1. Introduction
Infrared videos in ground-based imagers contain a lot of background clutter and flickering noise due to air turbulence, sensor noise, etc. Moreover, the target size in long-range videos is quite small and hence it is challenging to detect small targets from a long distance. Furthermore, the contrast is also poor in many infrared videos.
There are two groups of target detection algorithms for videos. One group is to utilize supervised learning algorithms. For instance, there are some conventional target tracking methods [
1,
2]. In addition, some target detection and classification schemes using deep learning algorithms such as You Only Look Once (YOLO) for larger objects in short-range optical and infrared videos have been proposed in the literature [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]. There are also some recent papers on moving target detection in thermal imagers [
22,
23,
24]. Training videos are required in these algorithms. Although the performance is reasonable for short ranges up to 2000 m in some videos, the performance dropped quite considerably in long ranges where the target sizes are so small. This is because YOLO uses texture information to help the detection. Moreover, the object sizes need to be large enough in order to have textures. The use of YOLO is not very effective for long-range videos in which the targets are too small to have any discernible textures. Some recent algorithms [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13] incorporated compressive measurements directly for detection and classification. Real-time issues have been discussed in [
21].
Another group belongs to the unsupervised approach, which does not require any training data. The latter group is more suitable for long-range videos in which the object size is very small. Chen et al. [
25] proposed to detect small IR targets by using local contrast measure (LCM), which is time-consuming and sometimes enhances both targets and clutters. To improve the performance of LCM, Wei et al. [
26] introduced a multiscale patch-based contrast measure (MPCM). Gao et al. [
27] developed an infrared patch-image (IPI) model to convert small target detection to an optimization problem. Zhang et al. [
28] improved the performance of the IPI via non-convex rank approximation minimization (NRAM). Zhang et al. [
29] proposed to detect small infrared (IR) targets based on local intensity and gradient (LIG) properties, which has good performance and relatively low computational complexity.
In a recent paper by us [
30], we proposed a high-performance and unsupervised approach for long-range infrared videos in which the object detection only used one frame at a time. Although the method in [
30] is applicable to both stationary and moving targets, the computational efficiency is not suitable for real-time applications. Since some long-range videos only contain moving objects, it will be good to devise efficient algorithms that can utilize motion information for object detection.
In this paper, we propose an unsupervised, modular, flexible, and efficient framework for small moving target detection in long-range infrared videos containing moving targets. One key component is the use of optical flow techniques for moving object detection. Three well-known optical flow techniques, including Lucas–Kanade (LK) [
31], Total Variation with L1 constraint (TV-L1) [
32], and (Brox) [
33], were compared. Another component is to use object association techniques to help eliminate false positives. It was found that optical flow methods need to be combined with contrast enhancement, connected component analysis, and target association in order to be effective. Extensive experiments using long-range mid-wave infrared (MWIR) videos from the Defense Systems Information Analysis Center (DSIAC) dataset [
34] clearly demonstrated the efficacy of our proposed approach.
The contributions of our paper are summarized as follows:
We proposed an unsupervised small moving target detection framework that does not require training data. This is more practical as compared to deep-learning-based methods, which require training data and larger object size.
Our framework incorporates optical flow techniques that are more efficient than other methods such as [
30].
Our framework is applicable to long-range and low-quality infrared videos that are beyond 3000 m.
We compared several contrast enhancement methods and demonstrated the importance of contrast enhancement in small target detection.
Our framework is modular and flexible in that newer methods can be used to replace old methods.
Our paper is organized as follows.
Section 2 summarizes the optical flow methods and the proposed framework.
Section 3 summarizes the extensive experimental results using actual DSIAC videos.
Section 4 includes a few concluding remarks and future directions. In the
Appendix A, we include some detailed comparisons of several contrast enhancement techniques to improve the raw video quality. Experiments were used to demonstrate which image enhancement method is better from the perspective of target detection.
2. Small Target Detection Based on Optical Flows
In our earlier paper [
30], the LIG algorithm only incorporates intensity and gradient information in a single frame. In some videos such as the DSIAC dataset, the targets are actually moving. In this paper, we focus on applying optical flow techniques by exploiting some motion information to enhance the target detection performance.
2.1. Optical Flow Methods
In this section, we briefly introduce three optical flow techniques to extract motion information in the videos.
2.1.1. Lucas–Kanade (LK) Algorithm
The LK algorithm [
31] is very simple. A sliding window (3 × 3 or bigger) scans through a pair of images. For each window, the grey value constancy assumption is applied. A set of linear equations is then obtained. A least square solution can then be used to solve for the motion vectors in that window. The process repeats for the whole image.
