Semi-Automatic Methodology for Fire Break Maintenance Operations Detection with Sentinel-2 Imagery and Artificial Neural Network

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
- Use of Sentinel-2 data instead of Landsat imagery, due to its increased frequency and spatial resolution;
- Identify only a specific kind of operation efficiently, dealing with the phenology and different types of vegetation;
- Use of common vegetation indices and other indices;
- Reduce the previous data used, identifying the maintenance as soon as possible, allowing a classification whenever a new observation is made, as in [15].
- Object-based classification—since an FB is a well-defined area, it will be defined as an object. This approach can—better capture its spatial characteristics;
- Temporal dynamics—the use of time-series allows the determination of the temporal dynamics, which is essential in change detection methods;
- Machine learning—the use of artificial intelligence techniques to enhance the change detection classification.
2. Materials and Methods
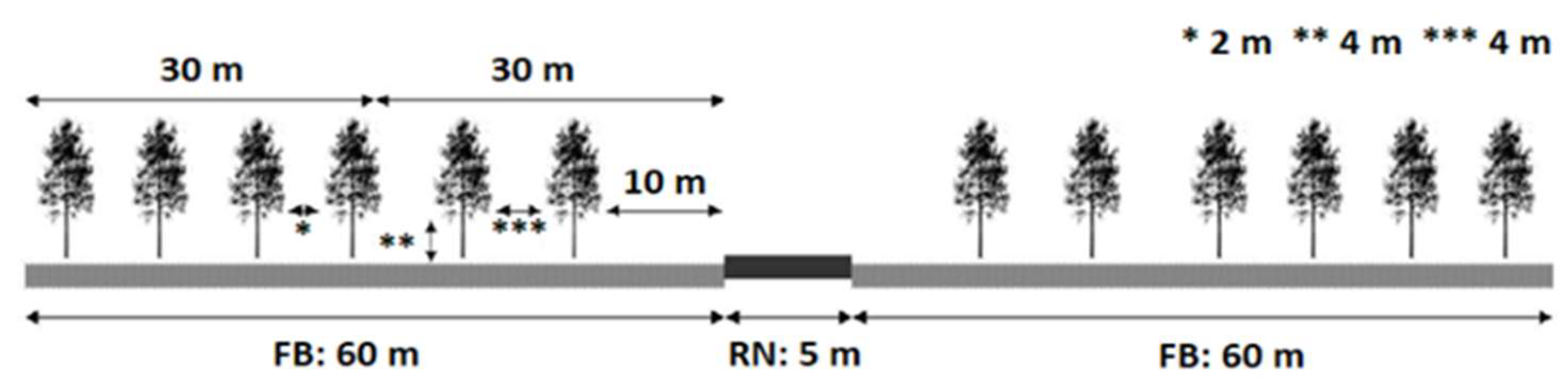
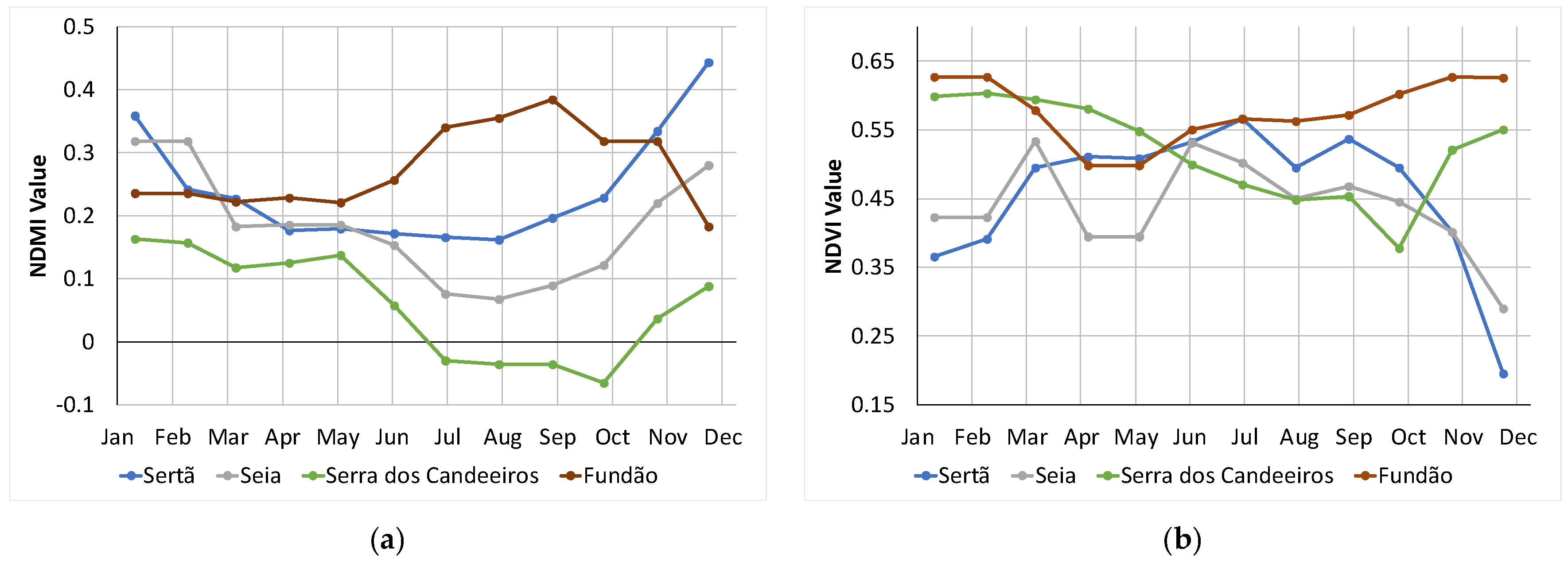
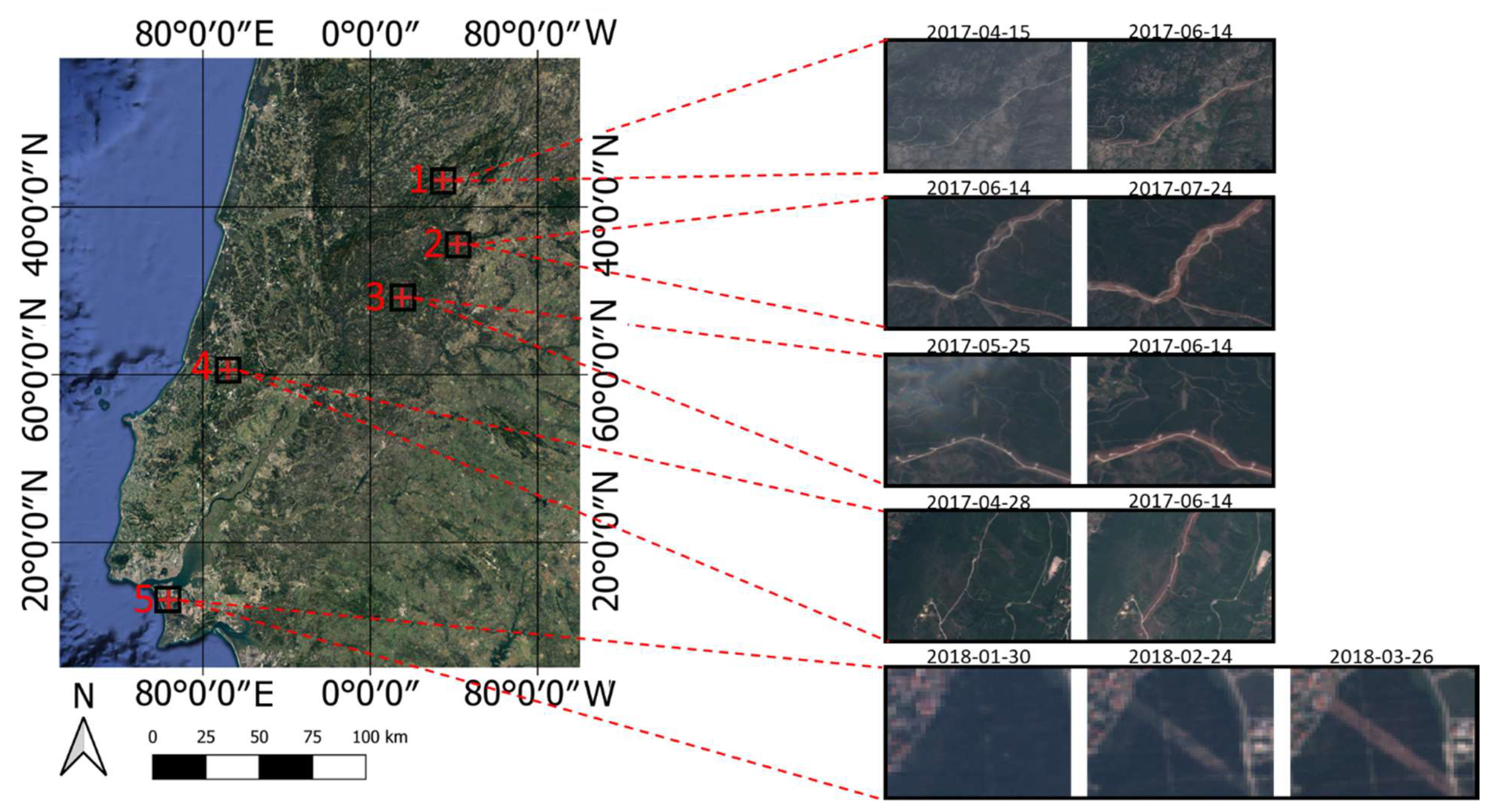
2.1. Study Definition
- Fundão: pinaster and eucalyptus forests and bush areas;
- Marisol: eucalyptus forests;
- Seia: artificial territories and bush areas;
