HierarchyNet: Hierarchical CNN-Based Urban Building Classification




Abstract

1. Introduction
Contributions
- proposes a new approach to the multi-label hierarchical classification of buildings—which can also be extended to other applications—which requires significantly less parameters than other existing hierarchical networks;
- solves the urban building classification problem better than state-of-the-art models as demonstrated in a new carefully designed dataset.
2. Literature Review
2.1. Building Recognition
2.2. Convolutional Neural Network Schemes
3. Proposed Datasets
3.1. Urban Buildings—Functional Purposes
- Residential: consists of buildings where people live and reside: mainly houses and apartment buildings
- Commercial: consists of those buildings with a commercial purpose: grocery stores, retail and department stores, restaurants, cafes, and malls
- Business: mainly includes office buildings, and corporate headquarters.
- Religious: consists of buildings with a religious spiritual purpose.
3.2. Urban Buildings—Architectural Styles
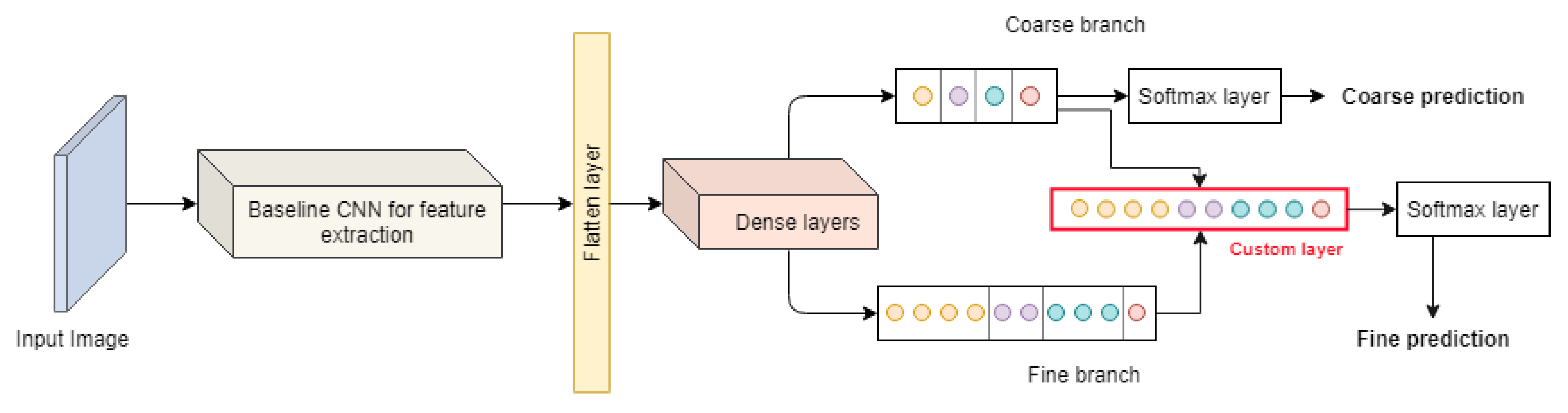
4. Proposed Method: HierarchyNet
- i denotes the sample in the mini-batch (mini-batch gradient descent is the optimization technique used)
- K is the number of levels in the label tree
- is the loss weight corresponding to the level contributing to the loss function
- The term is the cross entropy loss of the sample on the class tree level
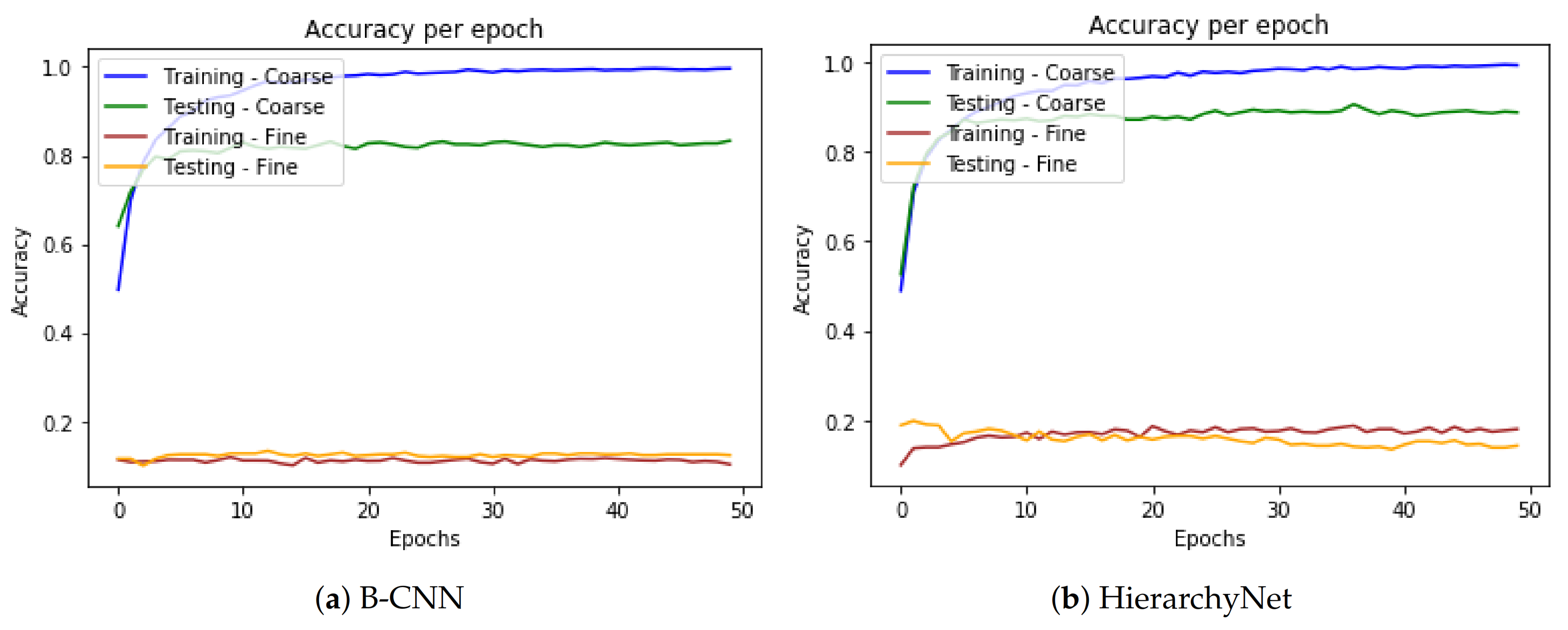
5. Experiments
5.1. Two-Level Urban Buildings Classification—Functional Purposes
- Task A: a 4-class classification across the classes: Business, Residential, Religious, Commercial
- Task B: a more detailed classification with the 10 fine classes: Mosque, Church, House, Office Building, ...
5.2. Two-Level Urban Buildings Classification–Architectural Styles
5.3. Performance on Other Public Benchmark Datasets
5.3.1. MNIST
5.3.2. CIFAR-10
5.3.3. CIFAR-100
5.3.4. Results on Benchmark Datasets
5.4. Parameter Sharing
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- 2018 Revision of World Urbanization Prospects. Available online: https://www.un.org/development/desa/publications/2018-revision-of-world-urbanization-prospects.html (accessed on 8 December 2020).
- You, Y.; Wang, S.; Ma, Y.; Chen, G.; Wang, B.; Shen, M.; Liu, W. Building detection from VHR remote sensing imagery based on the morphological building index. Remote Sens. 2018, 10, 1287. [Google Scholar] [CrossRef]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Liu, Q.; Liu, X.; Wang, W. CNN based suburban building detection using monocular high resolution Google Earth images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 661–664. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Seoul, Korea, 25–29 July 2015; pp. 1873–1876. [Google Scholar]