2.1.2. Total Variation with L1 Constraint (TV-L1)
One problem with the LK algorithm is that it may not perform well for noisy images. The TV-L1 algorithm [
32] considers more assumptions, including smoothness and gradient constancy. Moreover, the L1 regularization is used instead of the L2 regularization.
We first experimented with a TV-L1 implementation [
35]. However, the results did not correspond well with [
32]. More specifically, several key design parameters, such as the lambda, were not adjustable within this implementation. We found a better implementation directly from the authors of [
32] and incorporated it into a more robust Python-based workflow that is further discussed in
Section 2.3 and
Section 2.4.
2.1.3. High Accuracy Optical Flow Estimation Based on a Theory for Warping (Brox)
Similar to TV-L1, the Brox model [
33] considers the assumption of smoothness, gradient, and grey value constancy. These were used in conjunction with a spatio-temporal total variation regularizer.
2.2. LK Results
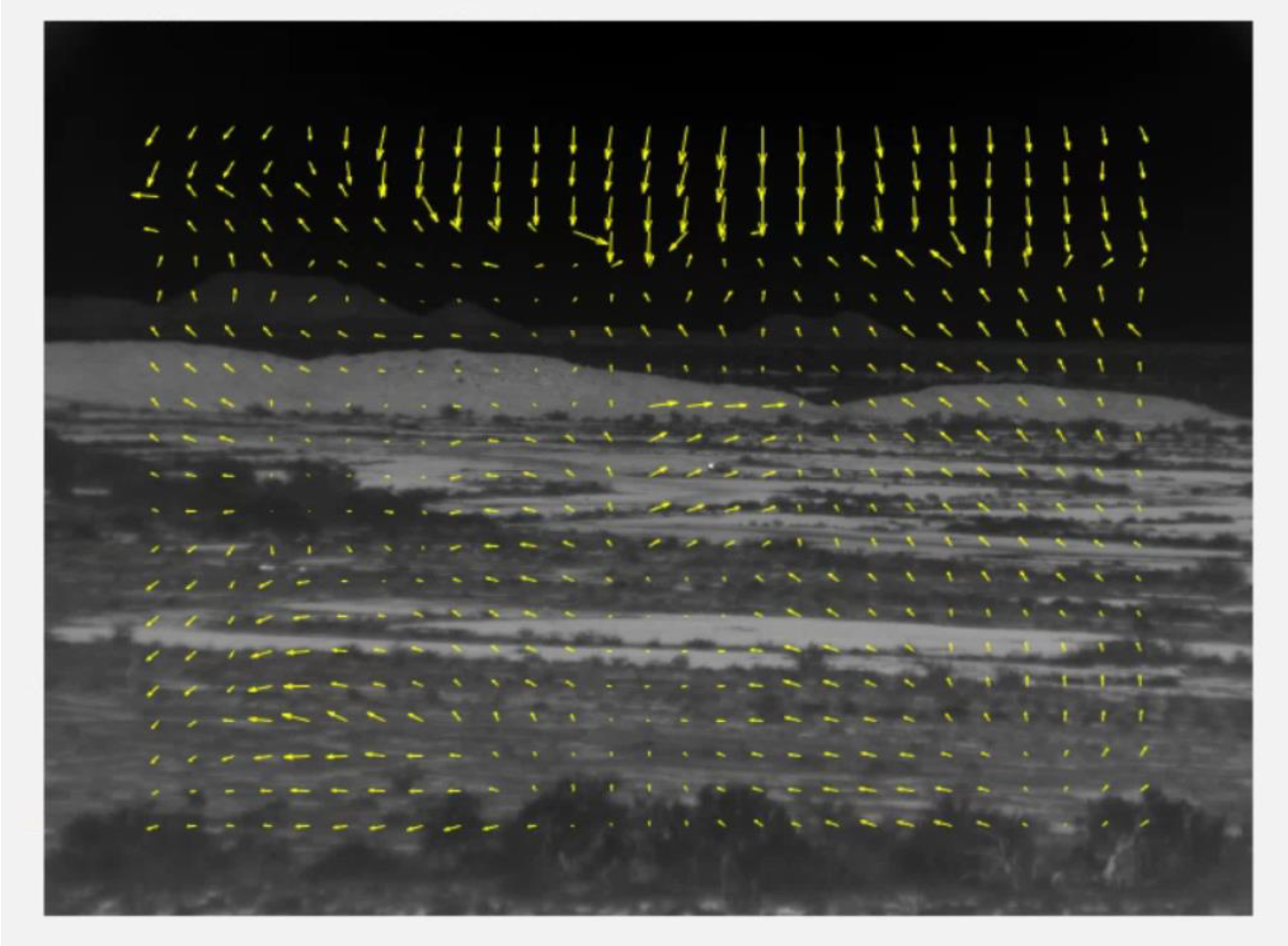
LK is a more traditional optical flow approach. Here, our objective is to see whether or not it would be effective at identifying the location of the target vehicles. The LK method had very poor results for the DSIAC MWIR videos. The motion vectors generated by the LK method show heavy motion outside of the target region, especially in the sky.
