1. Introduction
The global population is projected to reach 7.58 billion by the end of the year and an additional 27.7 million tonnes of edible oil will be required to fulfill food demands. With its greater per-hectare production and economic competitiveness, oil palm is a pivotal crop in ensuring sufficient edible oil is available in the global market [
1]. Agriculture has at times become a controversial topic among conservationists due to its negative impacts on the environment, such as biodiversity loss, deforestation, and increased carbon emissions [
2,
3,
4,
5]. Precision agriculture (PA), which involves informed decision making in agriculture using information interpreted from sensor-based data (such as the remote sensing data in this paper) or other sources, is currently sought as a solution for improved sustainable food production [
6,
7,
8,
9].
In fertilizer application, PA enables site specific management by determining macronutrient status and fertilizer requirement in individual plants. These macronutrients include nitrogen (N), phosphorus (P), potassium (K), magnesium (Mg) and calcium (Ca), which are essential for ensuring good plant health [
7,
8,
9,
10]. Like most plants, macronutrient levels in palm trees are diagnosed via removal of leaflets for destructive chemical analysis, such as the Kjeldahl method for N determination [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]. By relating remote sensing and GIS technology data with field results at promising accuracy and precision, the findings could be extrapolated to plantation scales, enabling more efficient, economic and non-destructive means of fertilizer management. This ensures global food security is met under sustainable terms via increasing crop production with available land and resource [
7,
8,
15,
20].
Spectroradiometers are the fundamental sensing tools utilized in nutrient prediction, due to their capacity to record reflectance readings ranging from the visible (VIS) to the shortwave infrared (SWIR) region of the electromagnetic spectrum (300–2500 nm) in hundreds of narrow wavebands. The data heaps from spectroradiometers warranted the use of machine learning (ML) subsequently, due to its ability to extract information from datasets with high dimensions and non-linear structures [
20,
21,
22]. Because ML algorithms acquire their solutions with different mathematical approaches, this prompts the adoption of at least two algorithms in most studies for comparison purposes [
18,
19,
20,
21,
22]. Successful predictions with spectroradiometer data have been seen in rice [
18,
23,
24,
25,
26], citrus [
11,
12], wheat [
10,
20,
27,
28,
29], oilseed rape [
13,
16,
30], pastures [
21,
22,
31,
32,
33] and other plants [
34,
35,
36].
It can be seen that the wavelengths selected in literature for N prediction are focused in the green (i.e., 510–550 nm) and red edge (i.e., 710–750 nm) regions, which correspond to chlorophyll characteristics [
12,
20,
37]; this is contrary to P and K, in which wavelengths at the SWIR region play a large role, in addition to those in the VISNIR region [
13,
14,
23,
29,
30,
32,
33,
34,
35]. Additionally, specific wavelengths identified as significant explanatory variables may be used to derive vegetation indices (VI) mathematically for improved prediction [
23,
29]. However, the exact wavelengths identified for predictions may differ between crops, their varieties, and methods used. The authors of [
20] identified 526 nm and 716 nm as ideal predictors for wheat N, while [
25] concluded 522 nm and 740 nm for rice N, with both studies using the ratio of the readings from the first derivatives of their respective wavelength pairs. On the other hand, [
13,
30] identified several highly similar wavelengths despite use of different methods for oil seed rape N prediction ([
13]: 513 nm, 542 nm, 718 nm, 928 nm, 1015 nm; [
30]: 574 nm, 719 nm, 918 nm, 1017 nm).
It remains unfortunate that spectroradiometers are unaffordable for most agricultural practitioners, in addition to its more laborious nature when plants have to be scanned individually for plantation-scale monitoring. Multispectral imaging from satellite sensors may offer a solution to wide-scale and affordable measures for nutrient monitoring. To date, a handful of research has attempted N prediction using high spatial resolution (<5 m) multispectral images captured from commercial satellites, such as QuickBird [
38], GeoEye-1 [
39], SPOT 7 [
40] and WorldView-2 [
41], with promising results. Sadly, free medium-resolution data from satellite sensors such as Landsat-8 OLI, Sentinel 2 MSI, ASTER and Sentinel 3 OLCI were even greater in rarity [
42,
43], or at best, simulated with spectroradiometer readings [
31]. In palm trees, similar platforms (i.e., spectroradiometer and high resolution images) have been explored for the prediction of N, P and K [
40,
44,
45,
46], although difficulty in its widespread application still remains with its inaccessibility to oil palm smallholders.
