1. Introduction
Since the introduction of perceptron by Rosenblatt in 1958 [
1], numerous studies in almost all scientific fields have been conducted to apply neural network models and test their performances. Starting with the first pioneering study of Benediktsson et al. [
2], artificial neural networks (ANNs) have been extensively used in remote sensing fields, frequently for the supervised classification of remotely sensed images in the production of thematic maps [
3,
4,
5,
6]. Historical development reveals that ANNs were initially applied for comparative studies with conventional classifiers (e.g., maximum likelihood classifier), and later with other machine learning algorithms (e.g., support vector machines, random forest) for a wide range of problems [
7,
8,
9,
10,
11]. In the last decade, new and advanced satellite sensors were launched, producing a vast amount of data repeatedly, at a higher number of bands. Both spatial and spectral resolutions of the sensors have increased; thus, the selection of the most appropriate data as inputs, known as feature selection, has become a more critical issue, particularly for neural networks. For this purpose, the pruning of neural networks has been suggested as an alternative to existing statistical methods [
12,
13,
14,
15].
The topology of Multi-Layer Perceptron (MLP) networks includes three types of layers called input, hidden, and output layers, each consisting of fully interconnected processing nodes, except that there are no interconnections between the nodes within the same layer. These networks typically have one input layer, one or more hidden layers, and one output layer. The input layer nodes correspond to individual data sources, which can be either spectral bands or other sources of data. The output nodes correspond to the desired classes of information, such as land use/land cover (LULC) classes in classification. Hidden layers are required for computational purposes. The values at each node are estimated through the summation of the multiplications between previous node values and weights of the links connected to that node. Since the nodes on input and output layers are usually pre-defined, except for the feature selection case where some irrelevant or highly correlated inputs are eliminated, the number of hidden layers and their nodes are the unknown hyper-parameters in the network, the choice of which directly affects the performance and generalization capabilities of the network. Several heuristics and formulations have been suggested in literature to estimate the optimal size for the hidden layer(s), but there is no universally accepted method that exists for estimating the optimal number of hidden layer nodes for a particular problem [
16,
17,
18,
19]. The use of ANNs in remote sensing has been reviewed by several studies, including [
17,
19,
20,
21]. Furthermore, the limitations and crucial issues in the application of neural networks have been discussed in [
17,
19,
21,
22].
Several approaches or methods exist in literature for the construction of optimal network architecture in addition to the heuristics mentioned above. These methods can be categorized as exhaustive search algorithms, also known as brute-force, constructive, pruning, and a combination of these methods. In the brute-force approach, after many small network architectures are formed and trained, the best smallest architecture producing the lowest error level or the highest accuracy for the dataset is selected. This approach is computationally expensive since many networks must be trained to obtain a solution [
22,
23]. Constructive methods start with a small network and add new hidden nodes to the network after each epoch if the training error or the proposed accuracy is not at the acceptable level. On the other hand, pruning methods work opposite to the constructive methods, in that a large network is selected and unimportant or ineffective links and/or hidden layer nodes are removed. Thus, overfitting to the training data can be avoided. These methods have the advantages of both small and large networks. For a start, the user has to determine the initial large network structure for the problem and the stopping criterion to end the training process. It was reported that training a large network and then pruning it is advantageous and favorable compared to that of training a small network [
17,
24]. There are also hybrid methods, also known as growing and pruning methods, that can both add and remove hidden layer units [
25,
26,
27,
28]. These methods are less popular due to the training of small networks suffering from the noisy fitness evaluation problem, and they are likely to be stuck into a local minimum together with a longer training time requirement.
The design of a neural network is not a simple task. The number of nodes in the hidden layer(s) should be large enough for the correct representation of the problem, but at the same time low enough to have adequate generalization capabilities [
29]. The optimum number of hidden layer nodes depends on various factors including the numbers of input and output units, the number of training cases, the complexity of the classification to be learned, the level of noise in the data, the network architecture, the nature of the hidden unit activation function, the training algorithm, and regularization [
30]. It is impractical to state that neural network topology is minimal and optimal since the optimality criteria actually varies for each problem under consideration [
31]. If the network is too small, it cannot learn from the data, resulting in a high training error, which is a characteristic of underfitting. Small networks can have better generalization capabilities, but there is a risk of not learning the problem under consideration due to the insufficient number of processing elements [
23,
32]. On the other hand, if the network is too large, a well-known overfitting problem occurs. In other words, it becomes over-specific to the training data and likely to fail with the test data, producing lower classification accuracies. However, large networks have better fault tolerance [
33]. Ideally, a close correspondence between training and testing errors is desired [
34]. From the above argument, it can be concluded that a large network should be preferred to a small one since underfitting is a more serious issue than overfitting as it can be avoided using training strategies and pruning techniques by downsizing the network wisely. The optimum structure for a neural network should be large enough to learn the underlying characteristics of the problem and small enough to generalize for other datasets [
17,
32]. The motivation in this study is to not only remove some interconnections or eliminate some hidden layer neurons to improve generalization capabilities, but also to reduce the dimension of the input layer by eliminating the least effective and correlated spectral bands, and thus achieve improved performance. This is particularly important for the processing of hyperspectral images that comprise many correlated and sometimes irrelevant spectral bands for the problem under consideration.
Sildir and Aydin [
35] suggested using a mixed-integer programming method in order to optimally and simultaneously design and train ANNs via superstructure optimization and parameter identifiability. In this study, a similar superstructure-based optimization technique is proposed for the classification of two benchmark hyperspectral images. The first essential part of the suggested method is to set up the superstructure formulation where inputs, number of neurons, and connections between inputs, hidden neurons, and outputs are all binary decision variables. At the same time, standard ANN parameters, e.g., connection weights, can take continuous values. This strong formulation brings about a mixed-integer program, usually, a nonlinear one (MINLP), which has to be solved with respect to a certain design metric. As a result, ‘redundant’ input variables, neurons, and connections for larger datasets are eliminated automatically.
