Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping





Abstract
1. Introduction
2. Materials and Methods
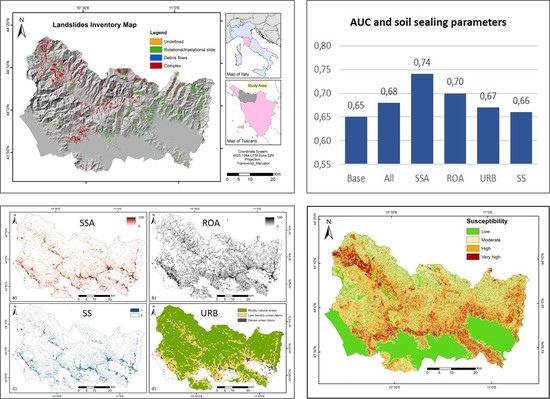
2.1. Study Area
2.2. Random Forest Algorithm
2.3. Basic Input Data
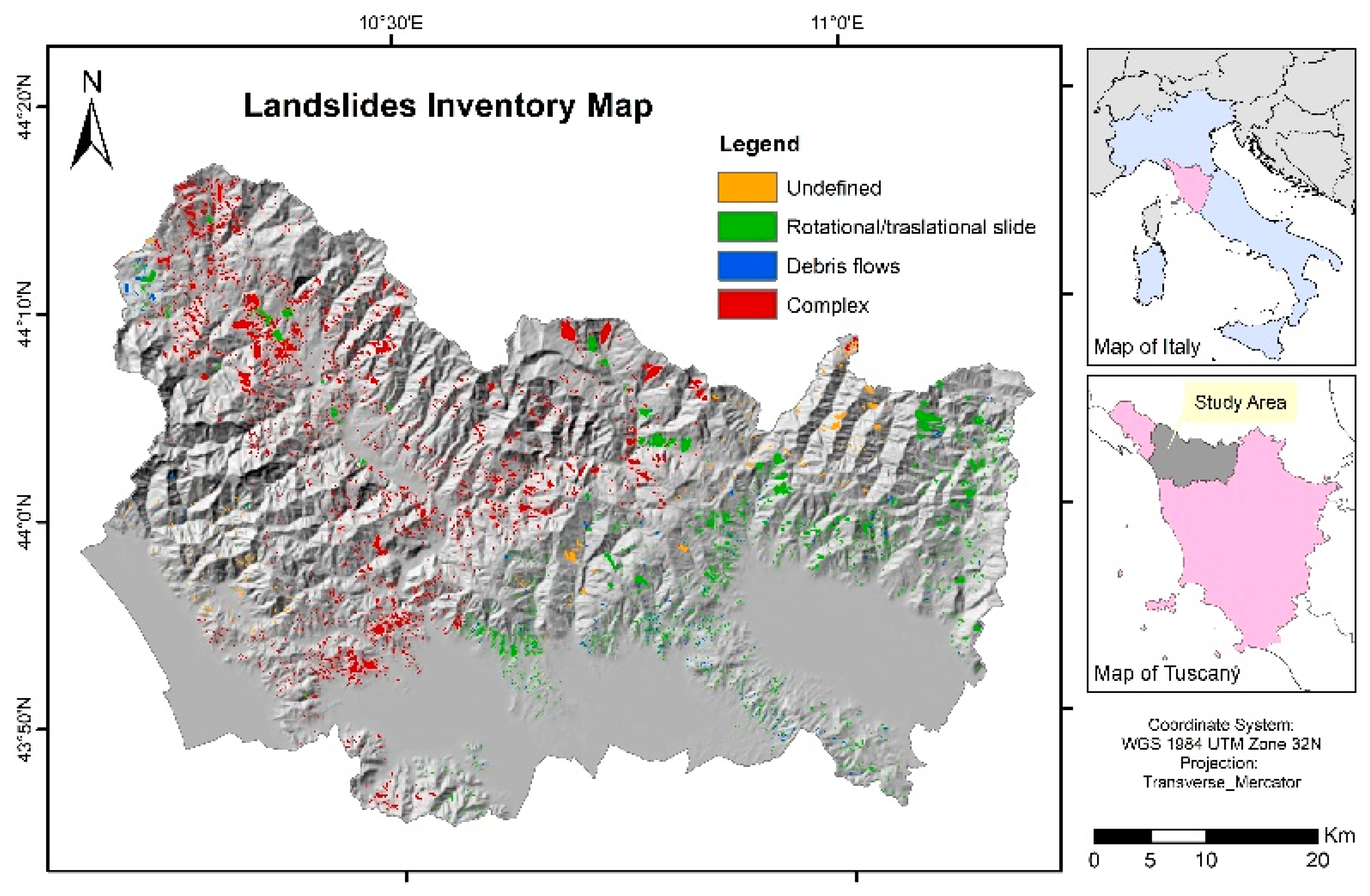
2.4. Soil Sealing Raw Data
2.5. Soil Sealing Parameterization for Landslide Susceptibility Mapping
2.5.1. Soil Sealing (SS)
2.5.2. Urbanization (URB)
- Predominantly natural areas;
- Low-density urbanized areas; and
- Predominantly artificial areas, with a high density of urbanization
2.5.3. Soil Sealing Aggregation (SSA)
2.5.4. Roads (ROA)
2.6. Description of the Landslide Susceptibility Tests
3. Results
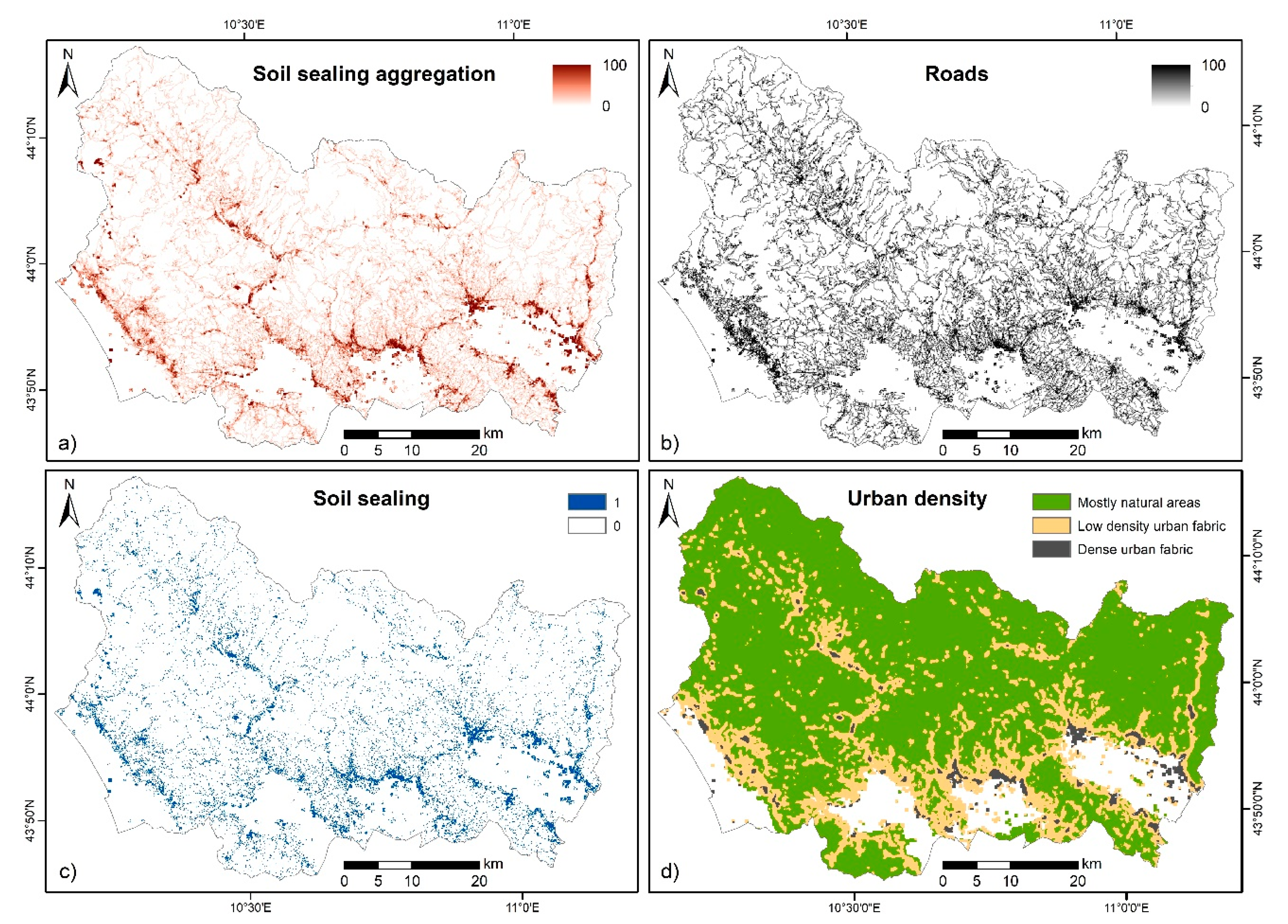
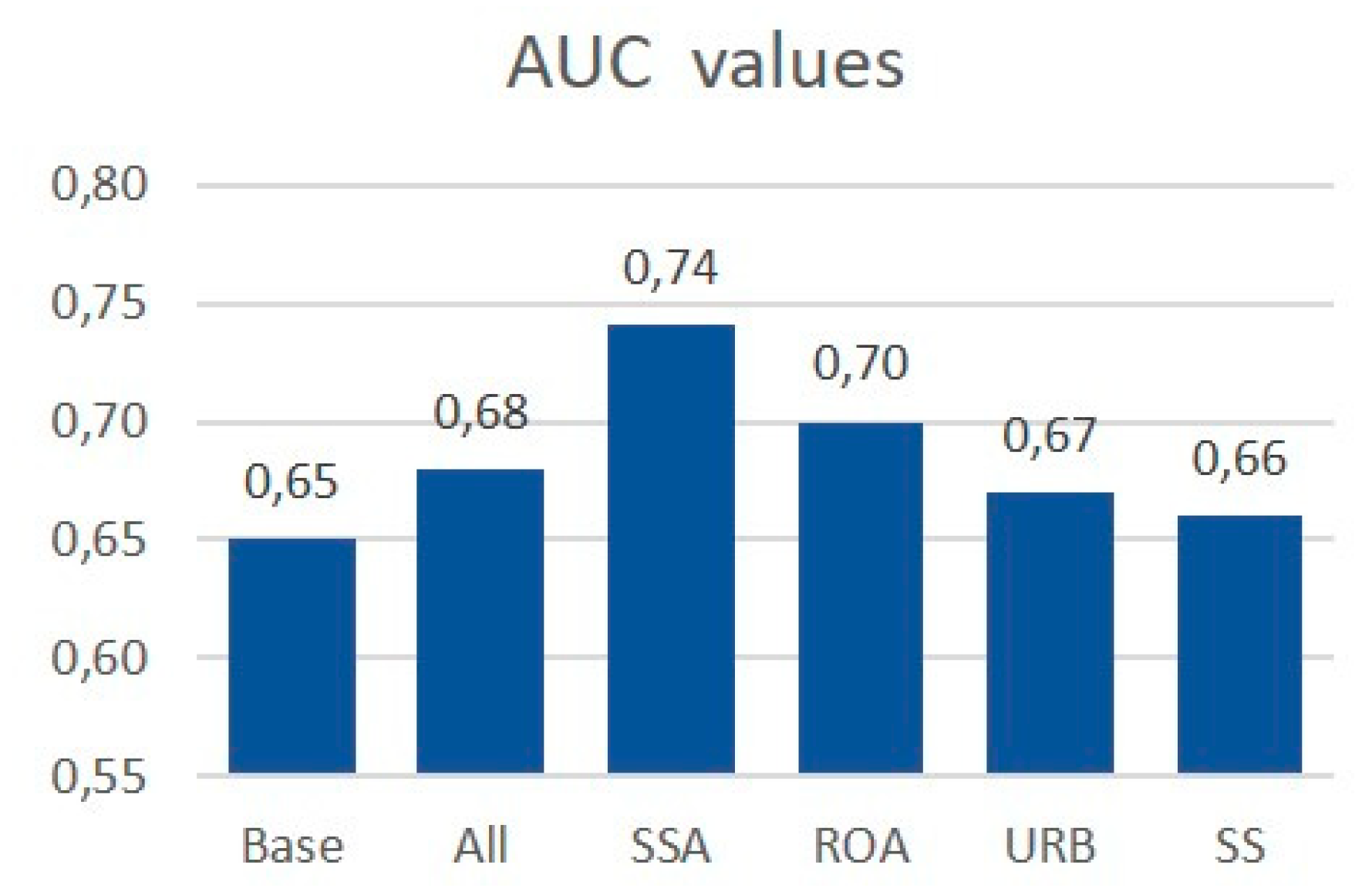
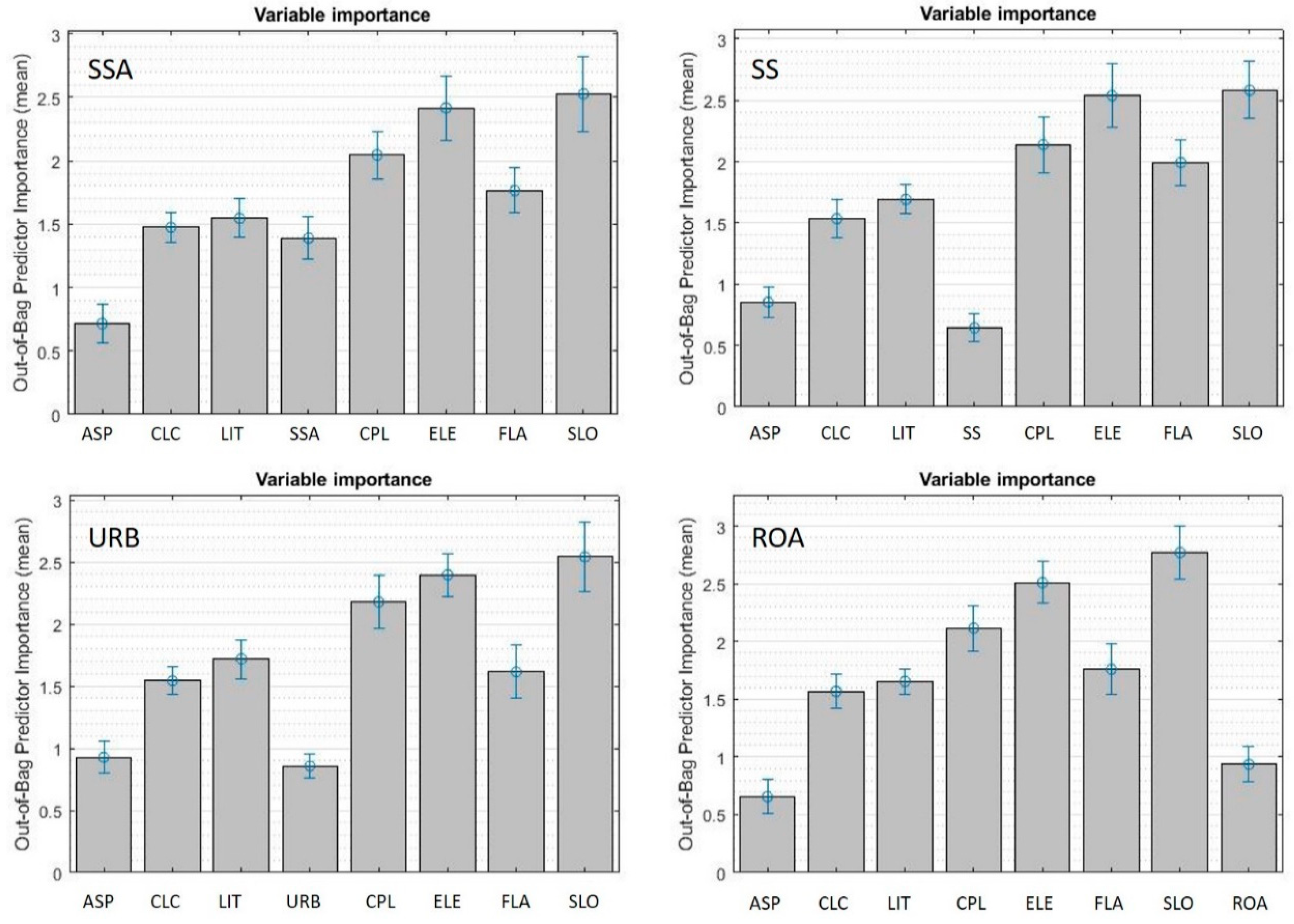
3.1. Sensitivity to Soil Sealing Parameterization
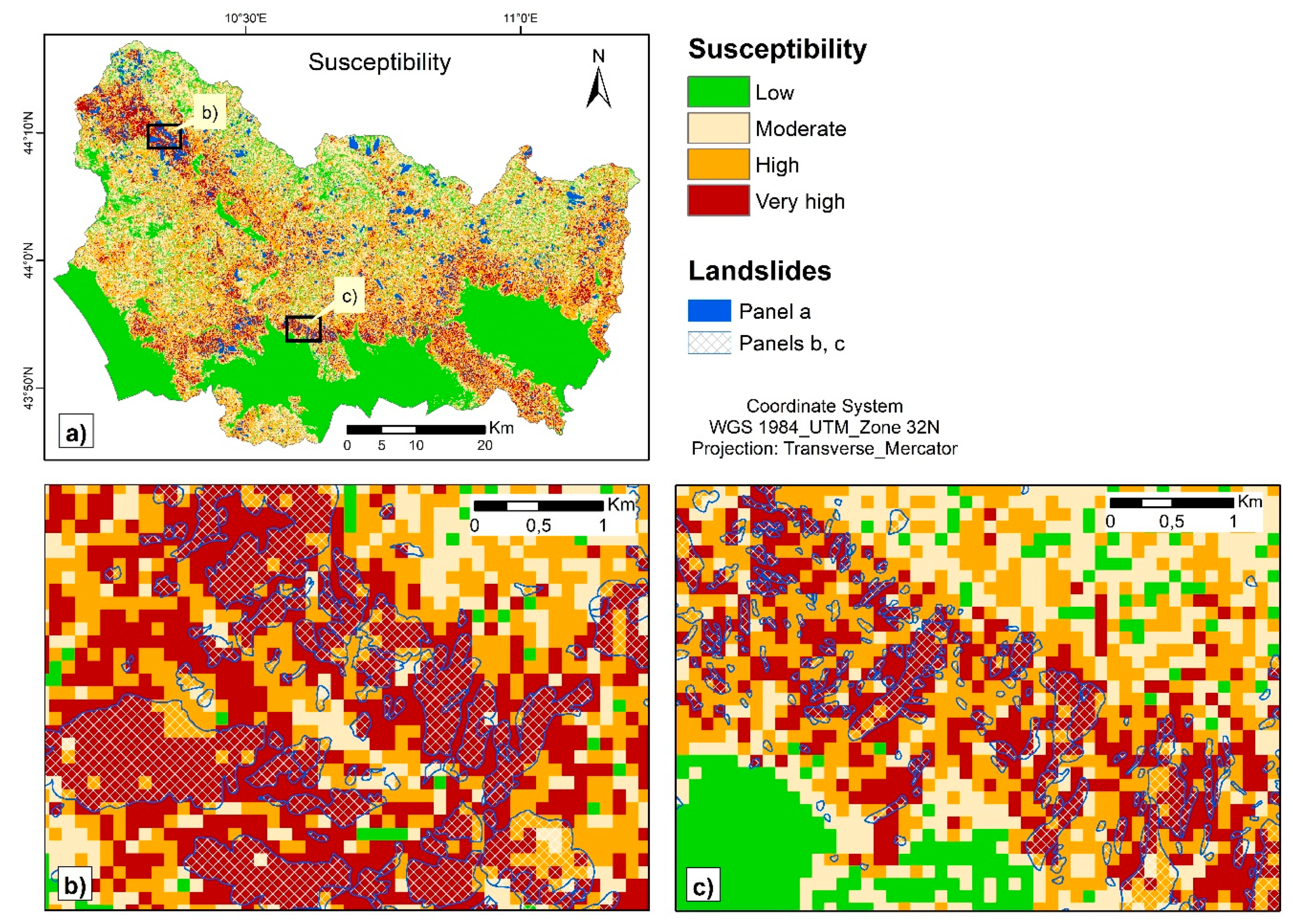
3.2. Susceptibility Mapping
4. Discussion
5. Conclusions
- Soil sealing data can be used to improve the effectiveness of landslide susceptibility assessments;
- Among the tested variables, “soil sealing aggregation” was the most promising, leading to the highest AUC and showing a relative importance within the model higher than other widely used parameters like land cover;
- In addition to the improved forecasting effectiveness, the use of soil sealing-derived parameters in landslide susceptibility studies seems promising because the original thematic layer is updated yearly, and this good temporal resolution allows for a quick and constant update of susceptibility maps accounting for the modifications induced by human activity on hillslope systems; and
- All the proposed variables were formulated in general terms to make their use reproducible in other susceptibilities studies, even in those based on spatial units different from those used here. The methodology is technically reproducible in Italy and in all other countries with similar environmental monitoring programs.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Corominas, J.; Copons, R.; Vilaplana, J.M.; Altimir, J.; Amigó, J. Integrated landslide susceptibility analysis and hazard assessment in the principality of Andorra. Nat. Hazards 2003, 30, 421–435. [Google Scholar] [CrossRef]
