Annular Neighboring Points Distribution Analysis: A Novel PLS Stem Point Cloud Preprocessing Algorithm for DBH Estimation



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Acquisition
2.2.1. Point Cloud Data
2.2.2. Reference Data
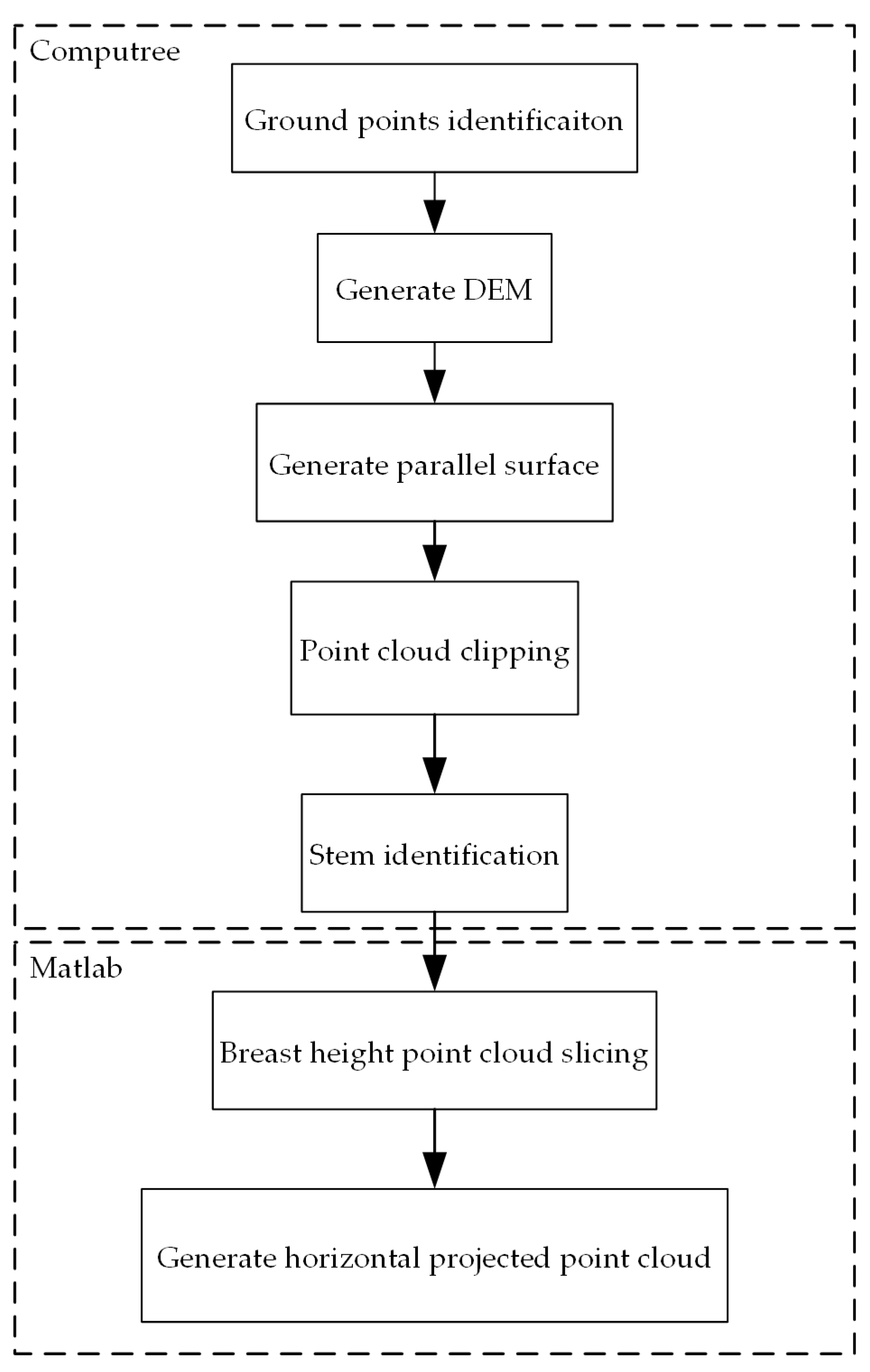
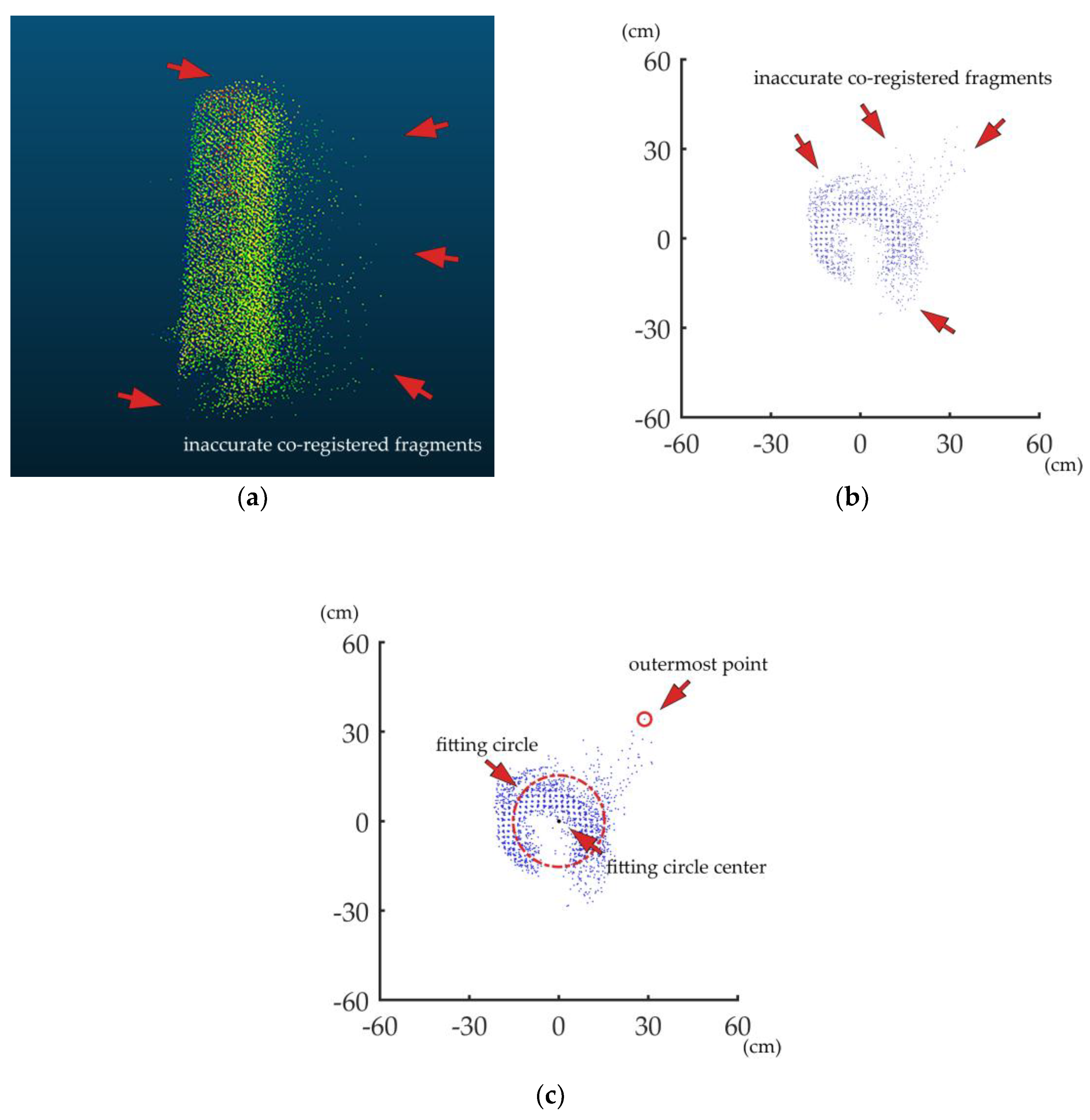
2.3. Essential Data Processing before Implementing ANPDA
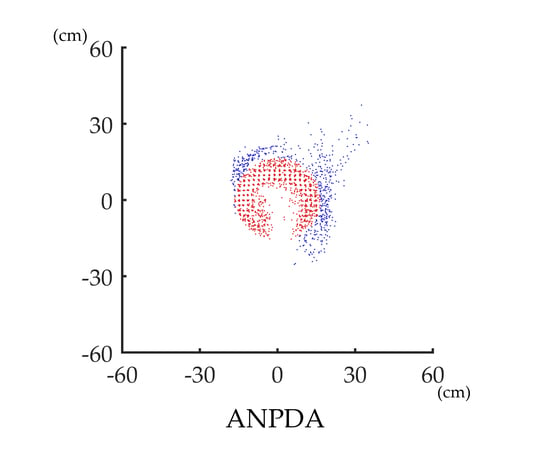
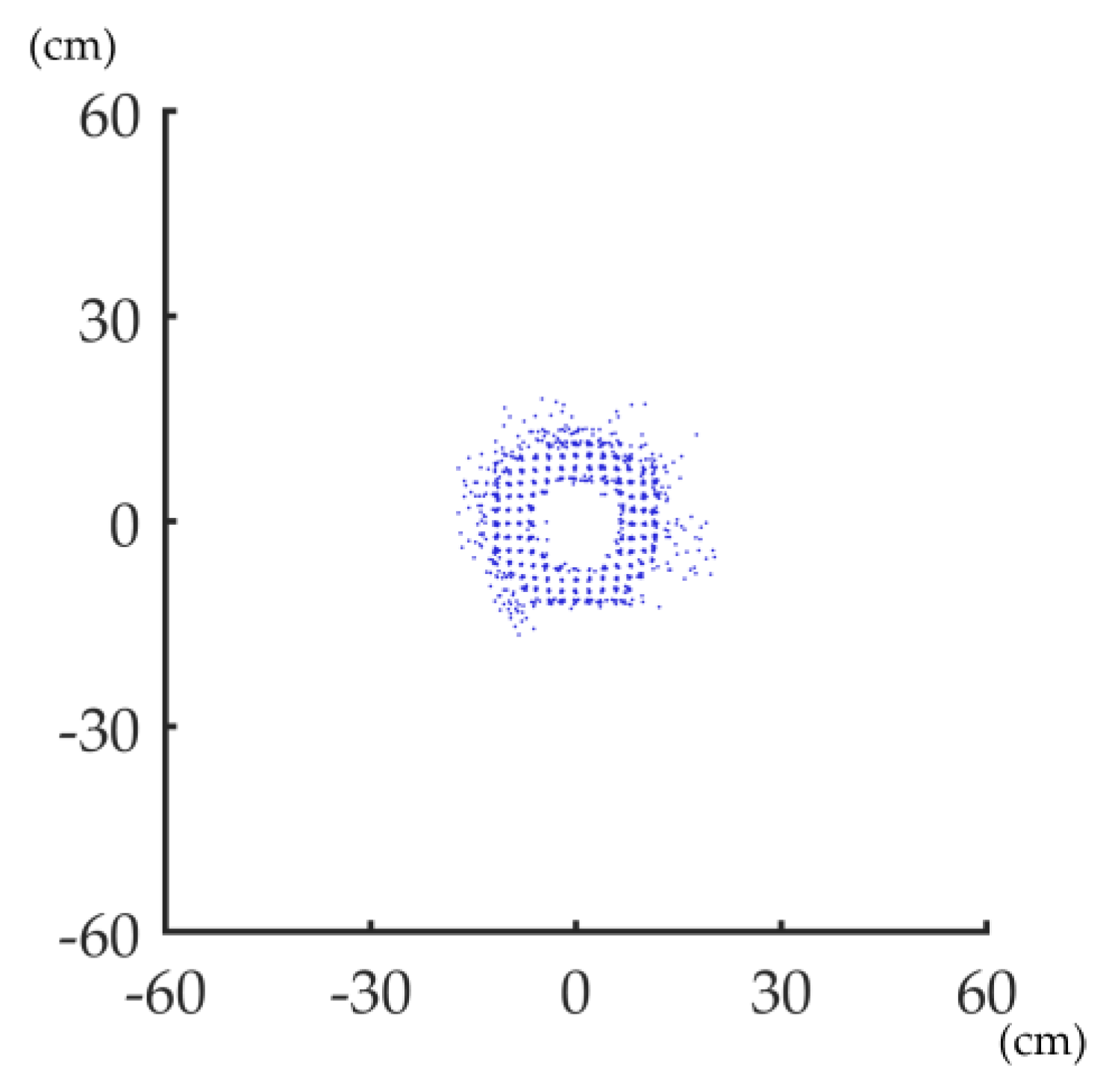
2.4. ANPDA
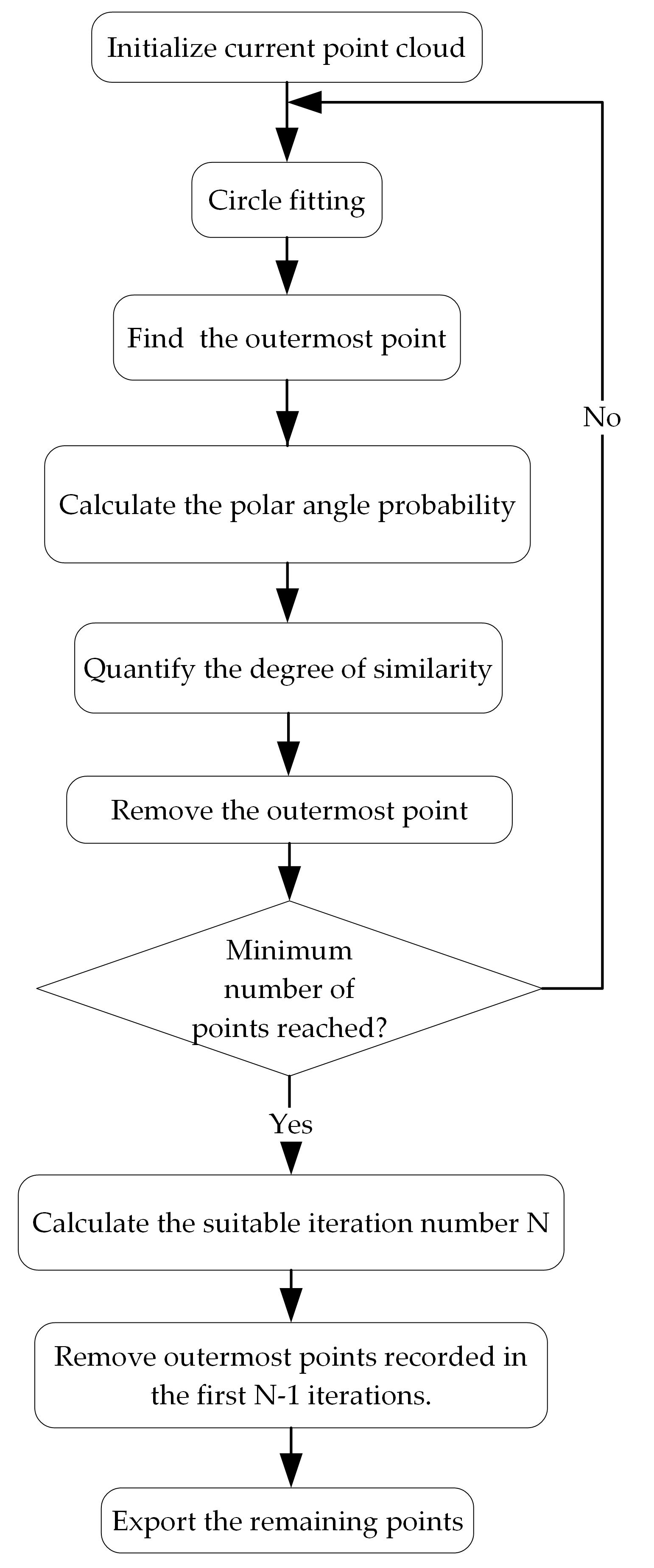
2.4.1. Overview
2.4.2. Circle Fitting
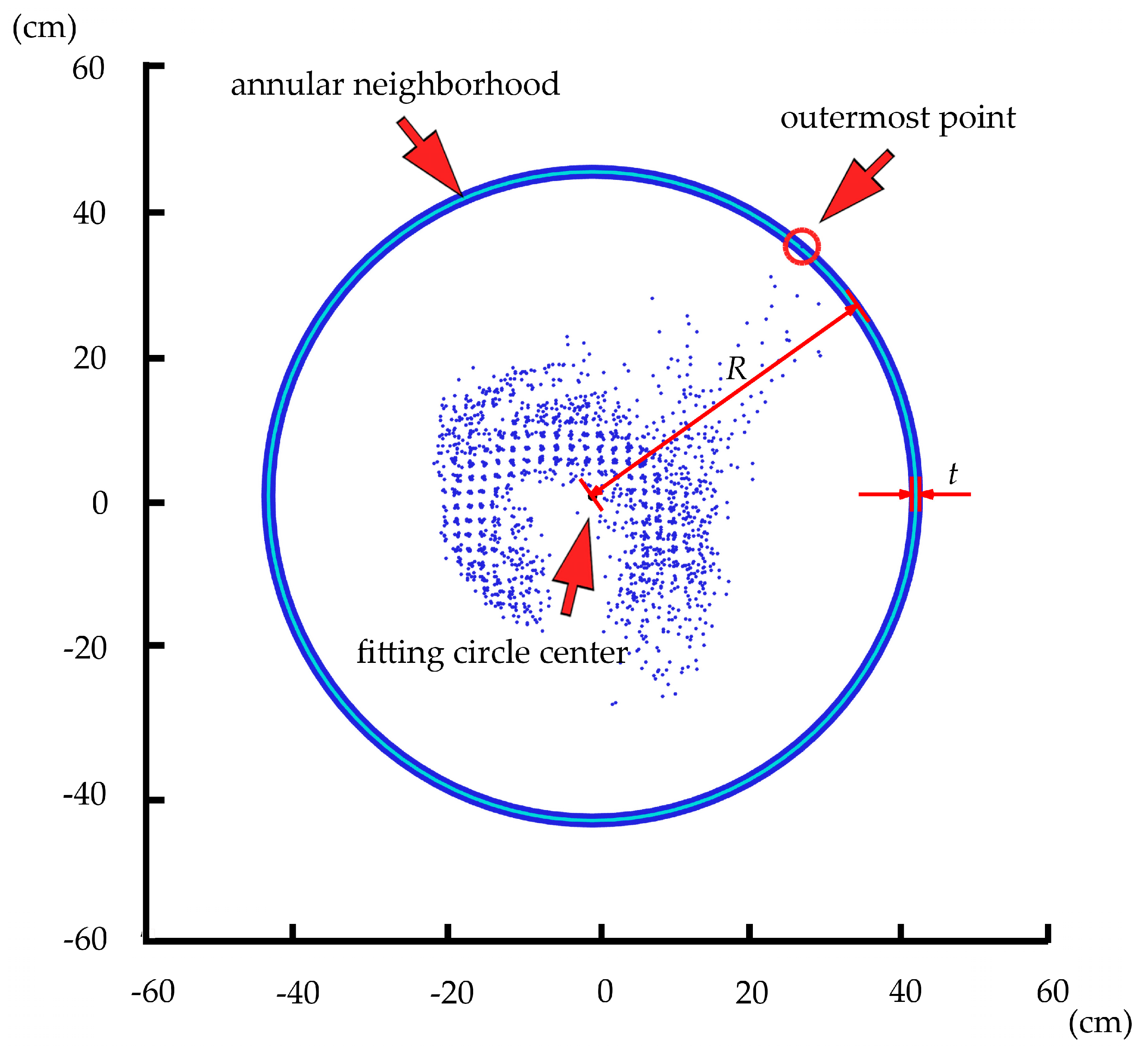
2.4.3. The Choice of the Annular Neighborhood Thickness Value
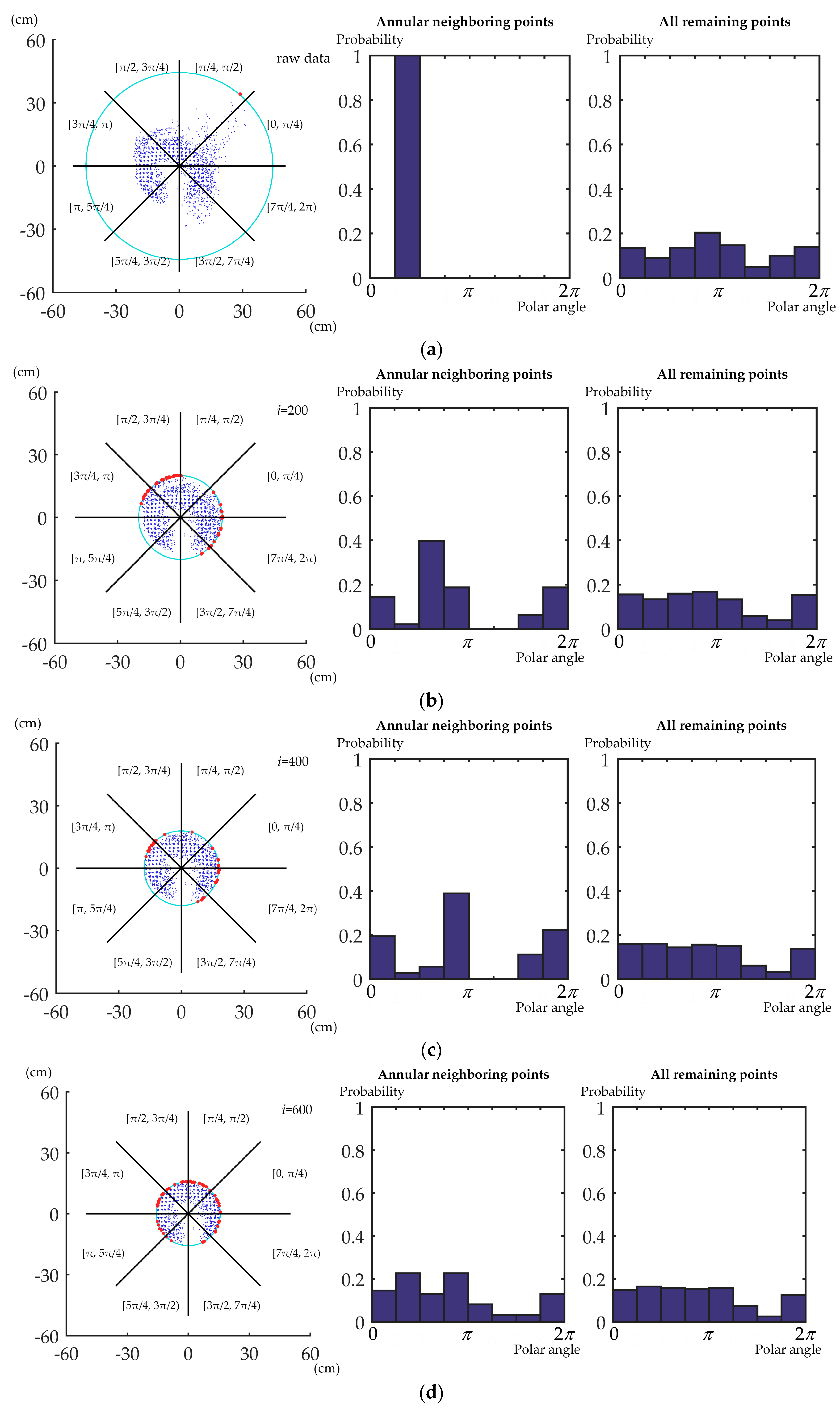
2.4.4. Polar Angle Probability Distribution Analysis
2.4.5. Distribution Similarity Quantification
2.4.6. The Termination Criterion
2.5. Evaluation of ANPDA
3. Results
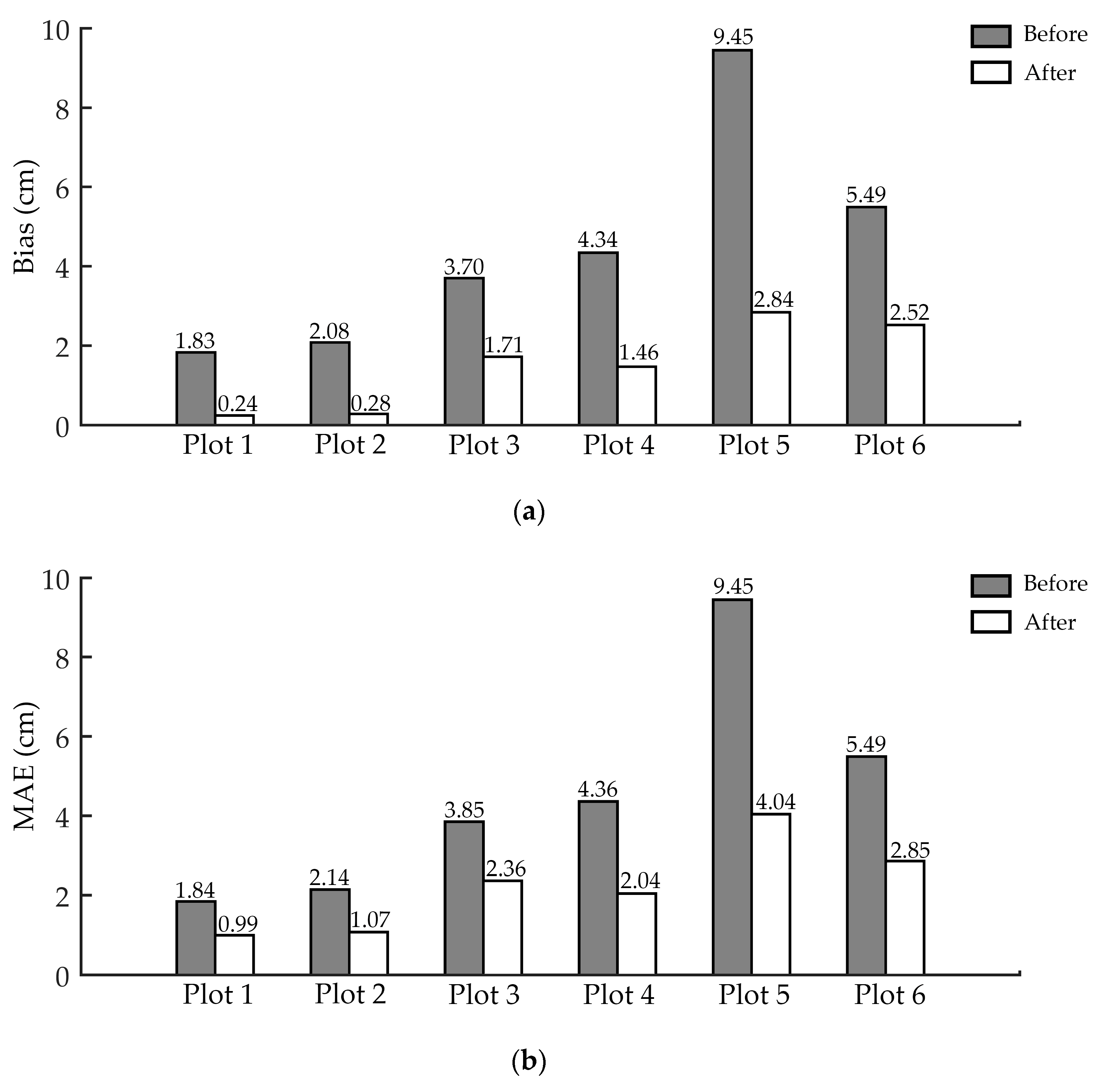
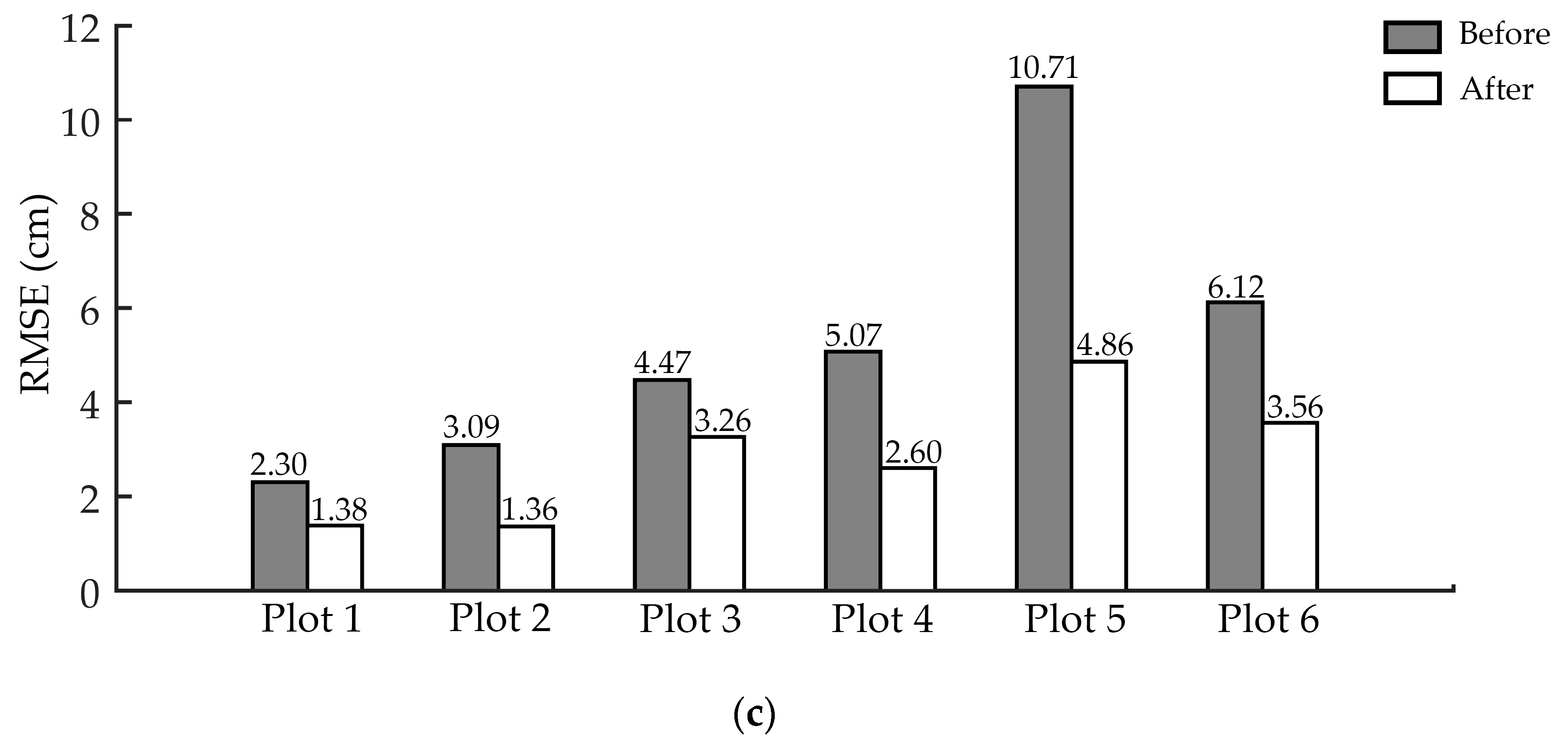
3.1. The Performance of ANPDA in Different Test Plots
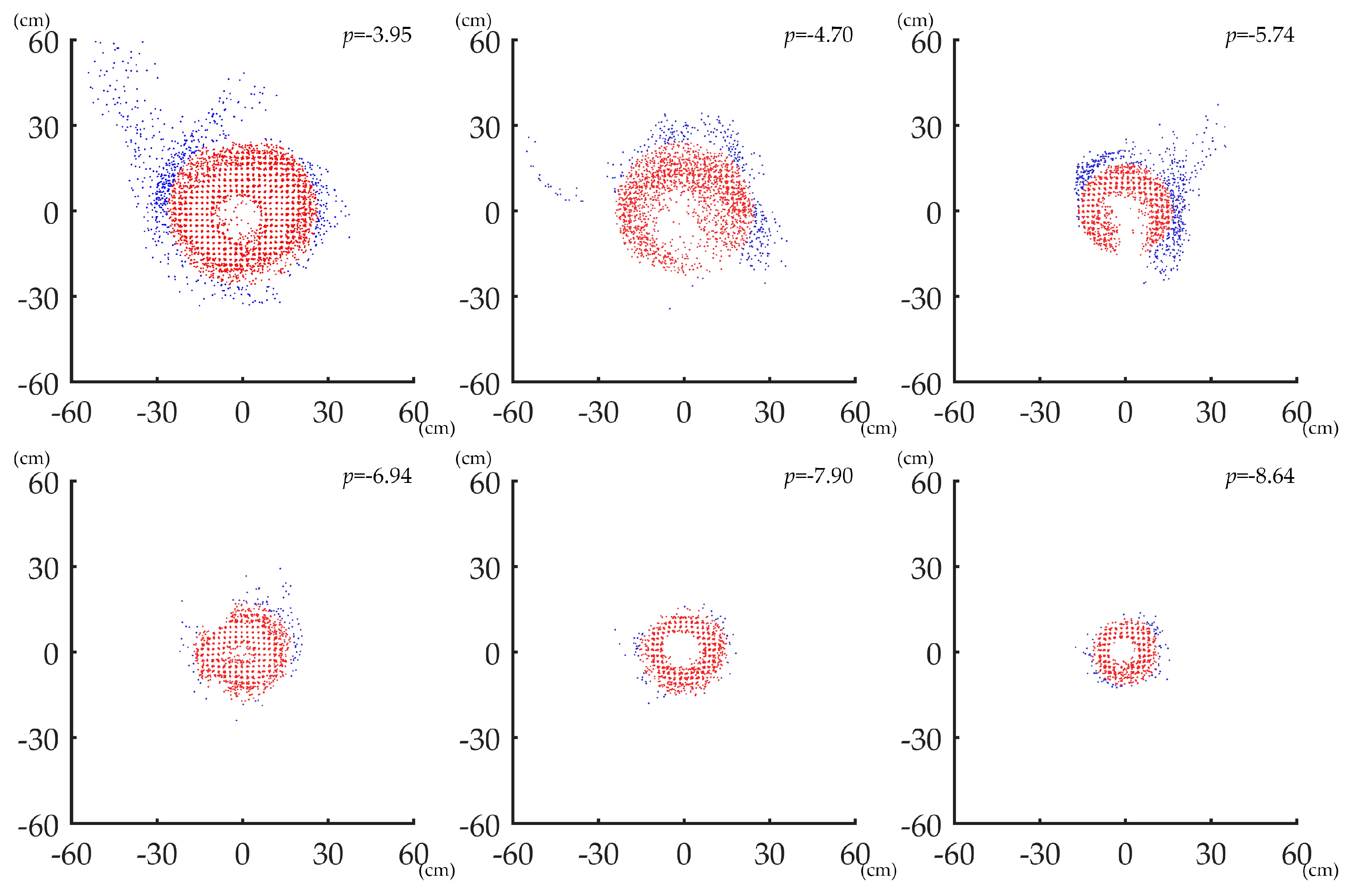
3.2. The Performance of ANPDA for Horizontal Stem Point Cloud Slices of Different Quality
4. Discussion
4.1. The Adaptivity of PLS for Forest Stands on the Slope
4.2. ANPDA for Horizontal Point Cloud Slices of Low Quality
4.3. ANPDA for Other Error Sources
4.4. ANPDA for Automatic and Hierarchical Semi-Automatic DBH Estimation
4.5. Outlook
