Shallow Landslide Susceptibility Models Based on Artificial Neural Networks Considering the Factor Selection Method and Various Non-Linear Activation Functions



Abstract
1. Introduction
2. Study Area and Spatial Database
2.1. Description of the Study Area
2.2. Landslide Inventory
2.3. Landslide Predisposing Factors
2.3.1. Morphological Types
2.3.2. Hydrological Types
2.3.3. Geological Types
2.3.4. Land Cover Types
3. Methodology
3.1. Preparation of Training and Validation Datasets
3.2. Landslide Predisposing Factor Analysis
3.2.1. Information Gain Ratio Analysis
3.2.2. Multicollinearity Analysis
3.3. Landslide Susceptibility Analysis
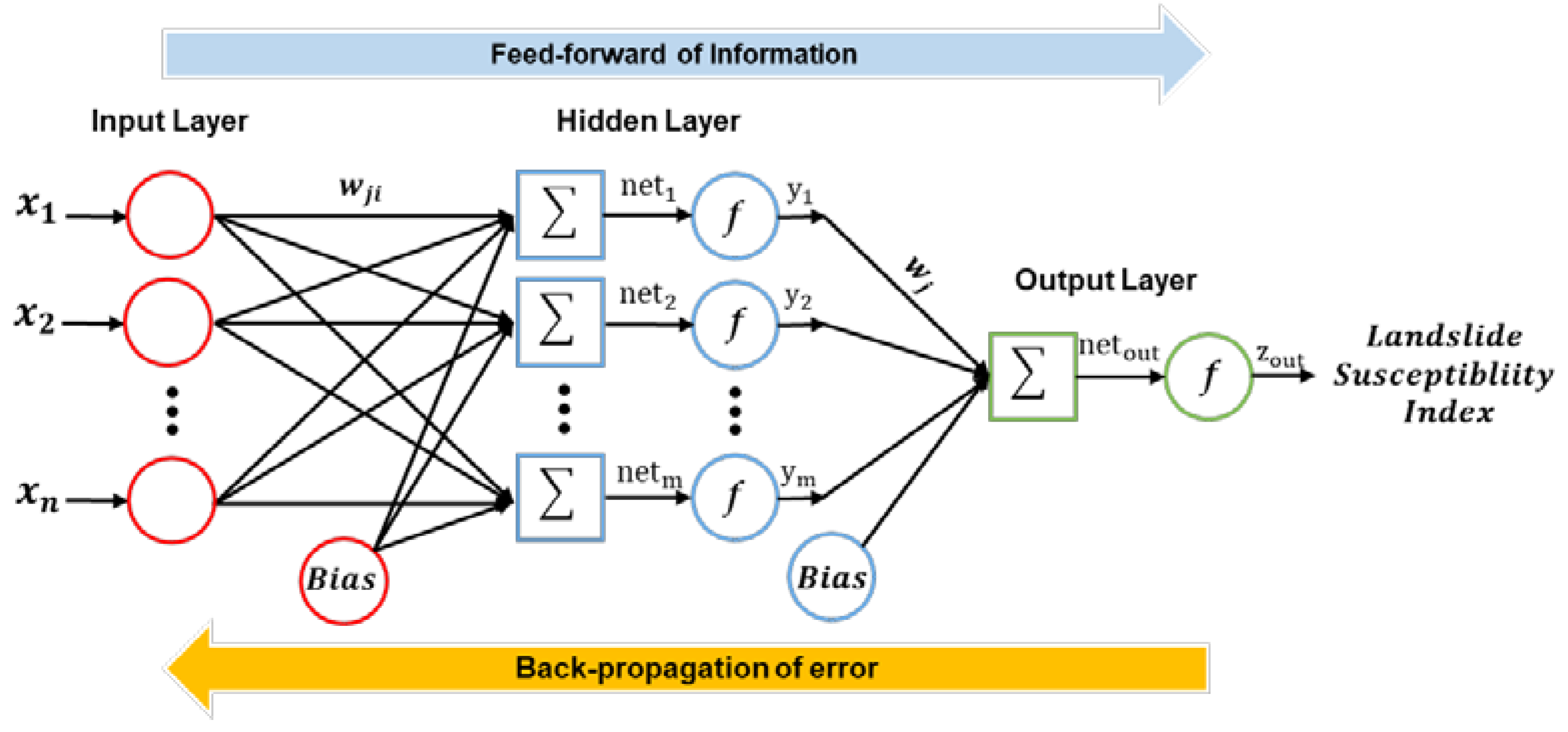
3.3.1. Artificial Neural Networks
3.3.2. Activation Functions
3.4. Assessment of Model Performance
3.4.1. Statistical Evaluation Measures
3.4.2. Receiver Operating Characteristic Curve
3.4.3. Non-Parametric Statistical Test
4. Results
4.1. Landslide Predisposing Factor Analysis
4.1.1. Predictive Ability Analysis
4.1.2. Multicollinearity Diagnostic Analysis
4.2. Landslide Susceptibility Modeling, Validation, and Comparison
4.2.1. Selecting the Best Number of the Neurons in the Hidden Layer
4.2.2. Evaluation of the Model Performance
4.2.3. Validation of the Model Performance
4.2.4. Comparison of the Model Performance
4.2.5. Production of Landslide Susceptibility Maps
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Class | No. of Pixels in Domain | % of Pixels in Domain | No. of Landslide | % of Landslide | Frequency Ratio 1 |
|---|---|---|---|---|---|---|
| Elevation | 23.4–68.3 | 40,715 | 0.17 | 14 | 0.09 | 0.54 |
| (m) | 68.3–113 | 88,856 | 0.37 | 36 | 0.24 | 0.64 |
| 113–158 | 57,120 | 0.24 | 51 | 0.34 | 1.41 | |
| 158–203 | 30,307 | 0.13 | 24 | 0.16 | 1.25 | |
| 203–248 | 16,333 | 0.07 | 26 | 0.17 | 2.52 | |
| 248–293 | 5949 | 0.02 | 0 | 0.00 | 0.00 | |
| Slope | 0–12 | 36,935 | 0.15 | 0 | 0.00 | 0.00 |
| (degree) | 12–24 | 129,945 | 0.54 | 38 | 0.25 | 0.46 |
| 24–36 | 64,684 | 0.27 | 98 | 0.65 | 2.40 | |
| 36–47 | 7479 | 0.03 | 15 | 0.10 | 3.18 | |
| 47–59 | 237 | 0.00 | 0 | 0.00 | 0.00 | |
| Aspect | Flat | 3713 | 0.02 | 0 | 0.00 | 0.00 |
| N | 29,017 | 0.12 | 11 | 0.07 | 0.60 | |
| NE | 28,588 | 0.12 | 19 | 0.13 | 1.05 | |
| E | 31,456 | 0.13 | 24 | 0.16 | 1.21 | |
| SE | 32,258 | 0.13 | 14 | 0.09 | 0.69 | |
| S | 32,651 | 0.14 | 24 | 0.16 | 1.16 | |
| SW | 29,854 | 0.12 | 21 | 0.14 | 1.11 | |
| W | 23,161 | 0.10 | 21 | 0.14 | 1.44 | |
| NW | 28,582 | 0.12 | 17 | 0.11 | 0.94 | |
| Curvature | Concave | 112,264 | 0.47 | 98 | 0.65 | 1.38 |
| Planar | 10,893 | 0.05 | 0 | 0.00 | 0.00 | |
| Convex | 116,123 | 0.49 | 53 | 0.35 | 0.72 | |
