Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion


Abstract
1. Introduction
- A dataset for ship detection in remote-sensing images (DSDR) is created. Deep learning methods need a lot of training data during the complicated training process. Thus, a ship dataset is badly needed. DSDR contains rich satellite remote sensing images and aerial remote sensing images, which is an important resource for supervised learning algorithms.
- We introduce data augmentation to supplement the lack of ship samples in military applications. Thus, preventing the model from overfitting can increase the detection accuracy of ship targets. We adopt an affine transformation method to change the perspectives of ships, thereby increasing the accuracy of ship detection in aerial images.
- A dark channel prior is adopted to solve the atmospheric correction on the sea scenes. We remove the influence of the absorption and scattering of water vapor and particles in the atmosphere by using the dark channel prior. The image quality is greatly improved by atmospheric correction. Atmospheric correction is beneficial to improving the accuracy of target detection in remote sensing images.
- A feature fusion network is used to comprehend different levels of convolutional features, which can better use the fine-grained features and semantic features of the target, achieving multi-scale detection of ships. Meanwhile, feature fusion and anchor design are helpful for improving the performance of small target detection.
- Soft non-maximum suppression (NMS) is used to assign a lower score for redundant prediction boxes, thereby reducing the missed detection rate and improving the recall rate of densely arranged ships. The detection accuracy is improved compared to the traditional NMS.
