HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images




Abstract
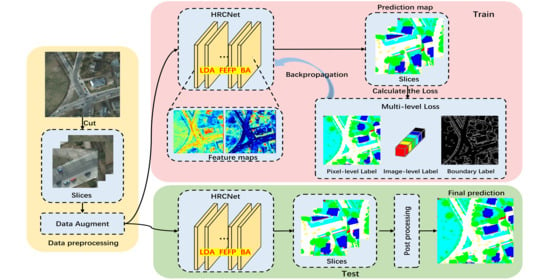
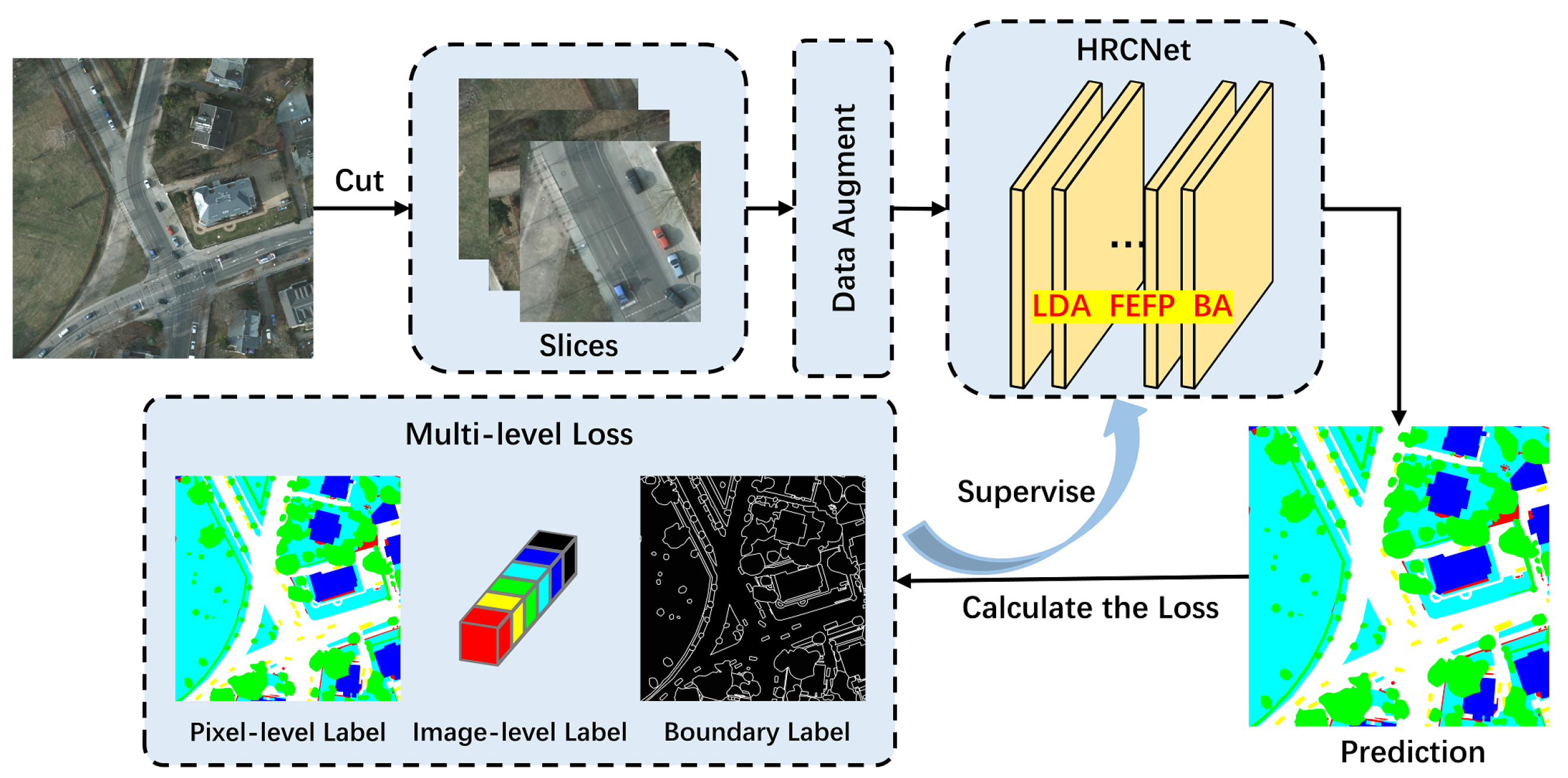
:
1. Introduction
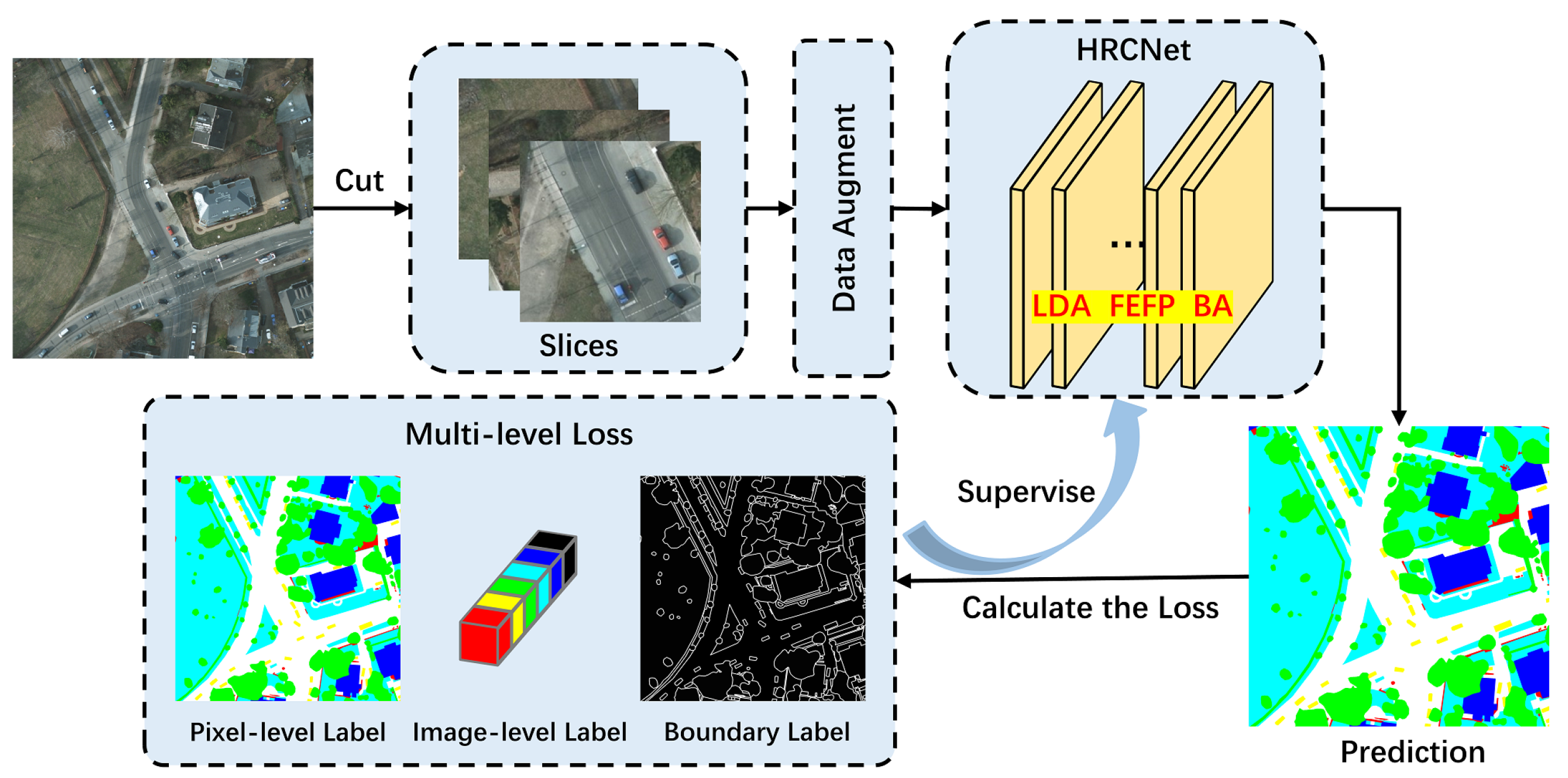
- Combining the light-weight dual attention (LDA) mechanism and boundary aware (BA) module, we propose a light-weight high-resolution context extraction network (HRCNet) to obtain global context information and improve the boundary.
- Based on the parallel-branch architecture of HRNet, we promote the feature enhancement feature pyramid (FEFP) module to integrate the low-to-high features, improving the segmentation accuracy of each category at different scales.
- We propose the multi-level loss functions composing of CEloss, BAloss, and SEloss to optimize the learning procedure.
