Probabilistic Mangrove Species Mapping with Multiple-Source Remote-Sensing Datasets Using Label Distribution Learning in Xuan Thuy National Park, Vietnam




Abstract

1. Introduction
- exploiting GF-3 SAR to classify mangrove tree species for the first time.
- investigating the combination of GF-3 full-polarimetric SAR and Sentinel-2 optical datasets.
- proposing to use LDL for the probabilistic mangrove species mapping.
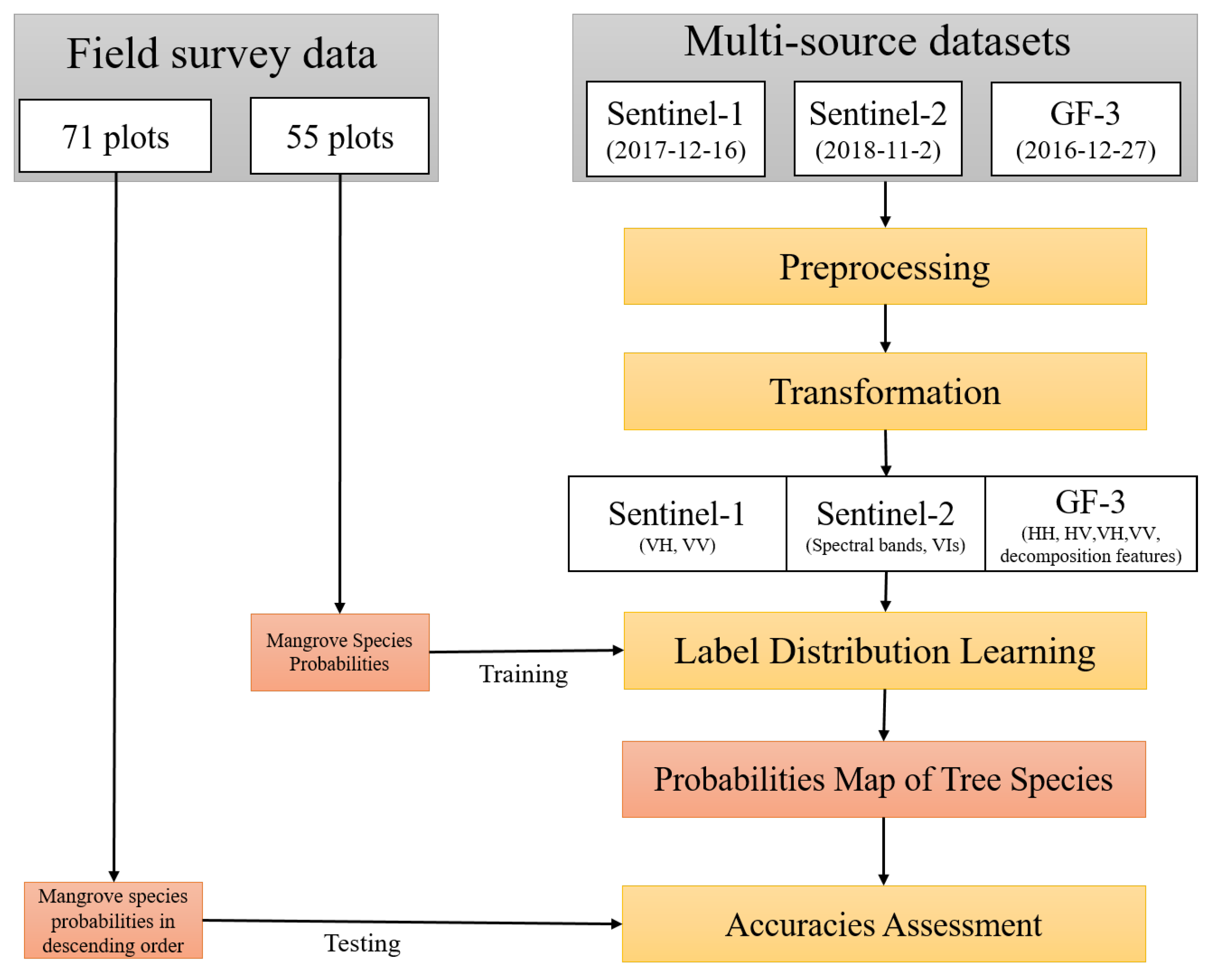
2. Materials and Methods
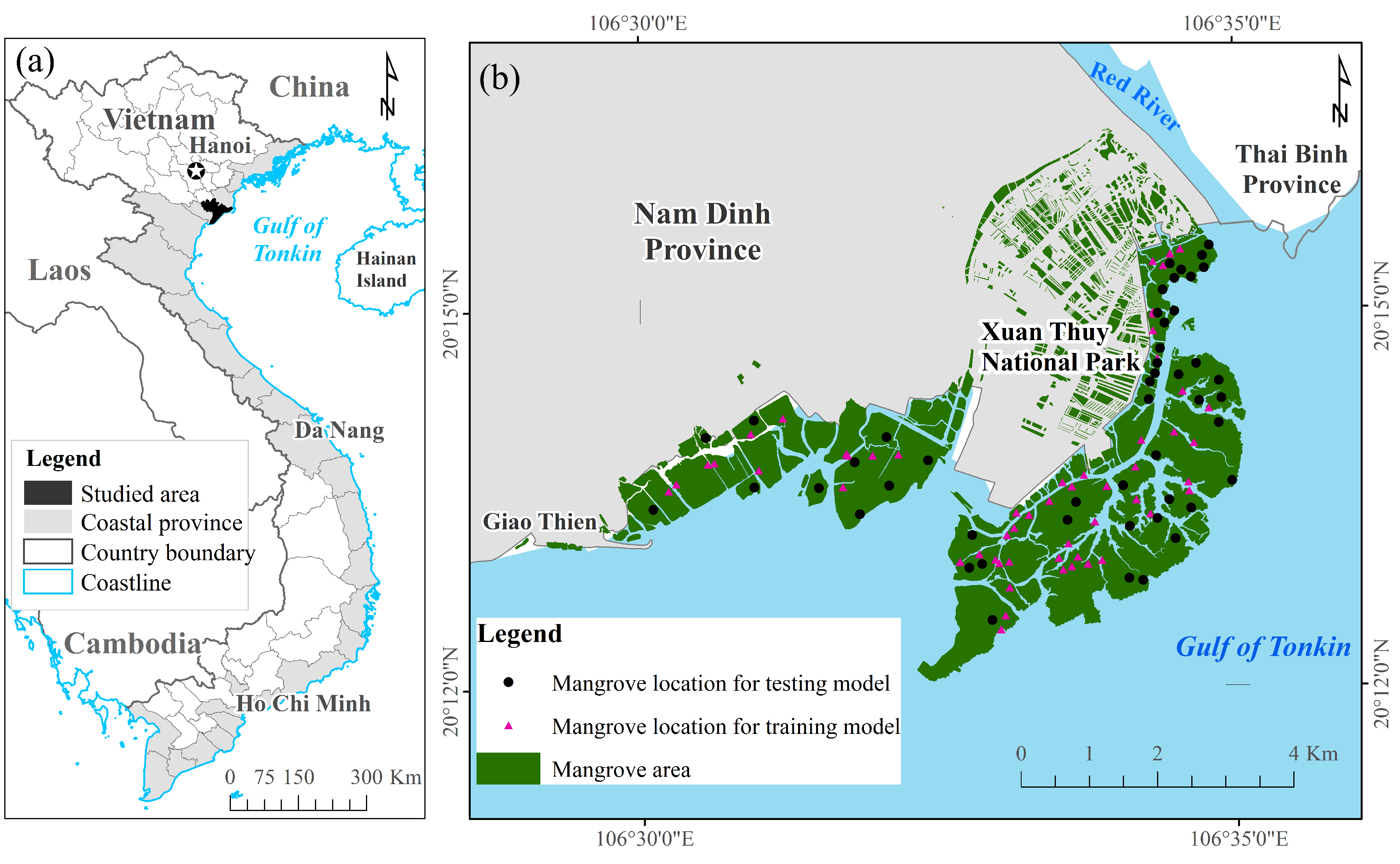
2.1. Study Area
2.2. Remote-Sensing Data
2.2.1. Remote-Sensing Pre-Processing
2.2.2. Transformation of Sentinel-2 and GF-3
2.2.3. LDL Classification
2.3. Field Data and Validation Analysis
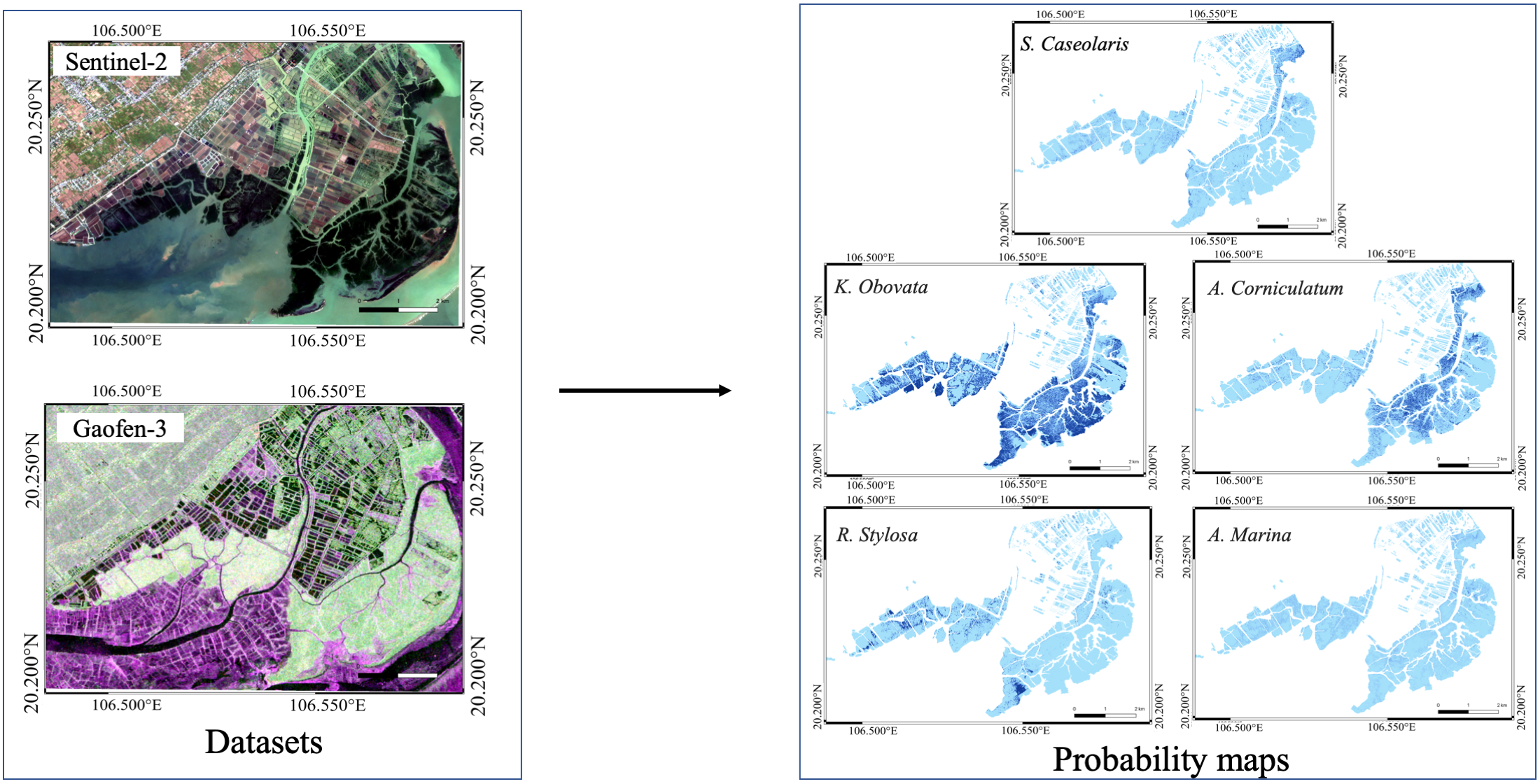
3. Results
3.1. Results with Different LDL Methods
3.2. Results with Different Sources of Datasets
4. Discussion
4.1. Contribution from the Full-Polarimetric SAR
4.2. Factors Affecting Accuracy Assessment
4.3. Investigations about Combinations and Methods
4.4. Limitation of This Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Wang, T.; Liu, M.; Jia, M.; Lin, H.; Chu, L.M.; Devlin, A.T. Potential of Combining Optical and Dual Polarimetric SAR Data for Improving Mangrove Species Discrimination Using Rotation Forest. Remote Sens. 2018, 10, 467. [Google Scholar] [CrossRef]
- Wang, D.; Wan, B.; Qiu, P.; Su, Y.; Guo, Q.; Wang, R.; Sun, F.; Wu, X. Evaluating the Performance of Sentinel-2, Landsat 8 and Pléiades-1 in Mapping Mangrove Extent and Species. Remote Sens. 2018, 10, 1468. [Google Scholar] [CrossRef]
- Künzer, C.; Bluemel, A.; Gebhardt, S.; Quoc, T.V.; Dech, S. Remote Sensing of Mangrove Ecosystems: A Review. Remote Sens. 2011, 3, 878–928. [Google Scholar] [CrossRef]
- Ahmed, N.; Glaser, M. Coastal aquaculture, mangrove deforestation and blue carbon emissions: Is REDD+ a solution? Mar. Policy 2016, 66, 58–66. [Google Scholar] [CrossRef]
- Wang, L.; Jia, M.; Yin, D.; Tian, J. A review of remote sensing for mangrove forests: 1956–2018. Remote Sens. Environ. 2019, 231, 111223. [Google Scholar] [CrossRef]