| TRI | 0–12 | 6751 | 0.03 | 0 | 0.00 | 0.00 |
| 12–24 | 54,262 | 0.23 | 5 | 0.03 | 0.15 | |
| 24–32 | 63,716 | 0.27 | 22 | 0.15 | 0.55 | |
| 32–42 | 59,885 | 0.25 | 45 | 0.30 | 1.19 | |
| 42–59 | 48,690 | 0.20 | 67 | 0.44 | 2.18 | |
| 59–95 | 5976 | 0.02 | 12 | 0.08 | 3.18 | |
| SRR | 0–0.23 | 5230 | 0.02 | 0 | 0.00 | 0.00 |
| 0.23–0.46 | 43,224 | 0.18 | 26 | 0.17 | 0.95 | |
| 0.46–0.53 | 130,487 | 0.55 | 92 | 0.61 | 1.12 | |
| 0.53–0.67 | 52,451 | 0.22 | 33 | 0.22 | 1.00 | |
| 0.67–0.89 | 7888 | 0.03 | 0 | 0.00 | 0.00 | |
| SEI | −58–−36 | 979 | 0.00 | 0 | 0.00 | 0.00 |
| −36–−14 | 46,387 | 0.19 | 41 | 0.27 | 1.40 | |
| –14–7.5 | 104,677 | 0.44 | 44 | 0.29 | 0.67 | |
| 7.5–29 | 82,189 | 0.34 | 54 | 0.36 | 1.04 | |
| 29–51 | 5048 | 0.02 | 12 | 0.08 | 3.77 | |
| TWI | 1.2–2.3 | 69,465 | 0.29 | 44 | 0.29 | 1.00 |
| 2.3–2.8 | 85,422 | 0.36 | 62 | 0.41 | 1.15 | |
| 2.8–3.5 | 59,651 | 0.25 | 37 | 0.25 | 0.98 | |
| 3.5–4.6 | 18,901 | 0.08 | 8 | 0.05 | 0.67 | |
| 4.6–9.9 | 5841 | 0.02 | 0 | 0.00 | 0.00 | |
| STI | 0–5 | 28,743 | 0.12 | 0 | 0.00 | 0.00 |
| 5–25 | 129,887 | 0.54 | 55 | 0.36 | 0.67 | |
| 25–50 | 55,727 | 0.23 | 64 | 0.42 | 1.82 | |
| 50–100 | 17,817 | 0.07 | 23 | 0.15 | 2.05 | |
| >100 | 7106 | 0.03 | 9 | 0.06 | 2.01 | |
| SPI | 0–5 | 13,142 | 0.05 | 0 | 0.00 | 0.00 |
| 5–50 | 103,820 | 0.43 | 34 | 0.23 | 0.52 | |
| 50–100 | 50,676 | 0.21 | 43 | 0.28 | 1.34 | |
| 100–500 | 58,628 | 0.25 | 63 | 0.42 | 1.70 | |
| >500 | 13,014 | 0.05 | 11 | 0.07 | 1.34 | |
| Distance | 0–21 | 79,705 | 0.33 | 46 | 0.30 | 0.91 |
| from | 21–43 | 73,801 | 0.31 | 45 | 0.30 | 0.97 |
| stream | 43–67 | 57,808 | 0.24 | 44 | 0.29 | 1.21 |
| (m) | 67–120 | 26,875 | 0.11 | 16 | 0.11 | 0.94 |
| 120–250 | 1091 | 0.00 | 0 | 0.00 | 0.00 | |
| Lithology | Metamorphic | 179,607 | 0.75 | 142 | 0.94 | 1.25 |
| Sedimentary | 57,344 | 0.24 | 9 | 0.06 | 0.25 | |
| No data | 2329 | 0.01 | 0 | 0.00 | 0.00 | |
| Weathering | High | 109,136 | 0.46 | 105 | 0.70 | 1.52 |
| Moderate | 127,815 | 0.53 | 46 | 0.30 | 0.57 | |
| No data | 2329 | 0.01 | 0 | 0.00 | 0.00 | |
| Effective | 1–33 | 90,774 | 0.39 | 100 | 0.66 | 1.70 |
| soil depth | 33–49 | 56,426 | 0.24 | 31 | 0.21 | 0.87 |
| (cm) | 49–56 | 68,307 | 0.29 | 20 | 0.13 | 0.46 |
| 56–69 | 21,444 | 0.09 | 0 | 0.00 | 0.00 | |
| No data | 2,329 | 0.01 | 0 | 0.00 | 0.00 | |
| Soil texture | Silty loam | 90,712 | 0.38 | 41 | 0.27 | 0.72 |
| Sandy loam | 146,239 | 0.61 | 110 | 0.73 | 1.19 | |
| No data | 2329 | 0.01 | 0 | 0.00 | 0.00 | |
| Soil type 2 | 117,481 | 0.49 | 109 | 0.72 | 1.47 | |
| 107,142 | 0.45 | 42 | 0.28 | 0.62 | ||
| 12,328 | 0.05 | 0 | 0.00 | 0.00 | ||
| No data | 2329 | 0.01 | 0 | 0.00 | 0.00 | |
