1. Introduction
Hyperspectral remote sensing imaging is a combination of imaging technology and spectral technology. It can obtain two-dimensional spatial information and spectral information of target objects simultaneously [
1,
2,
3]. Benefiting from the rich spectral information, hyperspectral images (HSIs) can be used to identity materials precisely. Hence, HSIs have been playing a key role in earth observation and used in many fields, including mineral exploration, water pollution, and vegetation [
3,
4,
5,
6,
7,
8,
9]. However, due to the low spatial resolution, mixed pixels always exist in HSIs, and it is one of the main reasons that preclude the widespread use of HSIs in precise target detection and classification applications. So it is necessary to develop the technique of unmixing [
2,
3,
10,
11,
12,
13,
14]. Thanks to the rich band information of hyperspectral images, which allows us to design an effective solution to the problem of mixed pixels. Hyperspectral unmixing (HU) is the process of obtaining the basic components (called endmembers) and their corresponding component ratios (called abundance fractions). The spectral unmixing can be divided into linear unmixing (LU) and nonlinear unmixing (NLU) [
2,
3]. LU assumes that photons only interact with one material and there is no interaction between materials. Usually, linear mixing only happens in macro scenarios. NLU assumes that photons interact with a variety of materials, including infinite mixtures, bilinear mixtures. For NLU, various models have been proposed to describe the mixing of pixels, taking into account the more complex reflections in the scene. Specifically, they are the generalized bilinear model (GBM) [
15], the polynomial post nonlinear model (PPNM) [
16], the multilinear mixing model (MLM) [
17], the p-linear model [
18], the multiharmonic postnonlinear mixing model (MHPNMM) [
19], the nonlinear non-negative matrix factorization (NNMF) [
20] and so on. Although different kinds of the nonlinear models have been proposed to improve the accuracy of the abundance results, they are always limited by the endmember extraction algorithm. Meanwhile, complex models often lead to excessive computing costs. The LMM has been widely used to address LU problem, while the GBM is the most popular model among the NLMMs to solve the NLU. The NLU is a more challenging problem than LU, and we mainly focus on the NLU in the paper.
The prior information of the abundance has been exploited for spectral unmixing. Different regularizations (such as sparsity, total variation, and low rankness) have been used on the abundances to improve the accuracy of the abundance estimation.
In sparse unmixing methods, sparsity prior of abundance matrix is exploited as a regularization term [
21,
22,
23]. To produce a more sparse solution, the group sparsity regularization was imposed on abundance matrix [
24]. Meanwhile, the sparsity prior is also considered on the interaction abundance matrix, because interaction abundance matrix is much sparser than abundance matrix [
25]. In order to capture the spatial structure of the data, the low-rank representation of abundance matrix was used in References [
25,
26,
27,
28].
Spatial correlation in abundance maps has also been taken advantage for spectral unmixing. By reorganizing the abundance vector as a two dimensional matrix (the height and width of the HSI, respectively), we can obtain a abundance map of
i endmember. In order to make full use of the spatial information of abundance maps, the total variation (TV) of abundance maps was proposed to enhance the spatial smoothness on the abundances [
28,
29,
30,
31]. Low-rank representation of abundance maps was newly introduced to LU in Reference [
32].
However, it is worth mentioning that all the regularizations mentioned above can provide a priori information about abundances. Specifically, the sparse regularization promotes sparse abundances. Total Variation holds the view that each abundance map is piecewise smooth. Low-rank regularization enforces the abundance maps to be low-rank. Furthermore, when solving an regularized optimization problem using ADMM, a subproblem composed of a data fidelity term and a regularization term is so called “Moreau proximal operator” or “denoising operator” [
33,
34,
35,
36].