- Pham, T.D.; Xia, J.; Ha, N.T.; Bui, D.T.; Le, N.N.; Takeuchi, W. A Review of Remote Sensing Approaches for Monitoring Blue Carbon Ecosystems: Mangroves, Seagrasses and Salt Marshes during 2010–2018. Sensors 2019, 19, 1933. [Google Scholar] [CrossRef] [PubMed]
- Wan, L.; Zhang, H.; Liu, M.; Lin, Y.; Lin, H. Early Monitoring of Exotic Mangrove Sonneratia in Hong Kong Using Deep Convolutional Network at Half-Meter Resolution. IEEE Geosci. Remote Sens. Lett. 2020, in press. [Google Scholar] [CrossRef]
- He, Z.; Shi, Q.; Liu, K.; Cao, J.; Zhan, W.; Cao, B. Object-Oriented Mangrove Species Classification Using Hyperspectral Data and 3-D Siamese Residual Network. IEEE Geosci. Remote Sens. Lett. 2020, in press. [Google Scholar] [CrossRef]
- Chakravortty, S.; Li, J.; Plaza, A. A Technique for Subpixel Analysis of Dynamic Mangrove Ecosystems With Time-Series Hyperspectral Image Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1244–1252. [Google Scholar] [CrossRef]
- Jia, M.; Wang, Z.; Zhang, Y.; Ren, C.; Song, K. Landsat-Based Estimation of Mangrove Forest Loss and Restoration in Guangxi Province, China, Influenced by Human and Natural Factors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 311–323. [Google Scholar] [CrossRef]
- Viennois, G.; Proisy, C.; Féret, J.; Prosperi, J.; Sidik, F.; Suhardjono; Rahmania, R.; Longépé, N.; Germain, O.; Gaspar, P. Multitemporal Analysis of High-Spatial-Resolution Optical Satellite Imagery for Mangrove Species Mapping in Bali, Indonesia. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3680–3686. [Google Scholar] [CrossRef]
- Son, N.; Chen, C.; Chang, N.; Chen, C.; Chang, L.; Thanh, B. Mangrove Mapping and Change Detection in Ca Mau Peninsula, Vietnam, Using Landsat Data and Object-Based Image Analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 503–510. [Google Scholar] [CrossRef]
- Wan, L.; Lin, Y.; Zhang, H.; Wang, F.; Liu, M.; Lin, H. GF-5 Hyperspectral Data for Species Mapping of Mangrove in Mai Po, Hong Kong. Remote Sens. 2020, 12, 656. [Google Scholar] [CrossRef]
- McCarthy, M.J.; Jessen, B.; Barry, M.J.; Figueroa, M.; McIntosh, J.; Murray, T.; Schmid, J.; Muller-Karger, F.E. Automated High-Resolution Time Series Mapping of Mangrove Forests Damaged by Hurricane Irma in Southwest Florida. Remote Sens. 2020, 12, 1740. [Google Scholar] [CrossRef]