| Soil density | Medium dense | 27,019 | 0.11 | 23 | 0.15 | 1.35 |
| Loose | 188,702 | 0.79 | 116 | 0.77 | 0.97 | |
| Very loose | 21,230 | 0.09 | 12 | 0.08 | 0.90 | |
| No data | 2329 | 0.01 | 0 | 0.00 | 0.00 | |
| Forest type | Coniferous | 5796 | 0.02 | 1 | 0.01 | 0.27 |
| Broadleaf | 216,285 | 0.90 | 140 | 0.93 | 1.03 | |
| Mixed | 14,914 | 0.06 | 9 | 0.06 | 0.96 | |
| No forest | 2285 | 0.01 | 1 | 0.01 | 0.69 | |
| Forest | Dense | 226,644 | 0.95 | 146 | 0.97 | 1.02 |
| Density | Moderate | 10,351 | 0.04 | 4 | 0.03 | 0.61 |
| No forest | 2285 | 0.01 | 1 | 0.01 | 0.69 | |
| Distance | 0–130 | 100,938 | 0.42 | 59 | 0.39 | 0.93 |
| from road | 130–300 | 59,632 | 0.25 | 43 | 0.28 | 1.14 |
| (m) | 300–550 | 43,386 | 0.18 | 23 | 0.15 | 0.84 |
| 550–900 | 17,734 | 0.07 | 13 | 0.09 | 1.16 | |
| 900–1500 | 17,590 | 0.07 | 13 | 0.09 | 1.17 |
References
- Cho, S.E. Prediction of shallow landslide by surficial stability analysis considering rainfall infiltration. Eng. Geol. 2017, 231, 126–138. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Lee, S.R.; Kim, Y.T. A shallow slide prediction model combining rainfall threshold warnings and shallow slide susceptibility in Busan, Korea. Landslides 2019, 16, 647–659. [Google Scholar] [CrossRef]
- Park, D.W.; Lee, S.R.; Vasu, N.N.; Kang, S.H.; Park, J.Y. Coupled model for simulation of landslides and debris flows at local scale. Nat. Hazards 2016, 81, 1653–1682. [Google Scholar] [CrossRef]
- Park, J.Y.; Lee, S.R.; Lee, D.H.; Kim, Y.T.; Lee, J.S. A regional-scale landslide early warning methodology applying statistical and physically based approaches in sequence. Eng. Geol. 2019, 260, 1–14. [Google Scholar] [CrossRef]
- Jeong, S.; Lee, K.; Kim, J.; Kim, Y. Analysis of rainfall-induced landslide on unsaturated soil slopes. Sustainability 2017, 9, 1280. [Google Scholar] [CrossRef]
- Park, H.J.; Lee, J.H.; Woo, I. Assessment of rainfall-induced shallow landslide susceptibility using a GIS-based probabilistic approach. Eng. Geol. 2013, 161, 1–15. [Google Scholar] [CrossRef]
- Kim, J.; Lee, K.; Jeong, S.; Kim, G. GIS-based prediction method of landslide susceptibility using a rainfall infiltration-groundwater flow model. Eng. Geol. 2014, 182, 63–78. [Google Scholar] [CrossRef]
- Formetta, G.; Capparelli, G.; Versace, P. Evaluating performance of simplified physically based models for shallow landslide susceptibility. Hydrol. Earth Syst. Sci. 2016, 20, 4585–4603. [Google Scholar] [CrossRef]
- Van Westen, C.J.; Terlien, M.T.J. An approach towards deterministic landslide hazard analysis in GIS. A case study from Manizales (Colombia). Earth Surf. Process. Landforms 1996, 21, 853–868. [Google Scholar] [CrossRef]
