Number of Building Stories Estimation from Monocular Satellite Image Using a Modified Mask R-CNN



Abstract
1. Introduction
- A new method of NoS estimation from monocular satellite images is proposed. Compared with the traditional method, it is not necessary for our method to estimate the height of buildings in advance, but to estimate NoS directly from end to end with the help of deep learning.
- From the perspective of network architecture, this paper proposes a multitask integration approach which detects building objects and estimates NoS simultaneously based on Mask R-CNN.
- A novel evaluation method of the model under the technical route of our method is designed. The experiment on our dataset was carried out for verifying the effectiveness of the proposed method.
2. Methods
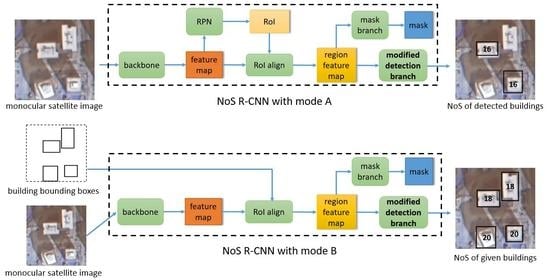
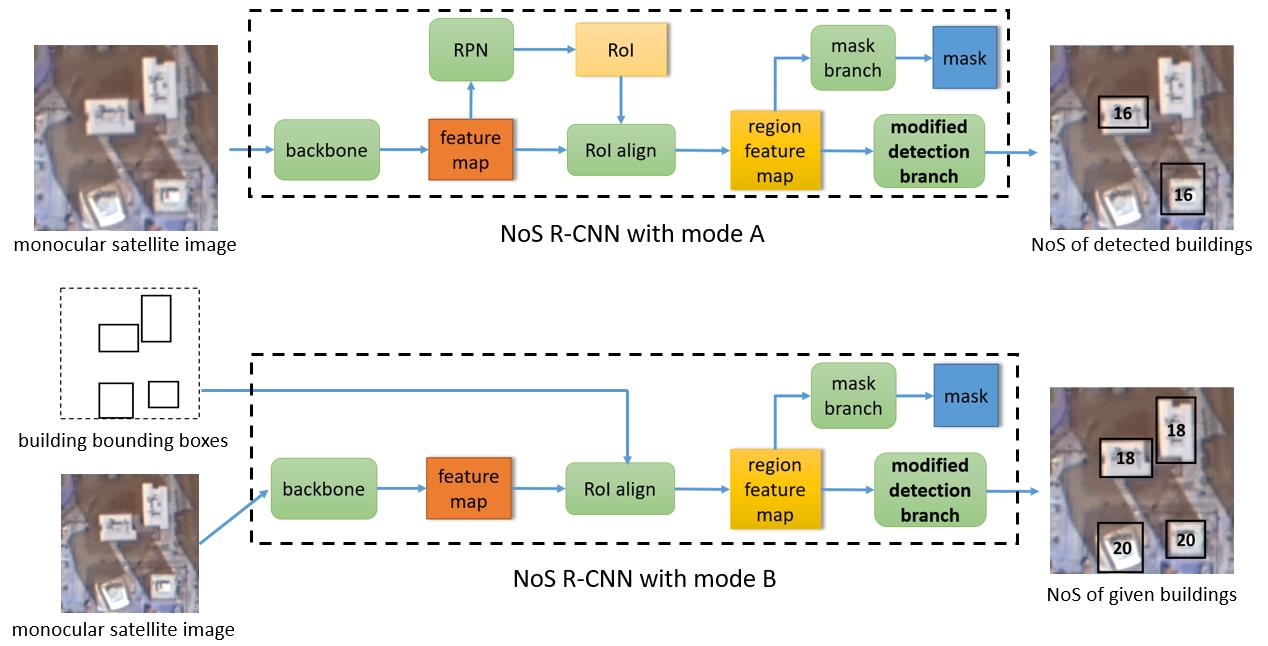
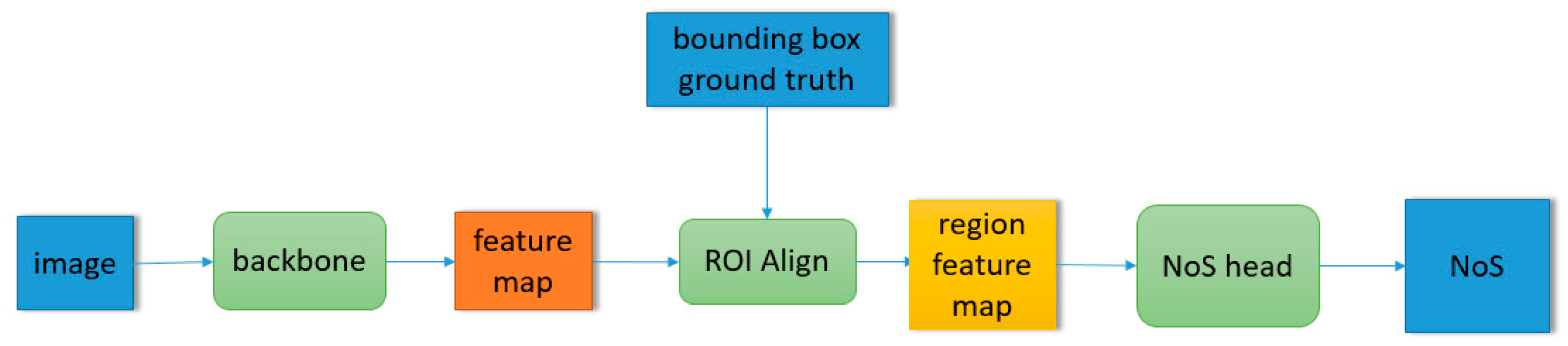
2.1. Network Architecture
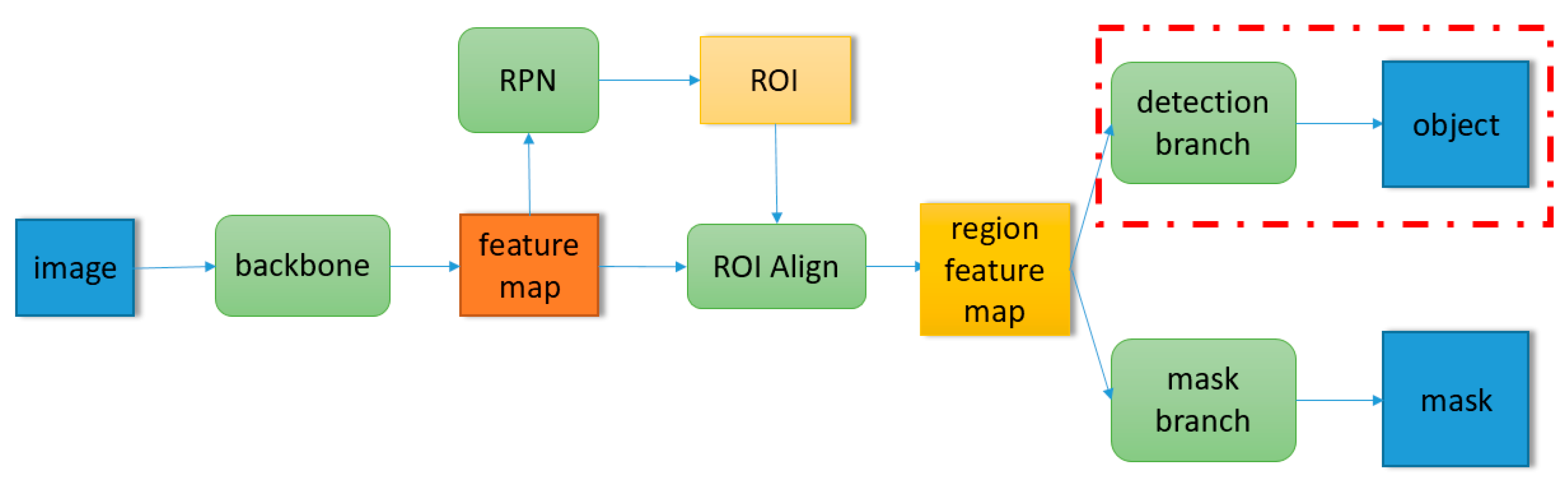
