1. Introduction
The aim of a supervised classification algorithm consists of labeling an image with the corresponding class according to its content. Conventional approaches are based on encoding handcrafted features with, for example, the bag of words model (BoW) [
1], the vector of locally aggregated descriptors (VLAD) [
2,
3] or the Fisher vectors (FV) [
4,
5,
6]. These latter strategies have proved successful results in a wide range of applications such as image classification [
4,
7,
8], text retrieval [
9], action and face recognition [
10], etc.
Recently, the emergence of deep learning algorithms has been demonstrated to outperform benchmark machine learning methods in many situations. In fact, neural networks are constructed to model the human brain, where each layer is responsible for automatically extracting and learning specific features from the input images [
11]. One of the most popular neural networks is the convolutional neural network (CNN), which has become a standard for image classification problems [
12,
13]. CNN is built from various hidden layers performing different kinds of transformation, such as convolutions, pooling, and activation functions.
In recent years, in order to benefit from both CNN architectures and encoding methods, many authors have focus on proposing hybrid architectures that consist of combining deep neural network architecture with FV/VLAD descriptors. For example, Perronnin et al., have introduced, in [
14] a network of fully connected layers trained on the FV descriptors. Inspired by the multi-layer structure of neural networks, Simonyan et al., proposed, in [
15], the Fisher network, which is composed of several stacked FV layers. In the same spirit, the NetVLAD layer has been proposed in [
16] to mimick a VLAD layer. To benefit of multi-layer representation, other strategies include the FV or VLAD encoding of CNN features from different layers of the network [
17,
18,
19,
20]. Nevertheless, all these strategies do not exploit second-order statistics, i.e., dependencies between features, which have been shown to be important in the human visual recognition process [
21].
To this aim, some authors have dedicated their works to exploiting the information behind second-order statistics using covariance matrix features. These have proved to be highly effective in diverse classification tasks, including person re-identification, texture recognition, material categorization or EEG classification in brain–computer interfaces to cite a few of them [
10,
22,
23,
24]. Several works have been proposed to extend the encoding formalism to covariance matrix descriptors. Therefore, since covariance matrices are symmetric positive definite (SPD) matrices, conventional Euclidean tools are not adapted. To deal with covariance matrices geometry, two Riemannian metrics are usually considered: the log-Euclidean and the affine-invariant Riemannian metrics. Since then, some authors have proposed to extend the usual coding methods to these two metrics, yielding to the proposition of the following approaches: the log-Euclidean bag of words (LE BoW) [
25,
26], the bag of Riemannian words (BoRW) [
27], the log-Euclidean vector of locally aggregated descriptors (LE VLAD) [
10] and the intrinsic Riemannian vector of locally aggregated descriptors (RVLAD) [
10]. Recently, FV descriptors extended to SPD matrices have been proposed. This has involved the log-Euclidean Fisher vectors (LE FV) [
28] and the Riemannian Fisher vectors (RFV) [
29,
30,
31]. When analyzing those two metrics, log-Euclidean and affine-invariant Riemannian metrics offer several invariance properties and can obtain comparable results for a large variety of applications [
31,
32] compared to the Euclidean metric. However, the log-Euclidean approach is much more straightforward. To model covariance matrices that lie in a Riemannian manifold, it merely consists in projecting them in a tangent space of a reference point classically chosen equal to the identity matrix.
On the other hand, traditional CNN models capture only first-order statistics. To benefit from both second-order statistics and deep learning architectures, different second-order convolutional neural networks architectures have recently emerged [
33,
34,
35,
36,
37,
38,
39,
40] for many applications including fine-grained classification. One first attempt was the pooled covariance matrix from CNN outputs [
33]. Later, He et al. presented in [
35] a multi-layer version: the multi-layer stacked covariance pooling (MSCP). One other way to exploit second-order statistics in a deep neural network is the Riemannian SPD matrix network (SPDNet) [
36]. The idea behind this network is to mimick the classical CNN fully connected convolution-like layers and rectified linear units (ReLU)-like layers to data, which do not lie in an Euclidean space. For that, the bilinear mapping (BiMap) layers and eigenvalue rectification (ReEig) layers were proposed. Inspired by this work, Yu et al. have introduced in [
37] a second-order CNN (SO-CNN), which is trained in an end-to-end manner. However, for these models, second-order representation is introduced only for the deepest layers. To overcome this issue, Gao et al. [
39] have proposed the global second-order pooling (GSoP) convolutional networks which permit to introduce higher-order representation in earlier layers. Nevertheless, training such a deep CNN model from scratch requires a huge labeled training set. Recently, the remote sensing community has started to build large scale datasets that can serve as pre-training, such as the BigEarthNet composed by Sentinel-2 image patches [
41]. However, for many practical applications, most of the remote sensing datasets are quite small.