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Liang, X.; Kankare, V.; Hyyppä, J.; Wang, Y.; Kukko, A.; Haggrén, H.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Guan, F.; et al. Terrestrial laser scanning in forest inventories. ISPRS J. Photogramm. Remote Sens. 2016, 115, 63–77. [Google Scholar] [CrossRef]
- Wang, D.; Kankare, V.; Puttonen, E.; Hollaus, M.; Pfeifer, N.J.I.G.; Letters, R.S. Reconstructing stem cross section shapes from terrestrial laser scanning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 272–276. [Google Scholar] [CrossRef]
- Chen, S.; Liu, H.; Feng, Z.; Shen, C.; Chen, P. Applicability of personal laser scanning in forestry inventory. PLoS ONE 2019, 14, e0211392. [Google Scholar] [CrossRef]
- Liang, X.; Kukko, A.; Kaartinen, H.; Hyyppa, J.; Yu, X.; Jaakkola, A.; Wang, Y. Possibilities of a personal laser scanning system for forest mapping and ecosystem services. Sensors 2014, 14, 1228–1248. [Google Scholar] [CrossRef]
- Ryding, J.; Williams, E.; Smith, M.; Eichhorn, M. Assessing Handheld Mobile Laser Scanners for Forest Surveys. Remote Sens. 2015, 7, 1095–1111. [Google Scholar] [CrossRef]
- Bauwens, S.; Bartholomeus, H.; Calders, K.; Lejeune, P. Forest Inventory with Terrestrial LiDAR: A Comparison of Static and Hand-Held Mobile Laser Scanning. Forests 2016, 7, 127. [Google Scholar] [CrossRef]