In addition to the superstructure formulation, we also suggest integrating the use of statistical measures, namely parameter uncertainty for the purpose of enhancing the prediction performance of ANNs. This statistical approach takes the covariance of ANN parameters into account and integrates the measure with the objective function of the training algorithm. To the best of authors’ knowledge, this paper is the first application of such an optimal and robust ANN algorithm addressing the classification of remotely sensed imagery. In addition to this novel application concept, extra linking constraints are added to this newer formulation that forces the optimization algorithm not to iterate for the continuous variables when certain binary variables are equal to zero, which in turn decreases the computational load of the resulting mixed-integer type ANN related problems significantly.
3. Optimal ANN Structure Detection and Training Methodology
Typical ANN structures usually contain a single hidden layer in addition to input and output layers containing identity activation functions. All those layers are fully connected in a traditional sense. The expression for a typical fully connected ANN (FC-ANN) is given by:
where
A,
B,
C, and
D are continuous weights with proper dimensions;
f1 and
f2 are output and hidden layer activation functions, respectively. For classification problems, the selected output activation function usually used for normalization. The softmax function is a typical example among other alternatives [
39]. Note that the output activation function also calculates the individual probabilities for the classification problems, whereas the hidden layer activation function is not necessarily limited to normalization.
For an FC-ANN, the weights are traditionally assigned as non-zero in order to represent the connections among the neural network variables and layers. Those weights are estimated in the training by nonlinear optimization through the solution of:
where
N is the number of training samples;
is the
ith sample vector;
is the
ith input vector. Note that Equation (2) might also include additional box constraints to either reduce the search space for the training of ANNs or for specifically tailoring the training formulation.
As mentioned above, the solution of Equation (2) is usually obtained via programming a non-linear optimization problem (NLP). This solution delivers the FC-ANN weights (continuous variables), which minimize the training error without considering parameter identifiability issues, architecture orientation, and overfitting. In theory, as the number of decision variables and connections increases, the ANN training formulation should generate more flexibility, which in turn enhances the representative nature of ANNs on more complex datasets. The numbers of outputs, inputs, and hidden layer neurons together represent the number of decision variables. Traditionally, the structural hyper-parameters including the number of neurons, contained layers with the neurons, and the activation functions are manually tuned after trial and error. In addition to the structural parameters, the selection of proper input variables is another vital decision that is not included in (2) explicitly. However, it should be noted that complex and large datasets contain a significant amount of correlation and redundancy, especially in the big data era. On the other hand, it should be mentioned that deep neural networks including dropout layers can easily deal with the overfitting issues in a sequential manner. Yet, using deep neural nets is not in the scope of this paper. The integration of the proposed novel structure detection and training algorithm with the deep neural networks, which can be carried out without a loss of generality, is left for a future study.
Once the number of neurons lifts up, the dimension of continuous variables increases proportionally, and more connections are introduced in FC-ANNs. As a result, FC-ANN architecture becomes more challenging to train. Moreover, the optimal estimation of those parameters suffers from identifiability issues when the ANN architecture is poorly designed, or the training data do not contain statistically significant information [
40,
41,
42,
43].
The covariance matrix of the continuous ANN parameters have been adopted as a measure of identifiability in previous studies ([
44]) and is used as a statistical metric in this study, for the elimination of the ANN variables including the number of neurons, connections, and input variables. Once the sum of the elements of the covariance matrix has a higher numerical value, the accompanying uncertainty in that estimated parameter leads to much larger prediction bounds due to the prorogation of uncertainty ([
45]). In addition, a significant amount of computational power might be required for the training of ANNs, since there are many combinations of parameter values resulting in similar training performances.
Sildir and Aydin ([
35]) proposed an MINLP formulation that realizes the optimal training of ANNs via superstructure modifications and parameter identifiability. They showed the contribution of the proposed formulation on regression problems. Results showed that the suggested method increases the predictive capabilities of ANNs with a significant reduction in the ANN superstructure compared to FC-ANNs. The MINLP formulation introduces additional binary variables to the traditional ANN equations in order to detect the optimal ANN architecture and to favor the optimal determination of input variables, hidden neurons, and connections for larger datasets among a maximum ANN structure. The modified one hidden layer ANN output equation is given as follows:
where
is the Hadamard product operator;
and
are matrices with binary values representing the existence of connections. The existence of a particular connection is defined by the binary variable
.
Aij is the continuous weight parameter of the connection between the
jth neuron and the
ith output and can be non-zero only if the connection is decided to exist after solving the training optimization problem. Similarly,
Bij represents the connection between the input and corresponding neurons. In practice, once a particular column of
Bij is zero, then the
jth input does not deliver information to the hidden layer and thus to the outputs as a result of feed-forward design.
and
are the binary vectors defining the existence of the neuron and input, respectively. For instance, if a particular element of
is zero, it makes the corresponding column of
zero, eliminating all the connections from the particular input; thus, the corresponding input is eliminated. These rules are realized via the introduction of extra linking constraints to the formulation, and the resulting problem exhibits a strong mixed-integer program formulation. The training optimization problem is given by:
where
γ is the tuning parameter for the multi-objective optimization;
and
are lower and upper bounds on
A respectively;
and
are lower and upper bounds on
B respectively ([
35]).
, which is a measure of parameter identifiability in this formulation, is the covariance matrix of the estimated ANN weights. Intuitively, diagonal elements of this refer to the variances of the corresponding weight. In theory, those values would increase significantly when overfitting occurs.