2. Data and Methods
2.1. Dataset
2.2. Data Preprocessing
2.2.1. Data Augmentation
2.2.2. Atmospheric Correction
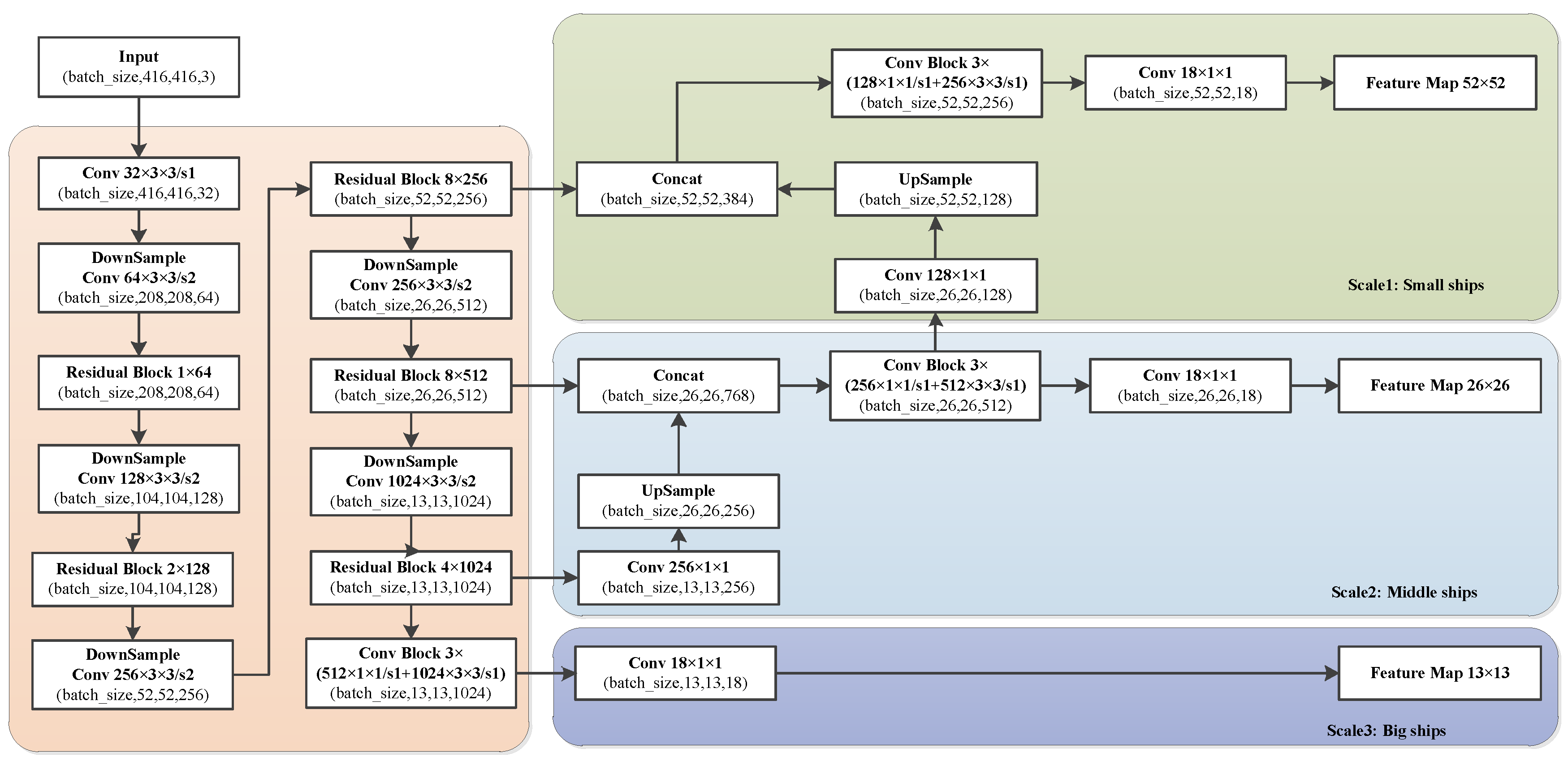
2.3. Detailed Description of the Network Architecture CFF-SDN
2.3.1. Feature Extraction Network.
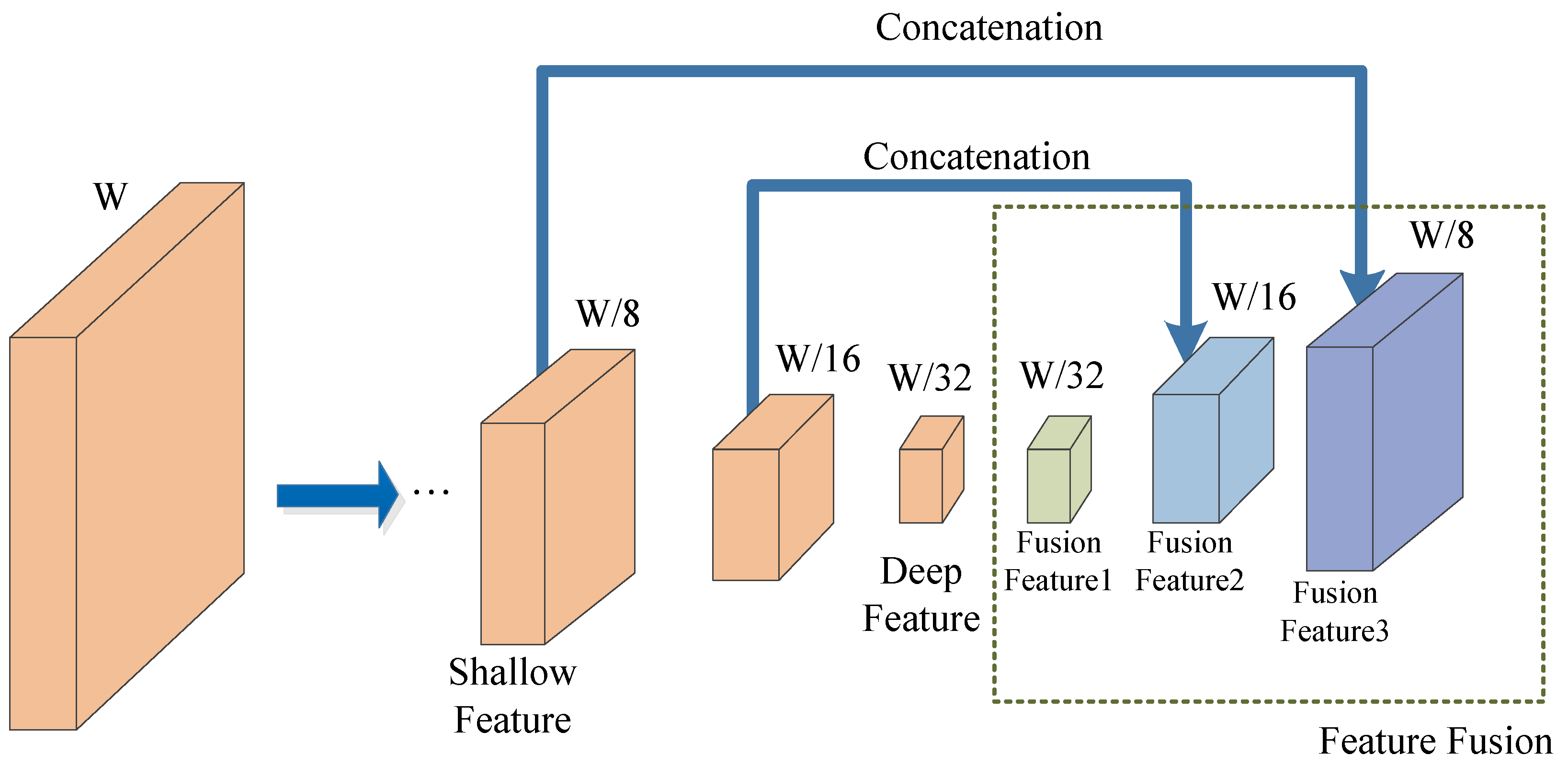
2.3.2. Convolutional Feature Fusion
2.3.3. Soft NMS
2.3.4. Loss Function
2.4. Model Pruning
3. Experiments and Results
3.1. Model Training
3.2. Model Evaluation
3.3. Comparison with Other Methods
3.4. Effect of Data Preprocessing
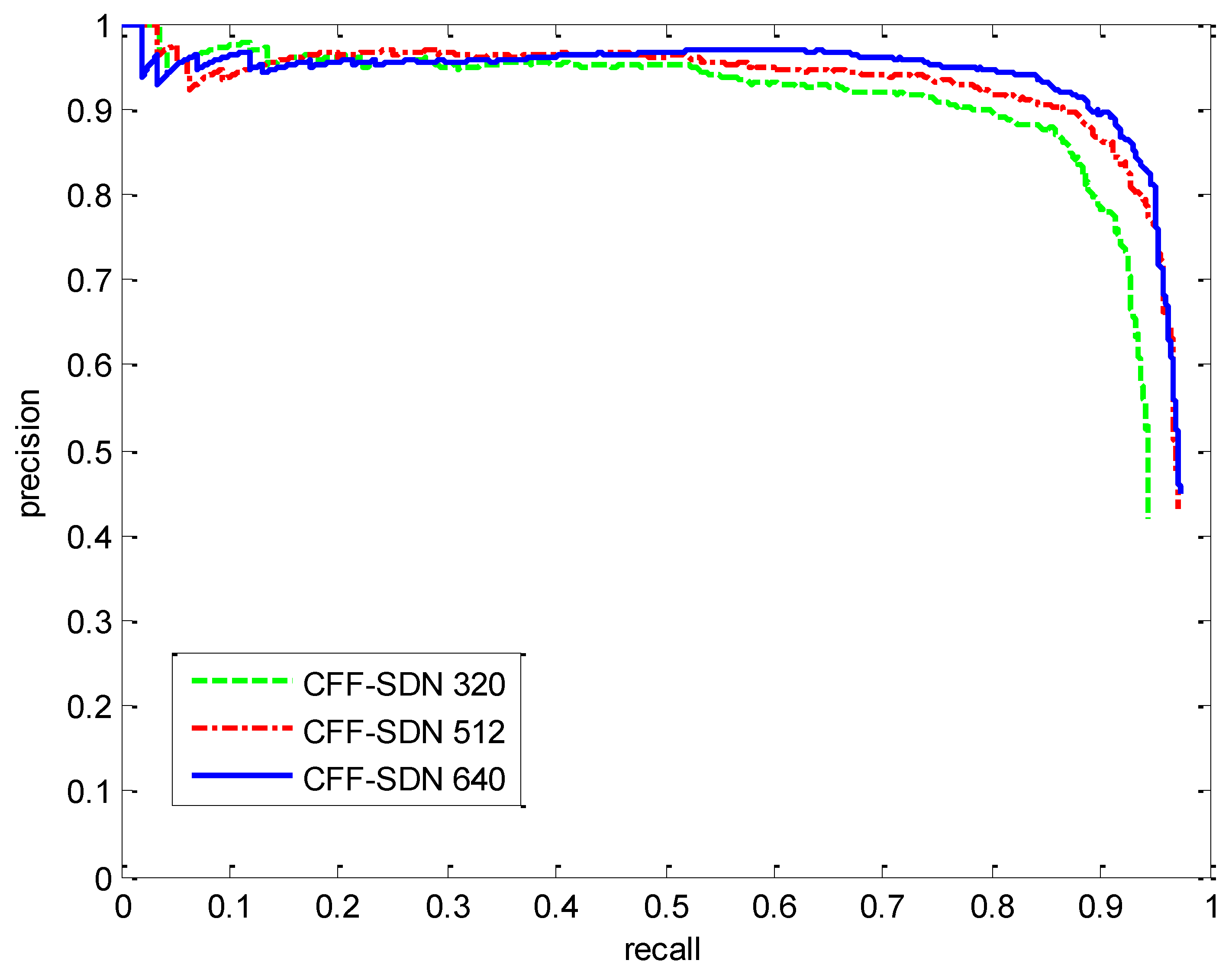
3.5. Performance Comparison of Different Image Sizes
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CFF-SDN | ship detection network based on multi-layer convolutional feature fusion |
| DSDR | dataset for ship detection in remote sensing images |
| SAR | synthetic aperture radar |
| UAVs | unmanned aerial vehicles |
| ROIs | the regions of interest |
| GBVS | graph-based visual Saliency |
| Faster R-CNN | faster regions convolution neural network |
| SSD | single shot multi-box detector |
| YOLO | you only look once |
| NMS | non-maximum suppression |
| GSD | ground sampling distance |
| BN | batch normalization |
| Leaky ReLU | leaky rectified linear unit |
| DBL | darknet convolution + BN + Leaky Relu |
| IOU | intersection over the union |
| mAP | the mean of average precision |
| TP | the number of true positives |
| FP | the number of false positives |
| FN | the number of false negatives |
| BFLOPS | billion floating point operations per second |
| VEDAI | vehicle detection in aerial imagery dataset |
| DOTA | dataset for object detection in aerial images |