- Marselis, S.M.; Yebra, M.; Jovanovic, T.; van Dijk, A.I.J.M. Deriving comprehensive forest structure information from mobile laser scanning observations using automated point cloud classification. Environ. Model. Softw. 2016, 82, 142–151. [Google Scholar] [CrossRef]
- Holmgren, J.; Tulldahl, H.M.; Nordlöf, J.; Nyström, M.; Olofsson, K.; Rydell, J.; Willén, E. Estimation of Tree Position and Stem Diameter Using Simultaneous Localization and Mapping with Data from a Backpack-Mounted Laser Scanner. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-3/W3, 59–63. [Google Scholar] [CrossRef]
- Seki, S.; Tsubouchi, T.; Saratat, S.; Hara, Y. Forest mapping and trunk parameter measurement on slope using a 3D-LIDAR. In Proceedings of the 2017 IEEE/SICE International Symposium on System Integration (SII), Taipei, China, 11–14 December 2017; pp. 380–386. [Google Scholar]
- Cabo, C.; Del Pozo, S.; Rodríguez-Gonzálvez, P.; Ordóñez, C.; González-Aguilera, D. Comparing Terrestrial Laser Scanning (TLS) and Wearable Laser Scanning (WLS) for Individual Tree Modeling at Plot Level. Remote Sens. 2018, 10, 540. [Google Scholar] [CrossRef]
- Giannetti, F.; Puletti, N.; Quatrini, V.; Travaglini, D.; Bottalico, F.; Corona, P.; Chirici, G. Integrating terrestrial and airborne laser scanning for the assessment of single-tree attributes in Mediterranean forest stands. Eur. J. Remote Sens. 2018, 51, 795–807. [Google Scholar] [CrossRef]