- Fell, R.; Corominas, J.; Bonnard, C.; Cascini, L.; Leroi, E.; Savage, W.Z. Guidelines for landslide susceptibility, hazard and risk zoning for land use planning. Eng. Geo. 2008, 102, 85–98. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Chung, C.F.; Fabbri, A.G. Validation of spatial prediction models for landslide hazard mapping. Nat. Hazards 2003, 30, 451–472. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat-Turkey). Comput. Geosci. UK 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Kavoura, K.; Sabatakakis, N. Investigating landslide susceptibility procedures in Greece. Landslides 2019, 17, 127–145. [Google Scholar] [CrossRef]
- Manzo, G.; Tofani, V.; Segoni, S.; Battistini, A.; Catani, F. GIS techniques for regional-scale landslide susceptibility assessment: The Sicily (Italy) case study. Int. J. Geogr. Inf. Sci. 2013, 27, 1433–1452. [Google Scholar] [CrossRef]
- Melo, R.; Zêzere, J.L.; Rocha, J.; Oliveira, S.C. Combining data-driven models to assess susceptibility of shallow slides failure and run-out. Landslides 2019, 16, 2259–2276. [Google Scholar] [CrossRef]
- Carrara, A. Multivariate models for landslide hazard evaluation. Math. Geol. 1983, 15, 403–426. [Google Scholar] [CrossRef]
- Ilia, I.; Tsangaratos, P. Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides 2016, 13, 379–397. [Google Scholar] [CrossRef]
- Thiery, Y.; Malet, J.P.; Sterlacchini, S.; Puissant, A.; Maquaire, O. Landslide susceptibility assessment by bivariate methods at large scales: Application to a complex mountainous environment. Geomorphology 2007, 92, 38–59. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.-H.; Won, J.-S.; Park, H.-J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Ermini, L.; Catani, F.; Casagli, N. Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 2005, 66, 327–343. [Google Scholar] [CrossRef]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah basin, Asir region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Xiao, T.; Segoni, S.; Chen, L.; Yin, K.; Casagli, N. A step beyond landslide susceptibility maps: A simple method to investigate and explain the different outcomes obtained by different approaches. Landslides 2019, 17, 627–640. [Google Scholar] [CrossRef]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, J.; Xu, C.; Xu, C.; Song, C. Local-scale landslide susceptibility mapping using the B-GeoSVC model. Landslides 2019, 16, 1301–1312. [Google Scholar] [CrossRef]