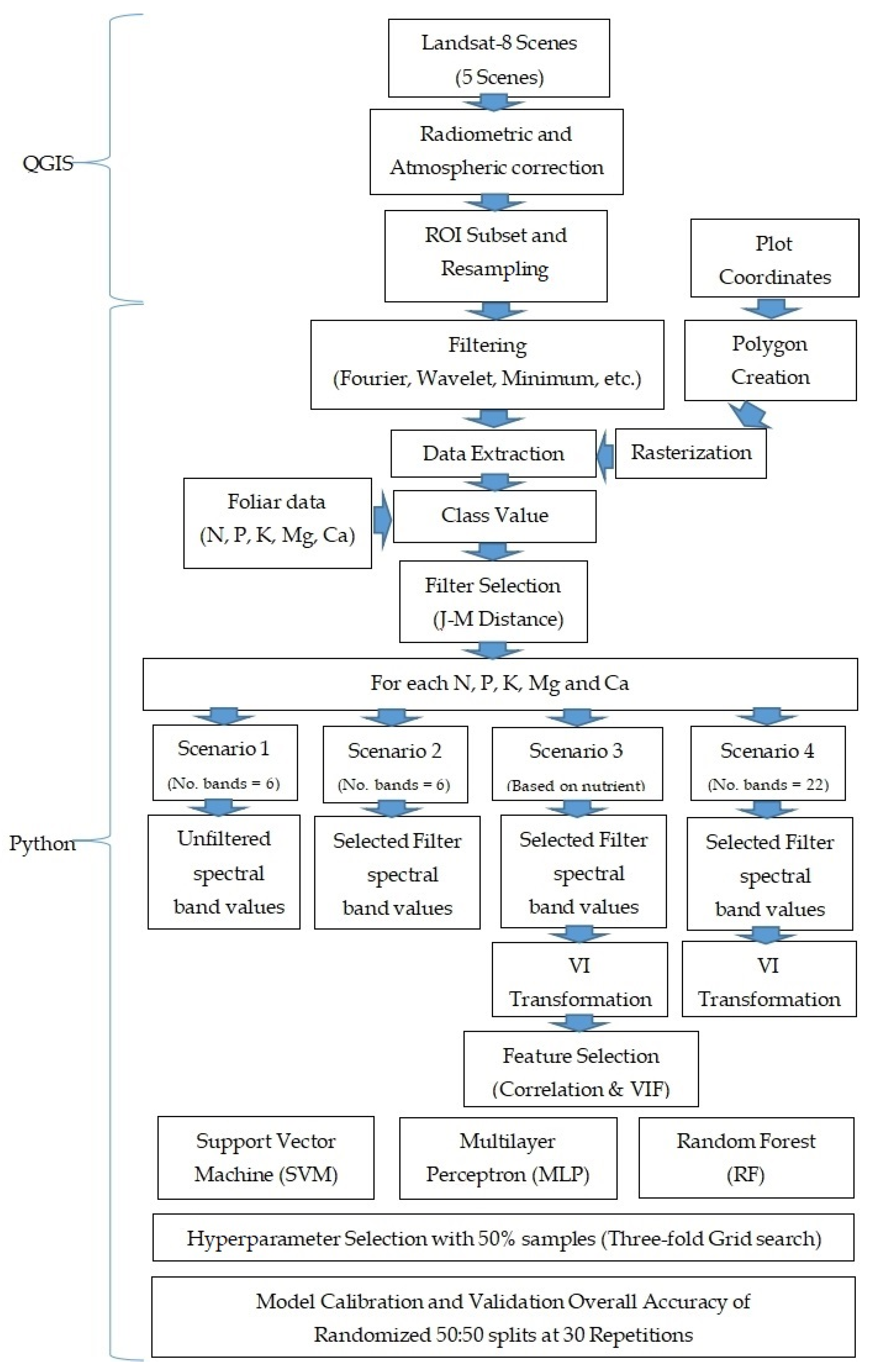
Taking leverage of its free availability and consistent revisit frequency, this study assessed Landsat-8 OLI satellite imageries and ML algorithms (i.e., Support Vector Machine (SVM), Artificial Neural Network (ANN), Random Forest (RF)) in classifying nutrient levels of palm trees with different treatments for the following macronutrients: nitrogen (N), phosphorus (P), potassium (K), magnesium (Mg) and calcium (Ca). Given its 30 m resolution, the study proposed an open-source and plot-based method to classify the nutrient status of palm trees via image processing, feature extraction and ML classification. The aim of this study is to produce a freely available nutrient level classification model with Landsat-8 OLI imageries as input. Studies to date on nutrient estimation have only focused on spectroradiometer data or high resolution imaging, particularly for N. The positive results acquired from this research will open insights to the potential of using easily available coarse satellite imaging in classifying plot N and other macronutrient levels via ML, subsequently allowing long-term monitoring of palm plantations at a large scale. This would not only promote efficient, convenient and cost-effective nutrient management at a plantation scale, but increase the accessibility of nutrient monitoring to smallholders.
