DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data



Abstract
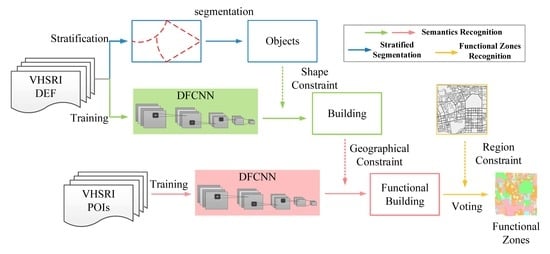
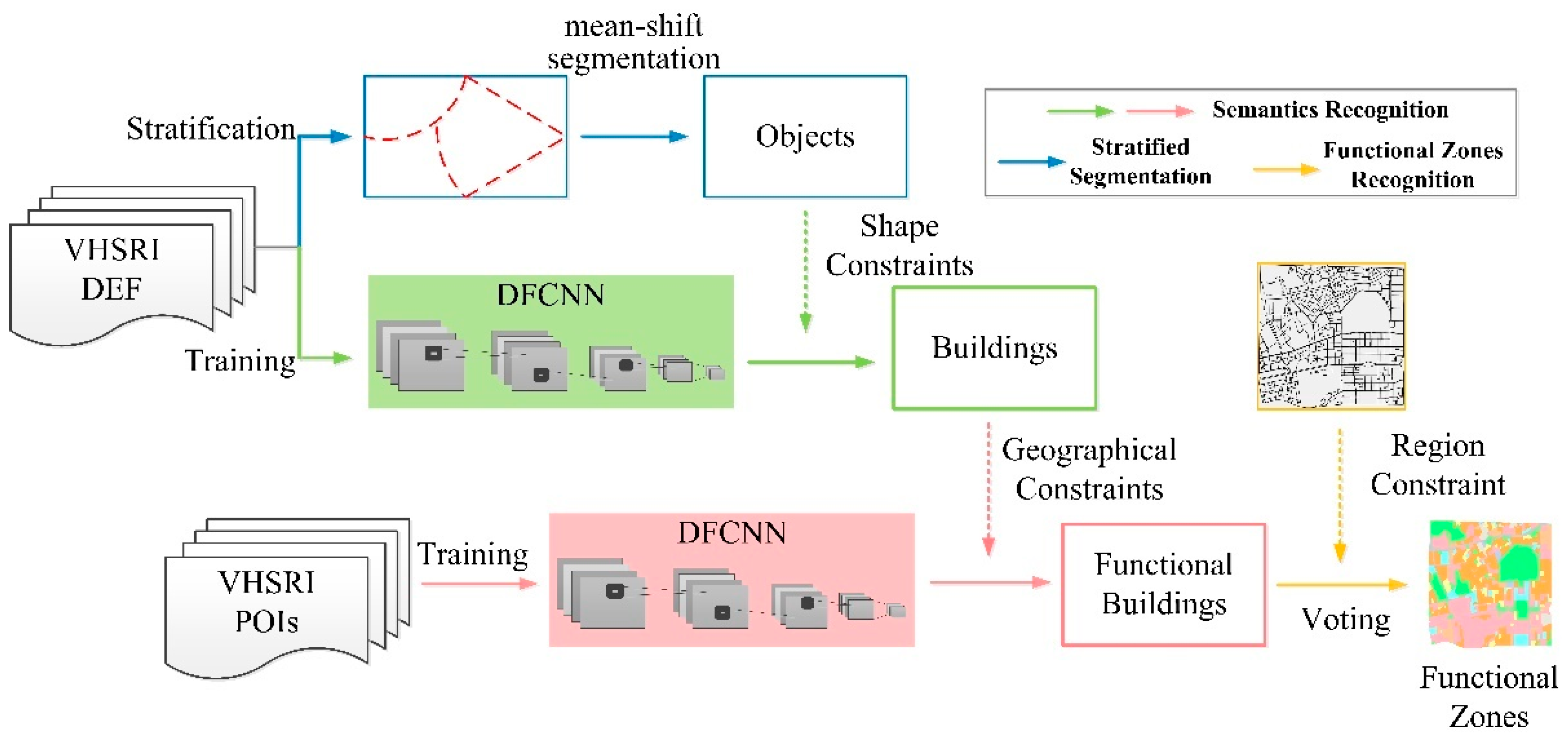
1. Introduction
2. Methodology
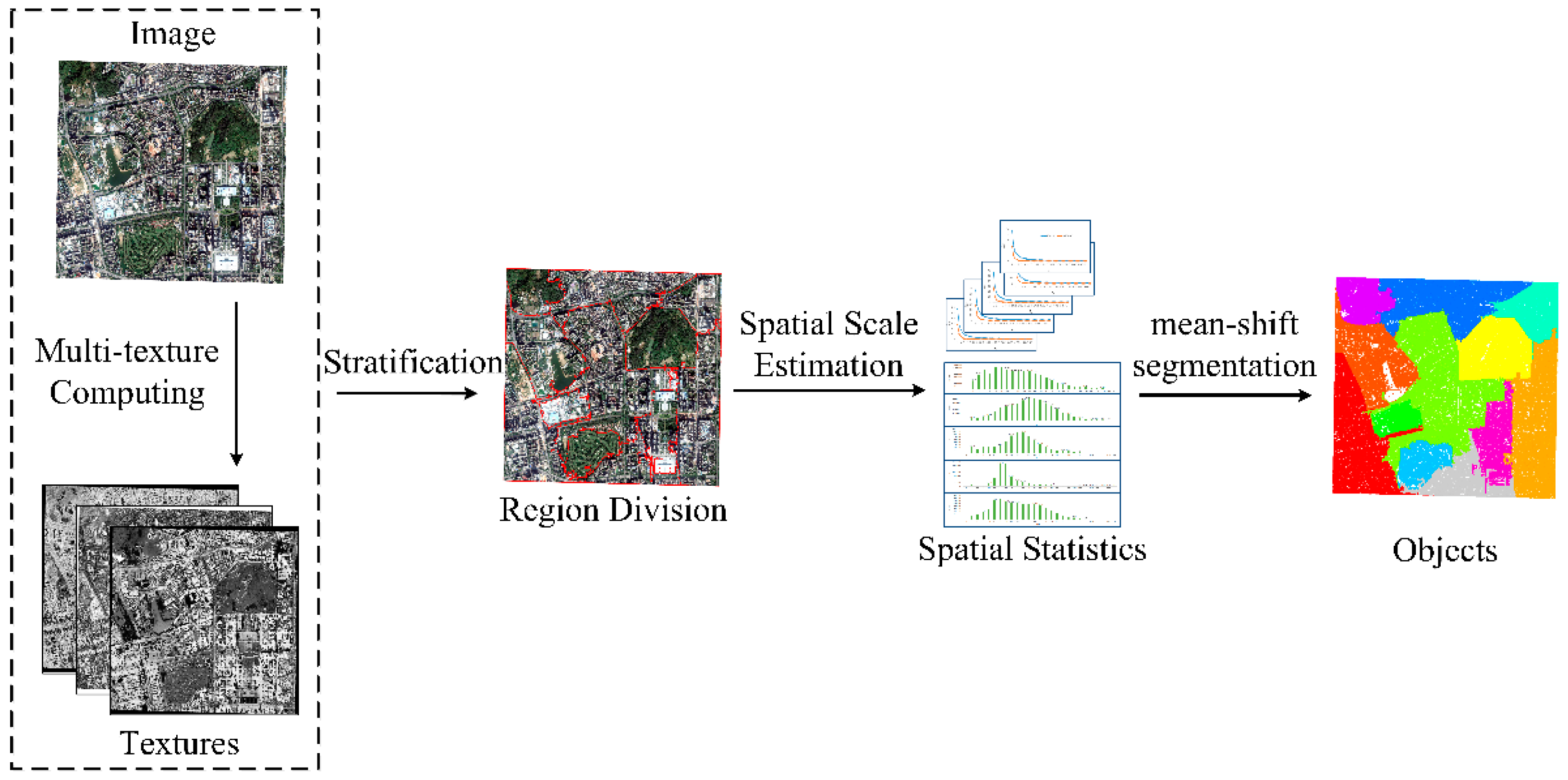
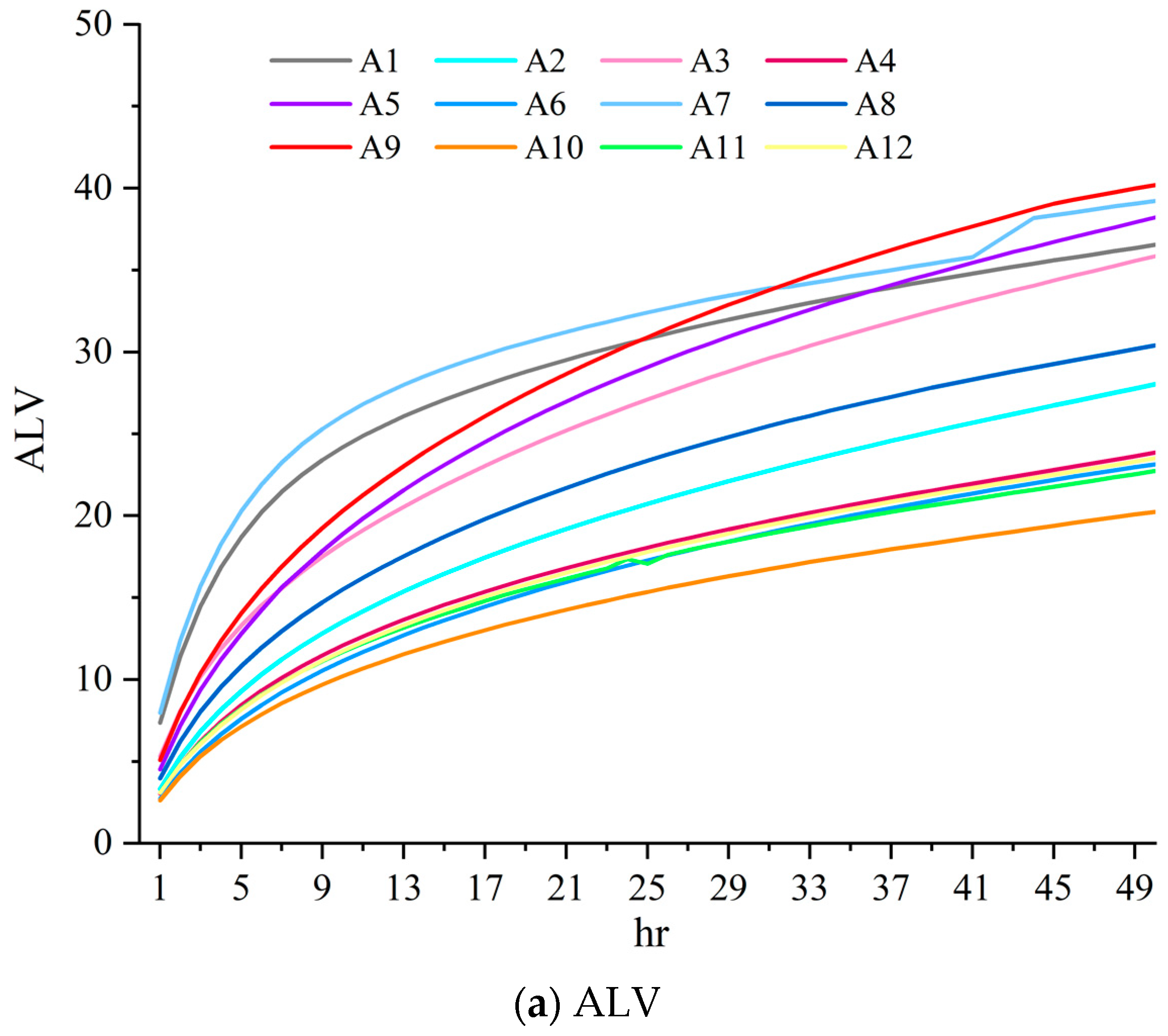
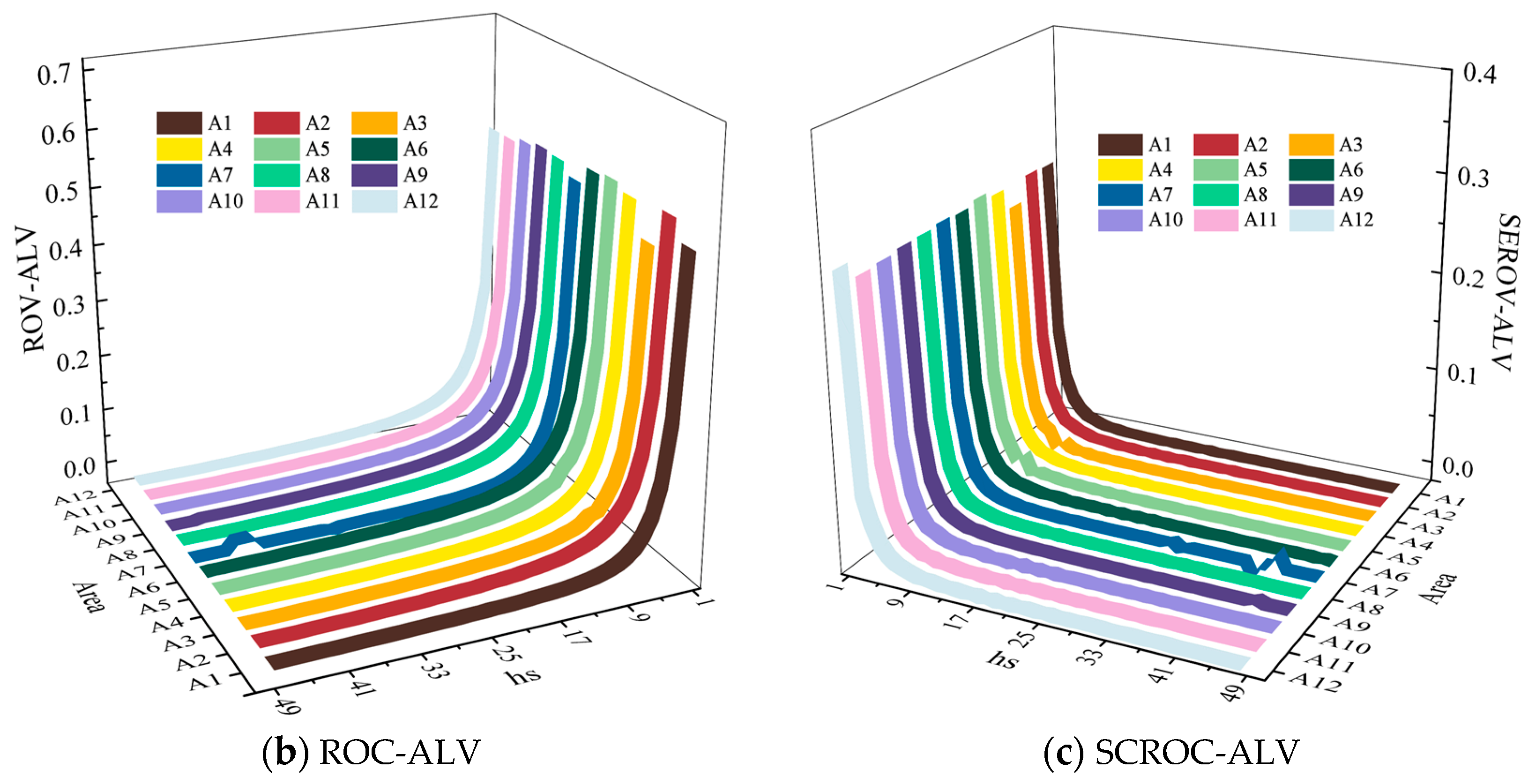
2.1. Stratified Scale Estimation Strategy
