1. Introduction
In order to protect ecosystems, it is necessary to have strong environmental monitoring and reliable 3D information in an agricultural context [
1]. The issue of acquiring noiseless and complete 3D point clouds is of paramount importance to support a wide variety of applications such as the 3D reconstruction of buildings [
2], precision agriculture, road models and environmental research, which are central in the fields of remote sensing and computer vision. Acquiring 3D data about buildings or monuments in a city can be utilized for the analysis, description and study of 3D city modelling [
3]. In fact, 3D information enables us to execute morphological measurements, quantitative analysis, and annotation of information. Moreover, we can generate decay maps, which allow easy access and research on remote sites and constructions. Generating 3D information for crops and plants can also contribute to plant growth and harvest yield quantification for agriculture and production. This is especially relevant to measure the effects of climate change on different land types [
4]. The main aim of this work is to create high quality 3D point clouds scanned with one snapshot from real objects for the purpose of having 3D models of buildings, plants or any other real objects for remote sensing and photogrammetry.
A 3D point cloud can be obtained from various methods. Many existing methodologies for reconstruction of 3D models are based on either Structure from Motion (SfM) or Dense Multi-View 3D Reconstruction (DMVR). However, these methods need multiple captures from different angles and significant user interaction when using an ordinary camera. For this reason, recent research has focused on the development of new strategies using less costly devices while continuing to minimize complexity [
5].
Given the current state-of-the-art, one very effective solution is to create 3D models from a single image. A single conventional 2D image has limited information about the 3D nature of objects or scenes, so accurate estimation of 3D geometry from a single image is difficult to achieve [
6]. Nevertheless, light field images, with the ability to capture rich 3D information with a single capture, offer an effective solution to this problem. The introduction of light field cameras (a type of plenoptic camera) has helped to reveal new solutions and insights into a wide variety of applications, including traditional computer vision, image processing problems and remote sensing research. Light field cameras capture rich information about the intensity, colour and direction of light, and can be used to estimate a depth map or 3D point cloud from a single captured frame. Light field camera technology has the potential to create 3D point cloud reconstructions in circumstances where standard multi-capture techniques can fail, such as dynamic scenes or objects with complicated material appearance. The unique features of light field images—e.g., the capture of light rays from multiple directions—provide the ability to reconstruct 2D images at different focal planes. This feature can also aid in reconstruction of scene depth maps [
5]. A light field image can have multiple representations, but two LF representation formats are more common for computer vision and image processing problems; the lenslet format and 4D LF format. In the work we report here, we used the 4D LF format as described below.
For the reconstruction of a 3D point cloud of an object, we developed a new method which is based on the transformation of the point–plane correspondences. The input of our system is a 4D LF image which can be captured by light field cameras, such as the Lytro Illum [
7] or created synthetically. The depth map of the LF can be produced by software bundled with the Lytro camera or similar third-party software. Our method is agnostic to the source of the depth map data.
Estimating a densely sampled depth map is essential for creating a 3D point cloud, but the initial depth map provided by commercial LF cameras such as the Lytro Illum is not accurate enough for 3D reconstruction.
Figure 1 shows the production of a 3D point cloud from an LF image, based on the proposed method. We devised an approach to enhance the depth map by using an initial LF image as an input image to substantially improve the quality of the recovered depth map.