4. Discussion
J-M distance was shown to be a strong separability metric in this study. This was observed by instances for N level classification: perfect classification of samples between Optimum (Opt) and Excessive (Ex) levels as well as low misclassification between Opt and Marginally Excessive (Mar Ex) levels, given the pairwise J-M distance values were at 1.99 and 1.87 respectively (
Table 10A). After filtering, pairwise distance of N for between Mar Ex and Ex as well as K or Ca for Opt and Mar Ex were increased by slight amounts. Unfortunately, this did not translate into any form of improved classification accuracy. Most samples from different classes of Mg or Ca remain misclassified with the given pairwise distance. These findings were consistent with those reported by [
58,
59,
60], who noted requirement of J-M distance values greater than 1.80 for effective class separability.
However, low J-M distance values may also be a result of uneven sampling encountered between classes for all nutrients in this study, particularly N, K and Ca. Uneven sampling could lead to model overfitting and complex decision surfaces formed and dominated by samples from the majority class. In remote sensing, RF is susceptible to uneven sampling between classes for classification problems, although findings regarding its impact remained inconclusive [
84]. For SVM in this study, more than 50% of all support vectors were selected from the majority class, leading to greater misclassification of samples from another class as the majority class (
Table 10B–D). Some SVM instances were noted to have high support vector to total sample ratio (50%) as well. An increase in ratio may subsequently result in increased overfitting and misclassification [
87,
88]. Although a high classification accuracy was acquired for Ca (
Table 9,
Figure 4) during the validation stage, it has to be reflected that most of the correct classifications (>90%) were from the majority class (
Table 10D). Taking into account the required J-M distance value greater than 1.80 for effective class separability [
58,
59,
60] and the need for even sampling, it is suggested that the classification of nutrient levels for Mg and Ca using Landsat-8 imagery remains inconclusive based on the limitations of the dataset.
Identification of SWIR2 as a strong predictor for N concurs with findings from [
44,
89], who conducted similar experiments with hyperspectral spectroradiometers instead. Several other researchers have also identified SWIR regions as potential regions for N predictions. The SWIR2 band (2.11–2.29 μm) region is associated with absorption features as a result of vibration activities from amide bonds of N-containing proteins. SWIR regions are also said to have low scattering by canopy structural variation, thus making them perfect candidates for canopy-level monitoring [
90,
91]. Sadly, the limited wavelength coverage by band reflectance from Landsat-8 OLI satellite prevented further comparison of other spectral regions as predictors for the studied nutrients. VIs were also applied in hopes of magnifying signals from biophysical parameters of vegetation. Several VIs related to soil-line and atmospheric adjustments were identified as potential predictors for N (i.e., SAVI, SARVI, EVI, MSAVI, EVI2 and GARI), while NIR-related indices for K (i.e., NDVI, TVI and IPVI). This may be attributed to the following: (1) the role of N in photosynthesis as well as the susceptibility of involved spectral regions (i.e., visible) to soil background or atmospheric effects and (2) the role of K in plant cellular structure maintenance, development and disease resistance, which may be spectrally reflected at the corresponding NIR region (i.e., 815–879 nm) of the applied band [
92,
93].