2.2. DFCNN-Based Semantic Recognition of Buildings
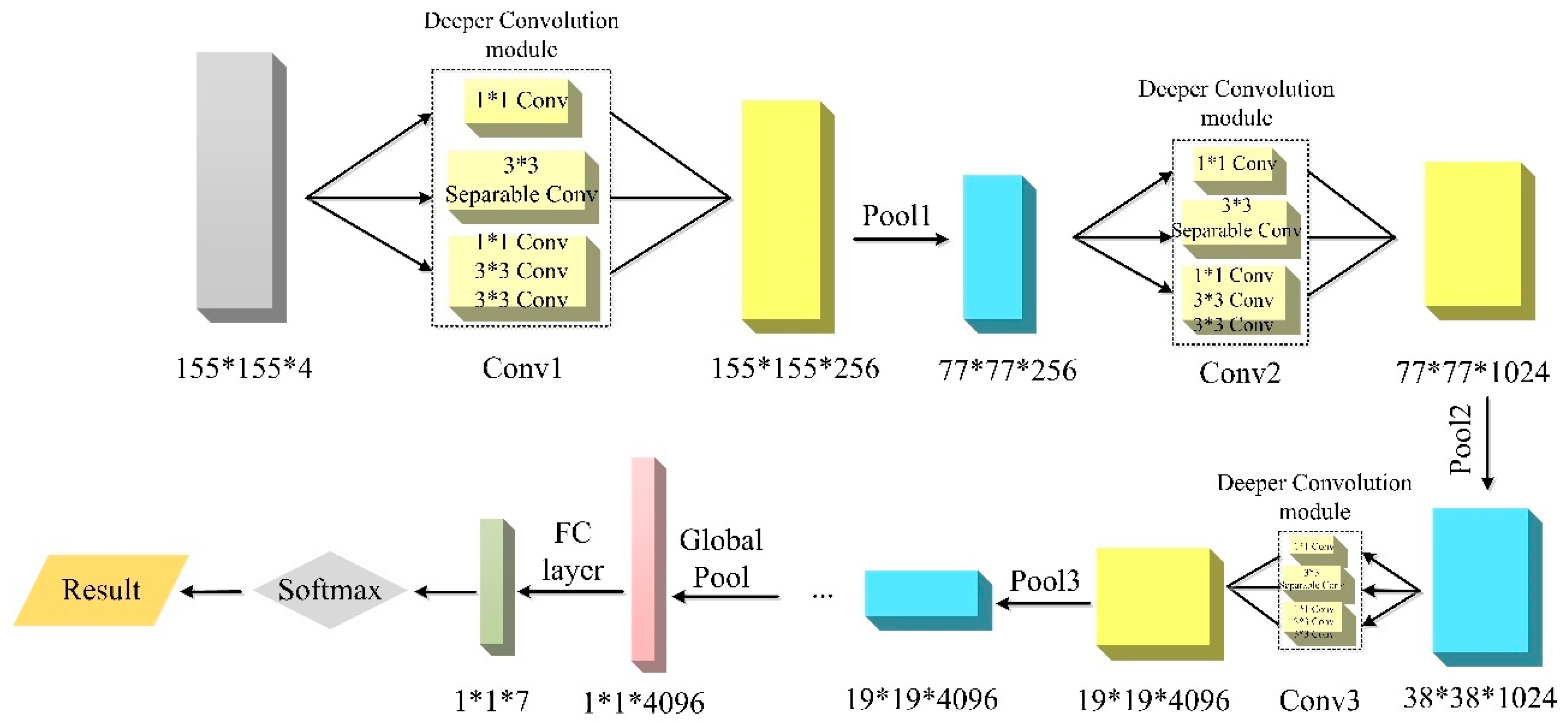
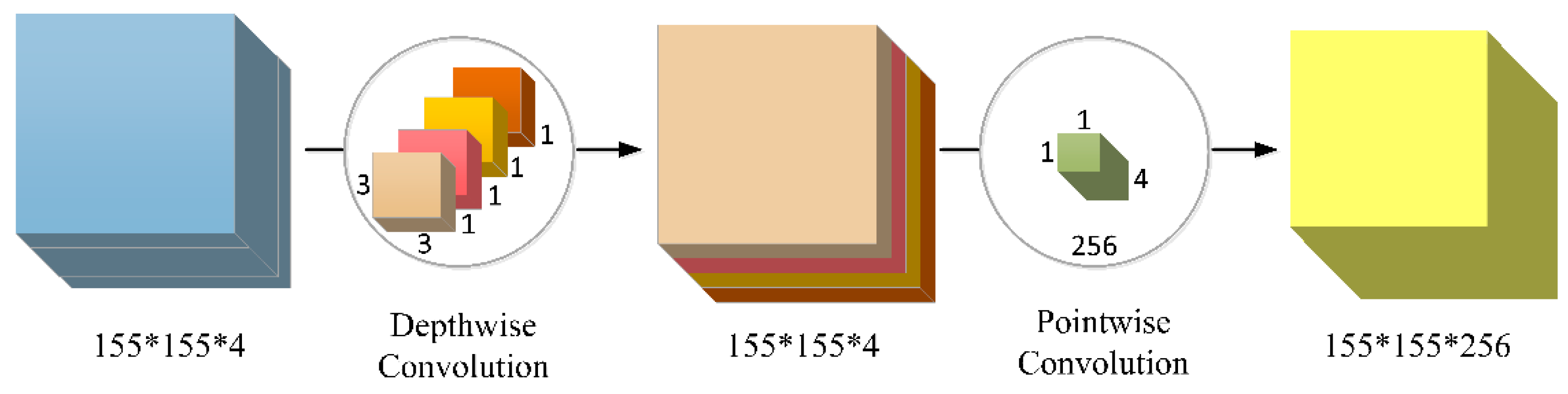
2.2.1. Deeper-Feature CNN (DFCNN)
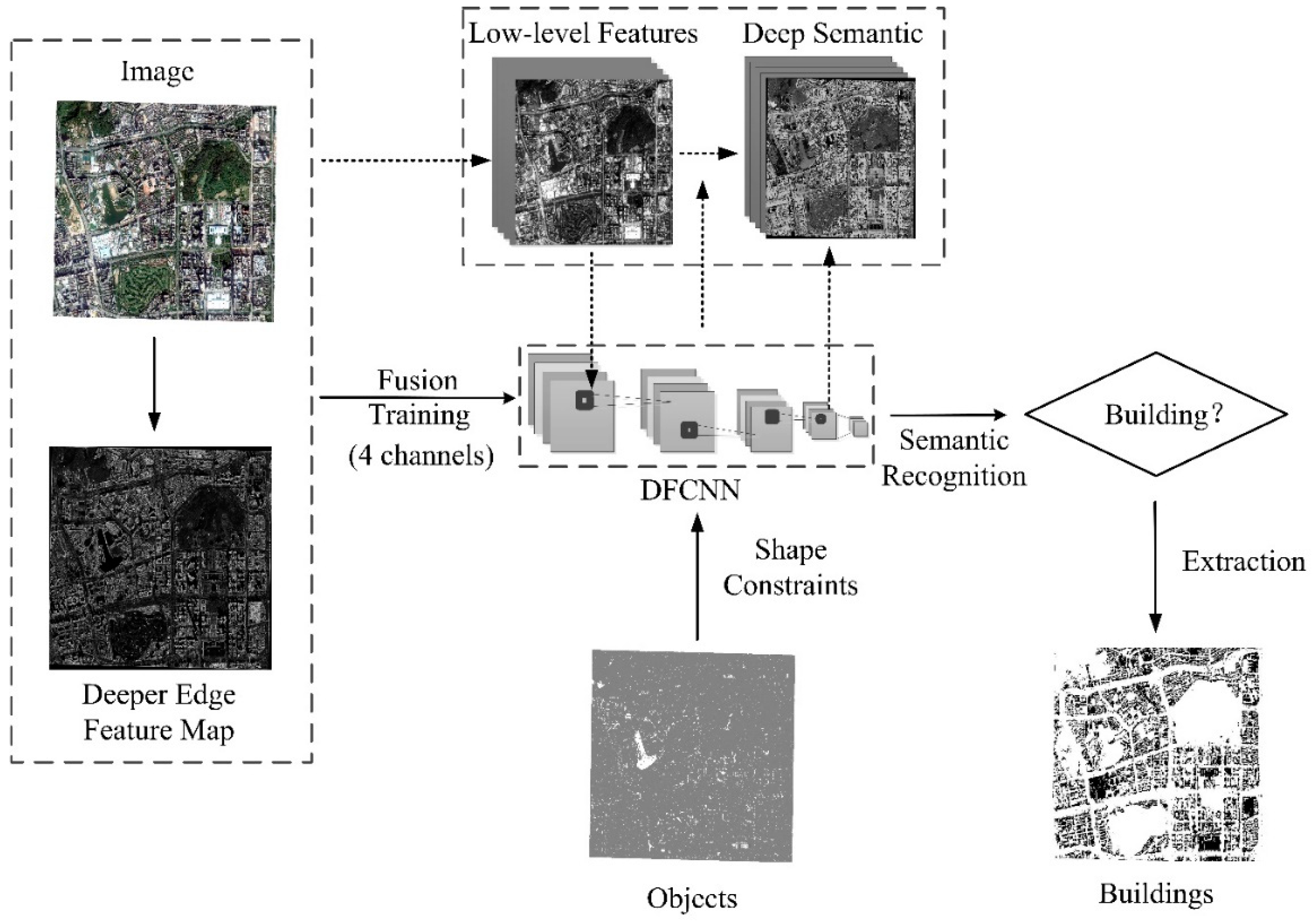
2.2.2. Physical Semantic Recognition of Buildings
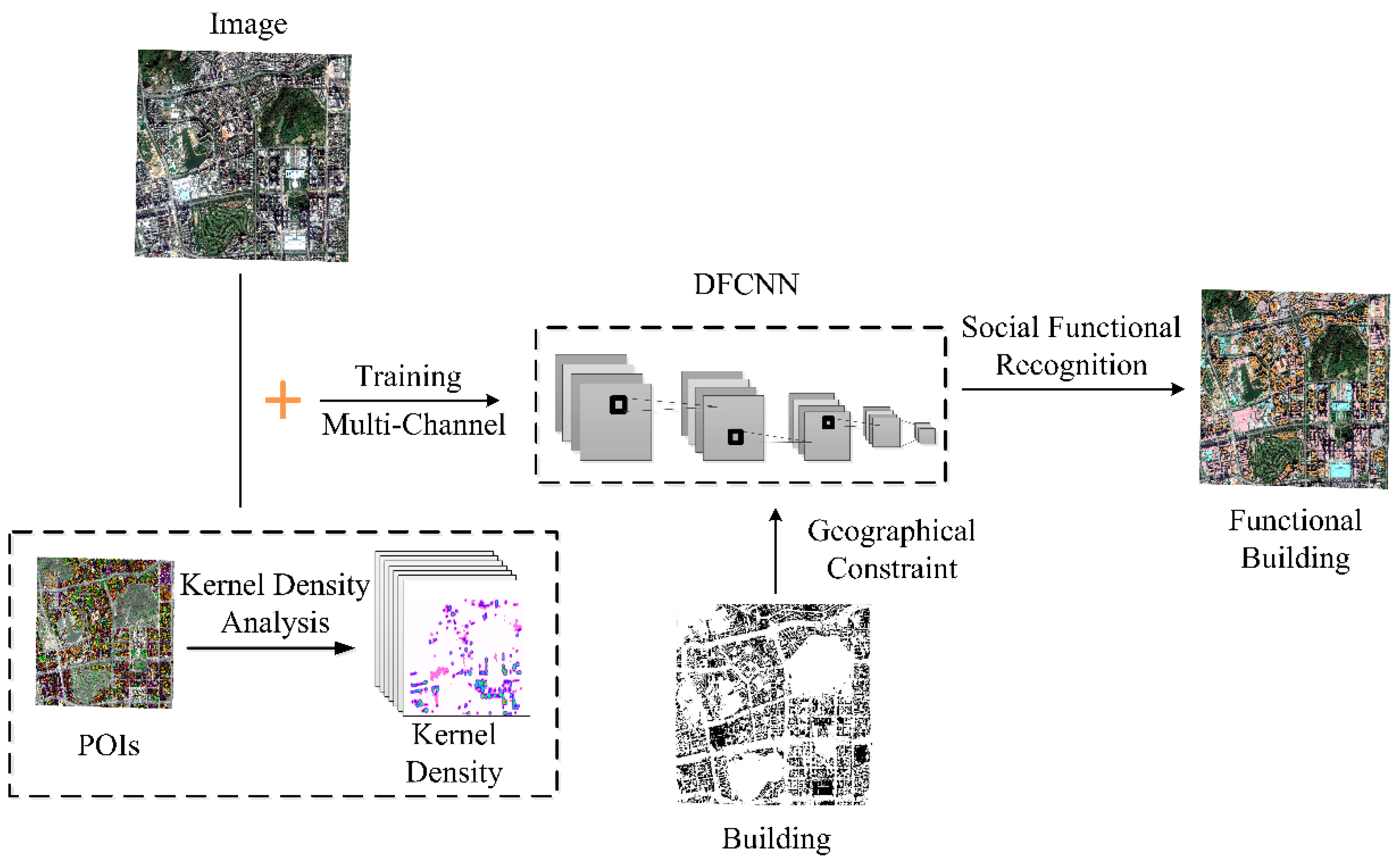
2.2.3. Social Semantic Recognition of Buildings