- Serra dos Candeeiros: agricultural zones and bush areas;
- Sertã: bush areas.
2.2. Materials and Datasets
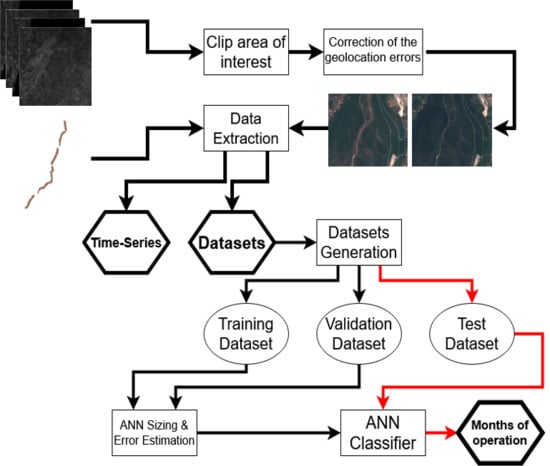
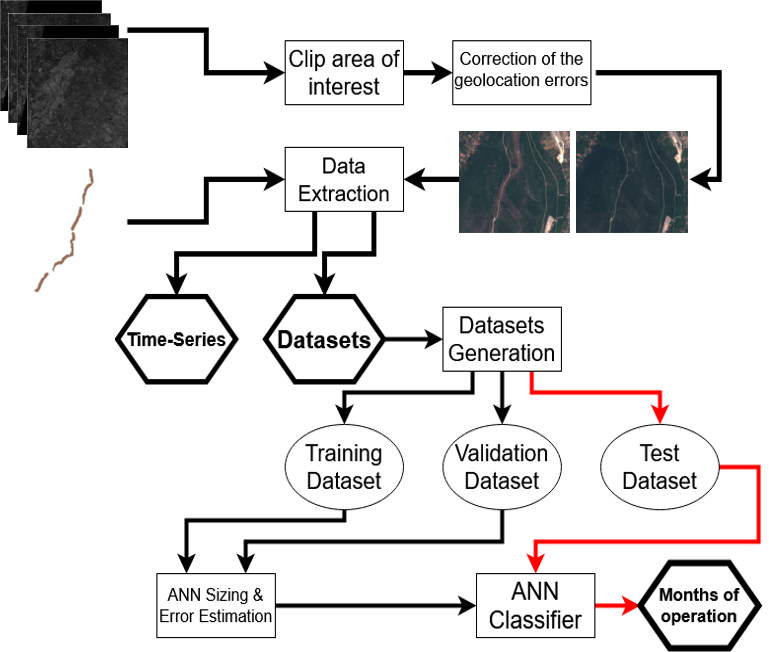
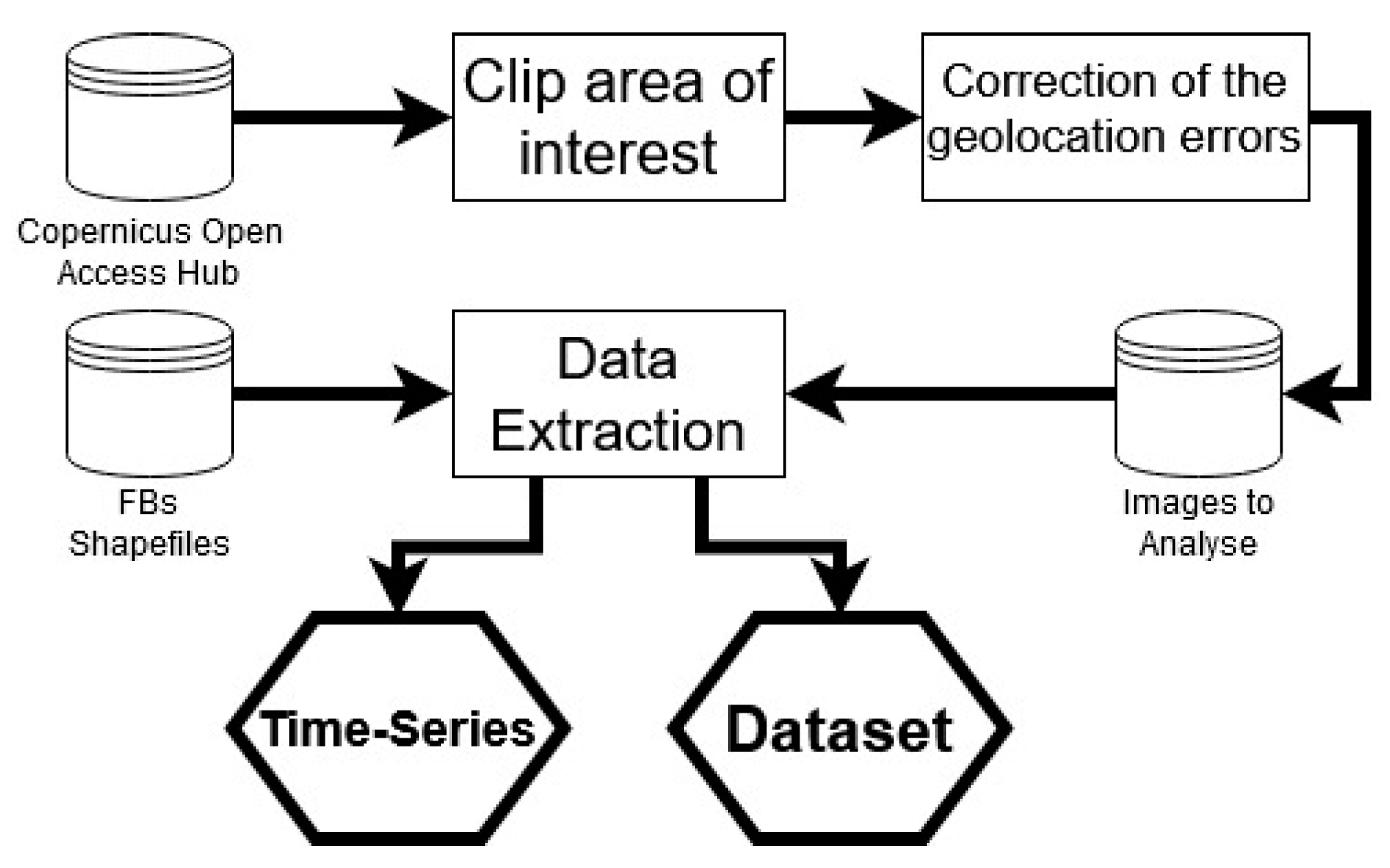
2.3. Data Extraction
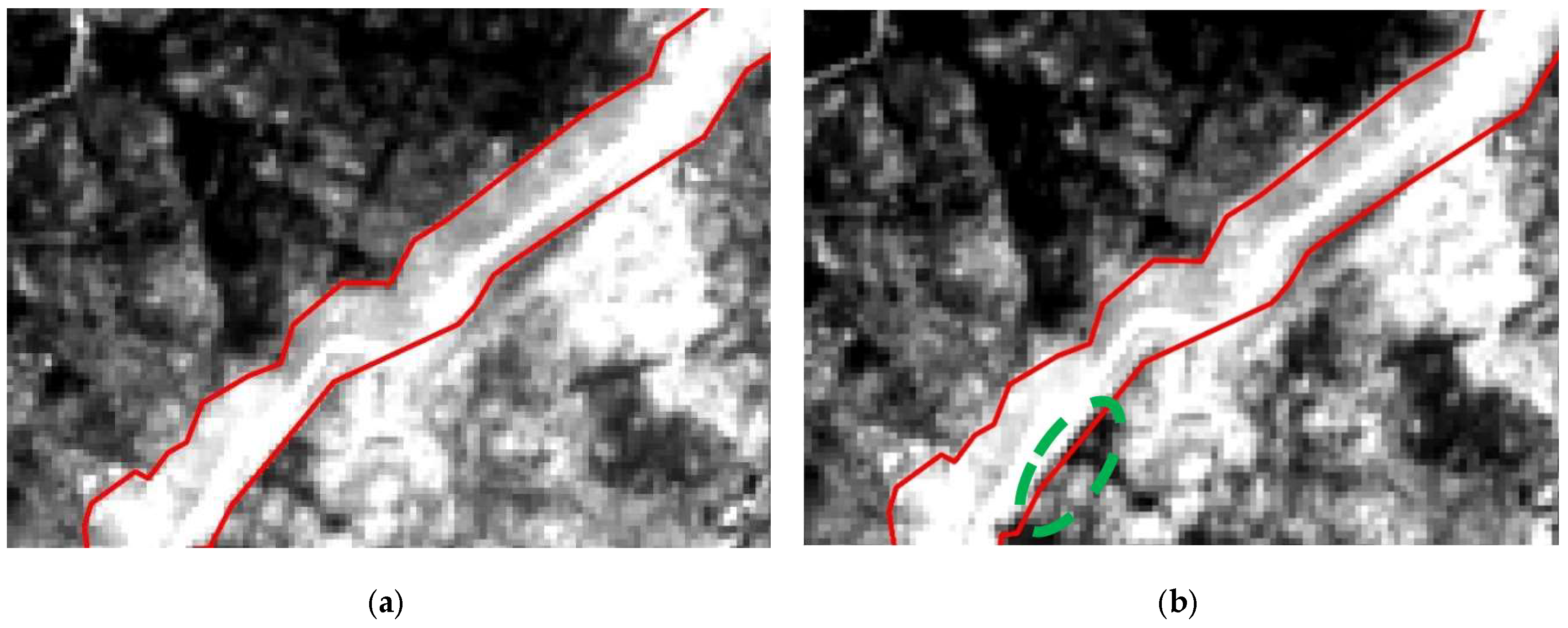
2.3.1. Geolocation Correction
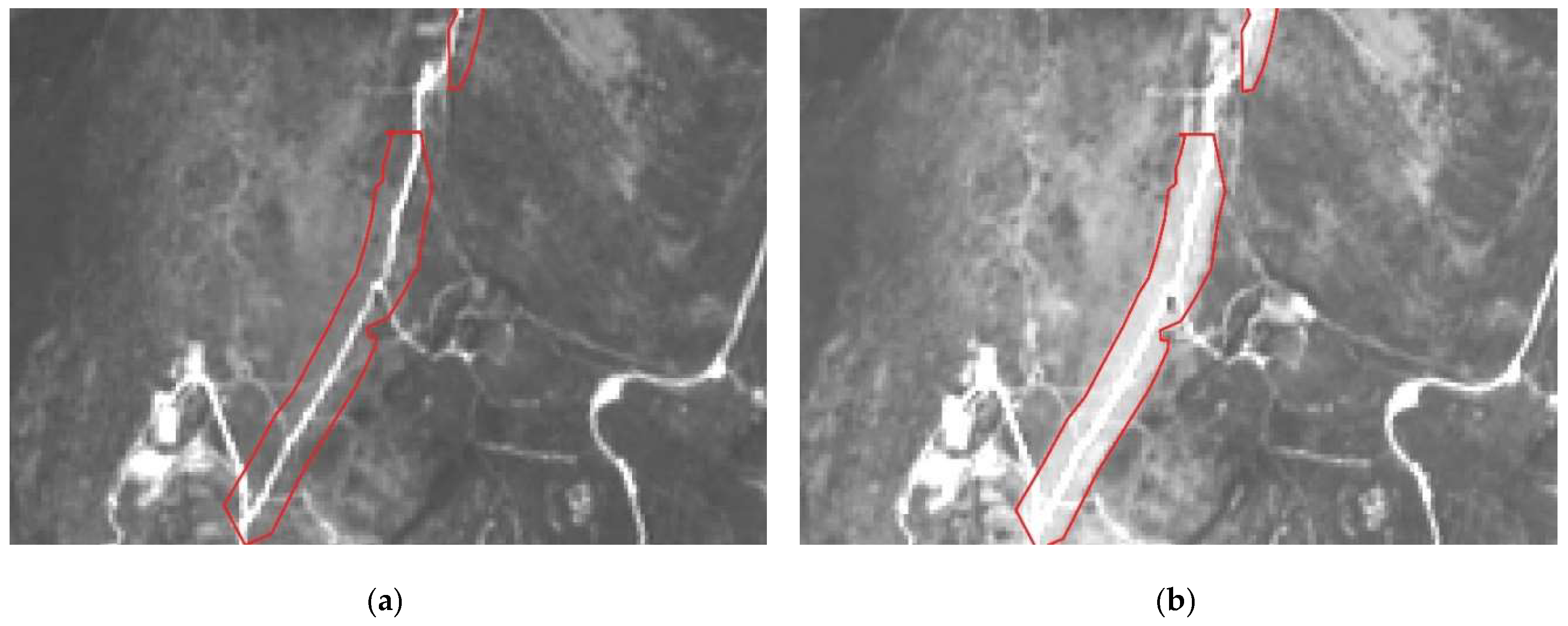
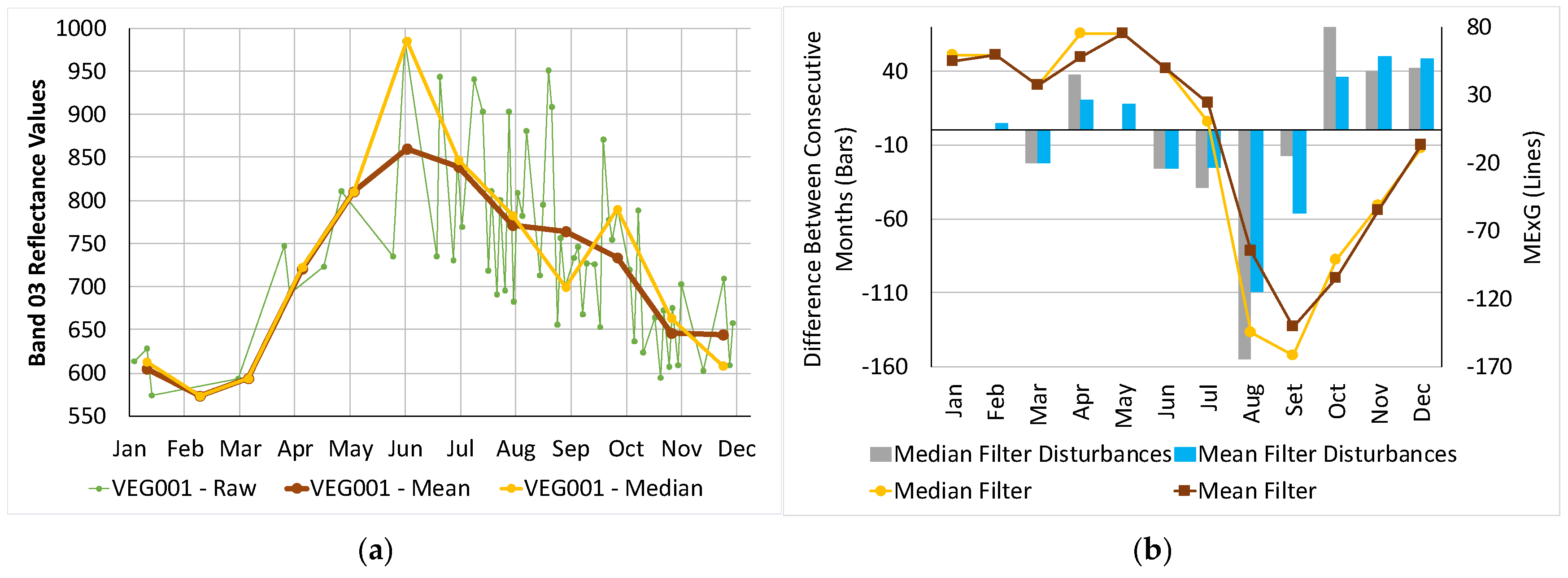
2.3.2. Image Data Extraction
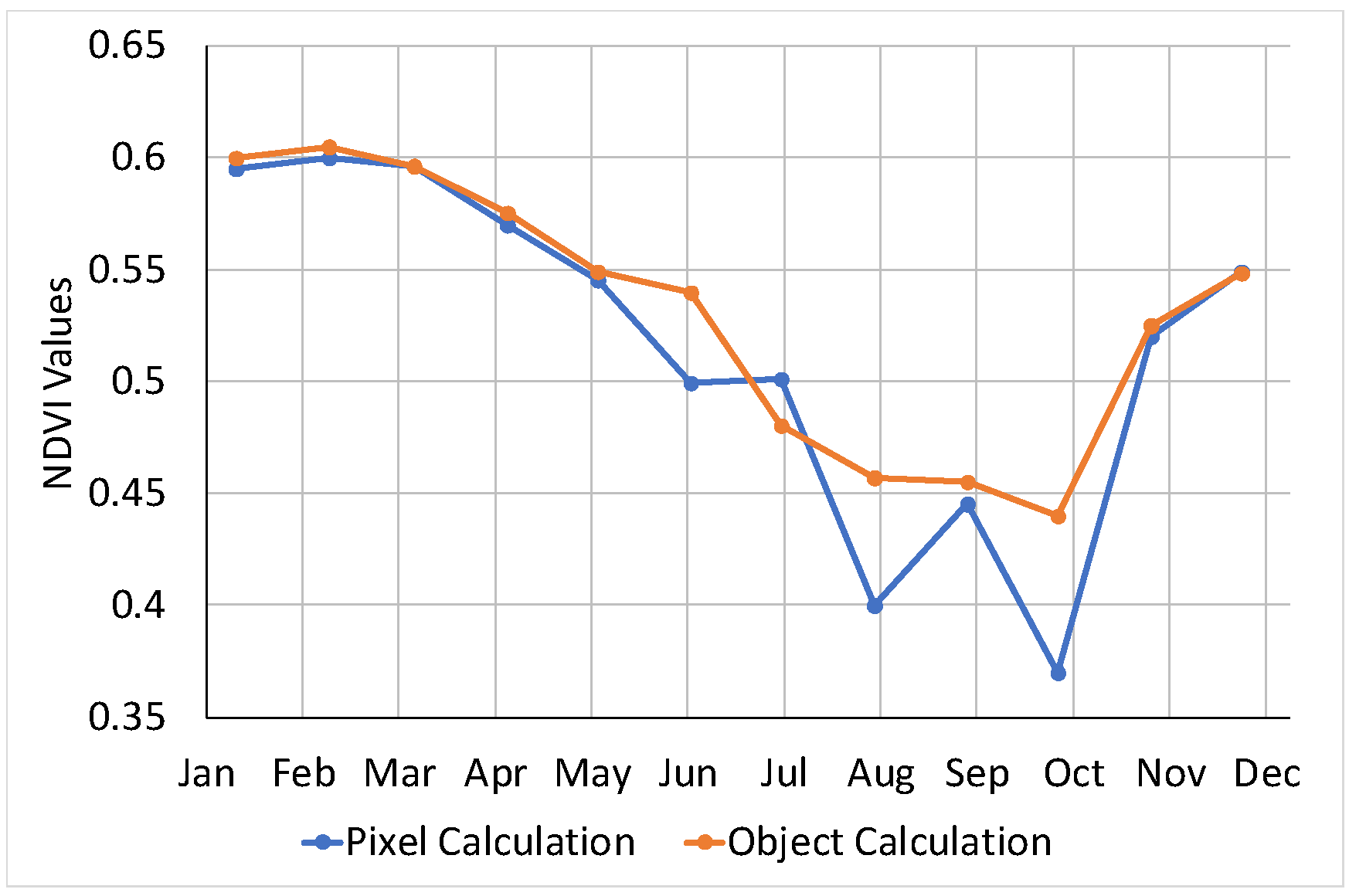
- Extraction of the pixel values from the FB for each band in analysis and calculation of the mean value for the object representation;
- Normalization of the band values;
- Generation of monthly values for the FB or VEG regions;