Figure 1 shows a sample output motion vector fields generated by LK. One can see that the motion vectors have diverse variations and it is difficult to pinpoint where the vehicle is. Although this is a single frame, we found that most optical flow outputs looked similar.
Because of the poor results of LK, we have focused on using TV-L1 and Brox methods in our experiments.
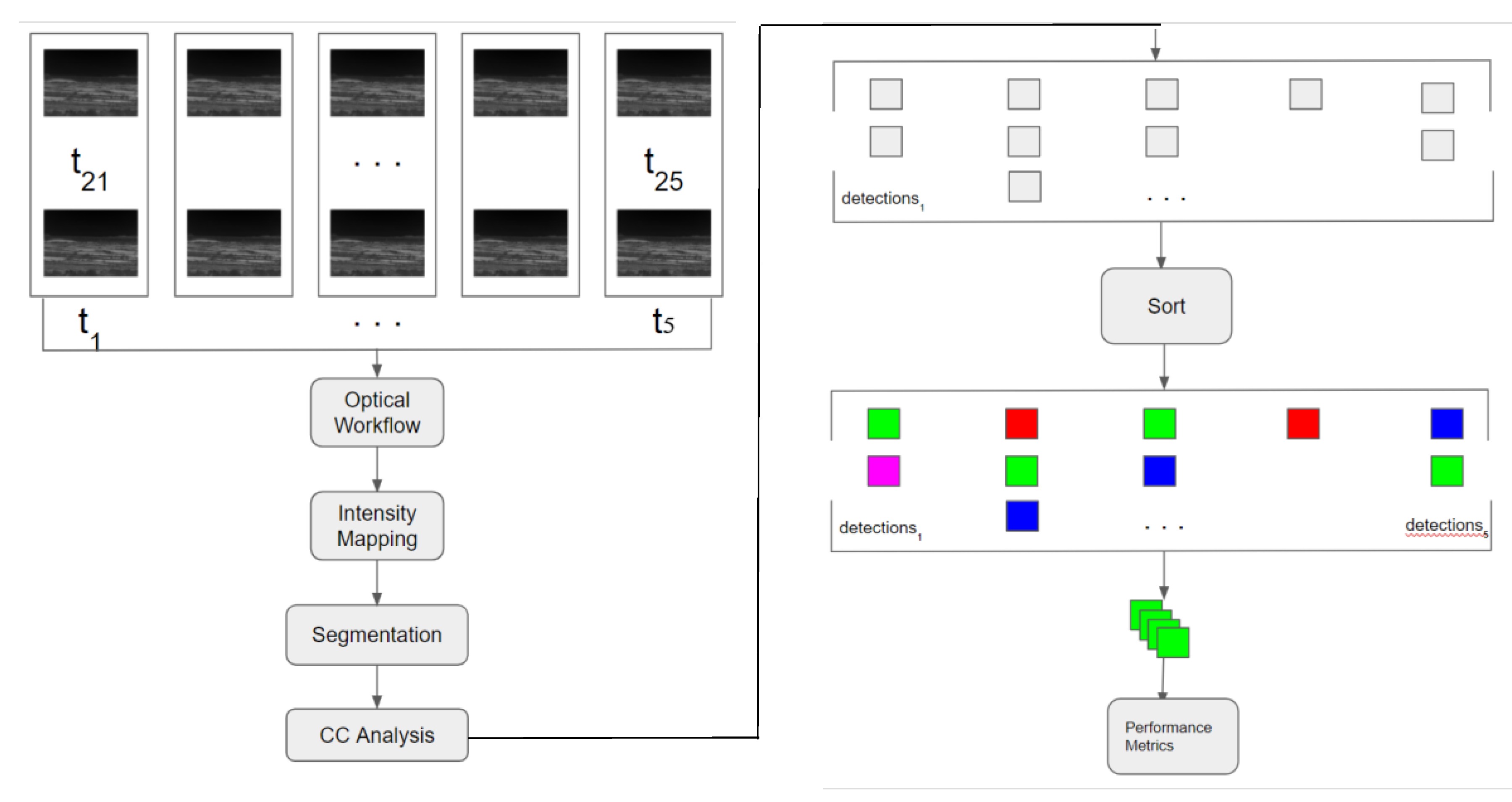
2.3. Proposed Unsupervised Target Detection Architecture for Long-Range Infrared Videos
The proposed unsupervised, modular, flexible, and efficient work flow was implemented in Python and is shown in
Figure 2. It should be emphasized that the raw video quality in DSIAC videos is poor and contrast enhancement is critical for optical flow methods. In the
Appendix A, we include a comparative study of some simple and effective enhancement methods to generate high-quality videos out of the raw videos. There are a number of steps in the proposed workflow. First, frame pairs are selected. In our experiments, the two frames are separated by 19 frames. This was done in order to increase the motion of the target. If adjacent frames are used, the motion in the DSIAC dataset is too subtle to notice. Second, optical flow algorithms are used to the frame pairs to extract the motion vectors. In our experiments, we have compared two algorithms: TV-L1 [
32] and Brox [
33]. Third, the intensity of the optical flow vectors is computed and used for determining moving pixels. Fourth, the intensity of the optical flow is thresholded based on the mean and standard deviation of the flow intensity. Fifth, a connected component (CC) analysis is performed to the segmented image. Finally, the detected areas are jointly analyzed using a Simple Online and Real-time Tracking (SORT) algorithm [
36]. Details of each step are shown below.
- Step 1:
Preprocessing
In order to better extract the motion in the frames, the input frame pair is the current frame and the 20th frame from the current frame. This was an important adjustment to the optical flow approach for the DSIAC videos because at the farther distances the motion of the vehicle was relatively minute. By using frames that are farther apart, the motion of the vehicle becomes much more apparent.
Since the image quality is not good, we improved the quality of the input frames within the workflow using contrast enhancement. Different algorithms can yield quite different target detection results. Details can be found in the
