Beach State Recognition Using Argus Imagery and Convolutional Neural Networks

 ,
, 
Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Field Sites and Data
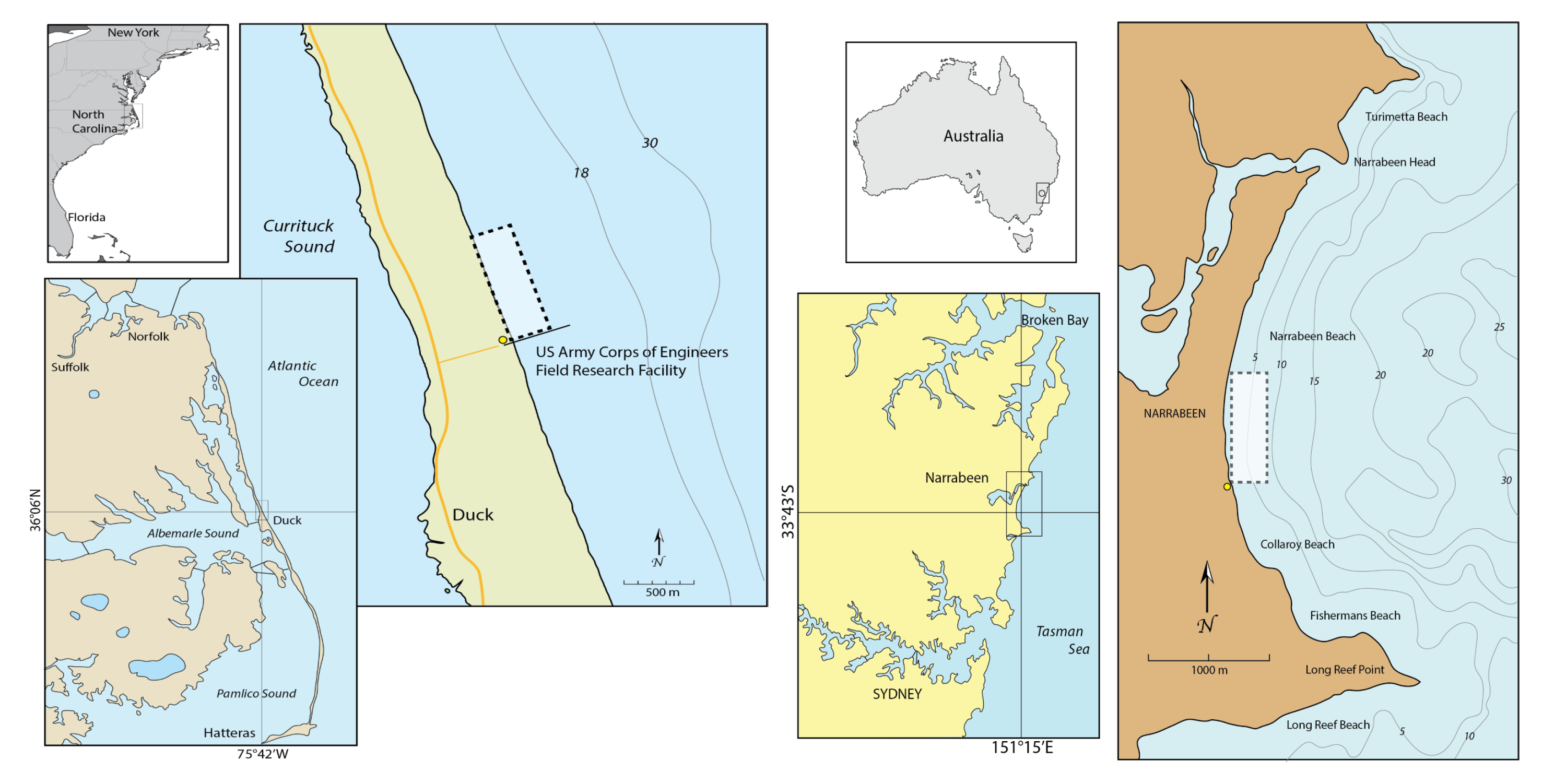
2.1. Field Sites
2.2. Dataset
3. Methods
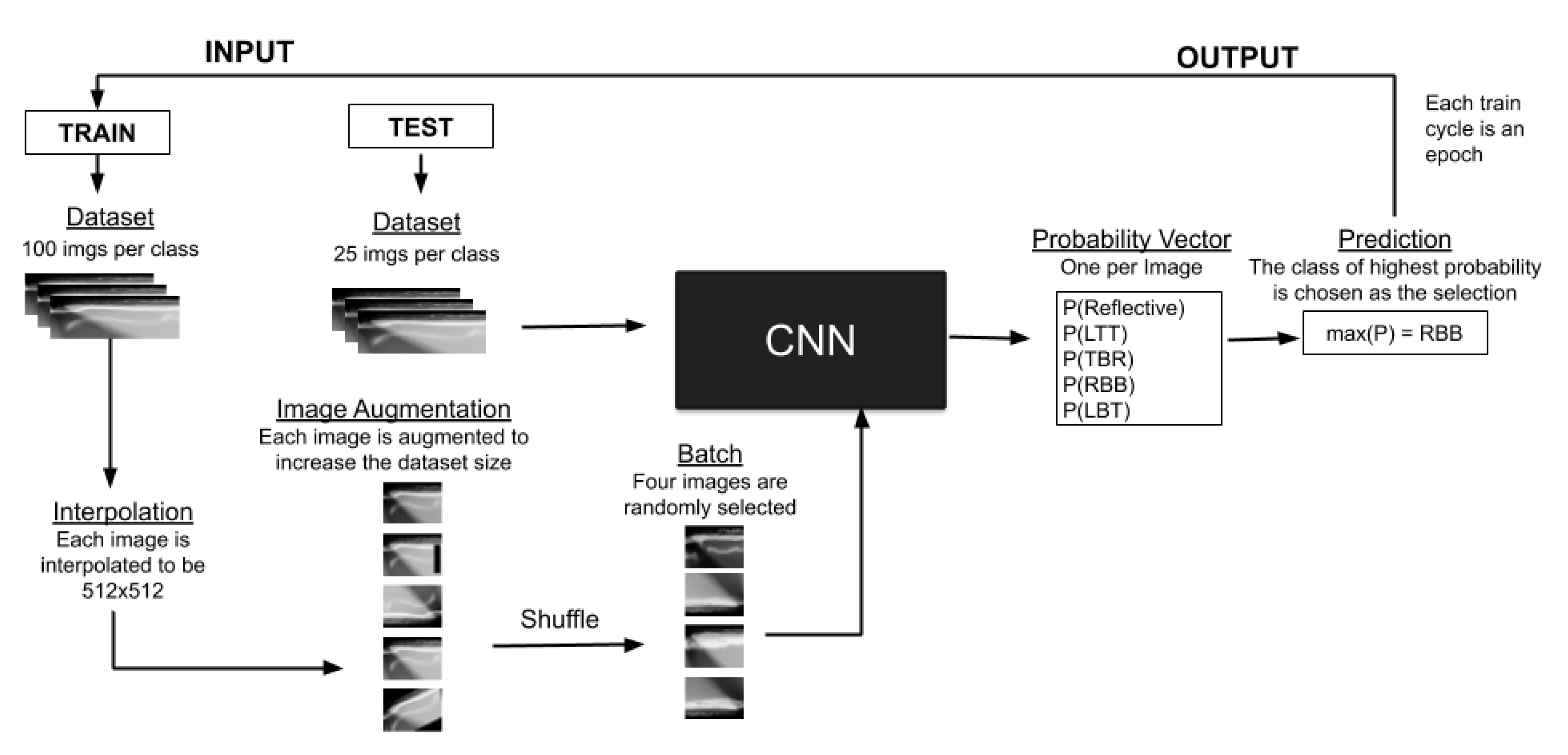
3.1. Dataset Preparation: Manual Labelling and Augmentation
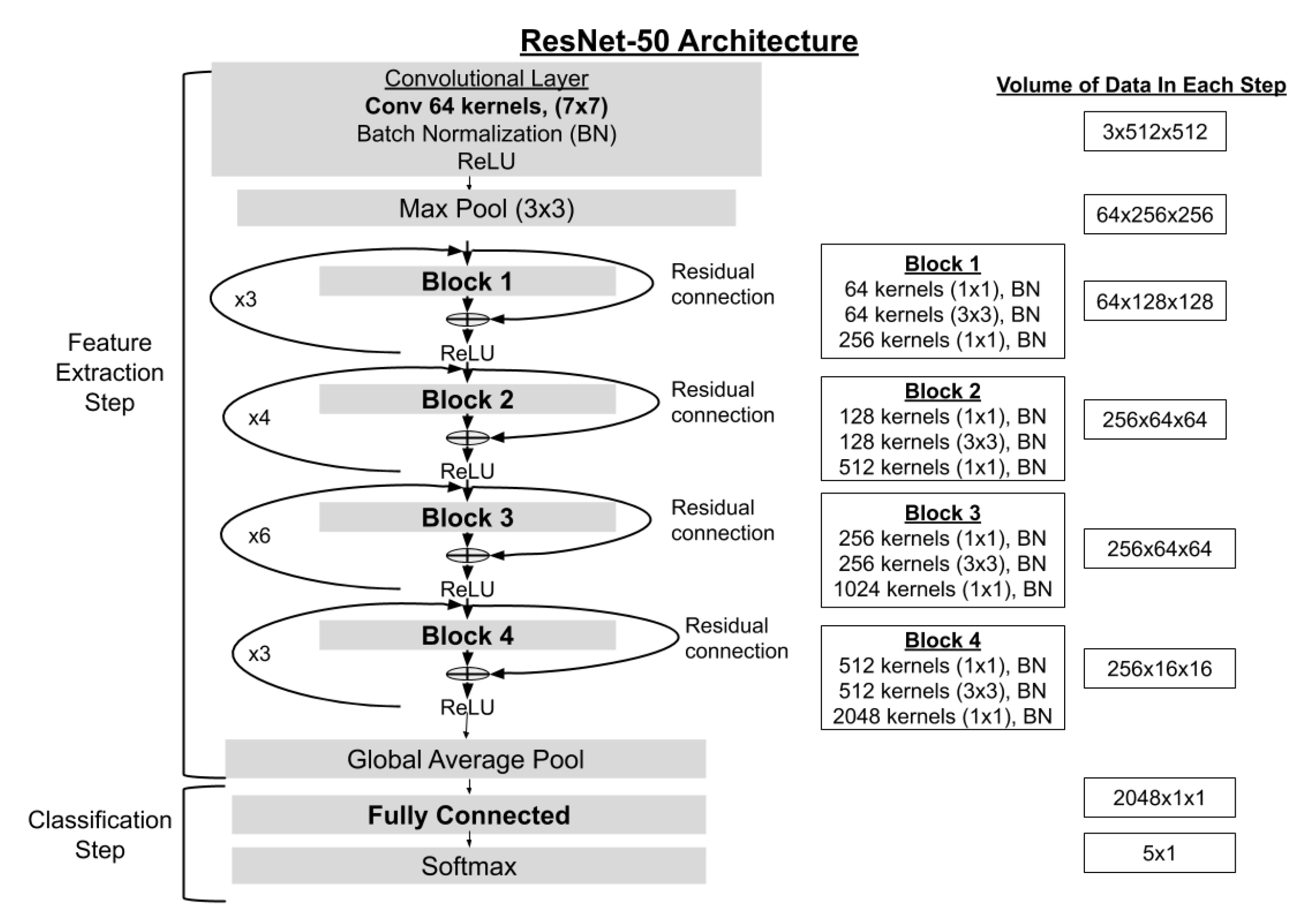
3.2. Convolutional Neural Network
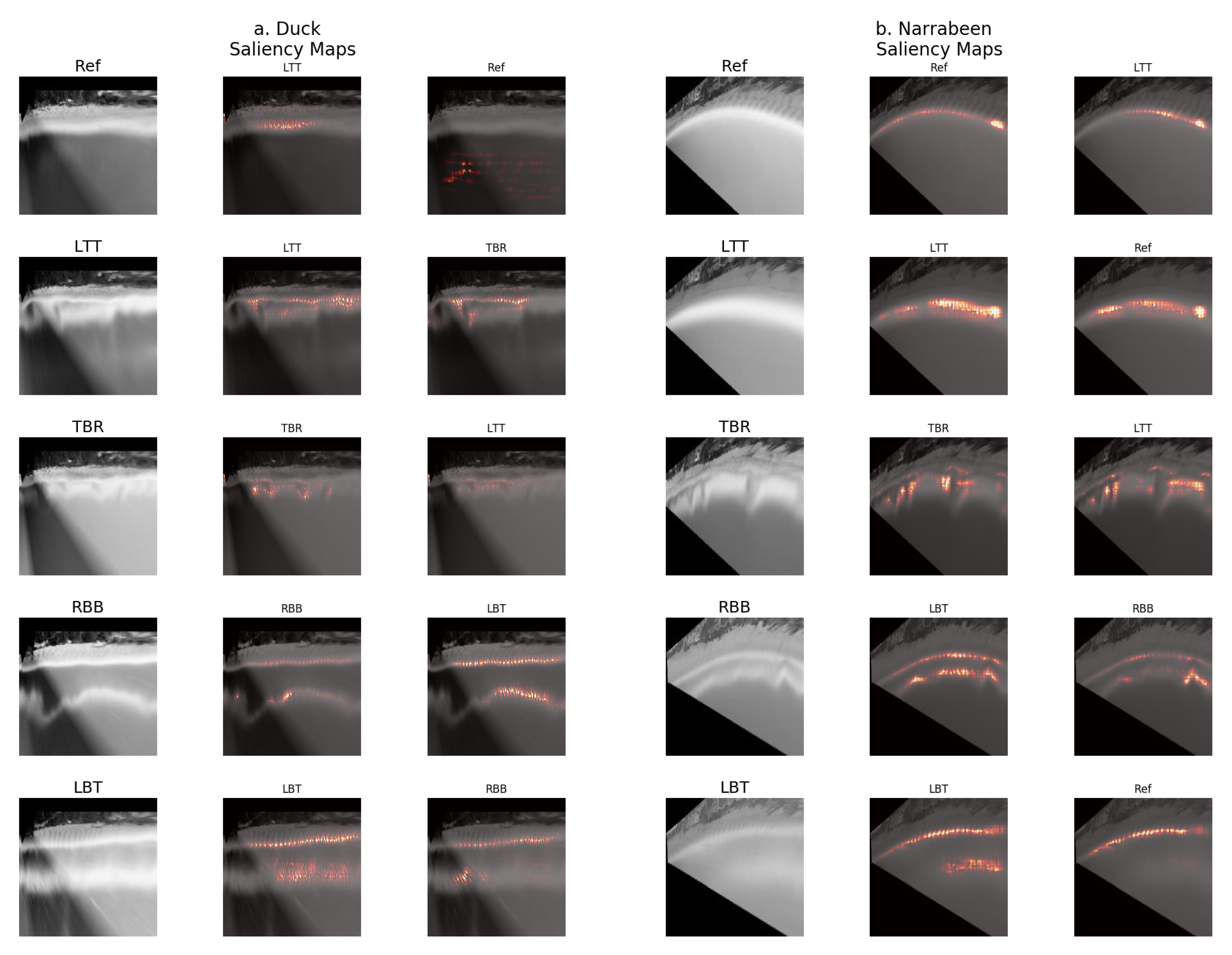
3.3. Visualization: Saliency Maps
3.4. Experiments
4. Results
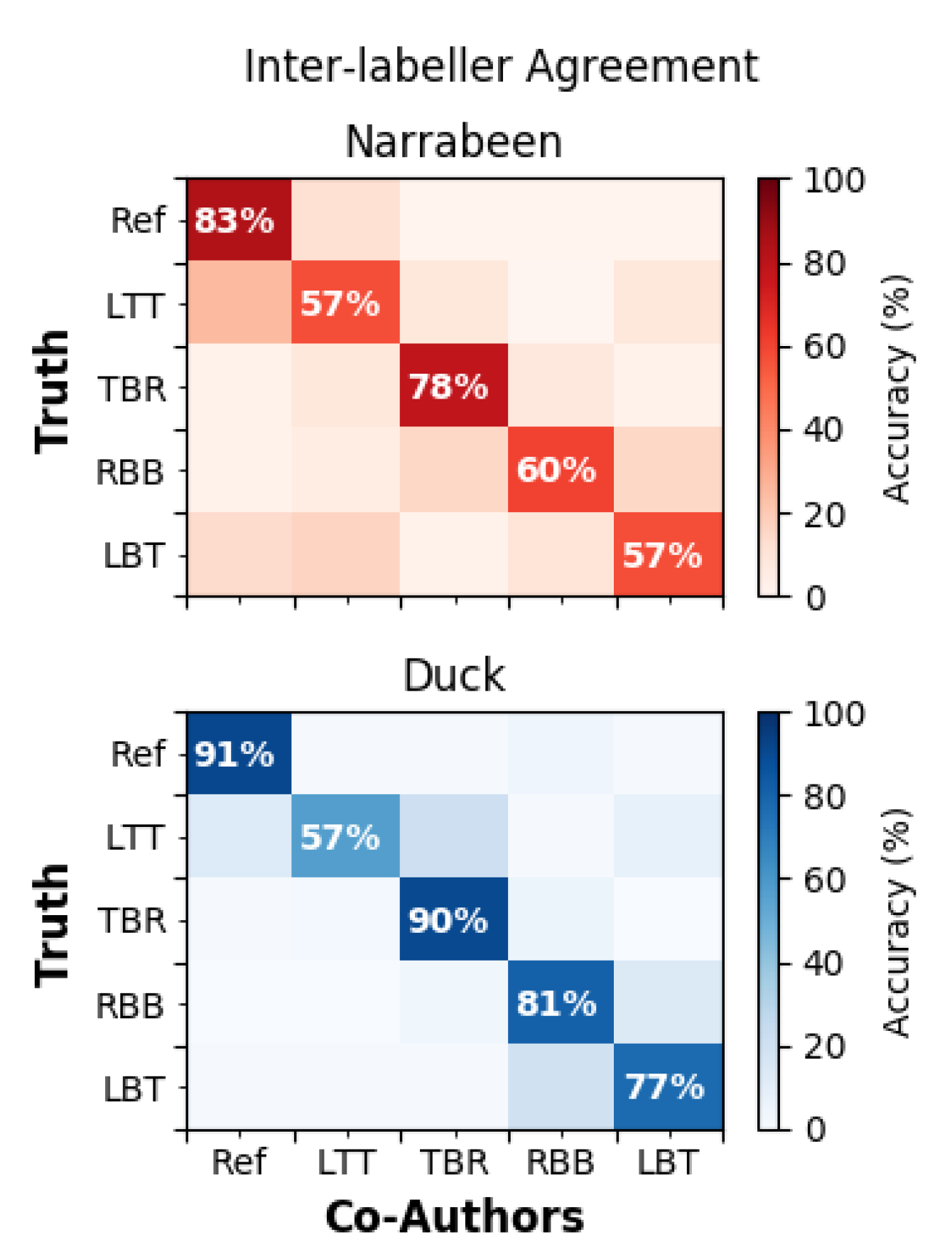
4.1. Inter-Labeller Agreement
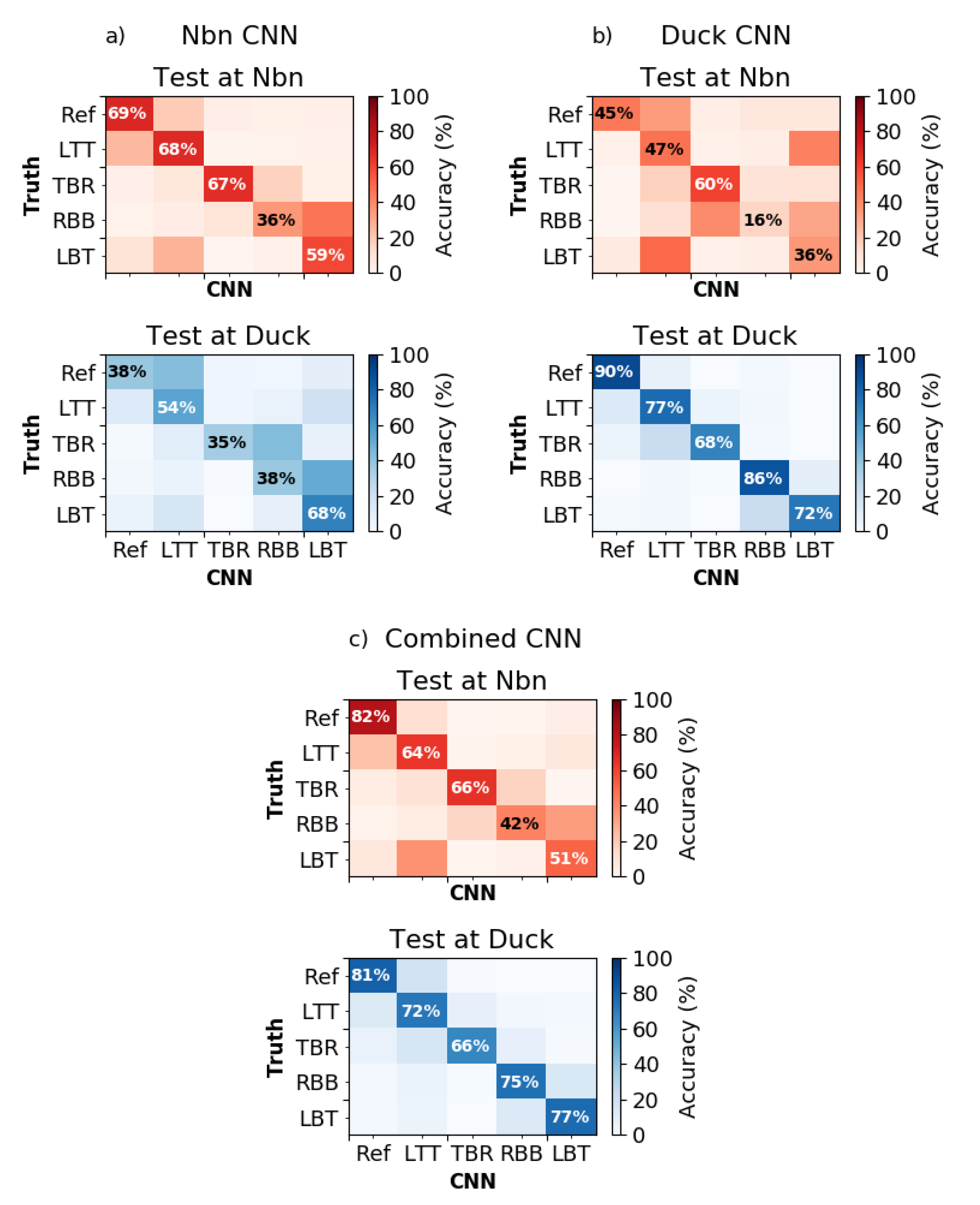
4.2. CNN Skill
5. Discussion
5.1. Beach State Classification
5.2. Site Imagery Differences Affecting State Identification
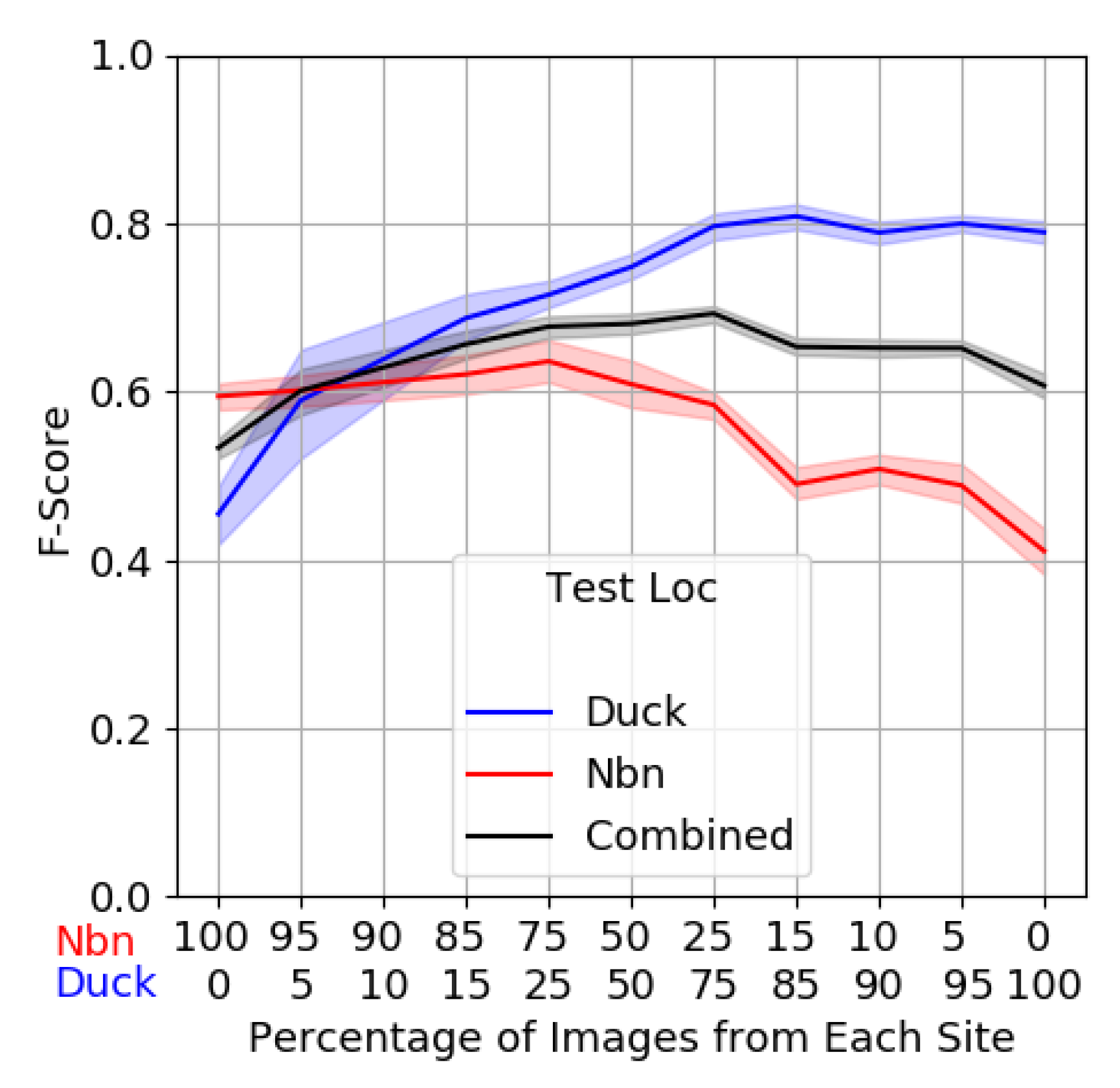
5.3. Data Requirements for Skillful Transfer of the CNN to New Sites
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Convolutional Neural Network Theory

Appendix B. Skill Metrics
References
- Holman, R.A.; Symonds, G.; Thornton, E.B.; Ranasinghe, R. Rip spacing and persistence on an embayed beach. J. Geophys. Res. Ocean. 2006, 111. [Google Scholar] [CrossRef]
- Turner, I.L.; Whyte, D.; Ruessink, B.G.; Ranasinghe, R. Observations of rip spacing, persistence and mobility at a long, straight coastline. Mar. Geol. 2007, 236, 209–221. [Google Scholar] [CrossRef]
- Wilson, G.W.; Özkan-Haller, H.T.; Holman, R.A. Data assimilation and bathymetric inversion in a two-dimensional horizontal surf zone model. J. Geophys. Res. Ocean. 2010, 115. [Google Scholar] [CrossRef]
- Inman, D.L.; Brush, B.M. The coastal challenge. Science 1973, 181, 20–32. [Google Scholar] [CrossRef] [PubMed]
- Grant, S.B.; Kim, J.H.; Jones, B.H.; Jenkins, S.A.; Wasyl, J.; Cudaback, C. Surf zone entrainment, along-shore transport, and human health implications of pollution from tidal outlets. J. Geophys. Res. Ocean. 2005, 110. [Google Scholar] [CrossRef]
