
Methodology for the Definition of Durum Wheat Yield Homogeneous Zones by Using Satellite Spectral Indices





Abstract
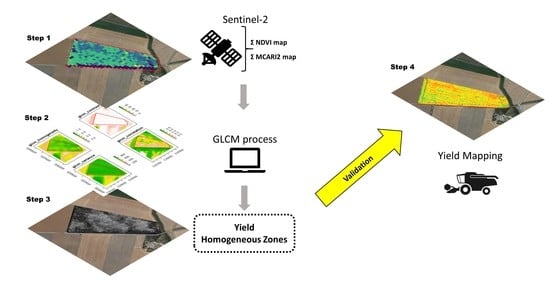
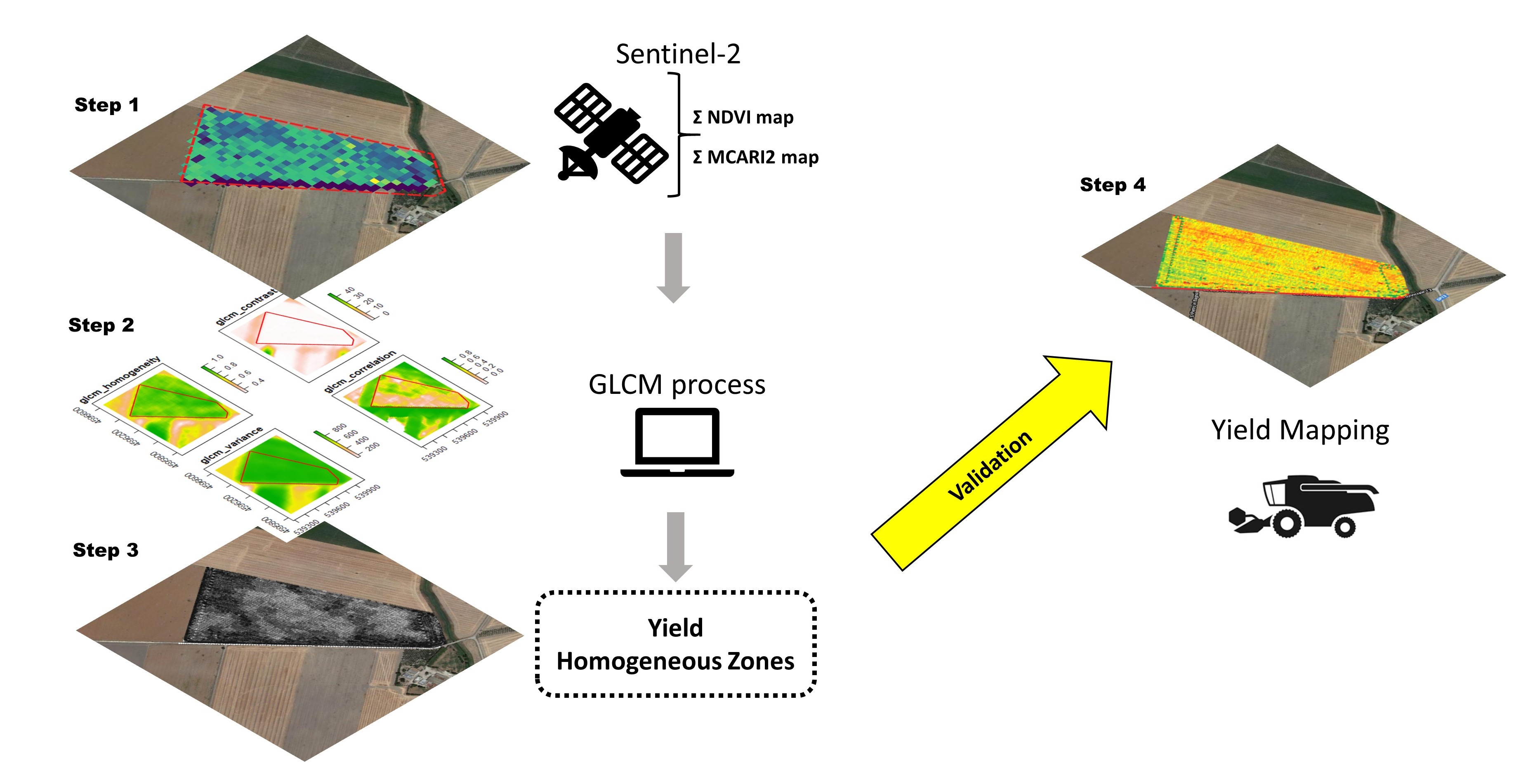
1. Introduction
2. Materials and Methods
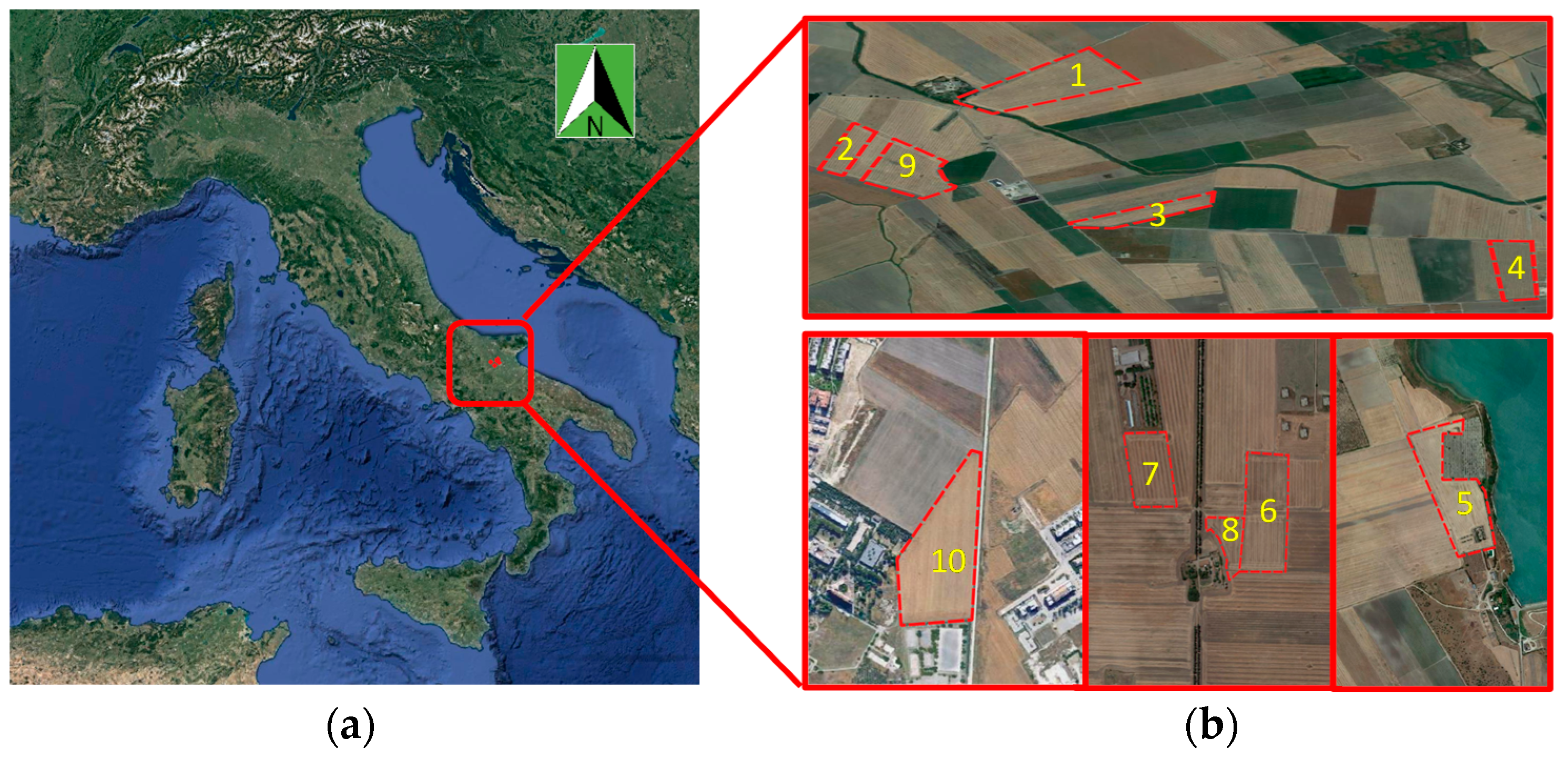
2.1. Study Site
2.2. Homogeneous Zones Definition
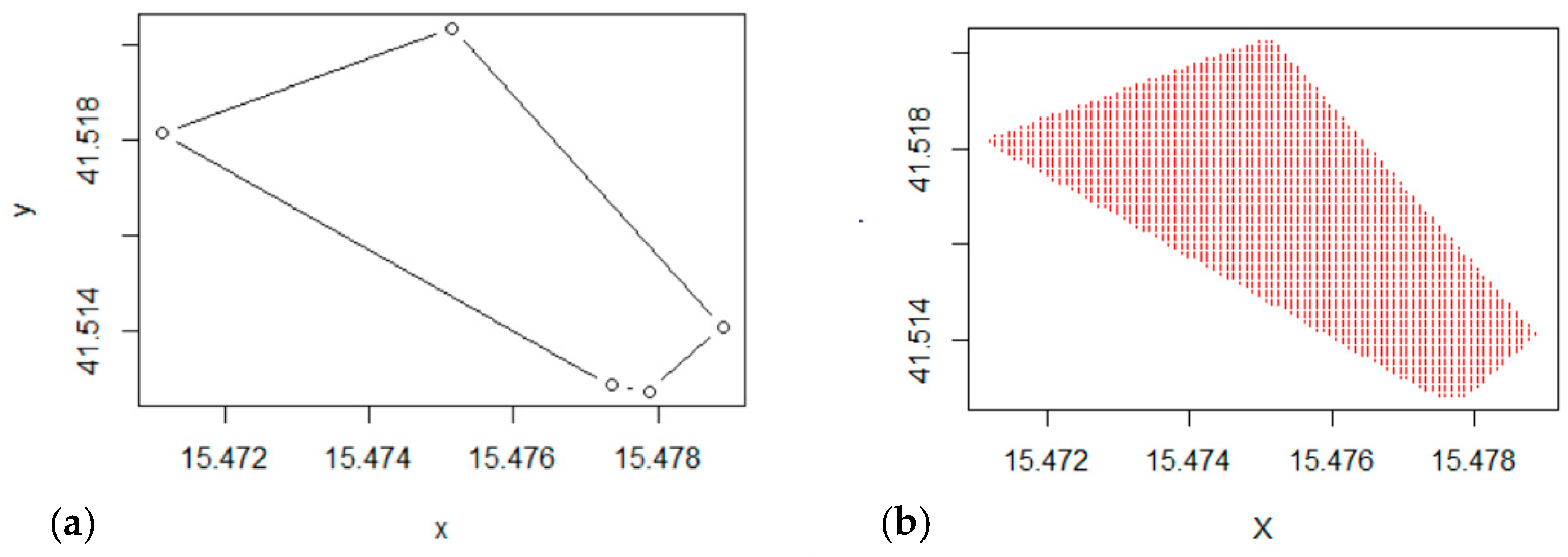
2.2.1. Yield Monitor-Based Maps
2.2.2. Satellite Data
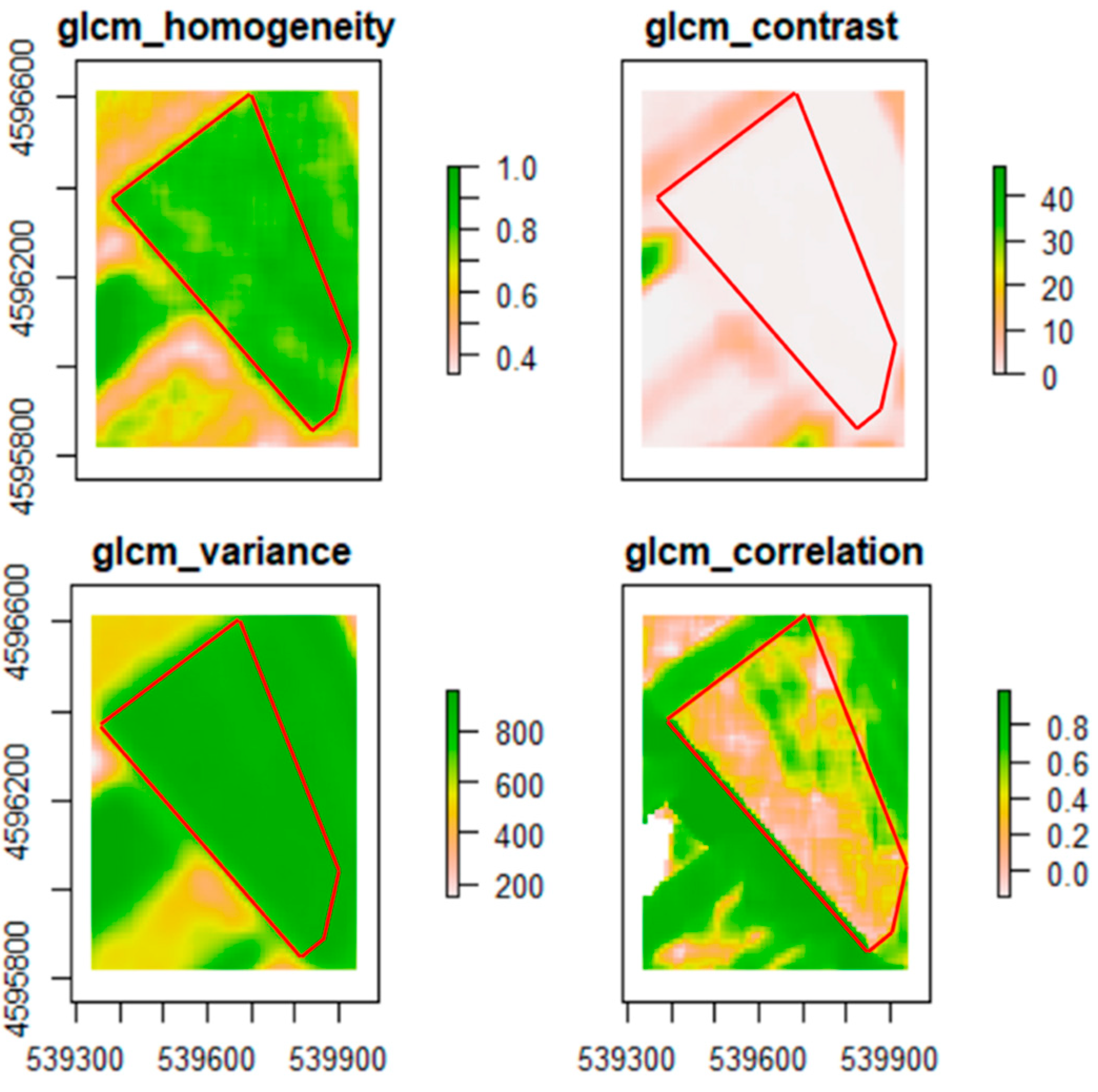
2.2.3. Texture Analysis
2.2.4. Modelling Analysis
2.2.5. Yield Maps Elaboration
2.3. Comparison Analysis
3. Results and Discussion
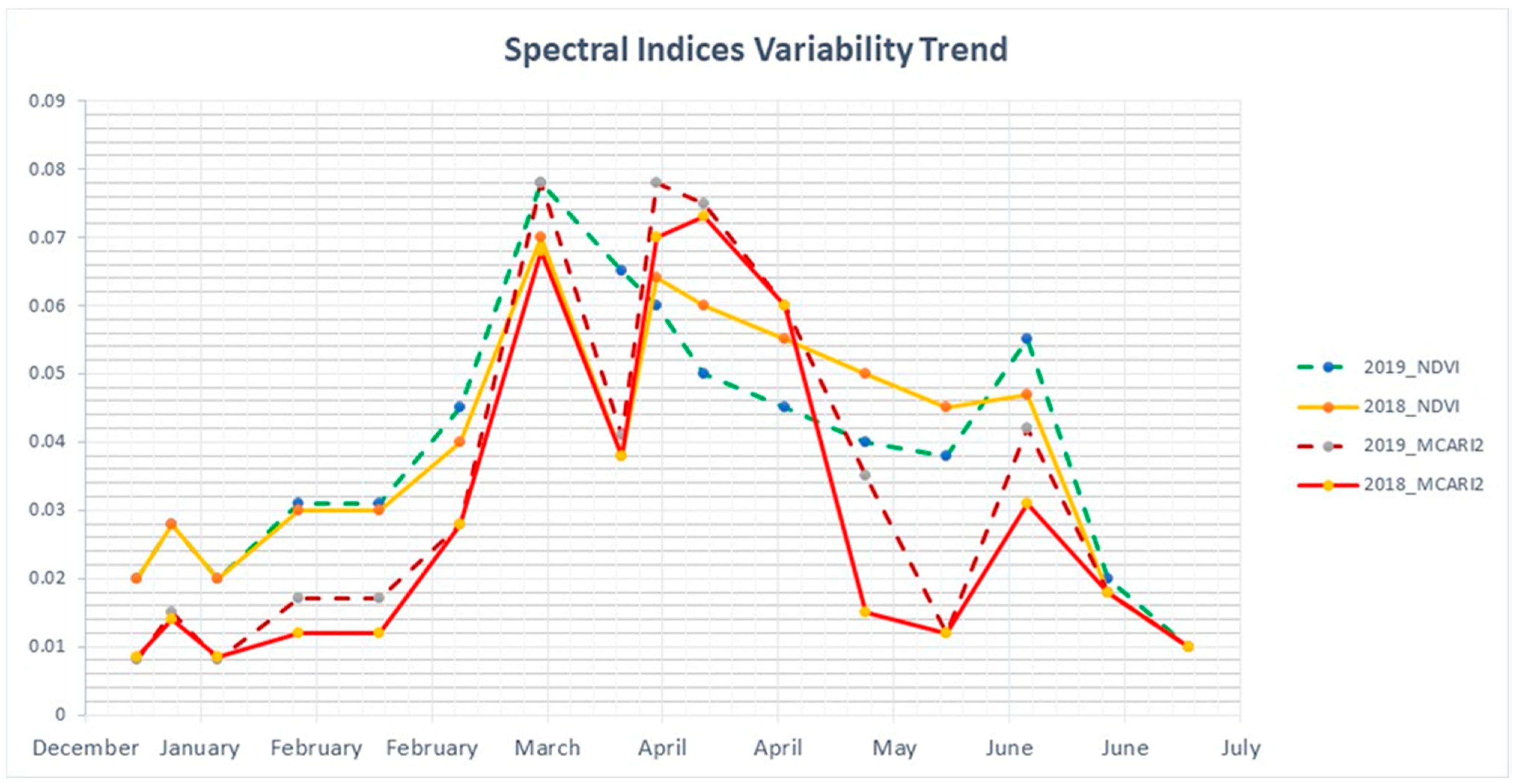
3.1. Vegetation Indices Derived from a Time Series of Satellite Imagery
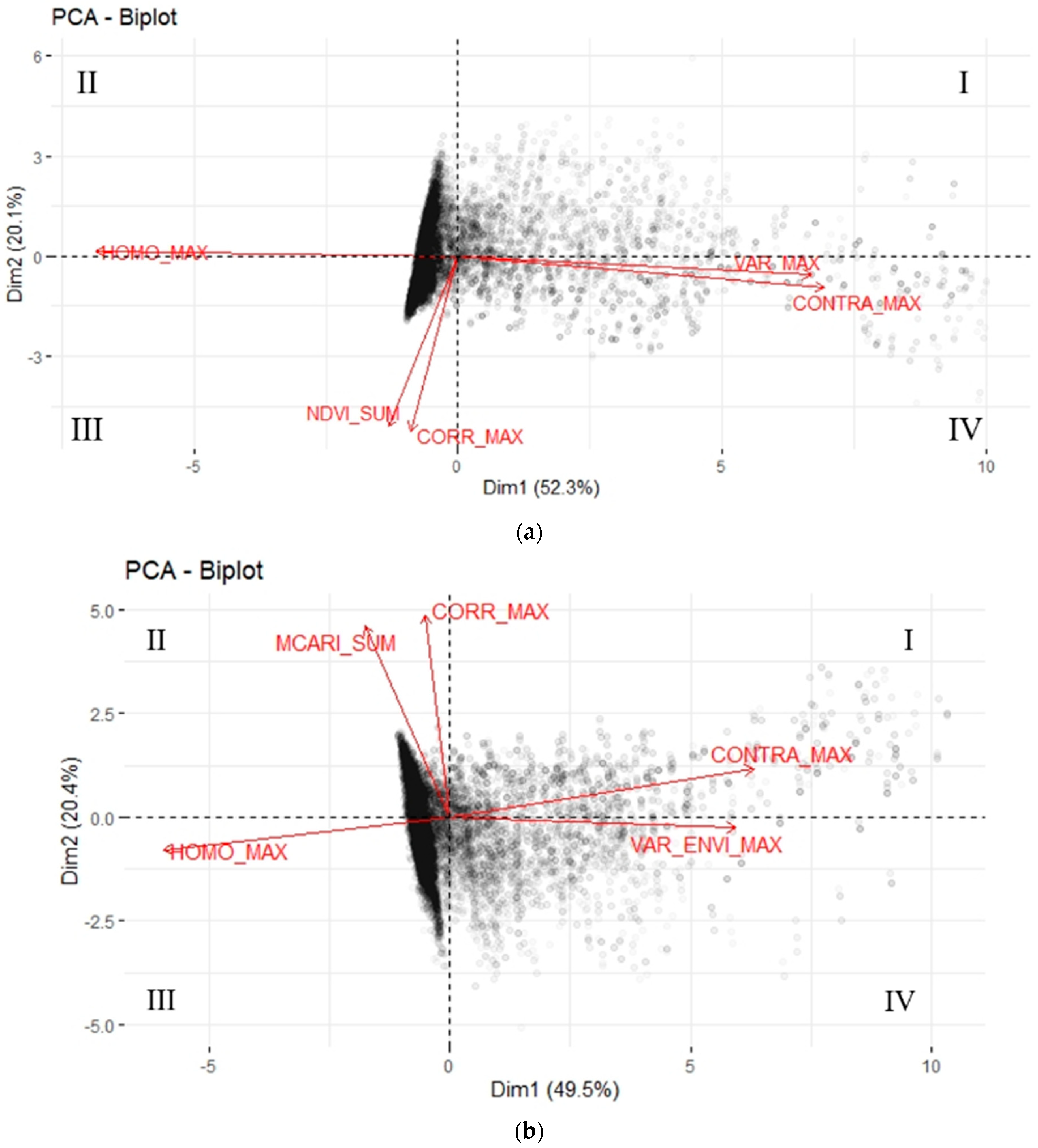
3.2. GLCM Processing and Clustering Analysis
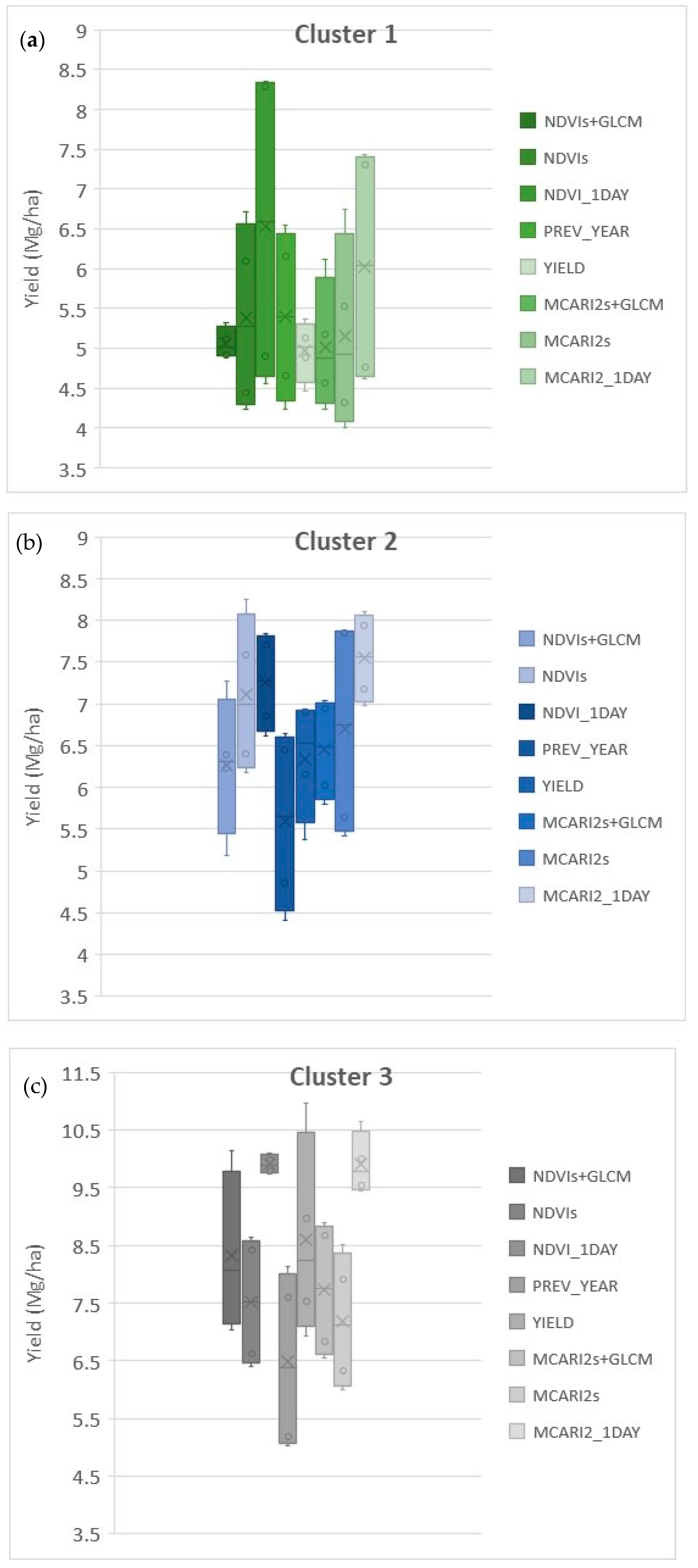
3.3. Comparison of Homogeneous Areas Obtained with Different Methods
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Van der Velde, M.; Baruth, B.; Bussay, A.; Ceglar, A.; Condado, S.G.; Karetsos, S.; Lecerf, R.; Lopez, R.; Maiorano, A.; Nisini, L.; et al. In-season performance of European Union wheat forecasts during extreme impacts. Sci. Rep. 2018, 8, 1–10. [Google Scholar]
- Lecerf, R.; Ceglar, A.; López-Lozano, R.; Van Der Velde, M.; Baruth, B. Assessing the information in crop model and meteorological indicators to forecast crop yield over Europe. Agric. Syst. 2019, 168, 191–202. [Google Scholar] [CrossRef]
- Toscano, P.; Castrignanò, A.; Di Gennaro, S.F.; Vonella, A.V.; Ventrella, D.; Matese, A. A precision agriculture approach for durum wheat yield assessment using remote sensing data and yield mapping. Agronomy 2019, 9, 437. [Google Scholar] [CrossRef]
- Kandagor, D.C. Evaluation of Spatial Variability of Selected Soil Chemical Properties, Their Influence on Coffee Yields and Management Practices at Kabete Field Station Farm. Ph.D. Thesis, University of Nairobi, Nairobi, Kenya, 2015. [Google Scholar]
- Buttafuoco, G.; Castrignanò, A.; Colecchia, A.S.; Ricca, N. Delineation of management zones using soil properties and a multivariate geostatistical approach. Ital. J. Agron. 2010, 5, 323–332. [Google Scholar] [CrossRef]
- Betzek, N.M.; de Souza, E.G.; Bazzi, C.L.; Schenatto, K.; Gavioli, A. Rectification methods for optimization of management zones. Comput. Electron. Agric. 2018, 146, 1–11. [Google Scholar] [CrossRef]
- Blackmore, B.S.; Moore, M. Remedial correction of yield map data. Precis. Agric. 1999, 1, 53–66. [Google Scholar] [CrossRef]