The problem given in Equation (4) is a relatively large scale and non-convex MINLP, which is quite challenging to solve to the global optimum. There are various efficient commercial solvers utilizing branch and bound ([
46]), generalized benders decomposition ([
47]), and outer approximation methods ([
48]) for solving convex MINLPs. Nevertheless, solving non-convex MINLPs to global optimality is still an open research area and is not in the scope of this study. We should also mention that both the training and testing performances of the ANNs can be increased dramatically when a global solution algorithm is implemented to solve the problem given in Equation (4).
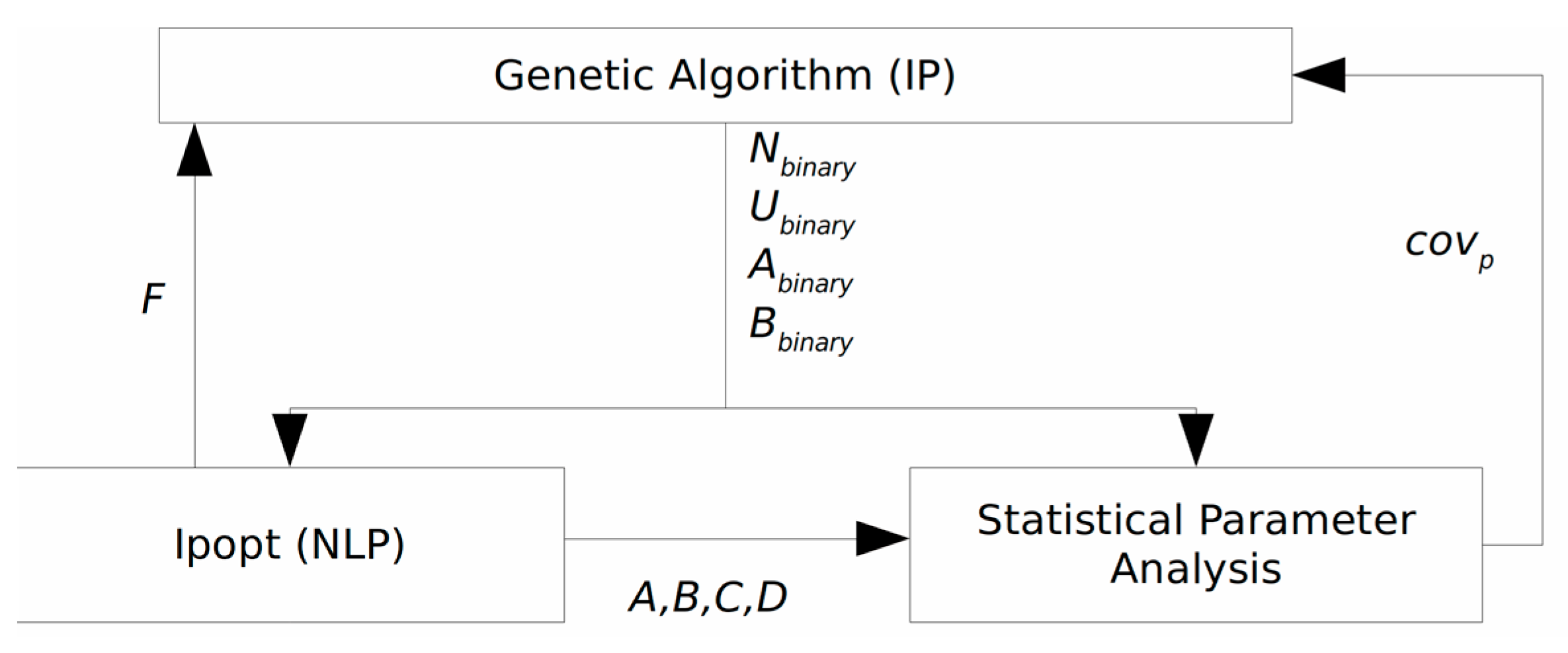
In this work, the adaptive, hybrid evolutionary algorithm suggested in [
35] is used to solve the non-convex MINLP program given by (4). This method decomposes the original MINLP into integer programming (IP) and nonlinear programming (NLP) problems ([
49,
50,
51]). IPs only include integer (or binary) decision variables that can be adjusted during optimization, whereas NLPs only involve continuous decision variables. For detailed information about the aforementioned optimization problems and their solution methods, we refer the reader to [
52]. The IP stands on the outer loop and is solved via the genetic algorithm-based IP solver of Matlab while the inner loop NLP is solved by an interior point-based open source nonlinear programming solver IPOPT ([
53]). Two problems are solved sequentially until the tolerance value of the original problem objective value or the maximum wall clock time is reached. This quasi decomposition feature is usually beneficial for solving large-scale problems. It should be noted that all the experiments in this study were carried out using our in-house programs in Matlab software (v.2019b). The fully connected network (FC) was trained using the Matlab Neural Net Toolbox, implementing a standard back-propagation algorithm for training. A pseudo-algorithm for the mentioned optimal ANN structure detection and training approach is shown in
Table 3. Also, a simplified diagram of the problem solution is shown in
Figure 3.
There are efficient duality-based decomposition algorithms, which have proven to be very powerful for solving non-convex MINLP problems to global optimality. Nevertheless, these methods often require the NLP to be solved to global optimality, which is a challenging task for highly nonlinear relations (e.g., the tanh function of ANNs), and they demand high computational power. Unless the NLP converges to global optima, the decomposition algorithm may converge to an infeasible point or even diverge. On the other hand, these requirements do not usually apply to adaptive black-box optimization methods, with the possible drawback of converging to local optima. As mentioned above, the solution of the suggested ANN training problem to global optimality is not in the scope of this work and is left to a future study.