- Austin, M.J.; Scott, T.M.; Russell, P.E.; Masselink, G. Rip Current Prediction: Development, Validation, and Evaluation of an Operational Tool. J. Coast. Res. 2013, 29, 283–300. [Google Scholar] [CrossRef][Green Version]
- Castelle, B.; Scott, T.; Brander, R.W.; McCarroll, R.J. Rip current types, circulation and hazard. Earth-Sci. Rev. 2016, 163, 1–21. [Google Scholar] [CrossRef]
- Wright, L.D.; Short, A.D. Morphodynamic variability of surf zones and beaches: A synthesis. Mar. Geol. 1984, 56, 93–118. [Google Scholar] [CrossRef]
- Leatherman, S.P. Coastal erosion and the United States national flood insurance program. Ocean Coast. Manag. 2018, 156, 35–42. [Google Scholar] [CrossRef]
- Helderop, E.; Grubesic, T.H. Social, geomorphic, and climatic factors driving US coastal city vulnerability to storm surge flooding. Ocean Coast. Manag. 2019, 181, 104902. [Google Scholar] [CrossRef]
- Thornton, E.B.; MacMahan, J.; Sallenger, A.H. Rip currents, mega-cusps, and eroding dunes. Mar. Geol. 2007, 240, 151–167. [Google Scholar] [CrossRef]
- Castelle, B.; Marieu, V.; Bujan, S.; Splinter, K.D.; Robinet, A.; Sénéchal, N.; Ferreira, S. Impact of the winter 2013–2014 series of severe Western Europe storms on a double-barred sandy coast: Beach and dune erosion and megacusp embayments. Geomorphology 2015, 238, 135–148. [Google Scholar] [CrossRef]
- Holman, R.A.; Stanley, J. The history and technical capabilities of Argus. Coast. Eng. 2007, 54, 477–491. [Google Scholar] [CrossRef]
- Lippmann, T.C.; Holman, R.A. The spatial and temporal variability of sand bar morphology. J. Geophys. Res. Ocean. 1990, 95, 11575–11590. [Google Scholar] [CrossRef]