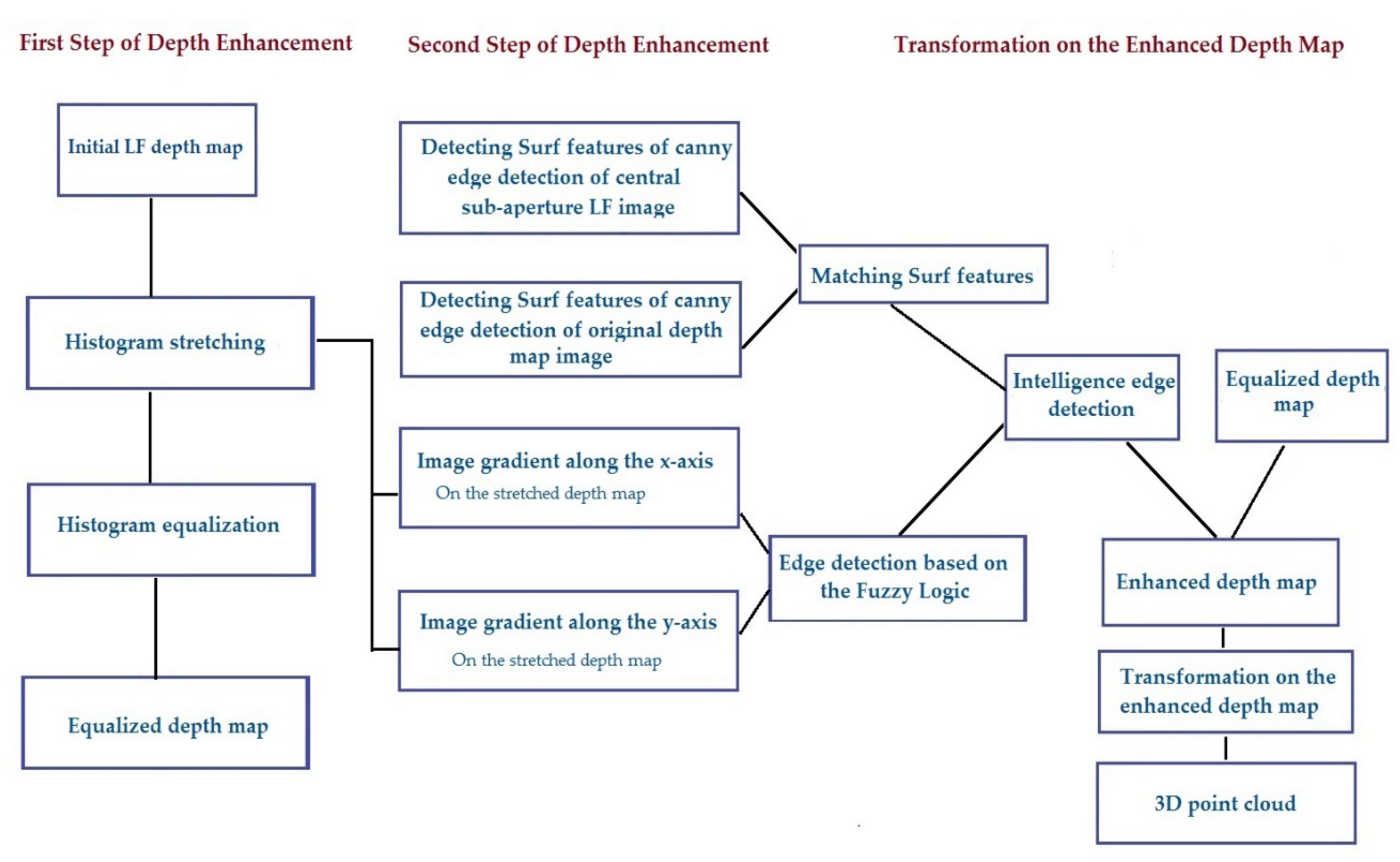
Figure 2 shows the detailed block diagram of our proposed method. Specifically, our approach applied histogram equalization and histogram stretching to the initial depth map. We then calculated the gradient of the stretched depth map along the
x and
y axes separately by comparing the intensity of neighbouring pixels and then, by using a fuzzy logic method, we computationally defined which pixels belonged to the edge of a region of uniform intensity. This kind of edge analysis can improve depth map estimation by leveraging pixel-wise classification, based on their colour mapping properties. In parallel, we detected and extracted Speeded-Up Robust Features (SURF) from Canny edge detection performed on the sub-aperture images of the LF and the original depth map. We then matched features between the edges of the original depth map and the sub-aperture image, and we then added the matched pixels to the edges determined by fuzzy logic analysis. For obtaining the final enhanced depth map, we combined this edge with the equalized depth map by considering the level of the reference image (depth map). We finally transformed the point-plane correspondences to acquire a 3D point cloud.
This proposed non-linear method obtains edges of a depth map and sub-aperture images with greater accuracy than what can be achieved by simply adding linearly the ordinary edge detection information provided by Canny or Sobel filters that alone carry considerably greater noise. Hence, this innovation in the enhancement of the recovered depth map from an LF image is a key contribution of the work we report here.
