496–1513. [Google Scholar] [CrossRef]
- Visacro, S.; Araujo, L.; Guimarães, M.; Vale, M.H.M. M-component currents of first return strokes in natural negative cloud-to-ground lightning. J. Geophys. Res. Atmos. 2013, 118, 12132–12138. [Google Scholar] [CrossRef]
- Rakov, V.A.; Crawford, D.E.; Rambo, K.J.; Schnetzer, G.H.; Uman, M.A.; Thottappillil, R. M-component mode of charge transfer to ground in lightning discharges. J. Geophys. Res. Atmos. 2001, 106, 22817–22831. [Google Scholar] [CrossRef]
- Thottappillil, R.; Rakov, V.A.; Uman, M.A. K and M changes in close lightning ground flashes in Florida. J. Geophys. Res. Atmos. 1990, 95, 18631–18640. [Google Scholar] [CrossRef]
- Thomas, R.J. Accuracy of the lightning mapping array. J. Geophys. Res. 2004, 109. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.J.; Zheng, D.; Lu, W.T. Characteristics and discharge processes of m events with large current in triggered lightning. Radio Sci. 2018, 53, 974–985. [Google Scholar] [CrossRef]
- Lyu, F.; Cummer, S.A.; Chen, M.; Qin, Z.; Lyu, W.; Sun, J. Three-dimensional mapping of two coincident flashes—An upward positive flash triggered by the in-cloud activity of a downward negative flash. Atmos. Res. 2021, 250, 105408. [Google Scholar] [CrossRef]
- Boccippio, D.J.; Heckman, S.; Goodman, S.J. A diagnostic analysis of the Kennedy space center LDAR network: 2. Cross-sensor studies. J. Geophys. Res. Atmos. 2001, 106, 4787–4796. [Google Scholar] [CrossRef]
- Pu, Y.; Cummer, S.A. Needles and lightning leader dynamics imaged with 100–200 MHz broadband vhf interferometry. Geophys. Res. Lett. 2019, 46, 13556–13563. [Google Scholar] [CrossRef]
- Fuchs, B.R.; Bruning, E.C.; Rutledge, S.A.; Carey, L.D.; Krehbiel, P.R.; Rison, W. Climatological analyses of LMA data with an open-source lightning flash-clustering algorithm. J. Geophys. Res. Atmos. 2016, 121, 8625–8648. [Google Scholar] [CrossRef]
- Takayanagi, Y.; Akita, M.; Nakamura, Y.; Yoshida, S.; Morimoto, T.; Ushio, T.; Kawasaki, Z.-I.; Yamamoto, K. Development of VLF/LF bands interferometer and its initial observations. Electr. Eng. Jpn. 2013, 185, 9–17. [Google Scholar] [CrossRef]
- Betz, H.D.; Marshall, T.C.; Stolzenburg, M.; Schmidt, K.; Oettinger, W.P.; Defer, E.; Konarski, J.; Laroche, P.; Dombai, F. Detection of in-cloud lightning with VLF/LF and VHF networks for studies of the initial discharge phase. Geophys. Res. Lett. 2008, 35. [Google Scholar] [CrossRef]
- Cummins, K.L.; Murphy, M.J.; Bardo, E.A.; Hiscox, W.L.; Pyle, R.B.; Pifer, A.E. A combined TOA/MDF technology upgrade of the U.S. National lightning detection network. J. Geophys. Res. Atmos. 1998, 103, 9035–9044. [Google Scholar] [CrossRef]
- Smith, D.A. The los alamos sferic array: A research tool for lightning investigations. J. Geophys. Res. 2002, 107. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Lu, W.; Zheng, D.; Zhang, Y.; Chen, S.; Huang, Z. Performance evaluation for a lightning location system based on observations of artificially triggered lightning and natural lightning flashes. J. Atmos. Ocean. Technol. 2012, 29, 1835–1844. [Google Scholar] [CrossRef]
- Naccarato, K.P.; Pinto, O. Improvements in the detection efficiency model for the Brazilian lightning detection network (BrasilDAT). Atmos. Res. 2009, 91, 546–563. [Google Scholar] [CrossRef]
- Burrows, W.R.; King, P.; Lewis, P.J.; Kochtubajda, B.; Snyder, B.; Turcotte, V. Lightning occurrence patterns over Canada and adjacent United States from lightning detection network observations. Atmos. Ocean 2002, 40, 59–80. [Google Scholar] [CrossRef]