- Wright, L.; Short, A.; Green, M. Short-term changes in the morphodynamic states of beaches and surf zones: An empirical predictive model. Mar. Geol. 1985, 62, 339–364. [Google Scholar] [CrossRef]
- Ranasinghe, R.; Symonds, G.; Black, K.; Holman, R. Morphodynamics of intermediate beaches: A video imaging and numerical modelling study. Coast. Eng. 2004, 51, 629–655. [Google Scholar] [CrossRef]
- Strauss, D.; Tomlinson, R.; Hughes, L. Numerical modelling and video analysis of intermediate beach state transitions. In Proceedings of the 7th International Conference on Hydroscience and Engineering, Philadelphia, PA, USA, 10–13 September 2006. [Google Scholar]
- Plant, N.G.; Holland, K.T.; Holman, R.A. A dynamical attractor governs beach response to storms. Geophys. Res. Lett. 2006, 33. [Google Scholar] [CrossRef]
- Siegle, E.; Huntley, D.A.; Davidson, M.A. Coupling video imaging and numerical modelling for the study of inlet morphodynamics. Mar. Geol. 2007, 236, 143–163. [Google Scholar] [CrossRef]
- Splinter, K.D.; Holman, R.A.; Plant, N.G. A behavior-oriented dynamic model for sandbar migration and 2DH evolution. J. Geophys. Res. Ocean. 2011, 116. [Google Scholar] [CrossRef]
- Dubarbier, B.; Castelle, B.; Ruessink, G.; Marieu, V. Mechanisms controlling the complete accretionary beach state sequence. Geophys. Res. Lett. 2017, 44, 5645–5654. [Google Scholar] [CrossRef]
- van Enckevort, I.M.J.; Ruessink, B.G. Video observations of nearshore bar behaviour. Part 2: Alongshore non-uniform variability. Cont. Shelf Res. 2003, 23, 513–532. [Google Scholar] [CrossRef]
- Castelle, B.; Bonneton, P.; Dupuis, H.; Sénéchal, N. Double bar beach dynamics on the high-energy meso-macrotidal French Aquitanian Coast: A review. Mar. Geol. 2007, 245, 141–159. [Google Scholar] [CrossRef]
- Price, T.; Ruessink, B. State dynamics of a double sandbar system. Cont. Shelf Res. 2011, 31, 659–674. [Google Scholar] [CrossRef]