Many authors have proposed several ideas to overcome this issue such as using a new kind of neural network called capsule network [
42] which has the ability to work with a small amount of training data. Compared to convolutional neural network, capsule network allows to address the “Picasso problem" in image recognition, i.e., images that show the right components but have not the right spatial relationships. For example, for a face image, the location of the eye and ear are swapped. For our application of remote sensing scene classification, this is not critical. For instance, in an harbour scene, the location of the scene elements (boats, pontoon, …) in the image is not so important. The key point is that the network is able to recognize them. Another effective solution for limited training set consists of transfer learning. In that case, CNN models are considered as feature extractors. Classically, deep CNN models pre-trained on the ImageNet dataset are used. Then, features are extracted from a single or multiple layers and processed with some machine learning algorithms. This technique has been proved to be efficient and permits outperforming traditional handcrafted feature-based methods [
13]. In a recent paper, Pires de Lima et al. have shown that transfer learning strategies based on feature extraction are among the best approaches for remote sensing scene classification, especially for the dataset with a low number of training samples [
43]. In this context, in order to the benefit of pre-trained deep neural networks and second-order representations, this work aims at proposing a novel ensemble learning approach based on covariance pooling of CNN features for remote sensing scene classification. It consists of a combination of two hybrid architectures exploiting second-order features. The former is based on the log-Euclidean Fisher vector encoding of region covariance matrices computed locally on the first layers of a CNN [
28] and its extension to the use of an ensemble learning strategy to combine multiple classifiers. The latter concerns an ensemble learning approach based on the covariance pooling of CNN features extracted from deeper layers [
44].
In summary, second-order representation (i.e., covariance pooling) has been shown to be useful for many signal and image processing tasks. Recently, in the remote sensing community, some works have shown interest in these second-order features for various remote sensing applications (e.g., remote sensing scene classification, texture recognition) [
35,
40,
45,
46]. Motivated by these works and the success of deep neural networks, we have recently proposed two hybrid transfer learning approaches based on covariance pooling of CNN features [
28,
44]. These two methods use either local or global second-order representation of CNN features. The main motivation of this journal paper is to unify these works by presenting a transfer learning approach which benefit of these approaches. The main contributions of the paper can be summarized as follows:
We propose a transfer learning approach, which efficiently combine local and global second-order representation of CNN features. For the local one, an ensemble learning extension of our log-Euclidean Fisher vector encoding of region covariance matrices [
28] is introduced. For the global one, our covariance pooling of deepest CNN features is considered [
44].
An ensemble learning approach based on the most diverse ensembles is proposed to combine these decisions and enhance the classification performance.
This transfer learning is validated on different labeled remote sensing datasets to illustrate its efficiency. Three are publicly available, namely UC Merced Land Use, SIRI-WHU and AID datasets. Two others are internal datasets, oyster racks and maritime pine forest datasets, which are manually labeled by thematic experts.
The paper is structured as follows. Since the second-order representation of CNN features is at the core of the paper,
Section 2 gives the mathematical background for the log-Euclidean representation of a covariance matrix. Next,
Section 3 introduces the proposed ensemble learning approach based on the log-Euclidean Fisher vector encoding of region covariance matrices. Then,
Section 4 recalls our ensemble learning approach based on covariance pooling (ELCP) of CNN features. In order to combine these two methods,
Section 5 presents the fusion scheme based on the most diverse ensembles. Next,
Section 6 summarizes a series of experiments performed on remote sensing scene classification. And finally,
Section 7 provides the main conclusions and perspectives of this work.
2. Log-Euclidean Framework for Second-Order Statistics of CNN Features
In the literature, second-order statistics have been proved to play an important role in the human visual recognition process [
21]. In practice, the covariance matrix of handcrafted descriptors, textural or deep convolutional features is computed and integrated into the classification algorithm. Since covariance matrices are symmetric positive definite (SPD) matrices, they have a specific geometry, and standard Euclidean tools are not adapted. The present section aims at explaining the geometry of SPD matrices and classical metrics used to manipulate these data. In fact, these datapoints lie inside the cone of positive definite matrices that is a Riemannian manifold.
Therefore, applying standard Euclidean operations on covariance matrices, for instance, computing the Euclidean distance between two covariance matrices, may lead to undesirable results such as the swelling effect as observed in [
47]. Many authors have raised the need of intrinsic tools to analyze SPD matrices [
32,
48]. As pointed out by Pennec et al., the log-Euclidean and the affine invariant Riemannian metrics enjoy desirable invariance properties compared to the Euclidean metric. The affine invariant Riemannian distance has the property of being invariant by affine transformations.