Appendix A.
- Step 2:
Optical flow
The first step is to use TV-L1 or Brox for generating the motion vectors. The basic principles of TV-L1 and Brox were described in
Section 2.1.
- Step 3:
Intensity mapping
A pair of frames is fed into the TV-L1 or Brox method. The optical flow in the horizontal and vertical (u,v) directions are then transferred to the custom intensity mapping block. Using Algorithm 1 below, we then map the amplitude of the motion vectors into an intensity map. It should be noted that we have incorporated an idea of using the product of intensity and pixel amplitude to weigh the optical flow intensity. This is necessary because, in some dark regions, there are strong motions due to air turbulence. Since the pixel amplitude is quite low in the dark regions, this will mitigate the motion detected in the dark background regions.
| Algorithm 1: Weighted optical flow intensity mapping of optical flow image |
Input: Horizontal (u) and vertical (v) components of the optical flow and pixel amplitude
P(i,j) of the current frame |
| Output: Intensity map I |
| For each pixel location (i,j), compute |
| (1) |u|, |v| |
| (2) Normalize |u| and |v| between 0 and 1 |
| (3) Compute weighted optical flow intensity map of I(i,j) = sqrt(u2+v2) * P(i, j) |
- Step 4:
Segmentation
We used Algorithm 2 below for target segmentation.
| Algorithm 2: Target segmentation |
| Input: Intensity image, I, of the optical flow |
| Output: Binarized image |
| (1) Compute the mean of I |
| (2) Compute standard deviation of I: std(I) |
| (3) Scan through the image; set pixel to 1 if >*std(I); should be between 2 and 4; otherwise, set pixel to 0. |
- Step 5:
Connected component (CC) Analysis to the intensity map
Since the segmented results may have scattered pixels, we then perform connected component analysis on the segmented binarized image to find clusters of moving pixels between frames. Unlike the LIG workflow in [
30], there is no use of dilation. Instead, the connected component analyses are using several rules to check whether the connected component is a valid detection or not. These rules involve checking if the area of the connected component is reasonable as well as comparing the max intensity of pixels between the connected components. If the area is over 1 pixel and less than 100 pixels, it is valid. Out of the remaining connected components, the one with the pixel with the highest intensity is then chosen as the target.