- Diacono, M.; Rubino, P.; Montemurro, F. Precision nitrogen management of wheat. A review. Agron. Sustain. Dev. 2013, 33, 219–241. [Google Scholar] [CrossRef]
- Diacono, M.; Castrignanò, A.; Troccoli, A.; De Benedetto, D.; Basso, B.; Rubino, P. Spatial and temporal variability of wheat grain yield and quality in a Mediterranean environment: A multivariate geostatistical approach. Field Crops Res. 2012, 131, 49–62. [Google Scholar] [CrossRef]
- Maestrini, B.; Basso, B. Predicting spatial patterns of within-field crop yield variability. Field Crops Res. 2018, 219, 106–112. [Google Scholar] [CrossRef]
- Basso, B.; Liu, L. Seasonal crop yield forecast: Methods, applications, and accuracies. Adv. Agron. 2019, 154, 201–255. [Google Scholar]
- Grisso, R.D.; Alley, M.M.; Holshouser, D.L.; Thomason, W.E. Precision Farming Tools. Soil Electrical Conductivity; Virginia Cooperative Extension: Blacksburg, VA, USA, 2005. [Google Scholar]
- Marino, S.; Alvino, A. Detection of homogeneous wheat areas using multi-temporal UAS images and ground truth data analyzed by cluster analysis. Eur. J. Remote Sens. 2018, 51, 266–275. [Google Scholar] [CrossRef]
- Tarnavsky, E.; Garrigues, S.; Brown, M.E. Multiscale geostatistical analysis of AVHRR, SPOT-VGT, and MODIS global NDVI products. Remote Sens. Environ. 2008, 112, 535–549. [Google Scholar] [CrossRef]
- Boken, V.K.; Shaykewich, C.F. Improving an operational wheat yield model using phenological phase-based Normalized Difference Vegetation Index. Int. J. Remote Sens. 2002, 23, 4155–4168. [Google Scholar] [CrossRef]
- Sultana, S.R.; Ali, A.; Ahmad, A.; Mubeen, M.; Zia-Ul-Haq, M.; Ahmad, S.; Jaafar, H.Z. Normalized difference vegetation index as a tool for wheat yield estimation: A case study from Faisalabad, Pakistan. Sci. World J. 2014. [Google Scholar] [CrossRef] [PubMed]
- Lopresti, M.F.; Di Bella, C.M.; Degioanni, A.J. Relationship between MODIS-NDVI data and wheat yield: A case study in Northern Buenos Aires province, Argentina. Inf. Process. Agric. 2015, 2, 73–84. [Google Scholar] [CrossRef]
- Peralta, N.R.; Assefa, Y.; Du, J.; Barden, C.J.; Ciampitti, I.A. Mid-season high-resolution satellite imagery for forecasting site-specific corn yield. Remote Sens. 2016, 8, 848. [Google Scholar] [CrossRef]
- Meng, S.; Zhong, Y.; Luo, C.; Hu, X.; Wang, X.; Huang, S. Optimal Temporal Window Selection for Winter Wheat and Rapeseed Mapping with Sentinel-2 Images: A Case Study of Zhongxiang in China. Remote Sens. 2020, 12, 226. [Google Scholar] [CrossRef]
