Axis Learning for Orientated Objects Detection in Aerial Images


Abstract

1. Introduction
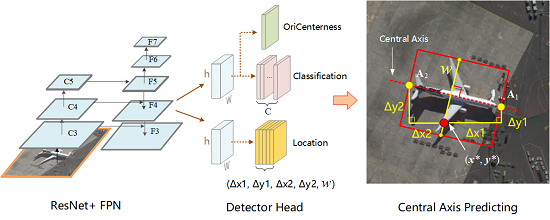
- We propose a new one-stage anchor-free detector for orientated objects, which locates objects by predicting their axis and width. This detector not only simplifies the format of detection but also avoids elaborating hyperparameters, and reduces the computational complexity compared with anchor-based methods.
- We design a new aspect-ratio-aware orientation centerness method to better weigh the importance of positive pixel points in different scale and aspect ratio labeled boxes, thus the method is able to learn discriminative features to distinguish foreground objects from a complex background.
2. Materials and Methods
2.1. Data
- DOTA [5] is a large dataset for both horizontal and orientated object detection in aerial images. The dataset contains 2806 aerial images with different sensors, resolutions, and perspectives. Image size ranges from around to pixels. The dataset consists of 15 categories of objects and 188,282 instances total, including Plane, Ship, Bridge, Harbor, Baseball Diamond (BD), Ground Track Field (GTF), Small Vehicle (SV), Large Vehicle (LV), Tennis Court (TC), Basketball Court (BC), Storage Tank (ST), Soccer Ball Field (SBF), Roundabout (RA), Swimming Pool (SP), and Helicopter (HC). Each instance’s location is annotated by a quadrilateral bounding box, which can be denoted as four vertices , and the vertices are arranged in a clockwise order. The dataset consists of training, validation and testing sets. We used both the training and validation sets for training, with 1869 images totally. We divided the images into subimages with sliding windows and 200 pixel overlaps, and no data augmentation is undertaken. Finally, we tested on the testing set by submitting detection results to the DOTA evaluation server.
- HRSC2016 [6]. The dataset was collected from Google Earth, and contains 1061 images with 26 categories of ships with large varieties of scale, position, rotation, shape, and appearance. The image size ranges from 300 × 300 to 1500 × 900, and most of them are greater than 1000 × 600. Following Liu et al. [21], we excluded submarines, hovercrafts, and those annotated with a “difficult” label. Then, the training, validation, and testing datasets contain 431, 175, and 444 images, respectively, and the images are resized to 800 × 800 with no data augmentation. The detection tasks in HRSC2016 include three levels, namely the L1, L2 and L3 tasks, and, for fair comparison, following Liu et al. [6] and Ding et al. [10], we evaluated the proposed method on the L1 task.Description of DOTA and HRSC2016 datasets is shown as Table 1.
