Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR



Abstract
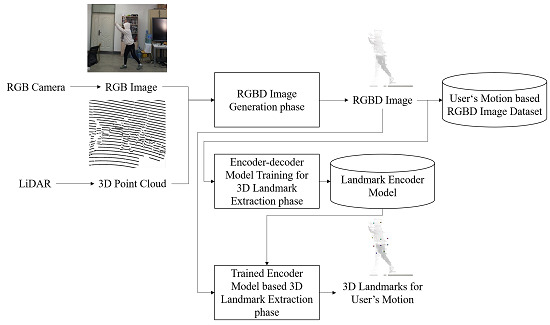
1. Introduction
- In existing deep learning research, manual supervision is needed to extract 3D landmarks. By using 3D point clouds and an RGB-based encoder–decoder model, 3D landmarks can be extracted automatically without manual supervision. These 3D landmarks can be utilized for modeling user’s motions without manual supervision.
- When observing the user’s motion through 2D landmarks, it is difficult to show the motion difference in forward and backward motions; 3D landmarks can express various user’s motions. They can evaluate the user’s motion by further reflecting the user’s body.
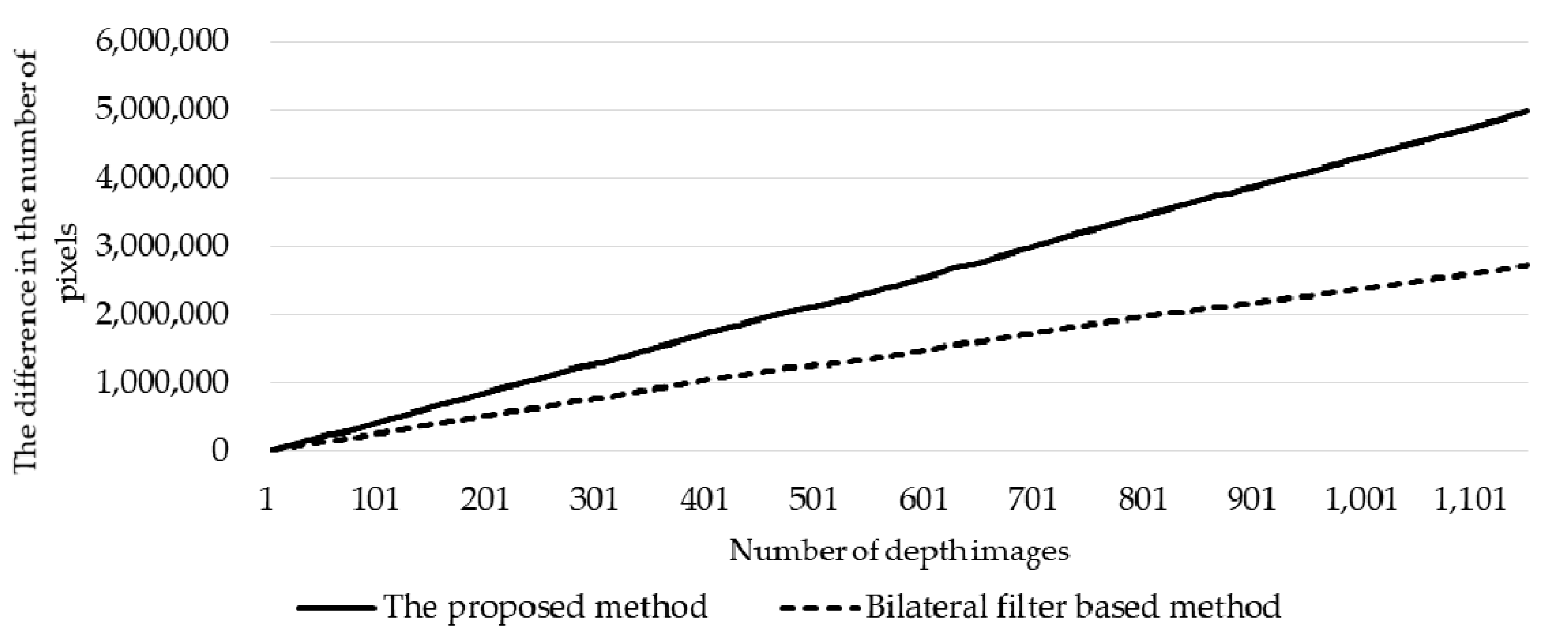
- The up-sampling method using bilateral filtering produces a depth image dependent on the number of points in a 3D point cloud of a user’s motion. However, the proposed method reduces the dependency on the number of points of a 3D point cloud. Hence, the depth image better represents the boundary of the user’s motion. The depth image can be generated by removing the disparities of a 3D point cloud.