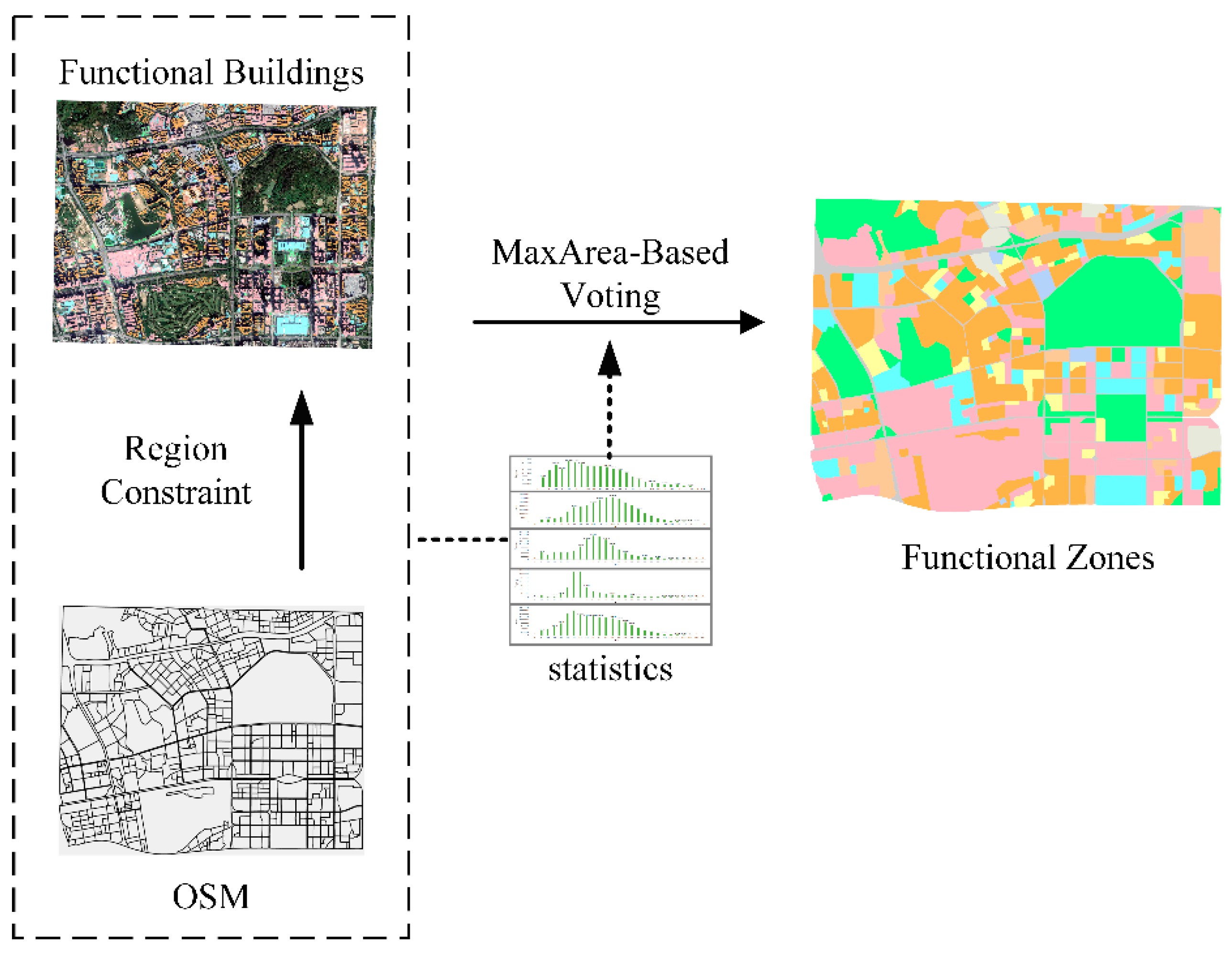
2.3. Maximum Area-Based Urban Functional Zone Recognition
3. Experiments and Results
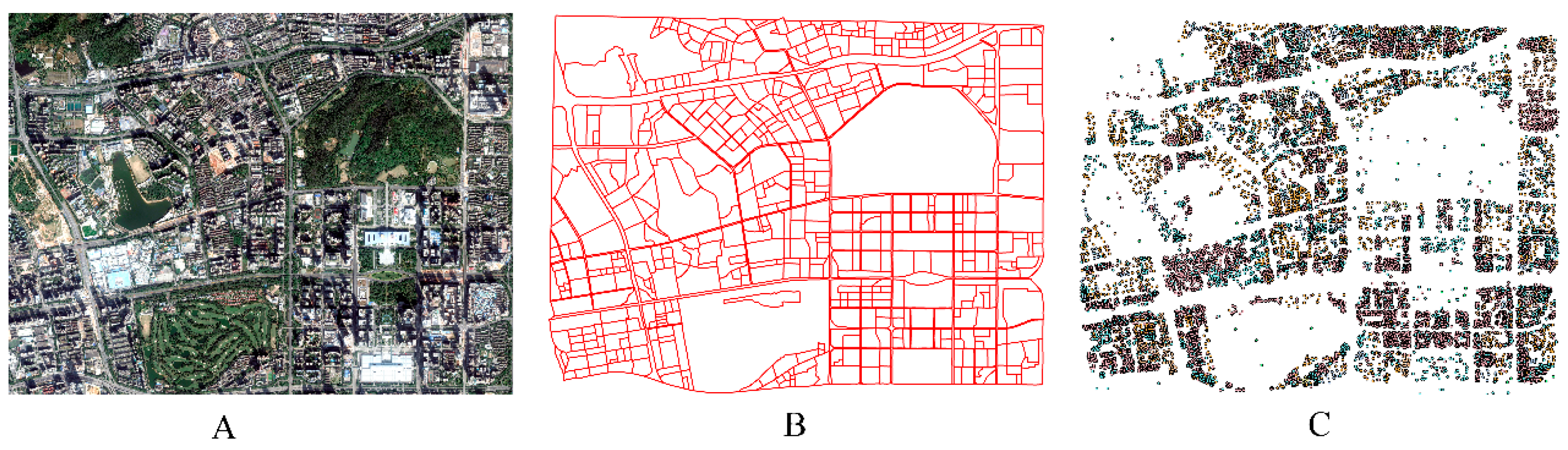
3.1. Study Area and Data Sets
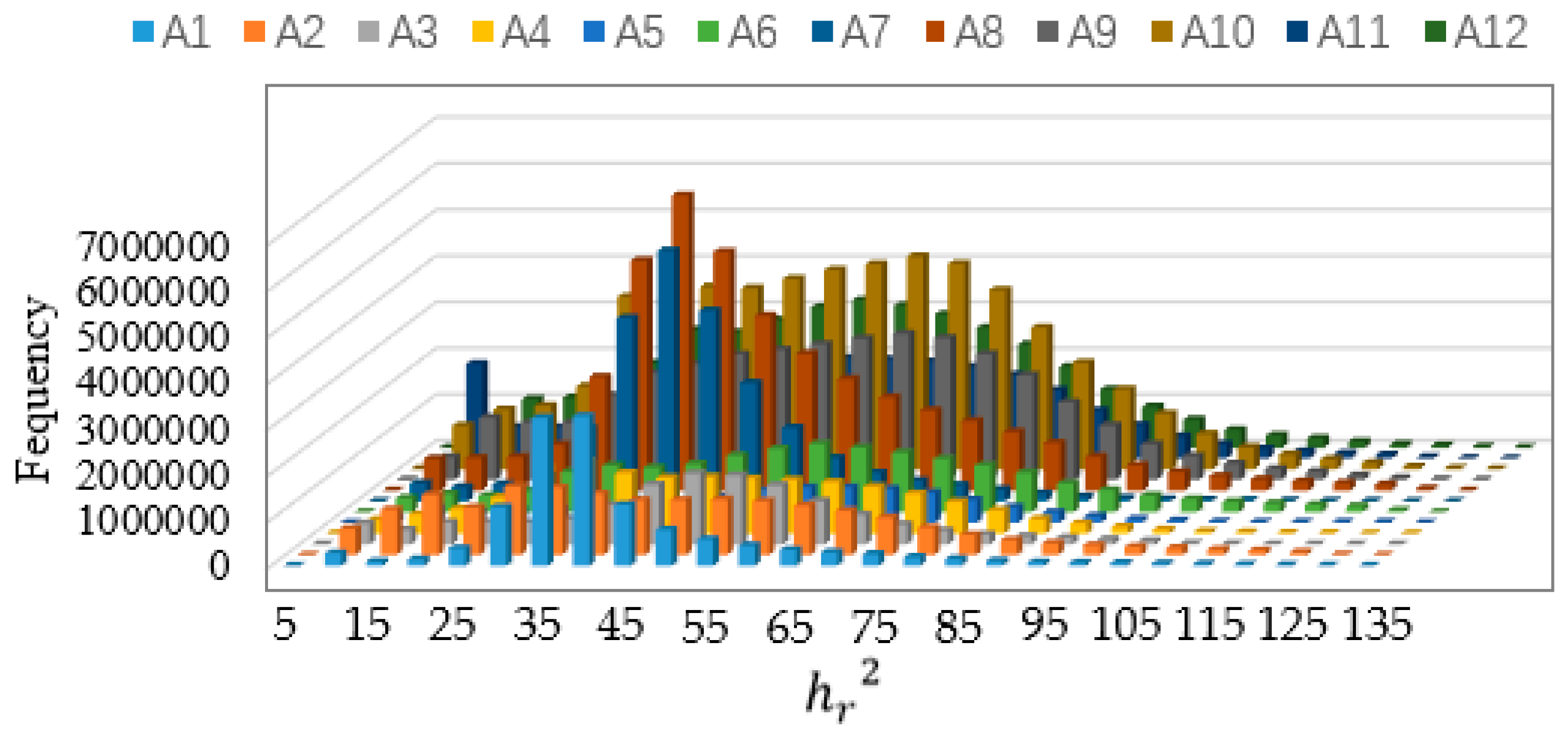
3.2. Results of the Stratified Scale Estimation
3.3. DFCNN-based Physical Semantic Recognition of Buildings