- Calculation of the defined spectral indices;
- Concatenation of the previous month values to each month, to include temporal information.
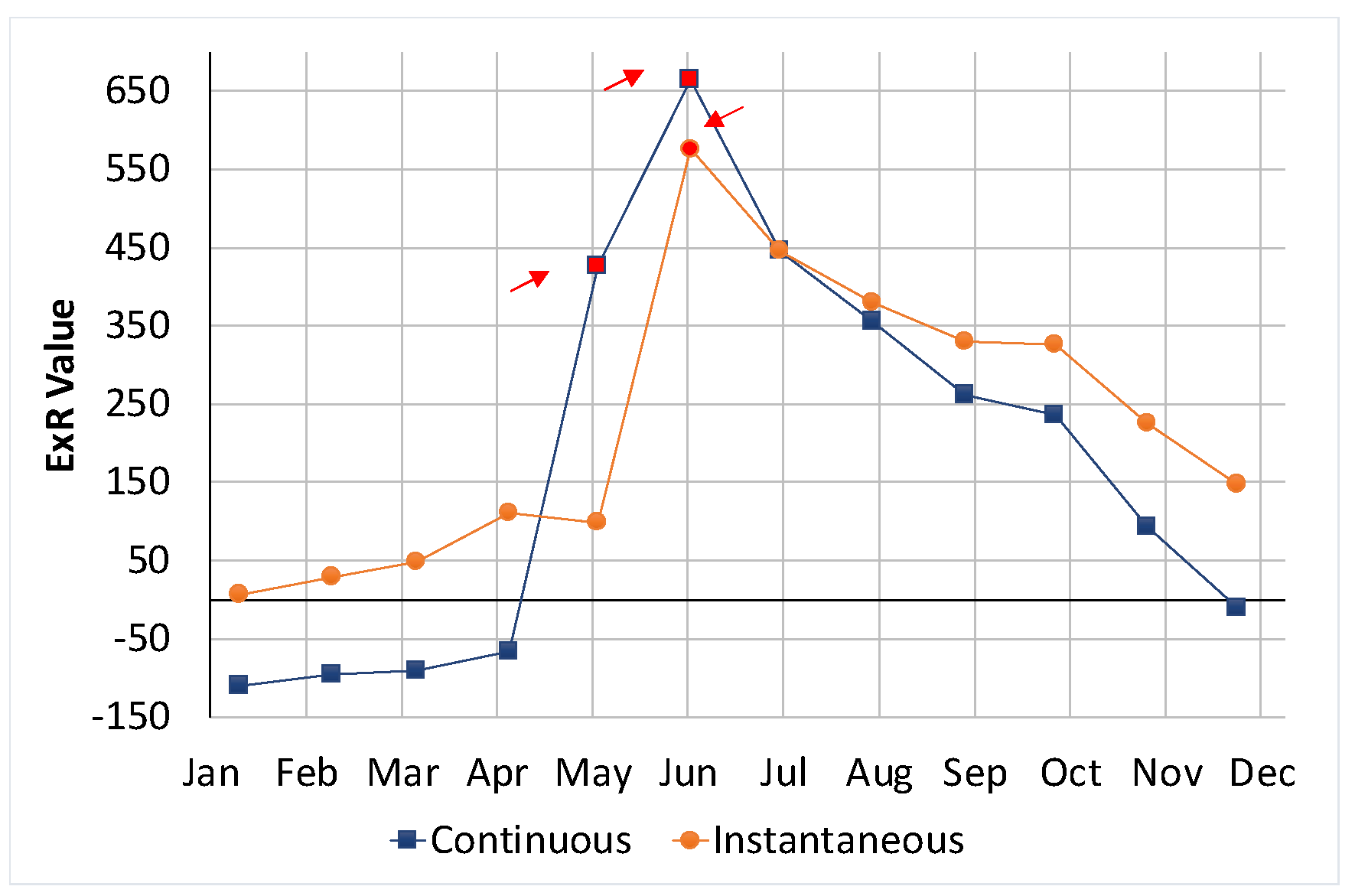
2.4. Maintenance Operations Detection
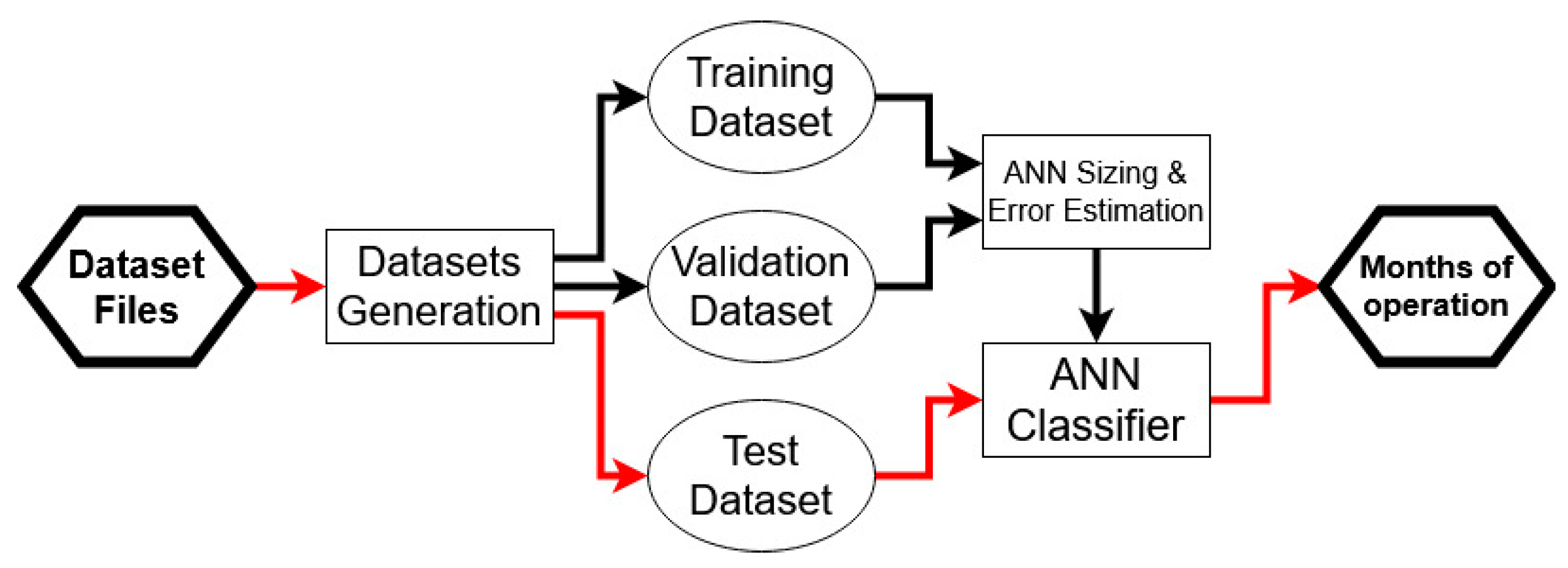
2.4.1. Artificial Neural Network Design and Training
2.4.2. Training, Validation and Test Error Estimation
3. Results
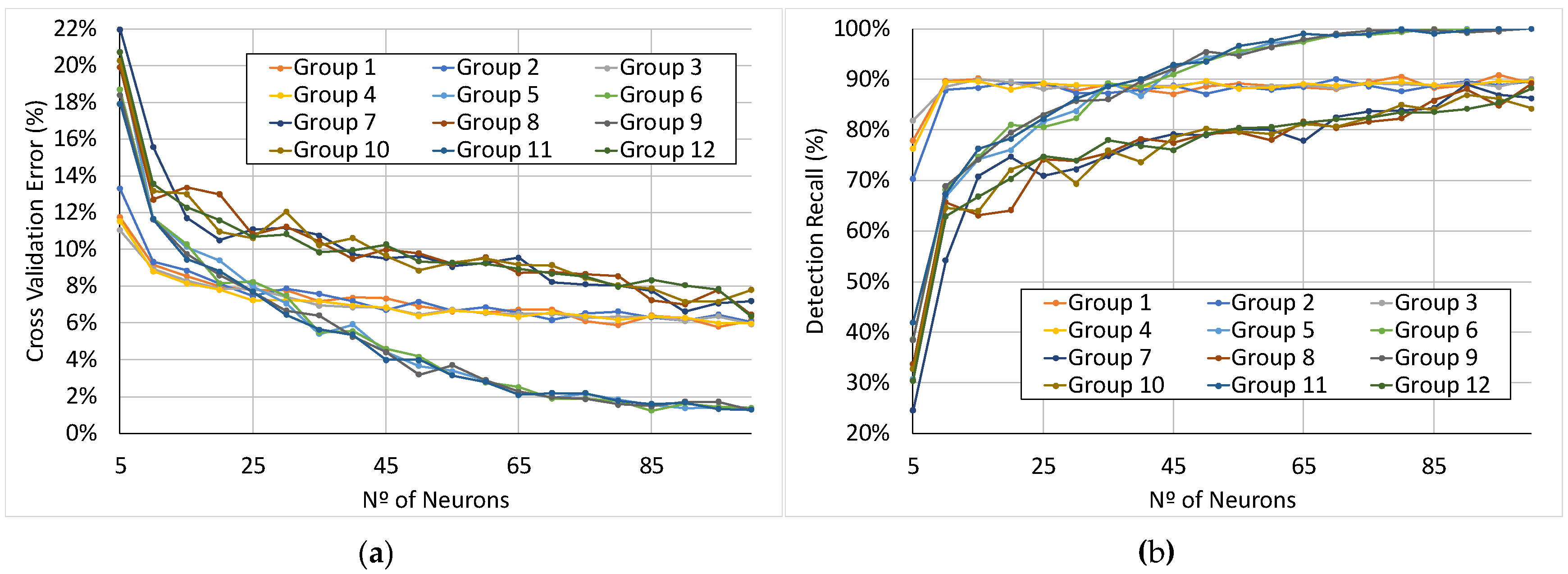
3.1. Feature Selection and Artificial Neural Network Sizing
3.2. Maintenance Operations Detection Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barbero, R.; Abatzoglou, J.T.; Larkin, N.K.; Kolden, C.A.; Stocks, B. Climate change presents increased