Plug and play technique is a flexible framework that allows imaging models to be combined with state-of-the-art priors or denoising models [
37]. This is the main idea of plug-and-play technique, which has been successfully used to solve inverse problems of images, such as image inpainting [
38,
39], compressive sensing [
40], and super-resolution [
41,
42]. Instead of investing effort in designing more powerful regularizations on abundances, we use directly a prior from a state-of-the-art denoiser as the regularization, which is conceived to exploit the spatial correlation of abundance maps. So we apply the plug-and-play technique to the field of spectral unmixing, especially in hyperspectral nonlinear unmixing. In particular, it is pointed out that NLU is a challenging problem in HU, so it is expected that such a powerful tool can be used to improve the accuracy of abundance inversion efficiently.
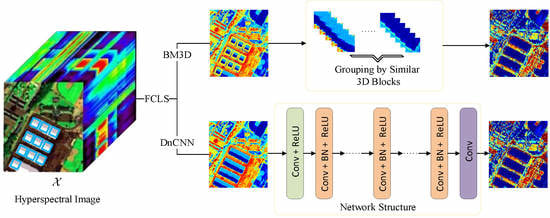
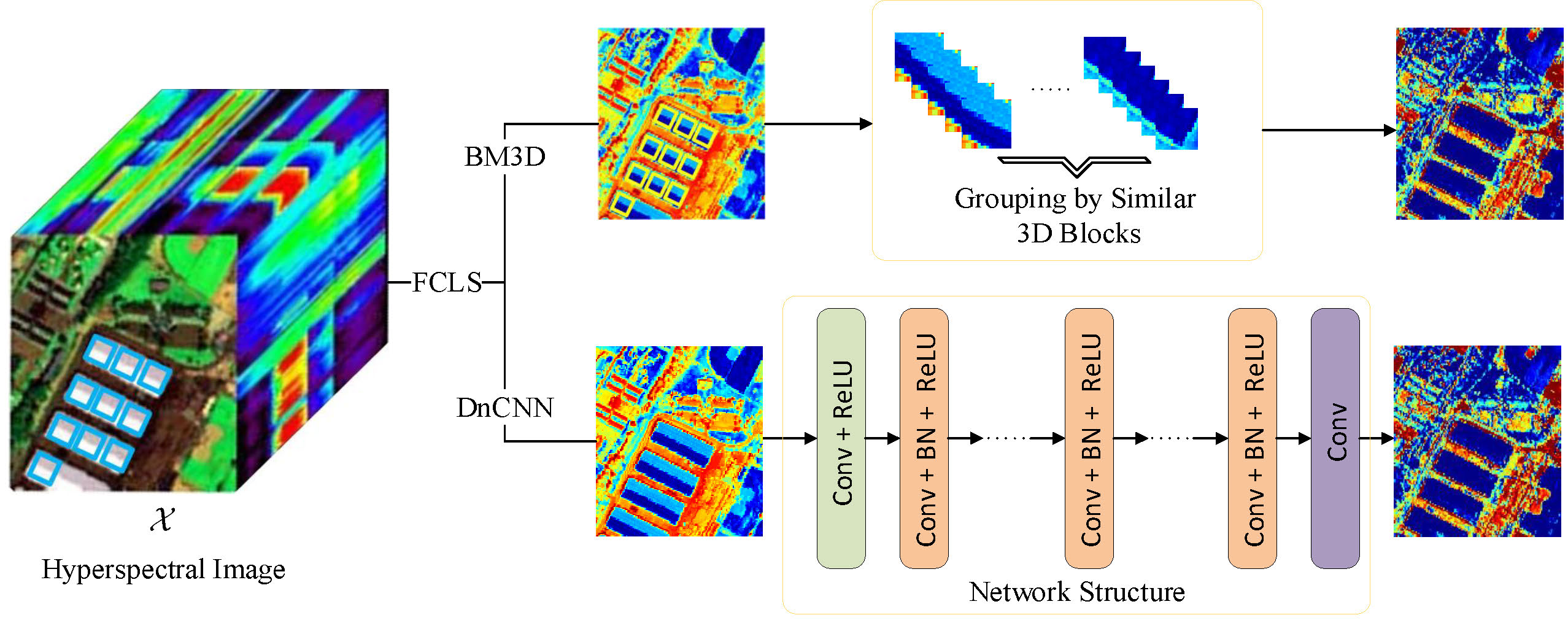
This paper exploits spatial correlation of abundance maps through a plug-and-play technique. We tested two of the best single-band denoising algorithms, namely Block-Matching and 3D filtering method (BM3D) [
43] and denoising convolutional neural networks (DnCNN) [
44].