2.2. Related Work
2.2.1. Anchor-Based Detector
2.2.2. Anchor-Free Detector
2.3. Method
2.3.1. Network Architecture
2.3.2. Axis Predicting
2.3.3. Pixel Point Assignment
2.3.4. Aspect-Ratio-Aware Orientation Centerness
2.3.5. Loss
2.3.6. Implementation Details
3. Results
4. Discussion
4.1. Effectiveness of OriCenterness
4.2. Speed–Accuracy Trade-Off
4.3. Advantages and Limitations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 39, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for detecting oriented objects in aerial images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 8232–8241. [Google Scholar]
- Liu, X.; Liang, D.; Yan, S.; Chen, D.; Qiao, Y.; Yan, J. FOTS: Fast Oriented Text Spotting with a Unified Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krähenbühl, P. Bottom-up Object Detection by Grouping Extreme and Center Points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. FoveaBox: Beyond Anchor-based Object Detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-Aware Convolutional Neural Network for Object Detection in VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 34–44. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2019. [Google Scholar]
- Wei, H.; Zhou, L.; Zhang, Y.; Li, H.; Guo, R.; Wang, H. Oriented Objects as pairs of Middle Lines. arXiv 2019, arXiv:1912.10694. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Lin, Y.; Feng, P.; Guan, J. IENet: Interacting Embranchment One Stage Anchor Free Detector for Orientation Aerial Object Detection. arXiv 2019, arXiv:1912.00969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–28 July 2017. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. Lect. Notes Comput. Sci. 2019, 150–165. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Categories | Size | Crop Size | Resize Size | Training Images | Instances |
|---|---|---|---|---|---|---|---|
| DOTA [5] | 2806 | 16 | 800 × 800 to 4000 × 4000 | 800 × 800 | - | 18,920 | 261,170 |
| HRSC2016 [6] | 1061 | 26 | 300 × 300 to 1500 × 900 | - | 800 × 800 | 617 | 1652 |
| One-Stage Methods | Backbone | Anchor-Free | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD [2] | SSD | × | 39.83 | 9.09 | 0.64 | 13.18 | 0.26 | 0.39 | 1.11 | 16.24 | 27.57 | 9.23 | 27.16 | 9.09 | 3.03 | 1.05 | 1.01 | 10.59 |
| YOLOv2 [35] | DarkNet-19 | × | 39.57 | 20.29 | 36.58 | 23.42 | 8.85 | 2.09 | 4.82 | 44.34 | 38.35 | 34.65 | 16.02 | 37.62 | 47.23 | 25.5 | 7.45 | 21.39 |
| RetinaNet-R [4] | ResNet-50-FPN | × | 88.92 | 67.67 | 33.55 | 56.83 | 66.11 | 73.28 | 75.24 | 90.87 | 73.95 | 75.07 | 43.77 | 56.72 | 51.05 | 55.86 | 21.46 | 62.02 |
| IENet [31] | ResNet-101-FPN | ✓ | 57.14 | 80.20 | 64.54 | 39.82 | 32.07 | 49.71 | 65.01 | 52.58 | 81.45 | 44.66 | 78.51 | 46.54 | 56.73 | 64.40 | 64.24 | 57.14 |
| Ours | ResNet-101-FPN | ✓ | 79.53 | 77.15 | 38.59 | 61.15 | 67.53 | 70.49 | 76.30 | 89.66 | 79.07 | 83.53 | 47.27 | 61.01 | 56.28 | 66.06 | 36.05 | 65.98 |
| Two-stage methods | backbone | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FR-O [5] | ResNet-101 | 79.09 | 69.12 | 17.17 | 63.49 | 34.20 | 37.16 | 36.20 | 89.19 | 69.60 | 58.96 | 49.4 | 52.52 | 46.69 | 44.80 | 46.30 | 52.93 |
| R-DFPN [36] | ResNet-101-DFPN | 80.92 | 65.82 | 33.77 | 58.94 | 55.77 | 50.94 | 54.78 | 90.33 | 66.34 | 68.66 | 48.73 | 51.76 | 55.10 | 51.32 | 35.88 | 57.94 |