- Mamma, H.; Huang, J.; Huang, H.; Ehang, X.; Ehu, D. Ensemble Forecasting of Regional Yield of Winter Wheat Based on WOFOST Model Using Historical Metrological Dataset. Trans. Chin. Soc. Agric. Mach. 2018, 49, 257–266. [Google Scholar]
- Kravchenko, A.N.; Robertson, G.P.; Thelen, K.D.; Harwood, R.R. Management, topographical, and weather effects on spatial variability of crop grain yields. Agron. J. 2005, 97, 514–523. [Google Scholar] [CrossRef]
- Lobell, D.B.; Ortiz-Monasterio, J.I.; Addams, C.L.; Asner, G.P. Soil, climate, and management impacts on regional wheat productivity in Mexico from remote sensing. Agric. For. Meteorol. 2002, 114, 31–43. [Google Scholar] [CrossRef]
- Agrawal, S.; Chakraborty, A. Evaluation of ESACCI satellite soil moisture product using in-situ CTCZ observations over India. J. Earth Syst. Sci. 2020, 129. [Google Scholar] [CrossRef]
- Spennemann, P.C.; Fernández-Long, M.E.; Gattinoni, N.N.; Cammalleri, C.; Naumann, G. Soil moisture evaluation over the Argentine Pampas using models, satellite estimations and in-situ measurements. J. Hydrol. 2020, 31, 100723. [Google Scholar] [CrossRef]
- Leroux, C.; Tisseyre, B. How to measure and report within-field variability: A review of common indicators and their sensitivity. Precis. Agric. 2019, 20, 562–590. [Google Scholar] [CrossRef]
- Le Ber, F.; Benoît, M. Modelling the spatial organization of land use in a farming territory. Example of a village in the Plateau Lorrain. Agronomie 1998, 18, 103–115. [Google Scholar] [CrossRef]
- Pedroso, M.; Taylor, J.; Tisseyre, B.; Charnomordic, B.; Guillaume, S. A segmentation algorithm for the delineation of agricultural management zones. Comput. Electron. Agric. 2010, 70, 199–208. [Google Scholar] [CrossRef]
- Schuster, E.W.; Kumar, S.; Sarma, S.E.; Willers, J.L.; Milliken, G.A. Infrastructure for Data-driven Agriculture: Identifying Management Zones for Cotton Using Statistical Modeling and Machine Learning Techniques. In Proceedings of the 8th International Conference & Expo on Emerging Technologies for a Smarter World, Hauppauge, NY, USA, 2–3 November 2011; pp. 1–6. [Google Scholar]
- Kumar, V.; Jain, S.; Tiwari, S. Energy efficient clustering algorithms in wireless sensor networks: A survey. Int. J. Comput. Sci. Issues (IJCSI) 2011, 8, 259. [Google Scholar]
- Fu, Q.; Wang, Z.; Jiang, Q. Delineating soil nutrient management zones based on fuzzy clustering optimized by PSO. Math. Comput. Model. 2010, 51, 1299–1305. [Google Scholar] [CrossRef]
- Liu, M.; Samal, A. A fuzzy clustering approach to delineate agroecozones. Ecol. Model. 2002, 149, 215–228. [Google Scholar] [CrossRef]