Even if the log-Euclidean metric does not yield full affine invariance, it is invariant by similarity (orthogonal transformation and scaling). The computations using this metric could be invariant with respect to a change of coordinates obtained by a similarity. From a practical point of view, Arsigny et al., have shown in [
32] that affine invariant and log-Euclidean frameworks perform better than the Euclidean one for the interpolation and regularization of their synthetic and clinical 3D diffusion tensor magnetic resonance imaging (DT-MRI) data. This has the advantage of more accurately capturing the underlying scatter of the data points (that are covariance matrices) than is possible with methods that treat data points as elements in a vector space. For many applications, the log-Euclidean framework has shown competitive results compared to the affine invariant Riemannian one [
31,
32]. This log-Euclidean framework is considered in this paper for its efficiency and ease of use. The basic principle is the following. Each covariance matrix
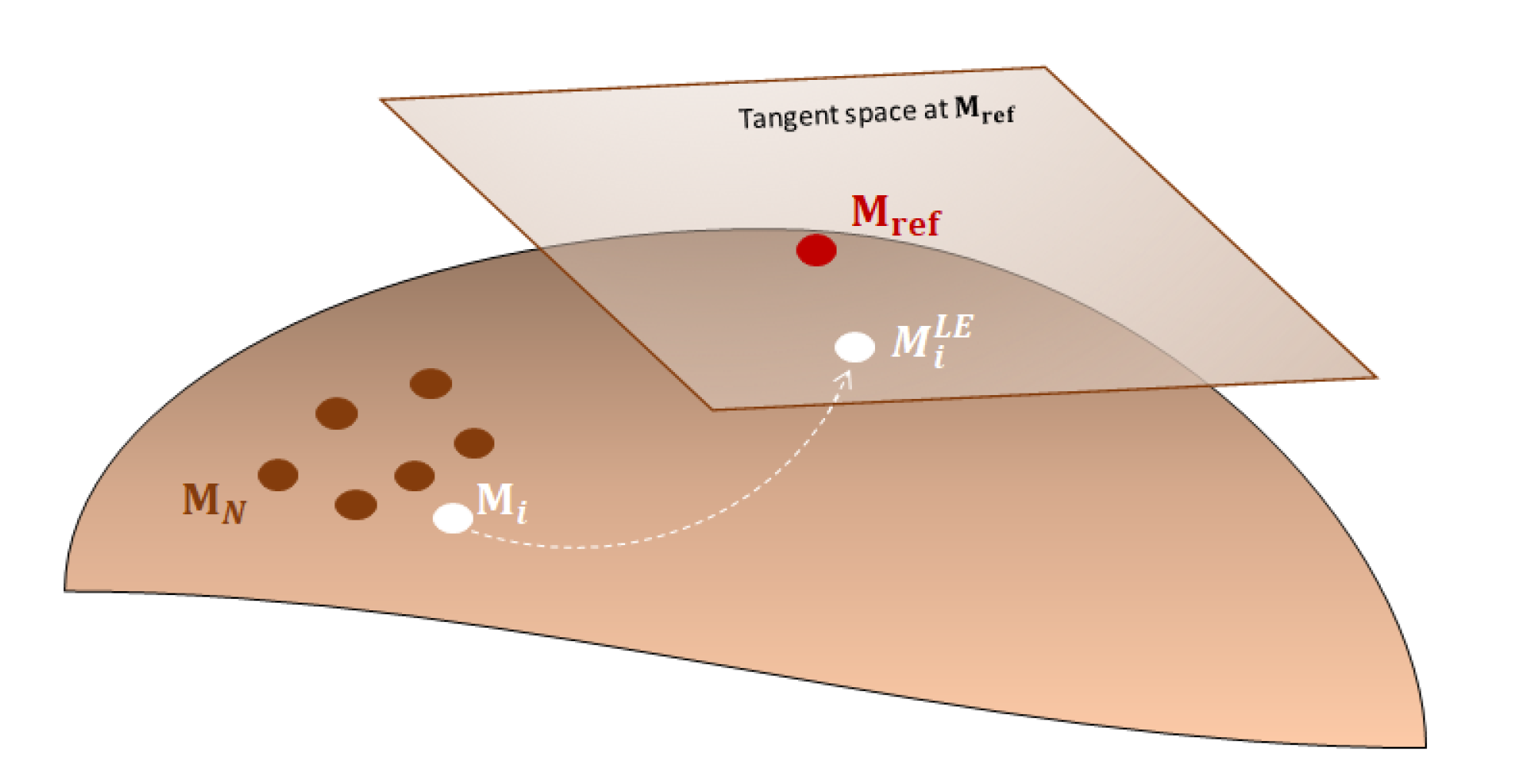
is mapped on the tangent space, as illustrated in
Figure 1 that locally flattens the manifold via the tangent space approximation. This consists of projecting covariance matrices onto a common tangent space of this manifold at the reference point
via the log map operator [
26,
32,
45] defined as:
means that covariance matrix
is projected on the tangent space at the reference point
. Then, to get the vector representation, a vectorization operation Vec() is performed such that:
with
the elements of
at row
i and column
j. Those two operations yield to the definition of the log-Euclidean vector representation of
computed at the reference point
, denoted
where:
These covariance matrices are projected on the tangent space at
; they lie in a vector space where conventional image processing and machine learning methods can be used. Within this framework, the tangent space is computed at a reference point
as shown in (
1). Different choices can be made for this reference point, such as the identity matrix, the center of mass or the median. The use of the identity matrix
for this latter is undoubtedly the simplest and the most usual way to map covariance matrices on the tangent space. This choice will be made for the following. In that case, the log map operator in Equation (
1) vanishes to:
This consists of computing the ordinary matrix logarithm. Let be the eigenvalue decomposition of an SPD matrix, the logarithm is defined as: . Since is the diagonal matrix of eigenvalues, is also a diagonal matrix whose diagonal elements are the logarithm of the eigenvalues. In the next two sections, this log-Euclidean framework is employed for two hybrid architectures where the covariance matrix is computed for CNN features.