- Step 6:
Target Association between frames
This workflow has several key differences from the LIG method in [
30]. Instead of using information from a single frame to determine the location of a target, one key new component is that we utilize a window of frames to better detect targets. The information of targets from past frames can provide useful information for the potential location of future targets. The current frame and the four previous frames are used to determine the location of a target in the current frame. We then utilize SORT to perform track association of the various detections across these frames. SORT will assign a tracking identity (ID) to each individual frame in the sliding window. The algorithm then selects the ID with the most occurrences within that sliding window as the most likely candidate to be the target. SORT uses target size, target speed, and direction as part of its algorithm to determine track association.
We would like to point out that we also experimented with an alternative target association scheme based on rules. In some cases, the rule-based approach worked better than the SORT algorithm.
Figure 3 better illustrates how the proposed workflow operates for a given set of frames. However, since there are missing detections in certain frames, it can disrupt the workflow and create negative effects for later frames. In order to resolve this problem, we used a simple extrapolation idea to estimate detections. Extrapolation allows us to estimate the next location of the target by using the previous frames. We take the difference in centroid location of the previous two frames and add this to the previous centroid and use that extrapolated centroid as the location for the target in the current frame. This is now implemented within the SORT module.
2.4. An Alternative Implementation without Using SORT
From the contrast enhancement results in the
Appendix A, it was still concerning to see Approach 3a, which is the best contrast enhancement method for all videos, underperforms Approach 1 in the 3500 m case. Upon further investigation, the SORT tracking association method in
Section 2.3 was not working as intended. SORT pays close attention to the target sizes and when we use optical flow, the target size of the detections can dramatically shift from frame to frame. SORT will assign different tracking IDs to these detected targets because their target sizes are too different for it to associate as the same target. There are two root causes of this issue. First, when performing dilation, nearby connected components can get merged in with the target connected component. Second, the actual size of the detection varies across frames due to natural fluctuation of pixel values.
Figure 4 below illustrates the variation of detected target size across frames.
Because of these inherent issues of using SORT, we revisited the original pipeline (
Figure 2) and revised it to the flow shown in
Figure 5 to see if we could further improve the overall system performance. The majority of the pipeline was left intact, but the rules analysis module shown in
Figure 5 was revised. In particular, we updated the sequencing of the rules analysis module. One of the issues with the earlier rules module was that it placed more emphasis on the maximum intensity of a connected component than its location. Our initial assumption was that the target would consistently have the highest optical flow value. Although this assumption is true to a certain extent, there are still a significant amount of cases that did not follow this assumption. Instead, the focus should be on finding relatively high intensity components in a tight range around previous detections.
Details of some rules are summarized in the following sections.
2.4.1. Nearest Neighbor Target Association Using Rules
To further reduce false positives, we implemented a simple distance rule to properly associate the components from one frame to another. For example, if we know the location of the target in the previous frame, we can assume that the target did not leave the surrounding area (i.e., 100 pixel radius). When implemented into the optical flow workflow, the results were discouraging. There were 0 correct detections on the 3500 m MWIR daytime video. The reason for this is that if the detected target is far enough outside the actual location of the target, this approach will struggle to correctly detect the target in future frames. The example below demonstrates the shortcomings of this approach for this particular dataset. For example, in the first frame of the 3500 m video, the detected target is in the bottom left. Even though the optical flow correctly detects targets in the proceeding frame, the rule-based analysis will eliminate it from the possible targets due to the original detection in the first frame.
2.4.2. Target Searching Radius
In the updated pipeline shown in
Figure 5, there is more emphasis on establishing the initial location of the target and searching closely around that area. We use a much tighter radius for searching, 20 pixels instead of 200. Although there can be cases of missing detections with such a tight search radius, if we use this in conjunction with extrapolation, we can overcome the issue of missing detections. It should be noted that the input frames for this workflow are the Approach 3a contrast-enhanced frames discussed in the
Appendix A.
2.4.3. Rules to Eliminate False Positives
Some simple rules are applied to eliminate some false positives. For example, one rule eliminates certain connected components that do not meet size criteria. If the size of the component is bigger than 10 pixels (for instance), then the component is discarded.
Figure 6 illustrates the impact of using rules. It can be observed that there are more false positives in the image without using rules.