- Huang, Y.; Zhuo, L.; Tao, H.; Shi, Q.; Liu, K. A novel building type classification scheme based on integrated LiDAR and high-resolution images. Remote Sens. 2017, 9, 679. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote. Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Cohen, J.P.; Ding, W.; Kuhlman, C.; Chen, A.; Di, L. Rapid building detection using machine learning. Appl. Intell. 2016, 45, 443–457. [Google Scholar] [CrossRef]
- Muhr, V.; Despotovic, M.; Koch, D.; Döller, M.; Zeppelzauer, M. Towards Automated Real Estate Assessment from Satellite Images with CNNs. In Proceedings of the Forum Media Technology, Pölten, Austria, 29–30 November 2017. [Google Scholar]
- Hoffmann, E.J.; Wang, Y.; Werner, M.; Kang, J.; Zhu, X.X. Model fusion for building type classification from aerial and street view images. Remote Sens. 2019, 11, 1259. [Google Scholar] [CrossRef]
- Cao, R.; Zhu, J.; Tu, W.; Li, Q.; Cao, J.; Liu, B.; Zhang, Q.; Qiu, G. Integrating aerial and street view images for urban land use classification. Remote Sens. 2018, 10, 1553. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Law, S.; Shen, Y.; Seresinhe, C. An application of convolutional neural network in street image classification: The case study of London. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, Redondo Beach, CA, USA, 7–10 November 2017; pp. 5–9. [Google Scholar]
- Law, S.; Seresinhe, C.; Shen, Y.; Gutiérrez-Roig, M. Street-Frontage-Net: Urban image classification using deep convolutional neural networks. Int. J. Geogr. Inf. Sci. 2018, 34, 1–27. [Google Scholar] [CrossRef]
- Shalunts, G.; Haxhimusa, Y.; Sablatnig, R. Architectural Style Classification of Building Facade Windows. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Wang, S., Kyungnam, K., Benes, B., Moreland, K., Borst, C., DiVerdi, S., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 280–289. [Google Scholar]
- Shalunts, G.; Haxhimusa, Y.; Sablatnig, R. Architectural Style Classification of Domes. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Fowlkes, C., Wang, S., Choi, M.H., Mantler, S., Schulze, J., Acevedo, D., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 420–429. [Google Scholar]
- Montoya Obeso, A.; Benois-Pineau, J.; Ramirez, A.; Vázquez, M. Architectural style classification of Mexican historical buildings using deep convolutional neural networks and sparse features. J. Electron. Imaging 2016, 26, 011016. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C.; Li, W. Building block level urban land-use information retrieval based on Google Street View images. GISci. Remote Sens. 2017, 54, 819–835. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V.; DeCoste, D.; Di, W.; Yu, Y. HD-CNN: Hierarchical deep convolutional neural networks for large scale visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–10 December 2015; pp. 2740–2748. [Google Scholar]
- Zhu, X.; Bain, M. B-CNN: Branch Convolutional Neural Network for Hierarchical Classification. arXiv 2017, arXiv:1709.09890. [Google Scholar]