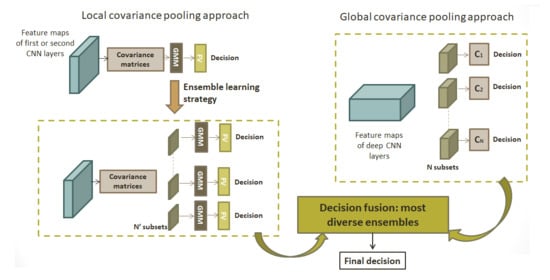
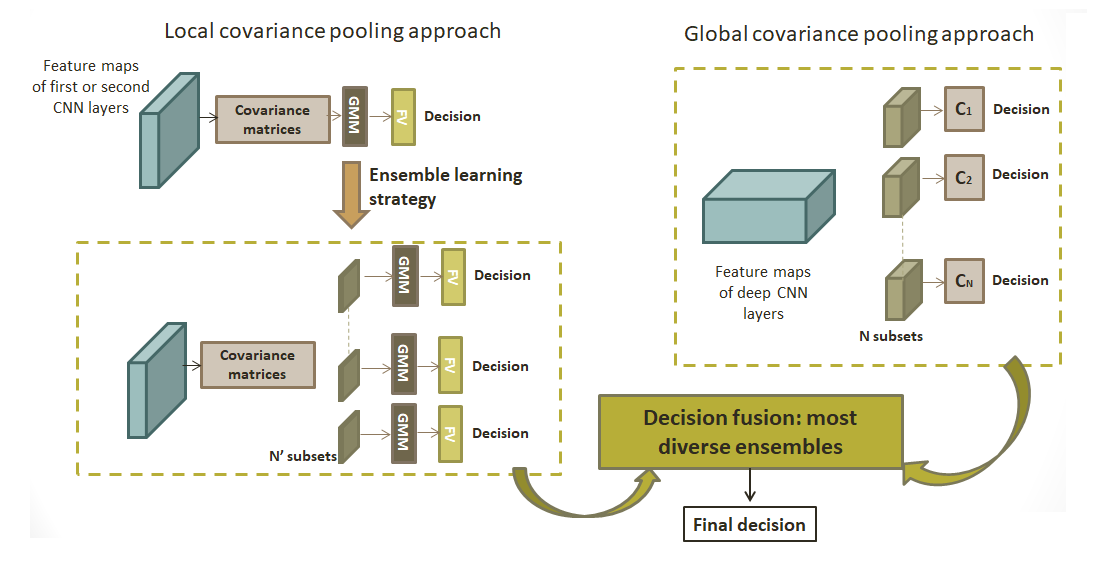
3. Local Covariance Pooling: Ensemble Log-Euclidean Fisher Vector Architecture
A scene image is composed by a set of visual elements. For example, an harbour scene is formed by many objects such as boat, water, pontoon, … In this context, coding based methods such as FV or VLAD descriptors have reached the state-of-the-art at the beginning of the 2000’s [
2,
3,
4]. These methods relies on the creation of a codebook where codewords represent meaningful object parts of the scene. More recently, deep learning models (and CNN in particular) have shown to outperform these coding methods by a significant margin. For instance, on the ImageNet large scale visual recognition challenge, deep learning based methods have won since 2012 [
13]. In order to benefit from both strategies, in the recent literature on scene classification, many authors have introduced hybrid architectures that combine CNN with some coding methods. For example, Perronnin et al. [
14] have proposed a network of fully connected layers trained on the FV descriptors. Simonyan et al. introduced in [
15] the Fisher network, which is composed of several stacked FV layers. Later, Arandjelovic et al. [
16] proposed the NetVLAD layer, which mimicks the VLAD layer. Building on the success of those latter hybrid architectures, more attention is given to a particular approach introduced in [
20]. In that paper, Li et al. have proposed a hybrid structure, which consists of encoding each output of the convolutional layers of a pre-trained neural network with FV. This technique has demonstrated competitive results for remote sensing scene classification. To capture various scale phenomenons when applying the FV encoding, a Gaussian pyramid is considered. This permits generating multiscale images by using a Gaussian smoothing and sub-sampling at different scales as detailed in [
20]. Classification results have demonstrated the interest of using multiscale images compared to a single input image. Therefore, a pyramid of three scale levels is retained in the following. Those multiscale images are fed into the CNN model, allowing the extraction of convolutional features which are then concatenated before being encoded with FV. Note that CNN models are used only to extract deep features without any retraining from scratch or fine-tuning. In fact, once the multiscale features are extracted from each convolutional layer, an individual codebook is generated. In this approach, the dimension
K of the codebook is the same for all the layers. The CNN features are then encoded with the improved FV [
5]. Next, those FVs are fused to represent the mid-level feature vectors of a scene image. Therefore, this approach does not consider second-order features, which have proved to be efficient in many classification problems and have shown to outperform first-order features for many image processing applications, including material recognition and person re-identification. To this aim, we have proposed in [
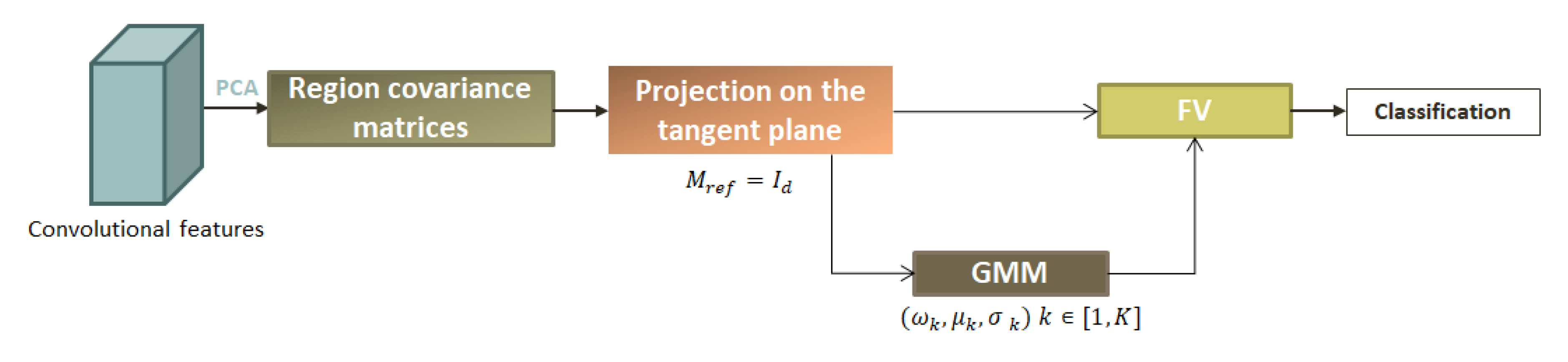
28] a novel hybrid architecture named Hybrid LE FV, which integrates second-order features in the classification algorithm, as illustrated in
Figure 2. This consists of the log-Euclidean Fisher Vector (LE FV) encoding of the covariance matrices of CNN features computed locally on layers output. The next