- Tofani, V.; Bicocchi, G.; Rossi, G.; Segoni, S.; D’Ambrosio, M.; Casagli, N.; Catani, F. Soil characterization for shallow landslides modeling: A case study in the Northern Apennines (Central Italy). Landslides 2017, 14, 755–770. [Google Scholar] [CrossRef]
- Canli, E.; Mergili, M.; Thiebes, B.; Glade, T. Probabilistic landslide ensemble prediction systems: Lessons to be learned from hydrology. Nat. Hazards Earth Syst. Sci. 2018, 18, 2183–2202. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Hoang, N.D.; Thanh, N.Q.; Nguyen, D.B.; Van Liem, N.; Pradhan, B. Spatial prediction of rainfall-induced landslides for the Lao Cai area (Vietnam) using a hybrid intelligent approach of least squares support vector machines inference model and artificial bee colony optimization. Landslides 2017, 14, 447–458. [Google Scholar] [CrossRef]
- Shahin, M.A.; Jaksa, M.B.; Maier, H.R. State of the art of artificial neural networks in geotechnical engineering. Electron. J. Geotech. Eng. 2008, 13, 1–25. [Google Scholar]
- Lee, S.J.; Lee, S.R.; Kim, Y.S. An approach to estimate unsaturated shear strength using artificial neural network and hyperbolic formulation. Comput. Geotech. 2003, 30, 489–503. [Google Scholar] [CrossRef]
- Lee, S. Landslide susceptibility mapping using an artificial neural network in the Gangneung are, Korea. Int. J. Remote Sens. 2007, 28, 4763–4783. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Ercanoglu, M. Landslide susceptibility assessment of SE Bartin (West Black Sea region, Turkey) by artificial neural networks. Nat. Hazards Earth Syst. Sci. 2005, 5, 979–992. [Google Scholar] [CrossRef]
- Arnone, E.; Francipane, A.; Noto, L.V.; Scarbaci, A.; La Loggia, G. Strategies investigation in using artificial neural network for landslide susceptibility mapping: Application to a Sicilian catchment. J. Hydroinformatics 2014, 16, 502–515. [Google Scholar] [CrossRef]
- Vasu, N.N.; Lee, S.R. A hybrid feature selection algorithm integrating an extreme learning machine for landslide susceptibility modeling of Mt. Woomyeon, South Korea. Geomorphology 2016, 263, 50–70. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg-Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171–172, 12–29. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.H.; Won, J.S.; Park, H.J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Ermini, L.; Catani, F.; Casagli, N. Artificial Neural Networks applied to landslide susceptibility assessment. Geomorphology 2005, 66, 327–343. [Google Scholar] [CrossRef]
- Madić, M.J.; Radovanović, M.R. Optimal selection of ANN training and architectural parameters using taguchi method: A case study. FME Trans. 2011, 39, 79–86. [Google Scholar]