- Ojeda, E.; Guillén, J.; Ribas, F. Dynamics of single-barred embayed beaches. Mar. Geol. 2011, 280, 76–90. [Google Scholar] [CrossRef]
- Armaroli, C.; Ciavola, P. Dynamics of a nearshore bar system in the northern Adriatic: A video-based morphological classification. Geomorphology 2011, 126, 201–216. [Google Scholar] [CrossRef]
- De Santiago, I.; Morichon, D.; Abadie, S.; Castelle, B.; Liria, P.; Epelde, I. Video monitoring nearshore sandbar morphodynamics on a partially engineered embayed beach. J. Coast. Res. 2013, 65, 458–463. [Google Scholar] [CrossRef]
- Short, A.; Hogan, C. Rip currents and beach hazards: Their impact on public safety and implications for coastal management. J. Coast. Res. 1994, 12, 197–209. [Google Scholar]
- Masselink, G.; Short, A.D. The Effect of Tide Range on Beach Morphodynamics and Morphology: A Conceptual Beach Model. J. Coast. Res. 1993, 9, 785–800. [Google Scholar]
- Loureiro, C.; Ferreira, S.; Cooper, J.A.G. Applicability of parametric beach morphodynamic state classification on embayed beaches. Mar. Geol. 2013, 346, 153–164. [Google Scholar] [CrossRef]
- Lippmann, T.C.; Holman, R.A. Quantification of sand bar morphology: A video technique based on wave dissipation. J. Geophys. Res. Ocean. 1989, 94, 995–1011. [Google Scholar] [CrossRef]
- Browne, M.; Strauss, D.; Tomlinson, R.; Blumenstein, M. Objective Beach-State Classification From Optical Sensing of Cross-Shore Dissipation Profiles. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3418–3426. [Google Scholar] [CrossRef]
- van Enckevort, I.M.J.; Ruessink, B.G. Effect of hydrodynamics and bathymetry on video estimates of nearshore sandbar position. J. Geophys. Res. Ocean. 2001, 106, 16969–16979. [Google Scholar] [CrossRef]