- Segoni, S.; Pappafico, G.; Luti, T.; Catani, F. Landslide susceptibility assessment in complex geological settings: Sensitivity to geological information and insights on its parameterization. Landslides 2020, 1–11. [Google Scholar] [CrossRef]
- Fressard, M.; Thiery, Y.; Maquaire, O. Which data for quantitative landslide susceptibility mapping at operational scale? Case study of the Pays d’Auge plateau hillslopes (Normandy, France). Nat. Hazards Earth Syst. Sci. 2014, 14, 569–588. [Google Scholar] [CrossRef]
- Süzen, M.L.; Doyuran, V. A comparison of the GIS based landslide susceptibility assessment methods: Multivariate versus bivariate. Environ. Geol. 2004, 45, 665–679. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko mountains, central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Sarkar, S.; Kanungo, D.P. An integrated approach for landslide susceptibility mapping using remote sensing and GIS. Photogramm. Eng. Remote Sens. 2004, 70, 617–625. [Google Scholar] [CrossRef]
- Lee, S. Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int. J. Remote Sens. 2005, 26, 1477–1491. [Google Scholar] [CrossRef]
- Hong, Y.; Adler, R.; Huffman, G. Use of satellite remote sensing data in the mapping of global landslide susceptibility. Nat. Hazards 2007, 43, 245–256. [Google Scholar] [CrossRef]
- Park, N.W.; Chi, K.H. Quantitative assessment of landslide susceptibility using high-resolution remote sensing data and a generalized additive model. Int. J. Remote Sens. 2008, 29, 247–264. [Google Scholar] [CrossRef]
- Jebur, M.N.; Pradhan, B.; Tehrany, M.S. Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens. Environ. 2014, 152, 150–165. [Google Scholar] [CrossRef]
- Pradhan, B.; Sezer, E.A.; Gokceoglu, C.; Buchroithner, M.F. Landslide susceptibility mapping by neuro-fuzzy approach in a landslide-prone area (Cameron Highlands, Malaysia). IEEE Trans. Geosci. Remote Sens. 2010, 48, 4164–4177. [Google Scholar] [CrossRef]
- Sezer, E.A.; Pradhan, B.; Gokceoglu, C. Manifestation of an adaptive neuro-fuzzy model on landslide susceptibility mapping: Klang valley, Malaysia. Expert Syst. Appl. 2011, 38, 8208–8219. [Google Scholar] [CrossRef]