Our main contributions are:
We acquire a 3D point cloud based on a single image from a light field camera, which provides valuable information in the field of remote sensing.
We design a novel approach for enhancing depth maps based on feature matching and fuzzy logic, which can overcome the common problem of introducing noise.
We develop a method for converting the enhanced depth map to a 3D point cloud.
2. Related Work
Existing 3D reconstruction approaches can be divided into three different groups: methods based on capturing multiple images, creating 3D point clouds based on Deep Learning and approaches based on 3D reconstruction from a single image.
2.1. 3D Reconstruction from Capturing Multiple Images
In general, the reconstruction of 3D point clouds from multiple image captures of the same scene is a computationally expensive process and requires significant user interaction. One of the common methods in this field is Structure from Motion (SfM) which requires the capture of photos of a scene from all feasible angles around the object, especially for fused aerial images and LiDAR (Light Detection and Ranging) data. While the number of images captured with SfM methods is dependent on application, for the same application, a light field approach still has the advantage of needing fewer captures to achieve the same result. In addition, a light field approach has the advantage of working for applications where objects being imaged are dynamic (such as the analysis of plant growth in situ or dynamic urban environments such as streetscapes). Currently such applications represent extreme challenges for SfM approaches. Pezzuolo et al. [
8] reconstructed three-dimensional volumes of rural buildings from groups of 2D images by using SfM methods. For working on unmanned aerial vehicle (UAV) images, Weiss et al. [
9] utilized RGB colour model imagery for describing vineyard 3D macrostructure based on the SfM method. Bae et al. [
10] proposed an image-based modelling technique as a faster method for 3D reconstruction. For image capture, they utilized cameras on mobile devices. One of the benefits of using image-based modelling is the accessibility of texture information that can enable material recognition and 3D Computer-Aided Design (CAD) model object recognition [
11,
12]. Moreover, some works used the reconstruction of 3D scene geometry for the purpose of control and management of energy in the field of 3D modelling of buildings [
13]. Pileun et al. [
14] estimated the positions and orientations of the object by using Simultaneous Localization and Mapping (SLAM). The 2D localization information is utilized for creating 3D point clouds. This reduces the time of scanning and requires less effort for collecting accurate 3D point cloud data but still needs user interaction.
2.2. Creating 3D Point Clouds Based on Deep Learning Techniques
Recently, approaches based on deep learning have drawn attention for solving many computer vision problems. A wide variety of deep learning models have been developed to create 3D point clouds but most of them require images capturing an object with an uncluttered background and a fixed viewpoint [
15]. Current techniques have limited application to real world objects. Yang et al. [
16] generated a point cloud based on a specific deep model named PointFlow. This model has the advantage of having two levels of continuous flows for normalizing the point cloud. The first level is for creating the shape and the second level is for distributing the points. For handling large scale 3D point clouds, Wang et al. [
17] developed a method based on the feature description matrix (FDM), combining traditional feature extraction with a deep learning approach. As deep learning alone is not efficient for creating a 3D point cloud, Vetrivel et al. [
18] combined a convolutional neural networks approach with 3D features to improve results. Wang et al. [
19] used deep learning for fast segmentation of 3D point clouds. They introduced a new framework called Similarity Group Proposal Network (SGPN). However, this method is still not efficient for real world objects.
2.3. 3D Reconstruction from a Single Image Approaches
Creating 3D point clouds from a single image has received significant attention from the research community. However, 3D reconstruction from a single projection still has many problems and is a challenging topic. Mandika et al. [
20] estimated 3D point clouds from a single input view by training an auto-encoder to learn a mapping from 2D input images to 3D point clouds. However this type of estimate is not very accurate and requires extensive training [
21]. To overcome the drawbacks of estimation of 3D point clouds from a single capture, light field cameras have been proposed. Using light field images as an input can lead to 3D point cloud estimates with low cost and complexity. Perra et al. [
5] used light field images as an input image to determine depth maps of scenes and then estimated 3D point clouds. The depth maps that are automatically acquired from light field cameras have some potential limitations when dealing with real objects such as having decreased efficiency and accuracy for dense scenes. To tackle this problem, we propose a novel algorithm for enhancing the depth map by adding multi-modal edge detection information, which provides more information about the depth map. Moreover, compared to the Perra et al. [
5] method, we used a transformation method for converting the depth map to 3D, which is more reliable and does not need the segmentation and extraction of occlusion masks required by their method.