- Oveland, I.; Hauglin, M.; Giannetti, F.; Schipper Kjørsvik, N.; Gobakken, T. Comparing Three Different Ground Based Laser Scanning Methods for Tree Stem Detection. Remote Sens. 2018, 10, 538. [Google Scholar] [CrossRef]
- Del Perugia, B.; Giannetti, F.; Chirici, G.; Travaglini, D. Influence of Scan Density on the Estimation of Single-Tree Attributes by Hand-Held Mobile Laser Scanning. Forests 2019, 10, 277. [Google Scholar] [CrossRef]
- Henning, J.G.; Radtke, P.J. Detailed stem measurements of standing trees from ground-based scanning lidar. For. Sci. 2006, 52, 67–80. [Google Scholar]
- Calders, K.; Newnham, G.; Burt, A.; Murphy, S.; Raumonen, P.; Herold, M.; Culvenor, D.; Avitabile, V.; Disney, M.; Armston, J.; et al. Nondestructive estimates of above-ground biomass using terrestrial laser scanning. Methods Ecol. Evol. 2015, 6, 198–208. [Google Scholar] [CrossRef]
- Kankare, V.; Puttonen, E.; Holopainen, M.; Hyyppä, J. The effect of TLS point cloud sampling on tree detection and diameter measurement accuracy. Remote Sens. Lett. 2016, 7, 495–502. [Google Scholar] [CrossRef]
- Bienert, A.; Georgi, L.; Kunz, M.; Maas, H.G.; von Oheimb, G. Comparison and Combination of Mobile and Terrestrial Laser Scanning for Natural Forest Inventories. Forests 2018, 9, 395. [Google Scholar] [CrossRef]
- Liu, C.; Xing, Y.; Duanmu, J.; Tian, X. Evaluating Different Methods for Estimating Diameter at Breast Height from Terrestrial Laser Scanning. Remote Sens. 2018, 10, 513. [Google Scholar] [CrossRef]
