Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images




Abstract
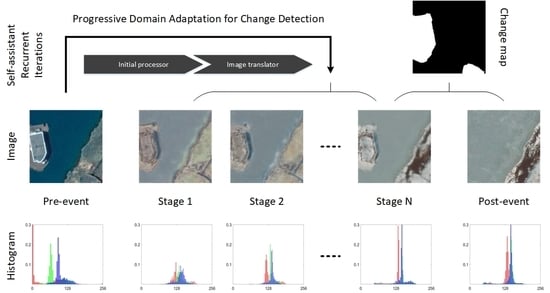
1. Introduction
- We develop a novel image transformation-based method that accommodated the specific demand for change detection tasks using season-varying remote sensing images. In this method, we emphasize the distribution consistencies of land cover categories in the paired unchanged regions.
- We propose a hybrid multi-model framework integrating strategies of ConvLSTM network and cGAN model. To the best of our knowledge, there has been no research into combing these two networks for change detection and especially for season-varying change detection
- We adopt a semantic stabilization strategy specifically for the original and translated images, to guarantee the distribution consistencies of land cover categories between them.
- Observing multiple constraints, we design a new full objective comprise of domain adversarial, cross-consistency, self-consistency, and identity losses to enforce satisfactory change detection results.
2. Background
2.1. Convolutional Long Short-Term Memory Network
2.2. Conditional Generative Adversarial Network
2.3. Image-To-Image Translation
3. Methodology
3.1. Problem Statement
3.2. Framework Architecture
3.2.1. Progressive Translation
3.2.2. Group Discrimination
3.3. Loss Function
3.3.1. Domain Adversarial Loss
3.3.2. Cross-Consistency Loss
3.3.3. Self-Consistency Loss
3.3.4. Identity Loss
3.4. Implementation
3.4.1. Network Architecture
3.4.2. Training Details
3.4.3. Predicting Details
4. Experiments
4.1. Datasets Description
4.2. Baseline Methods
4.3. Evaluation Metrics
4.4. Experimental Setup
- To boost the convergence of the weight and bias parameters in the initial processor, image translator, and domain discriminator, we perform instance normalization on all the channels of remote sensing images, from 0 to 255 to −1 to 1.
- Since the original remote sensing images are of large scale, which is inconvenient for computation, the original training and testing images are processed into small image patches with the same size of through randomly cutting them with certain overlaps and rotations.
- Specifically, for the paired pre-event and translated image patches, which are forwarded to the semantic categorizer, we perform mean-subtraction normalization on each band of them in two different seasonal domains.
4.5. Results Presentation
5. Discussion
5.1. Design of Network Architectures
5.2. Design of Loss Functions
5.3. Selection of Translation Direction
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Singh, A. Article Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A Split-Based Approach to Unsupervised Change Detection in Large-Size Multitemporal Images: Application to Tsunami-Damage Assessment. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1658–1670. [Google Scholar] [CrossRef]
- Demir, B.; Bovolo, F.; Bruzzone, L. Updating Land-Cover Maps by Classification of Image Time Series: A Novel Change-Detection-Driven Transfer Learning Approach. IEEE Trans. Geosci. Remote Sens. 2013, 51, 300–312. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.G.; Fry, J.; Xian, G. A comprehensive change detection method for updating the National Land Cover Database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Review ArticleDigital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Townsend, P.A.; Gross, J.E.; Cohen, W.B.; Bolstad, P.; Wang, Y.; Adams, P. Remote sensing change detection tools for natural resource managers: Understanding concepts and tradeoffs in the design of landscape monitoring projects. Remote Sens. Environ. 2009, 113, 1382–1396. [Google Scholar] [CrossRef]
- Rokni, K.; Ahmad, A.; Selamat, A.; Hazini, S. Water Feature Extraction and Change Detection Using Multitemporal Landsat Imagery. Remote Sens. 2014, 6, 4173–4189. [Google Scholar] [CrossRef]
- Ridd, M.K.; Liu, J. A Comparison of Four Algorithms for Change Detection in an Urban Environment. Remote Sens. Environ. 1998, 63, 95–100. [Google Scholar] [CrossRef]
- Malmir, M.; Zarkesh, M.M.K.; Monavari, S.M.; Jozi, S.A.; Sharifi, E. Urban development change detection based on Multi-Temporal Satellite Images as a fast tracking approach—A case study of Ahwaz County, southwestern Iran. Environ. Monit. Assess. 2015, 108, 187. [Google Scholar] [CrossRef] [PubMed]