- Elman, J.L. Learning and development in neural networks: The importance of starting small. Cognition 1993, 48, 71–99. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Xu, Z.; Tao, D.; Zhang, Y.; Wu, J.; Tsoi, A.C. Architectural Style Classification Using Multinomial Latent Logistic Regression. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 600–615. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features From Tiny Images; Technical report; Department of Computer Science, Univsersity of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. 2016. Available online: http://www.deeplearningbook.org (accessed on 21 October 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task A | Task B | |
|---|---|---|
| Accuracy | 87.34% | 78.22% |
| Loss | 0.38 | 0.67 |
| Coarse Branch Accuracy | Coarse Branch Loss | Fine Branch Accuracy | Fine Branch Loss | |
|---|---|---|---|---|
| B-CNN model | 82.35% | 0.51 | 79.85% | 0.60 |
| HierarchyNet | 92.65% | 0.23 | 82.10% | 0.89 |
| Coarse Branch Accuracy | Fine Branch Accuracy | |
|---|---|---|
| ResNet50 | - | 83.41% |
| HierarchyNet | 93.98% | 85.09% |
| Coarse Branch Accuracy | Coarse Branch Loss | Fine Branch Accuracy | Fine Branch Loss | |
|---|---|---|---|---|
| VGG-16 | - | - | 72.60% | 0.99 |
| B-CNN model | 83.18% | 0.56 | 73.42% | 0.91 |
| HierarchyNet | 86.85% | 0.37 | 76.08% | 1.15 |
| Base A | Base B | Base C |
|---|---|---|
| Input Image | ||
| conv3-32 | (conv3-64) | (conv3-64) |
| maxpool-2 | maxpool-2 | maxpool-2 |
| conv3-64 | (conv3-128) maxpool-2 | (conv3-128) maxpool-2 |
| conv3-64 | (conv3-256) maxpool-2 (conv3-512) | (conv3-256) maxpool-2 (conv3-512) |
| maxpool-2 | maxpool-2 | maxpool-2 (conv3-512) |
| Flatten | ||
| Models | MNIST | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| Base A | 99.27% | - | - |
| B-CNN A | 99.40% | - | - |
| HierarchyNet A | 99.47% | - | - |
| Base B | - | 82.35% | 51.00% |
| B-CNN B | - | 84.41% | 57.59% |
| HierarchyNet B | - | 84.90% | 55.64% |
| Base C | - | 87.96% | 62.92% |
| B-CNN C | - | 88.22% | 64.42% |
| HierarchyNet C | - | 88.57% | 64.65% |
| Model | Building Functionality Task | Building Style Task |
|---|---|---|
| VGG-16 conv. blocks | 14,714,688 | 14,714,688 |
| B-CNN | 79,163,470 | 72,631,251 |
| HierarchyNet | 21,190,606 | 27,746,899 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taoufiq, S.; Nagy, B.; Benedek, C. HierarchyNet: Hierarchical CNN-Based Urban Building Classification. Remote Sens. 2020, 12, 3794. https://doi.org/10.3390/rs12223794
Taoufiq S, Nagy B, Benedek C. HierarchyNet: Hierarchical CNN-Based Urban Building Classification. Remote Sensing. 2020; 12(22):3794. https://doi.org/10.3390/rs12223794
Chicago/Turabian StyleTaoufiq, Salma, Balázs Nagy, and Csaba Benedek. 2020. "HierarchyNet: Hierarchical CNN-Based Urban Building Classification" Remote Sensing 12, no. 22: 3794. https://doi.org/10.3390/rs12223794
APA StyleTaoufiq, S., Nagy, B., & Benedek, C. (2020). HierarchyNet: Hierarchical CNN-Based Urban Building Classification. Remote Sensing, 12(22), 3794. https://doi.org/10.3390/rs12223794