- Betz, H.D.; Schmidt, K.; Laroche, P.; Blanchet, P.; Oettinger, W.P.; Defer, E.; Dziewit, Z.; Konarski, J. LINET—an international lightning detection network in Europe. Atmos. Res. 2009, 91, 564–573. [Google Scholar] [CrossRef]
- Cai, L.; Zou, X.; Wang, J.; Li, Q.; Zhou, M.; Fan, Y. The Foshan total lightning location system in china and its initial operation results. Atmosphere 2019, 10, 149. [Google Scholar] [CrossRef]
- Cummins, K.L.; Murphy, M.J. An overview of lightning locating systems: History, techniques, and data uses, with an in-depth look at the U.S. NLDN. IEEE Trans. Electromagn. Compat. 2009, 51, 499–518. [Google Scholar] [CrossRef]
- Ma, Z.; Jiang, R.; Qie, X.; Xing, H.; Liu, M.; Sun, Z.; Qin, Z.; Zhang, H.; Li, X. A low frequency 3D lightning mapping network in north China. Atmos. Res. 2021, 249, 105314. [Google Scholar] [CrossRef]
- Wu, T.; Wang, D.; Takagi, N. Locating preliminary breakdown pulses in positive cloud-to-ground lightning. J. Geophys. Res. Atmos. 2018, 123, 7989–7998. [Google Scholar] [CrossRef]
- Karunarathne, S.; Marshall, T.C.; Stolzenburg, M.; Karunarathna, N.; Vickers, L.E.; Warner, T.A.; Orville, R.E. Locating initial breakdown pulses using electric field change network. J. Geophys. Res. Atmos. 2013, 118, 7129–7141. [Google Scholar] [CrossRef]
- Zheng, D.; Shi, D.; Zhang, Y.; Zhang, Y.; Lyu, W.; Meng, Q. Initial leader properties during the preliminary breakdown processes of lightning flashes and their associations with initiation positions. J. Geophys. Res. Atmos. 2019, 124, 8025–8042. [Google Scholar] [CrossRef]
- Zheng, D.; MacGorman, D.R. Characteristics of flash initiations in a supercell cluster with tornadoes. Atmos. Res. 2016, 167, 249–264. [Google Scholar] [CrossRef]
- Yoshida, S.; Wu, T.; Ushio, T.; Takayanagi, Y. Lightning observation in 3D using a multiple LF sensor network and comparison with radar reflectivity. Electr. Eng. Jpn. 2016, 194, 1–10. [Google Scholar] [CrossRef]
- Bitzer, P.M.; Christian, H.J.; Stewart, M.; Burchfield, J.; Podgorny, S.; Corredor, D.; Hall, J.; Kuznetsov, E.; Franklin, V. Characterization and applications of VLF/LF source locations from lightning using the Huntsville Alabama Marx Meter Array. J. Geophys. Res. Atmos. 2013, 118, 3120–3138. [Google Scholar] [CrossRef]
- Alammari, A.; Alkahtani, A.A.; Ahmad, M.R.; Noman, F.M.; Esa, M.R.M.; Kawasaki, Z.; Tiong, S.K. Lightning mapping: Techniques, challenges, and opportunities. IEEE Access 2020, 8, 190064–190082. [Google Scholar] [CrossRef]
- Honma, N.; Suzuki, F.; Miyake, Y.; Ishii, M.; Hidayat, S. Propagation effect on field waveforms in relation to time-of-arrival technique in lightning location. J. Geophys. Res. Atmos. 1998, 103, 14141–14145. [Google Scholar] [CrossRef]
- Wang, Y.; Qie, X.; Wang, D.; Liu, M.; Su, D.; Wang, Z.; Liu, D.; Wu, Z.; Sun, Z.; Tian, Y. Beijing lightning network (BLNET) and the observation on preliminary breakdown processes. Atmos. Res. 2016, 171, 121–132. [Google Scholar] [CrossRef]
- Shao, X.-M.; Stanley, M.; Regan, A.; Harlin, J.; Pongratz, M.; Stock, M. Total lightning observations with the new and improved Los Alamos Sferic Array (LASA). J. Atmos. Ocean. Technol. 2006, 23, 1273–1288. [Google Scholar] [CrossRef]
- Yoshida, S.; Wu, T.; Ushio, T.; Kusunoki, K.; Nakamura, Y. Initial results of LF sensor network for lightning observation and characteristics of lightning emission in LF band. J. Geophys. Res. Atmos. 2014, 119, 12034–12051. [Google Scholar] [CrossRef]