potential for very large fires in the contiguous United States. Int. J. Wildl. Fire 2015, 24, 892. [Google Scholar] [CrossRef]
- Tymstra, C.; Stocks, B.J.; Cai, X.; Flannigan, M.D. Wildfire management in Canada: Review, challenges and opportunities. Prog. Disaster Sci. 2020, 5, 100045. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Libertà, G.; Branco, A.; de Rigo, D.; Ferrari, D.; Maianti, P.; Vivancos, T.A.; Oom, D.; et al. Forest Fires in Europe, Middle East and North Africa 2017 2018; European Commission: Brussels, Belgium, 2019; ISBN 978-92-76-11234-1. [Google Scholar]
- Chuvieco, E.; Mouillot, F.; van der Werf, G.R.; San Miguel, J.; Tanasse, M.; Koutsias, N.; García, M.; Yebra, M.; Padilla, M.; Gitas, I.; et al. Historical background and current developments for mapping burned area from satellite Earth observation. Remote Sens. Environ. 2019, 225, 45–64. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Williamson, G.J.; Abatzoglou, J.T.; Kolden, C.A.; Cochrane, M.A.; Smith, A.M.S. Human exposure and sensitivity to globally extreme wildfire events. Nat. Ecol. Evol. 2017, 1, 1–6. [Google Scholar] [CrossRef] [PubMed]
- DPFVAP—ICNF Primary Fuelbreak Network Manual; Portugal. 2014. Available online: http://www2.icnf.pt/portal/florestas/dfci/Resource/doc/cartografia-dfci/manual-RPFGC-20mai2014.pdf (accessed on 1 January 2019).