- Kavzoglu, T.; Mather, P.M. The role of feature selection in artificial neural network applications. Int. J. Remote Sens. 2002, 23, 2919–2937. [Google Scholar] [CrossRef]
- Yune, C.Y.; Jeong, S.; Kim, M.M. Susceptibility assessment of rainfall induced landslides: A case study of the debris flow on July 27, 2011 at Umyeonsan (Mt.). In Proceedings of the 19th International Conference on Soil Mechanics and Geotechnical Engineering, Seoul 2017, Seoul, Korea, 17–22 September 2017; pp. 265–278. [Google Scholar]
- Jeong, S.; Kim, Y.; Lee, J.K.; Kim, J. The 27 July 2011 debris flows at Umyeonsan, Seoul, Korea. Landslides 2015, 12, 799–813. [Google Scholar] [CrossRef]
- Park, D.W.; Nikhil, N.V.; Lee, S.R. Landslide and debris flow susceptibility zonation using TRIGRS for the 2011 Seoul landslide event. Nat. Hazards Earth Syst. Sci. 2013, 13, 2833–2849. [Google Scholar] [CrossRef]
- Riley, S.J.; DeGloria, S.D.; Elliot, R. A Terrain Ruggedness Index that Quantifies Topographic Heterogeneity. Intermt. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Pike, R.J.; Wilson, S.E. Elevation-Relief Ratio, Hypsometric Integral, and Geomorphic Area-Altitude Analysis. Geol. Soc. Am. Bull. 1971, 82, 1079–1084. [Google Scholar] [CrossRef]
- Davies, K.W.; Petersen, S.L.; Johnson, D.D.; Davis, D.B.; Madsen, M.D.; Zvirzdin, D.L.; Bates, J.D. Estimating juniper cover from national agriculture imagery program (NAIP) imagery and evaluating relationships between potential cover and environmental variables. Rangel. Ecol. Manag. 2010, 63, 630–637. [Google Scholar] [CrossRef]
- Ray, R.L.; Jacobs, J.M. Relationships among remotely sensed soil moisture, precipitation and landslide events. Nat. Hazards 2007, 43, 211–222. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J.; Schofield, N.; Tagg, A.F. Testing a physically-based flood forecasting model (TOPMODEL) for three U.K. catchments. J. Hydrol. 1984, 69, 119–143. [Google Scholar] [CrossRef]
- Moore, I.D.; Burch, G.J. Physical basis of the length-slope factor in the universal soil loss equation. Soil Sci. Soc. Am. J. 1986, 50, 1294–1298. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological and biological applications. Hydrol. Process. 1984, 5, 3–30. [Google Scholar]
- Segoni, S.; Pappafico, G.; Luti, T.; Catani, F. Landslide susceptibility assessment in complex geological settings: Sensitivity to geological information and insights on its parameterization. Landslides 2020. [Google Scholar] [CrossRef]
- Carrara, A.; Cardinali, M.; Detti, R.; Guzzetti, F.; Pasqui, V.; Reichenbach, P. GIS techniques and statistical models in evaluating landslide hazard. Earth Surf. Process. Landf. 1991, 16, 427–445. [Google Scholar] [CrossRef]