- Taureau, F.; Robin, M.; Proisy, C.; Fromard, F.; Imbert, D.; Debaine, F. Mapping the Mangrove Forest Canopy Using Spectral Unmixing of Very High Spatial Resolution Satellite Images. Remote Sens. 2019, 11, 367. [Google Scholar] [CrossRef]
- Individual mangrove tree measurement using UAV-based LiDAR data: Possibilities and challenges. Remote Sens. Environ. 2019, 223, 34–49. [CrossRef]
- Pham, T.D.; Yokoya, N.; Xia, J.; Ha, N.T.; Le, N.N.; Nguyen, T.T.T.; Dao, T.H.; Vu, T.T.P.; Pham, T.D.; Takeuchi, W. Comparison of Machine Learning Methods for Estimating Mangrove Above-Ground Biomass Using Multiple Source Remote Sensing Data in the Red River Delta Biosphere Reserve, Vietnam. Remote Sens. 2020, 12, 1334. [Google Scholar] [CrossRef]
- Pham, T.D.; Yokoya, N.; Bui, D.T.; Yoshino, K.; Friess, D.A. Remote Sensing Approaches for Monitoring Mangrove Species, Structure, and Biomass: Opportunities and Challenges. Remote Sens. 2019, 11, 230. [Google Scholar] [CrossRef]
- Hamdan, O.; Khali Aziz, H.; Mohd Hasmadi, I. L-band ALOS PALSAR for biomass estimation of Matang Mangroves, Malaysia. Remote Sens. Environ. 2014, 155, 69–78. [Google Scholar] [CrossRef]
- Kovacs, J.M.; Vandenberg, C.V.; Wang, J.; Flores-Verdugo, F. The Use of Multipolarized Spaceborne SAR Backscatter for Monitoring the Health of a Degraded Mangrove Forest. J. Coast. Res. 2008, 241, 248–254. [Google Scholar] [CrossRef]
- Pham, T.D.; Yoshino, K.; Kaida, N. Monitoring Mangrove Forest Changes in Cat Ba Biosphere Reserve Using ALOS PALSAR Imagery and a GIS-Based Support Vector Machine Algorithm. In Advances and Applications in Geospatial Technology and Earth Resources; Tien Bui, D., Ngoc Do, A., Bui, H.B., Hoang, N.D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 103–118. [Google Scholar]
- Mougin, E.; Proisy, C.; Marty, G.; Fromard, F.; Puig, H.; Betoulle, J.L.; Rudant, J.P. Multifrequency and multipolarization radar backscattering from mangrove forests. IEEE Trans. Geosci. Remote Sens. 1999, 37, 94–102. [Google Scholar] [CrossRef]