- Shi, D.; Zheng, D.; Zhang, Y.; Zhang, Y.; Huang, Z.; Lu, W.; Chen, S.; Yan, X. Low-frequency E-field detection array (LFEDA)—construction and preliminary results. Sci. China Earth Sci. 2017, 60, 1896–1908. [Google Scholar] [CrossRef]
- Lyu, F.; Cummer, S.A.; Solanki, R.; Weinert, J.; McTague, L.; Katko, A.; Barrett, J.; Zigoneanu, L.; Xie, Y.; Wang, W. A low-frequency near-field interferometric-toa 3D lightning mapping array. Geophys. Res. Lett. 2014, 41, 7777–7784. [Google Scholar] [CrossRef]
- Wu, T.; Wang, D.; Takagi, N. Lightning mapping with an array of fast antennas. Geophys. Res. Lett. 2018, 45, 3698–3705. [Google Scholar] [CrossRef]
- Zhu, Y.; Bitzer, P.; Stewart, M.; Podgorny, S.; Corredor, D.; Burchfield, J.; Carey, L.; Medina, B.; Stock, M. Huntsville Alabama Marx Meter Array 2: Upgrade and Capability. Earth Space Sci. 2020, 7. [Google Scholar] [CrossRef]
- Fan, X.P.; Zhang, Y.J.; Zheng, D.; Zhang, Y.; Lyu, W.T.; Liu, H.Y.; Xu, L.T. A new method of three-dimensional location for low-frequency electric field detection array. J. Geophys. Res. Atmos. 2018, 123, 8792–8812. [Google Scholar] [CrossRef]
- Liu, B.; Shi, L.H.; Qiu, S.; Liu, H.Y.; Sun, Z.; Guo, Y.F. Three-dimensional lightning positioning in low-frequency band using time reversal in frequency domain. IEEE Trans. Electromagn. Compat. 2020, 62, 774–784. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Zheng, D.; Zhang, Y.; Fan, X.; Fan, Y.; Xu, L.; Lyu, W. A method of three-dimensional location for LFEDA combining the time of arrival method and the time reversal technique. J. Geophys. Res. Atmos. 2019, 124, 6484–6500. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, M.; Lyu, F.; Cummer, S.A.; Zhu, B.; Liu, F.; Du, Y. A GPU-based grid traverse algorithm for accelerating lightning geolocation process. IEEE Trans. Electromagn. Compat. 2020, 62, 489–497. [Google Scholar] [CrossRef]
- Zhu, Y.; Bitzer, P.; Rakov, V.; Ding, Z. A machine-learning approach to classify cloud-to-ground and intracloud lightning. Geophys. Res. Lett. 2021, 48. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Q.; Ma, Q.; Chang, S.; He, J.; Wang, H.; Zhou, X.; Xiao, F.; Gao, C. Classification of VLF/LF lightning signals using sensors and deep learning methods. Sensors 2020, 20, 1030. [Google Scholar] [CrossRef]
- Zhou, K.; Zheng, Y.; Dong, W.; Wang, T. A deep learning network for cloud-to-ground lightning nowcasting with multisource data. J. Atmos. Ocean. Technol. 2020, 37, 927–942. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Du, B.; Xiong, W.; Wu, J.; Zhang, L.; Zhang, L.; Tao, D. Stacked convolutional denoising auto-encoders for feature representation. IEEE Trans. Cybern. 2017, 47, 1017–1027. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, Y.; Fan, Y.; Wang, J.; Zheng, D.; Fan, X.; Xu, L.; Lyu, W.; Zhang, Y. Evolution characteristics during initial stage of triggered lightning based on directly measured current. Atmosphere 2020, 11, 658. [Google Scholar] [CrossRef]
- Zhu, Y.; Rakov, V.A.; Tran, M.D.; Stock, M.G.; Heckman, S.; Liu, C.; Sloop, C.D.; Jordan, D.M.; Uman, M.A.; Caicedo, J.A.; et al. Evaluation of ENTLN performance characteristics based on the ground truth natural and rocket-triggered lightning data acquired in Florida. J. Geophys. Res. Atmos. 2017, 122, 9858–9866. [Google Scholar] [CrossRef]