- Bălteanu, D.; Chendeş, V.; Sima, M.; Enciu, P. A country-wide spatial assessment of landslide susceptibility in Romania. Geomorphology 2010, 124, 102–112. [Google Scholar] [CrossRef]
- Shu, H.; Hürlimann, M.; Molowny-Horas, R.; González, M.; Pinyol, J.; Abancó, C.; Ma, J. Relation between land cover and landslide susceptibility in Val d’Aran, Pyrenees (Spain): Historical aspects, present situation and forward prediction. Sci. Total Environ. 2019, 693, 133557. [Google Scholar] [CrossRef]
- Trigila, A.; Frattini, P.; Casagli, N.; Catani, F.; Crosta, G.; Esposito, C.; Iadanza, C.; Lagomarsino, D.; Scarascia Mugnozza, G.; Segoni, S.; et al. Landslide susceptibility mapping at national scale: The Italian case study. In Landslide Sciences Practice; Margottini, C., Canuti, P., Sassa, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 1, pp. 287–295. [Google Scholar]
- Maricchiolo, C.; Sambucini, V.; Pugliese, A.; Munafò, M.; Cecchi, G.; Rusco, E.; Blasi, C.; Marchetti, M.; Chirici, G.; Corona, P. La Realizzazione in Italia del Progetto Europeo CLC2000; APAT Rapporti: Roma, Italy, 2005; pp. 1–86. [Google Scholar]
- Munafò, M.; Salvati, L.; Zitti, M. Estimating soil sealing rate at national level—Italy as a case study. Ecol. Indic. 2013, 26, 137–140. [Google Scholar] [CrossRef]
- Prokop, G.; Jobstmann, H.; Schöbauer, A. Overview on Best Practices for Limiting Soil Sealing and Mitigating Its Effects in EU-27; European Communities: Brussels, Belgium, 2011. [Google Scholar] [CrossRef]
- Munafò, M. Consumo di Suolo, Dinamiche Territoriali e Servizi Ecosistemici; SNPA: Rome, Italy, 2019; p. 224. [Google Scholar]
- Chen, L.; Sela, S.; Svoray, T.; Assouline, S. The role of soil-surface sealing, microtopography, and vegetation patches in rainfall-runoff processes in semiarid areas. Water Resour. Res. 2013, 49, 5585–5599. [Google Scholar] [CrossRef]
- Pistocchi, A. Hydrological impact of soil sealing and urban land take. In Urban Expansion, Land Cover and Soil Ecosystem Services, 1st ed.; Gardi, C., Ed.; Routledge: London, UK, 2017; pp. 157–168. [Google Scholar]
- Acquaotta, F.; Faccini, F.; Fratianni, S.; Paliaga, G.; Sacchini, A.; Vilímek, V. Increased flash flooding in genoa metropolitan area: A combination of climate changes and soil consumption. Meteorl. Atmos. Phys. 2019, 131, 1099–1110. [Google Scholar] [CrossRef]