- Proisy, C. Interpretation of Polarimetric Radar Signatures of Mangrove Forests. Remote Sens. Environ. 2000, 71, 56–66. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, R. Exploring the optimal integration levels between SAR and optical data for better urban land cover mapping in the Pearl River Delta. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 87–95. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, H.; Li, Y.; Zhang, Y.; Fang, C. Mapping urban impervious surface with dual-polarimetric SAR data: An improved method. Landsc. Urban Plan. 2016, 151, 55–63. [Google Scholar] [CrossRef]
- Souza, P.; Paradella, W. Use of Radarsat-1 fine mode and Landsat-5 TM selective principal component analysis for geomorphological mapping in a macrotidal mangrove coast in the amazon region. Can. J. Remote Sens. 2005, 31, 214–224. [Google Scholar] [CrossRef]
- Wong, F.K.K.; Fung, T. Combining Hyperspectral and Radar Imagery for Mangrove Leaf Area Index Modeling. Photogramm. Eng. Remote Sens. 2013, 79, 479–490. [Google Scholar] [CrossRef]
- Wong, F.K.K.; Fung, T. Combining EO-1 Hyperion and Envisat ASAR data for mangrove species classification in Mai Po Ramsar Site, Hong Kong. Int. J. Remote Sens. 2014, 35, 7828–7856. [Google Scholar] [CrossRef]
- Zhang, X.; Treitz, P.M.; Chen, D.; Quan, C.; Shi, L.; Li, X. Mapping mangrove forests using multi-tidal remotely-sensed data and a decision-tree-based procedure. Int. J. Appl. Earth Obs. Geoinf. 2017, 62, 201–214. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, H.; Wang, C.; Fu, Q. Classification of Chinese GaoFen-3 fully-polarimetric SAR images: Initial results. In Proceedings of the 2017 Progress in Electromagnetics Research Symposium—Fall (PIERS-FALL), Singapore, 19–22 November 2017; pp. 700–705. [Google Scholar]
- Liu, M.; Li, H.; Li, L.; Man, W.; Jia, M.; Wang, Z.; Lu, C. Monitoring the Invasion of Spartina alterniflora Using Multi-source High-resolution Imagery in the Zhangjiang Estuary, China. Remote Sens. 2017, 9, 539. [Google Scholar] [CrossRef]