The main contributions of this article are summarized as follows.
We exploit spatial correlation of abundance maps through plug-and-play technique. The idea of the plug-and-play technique was firstly applied to the problem of hyperspectral nonlinear unmixing. We propose a general nonlinear unmxing framework that can be embedded with any state-of-the-art denoisers.
We tested two state-of-the-art denoisers, namely BM3D and DnCNN, and both of them yield more accurate estimates of abundances than other state-of-the-art GBM-based nonlinear unmixing algorithms.
The rest of the article is structured as follows.
Section 2 introduces the related works and the proposed plug-and-play prior based hyperspectral nonlinear unmixing framework. Experimental results and analysis for the synthetic data are illustrated in
Section 3. The real hyperspectral dataset experiments and analysis are described in
Section 4.
Section 5 concludes the paper.
3. Experiments and Analysis on Synthetic Data
In this section, we illustrate the performance of the proposed PnP-NTF framework on the two state-of-the-art denoising method, named BM3D and DnCNN, for the abundance estimation. We compare the proposed method with some advanced algorithms to address the GBM, which contains gradient descent algorithm (GDA) [
49], the semi-nonnegative matrix factorization (semi-NMF) [
50] algorithm and subspace unmixing with low-rank attribute embedding algorithm (SULoRA) [
11]. For specifically, the GDA method is a benchmark to solve the GBM pixel by pixel, and semi-NMF can speed up and reduce the time loss. Meanwhile, the semi-NMF based method can consider the partial spatial information of the image. SULoRA is a general subspace unmixing method that jointly estimates subspace projections and abundance, and can model the raw subspace with low-rank attribute embedding. All of the experiments were conducted in MATLAB R2018b on a desktop of 16 GB RAM, Intel (R) Core (TM) i5-8400 CPU, @2.80 GHz.
In order to quantify the effect of the proposed method numerically, three widely metrics, including the root-mean-square error (RMSE) of abundances, the image reconstruction error (RE), and the average of spectral angle mapper (aSAM) are used. For specifically, the RMSE quantifies the difference between the estimated abundance
and the true abundances
as follows:
The RE measures the difference between the observation
and its reconstruction
as follows:
The aSAM qualifies the average spectral angle mapping of the estimated
ith spectral vector
and observed
ith spectral vector
. The aSAM is defined as follows:
3.1. Data Generation
In the simulated experiments, the synthetic data was generated similar to References [
32,
51], and the specific process is as follows:
Six spectral endmembers signals with 224 spectral bands were randomly chosen from the USGS digital spectral library (
https://www.usgs.gov/labs/spec-lab), namely Carnallite, Ammonio–jarosite, Almandine, Brucite, Axinite, and Chlonte.
We generated a simulated image of size , which can be divided into small blocks of size .
A randomly selected endmember was assigned to each block, and a low-pass filter was used to generate abundance map cube of size that contained mixed pixels, while satisfying the ANC and ASC constraints.
After obtaining the endmember information and the abundance information, then clean HSIs can be generated by the generalized bilinear model and the polynomial post nonlinear model. The interaction coefficient parameters in the GBM were set randomly, and the nonlinear coefficient parameters in the PPNM were set to 0.25.
To effectively evaluate the robustness performance of the proposed method on the different signal-to-noise ratio (SNR), the zero-mean Gaussian white noise was added to the clean data.
3.2. Evaluation of the Methods
The details of the simulated data can be obtained with the previous steps, then we generated a series of noisy images with SNRs = {15, 20, 30} dB to evaluate performance of the proposed method and compare with other methods.