- Martino, S.; Bozzano, F.; Caporossi, P.; D’Angiò, D.; Della Seta, M.; Esposito, C.; Fantini, A.; Fiorucci, M.; Giannini, L.M.; Iannucci, R.; et al. Impact of landslides on transportation routes during the 2016–2017 central Italy seismic sequence. Landslides 2019, 16, 1221–1241. [Google Scholar] [CrossRef]
- Dikshit, A.; Sarkar, R.; Pradhan, B.; Segoni, S.; Alamri, A.M. Rainfall induced landslide studies in Indian Himalayan region: A critical review. Appl. Sci. 2020, 10, 2466. [Google Scholar] [CrossRef]
- Collins, T.K. Debris flows caused by failure of fill slopes: Early detection, warning, and loss prevention. Landslides 2008, 5, 107–120. [Google Scholar] [CrossRef]
- Battistini, A.; Rosi, A.; Segoni, S.; Lagomarsino, D.; Catani, F.; Casagli, N. Validation of landslide hazard models using a semantic engine on online news. Appl. Geogr. 2017, 82, 59–65. [Google Scholar] [CrossRef]
- Carmignani, L.; Conti, P.; Cornamusini, G.; Pirro, A. Geological map of Tuscany (Italy). J. Maps 2013, 9, 487–497. [Google Scholar] [CrossRef]
- Casagli, N.; Dapporto, S.; Ibsen, M.L.; Tofani, V.; Vannocci, P. Analysis of the landslide triggering mechanism during the storm of 20th–21st November 2000, in northern Tuscany. Landslides 2006, 3, 13–21. [Google Scholar] [CrossRef]
- Rosi, A.; Tofani, V.; Tanteri, L.; Stefanelli, C.T.; Agostini, A.; Catani, F.; Casagli, N. The new landslide inventory of Tuscany (Italy) updated with PS-InSAR: Geomorphological features and landslide distribution. Landslides 2018, 15, 5–19. [Google Scholar] [CrossRef]
- Bianchini, S.; Raspini, F.; Solari, L.; Del Soldato, M.; Ciampalini, A.; Rosi, A.; Casagli, N. From picture to movie: Twenty years of ground deformation recording over Tuscany region (Italy) with satellite InSAR. Front. Earth Sci. 2018, 6, 177. [Google Scholar] [CrossRef]
- Segoni, S.; Rossi, G.; Rosi, A.; Catani, F. Landslides triggered by rainfall: A semi-automated procedure to define consistent intensity-duration thresholds. Comput. Geosci. UK 2014, 63, 123–131. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Brenning, A. Spatial prediction models for landslide hazards: Review, comparison and evaluation. Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Spizzichino, D. Quality assessment of the Italian landslide inventory using GIS processing. Landslides 2010, 7, 455–470. [Google Scholar] [CrossRef]