- Conforti, M.; Pascale, S.; Robustelli, G.; Sdao, F. Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment. Catena 2014, 113, 236–250. [Google Scholar] [CrossRef]
- Dietrich, W.E.; Reiss, R.; Hsu, M.; Montgomery, D.R. A process-based model for colluvial soil depth and shallow landsliding using digital elevation data. Hydrol. Process. 1995, 9, 383–400. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–170. [Google Scholar]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Pham, B.T.; Pradhan, B.; et al. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors (Switzerland) 2018, 18, 3777. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the Three Gorges Reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef]
- O’Brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Donald, F.; Glauber, R. Multicollinearity in Regression Analysis: The Problem Revisited. Rev. Econ. Stat. 1967, 49, 92–107. [Google Scholar]
- Belsley, D.A. A Guide to using the collinearity diagnostics. Comput. Sci. Econ. Manag. 1991, 4, 33–50. [Google Scholar]
- Bui, D.T.; Lofman, O.; Revhaug, I.; Dick, O. Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Nat. Hazards 2011, 59, 1413–1444. [Google Scholar] [CrossRef]
- Biswajeet, P.; Saied, P. Comparison between prediction capabilities of neural network and fuzzy logic techniques for L and slide susceptibility mapping. Disaster Adv. 2010, 3, 26–34. [Google Scholar]
- Kayri, M. Predictive abilities of Bayesian regularization and Levenberg-Marquardt algorithms in artificial neural networks: A comparative empirical study on social data. Math. Comput. Appl. 2016, 21, 20. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Foresee, F.D.; Hagan, M.T. Gauss-Newton approximation to Bayesian learning. In Proceedings of the International Joint Conference on Neural Networks, Houston, TX, USA, 12 June 1997; pp. 1930–1935. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Guzzetti, F.; Reichenbach, P.; Ardizzone, F.; Cardinali, M.; Galli, M. Estimating the quality of landslide susceptibility models. Geomorphology 2006, 81, 166–184. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Chung, C.J.; Fabbri, A.G. Predicting landslides for risk analysis—Spatial models tested by a cross-validation technique. Geomorphology 2008, 94, 438–452. [Google Scholar] [CrossRef]











| Type | Factor | Source | Scale (Resolution) | Organization |
|---|---|---|---|---|
| Landslide Inventory | Digital Ortho Images | 51 × 51 cm | NGII | |
| Morphological | Elevation | DEM | 1:5,000 | NGII |
| Slope | (5 × 5 m) | |||
| Aspect | ||||
| Curvature | ||||
| TRI | ||||
| SRR | ||||
| SEI | ||||