3.2.1. Parameter Setting
To compare all the algorithms fairly, the parameters in the all compared methods were hand-tuned to the optimal values. Specifically, the FCLS was used to initialize the abundance information in the all methods (including the proposed method). Note that a direct compasion with FCLS unmixing results is unfair and FCLS is served as a benchmark, which shows the impact of using a linear unmixing method on nonlinear mixed images. The GDA is considered as the benchmark to solve the GBM. The tolerances for stopping the iterations in GDA, Semi-NMF, and SULoRA were set to
. For the proposed PnP-NTF framework based method, the parameters to be adjusted were divided into two parts, one of which is the parameter of the denoiser we chosen, and the other part is the penalty parameter
. Firstly, the standard deviation of additive white Gaussian noise
is searching from 0 to 255 with the step of 25, the the block size used for the hard-thresholding (HT) filtering is set as 8 in BM3D, respectively. The parameters of the DnCNN is the same as Reference [
44]. Meanwhile, the penalty parameter
was set to
, and the tolerance for stopping the iterations was set to
.
3.2.2. Comparison of Methods under Different Gaussian Noise Levels
In our experiments, we generate three images of size
with 4096 pixels and 224 bands. More specifically, the ‘Scene1’ is generated by the GBM model, and the ‘Scene2’ is generated by the PPNM model. The ‘Scene3’ is a mixture of the ‘Scene1’ and ‘Scene2’, as half pixels in ‘Scene3’ were generated by the GBM and the others were generated by PPNM [
50]. The ‘Scene1’ is used to evaluate the efficiency of the proposed method to handle mixtures based on GBM, while the ‘Scene2’ and ‘Scene3’ were used to evaluate the robustness of the proposed method to mixtures based on different mixing models.
For the proposed method and the other methods, the abundances were initialized with the same method, that is FCLS. In a supervised nonlinear unmixing problem, the spectral vectors of endmember were known as a priori. Considering that the accuracy of abundance inversion depends on the quality of endmember signals, we used the true endmembers in the experiments for fair comparison.
Table 1 quantifies the corresponding results of the three evaluation indicators (RMSE, RE, and aSAM) in detail on the ‘Scene1’. As seen from the
Table 1, the proposed PnP-NTF based framework with the advanced denoisers provide the superior unmixing results, compared with other methods. Specifically, we tested two state-of-the-art denoisers, namely BM3D and DnCNN, and both of them obtained the best performance. The RMSE, RE, and aSAM obtained minimum values from the proposed PnP-NTF based frameworks, which show the efficiency of the proposed methods is superior compared with other state-of-the-art methods (shown in bold).
Figure 3 shows the results of the proposed algorithm and the others algorithms under three indexes (RMSE, RE, and aSAM). For the different levels of noise in ‘Scene1’, the proposed methods yield the superior performance in all indexes. Also we can see from the histogram of
Figure 4,
Figure 5 and
Figure 6 that the proposed methods obtain the minimum RMSEs in all scenes.
To evaluate the robustness of the proposed methods against model error, we generated ‘Scene2’ and ‘Scene3’ of size
. As shown in
Table 2 and
Table 3, the proposed methods obtained the best estimate of abundances in terms of RMSE, RE, and aSAM (shown in bold). We cannot provide the proof of the convergence of the proposed algorithm, but the experimental results show that it is convergent when plugged by BM3D and DnCNN (shown in
Figure 7 and
Figure 8).
3.2.3. Comparison of Methods under Denoised Abundance Maps
We make a series of experiments to show the difference between the proposed methods and the conventional unmixing methods (FCLS, GDA, and Semi-NMF) with afterwards denoising the calculated abundance maps by BM4D. The results in
Table 4,
Table 5 and
Table 6 show that the denoised abundance maps provided by FCLS, GDA, and Semi-NMF can obtain a better results than corresponding original abundance maps. However, for the proposed methods, we use directly a state-of-the-art denoiser as the regularization, which is to exploit the spatial correlation of abundance maps. The results show that using plug-and-play prior for the abundance maps and interaction abundance maps can enhance the accuracy of the estimated abundance results efficiently.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}