2. Related Work
2.1. Remote Sensing Applications
2.2. Model Design
2.2.1. Design of the Backbone
2.2.2. Boundary Problems
2.2.3. Attention Mechanisms
3. Methods
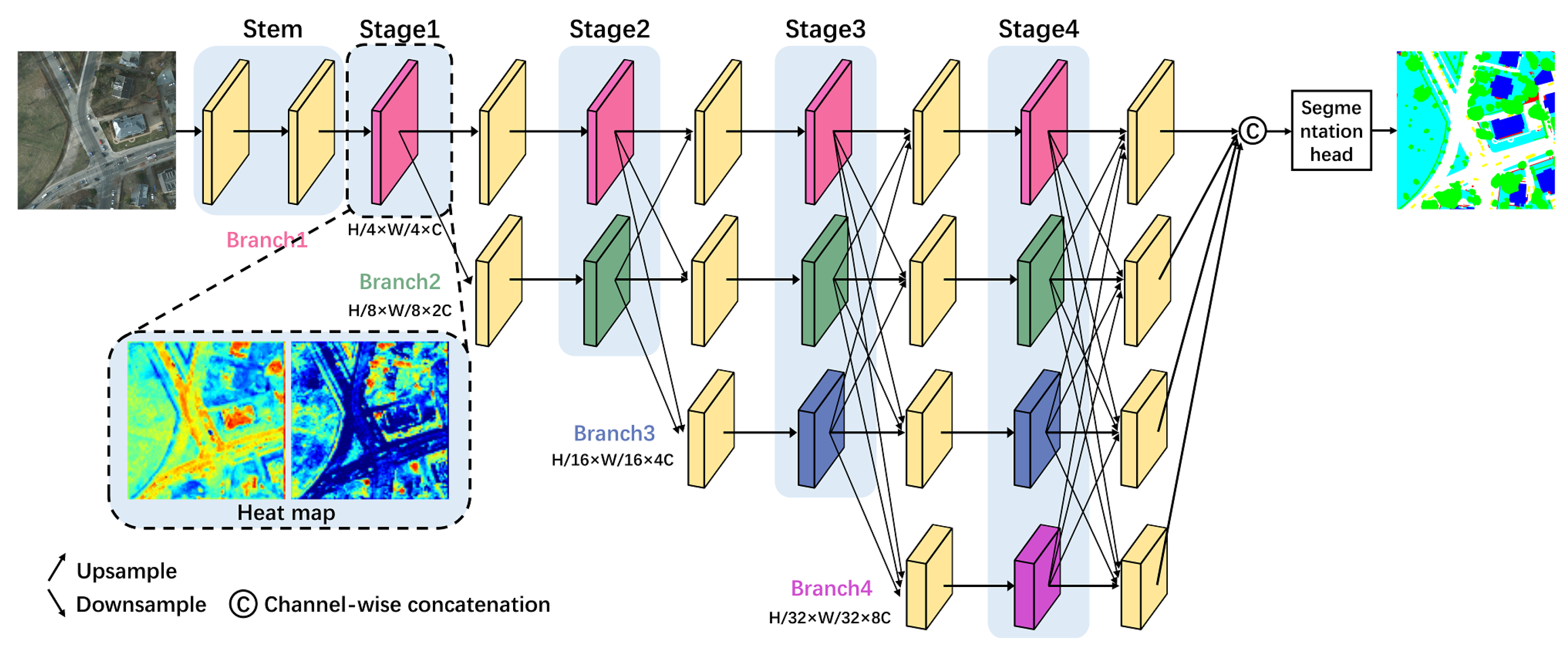
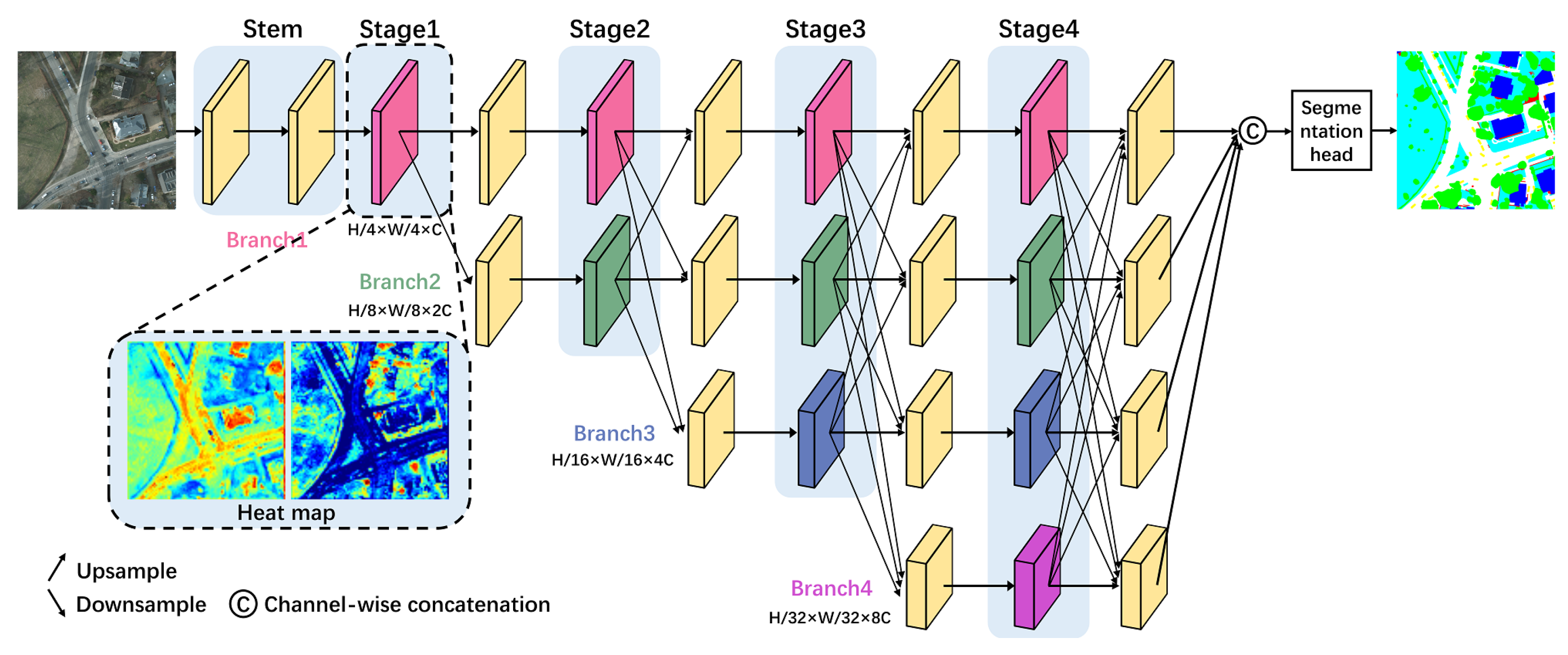
3.1. The Basic HRNet
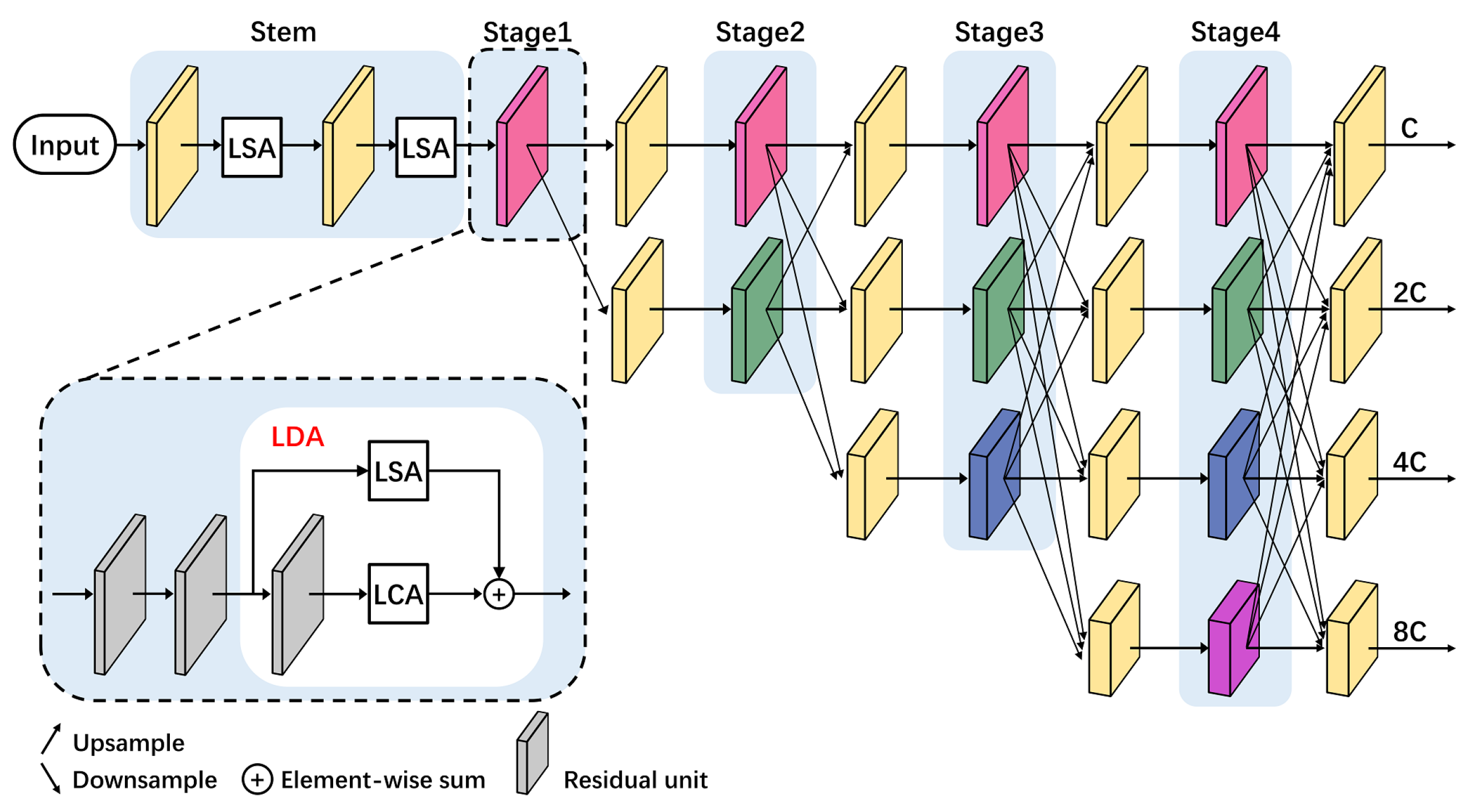
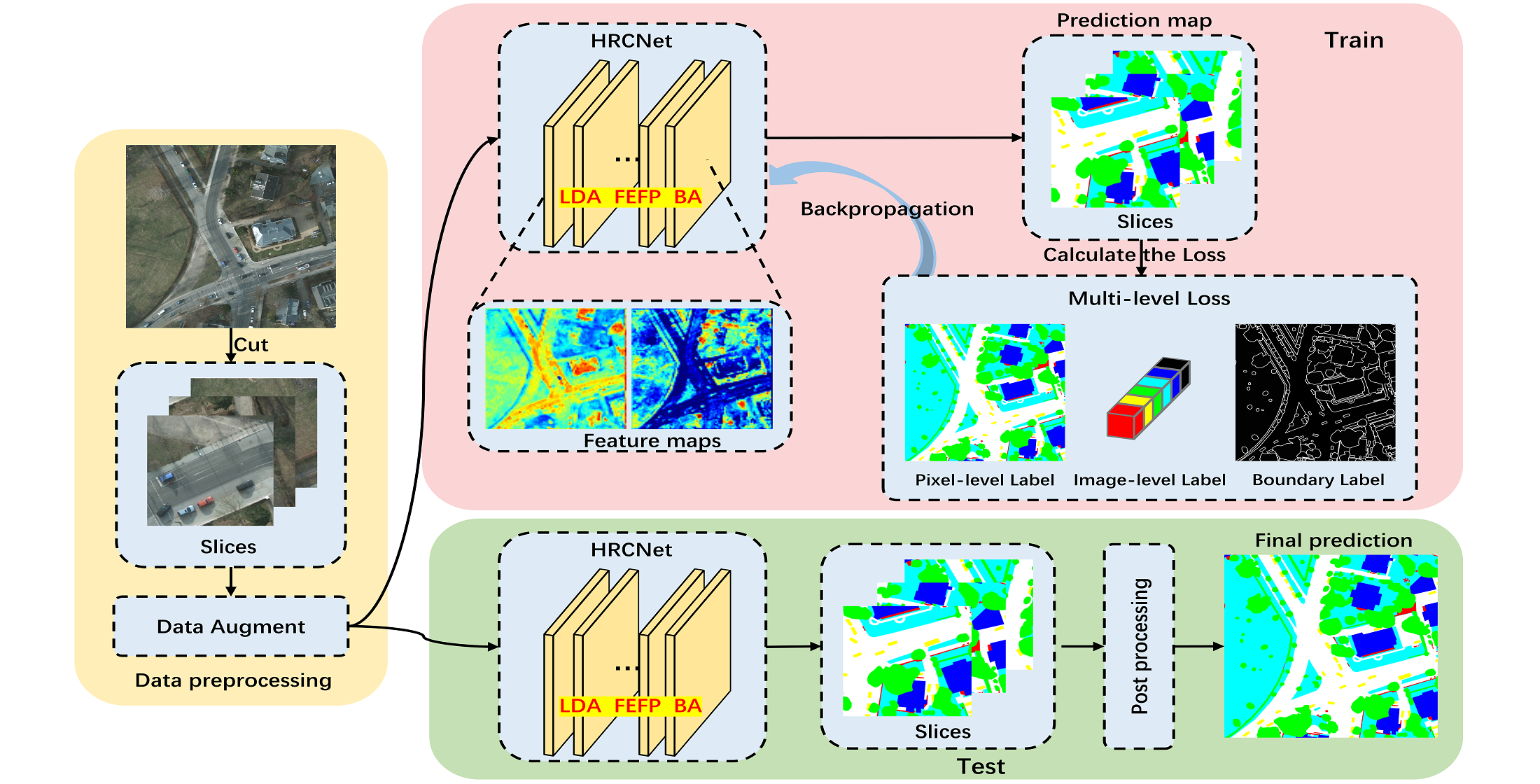
3.2. Framework of the Proposed HRCNet
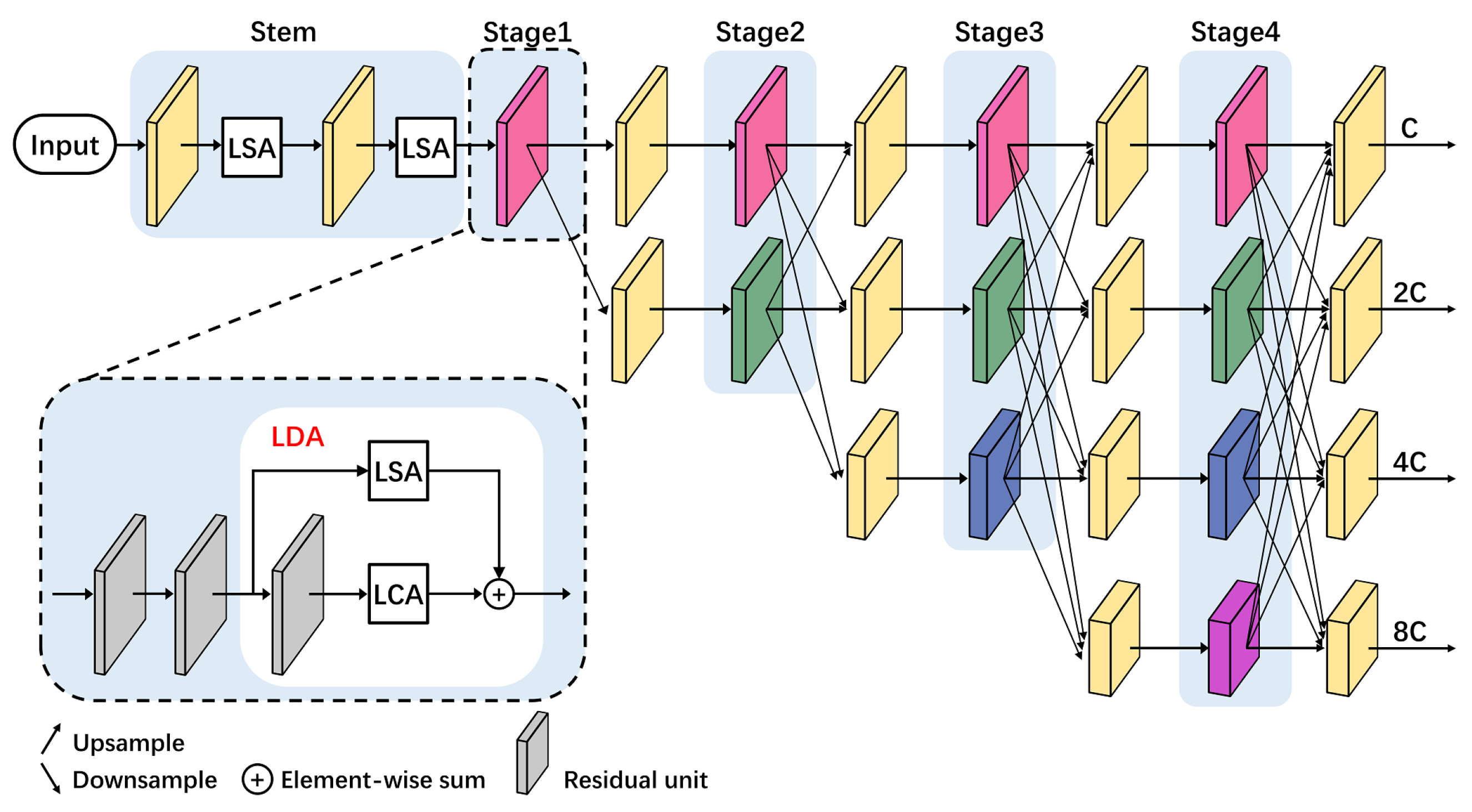
3.3. Light-Weight High-Resolution Network (Light HRNet)
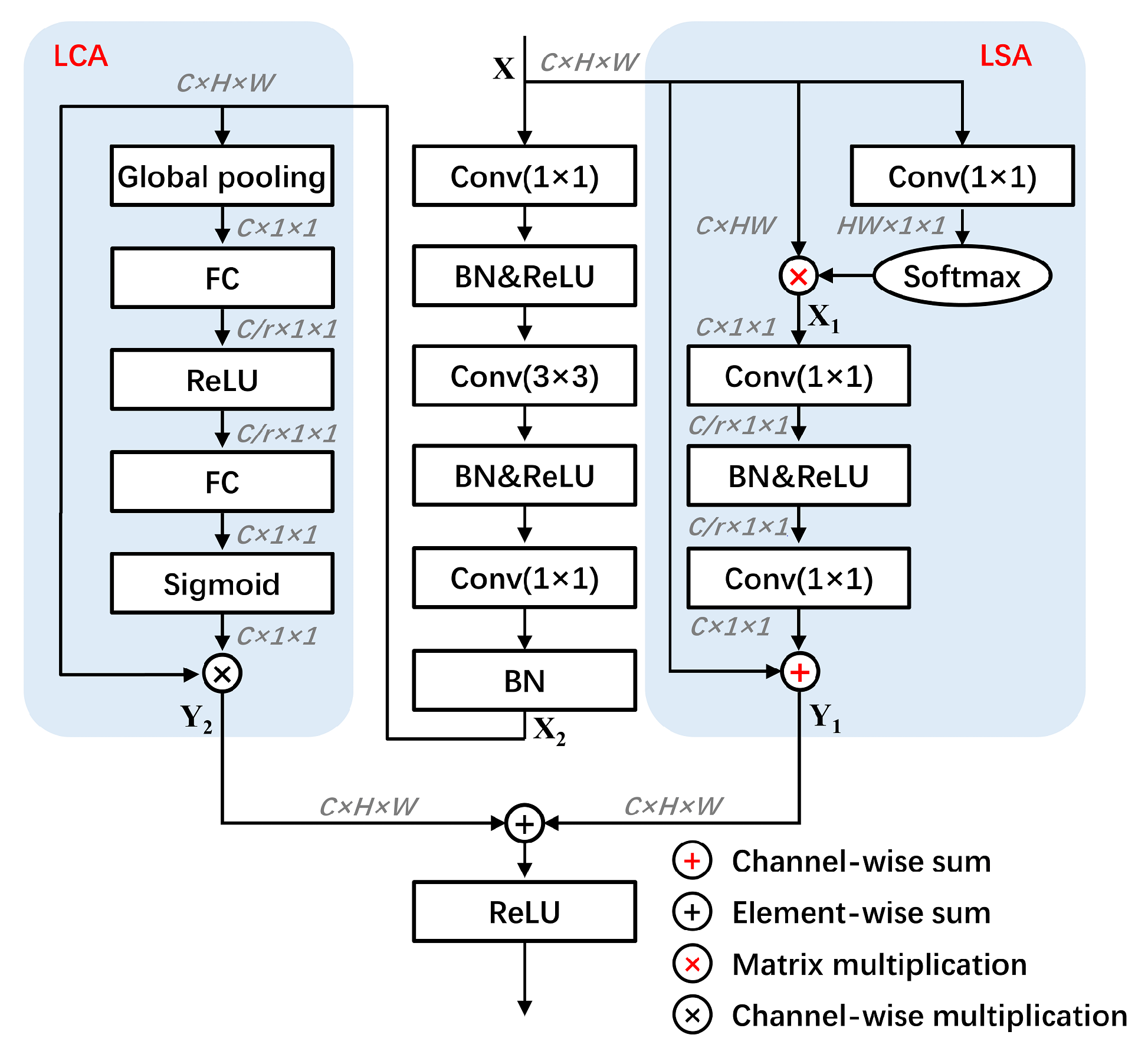