| Hydrological | TWI | DEM | 1:5,000 | NGII |
| STI | (5 × 5 m) | |||
| SPI | ||||
| Distance from stream | ||||
| Geological | Lithology | Forest Soil Map | 1:25,000 | KFS |
| Weathering | (5 × 5 m) | |||
| Land Cover | Soil effective depth | Forest Soil Map | 1:25,000 | KFS |
| Soil type | (5 × 5 m) | |||
| Soil texture | ||||
| Soil density | ||||
| Forest type | ||||
| Forest density | ||||
| Distance from road | ||||
| EL 1 | SL 2 | AS 3 | CU 4 | TRI | SRR | SEI | TWI | STI | SPI | LI 5 | SD 6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EL 1 | 1 | |||||||||||
| SL 2 | 0.31 | 1 | ||||||||||
| AS 3 | 0.12 | 0.10 | 1 | |||||||||
| CU 4 | 0.16 | 0.21 | 0.16 | 1 | ||||||||
| TRI | 0.76 | 0.80 | 0.13 | 0.10 | 1 | |||||||
| SRR | 0.06 | 0.07 | 0.07 | 0.18 | 0.11 | 1 | ||||||
| SEI | 0.04 | 0.06 | 0.06 | 0.33 | 0.00 | 0.01 | 1 | |||||
| TWI | −0.07 | −0.42 | 0.01 | 0.06 | −0.38 | −0.24 | 0.09 | 1 | ||||
| STI | 0.11 | 0.23 | 0.07 | −0.07 | 0.22 | 0.00 | 0.03 | 0.47 | 1 | |||
| SPI | −0.01 | −0.05 | 0.02 | −0.06 | −0.03 | 0.00 | 0.02 | 0.40 | 0.83 | 1 | ||
| LI 5 | −0.10 | −0.08 | −0.03 | 0.05 | −0.12 | −0.02 | 0.21 | 0.02 | −0.07 | −0.03 | 1 | |
| SD 6 | −0.27 | −0.11 | 0.02 | 0.06 | −0.23 | −0.05 | 0.18 | 0.24 | 0.12 | 0.11 | 0.64 | 1 |
| ST 7 | 0.34 | 0.11 | 0.3 | 0.15 | 0.25 | 0.02 | 0.09 | −0.15 | −0.12 | −0.09 | 0.29 | −0.22 |
| Number | Landslide Predisposing Factor | VIF | Tolerance |
|---|---|---|---|
| 1 | Elevation | 1.394 | 0.717 |
| 2 | Slope | 4.570 | 0.219 |
| 3 | Aspect | 1.256 | 0.796 |
| 4 | Curvature | 1.204 | 0.830 |
| 5 | SRR | 2.369 | 0.422 |
| 6 | SEI | 1.071 | 0.933 |
| 7 | TWI | 5.426 | 0.184 |
| 8 | STI | 2.396 | 0.417 |
| 9 | Lithology | 3.763 | 0.266 |
| 10 | Soil depth | 4.462 | 0.224 |
| 11 | Soil type | 2.878 | 0.347 |
| Measures | Hard-lims | Sat-lins | Rad-bas | ReLU | Log-sig | Tan-sig |
|---|---|---|---|---|---|---|
| True positive | 72 | 91 | 93 | 94 | 95 | 97 |
| True negative | 76 | 72 | 83 | 78 | 89 | 92 |
| False positive | 29 | 33 | 22 | 27 | 16 | 13 |
| False negative | 33 | 14 | 12 | 11 | 10 | 8 |
| Sensitivity (%) | 68.57 | 86.67 | 88.57 | 89.52 | 90.48 | 92.38 |
| Specificity (%) | 72.38 | 68.57 | 79.05 | 74.29 | 84.76 | 87.62 |
| Accuracy (%) | 70.48 | 77.62 | 83.81 | 81.90 | 87.62 | 90.00 |
| PPV (%) | 71.29 | 73.39 | 80.87 | 77.69 | 85.59 | 88.18 |
| NPV (%) | 69.72 | 83.72 | 87.37 | 87.64 | 89.90 | 92.00 |
| Kappa index | 0.410 | 0.552 | 0.676 | 0.638 | 0.752 | 0.800 |
| AUC | 0.837 | 0.863 | 0.936 | 0.930 | 0.964 | 0.968 |
| Measures | Hard-lims | Sat-lins | Rad-bas | ReLU | Log-sig | Tan-sig |
|---|---|---|---|---|---|---|
| True positive | 32 | 37 | 37 | 36 | 37 | 38 |
| True negative | 28 | 29 | 31 | 34 | 35 | 36 |