2. Related Works
2.1. Landmark Extraction Using Supervised Learning
2.2. Landmark Extraction Using Unsupervised Learning
2.3. Depth Image Generation Using Up-Sampling
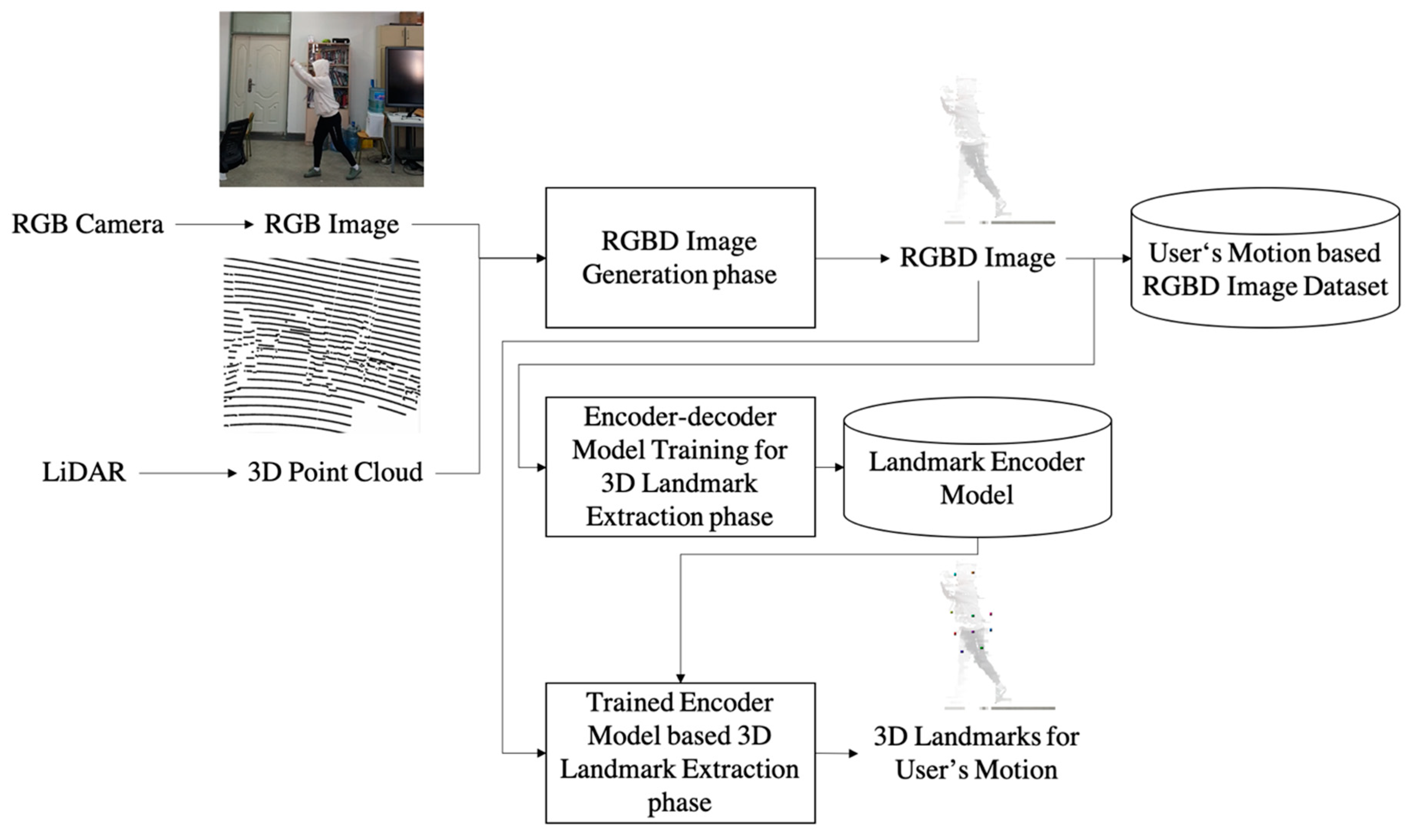
3. Encoder–Decoder-Based 3D Landmark Automatic Extraction System using 3D Point Clouds and RGB Images
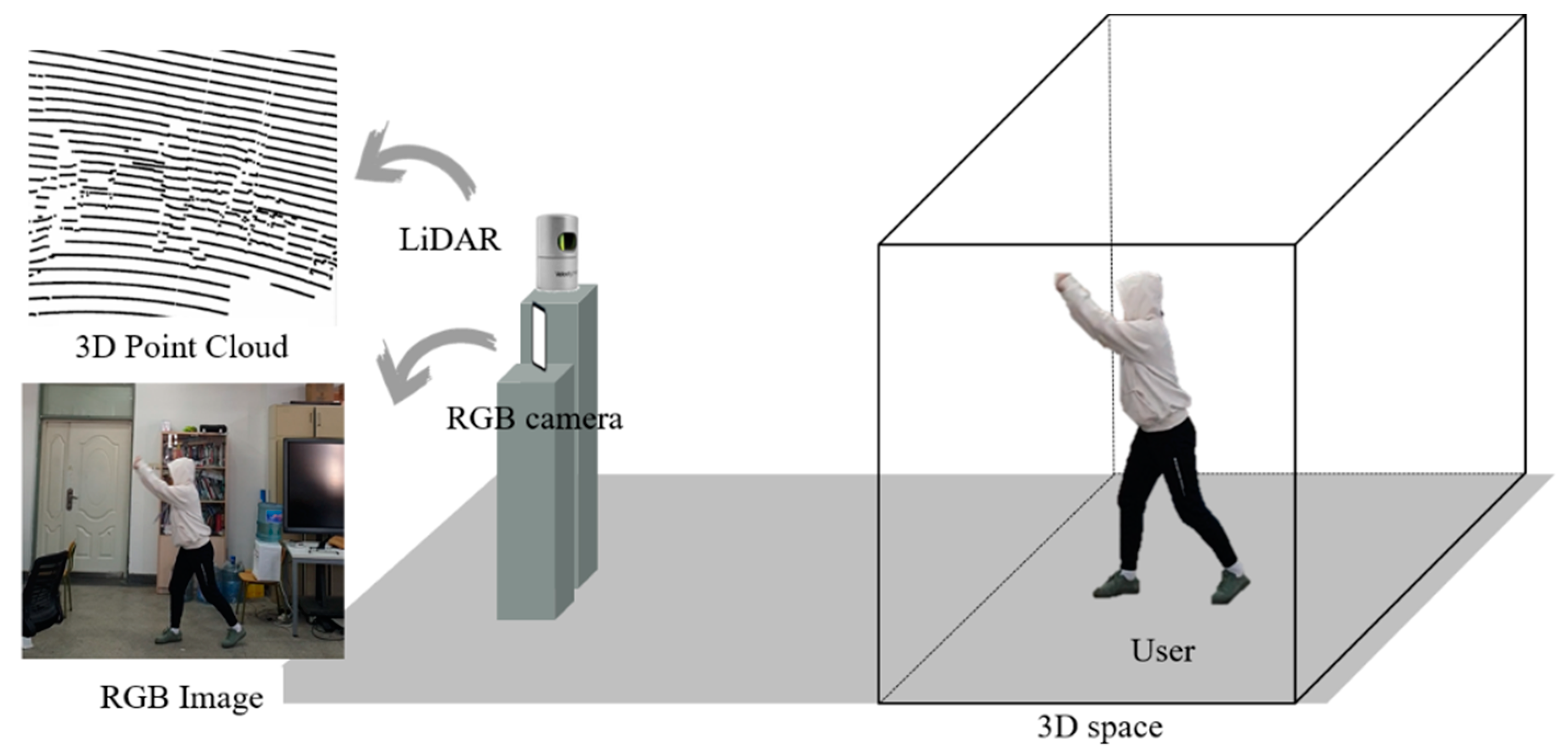
3.1. Overview
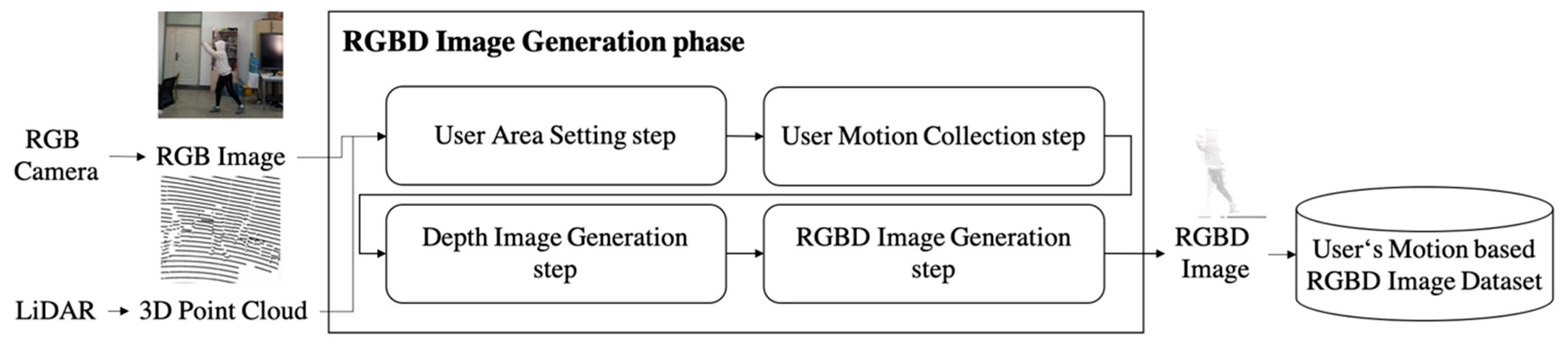
3.2. RGBD Image Generation Phase
| Algorithm 1: Pseudocode for depth image generation |
| FUNCTION GenerateDepthImage with , , BEGIN SET ←CALL InitializeVoxel SET ←CALL AddPointsInVoxel() SET ←CALL InitializeDepthImage FOR y←0 to height of FOR x←0 to width of SET END END SET ←CALL ChangeToGray() SET ←CALL ChangeToGray() SET ←CALL InitializeDifferenceImage FOR y←0 to height of FOR x←0 to width of IF -> THEN SET ←255 ELSE SET ←0 END END END SET ←CALL InitializeDepthImage FOR y←0 to height of FOR x←0 to width of IF is Equal 0 and is Equal 255 THEN SET DepthValueList←CALL FindKnownDepthPixel SET TotalDistance←CALL CalculateTotalDistance(DepthValueList) FOR n←0 to N SET ΝthDistance←CALL CalculateNthDistance() SET ←ADD END END END SET ←CALL AdddDepthImage(,) RETURN END |