3.3.1. Samples for Training and Testing
3.3.2. Parameter Setting for DFCNN
3.3.3. Ground Truth Validation Points
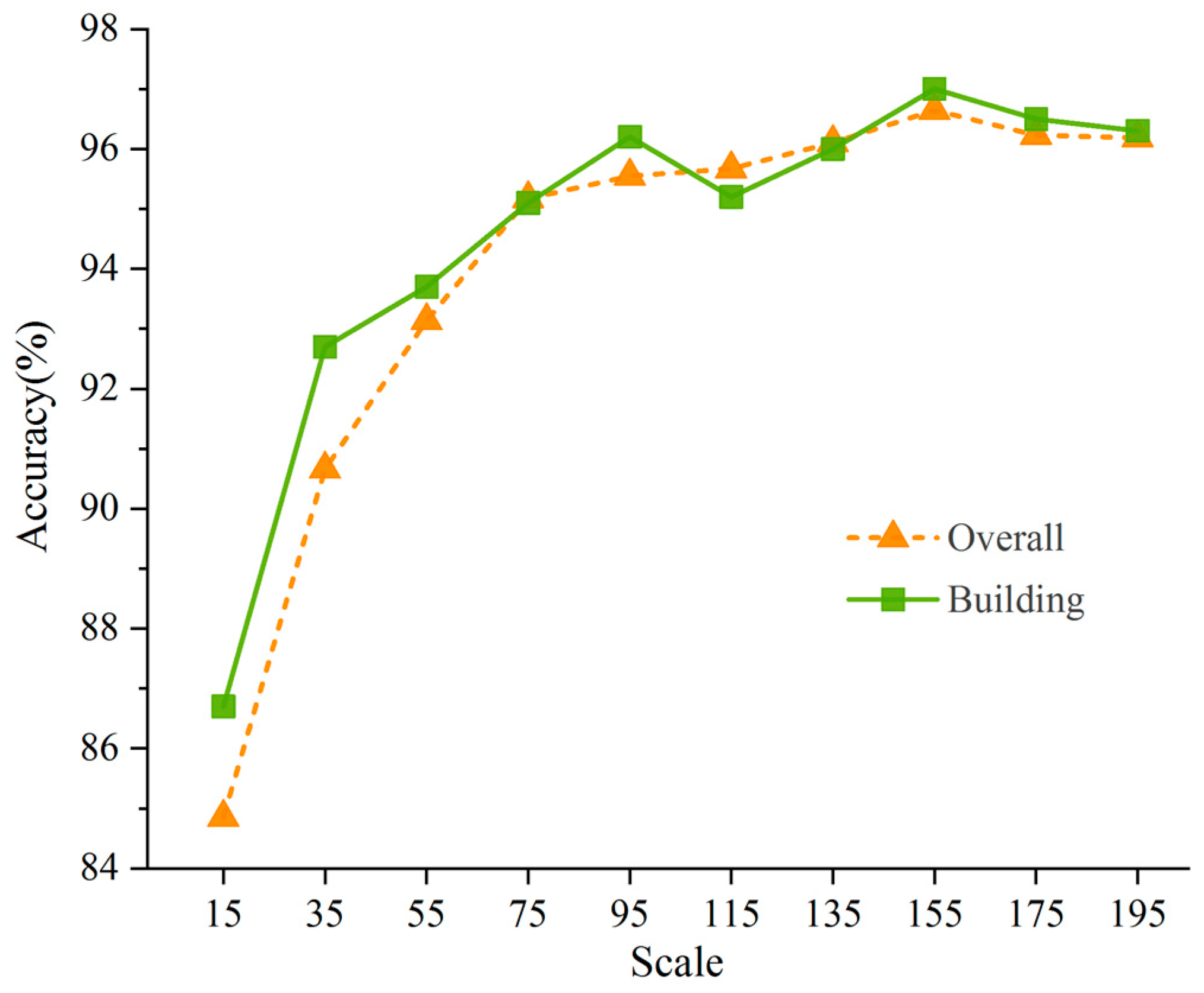
3.3.4. Results of the Building Extraction
3.4. Social Functional Semantic Refinement for Buildings
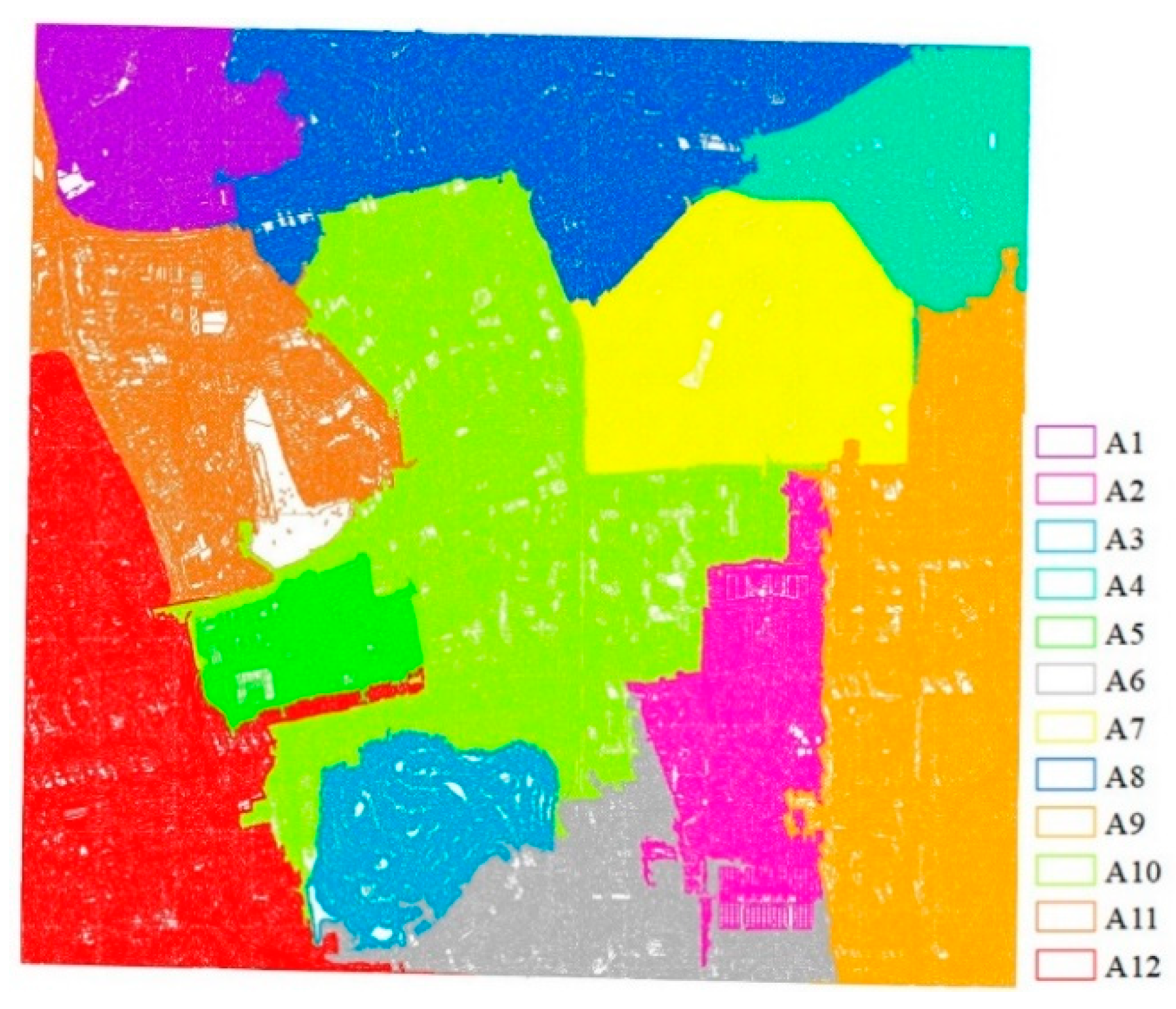
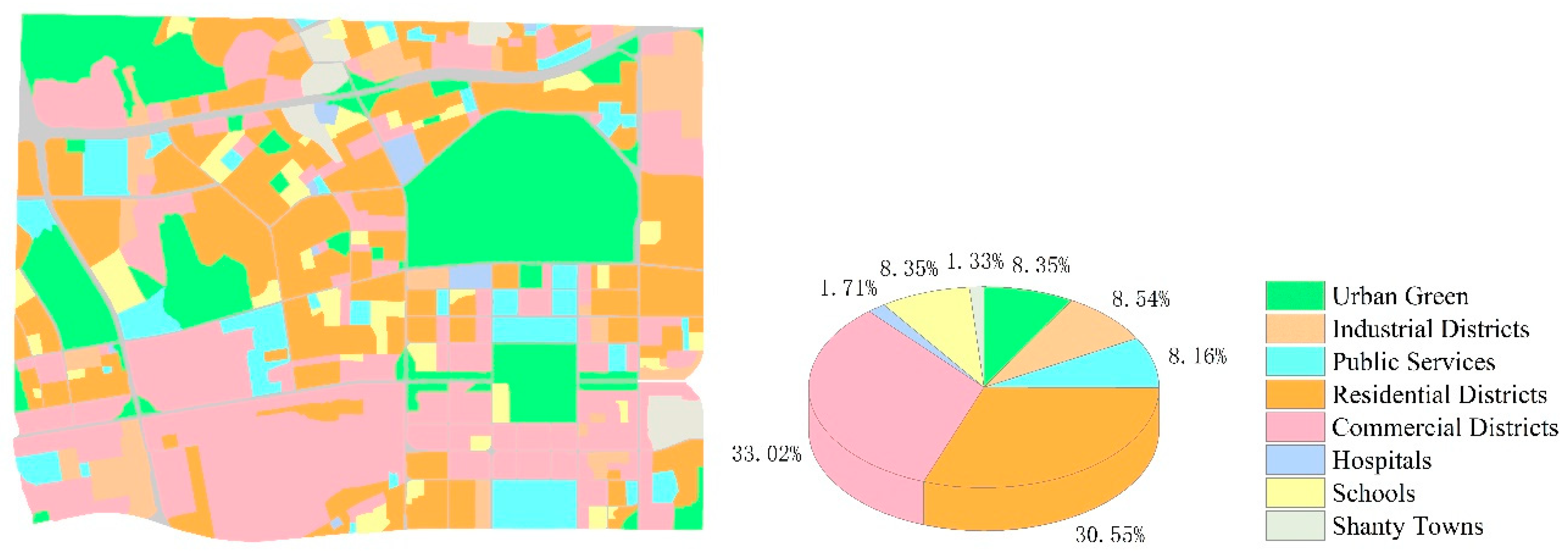
3.5. Results of the Urban Functional Zones