- Contardo, S.; Symonds, G. Sandbar straightening under wind-sea and swell forcing. Mar. Geol. 2015, 368, 25–41. [Google Scholar] [CrossRef]
- Splinter, K.D.; Harley, M.D.; Turner, I.L. Remote sensing is changing our view of the coast: Insights from 40 years of monitoring at Narrabeen-Collaroy, Australia. Remote Sens. 2018, 10, 1744. [Google Scholar] [CrossRef]
- Smit, M.W.J.; Aarninkhof, S.G.J.; Wijnberg, K.M.; González, M.; Kingston, K.S.; Southgate, H.N.; Ruessink, B.G.; Holman, R.A.; Siegle, E.; Davidson, M.; et al. The role of video imagery in predicting daily to monthly coastal evolution. Coast. Eng. 2007, 54, 539–553. [Google Scholar] [CrossRef]
- Holman, R.; Haller, M.C. Remote Sensing of the Nearshore. Annu. Rev. Mar. Sci. 2013, 5, 95–113. [Google Scholar] [CrossRef]
- Peres, D.; Iuppa, C.; Cavallaro, L.; Cancelliere, A.; Foti, E. Significant wave height record extension by neural networks and reanalysis wind data. Ocean Model. 2015, 94, 128–140. [Google Scholar] [CrossRef]
- Molines, J.; Herrera, M.P.; Gómez-Martín, M.E.; Medina, J.R. Distribution of individual wave overtopping volumes on mound breakwaters. Coast. Eng. 2019, 149, 15–27. [Google Scholar] [CrossRef]
- Ellenson, A.; Pei, Y.; Wilson, G.; Özkan-Haller, H.T.; Fern, X. An application of a machine learning algorithm to determine and describe error patterns within wave model output. Coast. Eng. 2020, 157, 103595. [Google Scholar] [CrossRef]
- Den Bieman, J.P.; de Ridder, M.P.; van Gent, M.R.A. Deep learning video analysis as measurement technique in physical models. Coast. Eng. 2020, 158, 103689. [Google Scholar] [CrossRef]
- Buscombe, D.; Carini, R.J.; Harrison, S.R.; Chickadel, C.C.; Warrick, J.A. Optical wave gauging using deep neural networks. Coast. Eng. 2020, 155, 103593. [Google Scholar] [CrossRef]