2.4. Problems of Existing Approaches and Our Solution
Each of the three aforementioned method types have some limitations for creating dense and accurate 3D point clouds and most of them require considerable effort to obtain 3D data. Methods that make use of multiple images, such as SfM and SLAM, usually require finely textured objects without specular reflections. Moreover, if the baselines used for separating the viewpoints are chosen to be large, it causes many problems for feature correspondences on account of occlusion and changes in local appearance [
15]. For deep learning approaches, despite the recent favourable results of deep learning models in some machine learning tasks, creating 3D point clouds remains challenging [
16]. This difficulty can be attributed to the lack of order in the 3D point cloud, so no static structure of the topology can be found for recognition and classification of the scene based on the deep learning. This means it will be problematic to use deep neural networks directly on the point clouds because points will not be arranged in a stable order like pixels are in 2D images.
Many attempts have been made to address the problem of 3D reconstruction from a single snapshot, however, when those methods are applied on real images, they will suffer from a sparsity of information. Since in the one snapshot there will be a single view of the image, some parts of the scene will therefore be invisible. This shortage causes the generation of 3D point clouds to be problematic. In contrast, we used a light field camera in this work, which by one snapshot provides multiple sub-aperture images, providing sufficient data for depth map estimation. As a result, compared to other single image methods, we can overcome the problem of this kind of deficiency. Moreover, we enhanced the depth map in a novel, multi-modal fashion by extracting SURF features from central sub-aperture matching and depth map images, and using fuzzy logic. This kind of enhancement provides for our work a more accurate point cloud compared to other methods in this area, and also makes the reconstruction of 3D point clouds much easier.
3. The Light Field Camera
In the field of environmental research, there are a wide variety of techniques trying to obtain 3D information about buildings and plants. Most of the previous techniques needed a high level of methodological complexity, but with the emergence of light field cameras, many problems have now been addressed in the areas of 3D modelling, measurement and monitoring. A light field camera, which is a type of plenoptic camera that with one image capture through an array of micro-lenses, can collect a wide variety of information about the colour, intensity and direction of light in a scene. This means, instead of utilizing two or more single camera captures to increase the number of viewpoints, light field cameras provide many viewpoints of a scene with a single snapshot and each such view is termed a “sub-aperture image”. In contrast, in a traditional digital camera, the lack of data about the directional intensity of light makes solving many problems of remote sensing and computer vision difficult. An early light field camera was developed in 2005 and was called the Lytro [