- Marchi, N.; Pirotti, F.; Lingua, E. Airborne and Terrestrial Laser Scanning Data for the Assessment of Standing and Lying Deadwood: Current Situation and New Perspectives. Remote Sens. 2018, 10, 1356. [Google Scholar] [CrossRef]
- Chisholm, R.A.; Cui, J.; Lum, S.K.Y.; Chen, B.M. UAV LiDAR for below-canopy forest surveys. J. Unmanned Veh. Syst. 2013, 1, 61–68. [Google Scholar] [CrossRef]
- Holopainen, M.; Kankare, V.; Vastaranta, M.; Liang, X.; Lin, Y.; Vaaja, M.; Yu, X.; Hyyppä, J.; Hyyppä, H.; Kaartinen, H.; et al. Tree mapping using airborne, terrestrial and mobile laser scanning—A case study in a heterogeneous urban forest. Urban For. Urban Green. 2013, 12, 546–553. [Google Scholar] [CrossRef]
- Wu, B.; Yu, B.; Yue, W.; Shu, S.; Tan, W.; Hu, C.; Huang, Y.; Wu, J.; Liu, H. A Voxel-Based Method for Automated Identification and Morphological Parameters Estimation of Individual Street Trees from Mobile Laser Scanning Data. Remote Sens. 2013, 5, 584–611. [Google Scholar] [CrossRef]
- Wallace, L.; Musk, R.; Lucieer, A. An Assessment of the Repeatability of Automatic Forest Inventory Metrics Derived From UAV-Borne Laser Scanning Data. IEEE Trans. Geosci. Electron. 2014, 52, 7160–7169. [Google Scholar] [CrossRef]
- Brede, B.; Lau, A.; Bartholomeus, H.M.; Kooistra, L. Comparing RIEGL RiCOPTER UAV LiDAR Derived Canopy Height and DBH with Terrestrial LiDAR. Sensors 2017, 17, 2371. [Google Scholar] [CrossRef] [PubMed]