- Buscombe, D. SediNet: A configurable deep learning model for mixed qualitative and quantitative optical granulometry. Earth Surf. Process. Landf. 2020, 45, 638–651. [Google Scholar] [CrossRef]
- Den Bieman, J.P.; van Gent, M.R.A.; Hoonhout, B.M. Physical model of scour at the toe of rock armoured structures. Coast. Eng. 2019, 154, 103572. [Google Scholar] [CrossRef]
- Hoonhout, B.M.; Radermacher, M.; Baart, F.; van der Maaten, L.J.P. An automated method for semantic classification of regions in coastal images. Coast. Eng. 2015, 105, 1–12. [Google Scholar] [CrossRef]
- Vos, K.; Splinter, K.D.; Harley, M.D.; Simmons, J.A.; Turner, I.L. CoastSat: A Google Earth Engine-enabled Python toolkit to extract shorelines from publicly available satellite imagery. Environ. Model. Softw. 2019, 122, 104528. [Google Scholar] [CrossRef]
- Buscombe, D.; Carini, R.J. A Data-Driven Approach to Classifying Wave Breaking in Infrared Imagery. Remote Sens. 2019, 11, 859. [Google Scholar] [CrossRef]
- Beuzen, T.; Goldstein, E.B.; Splinter, K.D. Ensemble models from machine learning: An example of wave runup and coastal dune erosion. Nat. Hazards Earth Syst. Sci. 2019, 19, 2295–2309. [Google Scholar] [CrossRef]
- Birkemeier, W.A.; DeWall, A.E.; Gorbics, C.S.; Miller, H.C. A User’s Guide to CERC’s Field Research Facility; Technical Report; Coastal Engineering Research Center: For Belvoir, VA, USA, 1981. [Google Scholar]
- Horrillo-Caraballo, J.; Reeve, D. An investigation of the link between beach morphology and wave climate at Duck, NC, USA. J. Flood Risk Manag. 2008, 1, 110–122. [Google Scholar] [CrossRef]
- Stauble, D.K. Long-Term Profile and Sediment Morphodynamics: Field Research Facility Case History; Technical Report 92–97; Coastal Engineering Research Center: Vicksburg, MS, USA, 1992. [Google Scholar]
