
SRR-LGR: Local–Global Information-Reasoned Social Relation Recognition for Human-Oriented Observation






Abstract
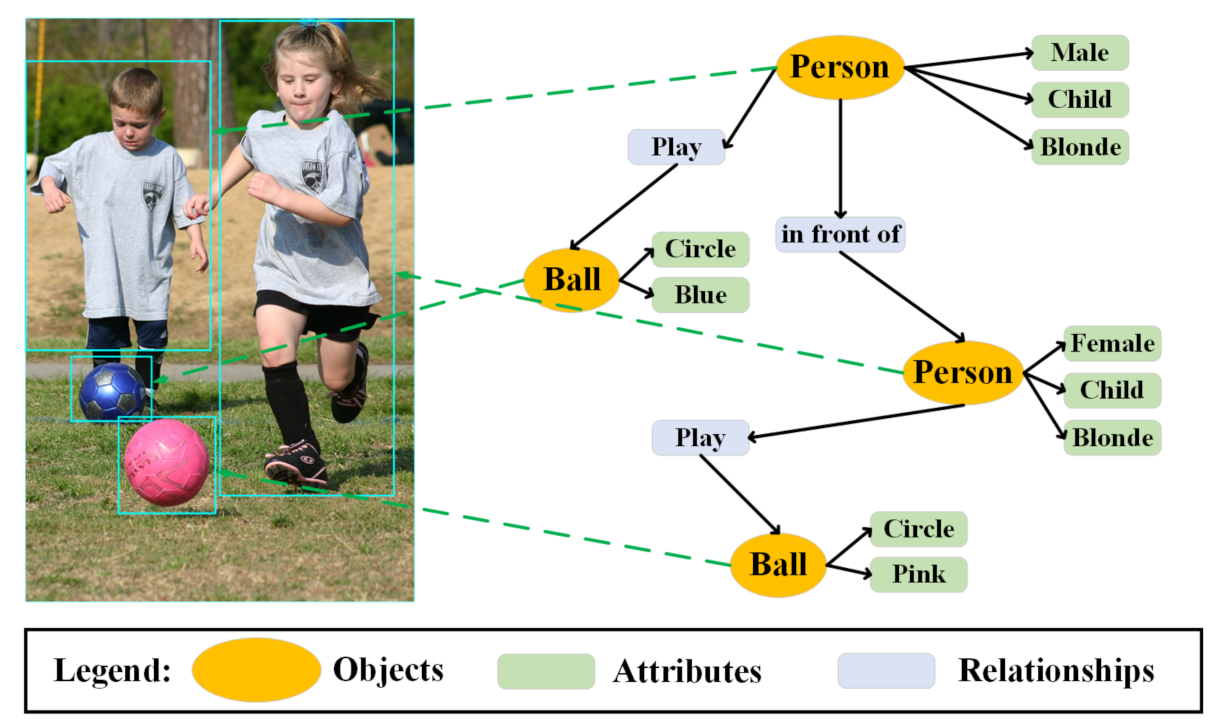
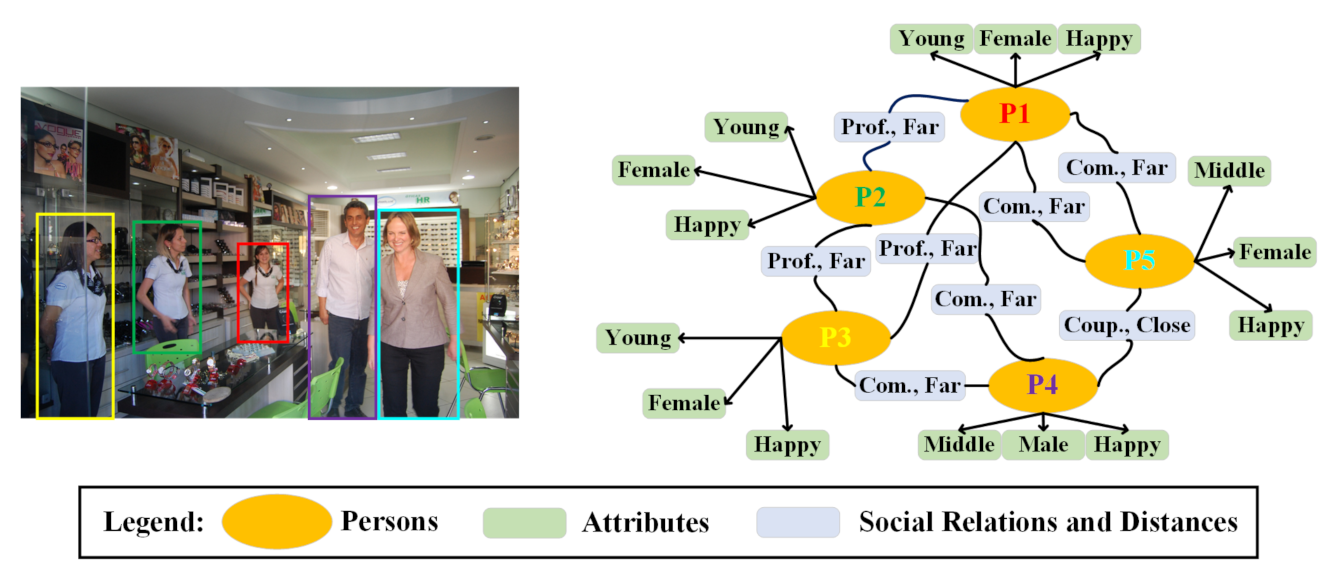
1. Introduction
2. Related Work
2.1. Social Relation Recognition
2.2. Graph Neural Networks
3. Method
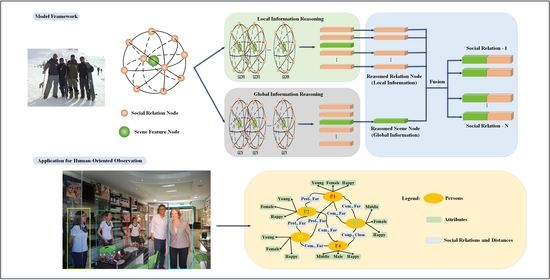
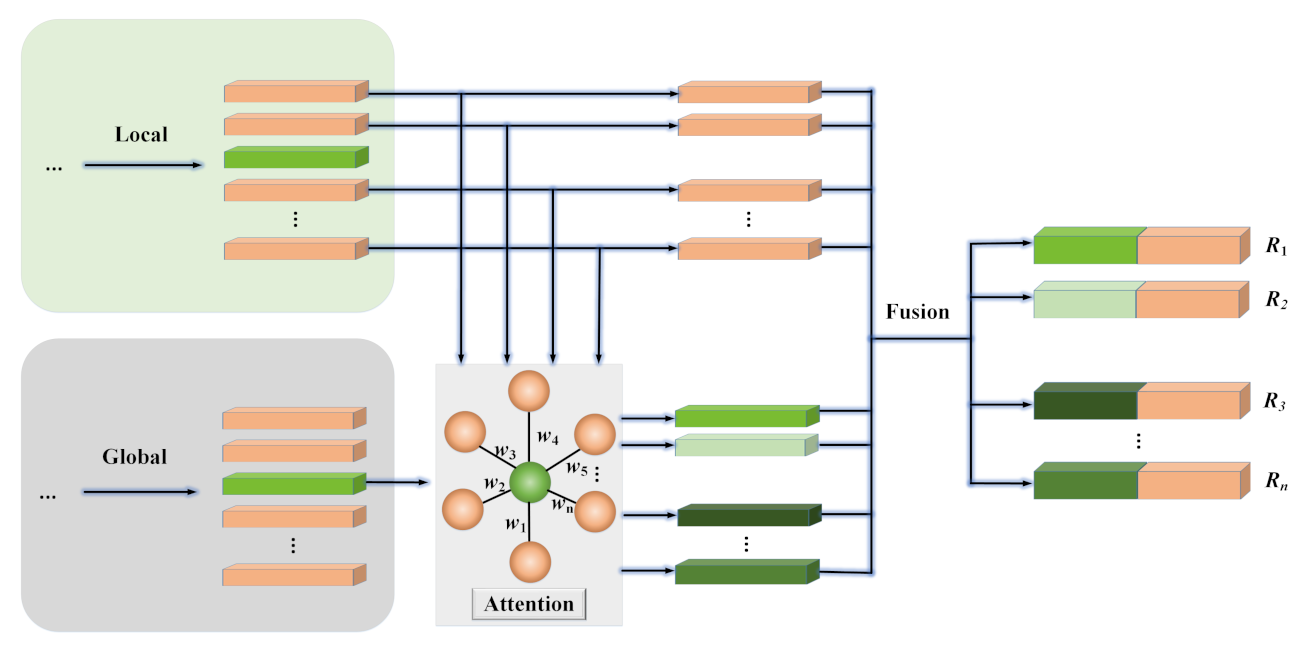
3.1. Overall Architecture
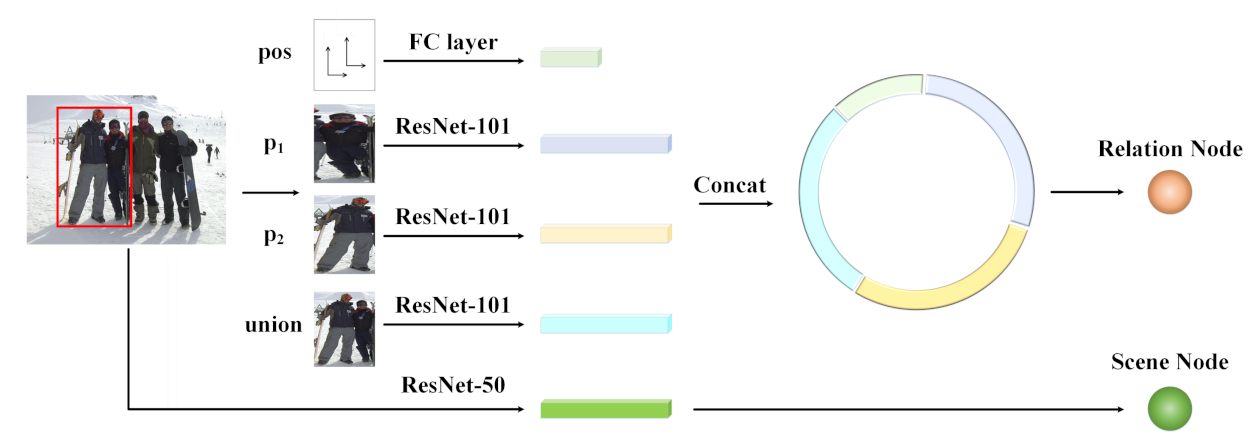
3.2. Node Generation Module
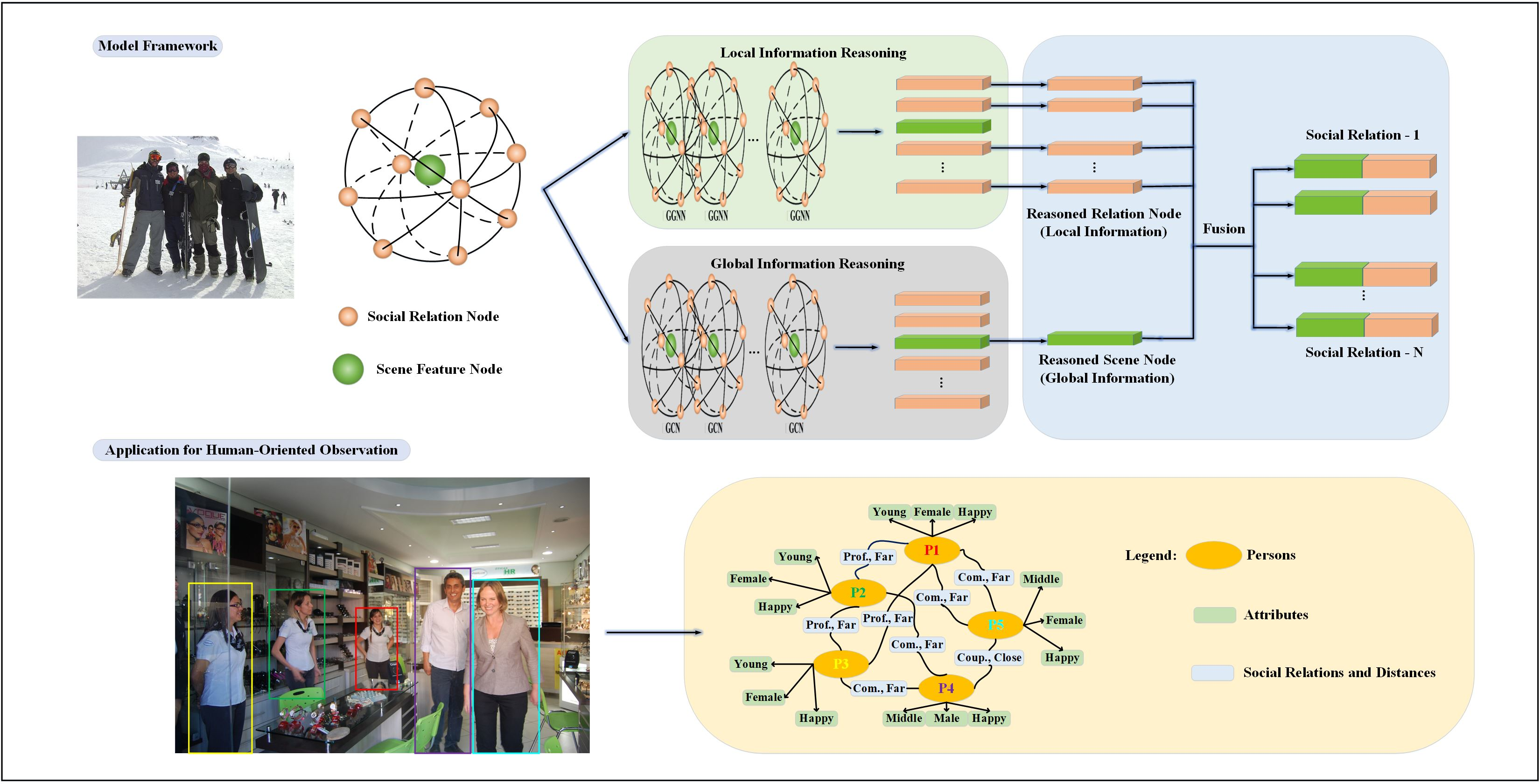
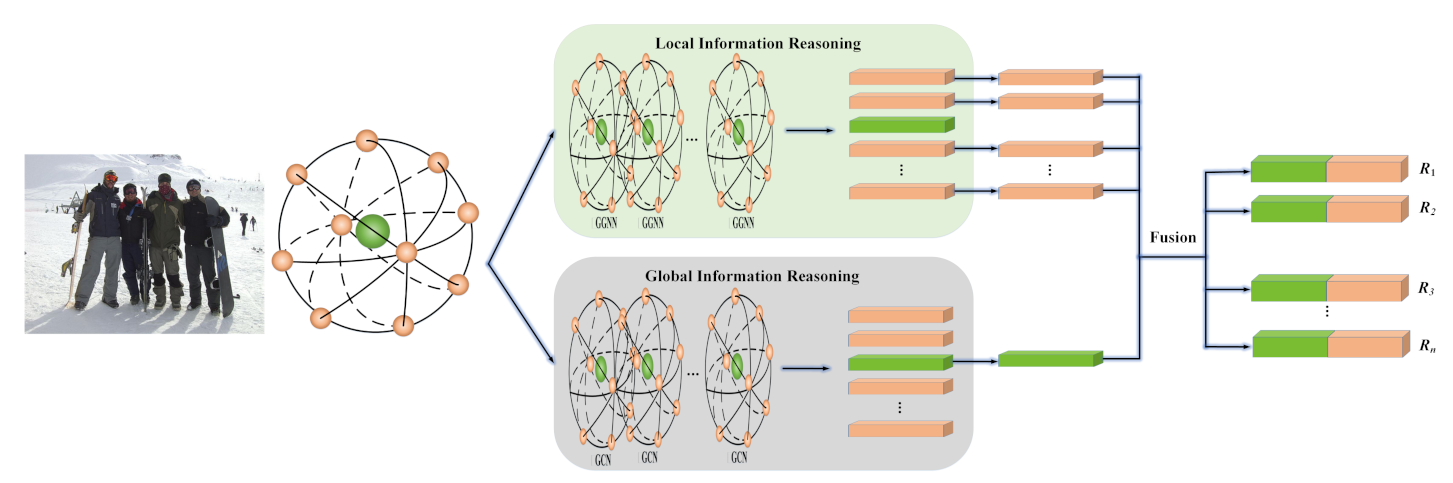
3.3. Local–Global Information Reasoning
3.4. Information Fusion and Classification
4. Experiments and Results
4.1. Datasets
4.2. Training Strategy and Parameter Setting
4.3. Comparison with State-Of-The-Art Methods
4.4. Ablation Study
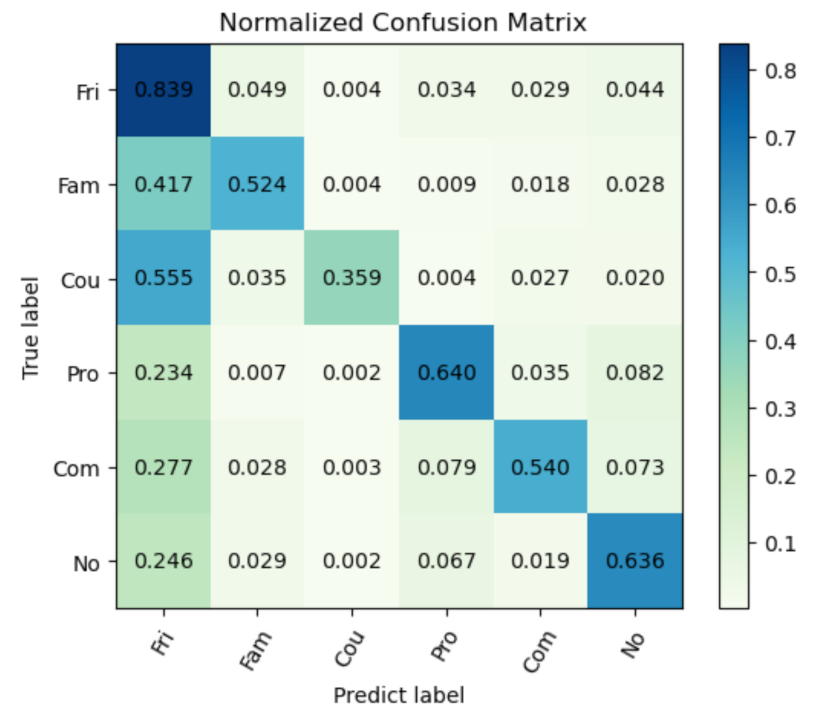
4.5. The Contribution of the Global Information for Different Social Relations
4.6. Running Time Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Reis, H.T.; Collins, W.A.; Berscheid, E. The relationship context of human behavior and development. Psychol. Bull. 2000, 126, 844–872. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M. Dual-glance model for deciphering social relationships. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2669–2678. [Google Scholar]
- Sun, Q.; Schiele, B.; Fritz, M. A domain based approach to social relation recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 435–444. [Google Scholar]
- Wang, Z.; Chen, T.; Ren, J.; Yu, W.; Cheng, H.; Lin, L. Deep reasoning with knowledge graph for social relationship understanding. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 1021–1028. [Google Scholar]