- Čerňava, J.; Mokroš, M.; Tuček, J.; Antal, M.; Slatkovská, Z. Processing Chain for Estimation of Tree Diameter from GNSS-IMU-Based Mobile Laser Scanning Data. Remote Sens. 2019, 11, 615. [Google Scholar] [CrossRef]
- Liang, X.; Litkey, P.; Hyyppä, J.; Kaartinen, H.; Kukko, A.; Holopainen, M. Automatic plot-wise tree location mapping using single-scan terrestrial laser scanning. Photogramm. J. Final. 2011, 22, 37–48. [Google Scholar]
- Tang, J.; Chen, Y.; Kukko, A.; Kaartinen, H.; Jaakkola, A.; Khoramshahi, E.; Hakala, T.; Hyyppä, J.; Holopainen, M.; Hyyppä, H. SLAM-Aided Stem Mapping for Forest Inventory with Small-Footprint Mobile LiDAR. Forests 2015, 6, 4588–4606. [Google Scholar] [CrossRef]
- Polewski, P.; Yao, W.; Cao, L.; Gao, S. Marker-free coregistration of UAV and backpack LiDAR point clouds in forested areas. ISPRS J. Photogramm. Remote Sens. 2019, 147, 307–318. [Google Scholar] [CrossRef]
- Lauterbach, H.; Borrmann, D.; Heß, R.; Eck, D.; Schilling, K.; Nüchter, A. Evaluation of a Backpack-Mounted 3D Mobile Scanning System. Remote Sens. 2015, 7, 13753–13781. [Google Scholar] [CrossRef]
- Rönnholm, P.; Liang, X.; Kukko, A.; Jaakkola, A.; Hyyppä, J. Quality Analysis and Correction of Mobile Backpack Laser Scanning Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-1, 41–47. [Google Scholar]