4. Results
The optimization problem given in Equation (4) was solved for the two public datasets considered in this study. The ANN architecture obtained from Equation (4) is called the optimal superstructure ANN (designated as OS hereafter) whose performance is compared to the fully connected ANN (designated as FC hereafter) to show the contribution of the current approach. Unlike FC, OS contains a significantly smaller number of neurons and connections, produced by eliminating the least effective or redundant hidden neurons, interconnections, and input variables. In order to test the effect of sample sizes used in the training process, 10% and 50% samples of the whole dataset were employed in the processing of FC and OS neural networks. For the Indian Pines dataset, 1082 training samples for the 10% sampling ratio and 5,173 training samples for the 50% sampling ratio using 200 spectral bands as inputs were considered for the prediction of 15 LULC classes.
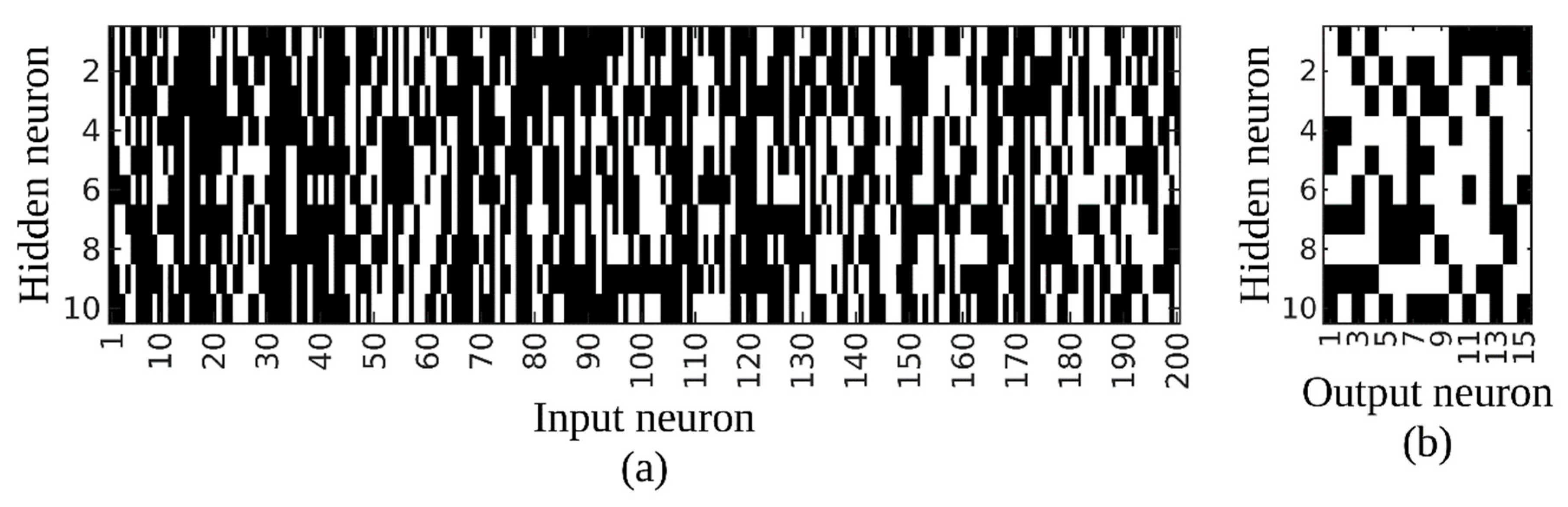
Figure 4 represents the remaining connections within the network with the white color representing a non-zero value, and thus existing connections, and the black color showing the removed connections for the network trained with approximately 10% sampling ratio. Whilst
Figure 4a shows the connections between input and hidden layers,
Figure 4b shows the connections between hidden and output layers. It can be noticed easily that no hidden layer node was removed from the network; thus, only the connections were removed by the proposed method. The final structure of the network was estimated as 158-10-15, indicating that 42 inputs (i.e., spectral bands) that have no connection to any hidden neuron were eliminated, represented by a black column in
Figure 4a. On the other hand, 1,271 of 2,150 connections, representing 61% of the total connections, were also removed from the network to simplify the network and improve its generalization capabilities.
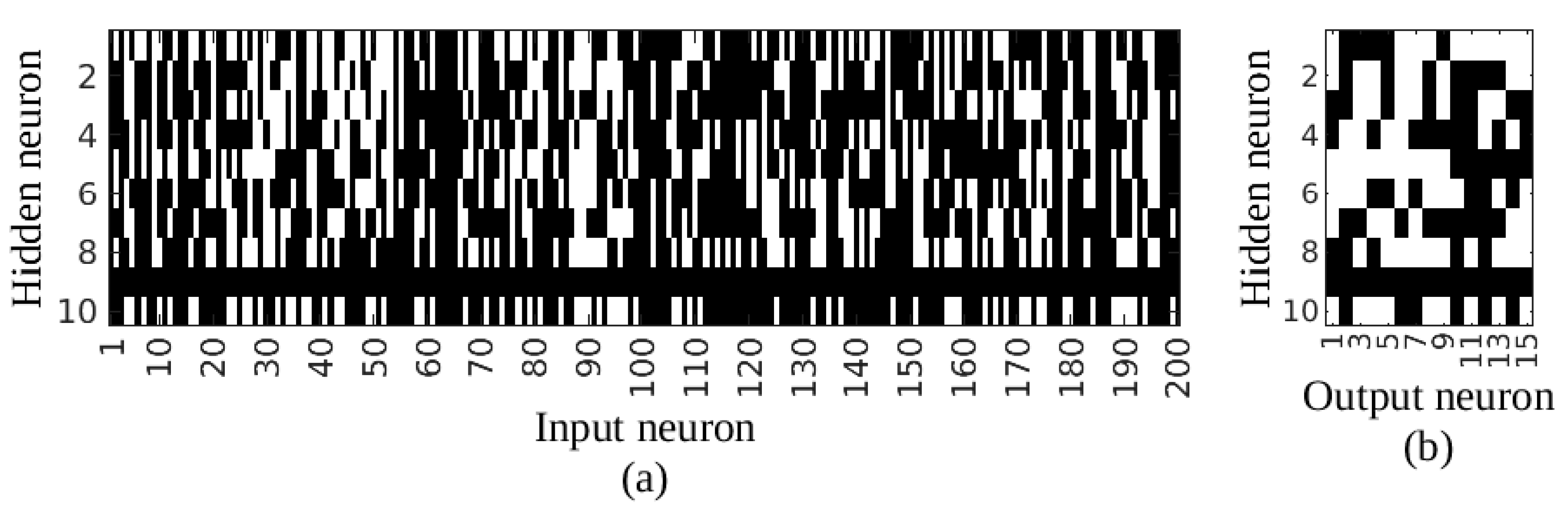
For the 50% sampling ratio, an optimal network superstructure with dimensions of 147-9-15 was calculated through the proposed approach, resulting in a significant reduction compared to the fully connected network of 200-10-15. The result of the process is given in
Figure 5, showing the ultimate connections in the network between input and hidden layers, and hidden and output layers, respectively.