- Goel, A.; Ma, K.T.; Tan, C. An end-to-end network for generating social relationship graphs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11178–11187. [Google Scholar]
- Zhang, M.; Liu, X.; Liu, W.; Zhou, A.; Ma, H.; Mei, T. Multi-granularity reasoning for social relation recognition from images. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1618–1623. [Google Scholar]
- Wang, M.; Du, X.; Shu, X.; Wang, X.; Tang, J. Deep supervised feature selection for social relationship recognition. Pattern Recognit. Lett. 2020, 138, 410–416. [Google Scholar] [CrossRef]
- Li, W.; Duan, Y.; Lu, J.; Feng, J.; Zhou, J. Graph-based social relation reasoning. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 18–34. [Google Scholar]
- Bugental, D.B. Acquisition of the algorithms of social life: A domain-based approach. Psychol. Bull. 2000, 126, 187–219. [Google Scholar] [CrossRef] [PubMed]
- Fiske, A.P. The four elementary forms of sociality: Framework for a unified theory of social relations. Psychol. Rev. 1992, 99, 689. [Google Scholar] [CrossRef] [PubMed]
- Kiesler, D.J. The 1982 interpersonal circle: A taxonomy for complementarity in human transactions. Psychol. Rev. 1983, 90, 185. [Google Scholar] [CrossRef]
- Lu, J.; Zhou, X.; Tan, Y.; Shang, Y.; Zhou, J. Neighborhood repulsed metric learning for kinship verification. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 331–345. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.; Tang, X. Learning social relation traits from face images. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3631–3639. [Google Scholar]
- Liu, X.; Liu, W.; Zhang, M.; Chen, J.; Gao, L.; Yan, C.; Mei, T. Social relation recognition from videos via multi-scale spatial-temporal reasoning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3561–3569. [Google Scholar]