- Lehtola, V.; Kaartinen, H.; Nüchter, A.; Kaijaluoto, R.; Kukko, A.; Litkey, P.; Honkavaara, E.; Rosnell, T.; Vaaja, M.; Virtanen, J.-P.; et al. Comparison of the Selected State-Of-The-Art 3D Indoor Scanning and Point Cloud Generation Methods. Remote Sens. 2017, 9, 796. [Google Scholar] [CrossRef]
- Laguela, S.; Dorado, I.; Gesto, M.; Arias, P.; Gonzalez-Aguilera, D.; Lorenzo, H. Behavior Analysis of Novel Wearable Indoor Mapping System Based on 3D-SLAM. Sensors 2018, 18, 766. [Google Scholar] [CrossRef] [PubMed]
- Zlot, R.; Bosse, M.; Greenop, K.; Jarzab, Z.; Juckes, E.; Roberts, J. Efficiently capturing large, complex cultural heritage sites with a handheld mobile 3D laser mapping system. J. Cult. Herit. 2014, 15, 670–678. [Google Scholar] [CrossRef]
- Lehtomäki, M.; Kukko, A.; Matikainen, L.; Hyyppä, J.; Kaartinen, H.; Jaakkola, A. Power line mapping technique using all-terrain mobile laser scanning. Autom. Constr. 2019, 105, 102802. [Google Scholar] [CrossRef]
- Dewez, T.J.B.; Yart, S.; Thuon, Y.; Pannet, P.; Plat, E. Towards cavity-collapse hazard maps with Zeb-Revo handheld laser scanner point clouds. Photogramm. Rec. 2017, 32, 354–376. [Google Scholar] [CrossRef]
- Cui, Y.; Li, Q.; Yang, B.; Xiao, W.; Chen, C.; Dong, Z. Automatic 3-D Reconstruction of Indoor Environment With Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 3117–3130. [Google Scholar] [CrossRef]
- GEXCEL. Available online: https://gexcel.it/en/solutions/heron-mobile-mapping/heron-ac-color (accessed on 1 February 2020).