- Peng, L.; Liu, K.; Cao, J.; Zhu, Y.; Li, F.; Liu, L. Combining GF-2 and RapidEye satellite data for mapping mangrove species using ensemble machine-learning methods. Int. J. Remote Sens. 2020, 41, 813–838. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, K.W.; Myint, S.; Du, Z.; Li, Y.; Cao, J.; Liu, L.; Wu, Z. Integration of GF2 Optical, GF3 SAR, and UAV Data for Estimating Aboveground Biomass of China’s Largest Artificially Planted Mangroves. Remote Sens. 2020, 12, 2039. [Google Scholar] [CrossRef]
- Kamal, M.; Phinn, S. Hyperspectral Data for Mangrove Species Mapping: A Comparison of Pixel-Based and Object-Based Approach. Remote Sens. 2011, 3, 2222–2242. [Google Scholar] [CrossRef]
- Geng, X. Label Distribution Learning. IEEE Trans. Knowl. Data Eng. 2016, 28, 1734–1748. [Google Scholar] [CrossRef]
- Geng, X.; Yin, C.; Zhou, Z.H. Facial Age Estimation by Learning from Label Distributions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2401–2412. [Google Scholar] [CrossRef]
- Geng, X.; Xia, Y. Head Pose Estimation Based on Multivariate Label Distribution; CVPR; IEEE Computer Society: Columbus, OH, USA, 2014; pp. 1837–1842. [Google Scholar]
- Zhou, Y.; Xue, H.; Geng, X. Emotion Distribution Recognition from Facial Expressions. In ACM Multimedia; Zhou, X., Smeaton, A.F., Tian, Q., Bulterman, D.C.A., Shen, H.T., Mayer-Patel, K., Yan, S., Eds.; ACM: Brisbane, Australia, 2015; pp. 1247–1250. [Google Scholar]
- Curnick, D.J.; Pettorelli, N.; Amir, A.A.; Balke, T.; Barbier, E.B.; Crooks, S.; Dahdouh-Guebas, F.; Duncan, C.; Endsor, C.; Friess, D.A.; et al. The value of small mangrove patches. Science 2019, 363, 239. [Google Scholar]
- Veettil, B.K.; Ward, R.D.; Quang, N.X.; Trang, N.T.T.; Giang, T.H. Mangroves of Vietnam: Historical development, current state of research and future threats. Estuar. Coast. Shelf Sci. 2019, 218, 212–236. [Google Scholar] [CrossRef]
- Nguyen, T.T.N.; Tran, H.C.; Ho, T.M.H.; Burny, P.; Lebailly, P. Dynamics of Farming Systems under the Context of Coastal Zone Development: The Case of Xuan Thuy National Park, Vietnam. Agriculture 2019, 9, 138. [Google Scholar] [CrossRef]
- Rouse, J.W.J.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with Erts; NASA Special Publication: Greenbelt, MD, USA, 1974; Volume 351, p. 309.
