
Multi-Resolution Supervision Network with an Adaptive Weighted Loss for Desert Segmentation



Abstract
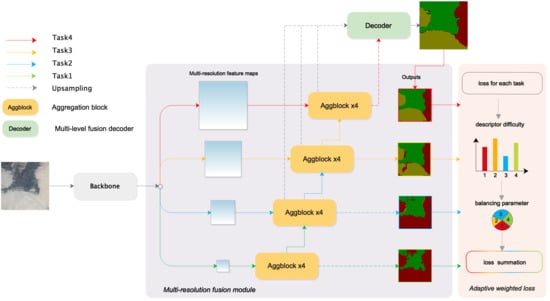
1. Introduction
2. Materials and Methods
2.1. Multi-Resolution Supervision Network
2.1.1. Backbone
2.1.2. Multi-Resolution Fusion Model
2.1.3. Multi-Level Fusion Decoder
2.2. Adaptive Weighted Loss Function
| Algorithm 1 Application of Adaptive Weighted Loss in the Training Process |
|
3. Results
3.1. Data and Pre-Processing
3.2. Experimental Results
3.3. Desert Segmentation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Zhang, G.; Zhang, Y.; Guan, X.; Guo, R. Global Desertification Vulnerability to Climate Change and Human Activities. Land Degrad. Dev. 2020, 10, 1380–1391. [Google Scholar] [CrossRef]
- Yue, Y.; Ye, X.; Zou, X.; Wang, J.; Gao, L. Research on Land Use Optimization for Reducing Wind Erosion in Sandy Desertified Area: A Case Study of Yuyang County in Mu Us Desert, China. Stoch Envrion. Res. Risk Assess 2017, 31, 1371–1387. [Google Scholar] [CrossRef]
- Zhang, L.; Yue, L.; Xia, B. The Study of Land Desertification in Transitional Zones between the MU US Desert and the Loess Plateau Using RS and GIS-A Case Study of the Yulin Region. Environ. Geol. 2003, 44, 530–534. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Liu, J.; Xu, Y. DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Zhang, F.; Tiyip, T.; Johnson, V.C.; Kung, H.; Ding, J.; Zhou, M.; Fan, Y.; Kelimu, A.; Nurmuhammat, I. Evaluation of Land Desertification from 1990 to 2010 and Its Causes in Ebinur Lake Region, Xinjiang China. Environ. Earth Sci. 2015, 73, 5731–5745. [Google Scholar] [CrossRef]
- Weng, L.; Wang, L.; Xia, M.; Shen, H.; Liu, J.; Xu, Y. Desert classification based on a multi-scale residual network with an attention mechanism. Geosci. J. 2020, 25, 387–399. [Google Scholar] [CrossRef]
- Xia, M.; Tian, N.; Zhang, Y.; Xu, Y.; Zhang, X. Dilated multi-scale cascade forest for satellite image classification. Int. J. Remote Sens. 2020, 41, 7779–7800. [Google Scholar] [CrossRef]
- Pi, W.; Du, J.; Liu, H.; Zhu, X. Desertification Glassland Classification and Three-Dimensional Convolution Neural Network Model for Identifying Desert Grassland Landforms with Unmanned Aerial Vehicle Hyperspectral Remote Sensing Images. J. Appl. Spectrosc. 2020, 87, 309–318. [Google Scholar] [CrossRef]
- Moghaddam, M.H.R.; Sedighi, A.; Fasihi, S.; Firozjaei, M.K. Effect of Environmental Policies in Combating Aeolian Desertification over Sejzy Plain of Iran. Aeolian Res. 2018, 35, 19–28. [Google Scholar] [CrossRef]
- Ge, G.; Shi, Z.; Zhu, Y.; Yang, X.; Hao, Y. Land Use/Cover Classification in an Arid Desert-Oasis Mosaic Landscape of China Using Remote Sensed Imagery: Performance Assessment of Four Machine Learning Algorithms. Glob. Ecol. Conserv. 2020, 22, e00971. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Moustafa, O.R.M.; Cressman, K. Using the Enhanced Vegetation Index for Deriving Risk Maps of Desert Locust (Schistocerca Gregaria, Forskal) Breeding Areas in Egypt. J. Appl. Remote Sens. 2015, 8, 084897. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sens. 2021, 13, 465. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell.. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar]
- Li, L. Deep Residual Autoencoder with Multiscaling for Semantic Segmentation of Land-Use Images. Remote Sens. 2019, 11, 2142. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Ulmas, P.; Liiv, I. Segmentation of Satellite Imagery Using U-Net Models for Land Cover Classification. arXiv 2020, arXiv:2003.02899. [Google Scholar]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Multi-Resolution Feature Fusion for Image Classification of Building Damages with Convolutional Neural Networks. Remote Sens. 2018, 10, 1636. [Google Scholar] [CrossRef]
- Song, X.; Jiang, S.; Herranz, L. Multi-scale multi-feature context modeling for scene recognition in the semantic manifold. IEEE Trans. Image Process. 2017, 26, 2721–2735. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.; Wang, K.; Song, W.; Chen, C.; Li, Y. Non-intrusive load disaggregation based on composite deep long short-term memory network. Expert Syst. Appl. 2020, 160, 113669. [Google Scholar] [CrossRef]