- Cruden, D.M.; Varnes, D.J. Landslide types and processes. In Landslide Investigation and Mitigation (Transportation Research Board, National Research Council); Turner, A.K., Schuster, R.L., Eds.; Transportation Research Board National Academy Press: Washington, DC, USA, 1996; Volume 247, pp. 36–75. [Google Scholar]
- Chacón, J.; Irigaray, C.; Fernández, T.; El Hamdouni, R. Engineering geology maps: Landslides and geographical information systems. Bull. Eng. Geol. Environ. 2006, 65, 341–411. [Google Scholar] [CrossRef]
- Segoni, S.; Tofani, V.; Lagomarsino, D.; Moretti, S. Landslide susceptibility of the Prato-Pistoia-Lucca provinces, Tuscany, Italy. J. Maps. 2016, 12, 401–406. [Google Scholar] [CrossRef]
- Segoni, S.; Tofani, V.; Rosi, R.; Catani, F.; Casagli, N. Combination of rainfall thresholds and susceptibility maps for dynamic landslide hazard assessment at regional scale. Front. Earth Sci. 2018, 6, 85. [Google Scholar] [CrossRef]
- Tigges, J.; Lakes, T.; Hostert, P. Urban vegetation classification: Benefits of multitemporal RapidEye satellite data. Remote Sens. Environ. 2013, 136, 66–75. [Google Scholar] [CrossRef]
- Munafò, M. Il Consumo di Suolo in Italia; SNPA: Rome, Italy, 2015; p. 90. [Google Scholar]
- Jiménez-Muñoz, J.C.; Sobrino, J.A.; Gillespie, A.; Sabol, D.; Gustafson, W.T. Improved land surface emissivities over agricultural areas using ASTER NDVI. Remote Sens. Environ. 2006, 103, 474–487. [Google Scholar] [CrossRef]
- Neinavaz, E.; Skidmore, A.K.; Darvishzadeh, R. Effects of prediction accuracy of the proportion of vegetation cover on land surface emissivity and temperature using the NDVI threshold method. Int. J. Appl. Earth. Obs. 2020, 85, 101984. [Google Scholar] [CrossRef]
- Matsuoka, M.; Yamazaki, F. Use of satellite SAR intensity imagery for detecting building areas damaged due to earthquakes. Earthq. Spectra 2004, 20, 975–994. [Google Scholar] [CrossRef]
- Lagomarsino, D.; Tofani, V.; Segoni, S.; Catani, F.; Casagli, N. A tool for classification and regression using random forest methodology: Applications to landslide susceptibility mapping and soil thickness modeling. Environ. Model Assess. 2017, 22, 201–214. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Frattini, P.; Crosta, G.; Carrara, A. Techniques for evaluating the performance of landslide susceptibility models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