7], and a professional version of the Lytro was introduced in 2014 (called the Lytro Illum). Light field cameras have several features such as post-capture refocusing, depth map estimation and illumination estimation. In the field of remote sensing, light field cameras are also suitable for generating 3D information for different kinds of monitoring applications, such as the monitoring of plant growth [
1].
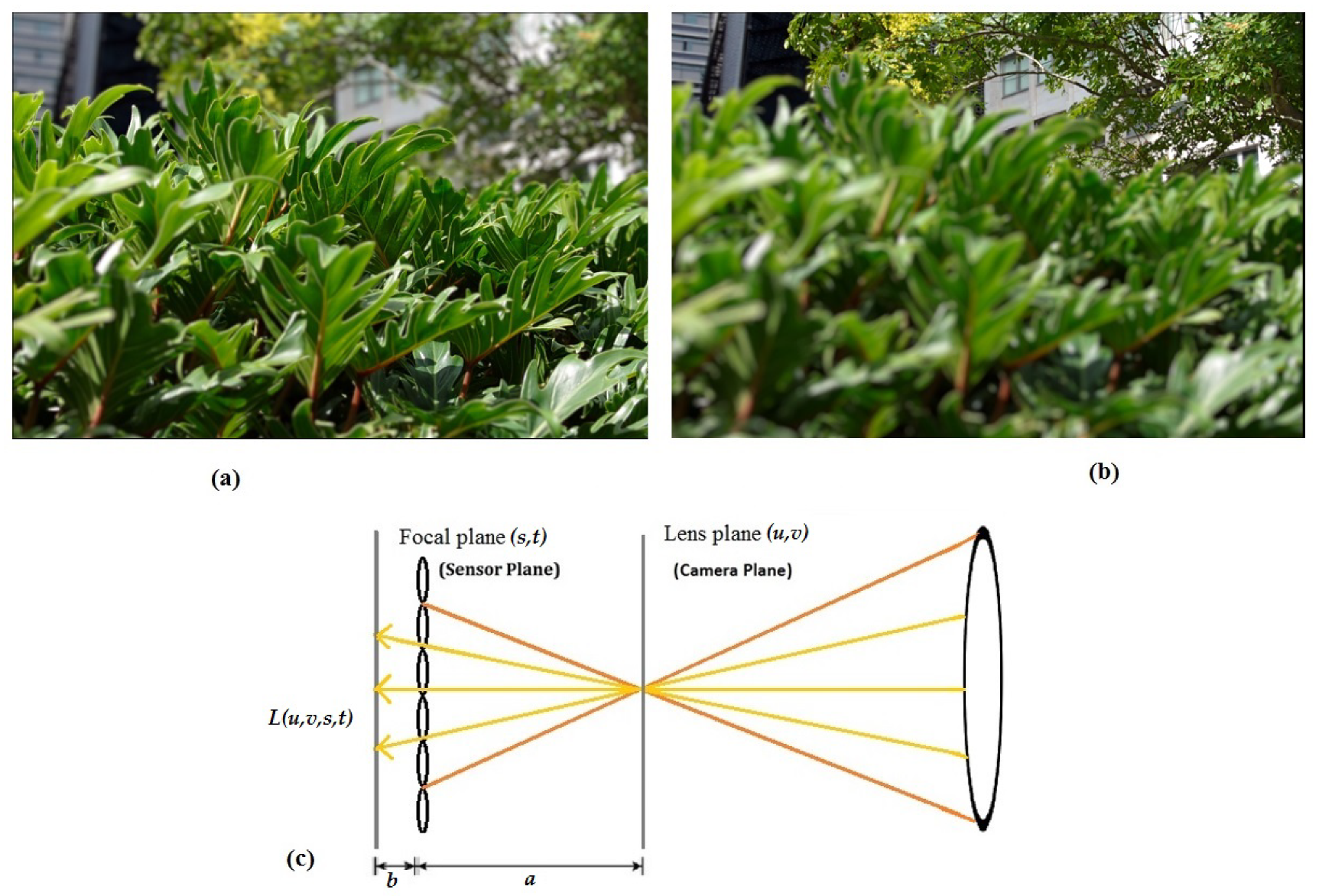
One of the significant features of light field cameras is shown in
Figure 3, which shows post-capture refocusing in two different focal planes. Refocusing allows for changing the focal plane to a different position post-capture. This feature has a significant role in the generation of a depth map from a LF image. A light field can be considered as a vector function
I(
u,
v,
s,
t) between two planes (lens plane and sensor plane) [
22] where
u and
v are coordinates on the lenses plane and
s and
t are co-ordinates on the sensor plane as shown in
Figure 3.
An aligned light ray is determined in a system when it first crosses the
uv plane (lens plane) at coordinate (
u,
v) and then crosses the
st plane (sensor plane) at coordinate (
s,
t), and can be encoded by the function of
I(
u,
v,
s,
t) [
22]. Each position on the sensor plane can be modelled as a pinhole camera viewing the scene from a position
s,
t on the sensor plane.
4. Proposed Method
In this work, we used a LF image and its depth map as an input image. Our approach is based on transforming the point–plane correspondences on an enhanced depth map. Since having an accurate depth map is of paramount importance to generate a complete 3D point cloud, we improved the depth map in two different steps. In the first step, we applied histogram stretching and equalization on the original depth map. In the second step of enhancement, we added multi-modal edge detection information to the equalized depth map, then we acquired the 3D point cloud by coordinate transformation.
4.1. Histogram Stretching and Equalization
In the first step of enhancement, we applied histogram stretching and equalization on the original depth map as one of the novel aspects of this work. Our input was an 8-bit grayscale 2D depth map image,
. In order to increase the distance between adjacent depth layers, we applied histogram stretching and then on the result of the histogram stretching, we applied histogram equalization. The equations below show the histogram stretching to improve the separation between the depth planes.
where
is a 2D depth map image with a minimum value denoted as
and a maximum value denoted as
and
is the histogram stretched depth map. Then, we applied histogram equalization on the result of the histogram stretching to spread the intensity values over full range of the histogram image and for enhancing the contrast of the depth map [
23].