- Bruzzone, L.; Bovolo, F. A Novel Framework for the Design of Change-Detection Systems for Very-High-Resolution Remote Sensing Images. Proc. IEEE 2013, 101, 609–630. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a Transferable Change Rule from a Recurrent Neural Network for Land Cover Change Detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hou, B.; Liu, Q.; Wang, H.; Wang, Y. From W-Net to CDGAN: Bitemporal Change Detection via Deep Learning Techniques. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1790–1802. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, F.; Dong, J.; Wang, S. Change Detection from Synthetic Aperture Rader Images Based on Channel Weighting-Based Deep Cascade Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4517–4529. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A detail-preserving scale-driven approach to change detection in multitemporal SAR images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2963–2972. [Google Scholar] [CrossRef]
- Inglada, J.; Mercier, G. A New Statistical Similarity Measure for Change Detection in Multitemporal SAR Images and Its Extension to Multiscale Change Analysis. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1432–1445. [Google Scholar] [CrossRef]
- Jackson, R.D. Spectral indices in N-Space. Remote Sens. Environ. 1983, 13, 409–421. [Google Scholar] [CrossRef]
- Malila, W.A. Change Vector Analysis: An Approach for Detecting Forest Changes with Landsat. In Machine Processing of Remotely Sensed Data; Burroff, P.G., Morrison, D.B., Eds.; Purdue University: West Lafayette, IN, USA, 1980; p. 385. [Google Scholar]
- Gao, F.; Dong, J.; Li, B.; Xu, Q. Automatic Change Detection in Synthetic Aperture Radar Images Based on PCANet. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1792–1796. [Google Scholar] [CrossRef]
- Gong, M.; Niu, X.; Zhang, P.; Li, Z. Generative Adversarial Networks for Change Detection in Multispectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2310–2314. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Gong, M.; Yang, H.; Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel Segmented Stacked AutoEncoder for Effective Dimensionality Reduction and Feature Extraction in Hyperspectral Imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Yang, M.; Jiao, L.; Liu, F.; Hou, B.; Yang, S. Transferred Deep Learning-Based Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6960–6973. [Google Scholar] [CrossRef]
- Zhang, P.; Gong, M.; Su, L.; Liu, J.; Li, Z. Change detection based on deep feature representation and mapping transformation for multi-spatial-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 116, 24–41. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A Deep Convolutional Coupling Network for Change Detection Based on Heterogeneous Optical and Radar Images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 545–559. [Google Scholar] [CrossRef]
- Fang, B.; Pan, L.; Kou, R. Dual Learning-Based Siamese Framework for Change Detection Using Bi-Temporal VHR Optical Remote Sensing Images. Remote Sens. 2019, 11, 1292. [Google Scholar] [CrossRef]
- Zhan, T.; Gong, M.; Liu, J.; Zhang, P. Iterative feature mapping network for detecting multiple changes in multi-source remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 38–51. [Google Scholar] [CrossRef]
- Niu, X.; Gong, M.; Zhan, T.; Yang, Y. A Conditional Adversarial Network for Change Detection in Heterogeneous Images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 45–49. [Google Scholar] [CrossRef]
- Ma, W.; Xiong, Y.; Wu, Y.; Yang, H.; Zhang, X.; Jiao, L. Change Detection in Remote Sensing Images Based on Image Mapping and a Deep Capsule Network. Remote Sens. 2019, 11, 626. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive Generative Adversarial Network for Raindrop Removal from A Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 2482–2491. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive Image Deraining Networks: A Better and Simpler Baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3932–3941. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR Moving Target Indication Using Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Petrou, Z.I.; Tian, Y. Prediction of Sea Ice Motion with Convolutional Long Short-Term Memory Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6865–6876. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 649–666. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5892–5900. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image Analogies. In Proceedings of the Special Interest Group on Computer Graphics, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse Image-to-Image Translation via Disentangled Representations. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 October 2018; pp. 36–52. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation. In Proceedings of the Structural Information and Communication Complexity, Ma’ale HaHamisha, Israel, 18–21 June 2018; pp. 179–196. [Google Scholar]