- Deur, M.; Gašparović, M.; Balenović, I. Tree Species Classification in Mixed Deciduous Forests Using Very High Spatial Resolution Satellite Imagery and Machine Learning Methods. Remote Sens. 2020, 12, 2072–4292. [Google Scholar] [CrossRef]
- Guastaferro, F.; Castrignanò, A.; De Benedetto, D.; Sollitto, D.; Troccoli, A.; Cafarelli, B. A comparison of different algorithms for the delineation of management zones. Precis. Agric. 2010, 11, 600–620. [Google Scholar] [CrossRef]
- Luo, P.; Liao, J.; Shen, G. Combining Spectral and Texture Features for Estimating Leaf Area Index and Biomass of Maize Using Sentinel-1/2, and Landsat-8 Data. IEEE Access 2020, 8, 53614–53626. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Pattey, E.; Zarco-Tejada, P.J.; Strachan, I.B. Hyperspectral vegetation indices and novel algorithms for predicting green LAI of crop canopies: Modeling and validation in the context of precision agriculture. Remote Sens. Environ. 2004, 90, 337–352. [Google Scholar] [CrossRef]
- Li, C.; Zhou, L.; Xu, W. Estimating Aboveground Biomass Using Sentinel-2 MSI Data and Ensemble Algorithms for Grassland in the Shengjin Lake Wetland, China. Remote Sens. 2021, 13, 1595. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Kwak, G.-H.; Park, N.-W. Impact of Texture Information on Crop Classification with Machine Learning and UAV Images. Appl. Sci. 2019, 9, 643. [Google Scholar] [CrossRef]
- Wulder, M.A.; Franklin, S.E.; Lavigne, M.B. High spatial resolution optical image texture for improved estimation of forest stand leaf area index. Can. J. Remote Sens. 1996, 22, 441–449. [Google Scholar] [CrossRef]
- Wulder, M.; Franklin, S.; Lavigne, M. Statistical Texture Properties of Forest Structure for Improved LAI Estimates from CASI. In Proceedings of the 26th International Symposium on Remote Sensing Environment 18th Annual Symposium of the Canadian Remote Sensing Society, Vancouver, BC, Canada, 25–29 March 1996; pp. 161–164. [Google Scholar]
- Soil Survey Staff. Soil Taxonomy: A Basic System of Soil Classification for Making and Interpreting Soil Surveys, 2nd ed.; U.S. Department of Agriculture Handbook 436; Natural Resources Conservation Service: Washington, DC, USA, 1999. [Google Scholar]
- Córdoba, M.A.; Bruno, C.I.; Costa, J.L.; Peralta, N.R.; Balzarini, M.G. Protocol for multivariate homogeneous zone delineation in precision agriculture. Biosyst. Eng. 2016, 143, 95–107. [Google Scholar] [CrossRef]
- Main, R.; Cho, M.A.; Mathieu, R.; O’Kennedy, M.M.; Ramoelo, A.; Koch, S. An investigation into robust spectral indices for leaf chlorophyll estimation. ISPRS J. Photogramm. Remote Sens. 2011, 66, 751–761. [Google Scholar] [CrossRef]