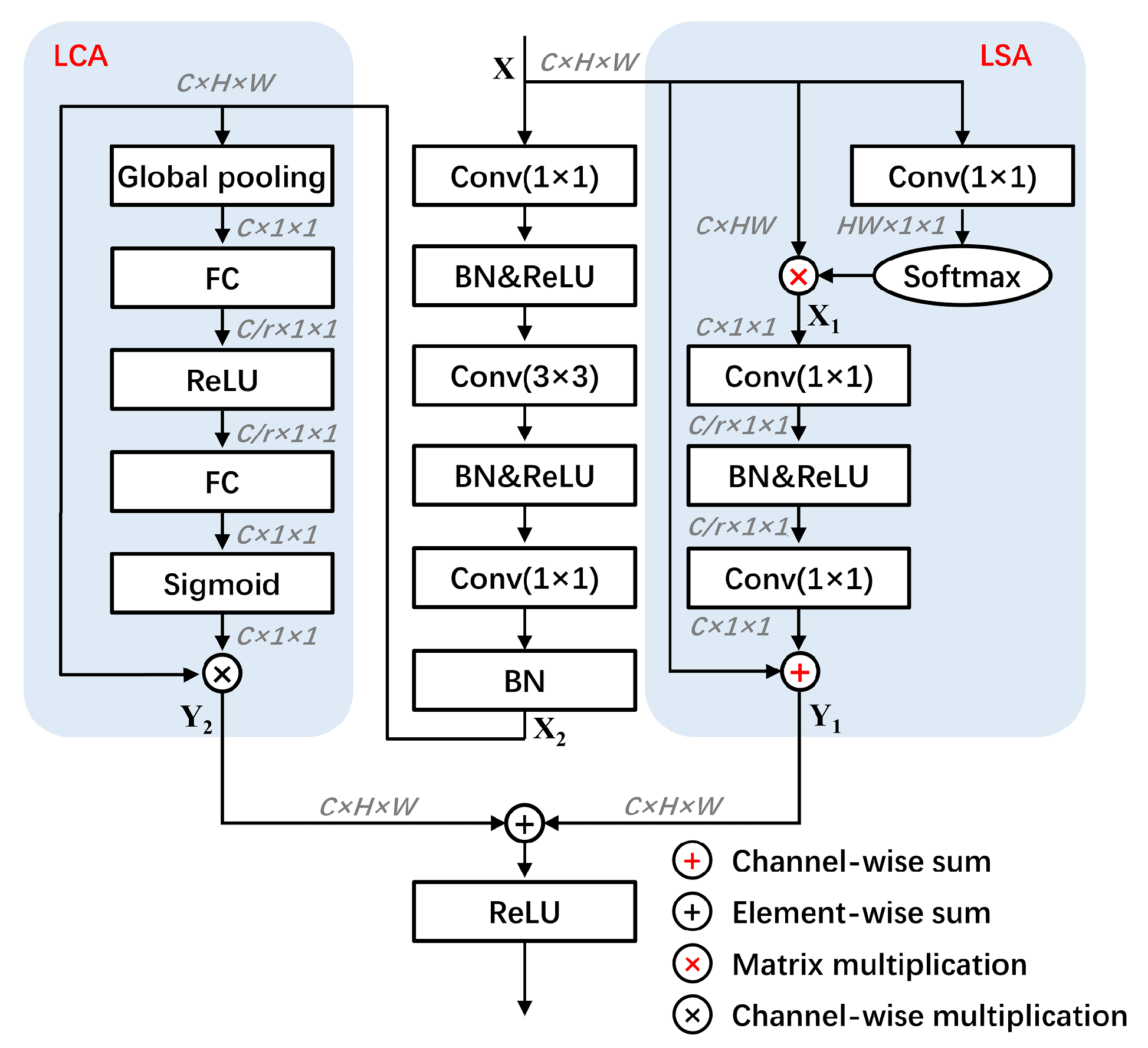
3.3.1. Light-Weight Dual Attention (LDA) Module
3.3.2. Light-Weight Spatial Attention (LSA) Module
- The first branch applies 1×1 convolution to to generate a feature map with the size of , then reshape it to and softmax function is applied after that. The second branch reshapes to . To this end, two branches’ results are multiplied to obtain the feature . denotes convolution operation, denotes softmax function, denotes reshape, and ⊗ in red denotes matrix multiplication.