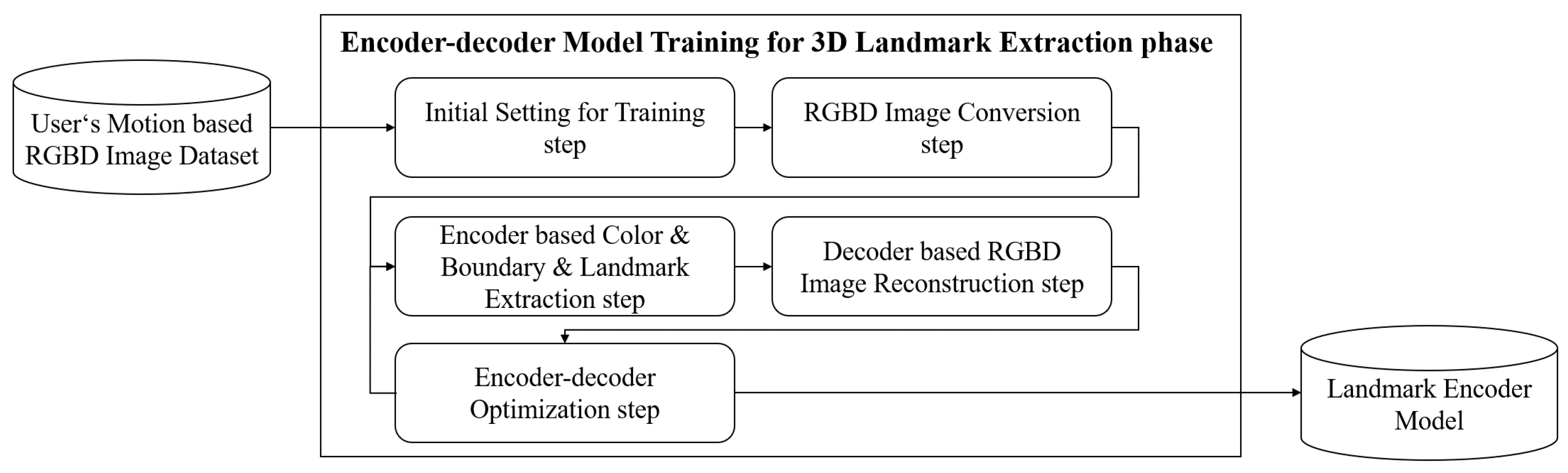
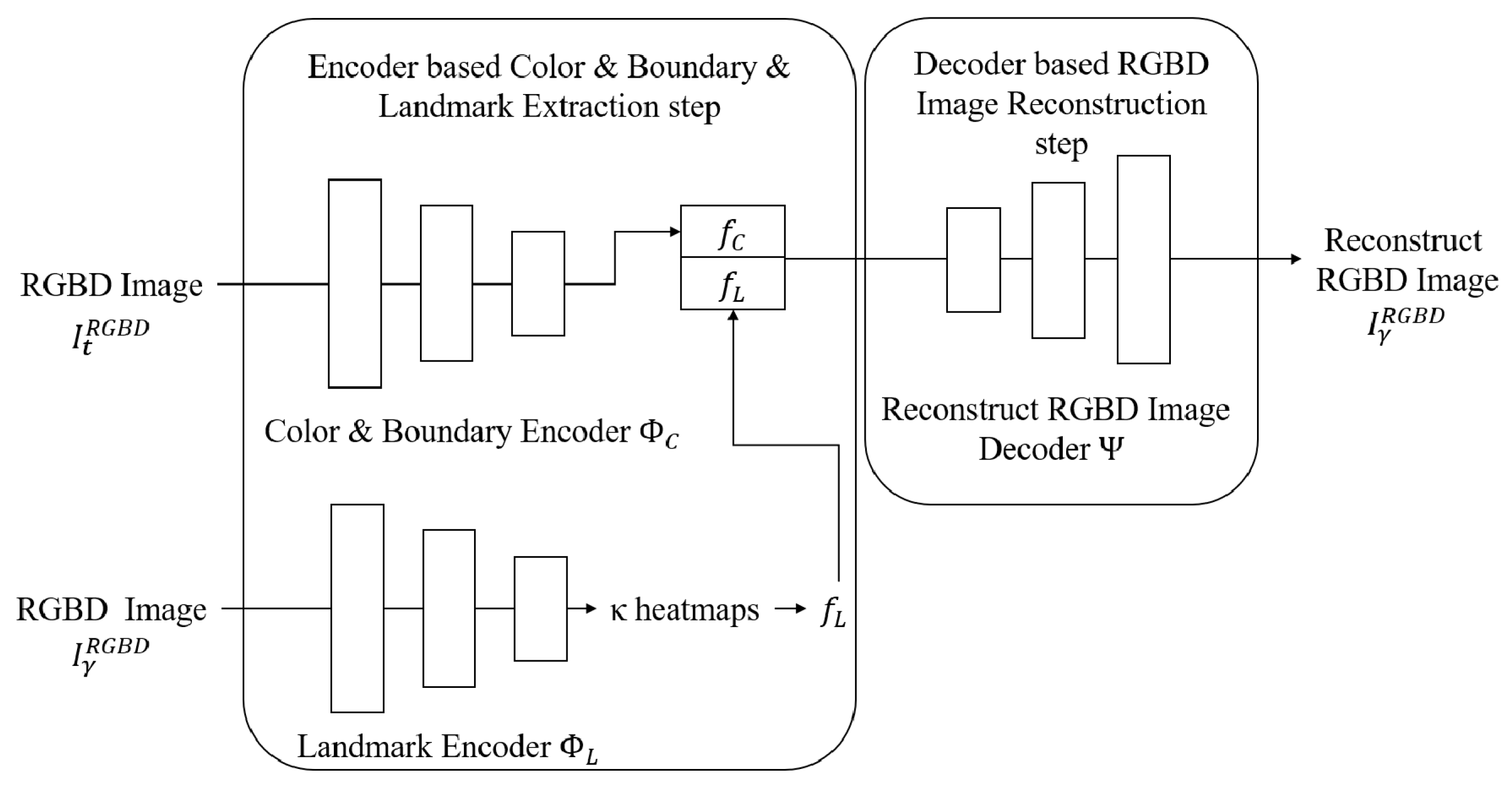
3.3. Encoder–Decoder Model Training for 3D Landmark Extraction Phase
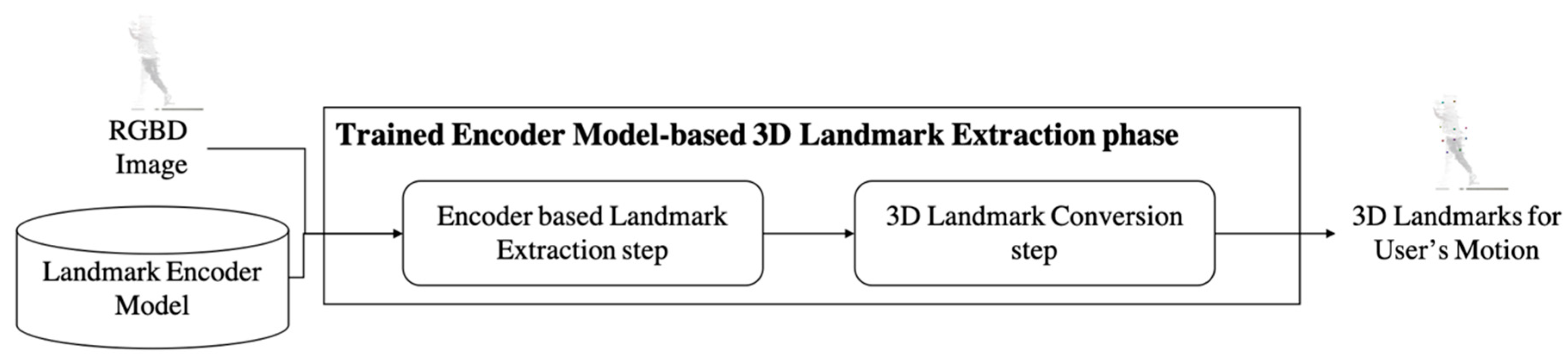
3.4. Trained Encoder Model-Based 3D Landmark Extraction Phase
4. Experiments
4.1. Experimental Environment and 3D Point Cloud and RGB Image Acquisition Results
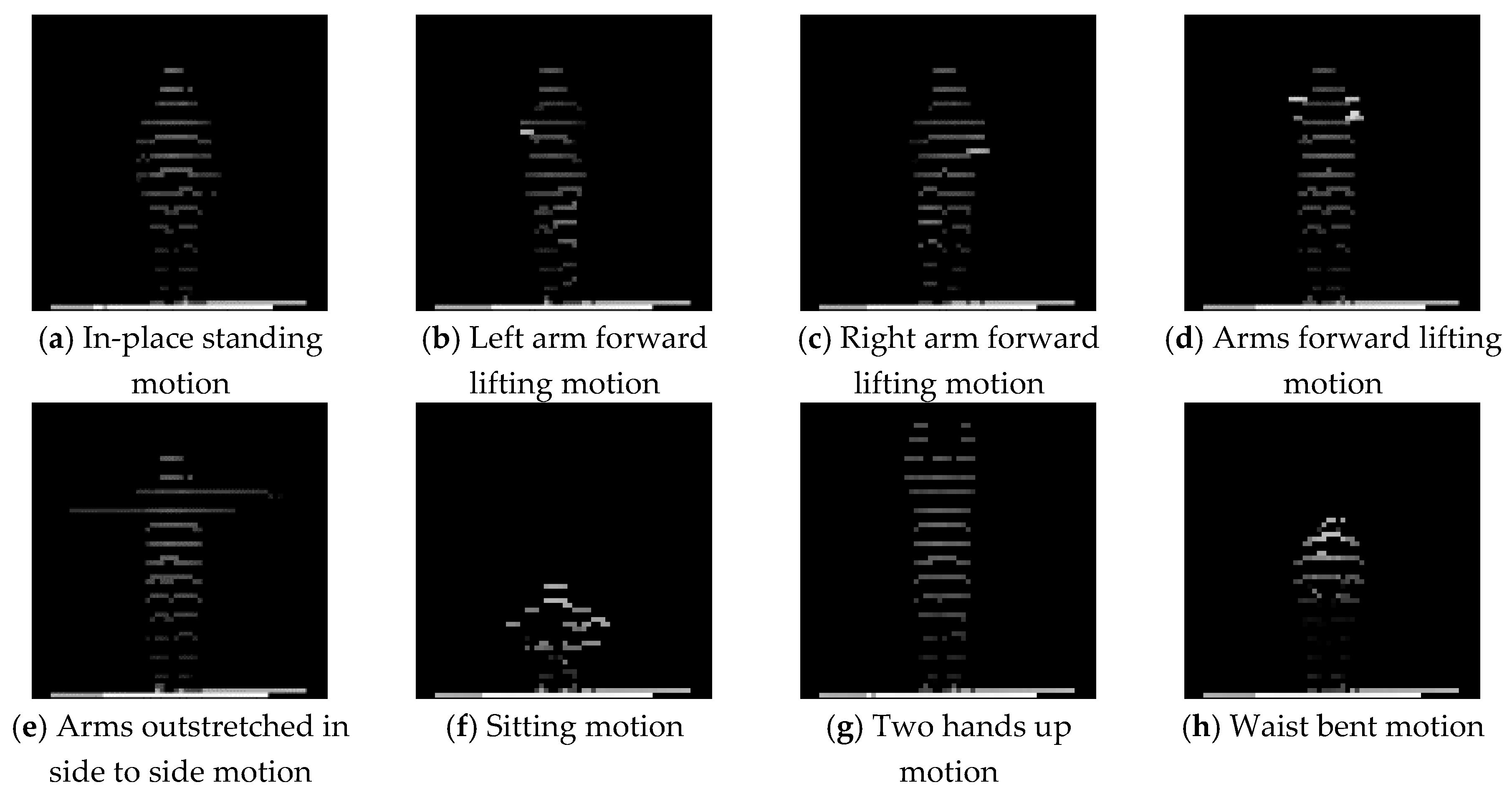
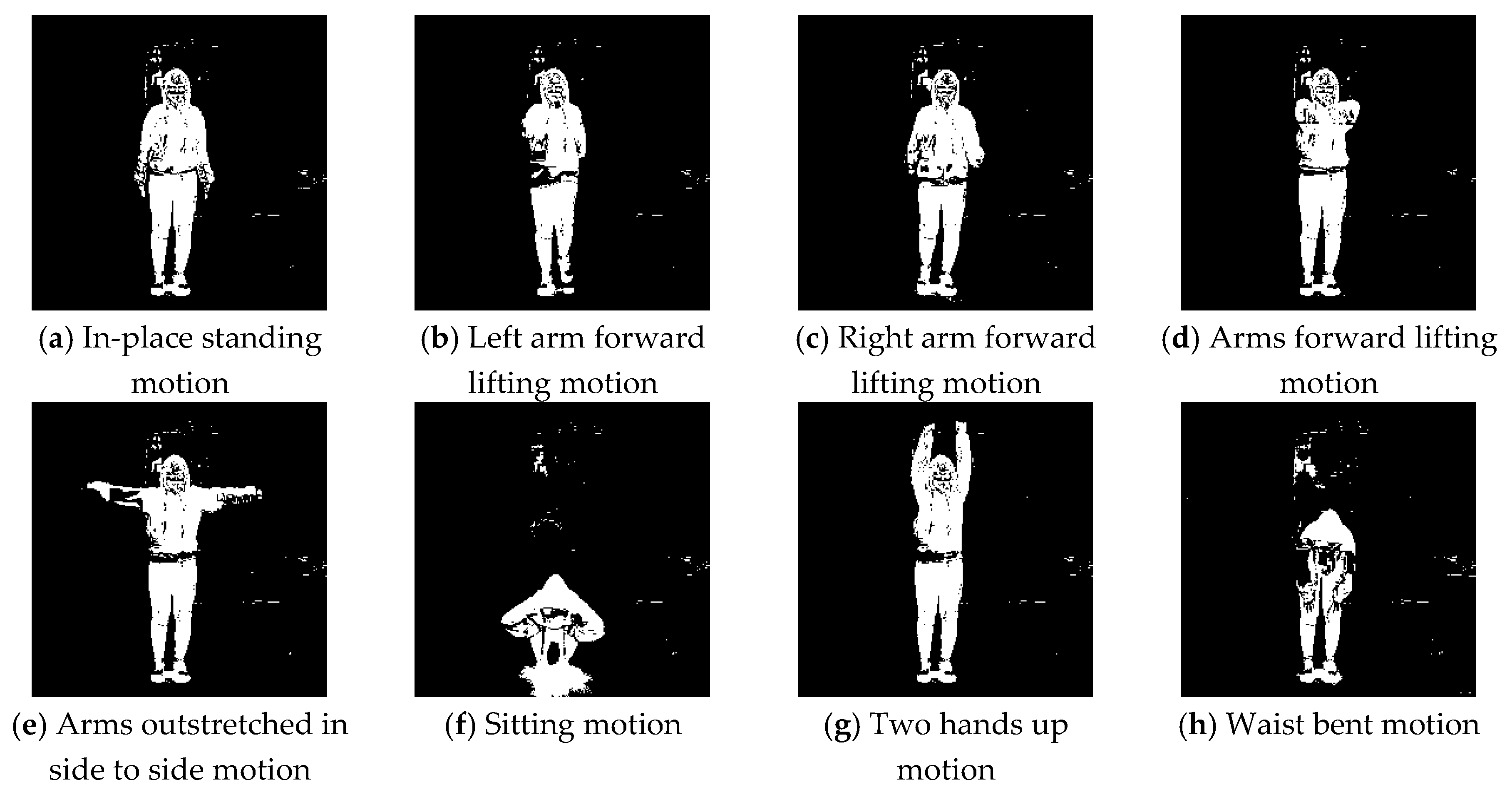
4.2. RGBD Image Generation Phase Results
4.3. Encoder–Decoder Model Training for 3D Landmark Extraction Phase Results
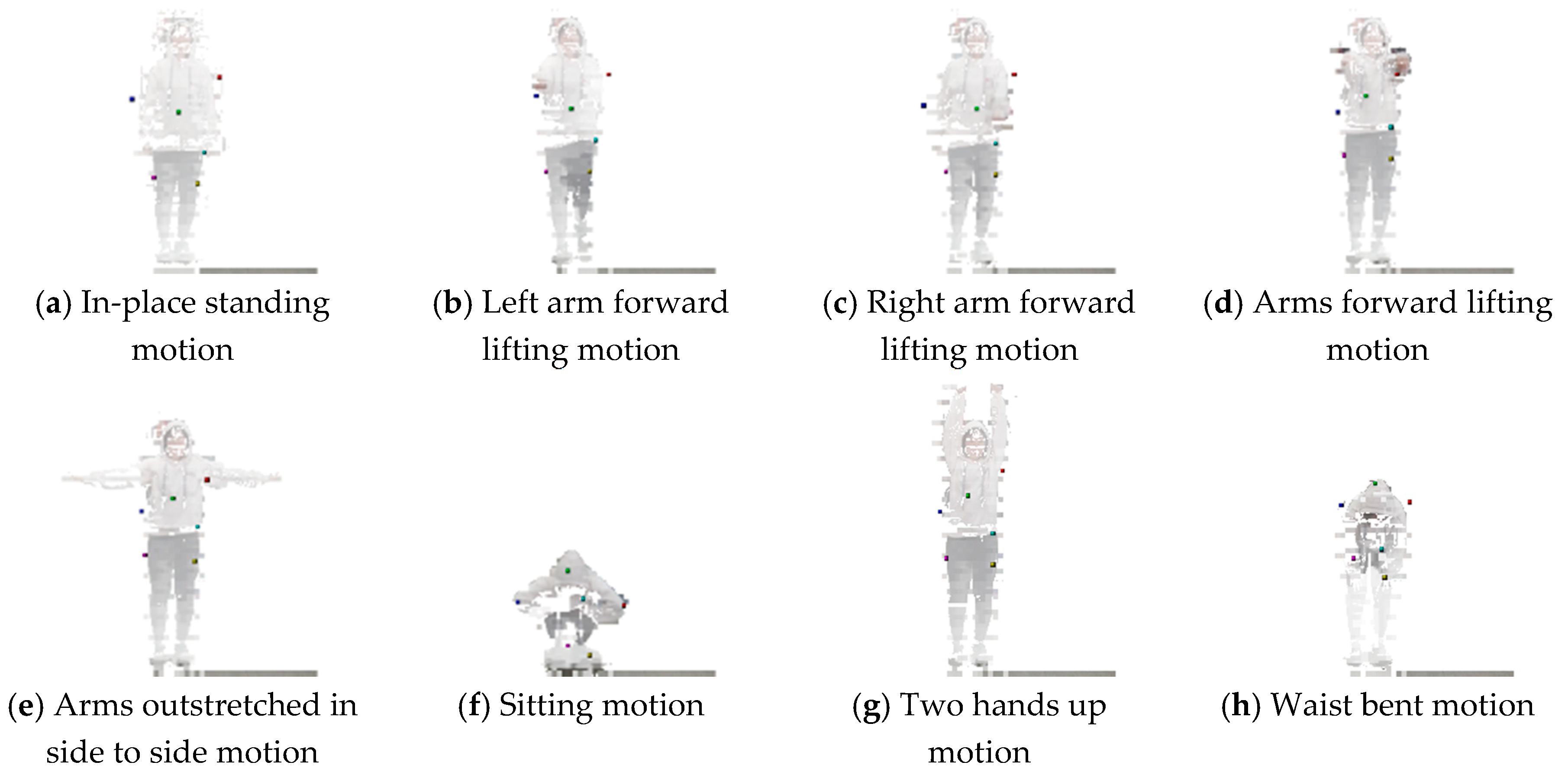
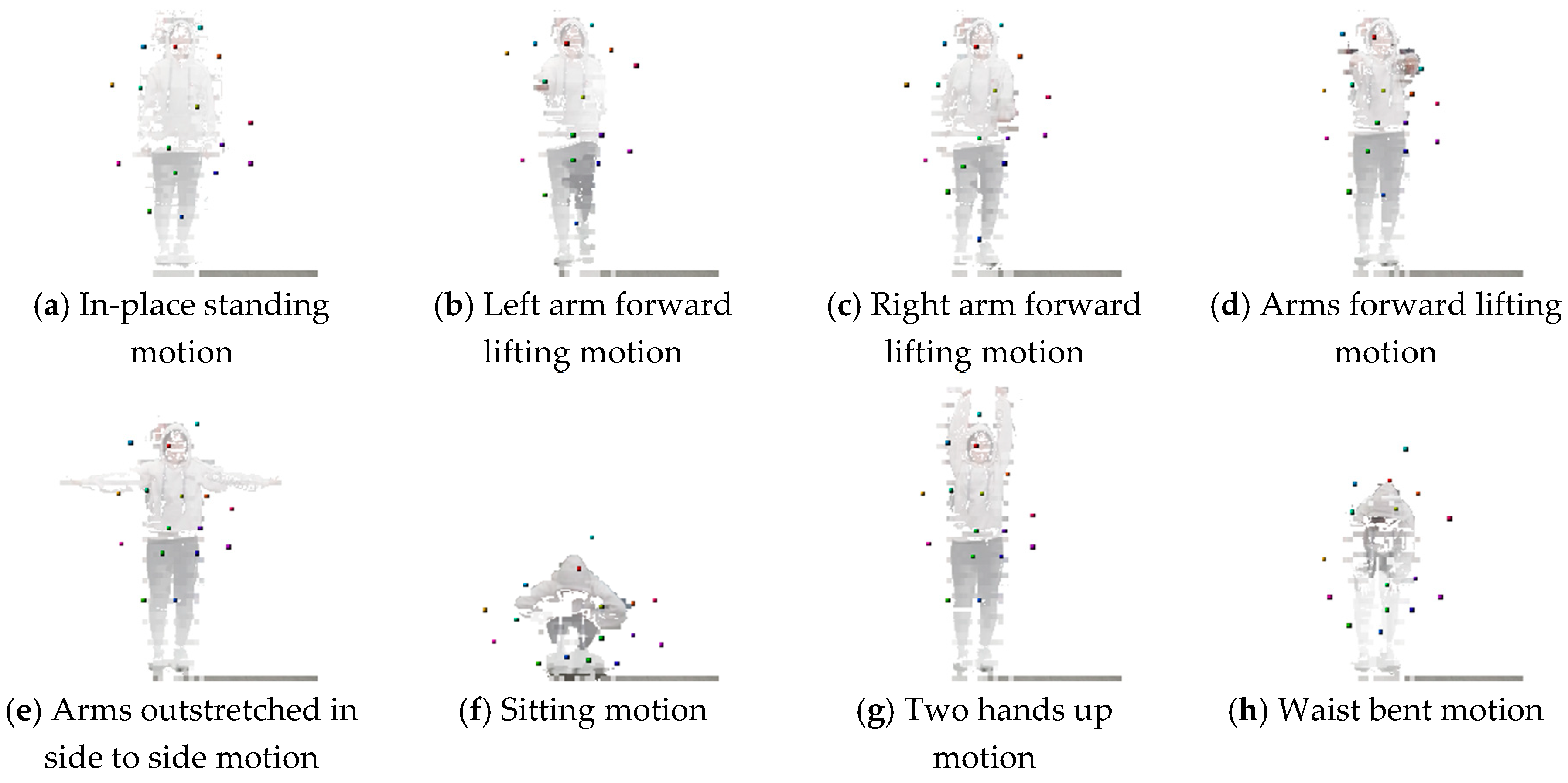
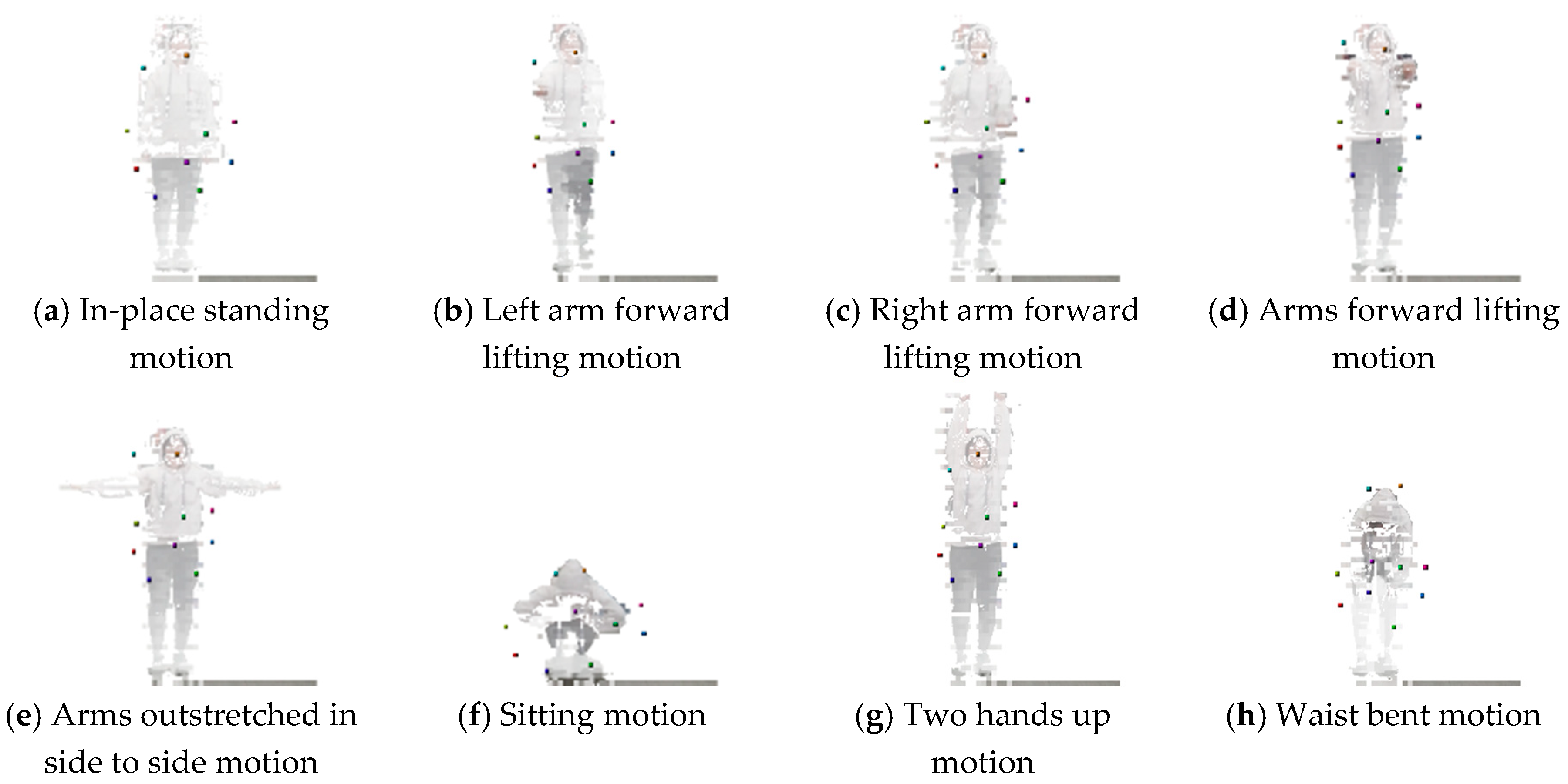
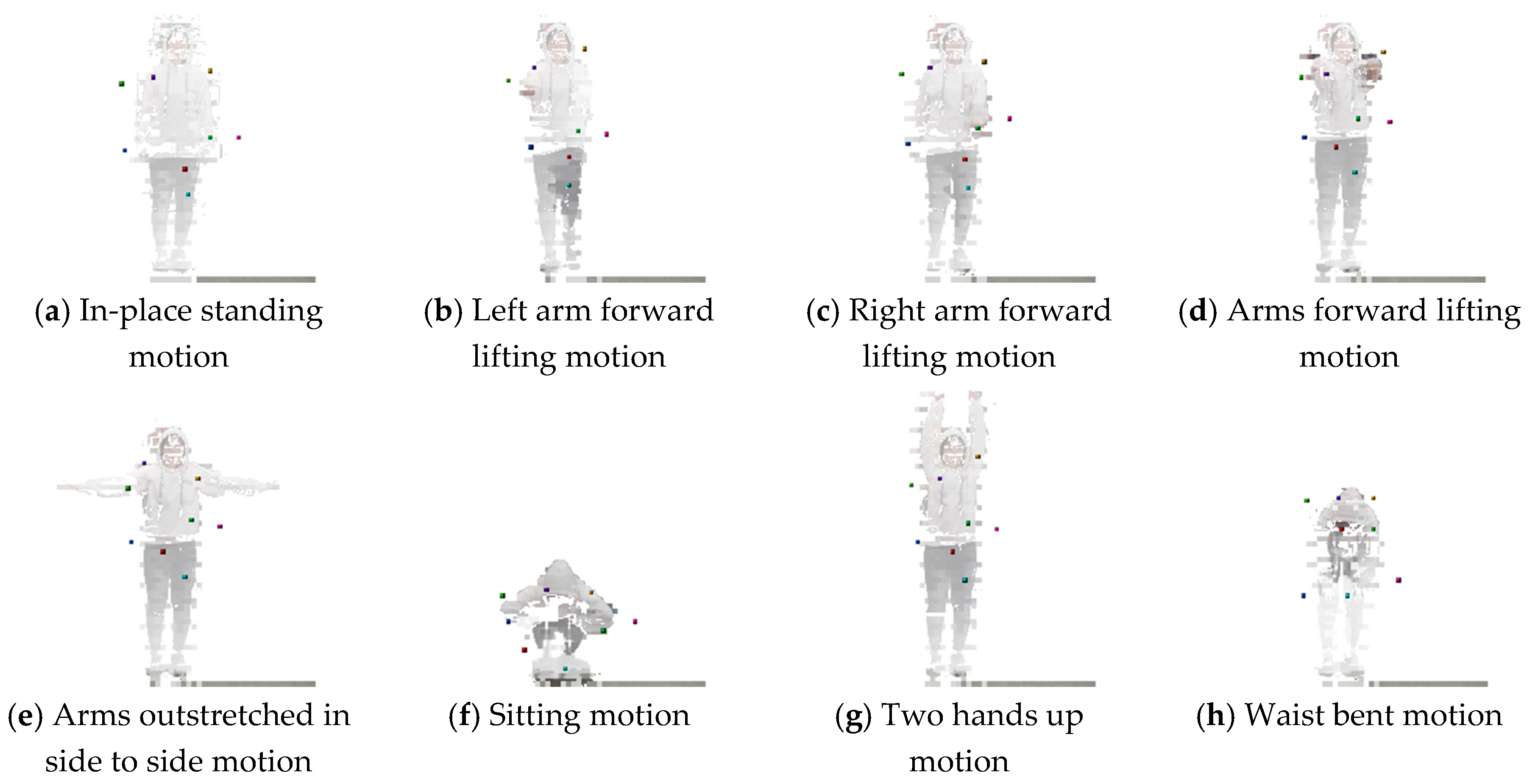
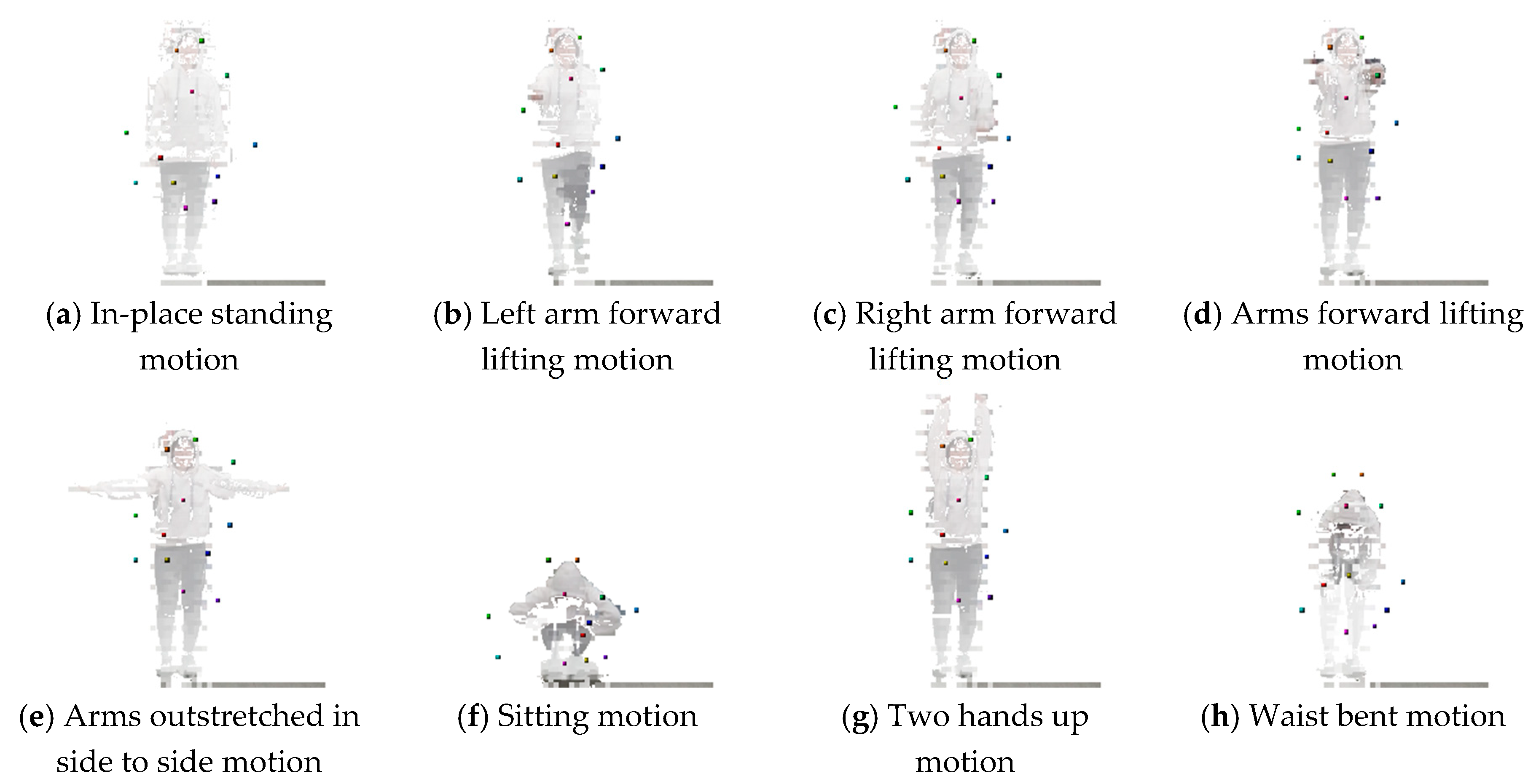
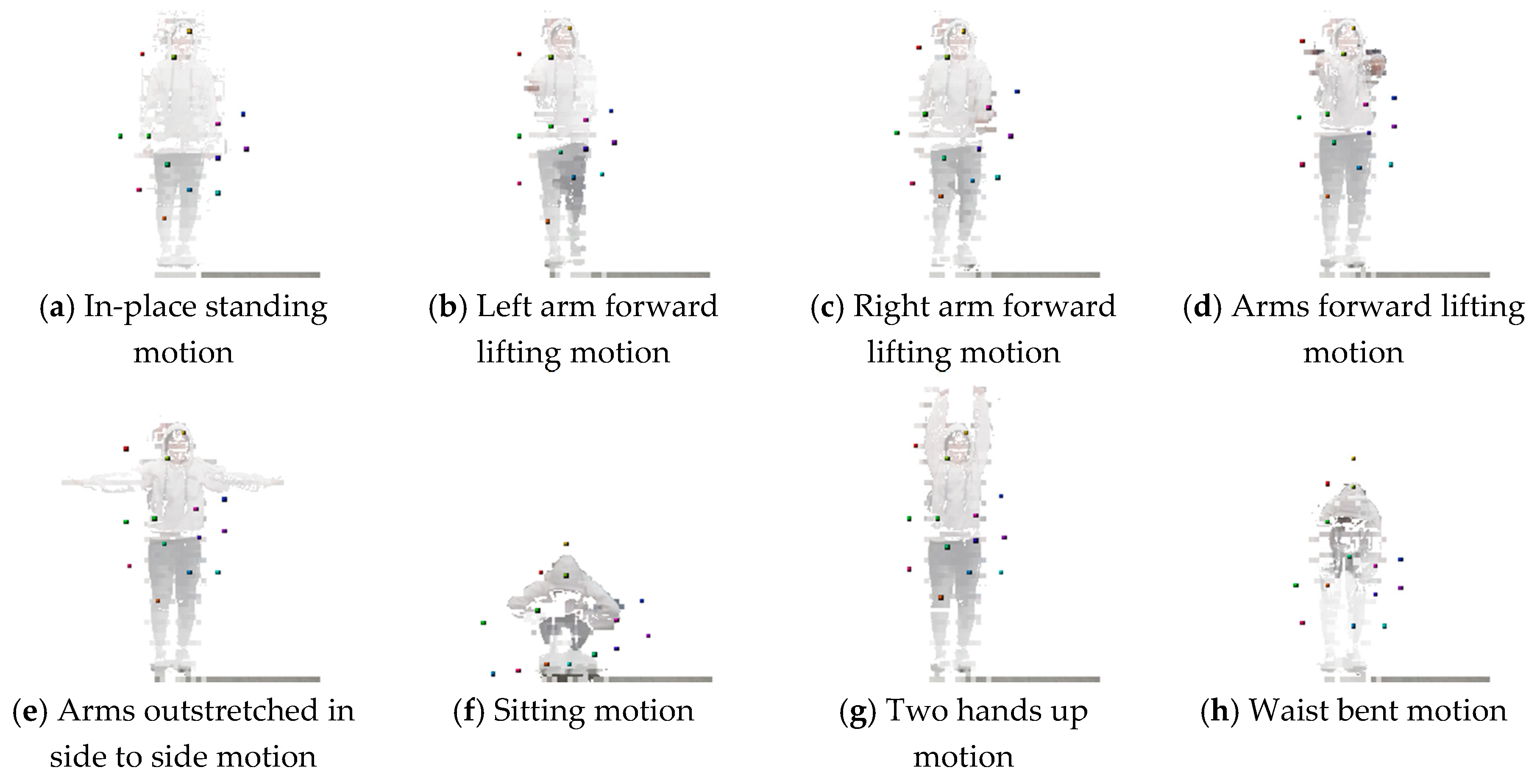
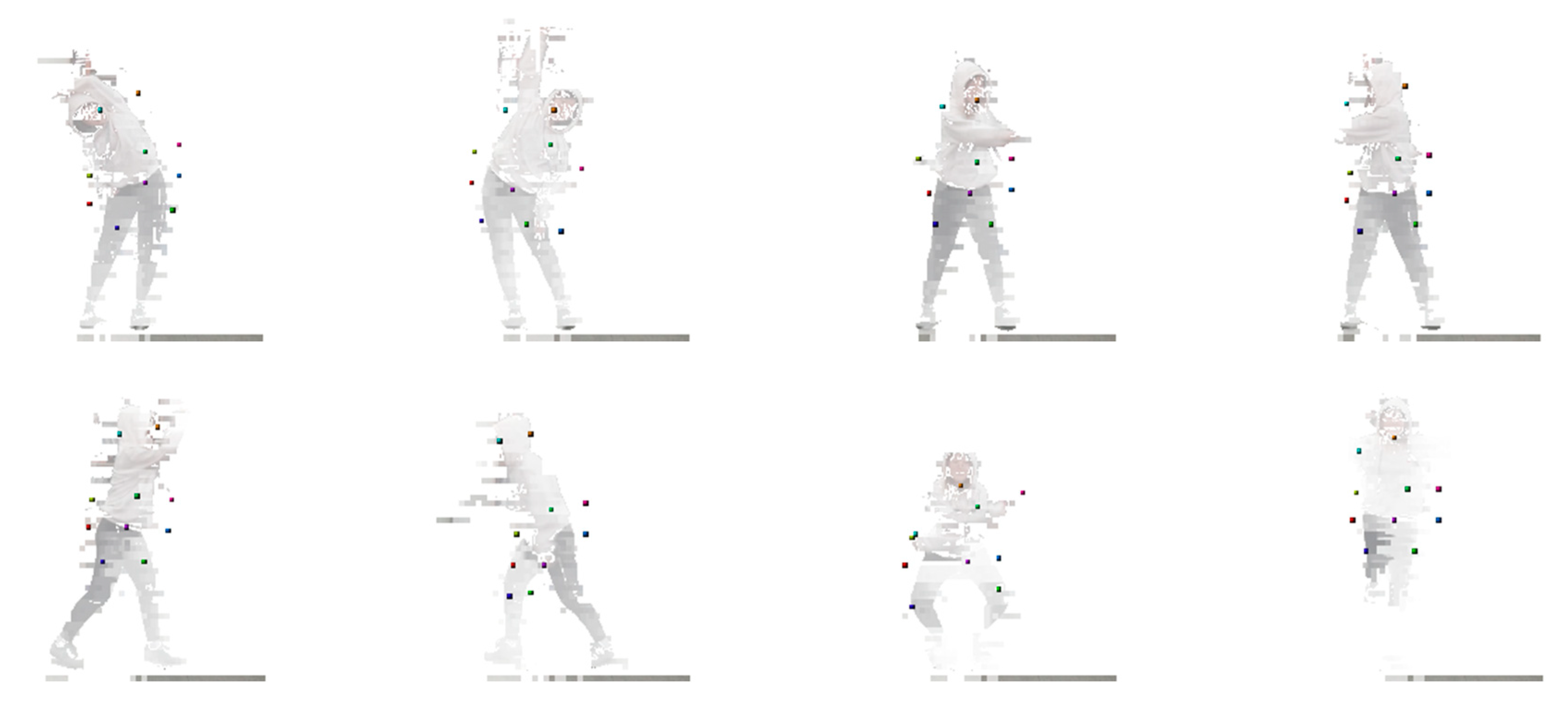
4.4. Trained Encoder Model-based 3D Landmark Extraction Phase Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A