- Hu, S.; Mo, X. Interpreting spatial heterogeneity of crop yield with a process model and remote sensing. Ecol. Model. 2011, 222, 2530–2541. [Google Scholar]
- Haboudane, D.; Tremblay, N.; Miller, J.R.; Vigneault, P. Remote estimation of crop chlorophyll content using spectral indices derived from hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 423–437. [Google Scholar] [CrossRef]
- Xue, G.P.; Guang, Y.; Xi, P.F. Decision Model of Variable Nitrogen Fertilizer in Winter Wheat Returning Green Stage Based on UAV Multi-Spectral Images. Spectrosc. Spectr. Anal. 2019, 39, 3599–3605. [Google Scholar]
- Zadoks, J.C.; Chang, T.T.; Konzak, C.F. A decimal code for the growth stages of cereals. Weed Res. 1974, 14, 415–421. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Park, Y.; Guldmann, J.M. Measuring continuous landscape patterns with Gray-Level Co-Occurrence Matrix (GLCM) indices: An alternative to patch metrics? Ecol. Indic. 2020, 109, 105802. [Google Scholar] [CrossRef]
- Bivand, R.; Keitt, T.; Rowlingson, B. rgdal: Bindings for the Geospatial Data Abstraction Library. R Package Version 0.8-16. 2014. Available online: https://cran.r-project.org/web/packages/rgdal/index.html (accessed on 18 May 2021).
- Vattani, A. K-means requires exponentially many iterations even in the plane. In Proceedings of the Twenty-Fifth Annual Symposium on Computational Geometry, Aarhus, Denmark, 8–10 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 324–332. [Google Scholar]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management Zone Analyst (MZA) Software for Subfield Management Zone Delineation. Agron. J. 2004, 96, 100–108. [Google Scholar] [CrossRef]
- Odeh, I.O.A.; McBratney, A.B.; Chittleborough, D.J. Soil pattern recognition with fuzzy-c-means: Application to classification and soil-landform interrelationships. Soil Sci. Soc. Am. J. 1992, 56, 505–516. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.C.; Lin, C.C. e1071: Misc Functions of the Department of Statistics (e1071), TU Wien. R Package Version 2014. Available online: https://cran.r-project.org/web/packages/e1071/index.html (accessed on 1 April 2021).
- Dray, S.; Saïd, S.; Débias, F. Spatial ordination of vegetation data using a generalization of Wartenberg’s multivariate spatial correlation. J. Veg. Sci. 2008, 19, 45–56. [Google Scholar] [CrossRef]
- Chessel, D.; Dufour, A.B.; Thioulouse, J. The ade4 Package I: One-Table Methods. R News 2004, 4, 5–10. Available online: https://cran.r-project.org/doc/Rnews/ (accessed on 1 April 2021).