Note that, due to the linking constraints in Equation (4), the connections to and from a neuron are eliminated once a particular neuron is eliminated. In that case, the connection to and from the hidden neuron nine was removed, shown as a black row in
Figure 5a,b. Therefore, it can be said that there is no information flow through the corresponding neuron. Similarly, 53 inputs that have no connection to any hidden neuron were eliminated, represented by a black column in
Figure 5a. As a result, a considerable number of connections were removed from the network. To be more specific, 1413 of 2150 connections (i.e., almost 66% of the total connections) were removed from the network.
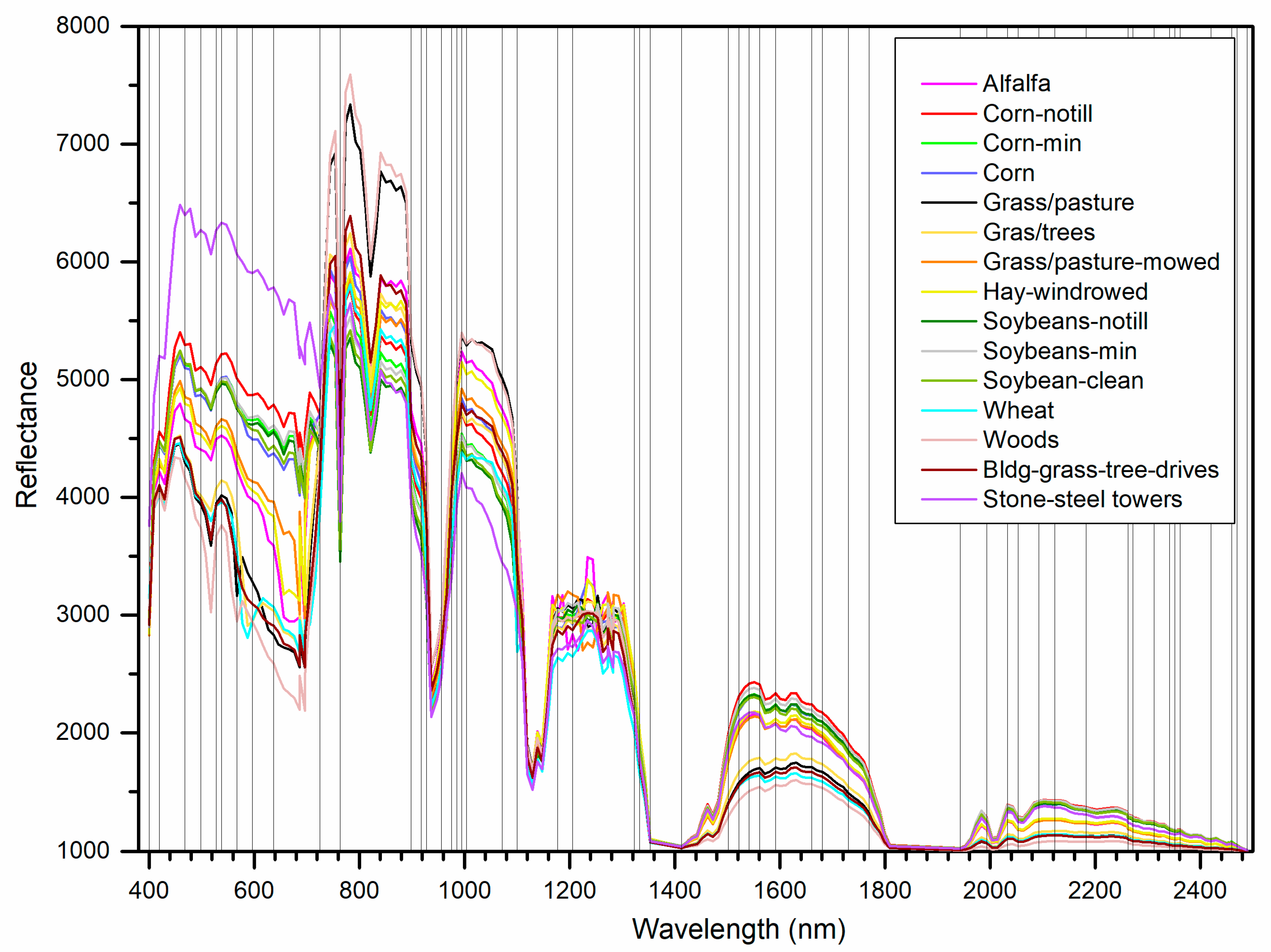
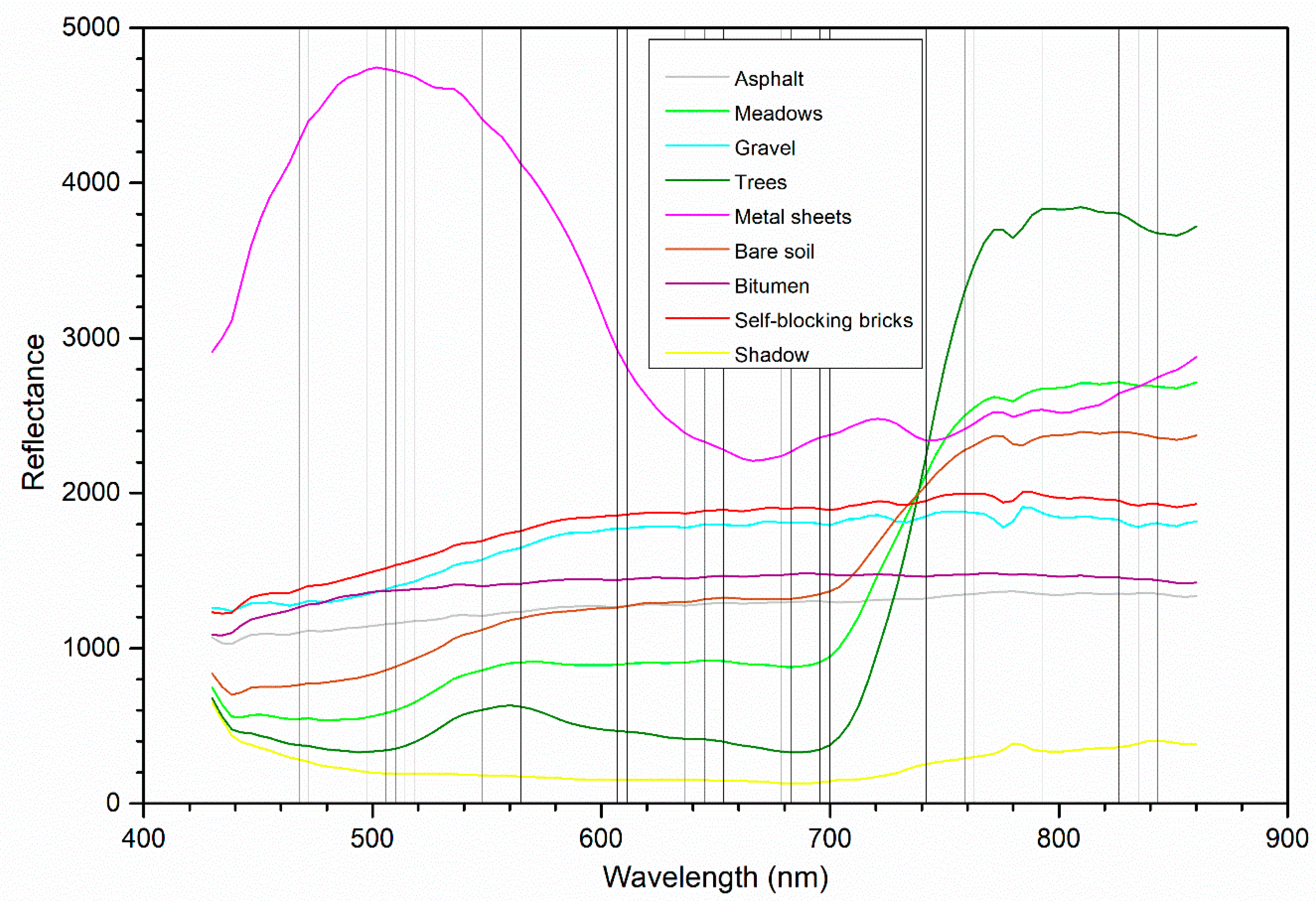
In order to show the position of the eliminated inputs (i.e., spectral bands), mean spectral signatures of 15 LULC classes in the Indian Pines dataset were extracted from the ground reference and the eliminated 53 bands for the 50% sampling ratio were depicted on the figure with vertical lines for further analysis (
Figure 6). Perhaps the most striking result is that the proposed method removed the spectral bands adjacent to the previously eliminated noisy bands from the original datasets. It was also noticed that the algorithm detected some spectral ranges (e.g., 764–898 nm, 1004–1071 nm, 1205–1322 nm, 1591–1660 nm) as more beneficial compared to the others for discriminating the LULC classes. However, the spectral bands at the ranges of 918–1004 nm and 1501–1591 nm that indicate similar reflectance measures with the remaining ones were eliminated. Therefore, it can be concluded