- Tucker, C. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J.F. Evaluation of Sentinel-2 Red-Edge Bands for Empirical Estimation of Green LAI and Chlorophyll Content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef]
- Blackburn, G.A. Quantifying Chlorophylls and Caroteniods at Leaf and Canopy Scales: An Evaluation of Some Hyperspectral Approaches. Remote Sens. Environ. 1998, 66, 273–285. [Google Scholar] [CrossRef]
- Huete, A. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Frampton, W.J.; Dash, J.; Watmough, G.; Milton, E.J. Evaluating the capabilities of Sentinel-2 for quantitative estimation of biophysical variables in vegetation. ISPRS J. Photogramm. Remote Sens. 2013, 82, 83–92. [Google Scholar] [CrossRef]
- Daughtry, C.; Walthall, C.; Kim, M.; de Colstoun, E.; McMurtrey, J. Estimating Corn Leaf Chlorophyll Concentration from Leaf and Canopy Reflectance. Remote Sens. Environ. 2000, 74, 229–239. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Krogager, E.; Boerner, W.M.; Madsen, S. Feature-motivated Sinclair matrix (sphere/diplane/helix) decomposition and its application to target sorting for land feature classification. In Proceedings of the SPIE Conference on Wideband Interferometric Sensing and Imaging Polarimetry, San Diego, CA, USA, 1 January 1997. [Google Scholar]
- Bayes Classifier. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: New York, NY, USA, 2009; p. 210. [Google Scholar]
- Lin, H.T.; Lin, C.J.; Weng, R.C. A note on Platt’s probabilistic outputs for support vector machines. Mach. Learn. 2007, 68, 267–276. [Google Scholar] [CrossRef]
- Xue, D.; Hong, Z.; Guo, S.; Gao, L.; Wu, L.; Zheng, J.; Zhao, N. Personality Recognition on Social Media With Label Distribution Learning. IEEE Access 2017, 5, 13478–13488. [Google Scholar] [CrossRef]
- Miller, D.J.; Zhang, Y.; Kesidis, G. Decision Aggregation in Distributed Classification by a Transductive Extension of Maximum Entropy/Improved Iterative Scaling. EURASIP J. Adv. Signal Process. 2008, 2008, 674974. [Google Scholar] [CrossRef][Green Version]
- Bazaraa, M.S.; Shetty, C.M. Nonlinear Programming: Theory and Algorithms; Wiley: New York, NY, USA, 1979. [Google Scholar]
- Kearns, M.; Ron, D. Algorithmic stability and sanity-check bounds for leave-one-out cross-validation. Neural Comput. 1999, 11, 1427–1453. [Google Scholar] [CrossRef]
- Zhen, J.; Liao, J.; Shen, G. Mapping Mangrove Forests of Dongzhaigang Nature Reserve in China Using Landsat 8 and Radarsat-2 Polarimetric SAR Data. Sensors 2018, 18, 4012. [Google Scholar] [CrossRef]
- Ferrentino, E.; Nunziata, F.; Zhang, H.; Migliaccio, M. On the Ability of PolSAR Measurements to Discriminate Among Mangrove Species. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2729–2737. [Google Scholar] [CrossRef]
- Silva, J.; Bacao, F.; Caetano, M. Specific Land Cover Class Mapping by Semi-Supervised Weighted Support Vector Machines. Remote Sens. 2017, 9, 181. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.; Zare, A.; White, E. Individual Tree-Crown Detection in RGB Imagery Using Semi-Supervised Deep Learning Neural Networks. Remote Sens. 2019, 11, 1309. [Google Scholar] [CrossRef]