- Galarza, R.; Mastaglia, N.; Albornoz, E.M.; Martinez, C.E. Identificación Automática de Zonas de Manejo en Lotes Productivos Agrícolas (Automatic Identification of Management Zones in Agricultural Production Lots). In Proceedings of the 5th Congreso Argentino de Agroinformática (CAI)—42da, Córdoba, Argentina, 3–7 September 2018; Available online: http://fich.unl.edu.ar/sinc/sinc-publications/2013/GMAM13 (accessed on 20 May 2019).
- Albornoz, E.M.; Kemerer, A.C.; Galarza, R.; Mastaglia, N.; Melchiori, R.; Martínez, C.E. Development and evaluation of an automatic software for management zone delineation. Precis. Agric. 2018, 19, 463–476. [Google Scholar] [CrossRef]
- Pinheiro, J.; Bates, D.; DebRoy, S.; Sarkar, D. R Core Team, nlme: Linear and Nonlinear Mixed Effects Models; R Package Version; R Foundation for Statistical Computing: Vienna, Austria, 2014; Volume 3, pp. 1–117. Available online: https://cran.r-project.org/web/packages/nlme/index.html (accessed on 1 April 2021).
- Campoy, J.; Campos, I.; Plaza, C.; Calera, M.; Bodas, V.; Calera, A. Estimation of harvest index in wheat crops using a remote sensing-based approach. Field Crops Res. 2020, 256, 107910. [Google Scholar] [CrossRef]
- Aranguren, M.; Castellón, A.; Aizpurua, A. Wheat Yield Estimation with NDVI Values Using a Proximal Sensing Tool. Remote Sens. 2020, 12, 2749. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, M.; Zhang, X.; Zeng, H.; Wu, B. Mapping Winter Wheat Biomass and Yield Using Time Series Data Blended from PROBA-V 100- and 300-m S1 Products. Remote Sens. 2016, 8, 824. [Google Scholar] [CrossRef]
- Prada, M.; Cabo, C.; Hernández-Clemente, R.; Hornero, A.; Majada, J.; Martínez-Alonso, C. Assessing Canopy Responses to Thinnings for Sweet Chestnut Coppice with Time-Series Vegetation Indices Derived from Landsat-8 and Sentinel-2 Imagery. Remote Sens. 2020, 12, 3068. [Google Scholar] [CrossRef]
- Farahani, H.J.; Peterson, G.A.; Westfall, D.G. Dryland cropping intensification: A fundamental solution to efficient use of precipitation. Adv. Agron. 1998, 64, 225–265. [Google Scholar]
- De Vita, P.; Mastrangelo, A.M.; Matteu, L.; Mazzucotelli, E.; Virzì, N.; Palumbo, M.; Cattivelli, L. Genetic improvement effects on yield stability in durum wheat genotypes grown in Italy. Field Crops Res. 2007, 1, 68–77. [Google Scholar] [CrossRef]
- Nielsen, D.C.; Vigil, M.F. Wheat yield and yield stability of eight dryland crop rotations. Agron. J. 2018, 110, 594–601. [Google Scholar] [CrossRef]
- Vannoppen, A.; Gobin, A.; Kotova, L.; Top, S.; De Cruz, L.; Vīksna, A.; Aniskevich, S.; Bobylev, L.; Buntemeyer, L.; Caluwaerts, S.; et al. Wheat Yield Estimation from NDVI and Regional Climate Models in Latvia. Remote Sens. 2020, 12, 2206. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Band Name | Sentinel-2A | Sentinel-2B | Resolution (Meters) | ||
|---|---|---|---|---|---|---|
| Central Wavelength (nm) | Bandwidth (nm) | Central Wavelength (nm) | Bandwidth (nm) | |||
| Multispectral | NIR | 835.1 | 115 | 833 | 115 | 10 |
| Multispectral | Red | 664.5 | 30 | 665 | 30 | 10 |
| Multispectral | Green | 560.0 | 35 | 559 | 35 | 10 |
| Indices | Description | Equation |
|---|---|---|
| Homogeneity | Measures image homogeneity. Sensitive to the presence of near diagonal elements in a GLCM, representing the similarity in gray level between adjacent pixels. | |
| Contrast | Measures the drastic change in gray level between contiguous pixels. High contrast images feature high spatial frequencies. | |
| Variance | A measure of heterogeneity, variance increases when the gray level values differ from their mean. | |
| Correlation | Measures the linear dependency in the image. High correlation values imply a linear relationship between the gray levels of adjacent pixel pairs. |
| Models | Variables |
|---|---|
| ∑NDVI | ∑NDVI by 1 year; Year; Standard deviation of NDVI by 1 year |
| ∑MCARI2 | ∑MCARI2 by 1 year; Year; Standard deviation of MCARI2 by 1 year |
| NDVI single-day | NDVI of a single day; Year |
| MCARI2 single-day | MCARI2 of a single day; Year |
| ∑NDVI +GLCM | ∑NDVI by 1 year; Year; Standard deviation of NDVI by 1 year; GLCM (Homogeneity, Contrast, Variance, Correlation) |
| ∑MCARI2 +GLCM | ∑MCARI2 by 1 year; Year; Standard deviation of MCARI2 by 1 year; GLCM (Homogeneity, Contrast, Variance, Correlation) |
| FIELD | ΣNDVI | ΣMCARI2 | ||
|---|---|---|---|---|
| μ | σ | μ | σ | |
| 1 | 9.15 | 0.39 | 4.11 | 0.36 |
| 2 | 8.81 | 0.33 | 3.96 | 0.33 |
| 3 | 8.72 | 0.37 | 3.88 | 0.30 |
| 4 | 8.74 | 0.38 | 3.88 | 0.28 |
| 5 | 8.97 | 0.29 | 4.05 | 0.22 |
| 6 | 8.98 | 0.34 | 4.05 | 0.27 |
| 7 | 9.02 | 0.33 | 4.09 | 0.28 |
| 8 | 9.05 | 0.42 | 4.03 | 0.37 |
| 9 | 9.01 | 0.28 | 3.99 | 0.23 |
| 10 | 8.38 | 0.49 | 3.56 | 0.39 |
| Model | Regression | R2 | RMSE |
|---|---|---|---|
| ΣNDVI+GLCM |  | 0.982 | 0.25 |
| Σ_NDVI |  | 0.695 | 1.03 |
| NDVI_Single-day |  | 0.626 | 1.14 |
| PREV_YEAR |  | 0.621 | 1.15 |
| ΣMCARI2+GLCM |  | 0.878 | 0.649 |
| ΣMCARI2 |  | 0.676 | 1.06 |
| MCARI2_Single-day |  | 0.785 | 0.862 |