In this study, atmospherically-adjusted indices (i.e., EVI, SARVI, ARVI, GARI) were prioritised over soil indices in N. This was suggested by the little-to-no difference in correlation coefficients between mathematically related indices; the correlation coefficient between N and ARVI was greater than N and SAVI, in addition to the former possessing a coefficient closer in magnitude to their composite, SARVI. Yet, soil-related indices were still important in this study. Developed by [
64], SARVI combined SAVI and ARVI to address both atmospheric and soil background effects. Using cotton plants, the index was shown to outperform ARVI and SAVI when atmospheric and soil effects were strong, particularly when LAI < 3. A similar conclusion could be drawn by observing greater coefficients of SAVI than OSAVI. SAVI had a higher L parameter (L = 0.5) set in this study compared to OSAVI (L = 0.16) which had greater performance when scenes contain greater soil background effects [
64,
71]. This suggests the presence of background soil effects from the study site, despite being visually confirmed to have closed canopy cover.
Based on literature [
63,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75], most indices were initially derived to quantify biophysical parameters such as LAI, vegetation cover or fPAR. Subsequently, one would expect growth in palm stands due to greater N and K levels to be captured in VIs [
94]. In addition, most identified VIs were originally derived from satellite data (i.e., Landsat and MODIS imageries), thus suggesting further compatibility in application [
63,
65,
67,
68,
69,
72,
75]. Still, many of the indices evaluated in this study were highly correlated with each other, due to indices being successions of other indices, such as EVI2 being a 2-band approximation of EVI [
68,
75]. Because of this, care should be taken to include VIs identified as strong predictors but uncorrelated with each other, such that issues related to multicollinearity could be avoided. The use of feature selection may aid in remediating the issue, as applied in Scenario 3.
Using scenarios, it could be seen that MLP experienced the greatest improvement for N and K in both classification accuracy and consistency with the use of filters (Scenario 2) or filters and feature selection (Scenario 3), as observed in improved minimum, mean and maximum accuracy, in addition to reduced standard deviation and boxplot size. MLPs are able to benefit from greater number of features which improves the description of the response variable to be classified [
80]. Increased accuracy was also identified in RF and SVM models under similar scenarios and nutrients. However, the use of filters and all features (Scenario 4) led to decreased mean accuracy and increased standard deviation of models for several models compared to Scenario 3: SVM for K, RF for K and MLP for N. It may be plausible to suggest the Hughes’ phenomenon or curse of dimensionality as its cause, where increasing data dimension with further inclusion of features resulted in sample points being so sparsely distributed such that models were unable to acquire a generalize solution or establishing an effective decision surface [
95]. Using VIF to address multicollinearity and dimension reduction (Scenario 3), it was found MLP and RF acquired their respective best performance for N during validation, despite number of features applied were less than the use of initial bands. This is consistent the previous finding for feature selection and may suggest the potential use of fewer indices to represent or improve the information captured in the initial bands of the images, including bands not applied in their derivation, such as the SWIR bands.
On another note, SVM or RF for N at Scenario 4 during validation was the best scenario despite reduced accuracy during calibration. SVM and RF possessed the upper hand in performance accuracy, variability and accuracy difference between scenarios compared to MLP. This suggests the robustness and stability conferred to these models in handling high dimensional data at low samples [
95]. The main contribution to such differences is each model’s approach in acquiring its respective generalized solution: SVM follows the structural risk minimization and the kernel method, thus focusing samples involved in constructing the decision boundaries only and allowing the ability to handle both low and high dimension data respectively; and RF is able to mediate these factors by applying bootstrap aggregation (or bagging) mechanism which involves decision making from hundreds of tree classifiers [
77,
86,
96]. MLPs require greater number of features to perform well and solve non-convex problems by minimizing observed errors, which may, at times, result in local optima convergence and overfitting [
83]. Still, it is worth noting MLP was able to classify several instances of N for the Ex class accurately using the selected features (
Table 11).
Overall, SVM has the best performance in terms of accuracy (i.e., minimum, mean, median, maximum) for both N and K while RF in terms of stability (i.e., boxplot size, standard deviation). Model performance and stability is summarized as SVM > RF > MLP and RF > SVM > MLP, respectively. The coefficient of variation (Cov) of models may be used as a compromise for both aspects when selecting a model of choice for a particular nutrient. Models with lower Cov (i.e., low standard deviation/high mean) are preferred due to lower performance dispersal.
Table 12 summarizes the performance of the best model in each ML algorithm for N and K. Based on the table, RF is preferred over SVM for both N and K, although SVM may be selected for K instead if accuracy is prioritised over standard deviation, as shown by the slight difference in Cov and a difference of 3% in mean classification accuracy.