Appendix B


References
- Song, W.; Zou, S.; Tian, Y.; Sun, S.; Fong, S.; Cho, K.; Qiu, L. A CPU-GPU Hybrid System of Environment Perception and 3D Terrain Reconstruction for Unmanned Ground Vehicle. J. Inf. Process. Syst. 2018, 14, 1445–1456. [Google Scholar]
- Kwak, J.; Sung, Y. Autonomous UAV Flight Control for GPS-Based Navigation. IEEE Access 2018, 6, 37947–37955. [Google Scholar] [CrossRef]
- Kwak, J.; Sung, Y. End-to-End Controls using K-Means Algorithm for 360-Degree Video Control Method on Camera-Equipped Autonomous Micro Aerial Vehicles. Appl. Sci. 2019, 9, 4431. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Medhane, D.V.; Han, T.; Hossain, M.S.; Muhammad, G. Enforcing Position-based Confidentiality with Machine Learning Paradigm through Mobile Edge Computing in Real-time Industrial Informatics. IEEE Trans. Ind. Inform. 2019, 15, 4189–4196. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Medhane, D.V.; Bian, G.B.; Ghoneim, A.; Alrashoud, M.; Hossain, M.S. Energy-Aware Green Adversary Model for Cyber Physical Security in Industrial System. IEEE Trans. Ind. Inform. 