- Cho, W.; Choi, S.; Park, D.K.; Shin, I.; Choo, J. Image-To-Image Translation via Group-Wise Deep Whitening-And-Coloring Transformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10631–10639. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised Cross-Domain Image Generation. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Benaim, S.; Wolf, J. One-Sided Unsupervised Domain Mapping. arXiv 2017, arXiv:1706.00826v2. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, C.; Wand, M. Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 702–716. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Lebedev, M.A.; Vizilter, Y.V.; Vygolov, O.V.; Knyaz, V.A.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 565–571. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs: | |
|---|---|
| fordo end for | |
| Outputs: | |
| Image Pair | Sample Number | Training Time | Testing Rate |
|---|---|---|---|
| I-a & I-b I-b & I-c I-c & I-d | 1683 | 64.78 h | 0.21 s/pair |
| II-1a & II-1b II-2a & II-2b | 1308 | 50.50 h | |
| II-3a & II-3b | 936 | 36.55 h |
| Image Pair | Metric | CVA | GETNET | PCANet | GAN | DSCN | DLSF | PDA |
|---|---|---|---|---|---|---|---|---|
| I-a & I-b | OA | 0.8540 | 0.8981 | 0.9212 | 0.9069 | 0.8863 | 0.9225 | 0.9311 |
| KC | 0.2058 | 0.6479 | 0.6516 | 0.6874 | 0.6649 | 0.7820 | 0.7383 | |
| F1 | 0.2855 | 0.7092 | 0.6959 | 0.7421 | 0.7340 | 0.8313 | 0.7784 | |
| I-b & I-c | OA | 0.7684 | 0.8786 | 0.8918 | 0.8706 | 0.7818 | 0.8946 | 0.8761 |
| KC | 0.3505 | 0.7483 | 0.7536 | 0.6284 | 0.4627 | 0.7711 | 0.7329 | |
| F1 | 0.4675 | 0.8501 | 0.8332 | 0.7074 | 0.5955 | 0.8525 | 0.8297 | |
| I-c & I-d | OA | 0.8514 | 0.8911 | 0.9063 | 0.9134 | 0.4034 | 0.9146 | 0.9347 |
| KC | 0.3084 | 0.6077 | 0.6658 | 0.7405 | − | 0.7513 | 0.7815 | |
| F1 | 0.3921 | 0.6710 | 0.7212 | 0.7939 | 0.2616 | 0.8045 | 0.8210 | |
| II-1a & II-1b | OA | 0.4748 | 0.5337 | 0.5819 | 0.9041 | 0.8094 | 0.9158 | 0.9272 |
| KC | − | 0.0605 | 0.0821 | 0.7006 | 0.5368 | 0.6703 | 0.7535 | |
| F1 | 0.1492 | 0.2275 | 0.2583 | 0.7581 | 0.6602 | 0.7167 | 0.7974 | |
| II-2a & II-2b | OA | 0.4738 | 0.6806 | 0.7218 | 0.8642 | 0.7925 | 0.8892 | 0.9150 |
| KC | − | 0.2195 | 0.2876 | 0.6057 | 0.3469 | 0.5940 | 0.7102 | |
| F1 | 0.0792 | 0.3763 | 0.4310 | 0.6894 | 0.4475 | 0.6565 | 0.7610 | |
| II-3a & II-3b | OA | 0.3701 | 0.4123 | 0.4328 | 0.7815 | 0.8176 | 0.8575 | 0.8994 |
| KC | − | − | − | 0.4587 | 0.5043 | 0.5341 | 0.6577 | |
| F1 | 0.2148 | 0.2851 | 0.2936 | 0.5937 | 0.6114 | 0.6136 | 0.7185 |
| Loss Combination | I-a & I-b | I-b & I-c | I-c & I-d | II-1a & II-1b | II-2a & II-2b | II-3a & II-3b |
|---|---|---|---|---|---|---|
| dom | 0.3870 | 0.3429 | 0.3764 | 0.2691 | 0.2566 | 0.2302 |
| dom+self | 0.5171 | 0.4744 | 0.4993 | 0.4212 | 0.3930 | 0.3687 |
| dom+corss | 0.8146 | 0.7372 | 0.8205 | 0.7643 | 0.7469 | 0.7013 |
| dom+cross+self | 0.9057 | 0.8553 | 0.9120 | 0.8478 | 0.8117 | 0.8025 |
| dom+cross+self+idt | 0.9311 | 0.8761 | 0.9347 | 0.9272 | 0.9150 | 0.8994 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kou, R.; Fang, B.; Chen, G.; Wang, L. Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images. Remote Sens. 2020, 12, 3815. https://doi.org/10.3390/rs12223815
Kou R, Fang B, Chen G, Wang L. Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images. Remote Sensing. 2020; 12(22):3815. https://doi.org/10.3390/rs12223815
Chicago/Turabian StyleKou, Rong, Bo Fang, Gang Chen, and Lizhe Wang. 2020. "Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images" Remote Sensing 12, no. 22: 3815. https://doi.org/10.3390/rs12223815
APA StyleKou, R., Fang, B., Chen, G., & Wang, L. (2020). Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images. Remote Sensing, 12(22), 3815. https://doi.org/10.3390/rs12223815