- Aleotti, P.; Chowdhury, R. Landslide hazard assessment: Summary review and new perspectives. Bull. Eng. Geol. Environ. 1999, 58, 21–44. [Google Scholar] [CrossRef]
- Van den Eeckhaut, M.; Reichenbach, P.; Guzzetti, F.; Rossi, M.; Poesen, J. Combined landslide inventory and susceptibility assessment based on different mapping units: An example from the Flemish Ardennes, Belgium. Nat. Hazards Earth Syst. Sci. 2009, 9, 507–521. [Google Scholar] [CrossRef]
- Alvioli, M.; Marchesini, I.; Reichenbach, P.; Rossi, M.; Ardizzone, F.; Fiorucci, F.; Guzzetti, F. Automatic delineation of geomorphological slope units with r.slopeunits v1.0 and their optimization for landslide susceptibility modeling. Geosci. Model Dev. 2016, 9, 3975–3991. [Google Scholar] [CrossRef]
- Arabameri, A.; Rezaei, K.; Cerdà, A.; Conoscenti, C.; Kalantari, Z. A comparison of statistical methods and multi-criteria decision making to map flood hazard susceptibility in Northern Iran. Sci. Total Environ. 2019, 660, 443–458. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Liu, G.; Chen, W.; Liang, S.; Chen, R.; Han, W. Human-induced landslide on a high cut slope: A case of repeated failures due to multi-excavation. J. Rock Mech. Geotech. Eng. 2012, 4, 367–374. [Google Scholar] [CrossRef]
- Notti, D.; Galve, J.P.; Mateos, R.M.; Monserrat, O.; Lamas-Fernández, F.; Fernández-Chacón, F.; Roldán-García, F.J.; Pérez-Peña, J.V.; Crosetto, M.; Azañón, J.M. Human-induced coastal landslide reactivation. Monitoring by PSInSAR techniques and urban damage survey (SE Spain). Landslides 2015, 12, 1007–1014. [Google Scholar] [CrossRef]
- Mendes, R.M.; de Andrade, M.R.M.; Tomasella, J.; de Moraes, M.A.E.; Scofield, G.B. Understanding shallow landslides in Campos do Jordão municipality-Brazil: Disentangling the anthropic effects from natural causes in the disaster of 2000. Nat. Hazards Earth Syst. Sci. 2018, 18, 15–30. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Typology | Values | Source Data |
|---|---|---|---|
| Lithology | Categorical, 6 classes | Conglomerates and weakly cemented limestones; compact clays; Massive rocks; Layered rocks (prevailing massive layers); Layered rocks (prevailing pelithic layers); Cohesive and granular soils | Regional geological map reclassified after [56]. |