| HRRSD | high-resolution remote sensing detection dataset |
References
- He, H.; Lin, Y.; Chen, F.; Tai, H.-M.; Yin, Z. Inshore Ship Detection in Remote Sensing Images via Weighted Pose Voting. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1–17. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-Quality Instance Segmentation for Remote Sensing Imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef]
- Dong, C.; Liu, J.; Xu, F. Ship Detection in Optical Remote Sensing Images Based on Saliency and a Rotation-Invariant Descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-Based Visual Saliency. In Proceedings of the 20th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 545–552. [Google Scholar]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Achanta, R.; Hemami, S.S.; Estrada, F.J.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Li, S.; Zhou, Z.; Wang, B.; Wu, F. A Novel Inshore Ship Detection via Ship Head Classification and Body Boundary Determination. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1–5. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Sun, M.; Zeng, D.; Wang, X. A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery. Remote Sens. 2017, 9, 280. [Google Scholar] [CrossRef]
- Margarit, G.; Tabasco, A. Ship Classification in Single-Pol SAR Images Based on Fuzzy Logic. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3129–3138. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised Ship Detection Based on Saliency and S-HOG Descriptor from Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef]
- Yi, Z.; Yongliang, S.; Jun, Z. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Lim, J.; Astrid, M.; Yoon, H.; Lee, S. Small Object Detection using Context and Attention. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-Aware Convolution Neural Network for Ship Detection in Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 781–794. [Google Scholar] [CrossRef]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for Ship Detection and Segmentation from Remote Sensing Images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Li, Y.; Peng, C.; Chen, Y.; Jiao, L.; Zhou, L.; Shang, R. A Deep Learning Method for Change Detection in Synthetic Aperture Radar Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1–13. [Google Scholar] [CrossRef]
- An, Q.; Pan, Z.; You, H. Ship Detection in Gaofen-3 SAR Images Based on Sea Clutter Distribution Analysis and Deep Convolutional Neural Network. Sensors 2018, 18, 334. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, Q.; Yu, H. Physics Inspired Methods for Crowd Video Surveillance and Analysis: A Survey. IEEE Access 2018, 6, 66816–66830. [Google Scholar] [CrossRef]
- Zhang, X.; Shu, X.; He, Z. Crowd panic state detection using entropy of the distribution of enthalpy. Phys. A Stat. Mech. Its Appl. 2019, 525, 935–945. [Google Scholar] [CrossRef]
- Song, P.; Qi, L.; Qian, X.; Lu, X. Detection of ships in inland river using high-resolution optical satellite imagery based on mixture of deformable part models. J. Parallel Distrib. Comput. 2019, 132, 1–7. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, T.; Zhang, H. Land contained sea area ship detection using spaceborne image. Pattern Recognit. Lett. 2020, 130, 125–131. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Pycharm. Available online: http://www.jetbrains.com/pycharm/ (accessed on 1 January 2020).