- Nag, A.; Mallick, S.; Rakov, V.A.; Howard, J.S.; Biagi, C.J.; Hill, J.D.; Uman, M.A.; Jordan, D.M.; Rambo, K.J.; Jerauld, J.E.; et al. Evaluation of U.S. National lightning detection network performance characteristics using rocket-triggered lightning data acquired in 2004–2009. J. Geophys. Res. 2011, 116. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Length of Encoding Feature | The Length of the Input Pulse Waveform | Correlation Coefficients |
|---|---|---|
| 8 | 25.6 μs | 0.745 |
| 16 | 25.6 μs | 0.935 |
| 32 | 25.6 μs | 0.992 |
| 64 | 25.6 μs | 0.998 |
| The Length of Encoding Feature | The Length of the Input Pulse Waveform | Correlation Coefficients |
|---|---|---|
| 32 | 25.6 μs | 0.992 |
| 32 | 12.8 μs | 0.985 |
| 32 | 6.4 μs | 0.978 |
| CHJ-1 | CHJ-2 | Matching Result | |
|---|---|---|---|
| XTC-1 | 0.999999 | 0.999995 | XTC-1, CHJ-1 |
| XTC-2 | 0.999985 | 0.999999 | XTC-2, CHJ-2 |
| SGC-1 | 0.999993 | 0.999968 | SGC-1, CHJ-1 |
| SGC-2 | 0.999990 | 0.999999 | SGC-2, CHJ-2 |
| ZCJ-1 | 0.999959 | 0.999912 | ZCJ-1, CHJ-1 |
| ZCJ-2 | 0.999950 | 0.999898 | ZCJ-2, CHJ-1(wrong) |
| CHJ-1 | CHJ-2 | Matching Result | |
|---|---|---|---|
| XTC-1 | 0.95147 | 0.78790 | XTC-1, CHJ-1 |
| XTC-2 | 0.66256 | 0.90240 | XTC-2, CHJ-2 |
| SGC-1 | 0.95339 | 0.79090 | SGC-1, CHJ-1 |
| SGC-2 | 0.82302 | 0.97719 | SGC-2, CHJ-2 |
| ZCJ-1 | 0.75171 | 0.58466 | ZCJ-1, CHJ-1 |
| ZCJ-2 | 0.83662 | 0.92085 | ZCJ-2, CHJ-2 |
| Number | Triggered Time | Number of Return Strokes |
|---|---|---|
| 1 | 11 June 2015, 18:05 | 1 |
| 2 | 11 June 2015, 18:22 | 2 |
| 3 | 11 June 2015, 18:29 | 11 |
| 4 | 12 June 2015, 16:05 | 7 |
| 5 | 12 June 2015, 16:12 | 3 |
| 6 | 12 June 2015, 16:16 | 2 |
| 7 | 22 July 2015, 18:16 | 9 |
| 8 | 22 July 2015, 18:22 | 1 |
| 9 | 13 August 2015, 18:26 | 7 |
| 10 | 13 August 2015, 18:32 | 7 |
| 11 | 14 August 2015, 15:25 | 13 |
| 12 | 17 August 2015, 16:03 | 4 |
| 13 | 17 August 2015, 16:07 | 9 |
| 14 | 15 June 2017, 21:16 | 6 |
| 15 | 16 June 2017, 00:05 | 1 |
| 16 | 16 June 2017, 17:44 | 11 |
| 17 | 8 July 2017, 18:52 | 3 |
| 18 | 8 July 2017, 18:59 | 6 |
| 19 | 10 July 2017, 15:07 | 10 |
| 20 | 10 July 2017, 15:27 | 8 |
| Matched Pulse Number | Effective Matches Number | Matching Efficiency | |
|---|---|---|---|
| New algorithm | 6544 | 2719 | 51.54% |
| TOA–TR 1 | 10154 | 1659 | 20.48% |
| TOA method based on pulse-peak feature matching | 14434 | 498 | 3.45% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, Y.; Tan, Y.; Chen, Z.; Zheng, D.; Zhang, Y.; Fan, Y. Fast and Fine Location of Total Lightning from Low Frequency Signals Based on Deep-Learning Encoding Features. Remote Sens. 2021, 13, 2212. https://doi.org/10.3390/rs13112212
Wang J, Zhang Y, Tan Y, Chen Z, Zheng D, Zhang Y, Fan Y. Fast and Fine Location of Total Lightning from Low Frequency Signals Based on Deep-Learning Encoding Features. Remote Sensing. 2021; 13(11):2212. https://doi.org/10.3390/rs13112212
Chicago/Turabian StyleWang, Jingxuan, Yang Zhang, Yadan Tan, Zefang Chen, Dong Zheng, Yijun Zhang, and Yanfeng Fan. 2021. "Fast and Fine Location of Total Lightning from Low Frequency Signals Based on Deep-Learning Encoding Features" Remote Sensing 13, no. 11: 2212. https://doi.org/10.3390/rs13112212
APA StyleWang, J., Zhang, Y., Tan, Y., Chen, Z., Zheng, D., Zhang, Y., & Fan, Y. (2021). Fast and Fine Location of Total Lightning from Low Frequency Signals Based on Deep-Learning Encoding Features. Remote Sensing, 13(11), 2212. https://doi.org/10.3390/rs13112212