- Xu, D.; Zhu, Y.; Choy, C.B.; Li, F. Scene graph generation by iterative message passing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3097–3106. [Google Scholar]
- Zhang, J.; Kalantidis, Y.; Rohrbach, M.; Paluri, M.; Elgammal, A.; Elhoseiny, M. Large-scale visual relationship understanding. In Proceedings of the 2019 AAAI Conference on Aritificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; pp. 9185–9194. [Google Scholar]
- Deng, Z.; Vahdat, A.; Hu, H.; Mori, G. Structure inference machines: Recurrent neural networks for analyzing relations in group activity recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4772–4781. [Google Scholar]
- Haanju, Y.; Emo, T.; Seo, J.; Choi, S. Detection of interacting groups based on geometric and social relations between individuals in an image. Pattern Recognit. 2019, 93, 498–506. [Google Scholar]
- Wang, G.; Gallagher, A.; Luo, J.; Forsyth, D. Seeing people in social context: Recognizing people and social relationships. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010; pp. 169–182. [Google Scholar]
- Xia, S.; Shao, M.; Luo, J.; Fu, Y. Understanding kin relationships in a photo. IEEE Trans. Multimed. 2012, 14, 1046–1056. [Google Scholar] [CrossRef]
- Dibeklioglu, H.; Salah, A.A.; Gevers, T. Like father, like son: Facial expression dynamics for kinship verification. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; pp. 1497–1504. [Google Scholar]
- Hu, J.; Lu, J.; Yuan, J.; Tan, Y. Large margin multi-metric learning for face and kinship verification in the wild. In Proceedings of the 12th Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014; pp. 252–267. [Google Scholar]