| NDVI | MCARI2 | |||
|---|---|---|---|---|
| FACTORS | PC1 (52.00%) | PC2 (20.10%) | PC1 (49.51%) | PC2 (20.45%) |
| Spectral_indices_sum | −0.11 | 0.69 | −0.16 | 0.67 |
| Homogeneity_max | −0.57 | −0.02 | −0.55 | −0.11 |
| Contrast_max | 0.58 | 0.13 | 0.59 | 0.17 |
| Variance_max | 0.56 | 0.07 | 0.55 | 0.55 |
| Correlation_max | −0.07 | 0.71 | −0.05 | 0.71 |
| NDVI | MCARI2 | ||||||
|---|---|---|---|---|---|---|---|
| Field | No. Cluster | 2 | 3 | 4 | 2 | 3 | 4 |
| 1 | XieBeni | 8.45 × 10−6 | 7.83 × 10−6 | 8.32 × 10−6 | 3.95 × 10−6 | 3.55 × 10−6 | 2.44 × 10−6 |
| FukSug | −1.01 × 105 | −1.18 × 105 | −1.01 × 105 | −1.02 × 105 | −2.95 × 105 | −1.31 × 105 | |
| PartCoef | 1.01 × 10 | 1.00 × 10 | 1.06 × 10 | 1.01 × 10 | 1.01 × 10 | 1.02 × 10 | |
| PartEntr | 9.94 × 10−2 | 9.16 × 10−2 | 9.43 × 10−2 | 2.15 × 10−2 | 1.99 × 10−2 | 3.04 × 10−2 | |
| 2 | XieBeni | 7.50 × 10−6 | 6.61 × 10−6 | 0.00000769 | 4.8 × 10−6 | 2.14 × 10−6 | 2.26 × 10−6 |
| FukSug | −1.04 × 105 | −1.09 × 105 | −1.05 × 105 | −3.26 × 105 | −1.42 × 105 | −4.26 × 105 | |
| PartCoef | 1.07 × 10 | 1.02 × 10 | 1.08 × 10 | 1.05 × 10 | 1.05 × 10 | 1.09 × 10 | |
| PartEntr | 9.20 × 10−2 | 9.19 × 10−2 | 9.55 × 10−2 | 3.56 × 10−2 | 1.14 × 10−2 | 1.30 × 10−2 | |
| 3 | XieBeni | 8.36 × 10−6 | 7.37 × 10−6 | 0.00000819 | 2.74 × 10−6 | 2.64 × 10−6 | 3.85 × 10−6 |
| FukSug | −1.03 × 105 | −1.08 × 105 | −1.05 × 105 | −2.17 × 105 | −4.10 × 105 | −5.14 × 105 | |
| PartCoef | 1.06 × 10 | 1.01 × 10 | 1.03 × 10 | 1.07 × 10 | 1.04 × 10 | 1.06 × 10 | |
| PartEntr | 9.96 × 10−2 | 9.18 × 10−2 | 9.91 × 10−2 | 2.73 × 10−2 | 1.29 × 10−2 | 3.51 × 10−2 | |
| 4 | XieBeni | 9.57 × 10−6 | 7.82 × 10−6 | 0.00000898 | 4.13 × 10−6 | 3.29 × 10−6 | 3.82 × 10−6 |
| FukSug | −1.06 × 105 | −1.08 × 105 | −1.06 × 105 | −3.17 × 105 | −1.89 × 105 | −4.63 × 105 | |
| PartCoef | 1.04 × 10 | 1.02 × 10 | 1.01 × 10 | 1.06 × 10 | 1.01 × 10 | 1.03 × 10 | |
| PartEntr | 9.77 × 10−2 | 9.54 × 10−2 | 9.71 × 10−2 | 3.32 × 10−2 | 1.27 × 10−2 | 3.91 × 10−2 | |
| 5 | XieBeni | 7.84 × 10−6 | 7.86 × 10−6 | 0.00000789 | 4.66 × 10−6 | 4.04 × 10−6 | 4.43 × 10−6 |
| FukSug | −1.08 × 105 | −1.09 × 105 | −1.02 × 105 | −4.60 × 105 | −1.79 × 105 | −2.69 × 105 | |
| PartCoef | 1.04 × 10 | 1.03 × 10 | 1.05 × 10 | 1.07 × 10 | 1.01 × 10 | 1.10 × 10 | |
| PartEntr | 9.57 × 10−2 | 9.20 × 10−2 | 9.60 × 10−2 | 3.06 × 10−2 | 1.37 × 10−2 | 2.01 × 10−2 | |
| 6 | XieBeni | 8.3 × 10−6 | 8.02 × 10−6 | 0.00000903 | 2.35 × 10−6 | 2.01 × 10−6 | 3.01 × 10−6 |
| FukSug | −1.01 × 105 | −1.07 × 105 | −1.05 × 105 | −3.69 × 105 | −1.56 × 105 | −2.52 × 105 | |
| PartCoef | 1.05 × 10 | 1.02 × 10 | 1.04 × 10 | 1.02 × 10 | 1.01 × 10 | 1.08 × 10 | |
| PartEntr | 9.20 × 10−2 | 9.32 × 10−2 | 9.32 × 10−2 | 2.79 × 10−2 | 1.07 × 10−2 | 1.35 × 10−2 | |
| 7 | XieBeni | 8.81 × 10−6 | 7.96 × 10−6 | 0.00000874 | 4.23 × 10−6 | 2.2 × 10−6 | 4.49 × 10−6 |
| FukSug | −1.04 × 105 | −1.06 × 105 | −1.05 × 105 | −3.62 × 105 | −3.85 × 105 | −4.59 × 105 | |
| PartCoef | 1.02 × 10 | 1.03 × 10 | 1.08 × 10 | 1.04 × 10 | 1.03 × 10 | 1.09 × 10 | |
| PartEntr | 9.73 × 10−2 | 9.67 × 10−2 | 9.68 × 10−2 | 1.89 × 10−2 | 1.77 × 10−2 | 3.13 × 10−2 | |
| 8 | XieBeni | 7.62 × 10−6 | 7.17 × 10−6 | 0.00000928 | 3.78 × 10−6 | 2.88 × 10−6 | 4.22 × 10−6 |
| FukSug | −1.02 × 105 | −1.07 × 105 | −1.06 × 105 | −3.77 × 105 | −3.91 × 105 | −3.27 × 105 | |
| PartCoef | 1.01 × 10 | 1.01 × 10 | 1.09 × 10 | 1.06 × 10 | 1.03 × 10 | 1.09 × 10 | |
| PartEntr | 9.81 × 10−2 | 9.45 × 10−2 | 9.93 × 10−2 | 3.96 × 10−2 | 1.85 × 10−2 | 3.42 × 10−2 | |
| 9 | XieBeni | 8.98 × 10−6 | 7.94 × 10−6 | 0.00000995 | 3.04 × 10−6 | 2.78 × 10−6 | 3.73 × 10−6 |
| FukSug | −1.06 × 105 | −1.08 × 105 | −1.07 × 105 | −3.72 × 105 | −1.57 × 105 | −4.35 × 105 | |
| PartCoef | 1.03 × 10 | 1.03 × 10 | 1.04 × 10 | 1.04 × 10 | 1.01 × 10 | 1.04 × 10 | |
| PartEntr | 9.07 × 10−2 | 9.01 × 10−2 | 9.43 × 10−2 | 3.78 × 10−2 | 3.29 × 10−2 | 9.51 × 10−2 | |
| 10 | XieBeni | 8.22 × 10−6 | 7.69 × 10−6 | 0.00000962 | 3.52 × 10−6 | 2.87 × 10−6 | 3.63 × 10−6 |
| FukSug | −1.06 × 105 | −1.08 × 105 | −1.05 × 105 | −2.31 × 105 | −1.68 × 105 | −3.97 × 105 | |
| PartCoef | 1.08 × 10 | 1.01 × 10 | 1.04 × 10 | 1.06 × 10 | 1.05 × 10 | 1.09 × 10 | |
| PartEntr | 9.44 × 10−2 | 9.42 × 10−2 | 9.63 × 10−2 | 2.19 × 10−2 | 1.45 × 10−2 | 3.15 × 10−2 |
| FIELD | ZONE | ∑NDVI +GLCM | ∑NDVI | NDVI Single-Day | Yield Map 2017 | Measured Yield | ∑MCARI2 +GLCM | ∑MCARI2 | MCARI2 Single-Day |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 5.01a | 5.27a | 6.42a | 5.40a | 4.80 ± 0.3 | 4.87a | 4.77a | 5.96a |
| Δμ% | 4.38% | 9.79% | 33.75% | 12.50% | 1.46% | −0.63% | 24.17% | ||
| 2 | 6.31b | 7.33b | 7.28a | 5.65a | 6.53 ± 0.4 | 6.48b | 6.75b | 7.56b | |
| Δμ% | −3.37% | 12.25% | 10.30% | −13.48% | −0.77% | 3.37% | 13.62% | ||
| 3 | 8.07c | 7.41c | 9.89b | 6.39b | 8.25 ± 0.7 | 7.76c | 6.95c | 9.78c | |
| Δμ% | −2.18% | −10.18% | 16.58% | −22.55% | −5.94% | −15.76% | 15.64% | ||
| 2 | 1 | 4.53a | 4.74a | 5.67a | 5.11a | 4.36 ± 0.3 | 4.42a | 4.39a | 5.50a |