- To reduce the number of parameters after the 1×1 convolution, feature turns into the size of , where r is the bottleneck ratio usually be set to 16. Then, batch normalization (BN [51]) and activation function (ReLU [52]) are applied to improve the generalization ability of the network. After that, the feature to the size of is restored and added to , getting the final output . ⊕ in red denotes the channel-wise summation operation, and denotes BN as well as ReLU.
3.3.3. Light-Weight Channel Attention (LCA) Module
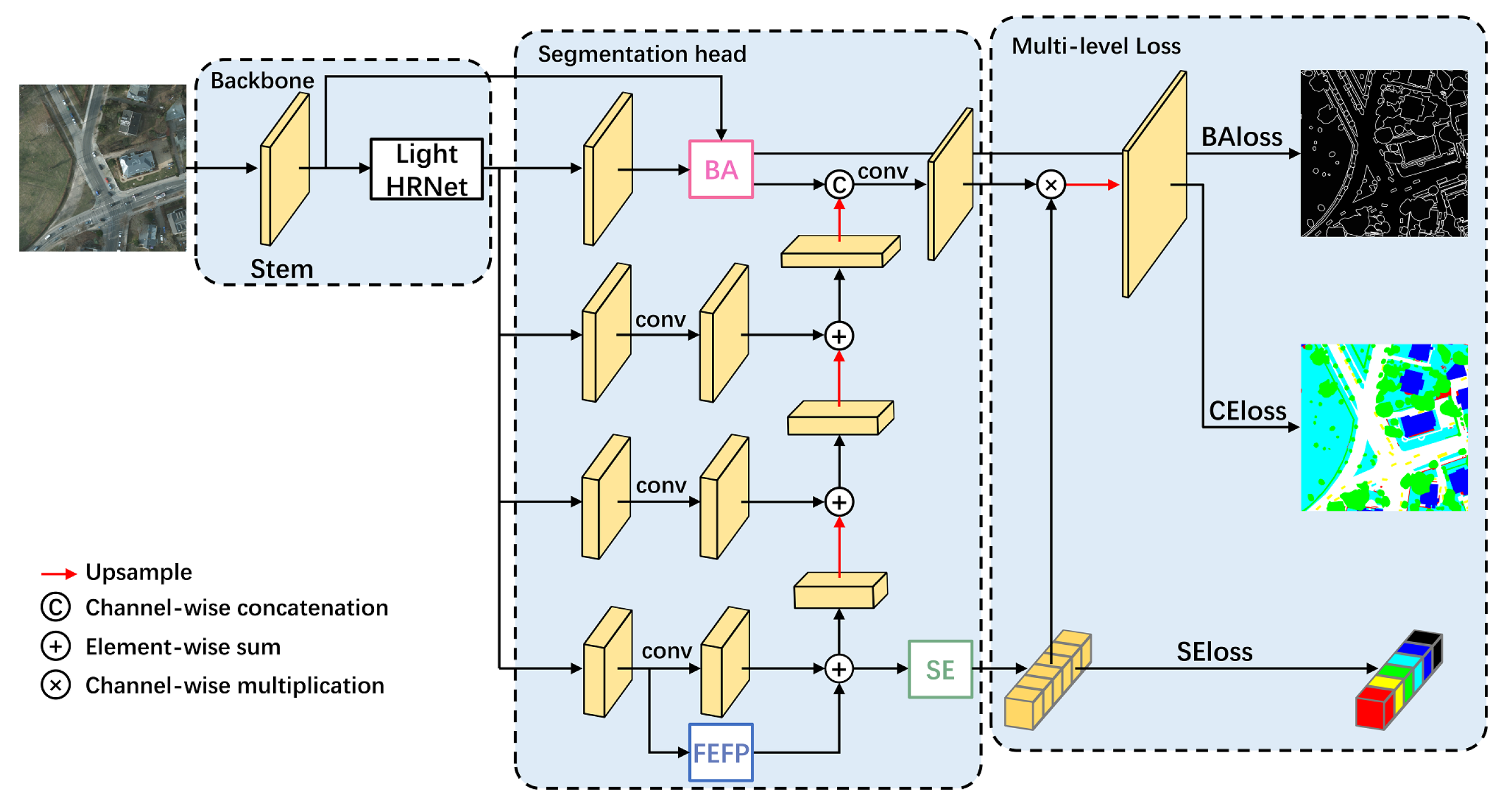
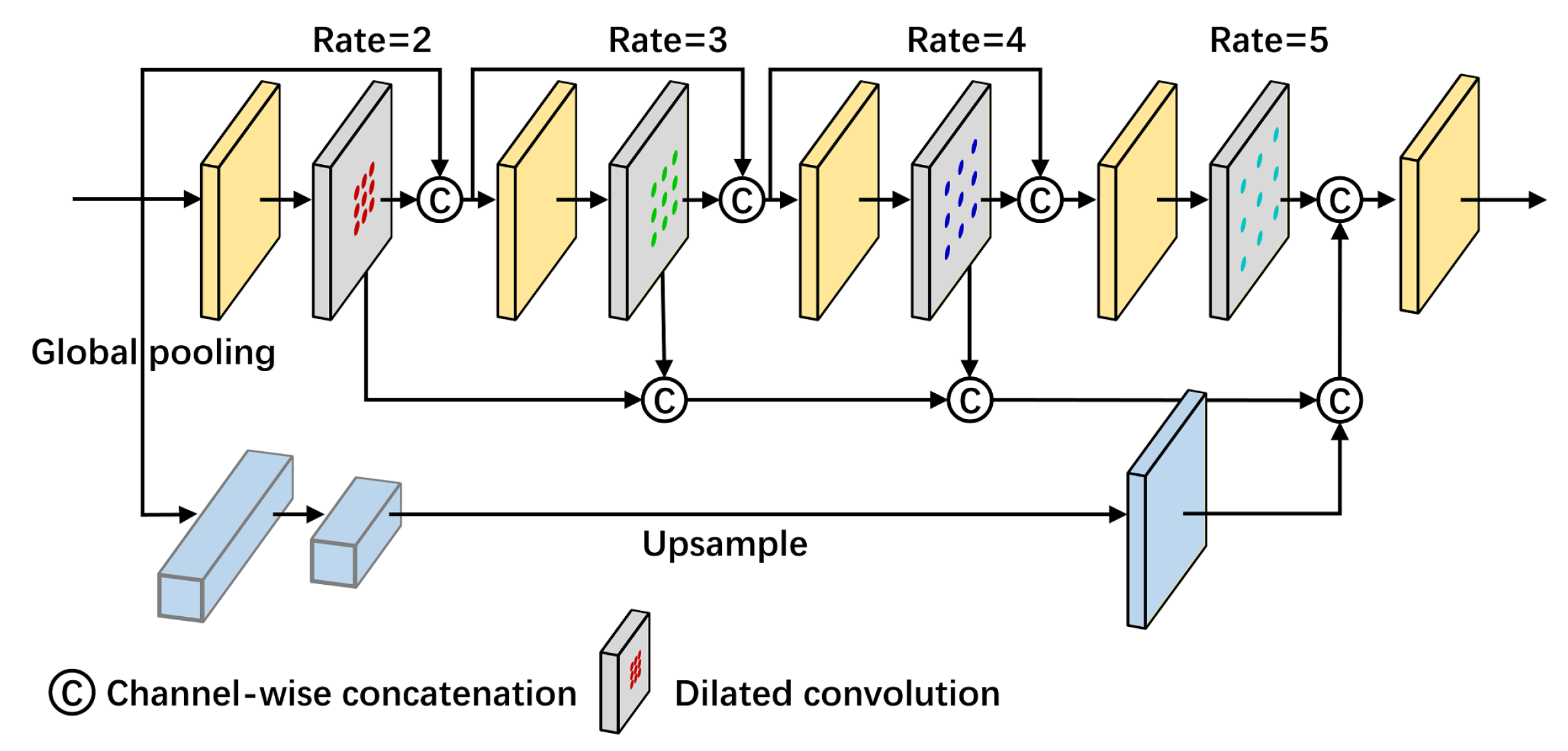
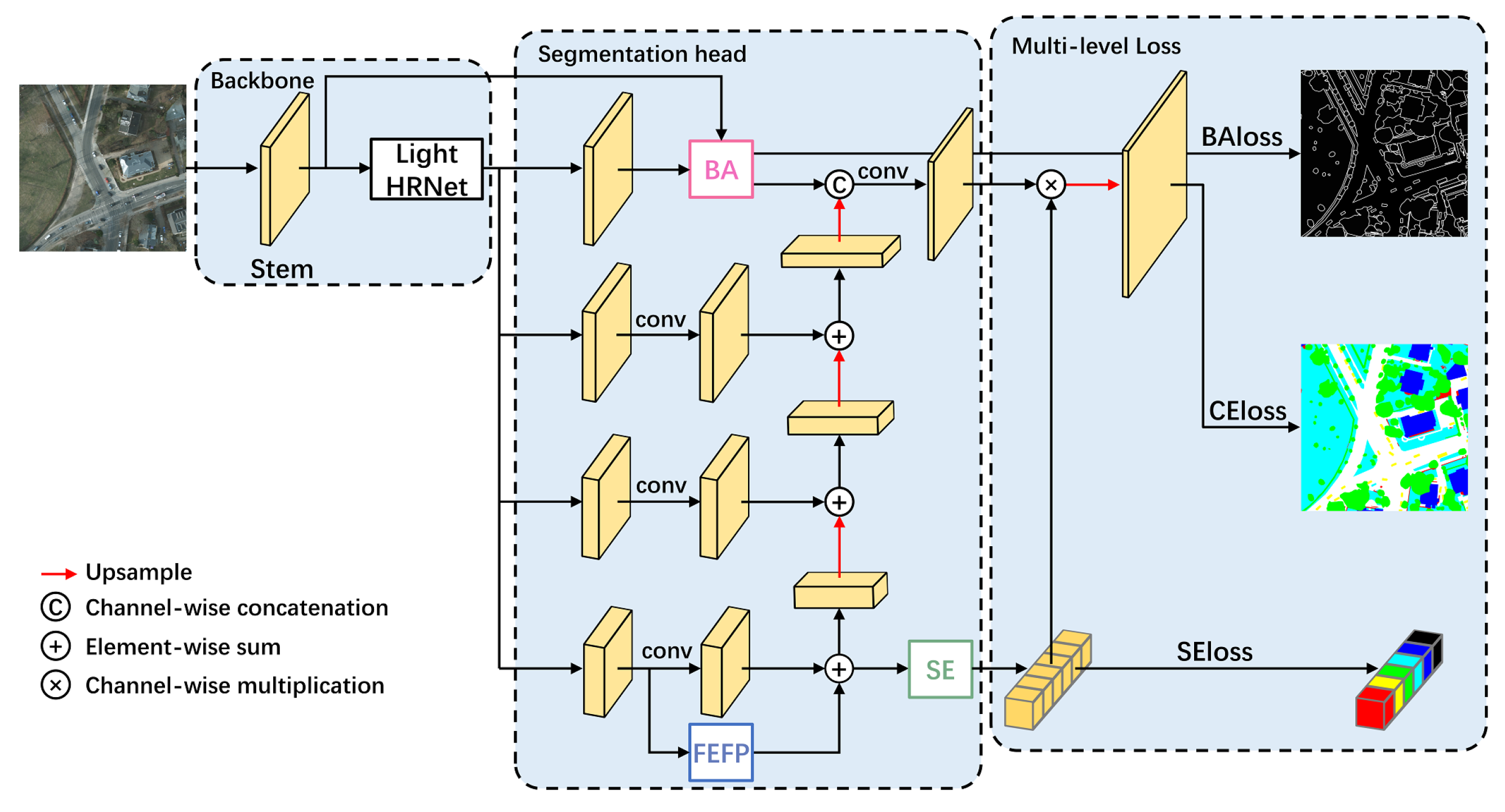
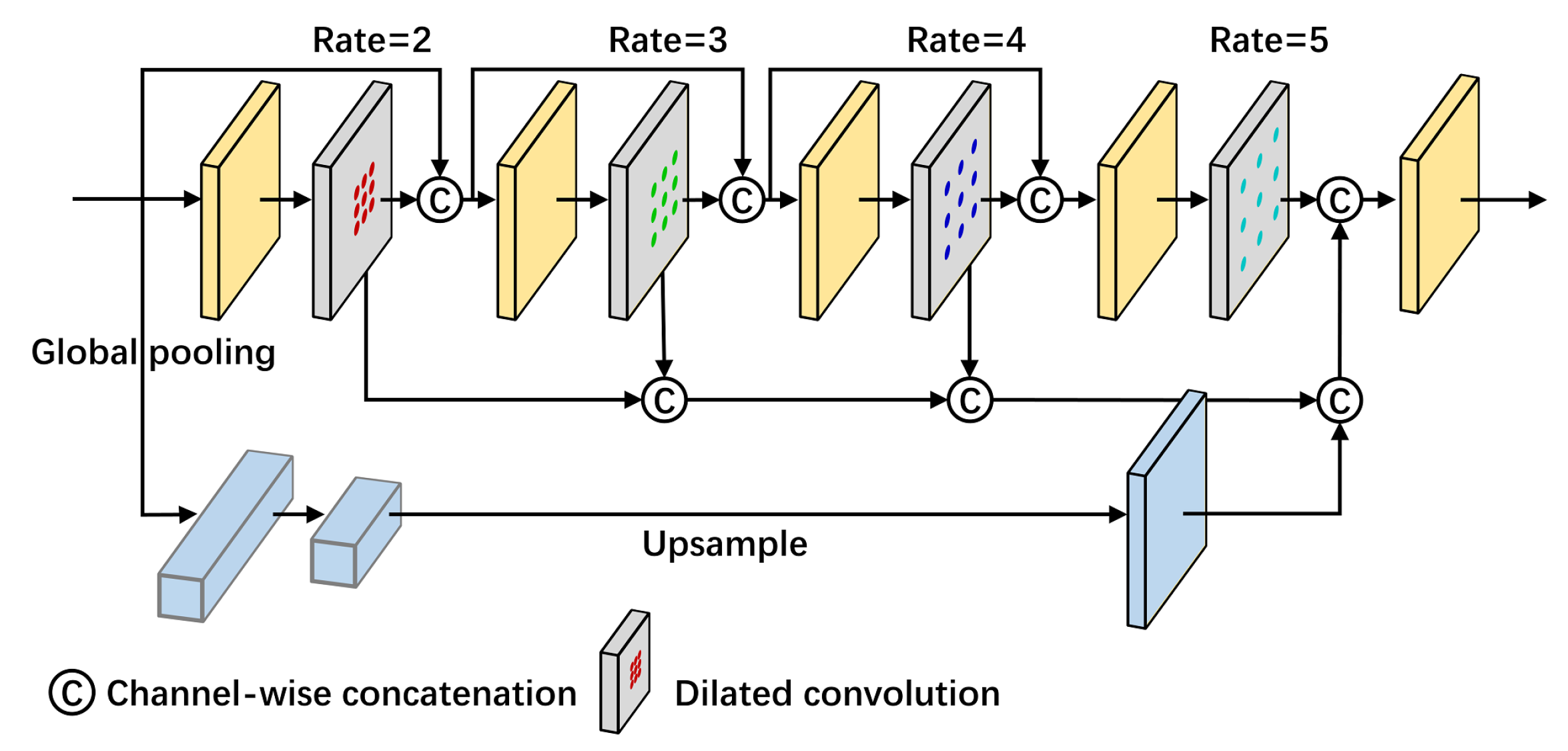
3.4. Feature Enhancement Feature Pyramid (FEFP) Module
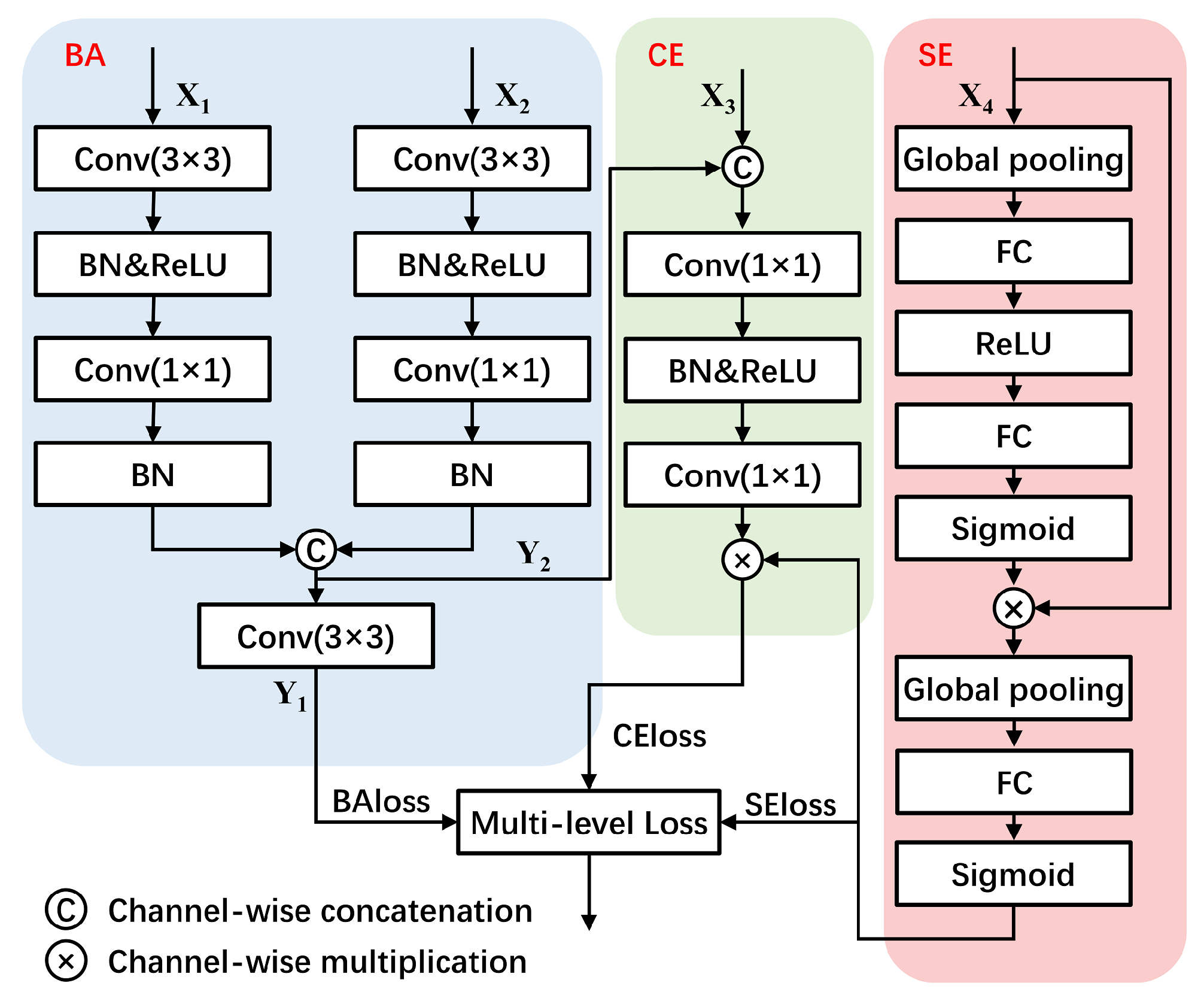
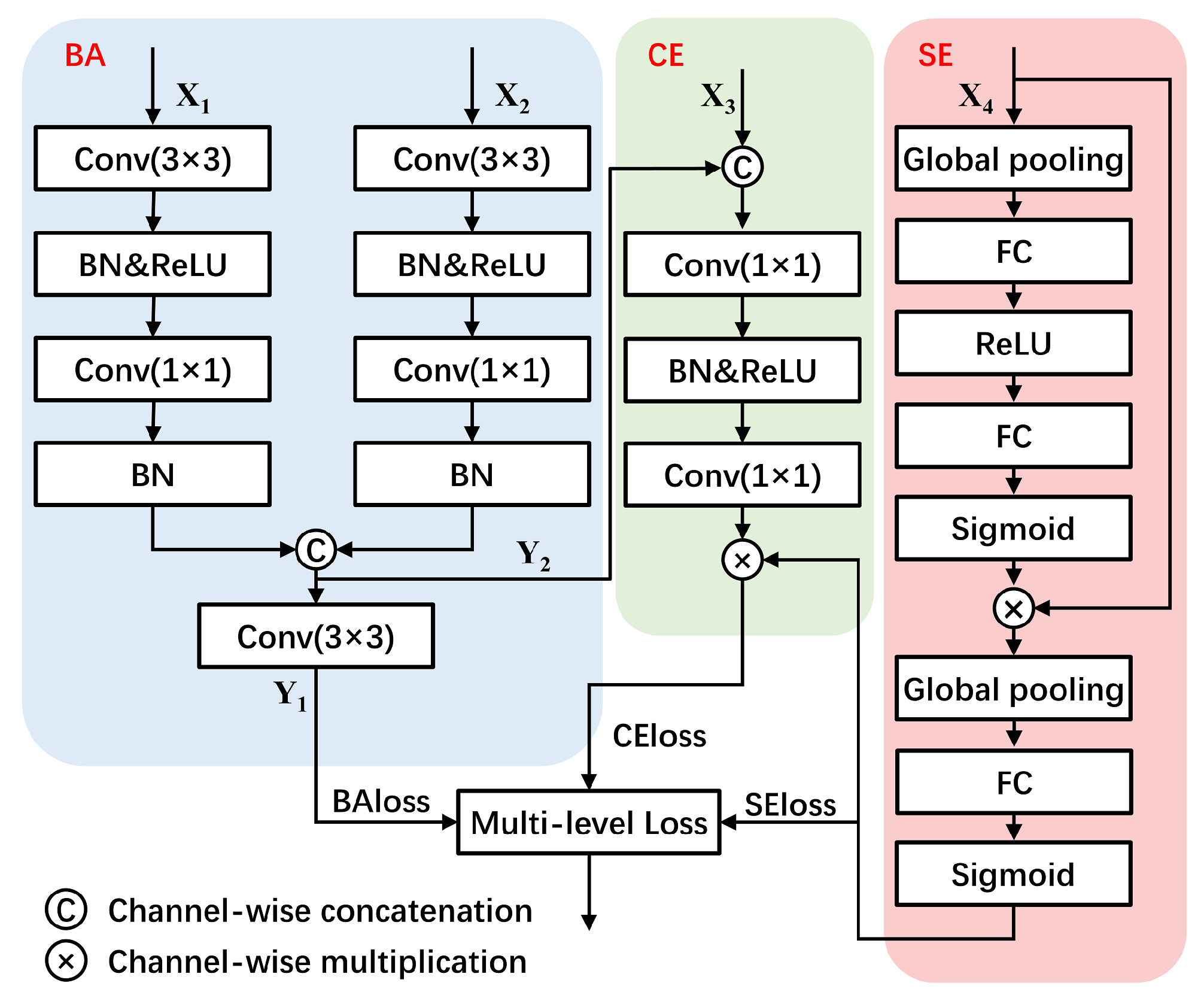
3.5. Multi-Level Loss Function
3.5.1. Cross Entropy Loss for Pixel-level Classification
3.5.2. Boundary Aware Loss for Region-level Classification
3.5.3. Semantic Encoding Loss for Image-Level Classification
3.5.4. Multiple Loss Functions Fusion
4. Experiment
4.1. Datasets
4.1.1. The Potsdam Dataset
4.1.2. The Vaihingen Dataset
4.2. Experiment Settings and Evaluation Metrics
4.3. Training Data and Testing Data Preparation
4.3.1. Training Data Preparation
4.3.2. Testing Data Preparation
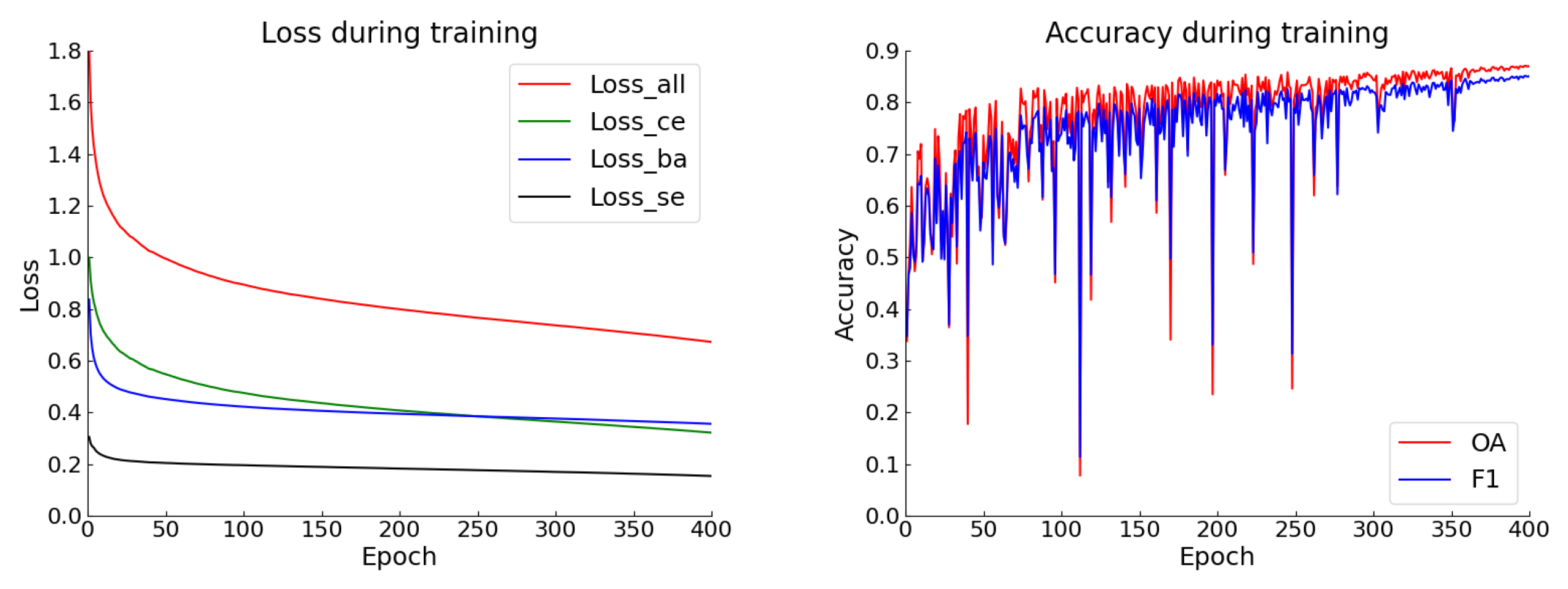
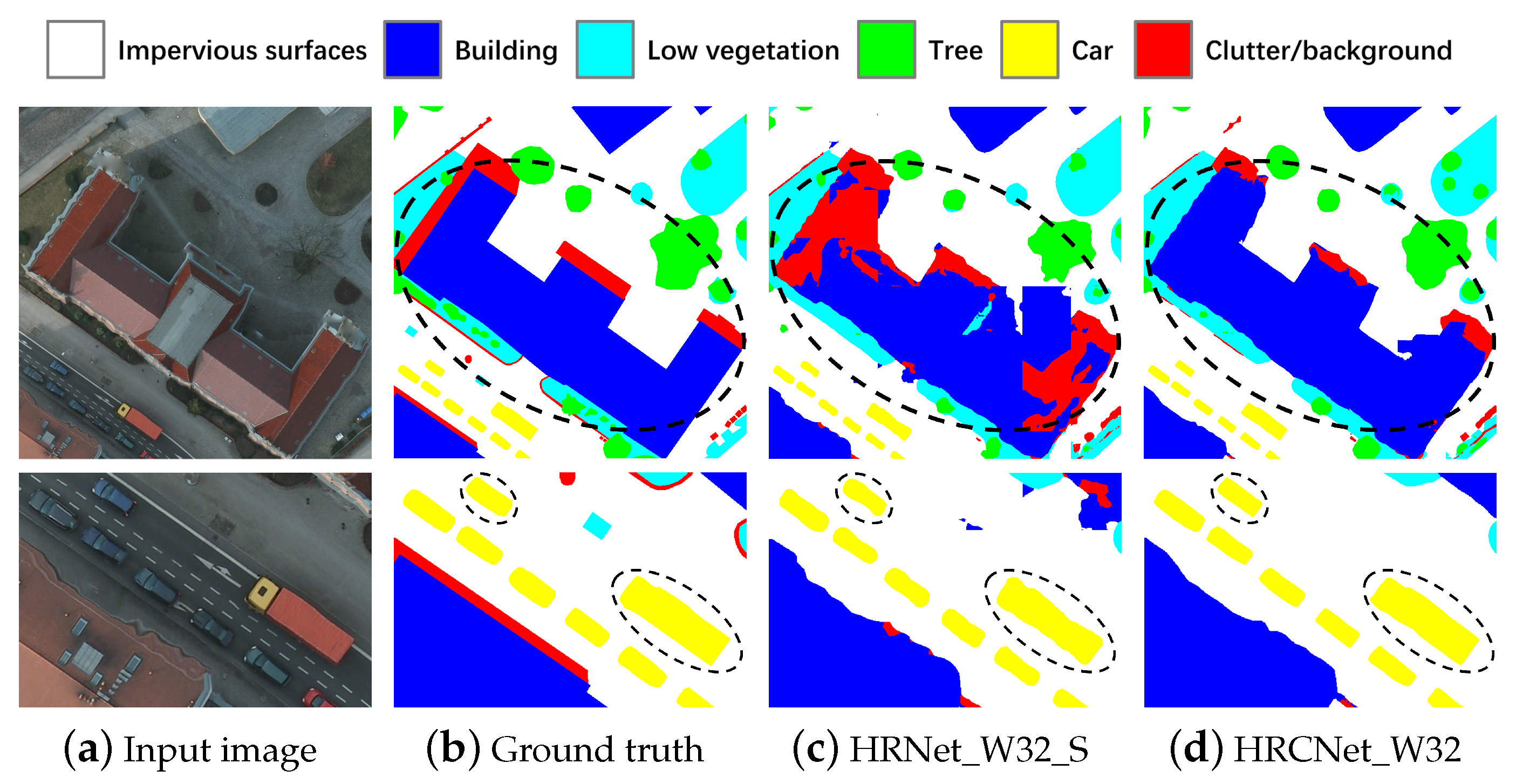
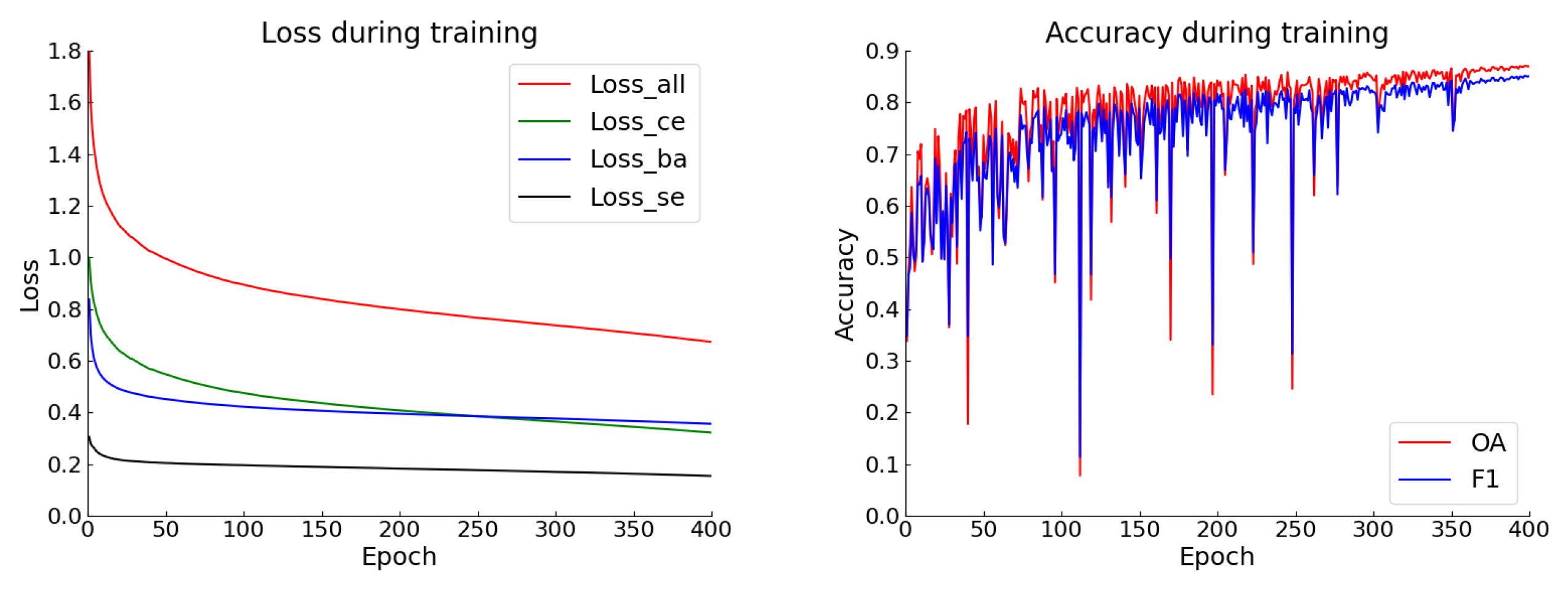
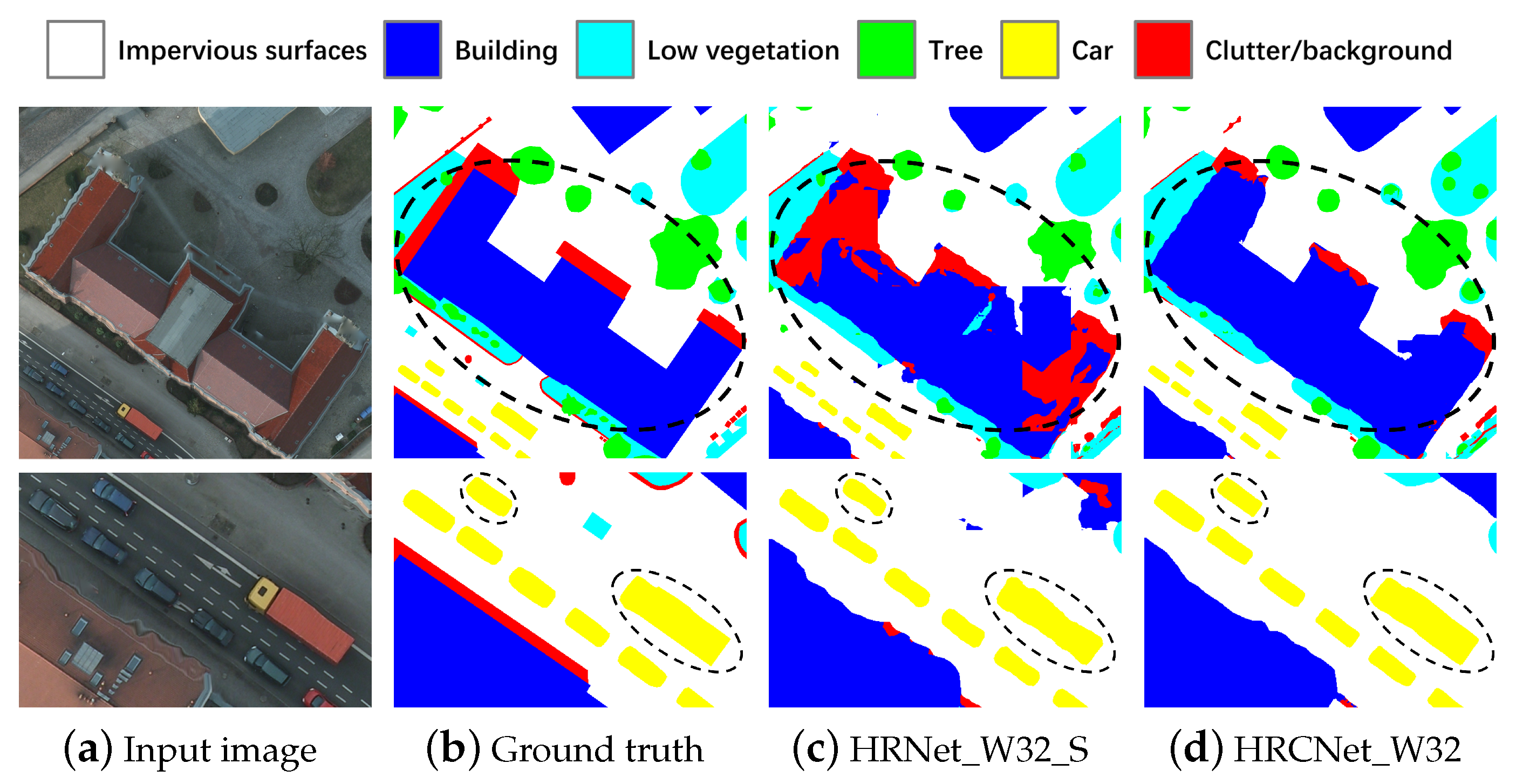
4.4. Experimental Results
5. Discussion
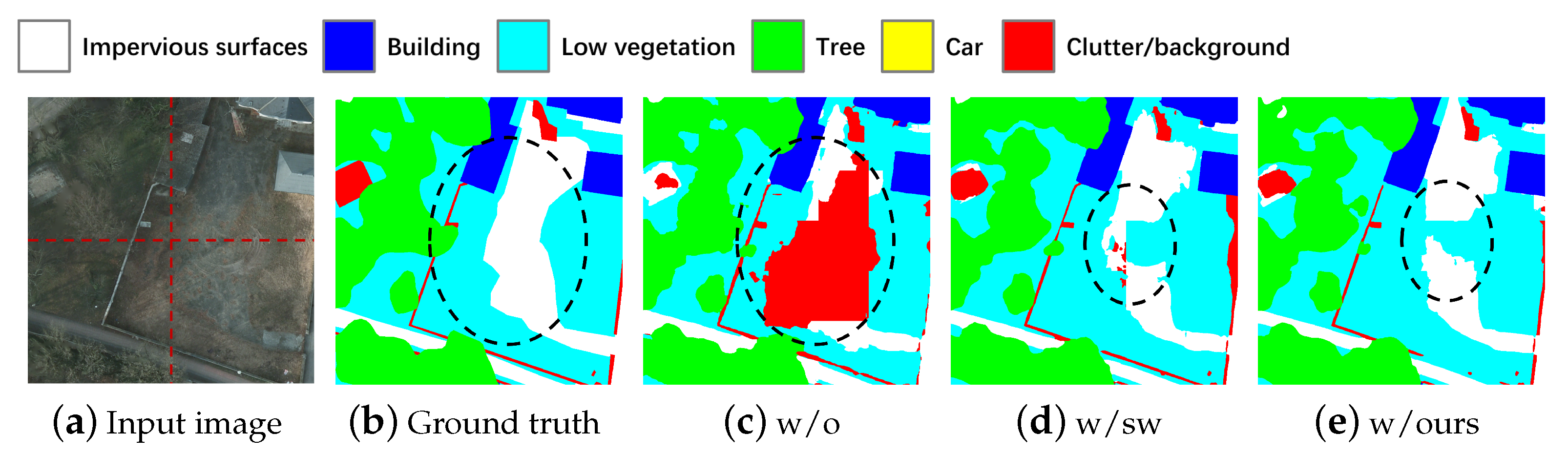