- Xia, M.; Zhang, X.; Weng, L.; Xu, Y. Multi-Stage Feature Constraints Learning for Age Estimation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Shahrezaei, I.H.; Kim, H.C. Fractal analysis and texture classification of high-frequency multiplicative noise in sar sea-ice images based on a transform-domain image decomposition method. IEEE Access 2020, 8, 40198–40223. [Google Scholar] [CrossRef]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Xue, X. Object detection from scratch with deep supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 99. [Google Scholar] [CrossRef] [PubMed]
- Hosono, T.; Hoshi, Y.; Shimamura, J.; Sagata, A. Adaptive Loss Balancing for Multitask Learning of Object Instance Recognition and 3D Pose Estimation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2587–2592. [Google Scholar]
- Chen, Z.; Badrinarayanan, V.; Lee, C.-Y.; Rabinovich, A. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks. In Proceedings of the International Conference on Machine Learning Research, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 794–803. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.-B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 680–688. [Google Scholar]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Mayer, H. A multi-resolution fusion model incorporating color and elevation for semantic segmentation. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 513–517. [Google Scholar] [CrossRef]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8691, pp. 346–361. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Multi-Resolution Fusion | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Branch | Operator | t | c | n | s | Outputs Size | Operator | c | n | Outputs Size |
| Branch 4 | Conv2d | - | 32 | 1 | 2 | aggblock | 64 | 4 | ||
| bottleneck | 1 | 16 | 1 | 1 | ||||||
| Branch 3 | bottleneck | 6 | 24 | 2 | 2 | aggblock | 64 | 4 | ||
| Branch 2 | bottleneck | 6 | 32 | 3 | 2 | aggblock | 64 | 4 | ||
| Branch 1 | bottleneck | 6 | 64 | 4 | 2 | aggblock | 64 | 4 | ||
| bottleneck | 6 | 96 | 3 | 1 | ||||||
| Method | Extra Skip-Connection | Upsampling Before Convolution | Adaptive Weighted Loss | mIoU(%) |
|---|---|---|---|---|
| Net1 | 44.4 | |||
| Net2 | ✓ | 47.3 | ||
| Net3 | ✓ | ✓ | 54.2 | |
| MrsSeg-AWL | ✓ | ✓ | ✓ | 58.0 |
| Loss Strategies | Branch 1 | Branch 2 | Branch 3 | Branch 4 | mIoU(%) |
|---|---|---|---|---|---|
| Single-branch | ✓ | 54.2 | |||
| Two-branches | ✓ | ✓ | 55.3 | ||
| Three-branches | ✓ | ✓ | ✓ | 56.1 | |
| Four-branches | ✓ | ✓ | ✓ | ✓ | 56.3 |
| Adaptive weighted | ✓ | ✓ | ✓ | ✓ | 58.0 |
| Backbone | mIoU(%) | FPS | Paramteter (M) |
|---|---|---|---|
| MobilenetV2 | 58.0 | 77.0 | 3.3 |
| ResNet-34 | 57.0 | 69.0 | 22.4 |
| ResNet-18 | 55.8 | 82.0 | 12.23 |
| SuffleNet | 54.6 | 70.0 | 2.3 |
| Method | Backbone | mIoU (%) | FPS | Parameters (M) |
|---|---|---|---|---|
| MrsSeg-AWL | MobilenetV2 | 58.0 | 77.0 | 3.3 |
| DeepLabV3+ | MobilenetV2 | 56.6 | 93.0 | 5.8 |
| MrsSeg | MobilenetV2 | 56.3 | 77.0 | 3.3 |
| DenseASPP | MobilenetV2 | 54.3 | 85.0 | 2.48 |
| UNet | - | 52.6 | 33.0 | 13.3 |
| ENet | - | 49.4 | 69.0 | - |
| FPN | MobilenetV2 | 48.0 | 128.0 | 4.4 |
| DFANet | - | 45.7 | 69.0 | 1.97 |
| FCN32s | Vgg | 20.1 | 27.1 | 134.4 |
| Method | Desert | Oasis | Gobi | River | Background |
|---|---|---|---|---|---|
| MrsSeg-AWL | 84.0 | 86.0 | 39.6 | 23.1 | 46.4 |
| DeepLabV3+ | 83.9 | 82.0 | 41.1 | 19.7 | 46.8 |
| DenseASPP | 81.5 | 81.9 | 38.9 | 15.1 | 44.7 |
| UNet | 75.2 | 86.3 | 35.1 | 14.1 | 43.0 |
| ENet | 78.5 | 80.2 | 37.3 | 11.8 | 41.9 |
| FPN | 76.1 | 78.1 | 27.3 | 10.9 | 39.6 |
| DFANet | 71.1 | 76.6 | 14.6 | 20.8 | 25.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Weng, L.; Xia, M.; Liu, J.; Lin, H. Multi-Resolution Supervision Network with an Adaptive Weighted Loss for Desert Segmentation. Remote Sens. 2021, 13, 2054. https://doi.org/10.3390/rs13112054
Wang L, Weng L, Xia M, Liu J, Lin H. Multi-Resolution Supervision Network with an Adaptive Weighted Loss for Desert Segmentation. Remote Sensing. 2021; 13(11):2054. https://doi.org/10.3390/rs13112054
Chicago/Turabian StyleWang, Lexuan, Liguo Weng, Min Xia, Jia Liu, and Haifeng Lin. 2021. "Multi-Resolution Supervision Network with an Adaptive Weighted Loss for Desert Segmentation" Remote Sensing 13, no. 11: 2054. https://doi.org/10.3390/rs13112054
APA StyleWang, L., Weng, L., Xia, M., Liu, J., & Lin, H. (2021). Multi-Resolution Supervision Network with an Adaptive Weighted Loss for Desert Segmentation. Remote Sensing, 13(11), 2054. https://doi.org/10.3390/rs13112054