- Computree-Official Site. Available online: http://computree.onf.fr/?lang=en (accessed on 15 December 2019).
- Othmani, A.; Piboule, A.; Krebs, M.; Stolz, C.; Voon, L.L.Y. Towards Automated and Operational Forest Inventories with T-Lidar. Available online: https://hal.archives-ouvertes.fr/hal-00646403/document (accessed on 1 February 2020).
- Mathworks. Available online: https://ch.mathworks.com/ (accessed on 15 December 2019).
- Thomas, S.M.; Chan, Y.T. A simple approach for the estimation of circular arc center and its radius. Comput. Vis. Graph. Image Process. 1989, 45, 362–370. [Google Scholar] [CrossRef]
- Fast Circle Fitting Using Landau Method. Available online: https://www.mathworks.com/matlabcentral/fileexchange/44219-fast-circle-fitting-using-landau-method (accessed on 15 December 2019).
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Koreň, M.; Mokroš, M.; Bucha, T. Accuracy of tree diameter estimation from terrestrial laser scanning by circle-fitting methods. Int. J. Appl. Earth Obs. 2017, 63, 122–128. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot ID | Species | Number of Trees | Slope | Ground Surface |
|---|---|---|---|---|
| 1 | Eucalyptus robusta | 52 | <5° | smooth and dry |
| 2 | Eucalyptus robusta | 35 | <5° | smooth and dry |
| 3 | Eucalyptus robusta | 36 | >20° | smooth and dry |
| 4 | Eucalyptus robusta | 39 | >20° | smooth and dry |
| 5 | Cunninghamia lanceolate and Michelia macclurei | 41 | >20° | soft and moist |
| 6 | Cunninghamia lanceolate and Michelia macclurei | 44 | >20° | soft and moist |
| Weight | 6 kg |
| Time of Initialization | ~30 s |
| Working Time | ~3 h/one battery |
| Indoors/Outdoors Working | Yes |
| Real-Time Visualization | Yes |
| Temperature | operating: −10 °C–60 °C storage: −40 °C–60 °C |
| Output Data | E57, las, ply |
| Final Global Accuracy | ~5 cm in short close rings |
| Local Accuracy | ~2 cm |
| Final Survey Resolution | ~2 cm |
| Sensor Mounting | Velodyne HDL-32E |
| Wavelength | 903 nm |
| Max Range | 80–100 m |
| Angular Field of View | Horizontal: 360° Vertical: +10.67°; −30.67° |
| Plot ID | DBH (cm) | Stem Density (Stems/ha) | ||
|---|---|---|---|---|
| Min | Max | Mean | ||
| 1 | 13.4 | 25.3 | 21.2 | 832 |
| 2 | 7.1 | 27.4 | 22.5 | 560 |
| 3 | 10.7 | 28 | 20.5 | 576 |
| 4 | 14.6 | 25.7 | 21.0 | 624 |
| 5 | 12.3 | 29.9 | 21.8 | 656 |
| 6 | 8.9 | 30.4 | 20.1 | 704 |
| Plot ID | Number of Qualified Stem Point Clouds | Error Reduction Rates after Applying ANPDA | ||
|---|---|---|---|---|
| Bias | MAE | RMSE | ||
| 1 | 52 | 87.13% | 46.20% | 39.96% |
| 2 | 34 | 86.36% | 49.84% | 56.02% |
| 3 | 32 | 53.80% | 38.82% | 27.17% |
| 4 | 39 | 66.27% | 53.06% | 48.76% |
| 5 | 30 | 69.92% | 57.30% | 54.61% |
| 6 | 42 | 54.09% | 47.99% | 41.92% |
| p-Value | Number of Qualified Stem Point Clouds | The Average of Error Reduction (cm) | Effective Rate |
|---|---|---|---|
| −9 to −8 | 6 | 1.16 | 66.67% |
| −8 to −7 | 126 | 1.19 | 81.75% |
| −7 to −6 | 64 | 1.73 | 89.06% |
| −6 to −5 | 20 | 3.67 | 100.00% |
| −5 to −4 | 10 | 3.67 | 100.00% |
| −4 to −3 | 3 | 2.78 | 100.00% |
| p-Value | Number of Qualified Stem Point Clouds | Error Reduction of DBH Estimation | ||
|---|---|---|---|---|
| Bias | MAE | RMSE | ||
| −9 to −8 | 6 | 63.05% | 38.39% | 39.79% |
| −8 to −7 | 126 | 66.82% | 40.00% | 32.23% |
| −7 to −6 | 64 | 62.79% | 47.98% | 42.30% |
| −6 to −5 | 20 | 67.72% | 56.17% | 47.25% |
| −5 to −4 | 10 | 71.65% | 69.39% | 62.87% |
| −4 to −3 | 3 | 68.95% | 68.95% | 68.88% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duanmu, J.; Xing, Y. Annular Neighboring Points Distribution Analysis: A Novel PLS Stem Point Cloud Preprocessing Algorithm for DBH Estimation. Remote Sens. 2020, 12, 808. https://doi.org/10.3390/rs12050808
Duanmu J, Xing Y. Annular Neighboring Points Distribution Analysis: A Novel PLS Stem Point Cloud Preprocessing Algorithm for DBH Estimation. Remote Sensing. 2020; 12(5):808. https://doi.org/10.3390/rs12050808
Chicago/Turabian StyleDuanmu, Jialong, and Yanqiu Xing. 2020. "Annular Neighboring Points Distribution Analysis: A Novel PLS Stem Point Cloud Preprocessing Algorithm for DBH Estimation" Remote Sensing 12, no. 5: 808. https://doi.org/10.3390/rs12050808
APA StyleDuanmu, J., & Xing, Y. (2020). Annular Neighboring Points Distribution Analysis: A Novel PLS Stem Point Cloud Preprocessing Algorithm for DBH Estimation. Remote Sensing, 12(5), 808. https://doi.org/10.3390/rs12050808