- Zhou, X.; Shang, Y.; Yan, H.; Guo, G. Ensemble similarity learning for kinship verification from facial images in the wild. Inf. Fusion 2016, 32, 40–48. [Google Scholar] [CrossRef]
- Zhao, Y.; Song, Z.; Zheng, F.; Shao, L. Learning a multiple kernel similarity metric for kinship verification. Inf. Sci. 2018, 430–431, 247–260. [Google Scholar] [CrossRef]
- Zhou, X.; Jin, K.; Xu, M.; Guo, G. Learning deep compact similarity metric for kinship verification from face images. Inf. Fusion 2018, 48, 84–94. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Y.; Lv, K.; Lu, J.; Feng, J.; Zhou, J. Graph-based kinship reasoning network. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceeding of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Y.; Zemel, R.; Brockschmidt, M.; Tarlow, D. Gated graph sequence neural networks. In Proceedings of the 4th International Conference on Learning Representation (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representation (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, N.; Paluri, M.; Taigman, Y.; Fergus, R.; Bourdev, L. Beyond frontal faces: Improving person recognition using multiple cues. In Proveedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA, 7–12 June 2015; pp. 4804–4813. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks (IJCNN), Montreal, QC, Canada, 31 July–4 August 2005; pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A. Graph echo state networks. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and Leman go neural: High-order graph neural networks. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4602–4609. [Google Scholar]