2.2. Two Kinds of Modes for Prediction
2.3. Loss Function
3. Experiment
3.1. Dataset
3.2. Implementation Details
3.3. Result
3.3.1. Building Detection Task
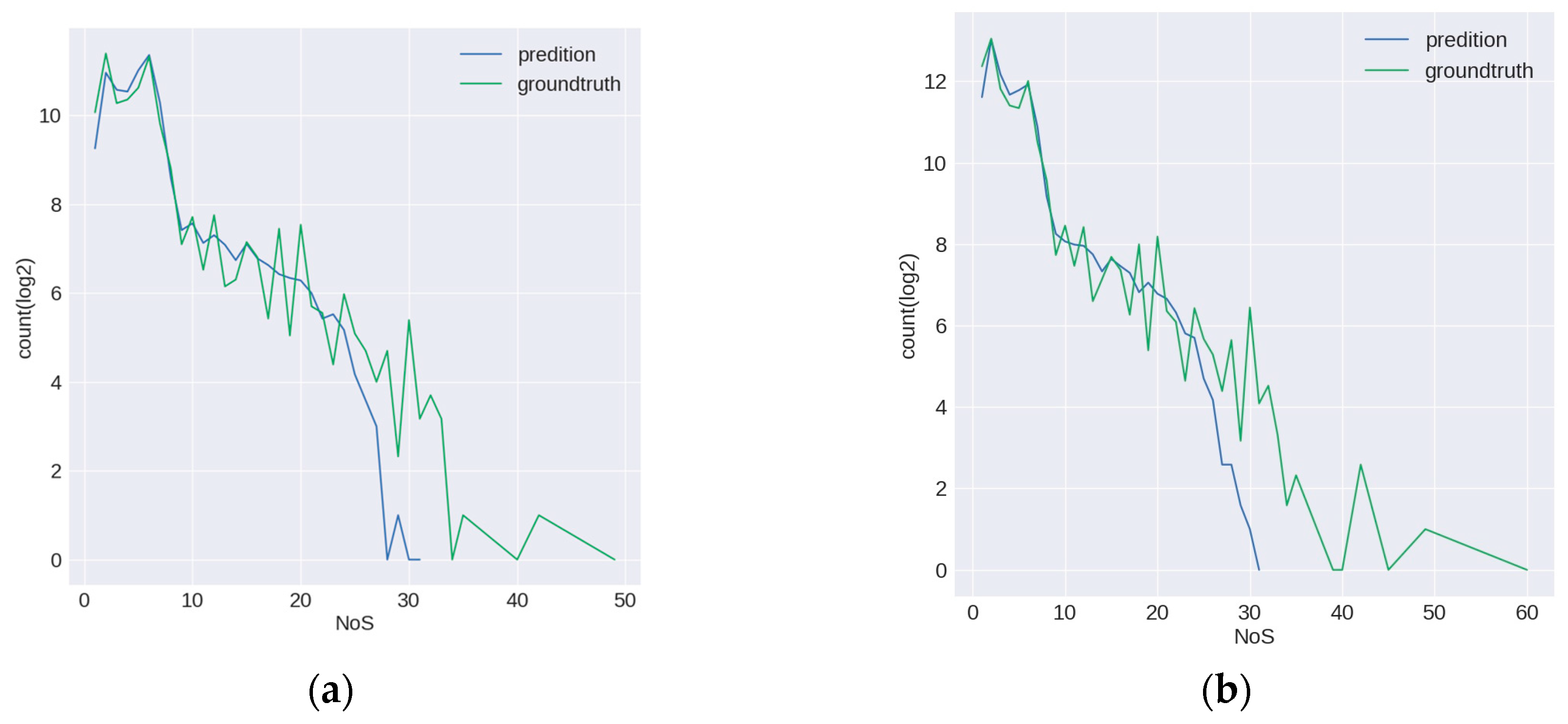
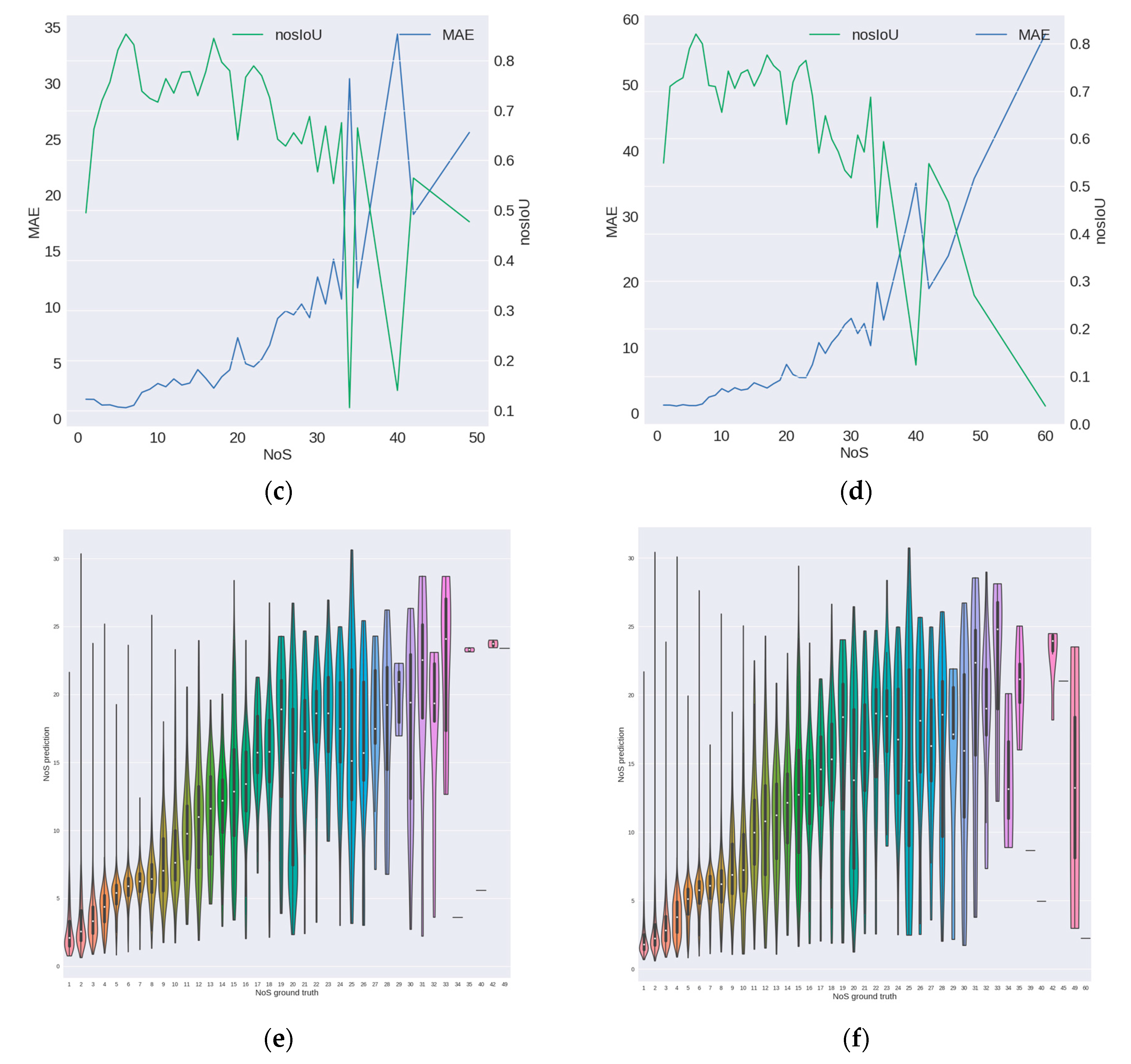
3.3.2. NoS Estimation Task
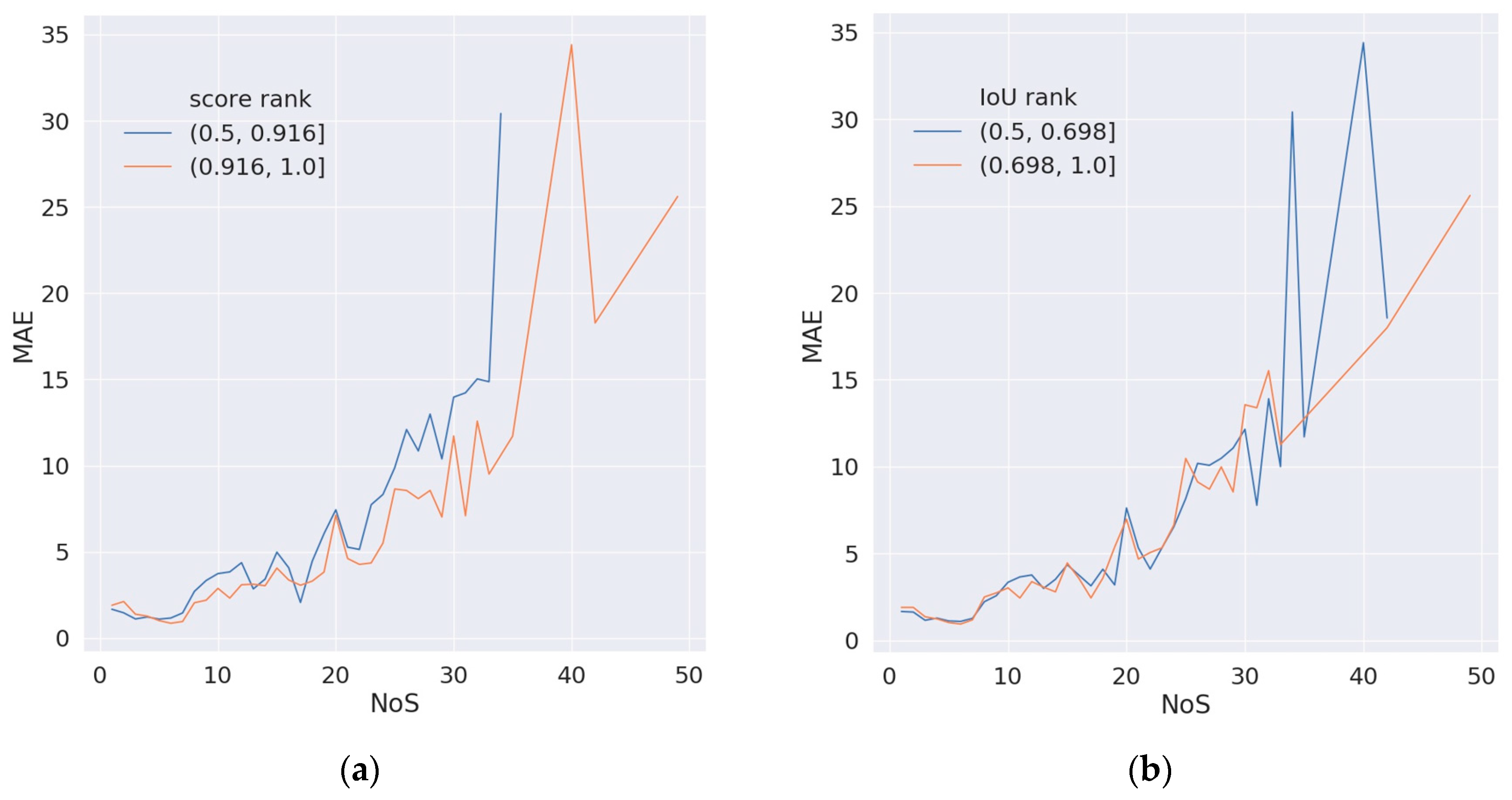
4. Discussion
4.1. Choice of Integration Mode
- Detection benchmark. Using the same network architecture as “detection branch integration”, λ in formula (2) was set to 0 in training stage. In this setting, the total loss of the network only includes the loss defined in the original Mask R-CNN and does not include the loss of NoS estimation task.