that the proposed algorithm removed the bands carrying similar information by considering the change or trend in the spectral curves. It is clear from the figure that most of the vegetation types have similar spectral signatures, but they have a varying range of reflectances at blue, green, near-infrared, and shortwave infrared (~1500–1700 nm) regions. The distinct spectral signature of stone-steel towers class can be also noticed.
For the analyses of the OS and FC networks using the test datasets, individual and overall accuracy measures were calculated (
Table 4). While the F-score measure indicating the harmonic mean of user’s and producer’s accuracies was estimated for individual class accuracy assessment, overall accuracy (OA), Kappa, and weighted Kappa coefficients were used to evaluate the accuracy of the thematic maps. When the 10% sampling strategy was employed, the total number of connections in the network decreased from 2,150 to 879, indicating a 61% shrinkage. Although the network was highly compressed, the overall accuracy increased by about 4%, Kappa and weighted Kappa coefficients increased by about 5%. The performance of the FC network dropped, which is obviously a result of the occurrence of overfitting (over 99% overall accuracy on the training data). In the case of OS, the network was prevented from overfitting to training data. On the other hand, for the 50% sampling case, the overall accuracy decreased from 83.80% to 82.72%, indicating only a 1% decrease in the classification performance by decreasing the size of the network by about 66%. Similar results were calculated for Kappa and weighted Kappa coefficients.