- Ahmed, A.; Hassan, Z.R.; Shabbir, M. Interpretable multi-scale graph descriptors via structural compression. Inf. Sci. 2020, 533, 169–180. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Kozareva, Z.; Dai, B.; Smola, A.; Song, L. Learning steady-states of iterative algorithms over graphs. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 1106–1114. [Google Scholar]
- Zhuang, C.; Ma, Q. Dual graph convolutional networks for graph-based semi-supervised classification. In Proceedings of the 2018 World Wide Web Conference (WWW), Lyon, France, 23–27 April 2018; pp. 499–508. [Google Scholar]
- Yu, W.; Zheng, C.; Cheng, W.; Aggarwai, C.C.; Song, D. Learning deep network representations with adversarially regularized autoencoders. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 2663–2671. [Google Scholar]
- Bojchevski, A.; Shchur, O.; Zügner, D.; Günnemann, S. NetGAN: Generating graphs via random walks. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stochholm, Sweden, 10–15 July 2018; pp. 610–619. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the 2019 AAAI Conference on Aritificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; pp. 922–929. [Google Scholar]
- Kearnes, S.; McCloskey, K.; Berndl, M.; Pande, V.; Riley, P. Molecular graph convolutions: Moving beyond fingerprints. J. Comput.-Aided Mol. Des. 2016, 30, 595–608. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, Y.; Zhao, D.; Chen, J. Graph-FCN for image semantic segmentation. In Proceedings of the 16th International Symposium on Neural Networks (ISNN), Moscow, Russia, 10–12 July 2019; pp. 97–105. [Google Scholar]
- Wu, J.; Wang, L.; Wang, L.; Guo, J.; Wu, G. Learning actor relation graphs for group activity recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9956–9966. [Google Scholar]