Given the histogram stretched depth map
, if we consider
as the dynamic range of intensities in the depth map, then the probability based on the histogram
can be calculated as below:
From this probability we can perform histogram equalization based on the below equation:
where
is the number of pixels and
is the result of histogram equalization.
4.2. Adding Edge Detection Information
The second step of enhancement was the most important part, where we added multi-modal edge detection information. This is another significant and novel aspect of this work. We developed a new strategy in this area, making use of the fuzzy logic-based edge information created from the depth map and feature correspondence matching between sub-aperture images to create a multi-modal edge estimation. This information was then combined to obtain a multi-modal edge detection. As a result, this kind of edge detection was more reliable compared to ordinary edge detection because noise was reduced compared to prior art edge detection methods such as Canny and Sobel. This means we determined edges efficiently in a multi-model fashion, based on the depth map in conjunction with the sub-aperture images, rather than selecting any edge which was created by current state-of-the-art edge detection methods working on the sub-aperture images alone. The details of this development are shown in
Figure 4 and
Figure 5, which also show the steps required for improvement of the depth map.
4.2.1. Fuzzy Logic
We found that a fuzzy logic approach can help us with detecting edges by comparing the intensity of neighbouring pixels, and based on the gradient of the image, we can find which pixels belong to an edge. This kind of logic is very helpful for depth map images because of the structure of level of depth map is based on the gradients.
We first obtained the image gradients based on the convolution of the image to acquire a matrix containing the u-axis and v-axis gradients of the depth map image.
For this purpose, we convolved the depth map
with gradient operator,
, using the convolution method. The gradient values were in the [−1 1] range.
Considering the gradients of the depth map as an input, we will create a fuzzy inference system (FIS) for edge detection.
FIS is made based on the decision of whether a pixel is belonging to an edge or not. Membership functions are needed to define a fuzzy system. We defined a Gaussian membership function for each input:
where
is a Gaussian function,
,
are the maximum and minimum value of gradient and
is the standard deviation associated with the input variable.
defines the final pixel classification as edge or non-edge.
where
are the fuzzy sets as a part of a fuzzy rule, similar to [
24] and
is the output class centre of fuzzy rule. As a result, the final fuzzy edge is defined by
where 0 indicates that the pixel is almost certainly not part of an edge and 1 indicates that the pixel is almost certainly part of an edge.
4.2.2. Feature Matching
In the second step of enhancement we also in parallel extracted the SURF features of intermediate results (Canny edge detection for the central sub-aperture image) and (Canny edge detection of original depth map). Then, we matched the features and extracted features with higher amplitude to add to the result of the edge detection using fuzzy logic.
For this purpose, we used the SURF detector for detecting features. The SURF detector extracts features based on the Hessian matrix, which is determined at any point
and scale σ=1.2 as the second order derivative of Gaussian filter.
where
are the convolution of the Gaussian second order at the point of
. This can be executed methodically if utilizing an integral image, as a result we calculate the integral image for those two input images:
The determinant of approximate Gaussians can be presented as follows:
Therefore, the interest points, which includes their locations and scales, will be detected in approximate Gaussian scale space [
25].
For matching the features of those two images, we used the nearest neighbour method similar to [
25]. In this way, image
has
directed line segments and image
has
directed line segments, and the nearest neighbour pair can be obtained by defining matrix K as below:
Then, we determined the features point with the highest amplitude from .
At the end of this step, we added the result of feature matching to the edge of fuzzy logic. As a result, we will have a multi-modal edge detection that we called
.