- Malouf, R. A Comparison of Algorithms for Maximum Entropy Parameter Estimation. In Proceedings of the Sixth Conference on Natural Language Learning (CoNLL-2002), Taipei, Taiwan, 21 August–1 September 2002; Roth, D., van den Bosch, A., Eds.; ACL: Stroudsburg, PA, USA, 2002. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Acquisition Date | Mode | Bands | Spatial Resolution (m) |
|---|---|---|---|---|
| Sentinel-1 | 16 December 2017 | Dual-Polarization | VH, VV | 10 |
| Sentinel-2 | 2 November 2018 | Multispectral Imager (MSI) | 11 spectral bands | 10/20 |
| GaoFen-3 | 27 December 2016 | Full-Polarization | HH, HV, VH, VV | 8 |
| Vegetation Index | Equation |
|---|---|
| Normalized Difference Vegetation Index (NDVI) [42] | |
| Difference Vegetation Index (DVI) [43] | |
| Normalized Difference Index using B4 and B5 (NDI45) [44] | |
| Ratio Vegetation Index (RVI) [45] | |
| Soil Adjusted Vegetation Index (SAVI) [46] | |
| Inverted Red-Edge Chlorophyll Index (IRECI) [47] | |
| Green Difference Vegetation Index (GNDVI) [48] | |
| Note: B8 = NIR, B7= Vegetation red edge, B4 = Red. | |
| ID | SC | KO | AC | RS | AM | ID | SC | KO | AC | RS | AM |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.36 | 0.00 | 0.64 | 0.00 | 0.00 | 29 | 0.00 | 0.33 | 0.67 | 0.00 | 0.00 |
| 2 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 30 | 0.00 | 0.80 | 0.20 | 0.00 | 0.00 |
| 3 | 0.00 | 0.32 | 0.68 | 0.00 | 0.00 | 31 | 0.00 | 0.96 | 0.04 | 0.00 | 0.00 |
| 4 | 0.00 | 0.43 | 0.57 | 0.00 | 0.00 | 32 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 5 | 0.00 | 0.48 | 0.52 | 0.00 | 0.00 | 33 | 0.00 | 0.52 | 0.48 | 0.00 | 0.00 |
| 6 | 0.26 | 0.74 | 0.00 | 0.00 | 0.00 | 34 | 0.00 | 0.76 | 0.24 | 0.00 | 0.00 |
| 7 | 0.17 | 0.53 | 0.30 | 0.00 | 0.00 | 35 | 0.00 | 0.65 | 0.35 | 0.00 | 0.00 |
| 8 | 0.00 | 0.88 | 0.12 | 0.00 | 0.00 | 36 | 0.00 | 0.83 | 0.17 | 0.00 | 0.00 |
| 9 | 0.00 | 0.55 | 0.45 | 0.00 | 0.00 | 37 | 0.00 | 0.40 | 0.60 | 0.00 | 0.00 |
| 10 | 0.54 | 0.46 | 0.00 | 0.00 | 0.00 | 38 | 0.36 | 0.00 | 0.64 | 0.00 | 0.00 |
| 11 | 0.20 | 0.69 | 0.00 | 0.11 | 0.00 | 39 | 0.23 | 0.00 | 0.77 | 0.00 | 0.00 |
| 12 | 0.67 | 0.20 | 0.08 | 0.05 | 0.00 | 40 | 0.00 | 0.48 | 0.52 | 0.00 | 0.00 |
| 13 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 41 | 0.00 | 0.90 | 0.10 | 0.00 | 0.00 |
| 14 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 42 | 0.38 | 0.00 | 0.62 | 0.00 | 0.00 |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 43 | 0.35 | 0.00 | 0.65 | 0.00 | 0.00 |
| 16 | 0.15 | 0.74 | 0.06 | 0.05 | 0.00 | 44 | 0.00 | 0.67 | 0.00 | 0.33 | 0.00 |
| 17 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 45 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 18 | 0.00 | 0.18 | 0.82 | 0.00 | 0.00 | 46 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 19 | 0.00 | 0.34 | 0.66 | 0.00 | 0.00 | 47 | 0.00 | 0.82 | 0.00 | 0.18 | 0.00 |
| 20 | 0.00 | 0.88 | 0.12 | 0.00 | 0.00 | 48 | 0.00 | 0.61 | 0.00 | 0.39 | 0.00 |
| 21 | 0.00 | 0.31 | 0.69 | 0.00 | 0.00 | 49 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 22 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 50 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 23 | 0.00 | 0.41 | 0.59 | 0.00 | 0.00 | 51 | 0.00 | 0.90 | 0.00 | 0.10 | 0.00 |
| 24 | 0.00 | 0.56 | 0.44 | 0.00 | 0.00 | 52 | 0.00 | 0.99 | 0.00 | 0.01 | 0.00 |
| 25 | 0.00 | 0.93 | 0.07 | 0.00 | 0.00 | 53 | 0.00 | 0.96 | 0.00 | 0.04 | 0.00 |