Section 3.1 presents in details the principle of this Hybrid LE FV approach starting from the extraction of region covariance matrices to the FV encoding with the learned codebook [
28]. Then, aiming at improving the classification performance, a proposition of an ensemble learning version of Hybrid LE FV strategy is detailed in
Section 3.2.
3.1. Hybrid Log-Euclidean Fisher Vector (Hybrid LE FV)
3.1.1. Region Covariance Matrices
The first step is to extract the region covariance matrices computed on a sliding window on the feature map of a CNN. Hence, each image is represented by a set
of covariance matrices
. As the size of the output CNN layer depends on layer depth, only the first and second layers of a CNN are considered for computing local covariance matrices. Indeed, for the deepest layers, the feature maps are of small spatial dimension which does not allow the extraction of a large set of covariance matrices. For this purpose, a particular attention is given to the choice of the CNN model. Here, the employed CNN model is a very deep convolutional network named vgg-vd-16 [
49]. It is composed of 16 weight layers and is characterized by using a simple
convolutional layer stack with a stride fixed to 1 pixel and a spatial padding of 1 pixel. Therefore, the size of the output feature map is preserved through the first two layers that permit the extraction of a sufficient set of region covariance matrices. Then, according to the log-Euclidean framework detailed in
Section 2, these region covariance matrices are encoded with the LE FV. For that, a codebook is first learned by considering a Gaussian mixture model on the manifold of SPD matrices.
3.1.2. Gaussian Mixture Model and Codebook Creation
Let’s consider the following GMM model:
where
is a multivariate Gaussian distribution defined on the tangent space of the identity matrix. Its probability density function is given by:
,
and
are respectively the weight, mean and covariance matrices for the
kth component of the GMM model. In addition, the classical assumption of diagonal covariance matrices
is made, i.e.,
is the variance vector [
4].
Moreover, Equation (
7) can be rewritten as:
where
is the log-Euclidean mean vector for the
kth component of the GMM model, and
is the LE vector representation of
given by Equations (
4) and (
5). Since covariance matrices are projected into the tangent space and represented by their corresponding LE vectors, all the algorithms developed on a vector space can be used. In particular, the EM algorithm for parameter estimation of a GMM model is used to estimate the weights, means, and dispersion parameters. The set of these estimated parameters represents the codebook that will further be used to encode the set of region covariance matrices extracted from each image.
3.1.3. Log-Euclidean Fisher Vector Encoding
Considering
be a set of
-dimensional log-Euclidean vectors extracted locally from the first convolutional layers of an image. The LE FV encoding consists of projecting these local features onto the codebook defined in the previous subsection. The LE FV descriptor assigned to
𝓧 is obtained by computing the gradient of the log-likelihood with respect to GMM model parameters, scaled by the inverse square root of the Fisher Information Matrix (FIM)
[
4]:
Here,
represents each of the distribution parameters (
,
and
). In practice, the derivatives with respect to the mean
and standard deviation
have been found to be the most useful [
4]. Hence, the following two FVs are obtained after deriving with respect to these two elements
where
(resp.