4. Discussion
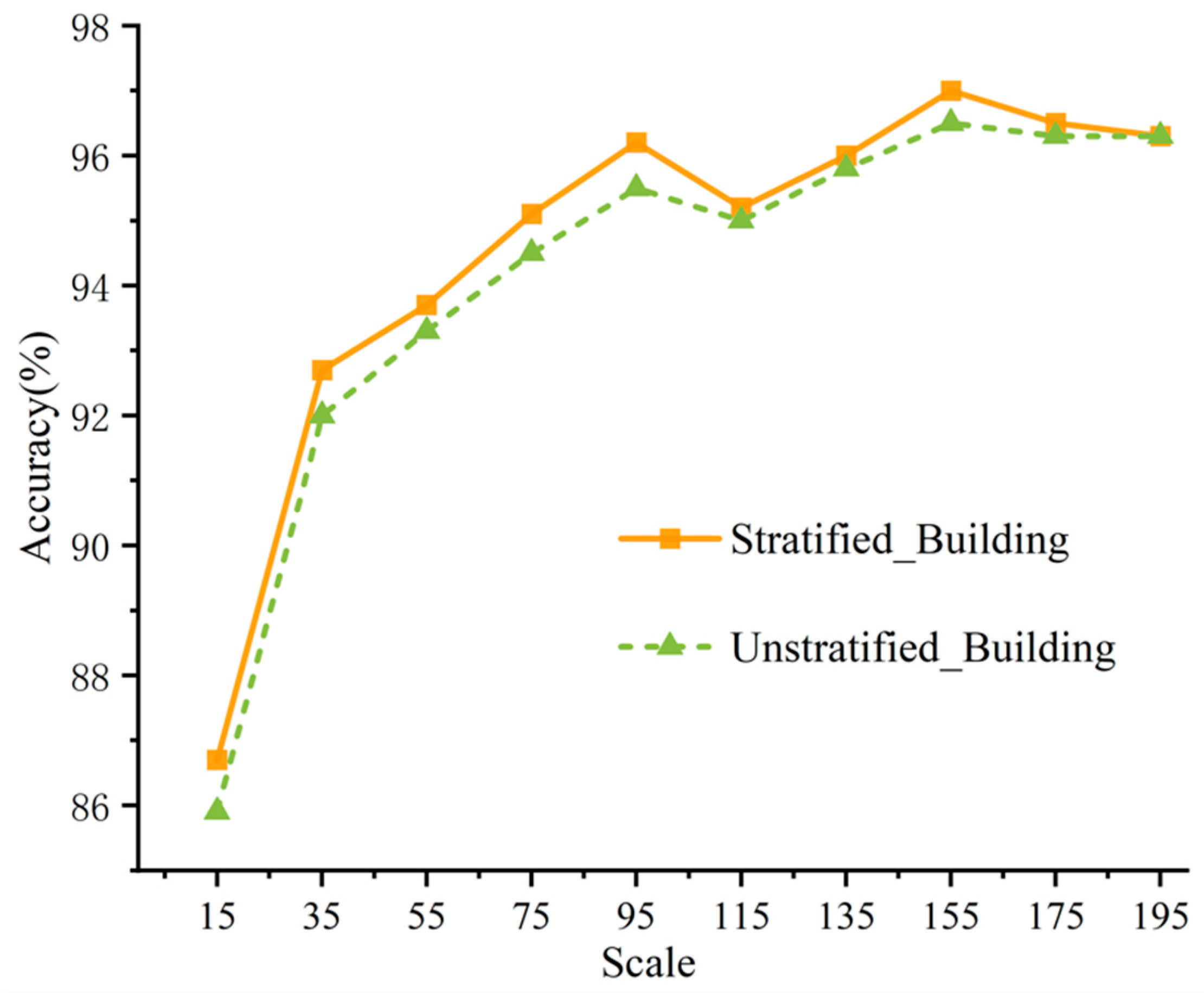
4.1. Effectiveness of the Stratified Scale Estimation
4.2. Contributions of DFCNN
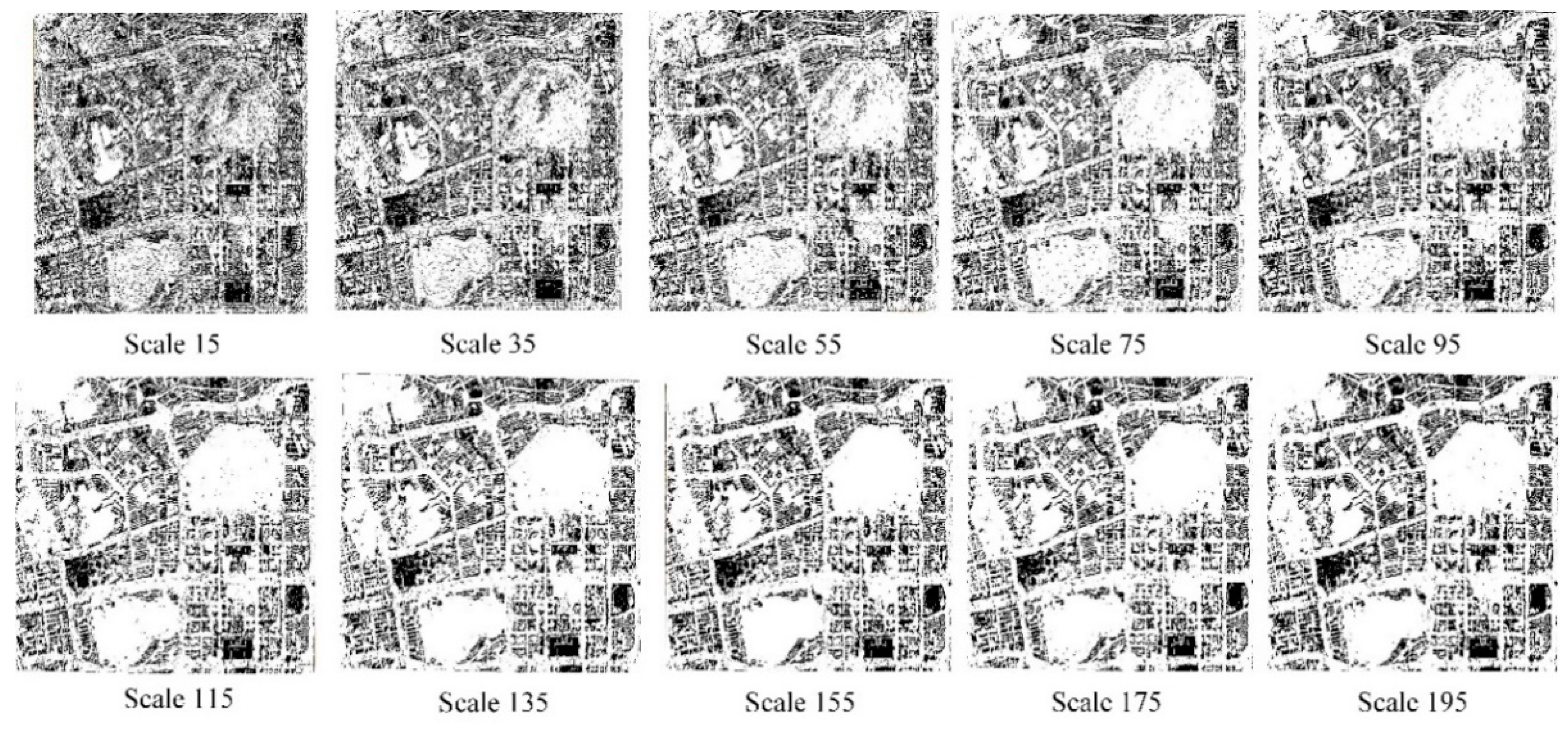
4.2.1. Efficiency of Deeper Edge Features
4.2.2. Effectiveness of the DFCNN Structure for Building Extraction
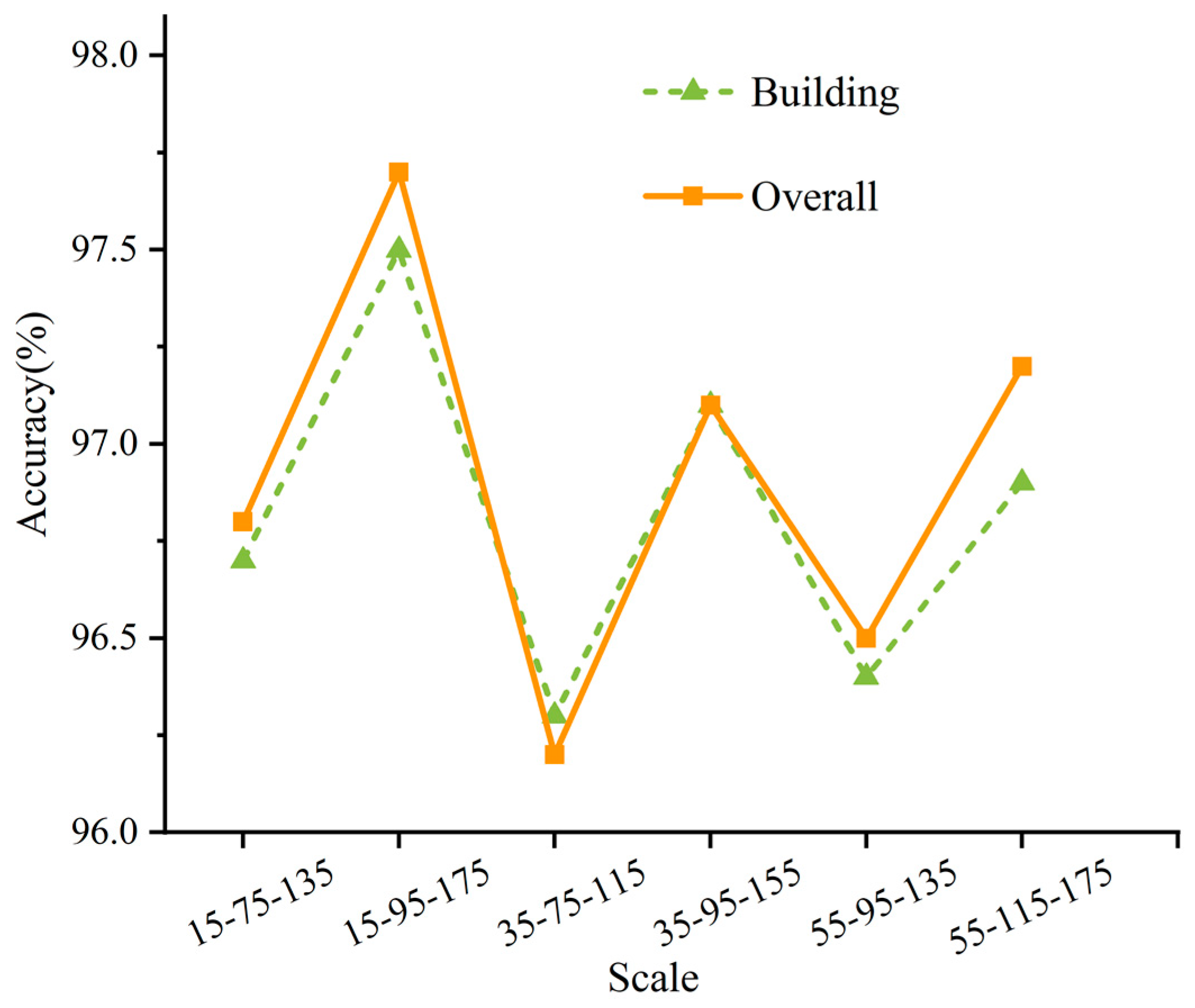
4.2.3. Multi-Scale Training
4.3. Pros and Cons
- The recognition of functional zones depends largely on the accuracy of the building extraction. The strategy of urban functional zone recognition in this paper is based on the functional semantics of buildings. Therefore, the misclassification and omission of buildings affect the division of functional zones.