4. Conclusions and Future Research
We propose an unsupervised, modular, flexible, and computationally efficient target detection approach for long-range and low-quality infrared videos containing moving objects. Extensive experiments using MWIR infrared videos collected from 3500 to 5000 m were used in our evaluations. Two well-known optical flow methods (TV-L1 and Brox) were used to detect moving objects. Compared with TV-L1, Brox appears to have a slight edge in terms of accuracy, but requires more computational time. Two object association methods were also examined and compared. The rule-based approach outperforms another method known as SORT. We also observed that the manipulation of the intensity/contrast of the input frames is especially essential for optical flow methods, as they are much more sensitive to background intensity differences across frames. Using a second order histogram matching method for contrast enhancement was shown to be effective at resolving contrast issues in the DSIAC dataset.
In the future, we will investigate faster implementation of optical flow methods using C or field programmable gate array (FPGA).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
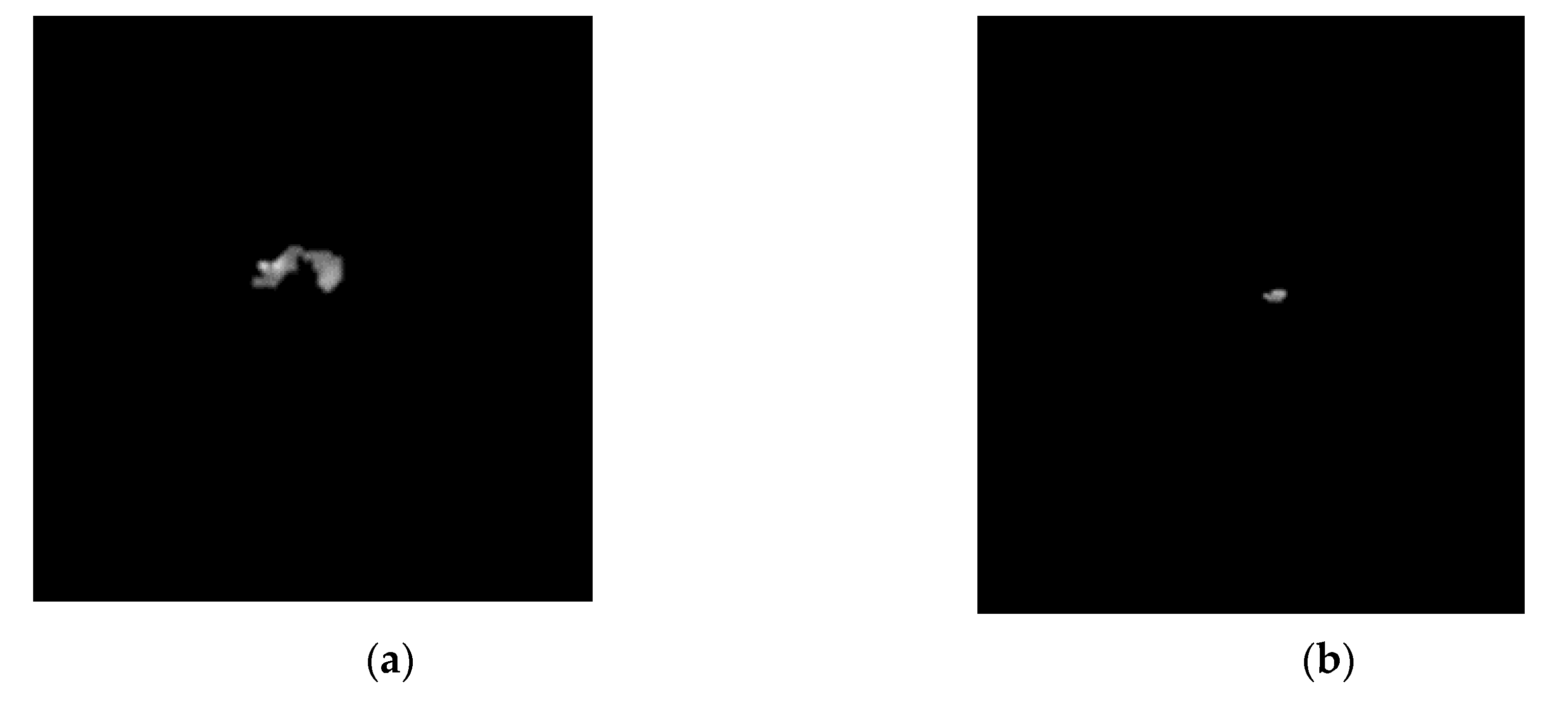{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