Nevertheless, the performance of all models in classifying nutrient levels of palm tree plots in this study remained optimistic, particularly for N and K. Despite the coarse resolution of Landsat-8 OLI/TIRS imageries, the study yielded models with performance greater or comparable to several studies [
14,
40,
46] which conducted similar research with data of higher spatial or spectral resolutions (i.e., SPOT7 imagery and spectroradiometer). In fact, in several iterations, merging samples from Ex to Mar Ex to produce a binary problem (i.e., Ex or Opt) for N resulted in a nearly perfect classification (>90%,
Figure 6). This may open opportunities for developing models which are able to detect nutrient excessiveness in palms and subsequently guide reduction in fertilizer application. If further validations reap consistent results, ML models trained with Landsat-8 images may become a possible approach to informed decision making in reducing excessive application of fertilizers. Contrary to this, further studies are required for N deficiency detection as no sample for the class was produced with the experimental set-up, although [
14] had shown such possibilities with reflectance from a spectroradiometer. While not performing as well as N, K levels may still be classified with satisfactory accuracy using SVM or RF.
Further studies are required to study the transferability of the models in terms of generalizing nutrient level classes. Oil palm trees are perennial crops with an industrial life cycle of approximately 25 years, which led to controlled experiments and monitoring being more challenging than annual crops (i.e., maize, rice, etc.). As such, studies on such applications for palm stands beyond the age range (i.e., 6.5–11 years) in this study are required. To gain better insights, higher-resolution imaging, such as UAV imaging, should be deployed to study nutrient prediction with ML on individual palm trees to check for consistency. The use of UAV data increases the variability in spectral and textural information captured for each plot and individual trees.
5. Conclusions
Precision agriculture plays an essential role in ensuring food security is sought sustainably in the near future. Thanks to their greater oil production on a per hectare basis, oil palm trees contribute to the sustainable production of edible oils by freeing up more land when compared to other oil crops. By applying sensor technology and ML models, this study assessed the ability of freely available satellite images from Landsat-8 OLI/TIRS and machine learning models in creating an open-source method for classifying nutrient levels of palm trees on a plot basis. This was conducted using mean reflectance extracted from each plot as predictors for nutrient levels acquired from chemical analysis of frond 17 in palm stands. In this study, the potential of separability metrics, image filters, VIs and feature selection were also put to the test via constructing models with the dataset on different scenarios.
Overall, nutrients with high pairwise J-M distances such as N and K were able to achieve satisfactory performance. However, the performance of most models was undermined by uneven sample distribution, resulting in possible overfitting by the majority class. Uneven sample distribution also poses a risk of result misinterpretation if not taken into account, as observed with Ca. Rank filter was selected as the filter of choice and the visible region had greater correlation than IR regions for K and Mg, with the inverse being true for N. For VIs, atmospherically or soil-corrected indices were selected for N (i.e., SAVI, SARVI, EVI, MSAVI, EVI2 and GARI), while those related to NIR (i.e., NDVI, TVI, IPVI) for K. Using VIF to address multicollinearity, the study further identified the potential of using fewer VIs, such as GARI and ARVI to represent information from all initial bands, including those not involved in their derivation.
When the considered algorithms were compared, SVM was superior to RF and was the best in terms of accuracy, while the inverse was true for model stability. In terms of scenarios, MLP gained the most from filters and selected features (Scenario 2 and 3), though use of filters and all features (Scenario 4) led to worse performance. SVM and RF experienced similar situations, though to a lesser extent. This may be caused by the Hughes’ phenomenon. The study concluded N and K as potential variables predictable by reflectance value from Landsat-8 imageries and respective machine learning algorithms (RF for N and RF or SVM for K), with the best mean accuracy reported at 79.7% and 76.6% respectively. In fact, the results acquired for N from this study by collapsing the classification problem into a simpler version may be the first to point towards the possibility of producing a one-of-its-kind classification model for excessive N detection in oil palm trees using freely available Landsat-8 imageries. Unfortunately, Mg and Ca remained not possible for classification in this study.
While this study has comparable or better results than several studies conducted with data of greater resolution, further research is required to ensure the models’ transferability, with rooms for further improvement via higher resolution data or different analytical approaches. The results from the free-source approach used by this study thus bring the palm plantation cultivation community one step closer to open-source precision agriculture.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