- Hu, G.; Cui, B.; He, Y.; Yu, S. Progressive relation learning for group activity recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 977–986. [Google Scholar]
- Zhou, J.; Zhang, X.; Liu, Y.; Lan, X. Facial expression recognition using spatial-temporal semantic graph network. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1961–1965. [Google Scholar]
- Lo, L.; Xie, H.X.; Shuai, H.H.; Cheng, W.H. MER-GCN: Micro-expression recognition based on relation modeling with graph convolutional networks. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020; pp. 79–84. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on graphs via spectral theory. Appl. Comput. Harmon. Anal. 2011, 30, 129–150. [Google Scholar] [CrossRef]
- Krisshna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Kim, J.H.; On, K.W.; Lim, W.; Kim, J.; Ha, J.W.; Zhang, B.T. Hadamard product for low-rank bilinear pooling. In Proceedings of the 5th International Conference on Learning Representation (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Johnson, J.; Krihna, R.; Stark, M.; Li, L.J.; Shamma, D.A.; Bernstein, M.S.; Li, F.F. Image retrieval using scene graphs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar]
- Newell, A.; Deng, J. Pixels to graphs by associative embedding. In Proceedings of the 31th Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Chen, T.; Yu, W.; Chen, R.; Lin, L. Knowledge-embedded routing network for scene graph generation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6156–6164. [Google Scholar]
- Luo, J.; Zhao, J.; Wen, B.; Zhang, Y. Explaining the semantics capturing capability of scene graph generation models. Pattern Recognit. 2021, 110, 107427. [Google Scholar] [CrossRef]