- Mora, A.; Santos, T.; Łukasik, S.; Silva, J.; Falcão, A.; Fonseca, J.; Ribeiro, R. Land Cover Classification from Multispectral Data Using Computational Intelligence Tools: A Comparative Study. Information 2017, 8, 147. [Google Scholar] [CrossRef]
- Johansen, K.; Coops, N.C.; Gergel, S.E.; Stange, Y. Application of high spatial resolution satellite imagery for riparian and forest ecosystem classification. Remote Sens. Environ. 2007, 110, 29–44. [Google Scholar] [CrossRef]
- Mallinis, G.; Koutsias, N.; Tsakiri-Strati, M.; Karteris, M. Object-based classification using Quickbird imagery for delineating forest vegetation polygons in a Mediterranean test site. ISPRS J. Photogramm. Remote Sens. 2008, 63, 237–250. [Google Scholar] [CrossRef]
- De Luca, G.; N. Silva, J.M.; Cerasoli, S.; Araújo, J.; Campos, J.; Di Fazio, S.; Modica, G. Object-Based Land Cover Classification of Cork Oak Woodlands using UAV Imagery and Orfeo ToolBox. Remote Sens. 2019, 11, 1238. [Google Scholar] [CrossRef]
- Temudo, M.P.; Silva, J.M.N. Agriculture and forest cover changes in post-war Mozambique. J. Land Use Sci. 2012, 7, 425–442. [Google Scholar] [CrossRef]
- Hamunyela, E.; Reiche, J.; Verbesselt, J.; Herold, M. Using space-time features to improve detection of forest disturbances from Landsat time series. Remote Sens. 2017, 9, 1–17. [Google Scholar]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. An integrated Landsat time series protocol for change detection and generation of annual gap-free surface reflectance composites. Remote Sens. Environ. 2015, 158, 220–234. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Hao, Y.; Chen, Z.; Huang, Q.; Li, F.; Wang, B.; Ma, L. Bidirectional Segmented Detection of Land Use Change Based on Object-Level Multivariate Time Series. Remote Sens. 2020, 12, 478. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Wang, W.; Chen, Z.; Li, X.; Tang, H.; Huang, Q.; Qu, L. Detecting spatio-temporal and typological changes in land use from Landsat image time series. J. Appl. Remote Sens. 2017, 11, 035006. [Google Scholar] [CrossRef]
- Chowdhury, E.H.; Hassan, Q.K. Development of a new daily-scale forest fire danger forecasting system using remote sensing data. Remote Sens. 2015, 7, 2431–2448. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant remote sensing vegetation indices: A review of developments and applications. J. Sens. 2017, 2017, 1–17. [Google Scholar] [CrossRef]
- Schultz, M.; Shapiro, A.; Clevers, J.; Beech, C.; Herold, M. Forest Cover and Vegetation Degradation Detection in the Kavango Zambezi Transfrontier Conservation Area Using BFAST Monitor. Remote Sens. 2018, 10, 1850. [Google Scholar] [CrossRef]
- Schultz, M.; Clevers, J.G.P.W.; Carter, S.; Verbesselt, J.; Avitabile, V.; Quang, H.V.; Herold, M. Performance of vegetation indices from Landsat time series in deforestation monitoring. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 318–327. [Google Scholar] [CrossRef]
- Pérez, A.J.; López, F.; Benlloch, J.V.; Christensen, S. Colour and shape analysis techniques for weed detection in cereal fields. Comput. Electron. Agric. 2000, 25, 197–212. [Google Scholar] [CrossRef]
- Guo, W.; Rage, U.K.; Ninomiya, S. Illumination invariant segmentation of vegetation for time series wheat images based on decision tree model. Comput. Electron. Agric. 2013, 96, 58–66. [Google Scholar] [CrossRef]
- Dong, Y.; Yan, H.; Wang, N.; Huang, M.; Hu, Y. Automatic Identification of Shrub-Encroached Grassland in the Mongolian Plateau Based on UAS Remote Sensing. Remote Sens. 2019, 11, 1623. [Google Scholar] [CrossRef]
- Clerc, S.; MPC Team. S2 MPC-L1C Data Quality Report-ESA. 2020. Available online: https://sentinel.esa.int/documents/247904/685211/Sentinel-2_L1C_Data_Quality_Report (accessed on 1 January 2019).