- Alexander, P.S.; Holman, R.A. Quantification of nearshore morphology based on video imaging. Mar. Geol. 2004, 208, 101–111. [Google Scholar] [CrossRef]
- Turner, I.L.; Harley, M.D.; Short, A.D.; Simmons, J.A.; Bracs, M.A.; Phillips, M.S.; Splinter, K.D. A multi-decade dataset of monthly beach profile surveys and inshore wave forcing at Narrabeen, Australia. Sci. Data 2016, 3, 160024. [Google Scholar] [CrossRef]
- Harley, M.D.; Turner, I.L.; Short, A.D.; Ranasinghe, R. A reevaluation of coastal embayment rotation: The dominance of cross-shore versus alongshore sediment transport processes, Collaroy-Narrabeen Beach, southeast Australia. J. Geophys. Res. Earth Surf. 2011, 116. [Google Scholar] [CrossRef]
- Holland, K.; Holman, R.; Lippmann, T.; Stanley, J.; Plant, N. Practical use of video imagery in nearshore oceanographic field studies. IEEE J. Ocean. Eng. 1997, 22, 81–92. [Google Scholar] [CrossRef]
- Ghosh, S.; Das, N.; Nasipuri, M. Reshaping inputs for convolutional neural network: Some common and uncommon methods. Pattern Recognit. 2019, 93, 79–94. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simon, M.; Rodner, E.; Denzler, J. ImageNet pre-trained models with batch normalization. arXiv 2016, arXiv:1612.01452. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2015, arXiv:1412.6806. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 412–424. [Google Scholar] [CrossRef]
- Chen, L.; Wang, S.; Fan, W.; Sun, J.; Naoi, S. Beyond human recognition: A CNN-based framework for handwritten character recognition. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 695–699. [Google Scholar]
- Pianca, C.; Holman, R.; Siegle, E. Shoreline variability from days to decades: Results of long-term video imaging. J. Geophys. Res. Ocean. 2015, 120, 2159–2178. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object Detectors Emerge in Deep Scene CNNs. arXiv 2015, arXiv:1412.6856. [Google Scholar]