) is the
jth element of vector
(resp.
) and
is the occupancy probability of
to the
kth Gaussian component of the GMM, also named the posterior probability, and is defined as:
Once FV descriptors are obtained, a post-processing step is conventionally used to enhance the classification accuracy [
5,
8]. This consists of a power and an
normalization. Furthermore, to avoid the curse of the dimensionality phenomenon when the dimensionality of the FV descriptor is high, a dimension reduction step can be used. In the following, the Kernel Discriminant Analysis (KDA) is considered [
50]. Finally, a classification with a linear SVM is performed to make the decision for each test image depending on the information contained in the FV vector representation.
3.1.4. Sensitivity Analysis
As explained in the previous subsection, two parameters have to be tuned for the proposed Hybrid LE FV method, namely the number of components
K in the GMM model and the dimension
d of the covariance matrices. To evaluate the influence of each parameter on classification accuracy, some experiments are carried out on the UC Merced Land Use Land Cover dataset [
51]. This dataset is composed of 21 classes where each class contains 100 remote sensing images of dimension 256 × 256 pixels.
Figure 3 shows some examples of the UC Merced dataset image classes. In order to prove the efficiency of the proposed approaches in challenging conditions, only a small set of
images is retrained for training for all experiments and the remaining images are used for testing. Classification results are evaluated in terms of overall accuracy averaged on five runs.
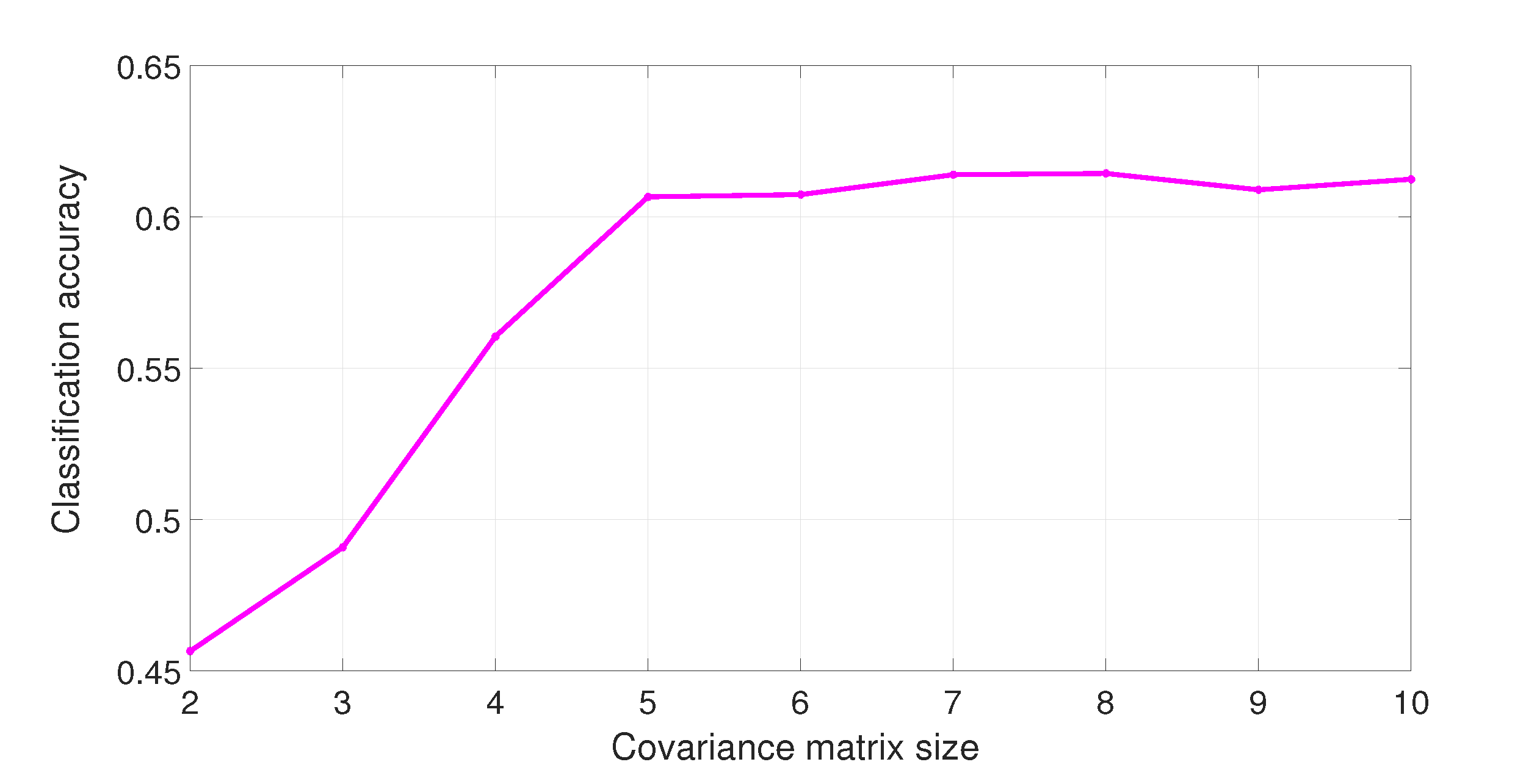
Figure 4 draws the evolution of the classification accuracy of the proposed Hybrid LE FV approach for the first convolutional layer as a function of the dimension
d of the covariance matrix. Here, the number of GMM components is fixed equal to 30. The dimension
d is the number of selected principal components. If
d is too small, a low number of principal components is retained. All the variability is not well explained, which leads to low classification accuracy. When
d increases, more variability is explained, and the classification performance also increases. But after a certain value (
in our experiments), the variance gain is not so important and the classification performance remains quite stable. Hence, it is recommended to consider a covariance matrix size greater than a value of
.