| Land use/land cover | Categorical, 9 classes | Urban areas; crops; grasslands; heterogenic rural areas; broad-leaves forests; conifers forests; shrubs; bare rocks; humid areas/water | Corine Land Cover 2018 |
| Aspect | Categorical, 9 classes | 8 classes centered on cardinal directions; an additional class for flat areas | DTM |
| Elevation | Continuous | 0–2026 m | DTM |
| Slope gradient | Continuous | 0–69° | DTM |
| Planar curvature | Continuous | −2–+3 | DTM |
| Flow accumulation | Continuous | 0–5725 cells | DTM |
| Sentinel-2 MSI Bands | Description | Wavelength (µm) | Spatial Resolution (m) |
|---|---|---|---|
| 1 | Atmospheric aerosol | 0.433–0.453 | 60 |
| 2 | Blue | 0.458–0.523 | 10 |
| 3 | Green | 0.543–0.578 | 10 |
| 4 | Red | 0.650–0.680 | 10 |
| 5 | Vegetation Red Edge | 0.698–0.713 | 20 |
| 6 | Vegetation Red Edge | 0.733–0.748 | 20 |
| 7 | Vegetation Red Edge | 0.773–0.793 | 20 |
| 8 | NIR | 0.785–0.900 | 10 |
| 8A | Near NIR | 0.855–0.875 | 20 |
| 9 | Water vapor | 0.935–0.955 | 60 |
| 10 | SWIR – Cirrus | 1.365–1.385 | 60 |
| 11 | SWIR | 1.565–1.655 | 20 |
| 12 | SWIR | 2100–2280 | 20 |
| Min | Max | Mean | SD | |
|---|---|---|---|---|
| SSA-ROA | −0.33 | 0.33 | 0.003 | 0.0395 |
| SSA-URB | −0.32 | 0.32 | 0.002 | 0.0399 |
| SSA-SS | −0.34 | 0.38 | 0.003 | 0.0399 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luti, T.; Segoni, S.; Catani, F.; Munafò, M.; Casagli, N. Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping. Remote Sens. 2020, 12, 1486. https://doi.org/10.3390/rs12091486
Luti T, Segoni S, Catani F, Munafò M, Casagli N. Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping. Remote Sensing. 2020; 12(9):1486. https://doi.org/10.3390/rs12091486
Chicago/Turabian StyleLuti, Tania, Samuele Segoni, Filippo Catani, Michele Munafò, and Nicola Casagli. 2020. "Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping" Remote Sensing 12, no. 9: 1486. https://doi.org/10.3390/rs12091486
APA StyleLuti, T., Segoni, S., Catani, F., Munafò, M., & Casagli, N. (2020). Integration of Remotely Sensed Soil Sealing Data in Landslide Susceptibility Mapping. Remote Sensing, 12(9), 1486. https://doi.org/10.3390/rs12091486