- Although the contribution of the buildings to the functional zones is huge, other geographic objects are also part of the functional zones. For example, in the park, the contribution of water and vegetation is greater, the greening rates of commercial and residential areas are different, and the complexity and grade of roads are also different. Therefore, a strategy that only considers the attributes of buildings has certain limitations, and the attributes of all geographic objects inside the area should be fully considered.
- Furthermore, spatial relationships and distributions were not fully taken into account. The construction of zones must follow certain spatial syntax, which is directly reflected in the spatial relationship between buildings, and even between various geographic objects [73,74]. Similarly, the relationship between geographic objects also affects the evolution of functional zones.
5. Conclusions
- Due to the complexity of urban ground features, we adopted a strategy of stratified scale estimation. To some extent, this method avoids the blindness and subjectivity of scale parameter selection and effectively improves the efficiency of the experiment. At the same time, it can also meet the suitability of different geographic object scales and can improve the accuracy of building extraction.
- In view of the diversity of the spectrum, shape, and texture of urban buildings, low-level information can no longer be satisfied in the recognition and extraction of buildings. In this paper, a DFCNN model was designed based on the inception module, and DEFM was used to mine higher-level semantics of buildings and to improve the accuracy of building extraction.
- The organic fusion of POIs and VSHRI was put into the DFCNN model to explore geographic objects and to comprehend the functional semantics information in the context of social functions. Then, the Maxarea voting strategy was adopted to label zones as the dominant function. This method effectively facilitated the combination of the building’s physical and social functional semantics and realized the recognition of urban functional zones. Compared with previous studies, the method proposed in this paper can accurately describe semantic buildings in complex urban environments. In addition, semantic buildings can be abstracted into functional zones through social functional information, which realizes the recognition of urban functional zones from the bottom to the top, from objects to scenes.
Author Contributions
Funding
Conflicts of Interest
References
- Leichtle, T.; Geiß, C.; Wurm, M.; Lakes, T.; Taubenböck, H. Unsupervised change detection in VHR remote sensing imagery—An object-based clustering approach in a dynamic urban environment. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 15–27. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhu, Q.; Zhang, L. Scene Classification Based on the Multifeature Fusion Probabilistic Topic Model for High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6207–6222. [Google Scholar] [CrossRef]
- Yao, Y.; Liang, Z.; Yuan, Z.; Liu, P.; Bie, Y.; Zhang, J.; Wang, R.; Wang, J.; Guan, Q. A human-machine adversarial scoring framework for urban perception assessment using street-view images. Int. J. Geogr. Inf. Sci. 2019, 33, 2363–2384. [Google Scholar] [CrossRef]
- Heiden, U.; Heldens, W.; Roessner, S.; Segl, K.; Esch, T.; Mueller, A. Urban structure type characterization using hyperspectral remote sensing and height information. Landsc. Urban Plan. 2012, 105, 361–375. [Google Scholar] [CrossRef]
- Hong, Z.; Ming, D.; Zhou, K.; Guo, Y.; Lu, T. Road Extraction from a High Spatial Resolution Remote Sensing Image Based on Richer Convolutional Features. IEEE Access 2018, 6, 46988–47000. [Google Scholar] [CrossRef]
- Li, M. A Review of Remote Sensing Image Classification Techniques: The Role of Spatio-contextual Information. Eur. J. Remote Sens. 2014, 47, 389–411. [Google Scholar] [CrossRef]
- Lu, T.; Ming, D.; Lin, X.; Hong, Z.; Bai, X.; Fang, J. Detecting Building Edges from High Spatial Resolution Remote Sensing Imagery Using Richer Convolution Features Network. Remote Sens. 2018, 10, 1496. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-Scale and Multi-Task Deep Learning Framework for Automatic Road Extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Chen, K.; Jian, P.; Zhou, Z.; Guo, J.; Zhang, D. Semantic Annotation of High-Resolution Remote Sensing Images via Gaussian Process Multi-Instance Multilabel Learning. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1285–1289. [Google Scholar] [CrossRef]
- Tokarczyk, P.; Wegner, J.D.; Walk, S.; Schindler, K. Features, Color Spaces, and Boosting: New Insights on Semantic Classification of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 280–295. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Zhang, L.; Benediktsson, J.A. A Novel Automatic Change Detection Method for Urban High-Resolution Remotely Sensed Imagery Based on Multiindex Scene Representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 609–625. [Google Scholar] [CrossRef]
- Zhu, Q.; Sun, X.; Zhong, Y.; Zhang, L. High-Resolution Remote Sensing Image Scene Understanding: A Review. In Proceedings of the IGARSS 2019, 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3061–3064. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; Association for Computing Machinery: San Jose, CA, USA, 2010; pp. 270–279. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Bei, Z.; Xia, G.S.; Zhang, L. Bag-of-Visual-Words Scene Classifier with Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1–5. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Yi, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Zhang, X.; Du, S. A Linear Dirichlet Mixture Model for decomposing scenes: Application to analyzing urban functional zonings. Remote Sens. Environ. 2015, 169, 37–49. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Negri, R.G.; Silva, E.A.; Casaca, W. Inducing Contextual Classifications with Kernel Functions Into Support Vector Machines. IEEE Geosci. Remote Sens. Lett. 2018, 15, 962–966. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Gao, L. Adaptive Spatial-Scale-Aware Deep Convolutional Neural Network for High-Resolution Remote Sensing Imagery Scene Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4736–4739. [Google Scholar]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Context-Enabled Extraction of Large-Scale Urban Functional Zones from Very-High-Resolution Images: A Multiscale Segmentation Approach. Remote Sens. 2019, 11, 1902. [Google Scholar] [CrossRef]
- Srivastava, S.; Vargas-Muñoz, J.E.; Tuia, D. Understanding urban landuse from the above and ground perspectives: A deep learning, multimodal solution. Remote Sens. Environ. 2019, 228, 129–143. [Google Scholar] [CrossRef]
- Zhao, W.; Bo, Y.; Chen, J.; Tiede, D.; Blaschke, T.; Emery, W.J. Exploring semantic elements for urban scene recognition: Deep integration of high-resolution imagery and OpenStreetMap (OSM). ISPRS J. Photogramm. Remote Sens. 2019, 151, 237–250. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Wang, Q.; Emery, W.J. Contextually guided very-high-resolution imagery classification with semantic segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Zhong, Y.; Wu, S.; Zhao, B. Scene Semantic Understanding Based on the Spatial Context Relations of Multiple Objects. Remote Sens. 2017, 9, 1030. [Google Scholar] [CrossRef]
- Qi, K.; Yang, C.; Hu, C.; Guan, Q.; Tian, W.; Shen, S.; Peng, F. Polycentric Circle Pooling in Deep Convolutional Networks for High-Resolution Remote Sensing Image Recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 632–641. [Google Scholar] [CrossRef]
- Jozdani, E.S.; Johnson, A.B.; Chen, D. Comparing Deep Neural Networks, Ensemble Classifiers, and Support Vector Machine Algorithms for Object-Based Urban Land Use/Land Cover Classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Zheng, Z. Heuristic sample learning for complex urban scenes: Application to urban functional-zone mapping with VHR images and POI data. ISPRS J. Photogramm. Remote Sens. 2020, 161, 1–12. [Google Scholar] [CrossRef]
- Qi, K.; Guan, Q.; Yang, C.; Peng, F.; Shen, S.; Wu, H. Concentric Circle Pooling in Deep Convolutional Networks for Remote Sensing Scene Classification. Remote Sens. 2018, 10, 934. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Zhou, W.; Ming, D.; Lv, X.; Zhou, K.; Bao, H.; Hong, Z. SO–CNN based urban functional zone fine division with VHR remote sensing image. Remote Sens. Environ. 2020, 236, 111458. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A New Method for Region-Based Majority Voting CNNs for Very High Resolution Image Classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Zhai, Y.; Yao, Y.; Guan, Q.; Liang, X.; Li, X.; Pan, Y.; Yue, H.; Yuan, Z.; Zhou, J. Simulating urban land use change by integrating a convolutional neural network with vector-based cellular automata. Int. J. Geogr. Inf. Sci. 2020, 1–25. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Chen, J. Supervised Generative Adversarial Network Based Sample Generation for Scene Classification. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3041–3044. [Google Scholar]