2020, 16, 3322–3329. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Hosseinabadi, A.A.R.; Sadeghilalimi, M.; Zhang, W. Energy Consumption in Point-Coverage Wireless Sensor Networks via Bat Algorithm. IEEE Access 2019, 7, 180258–180269. [Google Scholar] [CrossRef]
- Zhang, F.; Wu, T.; Pan, J.; Ding, G.; Li, Z. Human Motion Recognition based on SVM in VR Art Media Interaction Environment. Hum.-Cent. Comput. Inf. Sci. 2019, 9, 1–15. [Google Scholar] [CrossRef]
- Yao, Z.; Liu, Y.; Ji, Z.; Sun, Q.; Lasang, P.; Shen, S. 3D Driver Pose Estimation Based on Joint 2d-3d Network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Kang, N.; Bai, J.; Pan, J.; Qin, H. Interactive Animation Generation of Virtual Characters using Single RGB-D Camera. Vis. Comput. 2019, 35, 849–860. [Google Scholar] [CrossRef]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-Supervised Learning of 3D Human Pose using Multi-view Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, X.; Lin, K.; Liu, W.; Qian, C. Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Siarohin, A.; Lathuiliere, S.; Tulyakov, S.; Ricci, E.; Sebe, N. Animating Arbitrary Objects via Deep Motion Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, Y.; Guo, Y.; Jin, Y.; Luo, Y. Unsupervised Discovery of Object Landmarks as Structural Representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Jakab, T.; Gupta, A.; Bilen, H.; Vedaldi, A. Unsupervised Learning of Object Landmarks through Conditional Image Generation. In Proceedings of the Thirty-second Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Scholosser, J.; Chow, C.K.; Kira, Z. Fusing LIDAR and Images for Pedestrian Detection using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation. In Proceedings of theh International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Courtois, H.; Aouf, N. Fusion of Stereo and Lidar Data for Dense Depth Map Computation. In Proceedings of the 2017 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED UAS), Linköping, Sweden, 3–5 October 2017. [Google Scholar]