- Rezaei, M.; Azarmi, M. DeepSOCIAL: Social distancing monitoring and infection risk assessment in COVID-19 pandemic. Appl. Sci. 2020, 10, 7514. [Google Scholar] [CrossRef]
- Martinez, M.; Yang, K.; Constantinescu, A.; Stiefelhagen, R. Helping the blind to get through COVID-19: Social distancing assistant using real-time semantic segmentation on RGB-D video. Sensors 2020, 20, 5202. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Testing | |
|---|---|---|---|
| PISC-Coarse | 13,142/49,017 | 4000/14,536 | 4000/15,497 |
| PISC-Fine | 16,828/55,400 | 500/1505 | 500/1505 |
| PIPA | 5857/13,672 | 261/709 | 2452/5106 |
| PISC-Coarse | PISC-Fine | PIPA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Int. | Non. | No. | mAP | Fri. | Fam. | Cou. | Pro. | Com. | No. | mAP | Acc. | |
| Dual-glance [2] | 73.1 | 84.2 | 59.6 | 79.7 | 35.4 | 68.1 | 76.3 | 70.3 | 57.6 | 60.9 | 63.2 | 59.6 |
| DSFS [7] | - | - | - | - | - | - | - | - | - | - | - | 61.5 |
| GRM [4] | 81.7 | 73.4 | 65.5 | 82.8 | 59.6 | 64.4 | 58.6 | 76.6 | 39.5 | 67.7 | 68.7 | 62.3 |
| MGR [6] | - | - | - | - | 64.6 | 67.8 | 60.5 | 76.8 | 34.7 | 70.4 | 70.0 | 64.4 |
| SRG-GN [5] | - | - | - | - | 25.2 | 80.0 | 100.0 | 78.4 | 83.3 | 62.5 | 71.6 | 53.6 |
| GRN [8] | 81.6 | 74.3 | 70.8 | 83.1 | 60.8 | 65.9 | 84.8 | 73.0 | 51.7 | 70.4 | 72.7 | 64.3 |
| SRR-LGR | 89.6 | 84.6 | 78.5 | 84.8 | 83.9 | 52.4 | 35.9 | 64.0 | 54.0 | 63.6 | 73.0 | 66.1 |
| Social Relations | Fri. | Fam. | Cou. | Pro. | Com. | No. |
|---|---|---|---|---|---|---|
| Number of Samples | 12,686 | 7818 | 1552 | 20,842 | 523 | 11,979 |
| PISC-Coarse (mAP) | PISC-Fine (mAP) | PIPA (Acc.) | |
|---|---|---|---|
| Concatenation | 79.8 | 64.7 | 63.8 |
| Local Information | 84.7 | 71.2 | 66.7 |