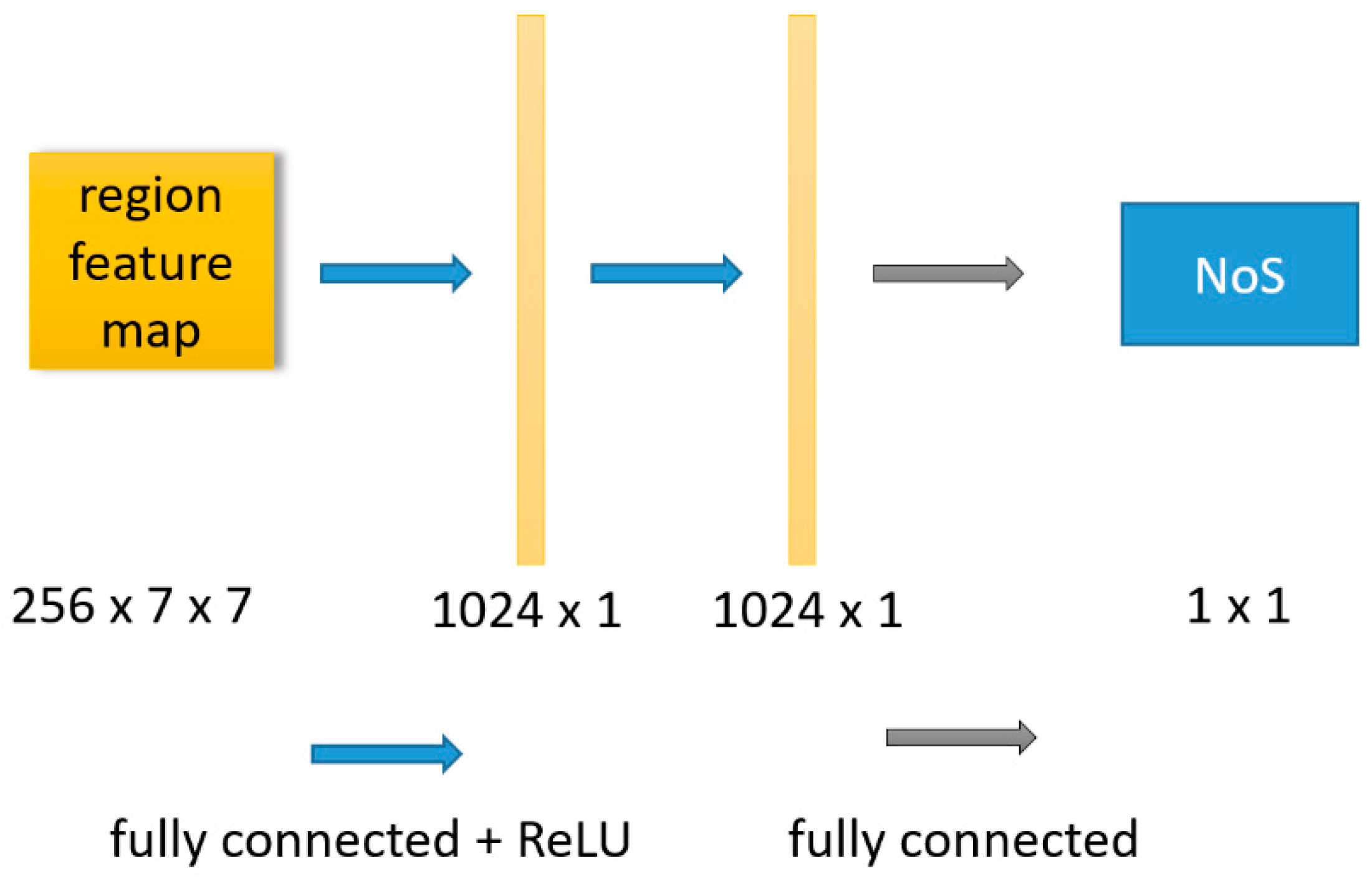
- GT proposal benchmark. Using the same network architecture as “detection branch integration”. In training stage, the input of RoI align is replaced by the predicted value of RPN with the building bounding box ground truth. The “NoS head” shown in Figure 4 is the detection branch. The total loss of the network only retains the loss of NoS estimation task.
- NoS branch. Using the architecture shown in Figure 8 and Figure 9. In order to maintain the comparability between experiments, the specific network architecture of NoS branch which is shown in Figure 9 remains similar to detection branch which is shown in Figure 2 in “detection branch integration”. In prediction stage with mode B, “NoS head” in Figure 4 is NoS branch. The loss function of the network is consistent with that in “detection branch integration”.