When individual class accuracies estimated for each class were analyzed, some important results were obtained. Firstly, both FC and OS networks produced highly accurate results for some classes, namely grass–trees, hay-windrowed, wheat, woods, and stone-steel towers. However, networks performed poorly for two particular classes, namely corn, and building–grass–trees–drives. The corn class was mostly confused with other corn related classes (i.e., corn-notill and corn-min). The confusion was severe for the fully connected network, producing a 9.92% F-score value for grass-pasture-mowed class, which clearly shows failure in the delineation of this particular cover type. The negative effects of limited and imbalanced data can be easily seen from this class since individual class accuracy varies by about 30% for the 10% sampling case and 11% for the 50% sampling case. The building–grass–trees–drives class covering buildings and their surrounding pervious and impervious features were mainly mixed with the woods class that resulted in a decrease in classification accuracy. Thematic maps produced for the whole dataset using FC and OS networks trained with 50% of whole samples are shown in
Figure 7. Misclassified pixels, particularly for the corn related ones, can be easily observed from the comparison of the thematic maps.
For the Pavia University dataset, a fully connected network of 103-10-9 was optimized throughout the training process to learn the characteristics of the nine LULC classes from 103 spectral bands, and networks of 69-10-9 and 69-7-9 were found optimal in terms of its size and performance for the 10% and 50% sampling ratios, respectively. For the 10% sampling ratio, 697 of 1120 connections were removed from the network, showing a 58% shrinkage. For the 50% sampling ratio, 718 of 1120 links were removed from the network, indicating a 64% shrinkage in the network. For both sampling cases, 34 inputs were removed, indicating a feature selection rate of 33%. In other words, the fully connected network was trimmed by an average of 61%, and 33% of the spectral bands were disregarded as a result of the input selection process. The eliminated and remaining network connections for the 10% sampling ratio were shown in
Figure 8. It can be noticed that a comparably smaller number of connections were removed between hidden and output layers, and none of the hidden layer nodes were removed by the proposed algorithm.
Figure 9 shows the final network connections between the layers for the case of the 50% sampling ratio. The removal of three hidden neurons, namely seven, eight, and nine can be easily noticed from the figure (black horizontal lines). Similar to the results produced for the 10% sampling ratio, a smaller number of connections were removed between hidden and output layers.
For a clear explanation of the eliminated spectral bands, mean spectral signatures of the classes in Pavia University data were obtained from the ground reference and the location of the eliminated 34 spectral bands for the 50% sampling ratio were shown on the same figure with vertical lines (
Figure 10). Similar results with the Indian Pines dataset were observed for the elimination of spectral bands as the highly correlated neighboring bands introducing similar reflectance values were mostly removed from the dataset. The method determines the spectral regions of 573–607, 704–742, and 793–822 nm as discriminating ones for the delineation of the characteristics of the LULC classes. In addition, it removed the spectral bands in the ranges of 468–527 and 607–653 nm. It can be observed that green and red-edge bands were mainly selected for the modeling of the problem. Spectral signature curves also revealed that there were high resemblances between bitumen and asphalt classes, also between gravel and self-blocking bricks classes. Metal sheets and shadow classes had distinct spectral reflectances compared to the other classes. On the other hand, a typical vegetation curve was observed for trees and meadows.
After the training stage for the FC and OS networks, the test data including the rest of the ground reference data for Pavia University were introduced to those networks, and corresponding network performances were presented in
Table 5. With the 10% sampling ratio, the overall accuracy of 87.26%, and a Kappa coefficient of 0.830 were obtained with the optimal superstructure network (OS) while overall accuracy of 84.63% and a Kappa coefficient of 0.796 was achieved by the fully connected network (FC). This clearly shows the robustness of the proposed method, producing about 4% improvement in classification accuracy. With the 50% sampling ratio, the overall accuracy of 89.21% and the Kappa coefficient of 0.856 was obtained with the optimal superstructure network (OS) while the fully connected network (FC) achieved an overall accuracy of 90.76% and Kappa coefficient of 0.877. The accuracy decrease was about 1% for overall accuracy. From these results, it can be stated that the proposed method performs well for a fewer number of samples.