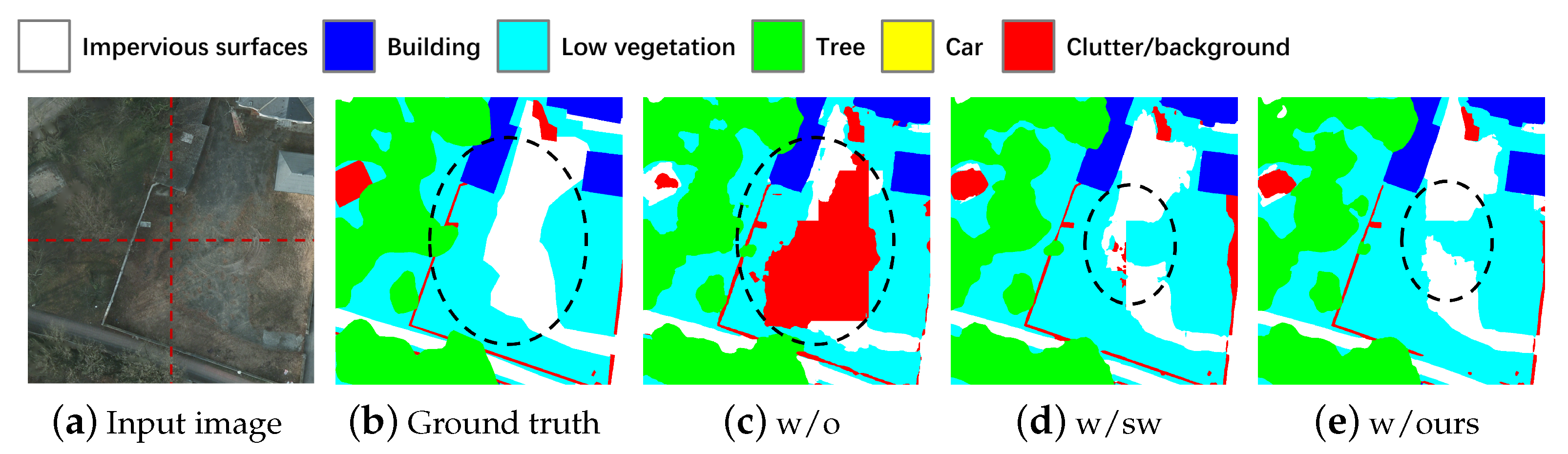
5.1. Ablation Experiments
5.2. Improvements and Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RSIs | Remote Sensing Images |
| CNNs | Convolutional Neural Networks |
| RCNN | Region-based CNN |
| HRCNet | High-Resolution Context Extraction Network |
| HRNet | High-Resolution Network |
| ISPRS | International Society for Photogrammetry and Remote Sensing |
| LDA | Light-Weight Dual Attention |
| LCA | Light-Weight Channel Attention |
| LSA | Light-Weight Spatial Attention |
| FEFP | Feature Enhancement Feature Pyramid |
| ASPP | Atrous Spatial Pyramid Pooling |
| TOP | True Orthophoto |
| DSM | Digital Surface Model |
| NIR | Near Infrared |
| HPC | High Performance Computing |
| SGD | Stochastic Gradient Descent |
| LR | Learning Rate |
| BS | Batch Size |
| mIoU | Mean Intersection Over Union |
| GFLOPS | Giga Floating-point Operations Per Second |
| Params | Parameters |
| OA | Overall Accuracy |
| BA | Boundary Aware |
| CE | Cross Entropy |
| SE | Semantic Encoding |
| MS | Multi-scale |
References
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Gkioxari, G.; Girshick, R.; Malik, J. Actions and attributes from wholes and parts. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2470–2478. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Zhang, W.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Jorgenson, M.T.; Kent, K. Transferability of the Deep Learning Mask R-CNN Model for Automated Mapping of Ice-Wedge Polygons in High-Resolution Satellite and UAV Images. Remote Sens. 2020, 12, 1085. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K. Use of Very High Spatial Resolution Commercial Satellite Imagery and Deep Learning to Automatically Map Ice-Wedge Polygons across Tundra Vegetation Types. J. Imaging 2020, 6, 137. [Google Scholar] [CrossRef]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K.; Jones, B.M.; Daanen, R.; Epstein, H.E.; Kent, K.; Griffin, C.G.; Agnew, A. Understanding the Effects of Optimal Combination of Spectral Bands on Deep Learning Model Predictions: A Case Study Based on Permafrost Tundra Landform Mapping Using High Resolution Multispectral Satellite Imagery. J. Imaging 2020, 6, 97. [Google Scholar] [CrossRef]
- Witharana, C.; Bhuiyan, M.A.E.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Daanen, R.; Griffin, C.G.; Kent, K.; Jones, M.K.W. Understanding the synergies of deep learning and data fusion of multispectral and panchromatic high resolution commercial satellite imagery for automated ice-wedge polygon detection. ISPRS J. Photogramm. Remote Sens. 2020, 170, 174–191. [Google Scholar] [CrossRef]
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense Semantic Labeling with Atrous Spatial Pyramid Pooling and Decoder for High-Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 20. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. arXiv 2020, arXiv:2007.10035. [Google Scholar]
- Zhen, M.; Wang, J.; Zhou, L.; Li, S.; Shen, T.; Shang, J.; Fang, T.; Quan, L. Joint Semantic Segmentation and Boundary Detection using Iterative Pyramid Contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13666–13675. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7479–7489. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Sun, Z.; Lin, D.; Wei, W.; Woźniak, M.; Damaševičius, R. Road Detection Based on Shearlet for GF-3 Synthetic Aperture Radar Images. IEEE Access 2020, 8, 28133–28141. [Google Scholar] [CrossRef]
- Afjal, M.I.; Uddin, P.; Mamun, A.; Marjan, A. An efficient lossless compression technique for remote sensing images using segmentation based band reordering heuristics. Int. J. Remote Sens. 2020, 42, 756–781. [Google Scholar] [CrossRef]
- Chen, G.; Li, C.; Wei, W.; Jing, W.; Woźniak, M.; Blažauskas, T.; Damaševičius, R. Fully convolutional neural network with augmented atrous spatial pyramid pool and fully connected fusion path for high resolution remote sensing image segmentation. Appl. Sci. 2019, 9, 1816. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3126–3135. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, S.; Du, H.; Zhou, G.; Li, X.; Mao, F.; Zhu, D.; Xu, Y.; Zhang, M.; Huang, Z.; Liu, H.; et al. Intelligent Mapping of Urban Forests from High-Resolution Remotely Sensed Imagery Using Object-Based U-Net-DenseNet-Coupled Network. Remote Sens. 2020, 12, 3928. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. RiFCN: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 99, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Cision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation. arXiv 2020, arXiv:2004.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324.