| Δμ% | 3.90% | 8.72% | 30.05% | 17.09% | 1.26% | 0.57% | 26.15% | ||
| 2 | 6.07b | 6.74b | 6.94b | 5.28a | 5.98 ± 0.4 | 6.02b | 6.35b | 7.11b | |
| Δμ% | 1.51% | 12.80% | 13.84% | −11.63% | 0.75% | 6.19% | 15.90% | ||
| 3 | 8.28c | 7.22b | 9.80c | 6.52b | 8.14 ± 0.7 | 7.88c | 7.24b | 9.68c | |
| Δμ% | 1.66% | −11.36% | 16.94% | −19.96% | −3.19% | −11.06% | 15.87% | ||
| 3 | 1 | 4.52a | 4.81a | 5.62a | 5.11a | 4.38 ± 0.2 | 4.34a | 4.40a | 5.46a |
| Δμ% | 3.20% | 9.94% | 28.34% | 16.69% | −0.80% | 0.46% | 24.80% | ||
| 2 | 5.33b | 6.23b | 6.36a | 5.05a | 5.49 ± 0.4 | 5.54b | 5.71b | 6.59b | |
| Δμ% | −2.91% | 13.48% | 13.61% | −8.11% | 0.82% | 3.92% | 16.69% | ||
| 3 | 7.85c | 7.01b | 9.22b | 6.65b | 7.74 ± 0.7 | 7.63c | 6.68c | 8.68c | |
| Δμ% | 1.42% | −9.43% | 16.01% | −14.08% | −1.49% | −13.76% | 10.83% | ||
| 4 | 1 | 4.67a | 4.94a | 5.72a | 5.17a | 4.56 ± 0.3 | 4.59a | 4.52a | 5.25a |
| Δμ% | 2.52% | 8.34% | 25.58% | 13.39% | 0.77% | −0.88% | 15.15% | ||
| 2 | 5.34a | 6.22b | 6.12a | 4.92a | 5.53 ± 0.4 | 5.48b | 5.65b | 6.26b | |
| Δμ% | −3.35% | 12.49% | 9.72% | −10.95% | −0.81% | 2.26% | 11.74% | ||
| 3 | 7.61b | 7.02b | 9.18b | 6.61b | 7.76 ± 0.7 | 7.54c | 6.69c | 8.68c | |
| Δμ% | −1.93% | −9.54% | 15.49% | −14.76% | −2.77% | −13.80% | 10.61% | ||
| 5 | 1 | 4.80a | 5.02a | 5.90a | 5.27a | 4.65 ± 0.4 | 4.70a | 4.60a | 5.36a |
| Δμ% | 3.12% | 7.96% | 26.88% | 13.33% | 1.08% | −1.08% | 15.16% | ||
| 2 | 5.61b | 6.44b | 6.29a | 5.02a | 5.83 ± 0.6 | 5.78b | 6.10b | 6.35b | |
| Δμ% | −3.69% | 10.56% | 7.39% | −13.91% | −0.86% | 4.72% | 8.20% | ||
| 3 | 7.91c | 7.16b | 9.85b | 6.49b | 8.13 ± 0.9 | 7.81c | 7.15c | 9.18c | |
| Δμ% | −2.71% | −11.88% | 17.47% | −20.18% | −3.94% | −12.00% | 11.49% | ||
| 6 | 1 | 4.98a | 5.15a | 6.11a | 5.36a | 4.79 ± 0.4 | 4.86a | 4.70a | 5.50a |
| Δμ% | 3.97% | 7.52% | 27.69% | 11.91% | 1.57% | −1.78% | 14.94% | ||
| 2 | 5.80b | 6.59b | 6.74a | 5.18a | 5.95 ± 0.7 | 6.01b | 6.13b | 6.76b | |
| Δμ% | −2.44% | 10.77% | 11.73% | −12.87% | 1.01% | 3.03% | 11.99% | ||
| 3 | 8.18c | 7.40b | 9.75b | 6.63b | 8.42 ± 1.1 | 8.02c | 7.19c | 9.44c | |
| Δμ% | −2.85% | −12.06% | 13.65% | −21.27% | −4.75% | −14.62% | 10.81% | ||
| 7 | 1 | 4.95a | 5.17a | 6.33a | 5.33a | 4.78 ± 0.4 | 4.84a | 4.70a | 5.78a |
| Δμ% | 3.66% | 8.17% | 32.46% | 11.62% | 1.36% | −1.57% | 20.94% | ||
| 2 | 5.86b | 6.71b | 6.87a | 5.43a | 6.07 ± 0.6 | 6.05b | 6.26b | 6.82b | |
| Δμ% | −3.38% | 10.55% | 11.72% | −10.55% | −0.25% | 3.13% | 11.07% | ||
| 3 | 8.91c | 7.94c | 10.44b | 6.99b | 9.05 ± 0.9 | 8.57c | 7.72c | 10.41c | |
| Δμ% | −1.55% | −12.27% | 13.36% | −22.72% | −5.31% | −14.65% | 13.11% | ||
| 8 | 1 | 5.1a | 5.61a | 6.40a | 5.56a | 5.01 ± 0.6 | 5.05a | 4.91a | 5.83a |
| Δμ% | 3.30% | 11.99% | 27.77% | 10.99% | 0.90% | −1.90% | 16.38% | ||
| 2 | 6.19b | 7.10b | 6.87a | 5.61a | 6.38 ± 0.7 | 6.31b | 6.59b | 7.26b | |
| Δμ% | −2.98% | 11.21% | 7.06% | −12.15% | −1.18% | 3.29% | 12.12% | ||
| 3 | 9.08c | 8.59c | 10.48b | 7.30b | 9.28 ± 1.2 | 9.02c | 8.21c | 10.39c | |
| Δμ% | −2.10% | −7.44% | 11.46% | −21.29% | −2.75% | −11.54% | 10.73% | ||
| 9 | 1 | 5.27a | 5.60a | 6.18a | 5.80a | 5.19 ± 0.7 | 5.20a | 5.12a | 6.12a |
| Δμ% | 1.54% | 7.91% | 19.19% | 11.76% | 0.29% | −1.35% | 17.94% | ||
| 2 | 6.28b | 7.18b | 6.98a | 5.68a | 6.43 ± 0.8 | 6.37b | 6.66b | 7.27b | |
| Δμ% | −2.41% | 11.66% | 7.81% | −11.66% | −0.93% | 3.50% | 11.49% | ||
| 3 | 9.43c | 8.81c | 10.58b | 7.93b | 9.54 ± 1.3 | 9.31c | 8.20c | 10.54c | |
| Δμ% | −1.10% | −7.66% | 9.83% | −16.83% | −2.36% | −14.05% | 9.49% | ||
| 10 | 1 | 4.42a | 4.70a | 5.14a | 4.71a | 4.29 ± 0.8 | 4.36a | 4.22a | 5.21a |
| Δμ% | 3.03% | 9.68% | 19.95% | 9.92% | 1.63% | −1.52% | 21.59% | ||
| 2 | 5.14b | 5.82b | 6.10b | 4.85a | 5.30 ± 1.0 | 5.22b | 5.49b | 6.30b | |
| Δμ% | −2.93% | 9.82% | 13.13% | −8.40% | −1.51% | 3.68% | 15.95% | ||
| 3 | 7.27c | 6.59b | 8.25c | 6.58b | 7.40 ± 1.2 | 7.30c | 6.62c | 8.49c | |
| Δμ% | −1.76% | −10.95% | 10.36% | −11.02% | −1.28% | −10.48% | 12.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romano, E.; Bergonzoli, S.; Pecorella, I.; Bisaglia, C.; De Vita, P. Methodology for the Definition of Durum Wheat Yield Homogeneous Zones by Using Satellite Spectral Indices. Remote Sens. 2021, 13, 2036. https://doi.org/10.3390/rs13112036
Romano E, Bergonzoli S, Pecorella I, Bisaglia C, De Vita P. Methodology for the Definition of Durum Wheat Yield Homogeneous Zones by Using Satellite Spectral Indices. Remote Sensing. 2021; 13(11):2036. https://doi.org/10.3390/rs13112036
Chicago/Turabian StyleRomano, Elio, Simone Bergonzoli, Ivano Pecorella, Carlo Bisaglia, and Pasquale De Vita. 2021. "Methodology for the Definition of Durum Wheat Yield Homogeneous Zones by Using Satellite Spectral Indices" Remote Sensing 13, no. 11: 2036. https://doi.org/10.3390/rs13112036
APA StyleRomano, E., Bergonzoli, S., Pecorella, I., Bisaglia, C., & De Vita, P. (2021). Methodology for the Definition of Durum Wheat Yield Homogeneous Zones by Using Satellite Spectral Indices. Remote Sensing, 13(11), 2036. https://doi.org/10.3390/rs13112036