When the individual class accuracies measured by the F-score accuracy measure were analyzed, it was noticed that the lowest accuracies were estimated for the gravel class that was mainly confused with the self-blocking bricks for both FC and OS networks. Similarly, bitumen pixels were confused with asphalt pixels. This is certainly related to the spectral similarity of the corresponding classes that can be easily observed from the mean spectral reflectance curves (spectral signatures) given in
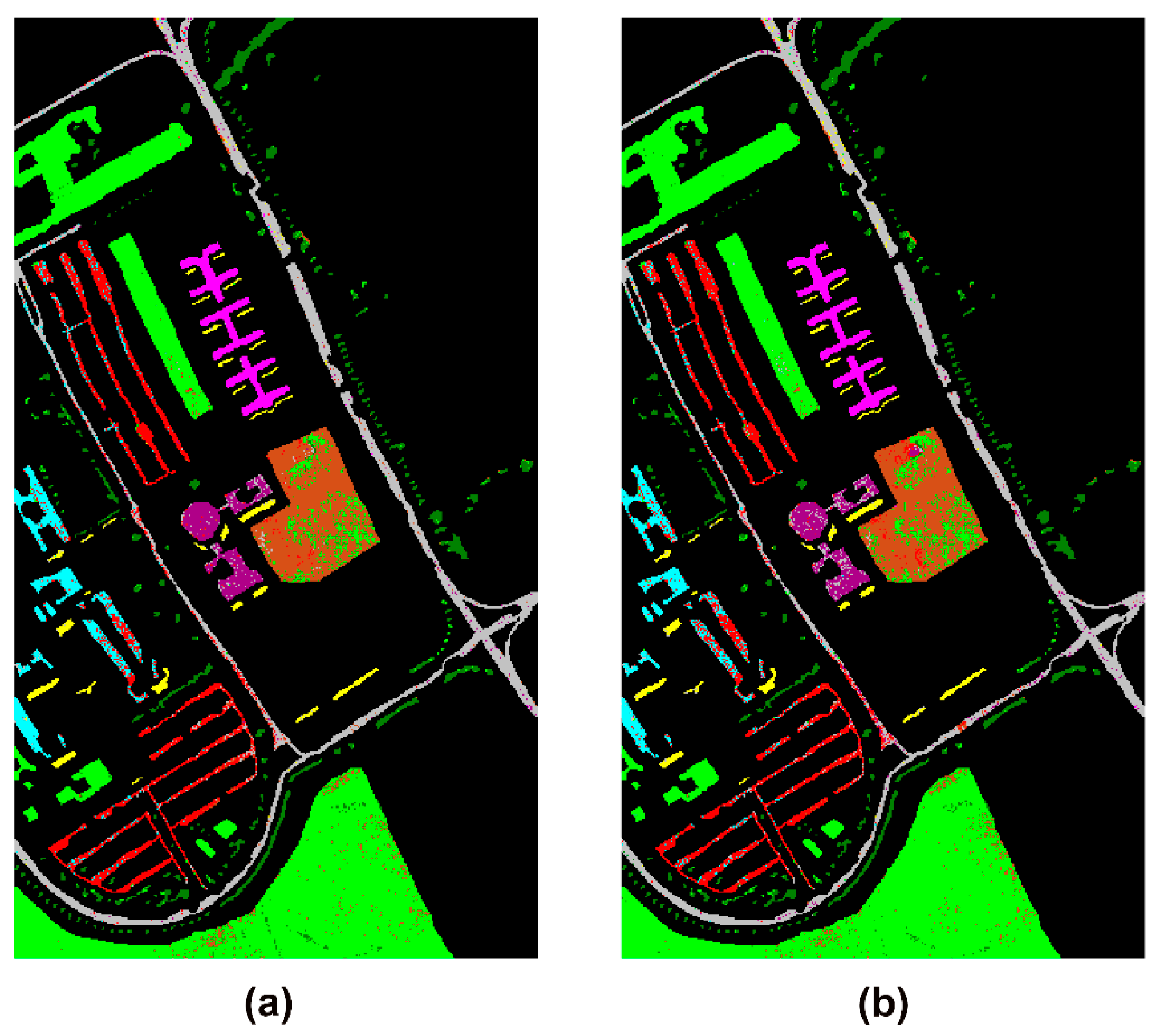
Figure 10. The highest individual class accuracy was achieved for the metal sheets class (over 99%), which has a distinct spectral signature compared to the other classes. The trained networks using the 50% sampling ratio were applied to the whole image to produce the thematic maps of the study, which is presented in
Figure 11. Confusion in the class definition for the above-mentioned classes can be observed clearly from the figure. The mixture of gravel and self-blocking bricks pixels is quite obvious in the thematic map produced with the OS network (
Figure 11b). Moreover, misclassified pixels within the meadows and asphalt fields are in the form of “salt-and-pepper” noise.
Performances of the FC and OS networks for both datasets were summarized in
Table 6. For the considered datasets, no hidden neuron was removed from the networks when limited training data (only 10% of the whole datasets) were considered. When the 50% sampling ratio was employed in the training phase, one hidden neuron was eliminated from the FC network for the Indian Pines data and three hidden neurons were removed for the Pavia University data. Smaller networks were found sufficient to learn the underlying characteristics of the LULC classes, and for both cases, the initial networks were trimmed by about 60% in terms of the total number of links, which can be regarded as a success of the proposed algorithm. In addition, a considerable number of inputs (i.e., spectral bands) were removed from the datasets, achieving even better classification performances (about 4% overall accuracy difference). With the implementation of the proposed superstructure optimization, the networks avoided overfitting, thus producing higher classification accuracies for the limited training data (i.e., 10% sampling ratio). It should be mentioned that the FC networks had low generalization capabilities, producing very high accuracy for the training data but comparatively lower accuracies for the test data. The obtained results are promising for the proposed algorithm, being a good alternative to feature selection methods, especially the statistical ones.
values in the table indicate the level of overfitting that occurred in the training process. The computed values were much higher for the fully connected networks, particularly the one calculated for the Indian Pines data. Finally, it should be also mentioned that the multiply accumulates (MACS) are directly proportional to the number of connections; therefore, they can be estimated from
Table 6.
The comparison of the CPU times of different sampling ratios for the two datasets is given in
Table 7. All the results were obtained using an Intel Core i5-6400 CPU 2.7 GHz 4 core 16 Gb RAM machine using a Linux operating system. It was observed that the CPU times of the proposed training method were larger than the FCs because of the MINLP programs. MINLPs are known to be NP-hard and cannot be solved in polynomial time, whereas standard training algorithms (NLPs) are P-only types. Therefore, the required computational time can be much higher for the proposed method. On the other hand, reduced and optimal ANN structures should result in faster CPU times since the number of required multiplication operations is much lower, which might also be a beneficial feature for testing larger ANNs, e.g., deep neural networks.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}