| Local–Global Information | 84.8 | 73.0 | 66.1 |
| Method | Batch Size | Accuracy | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | PISC-Coarse | PISC-Fine | PIPA | |
| GRM [4] | 0.294 | 0.171 | 0.089 | - | 82.8 | 68.7 | 62.3 |
| SRR-LGR (Ours) | 0.065 | 0.053 | 0.047 | 0.044 | 84.8 | 73.0 | 66.1 |
| Pair CNN [8] | 0.077 | 0.045 | 0.039 | 0.037 | 65.1 | 48.2 | 58.0 |
| GRN [8] | 0.046 | 0.025 | 0.021 | 0.021 | 83.1 | 72.7 | 64.3 |
| Flops (M) | Parameters (M) | Memory (MB) | |
|---|---|---|---|
| Node Generation | 109,195.02 | 183.52 | 700.10 |
| Local Information Reasoning | 1.57 | 0.79 | 3.00 |
| Global Information Reasoning | 0.52 | 0.26 | 1.00 |
| Social Relation Classification | 0.01 | 0.01 | 0.02 |
| Total | 109,197.12 | 184.58 | 704.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qing, L.; Li, L.; Wang, Y.; Cheng, Y.; Peng, Y. SRR-LGR: Local–Global Information-Reasoned Social Relation Recognition for Human-Oriented Observation. Remote Sens. 2021, 13, 2038. https://doi.org/10.3390/rs13112038
Qing L, Li L, Wang Y, Cheng Y, Peng Y. SRR-LGR: Local–Global Information-Reasoned Social Relation Recognition for Human-Oriented Observation. Remote Sensing. 2021; 13(11):2038. https://doi.org/10.3390/rs13112038
Chicago/Turabian StyleQing, Linbo, Lindong Li, Yuchen Wang, Yongqiang Cheng, and Yonghong Peng. 2021. "SRR-LGR: Local–Global Information-Reasoned Social Relation Recognition for Human-Oriented Observation" Remote Sensing 13, no. 11: 2038. https://doi.org/10.3390/rs13112038
APA StyleQing, L., Li, L., Wang, Y., Cheng, Y., & Peng, Y. (2021). SRR-LGR: Local–Global Information-Reasoned Social Relation Recognition for Human-Oriented Observation. Remote Sensing, 13(11), 2038. https://doi.org/10.3390/rs13112038