To evaluate the sensitivity of the proposed approach to number of GMM components,
Table 1 shows the classification accuracy using three values of
K in the GMM model. As observed, the approach isn’t sensitive to the codebook dimension.
3.2. Ensemble Hybrid Log-Euclidean Fisher Vector (Ens. Hybrid LE FV)
In machine learning, ensemble learning strategies have become more and more popular [
52,
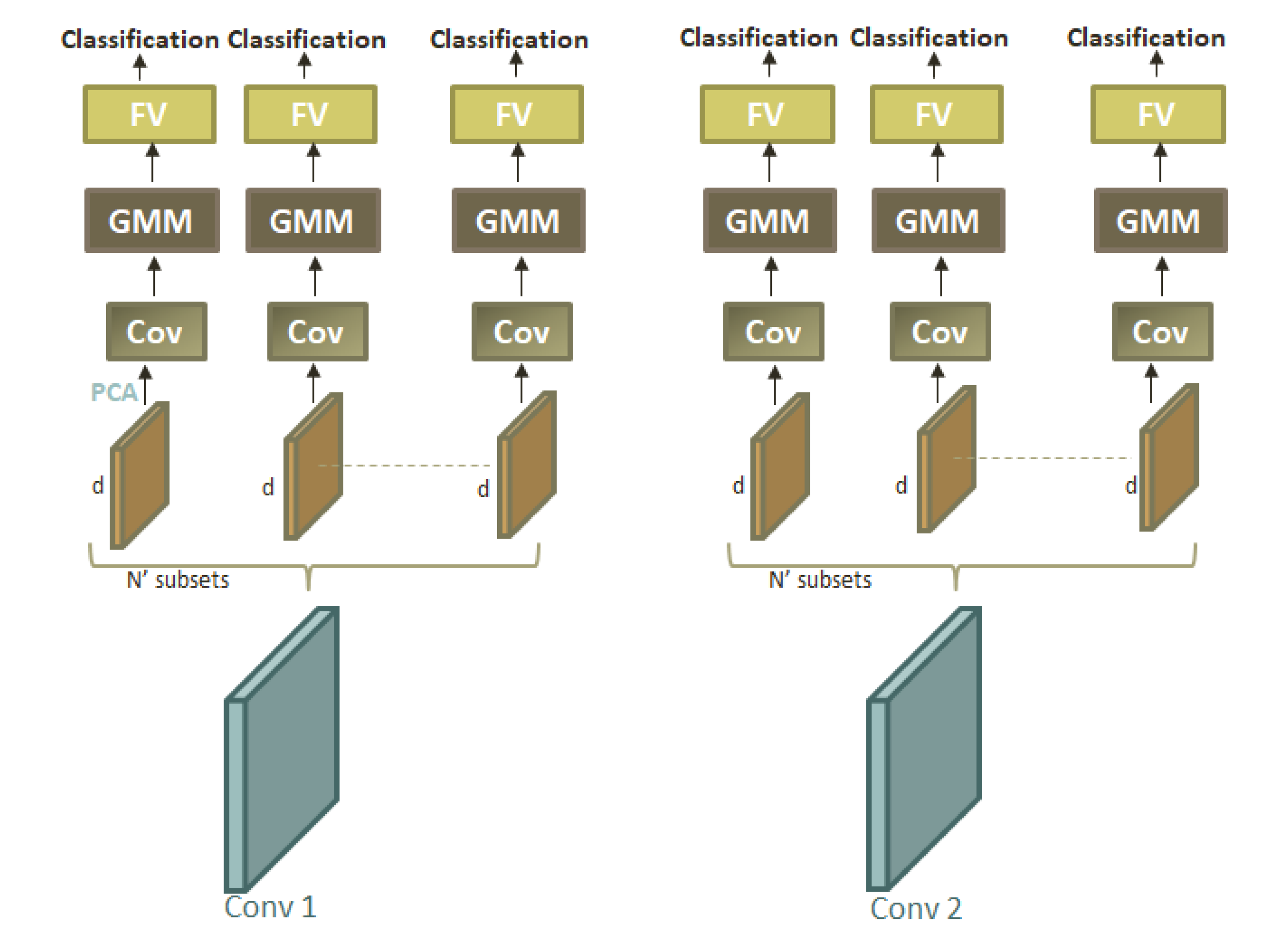
53]. They rely on the combination of multiple weak classifiers to form a stronger one, hence allowing improvements to the classification performance. Inspired by this idea, we introduce an ensemble learning approach for the hybrid log-Euclidean Fisher vector presented in the previous subsection. The workflow of this method named “Ens. Hybrid LE FV”, is shown in
Figure 5. As observed, for each convolutional layer (conv 1 and/or conv 2),
subsets are considered. For each subset,
d feature maps are randomly selected with replacement. Then, the hybrid log-Euclidean Fisher vector presented before is applied to obtain a decision for this subset. In the end, a majority vote over these decisions is considered to obtain the final prediction.