- Fan, R.; Wang, L.; Feng, R.; Zhu, Y. Attention based Residual Network for High-Resolution Remote Sensing Imagery Scene Classification. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1346–1349. [Google Scholar]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Schultz, M.; Voss, J.; Auer, M.; Carter, S.; Zipf, A. Open land cover from OpenStreetMap and remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 206–213. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.R.; Gu, C. Beyond Word2vec: An approach for urban functional region extraction and identification by combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Zhong, C.; Huang, X.; Müller Arisona, S.; Schmitt, G.; Batty, M. Inferring building functions from a probabilistic model using public transportation data. Comput. Environ. Urban Syst. 2014, 48, 124–137. [Google Scholar]
- Mu, L.; Wang, L.; Wang, Y.; Chen, X.; Han, W. Urban Land Use and Land Cover Change Prediction via Self-Adaptive Cellular Based Deep Learning with Multisourced Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5233–5247. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K.; Bragais, M.A.; Endo, I.; Magcale-Macandog, D.B. Employing crowdsourced geographic data and multi-temporal/multi-sensor satellite imagery to monitor land cover change: A case study in an urbanizing region of the Philippines. Comput. Environ. Urban Syst. 2017, 64, 184–193. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Tu, W.; Mai, K.; Yao, Y.; Chen, Y. Functional urban land use recognition integrating multi-source geospatial data and cross-correlations. Comput. Environ. Urban Syst. 2019, 78, 101374. [Google Scholar] [CrossRef]
- Guan, Q.; Ren, S.; Yao, Y.; Liang, X.; Zhou, J.; Yuan, Z.; Dai, L. Revealing the Behavioral Patterns of Different Socioeconomic Groups in Cities with Mobile Phone Data and House Price Data. J. Geo-Inf. Sci. 2020, 22, 100–112. [Google Scholar]
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Jiang, J.; Li, Q.; Li, Q. Portraying Urban Functional Zones by Coupling Remote Sensing Imagery and Human Sensing Data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Hou, J.; Yang, M.; Deng, M. Improving Building Change Detection in VHR Remote Sensing Imagery by Combining Coarse Location and Co-Segmentation. ISPRS Int. J. Geo-Inf. 2018, 7, 213. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S. Learning Self-Adaptive Scales for Extracting Urban Functional Zones from Very-High-Resolution Satellite Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 7423–7426. [Google Scholar]
- Zhang, X.; Du, S.; Wang, Q.; Zhou, W. Multiscale Geoscene Segmentation for Extracting Urban Functional Zones from VHR Satellite Images. Remote Sens. 2018, 10, 281. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Integrating bottom-up classification and top-down feedback for improving urban land-cover and functional-zone mapping. Remote Sens. Environ. 2018, 212, 231–248. [Google Scholar] [CrossRef]
- Johnson, A.B.; Jozdani, E.S. Identifying Generalizable Image Segmentation Parameters for Urban Land Cover Mapping through Meta-Analysis and Regression Tree Modeling. Remote Sens. 2018, 10, 73. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.; Zhou, W.; Bao, H.; Chen, Y.; Ling, X. Farmland Extraction from High Spatial Resolution Remote Sensing Images Based on Stratified Scale Pre-Estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef]
- Zhou, K.; Ming, D.; Lv, X.; Fang, J.; Wang, M. CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data. Remote Sens. 2019, 11, 2065. [Google Scholar] [CrossRef]
- Guo, X.; Li, X.; Li, L.; Dong, Q. An Efficient Image Quality Assessment Guidance Method for Unmanned Aerial Vehicle. In Intelligent Robotics and Applications; Yu, H., Liu, J., Liu, L., Ju, Z., Liu, Y., Zhou, D., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 52–62. [Google Scholar]
- Ming, D.; Li, J.; Wang, J.; Zhang, M. Scale parameter selection by spatial statistics for GeOBIA: Using mean-shift based multi-scale segmentation as an example. ISPRS J. Photogramm. Remote Sens. 2015, 106, 28–41. [Google Scholar] [CrossRef]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef]
- Du, S.; Zhang, X.; Luo, G. Urban scene classification with VHR images. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Sun, S.; Chen, Q. Hierarchical Distance Metric Learning for Large Margin Nearest Neighbor Classification. Int. J. Pattern Recognit. Artif. Intell. 2011, 25, 1073–1087. [Google Scholar] [CrossRef]
- Bailey, T.; Jain, A.K. A Note on Distance-Weighted k-Nearest Neighbor Rules. IEEE Trans. Syst. Man Cybern. 2007, 8, 311–313. [Google Scholar]
- Tsyurmasto, P.; Zabarankin, M.; Uryasev, S. Value-at-risk support vector machine: Stability to outliers. J. Comb. Optim. 2014, 28, 218–232. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Chen, Y.; Ming, D.; Lv, X. Superpixel based land cover classification of VHR satellite image combining multi-scale CNN and scale parameter estimation. Earth Sci. Inform. 2019, 12, 341–363. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Yuan, Z. Semantic and Spatial Co-Occurrence Analysis on Object Pairs for Urban Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2630–2643. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale Sequence Joint Deep Learning (SS-JDL) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Qi, K.; Yang, C.; Guan, Q.; Wu, H.; Gong, J. A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification. Remote Sens. 2017, 9, 917. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zhao, J. Multi-Scale Enhanced Deep Network for Road Detection. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3947–3950. [Google Scholar]
- He, D.; Zhong, Y.; Zhang, L. Spectral-Spatial-Temporal MAP-Based Sub-Pixel Mapping for Land-Cover Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1696–1717. [Google Scholar] [CrossRef]
- Wei, L.; Yu, M.; Zhong, Y.; Zhao, J.; Liang, Y.; Hu, X. Spatial–Spectral Fusion Based on Conditional Random Fields for the Fine Classification of Crops in UAV-Borne Hyperspectral Remote Sensing Imagery. Remote Sens. 2019, 11, 780. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, P.; Hong, Y.; Liang, Z.; Wang, R.; Guan, Q.; Chen, J. Fine-scale intra- and inter-city commercial store site recommendations using knowledge transfer. Trans. GIS 2019, 23, 1029–1047. [Google Scholar] [CrossRef]
- Chen, J.; Han, Y.; Wan, L.; Zhou, X.; Deng, M. Geospatial relation captioning for high-spatial-resolution images by using an attention-based neural network. Int. J. Remote Sens. 2019, 40, 6482–6498. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zones | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hs | 24 | 43 | 40 | 38 | 38 | 40 | 22 | 37 | 40 | 38 | 37 | 39 |
| hr | 6 | 5 | 7 | 5 | 7 | 7 | 6 | 8 | 8 | 8 | 7 | 7 |
| M | 144 | 462 | 400 | 361 | 361 | 400 | 121 | 342 | 400 | 361 | 342 | 380 |
| Category | Building | Vegetation | Soil | Shadow | Road | Grass | Water |
|---|---|---|---|---|---|---|---|
| Training | 3498 | 1956 | 1329 | 2678 | 2668 | 160 | 339 |
| Validation | 875 | 489 | 331 | 700 | 672 | 40 | 85 |
| Category | Building | Tree | Soil | Shadow | Road | Grass | Water |
|---|---|---|---|---|---|---|---|
| Number | 2075 | 1055 | 100 | 550 | 1010 | 125 | 95 |
| Category | UrbanGreen | Industrial Districts | Public Services | Residential Districts | Commercial Districts | Hospitals | Schools | Shanty Towns |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 1.0 | 0.978 | 0.915 | 0.976 | 0.972 | 1.0 | 1.0 | 1.0 |
| Scale | 15 | 35 | 55 | 75 | 95 | 115 | 135 | 155 | 175 | 195 |
|---|---|---|---|---|---|---|---|---|---|---|
| Original (%) | 0.858 | 0.916 | 0.923 | 0.934 | 0.942 | 0.930 | 0.936 | 0.946 | 0.939 | 0.938 |
| Original + DEFM (%) | 0.867 | 0.927 | 0.937 | 0.951 | 0.962 | 0.952 | 0.96 | 0.97 | 0.965 | 0.963 |
| Difference (%) | 0.9 | 1.1 | 1.4 | 1.7 | 2.0 | 2.2 | 2.4 | 2.4 | 2.6 | 2.5 |
| Methods | Random Forest | AlexNet | DFCNN |
|---|---|---|---|
| Accuracy of Allover (%) | 80.99 | 94.87 | 96.65 |
| Accuracy of Buildings (%) | 67.90 | 93.30 | 97.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, H.; Ming, D.; Guo, Y.; Zhang, K.; Zhou, K.; Du, S. DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data. Remote Sens. 2020, 12, 1088. https://doi.org/10.3390/rs12071088
Bao H, Ming D, Guo Y, Zhang K, Zhou K, Du S. DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data. Remote Sensing. 2020; 12(7):1088. https://doi.org/10.3390/rs12071088
Chicago/Turabian StyleBao, Hanqing, Dongping Ming, Ya Guo, Kui Zhang, Keqi Zhou, and Shigao Du. 2020. "DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data" Remote Sensing 12, no. 7: 1088. https://doi.org/10.3390/rs12071088
APA StyleBao, H., Ming, D., Guo, Y., Zhang, K., Zhou, K., & Du, S. (2020). DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data. Remote Sensing, 12(7), 1088. https://doi.org/10.3390/rs12071088