In the next step, we added this edge detection to the equalized depth map by applying a median filter, and the result will be saved in
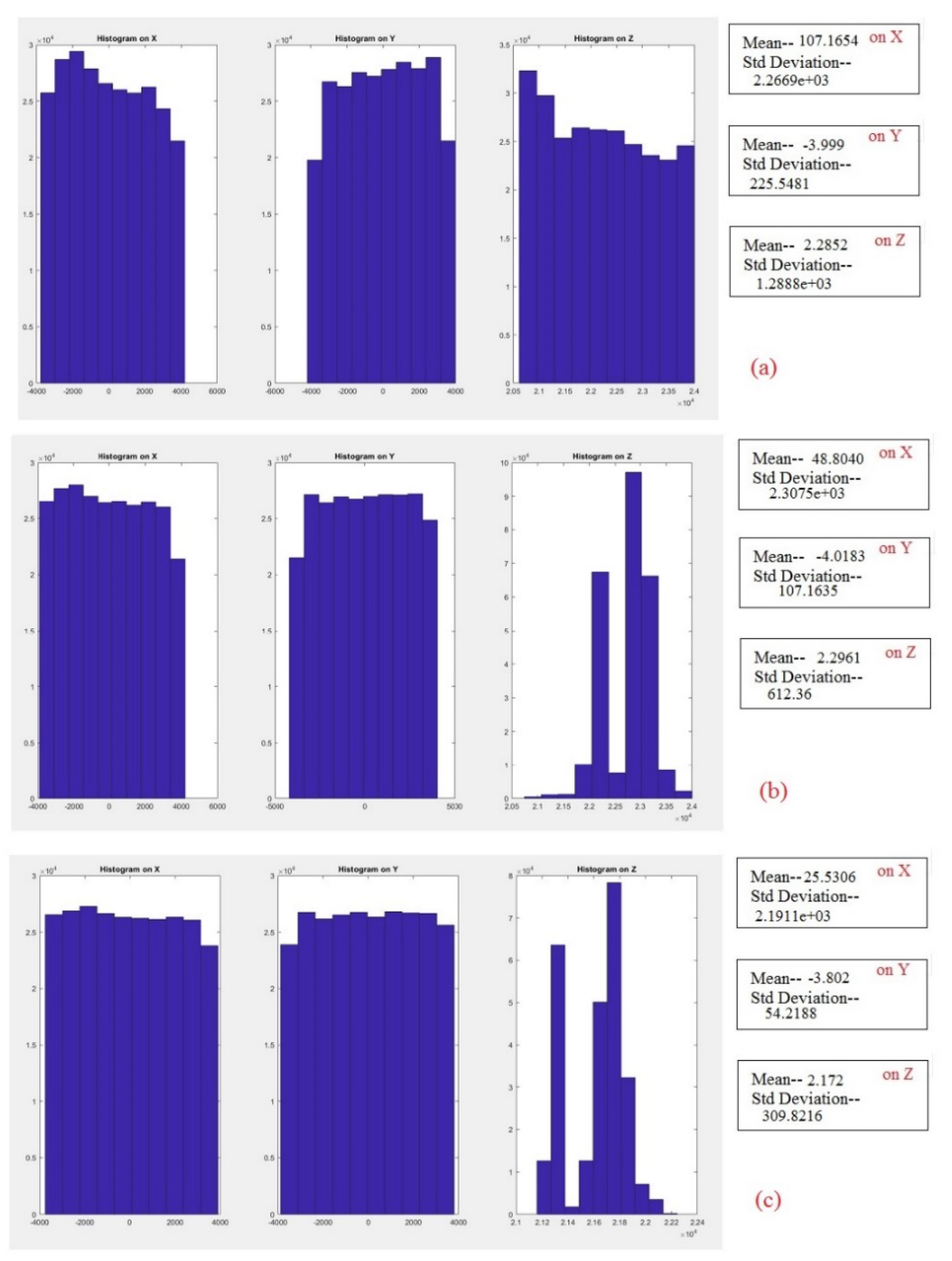
4.3. Creating 3D Point Cloud by Transforming the Point-Plane Correspondences
For estimation of the 3D point cloud, we needed to estimate (the z component of each point at position u,v) from which a point cloud can be created by transforming the point–plane.
For the points in the final point cloud, we started by selecting
and
, then for computing
:
where
is amount of the baseline,
is the focal length and
is the focus distance. The variable
is an intrinsic parameter and depends on the captured image. The variables
and
are extrinsic parameters and depend on the type of camera. The
x and
y coordinates of the point are then given by:
where
is the sensor size (mm). We then denote the estimation of 3D point cloud by
:













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}