| 26 | 0.00 | 0.09 | 0.91 | 0.00 | 0.00 | 54 | 0.00 | 0.95 | 0.00 | 0.05 | 0.00 |
| 27 | 0.00 | 0.13 | 0.87 | 0.00 | 0.00 | 55 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 28 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| Measure | PT-Bayes | PT-SVMs | AA-KNN | AA-BPNN | SA-IIS | SA-BFGS |
|---|---|---|---|---|---|---|
| Chebyshev (↓) | 0.3495 | 0.5339 | 0.3890 | 0.4372 | 0.3950 | 0.2346 |
| Clark (↓) | 2.0113 | 1.9479 | 1.8978 | 1.9043 | 1.8810 | 1.8736 |
| Canberra (↓) | 4.2004 | 4.0894 | 4.1231 | 3.9366 | 3.8553 | 3.7498 |
| KL (↓) | 0.065 | 0.084 | 0.078 | 0.082 | 0.045 | 0.034 |
| Cos (↑) | 0.7466 | 0.5555 | 0.7472 | 0.7238 | 0.7721 | 0.8778 |
| Intersection (↑) | 0.6407 | 0.4374 | 0.5999 | 0.5466 | 0.5904 | 0.7548 |
| Class | No. Samples | PT-Bayes | PT-SVMs | AA-KNN | AA-BPNN | SA-IIS | SA-BFGS |
|---|---|---|---|---|---|---|---|
| 2 | 63 | 98.41 | 0 | 20.63 | 6.35 | 6.35 | 47.62 |
| 3 | 32 | 3.13 | 0 | 0 | 0 | 0 | 6.25 |
| 4 | 10 | 0 | 0 | 0 | 0 | 0 | 60.00 |
| 5 | 4 | 0 | 0 | 0 | 0 | 0 | 25.00 |
| 2-1 | 25 | 0 | 0 | 60.00 | 96.00 | 100.00 | 92.00 |
| 2-3-1 | 4 | 25.00 | 100.00 | 100.00 | 75.00 | 75.00 | 25.00 |
| 2-4 | 63 | 0 | 96.83 | 47.62 | 79.31 | 87.30 | 36.51 |
| 3-1 | 79 | 0 | 0 | 64.56 | 79.71 | 65.81 | 64.56 |
| 3-2 | 110 | 5.45 | 0 | 15.45 | 24.55 | 0 | 34.55 |
| Overall accuracy (OA) | 17.95 | 16.67 | 33.33 | 43.83 | 35.64 | 44.87 | |
| Average accuracy (AA) | 15.81 | 21.87 | 34.25 | 40.10 | 37.16 | 43.50 | |
| Class | No. Samples | S2+VIs | S1+S2+VIs | S2+VIs+GF (4) | S2+VIs+GF (All) | S1+S2+VIs+GF (All) |
|---|---|---|---|---|---|---|
| 2 | 63 | 47.62 | 44.44 | 50.79 | 53.97 | 47.61 |
| 3 | 32 | 6.25 | 53.13 | 56.25 | 62.50 | 50.00 |
| 4 | 10 | 60.00 | 60.00 | 60.00 | 60.00 | 60.00 |
| 5 | 4 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 |
| 2-1 | 25 | 92.00 | 72.00 | 80.00 | 64.00 | 64.00 |
| 2-3-1 | 4 | 25.00 | 25.00 | 25.00 | 25.00 | 25.00 |
| 2-4 | 63 | 36.51 | 42.85 | 63.49 | 52.38 | 49.20 |
| 3-1 | 79 | 64.56 | 60.76 | 68.35 | 63.29 | 60.76 |
| 3-2 | 110 | 34.55 | 33.64 | 38.18 | 36.36 | 31.82 |
| Overall accuracy (OA) | 44.87 | 46.66 | 62.44 | 58.50 | 53.36 | |
| Average accuracy (AA) | 43.49 | 46.31 | 51.90 | 49.19 | 45.94 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, J.; Yokoya, N.; Pham, T.D. Probabilistic Mangrove Species Mapping with Multiple-Source Remote-Sensing Datasets Using Label Distribution Learning in Xuan Thuy National Park, Vietnam. Remote Sens. 2020, 12, 3834. https://doi.org/10.3390/rs12223834
Xia J, Yokoya N, Pham TD. Probabilistic Mangrove Species Mapping with Multiple-Source Remote-Sensing Datasets Using Label Distribution Learning in Xuan Thuy National Park, Vietnam. Remote Sensing. 2020; 12(22):3834. https://doi.org/10.3390/rs12223834
Chicago/Turabian StyleXia, Junshi, Naoto Yokoya, and Tien Dat Pham. 2020. "Probabilistic Mangrove Species Mapping with Multiple-Source Remote-Sensing Datasets Using Label Distribution Learning in Xuan Thuy National Park, Vietnam" Remote Sensing 12, no. 22: 3834. https://doi.org/10.3390/rs12223834
APA StyleXia, J., Yokoya, N., & Pham, T. D. (2020). Probabilistic Mangrove Species Mapping with Multiple-Source Remote-Sensing Datasets Using Label Distribution Learning in Xuan Thuy National Park, Vietnam. Remote Sensing, 12(22), 3834. https://doi.org/10.3390/rs12223834