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Guo, S.; Jin, Q.; Wang, H.; Wang, X.; Wang, Y.; Xiang, S. Learnable Gated Convolutional Neural Network for Semantic Segmentation in Remote-Sensing Images. Remote Sens. 2019, 11, 1922. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated Convolutional Neural Network for Semantic Segmentation in High-Resolution Images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, S.; Zoej, M.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Luo, L.; Xue, D.; Feng, X. EHANet: An Effective Hierarchical Aggregation Network for Face Parsing. Appl. Sci. 2020, 10, 3135. [Google Scholar] [CrossRef]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. Bi-directional cascade network for perceptual edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3828–3837. [Google Scholar]
- Zeng, C.; Zheng, J.; Li, J. Real-Time Conveyor Belt Deviation Detection Algorithm Based on Multi-Scale Feature Fusion Network. Algorithms 2019, 12, 205. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, J.; Shen, L.; Qiao, W.; Dai, Y.; Li, Z. Deep feature fusion with integration of residual connection and attention model for classification of VHR remote sensing images. Remote Sens. 2019, 11, 1617. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Potsdam | Vaihingen | ||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| Sample source | ISPRS | ISPRS | ISPRS | ISPRS |
| Bands provided | IRRGB DSM | IRRGB DSM | IRRG DSM | IRRG DSM |
| Bands used | RGB | RGB | IRRG | IRRG |
| Ground sampling distance | 5 cm | 5 cm | 9 cm | 9 cm |
| Sample size (pixels) | 6000 × 6000 | 6000 × 6000 | 1996 × 1995–3816 × 2550 | 1996 × 1995–3816 × 2550 |
| Use size (pixels) | 384 × 384 | 384 × 384 | 384 × 384 | 384 × 384 |
| Sample number | 24 | 14 | 16 | 17 |
| Slices number | 8664 | 13,454 | 817 | 2219 |
| Overlapping pixels | 72 | 192 | 72 | 192 |
| System | Ubuntu 16.04 |
|---|---|
| HPC Resource | NVIDIA RTX2080Ti GPU |
| DL Framework | Pytorch V1.1.0 |
| Compiler | Pycharm 2018.3.1 |
| Program | Python V3.5.2 |
| Optimizer | SGD |
| LR Policy | Poly |
| Loss Functions | CEloss, BAloss, and SEloss |
| LR | 0.01 (Potsdam), 0.08 (Vaihingen) |
| BS | 16 (Potsdam), 8 (Vaihingen) |
| Method | Recall | Precision | F1 | OA |
|---|---|---|---|---|
| HRNet_W32(w/o) | 89.19 | 88.28 | 88.62 | 88.05 |
| HRNet_W32(w/sw) | 89.57 | 88.62 | 89.08 | 88.45 |
| HRNet_W32(w/ours) | 89.75 | 88.85 | 89.20 | 88.62 |
| Method | Recall | Precision | F1 | OA | GFLOPS | Params |
|---|---|---|---|---|---|---|
| FCN [33] | 86.07 | 85.70 | 85.75 | 85.64 | 45.3 | 14.6 |
| PSPNet [63] | 90.13 | 88.95 | 89.45 | 88.78 | 104.0 | 46.5 |
| FPN [53] | 88.59 | 89.19 | 88.72 | 88.27 | 25.7 | 26.4 |
| UNet [12] | 89.42 | 88.13 | 88.67 | 87.76 | 70.0 | 12.8 |
| DeepLab_v3 [64] | 90.29 | 89.23 | 89.66 | 88.97 | 96.4 | 39.9 |
| DANet [17] | 90.13 | 88.80 | 89.37 | 88.82 | 115.6 | 47.3 |
| BiseNet_v2 [41] | 89.42 | 88.33 | 88.78 | 88.18 | 7.3 | 3.5 |
| SWJ_2 [65] | 89.40 | 89.82 | 89.58 | 89.40 | / | / |
| HRCNet_W32 | 90.30 | 89.43 | 89.77 | 89.08 | 11.1 | 9.1 |
| HRCNet_W32 + Flip | 90.60 | 89.67 | 90.05 | 89.37 | 11.1 | 9.1 |
| HRCNet_W48 | 90.44 | 89.70 | 89.98 | 89.26 | 52.8 | 59.8 |
| HRCNet_W48 + Flip | 90.69 | 89.90 | 90.20 | 89.50 | 52.8 | 59.8 |
| Method | Recall | Precision | F1 | OA | GFLOPS | Params |
|---|---|---|---|---|---|---|
| SWJ_2 [65] | 92.62 | 92.20 | 92.38 | 91.70 | / | / |
| HRCNet_W32 + Flip | 93.59 | 92.28 | 92.86 | 91.83 | 11.1 | 9.1 |
| HRCNet_W48 + Flip | 93.72 | 92.43 | 93.00 | 91.95 | 52.8 | 59.8 |
| Method | Imp Surf | Building | Low Veg | Tree | Car | Average (mIoU) |
|---|---|---|---|---|---|---|
| FCN [33] | 81.67 | 88.99 | 71.24 | 72.80 | 79.91 | 78.92 |
| PSPNet [63] | 82.71 | 90.21 | 72.62 | 74.22 | 81.11 | 80.18 |
| FPN [53] | 81.63 | 89.22 | 71.37 | 73.05 | 79.09 | 78.87 |
| UNet [12] | 82.58 | 90.08 | 72.58 | 74.22 | 81.38 | 80.17 |
| DeepLab_v3 [64] | 82.81 | 89.95 | 72.22 | 74.11 | 82.16 | 80.25 |
| DANet [17] | 82.27 | 89.15 | 71.77 | 73.70 | 81.72 | 79.72 |
| BiseNet_v2 [41] | 81.17 | 87.61 | 71.75 | 73.60 | 81.41 | 79.11 |
| HRCNet_W32 + Flip | 83.16 (+0.35) | 90.69 (+0.74) | 72.67 (+0.45) | 74.35 (+0.24) | 82.73 (+0.57) | 80.72 (+0.47) |
| HRCNet_W48 + Flip | 83.58 (+0.77) | 91.15 (+1.20) | 73.07 (+0.85) | 74.88 (+0.77) | 83.32 (+1.16) | 81.20 (+0.95) |
| Method | Recall | Precision | F1 | OA |
|---|---|---|---|---|
| FCN [33] | 80.89 | 83.14 | 81.46 | 87.11 |
| PSPNet [63] | 84.10 | 84.86 | 84.15 | 87.17 |
| FPN [53] | 82.21 | 84.50 | 82.94 | 86.70 |
| UNet [12] | 85.01 | 84.46 | 84.44 | 87.14 |
| DeepLab_v3 [64] | 84.38 | 85.09 | 84.42 | 87.32 |
| DANet [17] | 83.89 | 84.65 | 83.95 | 87.07 |
| BiseNet_v2 [41] | 83.16 | 84.77 | 83.57 | 86.88 |
| HUSTW5 | 83.32 | 86.20 | 84.50 | 88.60 |
| HRCNet_W32 | 85.48 | 85.75 | 85.31 | 87.90 |
| HRCNet_W32 + Flip | 85.71 | 86.12 | 85.60 | 88.11 |
| HRCNet_W32 + Flip + MS | 85.30 | 86.40 | 85.48 | 88.29 |
| HRCNet_W48 | 86.27 | 85.57 | 85.65 | 88.07 |
| HRCNet_W48 + Flip | 86.53 | 85.96 | 85.97 | 88.33 |
| HRCNet_W48 + Flip + MS | 86.29 | 86.47 | 86.07 | 88.56 |
| Method | Recall | Precision | F1 | OA |
|---|---|---|---|---|
| HUSTW5 [65] | 87.36 | 89.36 | 88.24 | 91.60 |
| HRCNet_W32 † | 90.71 | 89.70 | 89.86 | 92.03 |
| HRCNet_W48 † | 91.49 | 89.80 | 90.30 | 92.30 |
| Method | Imp Surf | Building | Low Veg | Tree | Car | Average (mIoU) |
|---|---|---|---|---|---|---|
| FCN [33] | 77.68 | 82.33 | 63.94 | 74.35 | 51.83 | 70.02 |
| PSPNet [63] | 78.90 | 84.26 | 65.34 | 75.14 | 56.18 | 71.96 |
| FPN [53] | 77.65 | 82.72 | 64.34 | 74.43 | 52.11 | 70.25 |
| UNet [12] | 79.02 | 84.46 | 65.23 | 75.13 | 57.07 | 72.18 |
| DeepLab_v3 [64] | 79.23 | 83.70 | 64.88 | 75.14 | 57.54 | 72.10 |
| DANet [17] | 78.55 | 82.10 | 64.18 | 74.80 | 56.36 | 71.20 |
| BiseNet_v2 [41] | 77.70 | 78.78 | 63.23 | 74.98 | 53.24 | 69.58 |
| HRCNet_W32 † | 80.21 (+1.19) | 85.87 (+1.41) | 66.01 (+0.78) | 75.88 (+0.75) | 58.40 (+1.33) | 73.27 (+1.09) |
| HRCNet_W48 † | 81.05 (+2.03) | 86.65 (+2.19) | 66.91 (+1.68) | 76.63 (+1.50) | 59.31 (+2.24) | 74.11 (+1.93) |
| Method | LSA | LCA | FEFP | F1 | OA |
|---|---|---|---|---|---|
| HRNet_W32_S | 89.20 | 88.62 | |||
| HRNet_W32_S | ✓ | 89.34 | 88.75 | ||
| HRNet_W32_S | ✓ | 89.32 | 88.71 | ||
| HRNet_W32_S | ✓ | ✓ | 89.42 | 88.81 | |
| HRNet_W32_S(HRCNet_W32) | ✓ | ✓ | ✓ | 89.60 | 88.93 |
| HRNet_W48 | 89.46 | 88.83 | |||
| HRNet_W48 | ✓ | 89.53 | 88.94 | ||
| HRNet_W48 | ✓ | 89.51 | 88.92 | ||
| HRNet_W48 | ✓ | ✓ | 89.57 | 88.99 | |
| HRNet_W48(HRCNet_W48) | ✓ | ✓ | ✓ | 89.74 | 89.13 |
| Method | CEloss | BAloss | SEloss | F1 | OA |
|---|---|---|---|---|---|
| HRCNet_W32 | ✓ | 89.60 | 88.93 | ||
| HRCNet_W32 | ✓ | ✓ | 89.72 | 89.05 | |
| HRCNet_W32 | ✓ | ✓ | 89.70 | 89.01 | |
| HRCNet_W32 | ✓ | ✓ | ✓ | 89.77 | 89.08 |
| HRCNet_W48 | ✓ | 89.74 | 89.13 | ||
| HRCNet_W48 | ✓ | ✓ | 89.90 | 89.25 | |
| HRCNet_W48 | ✓ | ✓ | 89.84 | 89.15 | |
| HRCNet_W48 | ✓ | ✓ | ✓ | 89.98 | 89.26 |
| Method | Recall | Precision | F1 | OA | GFLOPS | Params |
|---|---|---|---|---|---|---|
| HRNet_W32_S | 89.75 | 88.85 | 89.20 | 88.62 | 13.0 | 9.8 |
| HRCNet_W32 | 90.30 | 89.43 | 89.77 | 89.08 | 11.1 | 9.1 |
| HRNet_W48 | 89.97 | 89.14 | 89.46 | 88.83 | 52.8 | 62.8 |
| HRCNet_W48 | 90.44 | 89.70 | 89.98 | 89.26 | 52.8 | 59.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. https://doi.org/10.3390/rs13010071
Xu Z, Zhang W, Zhang T, Li J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2021; 13(1):71. https://doi.org/10.3390/rs13010071
Chicago/Turabian StyleXu, Zhiyong, Weicun Zhang, Tianxiang Zhang, and Jiangyun Li. 2021. "HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images" Remote Sensing 13, no. 1: 71. https://doi.org/10.3390/rs13010071
APA StyleXu, Z., Zhang, W., Zhang, T., & Li, J. (2021). HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 13(1), 71. https://doi.org/10.3390/rs13010071