A first experiment is conducted in order to evaluate the sensitivity of the proposed approach. This consists of evaluating the influence of the number of subsets
.
Table 2 shows the classification accuracy of the “Ens. Hybrid LE FV” strategy regarding the first convolutional layer of Vgg-vd-16 model. Five values of
are experimented (5, 7, 9, 11, and 13) for
of training images of the UC Merced dataset.
One can observe that results remain quite stable of the considered subsets
. For further experiments, the number of subsets
will be fixed to 7.
Table 3 highlights the classification results obtained on the UC Merced dataset for the first (conv 1) and second (conv 2) convolutional layers of vgg-vd-16 network. The proposed ensemble learning approach, “Ens. Hybrid LE FV”, is compared to two closely related state-of-the-art strategies. The first one, named “Hybrid FV”, consists of encoding the output of the convolutional layers with FV [
20]. Note that this approach considers only first-order statistics. The second one, named “Hybrid LE FV” is the one presented in
Section 3.1. It exploits second-order statistics but not in an ensemble learning approach [
28].
As observed in
Table 3, the benefit of exploiting second-order statistics is clearly demonstrated for the first and second CNN convolutional layers. A significant gain of 20% to 25% is reported for the proposed “Hybrid LE FV” and “Ens. Hybrid LE FV” methods compared to the conventional “Hybrid FV” approach. In addition, for these first two layers, a significant gain is observed when exploiting an ensemble learning strategy compared to the use of a single classifier. In this approach, only covariance matrices computed on the first layers of a CNN have been encoded with the LE FV. Indeed, as the deepest convolutional layers of the
vgg-vd-16 network are of relatively small spatial dimensions, it is irrelevant to compute a sufficient number of region covariance matrices. Nevertheless, the deepest layers may provide useful features for the classification. To alleviate this issue, instead of considering a local approach, the covariance matrix will be computed globally for the deepest feature maps. For that,
Section 4 introduces our ensemble learning approach based on a global covariance pooling of CNN features [
44].
6. Experiments on Other Datasets
In this section, experiments on other remote sensing scene classification datasets are conducted to evaluate the effectiveness of the proposed approach. For that, the SIRI-WHU Google dataset [
57], the AID dataset and two real texture datasets, respectively, for maritime pine forest and on oyster fields [
58,
59] were tested. In order to prove the efficiency of the proposed approaches in challenging conditions, only
of images were considered for training.
SIRI-WHU:
This is a 12-class Google image dataset, where each class contains 200 images of 200 × 200 pixels, with a 2-m spatial resolution. This dataset was acquired from Google Earth and covers urban areas in China.
Figure 8 shows some image examples of the dataset.
Maritime pine forest:
This dataset comprises four classes of panchromatic Pléiades satellite images with a spatial resolution of 50 cm, which represent a monitoring of growing maritime pine tree stands.
Figure 9 illustrates one image from each age class.
Oyster racks:
This five-class dataset is also formed from panchromatic Pléiades satellite high-resolution images. It is comprised, in particular, of images representing cultivated oyster racks and abandoned fields.
Figure 10 shows one image of each class of the oyster dataset.
AID:
This dataset contains 10,000 aerial images of dimension 600 × 600 pixels partitioned into 30 classes, with a 2-m spatial resolution.
Figure 11 illustrates some dataset images.
Table 6 below summarizes the main characteristics of the considered datasets.
The experiments carried out consist of validating the proposed fusion scheme of the two proposed ensemble learning approaches, namely the Fusion Ens. Hybrid LE FV-ELCP (MDE+MV) strategy.
Table 7 summarizes the main results. As observed, a similar conclusion can be draw from these four datasets. Firstly, the ELCP approach performs better than Ens. Hybrid LE FV on first and second CNN convolutional layers due to the considered convolutional layer depth. This clearly illustrates the interest of exploiting deep feature maps from CNN model, which characterizes high-level features compared to the first ones. Secondly, a similar conclusion can be drawn to the one obtained from the UC Merced dataset: the fusion of both local and global second-order statistics computation strategies permits enhancing classification performance, which illustrates the multi-layer fusion efficiency.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}