- Madsen, A.J.; Plant, N.G. Intertidal beach slope predictions compared to field data. Mar. Geol. 2001, 173, 121–139. [Google Scholar] [CrossRef]
- Plant, N.G.; Holman, R.A. Intertidal beach profile estimation using video images. Mar. Geol. 1997, 140, 1–24. [Google Scholar] [CrossRef]
- Balaguer, A.; Ruiz, L.; Hermosilla, T.; Recio, J. Definition of a comprehensive set of texture semivariogram features and their evaluation for object-oriented image classification. Comput. Geosci. 2010, 36, 231–240. [Google Scholar] [CrossRef]
- Bohling, G. Introduction to geostatistics and variogram analysis. Kans. Geol. Surv. 2005, 1, 1–20. [Google Scholar]
- Wu, X.; Peng, J.; Shan, J.; Cui, W. Evaluation of semivariogram features for object-based image classification. Geo-Spat. Inf. Sci. 2015, 18, 159–170. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ellenson, A.N.; Simmons, J.A.; Wilson, G.W.; Hesser, T.J.; Splinter, K.D. Beach State Recognition Using Argus Imagery and Convolutional Neural Networks. Remote Sens. 2020, 12, 3953. https://doi.org/10.3390/rs12233953
Ellenson AN, Simmons JA, Wilson GW, Hesser TJ, Splinter KD. Beach State Recognition Using Argus Imagery and Convolutional Neural Networks. Remote Sensing. 2020; 12(23):3953. https://doi.org/10.3390/rs12233953
Chicago/Turabian StyleEllenson, Ashley N., Joshua A. Simmons, Greg W. Wilson, Tyler J. Hesser, and Kristen D. Splinter. 2020. "Beach State Recognition Using Argus Imagery and Convolutional Neural Networks" Remote Sensing 12, no. 23: 3953. https://doi.org/10.3390/rs12233953
APA StyleEllenson, A. N., Simmons, J. A., Wilson, G. W., Hesser, T. J., & Splinter, K. D. (2020). Beach State Recognition Using Argus Imagery and Convolutional Neural Networks. Remote Sensing, 12(23), 3953. https://doi.org/10.3390/rs12233953