- Premebida, C.; Carreira, J.; Batista, J.; Nunes, U.J. Pedestrian Detection Combining RGB and Dense LiDAR Data. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2014), Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end Recovery of Human Shape and Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand PointNet: 3D Hand Pose Estimation using Point Sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Kosecka, J. End-to-end Learning of Keypoint Detector and Descriptor for Pose Invariant 3D Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Ernst, J.; Kosecka, J. Learning Local RGB-to-CAD Correspondences for Object Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Park, Y.; Yun, S.; Won, C.S.; Cho, K.; Um, K.; Sim, S. Calibration between Color Camera and 3D LIDAR Instruments with a Polygonal Planar Board. Sensors 2014, 14, 5333–5353. [Google Scholar] [CrossRef] [PubMed]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RGBD Image | RGB Image | ||||||
|---|---|---|---|---|---|---|---|
| 6 | 8 | 10 | 12 | 14 | 16 | 10 | |
| Align loss | 26.9212 | 34.5343 | 34.0486 | 44.0922 | 46.0914 | 64.3239 | 18.3621 |
| Decay loss | 0.5425 | 0.5493 | 0.5576 | 0.5671 | 0.5685 | 0.5761 | 0.5493 |
| Diversity loss | 0.0283 | 0.0927 | 0.1050 | 0.2134 | 0.2625 | 0.4270 | 0.0973 |
| RGBD Image | RGB Image | ||||||
|---|---|---|---|---|---|---|---|
| 6 | 8 | 10 | 12 | 14 | 16 | 10 | |
| Number of landmarks in body part | 6 | 8 | 8 | 9 | 9 | 11 | 3 |
| Number of landmarks in non-body part | - | - | 2 | 3 | 5 | 5 | 7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwak, J.; Sung, Y. Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR. Remote Sens. 2020, 12, 1142. https://doi.org/10.3390/rs12071142
Kwak J, Sung Y. Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR. Remote Sensing. 2020; 12(7):1142. https://doi.org/10.3390/rs12071142
Chicago/Turabian StyleKwak, Jeonghoon, and Yunsick Sung. 2020. "Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR" Remote Sensing 12, no. 7: 1142. https://doi.org/10.3390/rs12071142
APA StyleKwak, J., & Sung, Y. (2020). Automatic 3D Landmark Extraction System Based on an Encoder–Decoder Using Fusion of Vision and LiDAR. Remote Sensing, 12(7), 1142. https://doi.org/10.3390/rs12071142