- Dechoz, C.; Poulain, V.; Massera, S.; Languille, F.; Greslou, D.; de Lussy, F.; Gaudel, A.; L’Helguen, C.; Picard, C.; Trémas, T. Sentinel 2 Global Reference Image. In Proceedings of the Image and Signal Processing for Remote Sensing XXI, Toulouse, France, 15 October 2015; Volume 9643, p. 96430A. [Google Scholar]
- Guizar-Sicairos, M.; Thurman, S.T.; Fienup, J.R. Efficient subpixel image registration algorithms. Opt. Lett. 2008, 33, 156. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Lu, H.; Yu, L.; Yang, K. Comparison of the Spatial Characteristics of Four Remotely Sensed Leaf Area Index Products over China: Direct Validation and Relative Uncertainties. Remote Sens. 2018, 10, 148. [Google Scholar] [CrossRef]
- Casquilho, J.P.; Teixeira, P.I. Introduction to Statistical Physics; Cambridge University Press: Cambridge, UK, 2015; ISBN 978-1-107-05378-6. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, J.R. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Cheng, L.; Wang, Y.; Li, M.; Zhong, L.; Wang, J. Generation of pixel-level SAR image time series using a locally adaptive matching technique. Photogramm. Eng. Remote Sens. 2014, 80, 839–848. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Equation |
|---|---|
| Normalized Difference Moisture Index (NDMI) | |
| Normalized Difference Vegetation Index (NDVI) | |
| Ratio Vegetation Index (RVI) | |
| Normalized Multi-Band Drought Index (NMDI) | |
| Normalized Difference Index (NDI) | |
| Excess of Green (ExG) | |
| Excess of Red (ExR) | |
| Excess of Green minus Excess of Red (ExGR) | |
| Modified Excess of Green (MExG) |
| Study Area | Area [ha] | Clear Observations | Number of FBs | Operation Dates | |
|---|---|---|---|---|---|
| 2017 | 2018 | ||||
| Fundão | 71.2 | 28 | 23 | 3 | JUL/AUG/SEP 2017 |
| Marisol | 2.0 | 40 | 49 | 1 | MAR 2018 |
| Seia | 50.2 | 29 | 24 | 2 | JUN 2017 |
| Serra dos Candeeiros | 105.5 | 59 | 49 | 5 | MAY/JUN/JUL/AUG 2017 |
| Sertã | 53.2 | 30 | 19 | 3 | JAN/FEB/JUN 2017 JUL 2018 |
| Test | NRMSE |
|---|---|
| T1 | 9% |
| T2 | 4% |
| B04 | B05 | B11 | B12 | ExG | ExGR | ExR | MExG | NDI | NMDI | |
|---|---|---|---|---|---|---|---|---|---|---|
| B04 | 1 | 0.975 | 0.929 | 0.939 | 0.731 | 0.931 | 0.973 | 0.845 | 0.946 | 0.702 |
| B05 | 0.975 | 1 | 0.952 | 0.938 | 0.600 | 0.852 | 0.923 | 0.748 | 0.910 | 0.678 |
| B11 | 0.929 | 0.952 | 1 | 0.986 | 0.602 | 0.832 | 0.894 | 0.744 | 0.908 | 0.805 |
| B12 | 0.939 | 0.938 | 0.986 | 1 | 0.648 | 0.857 | 0.909 | 0.773 | 0.927 | 0.794 |
| ExG | 0.731 | 0.600 | 0.602 | 0.648 | 1 | 0.922 | 0.840 | 0.958 | 0.789 | 0.670 |
| ExGR | 0.931 | 0.852 | 0.832 | 0.857 | 0.922 | 1 | 0.984 | 0.981 | 0.941 | 0.754 |
| ExR | 0.973 | 0.923 | 0.894 | 0.909 | 0.840 | 0.984 | 1 | 0.941 | 0.962 | 0.754 |
| MExG | 0.845 | 0.748 | 0.744 | 0.773 | 0.958 | 0.981 | 0.941 | 1 | 0.892 | 0.748 |
| NDI | 0.946 | 0.910 | 0.908 | 0.927 | 0.789 | 0.941 | 0.962 | 0.892 | 1 | 0.83 |
| NMDI | 0.702 | 0.678 | 0.805 | 0.794 | 0.670 | 0.754 | 0.754 | 0.748 | 0.83 | 1 |
| Mean | 0.886 | 0.842 | 0.850 | 0.863 | 0.751 | 0.895 | 0.909 | 0.848 | 0.901 | 0.748 |
| Group | Features |
|---|---|
| 1 | B05, ExG |
| 2 | B11, ExG |
| 3 | B05, ExG, NMDI |
| 4 | B11, ExG, NMDI |
| 5 | B05, ExG, ExR |
| 6 | B11, ExG, ExR |
| 7 | B05, ExG, ExGR |
| 8 | B11, ExG, ExGR |
| 9 | B05, ExG, ExR, NMDI |
| 10 | B05, ExG, ExGR, NMDI |
| 11 | B11, ExG, ExR, NMDI |
| 12 | B11, ExG, ExGR, NMDI |
| Median Filter Data | Mean Filter Data | |||
|---|---|---|---|---|
| Detection | Yes | No | Yes | No |
| Recall | 9% | 98% | 97% | 99% |
| Precision | 94% | 98% | 89% | 97% |
| F1-Score | 93% | 98% | 93% | 98% |
| Relative Error | 3.1% | 3.3% | ||
| Median Filter Data | Mean Filter Data | |||
|---|---|---|---|---|
| Detection | Yes | No | Yes | No |
| Recall | 87% | 97% | 77% | 98% |
| Precision | 57% | 99% | 64% | 99% |
| F1-Score | 68% | 98% | 70% | 99% |
| Relative Error | 2.9% | 2.5% | ||
| Group | Number of Cases | Wrong Detections |
|---|---|---|
| 0%–25% | 3 | 0 |
| 25%–50% | 4 | 0 |
| 50%–75% | 2 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira-Pires, J.E.; Aubard, V.; Ribeiro, R.A.; Fonseca, J.M.; Silva, J.M.N.; Mora, A. Semi-Automatic Methodology for Fire Break Maintenance Operations Detection with Sentinel-2 Imagery and Artificial Neural Network. Remote Sens. 2020, 12, 909. https://doi.org/10.3390/rs12060909
Pereira-Pires JE, Aubard V, Ribeiro RA, Fonseca JM, Silva JMN, Mora A. Semi-Automatic Methodology for Fire Break Maintenance Operations Detection with Sentinel-2 Imagery and Artificial Neural Network. Remote Sensing. 2020; 12(6):909. https://doi.org/10.3390/rs12060909
Chicago/Turabian StylePereira-Pires, João E., Valentine Aubard, Rita A. Ribeiro, José M. Fonseca, João M. N. Silva, and André Mora. 2020. "Semi-Automatic Methodology for Fire Break Maintenance Operations Detection with Sentinel-2 Imagery and Artificial Neural Network" Remote Sensing 12, no. 6: 909. https://doi.org/10.3390/rs12060909
APA StylePereira-Pires, J. E., Aubard, V., Ribeiro, R. A., Fonseca, J. M., Silva, J. M. N., & Mora, A. (2020). Semi-Automatic Methodology for Fire Break Maintenance Operations Detection with Sentinel-2 Imagery and Artificial Neural Network. Remote Sensing, 12(6), 909. https://doi.org/10.3390/rs12060909