- The performance of “detection branch integration” and “NoS branch integration” is similar in both detection task and NoS estimation task, “NoS branch integration” performs slightly better in the detection task, while “detection branch integration” performs slightly better in the NoS estimation task.
- Compared with the “detection benchmark” which only retains the detection task, the performance in the detection task of the two networks integrated with NoS estimation task is slightly lower than the former, but there is no obvious degradation.
- By comparing the performance of the two integration methods and the “GT proposal benchmark”, which only retains the NoS estimation task and fed with the accurate bounding box for RoI align in training stage, we can see that the former is better than the latter, which indicates that the end-to-end training of NoS estimation task with the detection task in the training stage can help the model obtain better performance in the NoS estimation task. It should be pointed out that because the “GT proposal benchmark” does not learn for the detection task in the training stage, only “MAE@all” and “nosIoU@all” have reference significance.
4.2. The Impact of Detection Task on NoS Estimation Task
4.3. The Decision Basis of the Model
- The feature of building itself, including the shape, size, color, and texture of the roof of building reflected in the image. Although these features may not determine the NoS from the physical side, they may have some statistical significance. For example: buildings with very large or small roof areas are often not high-rise buildings. It should be pointed out that the image used in our experiment is 1 m resolution ortho-rectifying satellite image. We cannot see any side information of buildings even for the high-rise building from our image, such as windows or balconies of buildings (as can be seen in Figure 7). Therefore, our model does not use the side information of buildings. However, we believe that the side information of buildings in the appropriate image should play a more important role in the task of NoS estimation, but this point might need to be furthermore tested in the future related research.
- Context features around the building. Although the bounding box of the building itself for RoI align is utilized to extract the region feature of building in our method, the region feature of building was cropped by RoI align from the feature map which is convoluted by many layers of backbone. Every pixel in feature maps has a larger and larger receptive field in the process of forward computation. Therefore, the receptive field of region features extracted by RoI align is much larger than the corresponding bounding box and the region feature can contain the information outside the bounding box. This is different from the methods of cropping the local image based on bounding box first and then extracting its features, of which the receptive field cannot outside the bounding box. We call the information outside the bounding box as the context information, and we think that there are two kinds of context information that are meaningful for NoS estimation:
- (a)
- The shadow of buildings. The length of building shadow reflects the height of the building to a certain extent, and the height of the building has a high correlation with NoS. In a certain scene, the NoS of buildings with relatively long shadows are often bigger than that of buildings with relatively short shadows.
- (b)
- The relationship between adjacent building objects and the environment of buildings. For example: buildings with adjacent locations and similar roof features often belong to the same community, and they often have the same NoS. The possibility that high-rise buildings appear in suburbs or farmland is very low.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ning, W. Study on 3D Reconstruction for City Buildings Based on Target Recognition and Parameterization Technology; Zhejiang University: Hangzhou, China, 2013. [Google Scholar]
- Mou, L.; Zhu, X.X. IM2HEIGHT: Height estimation from single monocular imagery via fully residual convolutional-deconvolutional network. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Ghamisi, P.; Yokoya, N.; Plaza, J.; Plaza, A. U-IMG2DSM: Unpaired Simulation of Digital Surface Models with Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Shao, Y.; Taff, G.N.; Walsh, S.J. Shadow detection and building-height estimation using IKONOS data. Int. J. Remote Sens. 2011, 32, 6929–6944. [Google Scholar] [CrossRef]