| RCNN [37] | VGG16 | 80.94 | 65.67 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 60.67 |
| RRPN [8] | VGG16 | 88.52 | 71.20 | 31.66 | 59.30 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 61.01 |
| ICN [38] | Cascade ResNet-101 | 81.40 | 74.30 | 47.70 | 70.30 | 64.90 | 67.80 | 70.00 | 90.80 | 79.10 | 78.20 | 53.60 | 62.90 | 67.00 | 64.20 | 50.20 | 68.20 |
| RoI-Transformer [10] | ResNet101-FPN | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| Ours | ResNet-101-FPN | 79.53 | 77.15 | 38.59 | 61.15 | 67.53 | 70.49 | 76.30 | 89.66 | 79.07 | 83.53 | 47.27 | 61.01 | 56.28 | 66.06 | 36.05 | 65.98 |
| Methods | Backbone | Anchor-free | mAP | Resolution |
|---|---|---|---|---|
| Two-stage methods | ||||
| BL2 [21] | ResNet101 | × | 69.60 | half of original size |
| RCNN [37] | VGG16 | × | 73.07 | 800 × 800 |
| RoI Tran [10] | ResNet101 | × | 86.20 | 512 × 800 |
| One-stage methods | ||||
| IENet [31] | ResNet101 | ✓ | 75.01 | 1024 × 1024 |
| Ours wo OriCenterness | ResNet101 | ✓ | 73.91 | 800 × 800 |
| Ours with OriCenterness | ResNet101 | ✓ | 78.15 | 800 × 800 |
| Backbone | OriCenterness | mAP | Plane | Bd | Bridge | GTF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | - | 60.28 | 78.63 | 73.87 | 35.14 | 55.13 | 61.91 | 63.49 | 67.33 | 90.62 | 70.29 | 81.89 | 34.92 | 60.80 | 47.45 | 62.22 | 20.56 |
| ✓ | 64.04 | 79.68 | 73.86 | 37.37 | 57.95 | 62.93 | 65.10 | 67.16 | 90.68 | 76.41 | 82.90 | 45.70 | 58.61 | 53.87 | 60.22 | 48.14 | |
| ResNet101 | - | 65.50 | 79.78 | 75.47 | 36.09 | 59.68 | 68.51 | 69.80 | 74.23 | 90.41 | 78.27 | 83.38 | 44.51 | 59.41 | 55.80 | 66.03 | 41.15 |
| ✓ | 65.98 | 79.53 | 77.15 | 38.59 | 61.15 | 67.53 | 70.49 | 76.30 | 89.66 | 79.07 | 83.53 | 47.27 | 61.01 | 56.28 | 66.06 | 36.05 |
| Methods | Backbone | Anchor-Free | mAP | Tr-Time (s) | Inf-Time (s) | Resolution | Device |
|---|---|---|---|---|---|---|---|
| Two-stage methods | |||||||
| FR-O [5] | VGG-16 | × | 54.13 | 0.221 | 0.102 | 1024 × 1024 | Titan x |
| RoI Tran [10] | ResNet101 | × | 67.74 | 0.236 | 0.084 | 1024 × 1024 | Titan x |
| R3Det [27] | ResNet101 | × | 71.69 | - | 0.250 | 800 × 800 | 2080 Ti |
| One-stage methods | |||||||
| IENet [31] | ResNet101 | ✓ | 57.14 | 0.111 | 0.059 | 1024 × 1024 | 1080 Ti |
| Ours | ResNet50 | ✓ | 64.04 | 0.051 | 0.067 | 800 × 800 | Titan Xp |
| Ours | ResNet101 | ✓ | 65.98 | 0.091 | 0.071 | 800 × 800 | Titan Xp |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Z.; Qian, L.; Shao, W.; Tan, X.; Wang, K. Axis Learning for Orientated Objects Detection in Aerial Images. Remote Sens. 2020, 12, 908. https://doi.org/10.3390/rs12060908
Xiao Z, Qian L, Shao W, Tan X, Wang K. Axis Learning for Orientated Objects Detection in Aerial Images. Remote Sensing. 2020; 12(6):908. https://doi.org/10.3390/rs12060908
Chicago/Turabian StyleXiao, Zhifeng, Linjun Qian, Weiping Shao, Xiaowei Tan, and Kai Wang. 2020. "Axis Learning for Orientated Objects Detection in Aerial Images" Remote Sensing 12, no. 6: 908. https://doi.org/10.3390/rs12060908
APA StyleXiao, Z., Qian, L., Shao, W., Tan, X., & Wang, K. (2020). Axis Learning for Orientated Objects Detection in Aerial Images. Remote Sensing, 12(6), 908. https://doi.org/10.3390/rs12060908