| False positive | 18 | 17 | 15 | 12 | 11 | 10 |
| False negative | 14 | 9 | 9 | 10 | 9 | 8 |
| Sensitivity (%) | 69.57 | 80.43 | 80.43 | 78.26 | 80.43 | 82.61 |
| Specificity (%) | 60.87 | 63.04 | 67.39 | 73.91 | 76.09 | 78.26 |
| Accuracy (%) | 65.21 | 71.74 | 73.91 | 76.09 | 78.26 | 80.43 |
| PPV (%) | 64.00 | 68.52 | 71.15 | 75.00 | 77.08 | 79.17 |
| NPV (%) | 30.55 | 76.32 | 77.50 | 77.27 | 79.55 | 81.82 |
| Kappa index | 0.304 | 0.435 | 0.478 | 0.522 | 0.565 | 0.609 |
| AUC | 0.781 | 0.815 | 0.821 | 0.843 | 0.877 | 0.879 |
| Ranking | p-value (α = 0.05) | χ2 (Chi-square) | |||||
|---|---|---|---|---|---|---|---|
| Hard-lims | Sat-lins | Rad-bas | ReLU | Log-sig | Tan-sig | ||
| 3.61 | 3.73 | 3.55 | 3.42 | 3.06 | 3.63 | 1.78 × 10−4 | 24.445 |
| Hard-lims | Sat-lins | Rad-bas | ReLU | Log-sig | Tan-sig | |
|---|---|---|---|---|---|---|
| Very High | 0 | 0 | 16.6 | 5.3 | 27.2 | 35.8 |
| High | 0 | 0 | 17.2 | 20.5 | 21.9 | 22.5 |
| Moderate | 36.4 | 50.3 | 35.1 | 37.8 | 26.2 | 31.1 |
| Low | 32.5 | 37.1 | 17.2 | 22.5 | 15.2 | 4.6 |
| Very Low | 31.1 | 12.6 | 13.9 | 13.9 | 12.6 | 6.0 |
| Total | 100 | 100 | 100 | 100 | 100 | 100 |
| Classes | Hard-lims | Sat-lins | Rad-bas | ReLU | Log-sig | Tan-sig |
|---|---|---|---|---|---|---|
| Very High | - | 0.00 | 2.76 | 4.27 | 3.19 | 4.38 |
| High | - | 0.00 | 1.24 | 2.08 | 1.46 | 1.43 |
| Moderate | 2.86 | 3.61 | 1.53 | 1.65 | 1.20 | 1.40 |
| Low | 0.90 | 1.06 | 0.54 | 0.64 | 0.53 | 0.16 |
| Very Low | 0.61 | 0.26 | 0.55 | 0.45 | 0.49 | 0.24 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.-H.; Kim, Y.-T.; Lee, S.-R. Shallow Landslide Susceptibility Models Based on Artificial Neural Networks Considering the Factor Selection Method and Various Non-Linear Activation Functions. Remote Sens. 2020, 12, 1194. https://doi.org/10.3390/rs12071194
Lee D-H, Kim Y-T, Lee S-R. Shallow Landslide Susceptibility Models Based on Artificial Neural Networks Considering the Factor Selection Method and Various Non-Linear Activation Functions. Remote Sensing. 2020; 12(7):1194. https://doi.org/10.3390/rs12071194
Chicago/Turabian StyleLee, Deuk-Hwan, Yun-Tae Kim, and Seung-Rae Lee. 2020. "Shallow Landslide Susceptibility Models Based on Artificial Neural Networks Considering the Factor Selection Method and Various Non-Linear Activation Functions" Remote Sensing 12, no. 7: 1194. https://doi.org/10.3390/rs12071194
APA StyleLee, D.-H., Kim, Y.-T., & Lee, S.-R. (2020). Shallow Landslide Susceptibility Models Based on Artificial Neural Networks Considering the Factor Selection Method and Various Non-Linear Activation Functions. Remote Sensing, 12(7), 1194. https://doi.org/10.3390/rs12071194