- Liasis, G.; Stavrou, S. Satellite images analysis for shadow detection and building height estimation. ISPRS J. Photogramm. Remote Sens. 2016, 119, 437–450. [Google Scholar] [CrossRef]
- Raju PL, N.; Chaudhary, H.; Jha, A.K. Shadow analysis technique for extraction of building height using high resolution satellite single image and accuracy assessment. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Hyderabad, India, 9–12 December 2014. [Google Scholar]
- Srivastava, S.; Volpi, M.; Tuia, D. Joint height estimation and semantic labeling of monocular aerial images with CNNs. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5173–5176. [Google Scholar]
- Ghamisi, P.; Yokoya, N. Img2dsm: Height simulation from single imagery using conditional generative adversarial net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 794–798. [Google Scholar] [CrossRef]
- Amirkolaee, H.A.; Arefi, H. Height estimation from single aerial images using a deep convolutional encoder-decoder network. ISPRS J. Photogramm. Remote Sens. 2019, 149, 50–66. [Google Scholar] [CrossRef]
- Amirkolaee, H.A.; Arefi, H. Convolutional neural network architecture for digital surface model estimation from single remote sensing image. J. Appl. Remote Sens. 2019, 13, 016522. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Zhang, Y.; Mishra, R.K. From UNB PanSharp to Fuze Go–the success behind the pan-sharpening algorithm. Int. J. Image Data Fusion 2014, 5, 39–53. [Google Scholar] [CrossRef]
- Marcel, S.; Rodriguez, Y. Torchvision the machine-vision package of torch. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1485–1488. [Google Scholar]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building Extraction from Satellite Images Using Mask R-CNN With Building Boundary Regularization. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 247–251. [Google Scholar]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An Efficient Building Extraction Method from High Spatial Resolution Remote Sensing Images Based on Improved Mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, Y.; Smal, I.; Lindenbergh1et, R. Building segmentation from airborne vhr images using mask R-cnn. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Enschede, The Netherlands, 10–14 June 2019. [Google Scholar]
- Stiller, D.; Stark, T.; Wurm, M.; Dech, S.; Taubenböck, H. Large-scale building extraction in very high-resolution aerial imagery using Mask R-CNN. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Hu, Y.; Guo, F. Building Extraction Using Mask Scoring R-CNN Network. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–5. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8430–8439. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F1 | Precision | Recall |
|---|---|---|
| 0.449 | 0.482 | 0.421 |
| MAE@TP | MAE@all | nosIoU@TP | nosIoU@all | |
|---|---|---|---|---|
| All | 1.833 ± 2.67 | 1.673 ± 2.58 | 0.740 ± 0.21 | 0.709 ± 0.21 |
| Low | 1.329 ± 1.85 | 1.257 ± 1.73 | 0.742 ± 0.21 | 0.711 ± 0.21 |
| Middle | 3.546 ± 3.27 | 3.886 ± 3.42 | 0.739 ± 0.20 | 0.708 ± 0.22 |
| High | 8.317 ± 6.18 | 9.926 ± 7.32 | 0.687 ± 0.21 | 0.635 ± 0.24 |
| F1 | Precision | Recall | MAE@TP | MAE@all | nosIoU@TP | nosIoU@all | |
|---|---|---|---|---|---|---|---|
| Detection Benchmark | 0.458 | 0.482 | 0.437 | 5.90 | 4.656 | 0.026 | 0.030 |
| GT proposal benchmark | 0.033 | 0.020 | 0.090 | 1.642 | 1.739 | 0.675 | 0.698 |
| Detection branch integration | 0.449 | 0.483 | 0.420 | 1.833 | 1.673 | 0.740 | 0.709 |
| NoS branch | 0.451 | 0.480 | 0.426 | 1.827 | 1.676 | 0.739 | 0.707 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, C.; Tang, H. Number of Building Stories Estimation from Monocular Satellite Image Using a Modified Mask R-CNN. Remote Sens. 2020, 12, 3833. https://doi.org/10.3390/rs12223833
Ji C, Tang H. Number of Building Stories Estimation from Monocular Satellite Image Using a Modified Mask R-CNN. Remote Sensing. 2020; 12(22):3833. https://doi.org/10.3390/rs12223833
Chicago/Turabian StyleJi, Chao, and Hong Tang. 2020. "Number of Building Stories Estimation from Monocular Satellite Image Using a Modified Mask R-CNN" Remote Sensing 12, no. 22: 3833. https://doi.org/10.3390/rs12223833
APA StyleJi, C., & Tang, H. (2020). Number of Building Stories Estimation from Monocular Satellite Image Using a Modified Mask R-CNN. Remote Sensing, 12(22), 3833. https://doi.org/10.3390/rs12223833