- Zhang, X.; Ma, D.; Yu, H.; Huang, Y.; Howell, P.; Stevens, B. Scene perception guided crowd anomaly detection. Neurocomputing 2020, 414, 291–302. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Zhu, R.; Zhang, S.; Wang, X.; Wen, L.; Shi, H.; Bo, L.; Mei, T. ScratchDet: Training single-shot object detectors from scratch. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 2268–2277. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Samples | Number of Ships |
|---|---|---|
| Training set | 1146 | 2910 |
| Validation set | 369 | 959 |
| Test set | 369 | 950 |
| Total | 1884 | 4819 |
| Prediction Order | Receptive Field | Number of Anchor Boxes |
|---|---|---|
| 1 | Large | 2 |
| 2 | Medium | 3 |
| 3 | Small | 4 |
| Hyper-Parameter | Value |
|---|---|
| Learning rate | 0.001 |
| Learning change steps | 400,000, 450,000 |
| Learning change scales | 0.1, 0.1 |
| Batch size | 16 |
| Momentum | 0.9 |
| Decay | 0.0005 |
| Epochs | 2000 |
| Model | Precision | Recall | F1 Score | mAP |
|---|---|---|---|---|
| Faster R-CNN | 83.32 | 89.65 | 86.37 | 87.81 |
| SSD | 77.35 | 83.36 | 80.24 | 81.53 |
| YOLOv3 | 78.09 | 84.62 | 81.22 | 82.73 |
| CFF-SDN | 87.23 | 93.11 | 90.07 | 91.51 |
| Model | Faster R-CNN | SSD | YOLOv3 | CFF-SDN (Before Pruning) | CFF-SDN (After Pruning) |
|---|---|---|---|---|---|
| Time (ms) | 140 | 61 | 22 | 20 | 9.4 |
| Model | Data Augmentation | Atmospheric Correction | Precision | Recall | F1 Score | mAP |
|---|---|---|---|---|---|---|
| CFF-SDN | × | × | 85.02 | 91.12 | 87.96 | 88.84 |
| √ | × | 86.16 | 92.25 | 89.10 | 90.42 | |
| √ | √ | 87.23 | 93.11 | 90.07 | 91.51 |
| Model | Image Size | Precision | Recall | F1 Score | mAP | Inference Time | BFLOPS |
|---|---|---|---|---|---|---|---|
| CFF-DSN | 320 × 320 | 82.94 | 91.73 | 87.11 | 88.61 | 8.7 | 5.8 |
| 512 × 512 | 88.92 | 93.68 | 91.23 | 92.44 | 11.8 | 14.7 | |
| 640 × 640 | 89.98 | 94.62 | 92.24 | 93.25 | 14.6 | 22.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Guo, L.; Wang, Z.; Yu, Y.; Liu, X.; Xu, F. Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion. Remote Sens. 2020, 12, 3316. https://doi.org/10.3390/rs12203316
Zhang Y, Guo L, Wang Z, Yu Y, Liu X, Xu F. Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion. Remote Sensing. 2020; 12(20):3316. https://doi.org/10.3390/rs12203316
Chicago/Turabian StyleZhang, Yulian, Lihong Guo, Zengfa Wang, Yang Yu, Xinwei Liu, and Fang Xu. 2020. "Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion" Remote Sensing 12, no. 20: 3316. https://doi.org/10.3390/rs12203316
APA StyleZhang, Y., Guo, L., Wang, Z., Yu, Y., Liu, X., & Xu, F. (2020). Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion. Remote Sensing, 12(20), 3316. https://doi.org/10.3390/rs12203316